
Abstract
Text-to-Speech (TTS) technology converts text into human-like speech, aiding the visually impaired, providing voice assistants, and enabling automated news broadcasting. This study proposes P VALL-E, an efficient speech synthesis system enhancing Microsoft’s VALL-E model by replacing its Transformer architecture with Performer structures through a layer-wise strategy. The proposed mechanism improves processing speed for long texts and reduces parameter count, making the model suitable for resource-constrained environments. Pre-trained with English and Simplified Chinese speech data, P VALL-E leverages multilingual training to transfer knowledge to less-resourced Taiwanese speech data, improving performance across languages. A language embedding mechanism is also incorporated for accent control and personalized synthesis. Experimental results show P VALL-E matches the original VALL-E in accuracy while boosting generation speed by approximately 20%. Even with limited data, the proposed architecture performs well in multilingual settings. Add to this an Android app was developed, running the model on a server due to its high computational requirements, and transmitting results to users’ devices.
Introduction
In recent years, Text-to-Speech (TTS) synthesis has become a crucial aspect of modern technology, converting written text into spoken words with natural intonation and emotion. TTS systems find applications in various fields such as navigation systems, smart homes, educational resources, customer service robots, and reading articles like newspapers and magazines. Traditional TTS systems primarily utilized concatenative or parametric methods for voice generation, which often resulted in mechanical-sounding and less natural speech. The advent of deep learning has revolutionized TTS with models based on Convolutional Neural Networks (CNNs), 1 Long Short-Term Memory networks (LSTMs), 2 and Transformers. 3 These models have significantly improved the naturalness and expressiveness of synthesized speech by learning from large datasets.
Among the cutting-edge TTS systems, the VALL-E model leverages the in-context learning capabilities of large language models (LLMs) and over 60,000 hours of English speech data, enabling zero-shot performance. 4 VALL-E can accurately replicate a speaker’s tone and emotion with just a three-second reference, while also capturing the speaking environment. This capability allows VALL-E to generate realistic speech by understanding the context and nuances of the input text. However, the VALL-E model’s reliance on the Transformer architecture, with its large number of parameters and computational resources, poses efficiency challenges, especially when processing long sequences. Additionally, VALL-E’s training predominantly on single-language datasets limits its ability to fully exploit the contextual learning capabilities of language models. Expanding VALL-E’s capabilities to other languages, particularly those with less training data, remains an important area of research.
To address these challenges, this study proposes the use of the Performer architecture, an improved version of the Transformer, which enhances the efficiency of processing long sequences and reduces computational resource requirements. Furthermore, this study aims to utilize transfer learning to leverage extensive English and Chinese datasets, fine-tuning the model for multilingual training, thereby improving performance in languages with less available data. In summary, the proposed architecture enhances the state-of-the-art zero-shot TTS model VALL-E by replacing its Transformer architecture with the Performer model, resulting in a 20% reduction in parameter count and a 20% increase in execution speed. Additionally, the proposed method introduces multilingual training and transfer learning techniques to improve the performance of languages with limited data, and incorporates accent control features. Finally, the development of an Android application, deploying the P VALL-E model on a server for efficient speech generation, demonstrates the practical application of these advancements.
The remainder of this paper is organized as follows. Section II introduces related works. In Section III, the model architecture is presented. In Section IV, the experiments conducted in this study are described. Finally, conclusions are drawn in the last section.
Related work
Text-to-speech (TTS)
Text-to-Speech (TTS) technology converts text into speech and is used in various applications, such as assistive devices and voice assistants. Traditional TTS systems include concatenative synthesis, which uses pre-recorded speech segments, and parametric synthesis, which generates speech algorithmically. While concatenative methods yield natural speech, they require large datasets and may have unnatural transitions. Parametric methods, though flexible, often lack naturalness.Recent deep learning models, such as WaveNet, 5 have significantly improved TTS quality. Models like Tacotron, 6 FastSpeech, 7 and NaturalSpeech 8 have further enhanced naturalness and fluency. Modern TTS systems also incorporate features like accent and emotion control to personalize and enrich the speech output.9,10
Transformer
The Transformer 3 has become a cornerstone in sequence processing, particularly in NLP. It surpasses traditional models like RNNs and CNNs by effectively handling long-range dependencies through self-attention, which calculates relationships within a sequence. This mechanism enhances both accuracy and efficiency. Transformers have also shown success in image processing (e.g., ViT 11 ) and speech recognition (e.g., Conformer 12 ).
Self-attention is key to the Transformer’s capability, computing the importance of sequence elements. It uses query, key, and value vectors to generate attention weights and outputs, effectively capturing global sequence information. However, its
Language models
Language models have evolved from statistical approaches to deep learning architectures. The Transformer introduced a major shift with its self-attention mechanism, significantly improving long-range dependency capture in NLP tasks. Models like BERT 14 and GPT 15 have set new standards in NLP. Recently, large language models have also been applied in speech processing, with models like Whisper 16 and AudioPaLM 17 showing promising results. VALL-E 4 marks a key development in TTS, utilizing a large language model for zero-shot speech synthesis.
VALL-E
VALL-E 4 is a pioneering TTS model that employs a large language model architecture for zero-shot capabilities. Unlike traditional TTS systems that require extensive data, VALL-E uses a GPT-like Transformer to generate speech for unseen speakers, learning text-speech relationships from a vast pre-training dataset. Its architecture includes an audio encoder, Transformer, and speech decoder, enabling efficient and natural-sounding speech synthesis across a wide range of speakers.
Proposed architecture
System architecture
VALL-E leverages the Large Language Model (LLM) architecture to enable context-aware learning, achieving exceptional speech synthesis quality. However, this comes at the cost of substantial model parameters and computational resources. The original VALL-E model uses a Transformer architecture, which has a computational complexity that scales quadratically with input length, making it slow for processing long sequences. This is problematic in practical applications, such as when generating speech for long articles, as it leads to inefficiencies and poor user experience. Additionally, VALL-E is trained exclusively on English, limiting its support for multilingual speech synthesis and accent control, and failing to fully utilize the advantages of LLM training on multiple languages. This study addresses these issues by modifying the VALL-E model. The system, named P VALL-E, builds upon the VALL-E model by replacing the Transformer decoder with the more efficient Performer architecture, as shown in Figure 1. The Performer is an optimized version of the Transformer, reducing the number of model parameters and increasing processing speed, especially for long sequences. To introduce accent control, a language ID is added to the input, enabling the model to learn language embeddings and distinguish between different language characteristics.

P VALL-E system architecture.
Due to the quadratic computational complexity of the self-attention mechanism, the Transformer model struggles with long sequences. In recent years, various efficient Transformer variants have been proposed to address this issue. Evaluating different models can be challenging due to inconsistent benchmarks across tasks and datasets. To address this, Tay et al. introduced the Long Range Arena (LRA) benchmark, 18 specifically designed to evaluate model performance on long sequences. As shown in Figure 2, the Big Bird model 19 achieves the highest scores on the LRA benchmark by incorporating multiple improved attention mechanisms, demonstrating its strong performance on long text sequences. However, its speed improvements over the original Transformer are not significant. Performer and Linformer, on the other hand, offer a good balance between speed and accuracy, with both models being approximately five times faster than the Transformer, albeit with slightly lower accuracy. To reduce model parameters and computational complexity while maintaining accuracy, this study replaces the VALL-E Transformer layers with Performer layers. The Linformer was also experimented with, given its comparable performance to the Performer.
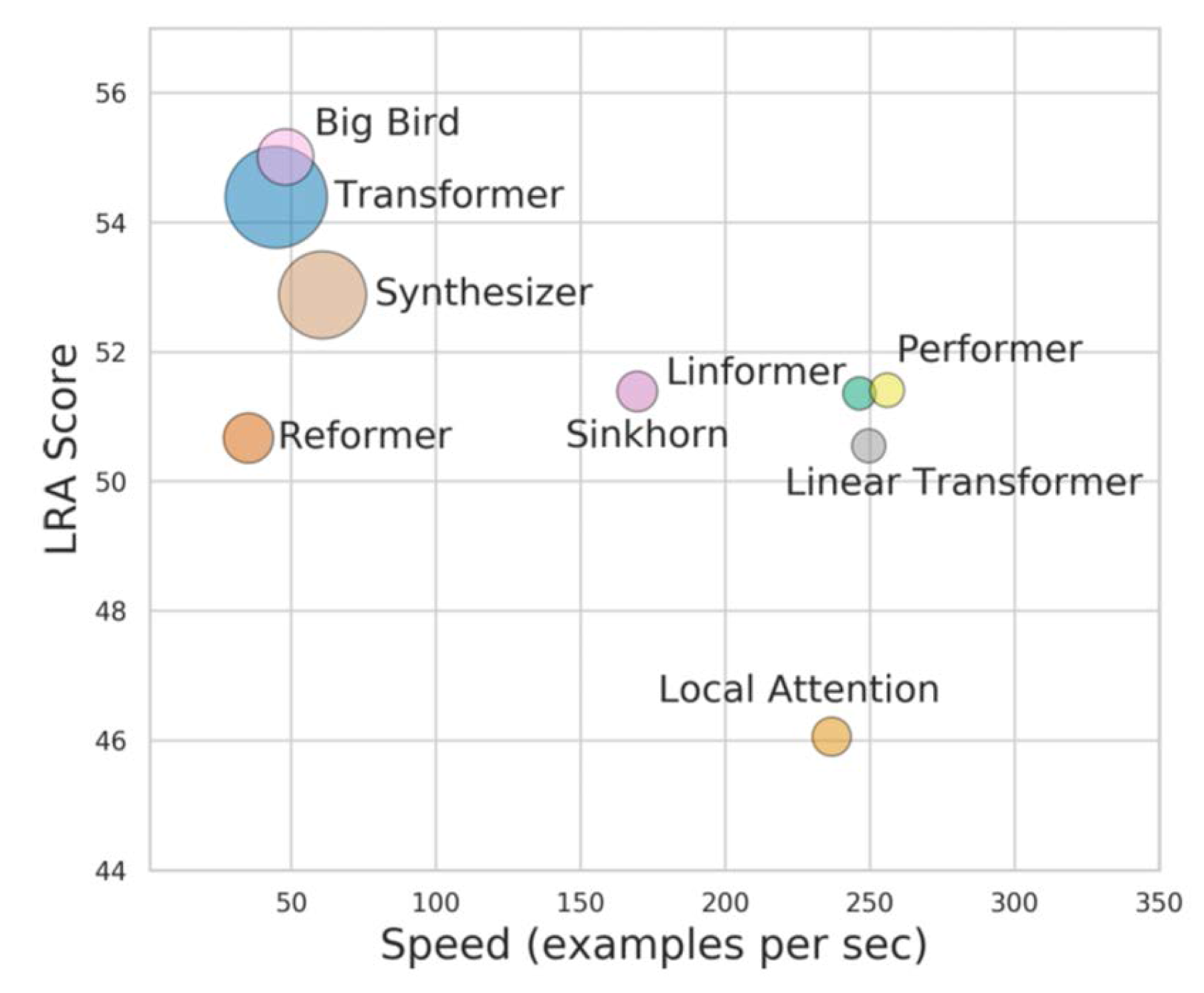
Long range arena benchmark. 18
The Linformer, proposed by Facebook AI Research, improves the efficiency of Transformers by addressing the computational and memory inefficiencies encountered when processing long sequences. The traditional Transformer model has a self-attention mechanism with a time and space complexity of

Next, the query vector

To address the high time and space complexity associated with long sequence processing, the Performer architecture
13
was proposed by Google’s AI research team. The Performer retains the basic Transformer structure while introducing innovations in the calculation process, particularly in the self-attention mechanism. The Performer reduces computational complexity by reordering matrix multiplications, performing the key (
This reordering, along with the use of an approximate softmax kernel to preprocess

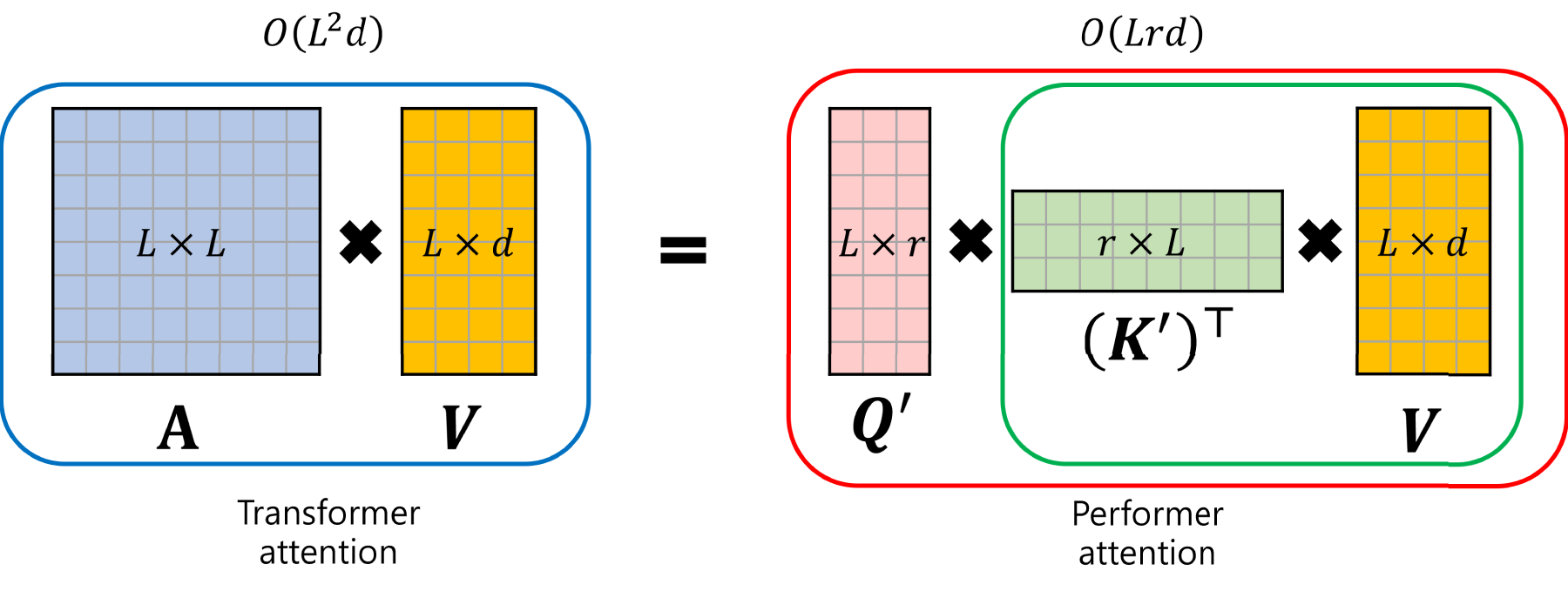
Performer attention mechanism.
To enable accent control in the speech synthesis system, this study proposes a method to set specific accents, allowing the model to simulate the pronunciation characteristics of speakers from different languages. For instance, the system can generate speech with a Simplified Chinese accent, British accent, or Taiwanese accent when reading Chinese sentences. Inspired by the YourTTS model, 20 a language ID is added to the input to specify the desired accent in the generated speech. To accurately identify and produce specific language characteristics, language embeddings from YourTTS are utilized, converting language features into vector representations. Each language ID corresponds to a specific embedding vector, enabling the model to learn and simulate various language accents. Language embeddings capture language-specific features such as phonetics, intonation, and pronunciation patterns, providing the model with essential linguistic information. For example, English and Chinese language embeddings differ due to significant differences in pronunciation rules and intonation between the two languages.In Table 1, an example is shown using the sentence “[EN]The truth must be told at all costs.[EN]” to illustrate how language cues are added at the beginning and end of a sentence. The [EN] tag indicates that the sentence should be synthesized with an English accent. By adding language cues to the sentence, the model can recognize the desired accent for synthesis, ensuring the speech output matches the expected accent. During inference, accent control can be achieved by setting the language ID to the desired language.
Language ID label example.

Language ID label example.
The goal of this study is to replace the Transformer decoders in VALL-E with Performer decoders to reduce the number of parameters and improve execution efficiency. Unlike replacing all Transformer layers at once, this study adopts a layer-by-layer replacement strategy while retaining the pre-trained weights of the remaining Transformer layers. The core idea is to use the retained pre-trained Transformer weights to guide the newly added Performer layers. This approach helps the new layers quickly learn the model’s existing knowledge, reducing parameters, enhancing computational efficiency, and maintaining stable model performance. The training process is outlined in Algorithm 1.

Figure 4 shows the Performer replacement process. By following this method, the Performer layers are replaced one by one in the original VALL-E Transformer layers, with a total of

Performer layer replacement process.
The experiments were conducted on a system running Ubuntu 22.04. The training was performed using an NVIDIA RTX 3080Ti GPU with 12 GB of memory, which meets the minimum memory requirement for the model.
Datasets
The superior performance of VALL-E is attributed to training on a large-scale semi-supervised English speech dataset, including automatically generated text labels. Due to resource constraints, we could not use a dataset of the same scale as VALL-E. Instead, we selected nine high-quality supervised Chinese and English speech datasets as substitutes. These datasets provide accurate manual annotations and cover a wide range of scenarios, including recordings made with different devices (such as studio equipment and smartphones) and under various environmental conditions. This diversity ensures that the model learns a broad spectrum of variations, improving its robustness. Thus, even with limited resources, the speech model’s performance can be effectively enhanced.
The English speech datasets used in this study are as follows:
The Chinese speech datasets include:
The Taiwanese speech dataset used is:
The summary of the datasets, including language, duration, and number of speakers, is provided in Table 2.
Summary of datasets.

Summary of datasets.
Speech data preprocessing
To ensure consistency in the input data for the model, all speech data were resampled to 24 kHz to meet the requirements of the original VALL-E model. These resampled audio files were then processed using the Encodec encoder to obtain corresponding discrete codes, which were stored for training. During training, the model directly reads these discrete codes, eliminating the need to reload the original speech data. This allows the training process to focus solely on the Transformer components of the VALL-E model, significantly improving training efficiency.
Text data preprocessing
To train VALL-E, paired speech and corresponding text data are required. The datasets used in this study mainly include labeled speech data. For speech data without text labels, a semi-supervised learning approach was adopted, utilizing OpenAI’s Whisper system 16 to automatically generate text labels. These automatically generated labels, known as pseudo labels, provide a cost-effective way to obtain a large, relatively high-quality labeled dataset, supporting the training of the speech processing model. Phonemes are the smallest distinguishable sound units in a language, capable of differentiating word meanings. This study describes the conversion of text data into phoneme sequences compatible with the VALL-E model. Phonemes were encoded as numeric vectors, allowing them to be used directly for training and generating speech.
Evaluation methodology
In this study, the performance of the VALL-E system was evaluated using the Top 10 accuracy metric, which differs from the traditional Mean Opinion Score (MOS) that relies on subjective human auditory evaluation. The Top 10 accuracy metric assesses the similarity between the discrete codes generated by VALL-E and the target speech’s Encodec discrete codes.
Top 10 accuracy measures the model’s prediction accuracy by checking whether the correct answer is among the top ten predictions.
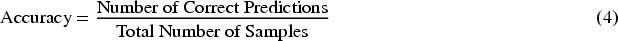
The evaluation was conducted using 20% of the data from various datasets, including LibriTTS, VCTK, AISHELL-1, AISHELL-3, Aidatatang, Primewords, THCHS-30, ST Chinese, and Common Voice, totaling approximately 300 hours. The validation data was carefully selected to ensure no overlap with the training speakers, maintaining the evaluation’s fairness and effectiveness. To facilitate comparison, the datasets were grouped by language into English (ENG), Simplified Chinese (ZH), and Traditional Chinese (TW), as shown in Table 3.
Dataset language comparison.

Dataset language comparison.
Four different architectures were tested in this study. Given the similar performance of Linformer and Performer in the Long Range Arena benchmark, we also experimented with replacing the Transformer in VALL-E with Linformer to create Lin VALL-E. Additionally, P
Comparison of model accuracy.

Comparison of model accuracy.
This section analyzes the training speed of VALL-E and P VALL-E models and explores the impact of different model architectures on training time. The experimental results in Table 5 compare the training time per epoch for the original VALL-E and P VALL-E models using Performer. The results show that the VALL-E model requires 10.2 hours per epoch, while the P VALL-E model requires 8.3 hours per epoch, indicating that P VALL-E has a significant speed advantage, being 1.23 times faster. This is mainly due to the linear computational complexity of the Performer mechanism, compared to the quadratic complexity of the traditional Transformer, which allows more efficient processing of large-scale datasets, reducing computational resources and time consumption. This result is significant for speech generation tasks requiring long-term, large-scale training. P VALL-E not only excels in generation speed but also demonstrates higher efficiency during training, shortening the overall development cycle.
Training speed comparison.

Training speed comparison.
This section compares the generation speeds of the VALL-E and P VALL-E models and examines the impact of different target speech lengths on the generation speed of these models. The experimental results in Table 6 compare the generation speeds of the original VALL-E and P VALL-E models for target speech lengths of 5, 10, and 20 seconds. The results indicate that when the target speech length is 5 seconds, the generation speed of P VALL-E is slightly lower than VALL-E. However, when the target length is 10 seconds, the generation speed of P VALL-E is significantly higher, being 1.21 times faster. This demonstrates the linear computational complexity advantage of Performer when processing longer sequences, compared to the quadratic complexity of the traditional Transformer. As the target speech length increases to 20 seconds, P VALL-E maintains high performance, being 1.69 times faster than VALL-E. This indicates that P VALL-E is more efficient in long-sequence speech generation tasks, particularly when processing longer sequences, where the linear complexity advantage of the Performer mechanism becomes more apparent.
Generation speed comparison.

Generation speed comparison.
This section analyzes the impact of multilingual training on different languages by comparing the results of single-language training and multilingual training, as shown in Table 7. The results indicate that multilingual training generally outperforms single-language training. This is because multilingual training leverages the contextual capabilities of the language model, transferring knowledge across different languages, allowing the model to perform better in various languages. For example, if the model has learned to pronounce words correctly, even if it has encountered limited types of sounds, it can use the learned linguistic knowledge to improve the similarity of generated sounds. Multilingual training improves accuracy by 0.68% for Simplified Chinese and 0.95% for English. The effect is less pronounced because these two languages already have abundant data. However, for languages with less data, such as Traditional Chinese, the improvement is 2.18%.
Impact on multilingual training.

Impact on multilingual training.
To explore the impact of multilingual training on low-resource languages, such as Taiwanese accent, we selected 120 hours of recordings from the Common Voice dataset, randomly selecting 1 hour as the training set and validating it on an additional 20 hours of recordings. The data in Table 8 shows that when the model is trained only on this 1 hour of Taiwanese accent data, overfitting is likely to occur, leading to poor performance on untrained test data. However, combining other languages with large amounts of training data for multilingual training can significantly improve the prediction accuracy of Taiwanese accent data, even if the structure of English is markedly different from Taiwanese accent. This proves that P VALL-E utilizes the language model’s strong contextual understanding ability, effectively transferring multilingual knowledge to languages with less data.
Impact of multilingual training on low-resource languages.

Impact of multilingual training on low-resource languages.
Finally, our experiments further explore the impact of training on small data amounts of Taiwanese accent by simultaneously using Simplified Chinese, English, and Traditional Chinese. The results show that when these three languages are trained together, the performance of speech synthesis for low-resource languages like Taiwanese accent is significantly improved. This multilingual training strategy fully leverages the correlations between languages and the generality of language models, demonstrating optimal performance in improving the identification and generation quality of Taiwanese accents. The experimental results confirm that multilingual training not only enhances the model’s adaptability to diverse languages but also significantly promotes the version of the language with less data (such as Taiwanese accent).
Impact of language ID
Table 9 shows the impact of adding Language ID to the P VALL-E system’s accuracy. The addition of Language ID improves accent handling and provides important linguistic context, enabling the model to recognize and distinguish the language of the input text and generate corresponding speech vectors. The experimental results show that adding Language ID improves overall system accuracy by approximately 0.5%, with English improving by 0.67%, Simplified Chinese by 0.43%, and Traditional Chinese by 0.5%.
Impact of language ID.

Impact of language ID.
This section explores the impact of different replacement orders when replacing Transformer layers with Performer layers on model accuracy. Table 10 shows the impact of replacement order on accuracy across three languages (ENG, ZH, TW) and the average accuracy across the three languages (Avg.). In the table, ”Front” indicates starting the replacement from the first Transformer layer (closest to the input layer), while ”End” indicates starting from the last Transformer layer (closest to the output layer). The results in Table 10 show that different replacement orders have varying effects on model accuracy when replacing Transformer layers. Based on the average accuracy (Avg.), the strategy of starting replacement from the last layer (”End”) has a smaller impact on accuracy. Starting replacement from the first layer (”Front”) leads to a significant drop in accuracy across all languages, as the Transformer layers close to the input layer are responsible for initial feature extraction and representation, and replacing these layers affects the model’s basic understanding of the input data. Starting replacement from the last layer (”End”) results in a smaller drop in accuracy, as the Transformer layers close to the output layer mainly integrate high-level features into the final output.
Impact of replacement order on accuracy.
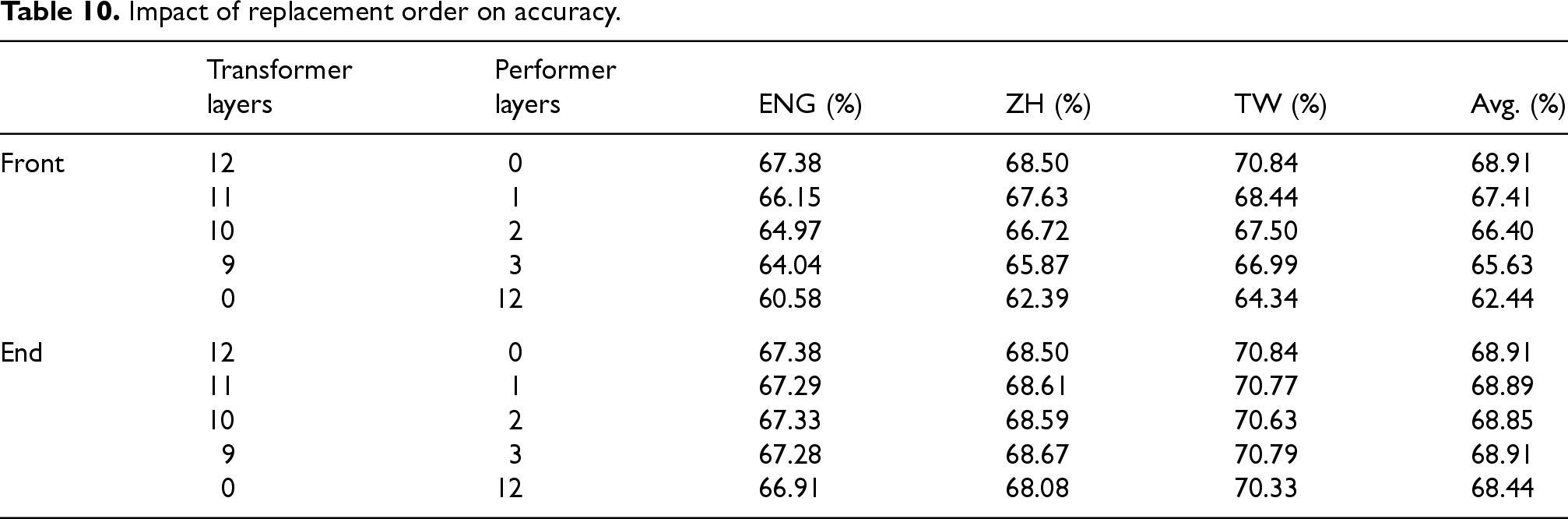
Impact of replacement order on accuracy.
In this study, the proposed architecture improved the VALL-E model by replacing its Transformer structure with Performer, reducing parameters and increasing processing speed. The enhanced model, trained extensively on English and Simplified Chinese and adapted for Taiwanese Mandarin, shows better synthesis quality and accent control. In addition, The P VALL-E model presented in this paper has made significant progress in multilingual support and computational efficiency, but several limitations remain. Support for low-resource languages still poses challenges, particularly as performance in data-scarce languages may not be on par with high-resource languages. Additionally, the model’s inference speed and computational resource requirements need further optimization, especially for applications on mobile devices and lower-end hardware. While Accent Control provides preliminary accent control, further improvements are needed for handling complex dialects and subtle speech differences. Future research could focus on improving performance for low-resource languages, optimizing computational resource demands, enhancing the precision and flexibility of accent control, and expanding the model’s applicability to multilingual and multicultural contexts. These improvements will better enhance the model’s practicality and its potential for widespread application. Add to this, future work will focus on further improving model accuracy through novel architectural or training advancements. Accent control for low-resource languages like Taiwanese Mandarin remains a challenge, requiring more diverse data and refined techniques. Additionally, exploring non-autoregressive models could further accelerate speech generation while maintaining quality.
Footnotes
Acknowledgements
This research is financially supported by National Science and Technology Council of Taiwan (under grant No. 113-2221-E-992 -116 -).
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.