
Abstract
Forecast combination has received a great deal of attention in the tourism domain. In this article, we propose a novel performance-based tourism forecast combination model by applying a multiple-criteria decision-making framework and the stochastic frontier analysis technique to determine combination weights for individual tourism forecast models. Thirteen time-series models are used to generate individual forecast tourism models, and five competing forecast combination models are selected to evaluate the forecast performance. Using the tourism forecast competition data set, we conclude that the proposed combination model significantly and statistically outperforms the five competing combination models in most cases based on multiple performance indicators. Our results show that the proposed model offers a good solution to identify optimal weights for individual tourism forecast models.
Introduction
The tourism industry contributes significantly to global economic growth and recovery, as it benefits a number of related service industries, such as transportation, retail, catering and hotels (Liu et al., 2018; Sun et al., 2019). According to a recent report from the Ministry of Culture and Tourism of the People’s Republic of China, in 2018, the total tourism revenue in China was USD870 billion, an increase of 10.8% over the previous year, accounting for 11.04% of China’s total GDP. 1 Correspondingly, tourism forecasting has received widespread attention from researchers and practitioners. Accurate tourism forecasting not only improves the ability of tourism firms to make decisions, such as in creating budget plans, making hotel investments and managing human resources, but it also helps governments make appropriate tourism policies in, for example, residential site planning, tourism marketing strategies and transportation system design (Jiao and Chen, 2018; Li et al., 2018).
Studies on tourism forecasting have continued to receive much attention in academic research. In a recent literature review of 171 papers published in 2007–2015, Wu et al. (2017) found that the most commonly used approaches in tourism forecasting can be classified into three categories: non-causal time-series methods, causal econometric methods and artificial intelligence methods. Although many tourism forecast models have been proposed in the literature, most researchers mainly use single forecast models to obtain the best forecasting performance. However, there is no universal single forecast model that outperforms others in all situations (Cang and Yu, 2014; Shen et al., 2011). Furthermore, empirical research in other fields has already shown that forecast combination modelling significantly improves forecast accuracy and often produces better results than the best individual forecast model (Cang and Yu, 2014; Timmermann, 2006). Although the idea of tourism forecast combination has received increasing attention in academia, it is still considered a new development in tourism forecasting (Wu et al., 2017). Since 2007, there have been several papers on tourism forecast combination. Table 1 shows a brief review of this literature.
An overview of selected tourism forecast combination literatures.

Tourism forecast combination is achieved by assigning weights to individual forecast models. The combination method used in tourism forecasting can be generalized as two weight generation schemes: the simple average (SA) and the optimal weight (OW) technique. The SA approach assigns constant weights to individual models, whereas the OW methods assign weights based on a function of forecast error-derived accuracy measures, which are used to evaluate the forecasting performance of an individual model. For example, one widely used OW technique is the variance–covariance combination (VACO) method (Cang and Yu, 2014). In VACO, the weights are proportional to the performance of the individual forecast models, with the performance of the individual models evaluated solely by mean square error (MSE). It may be unreliable to evaluate the performance of individual tourism forecast models based only on one accuracy measure, as there exist various accuracy measures, such as mean absolute error (MAE), mean absolute percentage error (MAPE) and others. Different accuracy measures have different advantages and disadvantages. Hyndman and Koehler (2006) conducted a comprehensive review of the accuracy measures used in the forecasting field and presented an exhaustive discussion of their advantages and disadvantages. For example, in the article, the authors concluded that the root mean square error (RMSE) and MSE are more sensitive to outliers than MAE, and that the measures based on percentage error (e.g. MAPE) are often highly skewed. Under this consideration, the results of performance evaluations for individual forecast models will vary depending on the accuracy measures used. In fact, studies from empirical forecast competitions, such as the M competition (Makridakis et al., 1982), the M3 competition (Makridakis and Hibon, 2000) and the NN3 competition (Crone et al., 2011), have found that the performance of forecast models varies considerably depending on the selected accuracy measures. Thus, we question why multiple accuracy measures are not used to determine the combination weight for individual tourism forecast models.
In this study, we argue that the performance evaluation results of individual tourism forecast models can be more reliable and robust by considering multiple accuracy measures, and we propose a novel performance-based combination model for tourism forecasting. Specifically, we consider the problem of performance evaluation for individual forecast models with multiple accuracy measures as a classic multiple-criteria decision-making (MCDM) problem, and we use the stochastic frontier analysis (SFA) technique to solve this MCDM problem. In other words, we use SFA to calculate the combination weight of individual forecast models based on their forecasting performance, which is denoted by the technique efficiency value obtained by SFA. To illustrate the effectiveness of the performance-based combination model, we adopt four widely used accuracy measures in our case study, RMSE, MAE, MAPE and mean absolute scaled error (MASE), to assign weights for 13 individual tourism forecast models. This illustration uses the renowned tourism forecast competition data set (Athanasopoulos et al., 2011) and is compared with five linear combination models. The tourism forecast competition data set contains 1311 tourism time series with different time intervals, including 518 yearly series, 427 quarterly series and 366 monthly series. The results show that the performance-based combination model significantly and statistically outperforms the five competing combination models in most cases based on the multiple performance indicators used.
This study offers several contributions. First, our article extends the tourism forecast combination literature by proposing a novel combination method in which the combination weight is generated based on a MCDM framework and the SFA technique. Our study extends the traditional work of tourism forecast combination research studies, such as Wong et al. (2007), Chan et al. (2010), Shen et al. (2011) and Cang and Yu (2014), which calculate the weights solely on one accuracy measure function (e.g. VACO). Second, our article offers a comprehensive comparison among forecast combination techniques, unlike traditional comparison studies that usually use one accuracy measure and combine two individual tourism forecast models (e.g., Chen, 2011). In this article, we consider 13 individual tourism forecast models and 5 forecast combination models. Furthermore, to give a comprehensive comparison, we use the tourism forecast competition data set, which contains 1311 tourism time-series data.
The article is organized as follows. The second section presents the related theories. The third section describes the model-building process. The fourth section demonstrates the experimental process and analyses the results. The fifth section reports our conclusions and discusses our findings.
Related works
Forecasting studies
Forecasting is concerned with the prediction of future values based on historical data and has extensive applications in a variety of topics in the business research domain, such as supply chain forecasting (Svetunkov and Boylan, 2019), order management (Van Gils et al., 2017), demand forecasting (Prestwich et al., 2014) and finance forecasting (Podsiadlo and Rybinski, 2016). Traditionally, forecasting studies have used statistical models, such as exponential smoothing (Petropoulos et al., 2018), autoregressive integrated moving average (ARIMA) (Azevedo and Campos, 2016) and the TBATS model (De Livera et al., 2011). Machine learning techniques, such as the neural network model (dos Santos and Vellasco, 2015), the support vector machine (Chen and Lee, 2015) and the k-nearest neighbour model (Cai et al., 2016), have also drawn a great deal of attention in the forecasting field. In these models, researchers identify the best single statistical model for prediction. Recently, there has been a transition from individual deterministic forecast to forecast combination. Forecast combination linearly integrates several individual models and has widely proved to be a highly successful forecasting strategy (Adhikari, 2015; Podsiadlo and Rybinski, 2016), as it significantly improves forecasting accuracy and often produces better results than the best individual forecast model (Cang and Yu, 2014; Timmermann, 2006).
As tourism planning and administration rely on efficient and accurate forecast techniques (Hirashima et al., 2017; Turner and Witt, 2001), tourism forecasting has become a relevant research field. A decision maker can choose from among several tourism forecast models. Deserted models might still have some useful information, and thus a combination strategy that incorporates several individual models might provide better accuracy. Combination strategy originated in the 1960s with the work of Bates and Granger (1969), and since then, it has been studied extensively in the forecasting domain. Indeed, it has been shown that combining several individual tourism forecast models can lead to superior performance in accuracy (Cang, 2011). Wong et al. (2007) first conducted a comprehensive investigation for three forecast combination strategies: SA, VACO and discounted mean square forecast error (DMSFE). They concluded that the combination strategies improve forecast accuracy, although such strategies might not always be better than the best individual forecast model in all situations. Following the research framework of Wong et al. (2007) and Shen et al. (2008), Song et al. (2009) further assessed tourism forecast combination. By carrying out comparisons among the same three combination strategies and individual forecast models, they found that combined forecasts are more accurate than individual tourism forecast models. Table 1 lists several tourism forecast combination studies since 2007.
From Table 1, we see that the tourism forecast combination technique can be generalized into two weight generation schemes: the SA and the OW methods. The SA technique assigns constant weights for individual models, whereas in the OW techniques, the weights are a function of forecast error derived from accuracy measures. For example, in the VACO method, the weight for each individual forecast is a function of the MSE with the aim of minimizing the in-sample error variance; in the DMSFE method, the weight is related to MSE, but it incorporates the discount factor. There are also several variations of the VACO method: the inverse of the mean square error (INV-MSE) method (Andrawis et al., 2011), the inverse of performance rank (IRANK) method (Andrawis et al., 2011) and the cumulative sum (CUSUM) method (Chan et al., 2010). There are also several regression models, such as ordinary least squares and constrained least squares (Andrawis et al., 2011) and the ridge regression method (Chan et al., 1999). However, the regression framework has proved to perform poorly in many cases (Sermpinis et al., 2012).
Despite the large number of combination approaches available, there is no unanimity on the best weighting approach in general empirical situations. One major reason might be that the combination weight for individual models relies solely on one accuracy measure, and the performance evaluation result for individual models might be different depending on the accuracy measure used.
Accuracy measures
To evaluate the performance of forecasting models, a large number of accuracy measures have been proposed in academic research including but not limited to the tourism field. However, such accuracy measures are bewildering and not generally applicable as different accuracy measures evaluate different types of forecast error and can produce misleading results. Hyndman and Koehler (2006) conducted a comprehensive examination on accuracy measures and classified these measures into four groups: scale-dependent measures, percentage error-based measures, relative error-based measures and relative measures. We briefly present these measures here.
Forecast error is defined as
The choice of appropriate accuracy measures to evaluate the performance of forecast methods is a topic of interest in the forecasting field. However, the choice of suitable accuracy measures remains controversial (Davydenko and Fildes, 2013). Here we illustrate the controversy with several examples: (i) In the original M competition, MAE was always used by Makridakis et al. (1982). However, as Armstrong and Collopy (1992) pointed out, MAE is not suitable for different time-series data. Armstrong (2001) also recommended against the use of RMSE in forecast accuracy evaluation even though RMSE has been popular in much of the literature because RMSE is more sensitive to outliers as compared to MAE or MdAE. Instead, Armstrong and Collopy (1992) suggested the choice of relative absolute errors. (ii) In the M3 competition, Makridakis and Hibon (2000) suggested MdRAE, sMAPE and sMdAPE. However, Swanson et al. (2000) and Coleman and Swanson (2007) showed that accuracy measures based on percentage measures have highly skewed distribution. (iii) MASE, which can overcome the shortcomings of percentage measures, was recommended by Hyndman and Koehler (2006). However, MASE has disadvantages. For example, MASE has a bias towards overestimating the benchmark model, and it is vulnerable to outliers (Davydenko and Fildes, 2013).
We conclude that many of the accuracy measures are not generally applicable. That is, although such measures have been used to evaluate forecast performance, all of them have shortcomings. Different accuracy measures can result in different performance outcomes. Makridakis and Hibon (2000) pointed out that the relative ranking of the performance of forecast models varies when different accuracy measures are chosen. Crone et al. (2011) had similar results from their NN3 competition research. As such, forecasting performance evaluation cannot obtain consistent results, as different accuracy measures might produce different results. We argue that it might be more reliable and robust to evaluate forecast performance by considering multiple accuracy measures so that these accuracy measures complement each other and take into account more information from individual forecast models. In this way, performance evaluation based on multiple accuracy measures can provide a more robust and convincing result, and thus the combination weight obtained from this performance evaluation result will also be more robust.
The performance-based combination model
The performance-based combination framework
There are three types of tourism forecasting methods: (i) non-causal time-series methods (Hassani et al. 2017), (ii) causal econometric methods (Wan and Song, 2018) and (iii) artificial intelligence methods (Li et al. 2018). In this article, we mainly focus on non-causal time-series methods, which involve the using of historical tourism data to predict the future.
First, in Table 2, we define the variables used in this article. We divide the tourism time-series data into two parts: the in-sample series of first t observations are used to train a forecast model, and the out-of-sample series of the last h observations are used to test the forecast model. If there are n individual forecast models, we can obtain a forecast vector that contains n forecast values for the out-of-sample series. The major challenge of tourism forecast combination is to assign weights for each individual forecast model based on a suitable weight generation scheme.
Basic variables.

As mentioned above, there are two major motivations: one is that the combination weight estimated solely upon one accuracy measure is not reliable and robust because it amplifies the variance of the combination and leads to biased results; the other is that the performance evaluation results for individual forecasts are different based on different accuracy measures as different measures evaluate different aspects of the forecast error. Therefore, we propose a novel performance-based combination model. Specifically, we first evaluate the performance of each individual forecast model by taking into account multiple accuracy measures. We consider such performance evaluation under multiple accuracy measures as a classic MCDM problem, succinctly defined as making decisions involving multiple attributes/objectives (Zionts, 1992). Then we obtain the performance value (PV) for each individual forecast model by solving the MCDM problem. Lastly, we calculate the weight for each individual model based on the proportion of its PV to the sum of all of the models. The upper part of Figure 1 shows the MCDM framework.

Performance-based forecast combination framework.
In the classic MCDM methodology, it is assumed that there are many alternatives and each alternative is measured by its value on each of the multiple attributes (Stewart, 1996). A decision maker must decide which alternatives are best and sort the alternatives. The MCDM methodology supports decision makers in evaluating the performance of the alternatives. In this article, the performance-based combination method is precisely in line with the MCDM methodology, in which the alternatives are the individual tourism forecast models and the attributes correspond to the multiple accuracy measures. In particular, we can obtain k accuracy measures, denoted as (
Here we use SFA to solve the MCDM problem. The PV of an individual forecast model can be measured by its technical efficiency value (TEV), and the TEV can be estimated by SFA. SFA is a parametric approach for benchmarking and has been developed simultaneously by Meeusen and van den Broeck (1977) and Aigner et al. (1977). SFA has several advantages: first, in SFA, the production function that shows the relationship between the input and output is supposed to be known and can be estimated statistically (Hailu and Tanaka, 2015); second, the error term integrates the stochastic component and the non-negative inefficiency component (Anaya and Pollitt, 2017); third, the hypothesis for SFA is statistically rigorous and can be theoretically tested, and the technical inefficiency effects model and the stochastic production model can be simultaneously estimated for the SFA technique (Charoenrat and Harvie, 2014).
Consider a set of n individual tourism forecast models, with each model j (j = 1,…, n), using k − 1 inputs
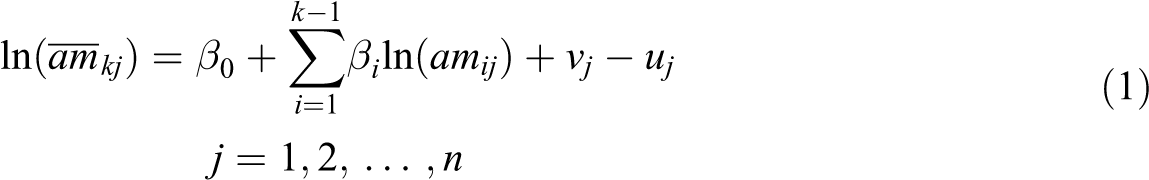
where
It is worth highlighting that uj denotes the ‘inefficiency’ term. To estimate the TEV for each individual forecast model, we transform the ‘inefficiency’ term into the ‘efficiency’ term with equation (2), as discussed in detail by, for example, Kumbhakar and Lovell (2003).

As the PV of an individual forecast model is measured by TEV, the weight wj for individual forecast model j can be calculated based on equation (3):

Competing forecast combination and individual tourism forecast models
In the proposed performance-based forecast combination, the weights are based on the PVs obtained by the SFA technique, which considers multiple accuracy measures. In the rest of the article, we refer to the proposed performance-based forecast combination as the SFA-based model. We use five different combination models in our tourism forecast combination model comparison: three, namely equal weight (EW), trimmed mean (TM) and Winsorized mean (WM), belong to the SA category, and the other two, the VACO model (Bates and Granger, 1969) and the IRANK model (Aiolfi and Timmermann, 2006), belong to the OW category. A summary description of the competing forecast combination models is provided in Table 3. In particular, the EW model, which simply assigns equal combination weights for all individual forecast models, is widely used and often considered as a benchmark combination approach in much of the forecast literature. The TM and WM weighting models are two variations of the EW model but are quite robust compared to the EW model. Trimming is the removal of extreme values, and winsorizing is reducing the outermost values in extremity. The VACO model is a classic OW method in which the weight generating is based on one accuracy measure, MSE. The IRANK model is a variant of the VACO model that considers the ranking order of the individual models. It is worth highlighting that there are many variants of VACO. In this article, we use the RANK model as a representative.
Summary description of the tourism forecast models.
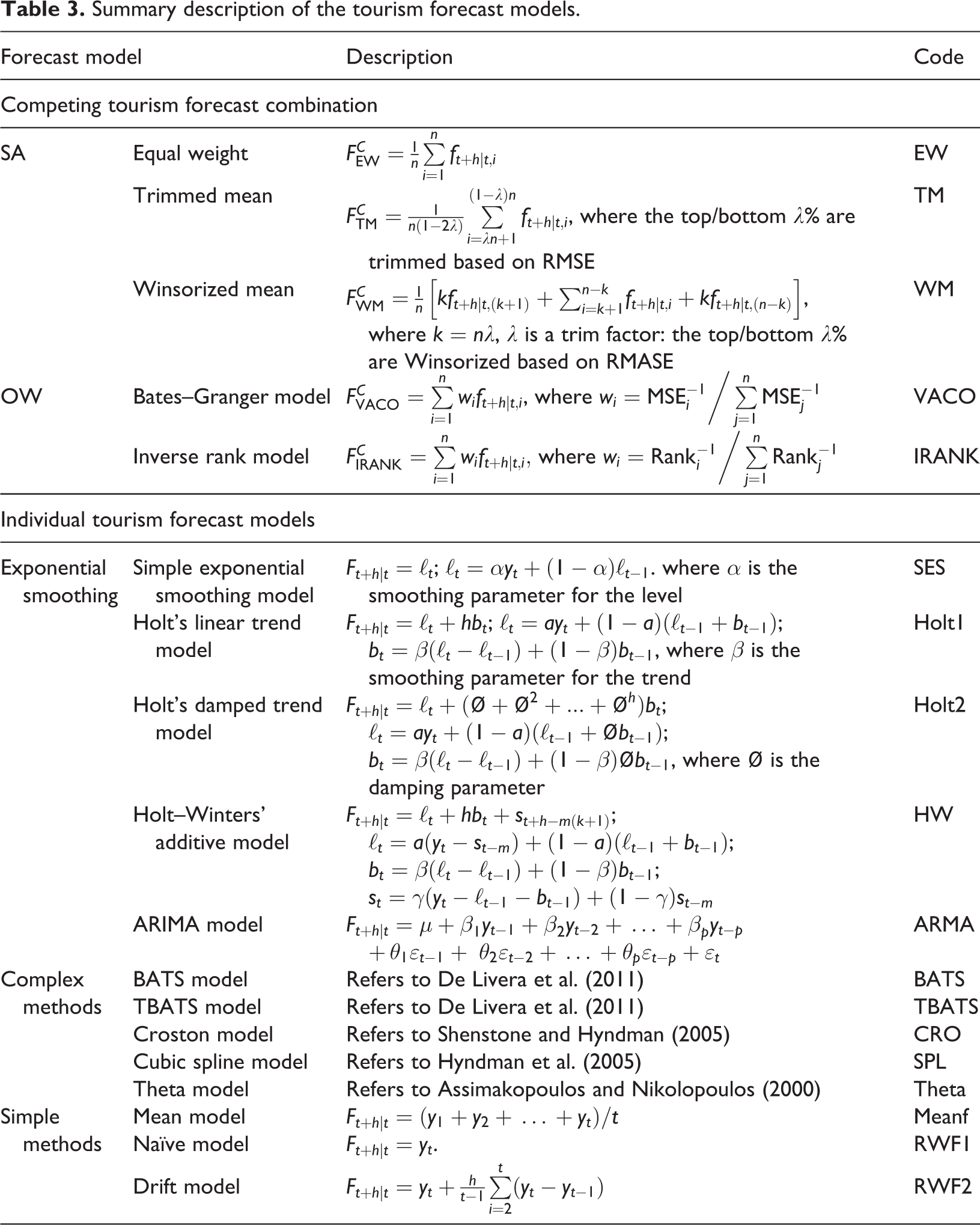
In this case study, 13 individual forecast models are built to form the forecast combination. A summary description of the individual forecast models is provided in Table 3. These individual models can be classified into four categories: exponential smoothing, ARIMA, complex methods and simple methods. Among these models are the most popular forecast methods, such as Holt’s linear trend model, Holt–Winters’ additive method and the ARIMA model. We also use five complex models that are newly emerging techniques – the BATS model, TBATS model, Croston model, cubic spline model and theta model – along with three simple methods, the mean model, naïve model and drift model, which are usually viewed as benchmark models in much of the time-series forecast literature.
Empirical investigation and analysis
Data sets and experimental design
In this study, to empirically compare the proposed performance-based tourism forecast combination model to the five competing combination models presented in ‘The Performance-based Combination Model’ section, we use the tourism data from the renowned tourism forecast competition data set (Athanasopoulos et al., 2011). The data set is available in the ‘Tcomp’ package in CRAN (https://cran.r-project.org) and contains 518 yearly series, 427 quarterly series and 366 monthly series. These data were supplied by various academics and several tourism bodies, such as Tourism New Zealand, the Hong Kong Tourism Board and Tourism Australia (Athanasopoulos et al., 2011). Table 4 reports in more detail the number of series and the length, frequency and forecast horizon for each frequency. The forecast horizon is also the length of the out-of-sample test data for each frequency in this study. Because of its diversification of data type, the tourism forecast competition data set has become an important data set for comparing alternative tourism forecast models.
Descriptive statistics of the tourism forecast competition data set.

As mentioned, the performance-based combination model is a classic MCDM problem. To realize the MCDM framework, we use the four accuracy measures of RMSE, MAE, MAPE and MASE to form the attributes in this framework as these measures are often used to compare tourism forecast models. For the SFA model, the inputs are RMSE, MAE and MAPE for each individual forecast model, and the output is the reciprocal of MASE. Thus, in the SFA framework, there are 13 individual forecast models, and each individual forecast model has three inputs and one output. The major processes in the experiment are described as follows.
Step 1: Preparing the data. For each time series in the tourism forecast competition data set, we divided it into two parts: the in-sample series for training the forecast model and the out-of-sample series for testing the model. The length of the out-of-sample data set for each series with a different frequency is consistent with its corresponding forecast horizon. The lengths of the out-of-sample data set for the monthly, quarterly and yearly series are 24, 8 and 4, respectively.
Step 2: Training the individual tourism forecast models. For each time series, we use the in-sample data set to train the 13 individual forecast models. We check the collinearity of these models.
Step 3: Computing inputs and outputs for each individual forecast model. In this case, we calculate RMSE, MAE, MAPE and MASE for each individual forecast model based on the in-sample data set for each series. We set RMSE, MAE and MAPE as the inputs and the reciprocal of MASE as the output.
Step 4: Combining the individual forecast models. We combine the individual forecast models into the proposed performance-based combination model and the five competing combination models.
Step 5: Comparing the forecast combination models. We compare the performance of the six forecast combination models based on the out-of-sample data set by using multiple performance indicators.
As mentioned in ‘Accuracy measures’ section, different accuracy measures may yield different results in validating the performance of the forecast model. Therefore, in this article, we introduce several performance indicators to identify the ‘effectiveness’ of the SFA combination model. As there are six forecast combination models and many time-series data, we use three relative accuracy measures: relative RMSE (Rel_RMSE), relative MAE (Rel_MAE) and relative MAPE (Rel_MAPE). The relative RMSE is the RMSE of a certain forecast combination model in relation to the RMSE of the baseline forecast. We set the best individual forecast model as the baseline forecast, although the best individual forecast model might be different for different accuracy measures or different time series. We also present the mean rank of each forecast combination model. Considering time series i, we rank the six forecast combination models based on the selected relative accuracy measure (i.e. Rel_RMSE) with the best model being ranked as one and the worst as six. The mean rank of one forecast combination model is thus the average of the rankings of the target combination model over all of the series. In addition to the relative accuracy measures and the mean rank, we construct two other performance indicators: the better performance percentage (BPP) and the average improvement percentage (AIP). The BPP value is the percentage of occasions in which the SFA-based model performs better than the competing forecast combination model in terms of one accuracy measure. The AIP value is the percentage of average improvement for all of the series in which the SFA-based model performs better than the competing forecast combination model in terms of one accuracy measure.
Analysis of results
In this subsection, we analyse the results of the experiment. Table 5 shows the mean and ANOVA values for the time series with different frequencies (yearly, quarterly and monthly) in terms of the three relative accuracy measures (Rel_RMSE, Rel_MAE and Rel_MAPE). The baseline model is the best individual model among the 13 tourism forecast models in terms of the corresponding accuracy measure. Therefore, through the relative accuracy measure, we can evaluate whether the tourism forecast combination model is better than the best individual model by checking whether the value is smaller than one. Among the three relative accuracy measures for the six forecast combination models, the smaller the better. First, from Table 4, we can see that the mean values of the three relative accuracy measures for the SFA-based model are always smaller than one for all of the time series, which reveals that the performance-based forecast combination model is better than the best individual forecast model for most time series. Second, for the yearly, quarterly and monthly series, the mean values of the relative accuracy measures for the SFA-based model are smaller than the corresponding values for the other five competing forecast combination models. Therefore, we can conclude that the SFA-based forecast combination model outperforms the five competing forecast combination models most of the time. Furthermore, we find that the performance of the TM and WM methods is always better than that of the EW method, which coincides with the results of Jose and Winkler (2008), as the trimmed and Winsorized means significantly reduce the extreme values.
Mean and ANOVA values for different tourism forecast combination models for time series with different frequencies in terms of relative accuracy measure (baseline model is the best individual forecast model).

To verify the existence of differences among the mean values of the relative accuracy measures for each forecast combination model, we perform a one-way analysis of variance (ANOVA) for each relative accuracy measure for the time series with different frequencies. From the ‘ANOVA’ column in Table 5, we can confirm that the null hypothesis of ANOVA is rejected at the 5% significance level, which indicates significant differences in the mean values among relative accuracy measures for the six forecast combination models for all of the time series with different frequencies.
We subsequently calculate the mean rank for the three relative accuracy measures. Table 6 shows the comparison results of the six forecast combination models for time series with different frequencies. We see from the table that the mean rank of the SFA-based model is the smallest for all of the time series with yearly, quarterly and monthly frequencies. We can conclude that the performance of the SFA-based model is better than the other competing models for the majority of the time series in the tourism forecast competition data set. However, the worst performances are given by the VACO model for the yearly and quarterly series, and by the EW model for the monthly series. We conduct Friedman’s test to verify whether the performance of the SFA-based model is significantly different from those of the five competing combination models. In Friedman’s test, the null hypothesis is that all of the forecast combination models are equivalent in forecast performance (denoting similar mean ranks). The Friedman’s test statistic is approximately distributed as χ 2 with k − 1 degrees of freedom (in our case k = 6). From the p value of Friedman’s test, we see that at a 5% significance level the performances of the six tourism forecast combination models are significantly different. Because the mean rank of the SFA-based model is smallest for the majority of the time, we can conclude that the SFA-based model outperforms the five competing forecast combination models in terms of the mean rank of the three relative accuracy measures.
Mean rank and Friedman’s test (FD test) values for different tourism forecast combination models for time series with different frequencies in terms of relative accuracy measure (baseline model is the best individual forecast model).

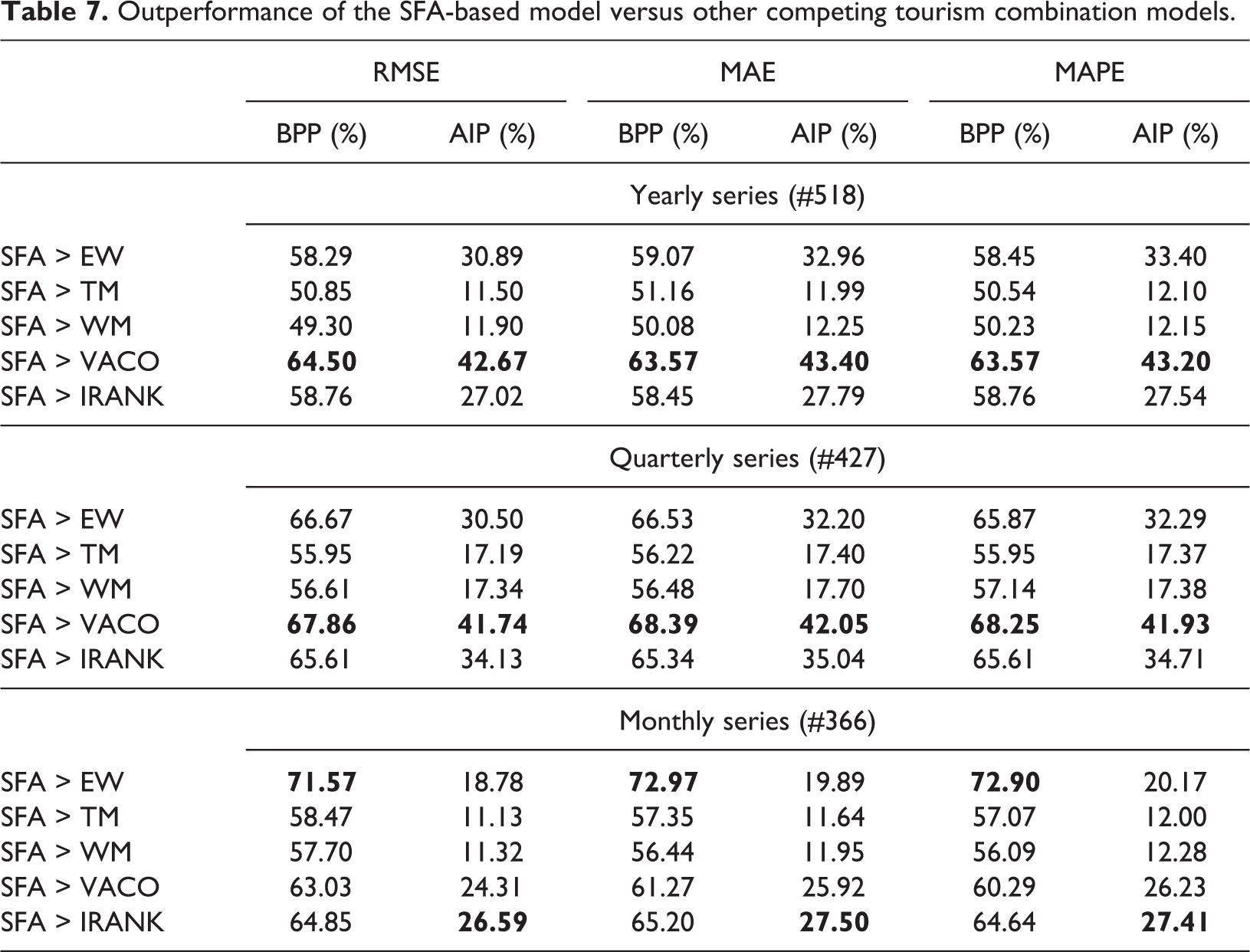
According to the result of the mean and the mean rank of the relative accuracy measures, following the ANOVA and Friedman’s tests, we confirm that the SFA-based tourism forecast combination model statistically significantly outperforms the competing models. We further investigate the extent of the outperformance. Table 7 shows the BPP and AIP of the three accuracy measures (RMSE, MAE and MAPE) for the SFA-based model with other competing models. BBI is the percentage of occasions that the SFA-based model performs better than certain competing forecast combination models, and AIP is the percentage of average improvement for all of the series for which the SFA-based model performs better than the competing forecast combination models. For example, considering the row ‘SFA > EW’ for the yearly series, the RMSE-related BBP is 58.29%, indicating that the number of occasions that the SFA-based model performs better than the EW model for the yearly series is 518 × 58.29% = 302 in terms of RMSE; the RMSE-related AIP is 30.89%, indicating an average improvement of 30.89% in the 302 yearly series. From Table 7, we see that the outperformance of the SFA-based forecast combination model is quite different for the time series with different frequencies and different accuracy measures. Taking the yearly series again as an example, the largest value of BPP is in the row ‘SFA > VACO’, whereas for the monthly series, it is in the row ‘SFA > EW’. Table 7 reveals that the majority of the BPP values are greater than 50% (the greatest value is 76.44%), which again illustrates that the SFA-based model is superior to the competing models. The performance enhancements of the SFA-based model, compared to EW and VACO, are much higher than those compared to the TM and WM models, findings that are supported by much of the related literature.
Outperformance of the SFA-based model versus other competing tourism combination models.
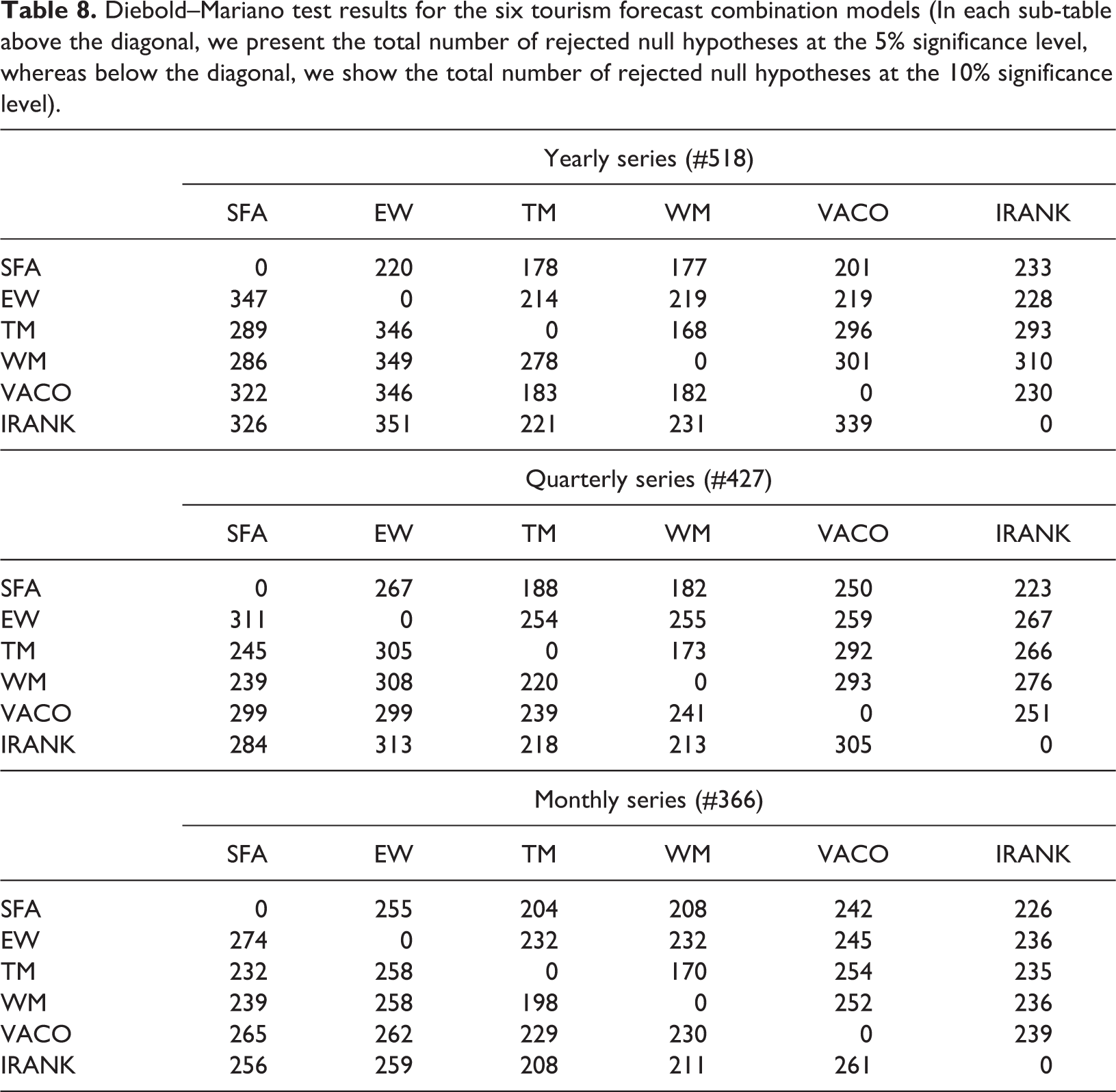
We also carry out the Diebold–Mariano test to compare the forecast accuracy between the SFA-based model and the five competing tourism forecast combination models. The null hypothesis of the Diebold–Mariano test is that there is an equal expected forecast performance for pairwise forecast combination models. The Diebold–Mariano test is executed to evert the time series, and the number of rejected null hypotheses for all of the time series with different frequencies are counted. Table 8 presents the results of the Diebold–Mariano test for the six forecast combination models. In each sub-table above the diagonal line of zeroes we present the total number of rejected null hypotheses at the 5% significance level. Below the diagonal, we show the total number of rejected null hypotheses at the 10% significance level. When the significance level is 5%, comparing the SFA-based model to the competing models, we conclude that the forecast performance of the SFA-based model is quite different for the majority of the monthly series values; for example, when compared with the EW model, 255 of 366 monthly series are statistically significant. However, the forecast performance of the SFA-based model is only different for a minority of the yearly and quarterly series. When the significance level is at 10%, the forecast performance of the SFA-based model is quite different from the other competing models for the majority of the time series with different frequencies; for example, when compared with the performance of the EW model, the SFA-based model performance is statistically significant for about 75% of the monthly series. From this table, we can conclude that the forecast performances of the five competing models are quite different.
Diebold–Mariano test results for the six tourism forecast combination models (In each sub-table above the diagonal, we present the total number of rejected null hypotheses at the 5% significance level, whereas below the diagonal, we show the total number of rejected null hypotheses at the 10% significance level).
Lastly, we focus on the computational complexity of the SFA-based model and the five competing forecast combination models. Indeed, there is a trade-off between accuracy and computational complexity in the domain of forecasting. Although computers are faster and have better computer memory, computational complexity remains an important issue. There are two resources for the analysis of computational complexity: time complexity and space complexity. In this article, we use computational time (CT), defined as the total time needed to run a tourism forecast combination model, to measure the time complexity. To measure space complexity, we use memory usage (MU), defined as the size of the memory needed to run a model. Table 9 shows the results of the computational complexity for the six tourism forecast combination models. From this table, we see that the CT and MU for the six tourism forecast combination models are all in the same order of magnitude. One reasonable explanation is that the SFA-based model and the five competing forecast combination models are all linear combination models, not non-linear combination models. Furthermore, the CT and MU for the SFA-based model is higher than the SA-based models (EW, TM and WM) but lower than the OW-based models (VACO and IRANK). The SA-based model assigns constant weights for the individual tourism models, but the OW-based model must solve an optimization problem based on a function of forecast error-derived accuracy measures. The SFA-based model only needs to solve the Cobb–Douglas production function with determined inputs and outputs.
Results of analysis of computational complexity for the six tourism forecasting combination models.
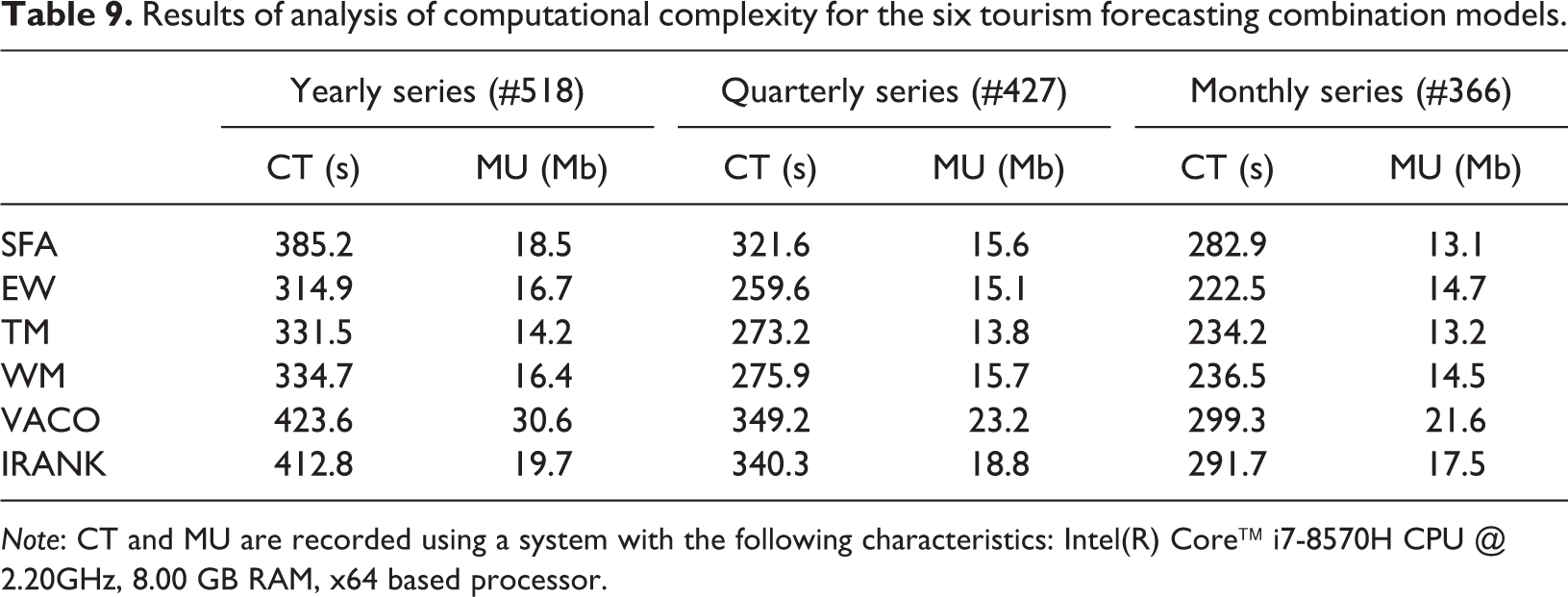
Note: CT and MU are recorded using a system with the following characteristics: Intel(R) Core™ i7-8570H CPU @ 2.20GHz, 8.00 GB RAM, x64 based processor.
Based on the experimental results of the multiple criteria performance indicators, we find that the SFA-based model statistically significantly outperforms the five competing forecast combination models for the majority of the time series in the tourism forecast competition data set. Furthermore, the results of the hypotheses’ three tests – the ANOVA, Friedman’s test and the Diebold–Mariano test – also statistically confirm and strengthen the finding.The computational complexity of the SFA-based model and the five competing forecast combination models are in the same order of magnitude, and it is indeed higher than that of the SA-based models (EW, TM and WM) but lower than that of OW-based models (VACO and IRANK). There are several reasons for this finding. First, because the SFA-based forecast combination model takes into account multiple accuracy measures, the performance evaluation for this model is more reliable and precise as multiple accuracy measures provide multifaceted information on the individual forecast model, and thus the combination weights generated by these performance evaluation results are much more rational and comprehensive. Second, multiple accuracy measures can complement each other as different accuracy measures have their different advantages and disadvantages, leading to more robust weights for the individual forecast model. Third, unlike traditional combination methods that usually combine two individual forecast models, in this experiment we use 13 individual models to form the forecast combination. Different individual models might capture particular patterns of the target time series, so a combination of these forecast models comes closer to representing the true patterns of the target time series. Fourth, the SFA-based model is a linear forecast combination model, so it has the same order of magnitude for computational complexity. In conclusion, the forecast performance of the SFA-based model is substantially better than that of the other competing models.
Conclusion and discussion
In this article, we propose a novel performance-based forecast combination model for tourism forecasting that takes multiple accuracy measures into account. In particular, we consider forecasting performance evaluation under multiple accuracy measures as an MCDM problem and use the classical SFA technique to solve the problem. To demonstrate the effectiveness of the proposed tourism forecast combination model, we conduct a comprehensive study to investigate its forecasting performance by using the tourism forecast competition data set. We empirically show that the performance-based forecast combination model statistically significantly outperforms the five competing forecast combination models in most cases. The proposed model provides us with a good solution to identify suitable weights for individual models as it takes into account multiple accuracy measures, and the SFA technique guarantees the rationality and preciseness of the performance evaluation results for the individual tourism forecast models. At the same time, the performance-based model does not increase the computational complexity required as it is a linear combination paradigm. This research enhances the tourism forecast combination literature as the traditional linear combination model only considers SA weight and the so-called OW, which usually depends solely on one forecast error derived from an accuracy measure (Chan and Pauwels, 2018). The research also presents a comprehensive comparison of the forecast combination techniques, as we build 13 individual tourism forecast models and five forecast combination models from 1311 tourism time-series data.
Although we have conducted a comprehensive study to demonstrate the effectiveness of the performance-based forecast combination model, some shortcomings in our research should be considered in future studies. First, the selection of the accuracy measures and individual forecast models used in the MCDM framework is a big challenge. There is no standard well-accepted criterion for the selection of accuracy measures in the traditional literature, primarily because a bewildering number of accuracy measures have been proposed to evaluate forecast models. Most of these accuracy measures are not generally applicable and can produce misleading results as different accuracy measures evaluate different aspects of forecast errors. Thus, the choice of the most suitable accuracy measure remains controversial (Davydenko and Fildes, 2013). The major work of our research is to empirically investigate whether the proposed performance-based combination model is feasible, so we have chosen just four accuracy measures to illustrate our proposed model’s effectiveness. However, the selection of appropriate accuracy measures in the MCDM framework is an interesting topic and a possible path for future work. Similarly, we use 13 individual tourism forecast models to form the forecast combination, and indeed the 13 models guarantee the diversification of individual models to some extent as they come from four categories: exponential smoothing, ARIMA, complex methods and simple methods. However, the models all belong to traditional statistical methods, and artificial intelligence techniques, such as ANN and SVM, have not been included in our study. Experiments should be conducted to tackle such artificial intelligence techniques in future research. These problems could be the start of further studies within the realm of tourism forecasting.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research study is supported by the National Natural Science Foundation of China (no. 71701172 and 71601190).