
Abstract
In this cognitive era, vast amount of data are accumulated every day. Analysing such unstructured information and obtaining insights will be challenging. To address this, Large language models have been developed to support analysis of extensive data corpora. However, it tends to cause hallucination due to a lack of proper knowledge sources. If the analysis has to be performed with respect to the health care domain or finance domain, the challenge is raised because of the lack of domain specificity. COVID-19 sentiment analysis is one of the complex responsibilities of the government since it needs to know the opinions of people to take necessary measures. This paper presents COVID-19 retrieval augmented and fine-tuning (RAFT), a novel framework that includes the analysis of COVID-19 vaccine tweets through retrieval augmented-based approaches. This integrated domain-specific knowledge through a retrieval-augmented generation-based approach with external knowledge sources. We employed a transformer-based semantic approach in embedding generation via vector database. Furthermore, this framework exhibited generalizability when integrated with domain knowledge. It uses parameter efficient fine tuning with quantization to use a large language model with a reduced number of parameters, which will allow a model to be used in low-resource-constrained devices. This framework achieved an accuracy of 0.886 on the Twitter dataset containing tweets specific to Indian region and 0.912 on the Twitter dataset with tweets from Global region.
Introduction
Background
Comprehending public attitudes regarding COVID-19 vaccines is essential for Government, healthcare organizations and researchers to evaluate vaccine hesitancy, the dissemination of misinformation, and the level of public confidence in vaccination initiatives.Textual sentiment analysis (TSA) of COVID-19 vaccines provides valuable insights into the perceptions of the public, which reveals a mix of hesitancy, positivity and spread of misinformation.1,2 Nevertheless, there are a number of difficulties in evaluating such unstructured large-scale text data such as bias, inconsistent facts and a lack of domain-specific expertise.
Currently, large language models (LLMs) such as GPT 3 and LLaMA 4 play a pivotal role in shaping the retrieval of information from large amounts of massive data. Many of the LLMs performed significantly well in language processing-related downstream tasks.Zero-shot and one-shot learning are some of the notable ways in which these models offer remarkable results. However,directly applying these models on these social media data may lead to Hallucination. 5 To maximize the performance gains from these models, domain-specific data and fine-tuning are essential.
Two important strategies are being investigated extensively to reduce hallucinations and enhance factual consistency:
For the COVID Vaccine sentiment analysis, fine-tuning enables the model to understand vaccine-related discussions from social media. But depending only on fine-tuning could lead to inaccurate information and restricted generalization. On the other hand, if RAG is used without any fine tuning, domain relevance may be diminished since the model might place too much emphasis on external knowledge and ignore the context found in user-generated content. In order to address these issues, we introduce a framework called Retrieval-Augmented Fine-Tuning (RAFT), which combines the two methods to improve domain-specific accuracy while preserving the consistency of the model. To enhance decision-making, our RAFT approach integrates sentiment categorization of tweets with retrieval from reliable sources, including government health recommendations and WHO reports. We also improve the RAG mechanism by adding confidence-weighted retrieval, which gives highly relevant and reliable information.
A vector database is used to store the generated embedding from documents. The question, i.e., prompt embedding, was compared with the matched embedding from the chunks. This was fed to the LLM to generate answers. Our RAG model was instructed to provide answers of either ‘Positive’ or ‘Negative’ or ‘Neutral’. By striking a balance between domain based retrieval and user sentiment extraction, this hybrid technique maximizes the model's performance.
Although domain-specific datasets can be used for sentiment analysis of COVID-19 vaccinations, depending just on user-generated content presents a number of difficulties, such as bias, inaccuracy and a lack of scientific context. Conventional fine-tuning on these datasets runs the risk of overfitting and not generalizing to fresh conversations about vaccines. We proposed a hybrid COVID Retrieval-Augmented Fine-Tuning (RAFT) framework, which combines model fine-tuning and external knowledge retrieval to address these problems. By allowing the model to learn from reliable sources like the WHO and scientific literature. As RAFT improves factual consistency and adaptability in contrast to conventional fine-tuning techniques, this method makes sentiment classification more dependable for practical uses in public health and policy analysis by ensuring that it stays strong, explicable, and impervious to false information.
Our contribution
In this proposed investigation, our main contributions can be distilled as follows:
We propose a novel RAFT framework customized for textual sentiment analysis of COVID-19 vaccines. By providing external domain-specific resources, the hallucinations of LLMs were reduced The inclusion of fine-tuning LLMs with parameter-efficient tuning and Quantized LoRa
8
to analyse social media tweets enabled the learning model to understand public perceptions of the COVID-19 vaccine. Inclusion of Retrieval augmented Generation with customized semantic sentence similarity RAFT for better domain adaptation which enhances the reliability of sentiment classification.
The remaining section of the paper is organized as follows: Section 2 discusses the related works of the approach. Section 3 discusses the proposed system design. Section 4 discusses the evaluation approach for the system. Section 5 presents the conclusion and summary of the work.
Related work
This section discusses domain specific and LLM based sentiment analysis approaches in three categories. The first category includes approaches that use domain-specific knowledge from different domains, such as health and finance. The second category includes approaches that use deep learning and transfer learning-related methods. The third category includes approaches that use LLM as a pretrained model,involving fine tuning or RAG.
Domain specific approaches
Aye Hninn Khine et al. proposed a new word embedding technique that learns the context from medical-related 9 sources and generates a domain-specific embedding, which is then passed to the convolution layer to learn the features. It achieves an accuracy maximum of 99.1% when the concatenated embeddings are tested with the medical review dataset. A new method to address word sense disambiguation in the Portuguese language was proposed 10 by using the fine-tuned version of BERT, which was trained on a task- and language-specific dataset and achieved 84% accuracy. To improve the domain-specific task, packages such as RSENTIMENT and STNZA have been developed, and the related evaluation measures were discussed by Amin Mahmoudi et al. 11 Bi-LSTM with capsule networks trained on a specific knowledge base performed well in hating speech identification and achieved an F1 score of 0.94. 12 A GUI-based tool was developed to support the coreference resolution of entities and events in multiple languages via node-based special annotations. 13 To increase the robustness of sentiment analysis, perturbations must be handled to leverage quantification. The method used to address this problem involves a fusion attention mechanism with graph embedding, which interprets the alteration and improves the accuracy by 93%. 14 Semantic linguistic rules also play a vital role in addition to semantic embedding via an attention mechanism, and they increase the performance of the system. 15 Hongtu Xie et al. 16 proposed a dialogue generation model based on an external knowledge base by preserving entity aware intention in dialogs with a two-stage training method and achieved 94% accuracy. To enhance the contextual understanding of ecommerce Chinese text, a unique embedding Attention capsule network 17 was developed, and it outperformed with 82% accuracy. The context of the sentiment changed with evolving time. To meet this challenge, a method was proposed to utilize knowledge graph embedding, which was concatenated with BiLSTM embedding and further processed with attention, and it obtained 84.72% accuracy with the REST14 dataset. 18 The perception capture system has also focused on specific cases, such as depression detection and vulnerability detection. In today's AI landscape, there is a significant demand for enhancing depression detection in social media forums. Detection, particularly in Weibo comments, was demonstrated by using domain knowledge-enhanced lexicons and an ensemble of eight machine learning models and achieved 94% accuracy (Z. 19 During the COVID-19 pandemic, depression rates were high due to constraints such as social isolation and financial instability. A multimodal framework was developed to detect depression by using extrinsic features taken from URLs and a visual feature vector generated by mining a user's post and related tweets, resulting in 91% accuracy. 20 A new lexicon generation model was created to incorporate vocabulary extension and porting to improve bilingual emotion detection with 73.24 accuracy. 21 The financial domain significantly contributes to sentiment analysis by providing insights into market trends and economic indicators. This case demands financial domain-specific lexicons or models. Prompt fine-tuning based on a lexicon was crafted instead of using an external knowledge base. In addition, the model also uses a pretrained model for fine tuning, yielding the lowest MAE of 0.384. 22 To handle domain-specific texts, emotion tagging with multiple labels, 23 the weighted voting technique, 24 and explainable specific lexicons 25 were established.
Extracting valuable information from COVID-19 pandemic or vaccine-related tweets demands the use of specialized domain-specific techniques. The mask attention model 26 was designed to identify the presence of personal health-related words. The epidemic season was analysed, and an information diffusion model using a Markov chain was developed to understand the impact of vaccination by Cong Li et al. 27 The importance of sentiment analysis in epidemic periods is crucial. 28 Language-specific medical entities were infused into the traditional Unified Medical Language System to enhance sentiment detection. 29 Xiangpeng Wan et al. discussed the evolving conversation around COVID-19 through topic modeling and analysed American digital news via the BART algorithm. 30
Other domain-related aspects were also prominently featured in the research, shedding light on their significance and implications. Noor Afiza Mat Razali et al. created a methodology employing hybrid lexicons and machine learning models for predicting political security threats. 31 A DNA fine-tuned language model 32 was built to determine the sequence specificity of DNA-binding proteins since the majority of DNA dependencies were eliminated via standard one-hot encoding. The Holy Books-specific model 33 and language-specific models 34 have garnered attention for their specialized approach. The Portuguese language-specific perception capture system yielded an F1 score of 0.91. The modified switch-based transformer 35 was designed to address Arabic sentiment analysis and attained an F1 score of 0.83. 36
Transformer-based and deep learning-based approaches
Table 1 highlights the related methods that use deep learning and transformer-based models employed in sentiment analysis.
Related methods based on transformer based models.
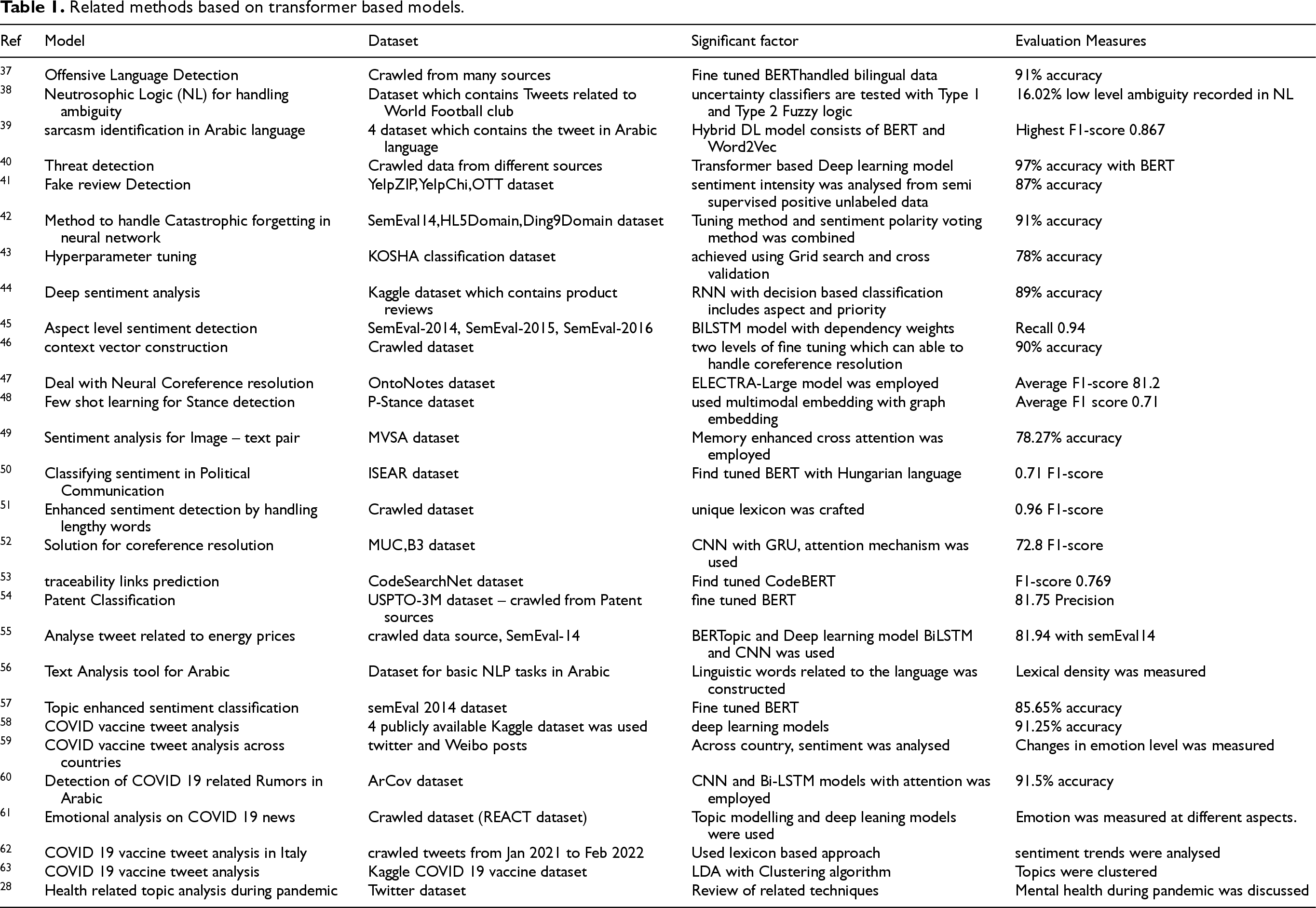
Related methods based on transformer based models.
Recent advancements in transformer architectures have significantly influenced both vision and language domains, driven by their ability to model long-range dependencies, dynamic context interactions, and hierarchical attention patterns. In the visual domain, WaveFormer 64 incorporates wavelet-based decomposition into transformer attention to enhance noise resilience in video inpainting, while ViGT 65 uses learnable tokens that dynamically attend to key regions to exhibit proposal-free video grounding. BVINet 66 takes this further by achieving blind video inpainting with zero annotations, leveraging masked token modeling similar to BERT-style self-supervised learning. In order to condition transformer-based image editing, Prompt-Aware Controllable Shadow Removal 67 incorporates textual prompts into the vision pipeline, demonstrating cross-modal flexibility.
Additionally, transformers can capture complicated temporal patterns and refine ambiguous samples using class prototypes, as demonstrated by hybrid temporal modeling for repetitive action counting 68 and prototypical calibration for micro-action detection. 69 When taken as a whole, these pieces show a developing trend in transformer adaptation for context-sensitive, fine-grained tasks in both spatial and temporal dimensions.
Parallel to these developments in vision, the textual domain has seen complementary innovations that similarly enhance transformer capabilities through retrieval, pretraining, and few-shot adaptation. While KILT 70 created a benchmark suite for knowledge-intensive activities to standardize evaluation, REALM 71 and RETRO 72 offered retrieval-augmented generation paradigms that integrate external knowledge into language models to increase factual accuracy and domain generalization. RAG frameworks for claim verification in the scientific realm were expanded by SciFact-RAG, 73 which demonstrated the value of integrating retrieval with generative reasoning in specific contexts.
DeBERTaV3 with prompt tuning 74 also showed that soft prompt-based transformers can perform well in few-shot sentiment categorization, particularly in domain-specific or low-resource settings. Together with the architectural patterns seen in vision, these pieces show a path toward convergence where token-level control, context-aware embedding, and prototype-informed inference are advantageous for both modalities. By combining retrieval-aware representation learning with semantic generation specifically designed for textual data, our work builds a domain-specific RAG transformer for sentiment analysis based on these common ideas.
With the boom of large language models, there has been a significant transformation in various fields, including NLP and artificial intelligence. As these models are continuously evolving, the integration of these into various aspects of society will lead to further innovation and shape the future of technology.
Llama is a model released by Meta, which was employed with PEFT to review the code automatically by Junyi Lu et al. 75 Since it is a generation task, it outperforms the evaluation measure BLEU score by 81.87. Mohaimenul Azam Khan Raiaan et al. discussed 76 the trends and challenges of large language models from BERT to Llama, such as the complexity of fine tuning, contextual constraints and complexity in evaluation. Zhe Li et al. developed(Z. 77 a fine-tuned language model for understanding agglutinative languages. The performance of LLMs such as GPT and FLAN-T5 was analysed across different benchmark datasets in sentiment detection, 78 which revealed the significance of prompt learning in the NLP field. Zero-shot learning performance was discussed with various language models across crypto-related tweets, from which DistillBERT achieved 91.87% accuracy. 79 LLMs also play significant roles in energy modelling. 80 A fine-tuned version of LoRA with a language model was employed to create a remarkable impact on tasks such as question answering and chat. 81 Large language models can be fine-tuned with biomedical-related sources such as PubMed 82 to perform domain-specific downstream tasks. Xinjie Sun et al. constructed a domain-specific knowledge base by means of pretrained language models and incorporated it for aspect-based sentiment detection of product reviews, which yielded an accuracy of 88.6%. 83 For low-resource languages, data augmentation was performed via language models and achieved significant performance improvement. 84 Rui Cao et al. designed a dictionary-based prompt tuning method using pretrained language models to emphasize the detection of domain-specific words. 85 Prompt-based learning has demonstrated improved performance in GLEU evaluation results when fine-tuned for specific languages. 86 This approach also excelled in code generation tasks across various programming languages, such as Go, Ruby, and Python, particularly when parameter-efficient fine-tuning was employed in low-resource settings. 87 Apart from the performance of LLM in summarization or generation, 88 it also assists in finding domain-related specific topic importance detection. ShaoBo Sun et al. used prompt learning to detect topic importance with respect to sentiment for financial news. For this purpose, the system 89 used Chinese financial news with a specific prompt-templated-based learning method involving multiple tasks and yielded 88.74% accuracy. Clinical nursing notes provide more domain-specific information. LLMs such as Llama performed well, with 89% accuracy in testing with these nursing records, which included ICD-10 codes and other patient information. 90 Konstantinos I. Roumeliotis et al. employed models such as Llama and GPT for training with e-commerce-related tweets and analysed their impact. 91 Fine-tuned models are employed across a diverse range of fields, highlighting their versatility and adaptability. In the cybersecurity domain, 92 they are used to detect specific terms related to threats and vulnerabilities, aiding in sentiment analysis and topic modelling to better understand and anticipate potential risks. In the financial sector, 93 these models analyse data to identify patterns indicative of crises, providing critical insights for preventive measures and strategic planning. Legal professionals 94 utilize fine-tuned models to evaluate and interpret complex regulations and rules, streamlining the analysis process and ensuring compliance. In the education sector, these models assess student responses, 95 generating scores that reflect understanding and performance, thereby contributing to more personalized and effective learning experiences. This broad application demonstrates the significant impact of fine-tuned models in enhancing decision-making and efficiency across various industries.
According to earlier research, transformer-based models require a lot of labeled data and have trouble in adapting to specific domains. By including domain-specific retrieval, RAFT lessens this problem and enables improved adaptation with fewer fine-tuning parameters.
Proposed COVID-19 vaccine textual sentiment analysis
Our proposed system for the COVID-19 vaccine TSA consists of three main modules : One was the fine-tuning LLM, the second was the RAG with custom similarity, and the third was the combination of both fine-tuning and the customized RAG. The proposed work is shown in Figure 1.
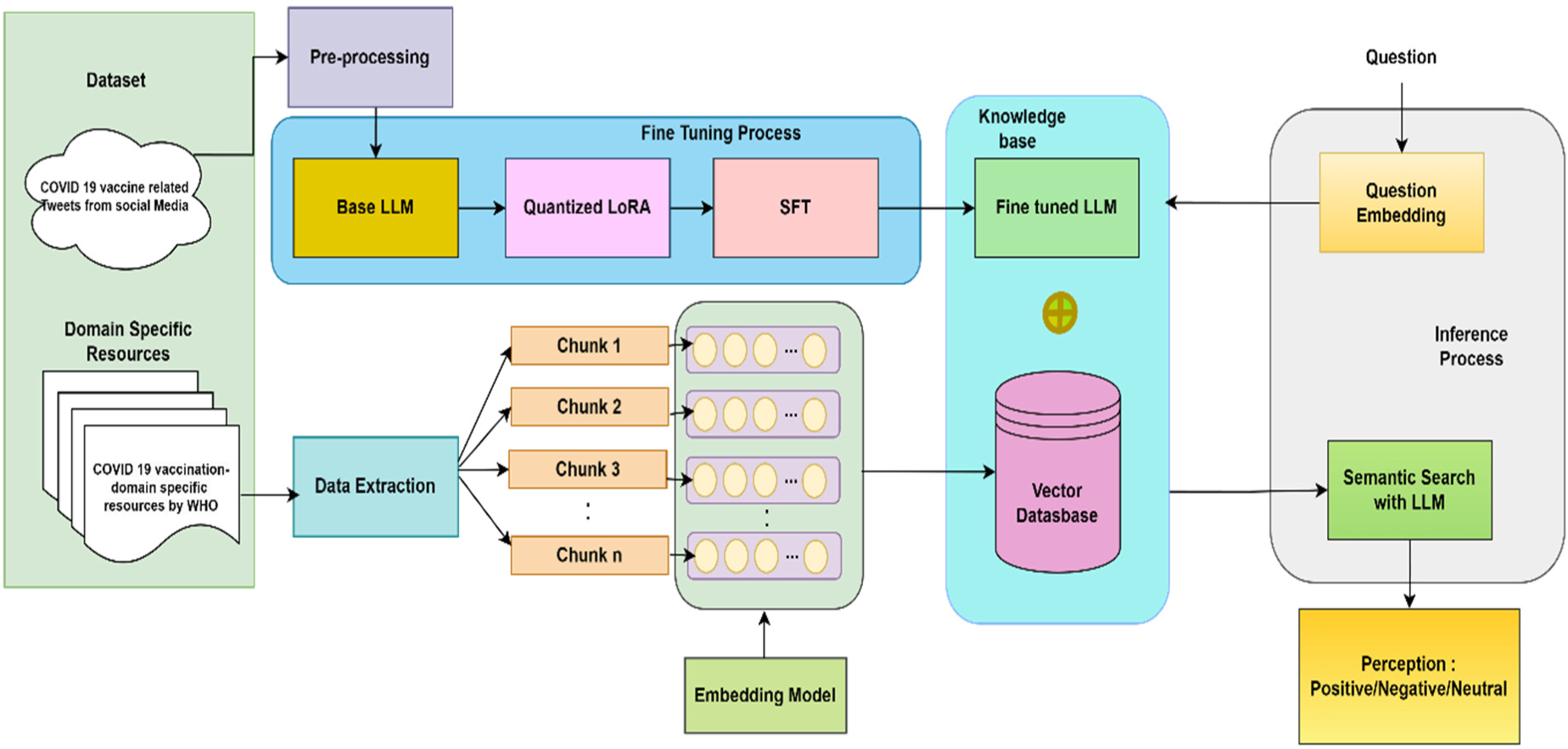
Proposed framework for COVID-19 vaccine TSA.
The dataset used for this research is collected from the X platform (known as ‘twitter’) via COVID-19 vaccine-related keywords (TD dataset). Developers must provide detailed use case examples and explain how tweets will be accessed for the chosen use case. Tweets were collected from July 2020 to March 2022 in India via keywords such as ‘COVID-19’, ‘Corona’, ‘COVID-19 vaccine’, ‘vaccinated’, ‘vaccination’, ‘pandemic’, ‘corona outbreak’, ‘corona wave’, and ‘vaccination campaign’. A total of 2,00,940 tweets were collected based on these keywords.
The TD dataset contains tweets from the Indian region. We also included a second dataset from Kaggle, 96 which included 228,207 tweets from different parts of the world, to examine the sentiment of COVID-19 immunizations globally (KG dataset). The majority of the tweets in the dataset are in English.Both datasets have a target column that depicts the polarity of tweets: ‘Positive’, ‘Negative’ and ‘Neutral’. Table 2 lists the complete information of the dataset.VADER (Valence Aware Dictionary and sEntiment Reasoner),a popular lexicon-based sentiment analysis tool, 6 was utilized to accomplish the annotation. VADER is appropriate for social media text analysis since it uses linguistic heuristics to assign sentiment scores.
Details of the dataset.
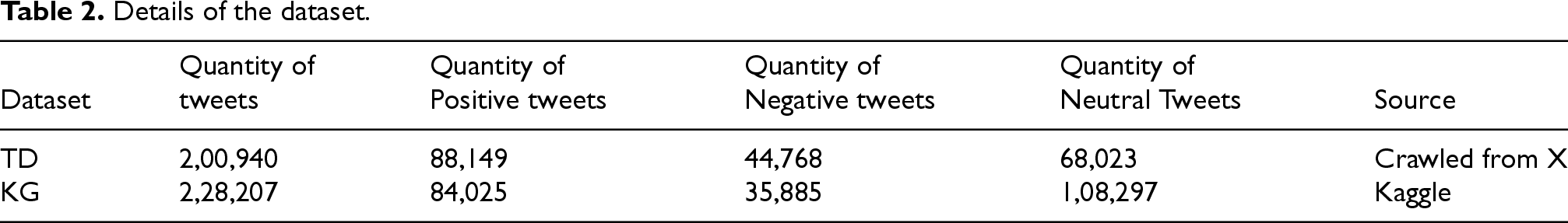
Details of the dataset.
Fine tuning allows the model to perform task-specific analysis. Since the proposed system focused on the COVID-19 vaccine TSA, it is an essential step in the learning process. It consists of the following steps:
Preprocessing the dataset Base LLM initialization Creating a prompt template Configuration of Parameter Efficient Fine Tuning with Quantization Fine-tuning process
Preprocessing the dataset
The dataset has columns such as id, name of the user, location of the user, description of the user, number of followers of the user, number of user friends, user_favorites, verified user or not, date, tweeted text, used hashtags, relevant source, retweet information, favourites, retweets or not and sentiment of the tweet. From this, only two columns were taken for mining: ‘text’, which contains the text content of the tweet, and ‘sentiment’, which contains the target label. From the text column, hyperlinks and emojis were removed since the base LLM chosen was trained to analyse the unstructured text content. These preprocessing was implemented using NLTK package. Figure 2 represents the word cloud form of positive, negative and neutral classes from the Global Tweets dataset. This pre-processed data was given as input to the base language model for training after the completion of the necessary configuration and prompt template creation.
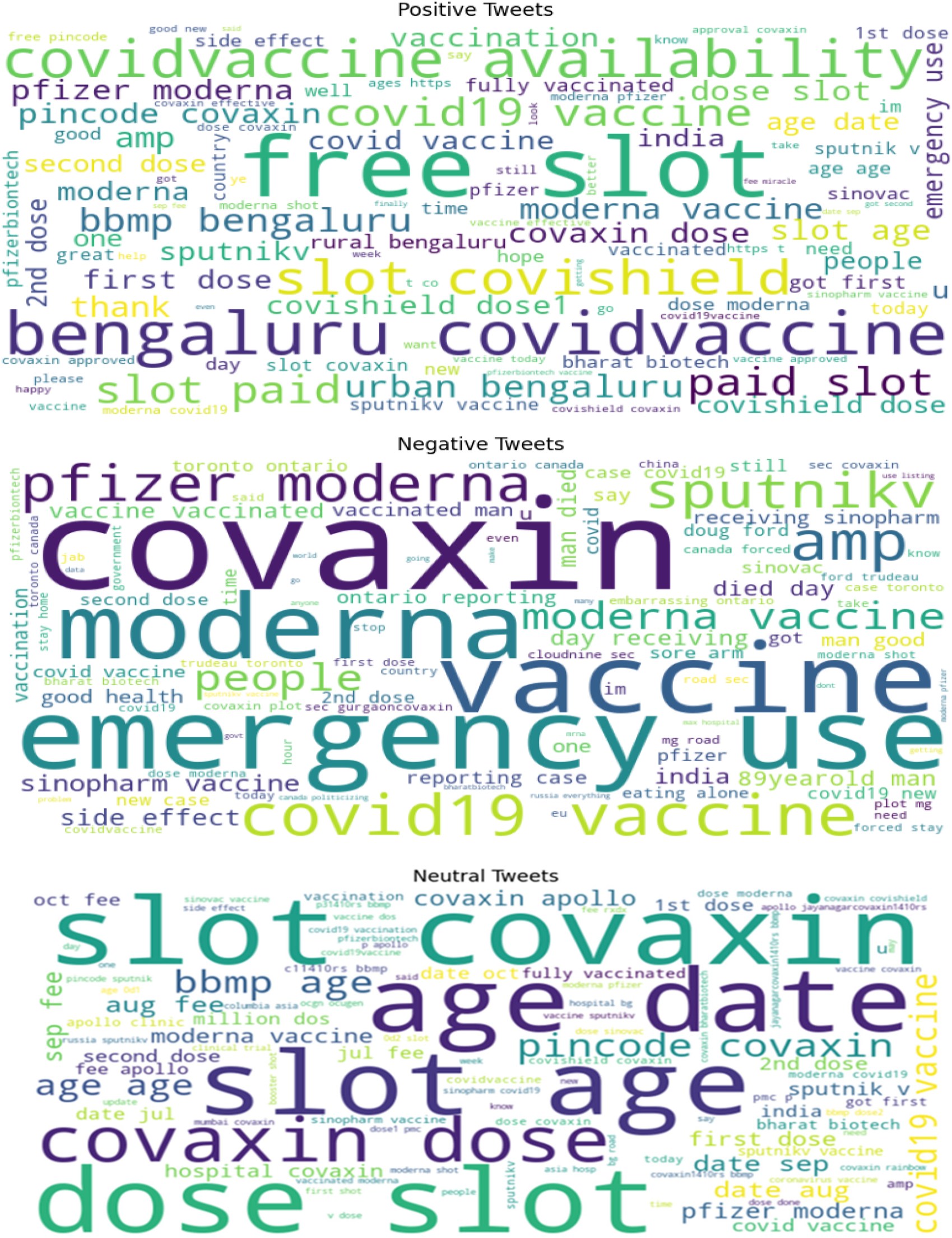
Word cloud representation of Tweets for Twitter dataset.
Owing to the abundance of large language models, the proposed framework uses the llama-3-8B model for fine-tuning and the RAG framework. This choice capitalized on the immense capacity of the llama-3-8B model to understand and process complex languages, providing a strong starting point for fine-tuning the model towards sentiment analysis of COVID-19 vaccines. By utilizing the RAG framework, the fine-tuning process can be further enhanced, potentially leading to more accurate sentiment analysis. This can be particularly useful for understanding language or references that the model might not have encountered in its pretraining data.
Creating a prompt template
This function created a consistent and well-defined prompt template for COVID-19 vaccine TSA. It leverages predefined instructions and incorporates specific text and sentiment labels from the training data to guide the large language model during the training process. An illustration of the creation of a prompt template from the dataset is shown in Figure 3. A prompt template was formed to instruct the LLM to perform the specific task. It was created with static strings such as the Introduction_string, Instruction, Input and Response and End key. The instruction_string provided the basic idea to the base LLM. Instruction offered the task specificity, and it needed to be combined with the text column where the response has to be integrated with the target column. End depicted the end of the prompt.
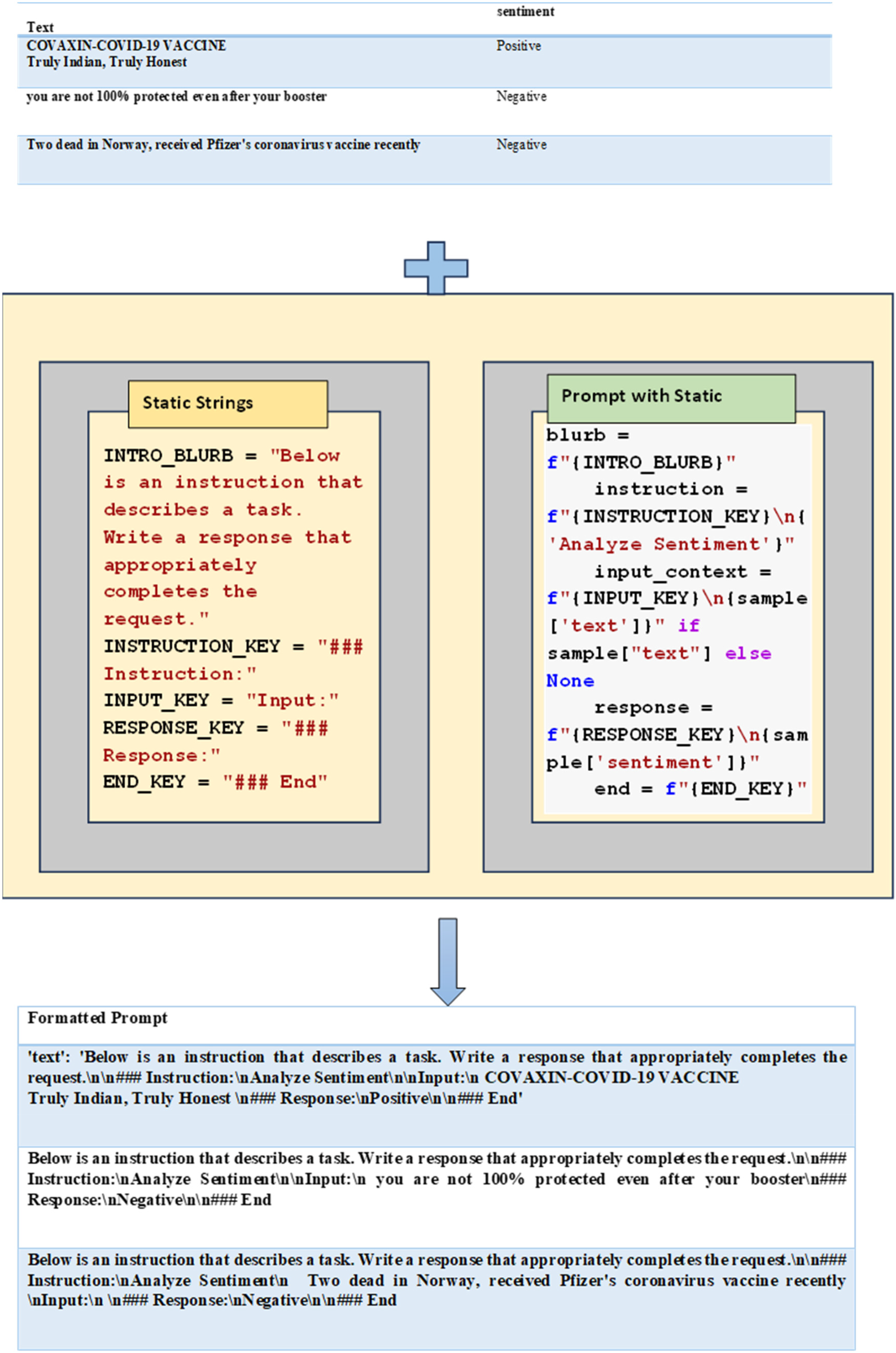
Workflow illustrating the creation of prompt templates derived from the dataset.
Training a massive number of parameters increases training time and energy consumption. This makes the model difficult to train on devices with low constraints. QloRA addresses this issue by introducing a small set of trainable “adapters” that capture task-specific information. This keeps the number of trainable parameters minimal. PEFT with QLoRA allows the powerful Llama3 model to be fine-tuned on specific tasks even with limited resources. This approach strikes a balance between efficiency and performance, making large language models more accessible and manageable. By training only the adapter layers, QLoRA focuses on learning sentiment-related patterns instead of retraining everything. This can help mitigate the influence of biases and misinformation present in the training data.
Fine-tuning process
After completing the necessary configurations, the language model was trained with the supervised fine-tuning module. It iterates through batches of text snippets from the dataset. Each snippet passes the text through the pretrained model and then through the adapter layers. It calculates the loss on the basis of the predicted sentiment and the labeled sentiment in the dataset. It uses the loss to backpropagate and update the weights of the adapter layers and the quantized weights. This iterative process continues until the model converges or a predefined number of training epochs is completed. As the RAFT framework is employed, fine tuning is integrated with the RAG for the final loss calculation.
Naïve RAFT framework
The system works with a naïve RAG framework for enhancing domain-specific knowledge from external sources. The following are the crucial components of this framework: knowledge sources, embedding generation and RAFT retrieval.
External knowledge sources
To understand the facts related to COVID-19 vaccines, the system depends on the domain-specific external knowledge sources as listed in Table 3. For this case, PubMed articles are not considered since the objective is to analyze the public opinion which does not require the extensive scientific literature.The main sources of the information includes the following:
External knowledge sources.
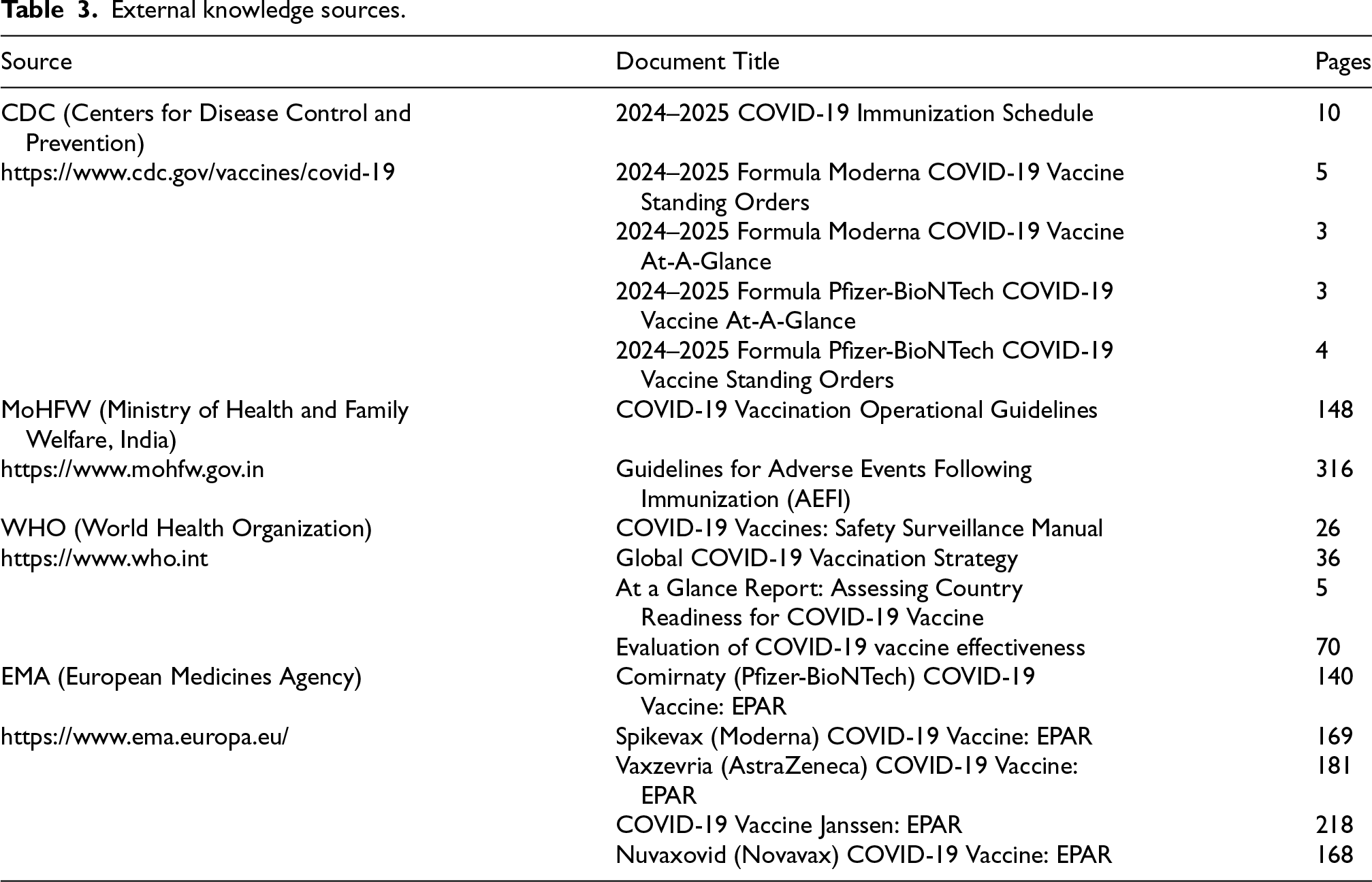
External knowledge sources.
COVID-19 vaccine regulations
This source contained documents related to COVID-19 vaccine regulations released by the WHO. It provides internal guidelines and regulatory information including key aspects such as dosage and booster doses.
Vaccine approval:
These documents were released by the Ministry of Health and Family Welfare, India. It contains information related to all approved vaccines, including their dosage information and possible side effects
COVID-19 vaccine operational guidelines
This source was released by the Ministry of Health and Family Welfare, India. This covers information about communication and social mobilization before and after vaccination, adverse events following immunization, details of the Co-WIN platform and the overall vaccination process. They also highlight the preventions and measures to be taken during pandemic. In addition to these sources,relevant literature on COVID-19 vaccines was incorporated into the RAG framework. All these documents contained the factual information that was used when the LLM was fine-tuned with a retrieval framework.
The naïve RAG framework uses cosine similarity or the Euclidean distance for semantic search. In this approach, we improve the semantic search by generating an embedding through sentence BERT. SBERT is a pretrained model that outperforms many SOTA results. 97 Our RAG framework leverages SBERT for embedding generation. The generated embeddings were stored in a vector database, which is a popular storage space for vectors in the LLM retrieval process. In our framework, we use Chroma DB as the vector database. Documents from the knowledge sources were split into chunks, and for each chunk, embedding was generated and stored in the ChromaDB which inturn enable efficient retrieval.
RAFT retrieval
Embeddings were generated for both the query and the retrieved documents. These embeddings are dense vector representations that capture the semantic meaning of the text. During the fine-tuning process, the model uses the embeddings generated from the Chroma DB to retrieve the result. It enhances the ability of the model to learn from a large amount of domain-related data for improved performance on downstream tasks such as sentiment analysis. An attention mechanism was used to determine the most important and relevant portions of the retrieved documents. The internal parameters of the model were updated on the basis of the input data and the content of the retrieved documents, which was guided by the attention weights. RAFT retrieval allows the model to eliminate the limitations of pretrained data by accessing and leveraging information from the ChromaDB. This approach benefits tasks that require domain-specific knowledge.
Compared with retrieval-based approaches, RAFT achieves reduced factually incorrect outputs by integrating relevant knowledge directly into the model during fine-tuning, which eliminates the need for external document lookups during generation.
Algorithmic framework
The proposed fine-tuned COVID RAFT for domain-specific knowledge is depicted in Algorithm 1. The inputs were queries, domain-specific documents and data, which were used to fine-tune the base LLM model. Here, the base LLM model was chosen as Llama 3.

Equation (1) represents the initial query embedding, which is generated with 768 dimensions represented as d embedded in the
The quantization process fine-tunes the model to optimize computational and memory efficiency. This involves the quantization of model parameters by means of applying low-rank factorization, which can be highlighted as follows:
where Regularization (
After the integration of the RAG, the process moved to response generation from the fine-tuned and optimized LLM, which is depicted in Equation (8). The response generated will be within the 3 possibilities since the prompt input was designed such a way to generate classification as positive or negative or neural. Equation (9) and Equation (10) represent the result fetching and the evaluation with respect to the test data, respectively.
Experimental results and discussions
In this section, we compared the proposed COVID-19 RAFT system with various other language models with fine-tuning and RAG methods. The base LLM for this approach was Llama-3-8B. It was trained with an NVIDIA A40 GPU with quantization hyperparameters he number of training epochs was fixed at 10, and the total training time was approximately 65 min. The model weights are subsequently stored and used for the inference process. The hyperparameter values are listed in Table 4.
Hyperparameter configurations applied in the model training phase.

Hyperparameter configurations applied in the model training phase.
Consider this tweet : “I got my COVID-19 vaccine today! Feeling great and happy to be protected. #VaccinesWork”. For this case retrieved documents are :
WHO – COVID-19 Vaccines: Safety Surveillance Manual which confirms vaccines are safe and effective.
CDC – 2024–2025 COVID-19 Immunization Schedule which lists recommended vaccines and schedules.
MoHFW – COVID-19 Vaccination Operational Guidelines which Provides guidance on vaccine administration.
Fine tuned LLM with the help of these Retrieved documents, the sentiment was evaluated as Positive.
For this tweet: the COVID-19 vaccine contains microchips to track people! Don’t trust the government!”
WHO – Global COVID-19 Vaccination Strategy which addresses vaccine misinformation.
EMA – Comirnaty (Pfizer-BioNTech) COVID-19 Vaccine: EPAR which provides scientific details on vaccine composition (no microchips).
MoHFW – Guidelines for Adverse Events Following Immunization which Describes real side effects, not conspiracy claims.
With this, Fine tuned LLM evaluate this as Negative.
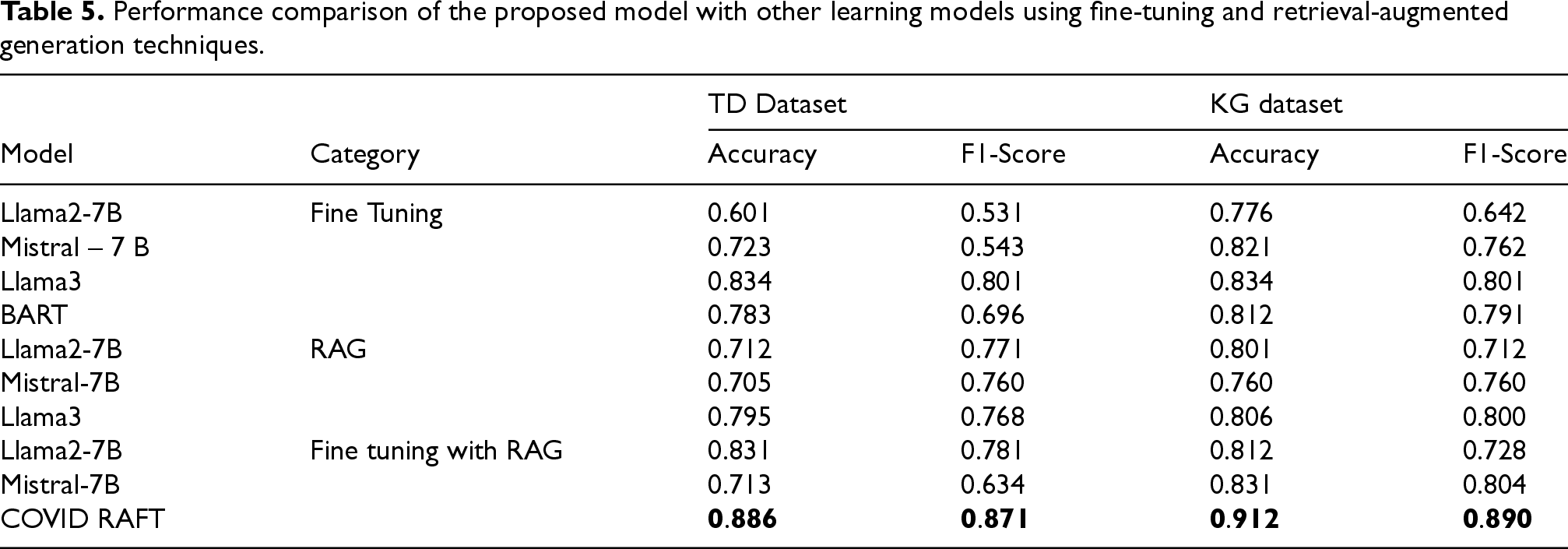
We compared our model with many other LLMs with fine tuning and with RAG separately. For comparison, we used Mistral 7B model, the Llama 2–7B model and BART. Table 5 depcited the evaluation metrics, including accuracy and F1 score. The evaluation was performed under 3 categories. First, the models are evaluated after fine tuning on the dataset. Second, the model was integrated with a RAG and tested with user prompts. Finally, the model was integrated with the RAFT framework. Table 5 shows that Llama 3 and Llama 2 performed better in fine tuning and RAG than the other models did. Within the RAFT framework, Llama 3 outperformed the other language models, which showcases the effectiveness among all evaluated models.
Performance comparison of the proposed model with other learning models using fine-tuning and retrieval-augmented generation techniques.
Since the framework was integrated with a quantized low-rank adapter for efficient fine tuning, we can train our model with an NVIDIA A40 GPU. For the evaluation of RAG, metric RAGAS (Shahul Es, 2023) was used. In particular, we make use of Context Precision (CP), Answer Relevance (Ansel), Answer Correctness(Ans correct), Answer Similarity(Ans_Sim), and Context Recall(CR). The cosine similarity is used to produce the Answer Relevance measure, which evaluates how relevant the generated response is to the query. Table 6 shows the evaluation of RAG with COVID RAFT framework.
Evaluation results of the retrieval-augmented generation framework.

Ans_Sim =
Ans_correct =
RAG shows less performance in all the models since it has only factual knowledge. While it encountered the tweet, it failed to obtain the context at appropriate. Figure 4 shows the loss curve of COVID RAFT.
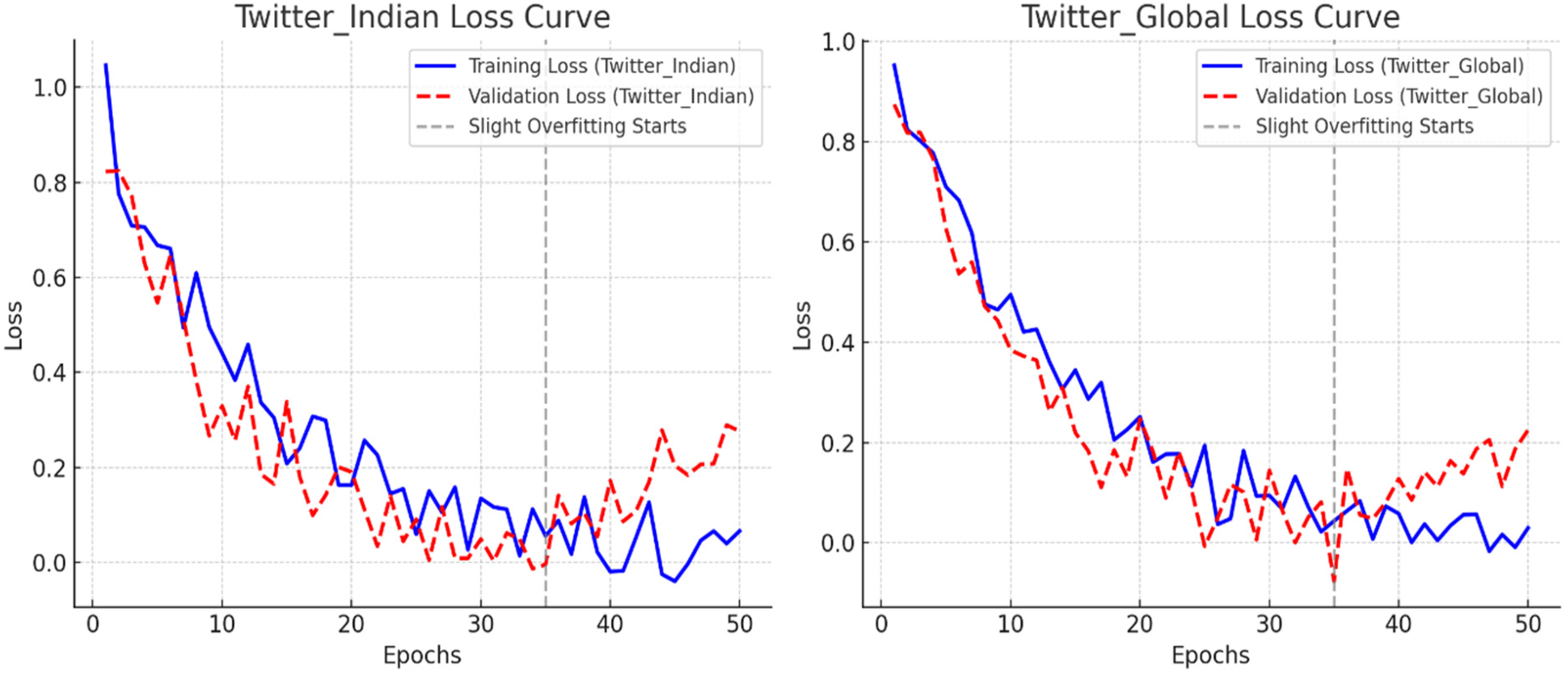
Comparison of training and validation loss curves for the Twitter_Indian and Twitter_Global datasets.
Plots of the model's performance over epochs reveal a moderate drop in loss and a little amount of overfitting following epoch 35. Figure 5 shows the RAFT framework results for the language models. The proposed COVID-19 RAFT framework outperformed the remaining models. Comparatively, the KG dataset yielded better performance than the TD dataset since the TD dataset had minimal language complexity. Since our model focused on a single language English, it skipped the code mixed data. To address code mixed data, a specific language model must be developed with additional low-resource language-related knowledge bases.
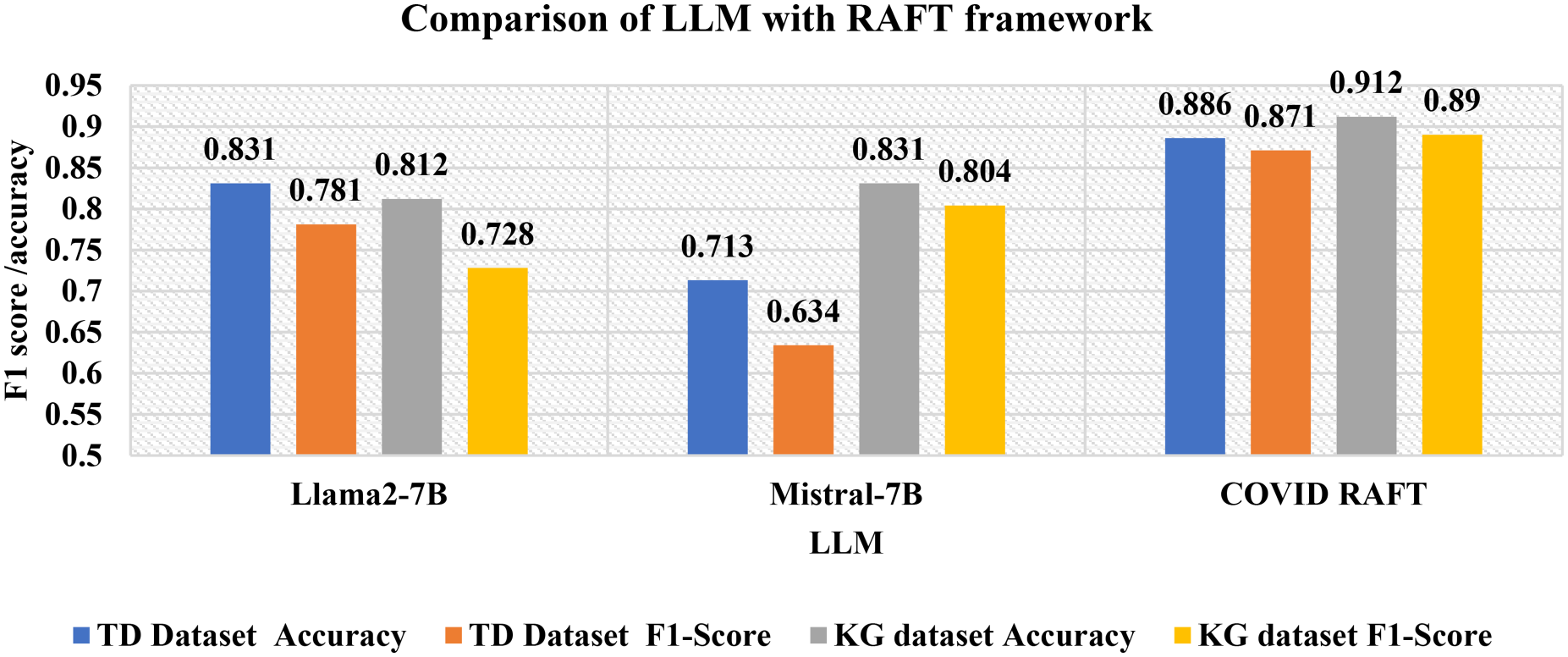
Language model comparison with RAG.
This work presented COVID-19 RAFT, a framework that uses LLM fine-tuning for COVID-19 vaccine TSA on Twitter. In addition to standard fine-tuning data, COVID RAFT leverages a RAG method for incorporating domain-specific knowledge. External sources such as documents released by the WHO, the Ministry of Health and Family Welfare and literary documents focused on the COVID-19 vaccine were used as knowledge bases for the RAG framework. Fine tuning leveraged the KG and TD datasets, which focused on COVID-19 vaccine tweeting analysis. After developing a fine-tuned LLM that integrates SFTs with PEFTs, the model uses the embeddings from the Vector Database. Query tweet embeddings were generated and compared with vector DB embeddings via BERT-based semantic search rather than cosine similarity to enhance the contextual understanding of the COVID vaccine domain. We compared our approach with other language models in terms of fine-tuning, RAG and RAFT aspects. On the TD dataset, it achieved an accuracy of 0.886 and a robust F1 score of 0.871. The KG dataset yielded an accuracy of 0.912 and an F1 score of 0.89. The first approach used for the COVID-19 vaccine domain was leveraging domain knowledge for the sentiment analysis task. We achieved the greater accuracy (0.912) attained on the Twitter_Global dataset as opposed to the Twitter_Indian dataset (0.886). Language diversity, dialectal variances, or regionally distinctive expressions in Indian tweets that might not be as well-represented in the underlying knowledge base could be the cause of this disparity. Furthermore, worldwide tweets might have more uniform linguistic patterns, which would facilitate more precise classification. In Future, improving retrieval algorithms to better capture regional language nuances will helps to boost the accuracy. Moreover, this RAFT can be enhanced in future to check the fact and misinformation detection.
Footnotes
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
This work presents a dataset of COVID-19 vaccine tweets related to both India and global regions. This dataset is available upon reasonable request from the corresponding author. Additionally, developers can collect similar data using the Twitter API, accessible through a Twitter developer account, available at ![]()