
Abstract
Network-based research in the management field largely assumes one-mode (unipartite) networks, despite the widespread presence of two-mode (bipartite) networks. In empirical work, scholars usually project a bipartite network onto a unipartite network, ignoring issues related to the interdependence of ties and potential loss of information. Yet new advances in measures and methods related to bipartite networks in the fields of sociology, physics, and biology may make such tactics unnecessary. This article presents an overview of three research streams related to bipartite networks, namely, (a) refinements related to the projections of bipartite networks onto unipartite networks; (b) the extension of networks measures from unipartite networks to bipartite networks, with a focus on clustering coefficients; and (c) approaches unique to bipartite networks, such as nestedness. We apply these approaches and compare the findings of a traditional unipartite network analysis using both a simple example and a sample of 10,223 directors of 1,528 Indian firms in 2009.
In the past decade, studies of social network analysis have expanded notably (Borgatti & Halgin, 2011), mostly in the form of studies of one-mode (unipartite) networks. In a unipartite network, the nodes are all of one type (e.g., individuals, firms), and ties link only these same types of nodes. Popular examples include friendship networks at the individual level or alliance networks at the firm level. Yet a considerable number of networks actually are two-mode (or bipartite or affiliation) networks, featuring ties between two different types of nodes, such as board networks (Davis, Yoo, & Baker, 2003), specialists involved in television productions (Zaheer & Soda, 2009), authors of team-authored research papers (Newman, 2001), firms as members of multiparty alliances (Greve, Baum, Mitsuhashi, & Rowley, 2010), and countries involved in product trade (Schweitzer et al., 2009).
Perhaps because of the lack of appropriate measures and methods to address these bipartite networks (Latapy, Magnien, & Vecchio, 2008; Wasserman and Faust, 1994), most empirical work projects bipartite networks onto unipartite networks. However, this approach creates issues involving information loss and tie interdependence (Conaldi, Lomi, & Tonellato, 2012). Furthermore, characteristics for affiliations are indirectly constructed via network attributes of their members rather than the affiliations’ network characteristics (e.g., Zaheer & Soda, 2009). The relevant concerns are relatively common, in that researchers often encounter either latent bipartite network structures, such as in the case of niche overlaps across resource complementarities (Chung, Singh, & Lee, 2000) or mutual forbearance (Lomi & Pallotti, 2012), or deliberately choose a unipartite network representation.
In the network analysis field, bipartite approaches trail unipartite views, yet in other areas, such as sociology, physics, and biology, we find significant advances in bipartite network analyses. We therefore recommend an excursion for management scholars, such that we look to other realms to discover the latest advances in network analysis (Dionne et al., 2012) in addition to those in the management literature with bipartite exponential graph models (Wang, Sharpe, Robins, & Pattison, 2009) and stochastic actor-based modeling for bipartite networks (Conaldi et al., 2012). Specifically, we present three streams of research related to bipartite networks. First, we introduce refinements related to projections of bipartite networks onto unipartite networks. Second, we note extensions of network measures from unipartite to bipartite networks, for which the focus is on clustering coefficient, a key measure for small-world characteristics, network cohesion, and embeddedness. Third, we consider approaches unique to bipartite networks. To synthesize these advances, we propose a two-dimensional framework of unipartite versus bipartite approaches and complementary node and network perspectives.
In the following sections, we begin with a simple example to illustrate the limitations of projecting bipartite networks onto unipartite versions. We then discuss some alternative approaches for analyzing bipartite networks and illustrate these approaches on the basis of an application to the director-board network of all publicly listed firms in India in the year 2009.
Bipartite Networks and Projections to Unipartite Networks
Background
Bipartite networks contain ties between two different types of nodes (Wasserman & Faust, 1994). In many cases, one of the node types is actors; the other might refer to events, such as membership in a group, meeting, corporate board, alliance, the environment, or markets. Such bipartite networks can be described with an incidence matrix (Figure 1a), with elements
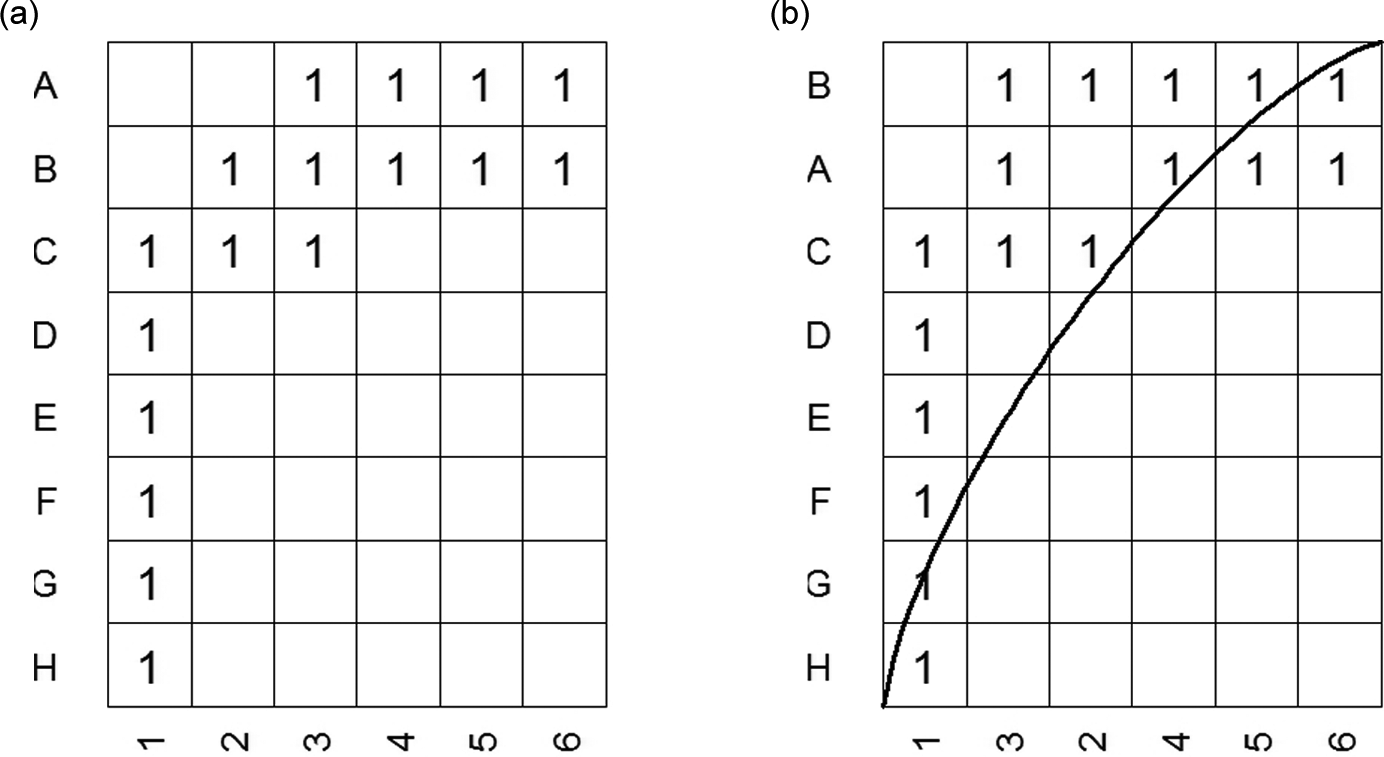
Bipartite network with Actors A to H and events 1 to 6. (a) Original order. (b) Nodes ordered along degree with isocline.
An incidence matrix usually is rectangular, because the number of actors and events does not need to be equal. If an actor participates in an event, the incidence matrix element
The two-by-two matrix in Figure 2 refers to the choice of network type (unipartite or bipartite) and the unit of analysis (node level or network level). Most research into bipartite networks appears in Quadrant I, that is, analyses of unipartite networks at the node level. Quadrant II encompasses analyses of unipartite networks at the network level, as reflected initially in the small-world analysis offered by Watts and Strogatz (1998). Since then, similar analyses have been applied to board networks (e.g., Baum, Shipilov, & Rowley, 2003; Davis et al., 2003). Quadrant III refers to analyses of bipartite networks at the node level, for which the analytic tools include centrality measures proposed by Borgatti and Everett (1997) and Faust (1997). These works have spurred research outside of management domain in areas such as ecological networks. Quadrant IV refers to the analysis of bipartite networks at the network level. In this realm, Faust (1997) discusses the structure of bipartite networks with Galois lattices; Battiston and Catanzaro (2004) further analyze distributions of bipartite node characteristics across different networks. However, Quadrant IV lacks network-level measures that capture structural properties of the network.

Decision matrix for the analysis of bipartite networks.
The choice of a quadrant in the matrix depends on the particular research questions, hypotheses, and data. If the objective is to use node characteristics, such as centrality measures, as explanatory variables in regression analyses, scholars might be interested in either Quadrant I or Quadrant III, depending on whether the network is a projected unipartite or the original bipartite. However, if the objective is to compare different networks, scholars focus on Quadrant II or Quadrant IV, again depending on whether the network is unipartite or bipartite. For each quadrant in Figure 2, we suggest transferring advances in analyses of bipartite networks from other disciplines to management research. We introduce these new methods in greater detail next.
Projections of Bipartite Networks to Unipartite Networks
Researchers often transform bipartite networks into unipartite networks using a projection to connect actors that participate in the same event with one another. The resulting projection for actors results in the unipartite network structure in Figure 3.
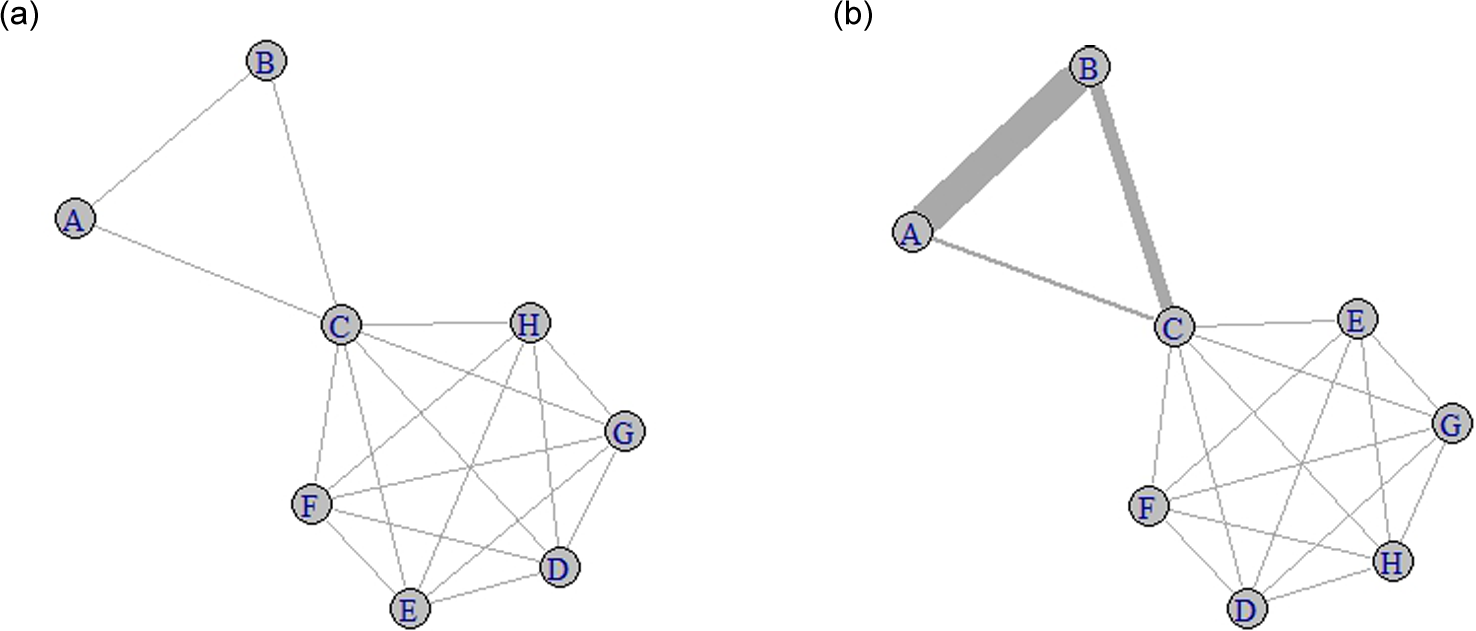
Example unipartite network with eight nodes and ties between them. (a) Binary projection. (b) Weighted projection.
Figure 3a illustrates a simple unipartite network with eight nodes and binary ties. As explained previously, the nodes might stand for employees in a firm, such that the ties between them result from their participation in common events, such as meetings, and lead to conduits for information flows. They can also symbolize firms, tied by their sale of products in the same national markets, such that the ties facilitate information flow or competitive actions. In Figure 3a, we can discern a core of well-connected nodes (C to H) and two peripheral nodes (A and B). Node C has a prominent position, connecting the dense core with the periphery, which allows it to control information flows. Such projections normally result in undirected networks, which is our assumption for the following discussion.
The projection example illustrated by Figure 3a demonstrates some limitations of deriving unipartite networks from bipartite networks. First, the ties between two employees in this example do not indicate the number of meetings they share. Even if such information determines the weight of the tie (Figure 3b), well-known network measures do not take such weights into account. Second, the ties of Nodes C-H are created simultaneously by their participation in the same meeting. However, in this large connected group, employees do not necessarily have personal ties with one another. As the meeting size increases, we obtain a larger group of connected employees, even as the likelihood of mutual interaction among any pair of employees decreases. Third, this approach ignores the possibility that bipartite networks have characteristics unique to their specific nature, which cannot be captured from a unipartite network perspective.
Although this projection can apply to both types of nodes, most researchers focus on the actor-oriented projection. Furthermore, the projected unipartite network is often binary, such that all existing ties appear equally important (weight = 1). However, granting equal weights to different shared events results in information loss. In this example, the binary network in Figure 3a ignores the information that Actors A and B share four events. Assigning weights to the ties equal to the number of co-occurrences can account for this difference, such that the tie between A and B should take a weight of 4, while the others exhibit a weight of 1. A similar weighting approach appears in several studies; for example, Kogut, Urso, and Walker (2007) use the number of deals between two venture capital firms, and Greve et al. (2010) note the number of shared routes between two shipping liners. Weighting by co-occurrence effectively accounts for the number of links, but it ignores the acquaintance of the focal actor with other actors in an affiliated organization.
Newman (2001) argues that in scientific collaboration networks, with researchers as actors and joint publications as events, the number of coauthors matter, such that authors’ interactions with their coauthors should be scaled by 1/(n – 1), where n is the number of coauthors. In the case of a two-author collaboration, the focal author interacts solely with the second author; in a case of three authors, the focal author’s interaction is shared between the other two authors. The same logic can apply in our illustration, resulting in a weight of 3.5 for the tie between A and B, 1.5 for the tie between B and C, and 0.2 for all other ties.
Measures of Weighted Unipartite Networks
The assignment of weights in the projection thus helps retain important information, but this tactic can be exploited only if methods for weighted networks are available. Here, we discuss extensions of centrality measures and clustering coefficients to weighted networks (Barrat, Barthelémy, Pastor-Satorras, & Vespignani, 2004; Opsahl, Agneessens, & Skvoretz, 2010). We use
Centrality measures
Barrat et al. (2004) extend degree centrality from binary to weighted networks, in the form of strength

This standard, commonly used definition of tie strength (e.g., Lin, Yang, & Irem, 2007) ignores the number of neighbors. For example, Node A, as well as Nodes D through H, have strength of 5 using the weight of co-occurrence, but their degree centrality and position in the network differ widely. The main contribution to A’s strength comes from its strong connection with B, whereas Nodes D through H exhibit weak ties to a rather large number of neighbors. Whereas A may receive more sticky information or tacit knowledge from B, through their repeated interactions, D to H are more likely to receive freely available information from a diverse group of nodes.
Opsahl et al. (2010) instead define centrality measures that take both the weight and the number of ties into consideration and acknowledge the relative importance of strength using a positive tuning parameter α, such that
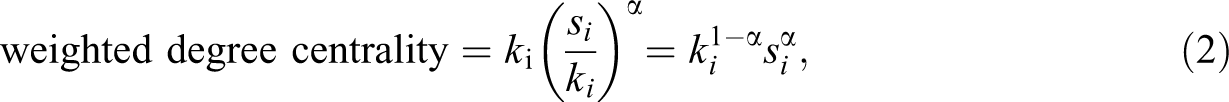
Table 1 contains the weighted degrees for four values of α. The weighted degrees for Nodes D through H remain unchanged, due to the binary weight of their ties, but those for Nodes A through C change with the tuning parameter and the relative values for all nodes. A low α value may be more suitable if the focus of the research is on the flow of easily available information, such as discussions in a meeting. In contrast, a larger value of α may be more suitable if the research interest pertains to the flow of sensitive information or tacit knowledge that requires a strong tie.
Weighted Degree Centralities for Simple Example Network With Co-Occurrence Weights and Different Values of the Tuning Parameter α.

Both betweenness and closeness centrality measures for two nodes, i and j, reflect the shortest path between the two nodes. For binary networks, it is the number of ties between node i and j. For example, in Figure 3, the shortest path between A and H is 2, through the Paths A-C and C-H. Opsahl et al. (2010) suggest extending both measures, using extensions of the shortest path 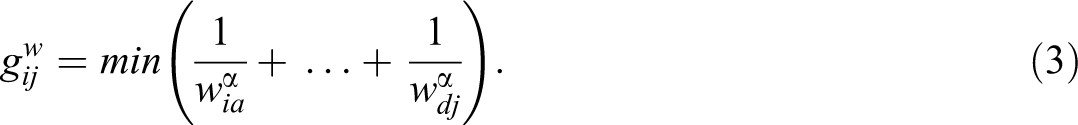
For α equal to 0,
In our example (Figure 3), the shortest path between A and D through C in the binary case changes to A-B-C-D when α = 1. Despite the additional intermediary node, this path may provide a faster conduit for information because the ties are rather strong. Although C remains the connecting node for the clique of D to H, B also assumes a nonzero betweenness centrality. For example, if the events are firms selling in different national markets, C may be able to gain information on A’s products in the Joint Market/Event 3, but it cannot learn A’s global strategy. However, C may receive some information from B, who observes A in more markets and can infer its strategy accordingly. If this example pertained to employees within a firm, we would suggest that more codified, accessible information can flow through weak ties, and a small α is appropriate, but more complex and tacit information flow is better described with a higher α.
All three extensions of the centrality measures match well-defined measures in binary networks for all weights equal to 1. Their key limitation is the assumption that the weights reflect a ratio scale. Although the exact choice of α is a concern for specifying a certain centrality measure, it also provides an opportunity to distinguish whether the weight of ties or the number of intermediate nodes is important by comparing the results of the unweighted measures with those of the weighted measures.
Clustering coefficient
The clustering coefficient measures the cliquishness of the local environments, according to the average local clustering by nodes in their neighborhoods. The neighborhood of node i with 

Such clustering coefficients have been subject to two main refinements in recent literature: corrections for the greater cliquishness of projected bipartite networks (Newman, Strogatz, & Watts, 2001) and accounting for extensions for weighted networks (Barrat et al., 2004; Opsahl & Panzaras, 2009).
The projection of bipartite networks leads to natural clustering of the projected unipartite networks. In our example, attendance at event 1 leads to a clique of six members, all connected with one another. The projected unipartite networks thus are a collection of cliques, connected by actors that join multiple events. Large events in the bipartite network result in large cliques that create a relatively highly clustered network. Newman et al. (2001) provide a comprehensive framework that seeks to generate functions for degree distributions and can account for such clustering; they thus propose the Newman-Strogatz-Watts (NSW) small-world coefficient. Conyon and Muldoon (2006) apply this method to board networks from Germany, the United States, and the United Kingdom and find that none of these networks showed clustering coefficients higher than expected from a bipartite random network with the same degree distribution. In Appendix A, we provide a detailed derivation of the formula to calculate the path length and clustering coefficient, using a given degree distribution for both types of nodes. We also illustrate it in our real example of Indian firms’ board networks.
Barrat et al. (2004) define a weighted clustering coefficient 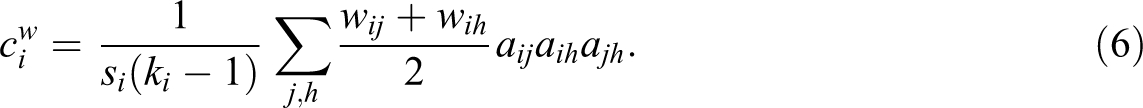
For each triplet in the neighborhood of the focal node i, the average weight of its ties, rather than the existence of a tie, counts. The sum over all triplets is normalized by the average weight and number of possible triplets, which guarantees that the weighted clustering coefficient falls between 0 and 1. For constant weights, Equation 6 is equivalent to the clustering coefficient defined by Watts and Strogatz (1998). The weighted global clustering coefficient
In our example, the weighted clustering coefficient for the Newman projection for Nodes D-H, with weights of 0.2, is still 1, because all the weights are the same. Therefore, this technique does not resolve the problem of inflated clustering coefficients for small-world analysis.
Bipartite Networks
Bipartite networks entered the organizational field nearly 40 years ago, in a seminal article by Breiger (1974) about the duality of people and groups. Despite this long history and the ubiquity of bipartite networks, analytical methods for assessing bipartite networks still lag behind those of unipartite networks (Wasserman & Faust, 1994). Some prominent efforts to devote more attention to bipartite networks include work by Borgatti and Everett (1997), Faust (1997), and Latapy et al. (2008), as well as the use of bipartite networks in food webs (who eats whom) in an ecological community (see Bascompte & Jordano, 2007). The centrality measures suggested by Borgatti and Everett (1997) are well established; here, we focus on clustering coefficients in bipartite networks, nestedness, and bipartite random networks.
Clustering Coefficients
The primary question for the local clustering coefficient in unipartite networks pertains to closure: To what extent do existing ties of node i to nodes j and k lead to the formation of a tie between the nodes j and k? In bipartite projections though, tie formation is not independent, such that triangles form simultaneously, as demonstrated in Figure 3. Furthermore, the definition of the clustering coefficient (Equation 4) cannot be extended to bipartite networks because the connection of direct neighbors of the same type is prohibited and triangles cannot exist.
Robins and Alexander (2004) introduce a bipartite clustering coefficient as an extension of the unipartite global version, that is, of the global measure based on the number of triangles in the network (often referred to as transitivity). A dual aggregation technique introduced by Breiger and Mohr (2004) acts on quantitative bipartite networks, defining the clustering coefficient for binary networks. Latapy et al. (2008) propose extending the local clustering coefficient to bipartite networks with a more abstract definition of overlapping neighborhoods, according to the directly connected nodes for i and j. The overlap equals the fraction of joint neighbors in both neighborhoods: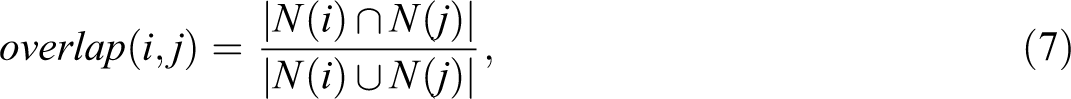
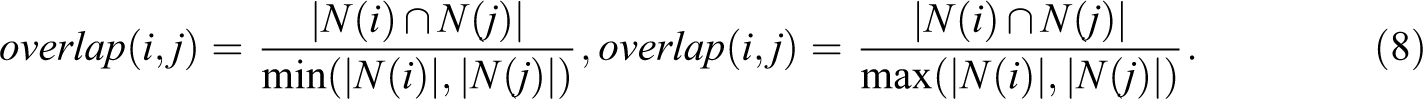
The bipartite local clustering coefficient for node i equals the average of its nonzero overlaps: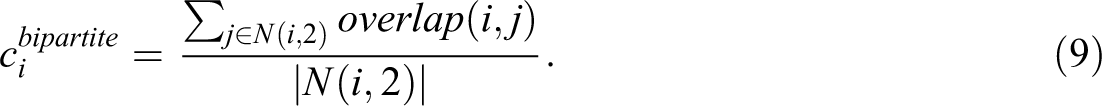
Clustering Coefficients for the Simple Network.

The three overlaps defined by Latapy et al. (2008) are all symmetric. In organizational ecology research, though (Podolny, Stuart, & Hannan, 1996), with their implicitly underlying bipartite networks of organizations and their environment (i.e., the niches of the organizations), the niche overlap is defined as the overlap of resource requirements of two organizations, divided by the width of the focal organization’s niche, which is asymmetric toward the two involved organizations. Thus, we would need to extend the overlap measure with normalization, based on the focal node’s niche width and an appropriate bipartite clustering coefficient. With such an extension, the crowding around an organization’s niche, as defined by the sum of a focal node’s overlap (Podolny et al., 1996), equals the numerator of the bipartite clustering coefficient. This bipartite clustering coefficient also can be used to derive measures at the group level, based on group membership in a multilevel context.
Nestedness
Whereas the bipartite local clustering coefficient is an extension of the unipartite concept of closure, the nestedness property is solely a bipartite network property (Ulrich, Almeida-Neto, & Gotelli, 2009). Nestedness is an important property of biological bipartite networks such as habitat communities (Atmar & Patterson, 1993) or pollinator-plant systems (Bascompte, Jordano, Melin, & Olesen, 2003) that are “highly nested; that is, the more specialist species interact only with proper subsets of those species interacting with the more generalists” (Bascompte et al., 2003, p. 9383). Specialists are nodes with a low degree, whereas generalists are nodes with a high degree, namely, the number of connected nodes. This definition is congruent with that of specialists and generalists in organizational ecology, in which organizations and their resource space get conceptualized as a bipartite network (Carroll, 1985; Freeman, Carroll, & Hannan, 1983). The niche width of an organization reflects its degree in the bipartite network, such that it measures the resources, the other type of node, on which the organization depends. Generalists have a broad range of environmental resources, whereas specialists focus on a narrow range. From a bipartite network perspective on mutualistic systems, the generalist and specialist lenses, can apply to both types of nodes. Thus in a nested network (e.g., employees and meetings in Figure 1a), meetings with a few participants (e.g., Meeting 6) tend to attract the proper subsets of the generalist employees who join large meetings (Meetings 1 to 5), while specialists who participate in only one meeting (G and H) tend to go to meetings attended by generalists who also attend many meetings (A-F).
This form of nestedness relates to structural cohesion and cohesive blocks, both elements of embeddeness in unipartite networks (Moody & White, 2003; White & Harary, 2001). Moody and White (2003) define structural cohesion as the minimum number of independent paths between each pair of actors. In a bipartite network, the joint events are the paths between actors. The nested structure of participants is identical to increasingly cohesive blocks, such that Employees A and B show the strongest cohesion. These cohesive blocks are identified by an algorithm, but in a bipartite nested network, they are identical to proper subsets of generalists. Moody and White also define nestedness on the node level, though in bipartite networks, it is a network property.
Finally, nested networks are ordered systems, as illustrated by the incidence matrix of the bipartite network ordered according to the degrees in both types of networks (Figure 1b). In a perfectly nested network, only ties in the upper left triangle exist, constrained by the isocline line that indicates the boundary of expected versus unexpected ties; all cells to the left of the isoclines have ties (Bascompte et al., 2003; Ulrich et al., 2009). A widely used measure of nestedness is temperature, which is assigned on the basis of the normalized sum of squared relative distances for the unexpected absences or existence of ties (Atmar & Patterson, 1993). A temperature of 0 describes a perfectly nested network; a temperature of 100 describes a completely unordered network. A more recent measure is the nestedness metric based on overlap and decreasing fill (or NODF), based on the overlap of rows and columns in the incidence matrix with decreasing degrees (Almeida-Neto, Guimãres, Guimãres, Loyola, & Ulrich, 2008). The NODF takes values between 0 and 100, where 100 indicates full nestedness. To decide whether a network has a nested structure though, we must compare the values with those of a benchmark random network.
Random Networks
Random networks, as introduced by Erdös and Rényi (1959), became more widely used after the small-world study by Watts and Strogatz (1998). Network analyses could compare the real network parameters with those of a random network containing the same number of nodes and ties. This random network retains the same density and probability to form a tie, but it is not the only possible random network. A random network that also reproduces the degree distribution underlies more constraints. Furthermore, for bipartite networks, the choice of the right benchmark random network is even more difficult: The least constrained network has the same number of nodes of actors, number of events, and number of ties (i.e., fixed density [FD]). Because a bipartite network has two degree distributions, we might keep the degree distribution of row nodes (fixed row, FR) or column nodes (fixed column, FC), the probability of tie formation based on the average row and column margins of a given cell (probability row and column, PRC), or both degree distributions with fixed rows and columns (fixed row, fixed column, FRFC). The choice of the appropriate random network, which defines the null model for comparison with the real network, is crucial, but not obvious. More constraints not only reduce the probability of Type I errors (i.e., falsely rejecting a correct null hypothesis) but also increase the chances of Type II errors (i.e., wrongly accepting a false null hypothesis; Gotelli & Entsminger, 2001; Gotelli & Ulrich, 2012; Ulrich et al., 2009).
A Real-World Illustration
After introducing several advances related to the analysis of bipartite networks, the question arises: When and how should we use them? In this section, we provide a series of questions to guide researchers in their application and to clarify their potential effects on the data collection, research design, and operationalization. We pose these questions from an actor perspective, to make them more tangible, though they also apply to the event perspective.
To illustrate the differences across the available approaches and measures, we use data related to board-director networks for the year 2009 for publicly listed firms in India. We obtain information on board memberships from the Directors Database, which is affiliated with the Bombay Stock Exchange (BSE), the largest stock exchange in India. As of 2010, there were 4,942 listed firms on the BSE, though of these, only 2,689 submitted details about their board composition to the BSE as of April 30, 2011. These firms constitute our base sample. Approximately 20,000 unique directors serve on the boards of these firms. We obtained information on the board membership for each of these directors to develop the director network for Indian firms. Then from this sample, we gathered the giant component—the largest, fully connected part of the network. Such a restriction to the giant component is commonly used (Kogut & Belinky, 2008) because only on a connected network can the shortest path be defined and thus reveal closeness and betweenness centrality.
We used the statistical language R (R Core Development Team, 2011) to support the network analyses. The package igraph (Csardi & Nepusz, 2006) provided the bipartite clustering based on neighborhood overlap, the package tnet (Opsahl, 2009) indicated the weighted projections and weighted measures, and the bipartite (Dormann, Gruber, & Fründ, 2008) and vegan (Oksanen et al., 2011) packages supported the nestedness analyses, including the creation of the different random networks. We created our own code to construct the random networks based on the average row and column degree (PRC) and bipartite clustering coefficient (see Appendix B).
The most important question is whether the duality and the connections of actors matter for research. The unipartite network in Figure 3 shows that node C loses its prominent position if, for example, A and H build a tie. However, only the bipartite network in Figure 1 reveals that this tie can be accomplished by Node H joining Event 6 and creating a simultaneous tie between B and H. In research that uses tie formation and deletion in multiparty events as dependent variables, the unipartite projection would violate the independence of observations; a bipartite research design is more appropriate. If the question is whether embeddedness in events (Fleming, Mingo, & Chen, 2007) or embeddedness in the actor network (Obstfeld, 2005; Podolny & Baron, 1997) matter, it is more appropriate to measure the embeddedness or cohesion of the actor using the clustering coefficient. The configuration of actors and classifications define the institutional logics that govern the actions taken by actors, linking the micro and macro levels of social action (Breiger & Mohr, 2004). If the research interest instead mainly focuses on the actor network, a unipartite projection is a suitable choice.
The next set of questions pertains to the importance of the strength of ties and event sizes. If a researcher is only interested in the number of ties, a binary projection suffices. If it is important to account for tie strength, due to the heterogeneous distribution of event sizes, a weight assignment, such as that suggested by Newman et al. (2001), can account for the intensity of the interaction. In our Indian board network example, we need to consider whether the boards are sufficiently small to enable directors to build a relationship. We note that most of these boards are rather small, with fewer than 10 directors (see Table A1, third column).
In Figure 4 we depict the correlation between the degree and average weight of the director and the board network, such that the size of the dots indicates the frequency of the degree. The overall correlation is 0.258. For directors with degrees less than 10, the average weight close to 1 implies that they serve on one board with an average board size of about 8. These directors will have a degree of board size minus 1 and a weight of 1. For degrees greater than 10, most directors serve on more than one board and are likely to share multiple boards with another director, producing a weight greater than 1. However, degrees larger than 25 do not lead directors to obtain more shared board memberships on average. Perhaps the increasing number of boards increases the diversity in boards in terms of their industry affiliation, for example. These directors are exposed to diverse information. The correlation for the board network differs: Overall, the correlation is negative, though not very strong (–.18), suggesting that a larger degree is associated with a lower weight. For boards to be connected to many other boards, their directors must have broad, nonoverlapping portfolios of board memberships. Directors with high degrees and weights of 1 share no boards with other directors. Thus, Figure 4 demonstrates that the average weight distribution constitutes nontrivial behavior.
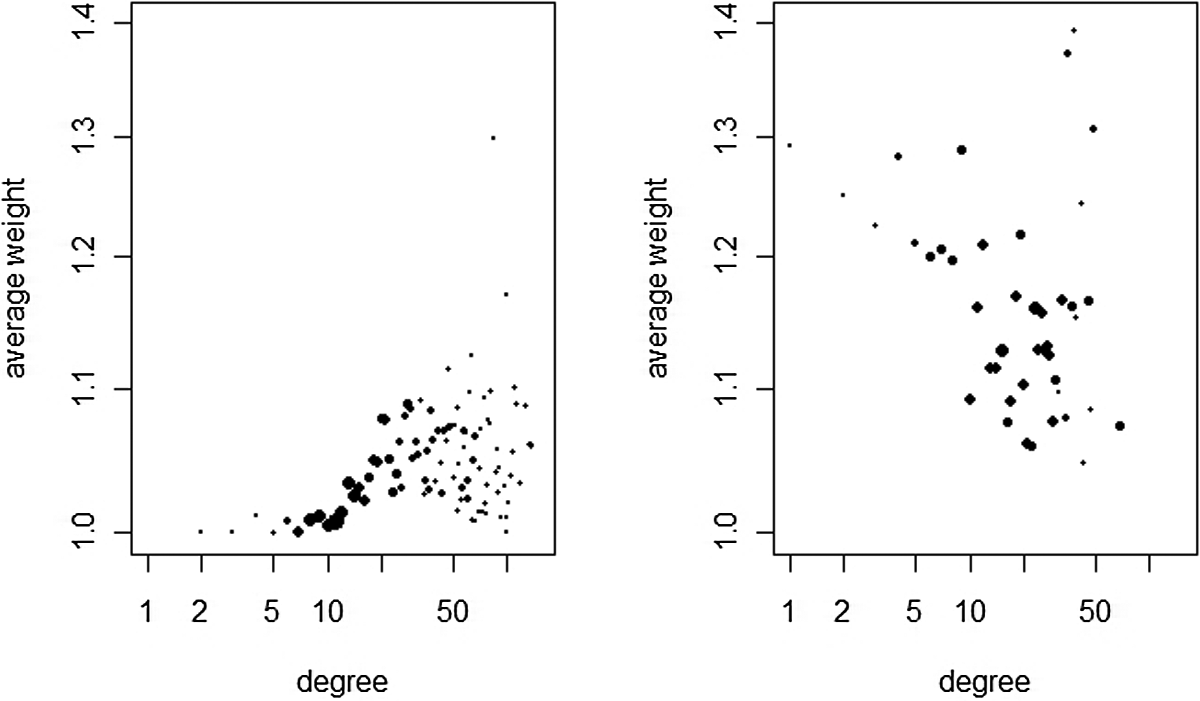
Correlation of degree and average weight for the director (left side) and board network (right side).
The tuning parameter
Figure 5 shows the correlation of betweenness centrality with weighted betweenness centrality for three different values of the tuning parameter α, as well as the correlation of the weighted measure for α = .5 and 1, normalized by the nonweighted betweenness centrality for the director network. The weighted betweenness centralities for tuning parameters of .5 and 1 correlate positively with the betweenness centrality (correlation coefficients of .97 and .91, respectively), whereas for α = .5 and 1, the correlation is much smaller. In particular, directors with betweenness centrality values between 100 and 100,000 exhibit much lower values for the weighted betweenness centrality. Similarly, Opsahl and Panzarasa (2009) find in the EIES data set of social network researchers that unweighted and weighted measures correlate highly, but a few actors exhibit huge changes across the two measures. Closeness centrality (not shown) reveals similar outcomes for board networks.
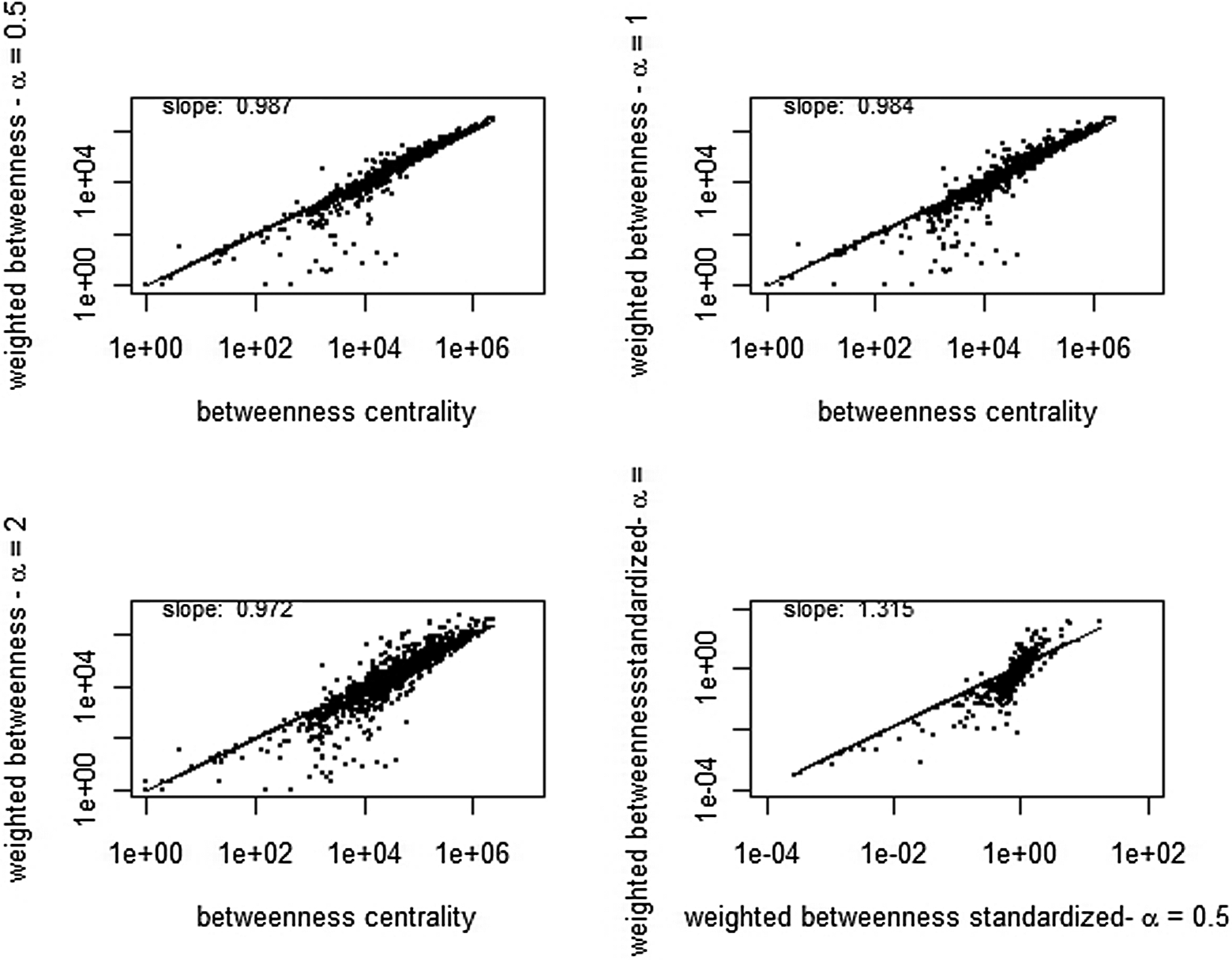
Correlation of betweenness centrality and weighted betweenness centrality for the director network for α = .5, 1, and 2 and the correlation for weighted betweenness for α = .5 and 2.
To illustrate the differences between the unipartite and bipartite clustering coefficient and the impacts of weighting, in Figure 6 we depict their correlation (the tie weights are co-occurrence weights). Although correlated, the bipartite clustering coefficient is generally smaller and spreads over a larger range as the unipartite coefficient increases. The difference is particularly pronounced for a unipartite value of 1, where the bipartite coefficient ranges from .18 to .96.
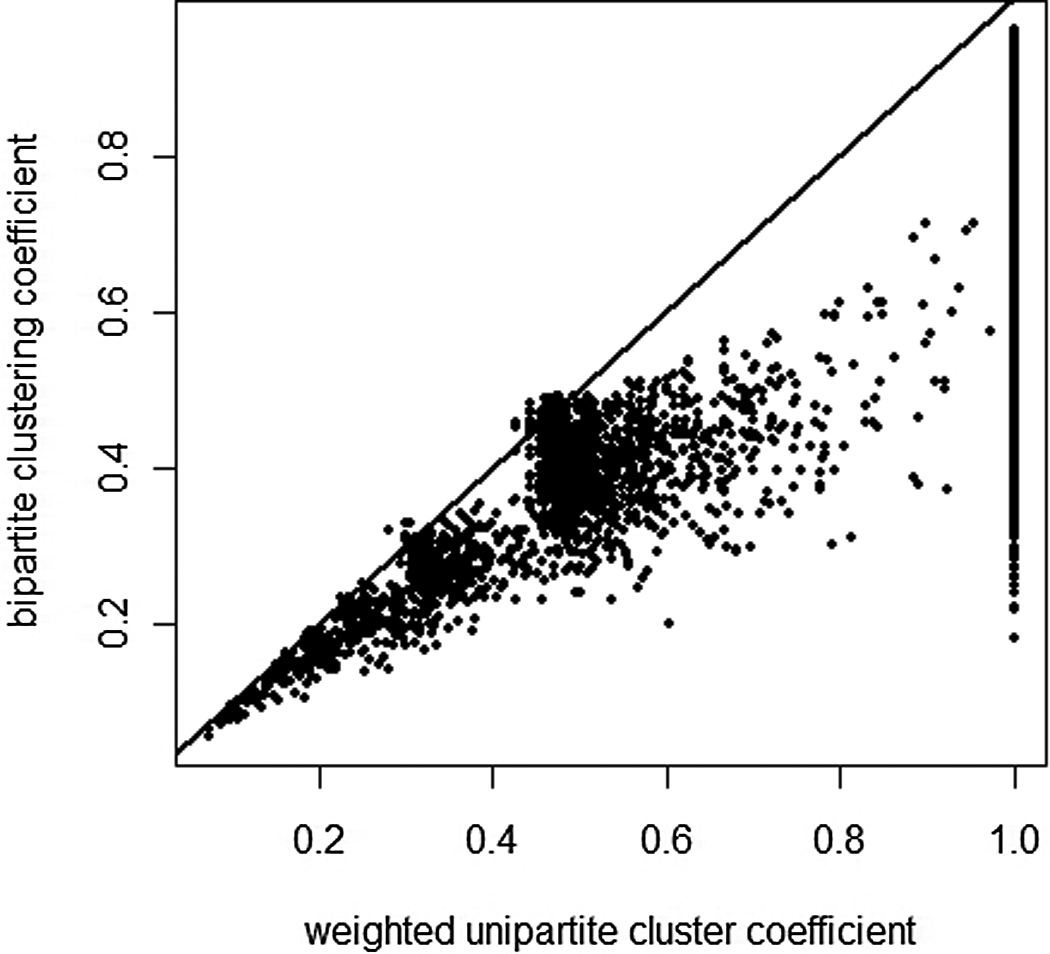
Correlation between weighted unipartite clustering and bipartite clustering coefficients.
For both unipartite and bipartite networks, the unit of analysis could be the node, the dyad, or the whole network. Thus far, we have illustrated node-specific characteristics that can be used as variables in regression analyses. To assess network properties, either the network itself or distributions of node characteristics may be compared against random networks. We therefore compare the distribution of clustering coefficient with random networks, as well as the small-world property and nestedness of the board network.
Table 3 shows the empirical clustering coefficient, the theoretical value in a unipartite network, the NSW coefficient with Newman et al.’s (2001) correction, the resulting small-world coefficient for the simple unipartite network analysis, and the NSW correction of the small-world coefficient. The empirical clustering coefficient for the director network is close to 1 (.90 and .93), reflecting cliques created by the projection. This rather large value sits in stark contrast with the very small theoretical value for unipartite networks, for which we assume independent tie formation. The NSW approach closely reproduces the clustering coefficient of the empirical network. The naive small network analysis would result in a small-world coefficient much larger than 1, suggesting that the Indian board network is a small world. Yet the NSW analysis results in a small-world coefficient close to (and even smaller than) 1, suggesting that this network is not actually a small world and rather that the extensive clustering is a result of the projection of the bipartite network. Similar results arise for the board projection. These results also hold for the full network as well as the giant component. This analysis suggests that the Indian board network is not a small world, in line with findings for other board networks (Conyon & Muldoon, 2006), but it is based on the degree distribution of directors and boards and thus uses the FRFC random network as benchmark. The FRFC suffers from rather large Type II errors, so this conservative test may lead to a failure to reject a false null hypothesis.
Small-World Characteristics for Full Network (full) and Giant Component (gc).

Demonstrating the nestedness of the board network is less suitable because the concept of nestedness is based on generalists and specialists, with many and few nodes, and thus a large variation in degree. As we show in Table 3, most directors serve on only one board. A more promising network appears in the affiliation of firms with specific industries and business groups. We therefore construct a business group–industry network, in which firms associated with a certain business group or industry are linked by a tie. Groups with only firms associated with one industry are not considered. The resulting bipartite network contains 171 business groups and 86 industries. The most generalist business group, with the largest degree, features commercial enterprises of the government, involved in 23 industries, followed by the Tata group, with 18 industries.
In Table 4 we compare the nestedness of the business group–industry network with those of four null models: an FD model with the same density, an FR model that maintains the degree distribution for rows (business groups), an FC model that retains the degree distribution for columns (industries), and the PRC model based on the combined row and column probabilities. Although the nestedness of the empirical network is rather low (7.44), it is significantly larger (p < .001) than those of the FD (4.07), FR (3.74), and PRC (5.76) null models. The rather small value indicates that the nestedness of the system is not very pronounced. Furthermore, the nestedness of the null model that preserves the degree distribution for the columns (i.e., industries) shows a significantly higher nestedness than the empirical network, indicating the importance of the choice of null models.
Nestedness of Business Group–Industry Network in Comparison With Four Random Networks.

Note: PRC = probability row and column.
***p < .001.
Discussion
Summary
We present several recent advances in network analysis that come from outside management literature, with the help of a two-by-two matrix that defines whether the analyzed network is the projected unipartite or original bipartite and whether the analysis pertains to the node level or the network level. We have illustrated several similarities and differences in the applicability of different approaches, using both a simple illustration and a real-world illustration with Indian board networks. Depending on their research question and theoretical objectives, researchers should determine the appropriate methodology accordingly.
Projections of bipartite networks onto unipartite networks should follow two steps to achieve a refined analysis. First, a suitable mechanism is needed to assign weights to the ties in the projection. Second, scholars need to use methods for weighted unipartite networks, such as weighted centrality measures and weighted clustering coefficients, to differentiate network mechanisms on the basis of their weak versus strong ties. A clustering coefficient based on the degree distribution of actor/event nodes can account for natural clustering, as well as the small-world property of projected unipartite networks.
Although weighted unipartite network analysis retains some information, we would still lose information about actors’ connections. To avoid this issue, analyses of an original bipartite network should use bipartite clustering coefficient and nestedness. The bipartite clustering coefficient extends the unipartite concept (based on neighborhoods) and provides a measure of embeddedness in the bipartite network. Nestedness is a bipartite network property that does not have a direct counterpart in the unipartite network analysis. Because nestedness is a unique property of mutualistic networks in ecology, it might serve as a good indicator of the mutual benefits that social networks provide to both types of nodes. Nestedness also may be useful in vertical market relationships, such as in the analysis of the New York garment industry (Saavedra, Reed-Tsochas, & Uzzi, 2009; Saavedra, Stouffer, Uzzi, & Bascompte, 2011). It can be used in situations in which actors are embedded in their environments, such as global trade networks, in which countries exhibit nested structures in product categories (Bustos, Gomez, Hausmann, & Hidalgo, 2012). To advance understanding of nestedness in social systems, further research in collaborative and mutualistic contexts (e.g., coauthorship) would be meaningful.
The measures for weighted networks and the bipartite clustering coefficient can be applied as refined measures of independent variables in regressions, if the unit of analysis is a node. If the unit of analysis is the network, the distribution or aggregation (to the network level) of these measures can be compared against those of appropriate random networks. In bipartite networks, different random networks can serve as null models with various levels of constraints, the choice of which depends on the trade-off between Type I and Type II errors (Gotelli & Entsminger, 2001; Gotelli & Ulrich, 2012). Our illustrations suggest that advanced analytic methods corresponding to different quadrants of the decision matrix (Figure 2) can complement and inform one another, as well as existing measures in unipartite and bipartite network analyses.
We have demonstrated the application of these advanced analytic approaches with two examples: a simple illustration of a bipartite network and a real-life example of the Indian board network in 2009. Our analyses demonstrate that the weighted unipartite network and its centrality measures and clustering carry additional information, making them distinct from the simple analysis of the projected network. Furthermore, the bipartite clustering coefficient differs from its unipartite counterpart and varies widely for given unipartite values, demonstrating the distinction between unipartite and bipartite embeddedness in the network. Our analyses also show that the choice of a random bipartite network is not trivial. The conclusion that the Indian board network is a small world and is nested in its industry structure depends fully on the choice of the random network. The correction of the NSW algorithm suggests that the Indian board network is not a small network, echoing findings by Newman et al. (2001) and Conyon and Muldoon (2006) for board networks of other countries. However, the bipartite degree distribution feeding into the algorithm may be too strong a constraint, leading to acceptance of a false null hypothesis of not being a small world. Researchers must remain aware of these intricacies in their study designs and make informed choices.
Recommendations
How can management scholars make the best use of these new methods? First, in most cases, we are interested in either the antecedents or the consequences of the network structure, but understanding the network topology provides important insights into the object of the investigation. A structural analysis of both types of the nodes also reveals key properties of the network and accounts for interdependence in the two types of nodes. Second, a comparison with random networks supports a determination of whether a network property provides information about the network or is a mere reflection of its basic parameters. In a bipartite network, the proper choice of the random network is crucial; a less constrained random network requires theoretical justification. Third, we focused here on the structural analysis, but the new measures can serve as explanatory variables too. Further research should test how they influence network consequences. Fourth, the enhanced bipartite measures provide additional means for a bipartite network analysis.
Comparability across studies would make it easier to transfer knowledge across fields and disciplines. For example, the unipartite clustering coefficient appears in innovation network studies as the local density of the focal node (Obstfeld, 2005). Understanding the equivalence of clustering coefficients and density measures suggests several new avenues for network research. For example, it would be worthwhile to note similarities in analyses of bipartite networks with research on population ecology. Population ecologies entail bipartite networks with organizations and niches; other concepts, such as niche width and generalist or specialist, might be expressed as notions of these bipartite networks. This conceptualization suggests new avenues for analysis (e.g., nestedness), as well as cross-disciplinary knowledge accumulation.
Researchers can use the analytic tools available for different quadrants in Figure 2 to compare networks across different disciplines. Measures of overlap, such as niche or technological overlap, represent different types of bipartite clustering coefficients. This insight may facilitate the conceptualization and analysis of populations as bipartite networks. Finally, a greater focus on the properties of bipartite networks would improve our understanding of the network itself, as well as inform node- and dyad-level analyses and perhaps spur more research on bipartite measures and random networks.
In summary, a proper understanding of unipartite and bipartite networks can help scholars analyze networks at different levels. In many cases, the bipartite structure stretches across two levels, such as individuals and groups or directors and boards, and thus can be used to derive multilevel measures at the individual (actor) or group (event) level. Conducting an analysis at the node and network levels enables scholars to examine local and global phenomena simultaneously. Acknowledging the bipartite nature of networks and the application of the advanced measures also might accelerate the accumulation of knowledge for management field.
Footnotes
Appendix A
The generating function for the degree distribution is
In a bipartite network, there are two generating functions
Here, µ and ν are the average number of node types in the network. Newman, Strogatz, and Watts (2001) derived formulas for the average path length L and the clustering coefficient
with
Our goal is not to provide the detailed derivation of Equations 14 through 16 but rather to describe their applications to bipartite networks. We therefore provide explicit formulas for the derivatives in Equations 14 through 16 by applying the chain rule to calculate the derivatives and substitute x = 1, as follows:
With the derivatives evaluated for x = 1, we can calculate the average path length and the clustering coefficient as a sum of the products of the empirical probabilities
We provide an explicit example of the calculation of the clustering coefficient as defined by Newman et al. (2001) for the giant component of the Indian board network in Table A1. The values of the line with the column sums can be plugged into Equation 23, which yields
Appendix B
Acknowledgments
The authors thank Chuck Pierce, Vikas Kumar, Debmalya Mukherjee, and participants at the 2012 Academy of Management Conference for comments on previous versions. This article benefited greatly from comments and advice provided by Associate Editor Adam Meade and three anonymous reviewers.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by grants from Rutgers University Research Council and the Technology Management Research Center of Rutgers Business School.