
Abstract
Treatment effect estimates from a regression discontinuity design (RDD) have high internal validity. However, the arguments that support the design apply to a subpopulation that is narrower and usually different from the population of substantive interest in evaluation research. The disconnect between RDD population and the evaluation population of interest suggests that RDD evaluations lack external validity. New methodological research offer strategies for studying and sometimes improving external validity in RDDs. This article examines four techniques: comparative RDD, covariate matching RDD, treatment effect derivatives, and statistical tests for local selection bias. The goal of the article is to help evaluators understand the logic, assumptions, data requirements, and reach of the new methods.
Keywords
Introduction
The regression discontinuity design (RDD) performs well across multiple criteria people use to judge the credibility of causal inferences. For instance, the RDD identifies a well-defined causal effect under a list of assumptions that are concrete and easy to understand in applications. The statistical analysis involved in an RDD is straightforward. The main results can be shown using graphs. Clear assumptions and visual evidence mean that the logic and results of RDD studies are accessible to a wide audience. Those are real advantages in evaluation research and practice.
A deeper virtue of the design is that violations of important assumptions often imply unusual patterns in the data (Dinardo & Lee, 2011; Wong, Steiner, & Cook, 2013). In a valid RDD, people are not able to obtain preferred treatments by precisely manipulating their assignment scores. Most of the time, it is hard to be sure that something like that did not happen in an evaluation study. But in an RDD evaluation, manipulation and sorting often leave trace evidence by creating discontinuities in the density of the assignment variable or the conditional distribution of covariates (Imbens & Lemiuex, 2008; McCrary, 2008; Wong & Wing, 2016). Careful evaluators can partially test the imprecise manipulation assumption by examining the data. The point is that the RDD is not only appealing because its assumptions are sufficient to identify a causal relationship. After all, many designs identify causal effects under specific assumptions. The option to probe the validity of key assumptions is part of what people mean when they say that RDD has high internal validity. In an article reporting on an RDD study, readers expect to see evidence on the key assumptions, and they use that evidence to judge the credibility of the overall results. In other quasi-experimental designs, such as matched comparison groups and difference in difference designs, it is often harder (not impossible) to construct partial tests of the core identifying assumptions.
Despite its advantages, RDD is not a perfect research design. The arguments supporting the design apply to narrow subpopulations that may be quite different from the populations that matter for program evaluation and policy analysis. In other words, RDD may have high internal validity, but it may also have low external validity. The problem of external validity arises in two specific ways in RDD. 1 First, RDD treatment effect estimates apply to the subpopulation of people with assignment scores near the cutoff. With enough data from a valid sharp RDD, we can learn the average treatment effect at the cutoff (ATEC). But even in a very large sample size, the RDD does not help us learn about parameters such as the average treatment effect (ATE) and the average treatment effect on the treated (ATT). Matters are even worse in a fuzzy RDD, which reveals the complier ATEC (CATEC). The CATEC is the average effect among people who score near the cutoff and comply with the assignment rule. This is the second sense in which RDD evaluations may lack external validity: Fuzzy RDD treatment effects apply to a subpopulation of a subpopulation.
Claims about external validity are usually weak in RDD evaluations because of the cutoff problem in sharp RDDs and the combination of the cutoff problem and the complier problem in fuzzy RDDs. In both cases, the overarching challenge involves extrapolation from a narrow study subpopulation to a broader population of interest. The assumptions justified by RDD do not support such extrapolations. However, there is a small literature on extrapolation and generalization in the context of RDDs. And there are four different strategies meant to improve or assess the quality of extrapolations in an RDD. Two of the methods work by combining the RDD with additional research design elements. Wing and Cook (2013) couple the standard RDD with a comparison group that facilitates extrapolation away from the cutoff. Angrist and Rokkanen (2015) show how to extrapolate under a conditional independence assumption that depends on a set of pretreatment covariates. The other two approaches do not require additional data or design elements. They exploit information from within the original RDD. Dong and Lewbel (2015) show how to identify and estimate the treatment effect derivative (TED) at the cutoff. They use the TED concept to shed light on the validity of small extrapolations and to analyze the effects of marginal changes in the location of the cutoff. Bertanha and Imbens (2014) present simple tests for selection bias at the cutoff in a fuzzy RDD. Their tests evaluate whether potential outcomes appear to vary across compliance types in an instrumental variables framework. Tests that rule out these correlations provide some justification for extrapolation beyond the complier subpopulation and beyond the cutoff.
External Validity in Regression Discontinuity Designs
Notation
Throughout, we use i = 1 … N to index members of a study population. Di is a binary variable set to 1 for people exposed to an active treatment and set to 0 for people exposed to a control condition. Xi is a continuous pretreatment covariate called the assignment score. Y(1)
i
and Y(0)
i
are potential outcomes, which record the outcome that the same person would experience under the active treatment and control condition. In practice, only one of the two potential outcomes is observable for any individual. The person’s realized outcome is
Extrapolation Beyond the Cutoff
The first problem of external validity in an RDD arises because of the RDD treatment assignment rule. In a sharp RDD, the assignment rule gives treatment to people with assignment scores above a known cutoff value, and it denies treatment to people with scores below the cutoff. If t is the cutoff value, then a sharp RDD sets
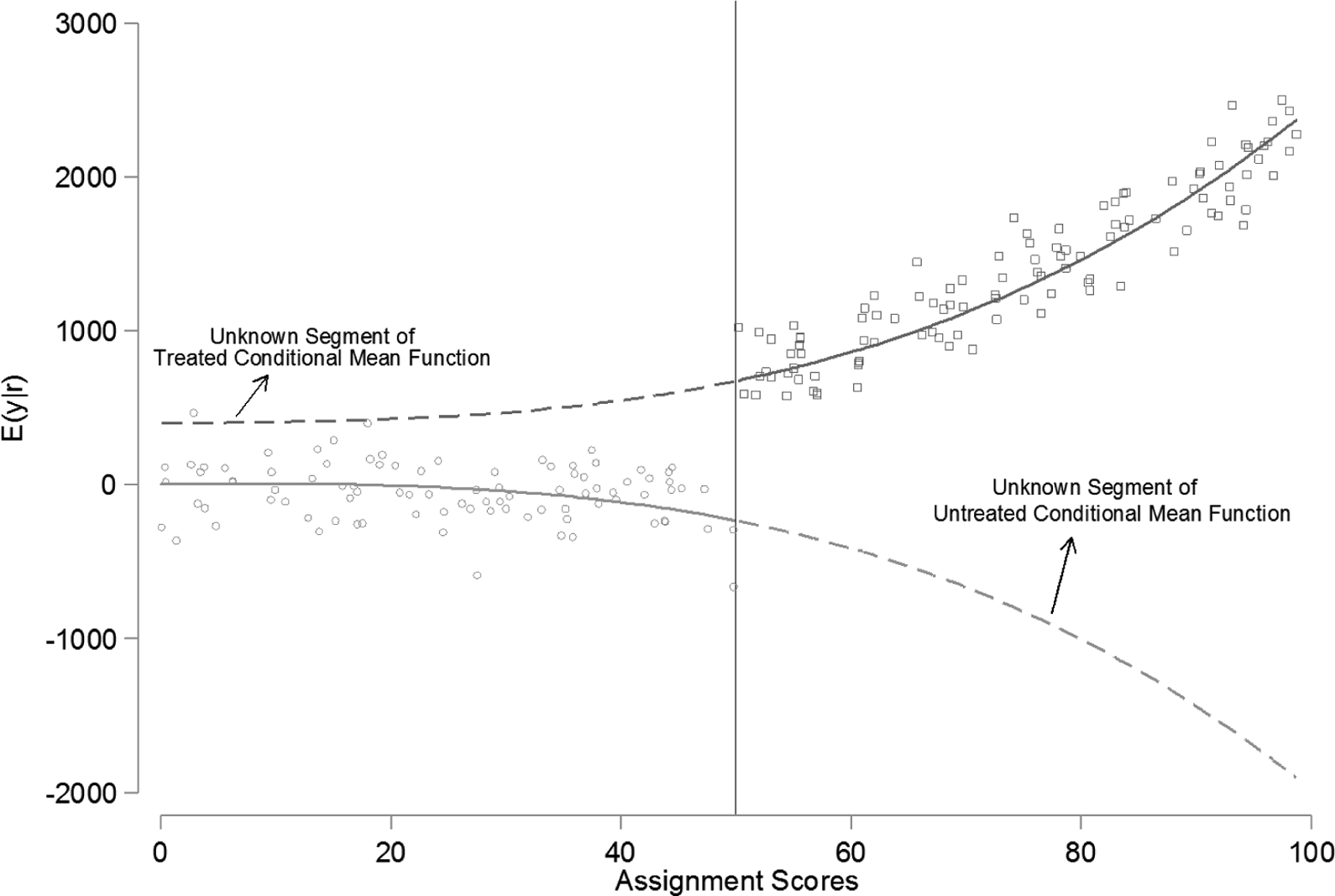
Extrapolation problem in regression discontinuity design.
Estimating the conditional mean functions that link average potential outcomes across levels of the assignment score is a key task in applied work. In Figure 1, solid lines show the segments of the treated and untreated conditional mean functions that you can estimate using the available data. Below the cutoff, the solid line shows how the average untreated potential outcome varies with the assignment variable. Above the cutoff, the line represents the relationship between the average treated potential outcome and the assignment variable. At the cutoff value, the two solid lines (nearly) overlap. The vertical distance between the solid lines at the cutoff is the average treatment effect at the cutoff (ATEC).
The difference between the two functions is unknown at any point away from the cutoff because one of the two solid conditional mean functions is always missing. The dashed lines represent the unknown (counterfactual) segments of the conditional mean functions. With valid estimates of each of the dashed and solid lines, evaluators could calculate treatment effects for any subpopulation defined by the assignment variable. In practice, the RDD provides no credible way to estimate the dashed lines, and the ATEC is the only causal parameter identified by the design. The worry for evaluators is that the ATEC is apt to be different from the treatment effect at other points along the assignment variable so that the results of the evaluation are not a good guide to the overall effect of the program. Figure 1 shows a case where the ATEC is smaller than the treatment effect at points above the cutoff. This is merely one example. Depending on the shape of the two conditional mean functions, the treatment effect at the cutoff may be smaller, larger, or equal to the average effects in other populations. In practice, learning about treatment effects in subpopulations away from the cutoff point requires some method of extrapolating beyond the range of available data. This is the first reason why RDD has high internal validity but may have low external validity.
Extrapolating Beyond the Compliers
The second problem of external validity in RDD arises in fuzzy RDDs, where the assignment rule only induces treatment exposure among a subpopulation of compliers. Under a fuzzy RDD assignment rule, the proportion of people exposed to treatment may vary smoothly across levels of the assignment variable so long as the rate of treatment exposure changes discontinuously at the cutoff value of the assignment score. Analytically, the fuzzy rule requires that
The logic of instrumental variables analysis provides one way to make sense of the fuzzy RDD. To see the idea, start with the group of people with assignment scores equal to the cutoff value: the cutoff subpopulation. Now imagine partitioning the cutoff subpopulation into four smaller compliance-type subpopulations. Membership in the compliance-type subpopulations depends on how a person responds to the assignment rule. People in the cutoff subpopulation who would participate in the treatment regardless of the location of the cutoff are always takers (ATs). People who would not participate in the treatment regardless of the location of the cutoff are never takers (NTs). Compliers (C) participate in treatment only when the cutoff is set below their assignment score, in other words, when they are assigned to treatment. Defiers (F) are people who avoid treatment only when the cutoff is set below their assignment score; they do not participate in treatment when they are assigned to, but they do otherwise. Use
Hahn, Todd, and Van Der Klaauw (2001) explain that when the conditional mean functions linking the potential outcomes with assignment scores are smooth and instrumental variable assumptions hold (locally) in the cutoff subpopulation, the Wald Ratio in the cutoff subpopulation identifies the CATEC. To see their results in more detail, let
The positive implication of their result is that fuzzy RDD identifies an interpretable causal effect parameter: the CATEC. However, the result also emphasizes the problem of external validity. Program evaluators seldom set out to study a subpopulation of compliers at the cutoff. They may be interested in the overall population at the cutoff or an even broader population. In some sense, evaluators settle for the complier subpopulation because they can learn about the compliers under credible assumptions. Thus, the second problem of external validity in some RDD studies involves efforts to extrapolate from the complier subpopulation at the cutoff to the overall population at the cutoff.
Four Methods for Studying External Validity in RDD
A sharp or fuzzy RDD assignment rule creates substantial differences in rates of treatment exposure between two groups of people who otherwise are very similar: People immediately above the cutoff are more likely to be treated than people immediately below the cutoff. The trouble is that the rule also creates large differences in treatment exposure between groups of people who have very different assignment scores and who may differ in other ways as well. Simple comparisons of the full set of treated and control observations amount to comparing apples and oranges in an RDD. The proper analysis limits attention to the cutoff and complier subpopulations, where apples to apples comparisons are possible. However, this approach gives up on external validity.
Avoiding the trade-off is difficult because the same underlying assignment rule is responsible for both the high internal validity and the low external validity. Nevertheless, four recent articles propose methods for studying and improving the external validity of evaluations based on RDD. This section of our article describes each method. We attempt to keep technical details in the background. Our focus is the rationale, assumptions, and data requirements associated with each method. We explain what evaluators can learn from each of the new methods and how that knowledge may be useful for evaluation research.
Comparative RDD
Wing and Cook (2013) show how to combine the standard RDD with a comparison group of people who were not subject to treatment at any level of the assignment score. Comparative RDD is a hybrid design that combines features of a difference-in-difference (DID) design with the standard RDD. Under the assumption that the RDD group and the comparison group have the same functional form—up to group-specific intercepts—the comparison group facilitates extrapolation away from the cutoff. The principle is similar to the parallel time trend assumption in the DID design. The difference is that in comparative RDD, the parallel functional forms occur in the cross-section defined by the assignment variable.
Figure 2 provides a simple representation of the logic of the comparative RDD. The graph contains the same standard RDD depicted in Figure 1. Untreated RDD observations appear as open circles below the cutoff. Treated RDD observations are open squares above the cutoff. However, Figure 2 also shows data from a comparison group of people who were never exposed to treatment and who were not subject to the RDD assignment rule. The solid circles show untreated observations from the comparison group across the full range of the assignment variable. The solid lines in the graph represent conditional mean functions estimated from available data.
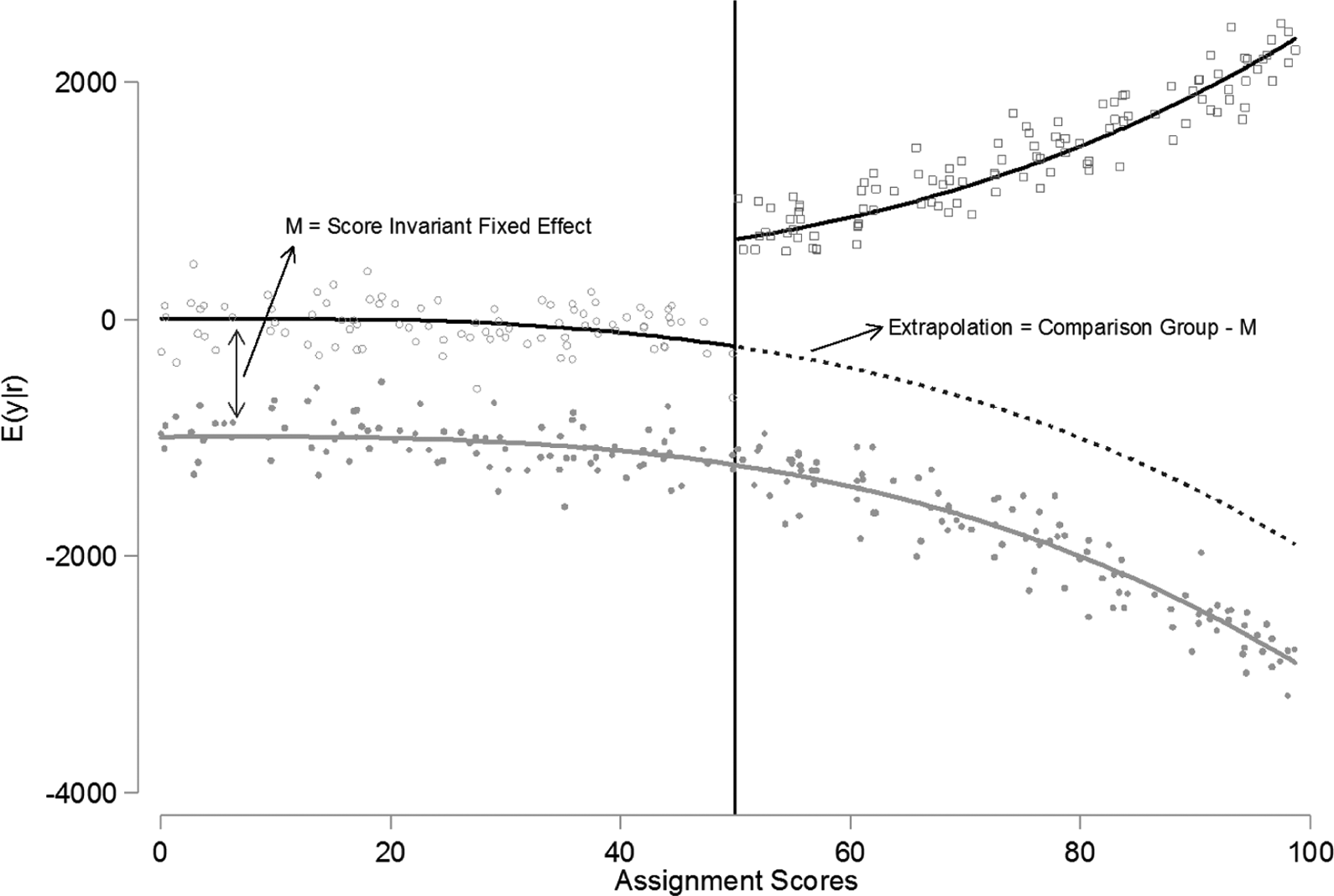
Comparative regression discontinuity design.
You can see that the RDD group and the comparison group are nonequivalent below the cutoff: The comparison group has a lower intercept than the RDD group. The key point is that the RDD group and the comparison group have “parallel” conditional mean functions below the cutoff. That is, the gap between the line summarizing the open circles and the line summarizing the solid circles is a fixed effect that does not vary across levels of the assignment score. In the graph, the score invariant gap between the comparison group and the RDD group is labeled M. The gap is a negative number in Figure 2, but the sign of the effect is not important. The comparative RDD would work just as well with positive nonequivalence, provided it was assignment score invariant.
With a valid comparison group in hand, evaluators can estimate M using data on the untreated RDD and non-RDD observations from below the cutoff. Wing and Cook (2013) explain how to estimate the score-invariant difference using two methods. The first is a semiparametric method based on a partially linear model (Robinson, 1988). The second method incorporates a group indicator into a polynomial series regression of outcomes below the cutoff on a smooth function of the assignment scores. In both cases, Wing and Cook extrapolate the untreated conditional mean function in the RDD group beyond the cutoff by subtracting the estimate of M from the comparison group data above the cutoff. Figure 2 shows the extrapolation as a dashed line that continues the path of the untreated outcome function under the assumption that the score-invariant difference estimated below the cutoff continues to be invariant above the cutoff. The comparative RDD makes it possible to form assignment-score-specific treatment effects at any point above the cutoff by computing the vertical distance between the RDD group conditional mean function and the extrapolated line. Averaging the pointwise treatment effects over the distribution of the assignment variable in the RDD group provides a way to estimate the overall ATT parameter. Figure 2 provides an example where the standard RDD really does lack external validity. The difference between the treated conditional mean function and the counterfactual untreated conditional mean function is smaller at the cutoff than it is at any point above the cutoff. This means that ATEC < ATT and that people with high assignment scores benefit more from the treatment than do people with assignment scores near the cutoff. This is only one example. In practice, treatment effects may vary in complex ways across levels of the assignment variable or they may be constant.
To implement a comparative RDD, evaluators require additional data on the outcomes and assignment scores of a comparison group of people who were not exposed to treatment at any level of the assignment score. The key assumption in the comparative RDD is that the RDD and non-RDD comparison groups have parallel untreated conditional mean functions. Evaluators can partially validate the assumption by comparing the two conditional mean functions below the assignment cutoff because untreated observations are available in both the RDD group and the non-RDD group in that region of the data. A regression-based test is easy to implement. For example, let RD i be a dummy variable that identifies observations from the RDD group. Then we could limit the analysis sample to observations with assignment scores below the cutoff and fit a model such as:

The equation uses a quadratic model to approximate the conditional mean function below the cutoff in both the RDD group and the non-RDD group.
2
Under the null hypothesis that the parallel mean function assumption is valid,
For evaluation researchers, the biggest challenge in applying the comparative RDD is identifying and obtaining data on a non-RDD comparison group that meets the parallel mean function assumption. Wing and Cook (2013) examine the performance of the method in the context of a within-study comparison based on data from the Cash and Counseling Demonstration Experiment. They use the experimental data to construct several different sharp RDDs. In each case, they use data on the resulting RDD group from a pretreatment time period as the non-RDD comparison group. In total, they estimate the ATEC using the standard and comparison RDD for nine scenarios and assess the performance of the comparative RDD estimator in terms of standardized bias and root mean square error. They find that the comparative RDD performs as well or better than standard RDD in terms of estimating ATEC. They also use the comparative RDD to estimate the overall ATT parameter. It is harder to gauge the performance of the comparative RDD estimates of the ATT because there is no nonexperimental alternative method that might serve as a benchmark. However, Wing and Cook point out that across their various analyses, the standard RDD estimator of the ATEC had an average standardized bias of about .095 SD. In comparison, the average standardized bias of the comparative RDD estimates of the ATT was only .05 SD, suggesting that the comparative RDD produces extrapolated estimates of the ATT that are approximately the same quality as the estimates of the ATEC produced by the standard RDD.
Covariate Matching RDD
Angrist and Rokkanen (2015) develop a covariate matching method for extrapolation in RDD studies. The overall approach depends on two assumptions: conditional independence and common support. Angrist and Rokkanen propose two ways to implement the method. The first is a regression approach, similar to the Oaxaca-Blinder decomposition from labor economics (Kline, 2011). The second approach uses inverse propensity score weights to construct effect estimates (Hirano, Imbens, & Ridder, 2003; Horvitz & Thompson, 1952). Both methods are logical, but the novelty of Angrist and Rokkanen’s proposal does not come from the details of the estimation strategies. Their main insight stems from the observation that evaluations based on covariate matching designs often lack credibility because conditional independence is difficult to validate and justify. Angrist and Rokkanen show how to use an RDD to determine whether the conditional independence assumption required by a proposed covariate matching strategy appear to hold in practice. The idea is that after validating a covariate matching strategy using an RDD, evaluators can use the matching estimator to form credible estimates of a wide range of treatment effect parameters that involve people well outside the cutoff subpopulation. In essence, the internal validity of the RDD serves as a tool for partially validating a matching study, and the matching study overcomes the external validity limitations of the RDD study.
The validation scheme depends on an implication of the conditional independence assumption in the context of an RDD. Specifically, if the independence assumption is valid then—after adjusting for covariates—the expected value of the potential outcome variables should not be associated with any function of the assignment variable. Angrist and Rokkanen demonstrate how to implement regression-based tests of the idea. Suppose Vi is a vector of matching covariates and Xi is the centered assignment variable. Now consider a linear regression of the outcome variable on a function of the covariates and the assignment variable:

The notation
Figure 3 provides a visual and informal representation of the test. The left panel shows a sharp RDD with evidence of a relationship between the outcome and assignment variables and a discontinuity at the cutoff. To remove the variation in outcomes explained by the covariates, we regress the outcomes on the covariates and store the residuals. The residuals represent the variation in outcomes that are not explained by the covariates. The right panel shows a plot of residual outcomes against the assignment variable. In the example, covariate adjustment erases the original relationship between the outcomes and the assignment variable. The right panel is consistent with the conditional independence assumption because it implies that the covariate-adjusted outcomes are unrelated to the assignment scores. If the graphs or regressions continued to show an outcome–assignment score relationship even after covariate adjustment, we would reject the conditional independence assumption.

Covariate matching.
Angrist and Rokkanen apply their method to data from an RDD study of the effects of Boston Exam Schools; see Abdulkadiroglu, Angrist, and Pathak (2014) for the original study. They reject the matching strategy for seventh-grade applicants but accept it for ninth-grade applicants. With the tests as support, they estimate treatment effects away from the cutoff for ninth-grade students at two exam schools in Boston. The results clarify the limitations of the RDD estimates. Rather than learn about the effects of elite schools for marginal (cutoff) applicants who were barely admitted to one of the schools, Angrist and Rokkannen are able to estimate the average treatment effects that a large pool of rejected applicants would have experienced if they had been admitted to one school. That is, the conditional independence assumption allows them to estimate the average treatment effect on the untreated (ATU). For the other school, they build estimates of the average effects experienced by all students who were admitted—the ATT.
Treatment Effect Derivatives
Dong and Lewbel (2015) observe that the external validity of RDD treatment effects depends on the way treatment effects vary with the assignment variable. Extrapolation is easy if the treatment effect is constant across levels of the assignment variable because the ATEC is equal to the ATE. The trouble is that assuming treatment effects are constant often lacks credibility in applied work. Dong and Lewbel show that, under differentiability conditions, the RDD identifies the causal effect of the treatment on the derivative (local slope) of the conditional mean outcome at the cutoff. They name the parameter the Treatment Effect Derivative (TED). They observe that the TED measures how and whether the treatment effect is changing in the region near the cutoff. If the TED is equal to zero, then the treatment effect is locally constant.
The intuition behind the method is clear in a low-dimensional polynomial series regression. For example, consider a sharp RDD with a conditional mean function that is allowed to differ on either side of the cutoff and is quadratic in the centered assignment variable:

The TED is the difference between the derivatives of the conditional mean function at the cutoff on each side of the cutoff. In the quadratic model mentioned earlier—with a centered assignment score that equals zero at the cutoff—the TED is equal to β1. Although the idea is easy to see in a parametric setting, you can also estimate the TED using nonparametric methods, such as (kernel weighted) polynomial regressions estimated using observations that fall inside an appropriate bandwidth around the cutoff. One caveat is that local regressions should allow for more nonlinearity in the assignment variable when the target parameter involves the derivative of the function rather than the level of the function. For example, to estimate the TED, it may be best to fit local quadratic regressions rather than local linear regressions. The logic of the TED also applies to fuzzy RDDs. Dong and Lewbel show that in a fuzzy RDD, the TED is given by a Wald ratio-type estimator that incorporates changes in the first stage. The result is an estimate of the TED for the complier subpopulation.
In many applications, estimating the TED does not require much extra work. It is based on coefficients from the same regression models used to estimate the ATEC. That is convenient, because the TED provides useful information about treatment effect heterogeneity and about the prospects for extrapolation away from the cutoff. Evaluators can interpret the TED as a local test of treatment effect heterogeneity. If the TED is equal to zero, then average treatment effects are locally constant across people with different levels of the assignment variable. Extrapolations—local extrapolations, at least—have more credibility when the TED is zero. In contrast, if TED is different from zero, then treatment effects are heterogeneous and extrapolations are apt to be less convincing. However, small extrapolations away from the cutoff will probably fare better if they allow for treatment effect heterogeneity based on the change in derivatives.
The sign of the TED indicates the direction of the change in the treatment effect in subpopulations away from the cutoff and that information may be substantively interesting in some evaluations. For example, a positive TED implies that the ATEC underestimates the treatment effect above the cutoff. Of course, the TED is itself a local estimate, and it is not clear how far from the threshold one would be willing to maintain the assumption of homogeneous treatment effects if the cutoff TED = 0. Likewise, evaluators might be uncomfortable assuming that the treatment effect grows at a constant rate across the assignment variable space simply because TED > 0 at the cutoff.
The simple interpretation of TED given so far is useful for answering questions about the (local) external validity of an RDD estimate of ATEC. For example, the TED sheds light on questions about the ATE in subpopulations of people who are a few points above or below the cutoff score. A somewhat different question is what the ATEC would be under counterfactual changes in the cutoff score used in the design. For example, consider an experimental educational program that enrolled all students who scored above 85 on an exam. A sharp RDD analysis of downstream test scores might find that the program increased test scores by .25 SDs among students who scored at the cutoff of 85. In this case, the TED would help answer questions about the effects of the program among people with a baseline score somewhat larger or smaller than the cutoff, say a baseline score of 82 or 88. A different question asks how treatment effects might change if the threshold itself changed. What would the ATEC be if the cutoff was set to 82 rather than 85?
Dong and Lewbel (2015) formalize the new question using a parameter they call marginal threshold treatment effect (MTTE). They show that MTTE = TED under a new assumption called local policy invariance, which rules out the possibility that changes in the cutoff alter the entire conditional mean functions that link potential outcomes across levels of the assignment variable. For example, local policy invariance would fail if changes in the cutoff led to large changes in the composition of the treated units, and those compositional changes had spillover effects that altered the effectiveness of treatment. Most program evaluation studies implicitly assume some form of policy invariance using assumptions like the stable unit treatment value assumption or by assuming that the program is too small to generate large behavioral adaptations in society at large. For instance, an RCT or RDD evaluation of a new tax credit might help identify the way individuals respond to the incentives created by the credit, holding the behavior of the other workers and firms constant. Scaling up the tax credit might lead to different results if the credit leads to substantial changes in employer labor demand and geographical location, or if the tax credit helps change social norms about the desirability of certain types of behavior. Policy invariance implies that altering the treatment or cutoff would not lead to these kinds of knock-on effects.
Dong and Lewbel (2015) estimated TED/MTTE for the sharp RDD presented by Goodman (2008), which is concerned with the impact of the Adams Scholarships program on college choice in Massachusetts. The program grants scholarships that provide free tuition at public colleges for students who achieve a minimum score on a Massachusetts standardized test. The outcome of interest in the empirical work is the fraction of students choosing a public college instead of a private one. Dong and Lewbel find that the ATEC of the Adams Scholarship increased enrollment at public colleges by about 8% and that the TED at the cutoff was about −1.9%, implying that the Adams Scholarship is less effective at inducing public college attendance for students scoring higher on the standardized test. Under a local policy invariance assumption, the TED is also equal to the MTTE and a negative MTTE implies that the scholarship program would induce more public college attendance if the cutoff were lowered slightly. They point out that the local policy invariance assumption could fail if the cutoff for the scholarship program altered the perceived quality of public colleges and that perception altered college preferences. That is, adopting a lower scholarship cutoff could make high scoring students opt for a private college if they believe that the quality of public college has declined.
Dong and Lewbel’s method is an appealing and simple extension of existing analytical practices. Estimating the TED does not require any extra information or assumptions beyond those made in the original RDD. It makes sense for evaluators to estimate the TED and consider its implications for the behavior of the treatment effect around the cutoff. Moreover, careful consideration of the local policy invariance assumption that undergirds the leap from TED to MTTE is needed, which can answer new counterfactual questions about hypothetical manipulations of the location of the cutoff.
Statistical Tests for Selection Bias
Bertanha and Imbens (2014) focus mainly on the second problem of external validity in RDD: Extrapolating from the complier subpopulation to the overall population at the cutoff. They consider extensions that support extrapolation away from the cutoff. Specifically, Bertanha and Imbens (2014) form tests of local external validity, which evaluate whether the distribution of potential outcomes differs across compliance types at the cutoff. The Bertanha-Imbens tests build on the logic of the selection bias tests developed by Hausman (1978) and Angrist (2004).
Evaluators can implement the Bertanha-Imbens selection bias tests using the same data that are available in a standard fuzzy RDD study. The idea is to partition the data into two subsamples: treated and control. The treated sample consists of everyone exposed to treatment at any level of the assignment variable. The control sample is everyone exposed to the control condition. A key insight is that, after partitioning, treatment status is constant across observations within the two subsamples. However, the RDD assignment rule implies that distribution of compliance types (always takers, never takers, compliers, and defiers) does vary within the treatment and control samples. In the treated sample, for example, people below the cutoff must be always takers. But people above the cutoff are a mix of compliers and always takers. The control sample is different. Below the cutoff, the control sample is a mix of compliers and never takers. Above the cutoff, everyone is a never taker. In conditional-on-treatment subsamples, the cutoff marks a discontinuous change in the mixture of compliance types while treatment status is held constant.
The problem of extrapolating from the complier population to a broader population is that average potential outcomes may differ across compliers, always takers, and never takers. One notion of local external validity in a fuzzy RDD is that CATEC = ATEC. That equivalence would hold under the assumption that compliance types are statistically independent of potential outcomes at the cutoff. Bertanha and Imbens (2014) point out that the assumption is partially testable in the conditional-on-treatment subsamples. Specifically, if the fuzzy RDD has local external validity, then the conditional mean function linking outcomes and assignment scores in the sample of treated units should be smooth at the cutoff. Since treatment status does not change at the cutoff, in the partitioned data the only reason to expect a discontinuity at the cutoff is a kind of selection bias that occurs when potential outcomes are correlated with compliance types. The same restriction applies in the control sample. If there is a discontinuity at the cutoff in either of the subsamples, we would reject the null hypothesis of local external validity and interpret the RDD results as the CATEC.
Figure 4 shows a scatter plot of outcomes in a hypothetical sample of treated subjects. The As are always takers and the Cs are compliers. The dashed line shows the conditional mean function below and above the cutoff. There is no evidence of local selection bias in Figure 4. The average treated outcome for always takers at the cutoff is approximately equal to the average treated outcome for always takers and compliers at the cutoff. Figure 5 gives a similar representation of the control sample, where Ns represent never takers. In this case, the conditional mean function is discontinuous at the cutoff, suggesting that never takers have higher untreated outcomes than compliers. Based on the evidence in Figure 5, we would likely reject the null hypothesis of local external validity and conclude that we should interpret the fuzzy RDD estimates at the CATEC rather than the ATEC.
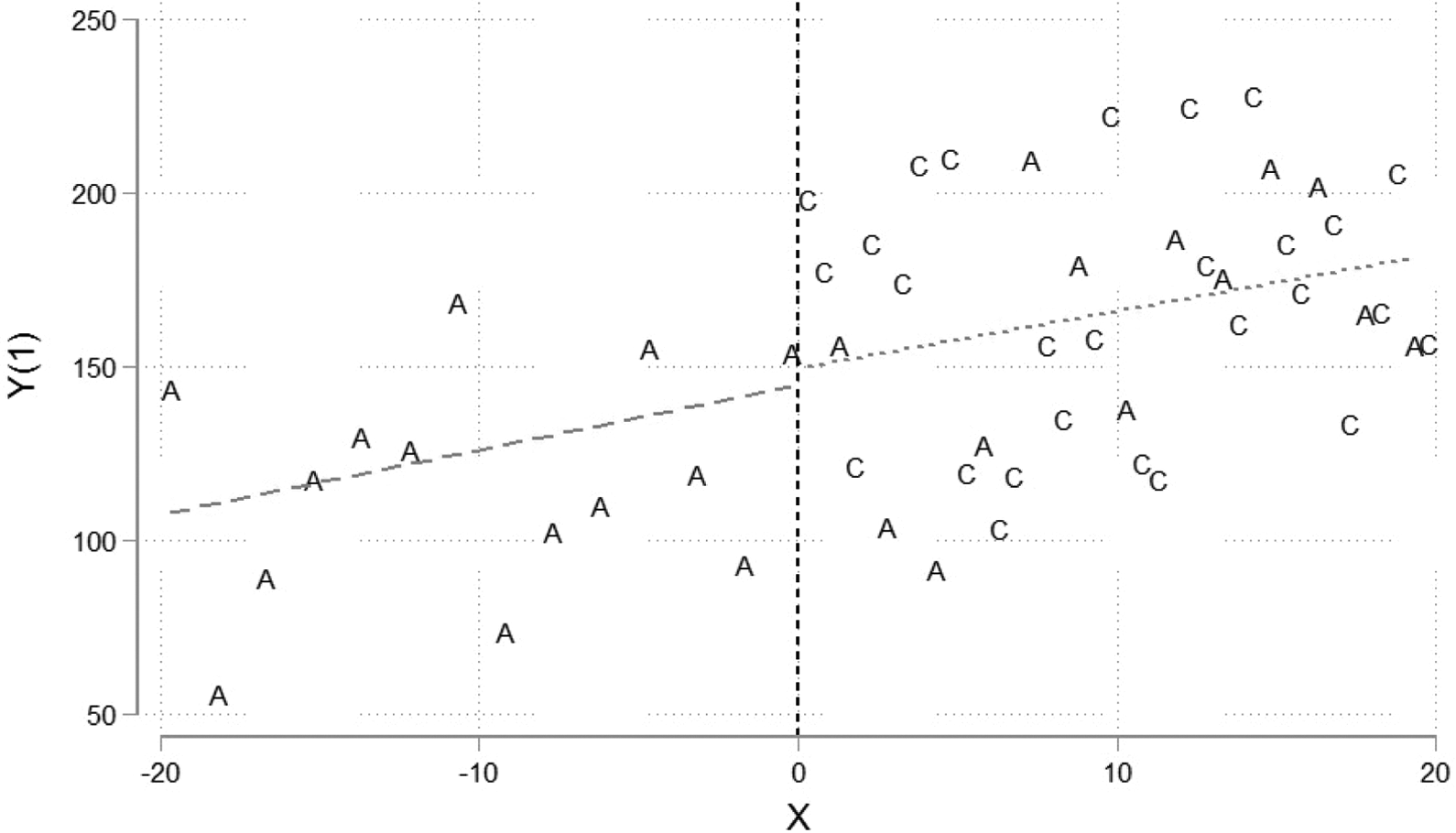
Testing local external validity in fuzzy regression discontinuity design (RDD). Treated observations.
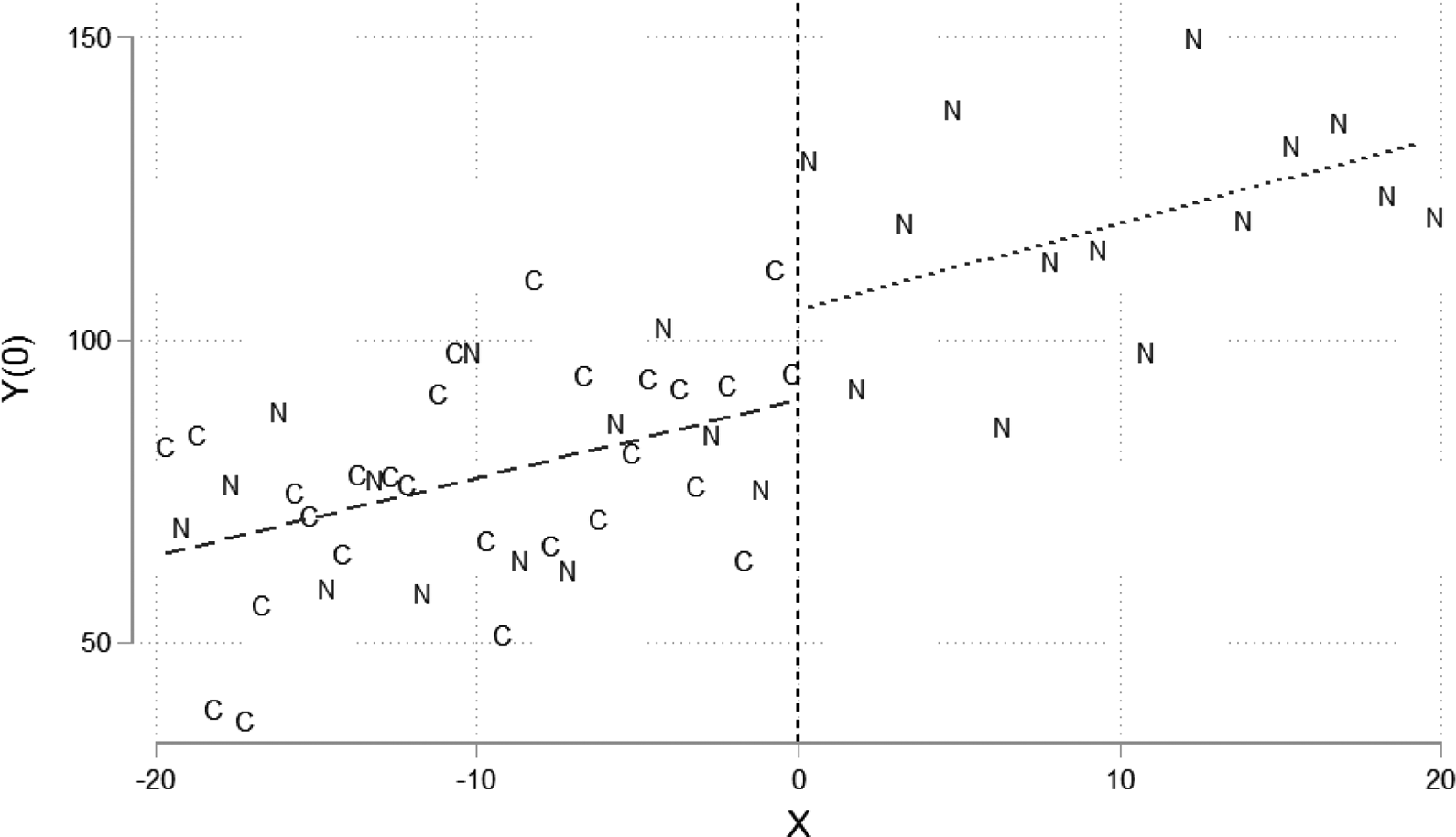
Testing local external validity in fuzzy regression discontinuity design (RDD). Untreated observations.
A more formal statistical test is easy to implement in a regression framework. Bertanha and Imbens (2014) implement their test by jointly estimating the conditional mean functions in a stacked regression framework. A simple alternative approach is to fit a single regression model that is fully interacted in the treatment variable. To illustrate the principle, let

The fully interacted model nests separate models for the treated sample and control sample. With Di = 1, the model traces out the conditional mean function in the treated sample, as it reduces to treated observations above the cutoff. When Di = 0, the second part of the equation drops out and the model traces out the conditional mean function in the control sample. The two tests depicted in Figures 4 and 5 are functions of the parameters in the regression. β2 measures the discontinuity in the control sample, and β2 + γ2 measures the discontinuity in the treatment sample. As Bertanha and Imbens (2014) indicate, the test of local external validity is more powerful if we test the compound null hypothesis that β2 = γ2 = 0. To implement the test, simply fit the fully interacted model and use the postestimation testing commands in statistical packages such as Stata, SAS, R, and SPSS. The example given here assumes a linear functional form. In practice, of course, it is important to model the functional form of the conditional mean functions carefully. It may be wise to fit the model using only those observations that fall within an appropriate bandwidth around the cutoff or to allow for a low-dimensional polynomial series in the assignment variable. Likewise, the standard errors underlying the hypothesis test should be estimated using a heteroscedasticity robust variance matrix and any other adjustments that are appropriate in a given example.
The upshot of the analysis is that rejecting local external validity confirms that fuzzy RDD estimates should be interpreted as the CATEC rather than the ATEC. In looser sense, failure to reject the null may provide some support for a claim that it is reasonable to interpret the CATEC as the ATEC, although such efforts depend on the statistical power of the test in application. Bertanha and Imbens (2014) also point out that under an additional—untestable—assumption that compliance types do not vary across levels of the assignment variable, evaluators can use the available data to extrapolate beyond the cutoff. The logic of the claim is straightforward: If the average outcomes do not vary across compliance types, then we can simply trace out the conditional mean outcomes of treated and untreated subjects across the whole range of the assignment variable. Provided there are both treated and untreated observations at each point along the assignment variable, it is possible to compute treatment effects by taking the differences in the height of the treated and control group at any point.
Bertanha and Imbens apply their tests to two fuzzy RDD studies on summer school programs; the original studies are Jacob and Lefgren (2004) and Matsudaira (2008). Bertanha and Imbens reject local external validity in both data sets. However, they incorporate a set of covariates that allow them to avoid rejection of the null hypothesis for the Jacob and Lefgren data and thus claim valid extrapolation of CATEC in this case.
Relevance for Applied Evaluations
So far, there are no applications of any of the methods outside the illustrative examples given in the original methodological articles. The TED analysis proposed by Dong and Lewbel seems like an easy way to get started. Without making recourse to additional data or assumptions, evaluators can use the TED to gain some small insight into the local external validity of the standard RDD treatment effect estimates. The TED analysis applies in both fuzzy and sharp RDD studies. In many cases, crude estimates of TED are a by-product of the methods evaluators already use to estimate treatment effects at the cutoff. It seems wasteful not to inspect the estimates of the TED and perhaps improve them by following the standard advice on derivative estimation in nonparametric regression. Under stronger assumptions about local policy invariance, Dong and Lewbel show how to use TED to make inferences about MTTE, which may be of interest in some evaluations. The credibility and relevance of this second step depends on the context and conditions of the study at hand, but the basic analysis of the TED should become standard practice in RDD studies. Although the TED is unlikely to be the final word on the external validity of an RDD study, such estimates may ground the discussion in data and in more specific target populations of interest.
The selection bias tests developed by Bertanha and Imbens (2014) are only applicable in fuzzy RDD studies. However, in a fuzzy RDD, the tests do not require any additional data or assumptions. The results of the tests may provide partial support for extrapolation outside the complier subpopulation. If potential outcomes do not appear to vary across compliance types, then evaluators may find it credible to interpret the CATEC as the ATEC. Under somewhat stronger assumptions, the tests suggest an extrapolation beyond the cutoff using the partitioned data available across the range of the assignment variable. Studying the extent to which covariates can explain any apparent differences in outcomes across compliance types also seems like a productive strategy. The statistical power of the tests proposed by Bertanha and Imbens mainly depends on the sample size and the degree of selection bias under the alternative model. In principle, testing the pair of null hypothesis jointly should improve statistical power.
The more ambitious methods—comparative RDD and covariate matching RDD—are only possible when evaluators have access to suitable ancillary data. Evaluators need data from a non-RDD comparison group to implement a comparative RDD, and they need unit-level covariate data to implement a covariate matching RDD. Even with extra data, the methods are only convincing if the new assumptions are valid in the application at hand. However, the comparative RDD and covariate matching RDD provide more in return for the data and assumptions. The expanded designs make it possible to estimate treatment effects beyond the cutoff.
One virtue of both comparison RDD and covariate matching RDD is that evaluators can use data to partially validate the assumptions of the expanded research design. The expanded designs will probably not replace the conventional RDD. However, there are advantages to supplementary analysis. When the expanded assumptions are credible, evaluators have an estimate of treatment effects outside the scope of a standard RDD study. And, when the data cast doubt on the expanded assumptions, evaluators have more concrete reasons to doubt the external validity of the standard RDD estimates. In most cases, a valid comparison RDD is apt to have more statistical power to reject the null of a zero treatment effect at the cutoff than a standard RDD simply because the comparison RDD will increase the total sample size considerably. It is unclear whether the covariate matched RDD should be expected to improve or reduce the statistical power of tests for a zero treatment effect at the cutoff. In principle, the covariate matched RDD does not increase the sample size, but some estimators may have more power when the covariates are strongly correlated with the outcomes.
Conclusions
Results from RDD studies may face at least two problems of external validity. The first problem arises when people look at the results of an RDD study and wonder if the results would have differed in a classical RCT that assigned treatments at random. Is the program more effective in the cutoff population than in the overall population? The second problem arises in fuzzy RDDs, where treatment effect estimates apply to the population of compliers within the cutoff subpopulation. The unanswered question in a fuzzy RDD is what we would have learned from a sharp RDD with the same cutoff. External validity is a murky topic and the methods described in this article improve the situation by clarifying the nature of the problem and by proposing solutions.
Table 1 summarizes the four approaches. Two methods layer additional quasi-experimental design elements onto a standard RDD. Wing and Cook (2013) propose adding a comparison group using logic that is similar to the DID design. Angrist and Rokkanen (2015) propose combining the RDD with a covariate matching strategy. These methods may work well in some applications, but they require evaluators to obtain access to additional data that satisfy new assumptions. In both cases, the new assumptions are partly testable using the original RDD as a benchmark. The hybrid methods of comparison RDD and covariate matched RDD seem to be stronger than either design would have been in isolation. These designs seem to complement the conventional RDD analysis, and it seems useful to pursue such analysis when the data are available and the assumptions seem reasonable.
Key Features of Four Methods to Improve External Validity of RDD.
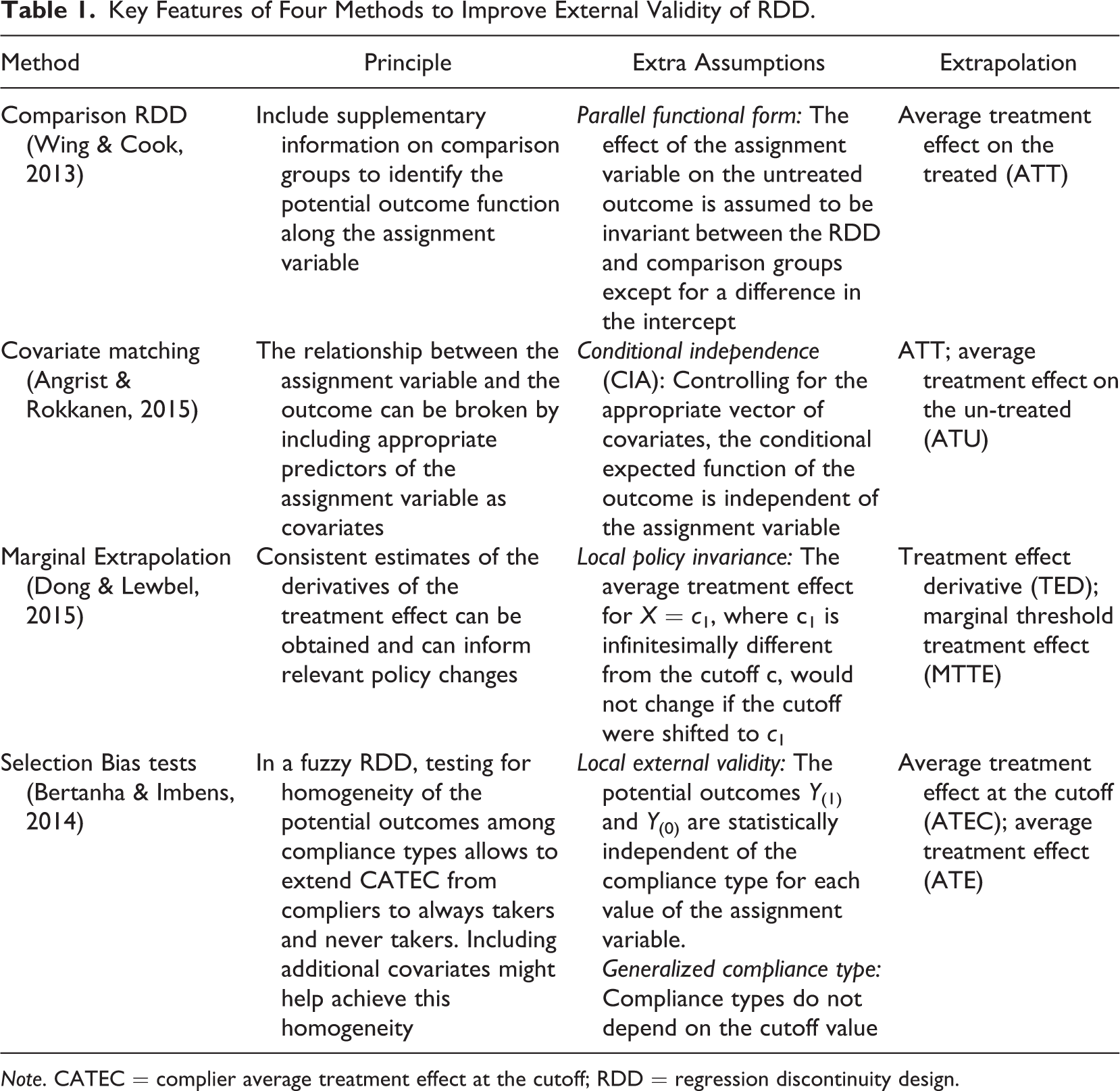
Note. CATEC = complier average treatment effect at the cutoff; RDD = regression discontinuity design.
Bertanha and Imbens (2014) propose selection bias test that is easy to implement and allows analysts to investigate the nature of selection bias at the cutoff. If there is evidence of selection bias at the cutoff, the argument that the standard RDD lacks external validity moves from a vague possibility to an empirical result. That is progress. Dong and Lewbel (2015) suggest an approach that differs from the other methods in two significant ways. First, they only claim extrapolation around the vicinity of the cutoff variable, not along a significant portion of the assignment variable range. Second, Dong and Lewbel’s method is the only one to discuss the effect of counterfactual manipulations of the cutoff value. Careful thinking about the effects of marginal changes in policy cutoffs and the meaning of policy invariance assumptions is a valuable addition to any program evaluation, given that many policy reforms involve incremental changes (Kowalski, 2016; Lindblom, 1979; Wing & Clark, 2017). Other generalizations of the RDD that may also have implications for external validity include multiple cut-point designs (Bertanha, 2017), tie-breaking experiments (Black, Galdo, & Smith, 2005; Campbell, 1969), and multiple assignment variable RDDs (Papay, Willett, & Murnane, 2011; Wong et al., 2013).
A key theme in this article is that questions about external validity are not beyond the scope of empirical analysis. Robustness checks and sensitivity analysis already play an important role in high-quality quasi-experimental studies (Athey & Imbens, 2016). In current practice, however, such tests and analysis focus on threats to internal validity. The articles considered here are notable because they bring a more disciplined and organized approach to the analysis of external validity. A second theme in the article is the value of multiple design elements in quasi-experimental research. An important idea is that the strong internal validity of one design may help partially validate and justify the use of other research designs that depend on stronger assumptions but deliver broader results (Rosenbaum, 1987; Stuart & Rubin, 2008). A potential concern is that the new methods are also new ways for evaluators to engage in an unproductive search for a model specification or subanalysis that yields results that are nominally statistically significant. Such concerns are grounded in genuine problems in the empirical social sciences. However, it seems unlikely that evaluators will make their studies more credible by deliberately ignoring threats to external validity.
Footnotes
Acknowledgments
The paper benefited from the presentations and comments of participants at the OPRE conference, and from informal conversations with Marinho Bertanha, Vivian Wong, Peter Steiner, Tom Cook, Steve West, and participants at the 2017 Quasi-Experimental Workshop at Northwestern University. Of course, the authors take full responsibility for the views expressed in this paper. The authors also thank Nicole Deterding and the anonymous reviewers for useful comments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.