
Abstract
Lawrence R. James spent the last 20 years of his 35-year career developing and validating a new theory of personality that he called conditional reasoning. This theory was focused on mapping and measuring core aspects of the implicit (i.e., unconscious) personality. In this article, we (a) review James’s seminal contributions to the theory and measurement of conditional reasoning, (b) discuss subsequent contributions made in the area of conditional reasoning, and (c) provide a brief “look under the hood” at James’s approach to test development and validation. This final section of our paper is designed to familiarize other researchers with the protocols that James and his colleagues have used over the past 20 years. Many of these protocols have gone unmentioned or only briefly acknowledged (e.g., in conference presentations or informal meetings); indeed, many of these validation protocols were “implicit” in the thinking of James and his approach to the study of personality. Having benefited from working closely with James, we were privy to many of these implicit assumptions and protocols that privately guided James’s early work on conditional reasoning.
Keywords
Conditional reasoning (CR) was originally presented by James (1998) as “a new measurement system for personality” (p. 132). This new measurement system was specifically designed to assess the implicit or unconscious aspects of personality. Implicit personality represents the part of personality that is not available to the individual via introspection and thus must be measured using an indirect approach. In contrast, the explicit aspects of personality are available via introspection and are frequently assessed via self-report surveys. In the following, we briefly (a) review James’s seminal contributions to CR, (b) discuss subsequent contributions to CR, and (c) close with suggestions for researchers seeking to build conditional reasoning tests (CRTs).
James’s Seminal Contributions to Conditional Reasoning
Justification Mechanisms
In the first CR paper, James (1998) introduced the concept of justification mechanisms (JMs), which he defined as “reasoning processes whose purpose is to enhance the logical appeal of [an individual’s] behavioral choices” (p. 131). More recently, James and LeBreton (2012) updated the description of JMs as describing: the unconscious [italics added] proclivities that shape the reasoning [italics added]…people use to build logical foundations for their rationalizations. Justification mechanisms may be thought of as implicit predispositions [italics added] that direct seeming logical ways of framing and reasoning that are in fact biased and serve rationalizations by making the rationalizations seem reasonable and sensible. (pp. 28-29) people with a strong [need, motive, or desire] to engage in a behavior will develop biased ways of reasoning that make the behavior seem rational and sensible as opposed to irrational and foolish…. Rationalization both masks the true motive and engenders its expression by creating the illusion that [the motive-driven behavior] is sensible and therefore justified. (pp. 30-31)
Justification Mechanisms for Aggression.

Note: This table is reproduced with the permission of Sage Publications and originally appeared as Table 1 in James, L. R., McIntyre, M. D., Glisson, C. A., Green, P. D., Patton, T. W., LeBreton, J. M., Frost, B. C., Russell, C. M., Sablynski, C. J., Mitchell, T. R., & Williams, L. J. (2005). A conditional reasoning measure for aggression. Organizational Research Methods, 8, 69-99.
Conditional Reasoning Theory of Personality
James et al. (2005) formalized a conditional reasoning theory of the motive to aggress (see Figure 1). Importantly, this theory is integrative and draws from traditions in general personality and clinical, social, and cognitive psychology. We highlight a few key aspects of this theory, but a more detailed discussion is available in Chapter 2 of James and LeBreton (2012).

The conditional reasoning theory for the motive to aggress. Figure 1 is reproduced with the permission of Sage Publications and originally appeared as Figure 1 in James, L. R., McIntyre, M. D., Glisson, C. A., Green, P. D., Patton, T. W., LeBreton, J. M., Frost, B. C., Russell, C. M., Sablynski, C. J., Mitchell, T. R., & Williams, L. J. (2005). A conditional reasoning measure for aggression. Organizational Research Methods, 8, 69-99.
First, drawing from the tradition in personality psychology, James et al. (2005) suggested that the primary catalysts of behavior are basic human motives (aggression, power, achievement, etc.; Murray, 1938; Schultheiss & Brunstein, 2010). Second, consistent with the tradition in clinical psychology, these (often unconscious) motives may come into conflict with a competing (often conscious) motive to see oneself as engaging in behavior that is wholly sensible, reasonable, rational, and appropriate, as engaging in behavior that is consistent with “doing the right thing” (i.e., acting in a moral and socially responsible manner; Freud, 1936; Vaillant, 1977). This intrapsychic conflict is believed to occur unconsciously and serves to activate or catalyze JMs associated with the motive of interest (e.g., aggression, power, achievement). Third, JMs represent the union of the psychological content from the traditions in personality psychology (i.e., human motives) and clinical psychology (i.e., psychological defense, intrapsychic conflict) with generic forms of cognitive biases largely identified in the social and cognitive traditions (e.g., framing biases, attributional biases; Kahneman & Tversky, 1984; Weiner, 1990). Finally, consistent with the tradition in clinical psychology (intrapsychic conflict) and the cognitive tradition (dissonance reduction), JMs serve as a tool for reducing conflict/dissonance.
Conditional Reasoning Test Problems
The last but not least of James’s seminal contributions to CR was the development of a novel, indirect measurement system designed to objectively measure the JMs linked to different personality motives. His approach to measurement uses a modified form of inductive reasoning. James referred to this approach as conditional reasoning and the test items as conditional reasoning problems because the extent to which a given solution to an inductive reasoning problem is judged to be correct is said to be conditional on the personality (i.e., motives) of the respondents. Specifically, James’s approach is based on the idea that the solution judged to be most logical (i.e., “correct”) will depend on the JMs of the person doing the reasoning.
Because most of the early studies on CR focused on James’s new approach to measurement, we want to clarify a few additional points about the items used to measure CR. First, CR items represent an indirect approach to measurement, meaning that CR items “neither inform the subject of what is being assessed nor request self-report concerning it” (Greenwald & Banaji, 1995, p. 5). Traditionally, those interested in assessing the implicit personality have relied on indirect measures such as projective tests (e.g., Rorschach Inkblot Test, Picture Story Tests) or response latency measures (e.g., Implicit Association Test), both of which have noted strengths and weaknesses (cf. Arkes & Tetlock, 2004; Blanton & Jaccard, 2006; James & LeBreton, 2012; Lilienfeld, Wood, & Garb, 2000, 2001). CR is designed to retain the strengths of these other measurement systems while also addressing several of the notable weaknesses (e.g., use of open-ended answers requiring time-intensive and expensive expert coding, mixed evidence of test reliability, and potential for test faking/impression management). Specifically, by relying on the use of inductive reasoning problems containing a limited number of responses, the CR approach is more objective (i.e., does not require the interpretation or coding of open-ended responses or extrapolation from response latencies to psychological processes). As we see in the following, CR items may be thought of as a form of “forced choice” projective test.
Conditional reasoning: An illustration
Table 2 contains an illustrative CR problem designed to measure the JMs associated with the motive to aggress. Like traditional inductive reasoning problems, individuals are presented with a series of premises and are then asked to make a logical inference regarding those premises. The inference task associated with this item asks respondents to infer which of the four possible solutions most weakens the conclusion drawn from the premises of the problem. Thus, the basic format of conditional reasoning problems is similar to what is found on typical assessments of reasoning or cognitive ability.
Illustrative Conditional Reasoning Item.

Like reasoning problems measuring cognitive abilities, this CR problem includes multiple answers that do not logically follow from the premises (i.e., “wrong” answers). These inductively invalid answers (sometimes denoted distractors) are easily identified as options A and C. Unlike reasoning problems used to measure cognitive abilities, this CR problem has multiple inductively valid answers (i.e., multiple “correct” answers). Option D is designed to capture aspects of the retribution bias and the potency bias JMs. In contrast, Option B was not built on rationalizations for aggression but rather is anchored in nonaggressive values, norms, thinking, and reasoning (see also Chapter 3 in James & LeBreton, 2012).
Conditional reasoning: Initial evidence
The first CRT (James, 1998) was designed to assess the competing implicit motive to achieve (or achievement motivation; AM) and the implicit motive to avoid failure (or fear of failure; FF). The test was denoted the CRT-RMS as it was designed to assess the relative motive strength of this pair of implicit motives. James identified six JMs describing the implicit defenses used to support AM and eight JMs used to support FF. A low score on the test indicates the fear of failure motive dominates the achievement motive, whereas a high score indicates the achievement motive dominates fear of failure. Data were presented from two student samples to demonstrate both discriminant and predictive validity for the CRT-RMS. Intellectual skills and CRT-RMS were both strong predictors of scholastic performance. Results from the second study also provided correlations between self-reports of achievement motivation, scholastic performance, and scores on the CRT-RMS. The self-reports of achievement motivation exhibited a small but significant positive correlation with scholastic achievement. Scores on the CRT-RMS and the self-report achievement motivation scale exhibited a small, nonsignificant correlation, which is consistent with over 50 years of research demonstrating the independence of implicit and explicit personality.
James (1998) also introduced a 14-item developmental version of the CRT-A, which was designed to measure six JMs associated with the motive to aggress. Pilot data from a sample of patrol officers suggested scores on the CRT-A were negatively correlated with supervisory performance ratings. This first article really represents a feasibility study designed to establish the potential viability of James’s approach to personality theory and measurement. Several years later, James and colleagues (James et al., 2005; James, McIntyre, Glisson, Bowler, & Terence, 2004) published a more comprehensive set of studies describing the evolution of his research program focused on the measurement of aggression. These studies provided additional psychometric and validity evidence for inference based on CRT-A scores (e.g., criterion-related validity, evidence of reliability, description of factor structure).
Summary
To summarize, James’s primary contributions included the articulation of a conditional reasoning theory of personality that positioned JMs as the central process mechanism linking implicit motives to behavior. In addition, James introduced a new indirect measurement system anchored in inductive problem solving. The initial feasibility studies focused largely on establishing the viability of his theoretical model, the core process mechanisms (JMs) in that model, and the use of inductive problem solving as a measurement tool for assessing personality.
Initial Impact of James’s Early CR Research
James’s early contributions had an immediate (albeit circumscribed) impact in the organizational sciences. For example, Dickson, Smith, Grojean, and Ehrhart (2001) referenced James’s contributions to support the rationale for hypotheses examining the relationship between leader values and organizational climate as it pertains to ethics. Specifically, Dickson and colleagues cited James when they argued that values act as cognitive filters through which people perceive reality and that a leader’s values and motives will influence their decisions and behavior based on those existing cognitive frameworks. In addition, Cortina (2008) referenced James in her discussion of workplace incivility. She noted that modern racists are unlikely to engage in uncivil behavior absent a seemingly rational justification mechanism for doing so and that the nature of a person’s implicit motives and drives may dictate the nature of the incivility he or she engages in. In addition, Cortina noted that CR represented a promising methodological avenue for studying which individuals may be more likely to engage in incivility at work. As a final example, Cogliser, Schriesheim, Scandura, and Gardner (2009) suggested CR could be used to indirectly assess implicit cognitions to better understand the processes underlying leader-member exchange (LMX) congruency. In general, James’s early contributions were referenced as both a grounding theoretical framework for research questions as well as offering a promising advancement for psychological measurement.
Subsequent Contributions to Conditional Reasoning Research
A number of studies have been published since James’s early CR articles. This research may be clustered into three themes including articles focused on: (a) psychometric/measurement issues; (b) accumulating, extending, and summarizing the validity evidence for the CRT-A and CRT-RMS; and (c) expanding the range of constructs assessed using CR.
Psychometric- and Measurement-Related Issues
The first cluster consisted of articles focused largely on psychometric- and measurement-related issues. For example, several articles have included examinations of the fakability or transparency of CRTs (J. L. Bowler & Bowler, 2014; J. L. Bowler, Bowler, & Cope, 2013; Galic, Scherer, & LeBreton, 2014b; LeBreton, Barksdale, Robin, & James, 2007). Most of these studies found that when CRTs were administered per the recommended guidelines (James & McIntyre, 2000), respondents did not appear to manipulate or distort their responses. Indeed, instructions to “fake good” appear to have little effect (or rather, the effect may be for respondents to work harder to find the “correct” answer to each problem). However, revealing the true purpose of CRTs has been shown to make the tests more transparent and thus more vulnerable to faking and impression management biases. This suggests that once the purpose of a CRT is known, it no longer acts as an indirect assessment of implicit cognitive biases (i.e., JMs).
Other measurement-focused papers have examined the fit of various psychometric models to CRT data and the psychometric equivalence of test scores across demographic groups. For example, DeSimone and James (2015) compared the fit of item response theory models to scores on the CRT-A and concluded that (a) the two-parameter logistic model was the best fitting dichotomous model and (b) the CRT-A is especially well suited for identifying individuals with higher levels of the motive to aggress. Galic and his colleagues (2014a) tested the equivalence of CRT-A scores across Croatian and U.S. samples. They found that measurement inequivalence existed on the CRT-A but that most of the problematic items measured the hostile attribution bias and the victimization by powerful others bias. They noted that these two biases likely take on different meanings in a country that experienced a recent civil war and was previously under the control of the Soviet Union. Finally, James and LeBreton (2012) summarized both published and unpublished studies linking scores on the CRT-A to participant sex and participant race. On balance, no systematic relationships were found with race, but small correlations were found between CRT-A scores and participant sex (with men scoring slightly higher than women on the CRT-A).
Accumulating and Summarizing Validity Evidence
A second cluster of articles emphasized accumulating or summarizing validity evidence for CRTs. One particular subset of articles has focused on integrative models, or how information about the implicit aspect of personality (measured via CRTs) might be integrated or combined with information about the explicit aspect of personality (measured via self-report surveys). For example, Bing, LeBreton, Davison, Migetz, and James (2007) presented a conceptual framework for integrating implicit and explicit personality and then illustrated the value of their framework using the construct of achievement motivation. They found that scores on the CRT-RMS and scores on a self-report measure of achievement striving tended to have additive effects in the prediction of various outcomes. In contrast, Bing, Stewart, and colleagues (2007) tested a model integrating measures of implicit (CRT-A) and explicit aggression and found these measures tended to have both additive and multiplicative effects (see also Frost, Ko, & James, 2007).
A second subset of articles focused on expanding the criterion side of the nomological networks for CRTs. For example, research using the CRT-A has linked implicit aggression (at an aggregated group level) to group performance, commitment, and cohesion via its impact on negative socioemotional behaviors (Baysinger, Scherer, & LeBreton, 2014). Scores on the CRT-A have also been linked to differences in the attributions made for failure as well as the corrective actions recommended for remedying that failure (M. C. Bowler, Woehr, Bowler, Wuensch, & McIntrye, 2011), divergent mental models (leading to a less effective training intervention; M. C. Bowler, Woehr, Rentsch, & Bowler, 2010), increased levels of reported sleepiness (Barber & Budnick, 2015), and malevolent creativity (Harris & Reiter-Palmon, 2015). Finally, Schoen (2015) found that implicit achievement motivation measured via CRT-RMS was associated with creative performance even when controlling for explicit achievement motivation.
Finally, a third subset of studies has focused on providing meta-analytic summaries of the validity of CRTs, namely, the CRT-A. In the first published meta-analysis of the CRT-A, Berry, Sackett, and Tobares (2010) summarized 17 effect sizes obtained from 11 different sources that included one peer-reviewed journal article, nine unpublished theses or dissertations, and the test manual for the CRT-A. Overall, the authors concluded that scores on the CRT-A were correlated with counterproductive workplace behaviors (CWBs) but that the effect size (we will report uncorrected, sample-weighted average correlations used throughout this discussion) was smaller than what had been suggested by James and colleagues (2005). Berry and coauthors found the effect size varied when including (r = .11) or omitting (r = .26) dichotomous outcomes/criterion.
The second meta-analytic review was offered by Banks, Kepes, and McDaniel (2012). These authors reanalyzed the data used by Berry and colleagues (2010) and found a similar effect size (r = .16). Banks and coauthors conducted additional analyses to examine whether this estimate may have been subject to publication bias. Even though only 1 of the 11 sources comprising the data analyzed was obtained from a primary article published in a peer-reviewed journal, Banks and coauthors nevertheless concluded that prior estimates of criterion-related validity evidence for the CRT-A were upwardly biased (r = .22, reduced to r = .06, following a trim and fill analysis). A final meta-analysis was described in the James and LeBreton (2012) book. These authors reported a small omnibus relationship between scores on the CRT-A and CWBs (r = .27). In addition, the authors also included an analysis based on a subset of studies described as representing the “best indicators” for validity (i.e., effect sizes from predictive designs using objective criteria). Only nine effect sizes met the criteria for “best indicators,” but the average weighted correlation with CWBs substantially increased (r = .41).
Although a limited number of studies were available, three meta-analyses were undertaken to examine the validity evidence for inferences drawn from scores on the CRT-A. Across these three studies, different results were obtained, but these differences are likely driven primarily by differences in the judgment calls made by each team of researchers. Specifically, judgment calls related to inclusion criteria and the estimation of effect sizes. For example, James and LeBreton (2012) omitted effect sizes based on explicit self-reported criteria, but such effect sizes were included by Berry and colleagues (2010) and Banks and colleagues (2012).
James and LeBreton (2012) and Berry and coauthors (2010) sought to address concerns related to publication bias by including a large number of unpublished theses and dissertations in their reviews. For example, of the 17 effect sizes included in the estimate provided by Berry and colleagues using CRTs to predict CWBs, only 3 (18%) were obtained from primary studies published in peer-reviewed journals, 4 (24%) were unpublished studies obtained from the CRT-A test manual, and the remaining 10 effect sizes (59%) were obtained from unpublished theses and dissertations. In contrast, Banks and coauthors (2012) relied on an empirical test of publication bias that is based on sampling distributions of the validities.
Overall, the validity evidence for the CRT-A is mixed, but based on the reviews by Berry and colleagues (2010) and James and LeBreton (2012), there appears to be evidence that scores on the CRT-A are indeed predictive of subsequent behavioral expressions of CWBs with uncorrected weighted correlations likely falling in the .20 to .30 range. Table 3 recaps the studies that have focused on accumulating and summarizing validity evidence for the original CRTs.
Accumulating and Summarizing Validity Evidence.

Note: CRT-A = conditional reasoning test for motive to aggress; CRT-RMS = conditional reasoning test to assess the relative motive strength of implicit motive to achieve and implicit motive to avoid failure. CWB = counterproductive workplace behaviors.
Extension to New Constructs
A final set of articles focused on extended CR to additional constructs, including: team orientation, addiction proneness, integrity, creative personality, and power.
Team orientation
O’Shea, Driskell, Goodwin, Zbylut, and Weiss (2004) created a CRT designed to measure team orientation (CRT-TO). These authors conducted a literature review based on research related to dominance, affiliation, and the explicit personality taxonomy of the five-factor model. Based on this review, the authors identified 12 facets of the team orientation construct and then linked these facets to “implicit assumptions” (a circumscribed variant of the JM concept that was loosely based on James’s notion of JMs). Using these facets and the accompanying implicit assumptions, 59 CR items were developed. These items were then used in a series of studies examining the psychometric characteristics and validity evidence for the CRT-TO.
On balance, small interitem correlations were observed, as were small correlations with self-report measures of explicit personality. Generally, the facet level scores on the CRT-TO were not related to supervisory ratings of soldier performance, with the exception being scores on the Negative World View, which was correlated with ratings of a cooperative work ethic (r = –.17, p < .05) and ratings of soldiers’ negative world view (r = .24, p < .05); however, this pattern did not cross-validate when tested in a new sample of soldiers. The Negative World View facet was also negatively related to soldiers’ commitment to both their teams and the broader military (with correlations in the .10s). Although this was an ambitious early effort, which offered a glimpse of promise for using CR, much has been learned over the past 15 years that we believe might help improve future assessment efforts.
Addiction proneness
J. L. Bowler et al. (2011) identified five JMs related to substance use and abuse: evasion of discomfort bias, immediate gratification bias, negative self-bias, self-revision bias, and the Displacement of Responsibility Bias. The authors presented the results of a feasibility study testing the predictive validity of a CR for addiction proneness (CRT-AP) designed to measure these JMs. They administered 23 CR items to a sample of undergraduate students and a sample of individuals with a known history of chemical dependency. After removing 8 items with low item-total correlations, the remaining 15 items were combined to create the CRT-AP scale. They found higher CRT-AP scores in the chemical dependency sample versus the student sample (d = .98). In addition, scores on the CRT-AP incremented the prediction over and above a self-report of addiction (▵R2 = .22, p < .001).
Integrity
Fine and Gottlieb-Litvin (2013) sought to extend the use of CR to assess a dispositional tendency toward integrity. Using a combination of self-report items, interviews with subject matter experts, and a review of the professional literature, the authors created 200 “justification scenarios,” and these scenarios were then condensed into 12 “justification types” that were then evaluated by 108 undergraduates. A principal component analysis yielded three components they labeled as JMs: denial, distortion, and projection. Each of these JMs included two facets, and each facet included two subfacets. The authors then tested an 18-item CR integrity test (CRIT) to predict self- and peer reports of CWBs and obtained mixed results. When the CRIT was administered under “honesty” instructions, it yielded significant criterion-related validities with both self- and peer ratings of CWBs (r = –.26, p < .01 and r = –.25, p < .05, respectively). In addition, CRIT was significantly correlated with a measure of overt integrity (r = .39, p < .001). However, when administered under “faking” instructions, CRIT scores were uncorrelated with both the criteria and the overt measure of integrity. We believe that this is a promising construct for assessment via CR but that future research should place greater emphasis on objective criteria and less emphasis on using the content of self-report surveys to generate the JMs that are believed to operate in a largely unconscious manner.
Creativity
In a recent study, Schoen et al. (2018) discussed the implicit components of creativity and identified a set of five JMs related to creative personality: impact bias, exclusivity bias, novelty appreciation bias, efficacy of tenacity bias, and malleability of social norms bias. The authors describe the development, validation, and revision of a CRT for creative personality (CRT-CP) using data from five samples. Although the test is a work in progress, the authors found that scores on the CRT-CP were significantly related to behavioral indicators of creativity (rs ranged from .27 to .33). In addition, scores on the CRT-CP significantly predicted entrepreneurial activities (e.g., owning a business; r = .44, p < .05). Scores on the CRT-CP exhibited small correlations with self-report measures of creative personality (e.g., openness to experience; rs in the .10s and .20s), and scores on the CRT-CP predicted creative performance and entrepreneurial activities above that predicted by self-reports of creative personality. Finally, as theorized, scores on the CRT-CP were related to both convergent and divergent thinking abilities (rs in the .20s).
Power and leadership
James, LeBreton, and colleagues (James et al., 2013; James & LeBreton, 2012) introduced the JMs believed to underlie the implicit motive for power: agentic bias, social hierarchy orientation bias, power attribution bias, and leader intuition bias. James and colleagues argued that the power motive is a valence-neutral motive. That is, the desire to exert control over others is not inherently good or bad. Rather, the expression of a power motive may be either instrumental or toxic, depending on other personality motives. They argued that power becomes toxic when it is channeled through a motive to aggress. Using this general framework, the authors described a new test for leadership potential that integrates the motive to aggress with the motive for power—the CRT for leadership (CRT-L).
Although this test has been used in several unpublished theses and dissertations, the only published validation study was summarized in a chapter by James et al. (2013). The authors reported that an empirical key containing a subset of the CRT-L items significantly correlated with leader performance (i.e., rs in the .3 to .4 range with store profits). This empirical key was built using store profits during the month of August as a criterion obtained for a sample of managers employed in a large retail store chain. This empirical key (based on August criterion data) was then used to predict the store profits reported during the previous 6 months (i.e., February through July with correlations ranging from .35 to .44). Thus, a true cross-validation sample was not included; however, the initial results appear promising, and the authors noted “the results suggest that nonaggressive managers with strong power motives managed the most profitable retail stores…[and] toxic managers—managers with a high power motive coupled with aggressive tendencies—ran stores that were significantly less profitable” (p. 259).
Summary
In general, a handful of attempts have been undertaken to extend CR to the assessment of new constructs, resulting in mixed results. Thematically, as we reviewed these extensions, we observed noticeable differences in the development and validation protocols used by researchers who were more versus less successful in their efforts to extend CR to new constructs. The final portion of our paper explicates some of these differences with the goal of deriving an initial set of suggestions for the development and validation of new CRTs.
Looking Ahead: Developing and Validating New Tests of Conditional Reasoning
In the final section of our paper, we expand on James’s initial contributions to CR by addressing 10 fundamental issues or questions that researchers new to this area may confront as they go about developing and validating their first CRT. To be clear, our answers to these questions are based on nearly 20 years of accumulated successes and (more importantly) failures. The bulk of these recommendations focus on strategies for writing and validating CR items.
Question 1: What Types of Constructs Can Be Assessed Using Conditional Reasoning?
The focal process mechanisms in the conditional reasoning theory of personality are justification mechanisms. Thus, constructs for which individuals are likely to develop JMs are the constructs most appropriate for measurement via CR. James and LeBreton (2012) noted, People with a strong motive (desire) to engage in a behavior will develop biased (i.e., defensive) ways of reasoning that make the behavior seem rational and sensible as opposed to irrational and foolish. The biases in…reasoning are referred to as justification mechanisms. (p. 18)
Looking at these descriptions, we conclude there are at least two essential characteristics of constructs that are candidates for measurement via CR. First, constructs should be relatively stable, enduring, and trait-like (i.e., a predisposition) rather than malleable, fluid, and state-like. Second, the candidate constructs should have the potential to motivate behaviors that could be viewed as socially unacceptable or problematic and thus would require individuals to develop justifications or rationalizations for such behaviors. Essentially, individuals are motivated to maintain a positive self-regard (James & LeBreton, 2012), and to maintain such positive self-regard, individuals must consciously evaluate themselves as pursuing behaviors that are logical, reasonable, and acceptable. Such behaviors may include those not sanctioned by society (e.g., aggression, addiction, low integrity) or those that are sanctioned but sometimes push against normative standards when taken to extremes (e.g., power, achievement, creativity).
Examples
Taken together, these characteristics suggest that constructs that are directly a function of changes in one’s environment, such as transient mood states, would not be a good candidate for measurement via CR. However, one could build a measure of CR that seeks to measure the enduring patterns of cognition that underlie perpetual feelings of negative affect/depression. For example, the negative self-bias may be an important JM underlying the broader construct of depression. James and LeBreton (2012) suggested that individuals with this bias are implicitly disposed to view themselves through a lens of inadequacy and to reason in ways that render them personally at fault for all or at least most of their perceived inadequacies…. This bias further engenders expectancies of failure in future endeavors. (p. 196) a predisposition to logically connect the use of power with positive behavior, values, and outcomes. Acts of power are interpreted in positive terms, such as taking initiative, assuming responsibility, and being decisive…the powerful are viewed as talented, experienced, and successful. In like manner, successful leadership is rationally attributed to the use of power. (p. 243)
Question 2: How Should One Go About Defining and Identifying JMs?
JMs are implicit biases that facilitate the rational appeal of motive-driven behaviors. Thus, the best way to identify JMs is to try and understand the differences in cognitive processing (framing, encoding, reasoning) that lead different individuals to pursue different courses of action when faced with the same situation/stimulus/scenario. The focus of JMs is not on specific behaviors or feelings, but rather, JMs represent the implicit biases used to rationalize and defend pursuing those behaviors or emotional experiences.
Examples
Table 4 contains a definition offered by James and LeBreton (2010) for the hostile attribution bias (HAB) as well as another version that was presented in James et al. (2005). It also contains an additional clarifying description of the HAB presented in LeBreton et al. (2007). Beginning with the James and LeBreton (2010) definition, we see that the HAB could be defined almost exclusively in affective terms. It largely describes the outcomes/experiences that someone with a strong HAB might experience, but it doesn’t articulate the underlying cognitive processes/mechanisms that this bias is believed to shape and influence. For example, this definition emphasizes feelings of “peril,” “alarm,” and “threat,” resulting from tendencies to “sense” hostility and danger emanating from other people. The feelings of “apprehension” are suggested to underlie the rational appeal of aggression as an act of self-defense.
Different Definiitions of the Hostile Attribution Bias

In contrast, the definition presented in 2005 places a greater emphasis on cognitive processes, especially attributional process. For example, the 2005 definition discusses how “implicit assumptions” shape inferences/conclusions about the motivations/intentions of others. It is clearly anchored in the cognitive process of attribution. Building off of the 2005 description, LeBreton et al. (2007) explicitly linked the attributional aspects of HAB to specific cognitive processes such as: selective attention, confirmatory information search strategies, and the overweighting of irrelevant information and the underweighting of relevant information. As we will discuss later, defining JMs in affective or behavioral terms rather than as cognitive biases can make it much more difficult to write effective conditional reasoning problems.
Tools for Defining JMs
One way to think about JMs is that they represent the union of a process bias with psychological content. For example, James and LeBreton (2012) catalogued a number of “generic” implicit biases, including: differential framing bias, attribution bias, halo bias, and discounting bias. They suggested that such biases by themselves were not JMs but rather represented the psychological processes through which JMs could shape and influence reasoning and rationalization. For example, the potency bias is defined as a tendency to differentially frame behavior “through a perceptual prism primed to distinguish (a) strength, assertiveness, dominance,…and bravery from (b) weakness, impotence, submissiveness,…and cowardice” (James et al. 2005, p. 74). This bias represents the union of a basic process mechanism (i.e., differential framing) with psychological content (i.e., the motive to aggress). We encourage researchers to carefully study basic process mechanisms/biases and consider how those mechanisms/biases are likely to be manifested in the constructs they wish to measure.
How to Find and Identify JMs
James and colleagues (James, 1998; James & LeBreton, 2012) suggested those hoping to work with CR should dig deeply in the psychology of the constructs they seek to measure. In addition to a careful review of the scientific literature, James relied heavily on nonscientific sources, including: biographies/autobiographies, documentary films, magazine and newspaper articles, and works of realistic/historical fiction. James’s philosophy was that psychologists did not hold a monopoly on understanding how people think, feel, and act.
The diversity of James’s sources is evinced in the works he cites as the foundation for developing his JMs. For example, James et al.’s (2005) definition of the HAB was developed using sources including a magazine article on street gangs published in the Atlantic Monthly as well as peer-reviewed research articles published in Psychological Bulletin and Journal of Personality and Social Psychology. Similarly, the psychological foundations for the victimization by powerful others bias emerged after reading an article in The New Yorker about White supremacists as well as a peer-reviewed article discussing the attributional processes that occur during marriage.
Ultimately, James’s approach to JM discovery was an inductive process. Our basic recommendations for finding JMs is as follows. First, we encourage researchers to follow James’s example of digging deeply into both the scientific literature and broader outlets such as documentaries, biographies, realistic fiction, and news articles. Second, when studying this broad array of resources, it may be useful to try asking questions like: “In what ways does a person characterized by construct X perceive the world and their place in it?” or “How does a person characterized by construct X convince themselves or others that his or her patterns of thinking, feeling, and behaving are reasonable, logical, and sensible?” Finally, we encourage researchers to consider how JMs may be born through the union of generic process biases (e.g., attribution bias, halo bias, discounting bias) with dispositional tendencies (e.g., motive to aggress, motive for power). Thus, when considering the psychology of some focal construct, it may be informative to consider how the generic process biases may be manifested in the cognition of individuals with a particularly high or low standing on that construct.
Question 3: How Many JMs and How Many Items Should Be Included in an Initial CRT?
Researchers (especially those who are in the early stages of developing a CRT) are advised to focus on an initial set of three to five JMs. Of course, more JMs may be identified in the literature, but an initial set of three to five should be a manageable starting point from which to begin developing CR items. Additionally, much like the item validation process for traditional self-report surveys, it is not uncommon for only a third of the CR items comprising the initial pool to survive the entirety of the validation process. In light of this, we strongly encourage researchers to include in the initial pool of items two to three times the number of items they hope to retain on the final CRT (Hinkin, 1998). Finally, CR items are labor intensive for participants and often time-consuming, so keep this in mind when determining the desired size of the final product. In the past, researchers have allotted 1 min per item when administering CRTs; however, in practice, respondents usually don’t require that much time (e.g., we allow 25 min to complete the 25-item CRT-A, but most complete it within 15 to 18 min).
Question 4: What Is the Most Common Problem Encountered When Writing Conditional Reasoning Problems for the First Time?
The primary obstacle that researchers encounter when constructing their first set of CR items is the difficulty associated with writing true inductive reasoning problems. Instead, the first draft of items may appear as inductive reasoning problems but actually are closer to (a) attribution items or (b) situational judgment test (SJT) items. James and LeBreton (2012) noted: “It is necessary to master building inductive reasoning problems…before attempting to build CR problems” (p. 77). Thus, to avoid problems writing CR items, we recommend that researchers first master the art of writing traditional inductive reasoning problems. In the following, we briefly review different forms of reasoning and summarize different prototypes of inductive inference. Finally, we provide illustrations of good and bad CR items.
Inductive and deductive reasoning
Inductive reasoning refers to a system of inference wherein respondents are asked to evaluate a set of premises and reach a conclusion, but the conclusion is only reached with probability, not certainty (Hurley, 1991). This type of reasoning stands in contrast to deductive reasoning. With deductive reasoning, tasks are self-contained, meaning that all of the necessary premises have been included in the stem of the item; consequently, conclusions reached using deductive reasoning are said to be reached with certainty. In contrast, inductive reasoning tasks are not self-contained, meaning that the respondent must go beyond the information provided in the stem of the item (e.g., recognize one or more unstated assumptions) prior to reaching an inductively plausible conclusion.
Formal and informal reasoning
Paralleling the distinction between deductive and inductive reasoning is the distinction between formal and informal reasoning. Formal reasoning problems are those that (a) contain all premises, (b) are self-contained, (c) may have explicit inference strategies to facilitate finding correct solutions (e.g., modus tollens), (d) have solutions that are often clear and unambiguous, and (e) often include item content that is circumscribed in nature (e.g., limited to academic topics). In contrast, informal reasoning problems (a) often include unstated (implicit) premises; (b) are not self-contained; (c) rarely have explicit rules or strategies for arriving at correct solutions; (d) do not have a single, clear solution but rather multiple ambiguous solutions; and (e) often include a wide array of item content, much of which is immediately relevant to everyday life (see Galotti, 1989, Table 1, p. 335). Consequently, inductive and informal reasoning problems differ appreciably from what many researchers might consider the typical or ideal form of reasoning—namely, formal, deductive reasoning that results in single solutions reached with absolute certainty.
Conditional reasoning
Conditional reasoning is best conceptualized as a form of inductive and informal reasoning. Like all reasoning problems, CR problems are comprised of a set of premises, an inference task, and a set of possible solutions to the inference task. However, like inductive and informal reasoning problems, CR problems contain multiple plausible solutions that are reached with probability, not certainty. However, unlike the traditional inductive or informal reasoning problem, the solutions to a CR problem are based on the JMs that have been linked to a particular motive (James & LeBreton, 2012).
Forms of inductive reasoning
To effectively write CR items, it is necessary for researchers to be familiar with the various forms of inductive reasoning. James and LeBreton (2012) summarized several forms or patterns of inductive reasoning, including: Inference: reaching conclusions after evaluating the veracity of a set of premises; Recognition of assumptions: identifying one or more implicit or unstated assumptions (premises) that are needed to solve the problem (i.e., reach a conclusion); Evaluation of evidence and inductive generalizations: evaluating the extent to which evidence (premises) provided in one context are likely to apply in other contexts; Analogies: inferring from the similarities (or differences) between two objects the likelihood that the objects share other similarities (or differences).
As researchers set about drafting an initial set of CR problems, they should first practice writing traditional inductive reasoning problems (and they may wish to focus primarily on one or more specific item formats as they develop new items). For example, inductive reasoning that is based on “arguments by analogy” assumes a relatively formulaic structure that once learned, could facilitate the development of CR problems. Later, we illustrate the argument by analogy but remind readers that this is but one of many forms that inductive/informal reasoning.
From inductive to conditional reasoning
James and LeBreton (2012) discussed how inductive reasoning problems can be converted to CR problems. The basic process is as follows: The thematic/substantive content of the reasoning problem must be psychologically evocative to the JM (or JMs) that is being assessed. For example, if one is seeking to measure achievement motivation, an item focused on social affiliation may be problematic. In contrast, an item that focuses on approach-avoidance conflicts related to scholastic achievement (e.g., whether to join a university honors program) may be quite evocative to individuals with an opportunity inclination bias and/or identification with achievers bias (James, 1998). Because inductive reasoning problems are amenable to multiple plausible solutions (i.e., multiple, probabilistic solutions vs. a single, certain solution), it is possible to derive multiple “correct” (i.e., inductively plausible) solutions that are derived from motive-based JMs (e.g., personal responsibility bias vs. external responsibility bias).
Illustration of Argument by Analogy
Table 5 contains the basic prototype for creating an argument by analogy. The basic logic underlying an argument by analogy is that one is able to draw conclusions about some unknown features or characteristics of one object using knowledge about the features or characteristics of a similar but different object. As noted by Moore (1998), arguments by analogy contain a common structure that forms the basis of inductive inferences. First, a premise is offered stating that two objects share a set of common attributes. Next, a second premise is offered stating that one object has additional attributes or properties. Finally, an inference is made suggesting that the second object is likely to share the additional attribute of the first object. Moore noted that to evaluate or analyze an argument that conforms to this structure, an individual must attend to (a) the number of shared attributes, (b) the relevance of the shared attributes, (c) the variety of known objects to which the unknown object is similar, and (d) the number of relevant disanalogies. Disanalogies represent critical differences between the two objects that might weaken, wound, or invalidate the analogy.
Argument by Analogy.

Moore (1998) also summarizes several strategies for strengthening arguments by analogy, including: increasing the number of shared attributes, including shared attributes with greater relevance, identifying more objects of similarity, and reducing the number of disanalogies. She also identified strategies for weakening or refuting arguments by analogy, including: pointing out relevant disanalogies, extending the analogies to absurdity, or generating a strong counter-analogy.
An ineffective CR item
The middle section of Table 5 contains a poorly structured CR problem. First, the inference task is not focused on “solving a problem” but rather attributing an emotional state to a character in the item stem. Second, the attributes shared by Steve and Bill do not appear to be particularly important for understanding why Joe may be on time for meetings with Steve but late for meetings with Bill. Although someone with a strong HAB might select option d, it is also possible that someone who is not aggressive but prone to rejection sensitivity (e.g., low self-esteem) may also find option d attractive. In its current form, this item does not appear to be a well-structured inductive or conditional reasoning problem. However, this problem can be salvaged following some substantial revisions.
An effective CR item
The lower section of Table 5 contains an actual item from the CRT-A designed to measure the HAB. This item has been shown to be an effective item. First, the inference task is not asking about imputing emotional states to characters but instead is asking respondents to reach a logical inference that may help reconcile contradictory (i.e., disanalogous) patterns of behavior. In addition, the item is based on the argument by analogy structure presented previously. It contains premises describing similarities across multiple objects (i.e., Joe’s temporal punctuality with his boss, clients, doctor, dentist, and priest). The default inference would be that Joe should be on time for his meeting with Bill. However, the item stem includes a disanalogy (i.e., Joe’s temporal tardiness with Bill) that must be reconciled. To understand the discrepancy in behavior, one must look to the shared attributes of the individuals with whom Joe is punctual. One attribute that they share is that they all assume very formal or professional positions in Joe’s social network. Professional relationships are often guided by mutual feelings of respect and admiration. Thus, one explanation for why Joe is always late when meeting with Bill is that he simply does not respect Bill. This was the logic underlying answer b. Such an inference is consistent with someone who has a strong HAB. In contrast, friendships are more informal, spontaneous, and less rigid. And individuals that are nonaggressive (i.e., don’t have a strong HAB) are inclined to be more flexible and forgiving with friends. This was the logic underlying answer d.
We hope that this example illustrates how individuals with a strong (and weak) HAB may differentially attend to information (e.g., disanalogies, shared attributes) and weigh that information when engaged in inductive reasoning. Researchers interested in writing their own CR problems are strongly encouraged to learn first about the structure and form of various forms of inductive reasoning before translating inductive problems into conditional ones. In addition, the interested reader is encouraged to familiarize themselves with Chapter 3 in James and LeBreton (2012).
Situational Judgement Items and Attribution Items: Close, but No Cigar
Table 6 contains several illustrative examples of items that on the surface look like CR items but that are actually situational judgment items or attribution/framing items. Situational judgment items often look like CR items but may change the frame of reference from a third-person view to a second-person view. In addition, the answers provided to situational judgment items often assume the form of an opinion, belief, or conviction. Likewise, attribution or framing items often appear to be CR items but are not necessarily structured as inductive reasoning problems with a correct or incorrect solution. Instead, the solutions to these items involve (a) respondents attributing meaning/intention/motivation to information presented in the item stem or (b) respondents interpreting information presented in the item stem.
“Close, but No Cigar” Items.

The items presented in Table 6 contain many of the characteristics of effective CR items. Specifically, each of the items in Table 6 include: (a) a set of premises, (b) an inference task, and (c) multiple solutions that appear to be reasonable solutions to the problem. However, a closer examination of these items reveals that they are not CR items.
SJ1
For example, as respondents read SJ1, they are placed in a second-person frame of reference (i.e., You are the coach…; In this situation, do you…). This frame of reference effectively transports the respondent into the situation/scenario described in the item and then asks the respondent for his or her opinion about the appropriate course of action. In contrast, effective CR items are written from a third-person point of view and ask respondents to identify the best solution to the inference task (e.g., What is the most logical solution? What answer most strengthens or weakens a particular conclusion or argument?
SJ2
The next item, SJ2, is written from a third-person perspective (i.e., “Maggie” rather than “You”). However, the inference task associated with SJ2 suffers from the same problem as the inference task used in SJ1. Specifically, the inference tasks for both SJ1 and SJ2 are asking respondents to furnish an opinion or belief concerning what is an appropriate course of action. In SJ1, respondents are asked what they think they would do in this particular situation. In SJ2, respondents are asked what they think Maggie should do. In contrast, the inference tasks used in CR items emphasize finding solutions to inductive reasoning problems. CR items do not ask respondents for their opinion about the correctness or incorrectness of a course of action; rather, CR items ask respondents to identify the logically correct solution to an inductive reasoning problem (e.g., inductive generalization, argument by analogy, causal inference, recognition of assumptions).
AF1
Attribution/framing items also look very similar to CR items but lack the structure of an inductive argument. For example, AF1 really looks like a CR item—it is written from the third-person perspective, contains premises, contains an inference task that is anchored in logical analysis, and includes multiple plausible solutions to the problem. However, AF1 does not have a strong inductive structure to it. The inference task asks respondents to identify the most logical explanation for the driver’s dangerous behavior. However, none of the information presented in the item stem is inductively connected to the solutions to this problem. Thus, while the inference task appears to be anchored in logical inference (i.e., “What is the most logical reason for…”), none of the available solutions to the problem flow inductively from the item stem. Stated alternatively, there is no “problem” that must be solved. Instead, the respondent is simply being asked to assign/impute/attribute meaning to the actions of the driver; they are being asked their opinion about why the driver behaved as he did.
AF2
AF2 is also lacking a strong inductive structure. The inference task is not to find the most logical solution to an inductive problem, nor is it to strengthen or weaken some argument or conclusion. Instead, the inference task is to find the most logical explanation for a behavior presented in the item stem. Thus, the respondent is not looking for a logical solution to a problem but rather is being asked for his or her opinion as to why a behavior occurred.
Summary
CR items engage respondents in problem solving. Respondents are focused on weighing pieces of evidence, identifying implicit or unstated assumptions, and drawing logical inferences. Effective CR items will follow the structure of an inductive reasoning problem (e.g., argument by analogy). Effective CR items will be written from a third-person perspective. Effective CR items will involve an inference task that focuses on solving an inductive problem (e.g., identifying an unstated assumption that most strengthens/weakens an argument or conclusion from the item stem). In contrast, ineffective items will lack an inductive structure, be written in the first-person or second-person, and include inference tasks that (overtly or covertly) solicit the opinions, beliefs, or attitudes of the respondent.
A telltale sign that one has written a situational judgment item is an inference task that is asking respondents about what “should” be done in a particular context. For example, SJ1 asks “In this situation, do you….” This is essentially asking respondents what should be done or what they would do in this situation. Likewise, SJ2 asks respondents to infer what “Maggie should [do]….” A telltale sign that one has written an attribution/framing item is an inference task that asks the respondent to explain why a behavior/event from the item stem likely occurred. For example, in AF1, the inference task asked, “What is the most logical reason for the driver’s behavior?,” and in AF2, the inference task asked, “What is the most logical explanation for why Mike is late and has not called home?”
Question 5: Is It Necessary to Include Distractor Answers in CR Problems? How Should Respondents Who Endorse the Illogical Distractor Answers Be Treated in Data Analyses?
Prior research has shown that when the true purpose of a CRT is revealed to respondents, the test no longer functions as an indirect measurement system and respondents are able to see through the test and manipulate their responses (J. L. Bowler & Bowler, 2014; LeBreton et al., 2007). One way to enhance the face validity of CRTs as measures of reasoning ability (and minimize the likelihood the purpose of CRTs is detected by respondents) is to include illogical/distractor responses. If scores differ under varying instructions (e.g., typical administration vs. a “fake good” condition), then this is indicative of poorly functioning items or a poorly functioning test.
Distractors also serve a second function as a validity check scale. For example, the test manual for the CRT-A (James & McIntyre, 2000) recommends removing participants who select five or more distractors. The reason for removing these individuals is that distractor responses are designed to be easily identified as illogical and thus should rarely if ever be selected. Thus, when a respondent regularly endorses illogical responses, his or her test protocol is deemed invalid because of (a) careless or random responding or (b) difficulty reading English (e.g., the CRT-A is targeted at a sixth-grade reading level). Computing validity scales based on distractors is consistent with test administration protocols (James & McIntyre, 2000) and is a common practice among CR researchers (LeBreton et al., 2007; Schoen, 2015; Schoen et al., 2018). We also direct the interested reader to DeSimone, Davison, Schoen, and Bing (2020) for an alternative interpretation of distractors.
Based on dozens of administrations across the CRT-A and the CRT-RMS, a reasonable decision heuristic is to remove respondents endorsing 20% to 25% of the illogical responses. In general, regularly selecting distractor responses is likely driven by difficulty with the English language or because of careless responding. After thousands of administrations (with both the CRT-A and CRT-RMS), we have found that less than 5% of respondents tend to be flagged as having problematic response patterns. Thus, when developing a CRT, researchers should consider using excessive distractor endorsement rates as a potentially validity screen to identify and remove problematic participants from subsequent analyses.
Question 6: What Forms of Reliability Are Most Appropriate When Evaluating CRTs?
A common question from those new to CR involves the estimation of test reliability. Researchers have typically sought to estimate internal consistency reliability using coefficient alpha (which is equal to KR-20 with dichotomous items; Nunnally & Bernstein, 1994). These authors correctly report that their estimates of reliability are quite low (often in the .40s or .50s), and they wonder how we obtained much higher reliabilities (often in the .70s or .80s). To answer this question, we will discuss the forms of reliability we have used in our prior work.
Test-retest reliability
Test-retest reliability is estimated by “testing the examinees twice with the same test and then correlating the results” (Allen & Yen, 1979, p. 76). Like Allen and Yen (1979), we recommend this form of reliability because it “seems to yield the most reasonable estimate of test reliability” (p. 77). Allen and Yen, however, concluded, “Test/retest reliability estimates are most appropriate for tests measuring traits that are not susceptible to carry-over effects and that are stable across the time interval used” (p. 77). Given that CRTs are designed to measure temporally stable differences in implicit motives, we believe the test-retest reliability coefficient is likely the most appropriate coefficient for establishing the reliability of CRTs.
Internal consistency reliability
Internal consistency reliability is estimated “using only one test administration and thus avoids the problems with repeated testings” (Allen & Yen, 1979, p. 76). Although a number of estimates exist, most estimates are closely based on coefficient alpha and/or the KR-20 equations (cf. Allen & Yen, 1979; Lord & Novick, 1968; Nunnally & Bernstein, 1994). However, the appropriateness of using internal consistency reliabilities was questioned by LeBreton and his colleagues (2007), who noted: Given that each test is developed with multiple JMs and that any given item response can be based on a unique combination of multiple JMs, high internal consistency…is neither expected nor required for the reliable measurement of implicit tendencies to aggress. It is possible that multidimensional tests will yield high alphas (Cortina, 1993); however, a mathematical prerequisite for such a situation to occur is moderate to high inter-item correlations. This is often not the case, and, indeed, there is no expectation that aggressive individuals will rely equally on all six JMs. Instead, individuals with high composite scores (8 or more out of a possible 22; James & McIntyre, 2000) are expected to be aggressive. An individual could arrive at such scores by relying on only a few JMs (but doing so repeatedly) or by relying on a larger cluster of JMs. (p. 7)
As Cortina (1993) aptly summarized, “[alpha] is a function of the extent to which items in a test have high communalities and thus low uniquenesses. It is also a function of interrelatedness, although one must remember that this does not imply unidimensionality or homogeneity” (p. 100).
To address the heterogeneity of within- and between-item content, we have computed estimates of internal consistency reliability using a variation on KR-20 presented by Gulliksen’s (1950, p. 389) Equation 21:

where, K is the number of items, S2 g is the variance of item g, and rg is the item-total biserial correlation. Or as recommended by James et al. (2005) and James and LeBreton (2012), using standardized variables, the variances are set to unity, and the equation simplifies to:
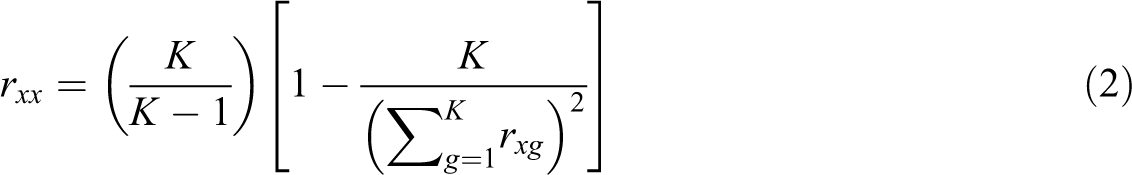
As proposed by Gulliksen (1950), these equations relied on point-biserial item-total correlations; however, when studying low-base rate phenomena (e.g., aggression), we strongly encourage researchers to replace point-biserials with their biserial counterparts. As James and LeBreton (2012) concluded: It is possible to infer that (a) the biserial is more likely than the point biserial to offer stable estimates of linear relationships and (b) correlations based on the point biserial will be necessarily “low,” which is to say underestimated, when p values for CR problems, or external criteria, are extreme, such as is the case with aggression. (p. 117)
Finally, it is also possible to compute estimates of factorial reliability by considering the internal consistency of items comprising distinct latent factors. For example, prior work on the CRT-A suggested three distinct factors: Externalizing Justifications for Aggression, Internalizing Justifications for Aggression, and Powerlessness. Although factorial reliabilities are based on fewer items (11, 6, and 5, respectively), the items comprising these factors seem to be more highly correlated with one another. Thus, these reliabilities tend to be slightly higher than estimates based on all 22 items, with estimates ranging from .87 to .81 (James & LeBreton, 2012).
Question 7: Is It Appropriate to Subject CR Items to a Traditional Factor Analysis?
The factor structure of the first CRTs were assessed in the original presentation of CR (CRT-RMS; James, 1998) and in subsequent presentations (CRT-A; James et al, 2005; James & LeBreton, 2012). However, factor structures were never a primary concern for James and his colleagues. Nevertheless, we do have a few suggestions for researchers interesting in subjecting their CR items to a traditional factor analysis.
First, while CR items are often designed to tap a specific JM, it is not unusual for response options to actually be a function of multiple JMs. This is not inherently problematic from a scientific perspective as JMs are not thought to operate independently of one another (James, 1998; James & LeBreton, 2012; Schoen et al., 2018). However, it may cause statistical problems if researchers are hoping to identify “clean” factor structures when analyzing CR items. If simple structure is the goal, then it is advisable to link only one JM to any given item response.
Second, exploratory factor analyses of CRTs often yield a large number of factors when adopting Kaiser’s criterion of retaining factors with “eigenvalues greater than 1.” What we have found is that extracting a large number of factors is often driven by a combination of item difficulty factors associated with the dichotomous nature of the typical item scoring protocol and substantive factors associated with the JMs included in the test. For example, the analysis of the 15 scored items of the CRT-RMS was reported to have 6 eigenvalues over 1 (James, 1998). The 22 scored items of the CRT-A were reported to have 11 eigenvalues over 1 (James et al., 2005; James & LeBreton, 2012). The 28 scored items for the CRT-CP were reported to have 12 eigenvalues over 1 (Schoen et al., 2018). And the 18 integrity CR items developed by Fine and Gottlieb-Litvin (2013) yielded 7 eigenvalues greater than 1.
For those hoping to explore the factor structure of their newly developed CRT, we provide the following suggestions. We recommend that researchers use large to very large samples to help ensure a stable factor structure (e.g., several hundred participants). We also recommend multiple criteria to aid in development and interpretation of the factor structure. This includes eigenvalues, scree plots, factor reliabilities, factor loadings, and the factor structure.
Finally, we recommend researchers iterate through various factor solutions (e.g., eight factor, seven factor, six factor, etc.) and try to map a substantive interpretation into the mathematical solution yielded by the analysis. While JMs might be theoretically distinct, they may not be empirically distinct (James et al., 2005). For example, the 22 item CRT-A is based on six JMs, but the most recent factor analysis suggests these JMs form three distinct factors (James & LeBreton, 2012). Factor 1 is comprised of items measuring hostile attribution bias and victimization by powerful others bias and is labeled External Justifications. Factor 2 is comprised of items measuring potency bias and retribution bias and is labeled Internal Justifications. Finally, Factor 3 is comprised of items focusing on perceived lack of control over one’s life with the primary JM being the social discounting bias and is labeled Powerlessness.
Question 8: Under What Conditions Should CRTs Be Administered?
The primary recommendation we have for administering CRTs is to treat them in a manner that is akin to a traditional test of cognitive ability. Thus, CRTs should be administered (a) with a strict time limit for completion (generally 1 min per item) and (b) under proctored circumstances (whenever possible). Time limitations and proctoring achieve several desired outcomes, including the inability for participants to cheat (e.g., asking a friend or significant other to help complete a CRT that was given as a “take home” survey) as well as encouraging participants to take the exercise more seriously. For the time being, we strongly recommend that CRTs be administered with a proctor under timed conditions (see James & McIntyre, 2000). Finally, it is important that the purpose of the assessment must not be revealed to participants by the proctor or any other party. As noted earlier, revealing the purpose of a CRT makes the test susceptible to faking. Thus, it is important never to reveal the true purpose of the assessment.
Question 9: What Are the Appropriate Validation Criteria for New CRTs?
Consistent with other researchers who have reviewed the predictive validity of implicit measures (Bornstein, 1999; Spangler, 1992), we recommend the use of objective (and highly reliable) criteria versus subjective (and/or unreliable) criteria. For example, in meta-analyses of the CRT-A (see Minton & DeSimone, 2009; James & LeBreton, 2012), stronger predictive validities were observed using objective criteria (sample weighted mean r = .24) compared to subjective criteria (sample weighted mean r = .18).
Deviating somewhat from this recommendation, Schoen and colleagues (2018) used the Creative Behavior Inventory (CBI), a self-report measure assessing creative performance as a criterion (Hocevar, 1979) when validating a new CRT for creative personality. However, this particular self-report measure contained a set of discrete (and relatively objective/verifiable) behaviors. Thus, if one is to rely on ratings (self or other) as a potential criterion, we recommend using scales that are comprised of more discrete and objective questions (e.g., yes-no responses to items such as “I have authored and published a book” or “I have been in a fight with another person that required them to seek medical attention”) versus more ambiguous or subjective questions (e.g., Likert responses to items such as “I tend to come up with novel solutions to problems” or “I get into fights often”).
This strategy proved somewhat effective for Schoen et al. (2018), who collected data from two student samples and found that scores on the CRT-CP were significantly correlated with both self-report scores obtained using the CBI and expert ratings of creative performance (observed correlations ranged from .27 to .33). Although self-reports and subjective ratings are not optimal criteria for prediction by measures of implicit constructs, these types of criterion may be “best in class” for some domains where the criterion of interest is inherently subjective in nature. Schoen and colleagues also used (but did not report) a more subjective self-report measure of creative performance (Shalley, Gilson, & Blum, 2009) and obtained the expected low correlations (r = .06 and r = .06 in two studies); however, correlations with self-reports of creative personality and self-reported creative performance were significant (ranging from r = .24 to r = .49 across the two samples with a number of self-report personality measures).
Thus, there is a growing literature supporting the idea that measures of implicit and explicit personality tend to predict different families of criteria. As demonstrated in the previous paragraphs, implicit personality is often more closely linked to objective criteria and/or measures of implicit and explicit personality may increment one another and/or interact with one another to predict such criteria (cf. Bing, LeBreton, et al., 2007; Bing, Stewart, et al., 2007; Bornstein, 1998, 2002; Frost et al., 2007; Hiller, Rosenthal, Bornstein, Berry, & Brunell-Neuleib, 1999; James & LeBreton, 2012; McClelland, 1987; McClelland, Koestner, & Weinberger, 1989; Winter, John, Stewart, Klohnen, & Duncan,1998).
Question 10: What Models for Item and Test Validation Are Recommended for CR Items?
When selecting items to retain on a test, researchers may be interested in maximizing internal consistency reliability or maximizing the correlation of items/tests with external criteria (Allen & Yen, 1979; Gulliksen, 1950). Yet, it is often difficult to simultaneously maximize reliability and criterion-related validity (Cho & Kim, 2015). For example, Allen and Yen (1979) noted, “When attempting to maximize internal-consistency reliability and validity, we can create a dilemma, since different items might be chosen to reach each of the two goals” (p. 125). Although we tend to think of longer tests as being more reliable (and thus yielding more valid inferences), Gulliksen (1950) noted that without information about item-criterion correlations, “increasing the number of items may well contribute to lowering the test validity” (p. 382).
Related to the issue of maximizing item-criterion correlations is the issue of empirical versus theoretical keying of items. At one extreme, the goal is to maximize validity, with limited focus on explaining why items predict criteria. At the other extreme, the goal is often to build a homogenous and internally consistent test, with limited (initial) focus on whether that test predicts important criteria. Within applied psychology, maximizing item-criterion relationships is not uncommon and often involves empirical keying of items against important behavioral criteria. For example, psychologists regularly construct empirical keys when developing biographical data questionnaires or with some personality questionnaires (Gatewood & Feild, 1998; Ployhart, Schneider, & Schmitt, 2006). Critics of empirically keying items largely point to (a) the atheoretical nature of the keying process and (b) the likelihood that any given key may capitalize on sampling error. Thus, many within industrial organizational/organizational behavior and allied fields have instead focused on maximizing the internal consistency reliability of their assessments; this focus on internal consistency is especially true of many personality questionnaires, attitude questionnaires, and cognitive tests (cf. Crocker & Algina, 1986; Hinkin, 1998; Nunnally & Bernstein, 1994).
Our approach to item/test development and validation may be considered a hybrid of the empirical/criterion-validity approach and the theoretical/reliability approach. Consequently, we refer to our approach as a “hybrid” form of item analysis broken down as follows: Step 1. Write CRT items derived from strong psychological theory; these items should be based on JMs identified via an exhaustive search, review, and summary of the literature. Step 2. Once an initial set of items has been written, they should undergo a series of criterion-related validation studies. Each study should include one or more behavioral (e.g., objective) manifestations of relevant criteria. Step 3. The theoretically developed items should then be subjected to empirical verification by examining the a priori theoretical keying of items against relevant criteria. Step 4. Items demonstrating a strong pattern of predictive validity across multiple criteria collected across multiple validation studies should be retained. Step 5. Items demonstrating a weak or inconsistent pattern of predictive validity may be dropped or revised and reevaluated with future validation studies. Step 6. Once a researcher has identified a set of items demonstrating strong criterion-related validity, efforts should be made to further establish the reliability of these items using the recommendations offered in our answer to Question 6.
The recommendations from the answers to the 10 questions presented here are summarized in Table 7.
Answers to Questions About Conditional Reasoning Tests.

Conclusions
Since the first article on conditional reasoning, 20 years ago (James, 1998), there has been a steady increase in the integration of conditional reasoning into the organizational sciences (for brief reviews, the reader is directed to LeBreton, in press; LeBreton & Schoen, 2017). However, notably absent from the literature has been a more detailed discussion of how James and his colleagues first set about the development and validation of CRTs. As a consequence, while more studies are using CRTs, they tend to be tests that James and his colleagues have developed. We hope that by more clearly articulating the test development and validation efforts of James and his colleagues, our article is able to catalyze and facilitate future work focused on expanding the library of constructs assessed via conditional reasoning. In closing, we wanted to share some of the ideas and goals that James was intending to pursue before his unexpected death. These ideas and goals (see Table 8) were taken from James’s personal notes, which his family generously shared with the first author. Although researchers have begun addressing several of the items on the list, it is clear that there is much left to be done. We hope that our article serves as a catalyst for other scholars to join us in the programmatic study and measurement of the implicit personality.
Some of James’s Goals for the Future of Conditional Reasoning (CR).

Footnotes
Acknowledgment
We thank Lawrence R. James for his counsel, support, and friendship. Correspondence concerning this manuscript may be directed to James M. LeBreton. Mailing address: Department of Psychology, 141 Moore Building, Pennsylvania State University, University Park, PA 16803. Email address:
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: James M. LeBreton is co-owner of Stonerowe LLC, which currently holds the rights to the conditional reasoning items/tests originally developed by Lawrence R. James to measure aggression (CRT-A), achievement motivation (CRT-RMS), and power/leadership (CRT-L). Jeremy L. Schoen holds the rights to the conditional reasoning items and test used to measure creative personality (CRT-CP).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was sponsored by the U.S. Army Research Institute for the Behavioral and Social Sciences (ARI) and was accomplished under Grant Number W911NF-16-1-0484. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Army Research Institute for the Behavioral and Social Sciences (ARI) or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.