
Abstract
Corpus linguistics studies real-life language use on the basis of a text corpus, drawing on both quantitative and qualitative text analysis techniques. This article seeks to bridge the gap between the social sciences and linguistics by introducing the techniques of corpus linguistics to the field of computer-aided text analysis. The article first discusses the differences between corpus linguistics and computer-aided text analysis, which is divided into computer-aided content analysis and computer-aided interpretive textual analysis. It then outlines the techniques of corpus linguistics for exploring textual data. In an exemplary analysis of letters to shareholders, the article demonstrates how these techniques can be applied to compare letters to shareholders from two different years. The article concludes with a discussion of the strengths and limitations of corpus linguistics for management and organization studies.
A lot of research in management and organization studies is conducted with textual data. Such data can originate from organizations in the form of annual reports, letters to shareholders, proxy statements, press releases, mission statements, values statements, or in-house magazines. In addition, textual data can be collected outside the organizational domain in the form of news reporting or can be solicited in the form of interviews. Organizational documents as naturally occurring materials are particularly rich and valuable data. They can provide insights into managerial cognitions, organizational values, culture, or identity, which surveys or interviews cannot provide in the same manner. Because of the recurring nature of some of these documents, they are particularly suited for longitudinal studies of events, changes, or developments in organizations (Caska, Kelley, & Christensen, 1992; Jablin & Putnam, 2001; Stanton & Rogelberg, 2002). Contingent on one’s epistemological positioning, these documents are either accounts of what an organization does or cultural artifacts constitutive of an organization (Taylor & Van Every, 2010, p. 92).
For both positions, the advantages of using software for the analysis of textual data are obvious, and given the ample availability of textual data in digital format, the question is no longer whether or not to use computer-aided text analysis, as it was in its beginning (R. A. Wolfe, Gephart, & Johnson, 1993), but which approach is the most insightful for a given data set. Although text analysis is an established method in the social sciences (e.g., Bailey, 1994; Bernard & Ryan, 1998; Roberts, 1997), management researchers analyzing textual data qualitatively or quantitatively are essentially entering linguistic terrain. The cooperation between linguistics and the social sciences with regard to text analysis has always been meager (Bernard & Ryan, 1998; Markoff, Shapiro, & Weitman, 1974; Popping, 2000; Roberts, 1989), which hinders the advancement of text analysis in the social sciences, including computer-aided approaches. When examining the reference lists of seminal works in computer-aided text analysis (Gephart, 1993; Gephart & Wolfe, 1989; Janasik, Honkela, & Bruun, 2009; Kabanoff, 1997; Kabanoff & Brown, 2008; Kabanoff & Holt, 1996; Roberts, 1989; R. A. Wolfe et al., 1993), one cannot fail to notice that they include primarily the content analysis literature and literature on qualitative methods in the social sciences but largely ignore literature from the field of linguistics. Corpus linguistics, which is a branch of linguistics that conducts computer-aided analyses of language, can contribute insights into the analysis of textual data in the social sciences. Corpus linguistics studies real-life language use on the basis of a text corpus. A corpus is defined as “a body of text which is carefully sampled to be maximally representative of a language or language variety” (McEnery & Wilson, 2001, p. 2). Corpus linguistics encompasses a number of analysis techniques that can be applied as needed rather than according to a particular protocol. Although there is a strong focus on quantitative language analysis techniques in corpus linguistics, an essential part of any corpus-linguistic study is the qualitative examination and interpretation of quantitative results (Biber, Conrad, & Reppen, 1998).
Corpus linguistics can be a meaningful addition and an alternative to existing computer-aided text analysis methods, including both quantitative, positivist analyses of content and qualitative, interpretive analyses of discourse. This article seeks to advance organizational research methods and in particular computer-aided text analysis by introducing developments from the field of corpus linguistics to the field of computer-aided text analysis. More specifically, the contribution of this article is threefold: First, two different approaches within computer-aided text analysis are discussed and compared to corpus linguistics in order to highlight where corpus linguistics can provide new insights. Second, the article introduces resources and analysis techniques from corpus linguistics that are currently not used or not fully exploited in computer-aided text analysis. Third, the article presents an exemplary analysis of letters to shareholders based on techniques from corpus linguistics in order to demonstrate in a hands-on manner how corpus linguistics can be used by nonlinguists. The article concludes with a discussion of the value and limitations of corpus linguistics for management and organization studies.
Computer-Aided Approaches for the Analysis of Textual Data
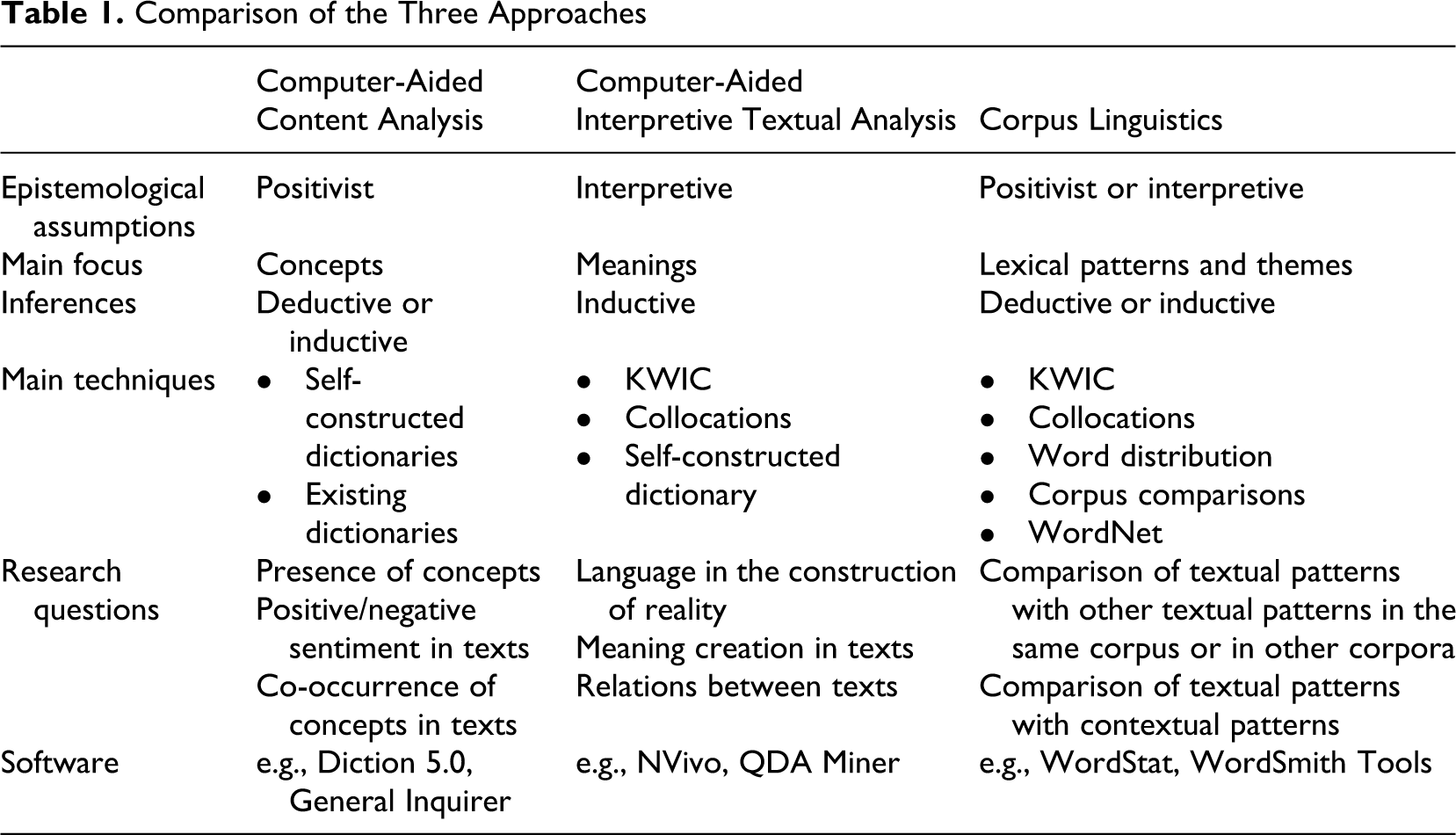
The analysis of textual data can focus on the manifest content of texts, which is transmitted through explicit vocabularies, or on the latent content, which denotes the implicit meaning in text (Merton, 1957; Phillips, Sewell, & Jaynes, 2008). Whereas quantitative-oriented forms of text analysis, for example, classic content analysis (Krippendorff, 1980), can produce indices of manifest content, text analyses following the interpretive tradition study both manifest and latent content, as the sociocultural framework in which the text has been produced is an integral part of the analysis, for example, as in grounded theory or discourse analysis. Both forms of text analysis can be supported by computer software. The following sections explain and compare two different computer-aided approaches: corpus linguistics and computer-aided text analysis, the latter of which is divided into computer-aided content analysis and computer-aided interpretive textual analysis. These three approaches are summarized in Table 1 , which provides an overview of the main characteristics of each approach.
Comparison of the Three Approaches
Corpus Linguistics
Parallel to computer-aided text analysis in the social sciences, a computation-oriented approach to text analysis has evolved in linguistics, which is called corpus linguistics. Seminal work in corpus linguistics goes back to the 1960s (e.g., Kucera & Francis, 1967), whereas modern corpus linguistics using large computer-based corpora emerged in the 1990s (e.g., Biber, 1996; Biber et al., 1998; Leech, 1992; McEnery & Wilson, 1996; Sinclair, 1991; Stubbs, 1996; Svartvik, 1992), stimulated by the rise in available computing power. Since the 1990s, corpus linguistics has become a dynamic branch of linguistics out of which research groups, associations, conferences, journals, monographs, and book series have emerged (Anderson, 2008). Definitions of corpus linguistics are many and varied. Although it is seen as a discipline by some (e.g., Teubert, 2005; Tognini-Bonelli, 2001) and as a methodology by others (e.g., McEnery & Wilson, 2001, p. 2), yet others see it as just “an approach” (Mahlberg, 2005), “a methodological basis” (Leech, 1992, p. 105), “a bundle of methods, procedures and resources” (Lüdeling & Kytö, 2008), or a “toolbox of techniques” (Lee, 2008, p. 87). As a discipline, corpus linguistics provides methodological innovations for computer-based analyses of texts. As a methodology, corpus linguistics is used by researchers from other fields who conduct computer-based language analyses (Mukherjee, 2010).
Neither is there a “unifying theory binding together corpus linguistics analyses” (Barlow, 2011, p. 5), nor are there uniform practices or techniques about how one “does” corpus linguistics. Corpus linguistics can be used in a primarily qualitative design to generate theory inductively or in a primarily quantitative, positivist design to test theory on language (McEnery & Wilson, 2001, p. 110). McEnery and Gabrielatos (2006) argue that the role of theory in corpus linguistics should be viewed as a continuum between testing theory as one endpoint and developing theory inductively as the other. The lack of a stringent methodology and the flexibility this entails mean that researchers employ an eclectic mix of techniques that are combined as needed for a particular inquiry, guided by their research questions (McEnery & Gabrielatos, 2006). This flexibility allows researchers to use corpus linguistics for a wide variety of inquiries. However, this flexibility has given rise to criticism against corpus linguistics, because one cannot rule out that an analysis is driven by mere intuition or the capabilities of the software rather than by a research question (McEnery, Xiao, & Tono, 2006; Tognini-Bonelli, 2001).
Corpus linguistics always analyzes corpus data both quantitatively and qualitatively in order to explain and interpret patterns rather than just count them (Biber et al., 1998). The techniques of corpus linguistics range from tools for the identification of meanings to descriptive, quantitative indices of textual data (Baker et al., 2008). The most central analysis techniques in corpus linguistics include (a) word frequencies and keyword-in-context (KWIC) searches, which display all instances of a given word in its immediate textual surroundings and help the researcher to connect words of potential interest to the context (M. Wood, 1974); (b) the comparison of corpora (McEnery & Wilson, 1996); (c) collocations, which denote the co-occurrence of two or more words (Sinclair, 1991); and (d) statistical procedures for the assessment of word frequencies (e.g., Lebart, Salem, & Berry, 1998; Manning & Schütze, 1999; Oakes, 1998).
The research questions corpus linguistics can answer address the association of textual patterns either with other textual patterns or with contextual patterns (Biber et al., 1998). For example, corpus linguistics can study language use in a particular text genre, in a particular kind of discourse, or in a particular social or communicative context (Barlow, 2011). Linguists of all persuasions have used these techniques in qualitative or quantitative designs, ranging from semantic studies of near-synonyms (Liu, 2010) to sociolinguistic studies of language variation (Kachru, 2008) and language change (Baker, 2009). Linguists have also paid attention to the integration of corpus linguistics into discourse analysis with a view to reducing the subjectivity inherent in discourse analysis (e.g., Hardt-Mautner, 1995; Baker, 2006). This integration can take the form of a corpus-informed discourse analysis, which is purely qualitative in nature. Alternatively, a corpus-supported discourse analysis or a corpus-driven discourse analysis can be conducted, both of which are qualitative and quantitative in nature. The difference between the latter two is that a researcher conducting a corpus-supported analysis starts out from a theoretical framework, whereas a researcher conducting a corpus-driven analysis approaches the data with very few preconceptions (Lee, 2008).
A full-text search for corpus linguistics in management journals in the EBSCO database yields only one article that conducts a corpus-based linguistic analysis. This article by Cornelissen (2008) contributes to the literature on the discursive construction of organizations by studying how people use metonymies (part-whole or whole-part relations between words) when they talk about organizations. It draws on the British National Corpus, a large, publicly available corpus of naturally occurring texts, such as books and newspaper articles, but does not report the use of any specific corpus-linguistic technique. The study concludes that people use conventionalized metonymic patterns when they talk about organizations.
Computer-Aided Text Analysis
Computer-aided approaches to text analysis in the social sciences are generally referred to as computer-aided text analysis (e.g., Dowling & Kabanoff, 1996; Duriau, Reger, & Pfarrer, 2007; Gephart & Wolfe, 1989; Kabanoff, 1997; Short, Broberg, Cogliser, & Brigham, 2010; T. Wolfe, 1990) or computer-aided content analysis (e.g., Dowling & Kabanoff, 1996; Duriau et al., 2007; Short & Palmer, 2008). Several scholars have argued that the two terms can be used interchangeably (Dowling & Kabanoff, 1996; Duriau et al., 2007; Popping, 2000). Krippendorff (2004, p. 261) and Short et al. (2010) see computer-aided text analysis as an approach to content analysis, whereas Kabanoff (1997) argues that computer-aided text analysis should be the broader term because it goes beyond the goals and possibilities of content analysis. This nomenclatural confusion may have its origin in the terminological inconsistency present at the level of traditional text and content analysis. Neuendorf (2002), for example, in her book on content analysis, considers text analysis to be “a part of content analysis research” (p. 25). Meanwhile, Titscher, Meyer, Wodak, and Vetter (2000, p. 55), Bauer (2000, p. 132), and Bernard (1998, p. 437 ) see classic content analysis as a form of text analysis, along with discourse analysis or narrative analysis. In this article, the latter position is maintained, arguing that content analysis is one approach to text analysis, which implies that computer-aided content analysis is an approach within computer-aided text analysis. Parallel to computer-aided content analysis, computer-aided interpretive textual analysis has evolved out of the qualitative, interpretive research tradition. Computer-aided text analysis thus is the encompassing term under which both computer-aided content analysis and computer-aided interpretive textual analysis fall.
Classic and computer-aided content analysis
Content analysis has its origin in communication studies, where it was first used in the beginning of the 20th century for comparative analyses of newspaper content (Krippendorff, 2004). The goal of content analysis is to make inferences from texts to context in an objective and systematic manner (e.g., Holsti, 1968; Krippendorff, 1980; Neuendorf, 2002). It follows a quantitative, positivist research approach that tries to produce thematic or semantic indices of observable and countable features of text on the basis of predefined categories. Research questions answerable with content analysis focus on the presence of concepts in texts, the presence of positive and negative sentiments in texts, or the co-occurrence of two concepts in texts (Krippendorff, 2004).
Content analysis began to use computer assistance as early as the 1960s, where attempts were made to analyze the content of texts with word-count text analysis methods (Popping, 2000) based on the premise that the frequency of particular words and concepts in a text is a measure of importance, attention, or emphasis (Krippendorff, 1980). This has led to the subfield of computer-aided content analysis, which uses content dictionaries to study the frequency and prominence of particular concepts. Two approaches to computer-aided content analysis can be distinguished, depending on the source of these dictionaries: Researchers can either make use of existing dictionaries or compile a dictionary specifically for a particular study. One such existing dictionary is the General Inquirer by Stone et al. ( Stone, Dunphy, Smith, & Ogilvie, 1966; Stone et al., 2000), which was at the time of its inception the first major attempt to create universal content dictionaries and apply them to texts with the help of computers. Other sets of content dictionaries and software tools include the Regressive Imagery Dictionary by Martindale (1975, 1990); the LIWC by Pennebaker, Mehl, and Niederhoffer (2003); and DICTION (cf. Short & Palmer, 2008). Those studies for which researchers construct their own dictionaries resemble classic content analysis more closely because the researchers essentially compile a coding frame based on the analytical constructs emerging from the research question and apply the coding frame to the texts. Self-constructed dictionaries can be derived deductively from theory or inductively from the corpus or from both in a combined approach (Short et al., 2010).
Researchers in management and organization studies have used both self-constructed and existing dictionaries. For example, self-constructed dictionaries have been used to study the extent of downsizing content in annual reports (Palmer, Kabanoff, & Dunford, 1997), to investigate justifications for CEO compensation in proxy statements (Porac, Wade, & Pollock, 1999; Wade, Porac, & Pollock, 1997), to explore metaphors for teamwork used in interviews on teamwork (Gibson & Zellmer-Bruhn, 2001), and to identify the distinctive lexicon of strategic management from abstracts of articles published in major journals (Nag, Hambrick, & Chen, 2007). Other scholars in management and organization studies have applied existing dictionaries to company documents, for example, to study categories of organizational values (Kabanoff, Waldersee, & Cohen, 1995), changes in organizational values (Kabanoff & Holt, 1996), or word choice in dispute resolutions in a study of online dispute settlements (Brett, Olekalns, Friedman, Goates, & Anderson, 2007). Further, researchers have drawn on existing dictionaries to explore news coverage, for example, the coverage of quality circles in a study on the life cycle of management fads (Abrahamson & Fairchild, 1999), the coverage of substance abuse as one variable in a study on workplace substance abuse (Spell & Blum, 2005), or positive coverage of companies in a study on firm reputation and celebrity (Pfarrer, Pollock, & Rindova, 2010).
Computer-aided interpretive textual analysis
When studying textual data, management scholars are not necessarily interested in measuring concept frequencies; they also may be interested in understanding meanings and interpretations, following the qualitative, interpretive research tradition. The interests of organizational researchers conducting such studies may, for example, lie in sensemaking (e.g., Gephart, 1993, 1997), impression management (e.g., Snell & Wong, 2007), organizational conflicts (e.g., Doucet & Jehn, 1997), legitimation (e.g., Vaara & Tienari, 2008), or attributions of organizational outcomes (e.g., Tsang, 2002). Since interpretative analyses are always inductive and iterative in nature, computer assistance for this kind of analysis is first and foremost valuable for mechanical tasks associated with handling data, locating themes, organizing them, and linking them (Kelle, 1995). The software used for such analyses therefore needs to be capable of organizing data, coding text segments, and examining words in their context, rather than counting frequencies and reporting statistics. Examples of such software tools include NVivo, QDA Miner, and ATLAS.ti.
Advances in text retrieval possibilities have led to the emergence of computer-aided interpretive textual analysis, which relies on computer assistance to uncover themes, meanings, and interpretations of events in the hermeneutic tradition. The research questions for which this approach is most suited focus on the role of language in constructing reality. Thus, it focuses on the use of particular concepts, on the way meaning is created in texts, and on the way meaning is shaped by relations between texts (Gephart, 1993). Analysis techniques include mainly word frequency lists and KWIC searches. Further, collocations can be explored to uncover meanings constructed by a particular word combination. Computer-aided interpretive textual analysis can involve textual statistics but only to identify important words and search for meanings rather than to produce quantitative results (Gephart, 1993, 1997, 2003). Examples of such studies include Gephart’s (1993, 1997) work on organizational sensemaking about hazards, which is based on an iterative process of KWIC searches for potentially interesting words and collocations, supplemented with expansion analysis.
The Techniques of Corpus Linguistics
Corpus linguistics is similar to computer-aided text analysis in that it can be used for both quantitative and qualitative inquiries. The main differences between corpus linguistics and computer-aided text analysis are that corpus linguistics (a) focuses on lexical patterns rather than on categories or meanings, (b) consists of a set of techniques without a methodological protocol, and (c) always involves a combination of quantitative and qualitative analysis. This section explains those analysis techniques and resources from corpus linguistics that can be relevant for a study in the social sciences. These pertain to word dispersion measures, corpus comparison and keywords, collocations, and the construction of dictionaries. All analysis techniques outlined in this section are performed or supported by commercially available corpus linguistics software or spreadsheet software. The appendix to this article contains an overview of various software tools, indicating which tool is capable of what.
Word Dispersion
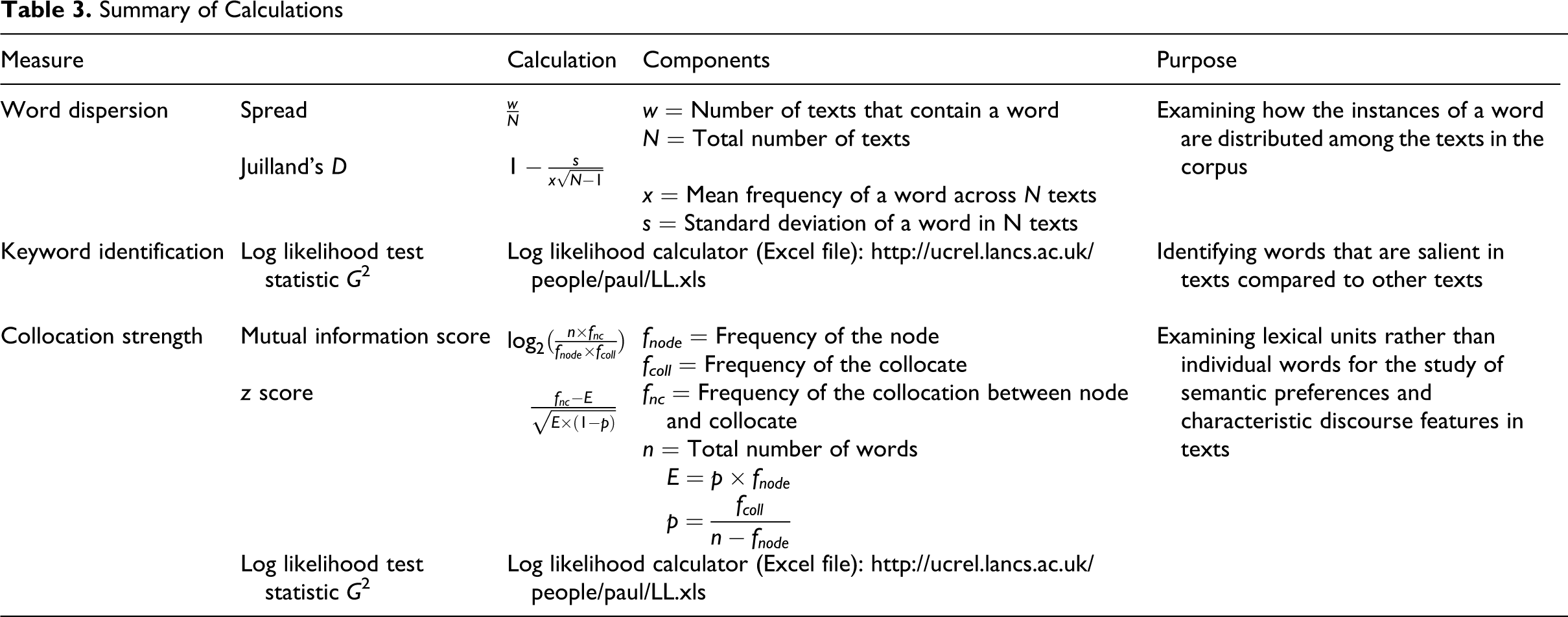
Textual data used in management and organization studies typically consist of a collection of texts rather than just one text, for example, a sample of annual reports, mission statements, corporate self-descriptions, or interview transcripts. Apart from looking at total word frequencies, a researcher might want to know whether words of interest cluster in one of the texts or are evenly distributed among the texts in the corpus. To assess the dispersion of a word, three analytical possibilities exist. First, the range (Leech, Rayson, & Wilson, 2001) or spread (Gabrielatos, Torgersen, Hoffmann, & Fox, 2010) of a word can be determined, which is the percentage of texts that contain a particular word, irrespective of how frequently it is used in these texts. A more precise measure is Juilland’s D (see Table 3 ; Leech et al., 2001, p. 18; Oakes, 1998), which is a ratio between 0 and 1, with 1 indicating the perfectly equal dispersion of a word among the various texts studied and 0 indicating a highly unequal dispersion. Juilland’s D, therefore, does not indicate where a word clusters but only to what extent it clusters. Ultimately, word dispersion can be studied in distribution plots, which visualize where in a set of documents a word clusters (Scott, 1999).
Corpus Comparison and Keywords
Frequency information is always most informative when corpora from different sources or different times are compared (Hunston, 2006). When comparing two corpora, words that occur significantly more frequently (positive keywords 1 ) or infrequently (negative keywords) in one corpus compared with the other one can be identified (Baker et al., 2008; Scott, 1999; Xiao & McEnery, 2005). This comparison should be made on the basis of a log likelihood test since word frequencies in a text are not normally distributed (Dunning, 1993). The keywords identified can indicate the saliency of certain text features, such as the “aboutness” of a text, stylistic characteristics, or descriptors of text genres. Although these keywords provide quantitative evidence of observations and therefore reduce researcher bias, these observations provide only interdictors of patterns, which must be interpreted by the researcher with the help of KWIC searches (Baker, 2004).
One can compare one’s own corpora with each other or with a very large, publicly available corpus as a reference corpus to establish what is “normal” and what is not. Such public corpora include, for example, the 100 million-word British National Corpus (http://www.natcorp.ox.ac.uk/), the American National Corpus (http://www.americannationalcorpus.org/), Collins Wordbanks Online English (http://www.collins.co.uk/Corpus/Corpussearch.aspx/), Cambridge International Corpus (http://www.cup.cam.ac.uk/elt/corpus/cancode.htm), or more specialized corpora such as the Corpus of Professional English (http://www.perc21.org/) and the Corpus of Professional Spoken American English (http://www.athel.com/cspa.html). Xiao and McEnery (2005), for example, have compared the latter corpus with the British National Corpus to compare the genres of conversation, speech, and academic prose in American English on the basis of positive and negative keywords. Similarly, Johnson, Culpeper, and Suhr (2003) have used keywords to compare three newspapers over a 5-year period against the British National Corpus in a discourse analysis of political correctness in British newspapers. Both studies have used keywords to identify words of potential interest, which were then examined qualitatively with KWIC searches. External corpora can thus be of relevance in a business and management context, when a researcher wants to study either a particular genre of organizational texts or a very specific concept.
Collocations
Collocations denote “the above chance co-occurrence of two word forms” (Sinclair, 1991). The analysis of collocations is considered to be “a natural extension of frequency lists” (Gries, 2009, p. 14) in that collocations capture multiword expressions rather than individual words only. Collocations can indicate a semantic preference for certain constructions or can uncover meaning imbued in words by those words they collocate with (Stubbs, 2001) and thus give insights into the mental lexicon of the text producer (Mollin, 2009). The frequency of certain collocations in language often leads to established, conventionalized expressions that language users choose instead of creating their own combinations of words (Sinclair, 1991, p. 170). Because of this repeated use, collocations can become carriers of cultural meanings or domain-specific meanings (Bartsch, 2004, p. 12). A collocation analysis therefore reveals discourse patterns and meanings that are evident neither from frequency lists of individual words nor from the readings of larger volumes of text in a manual analysis (Baker et al., 2008).
Corpus software can identify collocations in two different ways: First, the search for collocations can be open such that the software returns the most frequent word combinations within a predetermined word span. Second, when one word in particular is examined for other words it co-occurs with, the former is referred to as node and the latter as collocate (Sinclair, Jones, Daley, & Krishnamurthy, 2004). The search for collocations then begins with the specification of a node, and the corpus software finds all collocates within a predetermined word span, usually 3 to 5 words on each side of the node word (Bartsch, 2004). Collocations as such are not new to computer-aided text analysis, as they have also been used in computer-aided interpretive textual analysis (Gephart, 1993, 1997), although software at that time was not advanced enough to return frequent collocations without researcher input, but required the researcher to define node words. To judge how noteworthy a collocation is, there are multiple ways of determining their strength. This is necessary, as the mere frequency of a collocation is biased by the frequency of the two words making up the collocation; that is, more frequent words are more likely than less frequent words to appear as part of a collocation. Therefore, statistical measures of collocation strength are needed in order to account for the likelihood of two words to co-occur (Biber et al., 1998).
The strength of a collocation between two words can be measured by the mutual information (MI) score of these two words (see Table 3 for details; Church, Gale, Hanks, Hindle, & Moon, 1994), with a score higher than 3 being considered a strong collocation (Baker, 2006, p. 120). However, the MI score assigns higher scores to rare words that produce unique collocations than to collocations containing frequent words. An alternative is z scores (see Table 3 for details), which favor high-frequency words (Lindquist, 2009) and assume normally distributed data, which is, however, not the case (Dunning, 1993). They have also been used in computer-aided interpretive textual analysis (Gephart, 1993). To address the trade-off between saliency and frequency, a log likelihood test (see Table 3 for details) can be used as a compromise between MI scores and z scores. Corpus linguists argue that the best approach to determining collocation strength is to calculate the results with all three algorithms for several collocations, rank the collocations according to the scores obtained for each algorithm, and then draw conclusions based on a comparison of these rankings (Baker, 2006; Lindquist, 2009). Despite these measurement problems, collocation strength is still an important element of a collocation analysis, as a purely manual analysis may miss strong collocations or include weak ones (Baker et al., 2008). Examples of studies drawing on collocations include Koteyko’s (2010) qualitative study of the discourse of climate change, based on institutionalized compound words as well as on new coinages. Hamilton, Adolphs, and Nerlich (2007) examined the meanings of “risk” in Collins Wordbanks Online English and the Cambridge International Corpus, using both KWIC searches and strength measures. Caldas-Coulthard and Moon (2010) conducted a critical discourse analysis of the construction of gender in tabloid and broadsheet newspapers. They compared the use of collocations containing selected adjectives in these two corpora on the basis of KWIC searches and quantitative measures of collocation strength and concluded that the two types of newspapers label and categorize men and women differently.
Dictionaries and WordNet
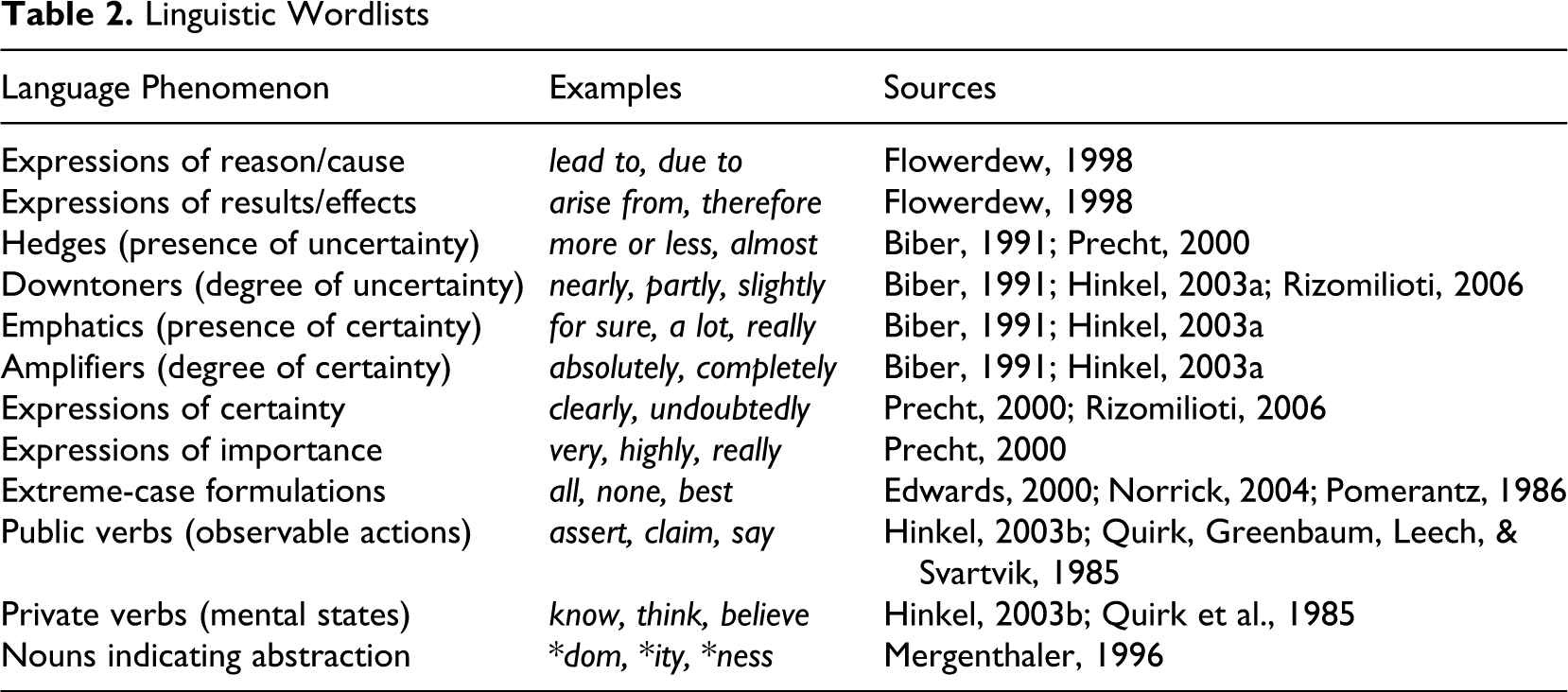
Although the construction of dictionaries is not a typical task in corpus linguistics, its resources can nevertheless be used for the construction of dictionaries that represent certain themes. Researchers in sociolinguistics and language acquisition have developed collections of words and expressions that fulfill certain communicative functions in texts. Table 2 contains a selection of such collections. 2 Precht (2000), for example, studied English stance markers based on the Longman Corpus of Spoken and Written English and compiled lists of, inter alia, markers of doubt and certainty. Further, Flowerdew (1998) developed a list of cause-and-effect markers to study how learners of English use these expressions. Management researchers can use such wordlists in order to determine whether particular communicative functions are present in a text. This can be important when a study is grounded in sensemaking, impression management, or identity construction to gain more insights into word choices. It is worth noting that the lists in Table 2 overlap to some extent. It may thus be meaningful to combine some of these lists, for example, hedges with downtoners, or emphatics and amplifiers with expressions of certainty.
Linguistic Wordlists
Researchers using computer-aided text analysis will sometimes have to compile their own dictionaries when no existing dictionary captures what they seek to study. Self-constructed dictionaries are typically compiled from words in the corpus (e.g., Gibson & Zellmer-Bruhn, 2001; Kabanoff & Holt, 1996; Palmer et al., 1997), which entails that the dictionary is biased toward corpus words. In addition to the strategies contributed by Short et al. (2010) for improving the validity of self-constructed dictionaries, another strategy to reduce this bias toward corpus words is to consult WordNet (2010), a lexical database for English containing more than 150,000 nouns, verbs, adjectives, and adverbs. WordNet places the conceptual–semantic relationships between these words in a hierarchical, treelike network (Fellbaum, 1998). WordNet is freely available to the public and can be used online or as a stand-alone application. To discover words related to those that have already been chosen for the dictionary, one can look up any given word in the WordNet database, which then returns all words that have lexical sense relations with the search word, including synonyms, antonyms, meronyms (part-to-whole relations), holonyms (whole-to-part relations), hyperonyms (type-to-subtype relations), or hyponyms (subtype-to-type relations). These relations can point to relevant dictionary words in addition to those the researcher has already noted, including both more general and more specific words.
This section has introduced keywords, word dispersion, collocations, linguistic dictionaries, and WordNet. These are applied in the demonstration example below. Table 3 provides a summary of the calculations and formulae mentioned above.
Summary of Calculations
Demonstration Example
This section illustrates how the resources of corpus linguistics can be applied to textual data. Letters to shareholders have been chosen as a text corpus for this demonstration. They are a relatively standardized component of annual reports (Bettman & Weitz, 1983) and therefore well suited for comparative analyses across companies or in longitudinal designs (Daly, Pouder, & Kabanoff, 2004). Although there is no doubt that a company’s communication department plays an active role in the drafting of this letter, the senior management team still has to find its content and language acceptable. Therefore, letters to shareholders can be seen as a reflection of the senior management team’s shared cognitions (Abrahamson & Hambrick, 1997). At the same time, most senior management communication can be characterized as “carefully crafted discursive performances” (Ng & De Cock, 2002) and is thus subject to impression management.
Numerous studies in management and organization journals have focused on letters to shareholders, using manual content coding, self-compiled dictionaries, existing dictionaries, or qualitative analysis. These studies have looked at attributions of organizational performance (Staw, McKechnie, & Puffer, 1982), causal reasoning patterns to explain organizational performance (Bettman & Weitz, 1983; Tsang, 2002), impression management (Fiol, 1995), senior management attentional foci (D’Aveni & MacMillan, 1990; Yadav, Prabhu, & Chandy, 2007), attentional homogeneity within industries (Abrahamson & Hambrick, 1997), cognitive mental models that characterize strategic groups (Osborne, Stubbart, & Ramaprasad, 2001), concealment of poor results (Abrahamson & Park, 1994), CEO commitment to the status quo (McClelland, Liang, & Barker, 2010), and espoused values (Daly et al., 2004). This illustrative study uses the techniques of corpus linguistics to examine the discourse in which poor financial results are embedded in shareholder letters. More specifically, the study tries to identify recurring discursive themes that serve as frames for the poor results. Themes in a corpus-linguistic study of discourse can comprise both content themes and linguistic themes, for example, the functional aspects of language or semantic themes (Conrad, 2002; L. A. Wood & Kroger, 2000).
For this illustrative analysis, a total of 155 letters to shareholders were collected from the largest European and U.S. banks listed on the Forbes 2000 list from 2009. Letters were collected from the years 2008, which was an extremely difficult year for banks, and the year 2006, which represents a normal financial year, that is, before the financial markets were hit by the financial crisis. Since one tenet of corpus linguistics is that frequencies can be meaningfully interpreted only when compared to other frequencies (Hunston, 2006), the 2008 shareholder letters were studied on the basis of a comparison to letters from 2006. Overall, the sample contains 80 letters from the year 2006 and 75 letters from 2008. The average length of these letters is 1,498 words in 2006 and 1,737 words in 2008.
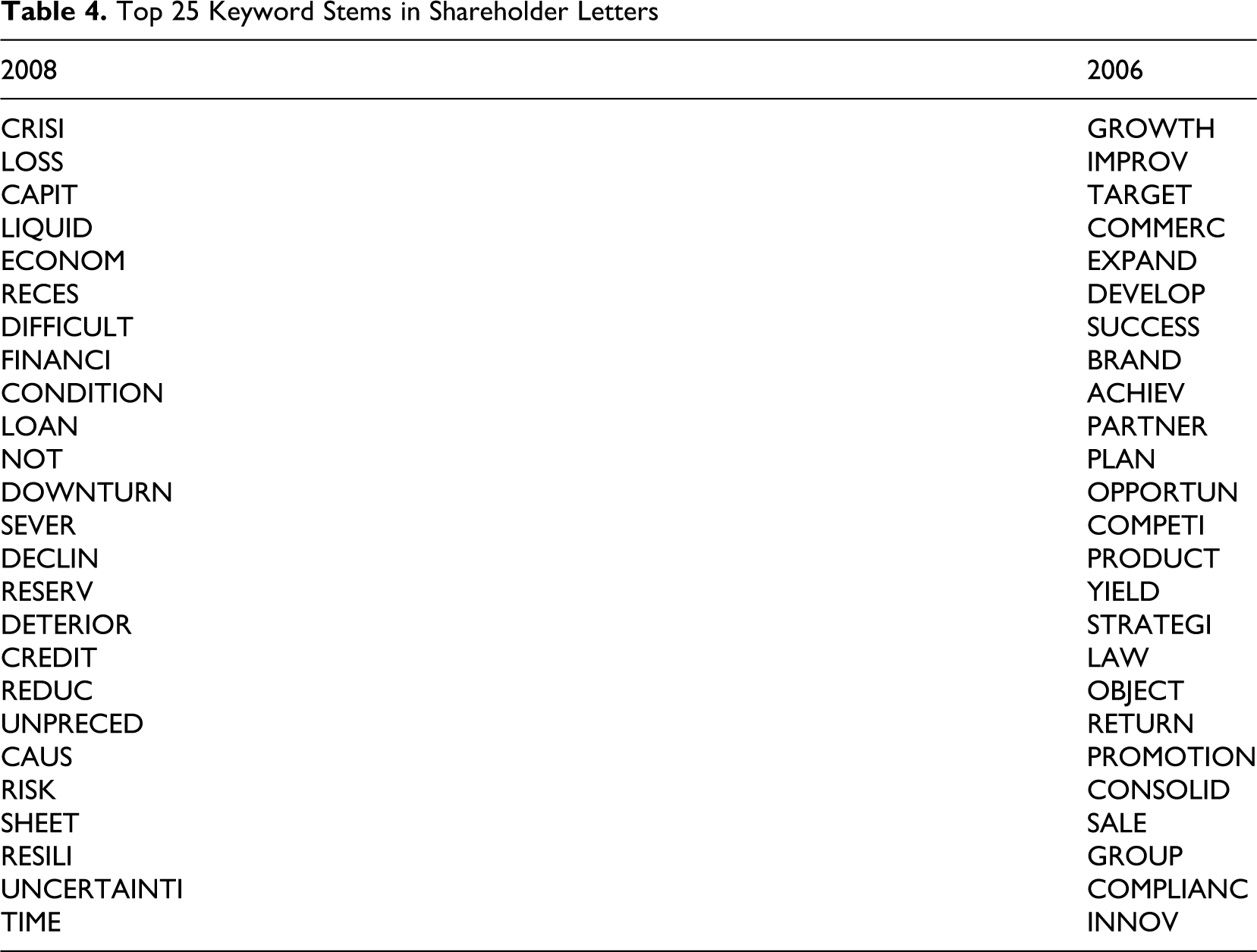
The first step in the analysis is to identify positive and negative keywords in the 2008 letters by comparing them with the 2006 letters, based on Dunning’s log likelihood test. These keywords can point to themes and attentional foci that are dominant in one corpus of letters but not in the other. This analysis was performed with WordSmith Tools. Table 4 shows the top 25 positive and negative keywords with the biggest differences in a comparison between 2008 and 2006. These differences are all highly significant (p < .001). In the 2008 letters, words revolving around the financial crisis dominate the top keyword list: crisi*, loss*, reces*, difficult*, downturn, declin*, deterior*, reduc*, and unpreced*. The top 25 negative keywords of 2008 (i.e., positive keywords of 2006) are dominated by word stems with positive and dynamic connotations among the top 10 (growth, improve*, expand*, success*, achiev*) and more general business terms afterward. Knowing the context out of which these letters have emerged, the results are fully plausible.
Top 25 Keyword Stems in Shareholder Letters
To identify the presence and absence of particular themes in the 2008 letters, all keywords identified for 2008 and 2006 with a significance level of p < .01 were examined, which included a little over 500 words. Apart from the two obvious themes, that is, crisis words in 2008 and success words in 2006, a number of other words were identified as potentially indicative of themes in the negative-results shareholder letters (see Table 5 ). Juilland’s D, which indicates the distribution of a word across multiple texts, was calculated to rule out that the words were keywords only because they were used excessively by a few companies. The calculation of the D values was performed with a spreadsheet package. All these keywords have D values of close to or above .8 in the year for which they were identified as keywords, which can be considered evenly distributed. The only exceptions are the words system and could. Upon closer inspection, it turned out that almost 50% of all instances of could and 33% of all instances of system were used by one particular company, which is why their D values are so low. They thus cannot be considered keywords of the 2008 shareholder letters.
Selected Keywords in Shareholder Letters
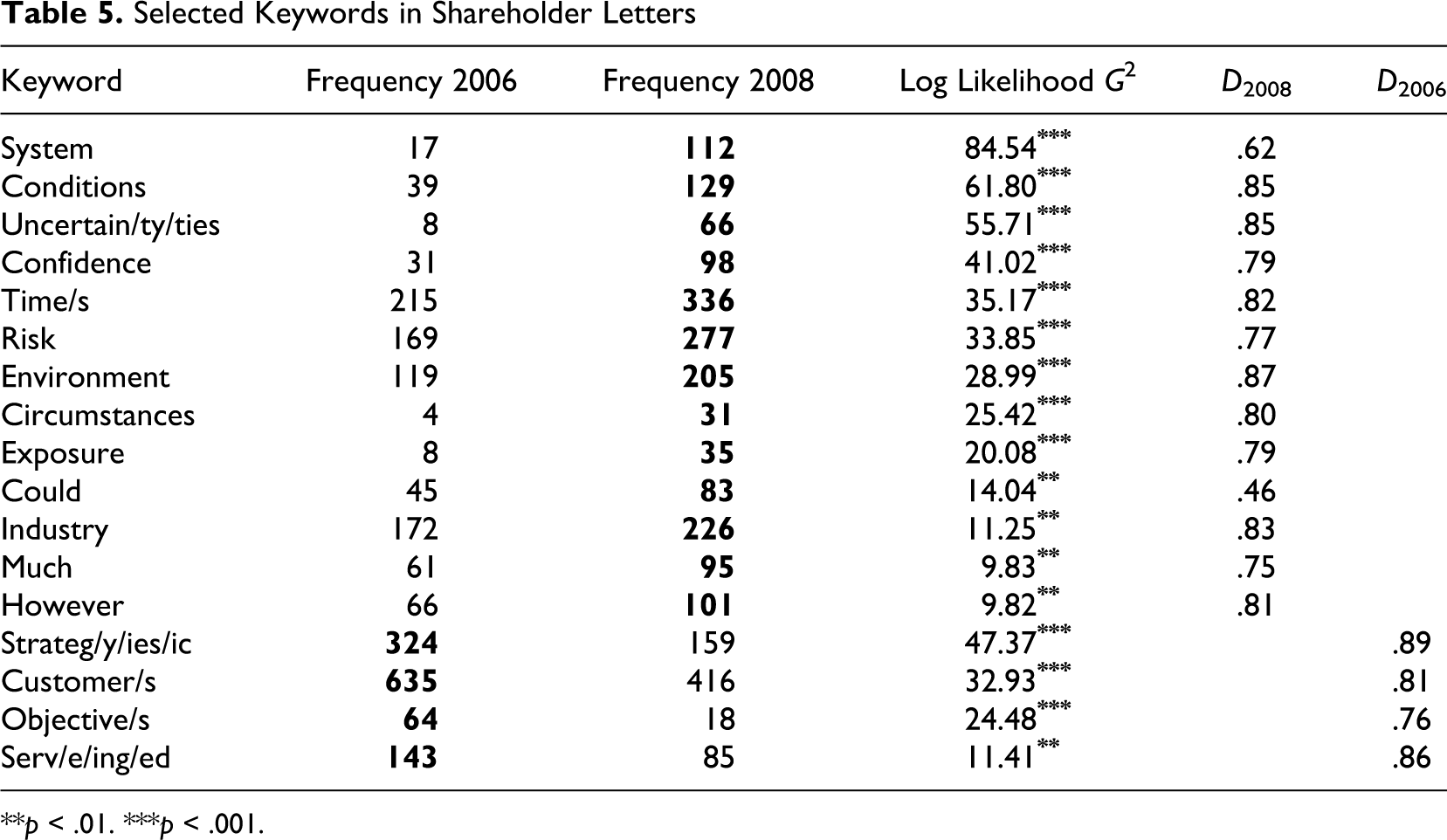
**p < .01. ***p < .001.
After an examination of the above keywords using KWIC searchers, the keywords identified were grouped into five different themes, with the exception of could, much, and however. The keywords assigned to these five themes were then used as seed words for a search for lexically related words in WordNet’s online search interface in order to identify additional related words. Table 6 shows the five themes that were identified, the words they include, the frequency of the themes, and the magnitude of the difference between 2006 and 2008. The WordNet search contributed the words hazard*, cautio*, and conservative to the theme Risk Management, as well as the words context and events to the theme Environment and the words assur*, reassure*, and hope*/hoping to the theme Reassurance. Additional words identified for the themes Strategy and People include goal, direction, focus, clients, and employees. The frequency of the themes differs significantly (p < .001) between the 2006 and the 2008 letters. The high D values of the themes indicate that the themes are sufficiently equally distributed among the letters.
Themes in Shareholder Letters
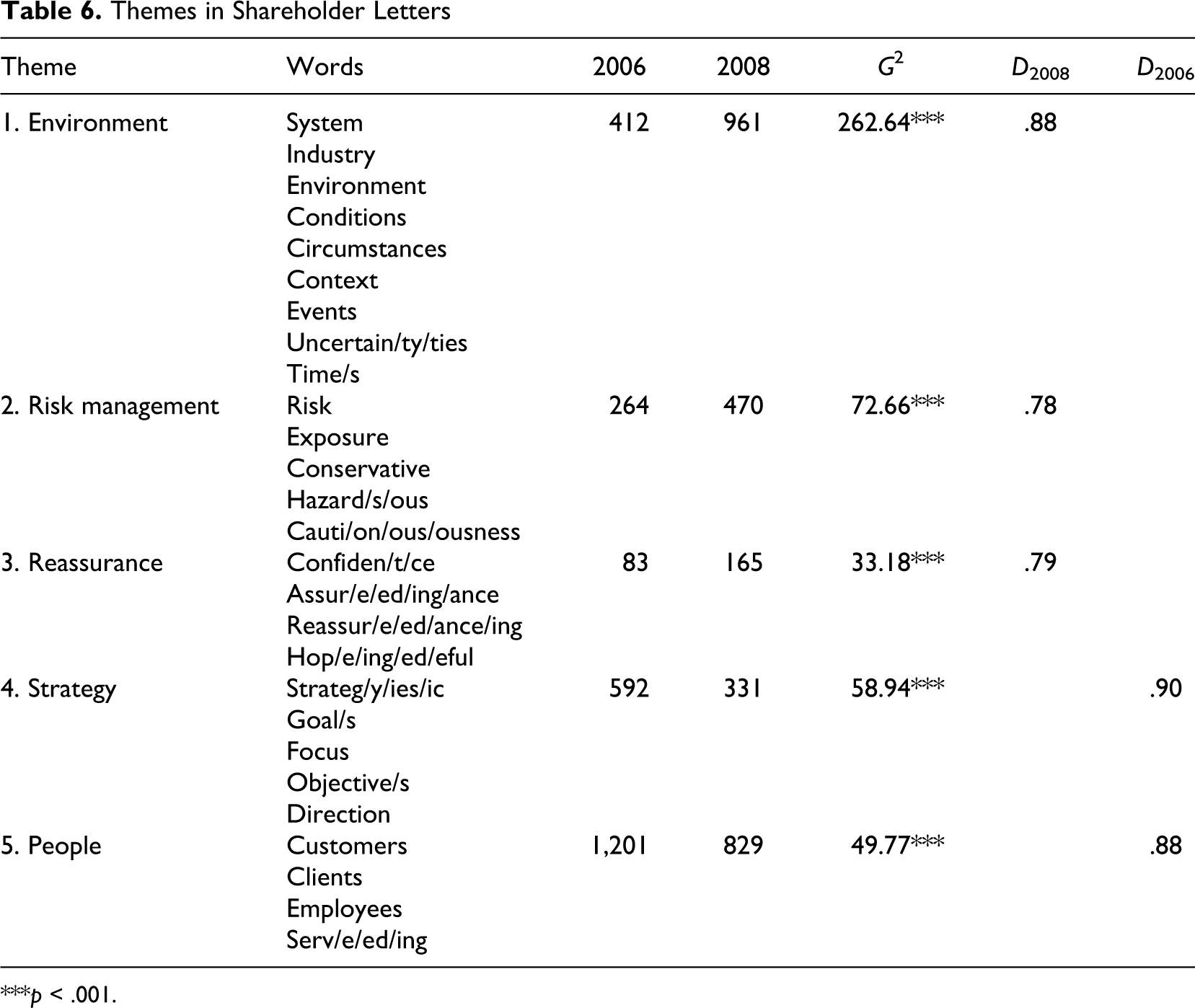
***p < .001.
The first theme identified based on keywords in the 2008 letters include words related to the environment, which serves as a justifying frame for the poor results. The exemplary statements in Table 7 illustrate how words belonging to this theme are used in the 2008 shareholder letters. In addition, the 2008 shareholder letters contain Risk Management as a significant theme, with the banks stressing their increased focus on risk. Another theme is Reassurance, which contains lexical items that express confidence and optimism about the future. In addition to the presence of environment, risk management, and reassurance, the 2008 letters are characterized by an absence of discourse about people and strategy relative to the letters from the year 2006. These themes apparently had to give way to themes that are related to the negative results communicated in the letters. Overall, the keyword comparison and the subsequent identification of themes with the help of KWIC searches and WordNet revealed three themes that received relatively more attention and two themes that received relatively less attention in the 2008 shareholders letters compared with the year 2006.
Exemplary Statements for the Themes
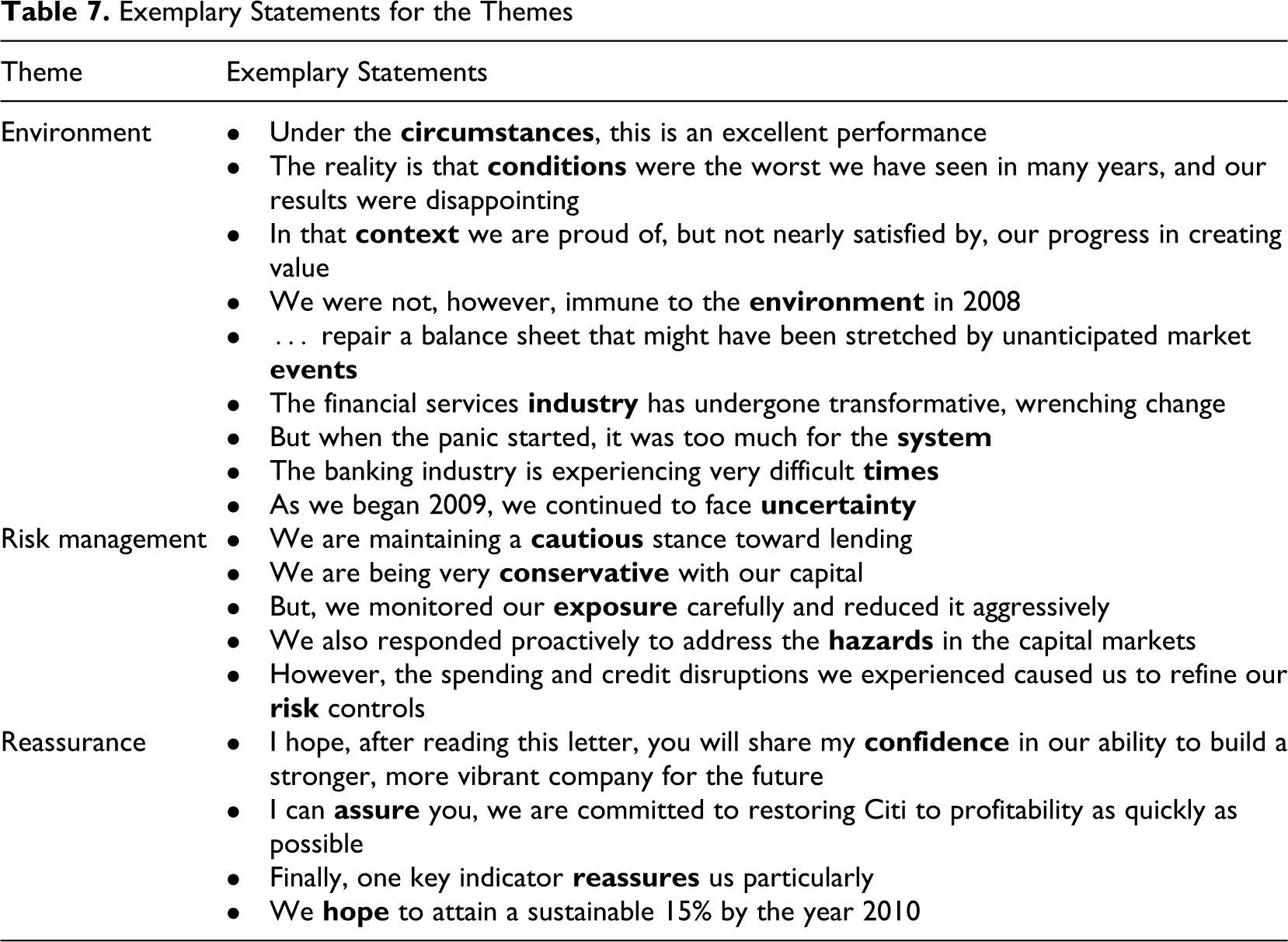
As a second lexical exploration, an open search for collocations, was conducted with WordStat, without the specification of a node word. This collocation search was performed for the entire corpus of shareholder letters as well as for the 2008 letters and the 2006 letters individually. These searches returned a large number of word combinations containing only function words (e.g., in which we) or financial phrases (e.g., in the fourth quarter). A number of collocations seemed worth examining further, though. They are listed in Table 8 with their total frequency in the two corpora, their D values, and their z scores, MI scores, and log likelihood test statistics G 2, all of which indicate collocation strength. The z scores, MI scores, and G 2 were calculated with a spreadsheet package. The results of the three measures are not unanimous, as expected. When ranking the collocations identified according to the three different scores, the results produced by MI scores and z scores are consistent, whereas the log likelihood test produces different results in particular for the top four collocations. The eight collocations identified differ substantially in terms of strength but can be classified as strong collocations, apart from all of, which is the least strong collocation according to all three algorithms and has substantially lower scores than the other seven collocations.
Collocations in Shareholder Letters
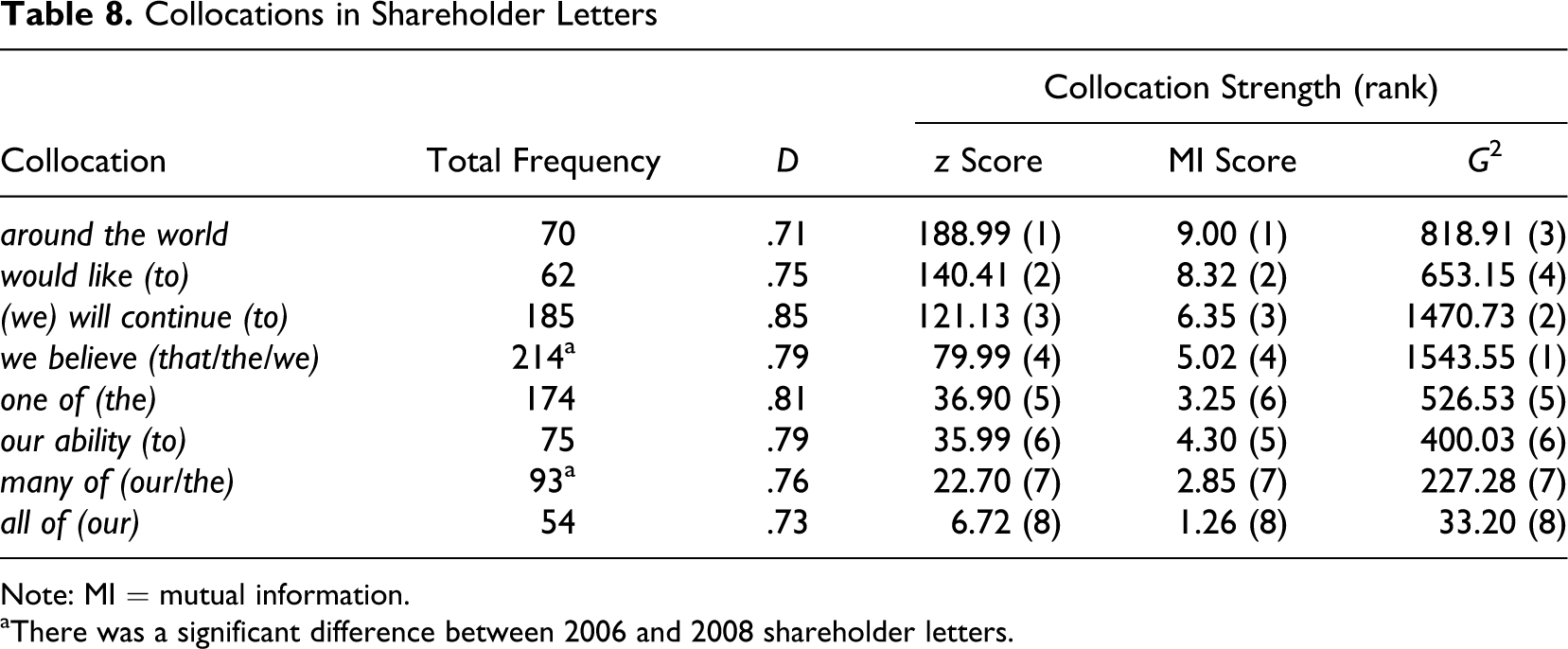
Note: MI = mutual information.
aThere was a significant difference between 2006 and 2008 shareholder letters.
Two collocations were found to differ significantly in terms of frequency between the 2006 and 2008 letters: we believe (that/the/we) and many of (our/the) were found more frequently in 2008 letters. While we believe (that/the/we) is a strong collocation, many of (our/the) is not but is still relevant because of the significant differences. These two collocations were then explored qualitatively with KWIC searches in WordStat. The other strong collocations (around the world, would like, will continue) seem to be standard features of shareholder letters in general, as they do not differ in terms of frequency between the two years. The KWIC search revealed that 65% of all instances of we believe in the 2008 letters denote a form of reassurance and trust restoration. For example, Based on what we know today,
This, together with the fact that this collocation occurs significantly more often in the 2008 letters, makes this collocation another facet of the theme Reassurance, which was identified earlier.
A KWIC search for many of revealed that the expression is used for comparisons with other companies in a self-congratulatory or a justifying manner, in addition to simply denoting a quantity. For example, We believe we are better positioned than
After reading the KWIC results of the statements in which companies made comparisons to other companies, Comparison was added as a theme. To study this theme in more detail, words used in those statements were added to the theme, including like, unlike, along with, most of, and position*. This theme is found significantly more often (G
2 = 32.67, p < .001) in the 2008 letters than in the 2006 letters and is well distributed (D = .87). Overall, the collocation search expanded the theme Reassurance and contributed the theme Comparison.
The third inquiry compared the corpus of 2008 shareholder letters against some of the linguistic wordlists presented in Table 2. In view of the poor results that were communicated in the 2008 shareholder letters, a number of language features can be expected to be found in the negative-results letters. First, expressions of reason/cause and results/effects (Flowerdew, 1998) explain causalities and may be relevant, given that poor results are generally attributed to outside forces and external events rather than to oneself (Schlenker, 1980), which has also been found in annual reports (Aerts, 1994). Second, extreme-case formulations are typically used for defenses and justifications when one’s legitimacy is challenged (Edwards, 2000). Therefore, they can be expected to be found more frequently in 2008 shareholder letters than in 2006 shareholder letters. Third, speakers or writers can increase the intensity of a statement and express confidence with markers of certainty (including amplifiers and emphatics). This is expected to be an important feature of shareholder letters commenting on poor results and seeking to provide reassurance. Ultimately, downtoners (including hedges) can soften the impact of a statement but also indicate a lack of confidence (Hinkel, 2003a; Holmes, 1982). Downtoners are expected to be used in the 2008 shareholder letters to make poor results seem less poor. However, since letters to shareholders are carefully crafted documents, it is not expected that downtoners are used in a manner that expresses a lack of confidence.
Following these hypotheses, five dictionaries were built based on the corresponding wordlists presented in Table 2: cause, certainty, downtoners, extreme case, and results. A log likelihood test conducted with WordStat indicated that all dictionaries occur significantly more frequently in the 2008 letters than in the 2006 letters (see Table 9 ). The corresponding D values, which were calculated with a spreadsheet package, are close to or above .8, with the exception of Downtoners. These results suggest that the need to comment on disastrous financial results in shareholder letters is connected with the use of all of the above types of linguistic features. With the smallest difference and the lowest D value, downtoners seem to be the least characteristic, whereas expressions of reason/cause and markers of certainty seem to be the most prominent ones in the 2008 letters to shareholders.
Linguistic Wordlists in Shareholder Letters
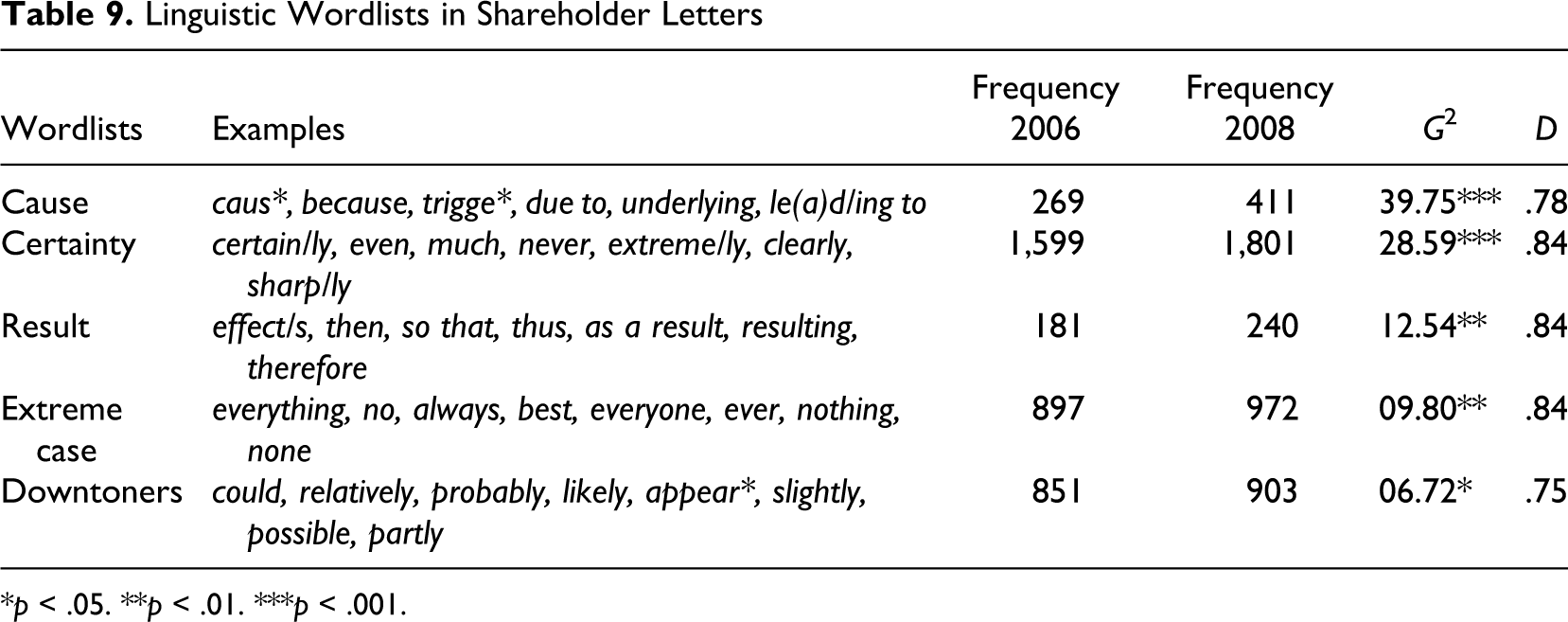
*p < .05. **p < .01. ***p < .001.
To study particularly prominent words from the dictionaries in more detail, the entries of each dictionary were examined individually and those words on which the 2008 letters and the 2006 letters differ significantly were identified. They all occur significantly more frequently in the 2008 letters. Table 10 shows these words together with the magnitude of the difference (G 2) and the distribution among the 2008 letters (D). Since caus*, certain/ly, and could (see results of keyword analysis above) are not well distributed, they can—by themselves—not be seen as characteristic words of the 2008 shareholder letters but only as part of the dictionaries. The other words were examined more closely in KWIC searches. The certainty markers even, much, and never, as well as the extreme-case formulations everything (e.g., everything we do, everything possible, everything in our power) and no (e.g., no question, no exception, in no way) are characteristic of 2008 shareholder letters both individually and as part of the dictionaries. The dictionary of certainty markers and the dictionary of extreme-case formulations contribute to the theme Reassurance because they communicate confidence and seek to eliminate doubts. The dictionary of reason/cause and the dictionary of results/effect form a theme of their own, titled Attribution, which includes all those words and expressions needed to explain how the poor results came about.
Words from Linguistic Dictionaries
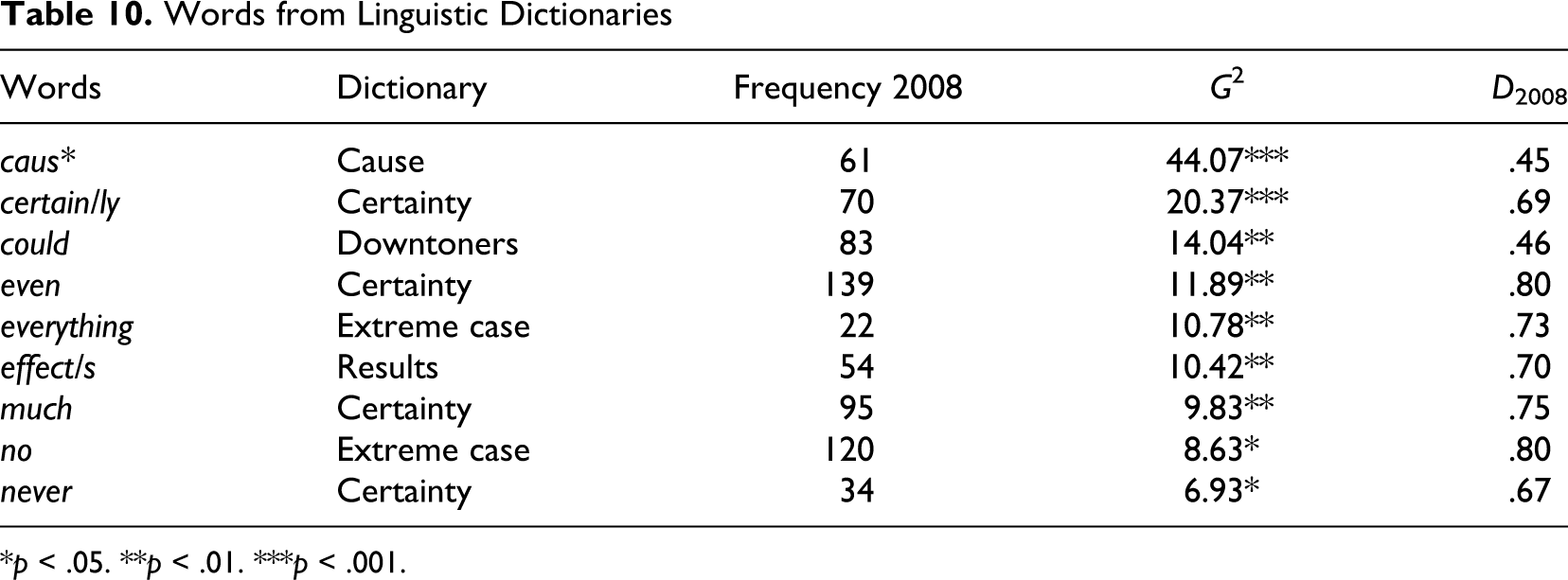
*p < .05. **p < .01. ***p < .001.
Overall, the corpus-linguistic analysis has revealed seven themes, five of which are more prominent in the 2008 shareholder letters (Environment, Risk Management, Reassurance, Comparison, and Attribution) compared to the 2006 letters, and two of which are less prominent (Strategy and People). Figure 1 summarizes the steps taken to arrive at these themes. First, keywords were identified based on a log likelihood test, followed by an examination of the dispersion of the keywords, KWIC searches, and WordNet searches. The collocation analysis began with an open search for collocations, followed by the calculation of their strength. Then their frequencies were compared in the two corpora together with their dispersion measures. This was followed by KWIC searches with the most noteworthy ones. Finally, linguistic word collections were used as dictionaries. Again, frequencies were compared, word dispersion measures were examined, and the most prominent words were examined with KWIC searches. Within each of these three strands, both qualitative and quantitative explorations were used to arrive at valid findings. The findings (i.e., the themes) were derived both inductively and deductively, including content themes and language themes. Together, they give a rich picture of the negative-results discourse of the 2008 letters to shareholders.
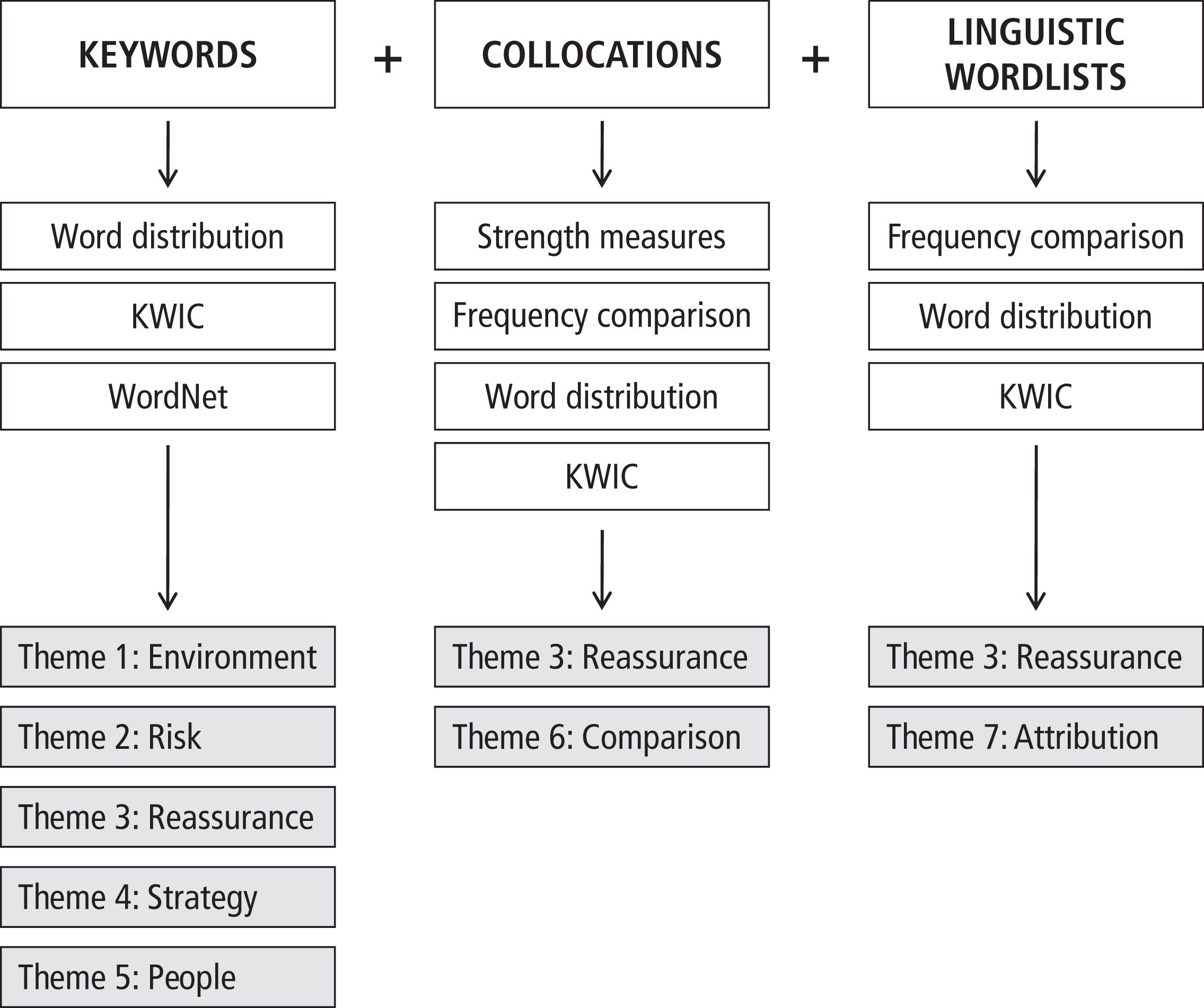
Summary of Analytical Steps
The above approach represents one possible way of combining the techniques of corpus linguistics into an inquiry. The demonstration example does not specifically draw on computer-aided content analysis or computer-aided interpretive textual analysis in order to show how a pure corpus-linguistic analysis is conducted. But, clearly, there are overlaps. First, some of the themes identified are content themes, resembling the content dictionaries employed in computer-aided content analysis. However, the corpus linguistic procedure identifies noteworthy themes rather than checking the presence of existing dictionaries such as DICTION. Second, collocations are also used in computer-aided interpretive textual analysis but only in qualitative explorations of particular node words. In the corpus-linguistic approach presented in this article, an open search for collocations is made in order to identify recurring and noteworthy patterns in text. Third, the linguistic wordlists resemble a content-analytical methodology with an existing dictionary but contain words that fulfill meta-communicative purposes rather than content words.
Discussion
In view of the lack of interaction between linguistics and the social sciences regarding text analysis (Bernard & Ryan, 1998; Markoff et al., 1974; Popping, 2000; Roberts, 1989), this article has set out to demonstrate how the resources of corpus linguistics can be meaningfully applied in the social sciences. This exemplary analysis of letters to shareholders has demonstrated how the use of corpus-linguistic analysis techniques can provide insights that computer-aided content analysis or computer-aided interpretive textual analysis alone would not provide. More specifically, these pertain to the comparison of corpora by means of keywords, the dispersion of words within a set of corpora, the identification of strong collocations, and the enhancement of self-constructed dictionaries with WordNet, all of which were employed in the demonstration example. Thus, corpus linguistics makes a contribution to organizational research methods in four areas: First, corpus linguistics has the techniques to identify and quantify recurring patterns in textual data. Second, corpus linguistics highlights the importance of examining collocations and multiword expressions rather than looking at individual words only. Third, corpus linguistics can provide techniques for the comparison of one’s own corpus with a large public corpus as well as for the comparison of different texts within a corpus. Ultimately, corpus linguistics contributes methodological innovations in the form of new or improved tools and resources for exploring and handling textual data.
Corpus linguistics can be of value for two types of studies in the field of management and organization. First, corpus-linguistic techniques can be more insightful than content analysis for quantitative, positivist studies drawing on large samples of texts from the same genre, for example, mission statements, letters to shareholders, annual reports, corporate social responsibility reports, corporate self-presentations on websites, executive speeches, e-mails, press releases, or news articles. In these studies, the focus is on the manifest content and surface features of texts in either a snapshot analysis or a longitudinal design. With corpus-linguistic techniques, lexical patterns can be identified, quantified, and compared across large samples to find commonalities. Alternatively, such studies can use large general-language corpora when general texts about organizations are needed (cf. Cornelissen, 2008) or more specialized corpora of professional English either as the main data source or as a reference corpus. A second stream of research to which corpus linguistics can add value is discursive or narrative studies on organizations, for example, on sensemaking and sensegiving, framing, emotions, or impression management. In addition to what computer-aided interpretive textual analysis can provide to such studies, corpus-linguistic techniques can add more elaborate measures of identifying interesting themes through collocations and their strength, the identification of keywords, and the calculation of word dispersion measures. Both positivist and interpretive studies can draw on the resources provided by researchers in linguistics, including WordNet for the identification of potentially interesting words or linguistic wordlists such as those used in the demonstration example. These techniques and resources can open up additional inquiry opportunities or refine existing ones.
The absence of a stringent methodology behind corpus linguistics is a strength when it comes to incorporating its techniques into other methodologies. Because it consists of a loose bundle of analysis techniques, corpus linguistics is flexible enough to be embedded into computer-aided text analysis or can be used as an alternative to computer-aided text analysis altogether. For example, one could strengthen a content analysis based on existing dictionaries with word dispersion measures. Further, a content analysis based on self-constructed dictionaries could be enriched with WordNet searches. An interpretive analysis could be enhanced with open collocation searches and collocation measures as well as linguistic wordlists. Clearly, corpus linguistics is not without limitations. First, some of the techniques presented in this article can only be applied to English text corpora, including linguistic wordlists, publicly available corpora, and WordNet. Second, applying corpus linguistics requires the researcher to have a good understanding of language and its irregularities, in particular spelling variants and words with multiple meanings, both of which can severely distort one’s findings if they are not accounted for in the analyses. Third, a researcher’s subjectivity is an inevitable element of any corpus-linguistic analysis, not only because of its qualitative elements but also because the researcher has to make decisions about corpus building, the selection of analysis steps, the construction of dictionaries, and the amount of validation work (cf. Baker et al., 2008). Subjectivity is also inherent in the interpretation of results, when researcher input is required for setting cutoff points for keywords or for the values of dispersion measures, as no firmly established standards exist yet. Therefore, constant checking, reflecting, critiquing, contextualizing, refining, and adapting have to be integral parts of any corpus study in order to minimize subjectivity and ambiguities. Only then can corpus linguistics provide management scholars with powerful methodological resources.
Conclusion
This article has introduced corpus linguistics as an enhancement of or an alternative to computer-aided text analysis. Based on an exemplary analysis of letters to shareholders, this article has demonstrated what the resources of corpus linguistics can contribute to organizational research methods. Given that corpus linguistics has been developed by scholars in the field of language studies, drawing on their expertise when it comes to exploring textual data can only be beneficial in future studies in the field of management and organization. With its methodological innovations for the identification of recurring lexical patterns, the comparison of corpora, and the enhancement of dictionaries, the field of corpus linguistics can fertilize the field of computer-aided text analysis if researchers are willing to broaden their methodological repertoire with its techniques.
Footnotes
Appendix
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author(s) received no financial support for the research, authorship, and/or publication of this article.