
Abstract
In this conceptual article, the relations between sensemaking, learning, and big data in organizations are explored. The availability and usage of big data by organizations is an issue of emerging importance, raising new and old themes for diverse commentators and researchers to investigate. Drawing on sensemaking, learning, and complexity perspectives, this article highlights four key challenges to be addressed if organizations are to engage the phenomenon of big data effectively and reflexively: responding to the dynamic complexity of big data in terms of “simplexity,” analyzing big data using interdisciplinary processes, responsible reflection on ideologies of learning and knowledge production when handling big data, and mutually aligning sensemaking with big data topics to map domains of application. This article concludes with additional implications arising from considering sensemaking in conjunction with big data analytics as a critical way of understanding unique aspects of learning and technology in the 21st century.
Introduction
This article identifies some major challenges to be faced if organizations and their members are to access, analyze, and generally engage big data as effectively, responsibly, and mindfully as possible. The central argument and contribution made lie in theorizing that the potential value of big data in improving organizational effectiveness is only as great as the successful interplay of sensemaking, learning, and complexity management processes underpinning big data practices. Specifically, big data’s overwhelming quantity can only be translated into accessible quality via the reflexive, critical, and flexible use of appropriate theories, cues, interpretive frames, routines, and learning mechanisms to bridge the gap between raw data and knowledge creation. Hence, this article focuses on the intersection of three topics of continuing relevance to organizations and their boundaries: sensemaking, learning, and big data.
Taking sensemaking first, it is widely recognized as a key process for effective organizing, although definitions and relevant theories vary widely (Maitlis and Christianson, 2014). A recent attempt at an integrated definition defines sensemaking as “a process, prompted by violated expectations, that involves attending to and bracketing cues in the environment, creating intersubjective meaning through cycles of interpretation and action, and thereby enacting a more ordered environment from which further cues can be drawn” (Maitlis and Christianson, 2014: 67). Sensemaking can also be defined in terms of a set of core principles or properties characterizing its attendant processes, in terms of being retrospective, ongoing, social, and linked to identity, cue extraction, and environmental enactment (Weick, 1995; Weick et al., 2005). Finally, it can also be broadly identified with closely related process terms that it has generated (e.g. sensegiving and sensebreaking) and the topics of broad relevance to organizations and organizing that it informs (e.g. crises, change, learning, and cognition) (Maitlis and Christianson, 2014; Maitlis and Sonenshein, 2010; Sandberg and Tsoukas, 2014). With its focus on reducing various interpretations for mentally modeling situations, ongoing sensemaking activity thus seems essential to the identification and fixing of valuable patterns learned from large, continuous streams of big data.
Learning is a second key area of organizational theory and practice of interest here and is also linked to sensemaking, although the exact terms used for the linkage may vary, in terms of the organizing, becoming, change, and interpreting processes that are being described (Clegg et al., 2005; Colville et al., 2013a). The concept of learning itself is challenging and poses an antithetical, oxymoronic challenge to the organizing aspects of sensemaking: “to learn is to disorganize and increase variety. To organize is to forget and reduce variety” (Weick and Westley, 1999: 190). Like sensemaking, and with some parallel similarity to it, learning remains something of a broadly contested concept, captured by evolving or competing definitions and metaphorical interpretations. Any broad definition of learning is likely to encompass the more cognitive acquisition of knowledge and skills on one hand, and the more socially situated, experiential participation in communities of practice on the other (Elkjaer, 2004). The attempt to reconcile these two perspectives into a mutually enriching “third way” (Elkjaer, 2004) mirrors efforts in the sensemaking literature to mutually and interactively relate perceptions to actions, individuals to collectives, and persons to environments. As a result, work on the learning organization (Senge, 1990) remains open to multiple critical readings of how organizations can learn collectively in terms of the distinctive activities and emphases of their practices (Örtenblad, 2007). In parallel, work on organizational learning continues to incorporate a range of important concepts such as emotions, intuitions, and networks, while acknowledging the many defensive barriers to individuals’ learning (Argyris, 2004). Linking organizational learning to big data can make crucial contributions to understanding knowledge creation when organizations generate varieties of interpretations and to how technological developments shape learning processes (Argote, 2011).
The third and final area of this article is the phenomenon of big data or big data analytics (the term analytics is almost invariably used alongside big data)—one that has been less extensively written about by academics than either sensemaking or learning. The distinctiveness of big data is debatable, with perhaps no totally robust definition available. However, it is generally recognized that it constitutes the latest phase of an ongoing data management and analytics journey, a phase where data are so big and complex it requires more advanced processing technologies to handle it, and can potentially offer organizational insights and sources of value that smaller scales of data processing cannot (Mayer-Schönberger and Cukier, 2013). The “bigness” of big data is often differentiated in terms of its volume (amounts generated over time in units such as petabytes or exabytes), its velocity (the speed and immediacy of data creation), and variety (the new sources, technologies, and media associated with the data; McAfee and Brynjolfsson, 2012). The contribution of the current analysis is to theoretically identify the need for and nature of interrelated organizational learning and sensemaking mechanisms that might support new epistemologies of knowledge creation amid the management of big data (Kitchin, 2014). Organizational learning through big data can thus be re-conceived of as a continuous, disruptive blend of induction, deduction, and abduction, occurring alongside data sensemaking routines and capabilities that seek to identify recurring patterns and link them to possible remedial actions.
Big data is generated from clickstream data from the Web, social media content (tweets, blogs, Facebook wall postings etc.) and video data from retail and other settings and from video entertainment. But big data also encompasses everything from call center voice data to genomic and proteomic data from biological research and medicine. (Davenport et al., 2012: 22)
The business models of leading tech companies like Google and Amazon appear to thrive on making sense of big data, while other companies like IBM or Deloitte offer analytical services for exploiting big data to companies and institutions around the world (Barton and Court, 2012). Most commentators describe big data analytics in terms of strategic opportunities and necessary changes to be made to organizations, but there is also a sense of pitfalls and a need for a deeper, critical understanding of the double-edged conditions and processes surrounding its use (Boyd and Crawford, 2012). Important questions are raised about effective statistical practices, how information technology (IT) functions across organizations, the importance of theory, and how big data analytics is different from more traditional analytics formats. Overall, “there is no question that organizations are swimming in an expanding sea of data that is either too voluminous or too unstructured to be managed and analyzed through traditional means” (Davenport et al., 2012: 22).
The remainder of this article thus reflects on the challenging issues raised by an era of big data analytics for organizations. Crucially, it is argued that big data can be complex and overwhelming for organizations trying to learn, change, and make sense of their environments. To make best use of big data, it is argued to require reflexively managing the epistemological dance of ongoing alternations between highly exploratory learning experiences that generate a variety of possibilities for interpretation and action and more deductive sensemaking possibilities captured by preexisting interpretive frames that work to reduce that variety (Weick and Westley, 1999).
Identifying four challenges in trying to make sense of and learn from big data
Big data raises debates about whether new formats and types of knowledge can be developed by organizations which will benefit from this new era of information management and how raw data should best be analyzed, interpreted, communicated, shared, and ultimately acted upon. Big data offers an excellent way to promote higher order forms of organizational learning, given that it can provide surprising glimpses of things outside of what is currently known. However, learning simultaneously depends on ongoing sensemaking activity to fix, frame, temper, and reveal forms of enduring, actionable meaning. Thus, the mutual relationship between the organizing activity of sensemaking and the disruptive, re-organizing activity of learning depends on reflexively engaging these tensions for big data (Clegg et al., 2005; Colville et al., 2012).
Big data analytics represents a situated, concrete arena where sensemaking and learning mutually struggle to extract revised meanings from altered conditions of relative complexity. The greater volume of complex information generated more fluidly and accessibly in real time means that big data can potentially foster learning in crisis (LiC), via the practicing of analytic and interpretive routines amid failures and unknown, emergent contingencies (Antonacopoulou and Sheaffer, 2014). Big data analysis may enable us to “see what we say” and “know what we think” much more interchangeably than ever before (Colville et al., 2012). However, it may also fuel its own crisis of meaning, as we are self-consciously overwhelmed by the freedom and burden to, respectively, create and share some form of meaning in context (Sack, 1988). Salvaging organizational learning from such a crisis may depend on managing sequences of other “sense” processes, such as the destruction of existing meanings (sensebreaking), the manipulative silencing of sources of meaning (sensehiding), and strenuous efforts to acquire information that casts doubt on established meaning (sensedemanding; Maitlis and Christianson, 2014). For sensemaking to support widespread organizational learning from big data, there need to be flexible ways of knowing: what data to look at, various available ways of looking at it, and possible reasons why one is looking at it in the first place.
Certain discourses are needed then to provide meaning to large quantities of numbers or text. Below, four key challenges are presented to better understand this overall issue, mainly by reflecting on theoretical debates in relation to the literature on complexity theory, sensemaking, learning, and the sociology of knowledge. A broad approach like this seems warranted, in keeping with the theoretical roots that influenced sensemaking itself (Weick, 1969). The value of the current approach is to show that bigger data on its own does not set us free from the burden to create meaning; cycles of sensemaking are still inevitably required to fix meaning, alongside learning, which departs from and updates meanings as data keep being generated under conditions of dynamic complexity. Too much learning may result in a floundering in the endless patterns of big data; too much sensemaking may result in a race to the bottom as big data is used to unilaterally confirm and pursue a certain a priori agenda.
The four challenges of meaning here concern simplexity, interdisciplinarity, ideological views of learning or knowledge production, and domains of application linked to big data and sensemaking. These four areas deal with how the context, content, and process aspects of ongoing big data analyses can be specified in practice. All four imply interrelated organizing and learning processes; cycles of interpretation and assembly rules that work on the phenomenon of big data to reduce its equivocality while keeping the possibilities of learning open (Weick and Westley, 1999).
Value is also offered from this analysis by outlining four themes crucial to supporting reflexivity in the interpretation of big data—ways to ensure that there is a dynamic and fruitful sorting through epistemological perspectives, interpretations, courses of (inter)action, and ways of knowing. The term “reflexivity” here is thus used in a fairly general sense, rather than pursuing an in-depth examination of the concept itself, which has many forms and uses (e.g. Holland, 1999; Johnson and Duberley, 2003). Sensemaking and learning can be connected further via reflexivity by adopting a reflexive epistemology (e.g. Zolo, 1990). Such a view maintains that all the data in the world cannot set organizations free from theories or empirical circumstances toward an abstracted universal knowledge or truth at a transcendental perspective of “nowhere”; any value-adding analysis instead requires pragmatically, continuously, and iteratively sorting through a multiplicity of contextual perspectives, lenses, judgments, and filters from “somewhere” (Nagel, 1986).
Getting from complexity to simplexity
Given the volume, velocity, and variety of information generated, a reflexive epistemology of big data rests in part on the interrelationships between complexity, simplicity, and simplexity (Cunha and Rego, 2010). Like sensemaking and learning or stability and change, simplicity and complexity are something of a duality, with each providing conditions for the promotion of the other (Cunha and Rego, 2010). This duality is expressed in the notion of “simplexity.” Simplexity can be defined in various ways, depending on how the complementary, dialectic, back-and-forth dynamics between simplicity and complexity are theorized to be operating (Kluger, 2008).
Certainly, organizations can become too single-mindedly simple over time and set themselves up to fail (Miller, 1993), yet there is also the possibility that they generate too much complexity and fail to realize coherent value or sufficiently clear communications (Siegel and Etzkorn, 2013). Complexity and simplicity also co-occur at different locations or levels; workers may be complex, but organizational structures and processes may be simple, for example (Cunha and Rego, 2010). It is frequently noted in this literature that ‘there is nothing simple about simplicity’ or that ‘simplifying is not simple’ (Berthoz, 2012). Simplexity then reflects this paradox—that there is a general need to try to make things simple, understandable, and general, but with the qualification that this very process of exhibiting deep simplicity is itself somewhat complex. Simplexity can thus also be defined by dynamically balancing complexity of thought with simplicity of action to better engage novel, complex, and changing circumstances (Colville et al., 2012).
Simplexity is relevant to big data given that large amounts of complex data can continually tempt organizations to action, surprising insights, storytelling, and ongoing, iterative studies of its flows, along with further processual cycles of collection, comparison, and interpretation (Weick, 2012). Sensemaking relates to efforts to reduce complexity in terms of its emphasis on a “vocabulary” of elements trying to continuously organize themselves to order and the “grammar” linking those elements into various configurations (Weick, 1969). Alternatively, organizational learning has been increasingly acknowledged as emergent and fluid, socially complex, and borne from the tensions residing in organizations as complex adaptive systems (Antonacopoulou and Chiva, 2007). In general, big data itself implicates the complexity–simplicity interface where mediating simplexity processes are needed—where models, metrics, search terms, and storage facilities are used to extract simplifying interpretations from complex data sources (McAfee and Brynjolfsson, 2012).
Achieving simplexity for big data in organizations therefore means being able to characterize the data beyond their generally “big” aspect; to understand that quantity does not always equal quality, but rather that the precise granular aspects of the data and the ways in which they are analyzed are what makes them “smart” data that lead to helpful insights (George et al., 2014). Using big data in this way to understand the dynamic complexity of “events that are variously unexpected, surprising, unorthodox, and rare” (Colville et al., 2013b: 1202) may mean striking a difficult balance of simplexity—between reductionism that aids sensemaking and playful multiplicity that denies unity of interpretation and accepts possibilities for learning (Serres, 1995).
Sensemaking may become discrepant in the search for simplexity as routines, cues, and frames co-occur and compete for attention (Colville et al., 2013b). For example, researchers and analysts working with big data may be in conflict over whether to use more familiar analytical cues inappropriately (e.g. p-values for significance of correlations) or less familiar but more appropriate cues (e.g. effect sizes, regression variance explained), as well as more sophisticated data mining and visualization techniques as frames (George et al., 2014). In striving for simplicity, the temptation to ‘lie with statistics’ (Huff, 1991), consciously or unconsciously, may distort sensemaking and suppress learning through overly simplistic interpretations. Big data closely juxtaposes sensemaking and organizational learning by indulging a motivation to “understand connections (which can be among people, places, and events) in order to anticipate their trajectories and act effectively” (Klein et al., 2006: 71).
Whether or not big data can aid effective interplays between sensemaking and organizational learning sits at the center of several contested myths around effective human–computer interactions and decision making. Specifically, there are key debates about the following: whether passively receiving automatically processed data will aid or hinder sensemaking, whether more information will lead to suboptimal sensemaking and greater overconfidence, whether problem solving can be too open-minded, whether heuristic biases are correctable to ensure reliable sensemaking, and whether sensemaking will follow neat waterfalls to refined understandings or more dynamic cycles (Klein et al., 2006). The “bigness” (volume, velocity, and variety) of big data allows us to tap into a more immediate, large-scale “sense” of what is happening across societies but requires simplexity of human cognition in recognizing a multiplicity of patterns that tells some, but never definitively all, of a particular story.
Another complexity question concerns how to relate the retrospective sensemaking of big data that has already accumulated across time to the enactment of more prospective forms of sensemaking and organizational learning. High-profile examples like Google’s “Project Oxygen,” identifying eight key behaviors of existing managers by drawing on large and diverse sources of company data, have yielded results that are not terribly surprising although, according to the project co-lead, were “about us, by us, and for us” (Garvin, 2013). Hence, big data is often used in the traditional retrospective sensemaking mode to consolidate and enact a partially existing reality identified by the data.
For big data to generate novel understandings, becoming prospective and forward-looking, corresponding prospective sensemaking can encourage the necessary simplexity. This can be achieved by supplementing big data analytics with various material practices (Stigliani and Ravasi, 2012), strategic devices like scenario forecasting (Wright, 2005), corporate futurists, and attempts at foresight or counterfactual thinking (MacKay, 2009). These prospective sensemaking motions remain relatively under-researched (MacKay, 2009), although big data may produce more evidence of devices and experts that stretch sensemaking toward the aspiration of learning about a potentially “‘knowable future’ extracted from the things that machines know better about us than we know ourselves” (Anderson and Rainie, 2012: 11).
An organizational example of this is where the large US insurer Allstate has developed a device called “Drivewise” that finds relatively simple trends amid complex amounts of data by providing minute-by-minute driving reports (King, 2014). This balances sensemaking with learning to structure car insurance and reward safe drivers with lower insurance rates, where in the past only demographic information and retrospective application of penalties post-collision could be applied, limiting more prospective learning. There is a striving to enact some simplicity from driving patterns, tempered by a simplexity dynamic in processing and acting on complex data. In learning terms, this also relates to a continuous mindfulness and preparedness for multiple futures, many of which may, of course, not ultimately occur and remain partially unknowable (Hernes and Irgens, 2013).
Interdisciplinarity as an interpretive frame for big data, learning, and sensemaking
Interdisciplinarity presents another ontological and epistemological challenge to the reflexive process of big data organizing, in terms of how individuals and collectives working with preexisting interpretive disciplinary frames make sense of and learn from the data. There is again a connection with complexity theory, if we see disciplines as an evolving network of interrelated elements and relations (Klein, 2004). In terms of sensemaking, it follows that to appreciate the complex features of big data by registering and reducing some of its ambiguity requires some corresponding complexity in terms of disciplines or subject areas. Rather than being arbitrary, random, or crudely chaotic, this complexity should be “effective” in terms of its requisite variety; it should match the variety of big data with a corresponding variety of frames that are as theoretically comprehensive as possible for interpreting the data (Boisot and McKelvey, 2010).
Michel Foucault—arguably an interdisciplinary scholar working with big data ahead of his time—has written extensively about the complex evolution and juxtaposition of disciplines, and his body of work shows how disciplines give rise to scientific discourses and framings of societal problems, with profound implications for what constitutes knowledge and the exercise of power over meaning (Foucault, 2002; Takács, 2004). Indeed, the history of literature, culture, and science can be seen in terms of an ongoing organizing exercise undertaken to make sense of disciplines and learn about the world (Moran, 2010). Interdisciplinarity also has relevant linkages with organizational learning, given the networks of knowledge, communities of practice, and reflexive, dialogic learning mechanisms that mixing disciplinary boundaries can potentially give rise to (Brewer, 1999; Cunliffe, 2002; Jordan, 2010; Syed et al., 2009).
In order for organizations to learn from big data, they simultaneously need to develop supporting capabilities for learning how to analyze it. Such learning implies at the very minimum an interdisciplinary base including statistics, computer science, applied mathematics, and economics (George et al., 2014), not to mention any task-specific disciplines brought to bear on the particular content at hand. In a work environment that is increasingly globally connected, rich in online media, and smart computational systems, sensemaking, interdisciplinarity, and computational thinking are being identified as part of an interrelated set of vital work skills for the future (Davies et al., 2011).
Indeed, to make sense of big data and refine the future skills that will be needed to analyze it effectively, a new profession of “data scientists” with their own growing communities of practice is emerging, although they remain in relatively short supply due to the interdisciplinary nature of the work (Davenport and Patil, 2012). This challenge again implicates the reflexive interplay between sensemaking and organizational learning. The social construction of “data science” and “data scientists” represents an attempt to make sense of the interdisciplinary skillset and mindset needed to extract general value from big data. However, much of the situation-specific value of big data will also require further interactive learning across the diversity and social complexity of other interdisciplinary actors (Antonacopoulou and Chiva, 2007), depending on the context and application (e.g. the arts; see Lazar, 2013).
In a review of literature on interdisciplinary organization (Siedlok and Hibbert, 2014), it is noted that interdisciplinarity eludes a singular meaning, but rather refers to a continuum of possible meanings and activities, with the core of the definition being “the integration or synthesis of two or more disparate disciplines, bodies of knowledge, or modes of thinking to produce a meaning, explanation, or product that is more extensive and powerful than its constituent parts.” (Rhoten and Pfirman, 2007, cited in Siedlok and Hibbert, 2014: 4)
Siedlok and Hibbert (2014) go on to specify four types of interdisciplinary organizing that vary in integration and duration: sourcing, consolidating, synergizing, and configuring. This parallels a sensemaking emphasis on processual verbs (Bakken and Hernes, 2006) and, in turn, the verbs of organizational learning (“acquiring,” “participating,” “experiencing”; Elkjaer, 2004).
Examples of organized interdisciplinarity in action often indicate the generation, integration, and analysis of big data to some extent—manipulating stem cells in a bioreactor, applying evolutionary modeling to geography research, the emergence of the field of systems biology, and the growth of nanoscale research (Siedlok and Hibbert, 2014). There are tendencies for disciplines to continually visualize data to see how problems and trends are related (Fox and Hendler, 2011). Furthermore, disciplines are managing data for making it available to one another (e.g. “biocuration”; see Howe et al., 2008) and generally working toward data ecosystems designed along socio-technical principles to be “discoverable, open, linked, useful, and safe collections of data, organized and curated using the best principles and practices of information and library science” (Parsons et al., 2011: 555). For example, OpenSearch is a tool that allows specialist data stewards to share search results across a federated system in a way that supports the tailoring and distribution of diverse, esoteric information not accessible to standard search engines. OpenSearch forms the commercial basis for the Amazon Marketplace and is beginning to be used in interdisciplinary science initiatives (Parsons et al., 2011).
What is common to most successful interdisciplinary endeavors is an effort to characterize complexity—often of a computational or scientific nature—using a blend of actors’ tools and techniques, together comprising a system of data metrics and material “boundary objects” (e.g. wikis and visualizations), to foster learning and sensemaking across diverse collectives and individuals (Nicolini et al., 2012; Stigliani and Ravasi, 2012). Just as interdisciplinary problem solving crosses the boundaries of disciplines, big data correspondingly crosses the boundaries of organizational forms, as big data project partners strategically reflect on their own variety in relation to the variety of data, signaling possibilities for interorganizational learning in evolving economies of information and knowledge (Evans and Wurster, 1997). For example, Climate Corp, a Silicon Valley start-up with origins in Google, was acquired by the large agricultural multinational Monsanto after it crunched decades of multi-source data to model global farming inefficiencies in efforts to minimize starvation and wastage (Chan et al., 2014). Similarly, in China, a crowdsourcing mapping project, Danger Maps, is drawing on the inputs of government data and citizens to highlight high pollution areas and environmental risk, with the charitable backing of e-commerce giant Alibaba, while other nongovernmental organizations (NGOs) follow suit in using big data to drive sustainable social activism (Chan et al., 2014).
By flowing around and between disciplines, big data invites sensemaking of a more pragmatic character within and across organizations, where disciplines and specialisms provide some rigorous organizing structures for making sense of big data. Regarding learning, the gaps and connections between these structures provide spaces for reflection and insights about messy practical issues relevant to reality and experience (Fendt, 2013).
Reflecting on ideologies of learning and knowledge production
When analyzing big data, organizational actors will not just dispassionately bring disciplinary backgrounds to it, but rather “as individuals develop their personalities, personal habits, and beliefs over time, organizations develop world views and ideologies” (Hedberg, 1981, cited in Fiol and Lyles, 1985: 804). Individuals and groups will hold various beliefs about how the form and content of big data should be managed, how inputs should be converted into outputs, and how knowledge will shape further rounds of actions and decisions. The defensive barriers to organizational learning apply just as strongly when working on big data, which under social observation will bring normative and sensemaking pressures to appear compliant, competent, decisive, and diplomatic (Argyris, 1976). The general way to address these biases is through questioning and changing underlying values or features of the status quo, transcending them via double-loop learning (Argyris, 2003). Thus, successful Ford CEO Alan Mulally’s favored saying “the data will set you free,” in relation to changing Ford’s entrenched corporate culture, probably says much more about Mulally’s vision, values, and empowering leadership style than it does about anything inherent to data per se (Hoffman, 2013; Kaipa and Kriger, 2010).
Crucially, much of the discourse surrounding the attractions of big data analytics for organizations may reflect a much broader attempted antinomic swing toward a rational ideology (away from a normative one), driven by a broad, deep cultural, and economic yearning for an emphasis on observable, orderly patterns of behavior (Barley and Kunda, 1992). Yet rather than big data itself being self-evidently valuable and enlightening, just as important, if not more so, are the values and ideologies that are brought to bear on the data, texturing the sensemaking and learning activities carried out. Big data might be viewed as an extended version of knowledge management and information science agendas, where the movements between data, information, and knowledge are shaped by contested cultures, capabilities, and viewpoints in complex social systems (Skyrme and Amidon, 1997; Zins, 2007). Sensemaking processes will help to construct delimited forms of knowledge from the data, while learning may involve returning to the data and experimenting with other ideologies and framings to create new knowledge and wisdom to be made sense of.
There is a complexity of views or orientations on what shapes the ultimate qualities of learning and knowledge (behaviorist, humanist, constructionist, etc.), with sensemaking nestled in among them (Schwandt, 2005). One key interpretive frame is philosophy of science discourse; entire organizational collectives make sense of their internal and external environments according to rationalized logics that draw on a range of philosophies: structural realism, instrumentalism, problem solving, foundationalism, and critical realism (Kilduff et al., 2011). These logics offer “alternative vocabularies of motive, frameworks for reasoning, and guidelines for practice” (Kilduff et al., 2011: 297). Institutions may thus vary in the emphasis they place on analyzing big data for getting at deeper truths in terms of epistemology and trying to represent reality in terms of ontology.
As an example, the Large Hadron Collider operation illustrates a scientifically pure, deductive, structural realist blue-sky approach, co-existing alongside socially catalyzing, critical realist organizations like Greenpeace and inductive, foundationalist organizations mining data in a fairly random, theoretically neutral trial-and-error fashion, all hoping to generate new knowledge from data in different ideologically informed ways (Kilduff et al., 2011). These philosophies of knowledge and learning can be related to processes of institutional sensemaking (Weber and Glynn, 2006), reflecting wider social and historical aspirations of collectives to pursue a certain constrained, distilled version of truth and reality. At lower levels of aggregation and over periods of organizational change, these institutional logics will be legitimized by sensegiving and sensemaking, embodied by storytelling around key events and interactions, albeit with competing stories dynamically vying for attention (Brown et al., 2009; Cunliffe and Coupland, 2012).
In a similar vein, an influential body of 20th century work on the sociology of knowledge considers how social organizations develop and test ideas and shape different types of shared knowledge from within the limits of our rationality and cognitions (Grandori and Kogut, 2002; Swidler and Arditi, 1996). The so-called paradigm wars also continue to shape how communities of scholars produce knowledge. In line with the current approach, their resolution rests on fostering enough reflexivity to avoid treating paradigms as incommensurable and to instead produce knowledge more pluralistically, more multi-paradigmatically (Shepherd and Challenger, 2013). There are also considerable debates about whether a particular mode of knowledge production—where organizations are the subject, object, or both—can be truly rigorous, relevant, and evidence-based, with ideological discourse and counter-discourse reinforcing a certain sense of relativism (e.g. Hessels and Van Lente, 2008; Morrell, 2008; Tourish, 2013).
Big data analytics adds a new dimension to these debates, with distinctive threats (e.g. privileging quantity over quality, correlation over causation, noise from multiple comparisons, and misinterpreting actionable knowledge) and opportunities (e.g. triangulation of sources for more fine-grained pattern detection, accurate forecasting, and machine learning) arising from more complex inputs to filter through our equally complex ideological schemes. Some practitioner-oriented literature emerging on big data contains descriptive starting points for conducting analyses (e.g. Hurwitz et al., 2013), where further mindfulness and reflection might be fruitfully directed. Furthermore, the data are not just coming from human sources but increasingly from networks of automated sensors (the “Internet of things”), and there are concerns about how overwhelming amounts of information can be made sense of; into feedback, automated algorithms, and segmentation of populations. At the same time, there are more emotive concerns that this will lead to massive threats to privacy, dramatic power shifts, and unwelcome deceptions (Anderson and Rainie, 2012; Brown et al., 2011).
Sensemaking of big data technologies will thus need to be supported via relatively novel techniques, occupations, divisions of labor and routines (Barley, 1996), such as real-time data forecasting (“nowcasting”), and software that makes inferences based on complex pattern recognition and prediction (Anderson and Rainie, 2012). However, the social and political projects of big data are still taking form because we have yet to fully map philosophies of learning and knowledge to guide our sensemaking practices as emerging users and producers of big data. The social and cognitive complexity of using, sharing, and applying big data to organizational learning and knowledge practices has yet to be fully, explicitly, and reflexively aligned with the technological complexity that gave rise to big data in the first instance. For example, IBM is still trying to develop and make sense of new roles and routines for turning the artificial intelligence Watson into a fully fledged healthcare service (Arnaout, 2012).
In some cases, a relatively inductive, analytics-driven epistemology may itself constitute a form of double-loop learning. One such example is the Moneyball story, where the general manager of the Oakland Athletics baseball team, Billy Beane, started using a “sabermetrics” system of novel analytics to question and radically change the existing decision making of scouts around how teams are assembled and organized, with other teams and organizations ultimately following suit in light of Beane’s success (Mayer-Schönberger and Cukier, 2013). In other organizational contexts, the formatted and extracted data being made sense of may pose more nuanced ethical and epistemological dilemmas, as spaces or moments for learning emerge (Weick and Westley, 1999). For example, online dating business OkCupid reveals subtle aggregate trends about the social and romantic preferences of its many diverse users, trends that they may be unaware of or deny as individuals, yet driving cycles of learning and sensemaking as users and organizational actors dynamically employ ideologies to theorize and engage with information patterns that affect and implicate them (Rudder, 2014).
In terms of addressing the complexity of big data, simply single-mindedly pursuing a highly positivistic scientific agenda is, on its own, highly unlikely to yield rich understanding and strategic adaptability. It is more likely to inflexibly run a system into the ground through a series of self-reinforcing, deviation-amplifying loops, generating an excess of delimited sensemaking, but a dearth of learning (McKenna, 1999; Weick, 1969). In sum, the key to leveraging balanced learning and sensemaking in relation to big data will partly be rooted in reflexivity, mindfulness, and heedful interrelating of the various ideologies underlying perspectives on learning and knowledge in organizations (Johnson and Duberley, 2003; Learmonth, 2008; Weick and Roberts, 1993).
Mutually aligning sensemaking and big data domains of application
The final big data challenge theorized here concerns how learning and sensemaking processes can formulate and shape the content of big data analyses and applications. In other words, sensemaking and organizational learning can help to map potential domains and topics for big data learning. Reflexive consideration of their respective domains and applications prompts the question—what can sensemaking and big data mutually learn from one another? Evidently, the potential scope for mutual alignment is huge, if a little unwieldy, with common overlaps (e.g. crisis management and organizational change) and distinctive gaps (e.g. sensemaking lacks quantitative analysis and big data lacks processes of social construction). Both sensemaking and big data can be applied, in theory, to almost anything. Sensemaking, for example, has been applied to culture, markets, globalization, technology, politics, interpersonal interactions, societal crises, organizational changes, and so on (Maitlis and Christianson, 2014). Big data topics and agendas are specified more concretely and contextually than some of the more academic framings of sensemaking, but there are clearly broad opportunities for synergies: cancer research, genetics, social media, terrorism, climate change, health, and other government-recorded domains (Boyd and Crawford, 2012).
Sensemaking work itself, with its theory-focused approach, complements the more problem-focused approach that big data seems to have encouraged, and together they have the potential to mutually re-constitute each other and set agendas that can better capture the complexity of organizational issues (Weick, 1992). This marriage between conceptual theory building and analytical problem solving is fruitful because it avoids dangers, specifically where “a potential danger of the AS [analytic scientist] is getting bogged down in infinite details; a potential danger of the CT [conceptual theorist] is ignoring them altogether for the sake of comprehensiveness” (Mitroff and Kilmann, 1978, cited in Weick, 1992: 174).
This mutual alignment is ongoing and necessitates continually resolving the pragmatic interplay between theory, practice, and production, with theory mediating a sense of scientific progress via projects and stakeholders (Shields, 1998). A pragmatic stance also offers ways of incorporating ethics and experimenting more usefully between extreme positivist and antipositivist positions (Hernes and Irgens, 2013; Wicks and Freeman, 1998). Big data needs sensemaking to reduce disorder and prioritize issues from within complex social systems comprising markets, laws, social norms, and forms of structured architecture (e.g. code; Boyd and Crawford, 2012; Lessig, 1999). Complementarily, sensemaking can open itself back up to learning from big data issues by bridging predominantly qualitative approaches with quantitative ones, combining levels of analysis, modifying computational properties of complex causal systems, and blending and interpreting metrics and text (Shah and Corley, 2006).
The value here lies in acknowledging that the topical applications of big data can be interwoven with the topical contents of sensemaking scholarship, while sensemaking and learning are also interwoven around big data as dialectical processes that prioritize, constrain, and enable what the precise forms and varieties of evolving topical agendas for big data (and sensemaking) might look like. For example, large retail organizations like Sears and Walmart have used big data not only to make sense of customer transactions and pricing but also to foster learning about how to combat fraud, run marketing campaigns, make supply chains more transparent, and support consumption patterns during crises or natural disasters, in many ways making sense of and learning from the sensemaking of their own stakeholders (Van Rijmenam, 2014).
The interplay of sensemaking and learning in organizations can thus facilitate the pragmatic social construction of relevant, rigorous, and ethical big data projects. Sensemaking can help to constrain, and learning to enable, various dynamic classifications of big data, in terms of sources (e.g. how openly accessible or man-made they are; Manyika et al., 2013), processes of data collection or creation (e.g. affective social media data, “exhaust” data from automated systems, “lifelogging” data of individuals’ daily activities), organizational sectors or operations where it has most potential for inquiry and innovation (e.g. finance, health care, information services, and HR), and analyses conducted (e.g. descriptive, predictive, or prescriptive; Brown et al., 2011; Davenport, 2013).
The intertwined social-cognitive processes of learning and sensemaking will thus continually flow through the medium of big data itself, in attempts to interpretively enact a “social physics,” at least wherever people are implicated (Pentland, 2014). The products of mutually aligning big data agendas with the contents and processes of sensemaking and organizational learning are likely to emerge in distinctive forms of knowledge or representation. These could be the culturally evolved units called “memes” (Bryant, 2004) or dynamic framings of “messy” or “wicked” policy problems (e.g. climate change, stem cell engineering, and Internet regulation) that defy single optimal solutions, contain contested elements where facts and values collide, and require pluralistic sensemaking processes to try and resolve them (Calton and Payne, 2003; Pedler and Trehan, 2008).
In summary, the reflexive challenge of achieving mutual alignment of topical domains where sensemaking and big data can both be applied to, driven by social-cognitive sensemaking and learning processes, represents a way of meaningfully structuring big data analytics offerings in the first instance. Studying the organizing and learning processes surrounding big data agenda formation can help to contextualize and resituate learning and sensemaking in a visible, future-oriented, technologically supported, and diversified 21st century medium (Easterby-Smith et al., 2000; Nicolini and Meznar, 1995; Weick et al., 2005). Furthermore, identifying the emergence of memes and messy problems links learning once more to conditions of dynamic (social) complexity, although work outlining the exact co-evolutionary, paradoxical mechanisms governing this complexity continues (Antonacopoulou and Chiva, 2007; Bryant, 2004; McElroy, 2000).
Drowning in data: implications and concluding remarks
In this article, big data has been related to the theorization of four process-oriented challenges to be addressed by a reflexive epistemology, where sensemaking continually reduces interpretive variety while learning works to keep various possibilities open, all under conditions of dynamic complexity. These conceptual arguments, as elaborated in the preceding sections, are summarized for the reader in a schematic form in Figure 1. This article has sought to build theory in a value-adding way, by taking a prescient focus on big data analytics as an emerging societal issue, as well as providing some utility by organizing sensemaking, learning, and complexity, bricolage fashion, around big data to frame and structure the challenges it creates (Boxenbaum and Rouleau, 2011; Corley and Gioia, 2011).
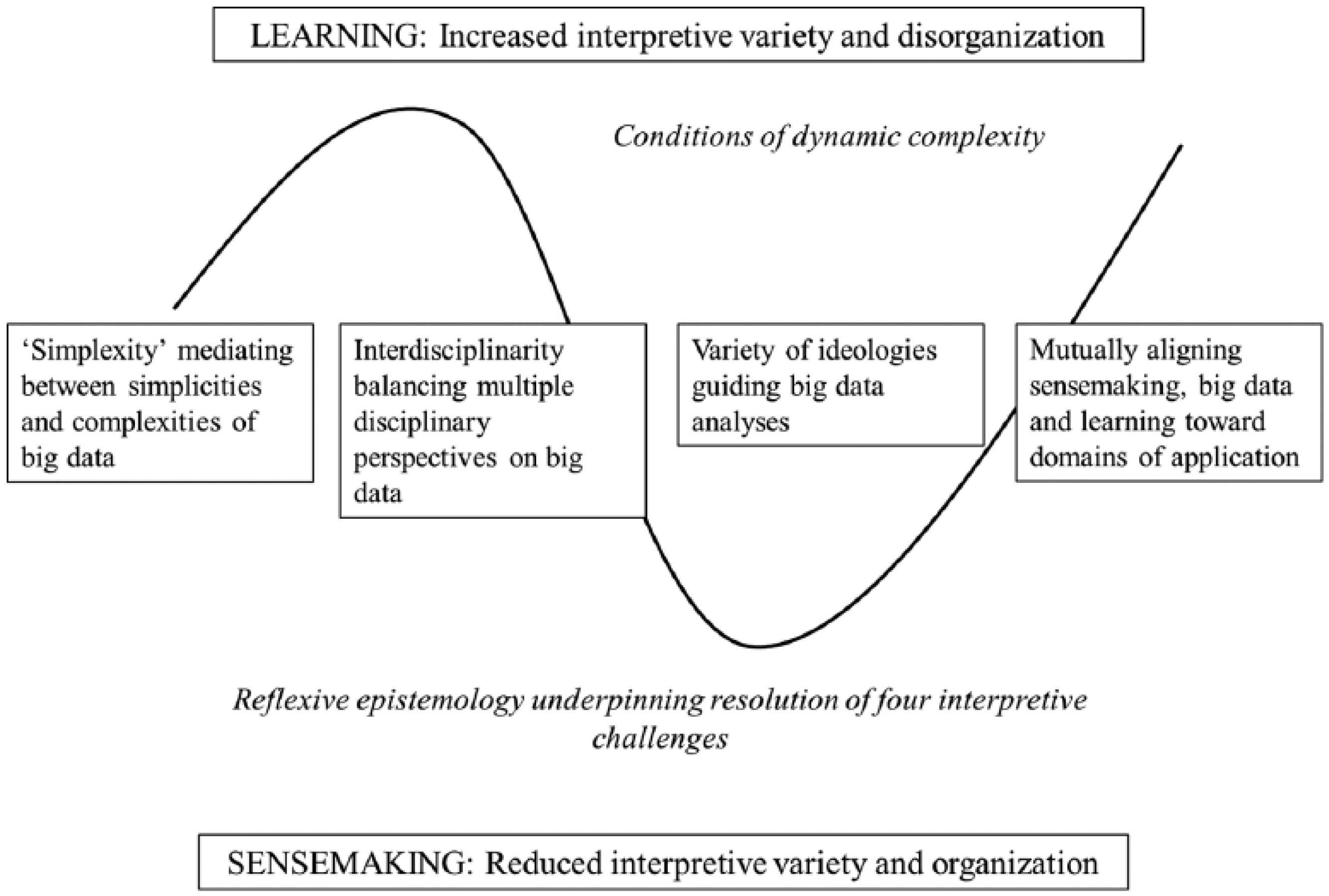
Challenges of sensemaking and learning through the lens of big data.
Future research and practice with big data analytics can work on further investigating and managing the four interrelated tensions between the countervailing tendencies of sensemaking and learning developed here—the continuous social construction of simplexity, interdisciplinary frames, ideologies of knowledge and learning, and the formalization of topics and agendas. An overall process perspective should prove useful in acknowledging how these challenges unfold across interactions and over time (Hernes and Maitlis, 2010), mediated by big data technologies that serve as artifacts—embodying, narrativizing, contextualizing, and even institutionalizing certain logics that arise from big data processing. As well as the variance inherent in these organizing processes, nouns, events, outcomes, and topics will remain complementarily important as structuring entities, nodes, spaces for action, and substantive content (Bakken and Hernes, 2006; Czarniawska, 2006). Interconnectivity, and its ongoing resolution and representation, will be a key theme for theory and also practice; big data is surrounded by interconnected mobile technologies that self-organize to make a digital ecosystem of platforms and services (Dean et al., 2013).
Another key area for future investigation and refinement of practice will be in terms of the sensegiving required for training, communicating, and leading effectively in big data environments. Communication to achieve shared knowledge representations will require a pragmatic blend of modalities, not just scientific-propositional but also narrative and visual modes (Worren et al., 2002). Big data communications may also reflect future-oriented, prospective sensemaking aspects. Careful attention can thus be given to the utopian or dystopian discourses and storytelling narratives that big data can create (Boyd and Crawford, 2012)—discourses of becoming that imply progress, hope, or fear, often masking more subtle shifts in complex socio-technical arrangements. Future research can analyze the complex forces of narrative and multi-vocal ante-narrative surrounding big data trends and phenomena. Work on prospective sensemaking will be able to draw links with learning and materiality (Bjørkeng et al., 2009; Stigliani and Ravasi, 2012), where practitioners will need to wrestle with metrics, databases, and other “boundary objects” to adaptively make sense of big data practices, ensuring coordinated patterns of predictable action and routines that balance order and disorder.
In addition, there will be value in linking sensemaking principles and technological discourses together more explicitly, as users and other stakeholders have evolving discussions about which features of technology they like or dislike, and innovative adjustments take form (Griffith, 1999). Big data implicates an entire cluster of technologies and hints at artificial intelligences on a grander scale. Sensemaking offers a welcome social constructivist perspective on the user-centered learning that occurs in experiencing technology, although the cultural antinomies of determinism–voluntarism and materialism–idealism need to be more explicitly acknowledged too (Leonardi and Barley, 2007).
In terms of complexity, chaos, and organizations, there is still much to understand about how far the mathematical underpinnings of the natural world and pure scientific systems can be faithfully applied to the change in dynamics of social systems (Burnes, 2005). Future research might then fruitfully address relationships between sensemaking and learning by accounting for how they occur across space and time (Antonacopoulou, 2014). Big data creates a scenario where complexity dynamics, social and natural, can more openly take form across time frames and spatial scales where data are generated and processed. Ironically, it may be that complexity theory and its concepts need to be simplified, typified, and made sense of to get beyond hyperbole and ensure their wider use (Manson, 2001). Big data being generated within more familiar, natural mediums (e.g. social media and mobile apps) is ripe for engagement with these areas.
Inherent in most of the preceding discussion is the notion of paradoxes. A central concern has been that sensemaking and learning exist in something of a paradoxical relationship concerning the uncertainty and variety of perception–action links (Weick and Westley, 1999). Learning is implicated in the tensions underlying most organizational paradoxes, and working through them requires managing cycles of dynamic equilibria so that the tense oppositions of multiple dualities can be continually worked through (Smith and Lewis, 2011). The four challenges in this article could thus usefully be conceptualized as paradoxes, in terms of managing the complex form and content of big data projects, as well as the ways chosen to interpret and act on analytic results. Future research and practice on big data analytics needs, therefore, to be concerned with successfully resolving paradoxes to achieve cycles of sensemaking and learning.
There is perhaps a self-referential irony posed by much big data, and to some extent all data, insofar as we create it, collect it, comment on it, refute it, enact it, manipulate it, make sense of it, and yet at the same time, it accumulates and evolves in ways that we struggle to comprehend, and learning is periodically required. Its presence has the capacity to act on us as an environmental sensemaking structure, yet at other times we are reflexive learners with the agency to interact with the data as object, and overall big data constitutes a fluid medium for cycles of organizing and learning activity. There is thus a potential interweaving of the inductive and the deductive, the subjective and the objective (Allard-Poesi, 2005), the layperson and the expert, and the collection of old data followed by the subsequent altered generation of new data.
Concerning the practicalities of big data then, there is a sensemaking-type need to try to fully understand and learn from discrepancies, errors, and even crises that can occur; for example, the “big data hubris” and over-reliance on certain algorithmic dynamics that ultimately led to erroneous predictions by the Google Flu Trends algorithm (Lazer et al., 2014), as well as other general possible abuses of metrics and analytical decision making (Davenport et al., 2010). In response to these issues, this article has presented a critical route for trying not to drown in but make sense of big data via a reflexive epistemology—one that lies in a continuous engagement with the variety-forming interplay between sensemaking and learning. More specifically, this means attending to regulatory processes and reflexive dynamics concerning simplexity, interdisciplinarity, ideologies, and topical agendas surrounding big data’s production and use as potentially valuable knowledge, evolving in conjunction and comparison with “smaller” traditional modes of theory testing and data analysis.
Footnotes
Acknowledgements
The author would like to thank the guest editors of this special issue and two anonymous reviewers for their invaluable comments and feedback on earlier versions of this article.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.