
Abstract
Multiple linear regression (MLR) remains a mainstay analysis in organizational research, yet intercorrelations between predictors (multicollinearity) undermine the interpretation of MLR weights in terms of predictor contributions to the criterion. Alternative indices include validity coefficients, structure coefficients, product measures, relative weights, all-possible-subsets regression, dominance weights, and commonality coefficients. This article reviews these indices, and uniquely, it offers freely available software that (a) computes and compares all of these indices with one another, (b) computes associated bootstrapped confidence intervals, and (c) does so for any number of predictors so long as the correlation matrix is positive definite. Other available software is limited in all of these respects. We invite researchers to use this software to increase their insights when applying MLR to a data set. Avenues for future research and application are discussed.
A continued goal of organizational researchers conducting regression analysis is to make inferences about the relative importance of predictor variables (cf. Nimon, Gavrilova, & Roberts, 2010; Zientek, Capraro, & Capraro, 2008), yet it is all too common to rely heavily (if not solely) on the regression coefficients from the analysis which optimize sample-specific prediction (minimize sum of squared errors). Instead, other metrics that operationalize relative importance in ways that are consistent with such researchers’ goals would seem more appropriate, and a range of metrics and approaches exists. In addition to regression weights and zero-order correlation coefficients that researchers likely report, MLR interpretation may be further informed by considering structure coefficients, product measures, relative weights, all-possible-subsets regression, dominance weights, and commonality coefficients. The current article offers software that cogently summarizes these metrics so that researchers can make more sophisticated judgments about the nature and meaningfulness of variables in a linear regression model than judgments from regression weights or any single metric in isolation. As noted by Nathans, Oswald, and Nimon (2012), each metric serves a different purpose and has certain features that support interpreting specific aspects of a multiple linear regression (MLR) model (see Table 1).
Regression Metric/Analysis and Their Associated Purpose and Features.

Note: Adapted from Nathans, Oswald, and Nimon (2012). p = number of predictor; IV = independent variable; DV = dependent variable; MLR = multiple linear regression.
aQuantifies IV importance when: (a) measured in isolation from other IVs (direct effect), (b) contributions of all other IVs have been accounted for (total effect), and (c) contributions to regression models of a specific subset or subsets of other IVs have been accounted for (partial effect). See Nathans et al. (2012) for more on advantages, disadvantages, and recommendations for practice.
The aforementioned metrics are reviewed here briefly, but for more details we refer the reader to other work, both recent and historical in nature (e.g., Budescu, 1993; Darlington, 1968; Johnson, 2000; Johnson & LeBreton, 2004; Kraha, Turner, Nimon, Zientek, & Henson, 2012; Krasikova, LeBreton, & Tonidandel, 2011; Lindeman, Merenda, & Gold, 1980; Tonidandel & LeBreton, 2011). This allows the current article to take a more practical focus on the software tool and its capabilities, with the support of two empirical examples.
Regression Weights
In MLR models, raw data yield unstandardized (raw) regression weights, and standardized data yield standardized regression weights. Regardless of whether or not the data are standardized, the values residing in the vector
It may be reasonable to assume that predictors with larger standardized coefficients (called betas henceforth) are more important than other predictors with smaller coefficients. Certainly this is true when variables are uncorrelated, because in that case, betas are exactly equal to the zero-order correlations between
Zero-Order Correlation Coefficients
Obviously, prediction of Y from each independent variable Xi is found in
Structure Coefficients
One relatively simple approach to determining the contribution of p independent variables in linear regression is through calculating a p × 1 vector of structure coefficients (
Structure coefficients have been used to indicate the relative contributions of each Xi
to the prediction of Y, but they cannot be interpreted in a straightforward manner when variables in
Pratt Measure
The Pratt measure, or product measure, of a predictor variable’s relative importance was proposed by Pratt (1987) and is defined simply as 
where each component of the sum is a Pratt measure (
Relative Weights
Relative weights are another way to partition an MLR model R2 across predictors. They are computed by first transforming p predictors into a new set of p variables that are uncorrelated with one another, yet are correlated as highly as possible with the original predictors; that is, given the data matrix
These elements for each column are used to weight each predictor variable according to its independence from other predictor variables (i.e., a higher weight will mean greater independence from that variable). In addition to this matrix, regressing
Thus, a relative weight multiplies or “glues” like elements from the two orthogonal vectors of 
and each of the p relative weights across is an independent part of the total model R2, meaning the weights add to R2 (
Relative weights are thus defined as the contribution of a given predictor to criterion variance, considering the predictor’s contribution alone as well as jointly with the other predictors in the model. Note that relative weights and general dominance weights have often been found to rank predictors similarly in terms of relative importance (Johnson, 2000); however, the current software program can verify where results converge or diverge.
All-Possible-Subsets Regression
As the name implies, all-possible-subsets (APS) regression involves running linear regression models on all 2 p – 1 subsets of predictors. In doing so, one often takes either a predictor-based approach or model-based approach to the set of results. APS is best compared to other metrics when taking a predictor-based approach, where a predictor deemed more important within a regression model will tend be one that is more important across submodels in APS regression. APS regressions can be analyzed in this manner for each predictor, or one can use commonality coefficients or dominance weights, to be discussed next, because these are based on the results of APS regressions.
In addition to the predictor-based approach, researchers and practitioners also may take a model-based approach to APS, because it is an exploratory approach to determining the tradeoff between model parsimony and model fit, where a submodel with fewer predictors retains a model R2 that is either similar to the full model R2 or is above some practical minimum established by the researcher or practitioner. Obviously, the model-based approach can be related to the variable-based approach when there is a consistent recommendation to include and/or exclude specific predictors across models.
Commonality Analysis
Commonality analysis partitions the R2 explained by all predictors in multiple regression into variance unique to each predictor and variance shared between each combination of predictors (see Mayeske et al., 1969; Mood, 1969, 1971; Newton & Spurrell, 1967; Onwuegbuzie & Daniel, 2003; Rowell, 1996). These components of variance are called commonality coefficients that can then be evaluated in terms of their magnitude, and they can be compared with one another. As partitions, commonality coefficients sum to the total R2 for the regression model.
There are two general types of commonality coefficients: unique effects and common effects. The unique effect of a predictor (also called the uniqueness coefficient) is the square of the semipartial correlation between a given predictor and the criterion. Thus, if predictors are all uncorrelated, then predictor importance can be entirely determined by ranking the unique effects. When predictors are correlated, as is usually the case, the common effects can indicate the extent and pattern of the predictors’ shared variance in predicting variance in the criterion (Mood, 1971).
Consider the hypothetical situation discussed by Hedges and Olkin (1981) in which two variables, X1 and X2, are used to predict a variable X0. For this regression equation, the explained variance (R2
0.12) can be partitioned into three components:


and they are computed as follows:


Commonality coefficients provide researchers with rich detail about how independent variables operate together in a given regression model. The coefficients are more specific than regression weights, relative weights, or general dominance weights. As Seibold and McPhee (1979) noted, “[Only by] determining the extent to which…independent variables, singly and in all combinations, share variance with the dependent variable…can we fully know the relative importance of independent variables with regard to the dependent variable in question” (p. 355).
Note that negative values of commonality coefficients generally indicate that a predictor exerts a suppressor effect, where it is removing (partialing out) the irrelevant variance in the other predictor(s) to increase the latter’s contributions to the model R2 (Zientek & Thompson, 2006). Unlike other metrics, commonality coefficients are uniquely able to pinpoint the predictors involved in a suppressor relationship and the specific nature of that relationship. Summing all negative common effects for a regression equation can quantify the amount of suppression present in the regression model as a whole.
Dominance Analysis
A regression metric was originally proposed by Chevan and Sutherland (1991), then elaborated upon by Budescu (1993), who detailed the procedure for conducting a dominance analysis. Dominance analysis involves computing each predictor’s incremental validity across all possible submodels that involve that predictor and using the incremental validity coefficients to evaluate complete dominance, conditional dominance, and general dominance. To make the dominance analysis procedure more concrete, see the dominance analysis formulas in Table 2 that support a three-predictor MLR model.
Dominance Analysis Formulas for Three Predictor Case.
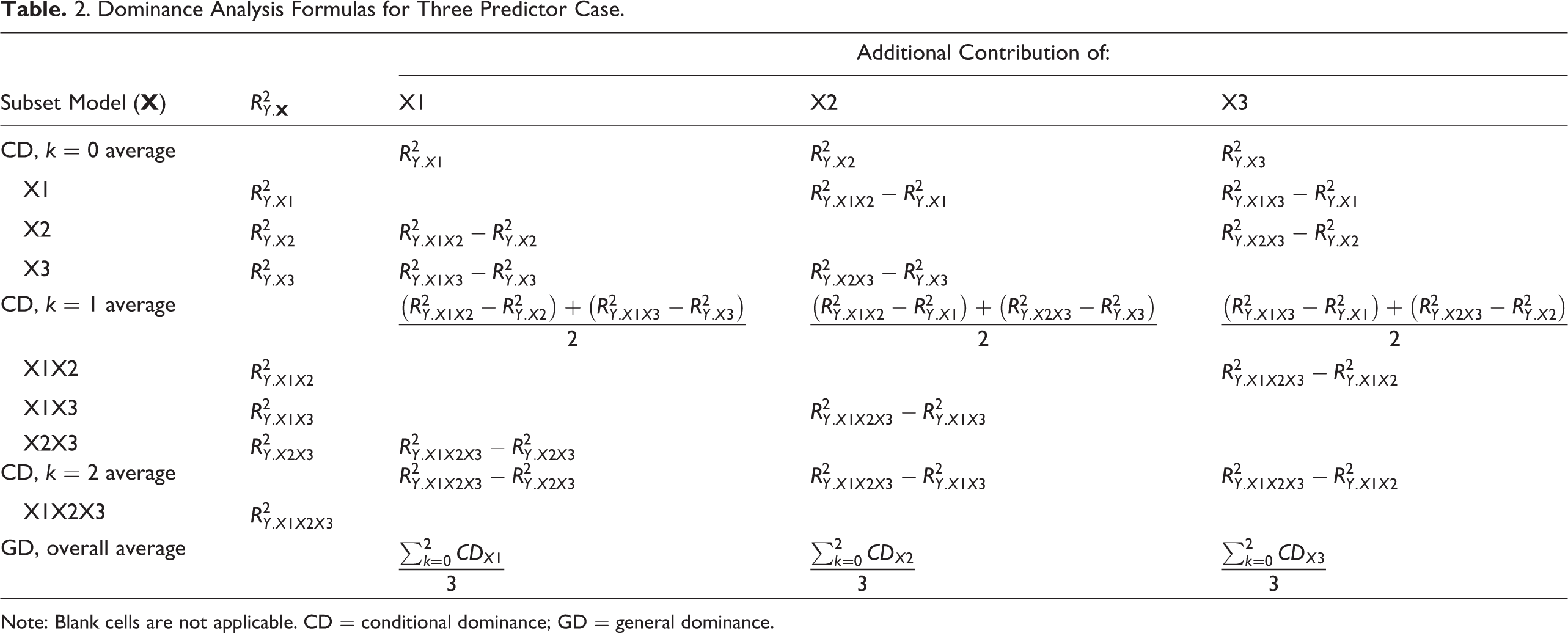
Note: Blank cells are not applicable. CD = conditional dominance; GD = general dominance.
If incremental validity is always higher for Xi than for Xj for every submodel, then Xi is said to show complete dominance over Xj . Complete dominance is a restricted form of dominance that may rarely occur. There is a more relaxed form of dominance called conditional dominance, which occurs when the average incremental variance within each submodel of sizes 0 to p − 1 is greater for one predictor than another across all model sizes. The average incremental variance components used to evaluate conditional dominance are called conditional dominance weights. Conditional dominance weights are averaged across p predictors to create general dominance weights that partition the model R2 across predictors. A predictor is said to show general dominance if it has the highest overall average incremental validity across regression submodels of sizes 0 to p − 1.
Dominance weights have two appealing properties: First, like relative weights, each general dominance weight is the average contribution of a predictor to a criterion, both on its own and when taking all other predictors in the model into account. Second, general dominance weights always sum to the overall model R2. Third, conditional dominance weights have the potential to illuminate the properties of model predictors that can get lost in commonality coefficients (which are numerous and can be difficult to interpret even when p = 3) or averaged away in more general metrics (e.g., relative weights, general dominance weights).
Software for Exploring the Predictor Space
The software tool we introduce was developed in R (R Development Core Team, 2013), and it offers a number of incremental contributions over both the literature and applications of the past addressing this topic of the relative importance of variables in linear regression analysis. First and most importantly, the software analyzes a wide variety of regression metrics within a single program. Recently, researchers have developed and provided computer programs, macros, and software packages to compute the metrics in linear regression to be discussed here, such as dominance analysis (Azen & Budescu, 2003) and relative weights (Grömping, 2006; Tonidandel, LeBreton, & Johnson, 2009). Although other researchers have integrated multiple metrics into their programs (Braun & Oswald, 2011), the current software is much more comprehensive in integrating all regression metrics reviewed here. Second, the software allows for some computational efficiencies; for instance, all-possible-subsets regression is computed and applied to multiple metrics rather than having to be computed each time within different programs. Third, the software computes confidence intervals (CIs) for all coefficients and for differences between specific pairs of coefficients. Confidence intervals are based on bootstrapping procedures and estimate an interval that 95% of the time, for example, contains the corresponding population parameter. Although this has been accomplished for some metrics (e.g., Algina, Keselman, & Penfield, 2010, for squared semipartial correlations; Lorenzo-Seva, Ferrando, & Chico, 2010, for bootstrapped regression coefficients, structure coefficients, and relative importance weights; and Tonidandel & LeBreton at the website http://relativeimportance.davidson.edu/ for bootstrapped relative importance weights in regression, multivariate regression [regression with multiple criteria], and logistic regression), this has not been accomplished to date across such a wide array of metrics within a more integrated software package as we have done here. To conduct statistical significance tests of metrics such as relative weights and general dominance weights, as in Tonidandel et al. (2009), one can include a randomly generated variable as an additional predictor in the model. This software will then automatically generate CIs on the differences between each predictor metric and the metric associated with the randomly generated variable, which can then be used to assess statistical significance. Our software program also graphs CIs, keeping in mind that the statistical differences between statistics may still be significant even when their respective CIs overlap (Cumming & Finch, 2005). Fourth, some software solutions have limited the number of predictors that are allowed; by contrast, our software computes metrics for as many predictors as are allowed by computer memory, by the positive definiteness of the predictor correlation matrix, and by the patience of the user. Fifth and finally, the software is available in R code, meaning that it is free to use, and anyone can read, learn from, revise, and extend the program code.
Method
We developed software to compute and bootstrap the regression metrics reviewed in this article, using R as our underlying platform. R is a “cutting-edge, free, open source statistical package” that runs on all commonly used operating systems (see R Development Core Team, 2013) and is gaining popularity across research disciplines (Culpepper & Aguinis, 2011). One major benefit of R platform is the opportunity for researchers to develop and update programs or “packages” to the R repository that extend the functions of the base system. To date, the R platform is supported by 4,461 user-contributed packages.
Extending the work of one of the user-contributed packages,
calc.yhat
The
The second set is called
The third set is called
The fourth set is called
boot.yhat
The
booteval.yhat
The
Descriptive Statistics
Regarding descriptive statistics,
Confidence Intervals
For data in the
However, when comparing the metric of one variable to another, overlapping CIs do not necessarily indicate a statistically nonsignificant difference between parameter estimates (see Cumming & Finch, 2001; Zientek, Yetkiner, & Thompson, 2010). One has to examine the distribution of differences between the two bootstrapped estimates of interest across replications. To that end,
plotCI.yhat
The
Other Functions
Several other new functions were also written to support these main functions, including but not limited to functions to conduct commonality analysis, dominance analysis, and relative weights analysis. Although the
Illustrative Example 1
To first illustrate the use of
Results for Illustrative Example 1
calc.yhat
In reviewing the results from
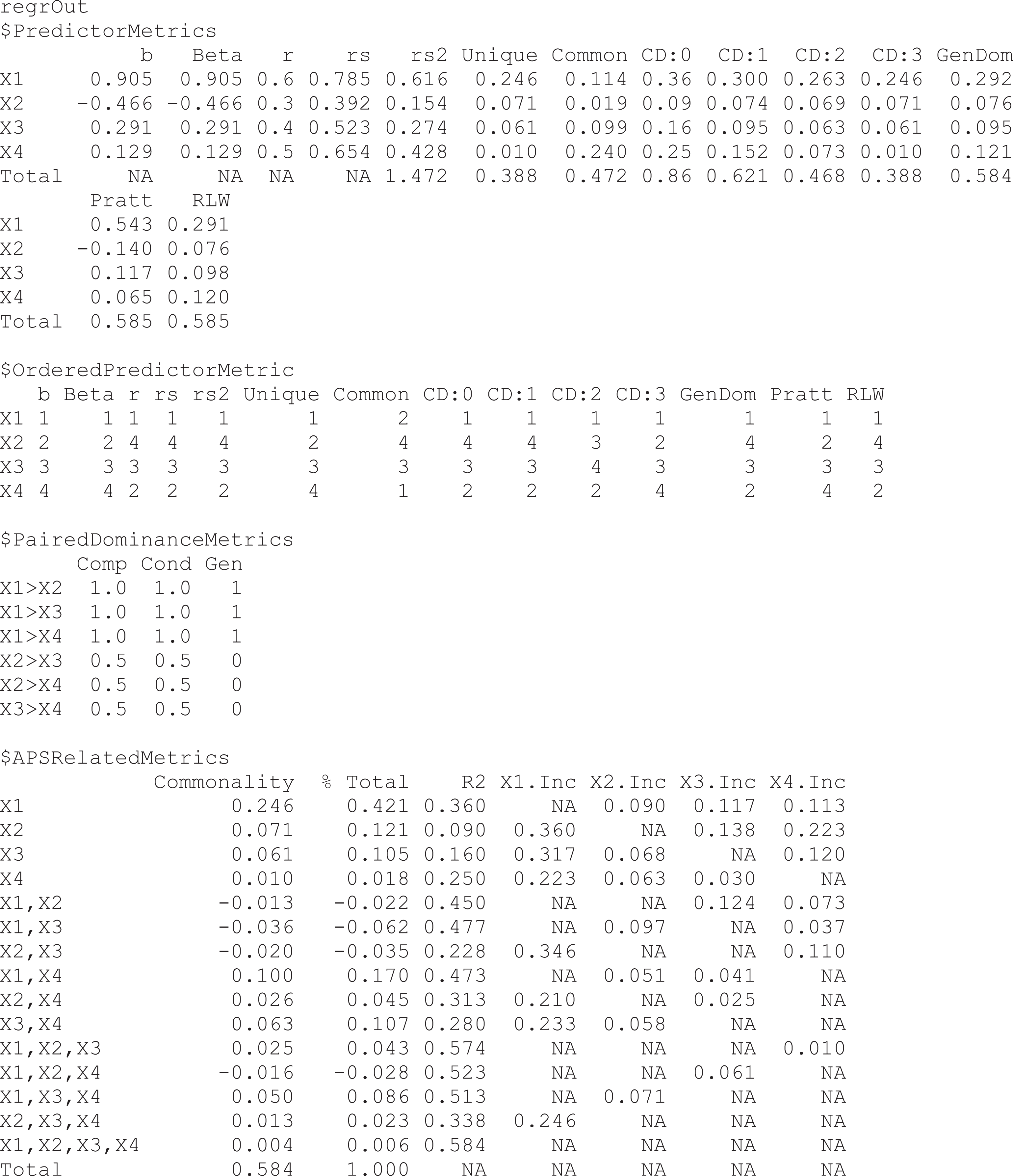
Output from calc.yhat for illustrative example.
The bs and betas values and ranks are identical, as expected with a data set whose variables have been standardized to have Ms of 0 and SDs of 1. The uniqueness coefficients and the conditional dominance weights for k = 3 (i.e.,
The Pratt weights diverge from the general dominance and relative weights, even though they also sum to equal the R2. This divergence likely stems from a disagreement in the signs of X
2’s beta and validity coefficient, which is suggestive of a suppression effect (cf. Thompson, 2006). However, the conditional dominance weights do not highlight X
2 as a suppressor because the conditional dominance weights for X
2 (i.e.,
The Dij
values in the
In reviewing the
booteval.yhat and plotCI.yhat
Figure 2 presents the bootstrapped CIs around select coefficients from the

Output from plot.yhat for select predictor metrics from illustrative example.

Select predictor metric differences from booteval.yhat for illustrative example.
Figure 4 presents the descriptive statistics of the bootstrapped Kendall’s tau correlation between the sample predictor metrics and the bootstrap statistics of like metrics. Across metrics, the order of b and betas (Ms = .948, .946) was most reproducible across bootstrapped samples. Note that the variance of the correlations across bootstraps is lower as the mean of the correlations is higher (in fact, the correlation between the mean and variance across metrics was –.98). Figure 4 also presents the sample Dij values along with their Ms, SEs, and probabilities and reproducibility over the 1,000 bootstrap samples. It is interesting to note that X 1 completely dominated X 2 in each of the bootstrapped samples. Given the hierarchical nature of dominance analyses, X 1 also conditionally and generally dominated X 2 in each of the bootstrapped samples.
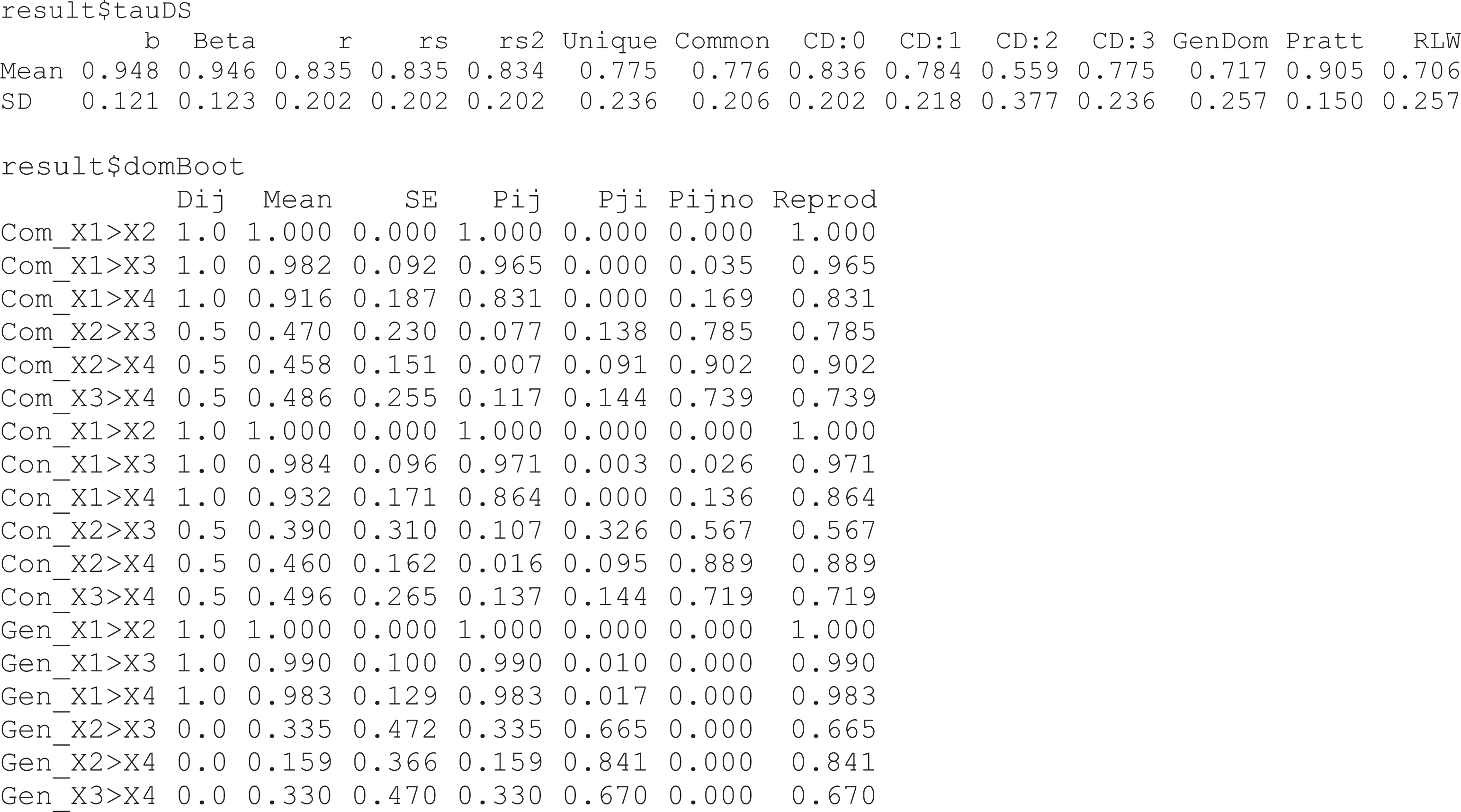
Descriptive statistics output from booteval.yhat for illustrative example.
Figure 5 presents the bootstrapped CIs around the coefficients in the
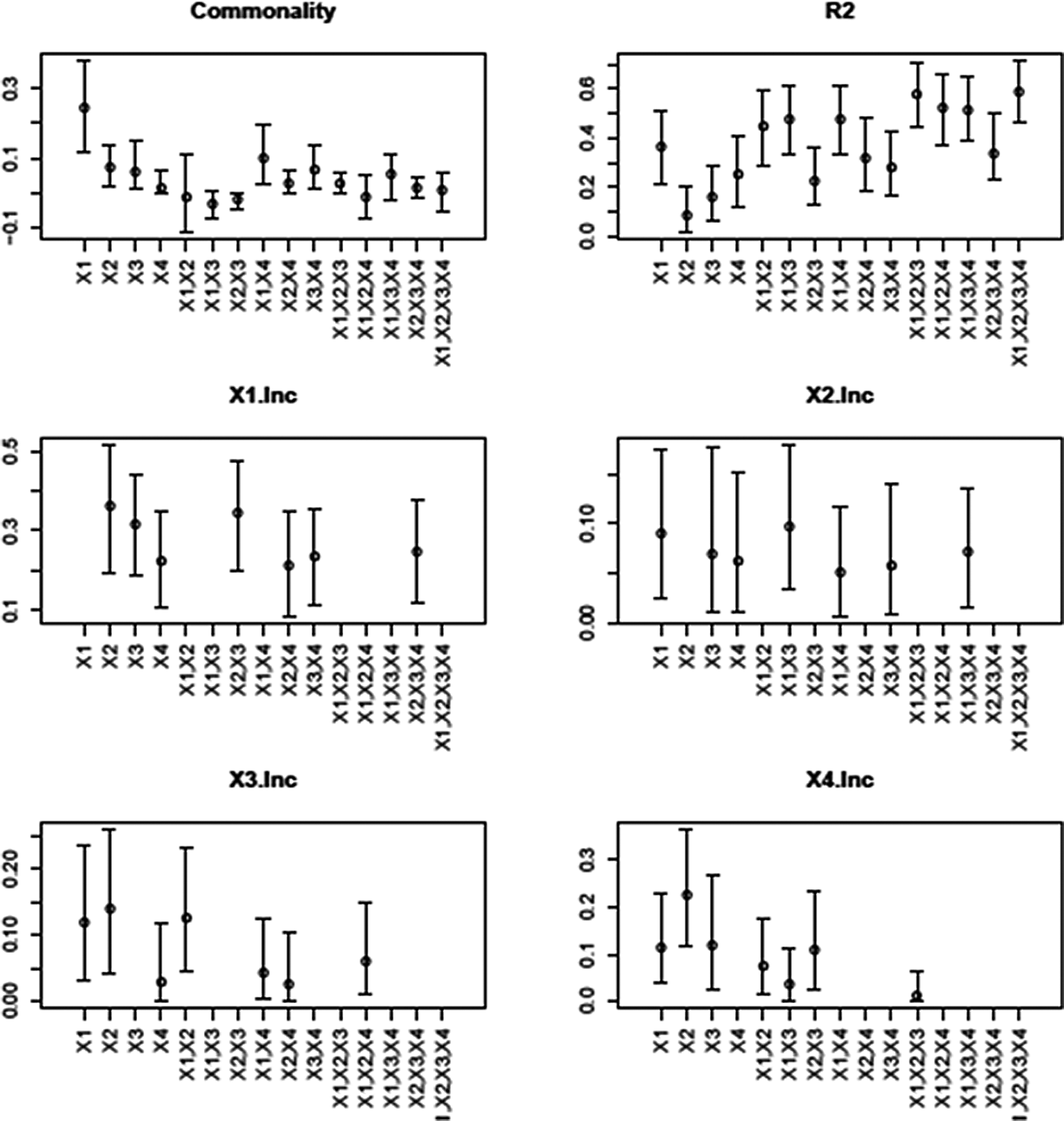
Output from plot.yhat for all-possible-subsets (APS)–related metrics from illustrative example.

Commonality coefficient and R2 differences from booteval.yhat for illustrative example.

Incremental predictor variance differences from booteval.yhat for illustrative example.
Illustrative Example 2
We also conducted a secondary data analysis on the correlation matrix reported in Podsakoff, Ahearne, and MacKenzie (1997) to provide an illustrative example of how one might write up the results from the software presented in this article to be suitable for publication. We examined the model that regressed work crew (n = 40) quantity on “crew members’ assessments of their crews’ helping behavior, civic virtue, and sportsmanship…aggregated at the work group level” (p. 265). We selected the model as it has been previously identified in the literature (e.g., Courville & Thompson, 2001; Nimon & Reio, 2011) as a model that benefitted from examining multiple metrics. Although prior literature has examined the regression model using bs, betas, rs s, and commonality coefficients, it does not appear that the model has been examined using other metrics presented in this article, including dominance analysis or relative weights. To analyze their model, we modified the example code previously presented to accommodate their correlation matrix, which we present in Table 3.
Correlation Matrix for Example 2.

Results for Illustrative Example 2
The model that regressed aggregated civic virtue, sportsmanship, and helping behavior on work crew quality was statistically and practically significant, F(3, 36) = 3.886, p = .017, R2 = .247. The aggregated organizational citizenship behaviors explained ∼25% of the variance in work crew quality. Tables 4 and 5, respectively, present the predictor and APS-related metrics, including 95% accelerated bootstrap confidence intervals that were produced over 1,000 iterations.
Predictor Metrics for Example 2.

Note: Unique = uniqueness coefficient; common = R2 – uniqueness; CD = conditional dominance weights; GenDom = general dominance weights; Pratt = Pratt measure; RLW = relative weights.
All-Possible-Subset–Related Metrics for Example 2.

Note: Civ = civic virtue; Sprt = sportsmanship; Help = helping behavior.
With the exception of betas that identify helping behavior as the most important predictor, followed by sportsmanship and civic virtue, the remaining predictor metrics identify sportsmanship as the most important predictor and helping behavior as the second most important predictor. This means that although sportsmanship (a) shares the most variance with the work crew quality and predicted work crew quality, (b) contributes the most unique and common variance to work crew quality, (c) adds the most incremental variance, on average, to models of different subsizes, and (d) accounts for the largest partition of R2 as computed with general dominance weights, Pratt measures, and relative weights, helping behavior is given the greatest credit in the regression equation. The predictor metrics also identify civic virtue as a suppressor variable. In addition to it contributing more unique variance to the regression effect than it has in common with the work crew quality and yielding a negative Pratt’s measure (as a result of inconsistent signs between its beta and validity coefficient), the conditional dominance weights for civic virtue do not decrease monotonically with more complex models (cf. Azen & Budescu, 2003).
The APS-related metrics show that civic virtue contributes the most incremental variance when added to a regression model that contains sportsmanship and helping behavior and that its addition suppresses irrelevant variance in sportsmanship and helping behavior, making them better predictors than if civic virtue was not included. This means that if sportsmanship and helping behavior are to have maximum impact in predicting work crew quality, the measures should be refined to eliminate irrelevant variance related to civic virtue. Analysis of the bivariate correlations and the incremental validity coefficients reported in Table 4 indicates that sportsmanship completely dominates helping behavior, which completely dominates civic virtue. This means that across all possible subset models, (a) sportsmanship adds more incremental variance than helping behavior and civic virtue and (b) helping behavior adds more incremental variance than civic virtue.
It is important to note that many of the study’s findings may not be replicable, given its small sample size. Across bootstrapped samples, the predictor order based on betas was most consistent with the sample data. As presented in Table 6, the average Kendall’s tau, correlating beta weight-based predictor order from bootstraps to sample data, was .641 (SD = .367). Predictor order based on unique variance was least replicable (M = .353, SD = .540). Bootstrap analysis of differences between predictor metrics found only a few statistically significant differences (see Table 7). Bootstrap analyses of differences between appropriate APS metrics found no statistically significant differences. For each order of predictor combinations, there were no statistically significant differences among the multiple R2 or commonality coefficient produced, nor were there statistically significant differences among the predictors’ incremental validity coefficients.
Descriptive Statistics for Kendall’s Tau Across Bootstrap Iterations.

Note: Unique = uniqueness coefficient; common = R2 – uniqueness; CD = conditional dominance weights; GenDom = general dominance weights; Pratt = Pratt measure; RLW = relative weights.
Differences in Predictor Metrics for Example 2.
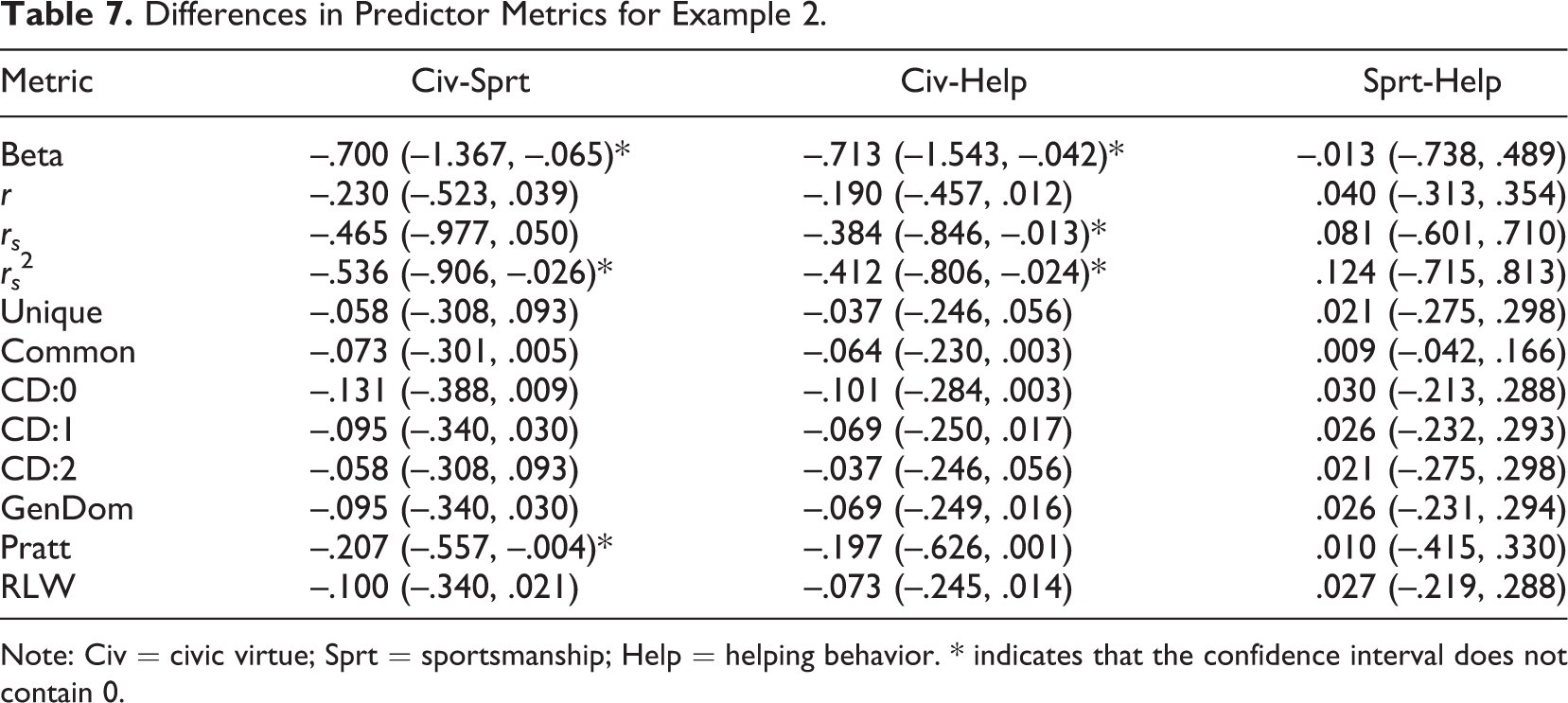
Note: Civ = civic virtue; Sprt = sportsmanship; Help = helping behavior. * indicates that the confidence interval does not contain 0.
Discussion
Although the interpretation of linear regression weights is straightforward when the goal is prediction, it has long been known that when the goal of a regression analysis is instead to make some conclusions about the relative importance of the predictors in the model, the intercorrelations between predictors (multicollinearity) undermine the use of regression weights for this purpose. Alternative metrics are required—and perhaps more than one set of metrics is interesting to consider because each is operationalized differently and carries different assumptions. Specific to the current article, we review regression weights, zero-order validity coefficients, structure coefficients, Pratt measures, relative importance weights, all-possible-subsets regression, commonality coefficients, and dominance weights.
Perhaps more important than this review of a wide range of metrics relevant to linear regression, our article offers a freely available software package in R code that (a) computes all of these indices at once, (b) computes associated bootstrapped confidence intervals, (c) compares pairs of predictors against one another in terms of their bootstrapped metric, and (d) performs these contributions for any number of predictors so long as the correlation matrix is positive definite (invertible). Other software is limited in all four respects.
We hope researchers will use this software to change their fundamental approach to conducting and interpreting linear regression analysis as applied to their data. Given the variety of weights available, it can be informative to consider an array of weights and to report the most appropriate importance weights, or to examine how they converge and diverge, rather than merely focus on the weights that are the most popular or typically available. The program we offer obviously requires the expertise of the researcher or practitioner to determine which set or sets of importance weights are most appropriate to report. Fortunately, Nathans et al. (2012) provided an accessible treatment of the metrics reported by the software presented along with strengths, limitations, and recommendations for practice. This along with other works that also address predictor importance in detail (e.g., Budescu & Azen, 2004; LeBreton et al., 2004) and the examples in the current article should provide researchers a general template for their own work in interpreting and reporting MLR models.
Although the regression indices we have reviewed can be informative, and the software can be a useful tool to make use of these indices, there are several avenues for future research that extend beyond the current purview. First, it is possible that the study of some psychological phenomena requires multiple criteria as well as multiple predictors, leading to a complex canonical prediction problem (e.g., Azen & Budescu, 2006; LeBreton & Tonidandel, 2008; Nimon, Henson, & Gates, 2010). Second, another frequent concern is the reliability or stability of importance-weight estimates across independent samples to which a regression model is supposed to generalize (e.g., Azen & Budescu, 2003; Johnson, 2004). We implemented bootstrapping to compute standard errors of the coefficients for all metrics and to address directly the problem of stability in a random sample; however, there is no guarantee that similar results would be obtained in a nonrandom sample, in particular a sample that is supposed to exhibit the same pattern of relationships and variable importance but that is a substantively different sample from the first one (e.g., an Army sample vs. an Air Force sample). Thus, research could examine replication and generalizability of these MLR metrics across samples of varying degrees of generalizability.
Third, we provide information on the submodels from all-possible-subsets regression for further investigation, and future research could quickly apply statistical and graphical exploratory tools to represent and test patterns within APS that go beyond the submodel summaries provided by general and conditional dominance analysis. Fourth, future research could consider MLR models that remain linear in their parameter estimates but include interaction terms and/or nonlinear terms, which would likely raise additional considerations (Dalal & Zickar, 2012). Perhaps many of these metrics could be extended to the hierarchical regression analysis framework; this might be something like APS yet would impose constraints or a structure on the sets of models to be tested. Fifth and finally, although we have covered a wide range of metrics, we also realize that other metrics could eventually be incorporated into the
Although all of these suggestions might prove worthy of consideration in future research, it was beyond the scope of this article to address them in detail. Again, our main focus is in providing a comprehensive and freely available program useful for bringing together and generating different types of predictor importance metrics in multiple regression analysis and to provide empirical examples that accompany the program, both of which we hope will allow researchers to think about and conduct regression analysis in a fundamentally different manner. Previously, such metrics were examined in isolation, often without much consideration of the other metrics available. Thus, regular use of the program in the future will hopefully provide researchers with new insights and guidance for the use of regression metrics that nobody—including ourselves—has yet offered.
Consider the work of Seibold and McPhee (1979) who examined the impact that cognition and social affect had in minority women’s intent to get a cancer screening test. Had the researchers only considered betas, they would have missed identifying cognition as a suppressor variable and the need to purify cognitive relevance from screening messages aimed at addressing social affect in order to have the maximum impact on intentions. To generalize from this example, we believe and envision that the software described can become an essential tool in substantive research, to understand the predictive relationships and interrelationships among variables in regression models more closely and from different perspectives, as well as in simulation research, to understand and appreciate statistical conditions that cause convergence and divergence among different regression metrics (extending the foundational work of LeBreton et al., 2004). Without conducting such detailed analyses, researchers may miss detecting and interpreting valuable relationships in their data.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.