
Abstract
The evaluation community has demonstrated an increased emphasis and interest in evaluation capacity building in recent years. A need currently exists to better understand how to measure evaluation capacity and its potential outcomes. In this study, we distributed an online questionnaire to managers and evaluation points of contact working in grantee programs funded by four large federal public health programs. The goal of the research was to investigate the extent to which assessments of evaluation capacity and evaluation practice are similar or different for individuals representing the same program. The research findings revealed both similarities and differences within matched respondent pairs, indicating that whom one asks to rate evaluation capacity in an organization matters.
In 2014, Preskill challenged evaluation scholars to address “the hard stuff” of evaluation capacity building (ECB). As part of this call to action, she encouraged the community to invest in studying ECB activities especially in light of recent reviews that indicate only half of all ECB activities are evaluated (Labin, Duffy, Meyers, Wandersman, & Lesesne, 2012). Other authors, in particular, Suarez-Balcazar and Taylor-Ritzler (2014), offer similar calls to action and request that the evaluation community provide a better understanding of the conditions under which ECB occurs and that they examine the effects of ECB. At the heart of these calls to action is the science and art of measuring evaluation capacity within organizations, a topic that has been largely unexplored to date in the empirical literature on evaluation.
When measuring organizational evaluation capacity with perhaps the most common data collection method used in the literature—a survey instrument—one nontrivial decision point is the selection of who will complete the instrument on behalf of the organization. To date, scholars vary in their choices regarding instrument administration. For example, in a study examining a model of evaluation capacity and demand in the Dutch Government, Nielsen, Lemire, and Skov (2011) administered their Evaluation Capacity Index to one or more evaluators per municipality. Taylor-Ritzler, Suarez-Balcazar, Garcia-Iriarte, Henry, and Balcazar (2013) requested responses to their evaluation capacity assessment instrument from one individual within each Chicago-area nonprofit organization included in their study. The respondents answering on behalf of each organization varied and included executive directors/administrators, managers, and service workers/clinical staff.
Decisions about the number and type of respondents to administer an organizational evaluation capacity assessment instrument to are based on a variety of factors including but not limited to the study or project purpose, organizational context, and feasibility. But how might these decisions affect the picture we ultimately paint regarding organizational evaluation capacity? In this article, we present findings from analyses of data collected through an online questionnaire about organizational evaluation capacity and evaluation practice to address the question, “To what extent are assessments of evaluation capacity and evaluation practice similar or different for individuals within the same program?” Given the limited literature on measurement in ECB, the analysis presented is primarily exploratory and the findings are intended to provide the evaluation community (both researchers and ECB practitioners) with empirical evidence to guide future measurement endeavors. In brief, our findings suggest that whom one asks to rate evaluation capacity in an organization matters.
Studying the Measurement of Evaluation Capacity
As part of a larger study finalized in 2012 (Fierro) that was designed to clarify the constructs of evaluation capacity and the intended consequences of building capacity, we performed a thorough review of the literature published between 1960 and 2010 on ECB in the United States. Found in the literature are writings related to describing evaluation capacity, descriptions of the approaches used in building evaluation capacity within organizations, and the factors that affect capacity building efforts. There is little in the literature about the potential consequences of building evaluation capacity within organizations.
Working with the extant literature on ECB, the first step in the current study was to identify the constructs of evaluation capacity by reviewing, inventorying, and coding frameworks of evaluation capacity or ECB (which included existing data collection instruments for measuring evaluation capacity). Frameworks included those published by Milstein and Cotton (2000), Preskill and Boyle (2008), and Boyle, Lemaire, and Rist (1999). Data collection instruments inventoried included the Pan Canadian Survey (Cousins et al., 2008), the Readiness for Organizational Learning and Evaluation (Preskill & Torres, 2000), the Evaluation Capacity Assessment Instrument (Taylor-Ritzler, Suarez-Balcazar, Garcia-Iriarte, Henry, & Balcazar, 2013), and the ECB Checklist (Volkov & King, 2007).
Because there was limited information in the extant literature about the consequences of evaluation capacity in organizations, the second step in the research process involved developing a data-driven set of constructs to describe the type of evaluation practice that would emerge in an organization that has effective evaluation capacity. Seven individuals representing a comprehensive sample (Goetz & LeCompte, 1984) of ECB scholars were asked to participate in semistructured telephone interviews. Individuals eligible for inclusion were those who published one or more articles on evaluation capacity or ECB within the past decade that pertained to theoretical or conceptual ideas on these topics in a well-recognized evaluation journal (i.e., American Journal of Evaluation, Canadian Journal of Program Evaluation, Evaluation and Program Planning, and New Directions for Evaluation). Four scholars agreed to participate. Interview recordings were transcribed and manually coded using deductive and inductive coding techniques.
We operationalized the evaluation capacity and evaluation practice constructs derived from the document review and interviews into a draft survey instrument that was tailored to the public health context (see Table 1 for general descriptions of the operationalization of each construct). The questions developed for this survey were newly created; items from existing instruments were not used verbatim. Next, as recommended by Ryan, Gannon-Slater, and Culbertson (2012), hybrid cognitive interviewing procedures were used to detect issues related to the clarity and interpretation of instructions, questions, and response options as well as with the questionnaire layout and ordering of questions (Willis, 2005). The findings from two rounds of cognitive interviews were used to refine the questionnaire. The questionnaire was then administered to managers and evaluation points of contact in four public health programs funded by a large, federal public health agency. For the purposes of this study, an organization was defined as the specific state, territorial, local, or tribal public health programs funded by the federal public health agency.
Description of Evaluation Capacity and Evaluation Practice Constructs as Operationalized.

Participants
Programs from the federal public health agency of interest were eligible for inclusion if they (1) had staff who were active in program evaluation (evidenced by their participation in the American Evaluation Association (AEA) annual conference or the AEA/Centers for Disease Control and Prevention (CDC) Summer Evaluation Institute or their membership in a team, branch, or division focused on program evaluation); (2) funded states or territories to implement a public health program that included a requirement for evaluation; and (3) provided technical assistance or guidance on program evaluation to their funded entities. To identify candidates for inclusion, we searched abstracts in the 2011 AEA conference program for presenters from the federal public health agency. A total of eight programs were identified as high priority based upon the extent to which the abstracts mentioned ECB or related activities.
Four programs from the federal public health agency agreed to participate in the study. These programs provided funds for over 200 grantee programs of specific interest to this study, and they assisted in efforts to obtain contact information for a manager and an evaluation point of contact for each program. Two hundred and eighty-nine questionnaires were distributed to individuals, representing 107 pairs. One hundred and sixty-two individuals completed a survey (56%) on behalf of 119 grantee programs. We received completed questionnaires from 43 respondent pairs (40%)—one individual who provided managerial support and another who served as the evaluation point of contact.
Overall, respondents fairly evenly represented evaluation (n = 65, 40%) and managerial perspectives (n = 83, 51%), with some representing both (n = 14, 9%). As shown in Table 2, the majority worked for government agencies (n = 99, 61%) and were not new to working with the grantee programs of interest—only 10% (n = 16) had done so for less than 1 year. Most had master’s degrees (n = 96, 58%) or 4-year college degrees (n = 28, 17%). These individuals most often had degrees in public health (n = 67, 44%) with a concentration in epidemiology (n = 18, 30%) or social and behavioral sciences (n = 17, 28%). Respondents had also received degrees in fields such as nursing, public administration, business, education, and psychology, among others. Most reported “very good” or “good” levels of knowledge about evaluation (n = 115, 71%), though 86% (n = 140) reported spending 50% or less of their time on these activities during a typical workweek.
Respondent Characteristics.

Grantee programs for which at least one individual completed a questionnaire represented all but five states in the United States, five territories or Pacific Islands, five American Indian/Alaska Native organizations, and two major metropolitan cities. The number of staff within programs ranged from 0 to more than 21. The mean number of program staff was 6 (SD = 4.4), with between two and five staff members being most common (n = 68, 57%).
Procedures
The four federal programs worked with us to obtain contact information for grantees to extend them an invitation. The manner in which this contact information was provided differed between the four programs: Two federal programs provided access to a complete listing of their grantee evaluation points of contact and program managers, one federal program referred us to a third-party committee that provided a listing of grantee program evaluation points of contact, and the last federal program requested permission from their grantee program managers for a researcher to contact them. In the last two cases, after contact with an evaluation point of contact or program manager was made, we requested participation from the grantees’ respective counterpart.
Invitations to participate in the online questionnaire were disseminated after the federal program provided the respondent list and distributed an advance e-mail to grantees. Each respondent was provided a unique link to the online questionnaire that allowed the researchers to track his or her progress and completion. All respondents were assigned a unique identification code as well as a “pair code”—a variable that allowed the researcher to match individuals from the same program during data analysis. The majority of individuals invited to participate had at least 1.5 weeks to complete the survey. Between one and two reminders were distributed to each potential respondent.
Analytic Procedures
We assigned values to available responses for each questionnaire item based upon the review and synthesis of the document review and interviews with ECB scholars. For questions designed to capture information about evaluation capacity, we assigned higher values to responses that are indicative of greater evaluation capacity. For example, respondents indicating that all of their staff members have access to information about practices associated with conducting program evaluation were assigned a value of 2, whereas those indicating some or none of their staff have access were assigned a value of 1 or 0, respectively. Similarly, we assigned higher values to responses that were in greater alignment with the vision scholars expressed about what evaluation practice might look like in an organization with good evaluation capacity.
In some instances, a value was assigned while taking into account a referent value. For example, in the case of questions relating to instrumental use, the baseline rate with which programmatic activities (e.g., making changes to the program) occurred had to be accounted for to properly interpret how frequently one might anticipate program staff using evaluation findings to inform the programmatic activity. Responses of “don’t know” or “not applicable” were recoded as missing values. Additional details regarding the assignment of scores to items can be found in Fierro (2012).
Instances of agreement or disagreement between members of a pair were identified by subtracting the value associated with the manager’s response for a single questionnaire item from the evaluator’s response on that same item. For the majority of questions, agreement was considered complete agreement with a difference score of 0 on the item. However, some questions included a fairly long ordinal response scale (five or more response options available), where a difference of 1 point on the scale may not represent a meaningful difference in an assessment of evaluation capacity or practice (e.g., a 1-point difference on a 7-point Likert-type scale). Three questions capturing information about evaluation practice had qualitative descriptors for each value on an ordinal scale (i.e., very easy/easy/difficult/very difficult/impossible/don’t know; always/usually/about ½ the time/seldom/never). In these instances, we allowed for a 1-point discrepancy in the paired responses as long as those differences were not opposite to each other—for example, if members of a pair responded “very easy” and “easy,” we considered them to be in agreement, whereas if they responded “easy” and “difficult,” they disagreed.
Findings
Across questions about evaluation capacity and evaluation practice, the mean percentage of pairs in which the evaluation point of contact and manager provided the same response was 57%. The range of pairs in agreement was very broad—with a minimum of 19% of pairs agreeing on the answer and a maximum of 98% of pairs agreeing. Most frequently, the percentage of pairs agreeing on the response to a question ranged between 41% and 70% (n = 48, 65% of questions).
When examined by the type of question—evaluation capacity or evaluation practice—the distribution of agreement between members of pairs differed. On average, more pairs agreed on the response for questions designed to capture information about evaluation capacity (M = 62%, SD = 12). For most evaluation capacity, items between 51% and 80% of pairs agreed on the response to the question (n = 34, 78% of questions). Across the 30 evaluation practice questions included in this analysis, the mean percentage of pairs in agreement was 49% (SD = 19), with a minimum of 19% and a maximum of 98%. The highest frequency of pair agreement for evaluation practice items was fairly evenly distributed between 21% and 70% (n = 25, 83% of the questions).
Evaluation Capacity Concordance/Discordance
Table 3 provides information for the frequency with which pairs agreed on each question related to evaluation capacity and the direction of disagreement when it occurred. Responses to questions under four of the constructs of evaluation capacity exhibited frequent agreement between members of pairs (i.e., higher than the mean value of 62%). Pairs frequently agreed about whether there was a routinely scheduled meeting for discussing evaluations (n = 27, 66%); whether there was an existing framework to guide the conduct of evaluation activities (n = 27, 68%); whether a centralized, electronic repository was available to store findings from past evaluations (n = 29, 76%); and on the collective attitudes of program staff toward evaluation (78–83% of pairs agreeing).
Frequency of Concordance and Discordance—Evaluation Capacity Items.
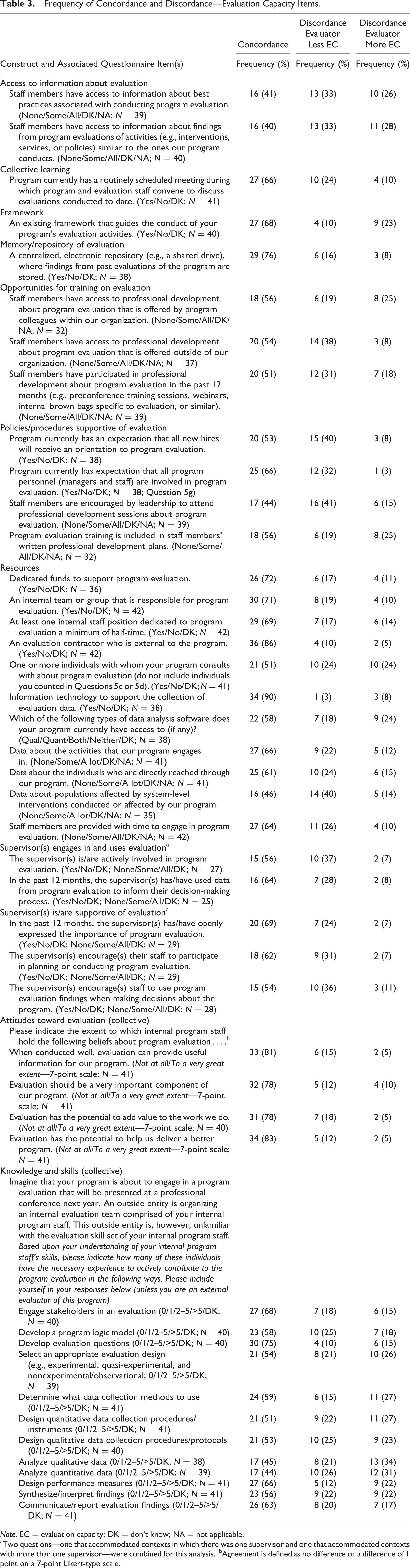
Note. EC = evaluation capacity; DK = don’t know; NA = not applicable.
aTwo questions—one that accommodated contexts in which there was one supervisor and one that accommodated contexts with more than one supervisor—were combined for this analysis.
bAgreement is defined as no difference or a difference of 1 point on a 7-point Likert-type scale.
The percentage of pairs agreeing was low for all questions contributing to two constructs of evaluation capacity—access to information about evaluation and opportunities for training on evaluation. Members of pairs frequently disagreed about the extent to which staff had access to information about best practices associated with conducting program evaluation (n = 23, 59%) and the extent to which they have access to findings from program evaluations of similar activities to the type their program conducts (n = 24, 60%). They also tended to disagree frequently about the extent to which staff members have access to professional development about program evaluation within (n = 14, 44%) and outside of their organization (n = 17, 46%).
For several constructs of evaluation capacity, the frequency with which pairs agreed on the response to specific questions under each construct varied. Pairs frequently agreed for most questions related to the resources their program has to perform evaluation. High levels of disagreement occurred with respect to whether the program consults with external sources on program evaluation (n = 20, 49%), the types of data analysis software the program currently has access to (n = 16, 42%), and whether they have data about the populations affected by system-level interventions performed by the program (n = 19, 54%). Pairs typically disagreed for the majority of questions designed to assess the extent to which the organization has policies and procedures supportive of evaluation, the collective knowledge and skills of the program staff, and the extent to which supervisors are supportive of evaluation and are engaged in and use evaluation.
When disagreements occurred, the evaluation point of contact was more likely to provide a lower rating of evaluation capacity than the program manager. Specifically, evaluation points of contact provided lower ratings of evaluation capacity than program managers for 30 out of the 44 items (68%). Also, evaluation points of contact frequently indicated lower evaluation capacity than the program manager on items related to policies and procedures associated with supporting evaluation capacity, the ability for staff members to access external program evaluation professional development, availability of data about populations affected by system-level interventions related to the program, and supervisor(s) active involvement in program evaluation.
Evaluation Practice Concordance/Discordance
Table 4 provides information for the frequency with which pairs agreed on each question related to evaluation practice. Pairs agreed most frequently (n = 40, 98%) for the question associated with one construct—conduct. This is not surprising since we expected all programs enrolled in the study to be engaged in some form of program evaluation. Low levels of agreement for constructs operationalized into 1 item occurred for the frequency with which staff learn something new from evaluation (n = 6, 21%), the extent to which responsibility for evaluation is diffused throughout the staff (n = 17, 40%), and how frequently internal staff or external consultants perform evaluation for the program (n = 16, 39%).
Frequency of Concordance and Discordance—Evaluation Practice Items.
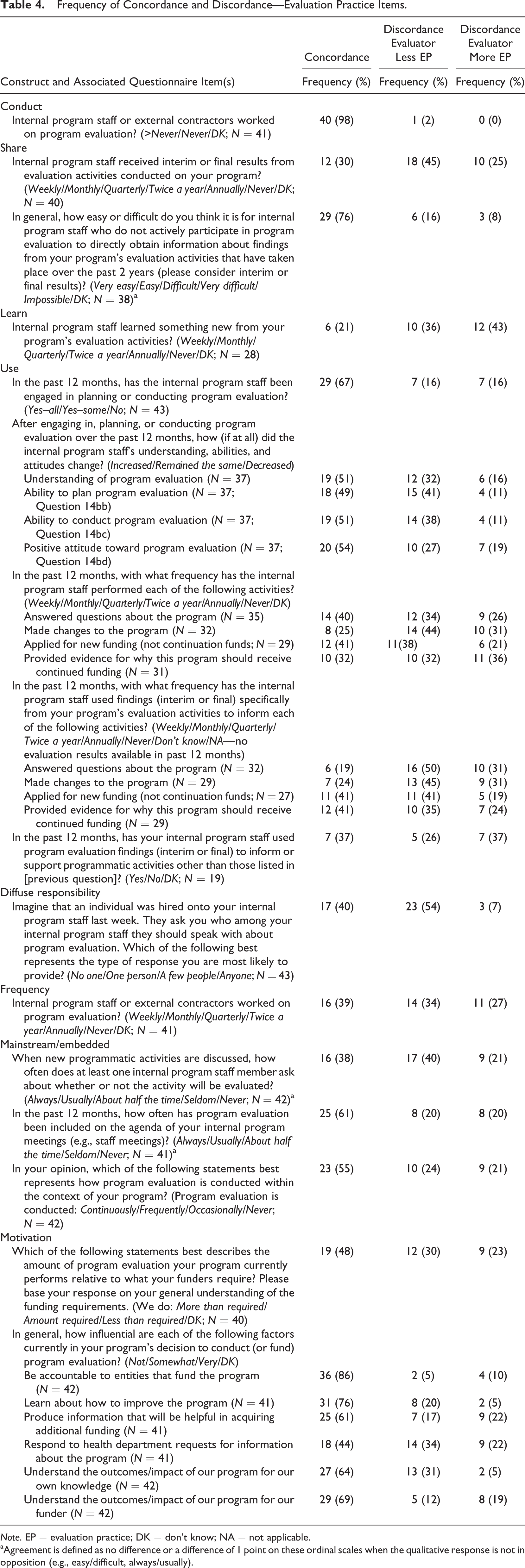
Note. EP = evaluation practice; DK = don’t know; NA = not applicable.
aAgreement is defined as no difference or a difference of 1 point on these ordinal scales when the qualitative response is not in opposition (e.g., easy/difficult, always/usually).
The percentage of pairs in agreement varied on the questions comprising the constructs of mainstream/embedded, motivation, and use. Pairs had fairly high agreement (relative to the mean pair agreement of 49%) for two out of the three questions comprising mainstream/embedded—one relating to the frequency with which program evaluation is included on internal meeting agendas (n = 25, 61%) and another relating to the regularity of evaluation activities in the context of the program (n = 23, 55%). Pairs frequently disagreed, however, with respect to the frequency with which internal program staff ask about whether an aspect of the program will be evaluated (n = 26, 62%).
Pairs frequently agreed on many of the questions that suggest the source of motivation for performing evaluation within the program. Over 49% of pairs agreed on five of the seven questions comprising this construct. Lower levels of agreement were seen when members of a pair were asked about whether their program performs more, less, or the amount of evaluation required by their funders (n = 19, 48%) as well as about the level of influence responding to health department requests about program information has on performing (or funding) evaluation (n = 18, 44%).
Extensive disagreement among pairs was seen across the majority of items comprising the construct of evaluation use. The frequency of pair disagreement was highest for questions contributing to instrumental use—including questions that asked about the frequency with which several common activities that could benefit from program evaluation findings were conducted by the program in the past 12 months (59–75% of pairs disagreeing on response) and the frequency with which evaluation findings were used for these activities in the past 12 months (59–81% of pairs disagreeing on response). Pairs were more likely to agree on items relating to process use.
Similar to what was found with evaluation capacity, when disagreements occurred, the evaluation point of contact was more likely to provide a lower rating of evaluation practice than the program manager. The evaluation point of contact provided a lower rating for 73% (n = 22) of the questions on evaluation practice. Specifically, the evaluation point of contact was more likely than the program manager to indicate that program staff did not increase in their ability to plan or conduct program evaluation after engaging in evaluation activities in the past 12 months, that the responsibility for evaluation was diffused across fewer program staff, and that understanding the outcomes/impact of their program for their own knowledge was not as influential in the program’s decision to conduct or fund evaluation.
Other Patterns in Discordance
One pattern that emerged in the data that deserves mention is a low response rate for pairs on questions associated with some constructs. In the case of evaluation capacity, two constructs related to supervisors (engage in and use evaluation, supportive of evaluation) had low response rates—the number of pairs contributing data to the difference calculation ranged from 25 to 29 (58–67% of pairs from whom we received surveys). The low response rate for these questions primarily stems from natural skip patterns in the survey. In order for a respondent to receive these questions, they first had to note that there was at least one supervisor in the program—there were three instances where the evaluation point of contact and four instances where the program manager indicated there were no supervisors. Additionally, members of four pairs did not agree on a screener question regarding the number of supervisors in the program and therefore received separate questions that could not be compared (one specific to programs with one supervisor, another specific to programs with more than one supervisor).
Low response rates for pairs also occurred for the evaluation practice construct of use, specifically questions related to instrumental use. The primary reason for this low response rate is the high frequency with which the evaluation point of contact for the program indicated that they did not know the response to the question at hand. We posed several questions to indicate whether instrumental use occurred—four questions about the frequency with which several common programmatic activities were performed over the past 12 months (i.e., answer questions about program, made changes to program, applied for new funds, and provided evidence for continuing funds) and four questions about the frequency with which results from program evaluations were used for each of these activities in the past 12 months. The evaluation point of contact frequently responded that they did not know whether the program performed the activities listed—the frequency of “don’t know” responses range from 14% (n = 6) to 22% (n = 9). In contrast, between 2% (n = 1) and 7% (n = 3) of program managers indicated they did not know the response to these same questions. Respondents who indicated that they were external evaluators more frequently responded “don’t know” than those who noted they were internal evaluators.
We saw similar patterns for questions asking about the frequency with which evaluation findings (interim or final) were used to inform these programmatic actions—“don’t know” or “not applicable” responses from evaluation points of contact ranged from 20% (n = 8) to 49% (n = 20). Program managers much less frequently responded that they did not know the response—3% (n = 1) to 12% (n = 5) selected this response for one of the associated questions. Program managers never selected the response “not applicable.” Similar to reports regarding baseline activities, respondents who indicated they were external evaluators more frequently responded “don’t know” regarding instrumental use than those who noted they were internal evaluators.
Does Individual Perspective Matters?
This study provides a glimpse into the potential outcomes of administering a single questionnaire designed to assess evaluation capacity (and potentially related practice) to individuals who hold different roles in an organization. Our findings indicate that who is asked to assess organizational evaluation capacity and practice matters. There were several constructs for which respondent pairs had fairly high levels of agreement—typically with respect to evaluation capacity. However, there was not agreement for all pairs on any 1 item and, in general, when agreement was found, it was with 50–70% of the sample. Furthermore, when pairs did not agree on items, evaluation points of contact typically provided less favorable ratings of evaluation capacity and practice than their managerial counterparts.
There are several potential explanations for our study findings. One explanation relates to the extent to which a given item is directly observable by most individuals within an organization. For example, we saw relatively high levels of agreement for several items related to the construct of resources—funds to support evaluation, presence of individuals who perform evaluations (internal or external), and available information technology to support data collection. Many individuals within an organization, particularly the program manager and evaluation point of contact, are likely able to observe whether each of these items exist. Alternatively, we might anticipate witnessing discordance when the respondents in a pair have different day-to-day experience within an organization. For instance, a program manager may be more likely than an evaluator to know whether instrumental use occurred, particularly whether evaluative findings were used to apply for new funding. Such will almost certainly be the case in instances where evaluators are not directly involved in program planning and implementation efforts.
Another factor that may help explain our findings, particularly the less favorable ratings provided for items by evaluation points of contact compared to program managers, relates to differing expectations of program managers and evaluation points of contact about what constitutes a sufficient level of capacity. For some items, a large majority of discordant pairs followed a pattern such as what was found with the item, “Program currently has expectation that all program personnel (managers and staff) are involved in program evaluation (yes/no/don’t know).” In this case, discordance between the evaluation point of contact and manager may be explained by what each respondent counts as a sufficient “expectation” for involvement—an evaluator, particularly one who employs a highly participatory approach may have higher expectations than a program manager. In addition, these expectations may be the result of differing individual levels of evaluation capacity between the evaluation points of contact and program manager.
Potential Implications for Assessing Evaluation Capacity and Practice
Our findings suggest that methods used to assess organizational evaluation capacity and practice stand to benefit greatly from the triangulation of respondents within an organization and the triangulation of data collection methods. ECB practitioners or researchers might organize dialogues among respondents who have completed an assessment instrument on behalf of the same organization. These exchanges would help elucidate the reasons for discordance and concordance between respondents and as such may highlight more accurately where evaluation capacity and practice is strong and where opportunities for improvements (including at the individual level) exist. In addition, these discussions could serve as an ECB strategy, as participants are likely to learn more about evaluative terminology and what is necessary to support evaluation practice within an organization (i.e., capacity) and arrive at a more representative and accurate vision of what evaluation capacity and practice could look like in their organization.
ECB practice and scholarship may also benefit from employing a mixed methods approach to data collection. Such efforts might include coupling survey administration with direct observations of program activities or document reviews—allowing for the corroboration or expansion of findings. Ideas about obtaining input from a heterogeneous mix of stakeholders and the use of mixed methods are not unfamiliar to evaluators (Alkin, 2012; Shadish, Cook, & Leviton, 1991). However, such principles have not been fully incorporated into how we assess evaluation capacity and the intended consequences within organizations.
Conclusions
Given the regularity with which evaluators now engage in ECB (Fleisher, Christie, & LaVelle, 2008; Fleischer & Christie, 2009; Manning, Bachrach, Tiedemann, McPherson, & Goodman, 2008) and the call to increase evaluations of ECB interventions (Preskill, 2014), it is important for the evaluation community to consider ways to improve how we measure evaluation capacity and the intended outcomes of having this capacity. The directionality of discordance we identified in our study—with evaluation points of contact typically providing less favorable ratings of evaluation capacity and practice than their managerial counterparts when discordance occurred—is consistent with findings from a previous study performed by Cousins et al. (2008). Our collective findings point to a potential for systematically under- or overestimating evaluation capacity depending upon who one asks to provide the assessment for an organization. Such systematic error in estimating reality can lead to a portfolio of research on ECB studies that are not necessarily comparable or provide puzzling patterns that simply result from how each researcher elected to measure capacity and suggest a strong call to action for improving the measurement of organizational evaluation capacity-related constructs.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.