
Abstract
Although ambiguity in label information poses challenges in the multiple-instance learning (MIL) paradigm, it has consistently drawn attention in various fields through the development of machine learning or neural network techniques. These approaches often demonstrate reasonable performance as solutions for MIL problems, but also suffer from a lack of interpretability. Meanwhile, case-based reasoning reinforces interpretation based on inference by identifying key causal factors. Building on this advantage, we propose MIL-CBR with a standard neural network: the neural network directly predicts bag labels by penalizing a positive bag with a lower score compared to a negative bag, where a bag consists of a pair of instances representing heterogeneity measured by Spearman’s correlation coefficient. MIL-CBR demonstrates comparable or superior performance against benchmark approaches. While no single approach dominates across all datasets, MIL-CBR showcases the potential of case-based reasoning as an effective solution for MIL problems.
Introduction
Label ambiguity is a challenge in multiple-instance learning (MIL), particularly since the introduction of molecular detection problems within the MIL paradigm, 1 which has consistently drawn attention across diverse domains.2–4 Within this framework, label information is associated with groups of instances, which are referred to as bags and labeled as either positive or negative. According to the standard assumption of MIL, a bag is labeled as positive if at least one of its instances is positive while a bag is labeled as negative if all instances in the bag are negative. Ambiguity arises in that we do not know which instance is positive in the bag. This insufficient label information always presents a challenge for MIL to achieve satisfactory performance compared to supervised learning. In particular, since models for MIL have to supervise entire sets rather than individual instances, it poses a fundamental problem in interpreting results with generalization. As a result, conventional machine learning models fail to effectively predict MIL problems.
Some techniques have been developed to solve MIL problems using machine learning.5–9 These approaches have adjusted traditional machine learning algorithms to the MIL paradigm or selected single representative instances based on embedding mappings. Additionally, neural network-based approaches have been developed that generate embedding mappings using convolution blocks10,11 as deep learning techniques have rapidly expanded. However, a shortcoming of these techniques is their lack of interpretability. To overcome this shortcoming, we propose a case-based reasoning approach within the MIL framework. While existing approaches based on neural networks incorporate an additional layer for pooling, our approach directly predicts labels using a standard neural network trained with pairs of instances that are selected based on a similarity metric.
After this introduction, we highlight benchmark algorithms in the next section. The problem is formulated based on standard assumptions, and we summarize our proposed approach, referred to as mi-CBR throughout the paper, after briefly describing the CBR procedure. The proposed approach is comprehensively evaluated in comparison with traditional benchmark algorithms in the Experiments and Results section. Finally, we discuss the strengths and limitations of our approach.
Related works
There are several well-received foundational algorithms under the MIL paradigm. The mi-support vector machine (mi-SVM) and MI-SVM 5 adapted support vector machines (SVMs) to the MIL setting by iteratively implementing SVMs to identify the maximal-margin hyperplane under the standard assumption of MIL. The mi-SVM assumes that at least one instance in a positive bag lies in the positive half-space, while MI-SVM assumes that the positive bag itself lies in the positive half-space. Diverse-density (DD) 7 and expectation-maximization (EM)-DD 8 have also gained significant recognition. These algorithms focus on identifying the most important features. 8 DD finds the target concept in the feature space by considering the likelihood of a hypothesis explaining both the presence of instances in positive bags and the absence of instances in negative bags near the location. DD estimates feature importance as feature values with scales, determining the location that maximizes DD. Later, EM-DD combined the EM technique with DD to identify the maximum DD, replacing the two-step gradient descent search method. Additionally, embedding mapping over feature space has been applied to MIL. MI learning via Embedded Instance Selection (MILES) 6 computes the maximal similarity between two instances selected by a 1-norm SVM and conducts SVMs over the feature space with maximal similarity for classification. This approach is straightforward yet facilitates instance classification based on scores representing each instance’s contribution to determining the bag label. These approaches assume instance independence. This assumption is relaxed in mi-graph, 9 which represents the bag as an undirected graph with instances as nodes. Mi-graph classifies affinity matrices containing clique information using a graph kernel. In the context of undirected graphs, instances are treated as interrelated components, potentially capturing relational information for learning. Recently, neural networks have been adapted to MIL paradigm. Mi-NET 10 predicts bag labels by pooling instance predictions. This approach typically convolves feature maps using different filter sizes and aggregates all instances into a bag. However, it is limited in explaining the importance factors, even for instances crucial to prediction. ProtoMIL 12 predicts bag labels through a case-based reasoning approach by dividing whole slide images into smaller patches to analyze similarity with prototypical parts. After accumulating similarity results, it predicts bag labels by adding another layer to the neural network. ProtoMIL applies attention weights to the most important patches, providing additional interpretation unlike other methods. Building on this advantage of enhanced interpretability, we propose a case-based reasoning approach using a simple neural network architecture. While traditional MIL implementations require additional neural network layers, our method operates with standard neural networks within a case-based reasoning framework.
Methods
Problem formulation
Suppose that there is
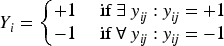
Case-based reasoning
Case-based reasoning is an artificial intelligence technique based on inference with four cyclic processes: retrieval, reuse, revise, and retain.13,14 When a target case occurs, the model retrieves cases from the case-base and revises the solution of previous cases in similar situations to solve the problem. Once the problem is solved, the target case is retained in the case-base for further reference. 15 Based on this cycle, the case-based reasoning approach always has its case-base up-to-date. This approach integrates machine learning or deep learning by retrieving the most similar case to the target through rules such as k-nearest neighbors or eager learning through transformation.16–20
MIL-CBR
The procedure of MIL-CBR can be illustrated in Figure 1 to adjust case-based reasoning inference to MIL problems:
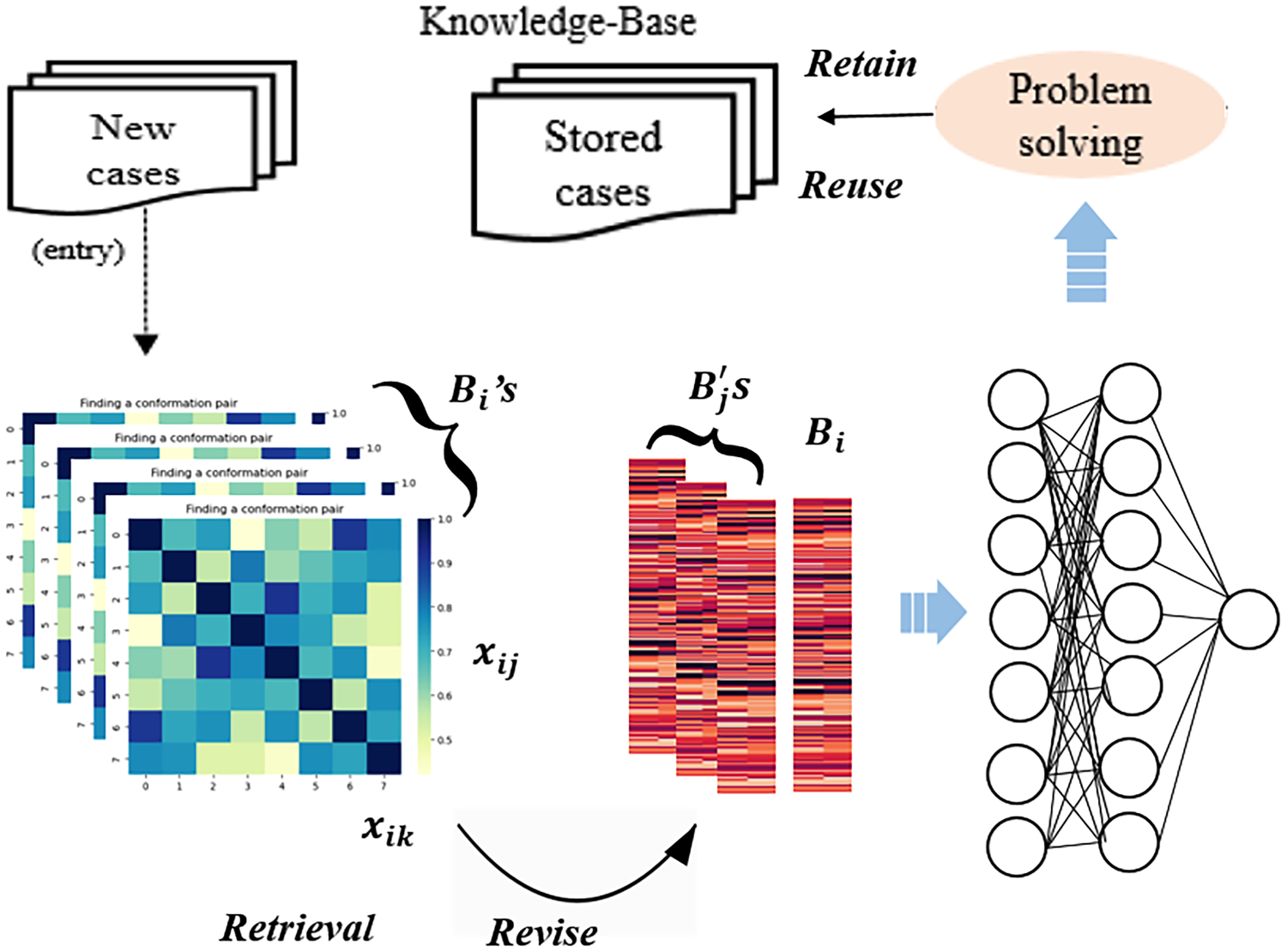
The cyclic procedure of MIL-CBR
Instance embedding
An instance embedding has been mapped for MIL. 6 Considering the MIL assumption, a single instance embedding would be enough if the label is negative because all instances are negative for a negative bag. However, positive bags are heterogeneous. Additionally, it is more probable that negative instances will be encountered more frequently than positive instances if a bag is positive, which indicates that positivity may be underrepresented with a single embedding. Accordingly, we aim to identify a pair of instances representing the maximum heterogeneity in a bag where maximum heterogeneity is defined as the maximum dissimilarity in terms of Spearman’s correlation coefficient.21,22 It is robust with respect to Type I error, especially when the observations are non-normally distributed. 21
For
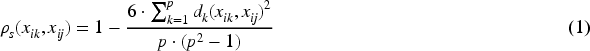
The value of
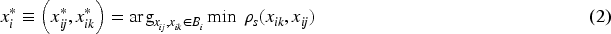
Hinge loss function
Neural networks are typically trained by minimizing a loss function,

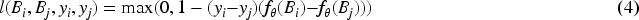

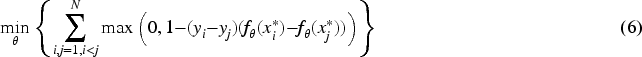
Implementation
For implementation, each bag is represented as a pair of instances according to Spearman’s correlation coefficient. All possible pairs of a positive bag
Classical benchmarks
For evaluation, we used benchmark datasets that have been traditionally used in the literature for MIL problems.5,9,26 Musk I and Musk II were used for molecular classification. Musk I consists of 47 aromatic, oxygen-containing molecules with musk odor and 45 homologs, while Musk II consists of 39 musk molecules and 63 homologs. The two datasets share 72 molecules, totaling 7,072 conformations. Each molecule is represented with 166 low-energy conformation features.1,2 For image classification, we used the Elephant, Fox, and Tiger datasets consisting of a set of features extracted from the segments of images. 26 Each dataset contains 200 images, with half containing the target animal and half containing other subjects. These datasets are challenging due to their coarse nature. The Tiger dataset consists of 1,220 instances, while the Elephant and Fox datasets contain 1,391 and 1,320 instances, respectively. All datasets are publicly available in the UCI machine learning repository. 27
MNIST-bags
Considering that the classical benchmark datasets are precomputed, we additionally assessed the performance on MNIST-bags. The MNIST dataset is a well-known image dataset consisting of 28
Performance comparison
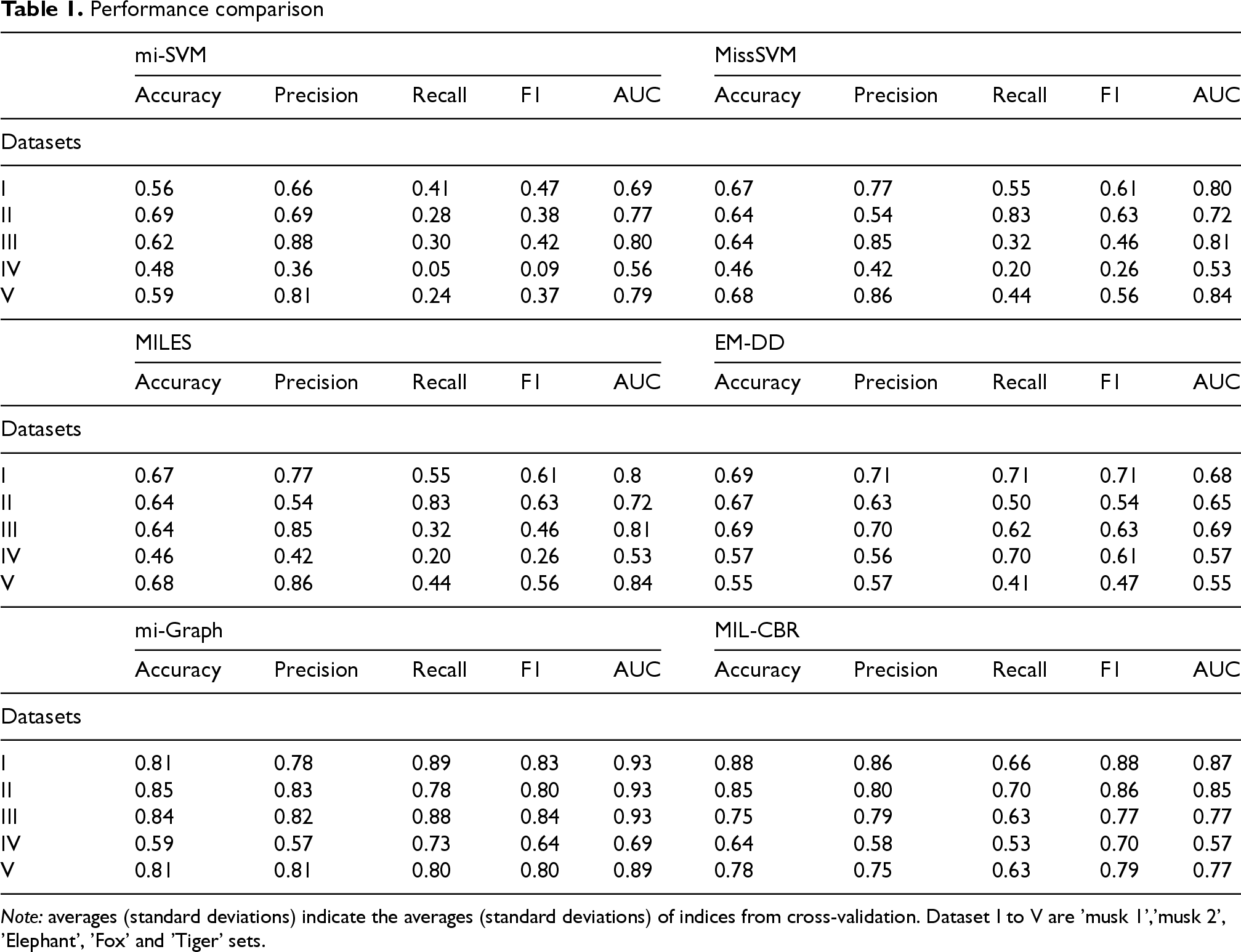
Performance comparison
Note: averages (standard deviations) indicate the averages (standard deviations) of indices from cross-validation. Dataset I to V are ’musk 1’,’musk 2’, ’Elephant’, ’Fox’ and ’Tiger’ sets.
We present results based on the experimental setting described in the above section. Besides MIL-CBR, we also conducted mi-SVM, MissSVM, MILES, EM-DD, and mi-Graph as reference algorithms. The performance is evaluated in terms of accuracy, precision, recall, F1 score, and area under the receiver operating characteristic curve (AUROC)to provide further information, as shown in the following.

Benchmark datasets
For the classical MIL datasets, we employed a seven-fold cross-validation scheme, conducting each run independently under identical settings. The results are presented in the first five rows of Table 1. On the Musk I and Musk II datasets, while mi-Graph achieved notable accuracies of 84% and 81% among the reference algorithms, MIL-CBR demonstrated superior performance with F1-scores of 88% and 86% as well as accuracies of 88% and 85% on these datasets, respectively. This performance advantage is maintained across other datasets. On the Elephant, Fox, and Tiger datasets, mi-SVM, MissSVM, and MILES showed comparable performance across all metrics, with maximum accuracies of 62%, 64%, and 64%, respectively. EM-DD exhibited slightly higher performance with 69% accuracy, although its AUROC scores were lower than those of the aforementioned three algorithms. Overall, mi-Graph and MIL-CBR demonstrated relatively superior performance compared to other algorithms. mi-Graph showed better performance on the Elephant dataset, achieving an 84% F1-score compared to MIL-CBR’s 77%, while MIL-CBR showed better performance on the Fox dataset, achieving 70% in F1-score compared to mi-Graph’s 64%. On the Tiger dataset, both mi-Graph and MIL-CBR showed similar F1-scores of 80% and 79%, respectively.
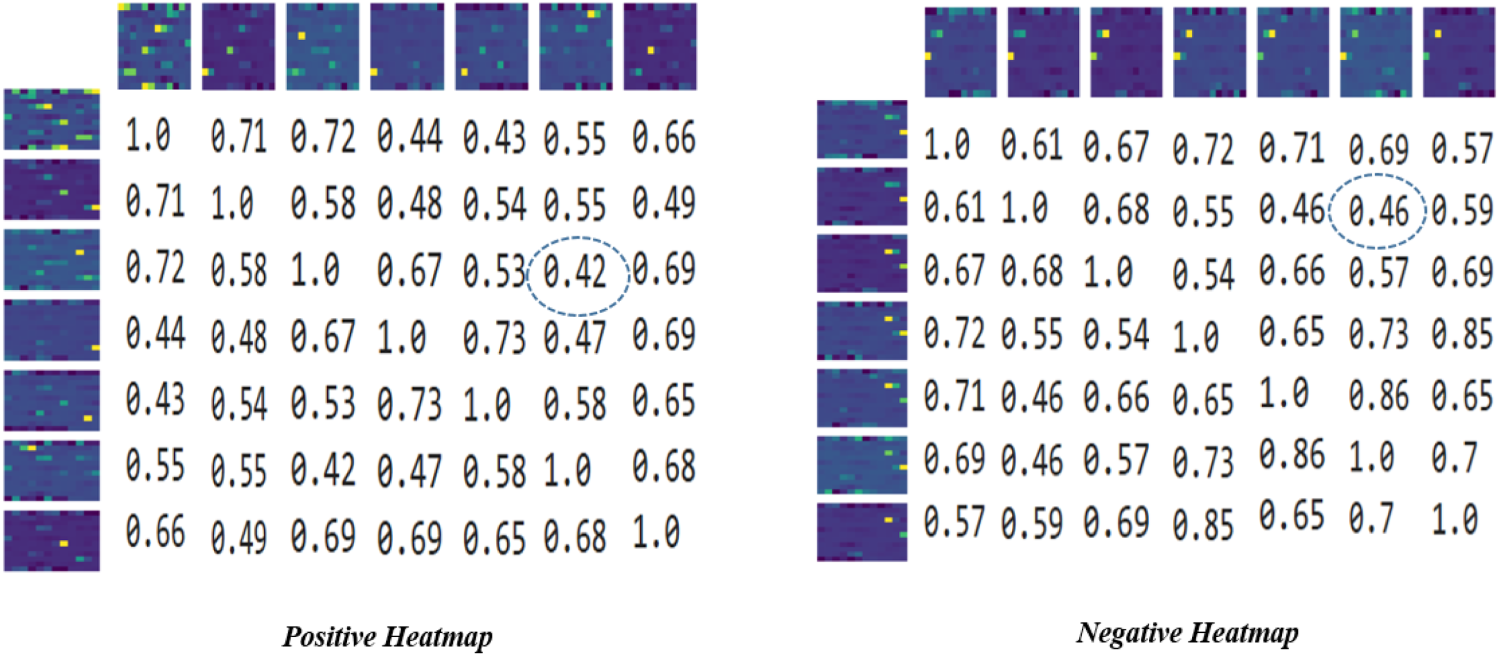
The left and right matrices represent heatmaps of positive and negative bags randomly chosen from benchmark datasets with sparse data matrices.

MNIST-bags:This 4-row matrix figure illustrates bag selections from two experiments. The upper two rows display randomly chosen negative and positive bags from Experiment I [‘9’ vs ‘7’], and the lower two rows show corresponding negative and positive bags from Experiment II [‘9’ vs. (‘7’,‘4’)]. In each row, two images are chosen according to Spearman’s correlation coefficients and highlighted with red-dotted outlines to denote their selection.

The left and right panels show the selection by Spearman’s correlation coefficients for a positive and a negative bag in Experiment III, which were randomly chosen for visualization. As above, the selections are highlighted with red-dotted outlines.
MNIST images are resized to
Discussion
To the best of our knowledge, ProtoMIL, besides our work, is the only approach that has applied case-based reasoning to MIL problems. ProtoMIL computes similarity metrics based on prototypical parts for whole slide images under case-based reasoning inference, 12 though these prototypical parts may be nebulous. In contrast, MIL-CBR directly computes similarity metrics between instances for a bag within the case-based reasoning inference. The maximum negative association in terms of Spearman’s correlation coefficients is interpreted as heterogeneity in the similarity context, and we select a pair of instances having the maximum heterogeneity for bags as representatives. Since positive bags contain both positive and negative instances, we hypothesized that the pair of instances showing the minimum correlation reflects a higher probability of different labels, if well represented. As a result, the data structure becomes homogeneous across bags through this selection, which reduces computational burden. Additionally, MIL-CBR is interpretable because the predicted score of neural networks is directly associated with significance, while neural networks conventionally require additional analysis for explanation. However, MIL-CBR may not perform well due to weak representation of all associations in terms of a single measure, although Spearman’s correlation coefficient is robust when the bag size is large and sparse or the contextual patterns are non-linear. Although no single approach is dominant across all techniques, the performance of MIL-CBR is on par with benchmark algorithms in experiments. In particular, MIL-CBR is one of the few studies that apply case-based reasoning inference to MIL problems. Therefore, we claim that MIL-CBR demonstrates its potential as an effective solution for MIL problems as groundwork.
Footnotes
Ethical considerations
Ethical approval was not required in this study.
Funding statement
This research was supported by Basic Science Research Program of the National Research Foundation of Korea (NRF) funded by the Ministry of Education (RS-2023-00237241). Also, this research is partly supported the Institute of Information & communications Technology Planning & Evaluation (IITP)-Innovative Human Resource Development for Local Intellectualization program grant funded by the Korea government(MSIT) (IITP-2025-RS-2020-II201741).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
All data are available in the UCI Machine Learning Repository (![]() )
27
)
27