
Abstract
The authors propose and find that the mixed results of prior research regarding disclosure antecedents are due in part to a failure to account for information sensitivity. Using prospect theory to examine willingness to disclose in an online service context, the authors propose and find that greater sensitivity of information requested produces weaker effects of customization benefits but stronger effects of information control and online privacy concern. The authors also find that customization benefits can overcome the negative effects of sensitive information requests when concern is lower or control is higher, and that perceived risk and firm trust are mechanisms through which disclosure antecedents operate. For theory, this research suggests that online disclosure models need to include sensitivity of information as a moderator. Moreover, the privacy paradox (consumers voice concerns but still disclose) may result from a failure to account for information sensitivity, since the authors find no effect of privacy concern on overall disclosure but find the predicted negative effect for higher sensitive information. For practice, our research suggests actionable strategies to aid online marketers in matching information requests with the needs and concerns of consumers by providing greater control and customization, enhancing firm trust, and adapting information requests to the situation.
Keywords
Companies are collecting more information than ever before from customers to better understand and serve them (Seiders et al. 2005; Simonson 2005). So prominent is information collection and disclosure in online retailing and service settings, that the way this information is used, handled, and protected is a key driver of online service quality (Collier and Bienstock 2006; Parasuraman, Zeithmal, and Malhotra 2005). Consumer self-disclosure should remain vital to firms since privacy-browsing modes can limit firm access to data collected via unobtrusive click-stream tracking (Levine 2008).
Thus, research continues to examine important antecedents of online disclosure. The current study focuses on three antecedents: (a) online privacy concern, (b) perceived control over how personal information is used, and (3) the perceived benefits associated with website customization. Research evidences mixed results for these antecedents, particularly for privacy concern and information control, where 40% of studies find no or mixed effects of these factors on online disclosure. Such results are notable since national polls suggest that a majority of consumers hesitate to provide information online due to concerns about information use and control (cf. Culnan and Milne 2001; Pew Internet & American Life Project 2008).
Notably absent from existing research on online disclosure is a consideration of the sensitivity of the information being requested. We believe that this omission may account for the variability in the results of prior research. Thus, a major aim of our research is to incorporate sensitivity of information into a broader framework of online information disclosure. Research shows that as the sensitivity of information increases, consumer willingness to disclose such information decreases (e.g., Culnan and Milne 2001; Rifon, LaRose, and Choi 2005). This main effect of sensitivity of information is well documented. However, research has not examined whether and why the effects of disclosure antecedents might differ depending on level of information sensitivity, despite Culnan’s (1993) call for such research over a decade and a half ago.
Failure to account for information sensitivity is important in terms of theory, research, and practice. For theory, failure to account for sensitivity of information leaves open questions about when and why disclosure antecedents affect online disclosure. For research, the frequent use of overall disclosure measures that do not account for information sensitivity contributes to the mixed results of prior research if, as we expect, the effects of disclosure antecedents vary depending on information sensitivity. For practice, failure to consider information sensitivity hinders progress in developing strategies to obtain sensitive information online or to adapt information requests to match the situation.
Thus, our contribution focuses on developing and testing hypotheses about the differential effects of disclosure antecedents on consumers’ willingness to disclose information online as a function of the sensitivity of the information requested. Using prospect theory, we propose and find that information of higher sensitivity produces weaker effects of perceived customization benefits, but stronger effects of perceived information control and online privacy concern on willingness to disclose online. We also propose and find that customization benefits can enhance willingness to disclose sensitive information more when privacy concerns are reduced or information control is enhanced. We test predictions using a scenario-based experiment in an online service context. While our primary focus is on the differential effects of disclosure antecedents on willingness to disclose online as a function of information sensitivity, follow-up studies and analyses explore the role of risk and trust in the online disclosure process.
Background
Disclosure and Disclosure Antecedents
Self-disclosure refers to the revealing of personal information such as name, preferences, and demographics by an individual to another entity (Collins and Miller 1994; Moon 2000; Nowak and Phelps 1995). We focus on willingness to disclose online, defined as an individual’s willingness to reveal personal information to a firm online. The three disclosure antecedents of interest appear next.
Online privacy concern can be broadly viewed as consumer uneasiness over the handling of their personal data (e.g., Lwin, Wirtz, and Williams 2007; Son and Kim 2008). Specific concerns include collection, errors, unauthorized sharing and access, and information use beyond its intended purpose (Metzger 2006; Smith, Milberg, and Burke 1996). We focus on consumer online privacy concern (hereafter, online privacy concern), defined here as consumer concerns about the use of their revealed information for marketing purposes, beyond its intended purpose. Our definition focuses on concern as a personal disposition, an approach which finds support in the literature (e.g., Malhotra, Kim, and Agarwal 2004; Son and Kim 2008).
Perceived information control is the extent to which consumers feel they have control (typically explicit) over their personal information and how it is used (Phelps, Nowak, and Ferrell 2000). We define firm-specific information control (hereafter, information control) as the extent to which a consumer believes that she or he can influence if and how the firm uses their personal information for marketing purposes (cf. Anderson and Narus 1984). Our definition focuses on control as a contextual factor rather than a personal disposition, an approach that finds support in the literature (see e.g., Metzger 2004; Son and Kim 2008). 1 Firms offer explicit information control in several ways, including opt-out features for information use and dissemination (Nowak and Phelps 1995; Olivero and Lunt 2004).
Website customization can involve adaptation of such factors as site content, offerings, layout, and communications (Alpert et al. 2003) that makes the site more beneficial because it is more pleasing to use, enhances the efficiency of the visit, and so on. Customization can be achieved in a passive manner, whereby the website automatically infers preferences (e.g., based on web browsing patterns), or in an active way in which consumers directly provide preference information (Alpert et al. 2003). We focus on the latter since it involves consumer disclosure, our key outcome variable. Thus, perceived customization benefits are defined as the perceived worth or value consumers attach to the degree of flexibility offered by a website to specify his/her needs or preferences (Chellappa and Sin 2005).
The Sensitivity of Information
An important aspect of personal information is its level of sensitivity. Sensitivity of information has been defined in terms of intimacy, where greater intimacy is related to information that is perceived as riskier to disclose due to the vulnerability to loss incurred by its disclosure (Lwin, Wirtz, and Williams 2007; Moon 2000). Potential losses due to disclosure of personal information include psychological (e.g., loss of self-concept due to embarrassment), physical (e.g., loss of life or health), or material (e.g., loss of financial or other assets; see Moon 2000). Thus, we define sensitivity of information as the potential loss associated with the disclosure of that information. This definition allows for the fact that sensitive information is perceived as riskier and more uncomfortable to divulge (Cranor, Reagle, and Ackerman 1999), but puts potential loss due to disclosure as the locus of sensitivity of information.
Prior Research on Online Disclosure
Table 1 summarizes online disclosure studies involving the three disclosure antecedents in our research and reveals a number of important characteristics and limitations. First, the results are mixed, particularly for online privacy concern and information control. Second, the way researchers measure disclosure varies considerably, but measures tend to fall into three categories: (a) checklists of information differing in sensitivity, added to form an unweighted index (e.g., Metzger 2006), (b) assessments of willingness to disclose on an item-by-item basis (e.g., Rifon, LaRose, and Choi 2005), and (c) overall assessments of willingness to disclose, with participants left to decide what types of information might be requested (e.g., Sheehan 1999). Each approach could contribute to the mixed results since (a) checklists vary across studies, (b) single items may not be valid or may vary across studies, and (c) respondent interpretation of information type may vary within and across studies in the absence of specification. Finally, and critical to our contribution, only two studies examine the effects of disclosure antecedents as a function of the sensitivity of information and they lack theory as to expected effects.
Research in Online Settings Relating Privacy Concern, Control, and Benefits to Online Disclosure
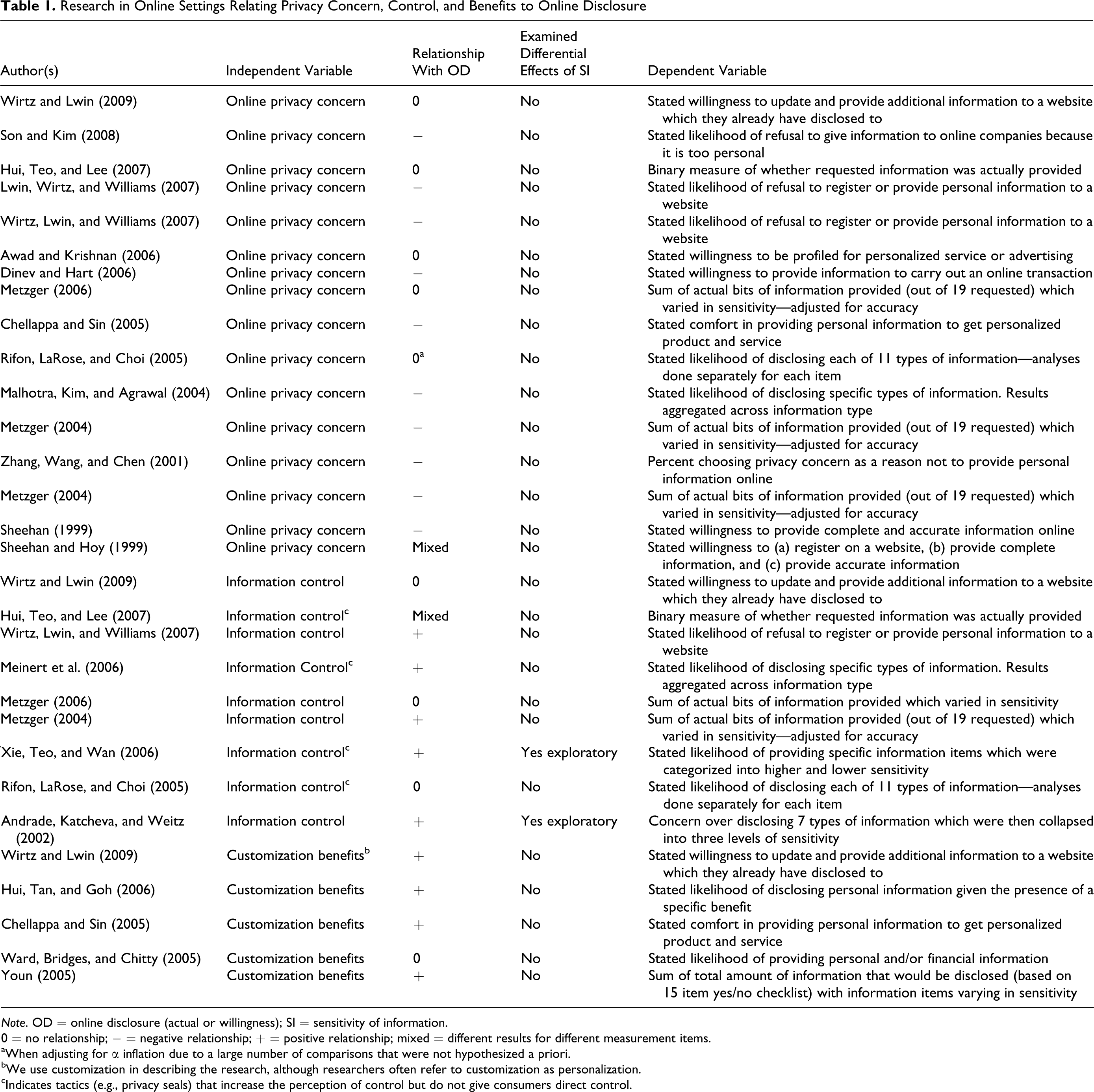
Note. OD = online disclosure (actual or willingness); SI = sensitivity of information.
0 = no relationship; − = negative relationship; + = positive relationship; mixed = different results for different measurement items.
aWhen adjusting for α inflation due to a large number of comparisons that were not hypothesized a priori.
bWe use customization in describing the research, although researchers often refer to customization as personalization.
cIndicates tactics (e.g., privacy seals) that increase the perception of control but do not give consumers direct control.
Applying Prospect Theory to Online Disclosure
We use prospect theory as a guiding framework to examine the differential effects of disclosure antecedents on willingness to disclose online as a function of the sensitivity of information requested. Prospect theory deals with how consumers evaluate gains and losses in making risky choices (Kahneman and Tversky 1979), such as the choice to disclose information online. It does so through the value function, which translates actual gains and losses into consumer perceptions of the value of those gains and losses. We propose that (a) higher levels of perceived customization benefits represent an increase in potential gains by making the website more valuable and useful (Chellappa and Sin 2005) and (b) disclosing information of increasing sensitivity represents an increase in potential losses associated with unwanted marketing efforts. Such losses might include financial (unintended spending), time (processing time), and psychological (frustration due to unwanted contact; Mitchell and Harris 2005). We note that our gains and losses are not commensurate, in contrast to traditional applications of prospect theory. However, our use of prospect theory as a guiding framework, though qualitative, provides useful theoretical insights. And, prospect theory and its core tenants have borne out even in multiattribute choice settings where gains (e.g., price decrease in $) and losses (e.g., quality decrease on a 5-point scale) were incommensurate (Chatterjee and Heath 1996).
Potential gains and losses convert to perceived value via prospect theory’s value function. Two aspects of the value function are relevant to understanding the differential role of the sensitivity of information as shown in Figure 1. First, prospect theory predicts that losses weigh more heavily than equivalent gains when individuals evaluate an outcome and that this effect increases with the relative size of the loss (Tversky and Kahneman 1992). This, aspect, termed loss aversion is represented in Figure 1 by the relative slopes of Vector A (typical function for gains) and Vector B (typical function for losses) whereby the slope for losses is roughly 2.5 times greater than that for gains (e.g., Chatterjee and Heath 1996; Tversky and Kahneman 1992). Therefore, gains can offset losses, but to do so they must be substantially larger than losses.
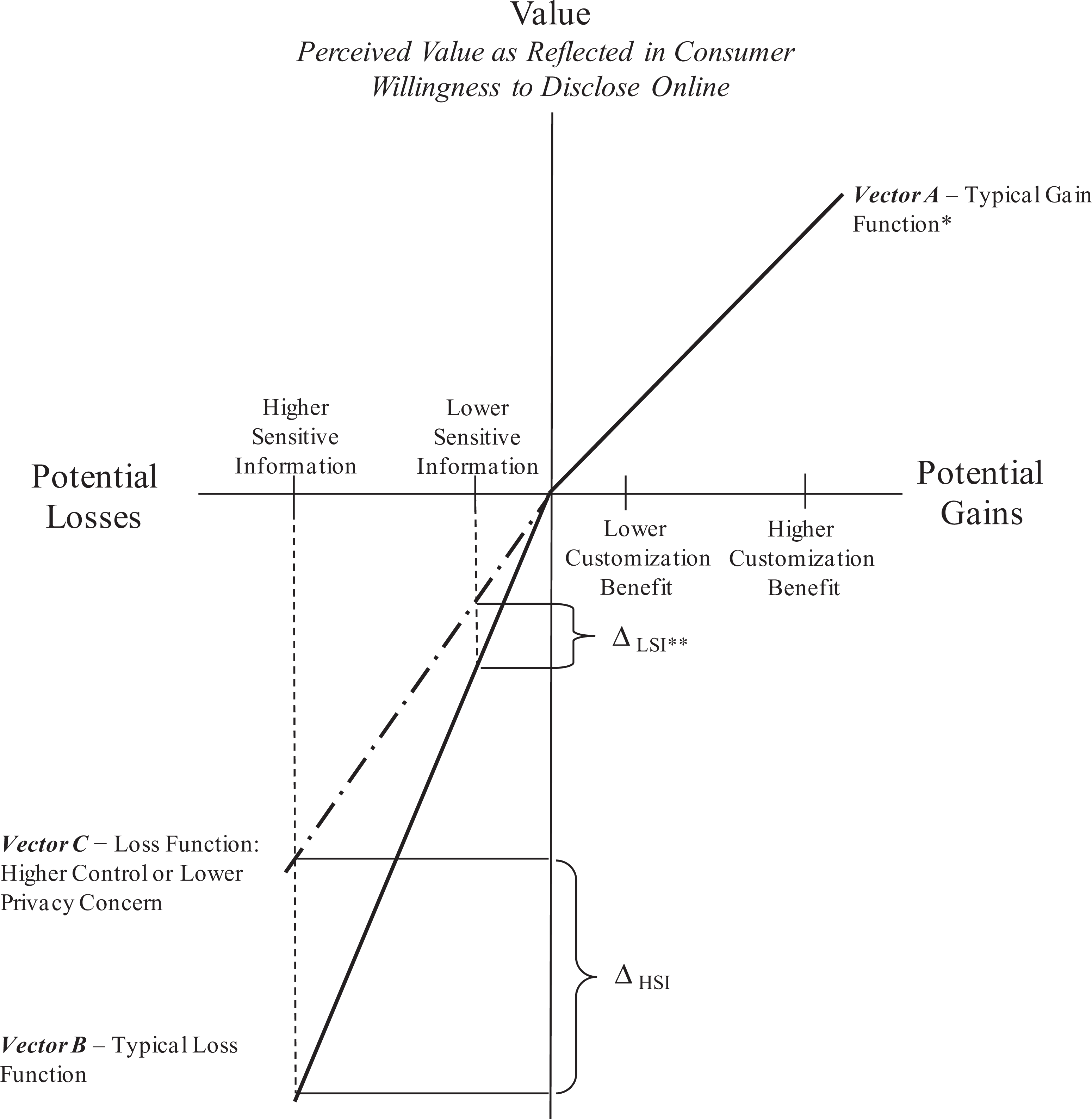
Prospect theory applied to online disclosure and sensitivity of information. Notes. *We do not incorporate the fact that the value functions evidence diminishing marginal sensitivity (concave in gains and convex in losses), since we do not expect it to affect our hypotheses. Diminished marginal sensitivity is comparable across losses and gains and the coefficient is estimated to be .88 (Tversky and Kahneman 1992) which is relatively shallow, and therefore a linear approximation appears to be robust (Chatterjee et al. 2000). **LSI (HSI) represents information of lower (higher) levels of sensitivity. ▵LSI (▵HSI) is the change in perceived loss for disclosing lower (higher) sensitive information as the slope of the loss function changes as a function of control or concern.
Second, individual and context factors can influence the slope of the loss function such that the perceived value of any given actual loss is altered (Saqib, Frohlich, and Bruning 2010). Indeed, the logic of Saqib, Frohlich, and Bruning (2010) suggests that any factor that decreases (increases) the perceived concern and/or lack of control regarding a loss will decrease (increase) the slope of the loss function. We propose that lower privacy concern and higher information control reduce the slope of the loss function, as represented by Vector C in Figure 1. Thus, for any given level of information sensitivity and associated actual loss (horizontal axis, Figure 1), an individual’s perceived value of that loss (vertical axis, Figure 1) will decrease as their online privacy concern decreases and/or as their information control increases. In Figure 1, as the slope of the loss function changes, we depict the change in perceived value of losses associated with disclosing information of higher (lower) sensitivity as ΔHSI (ΔLSI). These basic notions underlie our hypotheses regarding consumer willingness to disclose online.
Our focus is on value as reflected in consumer willingness to disclose online (vertical axis, Figure 1) since it is a key outcome of importance to both theory and practice. However, some evidence suggests that online disclosure is predicated on value-based processes, such as risk and trust. Specifically, decreased privacy concern and increased information control appear to enhance firm trust (Chellappa and Sin 2005; Wirtz and Lwin 2009), and trust appears to reduce the perceived risk of disclosure (Metzger 2004). These processes, though not addressed directly in our hypotheses, are examined later via additional data and analyses.
Model and Hypotheses
Our hypotheses appear in Figure 2. We first examine the effects of disclosure antecedents (online privacy concern, information control, and perceived customization benefits) on overall willingness to disclose online (Figure 2A). We then examine (a) the differential effects of these factors as a function of sensitivity of information (Figure 2B) and (b) how the differential effect of customization benefits varies by concern and control (Figure 2C). Finally, we examine antecedents of perceived customization benefits (Figure 2A) to broaden the theoretical and practical application of our research.
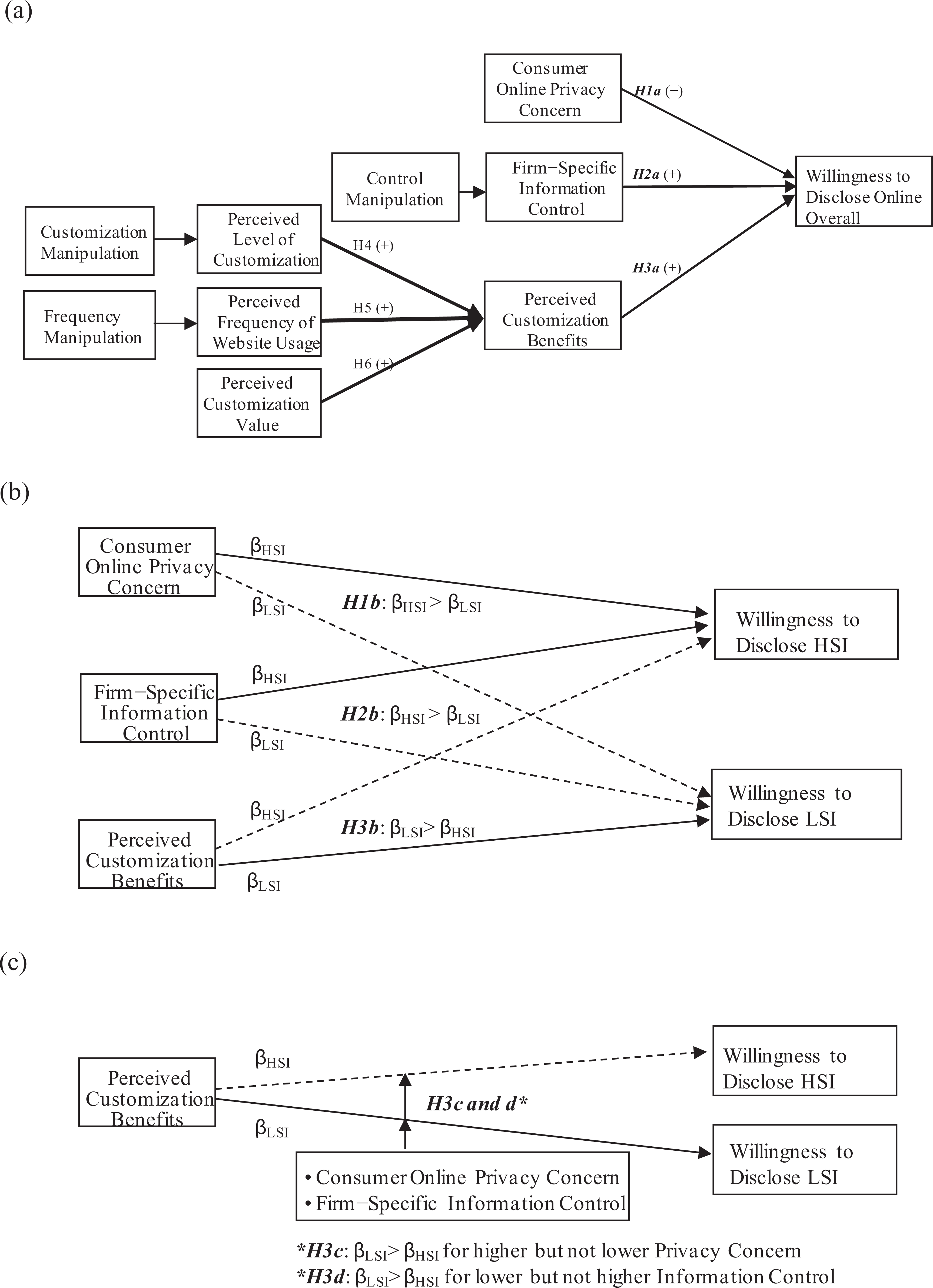
Hypothesized effects overall and as a function of the sensitivity of information. Note. HSI is information of higher sensitivity and LSI is information of lower sensitivity. In Figures 2B and C, for a given predictor, solid (dotted) lines are paths we predict to be stronger (weaker). (a) Effects on overall willingness to disclose. (b) Differential effects as a function of sensitivity of information. (c) Diffenetial perceived customization benefits effects as a function of online provacy concern and perceived information control.
Disclosure Antecedents and Willingness to Disclose Online (Hypotheses 1–3)
Online privacy concern
Research relating online privacy concern and online disclosure is mixed, although 63% of the studies report a negative-only relationship (See Table 1). Online privacy concern should influence the slope of the loss function. In Figure 1, Vector C represents lower online privacy concern; while Vector B represents higher online privacy concern (for simplicity, Vector B (typical loss function) is also used to show the loss function for higher concern and lower control since it represents a steeper loss function compared to Vector C).
Thus, for any given level of potential loss due to disclosure, increased online privacy concern should increase the individual’s perceived value of that loss, which should decrease willingness to disclose online, ceteris paribus. Figure 1 also indicates that increases in the perceived value of losses associated with increased online privacy concern should be greater when individuals disclose information of higher versus lower sensitivity, as indicated by ▵HSI > ▵LSI. Ceteris paribus, a greater increase in the perceived value of potential losses of disclosure should yield a stronger negative effect of privacy concern on willingness to disclose. Thus:
Information control
Research relating information control and online disclosure is also mixed, although 56% of the studies in Table 1 report a positive-only relationship. We argue that the amount of information control an individual feels she or he has in a given situation should influence the slope of the loss function. In Figure 1, Vector C (Vector B) represents higher (lower) information control. Thus, for any given level of potential loss due to disclosure, increasing levels of information control should decrease the individual’s perceived value of that loss which should, ceteris paribus, increase willingness to disclose online. Figure 1 also indicates that decreases in an individual’s perceived value of losses associated with increased information control should be greater in regard to disclosing information of higher versus lower sensitivity as indicated by ▵HSI > ▵LSI. Ceteris paribus, a greater decrease in the perceived value of potential losses of disclosure should produce a stronger positive effect of information control on willingness to disclose. Thus:
Perceived customization benefits
Research findings of perceived customization benefits on online disclosure are mixed, but they generally indicate positive effects. We argue that when an individual anticipates greater customization benefits, she or he will perceive greater value in the potential gains of disclosure, ceteris paribus, thus increasing their willingness to disclose.
Prospect theory suggests that consumers consider both gains and losses. This process involves Vectors A and B in Figure 1.
2
Given loss aversion and noting that the slope of the typical loss function is about 2.5 times greater than that of gains, for a given level of perceived customization, benefits should be increasingly less capable of overcoming or compensating for losses as the information to be disclosed increases in sensitivity. This suggests, ceteris paribus, that the positive relationship between perceived customization benefits and an individual’s willingness to disclose should be weaker when the information requested is more sensitive. Figure 1 is illustrative, in that, as depicted, higher customization could overcome the perceived losses associated with requests for information of lower but not higher sensitivity. Thus:
Hypothesis 3a: Perceived customization benefits positively influence willingness to disclose information online (Figure 2A).
Hypothesis 3b: Perceived customization benefits will have a stronger positive relationship with willingness to disclose information online of lower versus higher sensitivity (Figure 2B).
We note that Figure 1 is merely illustrative regarding Hypothesis 3b, since we have chosen absolute levels of gains (for customization) and losses (for information sensitivity) that are identical, which would not represent all situations. However, our overall point is that given loss aversion, increases in information sensitivity will be increasingly difficult to overcome with customization.
Figure 1 suggests additional hypotheses. Specifically, Hypothesis 3b depends on loss aversion as represented by the steeper slope of the value function for losses than gains. Any factor (such as decreased concern or increased control) which can reduce loss aversion should reduce the chance that Hypothesis 3b holds. It should do so by increasing the likelihood that customization benefits can compensate for potential losses even when requests for information of higher sensitivity are made; thus, increasing the likelihood that customization benefits will have comparable effects for disclosure requests for information of both lower and higher sensitivity.
Therefore, Hypothesis 3b (the differentially greater effect of perceived customization benefits on disclosing information of lower vs. higher sensitivity) should be most likely to occur when an individual’s loss aversion is strongest as represented by a steeper loss function (Vector B), which should occur when online privacy concern is higher or information control is lower. Hypothesis 3b should be least likely to occur when loss aversion is weakest, as represented by a shallower loss function (Vector C), which should occur when online privacy concern is lower or information control is higher. Thus, we hypothesize (Figure 2C):
Hypothesis 3c: When online privacy concern is higher, perceived customization benefits will have a stronger positive effect on willingness to disclose information online of lower versus higher sensitivity (Hypothesis 3b holds). When online privacy concern is lower, there will be no differential effect of perceived customization benefits on willingness to disclose information online of lower versus higher sensitivity (Hypothesis 3b does not hold).
Hypothesis 3d: When information control is lower, perceived customization benefits will have a stronger positive effect on willingness to disclose information online of lower versus higher sensitivity (Hypothesis 3b holds). When information control is higher, there will be no differential effect of perceived customization benefits on willingness to disclose information online of lower versus higher sensitivity (Hypothesis 3b does not hold).
Antecedents of Perceived Customization Benefits (Hypotheses 4–6)
Little theory or research focuses on the antecedents of perceived customization benefits. However, from e-commerce, researchers (e.g., Smith 2006) indicate that online customization often involves websites allowing consumers to specify their personal preferences directly. As such, one aspect driving the perceived benefits of the website’s customization is an individual’s belief regarding the extent to which the website allows for such customization, what we term perceived level of customization. From economics, a temporal perspective (e.g., Easton and Araujo 1994) suggests that one factor affecting individuals’ perceptions of the benefits of customization is their perceptions that they will utilize a service more often over time, what we term perceived frequency of website usage. Finally, attitude research suggests that individuals evaluate objects as attributes weighted by importance (e.g., Eagly and Chaiken 1993). So, those who perceive greater value to online customization generally (termed perceived customization value) should value a given level of website specific customization more. Thus, (Figure 2A):
Hypothesis 4: Perceived level of customization of a given website positively influences perceived customization benefits of the website.
Hypothesis 5: Perceived frequency of usage of a particular website positively influences perceived customization benefits of the website.
Hypothesis 6: Perceived customization value positively influences perceived customization benefits of the website.
Covariate
According to Pew Internet and American Life Project (2009), age is a major demographic factor influencing Internet use and purchase. To the extent that age differences might influence privacy perceptions (e.g., Dommeyer and Cross 2003), we include age as a covariate. Since we test our hypotheses with LISREL, the dependent variables (overall willingness to disclose and willingness to disclose information of higher or lower sensitivity) are first regressed on age and the residuals (i.e., the variables with covariate effects parceled out) are used to test the model. Age as a covariate does not alter our results and conclusions and is not discussed further.
Method
To test our model, we conducted an online experiment in an online service context, namely, a fictitious online TV program guide called YOURTV. We manipulated three variables relative to two of our disclosure antecedents, namely, perceived customization benefits and information control (see Figure 2A). Our rationale for these manipulations was twofold. First, we wanted to control how we operationalized customization and control, which would be difficult in a nonexperimental context. Second, the customization and control manipulations represent factors under the direct control of online firms and thus provide a linkage to practice. We measured the third disclosure antecedent, online privacy concern, which is a general individual difference variable not specific to a given website. We also measured the other variables in our model including (a) willingness to disclose information overall and (b) willingness to disclose information of higher and lower sensitivity, the latter being used to test differential effects across levels of information sensitivity. We created a website for YOURTV, within which we embedded our manipulations. An online TV program guide is a reasonable service context since consumers are generally familiar with TV guides and it is a context in which (a) requests for personal information are expected, (b) customization and control can be manipulated, and (c) willingness to disclose personal information can be measured.
Manipulations and Approach to Modeling the Data
We manipulated two factors relative to perceived customization benefits as follows: website customization (lower vs. higher) and expected frequency of use of the program guide (lower vs. higher). We manipulated one factor relative to information control, namely, level of information control (lower vs. higher). Thus, the experimental manipulations related to the key constructs in our model involve a 2 (website customization) × 2 (usage frequency) × 2 (information control) between-subjects design (a fourth factor, order of presentation of the customization and control manipulations, was used to control for potential carryover effects but did not affect results or conclusions and thus, is not discussed further).
We manipulate customization using statements appearing as a page on YOURTV’s website, related to adaptability to customer preferences, speed and ease of making changes, and communication mode. This approach is consistent with our focus on active customization, in which customization represents the flexibility offered by a website to specify customer needs or preferences (see Appendix A for screen shots). We manipulate use frequency in the instructions by having participants imagine they would use the program numerous times a day (higher) versus once every few weeks (lower).
We manipulate information control using statements appearing as a page on YOURTV’s website related to ownership rights of the information, the need for consent for future marketing or to sell/share information with other companies. This approach is consistent with our focus on consumers’ explicit control of the marketing usage of their personal information by a firm (see Appendix A for screen shots). Other than the manipulations, the treatments were identical. Pretests and the main study validate the manipulations; since manipulations are checked in the main study, pretest details are omitted.
We tested the hypotheses in Figure 2 using LISREL 8.8 which allowed us to (a) include both the experimentally manipulated variables and the measured constructs, (b) examine the intervening perceptual factors suggested in our model, and (c) account for measurement error. We include the manipulations in the structural model testing our hypotheses. This allowed us to check manipulations, while also allowing us to examine the link between our manipulations, downstream intermediate outcomes and willingness to disclose online. This approach finds justification in the literature (e.g., Blalock 2009; see also Alwin and Tessler 1985).
Participants and Procedure
Three hundred and forty-one upper-level business students at four large southern universities recruited 776 participants. The students received class credit and were thoroughly trained in the recruitment approach and sampling criteria. Others have successfully used this approach (see, e.g., Arnold and Reynolds 2003). It also may help increase the range of privacy concern in our sample, as those who might not normally participate might do so if approached by a friend or family member (Basi 1999).
The sample frame was nonstudent, Internet users, in the United States, over 18 years old, who watched television. Television was included to ensure the relevance of a TV guide product. Demographic characteristics indicate a diverse group of individuals participated in the study. The single largest age bracket in the sample are participants between 20 and 29 years of age (31%), followed by the next three older age brackets (in 10-year increments) each at roughly 20%. The sample is 57% female, 83% Caucasian, 59% married, and 54% with some higher education. These demographic characteristics are generally reflective of national census percentages for Internet users (U.S. Census Bureau 2003). In terms of online experience, over two thirds of the participants had used the Internet for more than 6 years, with three quarters using it daily.
We patterned the format of the website after real websites. Participants logged-on and engaged in the experiment from any location that had Internet access at any time (such differences should be randomly distributed across condition and thus not threaten internal validity). Once logged into the study, participants were randomly assigned to a treatment condition. Each session began with an introduction and instructions, followed by exposure to the website, which included the manipulations, and finally the research questionnaire. Prior to participation, each respondent e-mailed the researchers for a unique password and user ID, which they used to log onto YOURTV.com. This ensured that each respondent only participated once. Prior to the study, students provided the names of the people they had recruited. At the end of the survey, participants provided their first name, e-mail address, and the recruiting student’s name. After the survey was completed, we contacted 60% of the participants to validate their participation and crosscheck the information provided. No problems were detected.
Further, prior to analysis, we screened out 60 participants whose data patterns indicated a lack of care in terms of (a) a high number of missing values, (b) very short participation times, and/or (c) high uniformity (greater than 70%) of responses (e.g., all 1’s) across items and/or constructs. Thus, 716 participants remain for final analysis.
Measures
With the exception of the manipulations and willingness to disclose information (overall and higher vs. lower sensitivity), all constructs are reflective and measured on 7-point multi-item scales based on or adapted from prior research or developed for this study. First, we discuss the development of disclosure items and then discuss the study’s measures.
Development of disclosure items
In developing items to include in a measure for overall willingness to disclose, our criteria were that they (a) have a foundation in prior privacy, disclosure, and direct marketing research, (b) reflect typical online disclosure requests in a relationship-building services/retail context, and (c) reflect specific types of information ranging from lower to higher sensitivity of information. In order to develop the information items, we drew on the privacy and direct marketing literatures (e.g., Phelps, Nowak, and Ferrell 2000; Xie, Teo, and Wan 2006), as well as on an examination of 30 websites, representing a variety of service/retail categories (for details on sampled websites and information requested, see authors). From this we generated an initial set of 45 information items corresponding to nine overarching information types: (a) financial identifiers, (b) contact information, (c) general financial information, (d) family information, (e) self-information, (f) online lifestyle information, (g) offline lifestyle information, (h) media usage, and (i) perceptual information.
The initial 45 items were reduced to 26 via a pretest (Pretest 1, N = 65), in which we measured how comfortable individuals would be in disclosing each information item on a 1 (very comfortable) to 6 (very uncomfortable) scale. Using (dis)comfort as an indicator of information sensitivity has precedence in prior research (e.g., Cranor, Reagle, and Ackerman 1999) and as we discussed earlier, appears to be a correlate of the sensitivity of information, which we define in terms of the potential loss due to disclosure. We grouped items around the nine types of information to (a) maximize the match of the item to the information type, (b) create maximal within-type similarity on (dis)comfort levels, and (c) create maximal across-type differentiation on (dis)comfort levels. Items failing to meet one or more criteria were deleted. Also, we eliminated financial identifiers (and its two associated information items, social security number, checking account number) because these items deal more with security than privacy concerns. This is conservative with respect to finding differential effects across information sensitivity, since Pretest 1 found that financial identifiers were the most sensitive information type.
The 24 items, grouped by information type, along with average (dis)comfort levels appear in Table 2. 3 These eight information types represent a range of information sensitivity and produce minimal overlap in levels of (dis)comfort across information types (Table 2). There appear to be somewhat natural categories of information sensitivity, such that contact and general financial (media usage and website perceptions) form a higher (lower) level of sensitivity information group.
Sensitivity of Information: Definition and Validation of Information Types
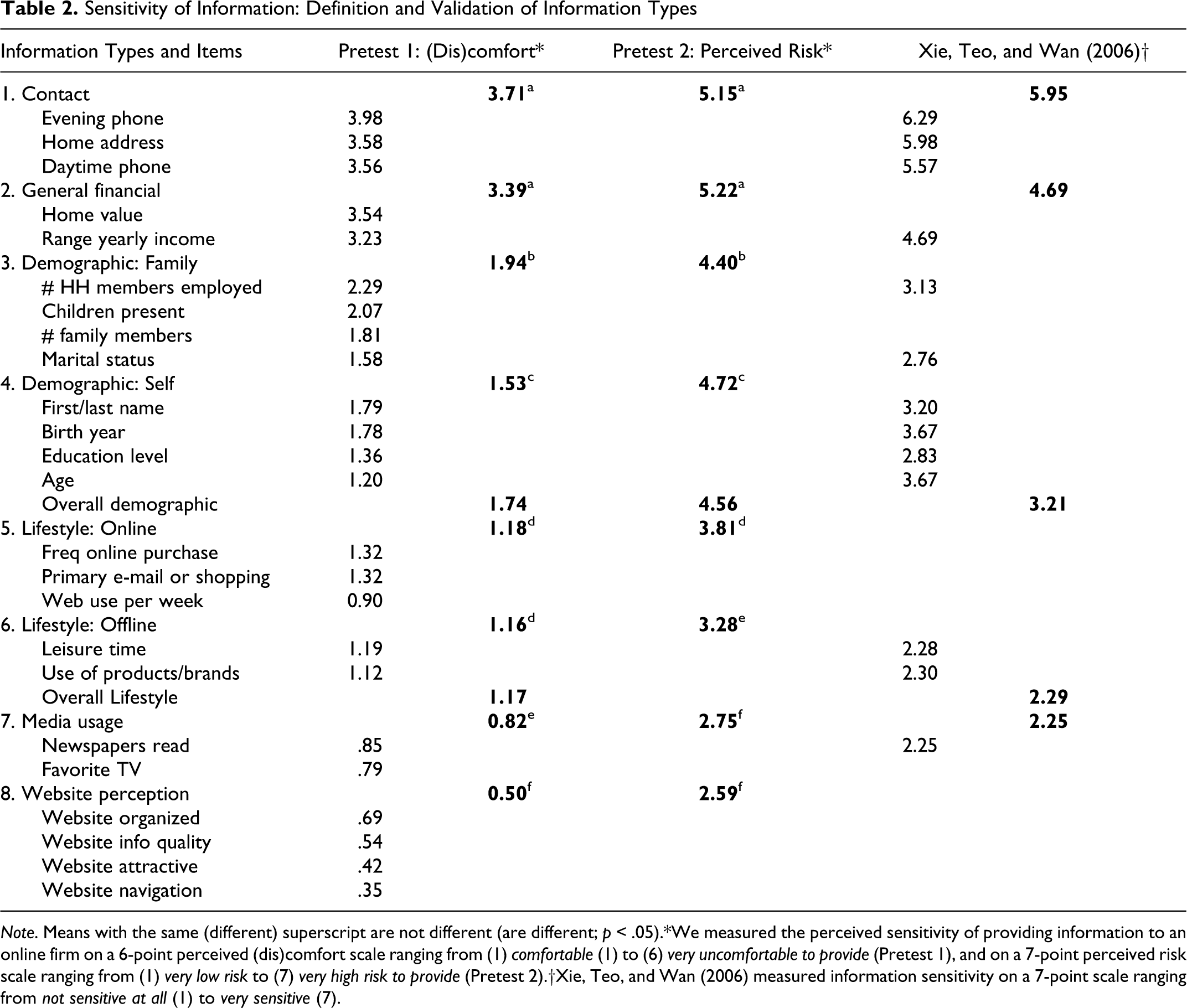
Note. Means with the same (different) superscript are not different (are different; p < .05).
*We measured the perceived sensitivity of providing information to an online firm on a 6-point perceived (dis)comfort scale ranging from (1) comfortable (1) to (6) very uncomfortable to provide (Pretest 1), and on a 7-point perceived risk scale ranging from (1) very low risk to (7) very high risk to provide (Pretest 2).
†Xie, Teo, and Wan (2006) measured information sensitivity on a 7-point scale ranging from not sensitive at all (1) to very sensitive (7).
A second test (Pretest 2, N = 200; see Table 2) was conducted on the eight information types to validate our categorization based on (dis)comfort. Pretest 2 examined the perceived risk of disclosing which, as discussed earlier, appears to be another correlate of sensitivity of information. Perceived risk of disclosure was measured for each of the eight types of information in Table 2 using a 7-point very low-risk (1) to very high-risk (7) scale. The results again indicate that contact and general financial information form a higher sensitive information group, while media usage and website perception information form a lower sensitive information group. Finally, Table 2 shows that our pretest results are comparable with Xie, Teo, and Wan (2006), who measured information sensitivity directly.
Measures
To capture willingness to disclose online, the eight types of information (and their underlying items) were measured on a 6-point scale, with response options ranging from 1 (0% willing to reveal) to 6 (100% willing to reveal) with 20% increments. For example, the contact information question asked “How willing are you to provide accurate information to YOURTV.com on how the firm could contact you, such as your home address, daytime OR evening phone numbers?” Note that the question itself provides the specific items in that category as examples of the type of information requested. This approach minimized respondent fatigue by reducing 24 individual items and questions to eight questions, each representing a type of information. We model overall willingness to disclose as an index, representing the average of the eight types of information. In addition, based on our pretests, (a) willingness to disclose information of higher sensitivity is an index representing the average willingness score for contact and general finance information (the two types of information in our pretests with the highest scores on (dis)comfort and risk) and (b) willingness to disclose information of lower sensitivity is an index representing the average willingness score for media usage and website perception information (the two types of information in our pretests with the lowest scores on (dis)comfort and risk).
Measures for the remaining reflective constructs were extensively pretested and validated. Table 3 provides the constructs, definitions, items, and measurement characteristics.
Constructs, Definitions, Items, and Measurement Results

Note. AVE =Average variance extracted.
aAll t values were statistically significant, p < .001; N = 716.
bNew measures developed and pretested for this study.
Results
In checking for demand effects (Shimp, Hyatt, and Snyder 1991), we found that few participants guessed a purpose close to that of the study (<5%) and that conclusions were unaltered by including or excluding these participants. Thus, all 716 participants appear in the final analyses. To check realism, participants indicated YOURTV website’s realism on a 1 (very unrealistic) to 7 (very realistic) scale; 74% indicated a realism score of 4 (midpoint) or higher.
Measurement Model
We initially screened the measures using item-total correlations and exploratory factor analysis, retaining all items. Following Anderson and Gerbing’s (1988) two-step approach, confirmatory factor analysis was conducted to establish valid and reliable measurement before hypothesis testing using a structural model. The six multi-item scales were assessed for reliability and validity. No items were dropped based on our confirmatory analysis (loadings shown in Table 3). Although the chi-square statistic is significant (χ2 = 229.75, df = 120, p < .01), fit indices not as heavily influenced by sample size indicate acceptable measurement model fit (non-normed Fit Index [NNFI] = .99; comparative fit index [CFI] = .99; root mean square error of approximation [RMSEA] = .036; Bollen 1989; Hair et al. 1995). The results support the internal consistency of each scale, as all composite reliabilities are equal to or greater than .80. There was also a high degree of shared variance between the indicators of each construct, as all estimates of average variance extracted are greater than .60.
Results support the convergent and discriminant validity of the scales. Each item loads highly on its respective construct, supporting convergent validity (Anderson and Gerbing 1988). In addition, all estimates of average variance extracted are greater than the squared phi estimate for all sets of constructs, supporting discriminant validity (Fornell and Larcker 1981). Construct summary statistics, including correlations, means, and standard deviations appear in Table 4 .
Construct Means, Standard Deviations, and Correlations
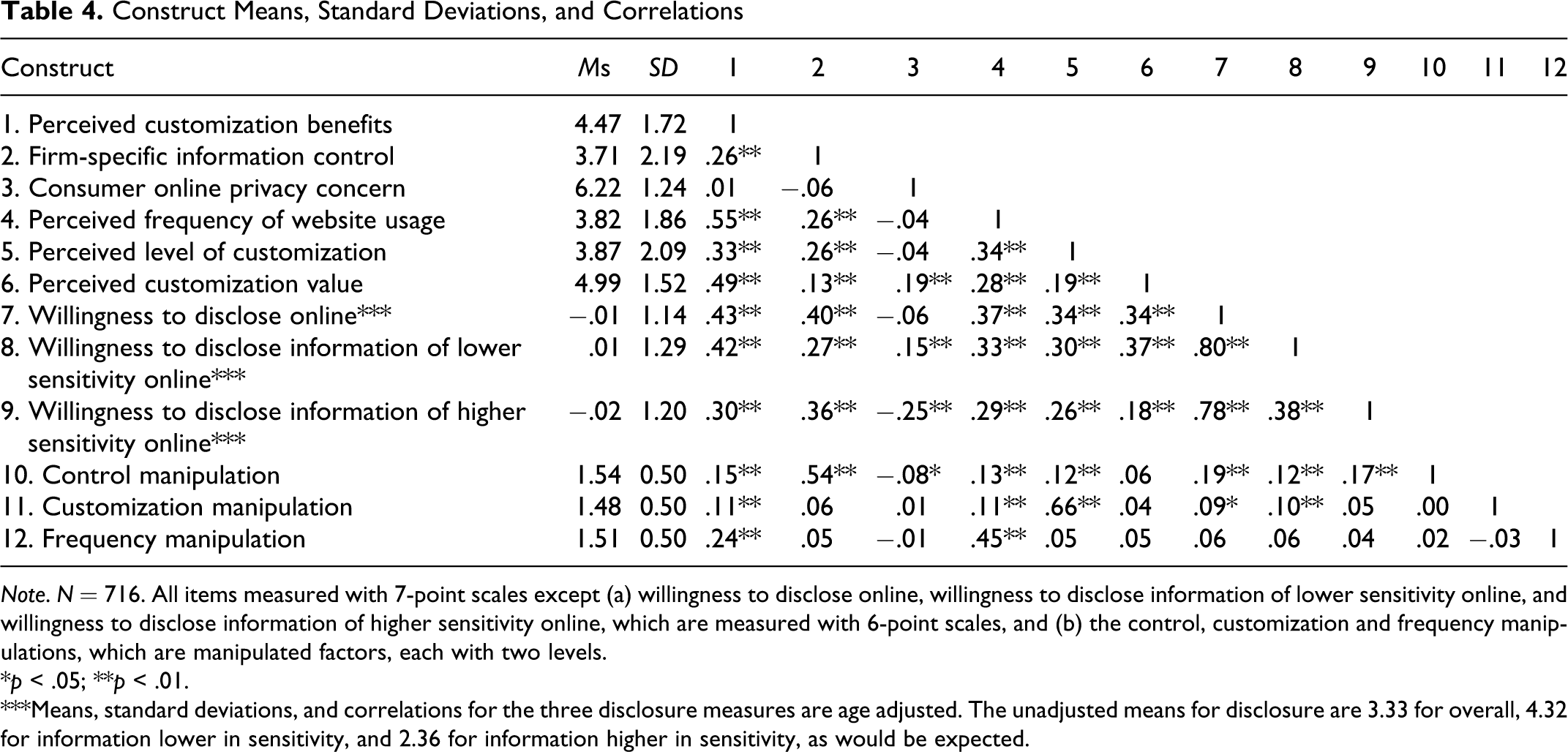
Note. N = 716. All items measured with 7-point scales except (a) willingness to disclose online, willingness to disclose information of lower sensitivity online, and willingness to disclose information of higher sensitivity online, which are measured with 6-point scales, and (b) the control, customization and frequency manipulations, which are manipulated factors, each with two levels.
* p < .05;
** p < .01.
***Means, standard deviations, and correlations for the three disclosure measures are age adjusted. The unadjusted means for disclosure are 3.33 for overall, 4.32 for information lower in sensitivity, and 2.36 for information higher in sensitivity, as would be expected.
Structural Model
We conducted various structural equation models to test our hypotheses. First, we estimated a structural model with overall willingness to disclosure as the dependent variable. Results for this model (Model 1) appear in Table 5 and provide an assessment of the main effects and manipulation checks depicted in Figure 2A.
Results of Structural Equation Models
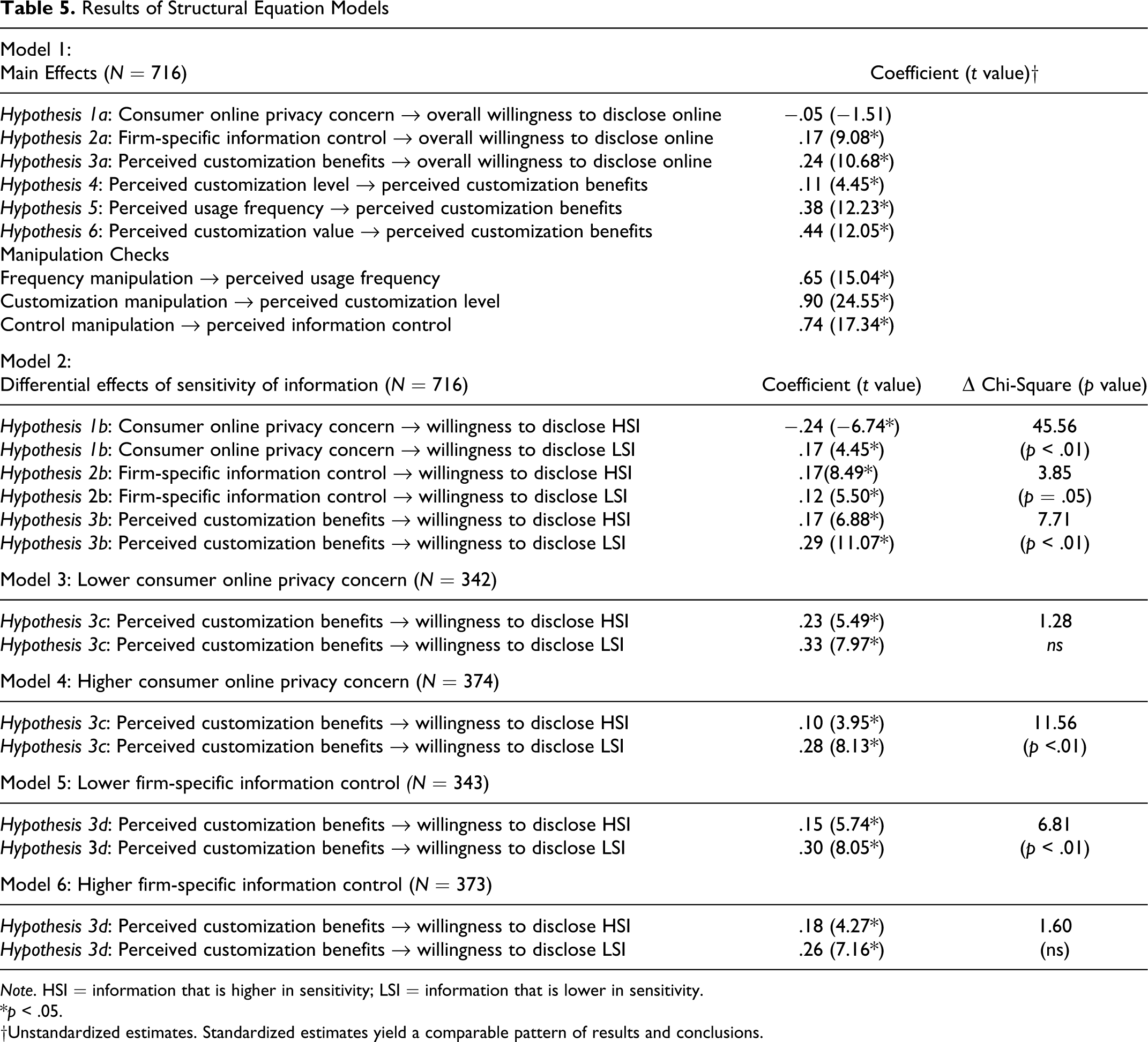
Note. HSI = information that is higher in sensitivity; LSI = information that is lower in sensitivity.
* p < .05.
†Unstandardized estimates. Standardized estimates yield a comparable pattern of results and conclusions.
Overall, fit indices indicate an acceptable model fit for Model 1 (χ2 = 287.13, df = 137, p < .01; NNFI = .99; CFI = .99; RMSEA = .04; χ2/df = 2.10). The manipulations were confirmed, in that the relationships between each manipulation and its perceptual check were positive and significant. Contrary to expectations, the relationship between online privacy concern and overall willingness to disclose was not significant (Hypothesis 1a, β = −.05, t = −1.51, p > .10). Consistent with expectations, information control and perceived customization benefits both positively influence an individual’s overall willingness to disclose (Hypothesis 2a, β = .17, t = 9.08, p < .05; Hypothesis 3a, β = .24, t = 10.68, p < .05). Also, consistent with expectations, perceived level of customization, perceived frequency of website usage, and perceived customization value all positively influence perceived customization benefits (Hypothesis 4, β = .11, t = 4.45, p < .05; Hypothesis 5, β = .38, t = 12.23, p < .05; Hypothesis 6, β = .44, t = 12.05, p < .05).
Model 2 (see Table 5) assessed the differential role of information sensitivity (Hypotheses 1b– 3b), by modeling individuals’ willingness to disclose information of higher (contact and general financial) and lower sensitivity (media usage and website perceptions) as two separate dependent variables as depicted in Figure 2B. The fit indices indicate an acceptable model fit (χ2 = 383.45, df = 153, p < .01; NNFI = .98; CFI = .99; RMSEA = .046; χ2/df = 2.51).
Hypotheses 1b–3b were tested by estimating the coefficients between the three focal disclosure antecedents and willingness to disclose information of higher versus lower sensitivity and then conducting separate one degree of freedom chi-square tests to assess whether constraining the paths for higher versus lower sensitivity resulted in a reduction in model fit (evidence that the paths are different). Consistent with Hypothesis 1b, online privacy concern had a stronger negative influence on an individual’s willingness to disclose information of higher versus lower sensitivity (β = −.24 vs. .17; χ2 diff = 45.56, df = 1, p < .01; the unexpected positive effect for information of lower sensitivity is examined in the discussion section). Consistent with Hypothesis 2b, information control had a stronger positive influence on an individual’s willingness to disclose information of higher versus lower sensitivity (β = .17 vs. .12; χ2 diff = 3.85, df = 1, p = .05). Finally, consistent with Hypothesis 3b, perceived customization benefits had a stronger effect on an individual’s willingness to disclose information of lower versus higher sensitivity (β = .29 vs. .17; χ2 diff = 7.71, df = 1, p < .01).
Hypothesis 3c indicates that the differentially greater effect of perceived customization benefits on willingness to disclose information of lower versus higher sensitivity (Hypothesis 3b) should hold for individuals with higher (but not lower) online privacy concern (Figure 2C). To test Hypothesis 3c, we did a median split on online privacy concern and ran one model for each level (Models 3 and 4 in Table 5). Both models had acceptable fits: Model 3 (χ2 = 200.35, df = 108, p < .01; NNFI = .99; CFI = .99; RMSEA = .05; χ2/df = 1.86); Model 4 (χ2 = 232.53, df = 108, p < .01; NNFI = .98; CFI = .99; RMSEA = .056; χ2/df = 2.15). Hypothesis 3c was assessed using the chi-square difference approach utilized in testing Hypotheses 1b–3b. Consistent with Hypothesis 3c, perceived customization benefits (a) did not differentially impact willingness to disclose information of lower versus higher sensitivity when online privacy concern was lower (Model 3: βLSI = .33 vs. βHSI = .23; χ2 diff = 1.28, df = 1, ns), but (b) did have a stronger impact when online privacy concern was higher (Model 4: βLSI = .28 vs. βHSI = .10; χ2 diff = 11.56, df = 1, p < .01).
Hypothesis 3d indicates that the differentially greater effect of perceived customization benefits on willingness to disclose information of lower versus higher sensitivity (Hypothesis 3b) should hold for lower (but not higher) information control (Figure 2C). To test Hypothesis 3d, we did a median split on information control and ran one model for each level (Models 5 and 6 in Table 5). Both models evidence acceptable fits: Model 5 (χ2 = 316.64, df = 157, p < .01; NNFI = .97; CFI = .98; RMSEA = .055; χ2/df = 2.02); Model 6 (χ2 = 281.58, df = 157, p < .01; NNFI = .99; CFI = .99; RMSEA = .046; χ2/df = 1.79). Hypothesis 3d was assessed using the chi-square difference approach utilized in testing Hypotheses 1b–3b. Consistent with Hypothesis 3d, perceived customization benefits (a) did have a stronger impact on willingness to disclose information of lower versus higher sensitivity when information control was lower (Model 5: βLSI = .30 vs. βHSI = .15; χ2 diff = 6.81, df = 1, p < .01), but (b) did not have a differential impact when information control was higher (Model 6: βLSI = .26 vs. βHSI = .18; χ2 diff = 1.60, df = 1, ns).
Statistical comparisons of Models 2–6 with Model 1 are not possible since they are not nested within Model 1. However, qualitative assessments show that the models are very consistent regarding indicators of model fit including CFI, RMSEA, and the ratio of χ2/df (see summary statistics in Table 6 ). Moreover, the value of Models 2–6 over Model 1 is in terms of testing contingency relationships critical to theory and practice.
Summary Model Statistics
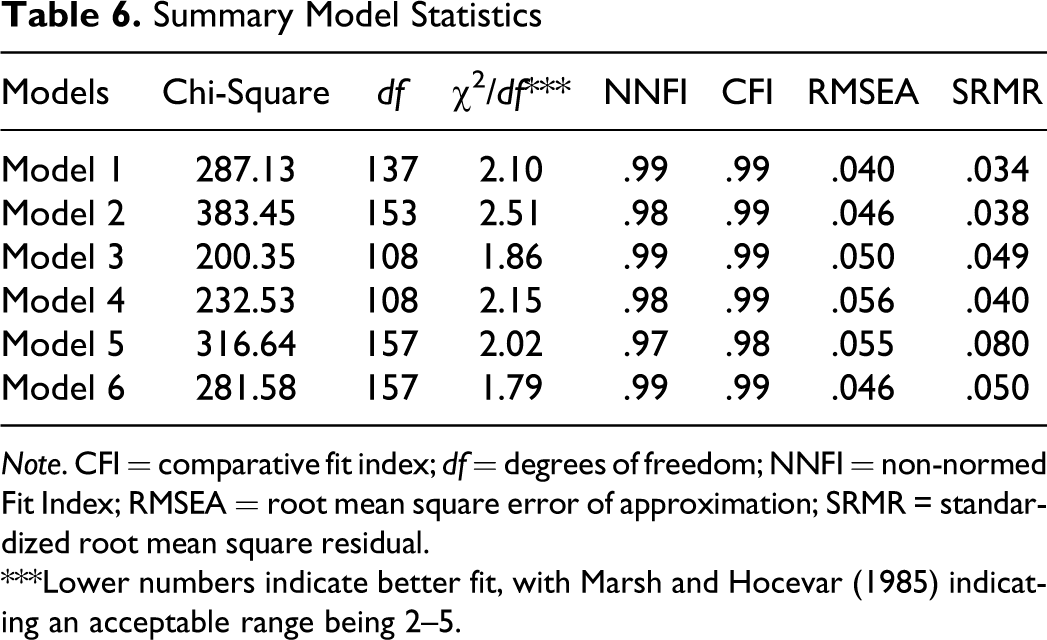
Note. CFI = comparative fit index; df = degrees of freedom; NNFI = non-normed Fit Index; RMSEA = root mean square error of approximation; SRMR = standardized root mean square residual.
***Lower numbers indicate better fit, with Marsh and Hocevar (1985) indicating an acceptable range being 2–5.
Testing Assumptions Regarding the Value Functions and Loss Aversion
Our theorizing suggests that effects comparable to those of Hypotheses 1b–3b should be found for outcomes that capture how consumers value (vertical axis in Figure 1) and trade-off losses and gains, in addition to disclosure. We assessed these possible effects in three follow-up studies using methods similar to those in the main study. The underlying assumption for Hypotheses 1b and 2b is that the value function gets steeper as concern increases or control decreases (a shift from Vector C to Vector B in Figure 1). This would suggest that the effect of concern and control on the perceived risk of disclosure should be higher (lower) for information that is higher (lower) in sensitivity (or as shown in Figure 1, ΔHSI > ΔLSI). Perceived risk due to disclosure was measured on 1 (very low risk) to 7 (very high risk) scales and was averaged to create perceived risk for higher sensitive (contact and general financial) and lower sensitive (media usage and website perceptions) information. Consistent with our logic, follow-up Study 1 (N = 200) shows the increase in perceived risk due to disclosure associated with increased privacy concern is greater for higher (vs. lower) sensitive information (M diff = .90 [ΔHSI] vs. .32 [ΔLSI], F(1, 196) = 4.54, p < .05). Similarly, using the same risk measures, follow-up Study 2 (N = 220) shows the increase in perceived risk due to disclosure for decreased information control is greater for higher (vs. lower) sensitive information (M diff = .93 [ΔHSI] vs. .36 [ΔLSI], F(1, 215) = 5.60, p < .02). 4 For Hypothesis 3b, the underlying assumption is that as information becomes more sensitive, loss aversion makes it increasingly difficult for customization benefits to outweigh the perceived risk due to disclosure. Consistent with this logic, follow-up Study 3 (N = 142) shows that increased customization is positively associated with the ability to outweigh the risk due to disclosure (measured on a 1 [strongly disagree] to 7 [strongly agree] scale) when the sensitivity of information is lower but not higher (M diff = 1.14 vs. .09, F(1, 135) = 4.64, p < .05). Together, these follow-up studies support our underlying logic regarding the value function and loss aversion, and mirror the main study results relative to disclosure.
Additional Analyses Regarding the Role of Firm-Specific Trust
The three disclosure antecedents we examine are important. They are actionable either directly (control and benefits) or indirectly (privacy concern) and their effects on disclosure have been mixed in prior research. Thus, we focused our main study on the antecedent’s effects on willingness to disclose online directly (and as a function of sensitivity of information). However, our earlier theorizing about control and concern suggests their influence on disclosure may operate through trust. If so, trust should mediate or otherwise serve as a proxy for the effects of concern and control on disclosure. 5 Firm trust was measured in the main study using 7-point strongly disagree-strongly agree scales assessing the extent to which YOURTV could (a) be trusted completely, (b) be counted on to do what is right, and (c) be relied on (Morgan and Hunt 1994). Analyses indicate acceptable measurement properties (see authors for details).
To test whether firm trust mediates the effect of concern and control, we added firm trust as an intervening variable between disclosure and concern and control in the model in Figure 2A. This model with firm trust had acceptable fit (χ2 = 426.93, df = 193, p < .01; NNFI = .99; CFI = .99; RMSEA = .042; χ2/df = 2.21). Results indicate trust mediates concern and control. First, online privacy concern (β = −.14, p < .05) and information control (β = .44, p < .05) affect firm trust, and firm trust (β = .35, p < .05) affects overall disclosure. Finally, Sobel tests of indirect effects confirm mediation via firm trust of online privacy concern (z = −3.19, p < .01) and information control (z = 11.42, p < .01) on willingness to disclose online.
Given the mediation results, it is not surprising that the results involving firm trust mirror all the results involving concern and control. That is, firm trust had a stronger effect on willingness to disclose information of higher than lower sensitivity (β = .40 vs. β = .20; χ2 diff = 16.67, df = 1, p < .01), similar to the results for Hypotheses 1b and 2b. In addition, Hypothesis 3b (benefits have a stronger effect on willingness to disclose information of lower than higher sensitivity) held when firm trust was lower (mirroring the effects of higher concern (Hypothesis 3c) and lower control (Hypothesis 3d); χ2 diff = 20.35, df = 1, p < .01); but not when firm trust was higher (mirroring the effects of lower concern and higher control; χ2 diff = 2.85, df = 1, ns).
Discussion
Summary
Results support our predictions in all but one instance. In terms of overall disclosure, higher levels of information control and perceived customization benefits increased willingness to disclose overall. In addition, perceived usage frequency, perceived level of customization, and perceived customization value increase perceived customization benefits. Contrary to expectations, online privacy concern did not decrease overall willingness to disclose.
As a function of the sensitivity of information, the predicted differential effects emerged such that (a) online privacy concern had a negative effect on willingness to disclose information higher (but not lower) in sensitivity; (b) information control had a stronger positive effect on disclosure of information of higher sensitivity; and (c) perceived customization benefits had a stronger positive effect on disclosure of information of lower sensitivity. Follow-up studies and additional analyses suggest that perceived risk due to disclosure and firm trust may provide theoretical explanations for the differential effects of the disclosure antecedents across information of differing levels of sensitivity. Finally, the stronger effect of perceived customization benefits on disclosure for information of lower (vs. higher) sensitivity only held when online privacy concern was higher or when information control was lower.
Theoretical Implications
The null effect of online privacy concern on overall willingness to disclose combined with the negative effect of online privacy concern on willingness to disclose information of higher sensitivity support our overall contention regarding the importance of considering the sensitivity of information as a moderator in models of online disclosure. As such, we advance theory in a number of ways by examining the role of the sensitivity of information within the framework of prospect theory. First, by examining the potential for online privacy concern and information control to influence the slope of the loss function, we predicted and found that the effects of online privacy concern and information control more strongly influence disclosure of more sensitive information. Follow-up data indicate that the increase in perceptions of risk due to disclosure accompanying greater online privacy concern (follow-up Study 1) or lower information control (follow-up Study 2) is greater when the sensitivity of information is higher (vs. lower). Taken together, the disclosure and risk results support our contention that online privacy concern and information control affect the slope of the loss function.
Second, the ability of online privacy concern and information control to influence the slope of the loss function also allows us to predict when customization benefits are most likely to offset potential losses; namely, when privacy concern is lower and/or information control is higher. Such effects go well beyond existing disclosure theory by suggesting that any given incremental increase in benefits can have a smaller/larger compensatory role in offsetting potential losses, depending on the level of privacy concern and information control. More generally, any factor that reduces the slope of the loss function should empower customization benefits to have a stronger positive effect on the disclosure of more sensitive information online.
Third, by utilizing loss aversion, we predicted that benefits have to be extremely large in order to offset potential losses and that the likelihood of that happening is lower when the requested information is more sensitive. Follow-up Study 3 finds that individuals perceive customization benefits as more capable of compensating for the risks due to disclosure, when the information requested is lower, rather than higher, in sensitivity. This result supports our contention that customization benefits can compensate for perceived risk due to disclosure, but that consistent with loss aversion, such an effect is weaker when the information requested is higher in sensitivity. However, simply considering losses and gains is not enough since the slope of the loss function can be attenuated by various factors, such as reduced online privacy concern and enhanced information control. When these conditions hold, customization benefits are more likely to be able to compensate for the potential losses due to disclosure even when the sensitivity of information is higher as found in our results supporting Hypotheses 3c and 3d.
Fourth, additional analyses indicate that firm trust mediates the effects of online privacy concern and information control on disclosure. This is an important linkage since it is the first evidence of which we are aware that suggests a link between firm trust and changes in the loss function. In this regard, we augment the research of Saqib, Frohlich, and Bruning (2010) by identifying factors beyond situational involvement (their focus) that alter the slope of the value function. We return to the trust effect when discussing managerial implications.
Our research suggests why prior research using overall measures of information disclosure has generated mixed results. Indeed, the lack of a main effect of online privacy concern on overall willingness to disclose online is useful in emphasizing the importance of considering the differential effects of various disclosure antecedents as a function of the sensitivity of information. In our research, online privacy concern had a strong negative effect on willingness to disclose when the sensitivity of the information was higher, but not when it was lower, which canceled out the effect of online privacy concern when assessed relative to overall disclosure (Hypothesis 1a). Thus, the mixed results of prior research on the online privacy concern → online disclosure relationship may be, in part, simply a failure to adequately account for the sensitivity of the information requested.
The privacy concern result speaks directly to an issue referred to as the privacy paradox—namely, that consumers say they are concerned about privacy and yet continue to provide information to online retailers. For example, Metzger (2006) uses the lack of a relationship between online privacy concern and online information disclosure as evidence of a privacy paradox. However, this conclusion is potentially problematic since Metzger’s measure of disclosure is an overall summation from a checklist containing information items of widely varying sensitivity. Thus, one factor contributing to the perception of a paradox (e.g., no relationship between privacy concern and disclosure) is a failure to consider the sensitivity of information.
Norberg, Horne, and Horne (2007) provide additional issues to consider including the distinction between actual disclosure and willingness to disclose. They find that consumers actually disclosed more information than they indicated they would when rating their intention to disclose (evidence of the paradox), an effect they attribute to risk playing a stronger role when consumers indicate their willingness to disclose, than when they actually disclose information. This is consistent with our theorizing, inasmuch as when risk plays a lesser role (the loss function becomes less steep), then overall disclosure should be higher. At a broader level, any factor changing the loss or gain functions in actual disclosure settings compared to those where consumers indicate willingness to disclose should alter actual disclosure behavior relative to disclosure intentions. Such effects and comparisons of our model using actual disclosure measures would be interesting to assess in future research.
Managerial and Public Policy Implications
Online service firms and retailers can benefit from providing consumers with increased levels of customization and information control, two factors over which firms have control. In addition, firms might examine the online privacy concern held by their consumers in regard to their specific website (along with underlying reasons) and use this information to improve their website perceptions, using factors, such as privacy seals, and broader factors, such as corporate reputation. By focusing on such factors, firms could reduce the online privacy concern held relative to their particular website, which, based on our results should affect firm trust and disclosure. Indeed, more generally, our results show that any factor that enhances firm trust should reduce the slope of the loss function, thereby increasing online disclosure, particularly, of information that is more sensitive. This should make it easier for benefits to offset potential losses of disclosure for consumers, particularly for more sensitive information.
There are limits, however, on the ability of customization to offset such losses and therefore, marketers need to tailor their information gathering. That is, marketers need to match disclosure requests with website and consumer characteristics. This idea of matching relates to Dolnicar and Jordaan’s (2007) notion that direct marketers can be more successful if they segment and target consumers based on their privacy concern and privacy-related behaviors. Further, if the situation does not require highly sensitive information to accomplish the marketing strategy, then the firm should not attempt to gather this information. If it is necessary to gather, however, the firm should attempt to (a) understand their customers in regard to privacy concerns; (b) manage website characteristics relating to customization and information control; and (c) manage privacy concerns with website/corporate strategies that enhance trust.
Finally, we identified several critical variables affecting online disclosure. Marketers can work with these tools. For example, firms need to insure that customers understand and value the customization benefits provided. It is also important for marketers to encourage greater usage of the website to maximize these benefits. Further, to minimize consumer privacy concerns, marketers should assure customers how they aim to reduce unwanted marketing contact.
In terms of public policy, Zauberman (2003) notes possible negative consequences of online disclosure. He found investments in setup costs (i.e., disclosing information to a firm) created an advantage for the selected firm, including lower future search and greater satisfaction, but less optimal consumer decisions. Such lock-in factors are worthy of additional research.
Limitations and Suggestions for Future Research
One unexpected finding was that online privacy concern positively affected disclosure when the sensitivity of information was lower. One explanation is that some segment of the sample views the disclosure of lower sensitive information as a gain. For this to occur, the reference state (represented by the intersection of the vertical and horizontal axis in Figure 1) would have to shift to the left of the point marked by lower sensitive information. While the reference point is often assumed to be zero, nonzero reference points are thought to occur due to factors such as expectations, aspirations, or perceptual adaptation (Kahneman and Tversky 1979). Regulatory focus theory provides a possible link by proposing that promotion-focused (prevention-focused) motives relate to maximizing gains (minimizing losses; Pham and Avnet 2004). Thus, promotion-focused individuals might have a reference point to the left of the lower sensitive information, causing them to view disclosure of lower sensitive information as a gain and higher sensitive information as less of a loss. Prevention-focused individuals might have a reference point that is further right of the lower sensitive information and thus view both lower and higher sensitive information disclosure as more of a loss.
Since control is a desired self-trait of prevention-focused individuals (Dholakia, Gapinath, and Bagozzi 2006), we utilized a measure of general desire for control (a 3-item measure adapted from Burger and Cooper (1979); α = .81). We took the median split of desire for control and re-ran the model testing Hypothesis 1b (Model 2 in Table 5). For those higher in desire for control (i.e., more prevention-focused), privacy concern had a stronger (compared to the overall results for Hypothesis 1b in Table 5) negative effect on providing more sensitive information (β = −.43, p < .01) and a negative but nonsignificant effect on providing less sensitive information (β = −.07, ns). For those lower in desire for control (i.e., more promotion-focused), privacy concern had a weaker negative effect on providing more sensitive information (β = −.18, p < .01), and an even stronger positive effect on providing less sensitive information (β = .20, p < .01).
While speculative, these results suggest a promotion-focused mindset of some sample members may at least partially explain the unexpected positive relationship between online privacy concern and disclosure of information of lower sensitivity. Just as important, our reasoning here suggests that reference-state effects within the context of prospect theory may be an important next area of focus in disclosure research. More theorizing and testing regarding factors that could shift the reference state could advance theory and practice in this area.
Sample self-selection is always a problem in research involving issues associated with the provision of personal information. Individuals high in privacy concern may not even complete a survey. The fact that our sample reported high levels of privacy concern (6.22 on a 7-point scale) suggests that this issue may not be too significant here.
Our research did not examine consumer lying, which affects data quality. In one survey, a third of the participants reported lying in a disclosure context (Culnan and Milne 2001). Horne and his colleagues (Horne, Norberg, and Ekin 2007) note that lying may be a function of the costs and benefits of providing personal information online. Researchers might examine the applicability of our model to online consumer lying.
Our research focuses on only one dimension of privacy concern, namely, usage of information for marketing purposes, beyond its intended purpose. While Miyazaki and Fernandez (2001) validate this focus, other privacy aspects such as concerns over collection, errors, and combining of data from different data sets, could be examined (Smith, Milberg, and Burke 1996). Future research might also examine disclosure antecedents with regard to security issues (Miyazaki and Fernandez 2001). Given the greater potential losses related to disclosure of security-related information (e.g., credit card information) versus privacy issues, the effects found here may hold even more strongly in this domain.
We utilized a fictitious online provider to control for consumer prior attitudes and knowledge. While this may have compromised external validity in favor of internal validity, a view based on prospect theory is that results using real providers would depend on numerous factors including corporate reputation and trust. Firms with a strong reputation and resultant trust should find it easier to get consumers to divulge more information in general, and more sensitive information, in particular. In addition, such firms should find it easier to utilize customization benefits to overcome the perceived risks due to disclosure and thus elicit disclosure even when information is highly sensitive given that the loss function should evidence a shallower slope for such firms. Nonetheless, examining these issues using actual website providers could potentially offset external validity concerns, particularly if researchers chose firms of varying reputation and trust and incorporated these variables in the study.
Our experimental setting and manipulations could have two countervailing effects. On one hand, it could be argued that the experimental setting could reduce the level and influence of any number of variables from privacy concerns (no unsolicited marketing will actually occur), to the perceived differences in potential losses due to disclosure (no losses could be reasonably expected to occur), and so on. If this is a problem in the current research, then it appears to be one of degree. Privacy concerns in general were high (6.22 out of maximum 7), and privacy concern did influence disclosure in the expected manner for higher sensitive information. However, noting that participants generally viewed the experiment as realistic, more realistic settings would most likely simply enhance these effects.
On the other hand, it could be argued that the manipulations were relatively strong in ways that might not occur in more naturalistic settings (e.g., statements related to information control are often embedded in privacy statements that consumers may not even read), and so on. This is a valid concern, although stronger, more obvious manipulations tend to be necessary in experimental settings for many reasons, including that mentioned earlier about consumers possibly taking a fictitious setting and the potential consequences of their actions less seriously. In a theory-testing setting such as the current study, it is customary to err on the side of ensuring the manipulations create the desired psychological state so a valid theory test is possible. In this sense, we traded external generalization for internal validity. Future research should attempt to replicate our work with different types and levels of manipulations embedded in different ways, perhaps involving some real participant consequences, to test the robustness of our findings.
Finally, the noncommensurate nature of our losses and gains is a limitation that could be examined in future research by creating scenarios that communicate losses and gains on a common metric. While our results appear to be consistent with the implications of prospect theory, research involving stimuli that make losses and gains commensurate would represent a step toward examining the robustness of our findings, particularly of those effects most impacted by this incommensurability, namely, the effects operating across gains and losses simultaneously (i.e., Hypothesis 3a through Hypothesis 3d).
Conclusion
We propose and find that the sensitivity of information requested is an important consideration for online marketers. Greater sensitivity of information requested leads to weaker effects of customization benefits but stronger effects of information control and online privacy concern. However, customization benefits can overcome the negative effects of sensitive information requests when concern is lower or control is higher. In addition, perceived risk and firm trust are mechanisms through which disclosure antecedents operate. Online disclosure models need to include the moderating role of sensitivity of information, and the privacy paradox may be a function of the failure to consider the sensitivity of information being requested. Finally, online marketers must match information requests with the needs and concerns of consumers by providing greater control and customization, enhancing firm trust, and adapting information requests to the situation.
Executive Summary
Consumer information is critical as companies tailor their efforts to better meet the needs of customers. Nowhere is this more true than in online services. Firms must understand how consumers evaluate the potential losses and gains to disclosing personal information and how that links to the strategies they can enact. According to the authors, “perhaps the most important aspect of our research is the revelation that the sensitivity of information requested plays a major role in how consumers view the losses and gains of information disclosure. When information is lower in sensitivity, consumers perceive lower potential losses to disclosure and as a result even consumers who exhibit relatively high levels of privacy concern are still willing to disclose. This is not the case, however, when information is more sensitive, in which case online privacy concern inhibits disclosure as one might expect.” Another intriguing aspect of this research is the role that firm level information control plays in the disclosure process. According to the authors, “consumers want to be able to control how firms handle their information in terms of usage beyond the initial purpose, sharing with other companies, and so on. This factor is particularly important when firms want to garner more sensitive information from consumers. Typically, consumers are more averse to disclosing more sensitive information. However, our findings show that this can be offset to some degree when firms provide consumers the ability to control the use of their information within their privacy and information policies.” Website customization is another important tool to enhance disclosure. According to the authors, “customization is a critical strategic tool for firms who want to enhance online disclosure. Although less effective when information is higher in sensitivity, it is a factor that can be used by firms to provide benefits to consumers that help offset the perceived losses associated with disclosure.” Beyond customization and control, firms should examine the online privacy concerns held by their consumers in regard to their specific website and the reasons behind these concerns. According to the authors, “firms should enact strategies at both the micro and macro level that improve consumer perceptions of the firm’s website and the firm itself. Our results show that firm trust is a major factor in enhancing consumer disclosure. Broad efforts such as corporate reputation building as well as more micro tactics such as privacy seals can help in this regard.” In recognizing the burdens of disclosure and the difficulty of overcoming consumer concerns, firms should consider matching their information requests to the specific needs at hand. According to the authors, “a one size fits all strategy to information gathering is not appropriate. Firms must consider both their information needs and the privacy concerns of their various consumer segments, and request the least sensitive information possible for effectively marketing to each of those segments.”
Footnotes
Appendix A
Experimental Stimuli
Notes
Acknowledgments
The authors wish to thank Joe Phelps and George Franke for their helpful comments and suggestions on an earlier draft.
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported, in part, by a University of Alabama, College of Commerce and Business Administration Summer Research Grant to the first author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.