
Abstract
The variable-centered approach is favored in management and applied psychology, but the person-centered approach is quickly growing in popularity. A partial cause for this rise is the finer-grained detail that it allows. Many researchers may be unaware, however, that another approach may provide even finer-grained detail: the person-specific approach. In the current article, we (a) detail the purpose of each approach, (b) describe how to determine when each approach is most appropriate, and (c) delineate when the approaches diverge to give differing results. Through achieving these goals, we suggest that no single approach is the “best.” Instead, the choice of approach should be guided by the research question. To further emphasize this point, we provide illustrative examples using real data to answer three distinct research questions. The results show that each research question can be fully addressed only by the appropriate approach. To conclude, we directly suggest certain research areas that may benefit from the application of person-centered and person-specific approaches. Together, we believe that discussing variable-centered, person-centered, and person-specific approaches together may provide a more thorough understanding of each.
To describe the differences between variable-centered and person-centered approaches,
1
Morin, Gagné, and Bujacz (2016) state, Whereas variable-centered approaches…assume that all individuals from a sample are drawn from a single population for which a single set of “averaged” parameters can be estimated, person-centered approaches…relax this assumption and consider the possibility that the sample might include multiple subpopulations characterized by different sets of parameters. (p. 8)
These approaches—variable-centered, person-centered, and person-specific—represent three important but distinct sets of methods. No approach is “better” than the other, but each can instead be used to address separate families of research questions. Given their respective popularities in management and applied psychology, it is our contention that many readers may not be entirely familiar with person-centered and person-specific approaches. Subsequently, it is our aim to expand researchers’ and practitioners’ methodological tool sets by (a) detailing the purpose and process of each approach, (b) describing how to determine when each approach is most appropriate, and (c) delineating when the approaches might lead to differing results. In doing so, we believe that our efforts can guide researchers and practitioners in identifying the best methods to answer their specific research and applied questions, and our efforts may also provide a deeper understanding of the three approaches through detailing their theoretical, methodological, and statistical differences.
To achieve our objectives, we review the three approaches below, paying a particular focus to the family of research questions that each most appropriately addresses. We also directly note the differences between the approaches, such as differences in modeling and interpretation. Then, we discuss ergodicity. Data are ergodic when the sample is completely homogeneous and stationary, which is the necessary condition for each approach to provide identical results to a single research question. This discussion concludes that data are very rarely ergodic, further emphasizing the need to apply the most appropriate approach for a particular research question. To aid our discussion and clearly demonstrate our suggestions, we include illustrative examples using real data. These examples investigate emergent features of employee performance and include analyses from the variable-centered, person-centered, and person-specific approaches. By viewing the approaches together, we believe that their methodological, statistical, and theoretical differences can be better understood, suggesting that they are complementary, not competitive, methods to address various research questions.
Background
Empirical research is first and foremost driven by the chosen research questions and/or hypotheses, which should determine the appropriate approach to apply. For this reason, it is important to understand which of the three approaches are most relevant to certain types of research questions and hypotheses. The following sections, along with Table 1, are offered as a summary guide to achieve this goal, and they also detail the many methodological as well as theoretical implications of variable-centered, person-centered, and person-specific approaches.
Comparison of the Three Separate Approaches.

Note: These three methods will produce equivalent conclusions only when data are ergodic.
Variable-Centered Approaches
The variable-centered approach is the traditional and dominant approach in the social sciences, and its purpose is to explain relationships between variables of interest in a population. Accordingly, the approach is appropriate for investigating research questions and hypotheses regarding the effects of one variable on another (examples below). To achieve this end, data are typically collected from many subjects across one or more occasions, and common associations are identified across a sample to summarize a population with a single set of parameters. The number of subjects and occasions differs based on the specific analysis applied (e.g., correlation, regression, t test). The suggested minimum sample size for variable-centered analyses range from 30 to a few hundred subjects, depending on the chosen analysis and expected effect size (Bosco, Aguinis, Singh, Field, & Pierce, 2015; Cohen, 1992), but researchers have collected samples as large as 14,825 (Marsh, 1990), 39,879 (Ellingson, Smith, & Sackett, 2001), or even more than 500,000 (G. Lewis & Sloggett, 1998). The number of occasions is often relatively small, such as one to four, when applying the variable-centered approach (Ployhart & Vandenberg, 2010; Ployhart & Ward, 2011).
At a conceptual level, changes in theoretical perspective are the largest sources of distinction between the three approaches (Sterba & Bauer, 2010a). While many attributes can be used to detail the differences in theoretical perspectives, we use two due to their clarity and simplicity: specificity (how precise are the results in describing the subjects) and parsimony (how simple are the results to meaningfully interpret). Of the three approaches, the variable-centered approach provides the least amount of specificity, as the entire sample is described together, but it is also the most parsimonious, as only a single set of averaged parameters is produced. Thus, variable-centered approaches result in a general set of parameters that is typically easy to interpret.
Furthermore, the theoretical perspective of the variable-centered approach, as well as the other two approaches, can be illustrated through the example of a researcher studying cognitive ability and job performance. A natural initial research question may be: What are the emergent dimensions of cognitive ability? And a follow-up research question may also be: What is the association of these cognitive ability dimensions with job performance? These research questions, by nature of their variable-focused content, indicate that the researcher should use a variable-centered approach. Using this approach, the researcher could collect data on many participants at one time point, then use factor analysis to identify the dimensions. Once the dimensions have been identified, the researcher could perform a regression analysis to determine the cognitive ability-performance parameters to describe an entire sample and, by extension, population. For both the factor analysis and the regression analysis, a single set of parameters would be provided that would be assumingly representative of the sample and population of interest.
Person-Centered Approaches
The person-centered approach (e.g., mixture models, cluster analyses) is quickly growing in popularity due to the finer-grained detail that it allows (Collins & Lanza, 2013; McCutcheon, 1987; Vermunt & Magidson, 2004). 3 This approach is used to identify the dynamics of emergent subpopulations in a sample based on a set of chosen variables, and it is appropriate for investigating research questions and hypotheses aimed at (a) categorizing subjects into common subpopulations based on substantive variables and (b) understanding the relations of these subpopulations with predictors, correlates, or outcomes.
Like the variable-centered approach, data are typically collected from many subjects across one or more occasions, but the exact number of subjects depends on the analysis. In general, larger sample sizes (>500) are often deemed most appropriate for mixture models; however, smaller sample sizes (>200) may be adequate in some circumstances or if appropriate modifications to the models are made (for further review, see Meyer & Morin, 2016; Nylund, Asparouhov, & Muthén, 2007). Small sample sizes that may be appropriate for variable-centered analyses, such as 30 to 200, may create convergence problems for person-centered analyses and make it difficult to identify smaller profiles (Vargha, Bergman, & Takács, 2016). Also, like the variable-centered approach, the number of occasions used in longitudinal research is often restricted to a relatively small number, but depends on the specific approach applied. For example, latent transition analysis often relies on only two or three occasions (Kam, Morin, Meyer, & Topolnytsky, 2016; Lanza, Patrick, & Maggs, 2010; Rinne, Ye, & Jordan, 2017), while growth mixture modeling typically employs three to five occasions (Griese, Buhs, & Lester, 2016; Henson, Pearson, & Carey, 2015; Kirves, Kinnunen, De Cuyper, & Makikangas, 2014).
Unlike the variable-centered approaches that produce a single set of population parameters, however, person-centered approaches may produce many sets of parameters. The goal of person-centered approaches is to determine and describe the optimal number of subpopulations in the sample that are needed to give the greatest chance that this finite number of sets of parameters will yield an accurate summary of the people in the sample (Collins & Lanza, 2013; McCutcheon, 1987). Subsequently, of the three approaches, the results of the person-centered approach provide a moderate amount of specificity, as multiple subpopulations are described separately rather than the entire sample together; and they provide a moderate amount of parsimony, as multiple sets of parameters are produced rather than only one. Thus, the person-centered approach results in multiple sets of parameters that more narrowly detail the identified subpopulations, but the results may be more difficult to interpret as each subpopulation results in these differing parameters.
Furthermore, the multitude of person-centered analyses allow for many research questions to be tested from this perspective. For example, latent class and latent profile analyses are used to identify latent subpopulations in a population based on a certain subset of variables, and the relation between subpopulation membership and a variety of covariates can then be analyzed (Collins & Lanza, 2013; McCutcheon, 1987). Latent transition analysis achieves a similar purpose, but it identifies profiles and a subject’s movement between these profiles over time (Collins & Lanza, 2013; Lanza, Bray, & Collins, 2013). Likewise, growth mixture models also identify profiles, but the profiles in this analysis are based on longitudinal trajectories (Griese et al., 2016; Meyer & Morin, 2016). Therefore, not only are cross-sectional research questions able to be addressed, but the person-centered approach can address an array of longitudinal research questions.
Using the same example as before, a researcher studying cognitive ability and job performance may create the following research questions: What emergent subpopulations can be identified through the dimensions of cognitive ability? What is the relation of these subpopulations to performance? Because these research questions suggest the existence of identifiable subpopulations, they indicate that the researcher should use a person-centered approach, and the researcher could again collect data on many participants at one time point. They could then perform a latent profile analysis to identify the emergent subpopulations and the relationship of each subpopulation with performance. The results would then be generalized to all subjects that may be represented by these subpopulations.
Person-Specific Approaches
The person-specific approach is currently underutilized in management and applied psychology, but it is growing in popularity—particularly with those studying change and development (Boswell, Anderson, & Barlow, 2014; Rose, Rouhani, & Fischer, 2013; Sterba & Bauer, 2010a). Many such authors have adopted a holistic-interactionist perspective (Keenan, 2010; Thelen, 2005; Trop, Burke, & Trop, 2013), which Sterba and Bauer (2010a) describe aptly: “an individual’s prior behaviors, genetic makeup, and contextual risk or protective factors operate as an integrated whole; taken in isolation, they may lose their meaning and consequence for that individual’s behavioral course” (p. 239). This perspective mandates that the individual must be viewed as an integrative and complex system, and statistical analyses need to treat individuals as such. If a research question or hypothesis is focused on the person, then analyses that aggregate across a sample to draw inferences about variables or even subpopulations are insufficient to address these research questions and hypotheses. Thus, in these cases, the variable- and person-centered approaches should not be applied, but the person-specific approach is ideal.
The person-specific approach is used to investigate effects that may be idiosyncratic to specific subjects. Data are usually collected from a small number of subjects, often as small as one, across many occasions. The suggested number of occasions differs based on the applied analysis (Jones & Nesselroade, 1990; Molenaar, 2004, 2015; Molenaar & Campbell, 2009). As data are analyzed across the many occasions to derive inferences about the individual, the statistical influence of the number of occasions is similar to the statistical influence of sample size for variable- and person-centered analyses. Prior researchers have collected as many as 80 (Molenaar et al., 2009), 90 (Borkenau & Ostendorf, 1998), or even more than 100 (Ram, Brose, & Molenaar, 2013) occasions when performing person-specific analyses.
When using the person-specific approach, researchers seek multiple models or sets of parameters that describe each of the subjects in the sample, and inferences are not necessarily meant to be made about populations. In some cases, a model or set of parameters may be reported for each individual subject. 4 Of the approaches, the results of person-specific analyses provide the most specificity, as each subject can be described separately, but the least parsimony, as a separate model or set of parameters is created for each subject. Thus, the person-specific approach results in models or sets of parameters that entirely detail the individual subject, but the results are often more difficult/time-consuming to interpret.
Perhaps the most popular person-specific techniques are state-space modeling, dynamic factor analysis, and p-technique factor analysis. As our empirical example below includes the latter of these, we detail the other two here. Both state-space modeling and dynamic factor analysis were created to model the idiosyncratic, within-subject, and time-lagged relationships of latent and/or measured variables (Chow et al., 2010; Gu, Preacher, & Ferrer, 2014; Ram et al., 2013), and dynamic factor analysis may even be considered a special instance of state-space modeling (Jungbacker & Koopman, 2008; Molenaar, 2003). Both of these methods use a framework similar to structural equation modeling (SEM). As Molenaar (2003) states, In the realm of signal analysis and time series analysis, state-space modeling occupies a similar position as structural equation modeling does in multivariate statistical analysis. The state-space model can be regarded as a kind of canonical model ranging over almost all linear models used in signal analysis and time series analysis. Moreover, the formal structure or layout of the state-space model bears a close relationship to the general structural equation model. (p. 2)
Person-specific analyses such as these have often been applied in high-stakes situations (due to the need to model the specific subject) or when subjects greatly vary from each other (due to the inability of other methods to adequately model person-specific effects) (Beltz, Wright, Sprague, & Molenaar, 2016; Molenaar, 2015; Wright et al., 2016). For instance, Wright et al. (2016) used the person-specific approach to better understand the individualized psychological structures of those with borderline personality disorder, as it is a widely varying condition with potentially severe outcomes. The results showed that participants’ psychological structures ranged from nuanced to basic, the latter only distinguishing between positive and negative emotions and stimuli; however, each of the exemplar cases was able to be matched with relevant, and often differing, psychological theory (Wright et al., 2016). In organizational research, employee coaching may have similar needs. Failed coaching endeavors are costly, and employees may have very different reactions to the same coaching techniques (Gregory & Levy, 2010; Heslin, Vandewalle, & Latham, 2006). Likewise, failed expatriate assignments are costly, and it is unrealistic to expect all expatriates to have similar experiences, perceptions, emotions, behaviors, and so forth (Chang, Gong, & Peng, 2012; Mendenhall & Oddou, 1985). By using the person-specific approach, researchers could better understand the individualized and contextualized nature of coaching and expatriate assignments, which could provide theoretical benefits. At the same time, the person-specific approach could allow organizations to better understand individual employees during these experiences.
The person-specific approach has also been used to model dynamics that change too frequently and irregularly to expect a single model or set of parameters to adequately explain an entire population or even a subset of the population (Molenaar & Campbell, 2009; Molenaar et al., 2009; Ram et al., 2013). Many authors have shown using person-specific analyses that people’s affect may change in unexpected ways, even when they undergo the same events (Hershberger et al., 1995; Molenaar et al., 2009; Ram et al., 2013). Perhaps more importantly, these person-specific investigations have shown that subject’s affect trajectories are highly personalized, and other approaches may provide a misleading depiction of affect due to their focus on samples or subsets. In other words, the personalized nature of affect may be lost in the aggregation required for the variable- and person-centered approaches (Molenaar et al., 2009; Ram et al., 2013). Studying affect in organizational settings using the person-specific approach would require few changes from these earlier investigations, and such studies could provide new perspectives on weekly, daily, and even hourly idiosyncratic fluctuations in affect (Hershberger, Corneal, & Molenaar, 1995; Molenaar et al., 2009; Ram et al., 2013). Beyond affect, recent authors have called for finer-grained research using the experience sampling methodology (ESM) across most all research domains (Beal, 2015; Fisher & To, 2012), and several authors have supported the use of person-specific analyses for “intensive longitudinal data” (i.e., many measurement occasions) that can be gathered using ESM (Gates & Liu, 2016; Hamaker, Grasman, & Kamphuis, 2016). Given that even the Big Five personality facets vary enough when measured via ESM for meaningful person-specific analyses (Borkenau & Ostendorf, 1998; Fleeson, 2001), ESM appears to be a clear avenue for the person-specific approach to provide new and meaningful perspectives.
Returning to the prior example, a researcher studying cognitive ability and performance may create the following research questions: What is the emergent dimensionality of cognitive ability for individual employees? What is the relationship of these individualized emergent dimensions with performance? Due to the focus on the individual subjects, these research questions indicate that the researcher should use a person-specific approach, and the researcher could collect data from a few participants at many time points. The researcher could then perform a dynamic factor analysis to identify the emergent dimensionality of cognitive ability for each subject and the relationship of these dimensions with performance—again for each subject. The resultant models would describe each individual subject, but specific individuals’ models may be unable to describe other individuals—unless multiple models were aggregated together.
Ergodicity: When the Three Approaches Converge
Thus far, we have emphasized the differences between the three approaches. While typically distinct, these three approaches can provide identical results under certain conditions. Collectively, these conditions are called ergodicity (Birkhoff, 1931; Krengel & Brunel, 1985; Molenaar, 1985, 2004). Data are ergodic when the sample is completely homogeneous (all subjects are exact replications and interchangeable) and stationary (constant mean, variance, and sequential covariance). When data are ergodic, a single model and set of parameters can accurately describe the sample as well as each subject. The further the data are from ergodicity, however, the further the results will be from identical (Birkhoff, 1931; Molenaar, 1985, 2004).
It should be noted, however, that data in the social sciences are virtually never ergodic. Subjects differ among themselves for almost any possible variable, even if only slightly, thereby violating the assumption of homogeneity. Similarly, subjects vary across time for almost any possible variable. Studies have shown that even traits, which are often believed to be relatively stable, are not perfectly unchanging (Cobb-Clark & Schurer, 2012; Specht, Egloff, & Schmukle, 2011). People undergo developments as they age, but they also express relatively short-term variations in many aspects of the self (Kernis, Cornell, Sun, Berry, & Harlow, 1993; Kernis, Grannemann, & Mathis, 1991). Both of these temporal changes violate the assumption of stationarity. Also, in every published investigation of ergodicity, researchers have never found any data that satisfied these necessary conditions (Lerner, Hershberg, Hilliard, & Johnson, 2015; Molenaar, 2008; Molenaar & Campbell, 2009). For these reasons, researchers applying the person-centered or person-specific approach often assume that data are not ergodic, no matter the sample or the collection of variables.
Furthermore, authors applying person-specific approaches have long argued that only person-specific approaches provide accurate results regarding individual subjects when data are not ergodic (Baltes, Nesselroade, & Cornelius, 1978; Cattell, 1951; Jones & Nesselroade, 1990; Molenaar & Campbell, 2009; Sterba & Bauer, 2010a). These authors argue that applying a single set of parameters, as in variable-centered analyses, or applying a small number of sets of parameters, as in person-centered analyses, inappropriately suggests that all subjects in a sample adhere to these parameters. In fact, prior research has shown that all subjects in a sample may greatly differ from the obtained set of parameters, and considering the set of parameters as representative of all individual subjects may be misleading (Molenaar, 2004, 2015). Based on these findings, it could be argued that specificity becomes more important when data are further from ergodicity, but it is often unclear exactly when specificity becomes more important than parsimony. Thus, because data are almost always guaranteed in research and practice to not be ergodic (to some extent), authors need to more strongly consider the tradeoff between specificity and parsimony in regard to the variable-centered, person-centered, and person-specific approaches. Choosing an approach that does not fit with the research question or hypothesis may result in inappropriate or inaccurate inferences.
At the same time, however, analyzing a different model or set of parameters for each subject may be a very cumbersome process with severely decreased utility in applied settings. For example, it would be extremely time consuming to analyze a person-specific model or set of parameters for each individual subject when investigating research questions and hypotheses regarding variables or subpopulations within a sample. For these reasons, it is even more critical that researchers and practitioners understand the purposes behind the three approaches, as they are not appropriate for all research questions. To aid in the identification of the appropriate approach for various research questions, we provide an illustrative example.
An Illustrative Example
Employee performance is often considered the ultimate outcome of organizational research, and it is regularly used to define employee success, thereby guiding personnel selection, training and development, and a host of other important organizational functions (Austin & Villanova, 1992; Bommer, Johnson, Rich, Podsakoff, & MacKenzie, 1995). A vast number of studies have analyzed performance through variable-centered analyses (Chiaburu & Harrison, 2008; Gilboa, Shirom, Fried, & Cooper, 2008; Judge, Heller, & Mount, 2002), and a much smaller number have analyzed performance through person-centered analyses (de Menezes, Wood, & Gelade, 2010). Virtually no studies have used person-specific analyses to study performance. To demonstrate the differences between each of these approaches, we apply the approaches separately to investigate the dynamics of employee performance. To do so, a unique dataset is required.
In general, the accuracy of variable- and person-centered approaches benefits from increasing the number of subjects, whereas the accuracy of person-specific approaches benefits from increasing the number of observations. For this reason, it is difficult to obtain an organizational dataset that is appropriate for variable-centered, person-centered, and person-specific approaches. Thus, we offer the following illustration, using actual player data from the National Basketball Association (NBA), as an example of the strengths of each approach. The player data include 10 common performance metrics that are detailed below.
When investigating player performance, a researcher may be interested in several different research questions: (a) What is the dimensionality of overall player performance? (b) What are the emergent subpopulations as defined by player performance? (c) What is the dimensionality of performance for individual players? No single approach can be used to answer each of these various questions. Rather the variable-centered, person-centered, and person-specific approaches, respectively, must each be used to answer the questions; each approach offers important information that could be used to make subsequent personnel and training decisions. Thus, no one approach is the “best.” Instead, the information provided by each approach addresses different research questions, and researchers should apply the approach that best fits with their purpose. It should be noted that space here is too limited to present the entirety of each analysis, but efforts will be made to highlight the important results and distinctions among the varying methods. All syntax is included in the appendix.
The Dataset
The dataset used to demonstrate each approach includes the game-by-game statistics of each NBA player during the 2011-2012, 2012-2013, 2013-2014, and 2014-2015 seasons. To ensure that sufficient data were present for each of the chosen analyses described below, players that played fewer than 50 games across these four seasons were removed. The number of occasions was the largest concern for the chosen person-specific analysis, and the choice to only retain those that played more than 50 games was guided by prior suggestions (Jones & Nesselroade, 1990; Molenaar & Nesselroade, 2009). This resulted in the inclusion of 520 players, which is a typical sample size in organizational research (Bartlett, Kotrlik, & Higgins, 2001; Bosco et al., 2015; Conway & Huffcutt, 2003). For each player and each game, 10 different performance metrics were recorded. These metrics were two-point field goals, three-point field goals, free throws, offensive rebounds, defensive rebounds, assists, steals, blocks, turnovers, and personal fouls. Each of these metrics is described below.
Two-point field goals—The goal of a basketball team is to score the most points in a game, and FGs are the most common method to score. A two-point field goal occurs when a player places the basketball through the hoop while inside of the three-point line.
Three-point field goals—A three-point field goal occurs when a player places the basketball through the hoop while outside of the three-point line.
Free throws—If a team performs certain fouls, the opposing team is rewarded with the opportunity to shoot a certain number of free throws, which is an unguarded shot from a certain place on the court. Each successfully made free throw is worth one point.
Offensive rebound—A player is credited with an offensive rebound when he or she retrieves the basketball after a missed shot at his or her own basket.
Defensive Rebound—A player is credited with a defensive rebound when he or she retrieves the basketball after a missed shot at the opposing team’s basket.
Assist—A player is credited with an assist when he or she passes the basketball to a teammate and the teammate successfully makes a two-point field goal or three-point field goal shortly afterward.
Steal—A player is credited with a steal when he or she takes the basketball from an opposing player.
Blocks—A player is credited with a block when he or she physically prevents the basketball from entering the hoop when a player is attempting to shoot it.
Turnover—A player is credited with a turnover when he or she loses the basketball, whether the player drops the basketball or through an opposing player stealing the basketball.
Personal Fouls—A player is credited with a personal foul when he or she performs certain activities that are against the rules of the NBA.
In addition, a note should be made about the typical structure of an NBA team. Almost all NBA teams have three primary positions: centers, forwards, and guards. While each position is expected to score points, the other objectives of these positions differ. Centers are expected to position themselves near the hoop to obtain rebounds and block shooting attempts. In doing so, centers are expected to be aggressive, which also results in the negative consequence of personal fouls. Forwards position themselves slightly further from the basket than centers, but they are expected to achieve many of the same outcomes—obtaining rebounds and blocking shooting attempts while unintentionally incurring personal fouls. Guards are expected to possess the basketball the most, resulting in assists as well as turnovers, and they are also expected to defend the other team’s guard, resulting in steals. Guards are also expected to be good distance shooters, resulting in three-point field goals. When analyzing the noted research questions, we would expect any emergent dimensions or subpopulations to possibly fall in these different positions. For this reason, we use these positions as an initial theoretical basis to interpret and understand our observed results.
Variable-Centered Approach: What Is the Dimensionality of Player Performance?
To investigate the dimensionality of overall player performance, the game-by-game statistics of each NBA player was averaged together across all of his games played, such that each NBA player had a corresponding single value for each of the 10 performance metrics. In other words, instead of analyzing game-by-game statistics, the variable-centered approach analyzed the players’ average game performance across the four seasons. Once the data were appropriately averaged, an exploratory factor analysis (EFA), which is the traditional method to identify the dimensionality of underlying constructs across a sample, was performed (Conway & Huffcutt, 2003; Costello & Osborne, 2005; Fabrigar, Wegener, MacCallum, & Strahan, 1999; Schmitt, 2011). EFA is typically considered a variable-centered method, as it provides inferences about the interrelatedness and the underlying latent factors among a set of observed variables. Thus, it places a sole focus on the relationships among variables.
The analysis decisions for the EFA were guided by prior recommendations (Costello & Osborne, 2005; Hinkin, 1995, 1998; Howard, 2016). A principal axis factoring method with direct oblimin rotation was chosen. To determine the number of emergent factors, three methods were chosen. First, the scree plot was visually analyzed for an “elbow” or sharp decrease in eigenvalues, which suggests that factors after the elbow provided little explanatory information compared to those prior to the elbow (Nasser, Benson, & Wisenbaker, 2002; Zhu & Ghodsi, 2006). Second, a parallel analysis was used. Parallel analyses compare the obtained eigenvalues to the eigenvalues of a randomized dataset with an equal number of variables and subjects. If the obtained eigenvalue is greater than its respective eigenvalue from the randomized dataset, then the results indicate that the factor provides a nontrivial amount of information and it should be retained (Garrido, Abad, & Ponsoda, 2013; Hayton, Allen, & Scarpello, 2004; O’Connor, 2000). Third, prior results and theory regarding the dimensionality of NBA player performance were considered (Barnes & Morgeson, 2007; Rotundo, Sackett, Enns, & Mann, 2012).
From the visual scree plot analysis, the elbow appeared after the second factor, suggesting that a two-factor solution is appropriate (eigenvalues = 4.976, 2.733, 0.614, 0.539). Likewise, the parallel analysis suggested that a two-factor solution is appropriate, as only the first two factors had greater eigenvalues than the randomized dataset (95% CI parallel analysis eigenvalues = 1.312, 1.227, 1.160, 1.108). Last, the two-factor solution is largely in agreement with prior results and theory regarding the dimensionality of NBA player performance. Rotundo and colleagues (2012) discovered a three-factor solution when performing an EFA on NBA player data, but—as discussed below—the content of their three factors overlap greatly with the content of the discovered two factors in the current factor analysis.
Factor loadings can be seen in Table 2. The following variables loaded onto the first factor: two-point field goals, free throws, assists, steals, and turnovers; the following variables loaded strongly onto the second factor: offensive rebounds, defensive rebounds, blocks, and personal fouls; and three-point field goals loaded onto both factors—positively for the first and negatively for the second.
Variable-Centered Exploratory Factor Analysis Results.
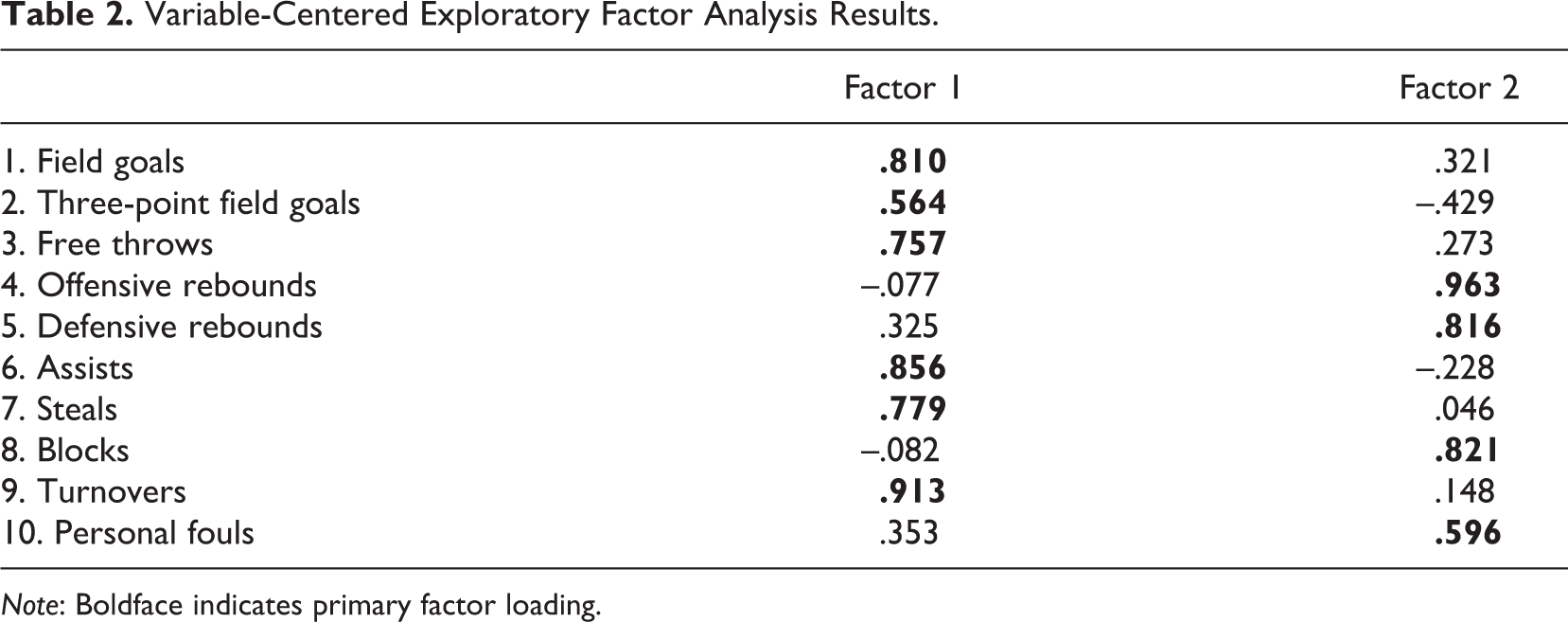
Note: Boldface indicates primary factor loading.
These results suggest that NBA basketball player performance can largely be separated into two separate domains. The first domain involves scoring and objectives usually performed by guards, assists and steals. This domain also includes the unintentional negative outcome that is also more often performed by guards, turnovers. Rotundo and colleagues (2012) labeled their factor that included solely assists and steals as “quick” (turnovers were not included in their analysis), but it was separate from their factor containing field goals and free throws that they labeled “scoring.” On the other hand, the second domain involves objectives usually performed by centers and forwards, rebounding and blocks, and the unintentional negative outcome that is more often performed by centers and forwards, fouls. Three-point field goals negatively loaded onto this factor. As centers and forwards position themselves close to the basket, it makes conceptual sense that this factor would include not obtaining three-point field goals. Rotundo and colleagues (2012) labeled their factor including rebounds and blocks as “tough” (fouls were not included in their analysis). Thus, these two emergent dimensions agree with the primary positions of basketball and prior research on the dimensionality of NBA player performance.
From applying the variable-centered approach and performing an EFA, these two dimensions describe the overall sample and can be used to understand the underlying domains of player performance. In general, players that score also obtain assists and steals, whereas players that rebound also obtain blocks. Now, these dimensions can be used to create standards of performance for guards as well as centers and forwards. A factor score could be created for each player for each dimension, and they could be ranked based on this factor score. Also, the parsimony of the results should be highlighted. A single set of factors and item loadings describe the entire sample, and there is not a need to interpret multiple models or sets of parameters. However, the results are not very rich. Little can be said that is specific to individual players or even subpopulations of players, unless these subpopulations are defined beforehand and analyses treat them as separate samples. With these results in mind, we now perform a person-centered analysis of NBA player performance data to illustrate the differences among the approaches.
Person-Centered Approach: What Are the Emergent Subpopulations as Defined by Player Performance?
Using the same dataset as the above variable-centered analysis—520 players’ average game performance across four NBA seasons—a latent profile analysis (LPA) was conducted. LPA is considered a finite mixture model which takes continuous variables as input to determine the optimal number of subpopulations (i.e., latent profiles) that are needed to maximize the chance of providing a good summary of the individuals in the sample (Lazarsfeld & Henry, 1968; Meyer & Morin, 2016). LPA also calculates the probability of each individual belonging to each of these subpopulations. LPA is considered a person-centered method, as opposed to a variable-centered method, because LPA seeks to determine patterns of multiple variables within individuals that then consistently recur across individuals, in contrast to the effects of single variables (or interactions) across individuals. Because of this, it might best be considered a hybrid method containing aspects of variable-centered and person-specific analyses. In the current context, LPA was used to detect and describe a relatively parsimonious set of profiles among the data. It should be noted here that LPA does not represent all person-centered analyses; rather, LPA is a part of one group of person-centered methods labeled mixture models which also includes methods such as latent transition analysis, growth mixture models, factor mixture models, and mixture regression (Meyer & Morin, 2016; B. Muthén, 2002).
To identify the ideal number of player profiles in the current dataset, Mplus v.7 (L. K. Muthén & Muthén, 2012) was used to compare models with one to five profiles from the game statistics—at which point the solutions failed to show adequate improvement or became unstable. Based on prior recommendations and empirical works (Meyer, Morin, & Vandenberghe, 2015; Morin et al., 2011; Peugh & Fan, 2013), we originally allowed all profile means and variances to be freely estimated. These models, however, tended to either converge on improper solutions (i.e., nonpositive definite Fisher information matrix) or did not replicate well despite increasing the number of random starts or iterations. Subsequently, a more parsimonious model whereby the means, but not the variances, were freely estimated across the profiles was deemed appropriate.
Selection of the best fitting model was based on several statistical fit criteria: Akaike information criterion (AIC), Bayesian information criterion (BIC), sample-size-adjusted Bayesian information criterion (aBIC), entropy, Lo-Mendel-Rubin likelihood ratio test (LMR), and bootstrapped likelihood ratio test (BLRT; Foti, Bray, Thompson, & Allgood, 2012; Lanza et al., 2013). The greatest weight, however, was placed on the conceptual interpretation of the model (Bray, Foti, Thompson, & Willis, 2014). See Table 3 for the statistical fit criteria. Better model fit is indicated by lower values for the AIC, BIC, aBIC, and higher values for entropy indicate greater classification accuracy—although informative, entropy should not be used to determine the number of profiles. Significant LMR and BLRT p values indicate that the current model fits better than one with one less profile. As can be seen from Table 3, most of the statistical fit criteria indicate better fit as more profiles are added to the model, which is not uncommon for LPAs. The 3-profile model was selected as the best fitting model because (a) the improvement in statistical fit values (i.e., LL, AIC, BIC, and aBIC) diminishes after the 3-profile model, (b) the LMR and BLRT p values suggest that the 3-profile model is better than the 2-profile model and that the 4-profile model is not better than the 3-profile model, and (c) the 3-profile model was interpretable on the basis of typical basketball player roles. To this last point, the proportions of the three profiles are all of sufficient size and appear accurate to what we might expect in the NBA population.
Model Fit and Selection Criteria for LPAs.
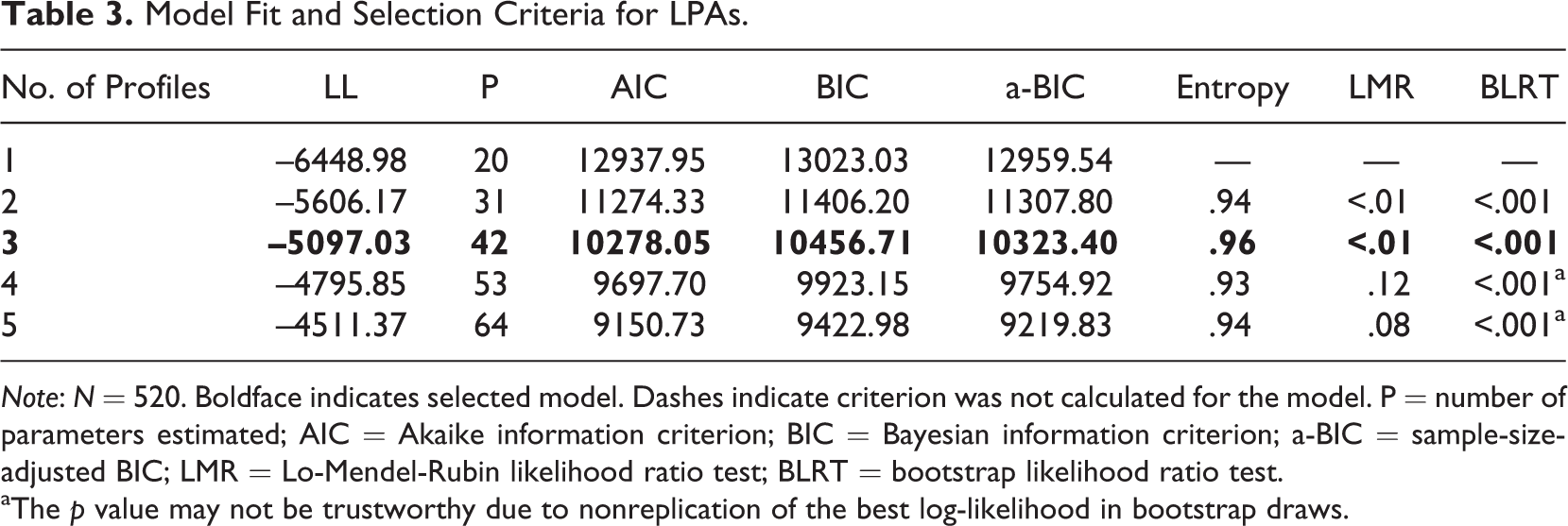
Note: N = 520. Boldface indicates selected model. Dashes indicate criterion was not calculated for the model. P = number of parameters estimated; AIC = Akaike information criterion; BIC = Bayesian information criterion; a-BIC = sample-size-adjusted BIC; LMR = Lo-Mendel-Rubin likelihood ratio test; BLRT = bootstrap likelihood ratio test.
aThe p value may not be trustworthy due to nonreplication of the best log-likelihood in bootstrap draws.
To interpret these three profiles, we focused on two sets of parameters: the item response means (i.e., variable means specific to each profile) and latent profile membership proportions (i.e., how many individuals probabilistically belong to each profile; Bray et al., 2014). Table 4 presents a summary of these parameters for the three-profile model, and Figure 1 visually depicts the profiles to compare emergent patterns. Within-profile item means and subpopulation rankings were used to interpret and subsequently name each profile in the model. Consequently, the profiles were labeled Typical Shooters, Big Men, and Playmakers.
Parameter Estimates for the Three-Profile Model.
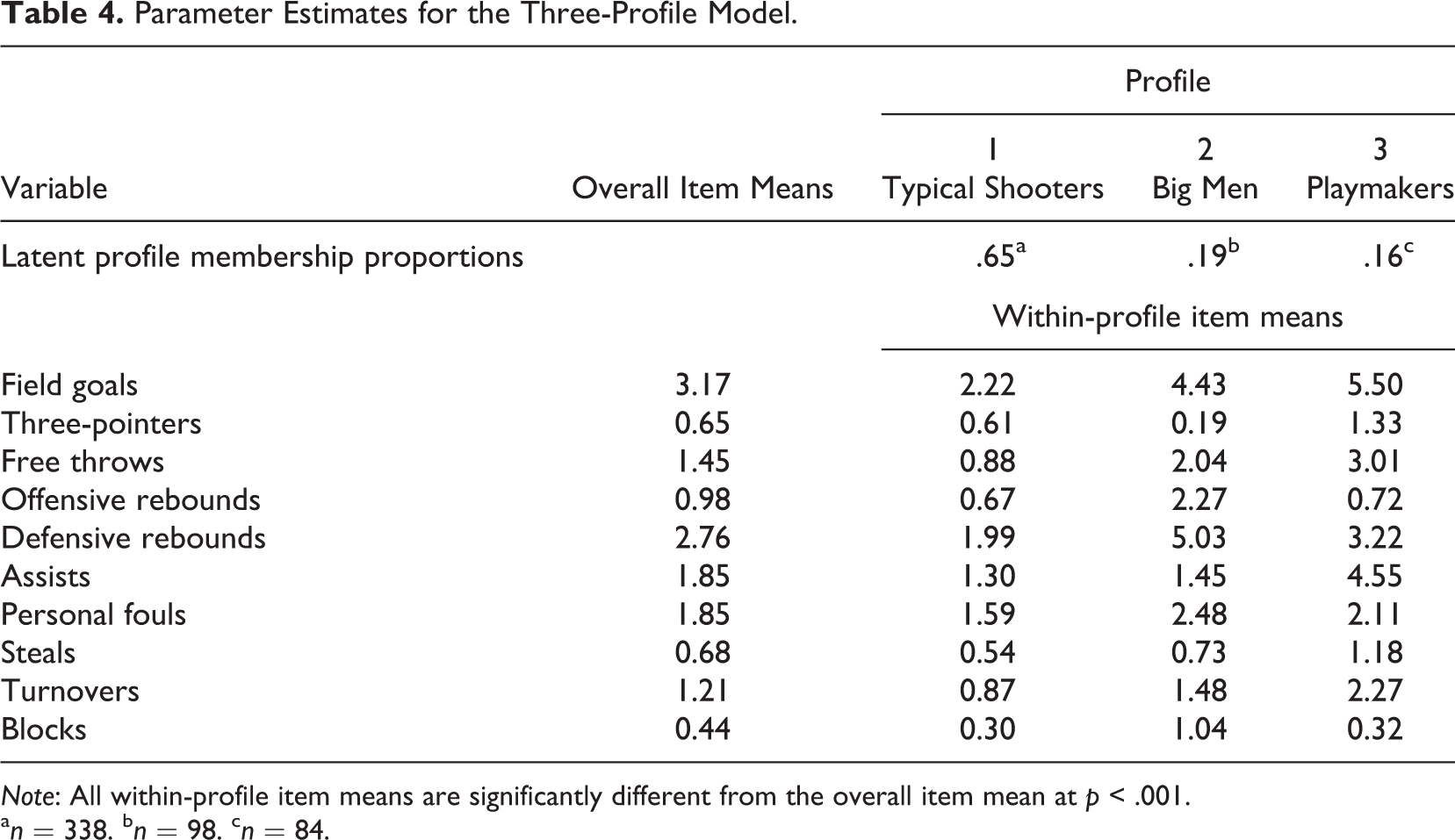
Note: All within-profile item means are significantly different from the overall item mean at p < .001.
a n = 338. b n = 98. c n = 84.
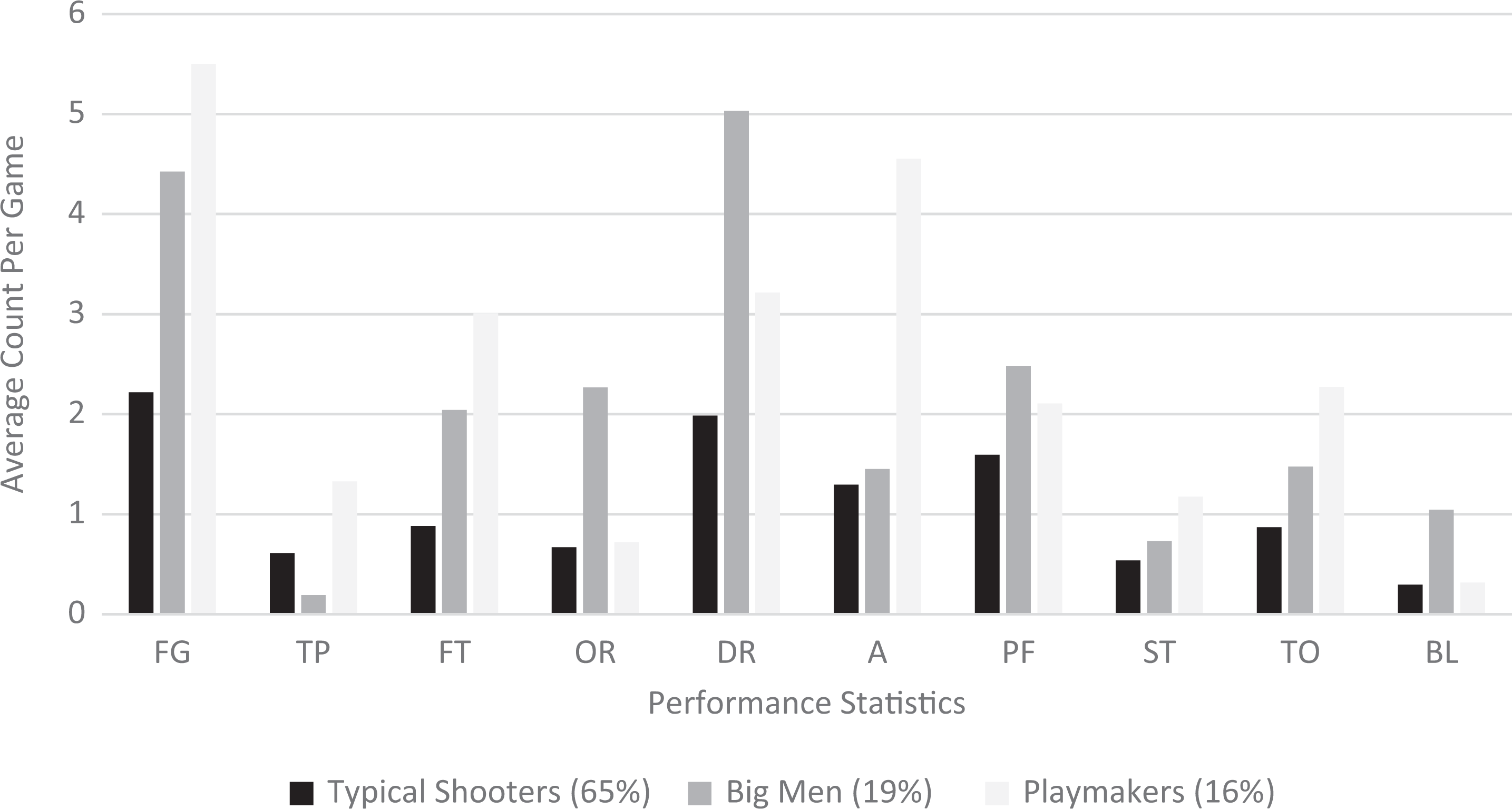
Within-profile item means.
Typical Shooters were characterized by generally low performance statistics across all metrics. These players were the lowest, on average, in every category except for three-point field goals. In addition, this was the largest profile, consisting of nearly 65% of the sample. In the three-point field goal category, Typical Shooters were higher than only Big Men. The Big Men (19% of the sample) profile statistics are characteristic of a basketball player role for individuals who play near to the basket—typical of the bigger players on a team (i.e., centers and forwards). This profile ranked second in two-point field goals, free throws, assists, steals, and turnovers. Where the Big Men profile really stands out, however, is in their relatively very high average statistics in offensive rebounds, defensive rebounds, and blocks. Last, the smallest profile (16% of the sample) of players was labeled Playmakers because they account for, on average, the highest scorers (i.e., two-point field goals, three-point field goals, and free throws) in the sample as well as the players who are responsible for the most assists and steals.
The results presented in this section share some conceptual overlap with the results presented in the variable-centered approach section, but also give us added information. While the variable-centered approach offered two factors that could be generally used to distinguish centers and forwards from guards, the person-centered approach offers three profiles that can be used to discriminate these groupings even further. Whereas with the variable-centered approach we made the assertion that players who score also obtain assists and steals, and players who rebound also obtain blocks, our description of these types of players can now be a little more fine-grained with the current approach. For example, with the LPA we found that the Playmakers profile did show that those individuals with the most assists also, on average, scored most often (i.e., FG, TP, and FT) and had the most turnovers, but we also found that the Big Men profile which represented the individuals who accumulated the most rebounds and blocks, also scored quite often (i.e., FG and FT). In addition, the Playmakers profile also accounted for a relatively high number of personal fouls which was primarily associated with rebounding and blocking (i.e., centers and forwards) in the variable-centered section. These more specific nuances of the three defined profiles are insights that did not emerge with the variable-centered approach. Moreover, if it is of value to our research, we would be able to make more specific comparisons between these subpopulations on each variable.
As can be seen by this summary, the person-centered LPA allows for a richer, more detailed picture of the data, but also affords relatively less parsimony than the variable-centered approach (i.e., two summarized factors vs. multiple detailed subpopulations) and requires more interpretation. Now let us turn to the richest, yet least parsimonious, of the three approaches.
Person-Specific Approach: What Is the Dimensionality of Performance for Individual Players?
To investigate the dimensionality of performance for individual players, the game-by-game statistics of each NBA player was analyzed directly and not averaged together, unlike the variable- and person-centered analyses. This resulted in each NBA player having their own respective dataset including each of the 10 performance metrics. A p-technique EFA was performed on each individual dataset. Traditionally, p-technique factor analysis is the most popular method to identify the idiosyncratic dimensionality of underlying constructs within individual people (Jones & Nesselroade, 1990; Molenaar & Campbell, 2009; Molenaar & Nesselroade, 2009). While observed variables of interest must be chosen, the focus on the emergent dimensionality within individual people causes p-technique EFA to be considered a technique within the person-specific approach.
The analysis decisions for the p-technique EFA were also guided by prior recommendations (Jones & Nesselroade, 1990; Molenaar & Campbell, 2009), which were largely in agreement with the recommendations for the variable-centered EFA (Costello & Osborne, 2005; Hinkin, 1995, 1998; Howard, 2016). A principal axis factoring method with direct oblimin rotation was chosen. To determine the number of factors, however, only one method was applied. Due to the large number of p-technique EFAs performed (520), a visual scree plot analysis could not be applied to each of them. Likewise, each p-technique EFA could not be considered in the context of prior theory and results. For these reasons, parallel analysis was chosen to determine the factor cutoff for each p-technique EFA, as it is among the most reliable methods to determine the number of factors and it can be applied in a relatively automated manner (Garrido et al., 2013; Hayton et al., 2004; O’Connor, 2000).
From performing a p-technique EFA and a parallel analysis to each individual player’s dataset, the emergent number of factors ranged from one to nine—almost the entire range of possible values. The average number of emergent factors was 2.48, the median was two, the mode was two, and the distribution of values had a positive skew (Figure 2). From these results, it is evident that the idiosyncratic factor structure for most individual players, obtained through a person-specific analysis, does not adhere to the factor structure for the overall sample obtained through a variable-centered analysis (169 participants with a two-factor solution, 351 participants without a two-factor solution). These differences indicate that the data are not ergodic, but they also highlight that each approach is used to address different families of research questions. Likewise, these results also differ from those obtained through the person-centered analysis. The p-EFA did not identify certain subpopulations within the sample or separate participants based on the probability of their belonging to these subpopulations. Instead, a single model and set of parameters was provided for each player.
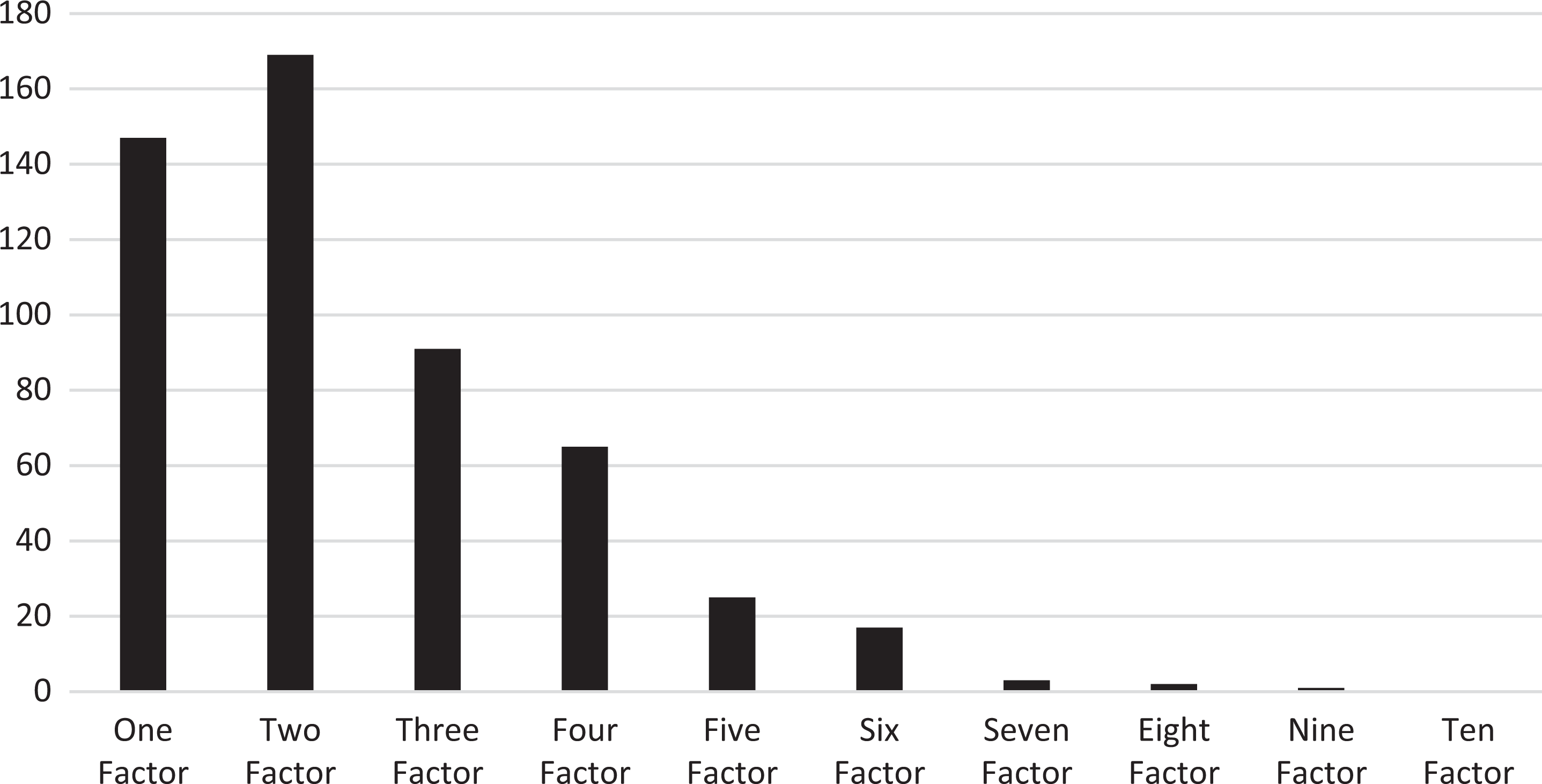
Number of emergent factors from p-technique exploratory factor analyses.
While the above results describe the emergent, idiosyncratic dimensionality of all players’ performance, it does not detail the dimensionality of performance for certain individual players. To answer this research question, the factor structure of certain individual players must be separately analyzed. Four player’s factor structures were separately analyzed, and these were chosen due to their illustrative benefits and differing number of factors: two, two, four, and nine.
The first chosen player was a guard, and he had a two-factor solution (Table 5). The first factor appears to represent a scoring dimension, as it consists of field goals and three-point field goals. The second factor appears to represent almost all other metrics, as it consists of all other metrics other than blocks. From this, it appears that the first player’s performance in scoring was largely independent of the other metrics of performance.
Person-Specific Exploratory Factor Analysis Results of Player 1.

Note: Factor loadings smaller than .30 not shown.
The second player was a center, and he had a two-factor solution (Table 6), but it was notably different from the first player. The first factor represents two-point field goals and steals, whereas the second factor represents rebounding (both offensive and defensive) as well as errors (turnovers and personal fouls).
Person-Specific Exploratory Factor Analysis Results of Player 2.

Note: Factor loadings smaller than .30 not shown.
The third player was a forward, and he had a four-factor solution (Table 7). These factors were also notably different from the first and second player, but they could be meaningfully interpreted. The first factor likewise represented a scoring dimension, as it consisted of field goals and three-point field goals. The second factor only consisted of free throws, and the third factor only consisted of offensive rebounds. The fourth factor consisted of defensive rebounds, assists, and turnovers. These results suggest that many aspects of the player’s performance were largely independent of each other, but certain aspects of performance were still closely linked.
Person-Specific Exploratory Factor Analysis Results of Player 3.

Note: Factor loadings smaller than .30 not shown.
Last, the fourth player was a forward, and he had a nine-factor solution (Table 8). Only one performance metric loaded onto each of these factors, indicating that each aspect of the fourth player’s performance was almost entirely independent.
Person-Specific Exploratory Factor Analysis Results of Player 4.
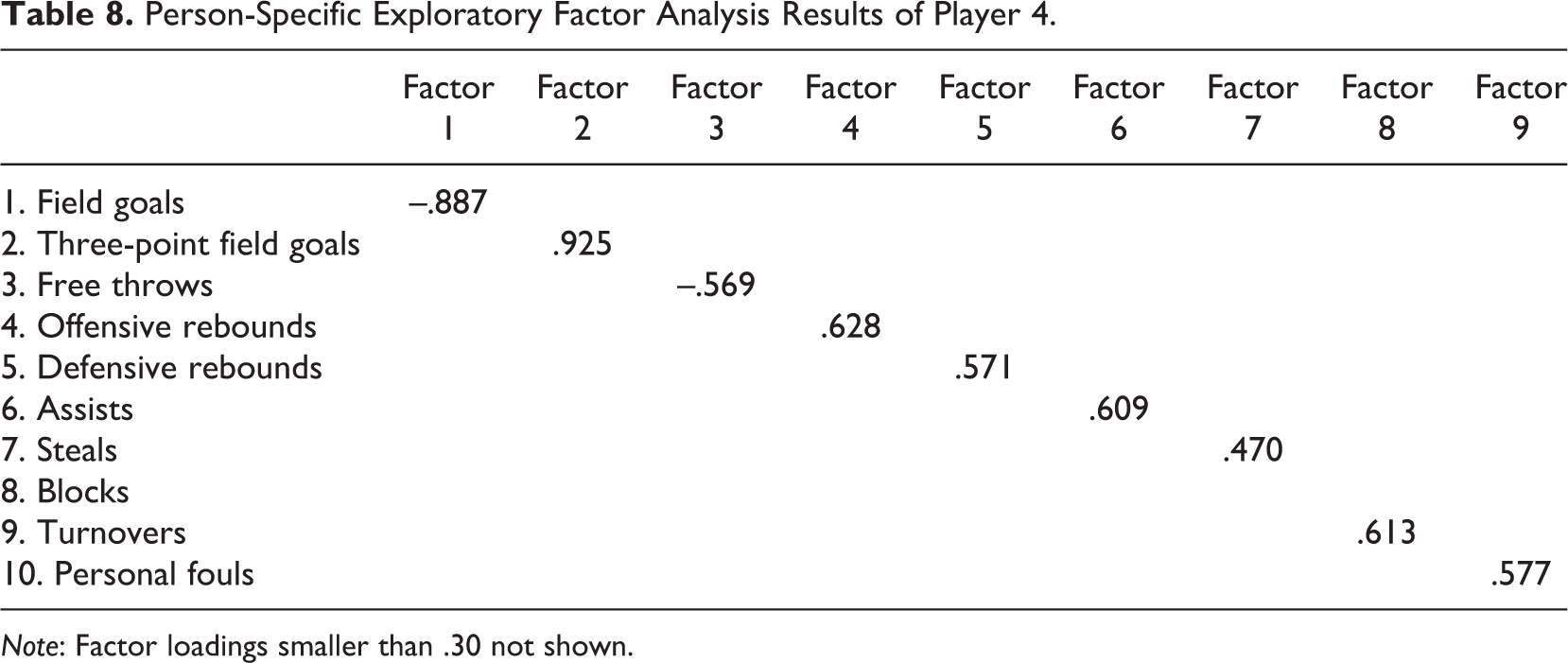
Note: Factor loadings smaller than .30 not shown.
From these results, several notes should be made about the nature of the person-specific approach and its differences with the variable- and person-centered approach. The p-technique factor analysis provided very rich results. A separate model and set of parameters could be provided for each player, which allows for a thorough understanding of the emergent dimensionality of person-specific performance. We could identify which performance metrics represented a common underlying dimension, and we were able to observe that these underlying dimensions had great variation among the players. On the other hand, the results were not very parsimonious. A separate model and set of parameters was reported for each individual player, causing a p-technique factor analysis of each player within the entire sample to be extremely cumbersome. Discussing only a few of the resultant factor models was the only method to concisely detail the nature of the observed differences. For this reason, the person-specific approach is less apt at answering questions akin to, “What is the dimensionality of overall player performance?” But the approach is quite apt at answering questions akin to, “What is the dimensionality of performance for certain individual players?”
Furthermore, the results obtained from the p-technique factor analysis were notably different from the variable- or person-centered approaches. The differences in results indicate that the data were not ergodic, causing the choice of approach to provide very different results. While these results may not entirely generalize to employee performance for many occupations, it nevertheless shows yet another instance in which data were not ergodic, and future research should analyze the ergodicity of performance for more traditional occupations.
Important Notes
Prior to concluding our illustrative example, a couple important issues are deserving of more attention. First, for the sake of clarity and ease in our examples we chose EFA and LPA for the variable-centered and person-centered illustrations, respectively. With the current dataset and research questions, a multilevel EFA and multilevel LPA with measurement instances at Level 1 and players at Level 2 would be the more appropriate analyses. In an attempt to keep the examples as simple as possible to maintain the focus on the overall comparisons between the approaches, however, we decided to forego these more complex analyses in favor of more common and easily understood analyses that most readers would be more familiar with. The fact that the current EFA and LPA examples explore between-person data and the person-specific p-technique example analyzes within-person data undoubtedly led to additional differences among the factor structures and subpopulations between the approaches. Nevertheless, because the data here are not ergodic, the factor structure and subpopulations would not have been equivalent even if the more appropriate analyses were conducted. Still, it should be recognized that both the variable- and person-centered approaches can incorporate techniques to explore within-person data.
Second, in the above illustration, the aim was to investigate and compare the three approaches in the context of a multidimensional dataset—using multiple indicators of performance. It is important to mention here, however, that similar methods from the three approaches can be conducted on longitudinal data of a single indicator (e.g., one rating of performance over many occasions). In this scenario, a latent growth model (variable-centered; Bliese & Ployhart, 2002), a growth mixture model (person-centered; B. Muthén & Muthén, 2000), and a single-subject time series analysis (person-specific; Molenaar, 2004, 2015) could be used to investigate research questions from the perspective of the three approaches. For the variable-centered and person-centered approaches, yearly or monthly averages may need to be analyzed depending on how often the single indicator is measured (i.e., daily or weekly); however, person-specific analyses are quite apt at analyzing a large number of measurement occasions, and averaging occasions would not be required. Again, these examples were not included above for the purpose of clarity in our overall message, but it is important for the reader to consider that these approaches can be applied to longitudinal data structures as well. Specific instances in which the research questions may differ in their investigation of longitudinal research questions and theory are detailed below.
Discussion
Variable-centered approaches are dominant in management and applied psychology, person-centered approaches are growing in popularity, and person-specific approaches have almost never been discussed. In the current article, we argued that discussing all three in tandem is the best method to truly understand the distinct function of each, with possibly the most important distinction being the domain of research questions that each approach may best address. We then discussed and contrasted the function of each approach, using NBA player data to further emphasize and illustrate our points. The results showed that each approach best answered a distinct set of research questions, whether focused on variables, subpopulations, or individuals. The results also showed that no approach is the “best.” Instead, each should be used to answer particular research questions of interest. With these findings taken into consideration, we note certain domains of theory, methodology, and statistics that may particularly benefit from the inferences within the current article.
Progression of Theory
Thus far, we have discussed how each approach carries with it a shift in theoretical perspective and method, but the expanded use of novel approaches may also incur larger theoretical implications for the field. Due to the nature of person-centered approaches and their ability to identify distinct subpopulations, these methods are quite adept at inductive theory building and have been used to expand our understanding of groups of individuals pertaining to variables heavily studied with the more traditional variable-centered approach—turnover (Woo & Allen, 2013), commitment (Meyer, Stanley, & Vandenberg, 2013), leadership (Bray et al., 2014), and emotional labor strategies (Gabriel, Daniels, Diefendorff, & Greguras, 2015), among other important domains. For instance, Gabriel and colleagues (2015) noted that emotional labor is often conceptualized as surface acting or deep acting, and employees are expected to enact one or the other; however, the authors also noted that “this variable-centered perspective ignores the possibility that there are subpopulations of employees who may differ in their combined use of surface acting and deep acting” (p. 863). From applying the person-centered approach, Gabriel and colleagues identified five distinct emotional labor profiles: nonactors, low actors, surface actors, deep actors, and regulators. These profiles were also shown to be distinguished by differing antecedents as well as produce differing outcomes, providing a deeper understanding of employees’ emotional labor strategies.
In most prior applications of the person-centered approach, authors have provided similar insights and argued that extant research and theory did not consider the more complex nature of a certain phenomenon. We urge authors to identify other areas in which extant research and theory may not be specific or rich enough to provide adequate explanations, similar to Gabriel and colleagues (2015) as well as the investigation of performance in the current article.
On the other hand, person-specific approaches are apt at investigating development and change, and they are commonly used to study developmental systems theory (DST; Molenaar, 2015; Thelen, 2005). This theory suggests that development (a) involves simultaneous influences that are context-sensitive, (b) is a constructive process with nonlinear dynamics, (c) and occurs on multiple time scales at multiple levels. DST accounts for not only the final outcome, development, but also the mechanisms that engender change (Ford & Lerner, 1992). For this reason, this holistic theory has been applied to identify how micro-time (seconds, minutes, or hours) events may build to effect macro-time (days, weeks, or years) development (Granic & Patterson, 2006; M. D. Lewis, 2005), which closely aligns with recent calls in management research to develop and test more event- and process-oriented theories (Langley, Smallman, Tsoukas, & Van de Ven, 2013; Morgeson, Mitchell, & Liu, 2015). Likewise, DST has been used to bridge the level of analysis from events and processes to their effect on lasting cognitive and emotional characteristics—domains that are often treated as entirely separate (Granic & Patterson, 2006; Molenaar, 2015). Proponents of DST often speculate that the theory can only be tested via person-specific analyses, as, for instance, person-specific analyses are often better able to analyze the many measurement occasions needed to study micro-time effects than variable- or person-centered analyses (M. D. Lewis, 2005; Thelen, 2005). Some authors even suggest that person-specific approaches always incorporate the three primary tenets of DST (Ford & Lerner, 1992; Granic & Patterson, 2006; M. D. Lewis, 2005; Molenaar, 2004), and person-specific approaches may therefore draw attention to understudied foci, such as events and processes, even when DST is not explicitly applied.
Also, person-specific approaches may also be used for conservative tests of theory and the identification of boundary conditions. In general, theories are initially developed with the intention of explaining a widespread and general phenomenon, and subsequent authors further test and refine the theory to identify boundary conditions (Busse, Kach, & Wagner, 2017; Dawson, 2014). Person-specific approaches may be used to identify these boundary conditions by first providing a thorough analysis of individuals and identifying those that do not adhere to theoretical predictions—thereby recognizing that many effects involve simultaneous influences that are context sensitive (Molenaar, 2015; Thelen, 2005). Then, subsequent research can identify the underlying characteristics and causes of any divergence from theoretical predictions, possibly resulting in a more formal identification of boundary conditions. Using this same process, researchers could use the person-specific approach to also understand when certain theories may be no longer accurate, though identifying when certain person-specific relationships may not hold over time, in addition to who and/or where the theories may not apply. While not the traditional method to identify and study boundary conditions, Busse and colleagues (2017) recently made a call for the discovery of boundary conditions using certain proposed methods, some of which are similar to the person-specific approach (although not labeled as such).
Related to this, it is important to consider that the typical approach of the social sciences is to discover knowledge that generalizes to a certain population of interest. The variable- and person-centered approaches may satisfy this goal quite well; however, the person-specific approach is often not meant to generalize to populations, which may be considered a key limitation. For this reason, researchers and practitioners should understand that the objectives of these three approaches differ, which is especially evident when discussing the research question that each may address. Furthermore, it is important to consider instances in which generalizing to populations may not be needed to provide theoretical contributions, such as identifying boundary conditions as noted above. Likewise, person-specific analyses may provide large implications for the future of case-study research, which is often used in initial theory creation (Gibbert & Ruigrok, 2010; Piekkari, Welch, & Paavilainen, 2009), and this implication is discussed further below—along with the broader progression of methodology and statistics provided by an integrative view of variable-centered, person-centered, and person-specific analyses.
Progression of Methodology and Statistics
Many considerations should be noted about the progression of methodology and statistics. While the current article presented the three approaches as largely mutually exclusive, there are certain instances in which their boundaries begin to blur. For instance, certain person-specific analyses can generate models specific to the individual, and similar models can subsequently be combined using a variable-centered approach to draw broader inferences. We suggest that future research should not view certain analyses as being firmly representative of a single approach. Otherwise, such a rigid viewpoint may cause researchers and practitioners to inappropriately apply (or not apply) certain analyses for research questions that do not fit (or fit).
To better understand the instances in which each approach and analyses are most appropriate, future research should place greater attention toward identifying the attributes of the three approaches (and representative analyses) that are responsible for theoretical and conceptual differences. In the current article, we distinguished the approaches by their specificity and parsimony, but many more attributes could be used. For example, Sterba and Bauer (2010a) differentiate certain types of analyses within the three approaches by their ability to test six principles of person-oriented theory, ranging from untestable, to conditionally testable, to limited testability, to testable. The authors argued that no types of analysis are able to test all six principles; however, Molenaar (2010) argued that single-subject analyses are able to do so, in which Sterba and Bauer (2010b) agreed. Discussions such as this are fruitful to determine when to apply certain analyses within the three approaches, particularly in regard to which research questions that each analysis is able to address. Perhaps more importantly, these discussions can help reveal the assumptions that are implicit in each approach.
Also, growing interest can be seen in using case studies and small sample size research to substantively inform theory (Gibbert & Ruigrok, 2010; Piekkari et al., 2009). Person-specific analyses can greatly benefit case studies due to their ability to answer research questions that are often asked through this research design. The quality of case studies is often determined by the number of research strategies applied to analyze the phenomenon of interest (i.e., interviews, archives, etc.), and authors have demonstrated a particular fondness for mixed-methods research that applies both quantitative and qualitative analyses (Eisenhardt, 1989; Hurmerinta-Peltomäki & Nummela, 2004); however, authors have likewise noted several concerns with these mixed-methods case-studies. Piekkari and colleagues (2009) argued that the qualitative and quantitative portions of case-studies are often presented as separate rather than mutually supportive, preventing a clear investigation of theory. All of their reviewed articles performed a person-specific qualitative case study followed by a variable-oriented cross-sectional survey. The separate reporting of these methods may be due to authors’ recognition that the methods provide very different results, one drawing inferences about the individual while the other draws inferences about populations, causing their subsequent inability to cohesively integrate the two perspectives. Person-specific analyses could resolve the discrepancy of inferences, as qualitative case studies and person-specific analyses both provide inferences about individuals, thereby allowing researchers to perform mixed-method studies with mutually supportive outcomes.
The application of these three approaches imposes certain methodological considerations. Many authors have touted the benefits and future possibilities of intensive longitudinal data (Chaffin et al., 2017; Jebb & Tay, 2017; Mengis, Nicolini, & Gorli, 2016). Currently, daily diary and ESM are likely the most popular methods to obtain this intensive longitudinal data, but recent authors have suggested that certain methods that can obtain even more repeated measurements, such as digital sensors, will become widespread in management and applied psychology in the near future (Chaffin et al., 2017; Jebb & Tay, 2017). Likewise, methods to obtain Big Data have already provided many opportunities to collect intensive longitudinal data, and the possibilities are likely to only grow in the future (Guzzo, Fink, King, Tonidandel, & Landis, 2015; Tonidandel, King, & Cortina, 2015). With the increased use of these data collection methods, we suggest that the application of person-specific approaches will become more popular—due to both the need of the person-specific approach for many measurement occasions as well as the types of research questions that such data will elicit. Thus, while each approach should be used to answer certain types of research questions, it is likely that the popularity of certain approaches will grow quicker in the future.
Last, new person-specific analyses that connect idiographic and nomothetic perspectives have perhaps the most potential to influence research. For instance, group iterative multiple model estimation (GIMME) identifies a model for each subject to describe longitudinal processes between measured variables, but GIMME also provides a model for the sample as well as statistics regarding the fit of this sample model for each subject. While the method was initially used to map functional neuroimaging data (Gates & Molenaar, 2012), it has since been used to analyze affect and behaviors reported via daily diary (Beltz et al., 2016). Methods such as these may encourage researchers that are wed to nomothetic perspectives to adopt person-specific analyses, and—more importantly—develop and test meaningful research questions from the person-specific approach. To do so, however, tools must also be created that allow for relatively easy access to these analyses. A lack of familiarity with existing programs that can be readily used for these analyses, such as MATLAB, may hinder the spread of these methods (Beltz et al., 2016), but scripts written in R or SPSS can be easily applied. The authors of Mplus have recently expanded its capabilities by adding a growing number of person-specific analyses (Asparouhov, Hamaker, & Muthén, 2017), which should certainly be commended and utilized by organizational researchers. Related to this, guides to use these person-specific tools are essential, which are sparse in the current literature (Gates & Molenaar, 2012).
Conclusion
While the variable-centered approach is the most popular across almost all research, new and innovative approaches are continuously being applied. Authors have praised the possibilities of the person-centered approach, and interest in the person-specific approach is growing. Many researchers and practitioners, however, may not be fully aware of their methodological, statistical, and theoretical implications. We have discussed the differences between these three approaches and provided illustrative examples. These efforts suggest that each approach has certain idiosyncrasies, but no approach is the “best.” Instead, each approach is most suitable for certain research questions. Researchers and practitioners should carefully pair the most appropriate approach with their specific research question. It is our hope that the current paper has offered researchers a better understanding of each approach so that they can make more informed decisions regarding the methodology they use, as well as to how subtle changes in research questions might offer new insights into their research.
Footnotes
Appendix
Acknowledgment
The authors would like to thank Alex McKay for his feedback on a prior version of the current manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.