
Abstract
This study explored the teaching and learning of vocabulary through listening among 137 senior high-school learners of English as a foreign language (EFL) in China. It compared different types of Lexical Focus-on-Form delivered to four treatment groups: post-listening vocabulary explanations in the L2; codeswitched explanations; explanations providing additional crosslinguistic information (Contrastive Focus-on-Form; CFoF); and no explanations (NE). It also investigated the impact of the intervention on learners’ listening comprehension. Learners completed aural vocabulary tests at pre-, post- and delayed post-test and listening assessments at pre- and post-test. For short- and long-term vocabulary acquisition, the three groups receiving explanations significantly outperformed the NE group. Gains for the CFoF group were significantly greater than for the L2 and Codeswitching groups, for both short-term and long-term learning. For listening comprehension, only the NE group made significant improvement from the pre-test to the post-test, as well as making significantly greater pre- to post-test improvement than the CFoF and the L2 groups did. The article concludes by discussing these findings in relation to theories of vocabulary acquisition and listening comprehension, as well as their pedagogical implications.
Keywords
I Introduction
The development of English proficiency is an important goal for high school learners in China, as it is in many contexts. Fundamental to that goal is the acquisition of a wide vocabulary (Bogaards & Laufer, 2004). Relatively little is known, however, regarding the relative benefits to vocabulary development of different classroom practices. In addition, while current educational policy in China encourages maximum second language (L2) use by high school teachers in the classroom, it is unclear whether this is, in fact, the optimum teaching approach (Silver, Hu & Iino, 2002). Aiming to fill this gap, this study explores the impact of different types of vocabulary instruction, comparing teacher codeswitching, cross-linguistic explanations, and exclusive L2 use, within English as a foreign language (EFL) teacher–learner interactions following listening activities.
Listening is also regarded as a ‘foundational skill’ (Gu, 2018), and vocabulary acquisition through listening is arguably of particular import given the centrality of oral input in communicative language teaching. In settings such as China, where traditionally language teaching has focused on written texts, there is a move towards a more communicative, oral-based approach (Lee, 2010), underscoring the importance of investigating how vocabulary can be best developed through oral input.
II Literature review
Within classroom-focused research, it is common to view L2 vocabulary learning as involving either intentional learning or incidental learning (Hulstijn, 2001). In the latter, learners learn vocabulary ‘as the by-product of any activity not explicitly geared to vocabulary learning’; conversely, intentional vocabulary learning refers to ‘any activity aiming at committing lexical information to memory’ (Hulstijn, 2001, p. 267). Although intentional vocabulary learning can result in better short-term outcomes compared to incidental learning (Laufer, 2009), both types of learning have different advantages, and in practice the division between them is not always entirely clear-cut (Hulstijn, 2001). Furthermore, both incidental and intentional learning can be enhanced by pedagogical activities that draw learners’ attention to key information about a word, an approach termed Lexical Focus-on-Form (Laufer & Girsai, 2008). As yet, however, relatively little research has been focused on incidental learning followed by intentional vocabulary instruction (Hennebry, Rogers, Macaro & Murphy, 2013).
Existing research has also tended to focus on learning through written input (Pellicer-Sánchez & Schmitt, 2010) rather than through oral input. The few studies undertaken show that vocabulary knowledge can be acquired incidentally through oral input, but levels and rate of acquisition differ from what is found for reading. For example, Vidal (2011) compared incidental vocabulary acquisition through oral and written input among 230 university learners of English. While oral input led to the retention of a smaller number of words than was the case for reading, retention was more durable in the listening condition (except in very low proficiency learners), perhaps because oral input can pass directly into phonological memory, with accompanying ‘stable long-term memory representations’ (Vidal, 2011, p. 244–245). Yet fewer words are retained than through reading, perhaps because in listening there tends to be a greater need to gain the overall gist of what is said, whereas reading ‘allows more attention to be focused on language form’ (p. 248). The fleeting nature of oral input and learners’ difficulties with speech segmentation make it more difficult to process such input, to isolate and focus on specific lexical items. This suggests that, more so than for reading, incidental learning needs to be supplemented by intentional, explicit Lexical Focus-on-Form teaching.
The role of the first language (L1) in such teaching, however, is also underexplored, although there is emerging evidence of an advantage from the use of teacher codeswitching or CS (Tian, 2011; Tian & Macaro, 2012). Potentially better learning from teacher CS can be explained theoretically through models of vocabulary representation and development such as that of Jiang (2000) in which the L1 occupies a central position. Jiang (2000) proposes that in the L1 lexical representation, morphological, phonological, orthographic, semantic and syntactic forms of information about a word are strongly integrated with each other, so that access to them is simultaneous when the lexical entry is ‘opened’ (p. 49). By contrast, lack of contextualized target language input may prevent L2 learners from developing these different forms of knowledge. Furthermore, the strong link between the L1 and the existing semantic system means that L1 translation will always feature heavily in L2 vocabulary learning. Hence, Jiang (2000) proposes three stages for the representation and processing of L2 lexical knowledge.
At the initial stage, only the formal information about the target L2 word is represented in learners’ minds, and the processing of the word relies heavily on L1 translation. During the second stage, the ‘L1 lemma mediation stage’, a link is made between the L2 word and its conceptual representations through the L1 lemma information, albeit weakly, because ‘the lemma information is copied from L1, rather than created in the process of learning the L2 words, thus not highly integrated into the entry’ (Jiang, 2000, p. 52). Teacher codeswitching to the L1 during vocabulary explanations could, therefore, aid the development of this second stage by providing a link between the L2 word and its concept. At the final ‘integration’ stage, L2 lemma and lexeme are highly integrated and represented in L2 learners’ mental lexicon.
Jiang (2000) does not however go so far as to advocate L1 use in actual L2 classroom vocabulary instruction (Tian, 2011) and indeed argues that abundant and contextualized L2 input is essential for learners’ L2 lexical representation. Furthermore, he argues that learners may be less motivated to extract further information about a word from contextualized input if they can access its meaning fairly automatically via the L1. Overall, it is unclear how much and what kind of L1 for instructional purpose is beneficial.
The impact of teacher codeswitching within vocabulary instruction after listening was explored in an important study involving 117 university-level learners of English in China by Tian (2011), aspects of which are also reported in Tian and Macaro (2012). Three groups of learners were studied: two intervention groups received vocabulary instruction (‘Lexical Focus-on-Form’) after listening to L2 texts, with vocabulary meaning provided through teacher CS (Chinese to English translation), or through the L2 (explaining word meanings using English only); and a third (control group) was exposed to listening texts without vocabulary instruction, discussing listening strategies instead. The groups receiving intentional vocabulary instruction made significant gains in tests taken at the end of each teaching session. These tests were not administered to the control group on the grounds that it would be inappropriate to assess learners on items for which they had not received instruction, according to Tian and Macaro (2012), although they do accept that their administration might have highlighted short-term vocabulary learning by the control group. Although intervention group scores declined significantly at the delayed post-test (taken by all groups), they were still significantly higher than at pre-test with better long-term vocabulary retention than found in the control group. Vocabulary instruction after listening comprehension activities was also shown to benefit younger L2 learners of French in Hennebry et al. (2013), a rare study in addressing school-level vocabulary learning. They found more effective vocabulary retention through direct teaching than from incidental learning through listening on one of the tests they administered but not on others.
Both Tian and Macaro (2012) and Hennebry et al. (2013) also found that participants who received teacher CS for vocabulary explanations outperformed those who were taught in L2-only. In the first study, this advantage was found for short-term learning through meaning-recall tests at the end of each session of vocabulary instruction, yet disappeared in delayed post-tests administered two to seven weeks after each instructional session. By contrast, Hennebry et al. (2013) found a longer-term advantage (between one and four weeks after the vocabulary instruction) for teacher CS over L2-only. Effect sizes were however small. Furthermore, in both studies the variation in the length of the gap between instruction and the delayed post-tests makes it difficult to judge how effective the instruction was for long-term learning, suggesting the need for further exploration.
It is possible that more durable and larger gains might be achieved through a third intentional vocabulary teaching method proposed by Laufer and Girsai (2008), in which cross-linguistic information about the target vocabulary is provided. In their study, learners completed text-based translation activities (L1 to L2 and vice versa), but also received information from the teacher that contrasted the L1 and the L2, termed contrastive Form-Focused Instruction. The authors highlight that such instruction does not involve ‘bilingual glosses which simply state the meaning of L2 words’ – namely codeswitching, in which any L1/L2 contrasts remain implicit – but rather ‘the kind of instruction which leads to learners’ understanding of the similarities and differences between their L1 and L2 in terms of individual words and the overall lexical system’, through the explicit highlighting of such differences (p. 696). Laufer and Girsai (2008) relate contrastive form-focused instruction to Schmidt’s (1990) ‘noticing’ hypothesis, arguing that the contrastive focus can make an L2 word more salient to the learner and hence more likely to be retained. To our knowledge, contrastive form-focused instruction has not been considered within vocabulary development through listening nor compared directly with CS and L2 explanations.
Finally, Tian and Macaro (2012, p. 371) raise the important question of ‘optimal L1 use’ and highlight the need for research to gain better insights into the ‘cost–benefits of Lexical Focus-on-Form by the teacher’. In other words, what impact do different kinds of Lexical Focus-on-Form have on other skills, most importantly on listening, the medium through which the instruction is delivered? To our knowledge, this question has not been explored by previous research, which from a pedagogical perspective as well as a theoretical one is an unfortunate omission. A statistically significant relationship between vocabulary and listening has been established in a number of studies, indicating that an approach leading to vocabulary growth might be accompanied by improvements in listening comprehension. Correlations are however typically weaker than those found for vocabulary size and reading, for example, around .70 in Stæhr (2009). These weaker correlations suggest that there is more to listening proficiency than lexical knowledge, as is also suggested in a study by Bonk (2000). He reports that some participants appeared to know under 75% of the words in a spoken text, yet had ‘good’ comprehension of that text. By contrast, others knew over 90% of the words but had ‘poor’ comprehension, perhaps suggesting weaknesses in what is called the ‘utilization’ phase of John Anderson’s (2010) model of second language listening, in which perceived linguistic information is related to (non) linguistic information stored in long-term memory in the form of schemata. Increasing learners’ vocabulary knowledge is therefore no guarantee of improved listening comprehension, an argument that also gains support from a systematic review of vocabulary interventions and L1 reading (Wright & Cervetti, 2017). The vast majority of the 36 reviewed vocabulary interventions (either directly teaching vocabulary meanings or teaching a small number of word-deciphering strategies) did not have a positive impact on learners’ general reading comprehension, but only on comprehension of passages that included the vocabulary items taught in the intervention.
In sum, there is a gap in research exploring vocabulary acquisition through oral input. The possible pedagogical value of teaching vocabulary through incidental learning plus intentional Lexical Focus-on-Form emerges from the above literature review, yet empirical evidence for this is limited. Furthermore, although using L1 to teach L2 vocabulary is theoretically supported by a psycholinguistic model of vocabulary acquisition and by a small amount of empirical research (notably mainly with university-level rather than school-level learners) no research to date explores specifically which type of L1 explanation is more valuable, namely teacher CS or contrastive (lexical) Focus-on-Form. Finally, even if learners’ vocabulary knowledge can benefit from intentional vocabulary teaching following listening activities, it is unclear what impact such instruction has on other aspects of language learning (notably listening).
III Research methodology
The above issues were explored through two research questions:
What is the impact on short- and long-term vocabulary learning of: teacher codeswitching; target language explanations; and contrastive Focus-on-Form within vocabulary instruction through listening for high school learners?
What is the impact of each type of instruction on learners’ listening comprehension?
1 Research design and participants
These two research questions were addressed through a quasi-experimental design drawing on Tian and Macaro (2012) and involving 137 first-year high school EFL learners from four intact classes in China from one school (aged 15–16, seven years’ English learning experience). Learners were preparing for the Gaokao, China’s national university entrance exam, and as such were considered to be of a proficiency level of around A2 to B1 on the CEFR, the Common European Framework of Reference for Languages (or around levels 3–4 on IELTS, the International English Language Testing System). The four classes were randomly assigned to three treatment groups, a second language (L2) group, a teacher codeswitching (CS) group and a Contrastive Focus-on-Form (CFoF) group, and a No Explanation (NE) group. All groups were instructed by the first author, whose L1 is Chinese.
The study lasted three months, beginning with pre-tests in vocabulary and listening comprehension (week one). Six teaching sessions (outlined below) took place between weeks four to nine. All groups completed an immediate vocabulary post-test at the end of each session. From the third teaching session inclusive (week six), an additional vocabulary delayed post-test was administered at the same time as the vocabulary post-test (six delayed post-tests in total). The delayed post-tests assessed long-term vocabulary retention for target items from the session delivered two weeks previously. For all items there was a delay of two weeks between the post-test and the delayed post-test (comparable with Tian & Macaro (2012) and Hennebry et al. (2013), whose delayed post-tests were administered with a variable delay of between two and seven and two and four weeks respectively). Finally, learners’ listening comprehension was reassessed in week 12. Figure 1 depicts the study design; for further details, see Zhang (2018).

Outline of all procedures.
2 Research instruments
a Vocabulary
At pre-test, a 160 item General English vocabulary test (henceforth, GEVT) was employed in order to gain a measure of general language proficiency as well as to assess knowledge of items to be included in the intervention. The test was based on the aural vocabulary levels test by McLean, Kramer and Beglar (2015) originally for Japanese EFL learners, translated into Chinese and testing only the first three 1,000-word frequency levels and the academic word list (as appropriate to the participants’ level of language proficiency and ascertained through piloting). Participants heard the researcher reading out the target lexical item and a neutral example sentence including it. They then needed to select the correct Chinese translation corresponding to the English word, as shown in this example (English translations added here for clarity): Participants hear: ‘School: This is a big school.’ a. 银行 (bank) b. 海洋动物 (sea animal) c. 学校 (school) d. 家 (house)
The 60 target lexical items to be presented in the intervention were intermingled with the 100 items from the general vocabulary test so that the participants would not know which items were the focus of the study. A test using meaning recognition with multiple choice was used at pre-test to facilitate the assessment of partial knowledge of a larger number of items. Cronbach’s alpha for this combined vocabulary test was .76, which is in line with what is commonly reported for multiple-choice type vocabulary tests, where test-taking strategies influence reliability to a certain degree (Gyllstad, Vilkaitė & Schmitt, 2015).
Changes in learners’ vocabulary knowledge were assessed through six post-tests and six delayed post-tests (both tests assessing ten items at a time) based on the assessment used by Tian (2011) but modified so that it took an aural form. The teacher read out the vocabulary items plus an additional sentence which included the target item but did not give contextual clues as to the item’s meaning. Learners then had to write down the meaning of each item, with the option of writing either in the L1 or the L2. The reliability for the combined vocabulary post-test (see Data Analysis) was .94, and .92 for the combined delayed post-test (Cronbach’s Alpha). The post-test and delayed post-test assessed meaning recall without multiple choice to measure growth from the meaning recognition assessed at pre-test. We outline measures taken to address the non-identical format of the tests in Section IV.
b Listening comprehension
At pre-test the first two sections of an IELTS listening practice test were administered. These first two sections include ‘a conversation between two people set in an everyday social situation’ and ‘a monologue set in an everyday social situation’ and as such were considered appropriate for the proficiency level of the participants, with IELTS Band 3–4 assessing comprehension of familiar situations (British Council, n.d.).
In order to avoid a practice effect a different but equivalent second version of the test was then used after the intervention as a post-test. Steps were taken to ensure that the two tests were of comparable level of difficulty, matching each on (1) vocabulary frequency levels; (2) number of words and speech rate; and (3) the number of global or local questions assessed. Reliability levels (pre-test, .62, post-test, .60) were rather low but consistent with those found in IELTS research reports for the first two sections of the test, namely around .67 (Breeze & Miller, 2012) and similar to levels reported for listening tests used in Stæhr (2009). Out of twenty questions in each test only five were in multiple choice format, in order to limit guessing.
c Teaching procedures
We followed Tian and Macaro (2012) as far as possible in the implementation of the teaching intervention, with the addition of a Contrastive Focus-on-Form condition. We thus had four groups: No Explanation (NE); teacher codeswitching 1 (CS); target language explanations (L2); and Contrastive Focus-on-Form (CFoF). The intervention was implemented over six sessions for all four groups, with each session lasting approximately 45 minutes. In each session for all groups learners heard a passage and then answered three questions which asked for general comprehension without focusing on the target items (see Supplemental Materials). More specific comprehension questions were asked orally at this stage in order to again focus learners’ attention on listening comprehension.
For the three intervention groups, the passage was then replayed sentence by sentence so that vocabulary explanations of the target items were given as they occurred in the passage, taking a different form for each experimental condition but ensuring that each intervention group received the same amount of vocabulary explanation, as follows (see also Figure 2).
L2 group: Learners firstly received an English explanation for the target item. Then, they were given an additional sentence including the target item with further L2 explanations.
CS group: The meaning of the target lexical item was given by the teacher in the L1. To maintain consistency with the amount of input received by the L2 group, learners were also given an additional L2 sentence including the target item.
CFoF group: Learners were initially given the L1 meaning of the target vocabulary item, then received an additional explanation in the L2 focusing on comparing and contrasting the L2 word and its L1 translation, especially when there was a mismatch between the two.

Examples of each type of vocabulary instruction.
All intervention groups also saw the written form of the target items, presented through PowerPoint, but they were not allowed to write them down, to prevent any revisiting of the items outside of class. The meaning of the whole listening passage was then summarized in English by the instructor once more and L2, CS and CFoF explanations for the target items were repeated (i.e. two lots of focused sentence encounters were given). Then the whole listening passage was played again. In other words, intervention groups heard the passage three times in total.
The NE group listened to the same passages as the intervention groups and also answered the comprehension questions. Instead of vocabulary explanations, however, they were given cultural and background information (in the L2) relating to the listening passage. To ensure that the NE group had as many focused exposures to the target items as the intervention groups, they were allowed to listen to the listening passage sentence by sentence twice, matching the two rounds of vocabulary explanations received by the treatment groups. Like the intervention groups they heard the passage three times in total and also saw it in written form after the final round of listening.
d Target lexical items and listening passages
Sixty target lexical items included 18 nouns, 13 verbs, 12 adjectives and 17 collocations. The 43 single words were selected from the 1, 2 and 3K frequency bands and from the academic word list while the 17 collocations were chosen as those included in the senior-secondary school English curriculum for learners at this level (Ministry of Education, 2003). The listening passages through which the vocabulary instruction was delivered came from an English text book, New Senior English for China. Passages were selected and modified according to the criteria of: topic relevance to learners; at least 95% of the vocabulary they contained would be familiar to learners (Tian & Macaro, 2012), according to the senior-secondary school English curriculum (Ministry of Education, 2003) and the textbook authors; they were of a standard length of approximately 250 words (Tian, 2011); and a uniform speech rate controlled at between 150–190 words/min (Brindley & Slatyer, 2002; Tauroza & Allison, 1990). The topics covered in the passages and the target lexical items did not overlap with those featuring in the listening pre- and post-tests.
3 Research ethics
Informed written consent was obtained from the head teacher, class teachers, parents and students. Issues relating to the appropriateness of assessing NE Group learners in post-tests on items they had not been explicitly taught were considered in consultation with the school and not felt to be problematic from an ethical perspective.
IV Data analysis
Vocabulary pre-, post- and delayed post-tests were scored by the first author. Post- and delayed post-tests were then second marked by another researcher, giving inter-rater reliability rates of between 98.76% and 99.22%. Items were marked either right or wrong, with no half marks. Exploratory factor analysis was firstly carried out on the six post-tests and six delayed post-tests (for descriptive statistics, see Supplemental Materials). This indicated only one factor for the post-test (explaining 77.71% of the variance) and one for the delayed post-test (explaining 57.56% of the variance), with relatively high factor loadings (between .58 and .94). Hence it was considered justifiable to aggregate scores for all six post-tests and delayed post-tests, giving one total score for each, following the approach used by Tian and Macaro (2012). For listening, as no half marks were awarded but misspellings were tolerated where these did not impede comprehension or alter the meaning of the answer, all scripts were marked by the first author and then a second marker double-marked 30% of the pre- and post-tests, giving inter-rater reliability rates of 99.34% and 99.56% respectively.
In order to establish comparability between the four groups on linguistic knowledge at baseline, we firstly explored whether they differed significantly on the GEVT. Using a non-parametric Kruskal–Wallis test because of many outliers in the CFoF and the NE group, we established that there were no significant differences between the four groups for vocabulary size (p = .25). In order to address the difference in format of the pre-test (meaning recognition, multiple choice) compared with the post- and delayed post-test format (meaning recall, no multiple choice), a series of logistic regression tests was performed using generalized linear mixed-effects models (GLMMs; ‘lmerTest’ package version 3.0-1, R version 3.4.3). These tests took into account the random effects that any test items may have had across different test time points because of the different testing format. Further details are given in Section V. For all tables, the following applies: * p < .05; ** p < .01, *** p < .001. For effect plots, values on the y axis are given as probabilities, with a maximum of 1. Effect sizes were calculated as odds ratios but were translated into Cohen’s d for ease of interpretation, with the latter interpreted as follows: Between-groups contrasts, small = .4, medium = .7, large = 1.0; Within-groups/pre–post contrasts, small = .6, medium = 1.0, large = 1.4 (Plonsky & Oswald, 2014). Where multiple comparisons were made, p-values were adjusted using the ‘Hommel’ procedure.
V Results
1 Short-term and long-term vocabulary learning
Our first research question explored the impact on short- and long-term vocabulary learning of the different types of teacher vocabulary explanations. Descriptive statistics were produced for all groups (Table 1). In order to examine whether the participants’ vocabulary knowledge varied according to two fixed effects: Time (1 = pre-test, 2 = post-test, 3 = delayed post-test), and Group (L2, CS, CFoF, NE), and their interaction, a series of logistic regression tests was undertaken using GLMMs for each possible Interpretation. NE and Time 1 were set as the baseline level of group and time to be compared with the other groups and test time points. The random factors were Participant and Item (60 items for pre-test, 60 items for post-test and 60 items for delayed post-test; wrong answer coded as 0 while correct answer coded as 1). Random effects were fitted using a maximal random effects structure (Barr, Levy, Scheepers & Tily, 2013). This included random intercepts for Participants and Items, by-participant random slopes for Time, and by-item random slopes for Time, Group, and their interaction.
Descriptive statistics (percentages) for vocabulary.
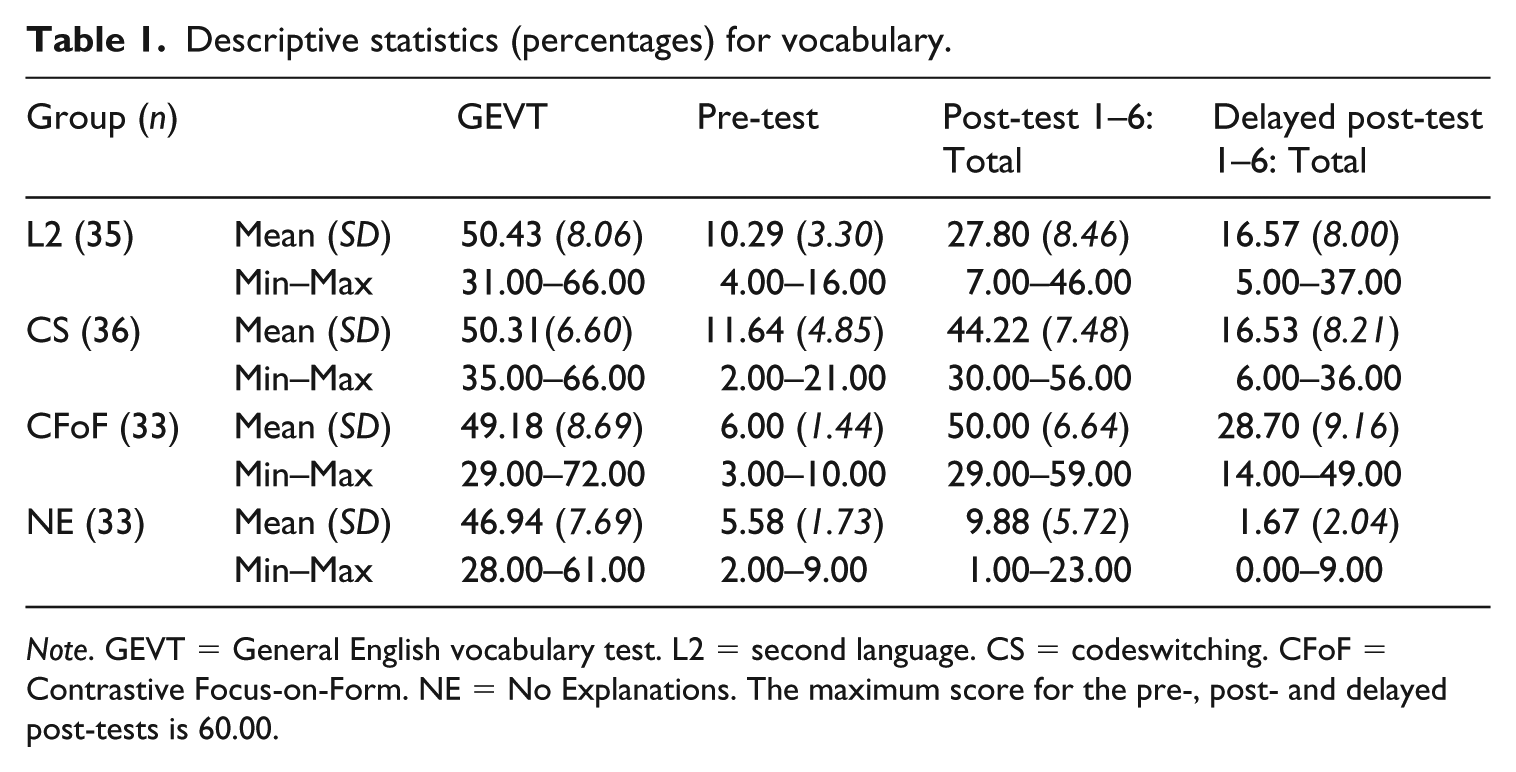
Note. GEVT = General English vocabulary test. L2 = second language. CS = codeswitching. CFoF = Contrastive Focus-on-Form. NE = No Explanations. The maximum score for the pre-, post- and delayed post-tests is 60.00.
Final model selection was then carried out followed the ‘backward selection’ procedure (Gries, 2013, p. 260), whereby a maximal model including the full fixed and random effects structure was fitted initially. Thereafter, while holding the fixed effects structure constant, the random effects structure was simplified by removing the random effect which contributed the least variance. A model comparison between the simplified model and the full model was then conducted. If the simplified model was not significantly different from the full model, the random structure was further simplified by removing another random effect which contributed the least variance, until the point was reached where significant differences were found between the simplified model and the full model. Finally, the fixed effects structure was simplified using the same procedure as for the random effects structure.
For our model for the vocabulary tests, the maximal model was retained as the final model, because removing any random or fixed effect made a significant difference to the model results. The final model represents a good fit to the data: C-value = 0.94, R2marginal = 0.40 and R2conditional = 0.80, and there was no significant overdispersion or collinearity (all GVIFs < 3.5; GVIF = generalized variance inflation factor). Since in our model, two fixed effects, Group and Time, had more than two categorical levels, several models were run using different baseline level of Group and Time in order to give a clear picture of each pairwise comparison. Interactions are shown in Table 2, and fixed effects of Time and Group in the Supplemental Materials.
Results from the generalized linear mixed effects model for the vocabulary tests.

Note. L2 = second language. CS = codeswitching. CFoF = Contrastive Focus-on-Form. NE = No Explanations.
Fixed effects indicate that all intervention groups made statistically significant progress between Time 1 and 2, with large effect sizes. While all intervention groups also significantly improved between Time 1 and 3, effect sizes were large for the CFoF group and approaching medium for the L2 group. There were significant declines between Times 2 and 3 (effect sizes ranging from small for the L2, to medium for the CFoF group and large for the CS group). For the NE Group, statistically significant progress occurred only between Time 1 and Time 2 (medium effect sizes), with a significant decline between Times 2 and 3. The decline between Time 1 and Time 3, although not statistically significant, showed a small effect size.
The Time × Group interactions (Table 2) showed that there were differences in the short-term and long-term progress made by the groups (see also Figure 3). The CFoF group significantly outperformed the other three groups for both short-term and long-term vocabulary learning, with large effect sizes in all cases. Once random effects had been controlled for, no statistically significant differences were found between the L2 and CS groups for short-term and long-term improvement, but there was an emerging advantage for the CS group in the form of a larger effect size for improvement from Time 1 to Time 2 (2.20 compared with 1.86 for the L2 group; see Supplemental Materials). While the CS group significantly outperformed the NE group for short-term learning (medium effect size), the L2 group was significantly superior to the NE group for long-term learning. Turning to declines in vocabulary knowledge between Time 2 and 3, most notably the L2 group lost significantly less vocabulary knowledge than the NE group (large effect sizes) and the CS group (medium effect sizes).
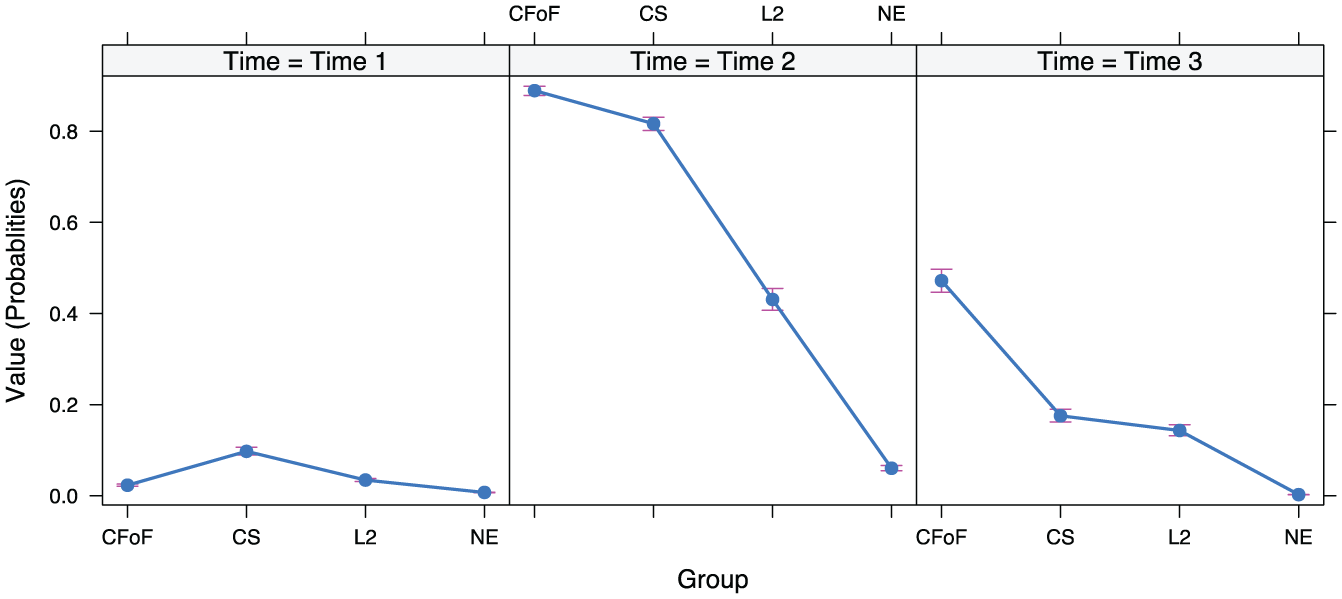
Time * Group effect plot: Vocabulary.
2 Listening comprehension
Our second research question investigated the impact of each type of instruction on learners’ listening comprehension. Descriptive statistics for the pre- and post-tests were first calculated (Table 3), removing scores for two learners (L2 and CFoF group) who did not participate in the post-test.
Descriptive statistics (percentages) for listening comprehension.
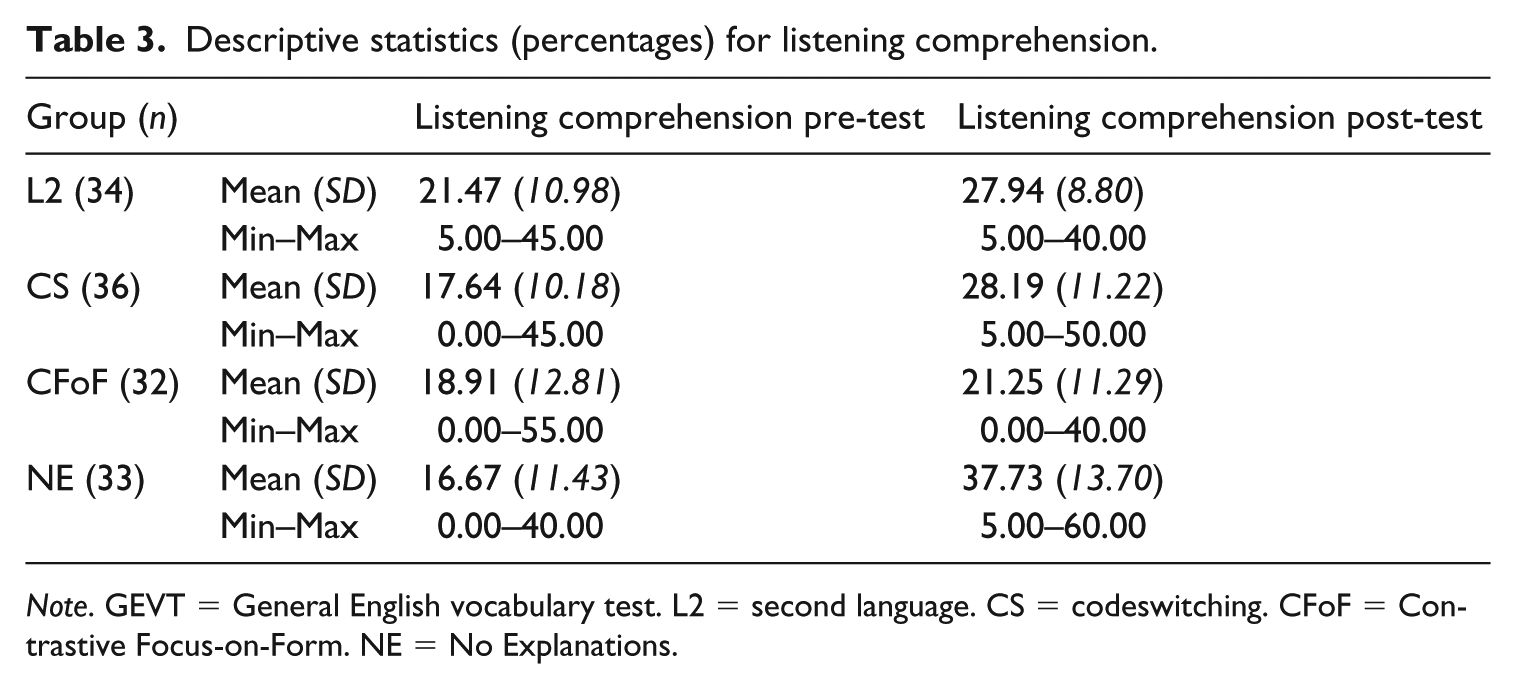
Note. GEVT = General English vocabulary test. L2 = second language. CS = codeswitching. CFoF = Contrastive Focus-on-Form. NE = No Explanations.
In order to analyse whether participants’ listening comprehension varied according to three fixed effects – Vocabulary size (GEVT), Time (pre-test vs. post-test) and Group (L2, CS, CFoF, NE), and their interaction – a series of logistic regression tests was performed using GLMMs for each possible Interpretation, with NE set as the baseline level of Group and Pre-test set as the baseline level of Time. The random factors were Participant and Item (20 items for pre-test and 20 items for post-test; wrong answer coded as 0 while correct answer coded as 1). Random effects were fit using a maximal random effects structure, which included random intercepts for Participants and Items, by-participant random slopes for Time, and by-item random slopes for Group, GEVT and their interaction. Model selection indicated that the full model could be simplified by removing the fixed effect GEVT from the random effects structure and the Time × Group × GEVT and Group × GEVT interactions from the fixed effects structure. Model comparison indicated that the final simplified model (AIC = 4326) did not significantly differ from the full model (AIC = 4333), χ2(6) = 5.04, p = .54.
There was no significant overdispersion or collinearity (GVIFs < 3.5) for the final model. C-value = 0.90 indicates that the model had a good fit to the data. The two R2s (R2marginal = 0.044, R2conditional = 0.59), however, indicate that a large part of the variance of the outcome variable was explained by the random effects. We therefore built a null model by removing the fixed effects from the final model and compared our final model with the null model. Results indicate that the final model (AIC = 4326) which includes the fixed effects was significantly different from the null model (AIC = 4342), X2(9) = 33.32, p < .001. In addition, comparing the model AIC-values shows that the final model was 2119 times better than the null model. Therefore, it was decided to include the fixed effects in the model as they significantly improved the model results.
Model results showed that only the NE group made significant improvement from the pre-test to the post-test, with a medium effect size (B = 1.75, SE = 0.76, z = 2.29, p = .022*, d = 0.96), as well as making significantly greater pre- to post-test improvement than the CFoF and the L2 groups did. There was also a main effect of Vocabulary at the Pre-test (B = 0.045, SE = 0.012, z = 3.75, p < .001***), indicating that learners’ vocabulary size significantly predicted their listening scores. As the fixed effect of Group included four levels, several models were run using each of the four groups as the baseline level of group respectively. Table 4 gives the combined results of all interactions, with effects plots shown in Figures 4 and 5. In addition, the Time × Vocabulary interaction indicates that the lower learners’ vocabulary size was at the outset, the more pre–post listening improvement they made.
Results from the generalized linear mixed effects model for listening comprehension.
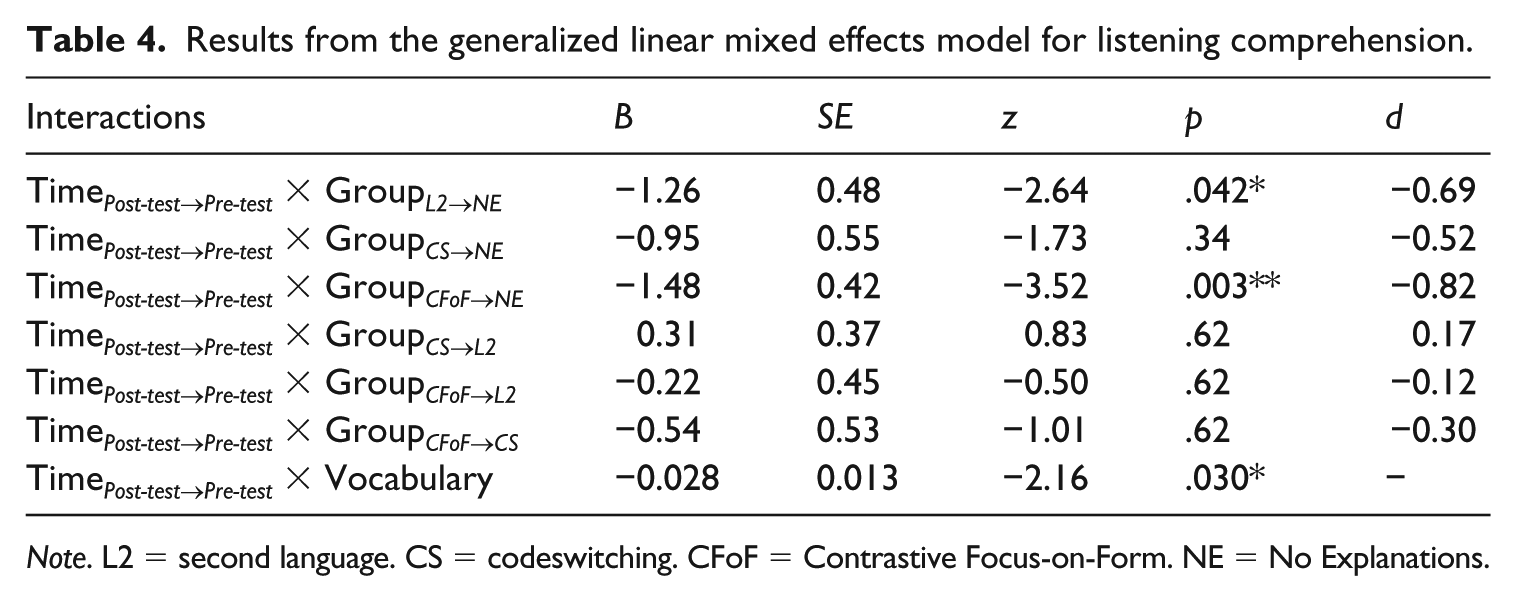
Note. L2 = second language. CS = codeswitching. CFoF = Contrastive Focus-on-Form. NE = No Explanations.
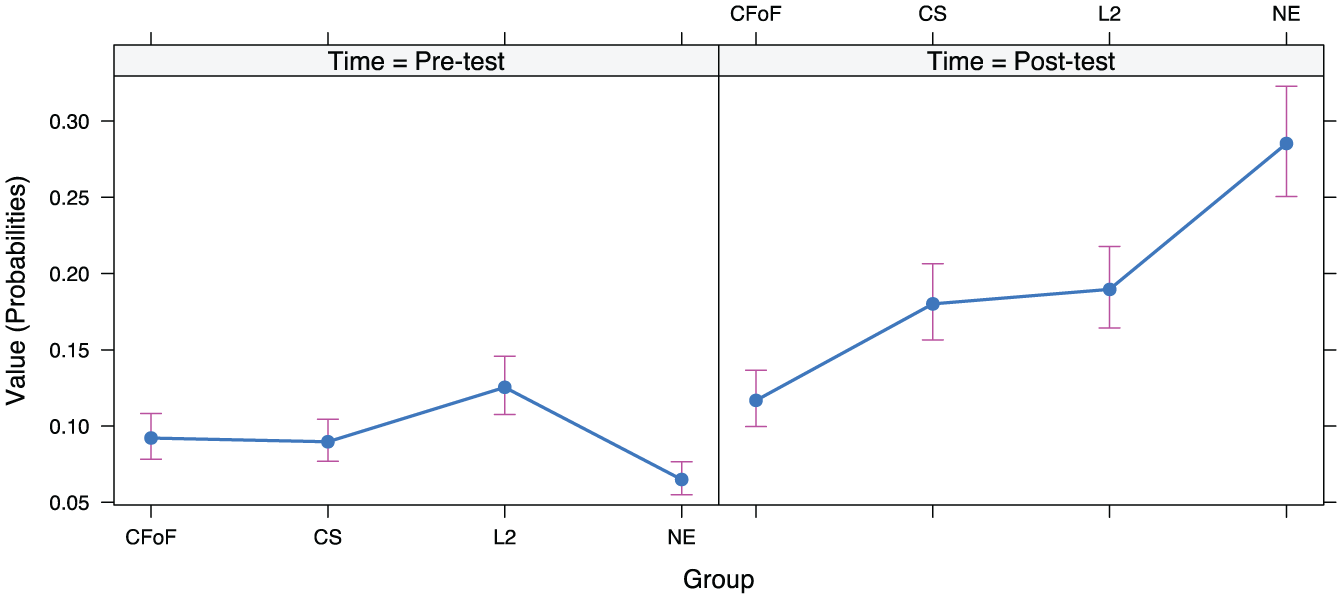
Group * Time effect plot: Listening comprehension.
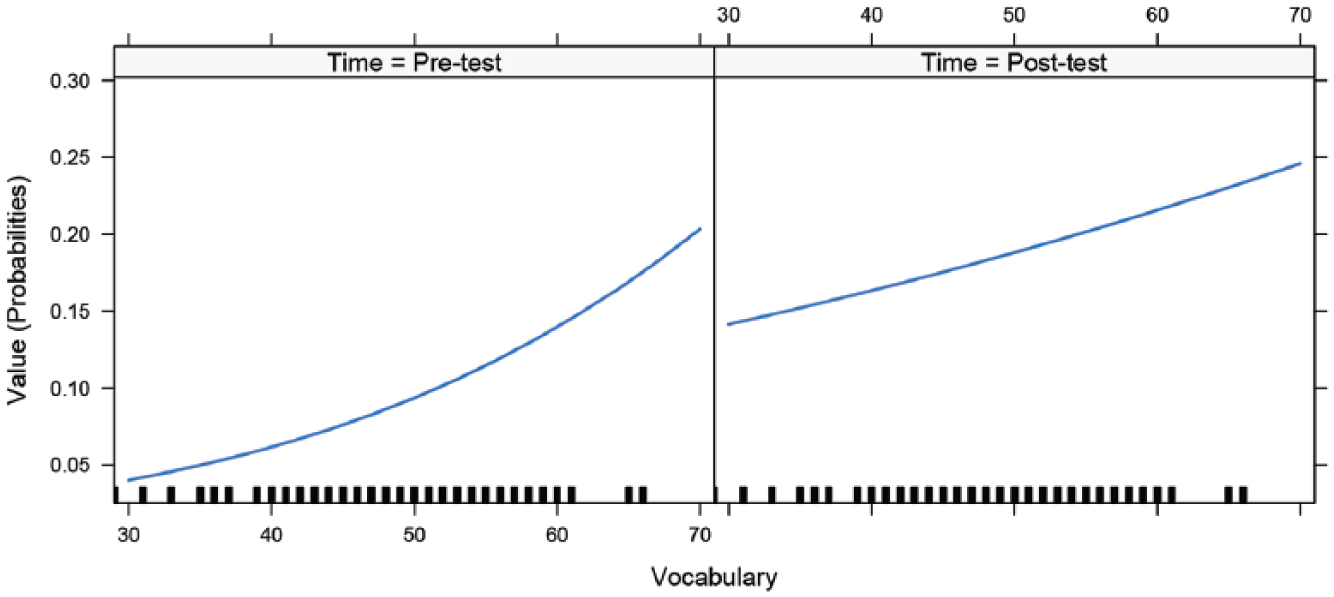
Time * Vocabulary effect plot: Listening comprehension.
VI Discussion
This study compared the impact of three types of intentional vocabulary instruction through listening, alongside listening only, on the short-term and long-term vocabulary learning of Chinese EFL learners. An emerging short-term advantage for vocabulary instruction with teacher CS was found compared with L2-only explanations, in terms of greater progress between Time 1 and Time 2, although not reaching statistical significance. Such a short-term advantage can be interpreted with reference to Jiang’s (2000) psycholinguistic model, namely that providing the L1 translation of the target L2 lexical item creates a link between the L2 word and its concept.
Any short-term advantage of the CS group over the L2 group disappeared, however, two weeks after the intervention, a finding similar to that of Tian and Macaro (2012) but differing from the longer-term advantage (1–4 weeks) reported by Hennebry et al. (2013) of using L1 translation over L2-only. In the latter study, however, for some items there was a delay of only one week, with gains made on those items potentially responsible for the overall advantage of the L1 translation group. Furthermore, in the present study, around 36% of the vocabulary knowledge recalled immediately after the intervention was retained two weeks later by the L2 group, compared with only 15% for the CS group. This is similar to what was found by Tian (2011), where learners in the non-codeswitching group retained 23% of the knowledge gained while the CS group only retained 17%. In other words, on balance the evidence suggests that teacher codeswitching for vocabulary explanations does not have long-term benefits when compared with L2-only instruction.
The present study differs from previous studies by exploring a third approach, Contrastive Focus-on-Form for vocabulary instruction. Results suggest both short-term and long-term value for CFoF over both teacher CS and L2, with the highest level of knowledge retention at the delayed post-test (52%). This supports Laufer and Girsai (2008)’s study, where learners who received contrastive form-focused instruction when completing reading comprehension tasks retained significantly more vocabulary items than their counterparts who received L2-only vocabulary explanations at both immediate post-test and one-week delayed post-test. The present study goes one step further however by comparing the giving of cross-linguistic information on vocabulary items with L1 translation as well as L2 vocabulary explanations. The long-term advantage of CFoF over both teacher CS and L2 points to the importance of ‘noticing’ (Schmidt, 1990), whereby cross-linguistic information makes an L2 word more salient to the learner and hence more likely to be retained.
Additionally, the benefits of teacher CS may be limited because of lexical fossilization, whereby learners do not move from the L1 mediation stage to the L2 integration stage suggested in the theory (Jiang, 2000), potentially because ‘the presence of L1 lemma within the L2 lexical entry may block the integration of L2 lemma information’ (Jiang, 2000, p. 55). Moreover movement to the L2 integration stage requires learners to extract further information about a word through contextualized input, something which, according to Jiang, may actually be less likely or slower to happen if learners can access the word’s meaning fairly automatically via the L1. The fact that learners who received CFoF instruction retained more vocabulary than both the L2 and the CS groups on a short-term as well as long-term basis suggests that CFoF can, to some extent, support L2 learners in moving to, or at least approaching, the L2 integration stage.
Regarding the NE group, although they scored significantly lower than the three treatment groups at post- and delayed post-test, they still made small but significant pre- to post-test vocabulary gains. This indicates that vocabulary knowledge can be acquired incidentally through listening, confirming what was found by Vidal (2011) among university-level students. Contrary to Vidal (2011) however, incidental learning through listening within the present study was found to be unstable in the long-term. The NE group’s performance dropped below pre-test levels at the delayed post-test. This may be attributable to the relatively low language proficiency of these school EFL learners, compared with the university-level participants in Vidal (2011). Like the lowest proficiency students in that study, whose vocabulary gains through listening were small and short-term compared with high proficiency students, learners in the present study may have struggled with speech segmentation, isolating lexical items, inhibiting the establishment of ‘stable long-term memory representations’ (Vidal, 2011, pp. 244–245) in phonological memory that Vidal sees as responsible for vocabulary retention through listening.
Turning to our second research question, and notably to the issue of the ‘cost–benefits of Lexical Focus-on-Form by the teacher’ (Tian & Macaro, 2012, p. 371), we found a complex relationship between vocabulary and listening comprehension. On the one hand, learners’ vocabulary size did significantly predict their listening scores, reflecting the strong relationship between these two factors that has been previously established (e.g. Stæhr, 2009). Likewise, learners across groups with the lowest vocabulary scores at the outset made the most progress in listening, suggesting that vocabulary instruction helped their listening. On the other hand, the NE group, who made the least progress in vocabulary learning, showed the most marked improvement in listening; likewise the CFoF group, who had the greatest vocabulary gains, did not improve the most in listening scores and indeed were significantly below the NE group on listening at post-test. Such findings are nevertheless consistent with conclusions reported for L1 reading comprehension (Wright & Cervetti, 2017), where comprehension gains were rarely found to occur where items taught in interventions did not feature in the comprehension tests used, as was the case in the present study. It is also possible that learners in the NE group, receiving no vocabulary explanations, sought to gain a more global understanding of the passages, and had to work harder to make sense of what they heard. While this focus on broader meaning may be less useful for vocabulary acquisition (Vidal, 2011), it may have helped the NE group to develop certain types of strategic behaviour which then enabled them to improve their ability to construct coherent meaning from the listening text.
VII Limitations
Random assignment at the individual level was not possible in the study and would also threatened its ecological validity. Establishing comparability between the four groups on the baseline General English Vocabulary Test was undertaken to minimize the limitations posed by non-random assignation, however.
Two further potential limitations concern the non-identical format of the vocabulary pre-test compared with the post- and delayed post-test, and target item selection. How far words are learnt incidentally depends, amongst other things, on how important they are for understanding the meaning of the passage (Wright & Cervetti, 2017) in which they feature. While the majority of target items we selected were important for overall understanding of the intervention passages, we did not control for this factor, which may have had a bearing on levels of incidental learning for the NE group. Both of these two potential limitations were however minimized through the use of generalized linear mixed-effects models.
VIII Conclusions and pedagogical implications
Alongside the advantages gained through the use of generalized linear mixed-effects models, the study’s strengths also lie in its use of aural rather than written vocabulary tests to bring greater consistency between the testing and teaching modality. Additionally, ensuring an equal testing delay for all vocabulary items, and that the NE group as well as the intervention groups completed all tests (Tian & Macaro, 2012), lends greater credibility regarding the findings relating to long-term and short-term learning. Consequently, we feel able to conclude that within communicative classrooms in which oral input is a more central component, it is worth promoting vocabulary learning through listening, given that all groups, including the NE group, made at least short-term vocabulary gains. However, vocabulary learning through listening should be supplemented by explicit Focus-on-Form teaching with some, but only short-term, advantage to be gained through code-switched explanations. In order to achieve the greatest vocabulary gains on a long-term basis, however, providing additional information about words through CFoF seems to have particular benefits.
Regarding learners’ listening comprehension performance, the CFoF approach, although achieving the most impressive vocabulary gains, was the least beneficial for listening development. By contrast, the NE group made the least progress in vocabulary learning, but showed the most marked improvement in listening. On a pedagogical level, these somewhat contradictory findings suggest that a balanced approach is needed, whereby teachers are clear about what it is they are aiming to achieve from certain classroom approaches. Arguably learners need both opportunities, to focus on listening in its own right, and to experience oral input with Contrastive Focus-on-Form teacher explanations as a way to enhance vocabulary knowledge.
In conclusion, the study not only contributes to our understanding of how vocabulary may be most effectively acquired through listening, but also provides new insights into the impact of such instruction on listening development. In so doing, it enhances understanding of the ‘cost–benefits of Lexical Focus-on-Form by the teacher’ (Tian & Macaro, 2012, p. 372), thus contributing to an under-researched area, with important implications for classroom practice.
Supplemental Material
Supplemental_materials_LTR – Supplemental material for Vocabulary learning through listening: Comparing L2 explanations, teacher codeswitching, contrastive focus-on-form and incidental learning
Supplemental material, Supplemental_materials_LTR for Vocabulary learning through listening: Comparing L2 explanations, teacher codeswitching, contrastive focus-on-form and incidental learning by Pengchong Zhang and Suzanne Graham in Language Teaching Research
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.