
Abstract
Most applications of person-centered methodologies have relied on data-driven approaches to class enumeration. As person-centered analyses grow in popularity within organizational research, confirmatory approaches may be sought to provide more stringent theoretical tests and to formalize replication efforts. Confirmatory latent class analysis (LCA) is achieved through placement of modeling constraints, yet there is variation in the types of potential constraints and a lack of standardization in evaluating model fit in published work. This article provides a comprehensive framework for operationalizing model constraints and demonstrates confirmatory LCA via two illustrations: (a) a dual sample approach (n = 1,366 and n = 1,367 in exploratory and validation samples, respectively) and (b) confirmatory testing of a hypothesized latent class structure (n = 1,483). We depict operationalization of threshold boundary and/or equality constraints under both illustrations to generate a confirmatory latent class structure, and explain methods of model evaluation and comparison to alternative models. The confirmatory model was well supported under the dual sample approach, and partially supported under the hypothesis-driven approach. We discuss decision making at various points of model estimation and end with future methodological developments.
Keywords
Person-centered analyses refer to a set of modeling techniques where individuals are classified into subgroups based on shared response patterns in an attempt to capture observed heterogeneity (Masyn, 2013; McLachlan & Peel, 2000; B. O. Muthén, 2002). Subgroup membership is reflected by values on a nominal categorical latent variable. One of the most common applications of person-centered analysis is latent class analysis (LCA; categorical indicators) and the related latent profile analysis (LPA; continuous indicators), both special cases of the broader family of finite mixture models. LCA and LPA are used with cross-sectional data to characterize subgroups of individuals similar to each other with regard to their collective responses to a set of observed measure (latent class indicators). In LCA and, more generally, in finite mixture modeling, a distinction is made between direct and indirect applications (Masyn, 2013; Titterington, Smith, & Makov, 1985). Indirect applications utilize a finite mixture model specification as an analytic tool to approximate a single unknown multivariate population distribution. Direct applications of finite mixture modeling, akin to person-centered analysis, use a probabilistic classifying approach to identify and understand unobserved subpopulations based on patterns among observed variables/indicators (Wang & Hanges, 2011). In practical terms, person-centered analyses relax the assumption that all individuals from a sample are drawn from a single population, with a purpose of identifying potential subpopulations representing qualitatively distinct configurations with regard to measured indicators.
Person-centered methodologies can be understood in the context of inductive versus deductive approaches to research, and placed along a continuum from exploratory to confirmatory. Inductive research has been conceptualized as bottom-up, data-driven, and/or exploratory, whereas deductive research reflects top-down approaches adhering to the test of a priori hypotheses within the context of a well-defined theoretical model (Woo, O’Boyle, & Spector, 2017). A recent set of articles suggests a preference for deductive research within organizational science, yet maintains that overreliance on deductive approaches limits full theoretical advancement and argues for the role of high-quality inductive research (Jebb, Parrigon, & Woo, 2017; Woo et al., 2017). In this article, we demonstrate that most applications of person-centered analyses to date may be placed toward the inductive side of the spectrum, and discuss the complementarity of exploratory versus relatively more confirmatory approaches. We discuss the underutilization of modeling constraints within person-centered research and address ways in which model constraints can be introduced and operationalized within LCA to provide more stringent theoretical tests and to formalize replication and validation efforts. Examples illustrating empirically driven and hypothesis-driven model constraints are provided, along with guidelines and research contexts for considering potential constraints.
Person-Centered Methodologies Under an Inductive Versus Deductive Research Framework
For direct applications of finite mixture modeling, investigators do assume, a priori, that the overall population is heterogeneous, consisting of a mixture of a finite number of latent, and substantively distinct, homogenous subpopulations (latent classes). However, beyond the assumption of population heterogeneity that motivates use of a person-centered approach and theoretical rationale that may guide indicator selection and class interpretation, the class enumeration/model selection process to date has been primarily data-driven in the sense that constraints are not placed or formalized during model selection (Meyer & Morin, 2016). In organizational research as well as more broadly, appraisal of the applied literature quickly demonstrates that class enumeration typically involves statistical comparisons of a series of unconstrained k class models, with statistical fit the primary criterion for the smaller number candidate models selected for further theoretical interpretation. The best fitting class structure is frequently synthesized in the context of an established theoretical literature and hypotheses may be made a priori regarding the number or nature of the latent subgroups; however, in the absence of model constraints, there are limits to the specificity of hypotheses that may be made, as well as the risk of data exploration methods later being presented as confirmatory (Jebb et al., 2017). Subsequent confirmatory-type model constraints used for construct validation (i.e., latent class regression) are therefore based on a measurement model that was primarily data-driven. We are not critical of this standard approach and are not intending to imply that prior applications have been atheoretical. When person-centered analyses are applied for the first time within a given research context, empirically based decision making is arguably the more principled and conservative approach. Nonetheless, if deductive applications are characterized as those in which the entire domain of theory must be specified a priori (Jebb et al., 2017), then applications of person-centered approaches firmly fit toward the inductive side of the spectrum. As person-centered analyses grow in popularity within organizational research, fully exploratory methods may become inadequate for advancing the literature. Application of model constraints within LCA/LPA that move these techniques closer to a deductive/confirmatory realm may be useful for improved theory refinement, to facilitate empirical comparison of competing theories, and to formally guide replication and validation efforts (Jebb et al., 2017; Laudy et al., 2005).
There have been some informal attempts to extend beyond data-driven approaches to class enumeration and evaluation of class structure. For example, there exist review studies that aim to synthesize results of various LCA/LPA applications within a specific topic area, but these tend to be of a descriptive nature without clear empirical guidelines for aggregating findings. An inherent problem with synthesizing results across latent class analyses is that various studies have different methods, including different indicators (number, quality, and makeup of indicators), different sample sizes, and different covariates/predictors, all of which can influence class enumeration and model specification (Wurpts & Geiser, 2014). There has also already been some formal attention to applying confirmatory principles to categorical latent variable models (Hoijtink, 2001). McCutcheon (1987) provides the first description, of which we are aware, of potential modeling constraints that may allow for confirmatory tests of a latent class model, and an early application of LCA was confirmatory in that a two-class model was hypothesized and tested, rather than basing class enumeration on relative fit of k class models (Rindskopf & Rindskopf, 1986). Laudy et al. (2005) discuss how inequality constraints may be applied to LCA models to provide more focused empirical testing of competing theoretical models, and Finch and Bronk (2011) provide an overview of confirmatory LCA (CLCA), discuss its underutilization in research, and provide examples on how to set parameter constraints to conduct CLCA. In recent years, a handful of substantive studies have applied one or more types of modeling constraints to arrive at a CLCA model (Donovan & Chung, 2015; Hettema, Aggen, Kubarych, Neale, & Kendler, 2015; Monahan et al., 2015).
Despite these advances, confirmatory approaches to LCA/LPA have not been well-integrated into the applied literature, and strengths and limitations of various forms of model constraint setting have not been sufficiently addressed in the methodological literature. Indeed, the small number of substantive studies that have used CLCA each used differing methods for constraint setting and model evaluation, indicating a lack of standard practice. As confirmatory approaches to LCA/LPA are more frequently utilized and methods better understood, applied investigators may wish to decide whether to maintain the common practice of estimating a series of k class unconstrained measurement models, or if constrained or partially constrained models may be more appropriate (akin to the complexities of decision making within the continuum of exploratory to confirmatory factor models in structural equation modeling). Decisions about whether or not to apply modeling constraints require content knowledge within a specific substantive research area, though broad considerations include (a) data availability, such as whether a dataset is sufficiently large to validate one’s model using a split sample; (b) extant empirical work, such as whether past studies have performed person-centered analysis of the same construct with similar/identical indicators to allow externally informed, empirically driven model constraints; (c) explicit theoretical advancement, where the theoretical literature conceptualizes a construct with enough specificity to inform theoretically driven model constraints; and (d) study goal (e.g., validation or replication of prior results, theoretical model testing, hypothesis generating).
If sufficient conditions are met to warrant a confirmatory approach, then investigators must decide how to operationalize model constraints and interpret constrained models. This is not a trivial undertaking, given that there are many ways to approach constraint setting and an existing lack of standardization around placement of constraints and evaluation of constrained models. This article provides a comprehensive framework for operationalizing and evaluating model constraints. In the context of two analytic examples, we illustrate several methods for placing model constraints to facilitate movement toward a confirmatory framework for class enumeration and specification of class structure. The data illustrations are specific to LCA, though extensions to LPA are considered in discussion. The first approach was a dual sample analysis, in which a completely exploratory LCA was conducted in one sample and then validated in a second sample using modeling constraints. The second example demonstrated a confirmatory approach drawn from the same research context as the dual sample analysis, but tested a model structure that was hypothesized a priori. The goal of including two types of illustrations was to cast as wide of a net as possible in providing a set of tangible, illustrative examples of CLCA. Applying both approaches to similar data sets within the same research context allowed common ground in underscoring commonalities and differences between empirically driven model constraints versus those based on specific hypotheses.
Model Parameterization in LCA
We briefly review the parameterization of an unconditional LCA measurement model to facilitate illustration of potential model constraints. Consider M binary indicators, u 1, u 2, u 3,…, uM , where umi represents the response to item m for individual i. The M items are assessed as indicators of an underlying latent categorical latent class variable, c, with K classes (ci = k if individual i belongs to Class k). The K classes representing the categorical latent variable are unordered, with πk representing the proportion of individuals in Class k (Pr(c = k)). The overall joint distribution of the observed indicators is expressed as a finite mixture of the K classes, with each class having its own class-specific distribution for the indicators, as expressed by
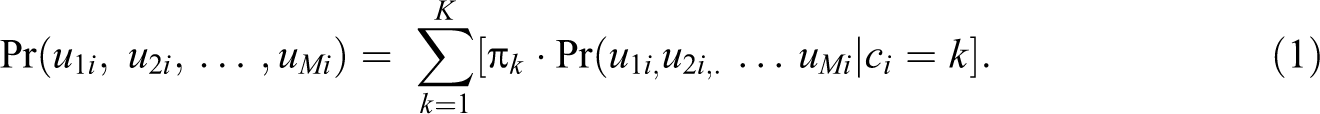
The K classes are exhaustive and mutually exclusive such that each individual has membership in only one of the latent classes and the sum of the πks is equal to 1. The relationship between each indicator and the categorical variable is typically parameterized as either class-specific indicator probabilities or as single thresholds (τ) on the inverse logit scale (such that negative threshold values are associated with higher probabilities that an item is endorsed within a class), as given by
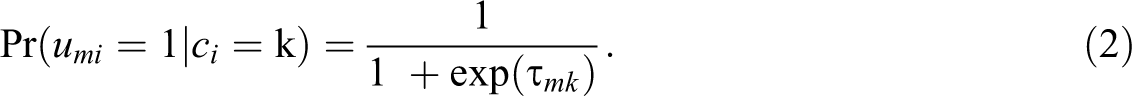
In the illustration, we demonstrate several methods of placing parameter constraints on model thresholds. In this unconditional measurement model, the structural parameters are limited to the class proportions, parameterized as intercepts on the inverse multinomial logit scale. We don’t place constraints on these structural parameters, though devote greater attention to structural parameters in discussion. As a final note, this model parameterization assumes conditional independence, or that latent class membership explains all shared variance among the observed indicators. This assumption can be at least partially relaxed in some situations, a topic revisited in the discussion in the context of extensions to LPA.
Placement of Model Constraints to Facilitate a Confirmatory Structure
Parameter constraints are intrinsic to confirmatory modeling approaches, though a unique aspect of person-centered analyses is the myriad of ways in which constraints may be operationalized. We first distinguish between two primary sources informing the constraints—empirical or theoretical. We further distinguish constraints related to class enumeration (i.e., the number of classes) and constraints related to the classes structure (i.e., the nature of the classes). Class enumeration in a confirmatory framework avoids a fully data driven model selection approach, though confirmatory testing of the fit of a single, final model without considering plausible alternative models is likely impractical and potentially limiting given reliance on relative fit indices. Instead, our confirmatory approach to class enumeration still focused on model comparison, though within a narrower range (e.g., k, k-1, and k+1 classes), and in the case of the dual sample, convergence of model selection between samples. Class structure was operationalized as degree of homogeneity and separation among indicators, where homogeneity reflects similarity with respect to a given item response among individuals belonging to the same class and separation reflects lack of similarity in item response patterns between those belonging to different classes (Collins & Lanza, 2010; Masyn, 2013). Typically class-specific response probabilities of approximately >0.70 or <0.30 indicate high within-class homogeneity. High separation in LCA is reflected by odds ratios of item endorsement between classes of approximately >5.0 or <0.2. Each latent class does not need to be homogenous or separated with regards to every indicator. However, ideally, each class should be homogeneous with respect to at least one indictor and every class should be separated from every other latent class by at least one indictor.
We propose four types of constraints and suggest general guidelines for their use. Table 1 provides a description of these constraints, how they were operationalized in the current analyses for the dual sample and the hypothesis-driven example (as appropriate), whether/how they target class enumeration and/or class structure, and research scenarios where a particular constraint may be most appropriate. Table 1 underscores the sheer amount of decision making faced by applied investigators wishing to carry out CLCA. The strictest constraints, fixed thresholds, were those based on model validation principles that fixed threshold values to a precise estimate generated from the empirical example (see Masyn, 2013), an approach not deemed practical/appropriate for the hypothesis-driven example. Other threshold constraints ranged in level of strictness and targeted homogeneity and/or separation; the general principles for these constraints were the same across both data illustrations. We targeted item homogeneity by setting boundary constraints on threshold values, and targeted item (non)separation by constraining item thresholds to equality. Homogeneity and separation were also addressed simultaneously using boundary and equality constraints within the same model. All threshold constraints were generated empirically in the dual sample illustration and conceptually in the hypothesis-driven example, with the specific operationalization more explicitly described below in the context of each illustration. Finally, we show how LCA in a multiple group framework (see Finch, 2015; Morin, Meyer, Creusier, & Biétry, 2016) can be used to assess the convergence of an observed solution between samples.
Methods of Placing Empirically Driven and/or Hypothesis-Driven Threshold Constraints.
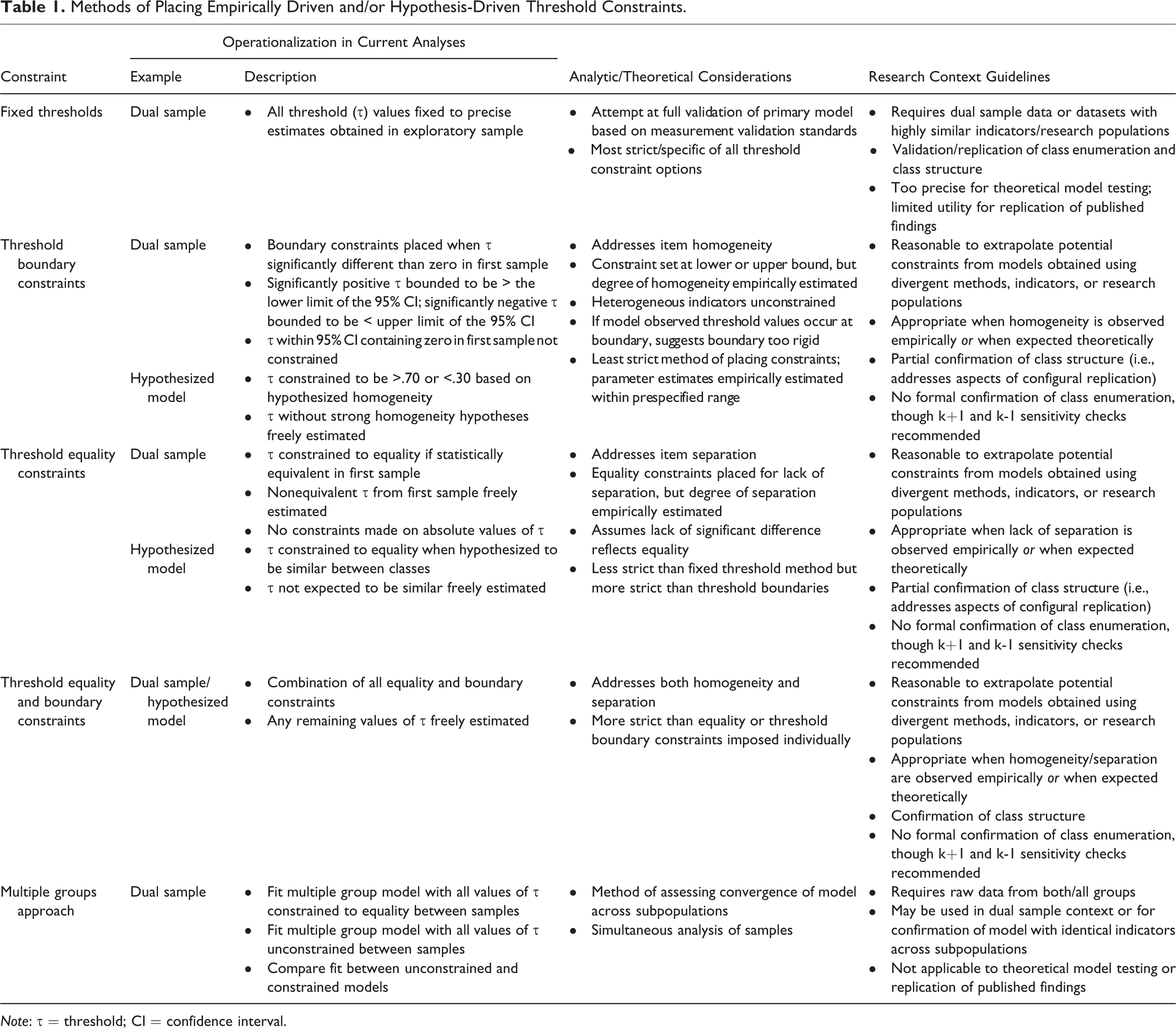
Note: τ = threshold; CI = confidence interval.
Data Illustration: Empirical Constraints Using a Dual Sample
Method
Data were from N = 2,733 graduate nurse residents nested within N = 50 organizations who participated in the University Health Consortium/American Association of Colleges of Nursing Post Baccalaureate Residency Program (Fink, Krugman, Casey, & Goode, 2008) in 2009. Nurses were measured as they were transitioning within the organization from a student role to that of a skilled employee. Nurses completed the Casey-Fink Graduate Nurse Experience Survey (Casey, Fink, Krugman, & Propst, 2004). The full scale consists of 24 items covering four domains that were previously identified, empirically and theoretically, by the scale developers: communication, patient safety, satisfaction, and support. For illustration purposes, we selected two representative items from each domain: 1. Communication: “I feel confident communicating with physicians” and “I feel comfortable making suggestions for changes to the nursing plan of care”; 2. Patient safety: “I am having difficulty prioritizing patient care needs” and “I feel I may harm a patient due to my lack of knowledge and experience”; 3. Satisfaction: “I am satisfied with my chosen nursing specialty” and “I feel my work is exciting and challenging”; 4. Support: “I feel my preceptor provides encouragement and feedback about my work” and “My preceptor is helping me to develop confidence in my practice.” Responses were dichotomized into endorsement (e.g., agree/strongly agree) versus nonendorsement (e.g., disagree/strongly disagree); negatively worded items were recoded so that item endorsement reflected positive behaviors. The data were randomly split into an exploratory dataset (n = 1,366) and a confirmatory dataset (n = 1,367). All latent class modeling was carried out using Mplus Version 7.4 (L. K. Muthén & Muthén, 2015), and annotated syntax files are provided in the online Supplemental Materials. The type = complex command was used to address nurses nested within organization, which corrects standard errors for nonindependence of observations using a sandwich estimator.
Results
Exploratory Approach
We estimated between 1 class and 7 class models, using multiple random perturbations of start values. All models converged, there were no red flags with regard to model identification, and the log likelihood value was replicated for all solutions. Model fit indices (shown in Table A1 of the online Supplemental Materials) overwhelmingly supported the 5-class solution. Based on measures of absolute and relative fit, and adequate classification precision, we interpreted the 5-class model results. Figure 1 depicts the model-estimated item response probabilities for each of the 8 indicators of the 5-class solution. The first class (“Lack Support”) was homogeneous with low endorsement rates for the satisfaction and support indicators and was well-separated from all other classes with respect to support. Class 2 (“Low Efficacy/Dissatisfied”) was homogeneous with low endorsement rates of the communication and satisfaction items and, to a lesser degree, of the safety items. Class 3 (“High Efficacy/Dissatisfied”) was homogeneous with high endorsement rates of the communication, safety, and support items and low endorsement rates of satisfaction items. Class 4 (“Satisfied and Supported”) was the most difficult class to characterize; this class was homogeneous with high endorsement rates of the satisfaction and support items, but heterogeneous in terms of communication and safety indicators. It was also not well-separated from most other classes with regard to high rates of support, nor from Class 5 with regard to high rates of satisfaction. Finally, Class 5 was homogeneous with high endorsement of items and was labeled the “Highly Effective” class. In summary, the 5-class model was supported as the optimally fitting model in relative and absolute terms, the average classification probabilities tended to be high, and overall the observed class structure was theoretically interpretable. We chose this as our final model for demonstration of confirmatory approaches to LCA in the second (split) sample.
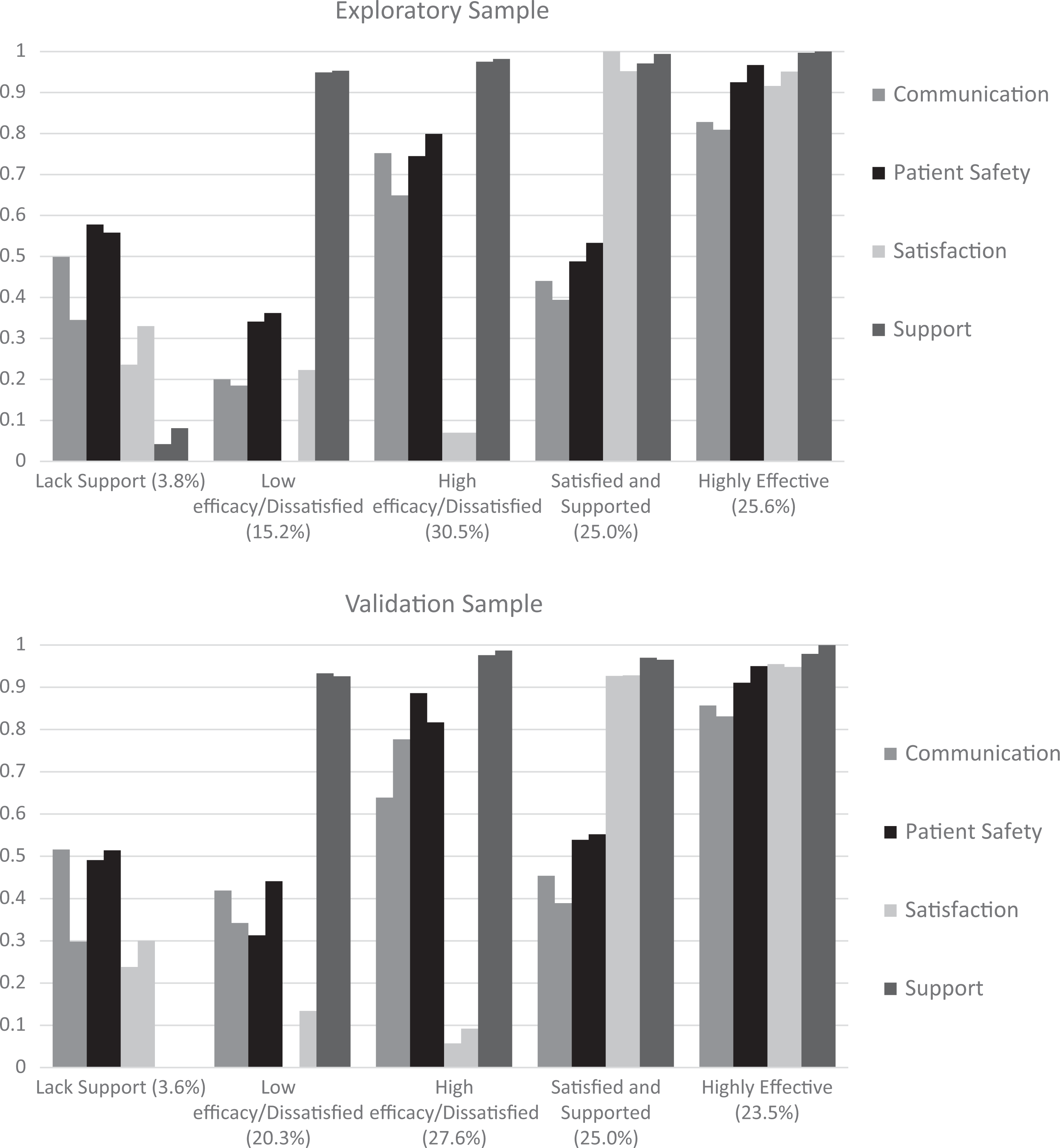
Model estimated item response probabilities based on the five-class unconditional LCA using exploratory (n = 1,366) and confirmatory (n = 1,367) subsamples.
Confirmatory Approaches
We tested a series of modeling constraints to confirm model fit and composition in the second subsample. These constraints were introduced at a conceptual level in Table 1, and coding details may be found in the annotated Mplus syntax as part of the online Supplemental Materials. The fixed threshold model constrained all thresholds in the confirmation sample to the precise corresponding maximum likelihood estimates from the 5-class model obtained using the exploratory sample. The threshold boundary model addressed homogeneity by placing constraints on threshold values in the confirmatory sample if the value was significantly different than zero in the exploratory sample. If the 95% CI did not include zero for a given threshold in the exploratory sample, significantly positive thresholds were constrained in the confirmatory sample model to be greater than the lower bound of the 95% CI and significantly negative thresholds were constrained in the confirmatory sample model to be less than the upper bound of the 95% CI. Equality constraints addressed separation by constraining class-specific thresholds to be equal if the difference between them was nonsignificant (at α = .05) in the exploratory sample. The fourth model included a combination of threshold boundary and equality constraints. Table 2 depicts results of model testing comparing the 5-class unconstrained solution in the confirmatory sample relative to the four proposed models with threshold constraints. The likelihood ratio χ2 test associated with each model provides some indication of absolute fit, but relative fit of the model in comparison to competing models is critical for model evaluation. With the exception of the fully constrained fixed threshold model, all other equality and boundary constraints demonstrated good fit to the data, both at an absolute level and relative to the unconstrained model. Overall this lends support to a 5-class solution that is constrained in accordance with the results of the exploratory sample.
Comparisons Among Constrained and Unconstrained Models as an Empirical Test of the Stability of the 5-Class Solution Across Exploratory and Confirmatory Subsamples.

Note: LL = log likelihood value; npar = number of parameters; LR = likelihood ratio; AIC = Akaike information criterion; BIC = Bayesian information criterion; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion.
With empirical confirmation using a dual sample approach, the goal is centered on convergence of a solution across samples, rather than the prioritization of the solution obtained in one sample over the other. Dual cross-validation methods are recommended as supportive of the final model in both samples (cf. Masyn, 2013). As an initial validation step, we carried out the same steps undertaken in the exploratory sample in the confirmatory sample. Model fit statistics for 1-class to 7-class solutions in the confirmation sample paralleled those for the exploratory sample in terms of a 5-class solution (Table A1 in the online Supplemental Materials), and provided initial evidence for replication of the class enumeration process in the confirmation sample. We next compared model constraints applied to the exploratory sample, using parameter estimates from the confirmatory sample. Table 2 also shows that each of the four constrained models demonstrated satisfactory absolute fit and, to some degree, better relative fit compared to the unconstrained model. As a final test of the convergence of fit between the confirmatory and exploratory samples, we drew from Morin et al. (2016) and Finch (2015), who demonstrated methods for comparing the similarity of class structures using a multiple groups approach. Sample was treated as a “knownclass” variable in Mplus and model parameters were estimated simultaneously between samples. The model where all thresholds were constrained to equality did not significantly differ from one where all thresholds were freely estimated (Table 2, p = .18), supporting model convergence between samples.
Brief Discussion
Using a large dataset that could be randomly split in half, we demonstrated a fully exploratory approach to LCA in the first sample, followed by several methods to confirm the obtained solution in the second sample. We demonstrated several methods for obtaining constraints empirically, if there is not sufficient theory to drive a confirmatory model structure. The first confirmation method was the most strict, placing precise parameter constraints on the confirmation sample using the observed threshold estimates from the exploratory sample. This fully constrained model was not unequivocally supported, though this method of placing specific parameter constraints was discussed in the context of measurement model validation (Masyn, 2013), and may therefore be too rigorous an approach when the focus is on theoretical confirmation of model structure and configuration. This may be a particularly high standard when investigators are attempting to confirm a model using two different data sources, rather than a split sample as we had here where variability was already reduced. We then presented alternative methods of model confirmation based on equality constraints and/or threshold constraints, as well as multiple group methods. Each of these approaches supported the 5-class model with similar structure in the confirmation sample. Despite taking a confirmatory approach in the second subsample, we fully estimated all 1-class to k-class (here, 7-class) models, given the necessity of using relative fit indices and because evaluating one’s final model in the context of plausible competing models strengthens confidence in the final solution. We used dual cross-validation techniques, though recent work demonstrating k-fold validation within mixture modeling is a promising future direction (Grimm, Mazza, & Davoudzadeh, 2016).
Data Illustration: Hypothesized Model Constraints
Method
The first data illustration approach assumed a sufficiently large dataset from which to create a split sample, or two or more distinct datasets with like indicators. There are instances where neither of these conditions may be met, yet the theoretical underpinnings of a model are advanced to a point to render a fully exploratory approach unsatisfying. An alternative CLCA approach is to set model constraints in accordance with hypotheses generated from a previously expounded theory or competing theories. This illustration used the same survey and general method as the first approach, with an independent sample of a randomly chosen subset of participants drawn from 2010 data collection (n = 1,483), as opposed to the first approach that drew from 2009 data. We used the same indicators as the dual sample illustration to more effectively draw parallels between commonalities and differences when constraints are empirically versus hypothesis-driven, but note that the hypothesized model presented here does not originate from published theory. However, the hypothesized structure was conjured independently from and naïve to the results obtained under the dual sample approach.
There are varying degrees of specificity that may drive a hypothesized model structure. It is realistic to approach the model with expectations about the number of classes manifest in the data, as well as with hypotheses about how these classes are characterized based on specific, distinguishable indicators. However, homogeneity and separation of all indicators across all classes is likely not tenable, nor possibly even theoretically useful, making it unrealistic in most applications to generate strong hypotheses for every class-specific measurement parameter. Constraints around structural parameters, here expected class sizes, are also typically not central to confirmatory measurement model testing. There are also decision points around each type of constraint to best match theoretical expectations. Finch and Bronk (2011) demonstrated several of these options, including equality constraints between indicators of two or more classes and values of one parameter relative to the values of another class (e.g., a given threshold may be half the value in one class than in another). Within these broader categories (equality/threshold), decisions around level of strictness are required. Investigators may wish to constrain two parameters to equality, may specify rankings among them, or may specify them as statistically equivalent, with a predefined notion of what constitutes equivalence. Parameters can be fixed at specific values, or may be specified in terms of expected range (e.g., item probability >0.80). Refer back to Table 1 for explication of threshold boundary constraints, equality constraints, and their combination, used in this illustration.
Hypothesized Model
The hypothesized class structure considered each of the four domains from which the 8 indicators were derived: communication, safety, satisfaction, and support. We certainly envisioned a “highly effective” class with high endorsement rates across items for all domains, operationalized as item endorsements of >0.70 for all items. We also theorized a subset of employees who were enthusiastic about their career choice and well-supported by their supervisors, but not yet skilled in their positions; low endorsement rates (<0.30) for communication and safety indicators and high endorsement rates (>0.70) for satisfaction and support indicators were expected for those in the Inexperienced/Satisfied class. A third hypothesized class was developed by considering individuals high in the extraversion personality trait; high endorsement rates (>0.70) were hypothesized for communication and support indicators, but no hypotheses were made regarding the level of homogeneity of safety and satisfaction items for this class. Finally, we hypothesized a subset of disgruntled employees, low in satisfaction and support (<0.30), but here did not have strong hypotheses with respect to homogeneity of communication and safety items. The threshold boundary constraints addressed hypotheses related to item homogeneity. Hypotheses related to item separation were imposed via equality constraints, both individually and in combination with threshold boundary constraints. Because the highly effective class is easily interpretable as having high endorsement rates on all indicators, we used this class as the point of reference for imposing equality constraints, and Table A2 in the online Supplemental Materials visually depicts translation of hypotheses to specific equality/inequality constraints. Note that we did not set threshold boundary/equality constraints for every indictor across every class; we maintain that imposition of constraints on every model parameter reflects the exception with regard to hypothesis specificity.
Results
We tested a series of models to evaluate the performance of model parameter constraints to arrive at our hypothesized model structure. We started with the unconstrained 4-class solution as a point of reference for our model constraints; in this model, we were conforming to the aspect of our hypothesized structure that suggested a 4-class solution, but were not placing additional constraints on model parameters. We then imposed threshold boundary constraints, equality constraints, and combination of the two to arrive at three possible confirmatory-type models. Given the importance of ruling out alternative model structures, we also estimated model performance for unconstrained 3-class and 5-class solutions, and we considered constraints on the 3- and 5-class models in accordance with the hypothesized structure. The 3-class model was constrained by removing the smallest class observed from the 4-class solution (following empirical examination of this solution); the 5-class model was constrained by placing threshold constraints on 4 of the 5 classes and allowing the 5th class to be freely estimated. This final model relaxes assumptions about class enumeration, but specifies a minimum of 4 classes that conform to hypothesized expectations.
Fit statistics for all models under consideration are presented in Table 3, and Figure 2 depicts model estimated item probabilities using either threshold or equality constraints. Table 3 shows that the unconstrained 4-class model demonstrated acceptable absolute fit to the data and may also be a reasonable candidate model in terms of relative fit. Although it is clear from Figure 2 that we were successful in specifying model constraints in accordance with our hypotheses, 4-class models with threshold and/or equality constraints demonstrated poor absolute and relative fit to the data, leading us to conclude low support for our hypothesized 4-class solution. The unconstrained and constrained 3- and 5-class models provide additional context for interpreting our hypothesized 4-class solution. The unconstrained 3-class model fit the data poorly, whereas the unconstrained 5-class model fit well. Fit of the 3-class model was significantly improved by fixing model parameters to match the three largest classes observed in the 4-class solution, lending some support to the proposed class composition. The 5-class solution with 4 of the 5 classes constrained in accordance with our original hypotheses is arguably the best fitting model. This provides partial confirmation of the hypothesized structure, where we confirmed expectations around having at least 4 classes that followed our expected structure, while allowing for additional population heterogeneity that was not specified a priori.
Model Fit Results for Hypothesized Confirmatory Model and Alternative, Competing Models (n = 1,483).
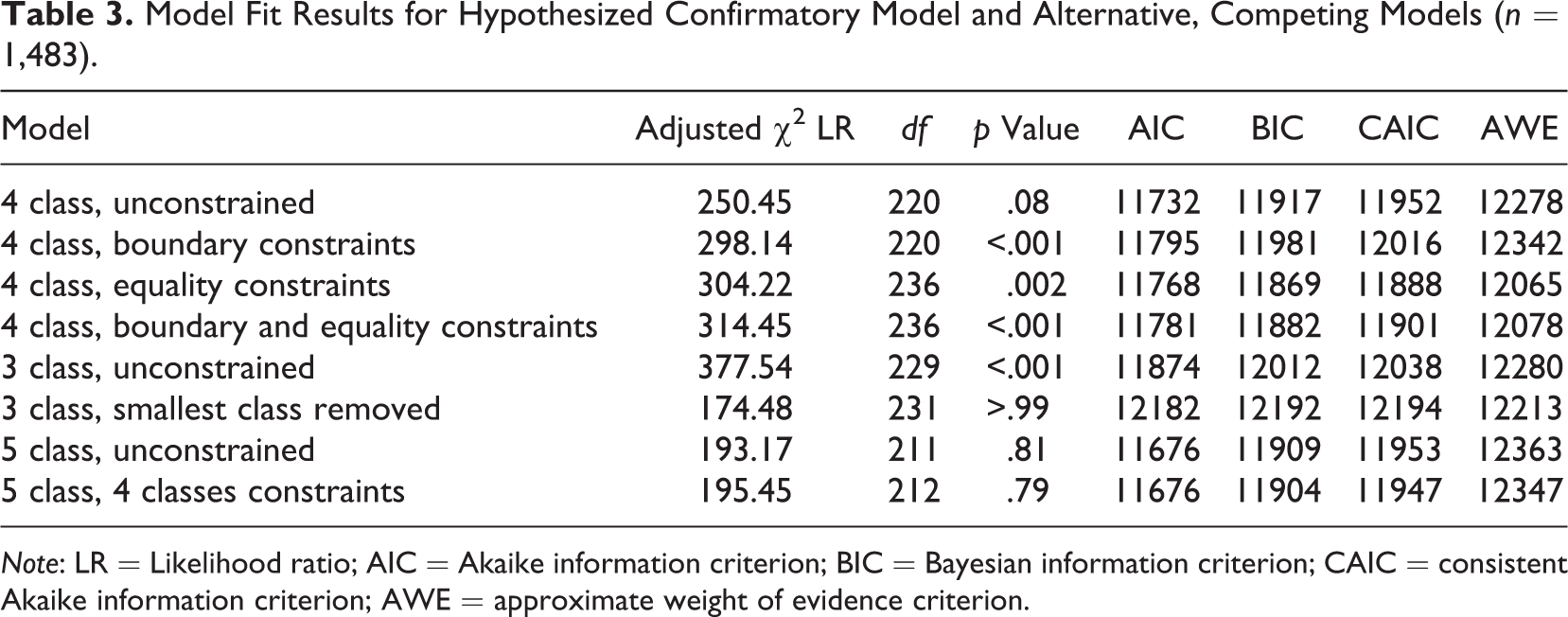
Note: LR = Likelihood ratio; AIC = Akaike information criterion; BIC = Bayesian information criterion; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion.
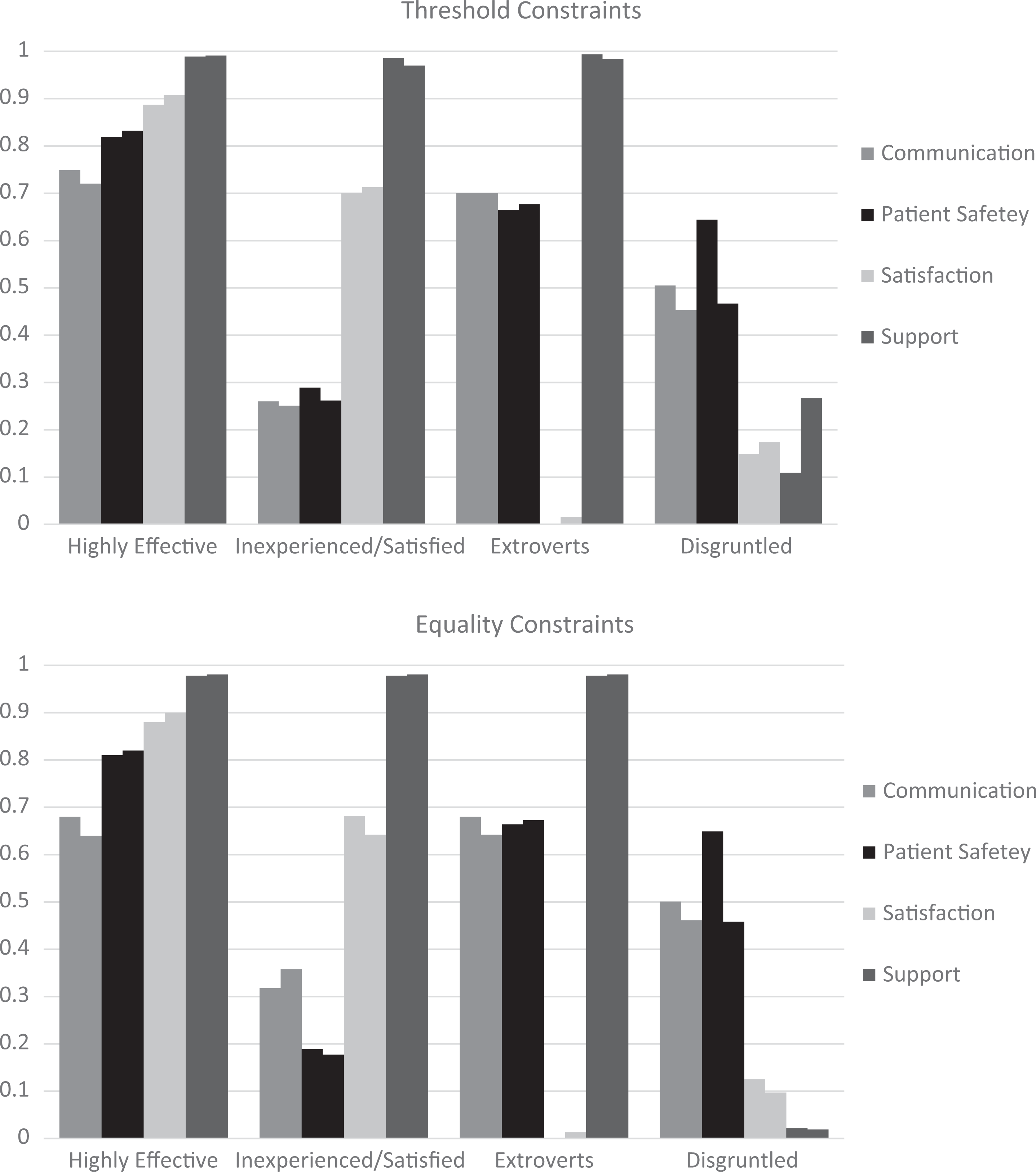
Model estimated item response probabilities generated using threshold and equality constraints to match hypothesized model structure (n = 1,483).
Brief Discussion
We attempted several approaches for placing constraints to arrive at our hypothesized model structure, and we were able to demonstrate procedurally how one might undertake this process. However, there were also several indications based on absolute and relative model fit and model interpretation suggesting that our hypothesized model was at best only partially supported. In addition, although solutions were obtained for all models we presented, we encountered a greater number of difficulties in model estimation under this approach compared to the first illustration, where the best log likelihood value was less likely to be replicated and thoughtful consideration of start values was required. These difficulties in fully confirming a hypothesized model structure could be an artifact of this structure being generated for illustration purposes rather than from strong theoretical underpinnings, though we suspect that a majority of theoretically driven mixture models face challenges in this arena. Theoretical model testing requires balance between the specificity and the complexity of the theory. Even models that are highly grounded in theory may still encompass several unknowns (or weaker hypotheses) that may not be well captured through setting model constraints; on the flip side, even theories that lack specificity are still quite complex. The sweet spot between theory specificity and complexity may indeed be very narrow. Unless the proposed theoretical model is easily specified and interpretable, an investigator might find themselves in an exploratory or a partially confirmatory realm, at minimum to understand sources and explanations for misfit/estimation problems. This is not to imply that investigators should avoid the development of theoretically driven person-centered models, but careful consideration of theoretical specificity and principled evaluation of alternative models are necessary; partially confirmatory models may be a more realistic goal. Even when undertaking a fully confirmatory approach, we estimated a greater number of models than we would have under a strictly exploratory approach. Although one approach would be to simply compare the hypothesized k-class model that included threshold/equality constraints to the same k-class model without constraints, we posit such an approach is not fully adequate for ruling out plausible alternative model structures; instead we recommend examining models that include upper and lower bounds (e.g., at least k-1 and k+1), both unconstrained and then constrained in accordance with theory, as demonstrated here.
General Discussion
Placing model constraints to move from an exploratory to a confirmatory realm in the context of person-centered methodologies may be useful in several respects, most notably in the formalization of replication and validation efforts, facilitating greater specificity of hypotheses during the class enumeration and validity testing phases, and allowing for empirical comparisons of competing theoretical models. Confirmatory approaches to person-centered analyses have not been widely applied within the literature, but may become increasingly sought after as person-centered methodologies grow in popularity and to facilitate use of deductive principles within organizational research. We demonstrated two approaches for conducting LCA within a confirmatory framework. Both methods required placement of constraints on model parameters, here either threshold boundary and/or equality constraints. The constraints were generated empirically in the first example and hypothesized in the second example. The empirically established constraints were well-supported in the confirmatory sample, which is perhaps not surprising given the split sample approach, whereas the constraints that were hypothesized a priori posed greater estimation problems and were only partially supported. The second example underscores the value of partially confirmatory models, but also that the level of specificity required for reasonable model estimation may be incompatible with the level of specificity that exists within a given theory. As was clear from both data examples, relative fit indices are of critical importance when evaluating the performance of candidate LCA models, and even a “confirmatory” approach requires careful consideration of alternative, plausible models. Though we estimated a higher number of competing models in a confirmatory realm than in an exploratory realm, the constrained models were testing more specific hypotheses than the unconstrained models.
Given increased attention to person-centered methodologies in organizational research, investigators may be faced with decisions about whether and how to impose constraints for a particular research question. These are complex decisions that must be made, in large part, within the context of one’s research area. Nonetheless, there are general principles that may be considered. Figure 3 visually depicts the continuum from exploratory to confirmatory model testing and synthesizes information about potential constraints and modeling considerations. The most exploratory model is a completely unconstrained approach to measurement model testing, the current standard in the vast majority of published applied literature. Though theory may guide indicator selection and model interpretation, constraints are not placed on the measurement model. An extension of this approach is to test unconstrained measurement models and then incorporate covariates in relationship to class membership of the final candidate model(s) to support the theoretical validity of the observed class structure. To move toward the confirmatory side of the spectrum, some type of constraint is imposed during the class enumeration process, with boundary constraints the least strict of these methods and fixed thresholds the most strict. We don’t advocate one single option for placing constraints, but instead recommend integration and comparison of model fit between the unconstrained model and various forms of constrained models. The goal is not to confirm the fit of a single model relative to the observed data, but rather to take a principled and logical approach to setting model constraints within the context of previously observed empirical or theoretical results. Another primary consideration, visually depicted in Figure 3 by the double-sided arrow between exploratory and confirmatory approaches, is that moving between exploratory and confirmatory realms is not a one way process. If a hypothesized model is not well supported, investigators can and should consider themselves back in an exploratory realm and report their findings accordingly (i.e., avoid reporting exploratory results as confirmatory; see Jebb et al., 2017). Investigators may also find partially confirmatory models to be the more realistic goal; with the exception of the fixed threshold model, all constrained models still included a portion of unconstrained measurement parameters. A final aspect of Figure 3 reflects upon general modeling considerations with regard to data availability, extant empirical work, explicit theoretical development, and study goals. Though it is unrealistic to be prescriptive regarding the approach a given investigator should take, Figure 3 summarizes these broad aspects and provides general suggestions for considering a more confirmatory approach (right pointing arrow) or an exploratory approach (left pointing arrow).

Synthesis of threshold constraints and modeling considerations along continuum of exploratory to confirmatory approaches.
Alternative Modeling Considerations and Future Extensions
We included various types of threshold constraints in both data illustrations and tested a range of values within these, for example, by placing the constraint at a boundary rather than a fixed value. Though such an approach increases confidence in the observed findings by relying on convergence of evidence across models, the results may nonetheless be influenced by constraint operationalization. Future simulation research is needed to empirically investigate the best performing methods for placing parameter constraints. These constraints also do not reflect an exhaustive list of potential options. As one example, an alternative type of constraint we considered, but were unable to adequately estimate, was one of equivalence between model parameters. Rather than specifying full equality, we attempted models constraining like parameters to be equivalent within a small range. Although these models did not converge in our example, we suspect we might have encountered greater success had we approximated the equivalence constraints using Bayesian methods (e.g., B. O. Muthén & Asparouhov, 2012).
The data illustration focused on LCA with binary indicators, both for improved interpretability and for greater simplicity from a pedagogical standpoint. Consideration of how the demonstrated confirmatory approaches translate to LCA with ordinal indicators need further attention. For example, operationalization of homogeneity and separation might be applied to cumulative probabilities across the ordered categories, or might instead be parameterized at the level of the latent response variable underlying each ordinal indicator. Another critical area for future study is enhancing the development of confirmatory approaches to LPA with continuous indicators and consideration of the additional complexities inherent in conducting LPA relative to LCA. Many of the general principles related to decision making around moving toward a confirmatory framework as well as types of constraints that may be placed (e.g., equality, equivalence, boundary, etc.) apply to LPA. However, the specific considerations are substantially more complicated under LPA. In LCA, the fact that the mean and variance structure do not exist independently from one another simplifies decision making. In addition to considering mean differences between classes, class enumeration and subsequent confirmatory model testing in LPA requires consideration of the potential for differences in the variance/covariance matrix among indicators across classes (Meyer & Morin, 2016). Whether or not the conditional independence assumption can be relaxed may be either an empirical or theoretical question, depending on a priori suppositions regarding shared antecedent causes among select latent class indicators, independent of the latent class variable. Beyond the need for additional constraints, there are complexities around operationalizing those constraints that do not apply to the same degree in LCA. For example, homogeneity may be operationalized in terms of the ratio of within class variance to the total or between class variance, a computationally more complex constraint lacking clear guidelines for boundary setting. Separation may potentially be operationalized in terms of a standardized mean difference, such as Cohen’s d, though such constraints cannot be considered independently of homogeneity constraints on the variance structure. Constrained LPA models, with consideration of the mean and variance/covariance structure and the assumption of within class multivariate normality, as well as the potential to relax the conditional independence assumption, are important areas for further inquiry.
There are numerous additional directions for future extensions. We focused on confirmatory approaches to measurement model testing where class proportions were the only structural parameters. Incorporating covariates as predictors or outcomes of class membership is important for theory development and validity testing (e.g., MIMIC models). A full discussion of the complexities around covariate inclusion in mixture modeling is beyond the scope of this article, though see Nylund-Gibson and Masyn (2016) and Masyn (2017) for recent advances. In the data illustrations, nurses were nested within health care organization. Intraclass correlation values were small and were addressed by correcting model standard errors rather than with multilevel modeling. The literature with respect to multilevel modeling within categorical latent variables is still evolving (e.g., Asparouhov & Muthén, 2008), and additional research is needed to clarify incorporation of between and within level variance structures into latent class measurement model testing (though see Dunn, Masyn, Johnston, & Subramanian, 2015). Confirmatory approaches to person-centered methodologies may also benefit from consideration of individual-level classification, for example, by estimating agreement in classification for a theoretically driven k-class model relative to an unconstrained k-class model (higher agreement indicates greater support for the proposed theory). Such an approach represents confirmation at the individual level, unique to person-centered methodologies. We currently lack standards for quantifying and evaluating agreement, though recent work on individual prediction within mixture modeling reflects a promising new direction (Cole & Bauer, 2016).
In summary, there is theoretical utility in considering confirmatory approaches to LCA and other person-centered methodologies, and we have shown several examples for moving from what has traditionally been a data-driven approach into a confirmatory realm in LCA. Decision making around when a confirmatory framework should be sought, as opposed to more traditional approaches to class enumeration, are dependent on the state of the theory within a particular research area, aspects of data availability, and study goals. As was evident from both illustrations, statistical software is fast, user-friendly, and flexible; though ease of estimating these models is advantageous in some respects, extremely careful consideration of model specification and interpretation by applied investigators is paramount. Regardless of the approach taken, we advocate for thoughtful and principled methods for generating and/or validating latent class models, full theoretical consideration of previous findings prior to the development of a measurement model in LCA/LPA, and careful theoretical and empirical consideration of alternative models. Though the placement of model constraints is unique to a confirmatory framework, transparency in one’s approach and thoughtful consideration of implications of the specific approach on observed findings are relevant across applications of person-centered methodologies.
Supplemental Material
Online_Supplementary_Material - Confirmatory Latent Class Analysis: Illustrations of Empirically Driven and Theoretically Driven Model Constraints
Online_Supplementary_Material for Confirmatory Latent Class Analysis: Illustrations of Empirically Driven and Theoretically Driven Model Constraints by Alexandre J. S. Morin, Aleksandra Bujacz, Marylène Gagné, Sarah J. Schmiege, Katherine E. Masyn, and Angela D. Bryan in Organizational Research Methods
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplementary material for this article is available online
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.