
Abstract
This meta-analysis investigates linguistic cues to deception and whether these cues can be detected with computer programs. We integrated operational definitions for 79 cues from 44 studies where software had been used to identify linguistic deception cues. These cues were allocated to six research questions. As expected, the meta-analyses demonstrated that, relative to truth-tellers, liars experienced greater cognitive load, expressed more negative emotions, distanced themselves more from events, expressed fewer sensory–perceptual words, and referred less often to cognitive processes. However, liars were not more uncertain than truth-tellers. These effects were moderated by event type, involvement, emotional valence, intensity of interaction, motivation, and other moderators. Although the overall effect size was small, theory-driven predictions for certain cues received support. These findings not only further our knowledge about the usefulness of linguistic cues to detect deception with computers in applied settings but also elucidate the relationship between language and deception.
Deception is a ubiquitous phenomenon, and people at all times have sought to find ways to detect it. Humans have searched for indicators of deception in physiological, nonverbal, and paraverbal behavior, and the very content of what people are saying. Since the beginning of experimental psychology, researchers have systematically investigated different types of cues assumed to reveal deception (Benussi, 1914; Freud, 1905/1959; Wertheimer & Klein, 1904; see Bunn, 2012; Grubin & Madsen, 2005; Sporer, 2008, for historical reviews). Despite these efforts, meta-analyses indicate that humans are not very good at discriminating between truths and lies (C. F. Bond & DePaulo, 2006). Reasons may lie in the complexity and difficulty of the task, incorrect beliefs about cues, and the use of invalid cues, as well as the pervasive biases in decision making (Global Deception Research Team, 2006; Reinhard, Sporer, Scharmach, & Marksteiner, 2011; Vrij, 2008b).
In this meta-analysis, we focus on the use of computers to overcome these limitations. However, we unpretentiously believe that the present contribution goes far beyond this goal. Based on a series of theoretical frameworks rooted in cognitive and social psychology, we posed (and tested) specific directional hypotheses concerning the potential utility to detect deception with a number of linguistic cues. Our findings are relevant not only in terms of the potential practical utility of computers to detect deception but also in terms of basic knowledge about the language of deception and the underlying theories predicting specific linguistic differences between truths and lies.
Human Judgmental Biases
Humans are biased lie detectors. Biases include a reliance on cognitive heuristics (Levine & McCornack, 2001), overestimation of dispositional factors (O’Sullivan, 2003), and an exaggerated focus on nonverbal relative to verbal content cues (Reinhard et al., 2011; Vrij, 2008b). Other researchers have shown that humans are prone to truth or lie biases (Levine, Park, & McCornack, 1999; Meissner & Kassin, 2002; Zuckerman, Koestner, Colella, & Alton, 1984), which are the tendency to judge statements as truthful—or as deceptive—regardless of their actual veracity. It has also been shown that observers’ veracity judgments are affected by factors unrelated to the veracity of particular statements, such as the sender’s facial appearance (Masip, Garrido, & Herrero, 2003). Likewise, C. F. Bond and DePaulo (2006) argued that people hold the stereotype that liars are “tormented, anxious, and conscience stricken” (p. 216), and that they may draw on this stereotype when judging the veracity of other people.
As a possible remedy to overcome these deficiencies in human judgments, physiological psychologists and brain researchers have utilized “machines” like the polygraph, voice stress analyzer, pupillometry, electromyogram, and brain imagery (e.g., electroencephalogram [EEG], functional magnetic resonance imaging [fMRI]) to detect deception. In the last 40 years, but particularly most recently, scientists from various fields have also sought to detect deception by analyzing speech content with computers, looking for specific word cues or sentence structures to reveal deception.
A computer system would arguably be less prone to the influence of biases and stereotypes than human judges. There would be virtually no top-down processing. In addition, online assessment of various deception cues from ongoing interactions or videos can tax the cognitive capacity of human judges and lead to errors. Computers can quickly analyze large amounts of information and provide more reliable data. These are the principal reasons for the appeal of the automatization of lie detection. However, we must not forget that computers do not make choices about definitions of word categories nor about the specific words to be contained in broader categories. Most importantly, computers do not make choices about the direction of any particular cue as a lie or truth indicator. It is important to stress that, for a computer to be able to detect deception, the linguistic characteristics to be analyzed must be revealing of deception. Here, in examining what linguistic cues identified with computers differ between truths and lies, we also contribute to our basic understanding about linguistic markers of deception.
Can Computers Be Useful to Detect Deception?
In an attempt to identify and quantify linguistic cues to deception, researchers had a (unrealistic) dream: Enter peoples’ words into a computer to find out whether they are telling the truth or not. In an early study, Knapp, Hart, and Dennis (1974) assessed several linguistic cues using a program called TEXAN on a CDC 6500 mainframe computer. The program analyzed word frequencies without taking contextual meaning into account. Most of the investigated cues significantly differed in the expected direction between truths and lies.
Many years passed until similar but more modern word frequency count approaches were used regularly to deception detection (at least in research contexts). The most common program, called Linguistic Inquiry and Word Count (LIWC; Pennebaker, Francis, & Booth, 2001), was developed to count words in psychology-relevant dimensions across multiple text files. LIWC has been used in numerous domains like personality, health, or psychological adjustment (see Tausczik & Pennebaker, 2010, for a review). LIWC analyzes typed or transcribed accounts on a word-by-word basis, where each word is compared against a dictionary of 2000 pre-selected words allocated to 72 linguistic categories. Although LIWC was not specifically designed to assess deception, Newman, Pennebaker, Berry, and Richards (2003) used it to calculate the percentages of specific linguistic cues in true versus deceptive statements, yielding above-chance accuracy of classifications for different types of lies. Subsequently, researchers from a variety of fields have also applied LIWC with the same purpose (see Appendix C).
Other researchers realized that the methods used ought to be more complex. As a result, specialized programs and algorithms have been developed that are oriented more directly to detecting deception. For example, Agent99Analyzer was created to specifically detect (linguistic cues to) deception in texts and videos (Fuller, Biros, Burgoon, Adkins, & Twitchell, 2006). One of its sub-tools is a natural language processing unit called “GATE” (General Architecture for Text Engineering; Cunningham, 2002; Qin, Burgoon, Blair, & Nunamaker, 2005). Other related automated text-based tools used were “iSkim” or “CueCal” (Zhou, Booker, & Zhang, 2002; Zhou, Burgoon, Nunamaker, & Twitchell, 2004). More specifically, smaller text units are analyzed and integrated in the context of the whole text through examining different levels of human language (e.g., sub-sentential, sentential, and discourse processing; see also Zhou, Burgoon, Nunamaker, & Twitchell, 2004). Recently, a growing body of research using machine-learning approaches of natural language processing emerged to detect linguistic cues to deception (Nunamaker et al., 2012).
A highly sophisticated program of this kind called “Coh-Metrix” (Graesser, McNamara, Louwerse, & Cai, 2004; McNamara & Graesser, 2012) goes beyond word frequency analysis. Specifically, in analyzing “cohesion relations,” Coh-Metrix takes into account meaning and context in which words or phrases occur in texts (http://cohmetrix.memphis.edu). Although not specifically developed to detect deception, Coh-Metrix was recently applied for this purpose (e.g., Bedwell, Gallagher, Whitten, & Fiore, 2011). A somewhat different detection deception software called Automated Deception Analysis Machine (“ADAM”; Derrick, Meservy, Burgoon, & Nunamaker, 2012) focuses on editing processes while typing messages (e.g., backspace, delete, or spacebar) and measures response latencies. The program includes an automated interviewer asking questions from an internal script.
Taken together, various computer programs from different research areas and labs originated in the last 15 years that were either applied to detecting deception or specifically developed for this purpose. The effectiveness of such programs can be better determined with a comprehensive and integrative quantitative analysis of the results on various linguistic cues to deception. This is the focus of the current meta-analysis.
The Importance of Theory
Is this dream of automated lie detection realistic? A quick preview of our results hints to the fragmented nature of the findings from computer studies. Effect sizes in our meta-analysis were coded in a way that positive gus are indicative of truth, whereas negative gus are indicative of deception. For 1,093 effect sizes we calculated for 79 linguistic cues, we obtained an approximately normal distribution centering on a mean effect size of gu = −0.01 (SD = 0.37) and a Mdn of 0.02. The effect sizes ranged from −1.95 to 1.43, and the first and third quartiles were −0.17 and 0.20, respectively. To get a more accurate picture of the diagnostic usefulness of linguistic markers of deception, we calculated the absolute magnitude of all effect sizes, assuming that all were in the expected direction as predicted by a priori specified hypotheses (Figure 1). The average absolute effect size was 0.26 (SD = 0.26) with a Mdn of 0.19 (first quartile = 0.09, third quartile = 0.34). This average effect size denotes the maximum possible mean of all cues if the results had actually been in the direction predicted. This mean effect size implies that across all studies and cues, only small effect sizes were obtained. This suggests that without a priori theoretical predictions, computer analyses of linguistic cues to deception are a futile exercise. Can larger effect sizes be observed if we classify cues into theoretically meaningful categories and consider possible moderators?

Distribution of all absolute values effect sizes (k = 1,093).
Theoretical Approaches Used to Predict Linguistic Cues to Deception
We cannot provide an exhaustive review of all approaches taken by different research groups. Some authors may prefer to emphasize the role of emotion, arousal, and motivation, whereas communication researchers may look at deception as strategic behavior. We will address some of these alternative interpretations where appropriate. Instead, we focus more on a cognitive and memory-oriented approach, supplemented by social-psychological considerations and self-presentation, which help us to pin down the differences in processes involved in telling true stories versus lies. Hence, we focus on four viewpoints resulting in six research questions: (a) recalling an experience from episodic memory versus constructing a lie from semantic memory. Constructing a lie may be more cognitively taxing (Research Question 1) and reduces the certainty with which lies are delivered (Research Question 2). (b) Again drawing on the literature on memory, we discuss the role of emotion and affect in recall of true experiences versus reporting lies (Research Question 3). (c) We discuss the role of the self as an organizational principle as well as self-presentational strategies and the role of immediacy in communication (Research Question 4). (d) We draw on the reality monitoring (RM) framework to derive predictions about sensory and perceptual cues (Research Question 5) and cognitive operations (Research Question 6).
For each question, we noted those linguistic cues that would elucidate differences between accounts of truth-tellers and liars, clearly specifying the direction of effect for each cue. Some of the theoretical approaches we discuss elaborate retrieval and construction processes truth-tellers engage in when reporting an event whereas others focus on lie construction. Furthermore, we developed clear operational definitions for each cue to provide consistency in the names and definitions used in different research areas (see Appendices A and B). Most cues investigated could be allocated to one of the six research questions. However, because some cues did not clearly fit in any theory or research question, they were relegated to the miscellaneous question category. Following are the principal research questions.
Research Question 1: Do Liars Experience Greater Cognitive Load?
Telling a lie can be more cognitively demanding than truth-telling, because it involves the execution of a number of concurrent tasks requiring a great deal of mental resources. In general, both liars and truth-tellers must tell a plausible and coherent story that does not contradict their own former statements or facts that the observer/interviewer may know about. Also, in some cases, lying requires suppressing thoughts about the truth (Gombos, 2006); this may inadvertently preoccupy the speaker’s thinking (Pennebaker & Chew, 1985; see also Lane & Wegner’s, 1995, model of secrecy). Furthermore, as communication researchers have emphasized, storytellers must monitor their own behaviors and observers’ reactions (Buller & Burgoon, 1996). Truth-tellers may also engage in some of these cognitive processes but for liars, this task is more difficult because they cannot easily draw on episodic memories. Instead, they must rely on the semantic memory system or on rather nonspecific scripts or schemata (Schank & Abelson, 1977; Sporer & Küpper, 1995).
When constructing a lie, a convincing scenario has to be communicated. However, due to the demands for cognitive resources, a lie may not include the complexities and richness of information that characterize reports of real experiences. In contrast, telling a story about a true event relies on retrieval of experienced events. Although this typically involves reconstruction, and may at times even take increased effort, recall of episodic memories and supporting details is generally rather automatic.
Much research on the cognitive load approach has not been grounded on well-articulated cognitive models of deception (Blandón-Gitlin, Fenn, Masip, & Yoo, 2014). Yet, a few such models have been proposed to specify cognitive processes involved in lie production (for reviews, see Gombos, 2006; Walczyk, Igou, Dixon, & Tcholakian, 2013). Some of these models (Sporer & Schwandt, 2006, 2007; Walczyk, Harris, Duck, & Mulay, 2014; Walczyk et al., 2013; Walczyk et al., 2005) have invoked Baddeley’s (2000, 2006) working memory model, which involves transferring information from long-term memory to an episodic buffer in working memory. While this should facilitate truth-telling, it should also make lying more difficult (see, for example, Walczyk et al., 2013; Walczyk et al., 2014; Walczyk et al., 2005).
Does research support the cognitive load assumptions? Numerous recent studies (for review, see Vrij & Granhag, 2012) have provided indirect evidence by experimentally increasing a storyteller’s task demands. This has elicited more discernible cues to deception than in control, lower cognitive load conditions. Note, however, that manipulating “cognitive load” is not equivalent to assessing the cognitive mechanisms postulated as a function of such manipulations (Blandón-Gitlin et al., 2014). More direct (and revealing) evidence comes from behavioral studies using response latencies and other indices of cognitive load (e.g., Debey, Verschuere, & Crombez, 2012; R. Johnson, Barnhardt, & Xhu, 2004; Walczyk et al., 2005; for a summary, see Walczyk et al., 2013). There is even evidence from brain-imaging studies (e.g., Abe, 2009; Christ, Van Essen, Watson, Brubaker, & McDermott, 2009) showing that telling lies, particularly those involving short responses, requires greater involvement of and access to key mental resources than truth-telling (Gamer, Bauermann, Stoeter, & Vosse, 2008).
Cues to deception theoretically connected to the cognitive load perspective have been found in previous meta-analyses, particularly for nonverbal and paraverbal behaviors (DePaulo et al., 2003; Sporer & Schwandt, 2006, 2007). In comparison with truth-tellers, liars had longer response latencies, tended to communicate shorter stories, made more speech errors, nodded less, and displayed fewer hand, foot, and leg movements. Particularly relevant for the analysis of linguistic markers are findings on verbal content cues that demonstrate that compared with true accounts, deceptive accounts appear less plausible, coherent, and detailed while including more phrase and word repetitions. These indices can be signs of the experience of cognitive load either from a taxed system (e.g., longer response latencies) or because of liars’ strategies to reduce cognitive load (Walczyk, Mahoney, Doverspike, & Griffith-Ross, 2009).
Predictions
From a cognitive load/working memory perspective, we predict that compared with true accounts, false accounts will be (a) shorter as indicated by word and sentence quantity cues; (b) less precisely elaborated as indicated by fewer content words (expressing lexical meaning), a lower type-token ratio (number of distinct content words, for example, house, walk, mother) divided by total number of words), and shorter words (i.e., less than six letters; average word length); (c) involve less complex stories as indicated by fewer verbs, fewer causation words (because, effect, hence) and fewer exclusive words (but, except, without), and (d) include more writing errors (possibly moderated by mode of production [orally telling a lie, handwriting, or typing]). (For a list of the operational definition of all cues included, see Appendices A and B.)
From a different perspective, based on DePaulo’s self-presentational perspective (DePaulo et al., 2003), one would expect that liars are less likely than truth-tellers to take their credibility for granted and therefore may take a greater effort and deliberately edit their communication (cf. Derrick et al., 2012). Note, however, that this editing process will also usurp cognitive resources detracting from successful lie constructions.
Research Question 2: Are Liars Less Certain Than Truth-Tellers?
DePaulo et al. (2003) contended that deceptive self-presentations are not as convincingly embraced as truthful ones. This may be a result either of the speakers’ moral scruples, which may lead them to feel guilty or ashamed when lying, or of liars not having as much personal investment in their claims as truth-tellers. The psychological closeness or distance between a speaker and his or her message might be reflected in language (Wiener & Mehrabian, 1968). Liars should display more linguistic markers indicative of psychological detachment than truth-tellers (Buller, Burgoon, Busling, & Roiger, 1996; Kuiken, 1981; Wagner & Pease, 1976; Zhou, Burgoon, Nunamaker, & Twitchell, 2004; Zhou, Burgoon, Twitchell, Qin, & Nunamaker, 2004). Indeed, in their meta-analysis, DePaulo et al. (2003) found that liars were verbally and vocally less involved and more verbally and vocally uncertain than truth-tellers but observed no reliable differences for tentative constructs and shrugs. Uncertainty words have been proposed as markers of psychological distance between a speaker and his or her account (e.g., Kuiken, 1981). Thus, liars’ accounts should contain more uncertainty words than truth-tellers’ accounts.
It may also be the case that deceivers withhold information not to give their lies away. Indeed, research shows that when lying to conceal their transgressions, people indicate that they try not to provide incriminating details (Hartwig, Granhag, & Strömwall, 2007; Masip & Herrero, 2013) and try to keep the story simple (Strömwall, Hartwig, & Granhag, 2006) or vague (Vrij, Mann, Leal, & Granhag, 2010). DePaulo et al. (2003) found liars to be significantly more discrepant/ambivalent than truth-tellers. Therefore, liars might provide vague, ambiguous, or uncertain replies in order not to expose their lies (Buller et al., 1996; Cody, Marston, & Foster, 1984).
Predictions
From these perspectives, it is expected that liars will be less certain and definite than truth-tellers. Consequently, deceptive accounts should contain fewer certainty words (always, clear, never) and more tentative words (guess, maybe, perhaps, seem) and modal verbs (can, shall, should) than truthful accounts. (It should be noted that modal verbs also include the verb must that expresses more certainty and purposiveness whereas all other modal verbs indicate more uncertainty.)
It may be argued that liars are aware that uncertainty indicates deception and thus may strategically incorporate certainty indicators to evade detection (e.g., Bender, 1987). However, research does not support this contention. To our knowledge, around ten reports have been published so far on liars’ and truth-tellers’ strategies to be convincing (for a brief review, see Masip & Herrero, 2013). Only rarely has certainty (or any related construct) emerged as a strategy, and in these instances, it has been mentioned (a) only infrequently and (b) equally often by liars and truth-tellers (e.g., Hines et al., 2010: “admit uncertainty”; for an exception, see Strömwall et al., 2006).
Research Question 3a: Do Liars Use More Negations and Negative Emotion Words?
Emotional approach
1 When people lie, they may experience feelings of guilt and fear of getting caught (Ekman, 1988, 2001). 2 Even when telling everyday lies of little consequence, people report feeling uncomfortable (DePaulo et al., 2003). Vrij (2008a) also noted that liars might make negative comments or use negative words that reflect negative affect induced by guilt and fear.
Numerous studies have shown that arousal is associated with specific emotions (see the meta-analysis by Lench, Flores, & Bench, 2011), some of which are likely to be experienced by liars, such as guilt and fear of punishment (Ekman, 2001; Zuckerman, DePaulo, & Rosenthal, 1981). These emotional states may elicit specific nonverbal and verbal cues to deception (see DePaulo et al., 2003; Sporer & Schwandt, 2006; Vrij, 2008a). Recent studies have used brain-imaging technology to specifically investigate the role of emotion in deception (for a review, see Abe, 2011). For example, Abe, Suzuki, Mori, Itoh, and Fujii (2007) found that neural structures associated with heightened emotions were also uniquely associated with deceiving an interrogator and that self-reported feelings of immorality (sense of sin) and anxiety were higher in deceptive conditions than in truth-telling conditions. These results support the notion that deception is associated with negative emotions.
Predictions
From an emotional approach perspective, we predict that compared with true accounts, lies will include (a) more negation words (no, never, not) because these reveal a more defensive tone or denial of wrongdoing, which is likely to be accompanied by negative emotions of the liar, and (b) more words denoting overall negative emotions (enemy, worthless, skeptic), anger (hate, kill, weapon), anxiety (unsure, vulnerable), and sadness (tears, useless, unhappy).
Research Question 3b: Do Liars Use Fewer Positive Emotion Words?
Research on autobiographical memory suggests that people’s emotional appraisal of past events tends to be positively biased (Walker, Vogl, & Thompson, 1997). One mechanism by which this bias occurs is a tendency for emotions associated with negative-event memories to fade faster than emotions associated with positive-event memories (Walker, Skowronski, & Thompson, 2003). In a review of this research, Walker and Skowronski (2009) suggested that this fading-affect bias leads people to generally remember events less negatively regardless of the original affect associated with the event. This effect is not due to forgetting of event details, as the accuracy of the memories is comparable for negative and positive events. It is the memory of the emotional intensity associated with the event that fades, with negative events fading at a faster rate than positive events.
Predictions
Because truth-tellers have a specific memory of the event, whereas liars cannot draw on such an episodic memory, we predict that compared with true accounts, lies will contain fewer words denoting positive emotions (happy, pretty, good) or positive feelings (luck, joy).
Research Question 3c: Do Liars Express More or Less Unspecified Emotion Words?
Many researchers from different fields, such as social psychology, psychology and law, or computer linguistics (e.g., Ali & Levine, 2008; Fuller et al., 2006, Newman et al., 2003), have investigated the frequency of occurrence of emotional and affective terms in true and deceptive accounts without taking the valence of these emotions into account. Therefore, we decided to also investigate the cues of unspecified emotions (positive and negative) and pleasantness or unpleasantness of the story despite the lack of theoretical specification of the direction in the original studies. Predictions could be derived from a social-psychological perspective. Depending on the seriousness of a lie, from a trivial lie in everyday life to high-stake lies, the situation may become increasingly emotional. Hence, one would predict higher frequencies of unspecified emotion words in lies than in truths.
Research Question 4: Do Liars Distance Themselves More From Events?
In the preceding section, we have assumed that people are more likely to experience different types of negative emotions when telling a lie. Given such negative experiences and emotions, from DePaulo et al.’s (2003) self-presentational perspective, we further assume that liars will distance themselves more from the story being told and, relatedly, will be less forthcoming than truth-tellers (see also Research Question 2 on certainty cues above). Possible linguistic indicators for this assumption are personal pronouns, cues to responsibility, and verb tense shifts. To clarify the predictions of specific cues, we present them within the theoretical accounts of immediacy, self-organization, egocentric bias, and narrative conventions.
Immediacy
A possible way to express ownership and take responsibility for an action or event is to tell a story from a first-person perspective, where the sender is reporting an event where he or she is the actor, not an observer-bystander. Evidence for this assumption comes from the long tradition of research on verbal and nonverbal communication that has investigated immediacy as a cue to truthful messages (Cody et al., 1984; Knapp et al., 1974; Kuiken, 1981; Mehrabian, 1972; Wagner & Pease, 1976; Wiener & Mehrabian, 1968; Zhou, Burgoon, Nunamaker, & Twitchell, 2004; Zhou, Burgoon, Twitchell, et al., 2004). In these studies, one aspect of immediacy has been operationalized as the psychological distance between the speaker and his or her communication. More specifically, immediacy can indicate the degree to which there is directness and intensity between the communicator and the event being communicated (Wiener & Mehrabian, 1968, p. 4). Taking this aspect of the definition of immediacy, deception researchers consider nonimmediacy as an indicator of deceptive communication by way of the speaker distancing from his or her own statement (e.g., Buller et al., 1996; Kuiken, 1981; Wagner & Pease, 1976; Zhou et al., 2004).
However, evidence for nonverbal and verbal indicators of the relationship between immediacy and deception is mixed. In the meta-analysis by DePaulo et al. (2003), there were no significant effects for self- or other-references, but more general indices of verbal immediacy (all categories) as well as verbal and vocal immediacy (impressions) were observed significantly more frequently or to a higher extent in truthful than fabricated messages. This latter effect appeared to be stronger when immediacy was measured subjectively than when assessed via more objective measures.
The self as an organizational structure
Another line of research we consider is social-psychological theorizing on social memory, which has emphasized the role of the self as an organizational structure. In fact, one of the primary distinctions between episodic and autobiographical memory is that the self provides an organizing principle that relates experiences to one’s self-schema. Experimental evidence comes from research on the self-reference effect (Rogers, Kuiper, & Kirker, 1977), which demonstrated that information is particularly well remembered when it has been encoded in relation to oneself, or when the person plays an active, rather than passive role (e.g., Slamecka & Graf, 1978). Variations on this theme are discussed under ego-defensive, self-serving, egocentric, or egotistic biases (see Greenwald, 1980). Greenwald (1980) went as far as referring to the self as a “totalitarian ego” that puts itself in the foreground, assuming a central role and ownership when talking about self-experienced past events and actions. This prevailing tendency should lead to more frequent uses of first-person pronouns (I, me, we, us, our, etc.) when telling the truth relative to lying.
However, while the egocentric bias may play a role when reporting (complex) autobiographical events, it may be restricted to positive outcomes and reversed for negative outcomes (Greenwald, 1980). Also, the so-called “better than average effect” refers to the tendency to evaluate oneself more favorably than an average peer (e.g., J. D. Brown, 2012). For instance, 70% of high school seniors estimated that they had above average leadership skills, whereas only 2% said their leadership skills were below average (College Board, 1976-1977). Another example of the positive outcome bias is a classic study by Bahrick, Hall, and Berger (1996; see also Bahrick, 1996) who found that students accurately recalled better high school grades than worse ones. Relatedly, in a classic study on the self-enhancing bias by Cialdini et al. (1976, Experiment 2), college students not only donned their school colors on Monday after their team had won but also identified, or distanced, themselves by use of different personal pronouns (“we won”; “they lost”). This suggests that first-person pronouns and statements of personal responsibility will be more prevalent among truth-tellers than liars, particularly for positive outcomes.
Predictions
In summary, from different theoretical perspectives, we assume more frequent use of first-person pronouns, and less frequent use of third-person pronouns for reports of self-experienced events. Self-experienced events should also be characterized by more statements of own responsibility, at least for positive outcomes. This prediction is more likely to hold for first-person singular than first-person plural because the plural may designate both the group the storyteller belongs to, and identifies with, as well as a communication partner who acts as an antagonist in an interaction (e.g., “we quarreled”). Thus, with plural pronouns, ownership and responsibility are less clear-cut than with singular pronouns. On the contrary, passive voice or generalizing terms in phrases like “one has to . . .” or “everybody does this . . .” signal less personal involvement and hence should be found more frequently in lies than truthful accounts.
Narrative conventions and verb tense shifts
Communication about past events follow narrative conventions (acquired during childhood) that require the storyteller to talk about who, what, when, where, and why (R. Brown & Kulik, 1977; Neisser, 1982) and to adhere to a temporal structure (Bruner, 1990). Anecdotal evidence from research on autobiographical memory for significant life events shows that people sometimes switch from telling a story in the past tense to the present tense at crucial moments of the event (Pillemer, Desrochers, & Ebanks, 1998). In many of these examples, it appears that the protagonist is reliving the past event, describing his or her sensory and perceptual experiences, making the accounts to appear more vivid (cf. the RM approach described in Research Question 5). Although present tense may be less concrete than past tense when it refers to repeated or routine actions (e.g., “I [usually] go to church on Sunday” versus “I went to church on Sunday”), when talking about a specific past event, present tense is more vivid than past tense. Whether verb tense shifts occur involuntarily or unconsciously, or are strategically used by skillful storytellers (like fiction writers) to communicate intensity and feeling to a recipient, cannot be answered by these archival type studies, nor by our meta-analyses.
Predictions
We expect reports of true events to be more likely to contain present tense verbs than lies, at least in accounts of personally significant events. For other types of lies, this prediction may not hold. The live character of these narratives may also diminish with repeated retellings of a story. Conversely, lies should contain more past tense verbs than true accounts.
Research Question 5: Do Liars Use Fewer (Sensory and Contextual) Details?
RM framework applied to deception
The RM model by M. K. Johnson and Raye (1981) describes how individuals differentiate between externally generated memories of actual experiences versus memories of internally generated events that involve thoughts, fantasies, or dreams. In contrast to imagined events, experienced events are encoded and embedded in memory within an elaborate network of information that typically includes more perceptual details, and contextual and semantic information. Conversely, internally generated memories are characterized by cognitive inferences or reasoning processes.
People differentiate between their own external and internal memories on the basis of these phenomenal characteristics (M. K. Johnson, Hashtroudi, & Lindsay, 1993), and similar features are also useful to differentiate between accounts of external and internal memories of other people (an attribution process that has been tagged “interpersonal reality monitoring”; M. K. Johnson, Bush, & Mitchell, 1998; M. K. Johnson & Suengas, 1989; Sporer, 2004; Sporer & Sharman, 2006).
Deceptive accounts can be characterized as representing internally generated memories, because in a deceptive situation, people imagine the event at the time of its construction (Sporer, 2004). Even if people lie by borrowing from actual experience, the time and place or the context in which the event occurred may be changed during construction (Sporer, 2004; Vrij, 2008a). Therefore, even partially true deceptive accounts may lack the typical characteristics of true accounts. With these considerations in mind, researchers have extrapolated from the RM model to make predictions about specific sets of criteria that may discriminate between true and deceptive accounts (e.g., Granhag, Strömwall, & Olsson, 2001; Sporer, 1997; for reviews, see Masip, Sporer, Garrido, & Herrero, 2005; Sporer, 2004; Vrij, 2008a). DePaulo et al.’s (2003) meta-analysis, which only included a few studies available then, showed small and nonsignificant effect sizes for RM criteria. However, in a more comprehensive review of studies, Masip et al. (2005) found that some of the RM criteria involving perceptual processes, contextual (including time) information, and realism/plausibility of the story were useful to discriminate between truth and deception.
Predictions
From a RM perspective, we predict that compared with true accounts, false accounts will (a) contain fewer perceptual details as indicated by sensory and perceptual word cues (taste, touch, smell), (b) be less contextually embedded as indicated by space (around, under) and time word cues (hour, year), and (c) include fewer descriptive words as indicated by prepositions (on, to), numbers (first, three), quantifiers (all, bit, few), modifiers (adverbs and adjectives), and motion verbs (walk, run, go). This latter set of cues involves words that describe events and actions in the story in more specific terms (e.g., “I took every short cut to get to work”). The lack of these words (e.g., “I went to work”) would make the account seem less real or vivid as would be predicted from the RM perspective (Sporer, 1997, 2004).
Research Question 6: Do Liars Refer Less (Yes, Less!) Often to Cognitive Processes?
The RM approach, unlike other verbal content cues based credibility assessment procedures, such as Criteria-Based Content Analysis (CBCA, Steller & Köhnken, 1989), does not only contain “truth criteria” (e.g., spatial and time details) but also one lie criterion. Specifically, RM predicts that references to internal processes at the time of the event (cognitive operations like reasoning processes) should be more likely contained in imagined than in self-experienced events. Applied to detecting deception, researchers have consequently postulated that references to cognitive operations can be used as a lie criterion (Sporer, 1997; Vrij, 2008a).
However, empirical evidence regarding this proposition is mixed. Perhaps, depending on the operationalization of this construct, some studies have found more references to cognitive operations in lies (e.g., Vrij, Akehurst, Soukara, & Bull, 2004), many studies have found no differences (e.g., Sporer & Sharman, 2006; 14 out of 19 studies reviewed in Vrij, 2008a), and some studies have found reliably more references to internal processes (like memory processes and rehearsal as well as thoughts) in true accounts (Granhag et al., 2001; Sporer, 1998; Sporer & Walther, 2006; Vrij, Edward, Roberts, & Bull, 2000).
From a different perspective, some 30 years of research on autobiographical memory has emphasized the associative nature of memories. Recollecting (personally significant) life events involves not only the conscious utilization of retrieval cues but also cross-referencing to supporting memories related to the event in question. It also involves rehearsal processes, which are important determinants of remembering (Conway, 1990). These processes can also be subsumed under cognitive operations. To the extent that studies on deception involve complex (autobiographical) events, like being questioned about a crime or reporting an alibi, such retrieval processes and supporting memories (cf. the CBCA criterion “External Associations”) are likely to be used and mentioned when recalling true events (e.g., “I know it was the day before Easter because Good Friday was my birthday.”).
Finally, there is empirical evidence from several studies that cognitive operations are positively correlated not only with other RM criteria (Sporer, 1997, 2013) but also with many CBCA criteria like “External Associations,” “Own Psychological Processes,” “Spontaneous Corrections,” or “Doubts about one’s own Testimony,” loading on a common underlying factor (Sporer, 2004, Table 4.4). All of these criteria are assumed to indicate truthfulness.
Predictions
Consequently, we predict that linguistic cues referring to cognitive operations including memory processes are more likely to be found in truths than in lies. The two cues under this research question are cognitive processes (cause, ought) and insight words (think, know, consider).
Miscellaneous Category
Because many linguistic cues were investigated without a specific theoretical background or directed predictions, we created a miscellaneous category including linguistic cues analyzed in more than five studies (e.g., inhibition, social processes, health, sports; see Appendix B).
Hypotheses for Moderator Variables
It would be unwise to assume that the above predictions will hold across all types of lies, motivation, level of interaction, production mode, and other contextual factors. Hence, we conducted a series of moderator analyses within the theoretical frameworks provided above.
Event Type and Personal Involvement
Across studies, senders described events or attitudes that differed in terms of personal involvement. We organized the studies into three categories. In the “Attitude/liking” paradigm, senders described their attitude toward a specific topic or person they like or dislike. In the “First-person experience” paradigm, senders experienced a staged event or mock crime, described a personal life event, or were involved in a real criminal case. Finally, the “Miscellaneous” category included studies where participants solved a problem, performed a specific task, or described a video scene. 3 We do acknowledge, however, that some attitudes/liking studies may also reflect high involvement but this would work against our hypothesis.
We argue that the higher the personal involvement in the event, the higher the cognitive load (e.g., due to a preoccupation with an interaction partner’s reactions) and arousal (negative or unspecified emotions) will be when telling a lie. Also, liars might express more uncertainty terms or try to distance themselves more from events when their personal involvement is high. In other words, we expect the effects under Research Questions 1, 2, 3a, 3c, and 4 to be larger for the “First-person experience” compared with the “Attitude/liking” or the “Miscellaneous” paradigms in the aforementioned direction.
Emotional Valence
The topics or events senders were asked to talk about were classified as positive (e.g., holidays), neutral (e.g., task performance), or negative (e.g., confession of wrongdoing) in nature. If we assume that more negative emotions accompany telling a negative rather than a neutral event, liars should express even more negative emotion words when the event is negative (Research Question 3a). Also, we assume that the amount of unspecified emotion words (Research Question 3a) will be higher when the event is not neutral. Moreover, cognitive load might also be higher because senders have to deal with additional negative emotions that may induce concern, leading to a decrease in word count and diverse and exclusive words (Research Question 1—Cognitive Load: cues 01, 02, 03).
Also, if liars are more negatively involved in their story, they could appear more uncertain (Research Question 2—Certainty) and try to distance themselves more using less self- and more other-references (Research Question 4—Distancing). In summary, we hypothesized that effect sizes under Research Questions 1, 2, 3a, 3c, and 4 would be highest (in the expected direction) if the emotional valence was negative rather than neutral (or positive).
Intensity of Interaction
The degree of interactions between the storyteller and another person varies widely in deception detection research (Vrij & Granhag, 2012). We differentiated four interaction levels: (a) no interaction: participants are only given a written or spoken instruction; (b) computer-mediated communication: participants are communicating via connected computers (e.g., only by typing words in studies included); (c) interview: interviewees are simply responding to questions from an interviewer (one-way direction); and (d) person to person interactions: sender and receiver are present in person and interacting bidirectionally. 4 We hypothesized that with increasing intensity of interactions from (a) to (d) (cf. Buller & Burgoon, 1996), effects would become stronger under Research Questions 1, 2, 3a, 3c, and 4.
Motivation
Researchers varied the level of motivation for their senders to appear credible. Some researchers did not motivate their senders at all, some others tried to motivate them with incentives or written instructions, and still others used accounts from real criminal cases, where the motivation to appear credible must have been high due to real consequences for getting caught (high-stake lies; cf. DePaulo et al., 2003).
DePaulo and Kirkendol (1989) postulated the motivational impairment effect, according to which highly motivated liars try to control their expressive behaviors to appear credible, but they are only successful in doing so with their verbal behavior, while their nonverbal behavior appears disrupted. In other words, liars’ nonverbal behavior should be impaired whereas their verbal behavior (i.e., the content of messages) should be improved. DePaulo, Lanier, and Davis (1983) provided support for these hypotheses, as highly motivated liars were easier to detect in the visual or audiovisual conditions, but less successfully detected in the verbal (transcript) condition (there was no difference in the audio-only condition).
Assuming that the motivational impairment effect also applies to linguistic cues as a form of verbal behavior, we hypothesized that highly motivated liars might try harder to control their words, so differences between liars and truth-tellers should become smaller under Research Questions 1, 2, 3a, 3c, and 5.
Production Mode
Participants’ accounts were handwritten, typed on a keyboard, or spoken (and audio- or videotaped). Horowitz and Newman (1964) proposed that, in general, speaking is easier than writing, because speakers have more liberty and feel less inhibited than writers. Also, writing involves more deliberateness (see also Hancock, Woodworth, & Goorha, 2010) and more serious commitment. Horowitz and Newman found support for their hypothesis in that speaking is more productive and elaborative than writing. This resulted in more words, more phrases, and more sentences when speaking than when writing. More recently, Kellogg (2007) hypothesized that writing is slower and less practiced than speaking and thus results in higher demands on working memory. He found that accounts of a recalled story were more complete and more accurate when spoken than written (cf. also Sauerland & Sporer, 2011).
Hence, we hypothesized that liars produce even fewer words, diverse words, and sentences (Research Question 1—Cognitive Load) when writing than speaking due to an increased cognitive load and decreased working memory capacity. Furthermore, liars should also use fewer sensory and contextual details when writing than speaking compared with truth-tellers (Research Question 5; see Elntib, Wagstaff, & Wheatcroft, 2014, for a recent empirical investigation of this issue). Regarding emotion-related cues (under Research Questions 3a and 3c), we hypothesized that liars use more negative and unspecified emotion words than truth-tellers when speaking than when writing, because emotions might be expressed more directly and frequently in direct speech.
An empirical issue for studies involving writing is whether handwriting or typing comes easier. Therefore, we separated written accounts into handwritten versus typed for our moderator analysis. Unfortunately, we do not know the level of typing skill of participants.
To sum up, differences between liars and truth-tellers should be more pronounced in written (typed or handwritten) compared with orally given accounts for linguistic cues under Research Questions 1 (cognitive load) and 5 (details), whereas for emotion-related cues (Research Questions 3a and 3c), the effect sizes should be larger if stories were spoken than written.
Program Type
Researchers from various fields used different computer programs to analyze deceptive and truthful accounts. The most common one is LIWC. Although it is a general program (i.e., not specifically designed to detect deception), we separated it from other general programs such as Coh-Metrix or WordScan. This is because LIWC was used in a disproportionally large number of studies. Other software, such as Agent99Analyzer or ADAM, was specifically developed to detect deception. We hypothesized that studies applying deception-specific programs should yield stronger effects for any linguistic cue than studies using LIWC or any other general program based on simple word counts.
Publication Status
The tendency that studies with nonsignificant findings are less likely to be written, submitted, and accepted for publication in peer-reviewed journals, is referred to as publication bias (H. Cooper, 2010; Sutton, 2009). In short, the publication of a study may partially depend on its results rather than on its theoretical or methodological quality (Rothstein, Sutton, & Borenstein, 2005). One method to statistically quantify a publication bias is to compare the effect sizes of published and unpublished studies (see Appendix E in supplemental online materials); another is to test for the association between effect sizes and sample sizes (Levine, Asada, & Carpenter, 2009).
Experimental Design
We also assessed experimental design as a moderator (between- vs. within-participants), assuming larger effects for the latter (see results in Appendix F in supplemental online materials).
Goals of the Meta-Analysis
The main goals of our meta-analysis were (a) to provide a comprehensive set of operational definitions for each linguistic marker, (b) to offer an elaborate theoretical background to specify directed predictions for each cue, (c) to provide a quantitative and comprehensive synthesis of linguistic cues to deception assessed with computer programs obtained from interdisciplinary research areas, and (d) to analyze the influence of important theoretical and methodological moderator variables on the outcome of linguistic cues to deception.
Method
Inclusion and Exclusion Criteria
Studies had to meet the following eligibility criteria to be included in our meta-analysis: (a) use of software to locate linguistic cues; (b) reports of specific linguistic cues (not just paraverbal/paralinguistic or nonverbal or physiological cues)—studies that reported word counts only, but no other linguistic cues were excluded 5 ; (c) independence of data sets: when analyses of the same data set of transcripts and cues were reported in multiple publications, we only included the source published in the journal with the highest publication standard (e.g., peer review) and excluded the other source(s) to ensure independence of all data sets; and (d) sufficiency of data to calculate effect sizes (see “Effect Size Measure” section below). Furthermore, (e) whenever a field study with statements from real criminal cases met the aforementioned criteria (e.g., ten Brinke & Porter, 2012), special care was taken to assure ground truth had not been established solely on the basis of a court verdict, but in addition from more than one type of external and independent source of evidence (e.g., physical evidence, witness statements, confessions, etc.). However, these studies should be treated with caution because linguistic aspects of the account may have affected the final case disposition (e.g., lie or truth).
Literature Search and Study Retrieval
As a first step, we searched through reference lists of most relevant studies or reviews (e.g., DePaulo et al., 2003; Newman et al., 2003; Tausczik & Pennebaker, 2010; Zhou et al., 2004). Next, several exhaustive literature searches were conducted from September 2011 to February 2012 in the most important psychological research literature databases, such as the Social Sciences Citation Index (with cited reference search), PsycInfo, Dissertation Abstracts, and Google Scholar, examining articles published between 1945 and February 2012.
The combination and permutations of three keyword clusters were used: (a) decept*, deceit, lie; (b) verbal, linguistic, language; and (c) automatic, computer, software, artificial. These searches resulted in 948 published and unpublished articles that were reduced to 394 after removing duplicates. Then, the inclusion and exclusion criteria were carefully applied. This reduced the number of articles to 99, from which we still had to exclude 54 for different reasons (see Appendix G in supplemental online materials), mostly incomplete reporting of data necessary for our analysis. This resulted in 44 relevant data sets that met all inclusion criteria.
Linguistic Cues to Deception
A total of 202 linguistic cues were extracted from the articles and sorted based on their name and operational definition (if available). In some cases, we merged cues with different names that had very similar operational definitions. For example, type-token ratio, unique words, lexical diversity, or different words, were all similarly operationally defined and refer to the same construct. We chose the name most commonly used (e.g., type-token ratio in the prior example).
All linguistic cues had to be calculated as a ratio of all other words (except raw frequencies of words, verbs, and sentences), and had to be investigated in at least k = 4 hypothesis tests. This resulted in 79 linguistic cues of which 50 were allocated to one of the six research questions based on their content and theoretical meaning. The remaining 29 cues could not be allocated to a theory or one of the research questions and were assigned to the miscellaneous category. All linguistic cues, with all of their names and final operational definitions, are listed in Appendices A and B.
Effect Size Measure
As an effect size measure, we used Hedges’s gu (Borenstein, 2009; Hedges, 1981; Lipsey & Wilson, 2001), an unbiased estimator of the standardized mean difference (Cohen’s d). Here, it is the standardized mean difference of the average frequency or ratio for each linguistic cue between deceptive and true accounts. If a specific linguistic cue occurred more often during deception than truth, gu has a negative sign. If it occurred more often during truth than deception, gu was assigned a positive value. To calculate gu, we coded means, standard deviations, and ns separately for deceptive and true stories. If this information was not given, other appropriate measures (t- or F-values with 1 degree of freedom in the numerator, or p values) were coded (for formula collections, see Borenstein, 2009; Lipsey & Wilson, 2001).
If no relevant statistical data were available, we e-mailed the researchers to request them. In some instances, there may be discrepancies between the effect sizes reported here and those in the original articles. Reasons for such differences are that some authors provided us with more (differentiated) data, that we sometimes chose specific subgroups for the analyses, or calculated the average effect size across subgroups, as explained in more detail under “Meta-Analytic Techniques” section below.
Independent Variables and Moderator Variables
After coding typical study characteristics (e.g., study ID, author names, year of publication, number of senders and gender, etc.), we coded for information that defined the moderator variables or further independent variables of potential interest. These were publication status (e.g., published, thesis, etc.), type of computer program (LIWC; other general programs like Wordscan, Microsoft Word, or Coh-Metrix; or specific programs like ADAM, Agent99Analyzer, GATE, iSkim, CueCal, or Connexor), language of accounts, theory presented (if any), cue selection (a priori, reported all or significant cues only), age of the senders, experimental design (between- or within-participants), preparation time, event type, event valence, interaction between sender and receiver, mode of production, and type/level of motivation to lie successfully.
Coding Procedures and Intercoder Reliability
Two trained raters coded all dependent and independent variables from the articles with a standardized coding manual. After discussing two articles as examples and agreeing on order of article review, each coder worked independently. For 11 continuous variables, intercoder reliabilities were highly satisfactory, with all coefficients ranging from Pearson’s r = .86 to r = 1.0 (except for preparation time: r = .77). For 8 categorical variables, intercoder reliabilities were excellent, with Cohen’s kappa (Cohen, 1960) ranging from .75 to 1.0. For 6 additional categorical variables, Cohen’s kappa ranged from .51 to .67, which was still a fair to good agreement (according to Fleiss, 1981). The few disagreements were resolved by discussion between the two coders. Final coding decisions of the moderator variables for each study are displayed in Appendix C.
Meta-Analytic Techniques
Dependencies of effect sizes
In some studies, in addition to accounts’ truth status, other independent variables were manipulated as between- or within-participants factors and the data were reported separately for these subgroups (e.g., Schelleman-Offermans & Merckelbach, 2010: high- vs. low-fantasy-proneness). In studies with additional within-participants factors, dependency was avoided by calculating effect sizes separately for each subgroup and averaging them to ensure that only one effect size per study per linguistic cue was included (Lipsey & Wilson, 2001). In two other studies, a second between-participants factor (Ali & Levine, 2008: denials or confessions; Qin et al., 2005: text chat, audio, face-to-face) was examined; here, we included each of these subgroups (with different stimulus persons) as independent data sets.
Superordinate categories and sub-cues
Sometimes a linguistic category of cues had differentiated effect sizes that seemed to represent a single construct. As an example, we defined cue 19 with the superordinate category (“umbrella term”) positive emotions and feelings including results from positive emotions only and positive feelings only. In studies using LIWC 2001, positive feelings and positive emotions/affects are treated as two different linguistic cues—and the data are reported separately for each (in LIWC 2007, they are combined). To ensure that only one effect size per construct is included, we combined sub-cues to a superordinate category (by averaging their effect sizes). However, we also calculated separate meta-analyses for each of these sub-cues (here: cue 19.1 positive emotions only and 19.2 positive feelings only) to investigate whether the results are more differentiated, or if merging these cues was justifiable. The same procedure was applied to cue 18 negative emotions and to cue 28 sensory–perceptual processes (see Table 1). These superordinate categories make results from LIWC more comparable with studies using other computer programs that did not differentiate between different sub-cues (e.g., anger, anxiety, sadness).
Meta-Analyses of Linguistic Cues under Research Questions 1 to 6.

Note. Pred. DOE = predicted direction of effect; k = number of hypothesis tests, where the second value behind the slash indicates the number of hypothesis tests with outliers; N = total number of accounts; gu = effect size Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; CI = 95% confidence interval; Q = homogeneity test statistic; I2 = descriptive measure of heterogeneity; M = Moderator analyses conducted; T = occurs more often in true accounts; wO = without outlier: Results after removal of outliers detected using Hedges and Olkin’s (1985) procedure; D = occurs more often in deceptive accounts;
Indicates that the specific linguistic cue is an umbrella term.
Weighted average effect size
For each of the 79 linguistic cues, individual meta-analyses under the fixed-effects model (Lipsey & Wilson, 2001; Shadish & Haddock, 2009; Sporer & Cohn, 2011) were calculated. Average effect sizes were weighted by the inverse of the variance to give more weight to studies with larger samples. For six studies, the total number of accounts was extremely large. To avoid unjustified extraordinary large weights, we adjusted the number of total accounts for these studies (see “Results” section).
Homogeneity of effect sizes
We report both the homogeneity test statistic Q (Lipsey & Wilson, 2001) and the descriptive homogeneity statistic I2 (Higgins & Thompson, 2002; Shadish & Haddock, 2009). In rare cases where I2 resulted in a negative value, it was set to 0. In case of heterogeneity, outlier and moderator analyses were conducted.
Outlier analysis
To test for the presence of outliers, we applied the two methods recommended by Hedges and Olkin (1985, chap. 12, and programmed by the fourth author). The number of outliers did not exceed 15% of the total number of effect sizes to avoid an artificial restriction of the variance between effect sizes. If outliers were detected, we calculated each meta-analysis with and without the outliers as sensitivity analyses (Greenhouse & Iyengar, 2009). Due to space limitations, we only report results without outliers in Table 1 (results with and without outliers are displayed in Appendix H in supplemental online materials).
Moderator analyses
We used categorical variables as potential moderators with Hedges’s analogue to ANOVA (Hedges, 1982; Lipsey & Wilson, 2001). Moderator analyses were only conducted if the homogeneity statistic was significant and if an individual meta-analysis of a specific linguistic cue contained enough hypothesis tests to avoid empty cell sizes and to increase power. Moderator analyses were only conducted without outliers to prevent biased results. To clarify potential confounds between moderator variables, we calculated their intercorrelations as well as all two-way and three-way cross-tabulations for each variable combination, to avoid empty or low frequency cells. As a consequence, only moderator analyses for k ≥ 13 hypothesis tests are reported.
Computer software for calculations
For computing individual effect sizes, weights, and confidence intervals (CIs), formulae were programmed in Microsoft Office Excel (2011) spreadsheets by the first and fourth author. Calculations of meta-analyses and outlier analyses were conducted using Excel spreadsheets programmed by the fourth author and cross-validated using Lipsey and Wilson’s (2001) SPSS macros (Wilson, 2002). Moderator analyses were also conducted using these macros.
Results and Discussion
Study Characteristics
We included k = 44 independent studies or data sets (see Appendix C for all individual coding decisions), dated between 2002 and February 2012. Most studies were published (k = 27), 11 were conference presentations (poster or paper), and the rest were 4 dissertations, 1 master’s thesis, and 1 submitted manuscript.
Computer program
More than half of the studies (58.1%) used LIWC (2001 or 2007), 23.3% used other general programs, and 18.6% applied a program specifically developed to detect deception. Three studies, where the type of program was not specifically described or labeled (e.g., “automated analysis method,” “natural language processing tool,” “message analyzing software”), were categorized under other general programs.
Senders
There were a total of 3,780 senders (k = 43) with an average of 87.91 (SD = 19.60, Mdn = 53) senders per study, ranging from 8 to 800. Information about senders’ gender was provided in 30 studies, with more male than female participants in total (Nmale = 1,254, Nfemale = 895), and on average per study (Mmale = 41.80, SDmale = 9.22; Mfemale = 29.83, SDfemale = 5.76). Exact information about senders’ age was reported in only 29.5% of the studies. Across all age groups, senders’ mean age was 19.33 years (SD = 8.45), ranging from 4 to 58 years. The mean age of N = 1,015 adults only was 24.17 (SD = 4.11) with a range of 17 to 58 years, whereas the mean age of N = 218 children (k = 4) was 8.45 years (SD = 1.57), ranging from 4 to 14 years.
Accounts
There were a total of 11,680 (Ntruth = 5,650, Nlie = 6,030) accounts originally. However, six studies contained an extremely large number of accounts, ranging from N = 608 (Schafer, 2007, Experiment 1) to N = 3,162 (Derrick et al., 2012), with a mean of 1295.17 accounts (SD = 948.98). In the other 38 studies, the mean was M = 102.87 (SD = 73.17), ranging from N = 13 (Ali & Levine, 2008, confessions) to N = 322 (J. E. Cooper, 2008). Therefore, we decided to adjust the number of total accounts for these six studies to N = 500 (ntruth = 250, nlie = 250) to avoid extraordinary high weights. Consequently, the final average number of accounts per study was M = 157.02 (SD = 153.66, Mdn = 103), with M = 82.02 (SD = 80.71) for truths and M = 75.00 (SD = 76.68) for lies. All accounts were provided in English except for four studies (two Spanish, one Dutch, one Arabic).
Preparation
Only eight studies provided information about how long senders had time to prepare their accounts. In four of these, senders had no opportunity, for the other four studies, senders had on average 1.31 min (SD = 0.71; range = 1-5 min) to prepare.
Theoretical background
Twelve studies referred to Newman et al.’s (2003) explanations (“LIWC approach”) to predict the outcome of specific linguistic cues, 3 used interpersonal deception theory (IDT; Buller & Burgoon, 1996), 2 RM (Sporer, 2004), and 12 a combination of IDT and RM. Twelve additional studies referred to other theoretical backgrounds, for example, media richness theory (Daft & Lengel, 1986) or verbal immediacy (Mehrabian & Wiener, 1966), and three studies did not mention any theory at all. A priori selections of linguistic cues were made for 37 studies while 7 reported only significant findings.
Interpretation of Effect Sizes
As a rule of thumb, Cohen (1988) classified the effect size d into three categories, with d = 0.20 as small, d = 0.50 as medium and d = 0.80 as large effect sizes. However, in meta-analyses about cues to deception, effect sizes are often much smaller (DePaulo et al., 2003: Mdn gu = 0.10; similarly low for Sporer & Schwandt, 2006, 2007). Richard, Bond, and Stokes-Zoota (2003) examined 322 meta-analyses in social psychology and provided an empirically based effect size distribution that might serve as a good comparison for our results (cf. Sporer & Cohn, 2011). It should be noted that in DePaulo et al.’s (2003) meta-analysis, positive effect sizes refer to stronger or more frequent cues in lies.
Research Questions
In this section, we present results for 50 linguistic cues to deception grouped according to six research questions (see Table 1). The weighted average gu, with the 95% CI, is reported for all analyses. Recall that positive effect sizes denote stronger presence in true accounts (similar to Sporer & Schwandt, 2006, 2007, but contrary to DePaulo et al., 2003). A data file with all dependent and predictor variables coded is available in supplemental online materials.
Research Question 1: Do Liars Experience Greater Cognitive Load?
(a) Are liars’ accounts shorter in terms of number of words (cue 01), number of sentences (cue 07), and average sentence length (cue 08)?
As expected, liars used fewer words than truth-tellers (word quantity, 0.24 [0.19, 0.29]), with gus ranging from −1.25 to 1.43, but no shorter sentences than truth-tellers (average sentence length, 0.05 [−0.03, 0.13]). Contrary to our prediction, liars used more sentences than truth-tellers (−0.33 [−0.44, −0.21]), although the distribution of effect sizes was also quite heterogeneous. The effect size for sentence quantity was derived from a small subset of nine studies compared with 42 studies serving data for word quantity. Therefore, word quantity is a more precise estimate for statement length.
Note that DePaulo et al. (2003) did not examine number of words per se but only response length defined as “length or duration” (cue 01, d = −0.03, k = 49, ns), or as talking time (cue 02, d = −0.35, k = 4, p < .05). Sporer and Schwandt (2006) found no reliable associations for number of words (d = −0.018, k = 8) nor for message duration (d = −0.078, k = 23). These differences in findings may be due to the stimulus accounts used. More recent studies analyzing verbal content cues to deception sometimes do (e.g., Ansarra et al., 2011) and sometimes do not find (e.g., Leal, Vrij, Warmelink, Vernham, & Fisher, 2013) differences between liars’ and truth-tellers’ length of accounts operationalized by the number of words.
(b) Are deceptive accounts less elaborated in terms of content word diversity (cue 02), type-token ratio (cue 03), or word length cues (cues 04, 05)?
Indeed, liars used fewer diverse content words (0.48 [0.34, 0.61]) and distinct words (type-token ratio: 0.14 [0.07, 0.21]) than truth-tellers. These findings could be attributed to liars’ increased cognitive load and reduced working memory capacity (relative to truth-tellers), which in turn is associated with a limitation of creative word production in speaking or writing. These findings also favor a cognitive over a social-psychological explanation, as it is unlikely that liars strategically use fewer diverse content and distinct words. However, the prediction that liars would provide shorter words was not supported (see Table 1). Presumably, the number of distinct words and word diversity indices are more sensitive to cognitive load and working memory capacity than word length.
(c) Are deceptive accounts less complex than true accounts, as indicated by fewer verbs (cue 06), causation (cue 09), and exclusive words (cue 10)?
Liars indeed used fewer exclusive words like but, except, or without, than truth-tellers (0.24 [0.17, 0.31]). Using few exclusive words results in simpler stories (Newman et al., 2003). Liars may resort to telling simple stories because their cognitive system is more taxed than that of truth-tellers. Our predictions that liars would use fewer words assigning a cause to his or her behavior (causation), or use fewer verbs than truth-tellers, were not confirmed (Table 1).
(d) Do liars commit more writing errors (cue 11) than truth-tellers?
No support was found for this hypothesis with or without two outliers (Lee, Welker, & Odom, 2009; Zhou & Zhang, 2004). This can be reconciled with DePaulo’s self-presentational perspective (DePaulo, 1992; DePaulo et al., 2003). Liars might be more self-aware and deliberate than truth-tellers; hence, they may edit their typing errors. Derrick et al. (2012) showed that liars were significantly more likely to edit their words on the keyboard (e.g., in using the backspace and delete button) than truth-tellers (−0.12 [−0.19, −0.05]). Whether their edits were aimed at correcting explicit typing errors was not investigated and should be examined more closely. In 6 of the 10 studies exploring writing errors, participants typed their stories on a computer keyboard; unfortunately, they did not measure editing behavior (with the exception of Derrick et al., 2012).
Research Question 2: Are Liars Less Certain Than Truth-Tellers?
Effects for certainty and modal verbs were not significant. The difference between DePaulo et al.’s (2003) findings (who found liars to appear more verbally and vocally uncertain: cue 31, k = 10, d = 0.30, p < .05) and ours could be due to different operationalizations. Whereas we included studies that automatically counted words expressing certainty, DePaulo et al. considered the subjective impression of uncertainty (“the speaker seems uncertain, insecure, . . .,” p. 114). The opposing findings suggest that (a) there is a difference between objective and subjective assessments of (un)certainty, and/or (b) liars may nonverbally give the impression of being uncertain without using fewer certainty words than truth-tellers.
Contrary to our prediction, deceptive accounts contained slightly fewer tentative words (such as may, seem, perhaps) than truthful accounts (0.13 [0.06, 0.20]; for an exception, see ten Brinke & Porter, 2012). A reason for this unexpected finding could be that liars think that tentative expressions diminish their credibility and therefore try to avoid them, although we are not aware of any empirical evidence that liars pursue this strategy to appear more credible. Note that DePaulo et al. (2003) also reported less “tentative constructions” (cue 30, k = 3, d = −0.16, ns) in lies. A different explanation for this finding could be derived from the literature on credibility assessment (e.g., Steller & Köhnken, 1989). The underlying assumption is that due to their motivation to appear credible, liars (here, alleged victims of sexual abuse) would probably not correct themselves spontaneously, admit a lack of memory, or raise doubts about their own statement. These criteria relate to uncertainty or tentative words to the extent that liars try to hide any kind of deficiencies or ambiguities in their statement to appear or stay credible (Sporer, 2004). Especially the criterion “admitting lack of memory” is less often expressed by liars than truth-tellers (DePaulo et al., 2003; cue 73, k = 5, d = −0.42, p < .05; Vrij, 2005). Research also shows that guilty suspects attempt to be firm in their denial of guilt (Hartwig et al., 2007); this is contrary to showing uncertainty.
Research Question 3a: Do Liars Use More Negations and Negative Emotion Words?
(a) To the extent that liars defend themselves or deny something they have done, do they use more negation terms such as no, never, or not (cue 17)?
This prediction was supported, with a significant negative effect of −0.15 [−0.22, −0.09] based on 20 studies (but large heterogeneity). Our results contradict Hancock, Curry, Goorha, and Woodworth’s (2008) view, who considered negations as a form of distinction marker (in addition to exclusive terms) expected to occur less frequently in deceptive accounts, presumably to avoid contradictions by being less specific than truth-tellers.
Our findings concur with those of DePaulo et al. (2003), who found a significant effect for negative statements and complaints (cue 52, d = 0.21, k = 9, p < .05) showing that liars use slightly more negative utterances than truth-tellers.
(b) Do liars use more negative emotion words in general (cues 18, 18.1), as well as more specific negative emotion words, such as anger (cue 18.2), anxiety (cue 18.3), or sadness (cue 18.4), than truth-tellers?
Contrary to the prediction that people might feel negative emotions while lying (Ekman, 2001; Zuckerman et al., 1981), liars did not use more negative emotion words (cue 18, −0.07 [−0.15, 0.01]). However, the sub-cue negative emotions only revealed a small but reliable negative effect (−0.18 [−0.24, −0.12]). 6 The difference between these results can be explained with their different operationalization. Whereas the superordinate category negative emotions (cue 18) contained all types of negative emotions (including anger, anxiety, and sadness), cue 18.1 encompassed only a reduced set of negative emotion words (e.g., hate, worthless, enemy).
A more differentiated picture of various negative emotions under investigation emerged when we look at the more specific type of emotion words used. Liars used more anger terms than truth-tellers (cue 18.2, −0.27 [−0.35, −0.19]), although no significant differences were found for anxiety (cue 18.3) or sadness (cue 18.4, see Table 1). Newman et al.’s (2003) assertion that “anxiety words are more predictive than overall negative emotion” (p. 672) was not supported. Rather, the present findings indicate that there are differences in words expressing feelings and/or different negative emotions while lying. Liars might not feel anxious or sad but rather feel angry, and this might be manifested in words like worthless or annoyed.
Research Question 3b: Do Liars Use Fewer Positive Emotion Words?
Did truth-tellers express more positive emotion (cue 19.1) or positive feeling (cue 19.2) words than liars? Although the effect for positive emotions only just missed significance (−0.07 [−0.15, 0.00]), overall, there was no support for this prediction (Table 1). DePaulo and colleagues (2003) also did not find a significant effect for being friendly and pleasant (cue 49, d = −0.16, k = 6, ns).
Research Question 3c: Do Liars Express More or Less Unspecified Emotion Words?
For 21 studies investigating unspecified emotion words (cue 15), liars used more unspecified emotion words than truth-tellers (−0.11 [−0.19, −0.04]). However, liars and truth-tellers did not differ in words expressing unpleasantness or pleasantness (cue 16, −0.10 [−0.25, 0.06]). DePaulo et al. (2003) also found no significant difference for being “friendly and pleasant” (cue 49, d = −0.16, k = 6, ns). Conversely, DePaulo et al.’s findings for two other subjectively rated cues associated with pleasantness, namely, “cooperation” (cue 50, d = −0.66, k = 3, p < .05) and “facial pleasantness” (cue 54, d = −0.12, k = 13, p < .05), showed that truth-tellers appeared more pleasant than liars. These differences might indicate that the pleasantness construct tracked by DePaulo et al.’s human-rated cues (subjective impressions) is different from the one operationalized in computer-based studies (objective word count). Alternatively, truth-tellers might only appear more pleasant than liars in their nonverbal or paraverbal behavior, but not in their choice of words.
Research Question 4: Do Liars Distance Themselves More From Events?
(a) Do liars use fewer first-person pronouns (cues 21, 22, 23) and more second-person (cue 24) and third-person pronouns (cue 25) than truth-tellers?
Although no significant differences were found for first-person singular, or first-person plural references (see Table 1), the weighted average effect size for total first-person pronouns was significant in the expected direction; that is, liars used fewer total first-person pronouns than truth-tellers (0.14 [0.06, 0.22], when the extreme negative effect size found by Brunet, 2009, both conditions: −1.63 [−1.98, −1.29] was excluded).
On the other side of the coin, we predicted second- and third-person pronouns to occur more often in liars’ than truth-tellers’ accounts. Our meta-analyses supported this prediction, with a negative gu = −0.10 (Table 1). The results indicated that liars in general tried to redirect the focus of attention to other people by using more references to their interaction partner(s) (you), or to (a) third person(s) (he, she, they) than truth-tellers.
Overall pronoun use
As researchers seem to be interested in the use of any type of pronouns (total pronouns, cue 20), we aggregated all of the pronoun effect sizes. The resulting effect size was not significant (0.06 [−0.02, 0.14]).
(b) Do deceptive accounts contain more passive voice verbs (cue 26) and generalizing terms (cue 27) than truthful accounts?
Although effect sizes for passive voice verbs varied considerably (see Table 1), all were nonsignificant. This is probably due to small sample sizes or a generally low frequency of occurrence (floor effect). Generalizing terms had a medium negative effect size (−0.37 [−0.79, 0.05]) that was nevertheless not significant because of the small number of studies and large heterogeneity. Similarly, DePaulo et al. (2003) did not find a significant effect for generalizing terms (cue 21, d = 0.10, k = 5, ns).
(c) Do lies include more past tense verbs (cue 47) and fewer present tense verbs (cue 48) than true accounts?
Significant differences were neither found for past tense verbs nor for present tense verbs (Table 1). A potential reason why the data did not support our predictions could be the way the dependent variable was operationalized. It is important to note that Pillemer et al.’s (1998) hypothesis stated that verb tense shifts occur more often in critical parts of experienced (i.e., true) autobiographical events. Here, we did not consider verb tense shifts, but absolute number of present and past tense verbs. Future research could construct a more suitable linguistic cue than counting the number of verbs only.
Research Question 5: Do Liars Use Fewer (Sensory and Contextual) Details?
(a) Do liars use fewer sensory and perceptual details than truth-tellers?
They did, according to our findings for sensory–perceptual processes only (cue 28.1), although the average effect size was very small (0.06 [0.00, 0.13]). For the variable sensory–perceptual processes overall (cue 28), the effect size was not significant (0.05 [−0.01, 0.12], after two outliers were excluded).
Some support came from the more specialized cue hearing (cue 28.4, 0.17 [0.09, 0.25]), showing that liars used fewer words expressing their acoustic impressions (like listen, sound, or speak) than truth-tellers. Indeed, in case of entirely fabricated lies (compared to partially fabricated lies or lies of omission), persons may not experience any audio(visual) impressions at all and do not seem to deliberately include these words in their lies. However, the cues seeing (cue 28.2) and feeling (cue 28.3) yielded nonsignificant results (see Table 1). Although DePaulo et al. (2003) also found no significant effects for sensory information (cue 05: d = −0.17, k = 4, ns) there have been many new RM studies we are currently synthesizing in an updated large scale meta-analysis.
(b) Are liars’ accounts less contextually embedded than those of truth-tellers, as indicated by fewer time and space words?
No significant effects emerged for time (cue 29), space (cue 30), or the combination of spatial and temporal details (cue 31). Our results for temporal and spatial details are in line with DePaulo et al.’s (2003) nonsignificant finding for contextual embedding (cue 76, d = −0.21, k = 6, ns), though it should be noted that contextual embedding goes beyond temporal and spatial details in that the event has to be connected to everyday occurrences, habits, relationships, and so forth (e.g., Steller & Köhnken, 1989). Again, many newer CBCA and RM studies found support for this assumption (see Masip et al., 2005; Vrij, 2005, 2008a) but linguistic analyses by computers do not seem to capture them.
(c) Relative to truth-tellers, do liars use fewer descriptive words, such as prepositions (cue 32), numbers (cue 33), quantifiers (cue 34), modifiers (adverbs and adjectives, cue 35), and motion verbs (cue 36)?
The only significant effect size was obtained for quantifiers (0.14 [0.02, 0.25]) indicating a slightly lower use of words such as all, bit, few, less, among liars. However, this finding was synthesized from four studies only, so we should not make strong conclusions for this cue in general.
Interestingly, liars produced more motion verbs (such as walk, go, or move) than truth-tellers (−0.09 [−0.17, −0.01]) after removing the only significant positive effect size (Liu et al., 2012; 0.38 [0.21, 0.56]), which was found to be an outlier. This finding is contrary to our prediction but is in line with the cognitive load approach (Research Question 1) and Newman et al.’s (2003) assumption that, when constructing a lie, “simple, concrete actions are easier to string together than false evaluations” (p. 667). Therefore, liars, who are cognitively taxed by the act of lying, “should use more motion verbs and fewer exclusive words” (Newman et al., 2003, p. 667).
Research Question 6: Do Liars Refer Less Often to Cognitive Processes?
As predicted, weighted average effect sizes for both cues (37 and 38) were significantly positive (see Table 1), indicating that liars expressed words relating to their inner thoughts (insight) and cognitive processes less often than truth-tellers.
Miscellaneous Category
Twenty-nine cues that could not be allocated to any research question were subsumed under the miscellaneous category. As displayed in Appendix D (in supplemental online materials), significant positive effect sizes (without outliers) were obtained for inhibition, humans, and for three cues expressing biological processes, namely, biology, physical states, and eating. Liars used fewer words from all of these word classes than truth-tellers. In contrast, negative effect sizes for future tense and leisure terms indicated that these terms occurred more frequently in deceptive than truthful accounts.
Moderator Analyses
Due to the large number of potential moderator analyses for all linguistic cues, we only report significant findings (all QBs were significant at p < .05) for both theoretically and methodologically important moderator variables. Specifically, we examined six moderator variables for 25 linguistic cues, with each analysis containing at least 13 studies. 7 Note that the overall number of studies is smaller for the moderator analyses as many studies did not report enough information to code them. Analyses of two additional moderators, experimental design (between- vs. within-participants) and publication status, are available in supplemental online materials (Appendices E and F). Also, it must be acknowledged that blocking groups of studies in meta-analyses analogous to ANOVA often introduces confounds (see Pigott, 2012) although we have taken great care to minimize them (see “Method” section).
Event type and personal involvement
We hypothesized that larger effect sizes would be found for Research Questions 1, 2, 3a, 3c, and 4 if the event was personally relevant to the participant (“First-person experience,” k = 21) than in the “Attitude/liking” paradigm (k = 7) or the “Miscellaneous” paradigms (k = 14; see Table 2). First, concerning cognitive load (Research Question 1), event type affected average sentence length only. Liars used shorter sentences than truth-tellers when articulating attitudes (0.17), but not under the other two paradigms. Second, regarding negative emotions and negations (Research Question 3a), liars used more negative emotion words than truth-tellers only if they had to tell a personally relevant story (−0.37, −0.57), and expressed more negations only in miscellaneous paradigms (−0.59). Thus, although liars might experience and express more negative emotions when the topic is personally relevant, they do not necessarily use more negations. Third, as expected, liars also expressed more unspecified emotions (Research Question 3c; −0.45) when talking about a personal experience than when having performed other tasks. Fourth, concerning distancing (Research Question 4), liars used fewer first-person plural pronouns primarily when describing a video (0.38), but fewer total first-person pronouns when talking about attitudes (0.31). This unexpected finding suggests that it may be especially hard for liars to refer to themselves while articulating a false attitude; however, liars may still use self-references while telling a personal event because it is common (in the English language) to refer to oneself as the actor. Also, it would be hard to avoid self-references when telling a story with oneself as the acting person, even when lying.
Effect Sizes of Linguistic Cues to Deception When Studies Used Different Type of Events and Personal Involvement.
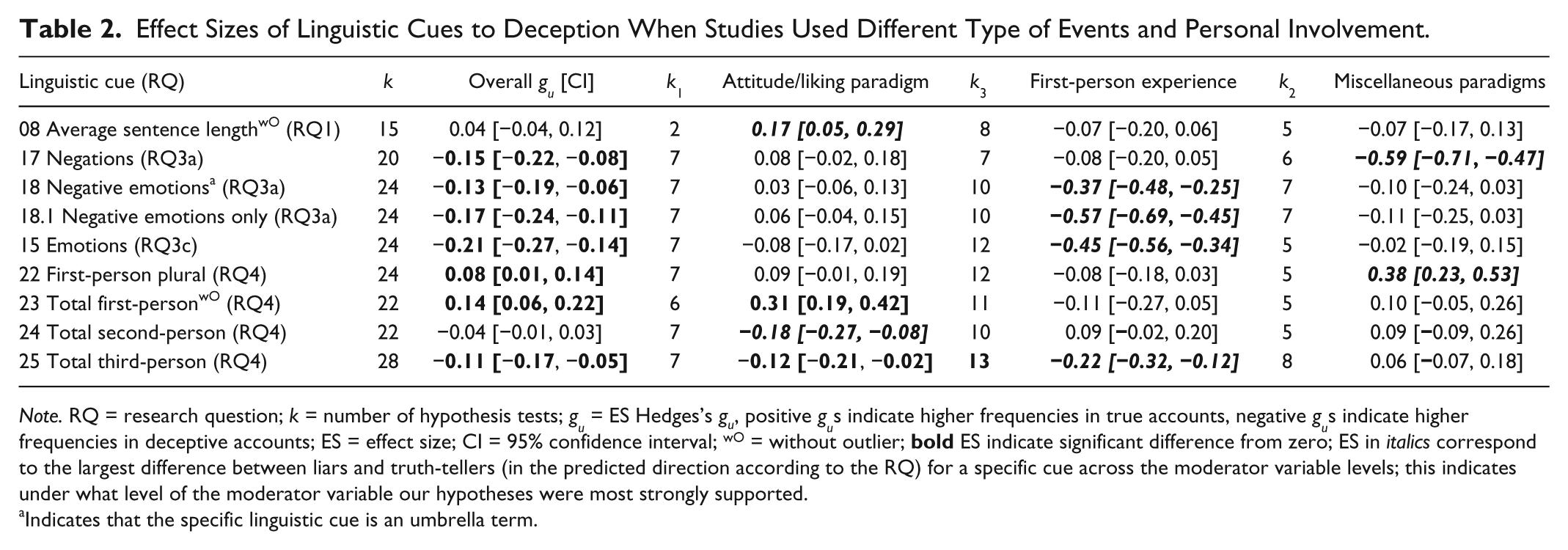
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; wO = without outlier;
Indicates that the specific linguistic cue is an umbrella term.
Liars used more total second-person pronouns only when talking about attitudes (−0.18), and more total third-person pronouns in all kinds of events except the miscellaneous paradigms. In general, thus, the predicted differences for Distancing (Research Question 4) between liars and truth-tellers appear enhanced in the attitude/liking paradigm—compared with the other two paradigms.
Emotional valence
We predicted effects for cues under Research Questions 1 to 4 to be larger for negative (k = 18) than for neutral events or themes (k = 17; see Table 3). 8 Indeed, liars used fewer words (Research Question 1—Cognitive Load; 0.54) only when the event was negative. In terms of negative emotions (Research Question 3a), liars also used considerably more negations (−0.42) and negative emotions (−0.39, −0.65) than truth-tellers, most notably when the event was negative. This supported the notion that telling a negatively toned lie might be accompanied by negative emotions.
Effect Sizes of Linguistic Cues to Deception When the Emotional Valence of the Event Was Neutral Versus Negative.
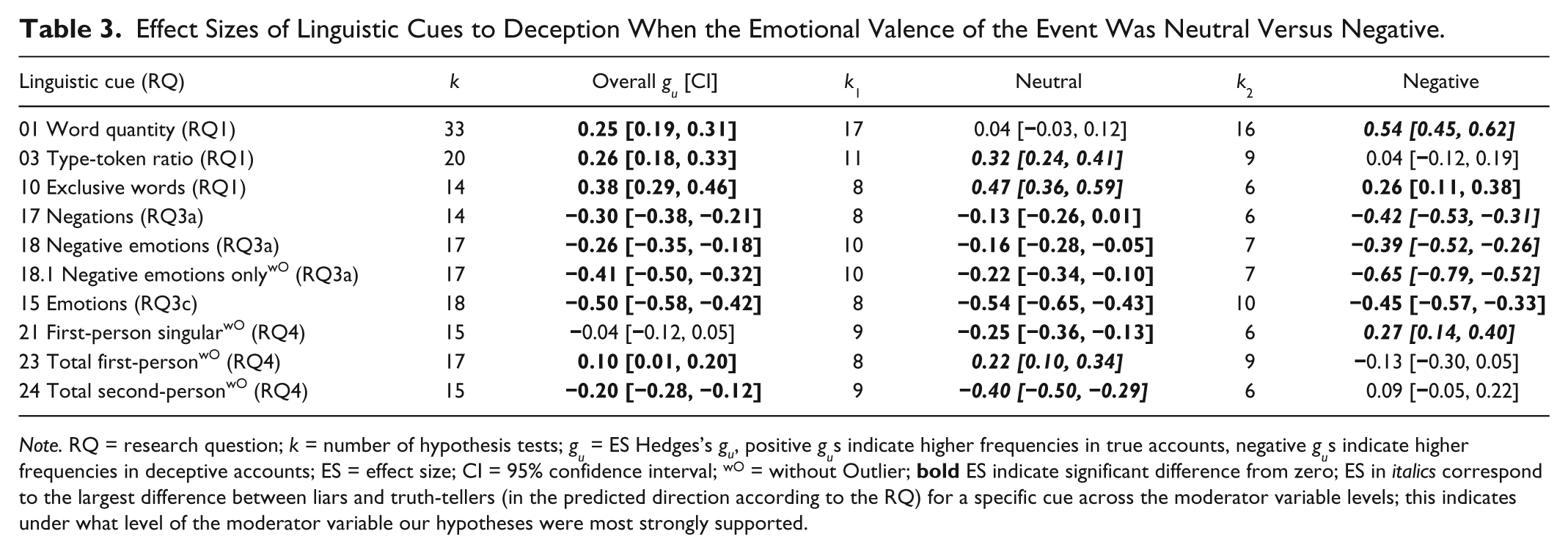
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; wO = without Outlier;
However, contrary to our predictions regarding the cognitive load cues (Research Question 1), differences between lies and truths for type-token ratio (0.32) and exclusive words (0.47) were larger when telling a neutral event rather than a negative event. Perhaps truth-tellers reporting a negative event are as emotionally involved as liars. This may imply using less elaborate language (compared with neutral events), which would explain the lack of difference in type-token ratio between liars and truth-tellers. Finally, no difference in the use of unspecified emotions (Research Question 3c) was found between neutral and negative topics: Liars used more emotion words overall for both (−0.54, −0.45).
Regarding distancing (Research Question 4), somewhat contradictory findings occurred for self-references. When telling neutral events, liars used more first-person singular pronouns (−0.25) but fewer total first-person pronouns (0.22) than truth-tellers. Also, when telling negative events, liars used fewer first-person singular pronouns than truth-tellers (0.27) but about the same amount of total first-person pronouns (−0.13). These findings clearly show that (a) differences exist between liars and truth-tellers in terms of referring solely to oneself or to oneself in addition to one’s group, and (b) these differences depend on the valence of the event. If we think about examples of wrongdoing as typical negative events, it perfectly makes sense to distribute responsibility to “we” (or “you and me,” “they and me”) than to take it on one’s own shoulders (“I”). Finally, liars expressed more total second-person pronouns only when the event was neutral (−0.40).
Intensity of interaction
We predicted that the higher the interaction level, the larger the effect sizes would be (Table 4). Indeed, effect sizes for word count (Research Question 1—Cognitive Load; 0.69), negative emotions (Research Question 3a; −0.48, −0.79), unspecified emotions (Research Question 3c; −0.63), and first-person singular pronouns (Research Question 4—Distancing; 0.34) were largest in person to person interactions. Note also that for computer-mediated communication the direction of effect (−0.41) reversed compared with other conditions. Furthermore, in the interview condition (which was considered as the second intense interaction category), effect sizes for word count, exclusive words, and negative emotions only, were in the expected direction. Interestingly, when no interaction took place, liars used significantly more first-person singular pronouns (−0.22) and total third-person pronouns than truth-tellers (−0.31).
Together, this evidence suggests that some verbal differences between liars and truth-tellers manifest themselves most when a bidirectional interaction between two persons—not only a one-way interview—took place.
Effect Sizes of Linguistic Cues to Deception When Studies Applied Different Type of Interaction Levels (Between Sender and Receiver).
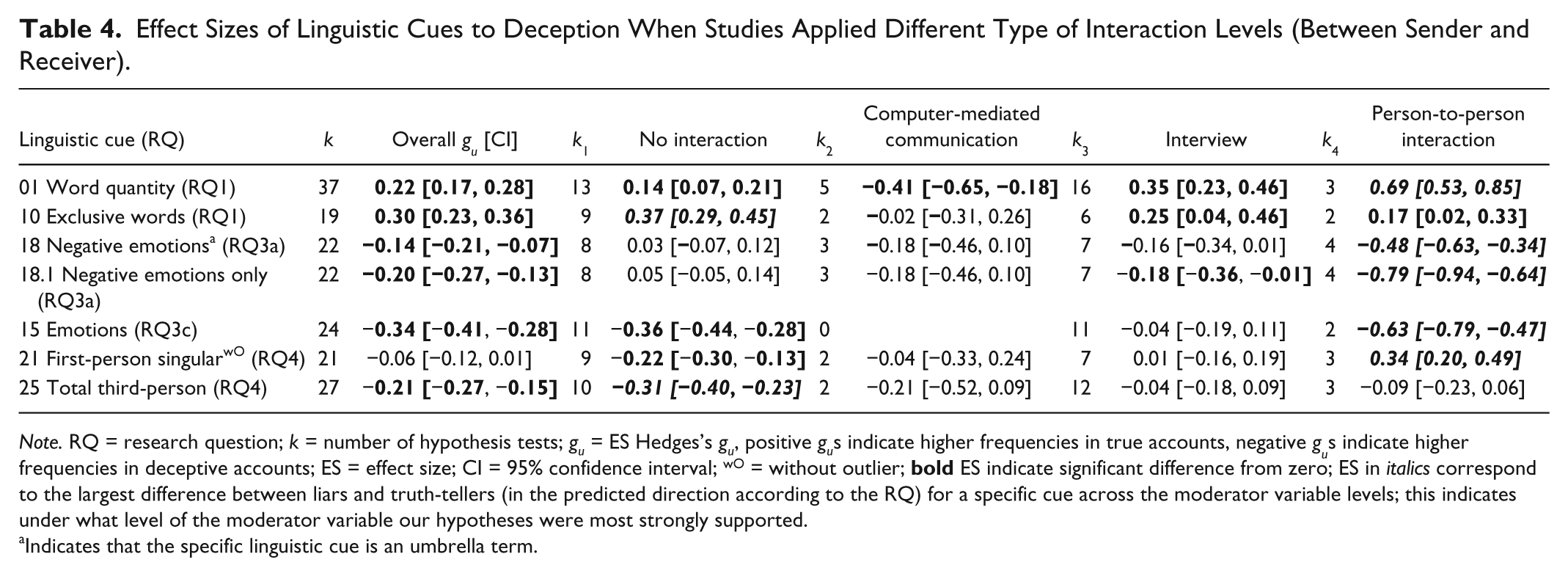
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; wO = without outlier;
Indicates that the specific linguistic cue is an umbrella term.
Motivation
In support for our hypotheses, larger effects occurred for not-motivated liars, who used fewer words (Research Question 1—Cognitive Load) than truth-tellers (0.47), compared with moderately (0.19) or highly motivated liars (0.18; see Table 5). Also, liars used fewer temporal details (Research Question 5 regarding details) only when no motivation was induced (0.20). These findings support the notion that highly motivated liars are more successful than unmotivated liars in controlling their verbal behavior (at least in terms of number of words and temporal details). Note that liars seem to be less able to control their paraverbal behavior under high motivation (e.g., for pitch, response latency; Sporer & Schwandt, 2006) nor their visual nonverbal behavior (e.g., for eye contact; DePaulo et al., 2003).
Effect Sizes of Linguistic Cues to Deception When Studies Induced Different Levels of Motivation.
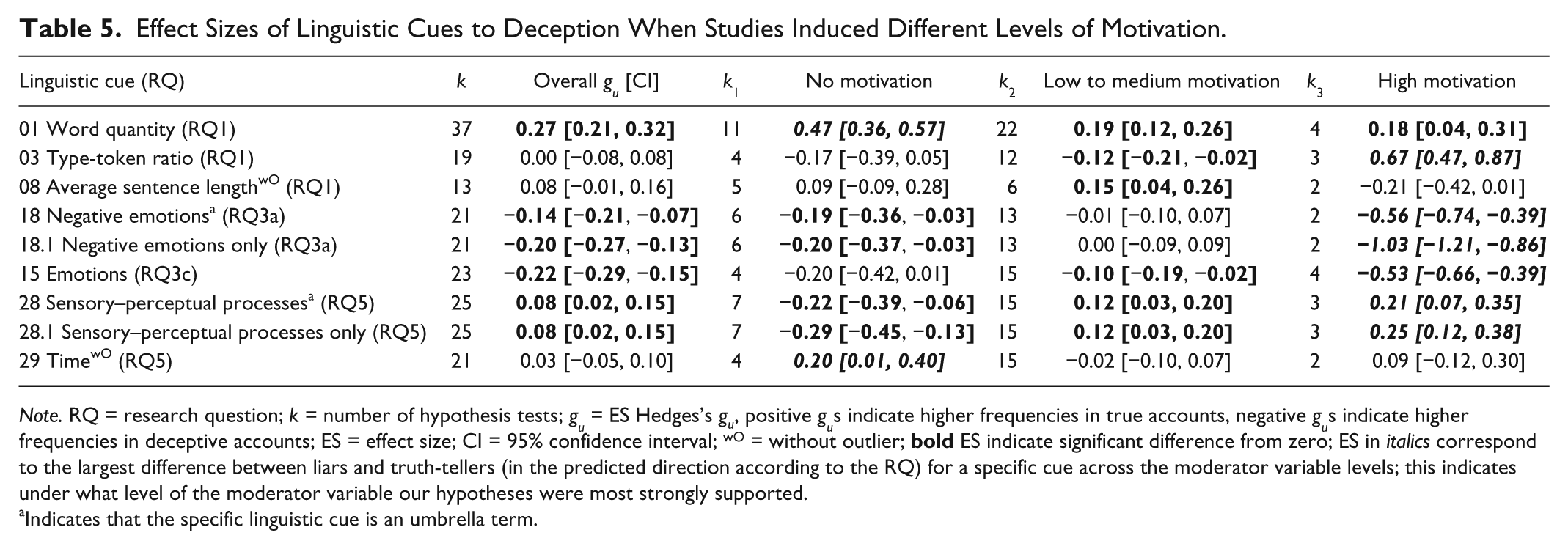
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; wO = without outlier;
Indicates that the specific linguistic cue is an umbrella term.
Other linguistic cues under various research questions showed findings contrary to our hypothesis (see Table 5): (a) Only highly motivated liars used fewer different words (type-token ratio: 0.67), (b) only moderately motivated liars built slightly shorter sentences (average sentence length: 0.15) than truth-tellers, (c) liars expressed more negative emotional words than truth-tellers only when they were highly (−0.56, −1.03) or not motivated (−0.20, −0.19), (d) liars expressed more unspecified emotions (−0.53) than truth-tellers when highly motivated, and (e) both highly (0.21, 0.25) and moderately motivated (both 0.12) liars reported fewer sensory–perceptual processes than truth-tellers, whereas not motivated liars tended to refer more often to these processes than truth-tellers (−0.22, −0.29).
Taken together, these results show a mixed picture. Our prediction that highly motivated liars would control their verbal behavior better than less motivated liars was confirmed for only two cues. However, our findings should not be over-interpreted because the number of studies with highly motivated participants was very small—calling for more research with highly motivated liars.
Production mode
Moderator analyses showed mixed findings (see Table 6). Liars used fewer words (Research Question 1—Cognitive Load) than truth-tellers under all production modes, though effects were larger for handwritten texts (0.33) and for transcripts from spoken accounts (0.26) than for typed texts (0.10). It seems that storytellers may use the opportunity to edit their accounts when typing, thus reducing the number of errors. More direct evidence for this point comes from a study by Derrick et al. (2012) who developed a specialized computer applet that clandestinely recorded edits and revisions during real time synchronous communication between a computer interviewer and senders. They found that when deceiving, people were significantly more likely to take longer and perform a greater number of edits to their responses (more frequently using the delete and backspace keys) than when telling the truth. To the extent that deceptive individuals are more likely to engage in such editing, differences in writing errors between true and false statements may be obscured. This might explain why the effect for number of typed words is smaller than for number of handwritten or spoken words.
Effect Sizes of Linguistic Cues to Deception When Studies Used Different Modes of Producing an Account.
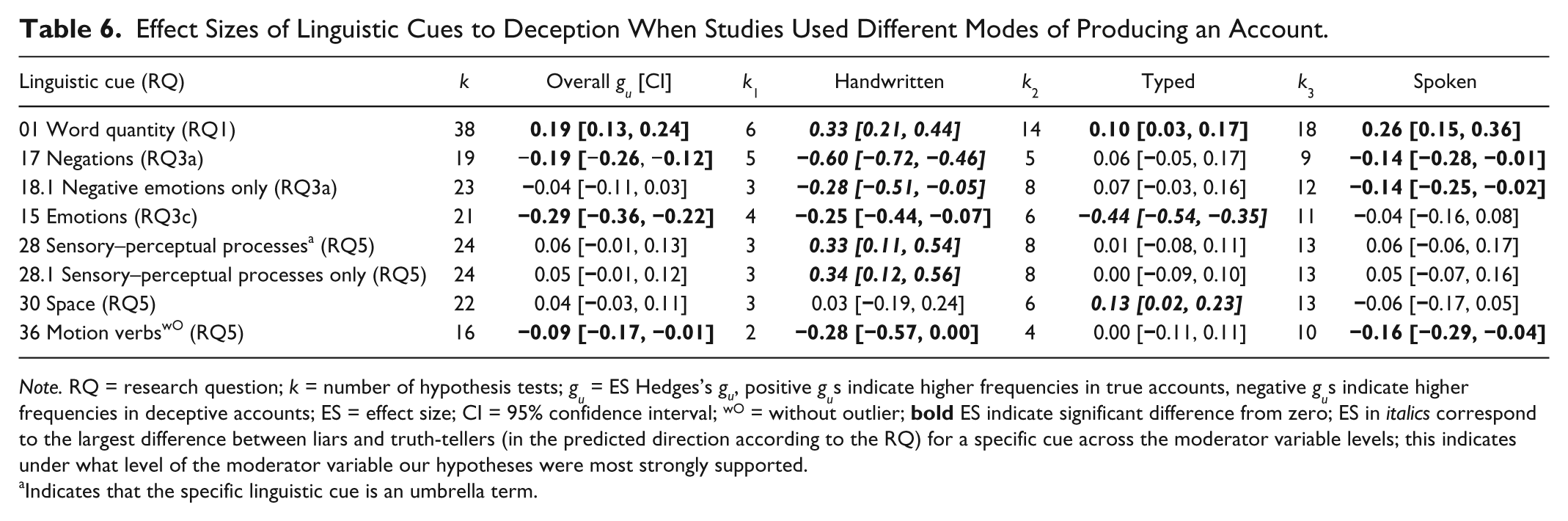
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; wO = without outlier;
Indicates that the specific linguistic cue is an umbrella term.
In line with our hypothesis concerning details (Research Question 5), liars expressed fewer sensory–perceptual words than truth-tellers only when writing their accounts by hand (0.33, 0.34), whereas liars used fewer spatial details than truth-tellers only in typed accounts (0.13). Contrary to our hypothesis (but in line with Newman et al.’s, 2003, assumption), liars used more motion verbs than truth-tellers when handwriting (−0.28) or speaking (−0.16), but not when typing them (0.00).
Our hypothesis concerning negative emotions (Research Question 3a) was not supported: Liars expressed more negations and negative emotions than truth-tellers when handwriting (−0.60, −0.28, respectively) rather than when speaking or typing. A potential reason for the larger effect in the handwriting condition could be that a writer might take more time to re-experience a negative emotion linked to the process of lying (see Ekman, 1988). Also, the special advantage to edit typed words could be a reason why the difference between liars and truth-tellers disappeared under this condition. Interestingly, regarding unspecified emotions (Research Question 3c), liars’ spoken messages—compared with truth-tellers’—showed no differences (−0.04) in unspecified emotion words but more when typing (−0.44) or handwriting (−0.25).
In conclusion, the question of how the mode of production affects the language of lying is not sufficiently answered. Again, other moderators such as interaction type or motivation may be confounded in these analyses. The pattern of findings that typed accounts showed smallest effects also converges with the finding that computer-mediated communication showed smallest effects (Table 4 above). Future studies should investigate interaction intensity and production mode in more detail, perhaps controlling for language proficiency and typing skill.
Computer program
The hypothesis that effects would be larger if statements were analyzed with programs specifically designed to detect deception (k = 8) rather than with LIWC (k = 26) or general programs (k = 11) was only confirmed for first-person plural pronouns (−0.31; see Table 7). Specific programs were more sensitive than LIWC or other general programs to differences in first-person plural pronouns, finding more of these words among liars than among truth-tellers. Contrary to our hypothesis, four linguistic cues were found to have larger effects if LIWC or other general programs were used than with more specific programs. The direction of the effect for word quantity was even reversed if specific lie detection software was used. A parsimonious explanation may be that these specific programs were developed and used for different types of accounts. It also demonstrates that the validity of linguistic cues to deception depends on the kind of program used. However, this conclusion is limited by the fact that we had to exclude quite a few studies using specialized software as these did not contain sufficient information to calculate effect sizes. Journal editors and grant agencies should emphasize completeness of data reporting including effect sizes (APA Publications and Communications Board Working Group on Journal Article Reporting Standards, 2008).
Effect Sizes of Linguistic Cues to Deception When Studies Used LIWC, a General Program or a Specific Program.
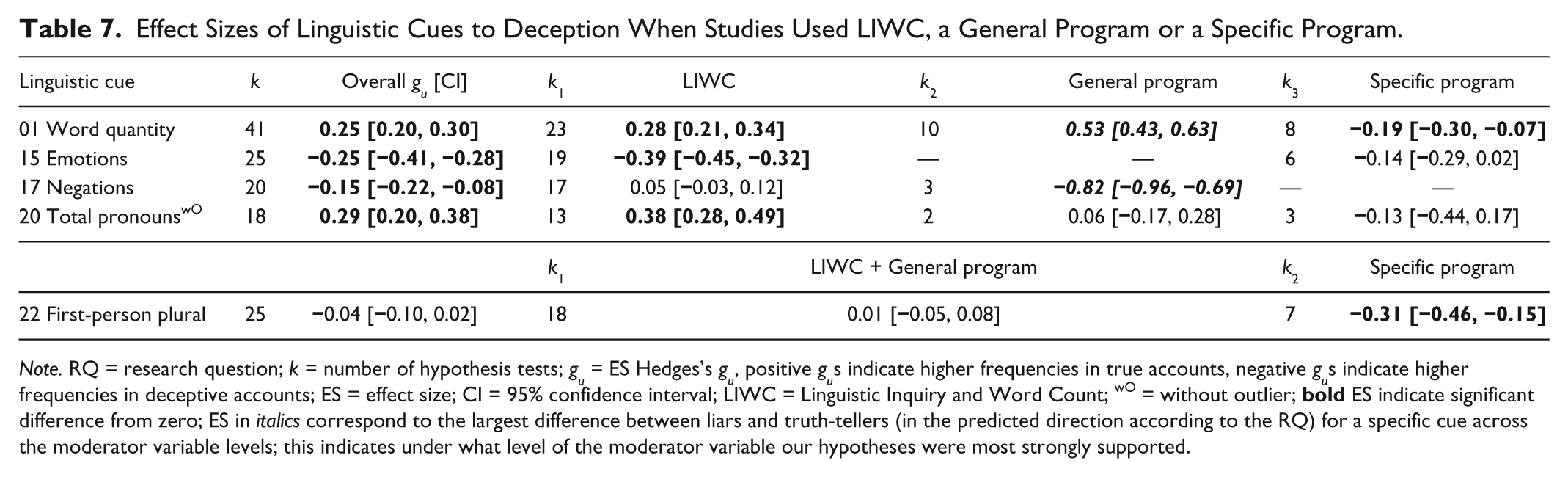
Note. RQ = research question; k = number of hypothesis tests; gu = ES Hedges’s gu, positive gus indicate higher frequencies in true accounts, negative gus indicate higher frequencies in deceptive accounts; ES = effect size; CI = 95% confidence interval; LIWC = Linguistic Inquiry and Word Count; wO = without outlier;
Publication bias
The correlation between sample sizes (number of accounts) and the absolute value of all effect sizes (excluding extremely large samples to avoid skewed distributions) was r(904) = −.11, p < .001. This negative correlation could be due to a publication bias, that is, a tendency for significant findings to be more likely to be published than unpublished (Levine et al., 2009). However, our moderator analyses showed that for 7 of 12 cues, for which there was a significant difference between published and unpublished studies, effects were actually greater in unpublished studies (see Appendix E in supplemental online materials). Thus, publication bias is unlikely to be a threat to the validity of our conclusions.
General Discussion
Setting some of the exceptions discussed under the moderator analyses aside we venture some take-home messages to our research questions, taking also rival theoretical approaches into consideration.
Research Question 1—Cognitive Load
Taken together, the notion that liars experience greater cognitive load was mainly supported. As predicted from the working memory model and the cognitive load approach, lies were shorter (fewer words and fewer sentences), less elaborated (fewer different words), and less complex (fewer exclusive terms) than true stories. Even if liars were to strategically withhold information that could give them away, doing so would heighten their working memory burden, thus indirectly also supporting the cognitive load approach.
Research Question 2—Certainty
Because only three cues were investigated here and they yielded contradictory results, this question could hardly be answered. In general, the prediction for this research question that liars look linguistically less certain than truth-tellers due to a lack of personal investment or feelings of ambiguity or guilt was not supported. Contrary to our prediction, truth-tellers used more tentative words than liars.
Research Question 3a—Negative Emotions
Altogether, the prediction that liars express more negative emotion words and defend themselves to a greater extent than truth-tellers due to the experience of negative emotions when lying was corroborated. More specifically, liars expressed more terms of anger (rather than other negative emotions like anxiety and sadness) and denied accusations more often than truth-tellers.
Research Question 3b—Positive Emotions
Our assumptions based on the fading-affect bias that truth-tellers express more positive emotions than liars were not supported. While this result may be dependent on the type of lie being told, it does run counter to our assumptions from the autobiographical memory literature (as well as CBCA and RM research): Taken together, it appears wise to differentiate specific emotions and feelings and separate them according to their valence.
Research Question 3c—Unspecified Emotions
In general, liars expressed more unspecified emotions (i.e., negative and positive emotions undifferentiated) than truth-tellers. Given the results for different types of negative emotions and positive emotions, linguistic researchers should revisit their analyses to separate different types of emotions.
Research Question 4—Distancing
As expected, liars distanced themselves from events more than truth-tellers by using fewer self-references (total first-person) and more other-references (total second- and total third-person). However, liars and truth-tellers did not differ in terms of generalizing terms, use of passive voice or verb tenses.
Research Question 5—Details
Overall, the RM approach was only partially supported. We only found small effects for some cues (sensory–perceptual processes only, particularly when motivation is high or the account is handwritten, hearing words and quantifiers) but null-findings for most other cues. In their review on international RM research, Masip et al. (2005) concluded that visual and auditory details, contextual and temporal information were the most discriminative criteria. The discrepancies may either be due to the fact that the RM criteria cannot easily be captured by word-counting programs like LIWC, or the fact that the LIWC categories were not created on the basis of RM theory (see Vrij, Mann, Kristen, & Fisher, 2007). Coding RM criteria and indicators involves much more than mere word counting, and only well-trained human raters, who also take the context of specific words or sentences, as well as the background or motivation of a statement into account, can do it.
Research Question 6—Cognitions
We found that truth-tellers used more words indicating cognitive processes than liars. The findings support our predictions from autobiographical memory theory that persons refer more often to retrieval processes, supporting memories, and cognitive operations when talking about true events but contradicts the assumption of many RM deception researchers who postulate the opposite (e.g., Vrij, 2008a).
Limitations
Several limitations restrict the generalizability of our findings. First, we had to exclude more than 50 studies for different reasons (see Appendix G in supplemental online materials). Most of these studies did not provide sufficient statistical data, or calculated linguistic patterns in a way not suitable for our analysis (e.g., Keila & Skillicorn, 2005). While we are grateful to all authors who provided us with additional data, journal editors should emphasize the reporting of all results, not just significant ones, along with effect sizes like Cohen’s d.
Second, we were able to find significant effects for many linguistic cues (see Table 1). These effects were generally very small according to Cohen (1988), but not much smaller than those for nonverbal and paraverbal cues meta-analyzed by DePaulo et al. (2003) and Sporer and Schwandt (2006, 2007). However, even if all cues had been in the predicted direction, the mean gu = 0.26 is rather disappointing compared with mean effect sizes in the social-psychological literature (Richard et al., 2003: M gu = 0.43; r = 0.21, SD = 0.15).
Third, for those linguistic cues where effect size distributions were quite heterogeneous, and sensitive to moderator variables, general conclusions can only be very tentative. Specific circumstances of individual studies documented in Appendix C should be considered for specific types of lies, topics, paradigms, or production modes.
Fourth, most findings were only available for the English language. As Newman et al. (2003) discussed, deception may be manifested through different linguistic cues in different languages. For example, Romanic languages do not require the use of specific personal pronouns, because pronouns are already expressed by the verb form (e.g., Masip, Bethencourt, Lucas, Sánchez-San Segundo, & Herrero, 2012). Unfortunately, no moderator analysis could be conducted for language, because only four studies analyzed accounts in languages other than English. Besides language, culture might also make a difference. For example, Taylor, Tomblin, Conchie, and Menacere (2011) found that North African participants used first-person pronouns most frequently when lying, whereas White British participants used them most frequently when telling the truth.
Fifth, differences between children and adults became evident as three out of four studies conducted with children were detected as significant outliers, though not for the same cues. This underscores the need to investigate differences between adults’ and children’s linguistic cues to deception separately. Furthermore, not all children are equal. Linguistic skills develop during childhood, and this may presumably influence the frequency of some potential linguistic deception markers. Children of different ages may show different linguistic cues to deception.
Despite these limitations, our meta-analyses were the first large effort to quantitatively synthesize research in this area. Therefore, they can be seen as the most accurate estimate to date of linguistic differences between liars and truth-tellers assessed by computer programs.
Conclusion and Implications for Future Research
The main goal of the present meta-analysis was to assess the extent to which computer programs are valid and useful tools to detect deception in verbal accounts. We provided clear operational definitions for each cue, derived from an analysis and integration of definitions from different research domains. We then posed theoretically based hypotheses as to the direction of effects for all cues, as well as concerning potential moderator variables. While not all results could be reported due to space limitations, additional appendices and analyses as well as all our raw data are available as supplemental online materials. Researchers are invited to peruse our rich database for additional analyses. Future research should also look at the intercorrelations between linguistic cues to arrive at a better theoretical understanding.
In addition, future research should consider the context of deceptive versus truthful utterances. A potential reason why only small to medium effect sizes were found in general could be that most computer programs simply count single words without considering the semantic context. If this suggestion goes beyond what computer programs can do at this time, perhaps the linguistic cues with greater effect sizes (for the respective paradigms) should be weighted more heavily than those with smaller or nonsignificant effects. A recent attempt in this direction was made by Chandramouli, Chen, and Subbalakshmi (2011), who employed several weighting mechanisms. They applied for an international patent for their invention of this weighing mechanism.
Ultimately, researchers should directly compare the performance of computers versus human raters. As context is relevant in analyzing and judging a statement, human raters’ assessments of certain linguistic cues might lead to more pronounced differences than objective computer-based codings. However, the advantages of computer-based coding should not be overlooked. Humans and computers are best at different skills. Humans are less accurate in manual counting of specific cues or in rendering accurate judgments of complex syntactic relationships, whereas computers cannot provide subjective, gestalt-like judgments or capture the meaning or intention of what people are saying (for an example of computer-assisted subjective codings, see Sporer, 2012).
Finally, we encourage researchers to further investigate the impact of (a) different interview and interaction conditions, (b) mode of production, (c) types of events, (d) age of sender, and (e) language on linguistic markers of deception. In line with Hancock and Woodworth (2013), we found that linguistic cues to deception are sensitive to contextual factors (see moderator variables). These variables are relevant in applied contexts (forensic, work and organizational settings). Researchers should strive to design experiments containing psychological features analogous to real world deceptive situations to enhance ecological validity (e.g., opportunity for preparation, or high motivation).
In sum, to answer the question whether computer programs are effective lie detectors, our answer must be rather skeptical at this time. The effects were not significant for many of the variables studied or small in magnitude, or moderated by situational variables. Alternative theoretical approaches may find other cues or moderators to be important. At this time, researchers’, and particularly practitioners’, (unrealistic) dream has yet to come true.
Footnotes
Appendix
Coding Decisions for Moderator Variables for Each Study.

| Authors (year) | Publication type | Program | Language | Theory | Selection | Age | Preparation | Event type | Valence | Interaction | Motivation | Mode |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ali and Levine (2008, denials) | publ. | LIWC01 | E | IDT/RM | a priori | adults | n/a | mock crime | neg. | interview | low | spoken |
| Ali and Levine (2008, confessions) | publ. | LIWC01 | E | IDT/RM | a priori | adults | n/a | mock crime | neg. | interview | low | spoken |
| Almela Sanchez-Lafuente, Valencia-Garcia, and Cantos Gomez (2012) | publ. | LIWC01 | S | none | a priori | adults | n/a | att./liking | neg./pos. | none | low | typed |
| Bedwell, Gallagher, Whitten, and Fiore (2011) | publ. | Coh-Metrix | E | other | sign. | adults | prep. | trivial LE | neutral | instruct. | low | spoken |
| G. D. Bond and Lee (2005) | publ. | LIWC01 | E | IDT/RM | a priori | adults | prep. | video | neg. | interact. | low | spoken |
| Brunet (2009) a | Thesis | LIWC01 | E | LIWC | a priori | child. | n/a | sign. LE | neg./pos. | interview | none | spoken |
| Burgoon and Qin (2006) | publ. | GATE | E | IDT/RM | a priori | adults | n/a | other | neutral | interview | low | spoken |
| Chen (2010; Dataset 3) | Diss. | LIWC01 | E | IDT/RM | a priori | adults | n/a | n/a | neutral | none | n/a | typed |
| Colwell, Hiscock, and Memon (2002) | publ. | Wordscan | E | other | a priori | adults | n/a | live | neg. | interview | n/a | n/a |
| J. E. Cooper (2008) | Diss. | Connexor b | E | IDT/RM | a priori | adults | n/a | other | neutral | n/a | n/a | typed |
| Derrick, Meservy, Burgoon, and Nunamaker (2012) | pres. | ADAM | E | IDT/RM | a priori | adults | n/a | other | neutral | none | low | typed |
| Dzindolet and Pierce (2005) | pres. | LIWC01 | E | LIWC | a priori | adults | n/a | att./liking | neg./pos. | instruct. | n/a | written |
| Evans et al. (2012, Interview 1) | publ. | LIWC01 | E | LIWC | a priori | child. | n/a | other | pos. | interview | none | n/a |
| Fuller, Biros, Burgoon, Adkins, and Twitchell (2006, Agent99A.) | pres. | Agent99A. b | E | IDT/RM | a priori | adults | n/a | real case | neg. | n/a | high | written |
|
Hancock, Curry, Goorha, and Woodworth (2008)
Duran, Hall, McCarthy, and McNamara (2010) |
publ. | LIWC01/Coh-Metrix | E | IDT/RM | a priori | adults | prep. | trivial LE | neg./pos. | cmc | n/a | typed |
| Humpherys, Moffitt, Burns, Burgoon, and Felix (2011) | publ. | Agent99A. | E | IDT/RM | a priori | adults | n/a | real case | neutral | none | high | typed |
| Jensen, Bessarabova, Adame, Burgoon, and Slowik (2011) | publ. | LIWC01 | E | other | a priori | adults | n/a | real case | neg. | interview | high | n/a |
| Koyanagi and Blandón-Gitlin (2011) | pres. | LIWC07 | E | IDT/RM | a priori | child. | no | other | neutral | interview | none | spoken |
| Krackow (2010) | publ. | LIWC07 | E | IDT/RM | a priori | adults | prep. | trivial LE | neg./pos. | instruct. | none | spoken |
| Lee, Welker, and Odom (2009) | publ. | LIWC01 | E | other | a priori | adults | n/a | other | neutral | cmc | low | typed |
| Liu, Hancock, Zhang, Xu, Markowitz, and Bazarova (2012) | pres. | LIWC07 b | E | LIWC | a priori | adults | n/a | real case | neg. | interact. | high | n/a |
| Masip, Bethencourt, Lucas, Sánchez-San Segundo, and Herrero (2012) | publ. | LIWC07 | S | IDT/RM | a priori | adults | no | trivial LE | pos. | instruct. | low | written |
| Morgan, Colwell, and Hazlett (2011, free recall) | publ. | “automated analysis method” | E | none | a priori | adults | n/a | n/a | neg. | interview | low | spoken |
| Morgan, Mishara, Christian, and Hazlett (2008, free recall) | publ. | n/a (general) | A | none | a priori | adults | no | mock crime | neg. | interview | med. | spoken |
| Newman, Pennebaker, Berry, and Richards (2003, Exp. 1) | publ. | LIWC01 | E | LIWC | sign. | adults | n/a | att./liking | neutral | instruct. | low | spoken |
| Newman et al. (2003, Exp. 2) | publ. | LIWC01 | E | LIWC | sign. | adults | n/a | att./liking | neutral | instruct. | low | typed |
| Newman et al. (2003, Exp. 3) | publ. | LIWC01 | E | LIWC | sign. | adults | n/a | att./liking | neutral | none | low | written |
| Newman et al. (2003, Exp. 4) | publ. | LIWC01 | E | LIWC | sign. | adults | n/a | att./liking | neg./pos. | instruct. | low | spoken |
| Newman et al. (2003, Exp. 5) | publ. | LIWC01 | E | LIWC | sign. | adults | n/a | mock crime | neg. | interview | low | spoken |
| Ott, Choi, Cardie, and Hancock (2011) | pres. | LIWC07 | E | IDT/RM | sign. | adults | n/a | att./liking | pos. | none | low | typed |
| Qin, Burgoon, Blair, and Nunamaker (2005, audio) | pres. | GATE | E | other | a priori | adults | n/a | mock crime | neg. | interview | low | spoken |
| Qin et al. (2005, face-to-face) | pres. | GATE | E | other | a priori | adults | n/a | mock crime | neg. | interview | low | n/a |
| Qin et al. (2005, text chat) | pres. | GATE | E | other | a priori | adults | n/a | mock crime | neg. | interview | low | typed |
| Rowe and Blandón-Gitlin (2008) | pres. | LIWC07 | E | IDT/RM | a priori | adults | no | other | neutral | interview | none | spoken |
| Schafer (2007, Exp. 1) | Diss. | MS Word | E | other | a priori | adults | n/a | video | neg. | n/a | none | written |
| Schafer (2007, Exp. 2) | Diss. | MS Word | E | other | a priori | adults | n/a | video | neg. | n/a | none | written |
| Schelleman-Offermans and Merckelbach (2010) | publ. | LIWC01 | D | LIWC | a priori | adults | n/a | sign. LE | neg. | n/a | none | typed |
| Suckle-Nelson et al. (2010, free recall) | publ. | Wordscan | E | IDT/RM | a priori | adults | n/a | staged | neg. | interview | none | spoken |
| ten Brinke and Porter (2012) | publ. | LIWC01 | E | LIWC | a priori | adults | n/a | real case | neg. | interact. | high | spoken |
| Van Swol, Braun, and Malhotra (2012) | publ. | LIWC07 b | E | IDT/RM | a priori | adults | n/a | other | neutral | interact. | med. | spoken |
| Williams, Talwar, Lindsay, Bala, and Lee (2012) | subm. c | LIWC07 | E | LIWC | a priori | child. | n/a | sign. LE | neutral | interview | none | spoken |
| Zhou (2005) | publ. | “NLP tool” | E | other | a priori | adults | n/a | other | neutral | cmc | low | typed |
| Zhou et al. (2004) | publ. | iSkim/CueCal | E | other | a priori | adults | n/a | other | neutral | cmc | none | typed |
| Zhou and Zhang (2004) | pres. | “Message analyzing software” | E | other | a priori | adults | n/a | other | neutral | cmc | low | typed |
Note. publ. = published; pres. = presented (poster or paper); Diss. = Dissertation; subm. = submitted; LIWC = Linguistic Inquiry and Word Count; LIWC01 = LIWC 2001; LIWC07 = LIWC 2007; GATE = General Architecture for Text Engineering; ADAM = Automated Deception Analysis Machine; Agent99A. = Agent99Analyzer; MS Word = Microsoft Word; NLP = natural language processing; Language: A = Arabic; D = Dutch; E = English; S= Spanish; IDT = interpersonal deception theory; RM = reality monitoring; sign. = significant; child. = children; prep. = preparation; n/a = not available; att. = attitude; LE = life events; staged = staged event; instruct. = instruction; med. = medium; cmc = computer-mediated communication.
In the meantime, Brunet et al. (2013) formally published the data of Brunet’s thesis.
Study additionally applied a second program.
In the meantime, Williams et al. (2012) published their (at the time of conducting the meta-analyses unpublished) manuscript.
Acknowledgements
The authors wish to thank all the authors of primary studies who took the effort to respond to our inquiries. The authors also wish to thank Dr. Mark Schaller and three anonymous reviewers for their insightful comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: During the final part of this research, the third author was supported by a grant from the Spanish Ministry of Education, Culture, and Sports, “Programa Nacional de Movilidad de Recursos Humanos del Plan Nacional de I-D+i 2008-2011 (prorrogado por Acuerdo de Consejo de Ministros de 7 de octubre de 2011)” (Ref. PRX12/00209).
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.