
Abstract
This article investigates the intersection of generative Artificial Intelligence (AI) and the book industry, focusing on the use of copyrighted literary works for training large language models (LLMs). As LLMs require enormous volumes of content for training, published books and other media have become valuable sources of data. Many training datasets appear to have been assembled without authorization or transparency, raising acute legal, ethical and cultural questions. In this article, we provide a detailed empirical analysis of the Scandinavian content within the Books3 dataset, used to train multiple major AI systems, characterizing it by publication year, publisher, authorship, genre, and language. As comparatively small language markets situated outside of the main hubs for AI development, the Scandinavian countries provide a relevant context for exploring the local implications of global AI deployment. The findings are discussed through a theoretical lens drawing on Michel Serres’s concept of the “parasite.” We argue that the inclusion of Scandinavian books in Books3 is part of a multidimensional ecology of parasitic exchange. This framework interprets the relationship between AI developers, shadow libraries, and publishers as a cascade of information appropriation, signifying a reconfiguration of cultural production and ownership in the age of generative AI.
Introduction
The emergence of generative artificial intelligence (AI) models has prompted wide-ranging debates about the legal, ethical, technological, and cultural implications of AI systems trained on existing cultural content (Anantrasirichai and Bull, 2022; Bender, 2024; Epstein et al., 2023; Erickson, 2024; Feher, 2025; Filimowicz, 2023). Central to these debates is the question of how AI models acquire the vast quantities of data necessary to generate human-like text, images, sound and video, and to what extent such data are used with or without the consent of copyright holders (Chesterman, 2025; Haidemariam and Gran, 2025; Henderson et al., 2023; Karamolegkou et al., 2023; Lee et al., 2024; Samuelson, 2023). As language models require enormous volumes of high-quality, diverse content for training, published books, journal articles, and other media have become valuable sources of data (Jia and Nagaraj, 2025; Rowberry, 2025). While some AI companies have established licensing agreements with publishers and media organizations (Guaglione, 2024; Wiggers, 2023), other datasets appear to have been assembled through large-scale scraping or repurposing of copyrighted materials without authorization, raising acute legal, ethical, and cultural questions.
The issue of media content as training data exemplifies the encounter between the media and cultural industries and the AI industry and its high stakes. In the context of the book industry, authors and publishers have filed multiple lawsuits against major technology companies such as OpenAI, Meta, Alphabet, and Anthropic, alleging copyright infringement and uncompensated exploitation of their work. 1 The European Writers’ Council has gone so far as to describe the success of generative AI in the book industry as being “based on theft” (European Writers Council, 2023). The 2025 settlement of 1.5 billion USD between Anthropic and authors signals both a significant copyright recovery and an acknowledgement of the value of books as training data (Press, 2025).
Public awareness of book content being used for AI training grew substantially in 2023, following the revelation by US news magazine The Atlantic that a large corpus of digital books, known as Books3, had been used to train AI models (Reisner, 2023). The corpus contained nearly 200 000 books, many of them copyrighted, obtained from the “shadow library” Bibliotik. The Books3 case illustrated the opacity surrounding AI training data and raised concerns about the unacknowledged use of literary works in machine learning.
In Scandinavia, the empirical context for this study, the Books3 revelations resonated strongly within national debates on copyright, creative labor, cultural heritage and cultural policy. In Denmark, the author rights organization Rettighedsalliancen (“The Rights Alliance”) was instrumental in bringing attention to the case, even globally (Knibbs, 2023). Danish news outlet Zetland described the inclusion of Danish books in AI training as “the biggest copyright theft in history” (Kulager, 2023). Similar reactions emerged in Norway, where national daily newspapers VG and Aftenposten published editorials condemning the use of Norwegian books in AI datasets as a threat to both cultural production and linguistic sovereignty (Norli, 2023; Tjønn et al., 2023). Sweden also saw coverage of the issue, though with less intensity (Jerräng, 2023). Across the region, these discussions revealed a deep unease about how the literary infrastructure of small-language markets might be appropriated by global AI systems.
The Books3 controversy also exposed a broader cultural and historical continuity between older digitization initiatives and contemporary AI training, most concretely because there is a direct link between book “piracy” and AI training, through the intermediating infrastructure of the shadow libraries. Moreover, the same contestations of access, ownership, and cultural value that characterized the era of “mass digitization” (Thylstrup, 2019), would now reappear. The Books3 case thus provides an analytical entry point for understanding how digital infrastructures, whether they are built for access, commerce or preservation, have become resources for computational extraction.
Our study contributes to the growing body of scholarship that goes beyond strictly technical issues and legal issues like copyright to understand the encounter between the media and cultural industries and AI industry (e.g., Haidemariam and Gran, 2025; Natale et al., 2025; Rowberry, 2025; Thylstrup, 2022). We provide a detailed empirical analysis of the Scandinavian dimension of the Books3 dataset, adding to the emerging literature on how AI developments, ethics and policy play out in various socio-political contexts, national as well as global (Arora and Natale, 2025; Chateau et al., 2025; Mager et al., 2025; Natale et al., 2025; Terui and Chen, 2025). This article asks what the inclusion of Scandinavian books in Books3 reveals about the form of extraction at work.
Our use of the concept “digital parasitism” goes beyond a moral label; rather, it serves as an analytic lens for three observable features of the Scandinavian subsets: first, the extraction of value from commercially published books; second, the opportunistic and uneven composition of the corpus; and third, the appropriation of small-language publishing infrastructures for AI systems developed largely outside Scandinavia. The findings are therefore read not merely as descriptive metadata, but as evidence of how localized literary and publishing infrastructures become resources in global AI training.
We interpret the relationship between AI developers, shadow libraries, and publishers as a complex ecology of parasitic exchange. The aim is to situate the Scandinavian book market within a global techno-capitalist context, to clarify the material and symbolic stakes of using book content in AI training, and to open broader discussions on cultural ownership in the age of generative AI. The Scandinavian countries are comparatively small language markets with strong copyright cultures, situated outside of the main hubs for AI development; as such, they provide a relevant context for exploring the local implications of global deployment of generative AI systems.
The empirical part of this article addresses the question of what the characteristics of the Scandinavian contents in the Books3 corpus are in terms of publication year, authorship, publishers, genres, and languages. This material, presented in our Findings section, is subsequently discussed within a theoretical framework which draws on the concept of digital parasitism, outlined in the next section.
Theoretical framework: Digital parasitism
Parasitism in Michel Serres’ understanding is not a simple process of exploitation but one of relation and transformation (Serres, 2007). Rather than seeing parasitic activity as one-dimensional, that is, one organism feeding off another without giving anything in return, the provocative argument is that parasites can also be a generative force. Serres’ notion, outlined across a wide range of parables and examples in the 1980 publication Le Parasite (English translation in 1982), derives from the three meanings of the word parasite in French, in which it can be a microbe which feeds on its host, a guest who exchanges talk, praise and flattery for food (similar to the freeloader or sycophant), and noise, interference in the channels of communication. The three parasitic activities are related and have the same function in a (social or technical) system, that of the “excluded third” or an “uninvited guest.” It is easy to see how the AI model can be conceived as an uninvited guest, the annoying freeloader, who consumes the creative output of the book industry, transforming it into informational capital without due acknowledgment or compensation. But Serres’ parasitism is also an interaction in which the ecosystem of the parasitic exchange is ever-changing and where the host may become the parasite and vice versa.
Serres’ concept of the parasite has been employed by scholars of technology and media to distinguish between different understandings of legitimate and non-legitimate digitization. Aradau et al. (2019) conceptualize hacking as an act of “digital parasitism,” subtly disrupting digital ecosystems. While their case of humanitarian apps differs from our case of books as training data, we have adopted the term digital parasitism to describe the relationship between the various actors involved in making book content the fodder of AI services. Thylstrup (2019) uses Serres’ concept to explore how shadow libraries act as non-legitimate digital infrastructures. In her application of the concept, parasites have the capacity to create relationships, not just to exploit them (Thylstrup, 2019: 81). Wagenknecht (2018) uses the figure of the parasite to go beyond simple dichotomies of use/non-use of digital technologies, suggesting that parasitism “evades any clear-cut moral judgment because it thrives as a, potentially infinite, networked chain” (2018: 2239).
To illustrate how parasitic cascades work, Serres uses the parable of the city rat and the country rat, feasting on leftovers from a farmer, only to be interrupted by the house owner. The parable suggests that they are all parasites, one way or the other: “the custom house officer makes life hard for the working man, the rat taxes the farmer, the guest exploits his host” (Serres, 2007: 4). In this logic, it may seem that the last parasite in the chain wins the game. But there is no guarantee that peace will be undisturbed, as every parasite “seeks to eject the parasite on the level immediately superior to his own” (Serres, 2007: 4).
In our context, parasitism provides us with a vocabulary with which to discuss the relationships between authors, publishers, digitization operatives, AI developers, media conglomerates etc. We treat digital parasitism as empirically visible when the dataset shows: (1) asymmetrical value extraction from commercially produced books; (2) opportunistic accumulation rather than curated collection-building; and (3) the transformation of localized linguistic and publishing resources into general purpose training data. The Scandinavian subset cannot reveal every step by which titles entered Books3, but it can show what kinds of books, languages, and publishing structures became available for such extraction.
Background: Digitization, shadow libraries and AI training datasets
To understand the entanglements between AI development and the book industry, it is necessary to provide a short background description of digitization in the book industry and how it relates to shadow libraries and AI training datasets.
The use of books to train AI models is first dependent on the availability of digitized books, a development that can be traced back to the establishment of the Project Gutenberg library in 1971 as a repository of digitized works (Rowberry, 2023). The Project Gutenberg library contains titles out of copyright and has been widely used for AI training (Rowberry, 2025). The emergence of a sustainable commercial market for digital books arrived later. A major breakthrough came with Amazon’s introduction of the Kindle tablet reader in 2007 and the provision of ebooks through Amazon.com and other digital channels (Thompson, 2010, 2021), including in the Scandinavian book markets (Bergström et al., 2017; Colbjørnsen, 2012, 2014; Hjarvard and Helles, 2013).
Digital book files also originated from mass digitization projects that aimed at converting print books to digital files and making them available, such as the Google Books project initiated in 2004 (Darnton, 2009; Marcum and Schonfeld, 2021) and digitization projects by established actors such as the Norwegian National Library (Gran et al., 2019), the Open Content Alliance (Coyle, 2006), the Internet Archive (Mercanti, 2024), and the cultural heritage organization Europeana (Thylstrup, 2019).
Besides commercial digital book developments and the mass digitization efforts undertaken by both private and public actors, there are organizations and loosely formed networks that converge around the provision of open access (OA) content. The OA movement emerged in the early 2000s, with the Budapest Open Access Initiative in 2001 marking a key moment (Suber, 2012). One strand of the OA movement diverged into the development of so-called “shadow libraries” (also known as pirate libraries or black open access), “online collections of copyrighted publications that have been made available for free without the permission of the copyright holders” (Maddi and Sapinho, 2023: 5648). The first instances of the shadow libraries were set-up to circumvent state censorship in Russia and Eastern Europe but subsequently developed alongside other OA initiatives to become an alternative to commercial academic publishing (Bodó, 2018b; Maddi and Sapinho, 2023; Ostromooukhova, 2021). Shadow libraries like Sci-Hub, Bibliotik, Library Genesis, and Anna’s Archive operate outside of the sphere of legitimate media distribution, amassing digital files at scale to be freely downloaded by anyone with an Internet-connected computer (Karaganis, 2018). Academic content, including textbooks and journal articles, have been highlighted as important parts of the shadow libraries’ catalogues, but so-called “trade books,” including fictional content like novels and non-fiction content like biographies are also crucial (Bodó, 2018a; Thylstrup, 2019).
These intertwined digitization processes resulted in a large number of digital book files circulating in and between various infrastructures that emerged in the early and mid-2000s. Some of these infrastructures were official and legitimated by business models and market forces; others existed as parts of what scholars have referred to as “informal media economies,” understood as sectors of cultural production that fall largely outside of state policy, regulation, taxation, and measurement (Lobato and Thomas, 2012, 2015). While copyright protection and Digital Rights Management were issues high on the agenda for book publishers at this time, the expansion of the Internet and the prevalence of file sharing initiatives meant that complete control was unattainable (Thompson, 2010: 355–356). One result is that ebook files of various origins would come to form the basis of training data sets for AI development, whether by design or by unforeseen circumstance. For instance, Rasenberger argues that the development of Google Books was indeed motivated by the prospect of AI training, quoting an unnamed Google employee: “[W]e are not scanning those books to be read by people. We are scanning them to be read by Al” (Rasenberger, 2021: 323). Outside of corporations such as Google, Meta and X, each with its own supply of training data, shadow libraries would represent an enticing option to easily obtain non-licensed training data for free (Rowberry, 2025).
The rapid progress of large language models (LLMs) has been fueled by vast amounts of training data, which determine not only the linguistic fluency of these systems but also their cultural knowledge, reasoning capacity, and capacity for memorization (Bommasani et al., 2023; Brown et al., 2020). The pre-training phase of LLMs is resource-intensive and critically dependent on the scale and diversity of data sources (Liu et al., 2024; Pandey et al., 2024). Yet, despite the centrality of datasets, there is limited transparency regarding the precise corpora used (Bommasani et al., 2023; Rowberry, 2025). This lack of clarity has made datasets like Books3 emblematic of the controversies surrounding AI training data (Haidemariam and Gran, 2025; Jia and Nagaraj, 2025).
Books3 consists of approximately 197 000 full-length books. The corpus was compiled in October 2022 by Shawn Presser, an independent AI researcher. Presser used content from Bibliotik, a BitTorrent tracker for ebooks established in 2009 and similar to Pirate Bay for music and Cinematik for movies (Jia and Nagaraj, 2025; Knibbs, 2023; Reisner, 2023). Unlike many other book content corpora, Books3 is not limited to self-published works and public domain content but includes thousands of comparatively recent titles from major publishers (Jia and Nagaraj, 2025). Embedded within EleutherAI’s open-source corpus The Pile, Books3 alone contributed over 100 GB of text, representing one of the largest single sources of long-form literary data (Gao et al., 2020). While the AI companies are evasive about sources for training data, reports suggest that the Books3 corpus has been used by Meta, Bloomberg, and EleutherAI (Reisner, 2023), as well as by Microsoft and Nvidia (Schoppert, 2023a). The corpus has not been subject to any full-scale analysis previously, but Schoppert’s (2023b) analysis of a sample of English-language titles provides some details.
Studies of the effect on LLM performance by including book content suggest that the effect on ability to generate more diverse texts is clear, while it may in fact have detrimental effects on other performance indicators (Rosa et al., 2025). Jia and Nagaraj (2025) found that the improvement effects from Books3 was strongest for less popular works, where fewer substitutes existed in the training corpus, highlighting the value of unique content in enhancing model learning. Books hold value as training data as edited and curated long-form content, and the relatively current nature of the titles in Books3 further adds value (Liu et al., 2024; Rowberry, 2025). However, research indicates that the configuration of Bibliotik and, consequently, Books3, is the outcome of opportunistic practices to gain a mass of training data, resulting in largely non-curated and fragmentary assemblages of books with missing titles that would be expected in a curated collection, such as sequels in a series of books, and also multiple duplicates (Haidemariam and Gran, 2025; Rowberry, 2025). The bibliographic information in Bibliotik/Books3 is also superficial and halfheartedly compiled, prioritizing scale and ease of access over quality and provenance (Rowberry, 2025).
Methods and materials
The empirical basis for the study is the Books3 corpus which encompasses the entire collection of Bibliotik, consisting of approximately 197 000 books, in plain.txt format. More specifically, we have created country-specific subsets for Sweden, Denmark, and Norway to determine the inclusion of Scandinavian books within the corpus. The compiling of these lists was achieved by performing an ISBN-based search. ISBN, the international standard for assigning unique identifiers to published books, enables the identification of localized content through the country specific prefix (specifically, the third and fourth digits of ISBN-13). Peter Schoppert, who first identified the method, employed a RegEx-based search method to compile a comprehensive list of ISBNs corresponding to 125 000 authors (psmedia, 2025; Schoppert, 2023a, 2023b).
ISBN can have 10 or 13 digits, as 13-digit ISBN identifiers were standardized from 2007. The RegEx pattern used by Schoppert only matches ISBN-13 formats and not ISBN-10, including various delimiters and optional “ISBN” prefixes. This largely explains the discrepancy between the total number of titles in the Books3 corpus (197 000) and the number of extracted ISBN-13s (125 000). Additionally, there are some books in the relevant file that do not include ISBN at all. Some of these books may be self-published titles that were included in the Bibliotik torrent. In other cases, the ISBN may have been stripped by another process. For example, the book “Intangible.epub” by C. A. Gray, according to Schoppert, is an edition from the self-publishing platform Smashwords, and it is unclear if it is duplicated in the BooksCorpus dataset. Assigning an ISBN to a book publication is not mandatory.
Overview of materials and subsets.

From the list of ISBNs, other information about the books could, in principle, be obtained from Swedish, Danish and Norwegian sources. In the case of the small Norwegian list, we conducted a manual search through isbnsearch.org and various online databases and bookstores. For the larger Swedish and Danish subsets, the method planned was to construct a script that would, for each ISBN, retrieve a metadata record (MARC 21 format) from a library database (cross-national or local) with an API.
For the Swedish case, LIBRIS (belonging to the Swedish national library) allowed us to send queries for each of the books by ISBN. The records returned were in xml-format, making them relatively easy to parse. Denmark had abolished all use of APIs for accessing metadata in both national and local library services in anticipation of a new retrieval API based on Graphql, currently under construction. We contacted DBC, the central library service of Denmark, who offered to provide records based on our list of ISBNs. The Danish records were provided in a line format, which required some treatment to extract the relevant characteristics. To supplement where metadata was missing or partial, manual searches in isbnsearch.org were conducted, as well as open web searches.
Data analysis and visualization
We conducted a quantitative descriptive analysis of the Scandinavian segment of the Books3 corpus to characterize the scope and structure of unauthorized inclusion of Swedish, Danish, and Norwegian books in Books3. Using the metadata already identified in our corpus work, we first constructed country-specific subsets (Norway, Denmark, and Sweden) and calculated basic distributional statistics as well as descriptive analysis, including total number of titles per country, publication year ranges, publishers represented and their corporate organization, genre composition (limited to broad categories of Fiction, Non-fiction and Children and youth), authors represented, and languages in the material. To communicate these patterns in our material, we provide descriptive statistics and a set of visualizations. All analyses were done in Microsoft Excel. Because there are limitations to the amount of data that can be included in the article, we have chosen to present selected data where that is relevant. The complete dataset is available on GitHub: https://github.com/Haidemat/Scandinavian-Books-Dataset-Books3-Subsets-
Findings
The Scandinavian subsets are quite dissimilar in size, with the large Swedish subset outsizing the Danish, and particularly, the Norwegian dataset. These discrepancies do not mirror the actual size of the respective book markets and indicate that the subsets are far from representative of the national book market.
Publication year
The timeline for publication year across the three subsets (Figure 1) indicates a dispersion from the earliest publication year in 2000 (A Swedish translation of the French author Michel Houellebecq’s Les Particules élémentaires (Swe: Elementærpartiklarna)) to the most current publication in 2023 (The Danish title Hafnia Punk by author Benn Q. Holm). The median year of publication across all three countries is 2014. As shown in Figure 1, 2014 is also the most frequent year, accounting for 27% of all published titles across the subsets. Publication year distribution for all three subsets.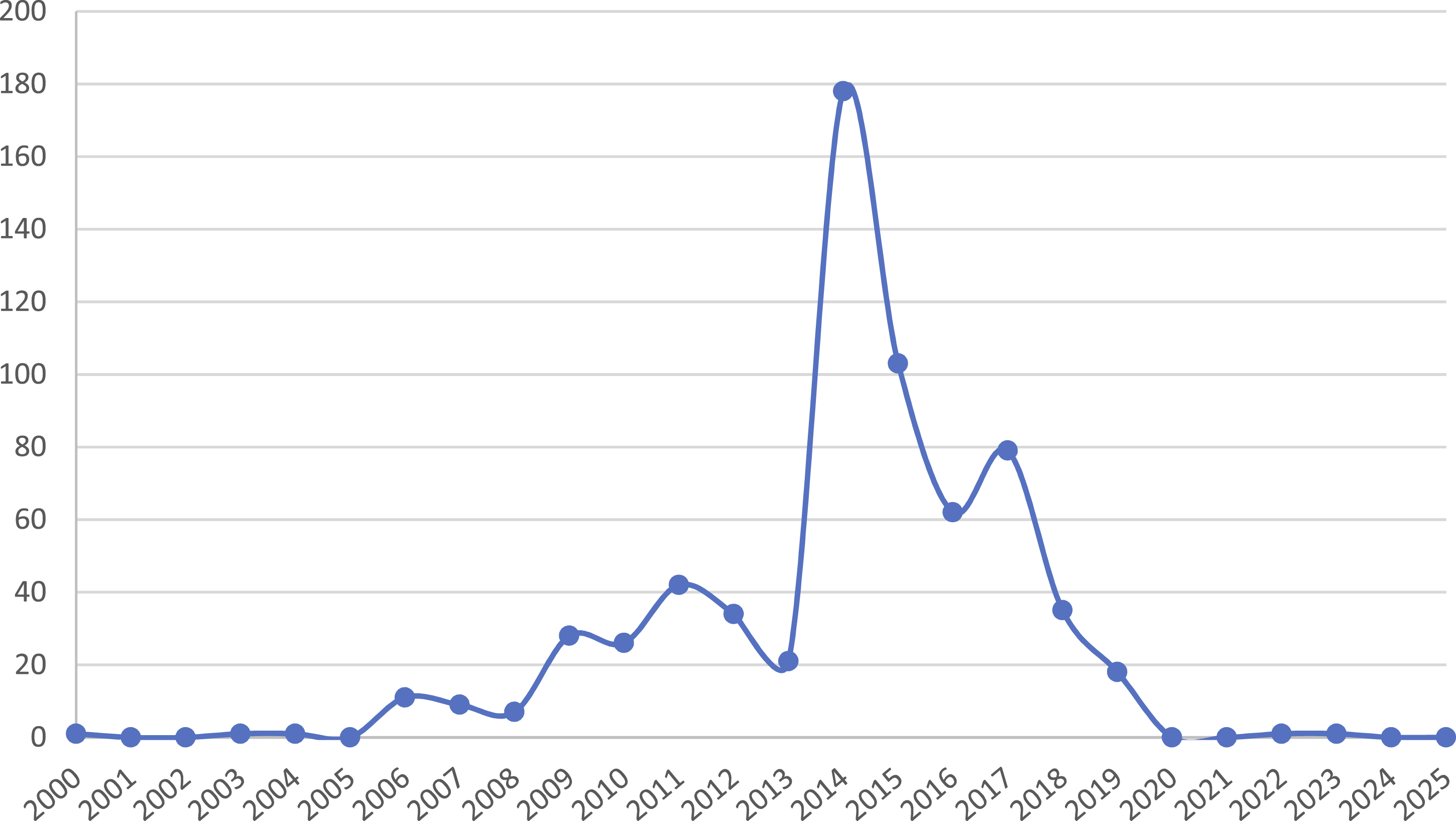
It is worth noting that while the window between 2000 (first publication) and 2023 (most current publication) is fairly wide in the context of the history of the digitization of books, the 2011 to 2017 frame, which accounts for 79% of the publications, is quite narrow. Publication year does not by itself tell us when files entered Bibliotik or Books3, but the strong concentration between 2011 and 2017 suggests that Scandinavian books from this period became disproportionately available for later extraction. Bibliotik was introduced in 2009, so the peak happens after this, even if some titles predate the BitTorrent tracker’s emergence.
We also analyzed publication year distribution patterns for each country. The timelines indicate certain clusters with Danish titles clustering earlier than Swedish, and with Norwegian titles (although few) clustering latest. Median years of publication for each subset show the same: 2014 for Sweden, 2012 for Denmark, and 2017 for Norway.
The publication date patterns in our material largely resemble the ones that Schoppert found across English-language titles, where 2012-14 represent the most frequent publication years (Schoppert, 2023b). The concentration of publication years between 2011 and 2017 suggests that the Scandinavian subset is shaped less by cultural representativeness than by what became digitally available during a particular phase of ebook circulation.
Publishers
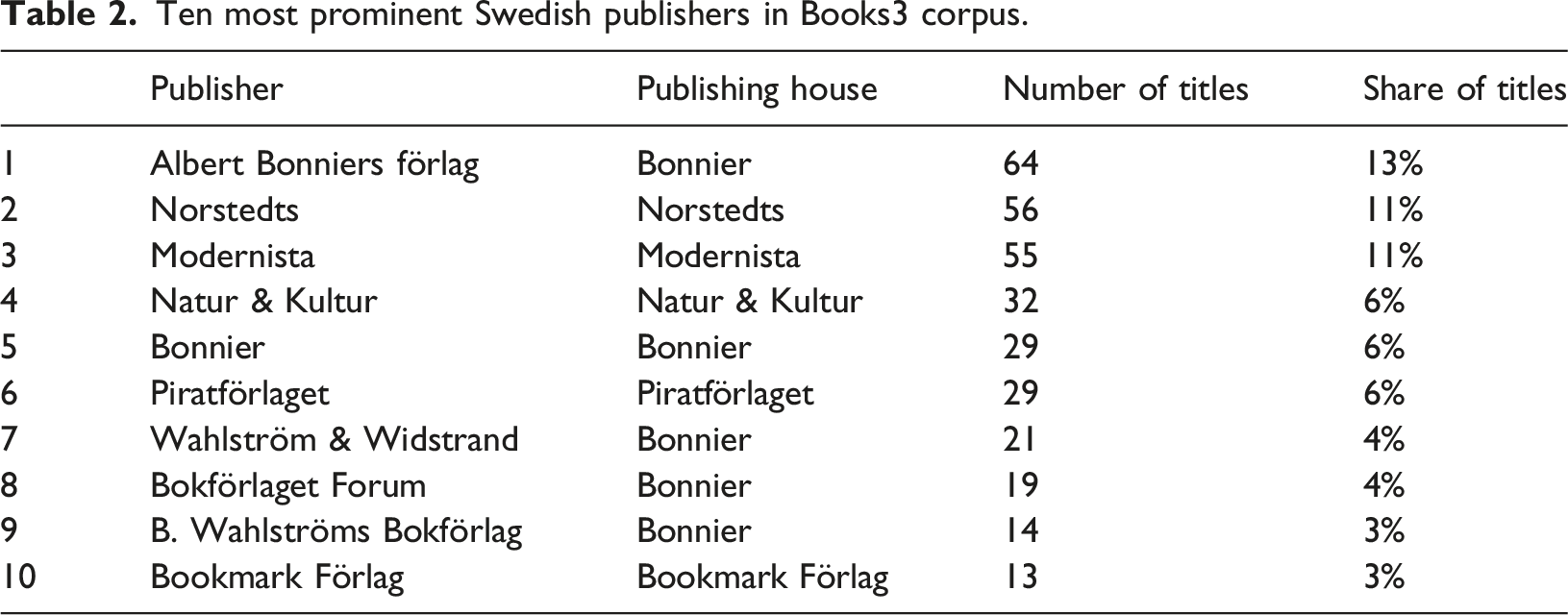
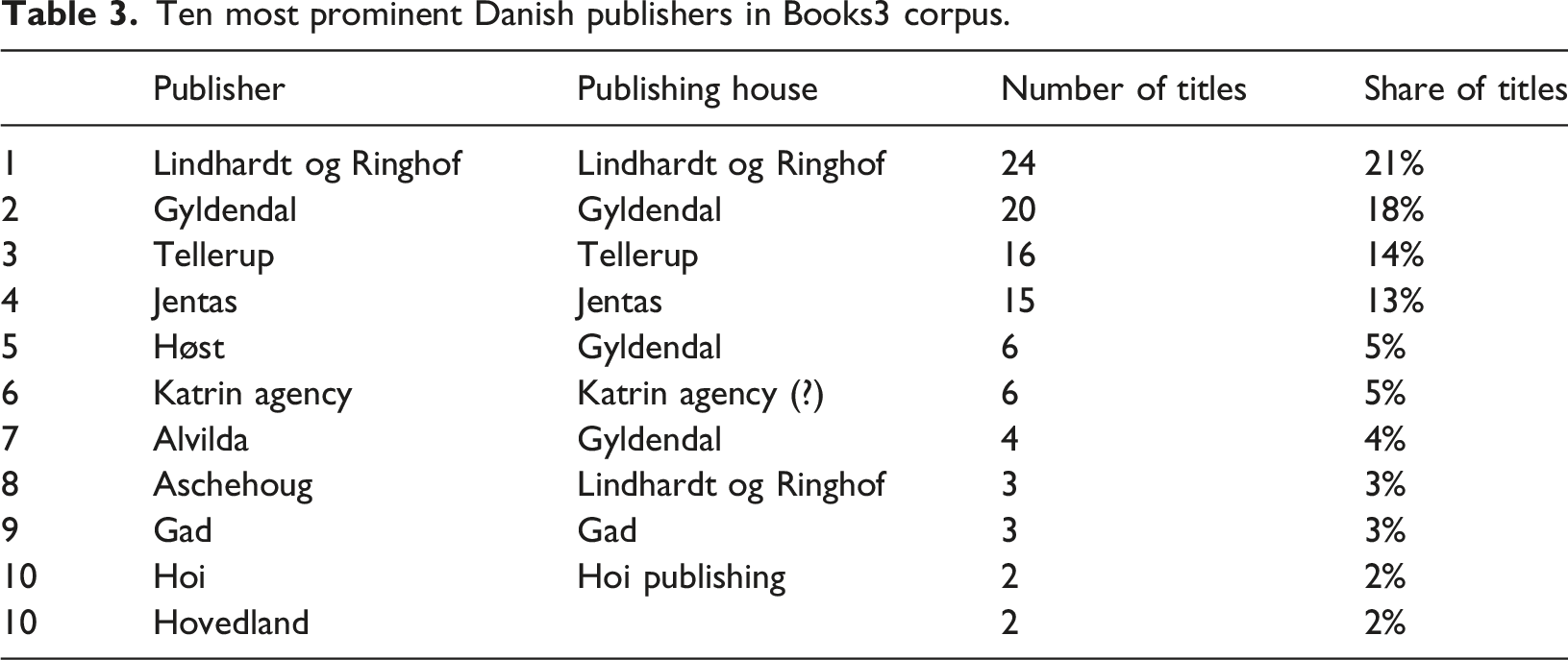
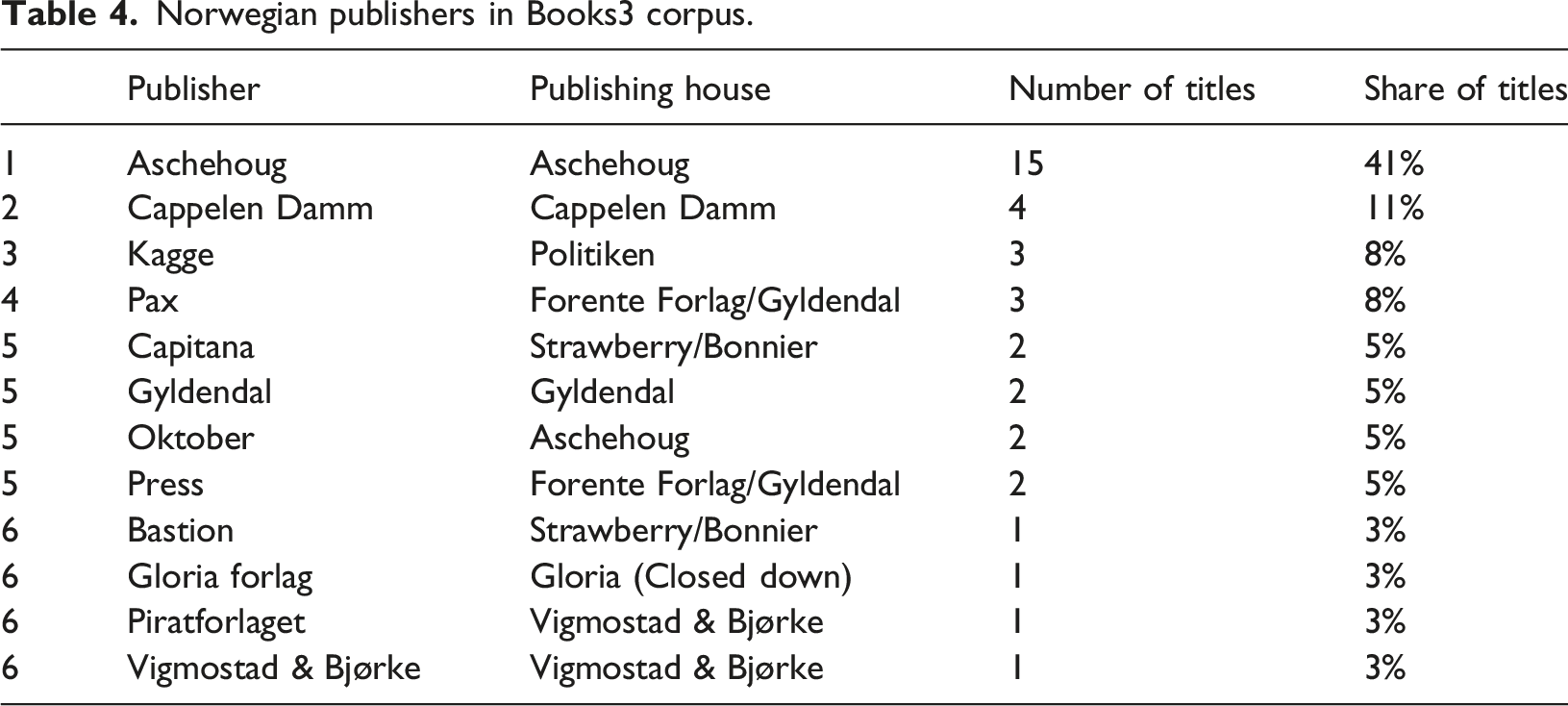
To assess the publishers behind each ISBN for the three country subsets, we relied on metadata records and supplemented with manual searches where the data was missing. We also conducted a mapping of whether the most frequent publishers were part of a larger publishing corporation. Most of the big publishing houses, such as Swedish Bonnier and Norwegian Gyldendal, own multiple smaller publishers (imprints). Still, our material shows a wealth of Scandinavian publishing houses, big and small. The Swedish subset consists of 72 individual publishers/imprints, while the Danish list contains 24 and the Norwegian list contains 12. 36 of the Swedish publishers have only one title in the corpus (Denmark: 13; Norway: 4). A striking find is that only a fraction of the Scandinavian ISBNs belongs to pure academic publishers and textbook publishers; Scandinavian University Press is the obvious exception. The publishers are overwhelmingly either big corporations with publications across multiple categories and genres (e.g., Bonnier, Lindhardt og Ringhof and Gyldendal), or smaller fiction and/or mass-market non-fiction publishers (e.g., Jentas and Natur & Kultur).
Ten most prominent Swedish publishers in Books3 corpus.
Ten most prominent Danish publishers in Books3 corpus.
Norwegian publishers in Books3 corpus.
The publishing house Bonnier, Sweden’s largest, holds the most titles in the list with Albert Bonniers förlag at 13% share. However, this percentage actually diminishes its overall contribution, since its multiple publishers and imprints associated, including five in the top ten, means Bonnier accounts for a 32% share of the total number of Swedish books. The list otherwise reflects the situation in Swedish publishing, with the second largest publisher Norstedts in second place.
Denmark’s two largest publishing houses, Lindhardt og Ringhof and Gyldendal, are also the two most prominent on the list of titles, with a combined share of 50% of items in the Danish subset.
The Norwegian list is dominated by the Aschehoug publishing house, with a combined 46% of titles (Aschehoug and Oktober). The list otherwise gives an indication of the structure of vertical integration and international ownership in Norwegian publishing: All publishers are part of a larger publishing structure. Danish Politiken owns Kagge, and Swedish Bonnier owns Capitana and Bastion.
The prominence of major trade publishers indicates that the extracted material is not peripheral residue but commercially valuable, institutionally produced book content.
Genres and categories
The partial metadata only allowed for broad genre categorizations. We focused on determining whether titles were Fiction (including novels, short stories, historical fiction and genre fiction such as thrillers, crime, and romance), Non-fiction (biographies, documentaries etc.) or Children & Youth (including children’s books and books aimed at young adults). Across the three subsets, Fiction is by far the largest category with 76% of titles. 16% of combined titles are Non-fiction, while 7% are categorized as Children & Youth. However, there is substantial variation between the three countries, as indicated by Figure 2. Genres represented in the three subsets.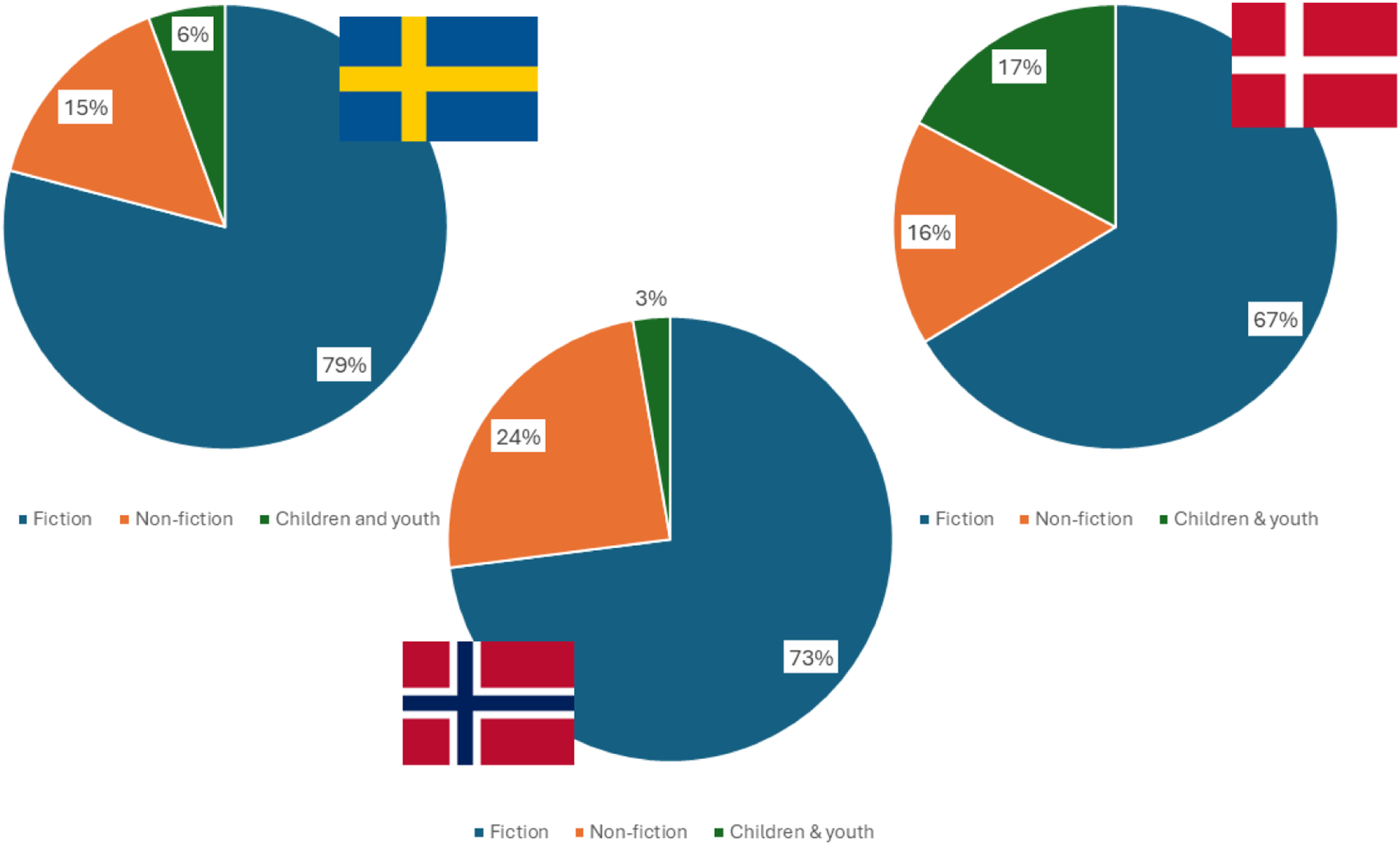
Sweden, the largest subset, is also the most Fiction-leaning (79%). The Danish titles contain more Children & Youth titles than the other two (17%), while Norwegian-published Non-fiction titles are more prevalent than for the combined average (24% v. 16%). Note that sample sizes are small, particularly for Norway.
The genre configuration clearly indicates that this localized part of Books3, is fiction-based rather than a scholarly resource. The vast majority of titles can be defined as belonging to the mass market for books, typically fulfilling needs for entertainment and cultural experiences. The fiction-heavy composition suggests that Books3 draws heavily on edited, market-facing long-form prose rather than primarily scholarly or reference-oriented content.
Authorship
There is a wide variety of author names present in the Books3 material. Only in the Swedish subset are 270 unique author names (Denmark: 36; Norway 27). Bestselling local, contemporary authors feature alongside international stars like Stephen King and Ngũgĩ wa Thiong’o, as well as classics from Aesop, Dostoevsky, and Michel de Montaigne. Some authors are represented by only one title in each country-specific subset, while others have multiple titles represented. The most represented author in terms of titles per subset is Margit Sandemo (1924–2018) with 21 titles from her 47-volume Legend of the Ice People fantasy and historical fiction book series, published 1982–1989. With Sandemo representing the genre fiction end of the literary spectrum, the Russian 19th century author Fyodor Dostoyesky (1821–1881) (most represented in the Swedish subset with 15 titles) may represent the more acclaimed, literary fiction end of the spectrum.
Authorship in Swedish subset, 5 most represented authors.

Authorship in Danish subset, 5 most represented authors.

Authorship in Norwegian subset, 5 most represented authors.

The mix of local authors, translated works, and non-Scandinavian authors published in Scandinavian editions indicates that what is being appropriated is not only local authorship, but the regional infrastructure that selects, translates, edits, and circulates books.
Languages and translations
95% of the titles in the list from Sweden are Swedish language books, the remaining 5% being English language titles. Among the Swedish language books, 34% are listed as translations from other languages, but the metadata is not reliable in the case of translation languages.
In the Danish subset, 80% of titles are Danish originals, with 19% being English language originals (all but one of them from the Legend of the Ice People book series). The one remaining title is a German language original. The list of translation languages is not reliable, with lots of metadata missing.
The Norwegian list reflects the language situation in Norway, with two official forms of written Norwegian, Bokmål and Nynorsk. 87% of titles are in Bokmål, the dominant variant, while 8% are in Nynorsk. In addition, there is one title in Swedish. 63% of titles are Norwegian language originals, while 32% are translated works. While the large majority across all subsets are original language publications, translated authorships nonetheless feature high on the list of represented authors, as indicated by Tables 5–7.
Discussion
The story of how book content became significant training data for AI developers illuminates the historically contingent ways that book industry actors, shadow libraries and AI companies have become related. Digital parasitism offers a lens through which we can understand these complex and dynamic relationships. The Scandinavian subset of Books3 allows us to specify more concretely what digital parasitism looks like in practice. Our findings point to three interrelated dimensions:
First, the prominence of major trade publishers, together with the dominance of fiction and other mass-market titles, shows that what is being appropriated is not marginal textual residue but commercially produced, edited, and culturally valued book content. The authors represented are a mix of mostly bestselling fiction writers, both literary fiction and genre fiction. The single most represented author in our material is Margit Sandemo, author of The Legend of the Ice People, a 47-volume series published 1982-1989 within a segment of fantasy and historical fiction that has often been classified, condescendingly, as trivial literature or light reading. The genre configuration clearly indicates that this localized part of Bibliotik, and by extension, Books3, is not a scholarly resource, plugging the gaps in a malfunctioning academic publication system. The vast majority of titles belong to the mass market for books and are published by broad omnibus publishers and fiction publishers, consistent with Schoppert’s (2023b) findings and indicative of the corporatization of modern-day book publishing (Thompson, 2010). In this sense, parasitism operates as value extraction from the formal publishing economy.
Second, the uneven distribution between Sweden, Denmark, and Norway, the concentration of titles within a relatively narrow publication window, and the fragmentary character of the material suggest that concerns of curation, completion, transparency, and provenance are secondary to AI training corpora. Previous research has indicated that the configuration of Books3 is the outcome of opportunistic practices that resulted in a non-curated, fragmented and superficially compiled assemblage of books (Haidemariam and Gran, 2025; Rowberry, 2025). We find similar indicators in our material, such as more than half the titles missing in the Legend of the Ice People series by Margit Sandemo.
Third, the strong presence of Swedish, Danish, Bokmål, and Nynorsk titles, alongside translations and internationally circulating authors in Scandinavian editions, shows that AI training draws not only on authorship, but also on the localized infrastructures that translate, edit, package, and circulate books in small-language markets. In a peculiar pan-Scandinavian twist, our most represented author, Margit Sandemo is Norwegian-born but wrote mostly in Swedish. The Legend of the Ice People has been translated into multiple languages, and it is an English language translation by two Danish publishers which found its way into Books3. The Scandinavian material thus makes visible a cascade in which literary and publishing labor is progressively detached from its original market and cultural contexts and revalorized as training data for AI systems developed largely outside those contexts.
While AI systems feed on human cultural labor in ways that resemble how the biological parasite depends on a host for sustenance, this is not a one-dimensional or static relationship. The parasitic relationship goes beyond a simple dyadic bond between a parasite and a host (Serres, 2007; Thylstrup, 2019; Wagenknecht, 2018). In the case of books as AI training data, multiple actors are involved, in a sequence of interactions: As the first links in the chain, authors create manuscripts that publishers will turn into commodified goods with a monetary value. By appropriating these works without compensation or consent and making them widely available outside of a market system, the shadow libraries undermine the commercial ecosystem of publishing. They essentially decommodify the book content, pulling books back from a market sphere in which the authors and publishers can see revenue.
Still, as parasites, the shadow libraries also sustain an informal media economy (Lobato and Thomas, 2015), a system of cultural and scholarly circulation that exists parallel to the formal media economy of publishers, booksellers, contracts and royalties. Shadow libraries are typically distributed services, operating in a system that is, according to Thylstrup, simultaneously “resistant to any single point of failure or control” while also being “ephemeral, without a central point of back-up” (2019: 83). This illegitimate ecology supplies books and other media to users that may not have access any other way (Karaganis, 2018). Intentionally or not, shadow libraries also enable digital books to be used for other purposes. As the libraries become sources for AI training, the parasitic chain continues, expanding the informal media economy. For opportunistic AI developers in search of free training data, including all the big AI labs (Reisner, 2023, 2026), vast resources like Books3 are available and alluring. Thus, companies like Meta, Bloomberg, Microsoft, and Nvidia chose to attach themselves to this corpus, creating another cascade founded on theft of information (Serres, 2007: 37).
The result of acts of digital parasitism and the undermining of market infrastructures is loss of control, copyright, and remuneration. Meanwhile, as the parasites alter the ecosystem of the host, new connections appear in a parasitic infrastructure: Machines attach themselves to machines, humans to humans and humans to machines. The AI models constitute an infrastructure of their own, capable of spurring even more (parasitic) activities, resulting in both pains and gains (in visibility or innovation) for authors and creative workers. As models for compensation spring forth, new forms of sustenance also emerge. The large-scale settlements between AI companies and rightsholders (Brittain and Brittain, 2025; Press, 2025), as well as the emergence of licensing models for media content to train AI models (Longpre et al., 2024; Wiggers, 2023), indicate new cascades and a transformation of the media and cultural industries as we know them. Now, the parasitic activity can be turned into a source of revenue.
The characteristics of content for training data is significant, as the LLMs require high-quality material, free of error, natural and diverse in language in order to mimic that same language in their output through chatbots and agents. But equally important is the fact that content can be translated, metamorphosed in Serres’ vocabulary (2007: 150), to gain value for a new actor. As ebook files move from a (shadow) library resource to training corpora, they are also transformed into tokens, the units that LLMs work with. Tokenization breaks words, texts, and language into chunks that can be processed by the models. In that process, it becomes clear how and why a training set like Books3 holds value in spite of it being randomly and opportunistically composed. By breaking apart the books, tokenization recommodifies the content.
The analysis of Scandinavian subsets does not show how models later performed in Swedish, Danish, or Norwegian, nor does it by itself measure cultural harm. What it does show is that small-language publishing infrastructures became part of the resource base from which general-purpose AI systems could be built. In that sense, the Scandinavian case is important not because it proves downstream effects directly, but because it reveals which localized linguistic and editorial resources were rendered extractable. AI training parasitizes not only authorship, but also the mediating work of translation, editing, packaging, and regional distribution. The presence of international authors in Scandinavian-language or Scandinavian-published editions indicates that what is extracted is a publishing infrastructure that localizes global literature for Scandinavian readers.
Fundamentally, Books3 underscores the tension between the ideals of democratizing AI research and the rights of content creators. An initiative borne out of the open access movement, the compiling of Books3 was initially framed as a way to “level the playing field” for open research initiatives (Reisner, 2023). Shawn Presser has stated that he saw Books3 as a way to democratize access to training data that would otherwise only be available to companies like OpenAI. Jia & Nagaraj terms it “an act of benevolent piracy” (2025: 4). As such, Presser has a lot in common with the initiators behind the shadow libraries, people like Alexandra Elbakyan of Sci-Hub (Karaganis, 2018). Yet, the dataset’s reliance on scraping without consent raises pressing ethical and economic questions about appropriation, compensation, and the sustainability of creative industries (Haidemariam and Gran, 2025; Rowberry, 2025). Much like Thylstrup, we find it constructive to consider shadow libraries and OA activism like Shawn Presser’s as forms of noise, a disturbance which can also serve to make visible infrastructures and flows that are obscured, such as the unsustainable system of commercial academic publishing. The irony of the benevolent piracy of Shawn Presser is that it may end up serving the corporate interests that he and others in the open science movement tried to bypass, with wealthy companies like Meta, Microsoft, and Nvidia taking advantage of the free corpus.
Limitations and directions for future research
The constraints of the search methodologies result in some limitations: The inability to perform a comprehensive RegEx-based search directly on the entire corpus represents a significant limitation. Such a search would potentially allow for the identification of a broader range of books, including ISBN-10 titles and titles without ISBN, through more sophisticated pattern matching, thereby enhancing the depth and accuracy of our analysis. While the use of RegEx for identifying ISBNs is robust, it relies heavily on the accuracy and completeness of the ISBN metadata within the Books3 corpus. Any errors or omissions in this metadata could result in missed instances of authors’ works. While manual searches have been helpful in supplementing metadata, this approach is time-consuming and was abandoned for the more specific genre analysis originally planned. Our study focused exclusively on books by Swedish, Danish, and Norwegian publishers. While this provided a relevant and manageable scope for analysis, it limits the generalizability of our findings. Future research can benefit from comparative analyses across more national and regional subsets, or by including other training corpora in the analysis.
Despite the limitations listed above, our study provides valuable insights into the presence of Scandinavian books in Books3 and their characteristics. Specifically, we believe that our method of adding details that go well beyond author search capabilities and descriptive title lists, such as genre and language, provides empirically grounded and localized knowledge on the specifics of the training data. Future research could build on the datasets compiled for this research but can also benefit from the development and application of more advanced search methodologies, including comprehensive RegEx-based searches, to further enhance the identification and analysis of media content in large datasets.
Conclusion
This study does not establish exactly how each Scandinavian title entered Books3, nor does it measure downstream model behavior directly. Its contribution is different: it identifies what kinds of Scandinavian-published books became available for extraction. The subsets are recent, strongly fiction-oriented, commercially produced, linguistically localized, and unevenly assembled. Read through Serres, these patterns show digital parasitism not as an abstract metaphor, but as the conversion of localized cultural and publishing infrastructures into training data for global AI systems.
Our analysis of content from Scandinavian publishers within the Books3 corpus reveals to what extent generative AI is more than a technological innovation; it relies on creative labor that often goes unacknowledged when training data sources remain hidden. This study goes beyond prior research by detailing the precise characteristics of a fragment of training data, emphasizing that it consists of books written by human authors in a particular genre and language, made public by an array of publishers. Our Scandinavian outlook provides a glimpse of how the literary infrastructure of small-language markets can be appropriated by global AI systems. The tension we can observe between the Scandinavian book industries and AI developers is not just between two different industries or institutions; it is a struggle between localized and globalized actors. Even a global phenomenon like AI deployment will be situated in local contexts and cultures, impacting how they are implemented, used, and accepted (Natale et al., 2025). Natural language is the sustenance on which the LLMs thrive and grow. Much of those language resources come in the form of published material like books (whether in or out of copyright). Crucial to the global expansion of generative AI is also the availability of diverse language, in the form of both creative and linguistic diversity. As such, the localized subsets of Scandinavian book titles form an asset: LLM performance in a language depends on exposure to that language during training.
The measurable impact of book content on AI model accuracy suggests that literary works substantially enrich LLM capabilities. At the same time, its illegitimate provenance has sparked legal challenges and policy debates that will shape the contours of AI development. Regulatory initiatives, like the EU AI Act, aim to ensure transparency regarding training data sources. Compliance will depend on model developers’ willingness to disclose and license their datasets. From our perspective, it has been important to highlight that the issue of using media content as training data encompasses questions that go beyond both technical issues like tokenization and model performance and legal issues like copyright. Employing Serres’ concept of the parasite, we have explored the relationship between the book industry and AI development.
Let us be clear: Digital parasitism by commercial AI companies that take advantage of cultural content for training data without considering compensation or consent is a form of exploitation. It is also a form of parasitism that combines opportunism and strategy. Moreover, as we have indicated, the parasitic extraction of text for AI training exposes how older digitization regimes, such as Google Books and shadow libraries, laid the infrastructural groundwork for today’s data economies. In these relationships of extraction, the much larger AI companies freeloaded on the copyrighted content made by Scandinavian publishers.
Footnotes
Ethical considerations
The project does not involve human research subjects. We have not deemed it necessary to seek ethical approval or consent for the research as it involves publicly available data.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study did not receive external funding but the first and second authors wish to acknowledge affiliation with the research network MishMash—Centre for AI & Creativity, funded by the Norwegian Research Council.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.