
Abstract
Partial least squares path modeling (PLS) has been increasing in popularity as a form of or an alternative to structural equation modeling (SEM) and has currently considerable momentum in some management disciplines. Despite recent criticism toward the method, most existing studies analyzing the performance of PLS have reached positive conclusions. This article shows that most of the evidence for the usefulness of the method has been a misinterpretation. The analysis presented shows that PLS amplifies the effects of chance correlations in a unique way and this effect explains prior simulations results better than the previous interpretations. It is unlikely that a researcher would willingly amplify error, and therefore the results show that the usefulness of the PLS method is a fallacy. There are much better ways to compensate for the attenuation effect caused by using latent variable scores to estimate SEM models than creating a bias into the opposite direction.
Partial least squares path modeling (PLS) has recently gained popularity in several disciplines as an alternative approach to structural equation modeling (SEM) or as an alternative to SEM (Hair, Sarstedt, Ringle, & Mena, 2012; Ringle, Sarstedt, & Straub, 2012; Rönkkö & Evermann, 2013). The route through which PLS emerged into the mainstream is rather unorthodox. The PLS method was initially developed by the econometrician Herman Wold (Dijkstra, 2010; Wold, 1982), but the method never gained much attention from other econometricians or other researchers specializing in statistical analysis, and consequently the PLS method is currently almost nonexistent in the mainstream research methods journals (Rönkkö & Evermann, 2013). Instead the method reemerged through the marketing and information systems disciplines (Hair, Ringle, & Sarstedt, 2012), where the popularization of the method can be attributed to a number of introductory articles that present PLS as a SEM method that has less stringent assumptions about the data and avoids many of the perceived difficulties of SEM.
A review of the past 10 years (2003-2012) of papers in all the journals on the Financial Times 45 journal list (“45 Journals Used in FT Research Rank,” 2012) shows that the PLS method is being adopted increasingly but unevenly by many fields where the method has traditionally not been used. Searching the full text content of these journals with term structural equation, confirmatory factor, RMSEA, partial least, and PLS and manually screening the results for papers that used either latent variable SEM or PLS as an analysis method resulted a list of 1,838 studies, of which 247 used PLS. Among those journals that published studies using these methods, the PLS papers were very unevenly distributed. On one extreme, in the Journal of Applied Psychology only 2 papers out of 300 used PLS. This is contrasted against MIS Quarterly and Information Systems Research where 115 of a total of 178 studies used PLS, accounting for almost half of all PLS-based papers on the list of 45 journals. Excluding these 2 information systems journals, 93 of the remaining 128 PLS studies were published during the past 5 years (2008-2012) presenting an almost threefold increase compared to the first 5-year period (2003-2007).
Figure 1 shows the popularity of PLS compared to latent variable SEM in the 15 journals, in which the method was used the most, split into two 5-five year periods. The two information systems journals stand out in the figure being the only two journals where PLS was more popular than latent variable SEM for both time periods. In addition to the large number of empirical applications in MIS Quarterly, there were 13 papers either discussing or analyzing the PLS method, more than in all the other journals combined. Only one of the methodological studies was critical of PLS (Goodhue, Lewis, & Thompson, 2012b), and even this study included a mildly positive assessment of PLS in the conclusions. The enthusiasm on PLS in the information systems community can be explained by a potential bias toward papers that reinforce the status quo in the top information systems journals not unlike the positive bias toward formative measurement observed by Hardin and Marcoulides (2011). On the one hand, papers that advance or reinforce the current methodological practices seem to be accepted, sometimes even without any evidence of the usefulness of the proposed methodological approach (e.g., Liang, Saraf, Hu, & Xue, 2007). On the other hand, some researchers feel that the journals actively discourage papers critically examining the current methodological practices (Goodhue et al., 2012a). There are also a few examples of papers challenging the current methodological stance being rejected by MIS Quarterly and later appearing in research methods journals (Hardin & Marcoulides, 2011; A. Hardin, personal communication, May 1, 2013; Treiblmaier, Bentler, & Mair, 2011; H. Treiblmaier, personal communication, December 5, 2011). The problem of possible positive bias toward PLS in the information systems journals is not limited to the information systems discipline because researchers in other disciplines are drawing on these papers for information about the PLS methods and recent papers are actively encouraging them to do so (Gefen, Rigdon, & Straub, 2011).
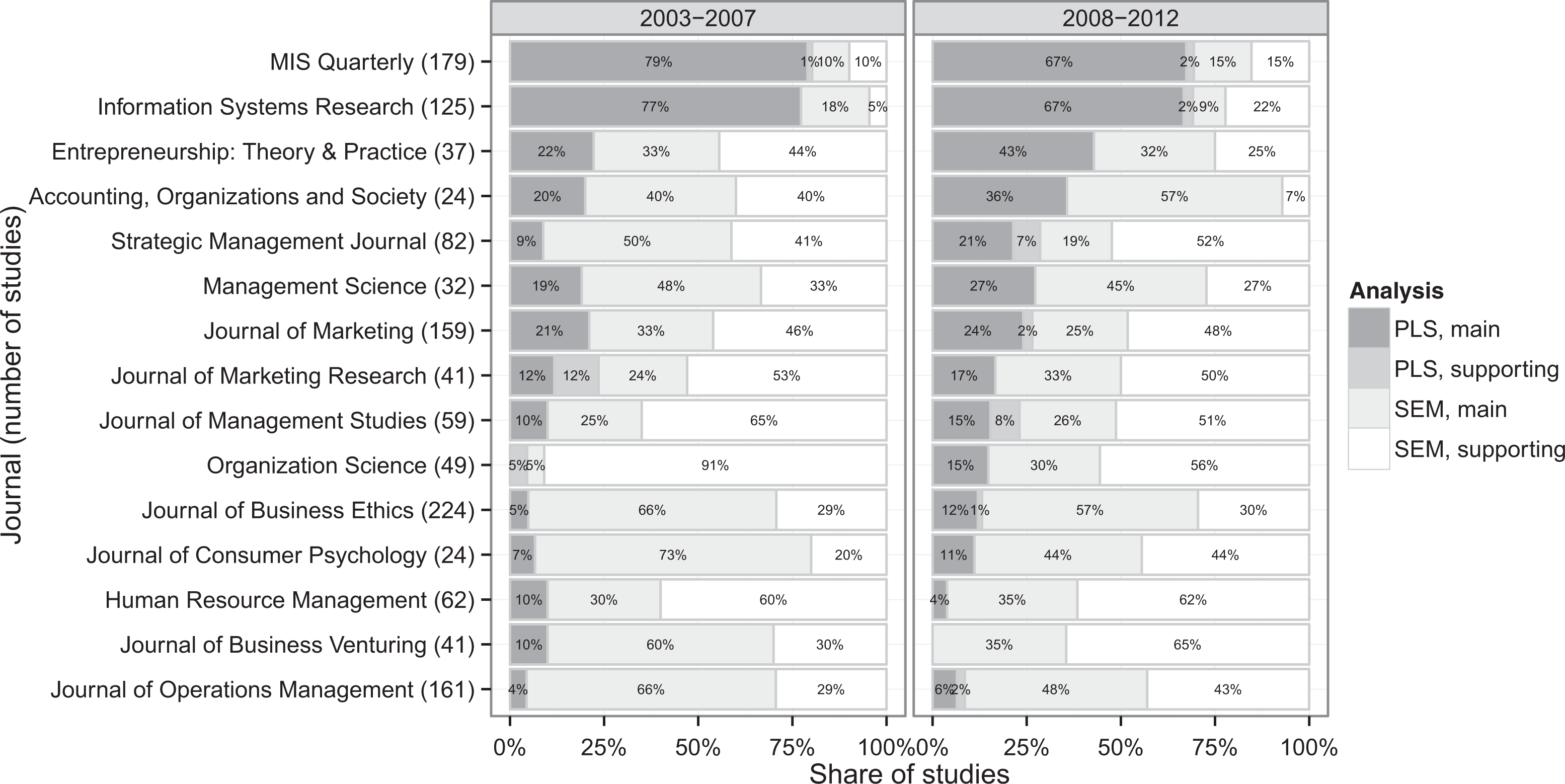
Use of partial least squares (PLS) in high-quality business journals in 2003-2012.
The adoption of PLS in the management disciplines seems to follow a pattern where it is first introduced to a discourse from another discipline by a paper or two that use the method, after which further studies are legitimized by citing these earlier papers. A reviewer who then wants to challenge the legitimacy of PLS may find herself in a difficult position, as the authors now have the prior studies as well as introductory level books (Hair, 2010, Chapter 15; Kline, 2010, pp. 287-288; Rigdon, 2013; Savalei & Bentler, 2007) and multiple introductory articles (e.g., Gefen et al., 2011; Hair, Ringle, et al., 2012; Peng & Lai, 2012) that can be cited to support their methodological choice. While there are some methodological papers that challenge the use of PLS (Goodhue et al., 2012b; Rönkkö & Evermann, 2013), there are many more that reach the opposite conclusions (e.g., Cassel, Hackl, & Westlund, 2000; Chin & Newsted, 1999; Reinartz, Haenlein, & Henseler, 2009), thus making any evidence-based arguments for and against PLS rather unevenly matched. The position of a PLS skeptic is not helped by the fact that the results of both the recent papers have already been challenged: In the case of Goodhue et al. (2012b), Marcoulides, Chin, and Saunders (2012) dismiss the study as an inappropriate comparison due to incorrect parameterization. Similarly, some of the main arguments by Rönkkö and Evermann (2013) were quickly challenged by Henseler et al. (2014; see also McIntosh, Edwards, & Antonakis, 2014).
The papers that are critical of PLS are also hampered by their focus on disproving positive beliefs about the method rather than focusing on the disadvantages. For example, in the case of Goodhue et al. (2012b) the authors showed that PLS does not correct for measurement error, but nevertheless concluded the paper by stating that PLS would be an appropriate method for many situations. Another problem with the existing studies is that they largely fail to explain why some other studies have produced the opposite results. Rönkkö and Evermann (2013) touch this issue by showing that in a simulation with a with two latent variable model, PLS capitalizes strongly on chance correlations—correlations that do not exist in the population, but are non-zero in a sample because of sample variability—between error terms and suggest this as an explanation for the earlier, positive results but nevertheless do not pursue the argument further. In sum, while these papers show that PLS may not have the capabilities that many papers argue it has, they do not directly argue that PLS is altogether a flawed method.
This paper takes a different approach by focusing on what the PLS method actually does, which turns out to be is to capitalize on chance correlations in a way that is not documented in the earlier literature and that also explains the earlier, positive results. The purpose of this paper is twofold: First, the paper provides important, new evidence that a researcher skeptical of PLS can use to support her position. Whereas Rönkkö and Evermann (2013) stated that their study casts strong doubts on the effectiveness of PLS, the evidence presented in this paper should remove any such doubts by showing that what the PLS method actually does is to amplify the effect of chance correlations in a unique way, and this is almost certainly not something that a researcher would want to do. Second, there are ongoing efforts to improve or fix PLS by improving its asymptotic properties (Bentler & Huang, 2014; Dijkstra, 2014; Dijkstra & Henseler, 2012; Dijkstra & Schermelleh-Engel, 2013). These studies correctly observe that PLS is not consistent and introduce changes or corrections that would result in a consistent estimator. This study exposes a previously unknown and serious flaw in PLS that would also need to be addressed to make PLS a useful method for estimating SEM models.
Prior Simulation Evidence on the Performance of the PLS Method
PLS is often presented as a component-based estimator for SEM. No explicit definition for component-based estimation is given in the literature, but there seems to be an implicit understanding that such estimation proceeds in two steps: (1) calculating latent variable scores as weighted linear combinations (composites) of the indicator variables and (2) estimating the relationships between the composites using separate regression analyses (Hwang, Malhotra, Kim, Tomiuk, & Hong, 2010; Lu, Kwan, Thomas, & Cedzynski, 2011; Tenenhaus, 2008). Using this definition, the most typical component-based SEM estimator would be regression with summed scales or factor scores. The distinct feature of PLS and the only difference between these more traditional analysis methods is the iterative indicator weighting system (Chin, Marcolin, & Newsted, 2003; Goodhue et al., 2012b), which is explained in more detail later in the paper.
Regardless of the chosen weighting system, a key weakness in forming composite variables of indicators that contain measurement error is that any estimates produced with these composites will generally be inconsistent, although there are special cases where consistency can be achieved (Lu & Thomas, 2008). The fact that PLS is not consistent is readily acknowledged in the PLS literature (e.g., Chin, 1998). Rather, the argument for PLS has been that there are situations where a consistent estimator (typically ML SEM) may not be available or may perform poorly because of small sample size or violation of assumptions, and in these cases PLS, while inconsistent, would be the best available alternative. In theory, there are indeed some cases where an inconsistent estimator with known bias may be preferable to an unbiased estimator if the bias is well understood and the variance of the biased estimator is small compared to the unbiased one (Lehmann & Casella, 1998, p. 84). However, one cannot categorically conclude that when ML SEM fails or performs poorly, PLS should be used instead because it is possible that one of the other alternative component-based estimation approaches (e.g., regression with summed scales or factor scores) would outperform PLS or that the data are just inappropriate for any statistical analysis.
The lack of consistency of PLS suggests that it should not perform well when compared against consistent SEM estimators. Table 1, which lists prior Monte Carlo studies of PLS, shows that this is indeed generally the case. Interestingly many of the papers also show that when compared to regression analysis with summed scales, PLS results are less biased, suggesting that PLS may have an edge over other component-based estimators. In a recent paper Goodhue et al. (2012b) argued that the difference in bias was not statistically significant, but this conclusion was based on inappropriate use of prediction intervals. When the data were reanalyzed with the appropriate tests, the difference was statistically significant (D. L. Goodhue, personal communication, April 10, 2012). In fact, all the studies that compare bias of regression with summed scales and PLS show that the latter is less biased. The analysis presented later in the paper shows why this happens, why this is the wrong thing to look at, and particularly why this cannot be used as evidence that recent criticism toward PLS would be wrong.
Studies Evaluating Partial Least Squares (PLS) With Monte Carlo Methods.
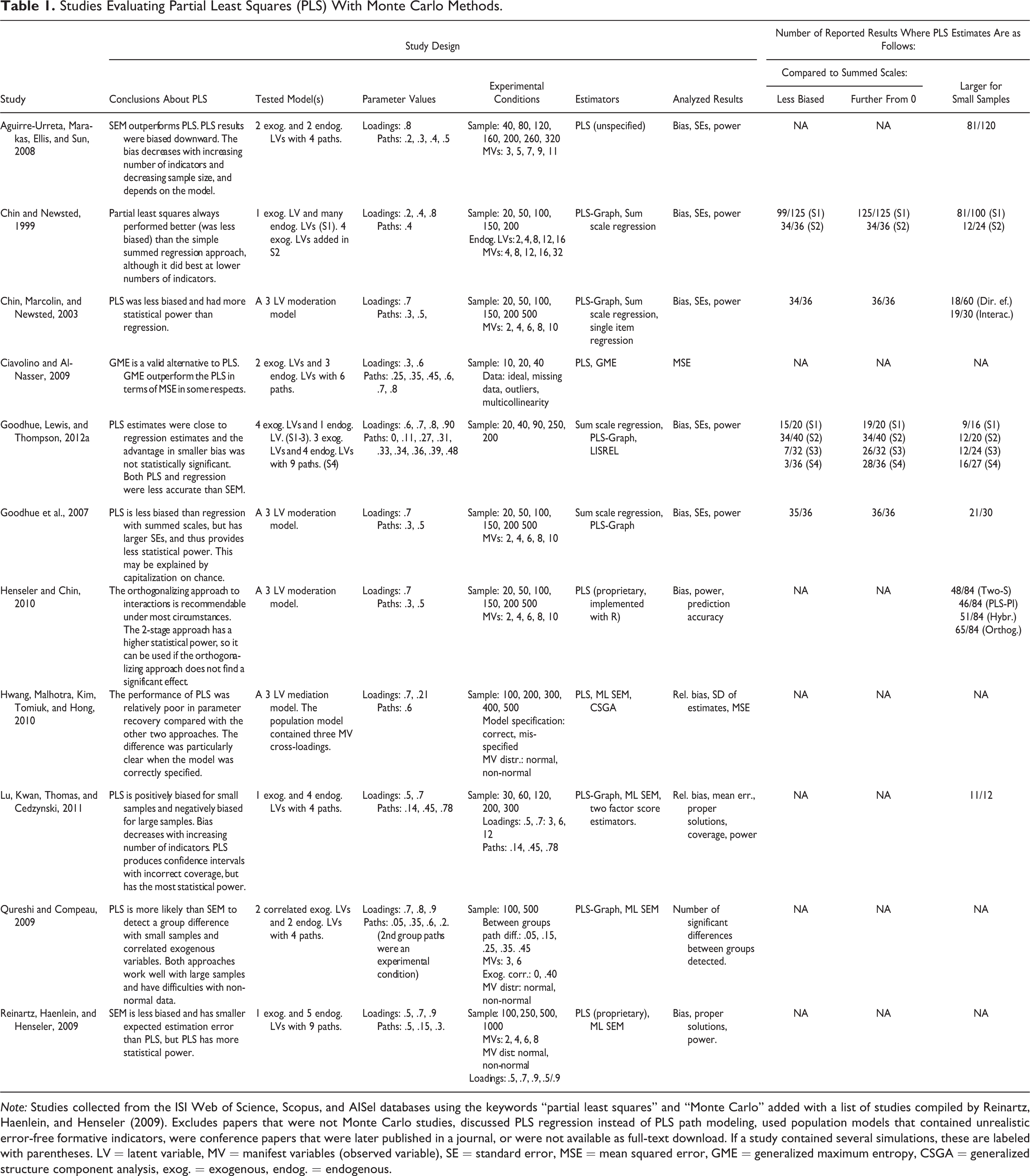
Note: Studies collected from the ISI Web of Science, Scopus, and AISel databases using the keywords “partial least squares” and “Monte Carlo” added with a list of studies compiled by Reinartz, Haenlein, and Henseler (2009). Excludes papers that were not Monte Carlo studies, discussed PLS regression instead of PLS path modeling, used population models that contained unrealistic error-free formative indicators, were conference papers that were later published in a journal, or were not available as full-text download. If a study contained several simulations, these are labeled with parentheses. LV = latent variable, MV = manifest variables (observed variable), SE = standard error, MSE = mean squared error, GME = generalized maximum entropy, CSGA = generalized structure component analysis, exog. = exogenous, endog. = endogenous.
When two latent variables are approximated with composites, the correlation between these approximations will underestimate the true correlation because of the well-known attenuation effect, which depends on the reliability of the approximations (Bollen, 1989, pp. 166-167; Cohen, Cohen, West, & Aiken, 2003, pp. 38-39; Goodhue et al., 2012b). The effects are more complex in multiple regression models, but on average random measurement error causes underestimation of the path coefficients, also in PLS (e.g., Gefen et al., 2011). The smaller bias in PLS estimates has been interpreted earlier as evidence of better reliability of the PLS composites (e.g., Chin et al., 2003), but it will be shown later that this is an incorrect interpretation.
A few of the reviewed papers noticed that there is something peculiar in the PLS estimates. Aguirre-Urreta, Marakas, Ellis, and Sun (2008) note that the PLS estimates tend to get larger when sample size decreases, but could not explain why this happens. Goodhue et al. (2007) noted that when analyzing interaction effects, the PLS estimates of the interaction term seem to be higher than regression with summed scales. They offered capitalization on chance as a possible explanation for this finding, but did neither provide any direct evidence to support this idea nor attempt generalize it outside the interaction effect. Their latest paper (Goodhue et al., 2012b), which is a more general criticism toward PLS, does not discuss capitalization on chance at all. Schermelleh-Engel, Werner, Klein, and Moosbrugger (2010) reinterpreted the data presented by Goodhue et al. (2007) and noted that capitalization on chance may explain the sampling distribution of the interaction effect, but they too do not attempt to generalize the effect outside interactions. Rönkkö and Evermann (2013) discuss the effect of correlated errors on PLS estimates and show that in a simple two-construct case, PLS seems to be sensitive to chance correlations resulting in decreased reliability of the latent variable estimates. While they argue that there is no reason to believe that the findings would not generalize, they too fail to provide direct evidence of capitalization on chance or any evidence of the generalizability of their analysis.
The existing studies listed in Table 1 contain several anomalies that could be explained by capitalization on chance. First, if PLS inflates path coefficients by capitalizing on chance, the PLS estimates should be further from zero than summed scales estimates that have fixed indicator weights and therefore cannot capitalize on chance. The second and third columns from right compare how often the PLS estimates are less biased and how often they were simply larger than summed scales estimates, showing that the latter is more often the case. Moreover, some studies, particularly the study by Chin and Newsted (1999), show results with positive bias in simple regressions. Simply increasing reliability of the composites to overcome the attenuation effect cannot result in this type of results, but the authors fail to note and explain these anomalies. Second, because chance correlations increase with decreasing sample size, the PLS estimates should increase when sample size decreases. I analyzed the result tables of the studies included in Table 1 by counting the number of simulation conditions in which the PLS estimates were larger than in the condition with the next higher sample size. These results are listed in the last column and they show that the effect is present to some extent in all of the studies except in the study by Chin et al. (2003). One possible explanation for this anomaly would be the effect of multicollinearity in their interaction model. This explanation is consistent with the fact that in a later study with the same data generation procedure (Henseler & Chin, 2010), the effect of increasing path estimates is strong when multicollinearity is eliminated through orthogonalization. Third, sometimes there may be a strong chance correlation to the opposite direction of the effect, which should cause the sampling distribution of the PLS estimates have a long tail and a secondary mode on the opposite side of zero. This effect is seen clearly in both of the studies by Goodhue et al. (2007, 2012b) and the study by Rönkkö and Evermann (2013), which are the only reviewed studies that presented any information about the shape of the distribution of the PLS estimates.
Reviewing the existing studies, there seems to be some indirect evidence of PLS capitalizing on chance although it has rarely been interpreted as such. Because the attenuation effect causes the parameters to be underestimated and capitalizing on chance correlations causes bias that is often toward the opposite direction, PLS indeed often has smaller bias than regression with summed scales. However, interpreting this as an advantage, like many of the reviewed studies did, is seriously misguided. The next two sections show how PLS capitalizes on chance correlations between the error terms in a general case and then show direct simulation evidence that this is a very strong effect, which makes PLS unsuitable for any type of statistical inference.
Formal Analysis of How and Why the PLS Method Capitalizes on Chance Correlations
The PLS weights and therefore also the path estimates are completely determined by the sample covariance matrix (Lohmöller, 1989; Rönkkö, 2013), which is a sample realization of the population covariance matrix of the indicator variables. For a common factor model, the population covariance matrix of the indicators is (cf., Bollen, 1989, p. 35):
where
As explained earlier, PLS uses weighted composites as approximations for latent variables. The indicators are arranged as indicator blocks so that each block is associated with exactly one composite and each indicator belongs to exactly one block according to a (p × n) matrix of outer weights W. Starting with unit weights, the weights are adjusted iteratively in two steps called inner estimation and outer estimation until convergence. To simplify the equations, I will assume that all the variables, including the latent variables in the population, the observed data, and the calculated composites are always standardized. The correlation matrix between the weighted composites is
During inner estimation, this matrix is used to calculate a (n × n) matrix of inner weights E. The PLS literature describes three alternative inner estimation schemes, but because these have been shown to produce nearly identical results (Noonan & Wold, 1982), I describe only the simplest one, the centroid weighting system. In this scheme the cell Eij
is set to sign of 
where

where λ are the sample correlations between indicators and latent variables, φ are the sample correlations between latent variables, and θ are the sample correlations between the error terms. (Some effects of sample correlations between error terms and latent variables are omitted for clarity.) Equation 4 contains two terms, which I call structural effects term and error correlations term. Because the diagonal of E is zero, the correlations between indicators in the same block are ignored and only correlations across indicator blocks are used. In the asymptotic case, θ is a diagonal matrix. Each row of W has exactly one non-zero element and the elements on the diagonal of E are all zero, and therefore all the elements that are non-zero in W are zero in WE. Multiplying WE with a diagonal θ will simply scale each cell of WE with a scalar. As a result, the elements θ that are used in the indicator weighting process are zeros and thus the error correlations term has no impact on the indicator weights in the asymptotic case.
In the structural effects term, the factor loadings λ are multiplied by
In a finite sample, things get more complicated because the correlations between the errors are almost never exactly zero in a sample because of random sampling variations (θ is no longer diagonal). This results in indicators with error correlations in the same direction as the correlation caused by the latent variables receiving higher weights. Because the factor loadings are multiplied by
After the indicator weights are calculated, the correlation matrix between the composites, which completely determines the latent variables, is calculated according to Equation 2. Substituting S with the same sample correlations as earlier and rearranging yields:
I will again call these two terms structural effects term and error correlations term. The equation shows that if rC are used as estimates of the correlations between the latent variables (ϕ) there are two sources of error. In the structural effects term the
The second source of error is the error correlations term. When using equal weights, this second source of error increases the variance of the parameter estimates, but because the expected value of each error correlation is zero and they are mutually independent, the expected value of their sum is zero resulting in no bias. With PLS, the effect is different because the indicator weights depend on the error correlations, as shown in Equation 4. Consider again that a population path is positive. In this case, indicators with positive error correlations receive larger weights, and the indicators with negative error correlations receive smaller weights resulting in non-zero expected value and a positive bias in the results.
Monte Carlo Study of the Sampling Distribution of PLS Estimates
The previous described a potential problem in the PLS algorithm but did not address the magnitude of the problem. This section address the severity of the problem with a Monte Carlo simulation. The full R code for the study is included in Appendix 1, available online. Also, a picture is worth a thousand words, and the distribution plots that will soon follow communicate the problem in a much more clear way than the formal analysis presented in the previous section.
Simulation Design
Prior studies have argued that the structure of the estimated model can affect the bias (Aguirre-Urreta et al., 2008; Cassel et al., 2000) and the number of false positives (Goodhue et al., 2012b) in a PLS analysis. Therefore, to avoid capitalizing on idiosyncrasies of one particular model, I chose to generate a new, random population model for each simulation round. These random models consisted of six latent variables with eight paths reflecting typical empirical applications of PLS (Hair, Sarstedt, et al., 2012; Ringle et al., 2012). The path values were randomly set using values –.3, –.2, –.1, .1, .2, and .3 with equal probabilities. The measurement model varied according to the first two experimental factors listed in Table 2. The population values of the factor loadings were set by taking the factor loading based value and adding a random number from uniform distribution [–.1, .1] to each loading to simulate uneven reliability of the indicators. Although the population factor loading of .4 is low, such low values can be mistakenly accepted as reliable measurements because PLS severely overestimates low factor loadings (Rönkkö & Evermann, 2013).
Monte Carlo Simulation Design Factors and Values.

I generated the data by first generating a sample of latent variable true scores by drawing multivariate normal samples using a covariance matrix calculated from the population model. Then I generated the indicator base data by multiplying the latent variable true scores with the factor loadings and used each base data to generate two sets of indicator data. The original data were created by adding error terms drawn randomly from multivariate normal distribution with zero population correlations scaled so that the population variances of the indicators were one. The manipulated data were generated by taking the error terms used in the original data and orthogonalizing them maintaining their variances before adding them to the indicator base data. The manipulated data were thus in all respects identical to the original data with the exception that chance correlations between error terms were artificially removed.
I used each set of original data to estimate three models according to the fourth experimental factors: the correct model, which was identical to the population model, and two misspecified models that were created by removing paths and adding nonexisting paths randomly. This resulted in a full factorial design of 81 cells (3 × 3 × 3 × 3). For each cell, 500 independent replications were used. Each model was estimated with PLS, SEM, and regression analysis with summed scales. The simulation was conducted using the R statistical programming environment (version 2.15.2, R Core Team, 2013) using the plspm package (version 0.3.7, Sanchez & Trinchera, 2013) to for the PLS analysis and lavaan (version 0.5-12, Rosseel, 2012) for the SEM analysis.
Simulation Results
A key argument by the PLS proponents is that the way in which PLS weights the indicators does maximize the reliability of the composites or minimize the effect of random errors (e.g., Chin et al., 2003; Gefen et al., 2011), but there is no direct evidence that this would be the case (Rönkkö & Evermann, 2013). I tested this argument by comparing the squared correlations between the composites and the latent variable true scores that they were approximating. The unweighted summed scales were more reliable in every one of the 81 experimental conditions.
Then I compared the path estimates from these two methods and SEM. The PLS estimates were always less biased and always on average further from zero than estimates from regression with summed scales. The mean squared error (MSE), which measures the inaccuracy of an estimator (i.e., risk, Lehmann & Casella, 1998, pp. 5-7), was statistically significantly higher for PLS in 71 out of 81 conditions. In the remaining 10 conditions MSEs were identical to the third decimal between the methods. Comparing PLS and SEM revealed that SEM was almost always less biased than PLS but had larger MSE, particularly with smaller sample sizes. This result is expected because the ML estimator is inaccurate with small samples (Bollen, 1989). Comparing PLS estimates across conditions revealed that on average, the PLS estimates were further from zero with smaller samples. All these results are consistent with the earlier studies shown in Table 1 and support the argument that PLS capitalizes on chance. The full set of comparison tables is included in Appendix 2.
Figure 2, Figure 3, and Figure 4, showing the distribution of path estimates for PLS, regression with summed scales, and SEM for the cases in which the population parameter is 0 (i.e., no path exists in the population), has an absolute value of .1, or has an absolute value .3, respectively. The purpose of these analyses is not to show that chance correlations have an effect on the PLS weights per se, but to assess the impact that the chance correlations have on the path coefficients when the indicator weights have been calculated with realistic data where chance correlations exists in the sample. The distributions marked with solid lines are calculated using the original data, where the errors were uncorrelated in the population. The second set of results, marked with dashed lines, are calculated using the indicator weights from the analysis using original data but using the manipulated data, where the error terms were orthogonalized in the sample, to calculate the final composites. This is identical to removing the error correlations term from Equation 5 and can therefore be used to analyze how strongly chance correlations affect the results. Because SEM does not use indicator weights, estimating the effect of chance correlations this way was not possible for this method and therefore only one set of results is included for SEM.
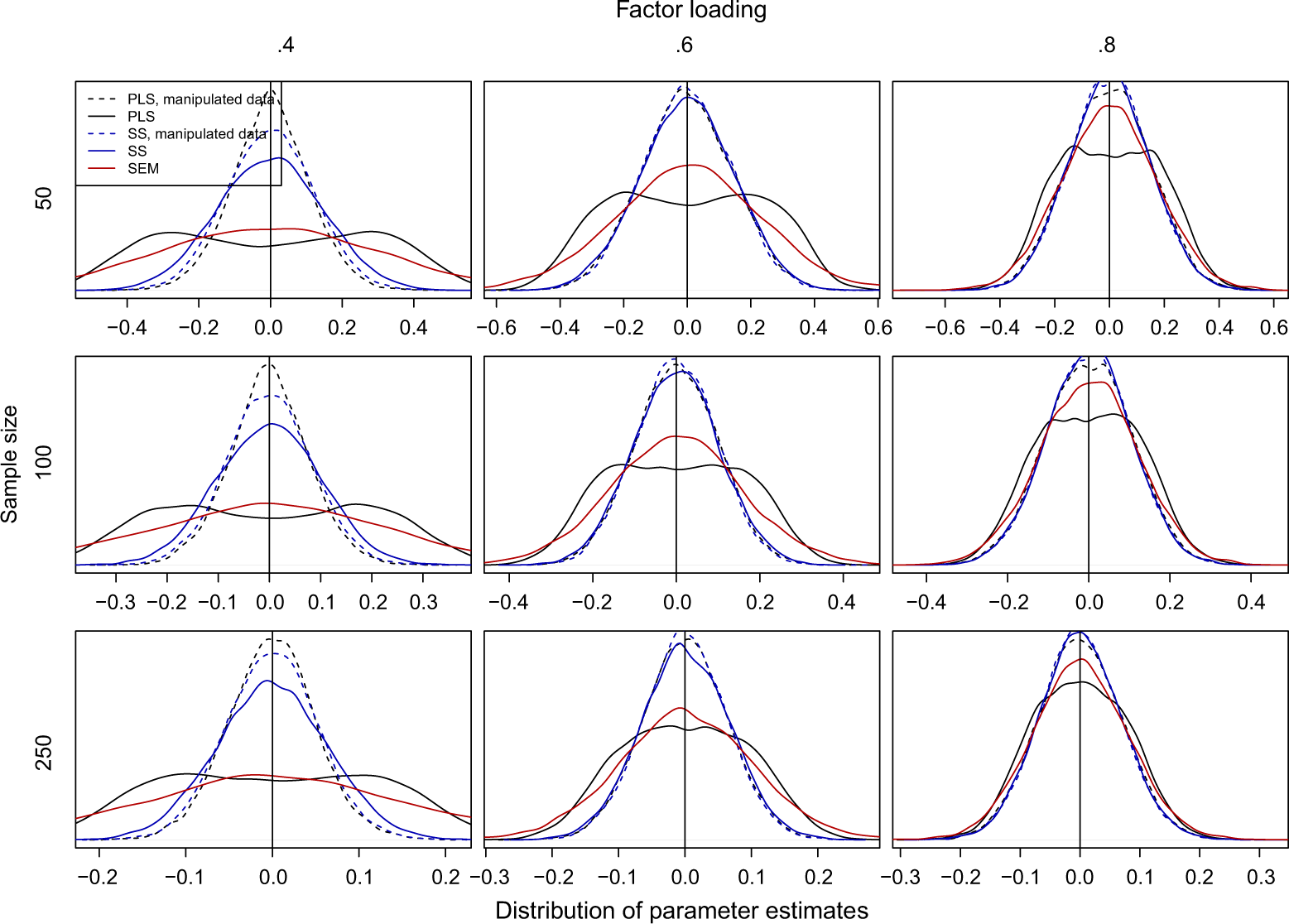
Distribution of the path estimates (kernel density estimates) when the population parameter is 0.
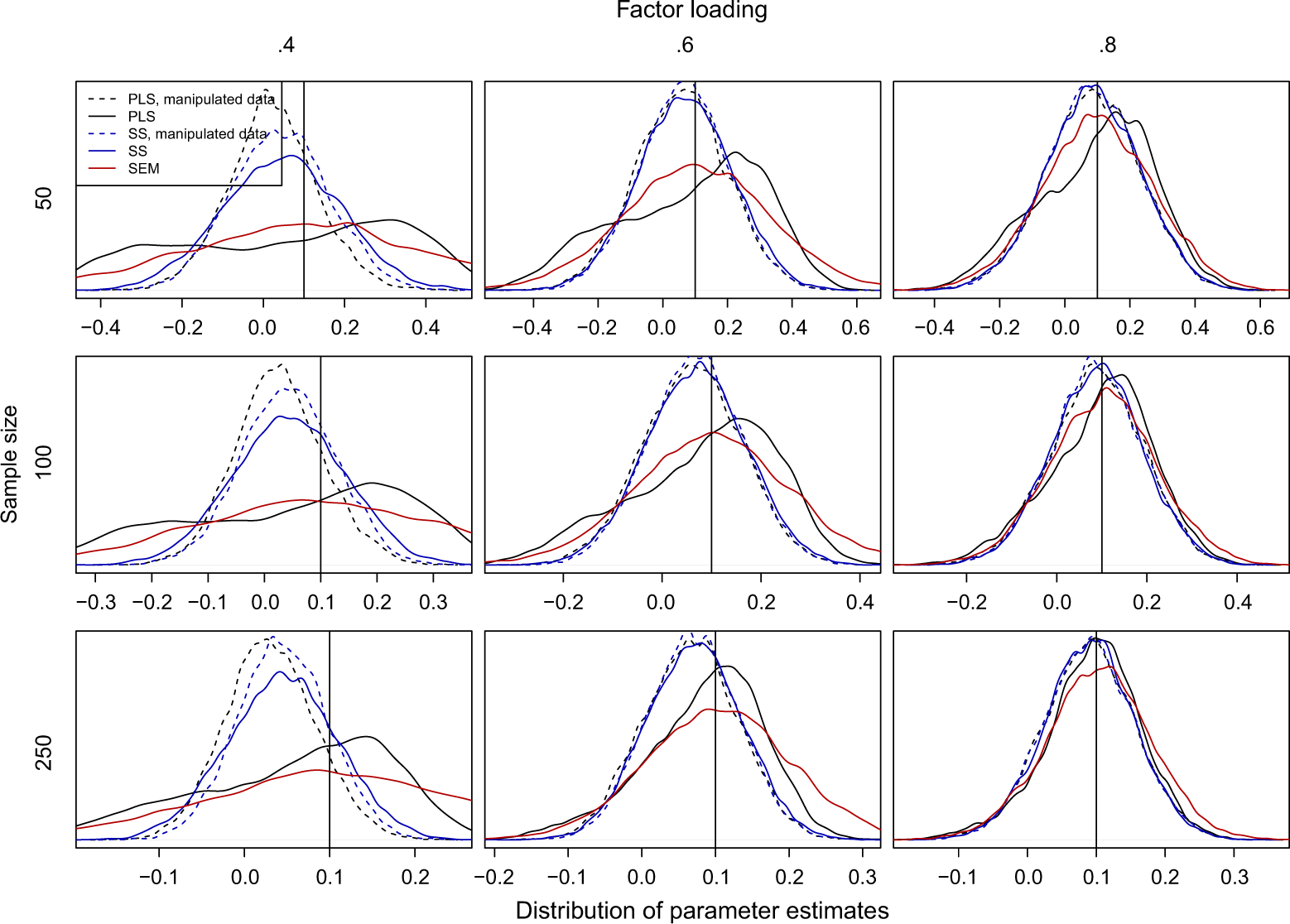
Distribution of the path estimates (kernel density estimates) when the population parameter is .1.
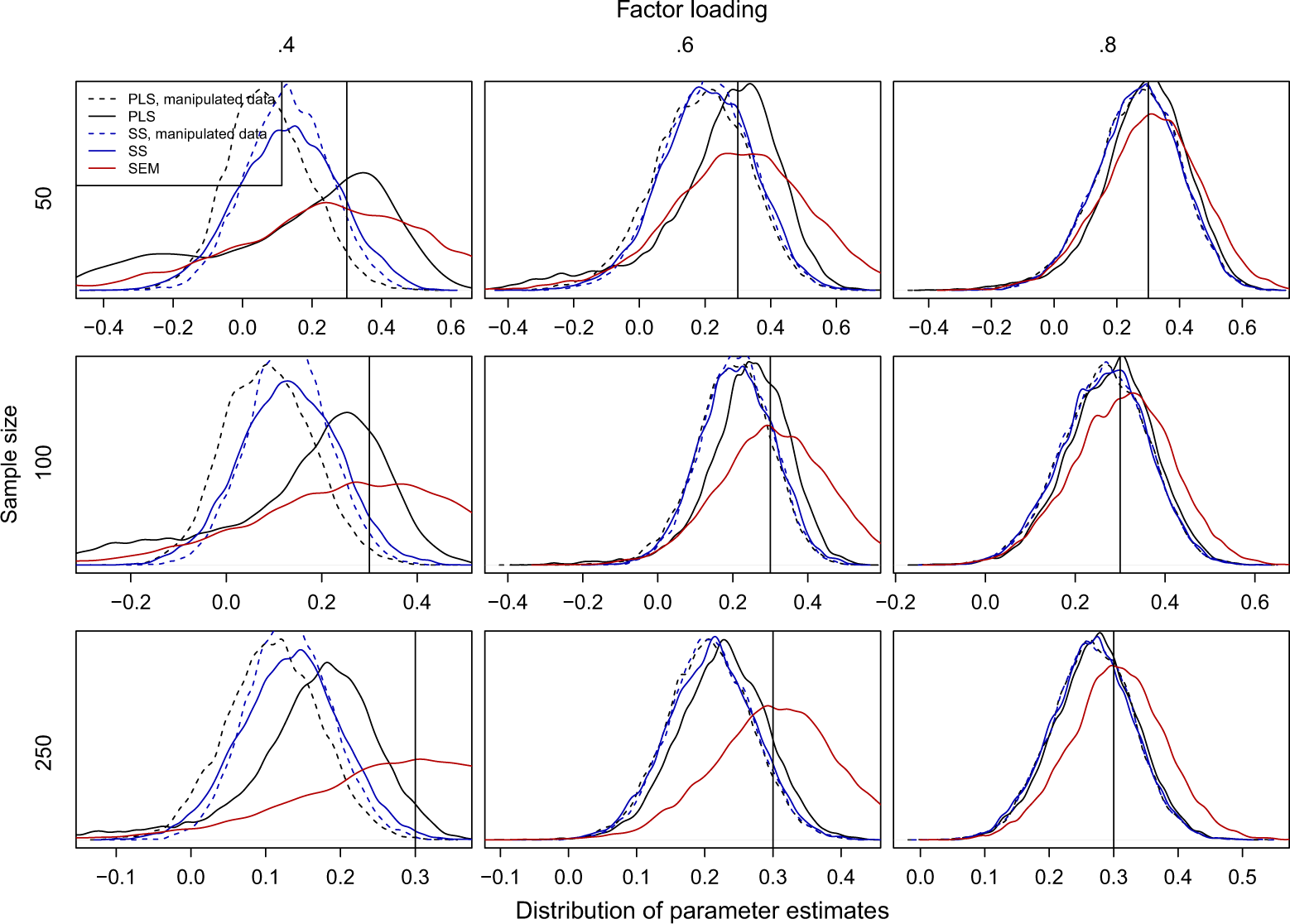
Distribution of the path estimates (kernel density estimates) when the population parameter is .3.
In Figure 2, the PLS estimates and the summed scales estimates are approximately unbiased because they are distributed evenly around zero. For the summed scales, the shape of the distribution is similar for both sets of data, but the variance of the estimates is slightly smaller when chance correlations between errors were removed. This scenario is expected because the error caused by chance correlations has a non-zero variance but has an expected value of zero. In contrast, with PLS composites, the variance of the estimates increases substantially, and the distribution changes into a bimodal form, which resembles the distribution reported for the two latent variable model by Rönkkö and Evermann (2013), but does not follow any known probability distribution. This is very problematic because virtually all current PLS studies use the method for null hypothesis significance testing of the path coefficients comparing the ratio of the parameter estimate and its standard error (t-statistic) with t-distribution. However, because the underlying distribution of parameter estimates is non-normal, the ratio of the parameter estimate and its standard error cannot follow the t-distribution regardless of how the standard error is estimated. Because the t-statistic does not follow the t-distribution, using the t-distribution to obtain a p-value, as is the current practice, is not appropriate (Rönkkö & Evermann, 2013).
Figure 3 and Figure 4 depict the same analysis for paths with an absolute value of .1 or .3 in the population, respectively. In these figures, the PLS estimates are slightly smaller than the summed scale estimates obtained when the effect of chance correlations between the error terms is eliminated from the path coefficients. This is expected because PLS composites were less reliable and the strength of the attenuation effect depends on reliability. With the original data, the effect of the error correlations biasing the PLS estimates away from zero, which was already observed in Figure 2, is again visible. When the true parameter value is small (absolute value is .1), the peak of the distribution is to the right of the true value, meaning that the parameters are mostly overestimated. With the larger population values (absolute value is .3), the peak of the PLS estimates is closer to the population value, but the paths are mostly underestimated. These results show that the widely held belief that PLS underestimates path coefficients (e.g., Chin, 1998) is incorrect because small path coefficients are clearly overestimated.
The figures show that in addition to the well-known attenuation effect, the PLS estimates suffer from also another source of bias that is to the opposite direction and these two sources of bias can in some instances cancel out each other. The question thus becomes is creating a new and thus far unknown source of bias the best way to compensate for the attenuation effect? There are at least three reasons why this is definitely not the case: First, the absolute size of the attenuation effect depends on the true value of the regression path and the factor loadings, whereas the bias caused by the error correlations does not, at least not directly. Second, the correction for attenuation should not depend on the strength of the error correlations, unlike the bias in the PLS results. Third, capitalizing on chance correlations prevents significance testing of path estimates because the sampling distribution of estimates corrected this way is no longer known. The problem of attenuation is well known and we have decades of research on how the bias can be corrected resulting in unbiased estimates without sacrificing the shape of the distribution of the estimates (Charles, 2005; Le, Schmidt, & Putka, 2009; Lu & Thomas, 2008; Muchinsky, 1996; Zimmerman, 2007; Zimmerman & Williams, 1997). I compared the PLS estimates with disattenuated regression estimates confirming that also in these simulation conditions the results from disattenuated regression were substantially less biased than PLS estimates. While the correction for attenuation is a statistically sound approach and has been shown to produce unbiased estimates in fairly general conditions, the resulting estimator is inefficient (Zimmerman & Williams, 1997) and SEM with latent variables has superseded this approach for many practical applications (Cohen et al., 2003, Chapter 12).
Discussion and Conclusions
Like other indicator weighting systems that can be used with regression analysis, PLS suffers from the well-known attenuation problem. In addition to this known problem, this article has showed that PLS suffers from an additional problem of amplifying the effect of chance correlations between error terms. While there is some earlier evidence that PLS does not have the advantages that the proponents of the method argue (e.g., Goodhue et al., 2012b; Rönkkö & Evermann, 2013), the conclusions of these studies have been relatively mild. For example, Goodhue et al. (2012b) concluded their paper by stating that “PLS is still a convenient and powerful technique that is appropriate for many research situations” (p. 999) and Rönkkö and Evermann (2013) merely state that their results cast strong doubts on the usefulness of the method and make it difficult to justify the use of the method.
Understanding the effects of chance correlations on the PLS estimates is also important because the proponents argue that while this may be a problem, it is limited in scope. “Capitalization on chance is indeed an issue, but is mainly limited to very small models with weakly related constructs,” but also continue that “It is pivotal to understand under which conditions this phenomenon occurs” (Rai, Goodhue, Henseler, & Thompson, 2013, p. 2). This paper presents results that hopefully bring about that pivotal understanding: The results show that the apparent advantage of PLS is a fallacy caused by ignoring the effect of chance correlations on the PLS results. These findings also provide an explanation for the positive conclusions about the statistical power of PLS that some studies Table 1 make. Because capitalization on chance makes PLS estimates non-normally distributed, these conclusions may just be results of inappropriate use of the t-test for non-normal data and not reporting false positives when doing so (Rönkkö & Evermann, 2013). It is rather unlikely that anyone would deliberately want to amplify the effect of chance correlations that are idiosyncratic to a sample in their study, particularly when this means also sacrificing the ability to test the statistical significance of the resulting parameter estimates.
The results also show that the existing attempts of fixing PLS by addressing its asymptotic properties and consistency (Dijkstra & Henseler, 2012; Dijkstra, 2014) are unlikely to succeed as long as they ignore an equally severe problem of amplifying the effect of chance correlations that only manifests in finite samples. The best way to eliminate this effect would be to substitute the model-dependent weighting system with equal weights or factor scores weights. In other words, the best way to fix PLS would be to abandon the PLS indicator weighting method altogether and instead focus improving existing component-based SEM methods that do not share the key weakness of PLS exposed in this paper.
The results raise two important questions: (1) On a higher level of abstraction, why does PLS perform poorly when it is applied to data originating from a common factor model? (2) How has the effect of amplifying chance correlations gone unnoticed for so long? The answer to the first question is that PLS was initially developed with a strong focus on prediction. In fact, in analyzing the work of Wold, the developer of PLS, it is difficult to find any recommendations for using the method for statistical inference. In contrast, Dijkstra, Wold’s student, concluded his dissertation on PLS by specifically recommending against using PLS for statistical inference (Dijkstra, 1981, p. 191). While PLS has been shown to produce construct scores that predict one another better than summed scales (Chin, 2010), prediction ability of a model and construct validity that is important when working with theory are two fundamentally different things (cf. Nunnally, 1978, Chapter 3). Thus, by maximizing prediction, PLS sacrifices construct validity and the ability to do null hypothesis significance testing.
The reason why this effect was not noted earlier is most likely because PLS, although used extensively in some disciplines, has not been extensively studied. For example, in Table 1, all but two studies were published in the past five years, and only three were published in research methods journals, the remainder of which were book chapters and papers in applied disciplines. In fact a review of several current beliefs about the PLS method by Rönkkö and Evermann (2013) indicated that many of the prevalent beliefs about the PLS method fit the definition of methodological myths and urban legends: Instead of being based on known statistical principles or rigorous simulation studies, most papers about the PLS method just repeat what earlier similar papers have stated. The fact that PLS has started to enter some of the mainstream textbooks about statistical analysis (Hair, 2010, Chapter 15; Kline, 2010, pp. 287-288; Rigdon, in press), makes these results that expose a previously unknown flaw in the PLS method even more important and timely.
Footnotes
Author’s Note
The paper is loosely based on a paper presented in the 2010 International Conference on Information Systems. The author wishes to thank Jukka Ylitalo for his valuable help with the early versions of the paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.