
Abstract
This study explored the relative effect of recasts on second language (L2) Korean learners’ accuracy development of the object relative clauses (RCs) and the honorific subject–verb (S-V) agreement in Korean and its relationship with language analytic ability (LAA). Forty-five L2 Korean learners participated in the study and five Korean native speakers participated as their dyadic partners. The learners were assigned into the recast group (n = 27) and the control group (n = 18). The recast group received recasts to their errors of the target forms from an interlocutor, a native Korean speaker, during their engagement in four communicative activities, but no recasts were provided to the control group. Three language tests (i.e. a pretest, an immediate posttest, and a delayed posttest) to measure accuracy development and a LAA test were applied to both groups. The study found that recasts benefited L2 Korean learners’ accuracy development of both forms, but their effects were not equal: recasts were more effective for the object RCs than the honorific S-V agreement. In addition, the results showed that LAA had a positive effect on the extent to which the learners benefited from recasts.
Keywords
I Introduction
The field of second language acquisition (SLA) has witnessed the proliferation of research into recasts for the past few decades (Li, 2010; Lyster & Saito, 2010; Nassaji, 2016; Sheen & Ellis, 2011). A recast is a type of corrective feedback (CF) generally defined as ‘a reformulation of all or part of a learner’s immediately preceding utterance in which one or more nontargetlike (lexical, grammatical, etc.) items is/are replaced by the corresponding target language form(s)’ (Long, 2007, p. 77). This definition evinces several reasons why recasts have received a great deal of attention from SLA researchers. First, as noted in the definition, recasts are offered immediately after a learner has made an error, and this can lead to the juxtaposition of the incorrect form and the correct form. In addition, since a recast is a reformulated version of what a learner has just said, she has a clear understanding of the meaning delivered in the recast. The juxtaposition of the forms allows for noticing the gap and the meaning the learner intends to convey still remains in the recasts. All of these advantages can lead to generating an optimal condition for form-meaning mapping and for successful second language (L2) learning (Doughty, 2001; Long, 2007; Schmidt, 2001). Recasts are also generally classified as an implicit CF strategy since they do not explicitly point out that learners made errors and, therefore, are less likely to interrupt the flow of communication in L2 classrooms.
SLA researchers have conducted a great deal of research to empirically examine the aforementioned advantages inherent in recasts; however, the findings are mixed. Based on these mixed findings, researchers have identified a number of factors that determine the degree to which recasts facilitate L2 learning (Goo & Mackey, 2013; Lyster & Saito, 2010). The factors are largely grouped into two types: learner internal factors (Li, 2013; Révész, 2012) and learner external factors (Li, 2013; Mackey, Gass, & McDonough, 2000; Nassaji, 2009). Learner external factors include the focus of L2 instruction (e.g. meaning vs. form-based instruction), target language features (e.g. morphosyntactic vs. lexical features), and the form of recasts (e.g. declarative vs. interrogative form). Learner internal factors include language proficiency, working memory capacity, language aptitude, and so on. Although it has been claimed that these external and internal factors may affect the effectiveness of recasts on L2 development, there is still a need for exploring how these factors interact in the process of L2 learning.
To this end, the current study focused on one external factor and one internal factor: target language features and language aptitude. While previous studies examined the role of recasts in English as an L2 and a few examined other Indo-European languages, scant research has been conducted to examine how recasts affect the process of learning Korean language as an L2 (for written CF, see Park, Song, & Shin, 2016). For this reason, the study investigated the relative effects of recasts on learning two different forms in Korean. Moreover, taking into account the growing interest in how language aptitude influences the ways in which learners benefit from CF (Li, 2013, 2015a, 2015b; Robinson, 2005; Skehan, 2014; Yilmaz, 2013), the study examined how recasts differently affected L2 accuracy improvement according to learner language aptitude, especially language analytic ability.
II Literature review
1 Effects of recasts on different linguistic forms
The differential effects of recasts according to the type of target features, especially in languages other than English, require further empirical investigation. One of the studies that addressed this issue is Li (2014). Li compared the effects of recasts with metalinguistic feedback on the development of the Chinese perfective -le and classifiers. Li also considered learner proficiency levels. The study reported that, overall, metalinguistic correction had larger effects than recasts at the low proficiency level, but high-proficiency learners benefited equally from metalinguistic feedback and recasts. However, the effects of recasts were constrained by the target features. For the perfective -le, recasts were only beneficial for the high-proficiency level while recasts were effective for the development of classifiers at both levels. Li noted that ‘[c]lassifiers are salient, involve transparent form-meaning mapping’ (p. 391) and that this allowed for learners’ noticing of recasts regardless of their proficiency levels.
Jeon (2007), the most relevant study to date for the current study, also attributed the differential effectiveness of recasts to the salience of the target forms. Jeon investigated the role of recasts on the development of lexical items and two morphosyntactic forms, the object relative clauses (RCs) and the honorific subject–verb (S-V) agreement in Korean. Forty-one Korean L2 learners participated in the study, and they had a one-on-one interaction with a native speaker of Korean while engaging in communicative activities. Errors of the target forms were corrected with recasts. The study reported that recasts were effective only for lexical items and the object RCs because the forms were more salient in input compared to the honorific form.
Like Jeon (2007), Lee (2002) examined L2 Korean learners’ incorporation of corrective recasts targeting the object RCs and the honorific morpheme -si in a small-scale study. Nine students were exposed to two treatment conditions (i.e. receiving model forms or recasts) during an oral picture-description task. The number of correct production of the target forms after each treatment was counted. The study reported that recasts resulted in a higher rate of correct production than models in both forms, and, in particular, recasts had a greater effect on the honorific morpheme -si. This result was not congruent with Jeon (2007). Lee did not explain why recasts were more effective for the honorific -si, so it is unclear whether or not and how Lee related the salience of the target forms to the differential effects of recasts.
Unlike previous studies that have considered salience as a determining factor of the effectiveness of CF, Yilmaz and Yuksel (2011) found no relationship between the salience and the effects of recasts. Twenty-four English native speakers with no Turkish background participated in the study. Prior to the experiment, the participants studied 51 Turkish words which would be used during the experimental tasks. Two target structures, the plural morpheme /-lAr/ and the locative case morpheme /-DA/, were selected, and the plural was categorized as a more salient morpheme than the locative case based on Goldschneider and DeKeyser’s (2001) work. Recasts were given to the target forms during communicative tasks, and they equally contributed to developing both forms. However, using the same design of Yilmaz and Yuksel (2011), Yilmaz (2012) reported counterevidence, proving that the salience of target language features mediated the effectiveness of both explicit correction and recasts.
Salience has been valued as an important factor that mediates the effectiveness of CF. However, the salience of a form does not ensure that learners will notice the form, nor do learners attend only to the salient form (Leeman, 2003). Following Jeon (2007), the current study examined the influence of recasts on the accuracy development of two different forms with different levels of salience: the object RCs and the honorific S-V agreement in Korean. Jeon’s study is noteworthy in that it examined an underexplored area: the relative effects of recasts on L2 Korean learning. However, the study has a few critical methodological constraints, including the lack of controlling participants (e.g. no distinction was made between heritage and non-heritage learners and an uneven number of participants was tested for the target features), and not accounting for the number of times participants were exposed to the forms. The current study noted these limitations and attempted to overcome them while examining the same morphosyntactic forms in L2 Korean. Detailed explanations of the two forms are presented in the method section.
2 Corrective feedback and language analytic ability
Learners differ from each other enormously with regard to cognitive factors such as language aptitude, intelligence, and learning strategies, and it has been argued that these individual differences affect language learning processes and outcomes (Dörnyei, 2005; Sanz & Lado, 2015). In particular, the influence of language aptitude on L2 learning has been debated in SLA literature for the past few decades and still remains controversial (Granena, 2013; Li, 2015a; Skehan, 2014, 2016). Language aptitude generally consists of three distinctive abilities: auditory ability, language analytic ability (LAA), and rote learning ability (Skehan, 1998). In his Macro-SLA aptitude model, Skehan (2016) proposed that different components of language aptitude should be effectively linked to various SLA developmental stages and their associated cognitive processes: auditory ability and rote learning ability are most likely related to the initial stage of input processing and to noticing, while LAA is related to the stages of pattern identification and restructuring, and extending. The current study focused on LAA because it is closely related to learning language rules and developing accuracy.
Several studies have examined the role LAA plays in L2 learning (Erlam, 2005; Granena & Long, 2013; Li, 2015b), but the outcomes are inconsistent. Erlam (2005), for instance, investigated the relationship between LAA and three different instruction types (i.e. deductive, inductive, and structured input). While LAA was not related to the learning outcome in the deductive instructional intervention, learners with greater LAA benefited more from the inductive and structured input settings than learners with lower LAA. This result suggests that when learners are in the conditions where they need to find some language norms on their own, LAA plays an important role. However, Granena and Long’s (2013) research into language aptitude and L2 ultimate attainment reported a different finding. L1 Chinese speakers of L2 Spanish participated in the study, and they were divided into three groups according to when they began learning Spanish (i.e. before the age of 6, between the age of 7 and 15, and after the age of 15). No relation was found between learners’ LAA and their performance on grammar competence in any of the groups (for a more comprehensive meta-analysis, see Li, 2015a).
The research into LAA in relation to different types of CF has also resulted in conflicting outcomes. Sheen (2007) compared the effects of recasts and metalinguistic feedback in the acquisition of English articles and explored whether or not LAA mediated the effects of CF. She reported that the effect of metalinguistic feedback was strongly related to LAA while the effect of recasts was not. In a similar vein, Li (2015b) reported that higher LAA was not connected to learners’ development of the Chinese perfective -le in response to recasts. However, other aptitude and CF research has resulted in opposite outcomes. Trofimovich, Ammar, and Gatbonton (2007) found a strong relationship between computerized recasts and LAA in the development of French speakers’ use of English possessive pronouns. Similarly, in Li (2013), the benefits of recasts on developing the accurate use of the Chinese classifiers were found to be sensitive to learners’ LAA, proving that LAA was a reliable predictor of accuracy gains via recasts.
Li (2015b) accounted for the inconsistent outcomes in the aforementioned studies based on the characteristics of the linguistic target. The English article a/the studied in Sheen (2007) and the Chinese perfective -le examined in Li (2015a) are non-salient and semantically opaque, while the English possessive determiners (his/her) in Trofimovich et al. (2007) and the Chinese classifiers in Li (2013) are relatively salient and simple structures. Li explained that even learners with high LAA had difficulty recognizing recasts that targeted non-salient features. This is a partly true and persuasive explanation, but it is an empirical question that needs more investigation. To answer the aforementioned ongoing issues on recasts, the current study investigated the following research questions:
To what extent do recasts have positive effects on the accuracy development of two different linguistic forms of Korean? Does the effectiveness of recasts differ across the forms?
Is a learner’s language analytic ability related to how much the learner benefits from recasts in improving accuracy?
III Methods
1 Participants
Forty-five learners of Korean as a foreign language who had attended or were attending Korean language institutes affiliated with three different universities in Korea participated in the study. They had different nationalities (i.e. 11 were American, 8 were Canadian, 8 were German, 6 were Italian, 6 were Australian, and 6 were Spanish). They were recruited via flyers seeking specifically non-heritage learners of Korean whose native languages (NLs) were Indo-European languages and who did not have a learning experience of other Asian languages, such as Japanese or Chinese. Limiting participants’ NLs and learning experiences had the goal of minimizing the potential effects of NL on the results of the current study. Originally 58 learners applied, but the study used data from only 45 learners. Although all of the participants self-identified as intermediate learners based on the level of Korean classes they attended, it would not be accurate to affirm that they had the same level of Korean proficiency because they were enrolled in different institutes. Thus, as a means of minimizing the influence of the participants’ prior knowledge of the two target forms on the research outcome, a pretest was used to screen out possible individual variations. The data from 13 out of 58 participants who either showed no knowledge of the target forms or gained high scores (above 70 percent of accuracy rates) in the pretest were excluded.
Among 45 learners, 15 learners had studied Korean before coming to Korea and the mean time of studying Korean in their home countries was 5.7 months. Seven of them had learned Korean on their own using media and online materials, and the other 8 had attended Korean classes. Thirty of the students started studying Korean as they arrived in Korea by taking classes but their previous exposure to Korean via the media in their countries of origin was limited, and their average time studying Korean was 4.8 months. The average time studying Korean of all the participants was 7.5 months, and their average time residing in Korea was 6 months (for learner profiles, see Appendix 1). The participants were randomly assigned to an experimental group (n = 27) and a control group (n = 18). The experimental group consisted of 16 English speakers, 5 German speakers, 3 Italian speakers, and 3 Spanish speakers. The control group was comprised of 9 English speakers, 3 German speakers, 3 Italian speakers, and 3 Spanish speakers. The age of participants ranged from 18–25. Five Korean native speakers who were master’s degree students at the department of Korean Studies at a university participated as dyadic partners. They were familiar with the procedure for providing recasts and also practiced recasts with the researcher.
2 Target language forms
a Relative Clauses (RCs)
The RC construction in Korean has the following characteristics. First, the RC precedes the noun it modifies. In addition, there is no relative pronoun; instead, relativization is signaled by a set of adnominal verbal suffixes, -(u)n, -nun, and -(u)l, called relative markers, which are attached to embedded predicates (Sohn, 1999) as shown in (1) and (2).
(1) Subject RC: [namca- man-ACC push-REL.PRE woman ‘the woman who pushes the man’ (2) Object RC: [namca- man-NOM push-REL.PRE woman ‘the woman that the man pushes’ (ACC = accusative marker, REL = relative marker, PRE = present tense, NOM = nominative marker)
One of the most robust findings in the field of L2 syntax is that English subject RCs are easier to produce and understand than direct object RCs regardless of NL backgrounds (Doughty, 1991; O’Grady, 2011). O’Grady, Lee, and Choo (2003) also reported that learners of Korean had a strong preference for subject RCs over direct object RCs, just like learners of English, despite the very substantial differences between the two languages with respect to the structure of RCs. Based on these previous findings, the current study focused on the use of direct object RCs in Korean, the relatively more difficult RCs for L2 Korean learners.
b Honorific subject–verb (S-V) agreement
Honorification is defined as a ‘direct grammatical [encoding] of relative social status between participants, or between participants and persons or things referred to in the communicative event’ (Brown & Levinson, 1987, p. 179). Korean language has a complex and systematic lexical and morphological honorification rule, and it is very important to use appropriate honorific forms to express politeness toward the person being addressed. This study focused on the agreement of the honorific nominative case marker -kkeyse and the honorific verb suffix -si in an honorific sentence (3).
(3) Honorific S-V Agreement ( Halapeci- Grandpa-SUBJ.HON newspaper-ACC read-u-HON-SEN.ENDER ‘Grandpa reads a newspaper.’ (SUBJ.HON = subject honorific, ACC = accusative marker, HON = honorific verbal suffix, SEN.ENDER = sentence ender)
Generally, in the Korean language curriculum most widely used across institutes, the honorific S-V agreement is introduced prior to the object RCs, but the two forms are taught at the beginning levels before learners move to the intermediate levels. L2 Korean learners whose NLs have a different RC construction system and do not have honorification typically find it difficult to learn these features. Compared to the RCs, it can be argued that the honorific S-V agreement has relatively lower perceptual and constructed salience (Gass, Spinner, & Behney, 2018). Perceptual salience refers to intrinsic salience: ‘how noticeable and or explicit a linguistic structure is in the input’ (Loewen & Reinder, 2011, p. 152; emphasis in original). Constructed salience takes place ‘when some outside source creates a context for some feature to become prominent’ (Gass et al., 2018, p. 7). Goldschneider and DeKeyser (2001) noted that morphophonological regularity influences perceptual salience. They defined morphophonological regularity as ‘the degree to which the functors are (or are not) affected by their phonological environment’ (p. 26), and suggested that functors with more alternations are less salient and acquired later. The honorific verb suffix -si has three variations according to the phonological environment: (1) the morpheme -si occurs with an epenthetic vowel [u] when the verb stem ends in a consonant, but (2) when the verb stem ends [l] sound (e.g. mil-da), [l] gets dropped and [u] is not inserted; (3) when the verb stem ends in a vowel, no epenthetic vowel is added. These variations can make the honorific S-V agreement less salient in input. In addition, the communicative value of the honorific form can create not only low perceptual salience but also low constructed salience. Communicative value refers to ‘the relative contribution a form takes to the referential meaning of an utterance and is based on the presence or absence of two features: inherent semantic value and redundancy within the sentence-utterance’ (VanPatten, 1996, p. 24). The honorific case marker -kkeyse and the honorific suffix -si are redundant in the sense that the subject such as grandfather or grandmother indicates that a speaker is talking about a person who is an elder. Thus, this can create low perceptual salience. Furthermore, in the current study, the learners were engaged in negotiation for meaning via communicative activities (see Treatment Materials). The accurate use of the object RCs is critical for meaning negotiation while the correct use of the honorific S-V agreement is not due to the communicative redundancy, and this context can generate low constructed salience in the honorific S-V agreement.
3 Design, procedures, and materials
a Overall procedures
In the first session of the study, the participants took a pretest of target forms, a LAA test, and answered background questionnaires. In the second and third sessions, each learner participated in two communicative activities with a Korean native speaker. While recasts mainly focused on the target forms, the learners in the recast group received recasts to the errors of the target forms from the interlocutor and other errors that led to communication breakdowns from the interlocutor. In contrast, the learners in the control group did not receive any corrections. Immediately after the third session, the learners took posttests, and then they took delayed posttests two weeks later (see Table 1 for overall procedures). All instructions related to the activities, the tests, and other information were provided in both Korean and English.
Overall procedures.
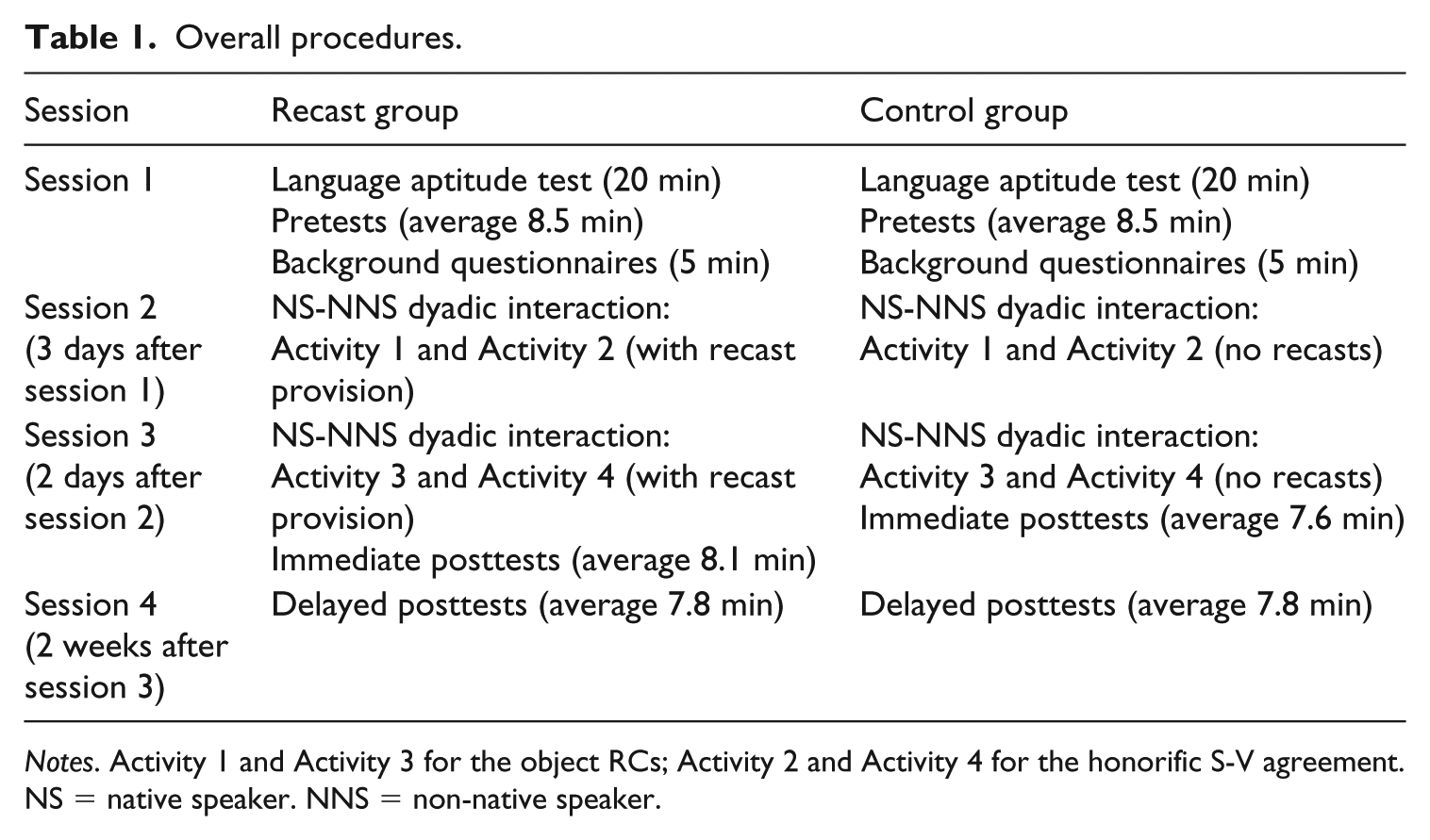
Notes. Activity 1 and Activity 3 for the object RCs; Activity 2 and Activity 4 for the honorific S-V agreement. NS = native speaker. NNS = non-native speaker.
b Treatment materials
Four communicative activities were designed to put the learners in a situation that required them to use the target forms in order to complete assigned tasks (for examples, see Appendix 2 and 3). In the first session, two activities were used, Activity 1 and Activity 2. In the second session, two other activities were used, Activity 3 and Activity 4. Activity 1 and Activity 3 were aimed at eliciting the use of object RCs. In Activity 1 and Activity 3, native speakers (NSs) and non-native speakers (NNSs) each had similar pictures with circles drawn around different objects and people. They were required to describe the pictures to each other to find out where the circles were drawn in their partner’s pictures. In each Activity, 16 circles were drawn to elicit the object RCs and 10 for the subject RCs. Activity 2 and Activity 4 were designed to elicit honorific forms. In both activities, NS and NNS interlocutors were asked to describe the people in the pictures to find out what actions they were executing. In each Activity, 16 items were designed to produce honorific expressions, and 10 items for non-honorification. In order to control the frequency counts of the target forms, the same numbers of object RCs and honorific S-V agreement were elicited and provided. The average time the learners spent on each activity was 13.8 minutes. Even though the activities were designed to elicit the target forms, they were classified as a two-way information gap activity. Since the main purpose of the interaction was to locate where the circles were drawn and what people were doing in their partner’s pictures through communication, the activities had communicative purposes (Moss & Ross-Feldman, 2003).
A great deal of research has revealed that the effects of recasts could be shaped by the way recasts are provided (Kim & Han, 2007; Sheen & Ellis, 2011). Thus, recasts in the current study were offered in a consistent manner: declarative form with a prosodic stress on the corrected form, as seen in (4) and (5) of the current study.
(4) Recasts on object RCs: NNS: Inho ankoiss-nun yeca-ey tongkulamika isseyo. Inho hold-REL woman-LOC Circle.TOP be-SEN.ENDER. NS: Inbo- Inho-NOM hold-REL woman-LOC Circle.TOP be-SEN.ENDER. ‘The circle is on the woman Inho is holding.’ (ACC = accusative marker, REL = relative marker, NOM = nominative marker, SEN.ENDER = sentence ender) (5) Recasts on honorific S-V agreement: NNS: Apeci-kkeyse kulim-ul kulie-yo. Father-SUBJ.HON picture-ACC draw-SEN.ENDER NS: Apeci-kkeyse kulim-ul kuli- Father-SUBJ.HON picture-ACC draw-HON-SEN.ENDER ‘Father is drawing a picture’. (SUBJ.HON = subject honorific, ACC = accusative marker, HON = honorific verbal suffix, SEN.ENDER = sentence ender)
c Testing materials and data coding
Knowledge of the object RC constructions was assessed through picture description tests. NNSs were required to orally describe where the 25 circles were drawn in the pictures (15 for object RCs and 10 for distractors). Three versions of the test, each with different items, were used as a pretest, an immediate posttest, and a delayed posttest. The learners’ answers were recorded. All of the correct and incorrect object RCs produced by the learners were first identified and coded. One point was given to a correct construction of object RCs (e.g. correct use of a nominative subject along with its correct particle and correct use of relative marker along with correct verbal inflection). A half point was given to an incomplete target-like construction. For instance, a learner correctly produced a relative marker but failed to use the nominative case marker for the subject of the embedded sentence; see (4). When all elements of a RC were incorrect, no points were given. A perfect score in each test equaled 15.
To test the knowledge of honorific S-V agreement, a specific context was generated which played a crucial role in the appropriate use of honorifics in Korean. The learners were instructed to talk about family members and other people in the picture (15 cases were for honorification and 10 for distractors). Three different versions of the test, each with different items, were used in a pretest, an immediate posttest, and a delayed posttest. The learners’ answers were recorded and coded. One point was awarded when a learner correctly used the honorific case marker -kkeyse in the honorific subject and correctly conjugated the verb with the honorific suffix -si. A half point was given when a learner produced a partially correct form. For example, a learner correctly used the case marker but failed to correctly conjugate the verb with the suffix –si; see (5). No points were given if no form of honorific morpheme was produced. A perfect score of each test was 15. A subset (35 percentages) of the data from the language tests was also coded by an independent rater. The inter-rater reliability was measured by Cohen’s Kappa coefficient: .86 for the object RCs and .81 for the honorific S-V agreement. The result proved that there were near perfect agreements between the raters (Landis & Koch, 1977).
The study used the LAA test employed by Schmitt, Dörnyei, Adolphs, and Durow (2003). A list of words and sentences from an artificial language that included English translations was given to the learners. They were asked to choose the correct English translation for 14 sentences from the choices provided in the artificial language. In order to select the correct translation, the learners needed to induce the rules behind the artificial language from the examples provided. Since the test was new and challenging to the learners, the researcher guided them through the first question in the test. A perfect score for the test equaled 14.
IV Results
Prior to answering the two research questions based on the results from the tests, here the number of the obligatory contexts, of the target forms the learners attempted to use, and of the errors the learners produced during the communicative activities is addressed. Each individual learner in both the recast and control groups was given an equal number of obligatory contexts while engaging in the activities. In the case of the recast group (n = 27), while engaging in Activity 1 and Activity 3 targeting the object RCs, the learners attempted to produce 706 instances of the target form out of 864 required situations (81.71%) (i.e. 432 cases in each activity; 16 obligatory contexts in each activity multiplied by the number of learners: 16 × 27 = 432), following the rule they were given (see Appendix 2). In the other 158 cases, the learners violated the rule (e.g. just saying where the circle is in Korean such as ‘pangwul’). Out of the 706 instances, they committed 377 errors in the target form (53.40%), and the errors were treated 321 times with recasts (85.15%). In Activity 2 and Activity 4 targeting the honorification, the learners made 505 errors out of 864 attempts (58%), and recasts were provided for 441 cases (87.33%). In the case of the control group (n = 18), in Activity 1 and Activity 3, the learners attempted to use 432 instances of the object RCs out of 576 obligatory cases (75%) (i.e. 288 cases in each activity, 16 obligatory contexts in each activity multiplied by the number of learners: 16 × 18 = 288). In the other 144 cases, they did not follow the given rule. Out of the 432 instances, they made 299 errors in the object RCs (69%). In Activity 2 and Activity 4, targeting the honorific S-V agreement, the learners made 410 errors out of 576 attempts (71%).
When comparing the number of attempts made by the recast group and the control group, it appeared that the recast group made slightly more efforts to use the form in Activity 1 and Activity 3. However, when the attempts made in each activity were counted separately, in Activity 1 the control group made relatively more attempts to use the target form (210 out of 432, 48.87%) compared to the recast group (308 out of 706, 43.63%). In contrast, in Activity 3 the recast group attempted to use the form (398 out of 706, 56.37%) more often than the control group (222 out of 432, 51.13%). It can be assumed that the recast group made more attempts to use the target form after the first treatment session took place during Activity 1. When the number of errors committed by the two groups was considered, the recast group made less errors during the communicative activities. However, this should not be interpreted to mean that the recast group performed better than the control group in the first place. When the errors occurring in each activity were counted, in Activity 1 and Activity 3 targeting the RCs, the recast group made 201 errors out of 308 attempts (65%) and the control group produced 140 errors out of 210 attempts (67%) in Activity 1. In Activity 3 the recast group committed 176 errors out of 398 attempts (44%), and the control group produced 159 errors out of 222 (71%). In Activity 2 and Activity 4, targeting the honorific form, the recast group made 275 errors out of 432 (64%) and 230 errors out of 432 (53%) respectively and the control group committed 201 errors out of 288 (70%) and 209 errors out of 288 (73%) respectively. The number of errors the recast group made decreased as the activity proceeded.
1 Effects of recasts on two different linguistic forms
In order to examine the differences between the recast and the control groups’ accuracy in the use of both forms prior to the feedback session, an independent t-test was employed. The accuracy development of the two forms over the testing period was assessed by conducting mixed between-within group repeated ANOVAs with test scores as a dependent variable and with time as a within-group independent variable and feedback treatment as a between-group independent variable. Effect size for the ANOVAs were calculated as eta-squared (ŋ²) with values of .01, .06, and .14 indicating small, moderate, and large effects, respectively (Cohen, 1988). A Bonferroni post-hoc analysis was performed.
Table 2 shows the descriptive statistics for the object RCs and the honorific S-V agreement over the three testing periods: pretest, posttest 1 (immediate posttest), and posttest 2 (delayed posttest). An independent t-test found no statistically significant differences in the pretest scores between the experimental and the control groups in both target forms, t(43) = .60, p = .55, d = .21 for the RCs and t(43) = −1.59, p = .12, d = .46 for the honorific S-V agreement. The small effect size (d value) of the t-test (Plonsky & Oswald, 2014) 1 verified that there was little difference between the accuracy scores of the recast group and the ones of the control groups for the target forms in the pretest.
Descriptive statistics of the object RCs and the honorific S-V agreement.
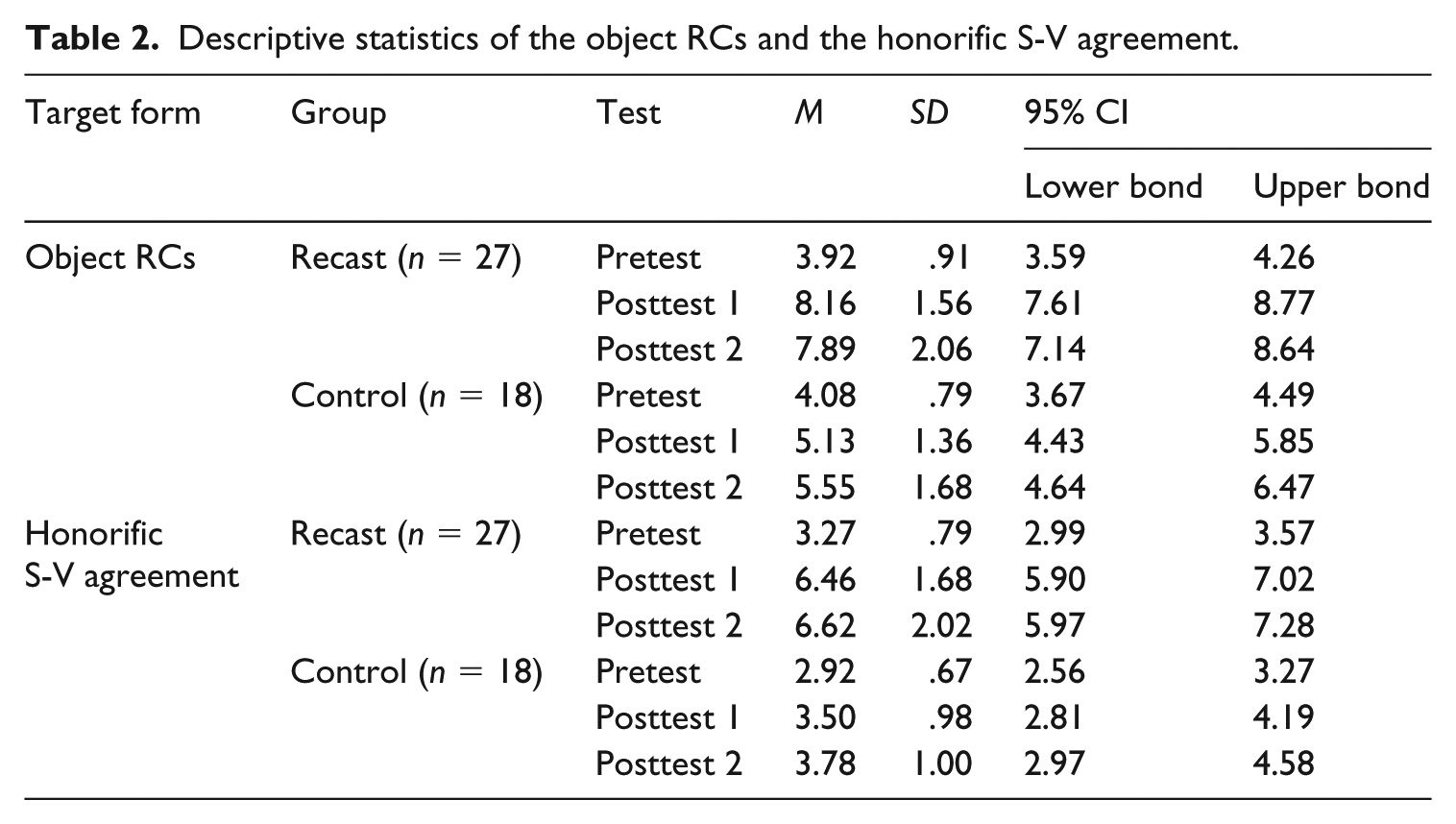
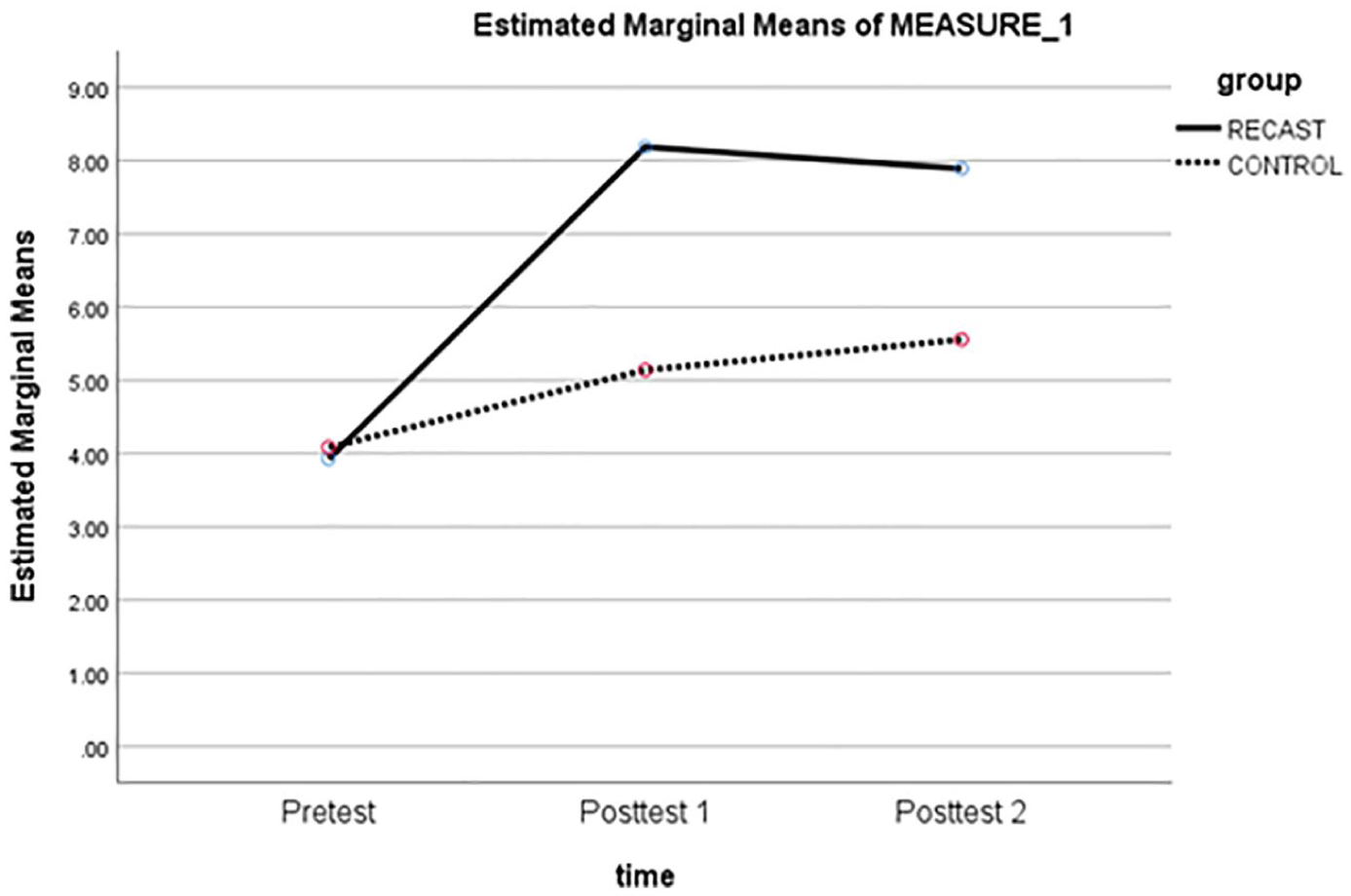
The analysis of ANOVA for the RCs proved that there were significant effects for group and time and a significant time × group interaction (see Table 3 and Figure 1). 2 This means that the recast group showed notable accuracy improvements over time and performed significantly better than the control group. The large effect sizes indicated the substantive significance of recasts in the accuracy gains for the RC over time. Post-hoc pairwise comparisons between the test scores in the recast group revealed that while there were significant differences between the pretest and the posttest (p <. 001) and the pretest and the posttest 2 (p <. 001), there was no significant difference between the posttest 1 and the posttest 2 (p = .484). This indicated that the recast group significantly improved accuracy of the RCs over time and that the gains remained throughout the study.
Results of repeated-measures ANOVAs.
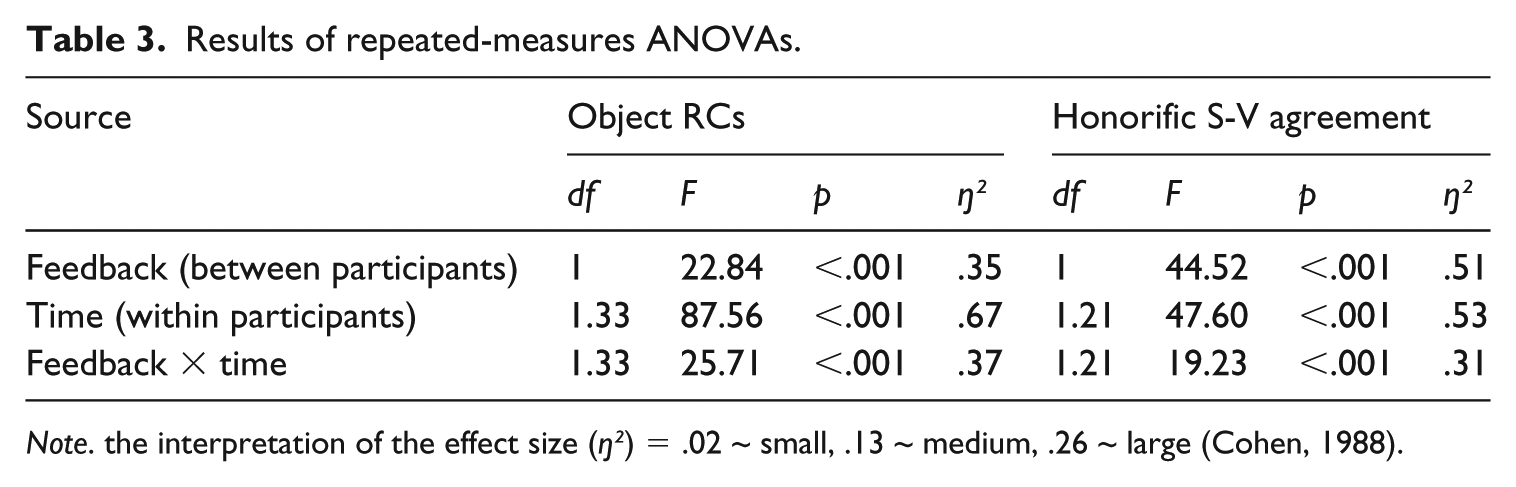
Note. the interpretation of the effect size (ŋ²) = .02 ~ small, .13 ~ medium, .26 ~ large (Cohen, 1988).
Test scores of recast and control groups: Object RCs.
An additional mixed between-within group ANOVA was performed to investigate the learners’ improvement in the use of honorific S-V agreement over the testing period (see Table 3 and Figure 2). The result showed significant effects for group and time and a significant time × group interaction. This indicated that the recast group showed significant accuracy improvements over time and also improved far more than the control group. The large effect sizes verified the substantive significance of recasts in the accuracy development for the use of honorific S-V agreement over time. A post-hoc analysis of the test scores in the recast group found significant differences between the pretest and the posttest 1 (p < .001) and the pretest and the posttest 2 (p < .001), but no difference was observed between the posttest 1 and the posttest 2 (p > .05). This showed that recasts were effective in the accuracy development of the honorific S-V agreement, and its effects remained throughout the study. This result is congruent with the learners’ accuracy gains in the object RCs.

Test scores of recast and control groups: Honorific S-V agreement.
A within group repeated ANOVA revealed that the learners in the recast group showed greater improvement in their use of the object RCs than in their use of the honorific S-V agreement, F(1, 26) = 24.51, p < .001, ŋ² = .49 (see Figure 3). This indicates that recasts were more effective for the object RCs compared to the honorific S-V agreement.
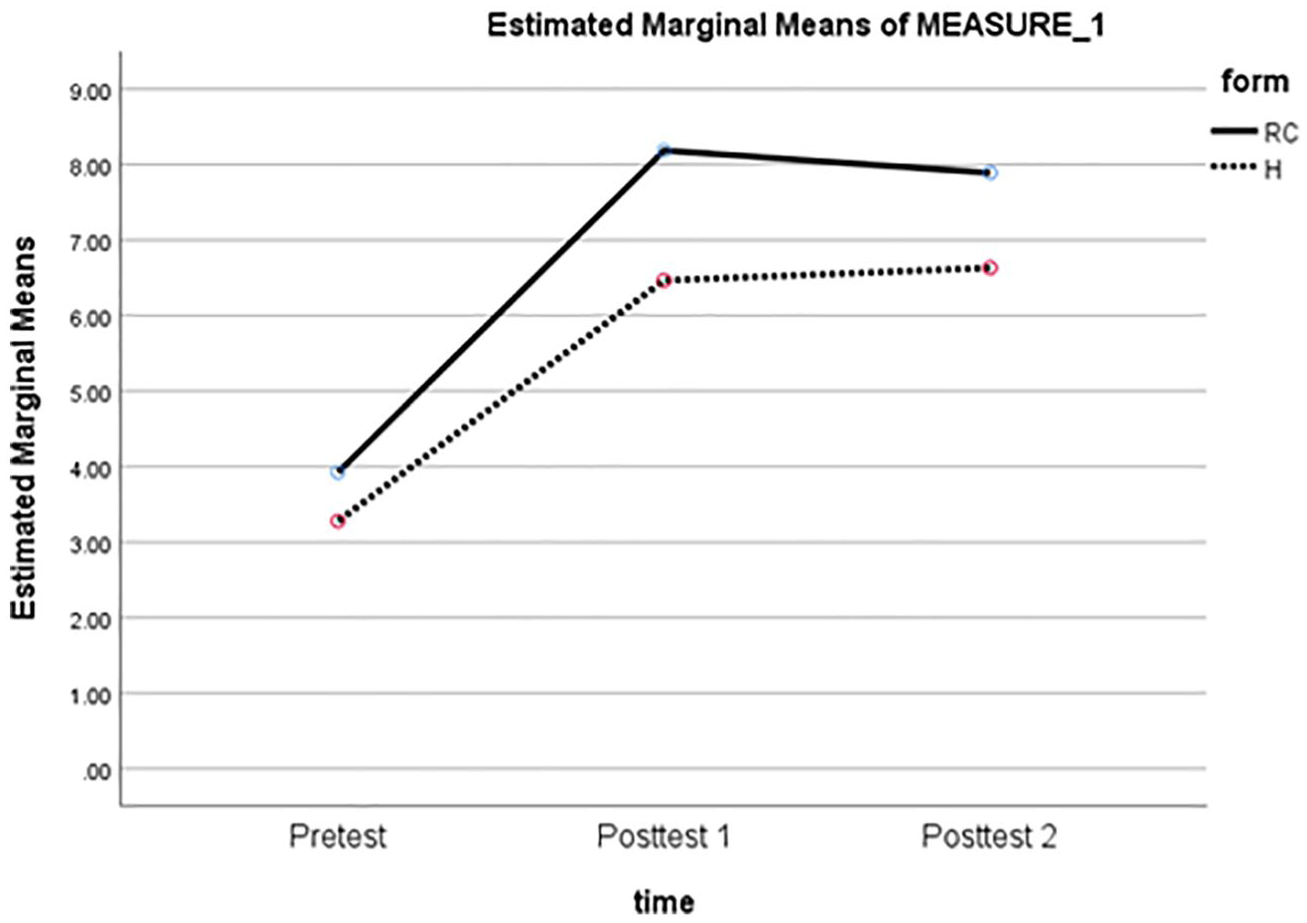
Test scores of RCs and honorific S-V agreement: Recast group.
2 Recasts and language analytic ability
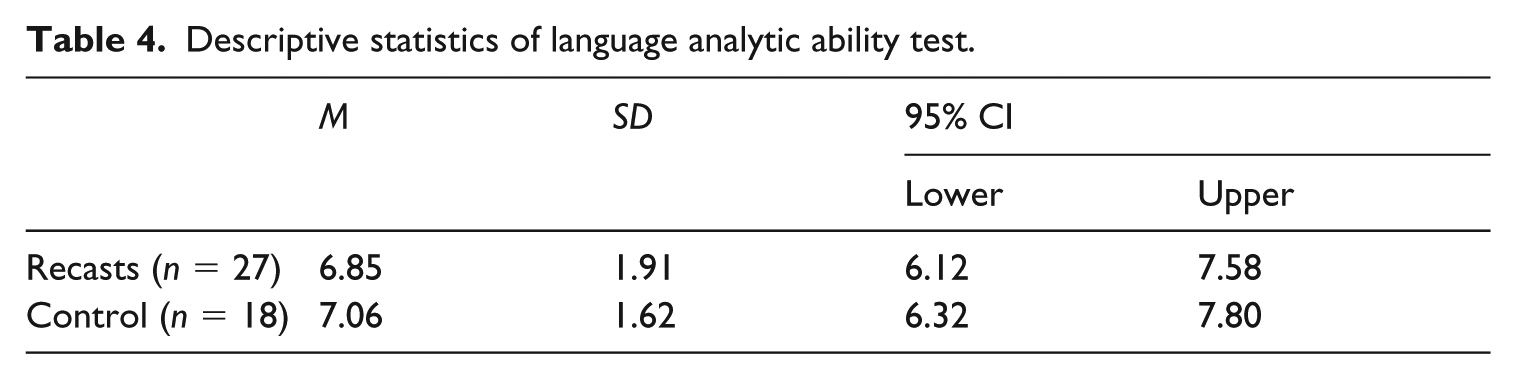
Table 4 shows descriptive statistics of the learners’ LAA in both groups. An independent t-test was performed to check whether the groups’ LAA test scores differed. The test result proved no significant group difference, t(43) = .37, p = .713, d = .11. In order to examine the possible L1 influence on the LAA test results, the mean scores of the LAA test in the recast and the control groups across L1s were calculated:16 English speakers (M = 6.94), 5 German speakers (M = 6.80), 3 Italian speakers (M = 6.67), and 3 Spanish speakers (M = 6.67) in the recast group; 9 English speakers (M = 7.12), 3 German speakers (M = 7.0), 3 Italian speakers (M = 7.00), and 3 Spanish speakers (M = 7.33) in the control group. In addition, the mean scores of the LAA test across L1 groups were calculated: 25 English speakers (M = 6.96), 8 German speakers (M = 6.87), 6 Italian speakers (M = 6.83), and 6 Spanish speakers (M = 7.0). Due to the uneven number of learners in each L1 group, conducting a statistical analysis was not appropriate. However, based on the mean scores, it could be suggested that learner L1 only had a minor influence on the LAA test results.
Descriptive statistics of language analytic ability test.
A Pearson product-moment correlation coefficient was computed to assess the relationship between LAA and the improvement the learners showed between the pretest and the posttest 1, the pretest and the posttest 2, and the posttest 1 and the posttest 2. There was a significant relationship between LAA and development in both forms. As seen in Table 5, for the object RCs, the students’ accuracy gains exhibited between the pretest and the posttest 1 (r = .77) and the posttest 2 (r = .88) were strongly related to their LAA (Plonsky & Oswald, 2014). A similar result was reported for the honorific S-V agreement: Pretest – Posttest 1 (r = .81) and Pretest – Posttest 2 (r = .79). The strength of the relationship between the two posttests became moderate (r = .56 for the RCs and r = .42 for the honorification) (Plonsky & Oswald, 2014), but it was still meaningful. In short, the learners with high LAA gained more benefits from recasts than those who had low LAA.
Correlation between language analytic ability and accuracy gains.
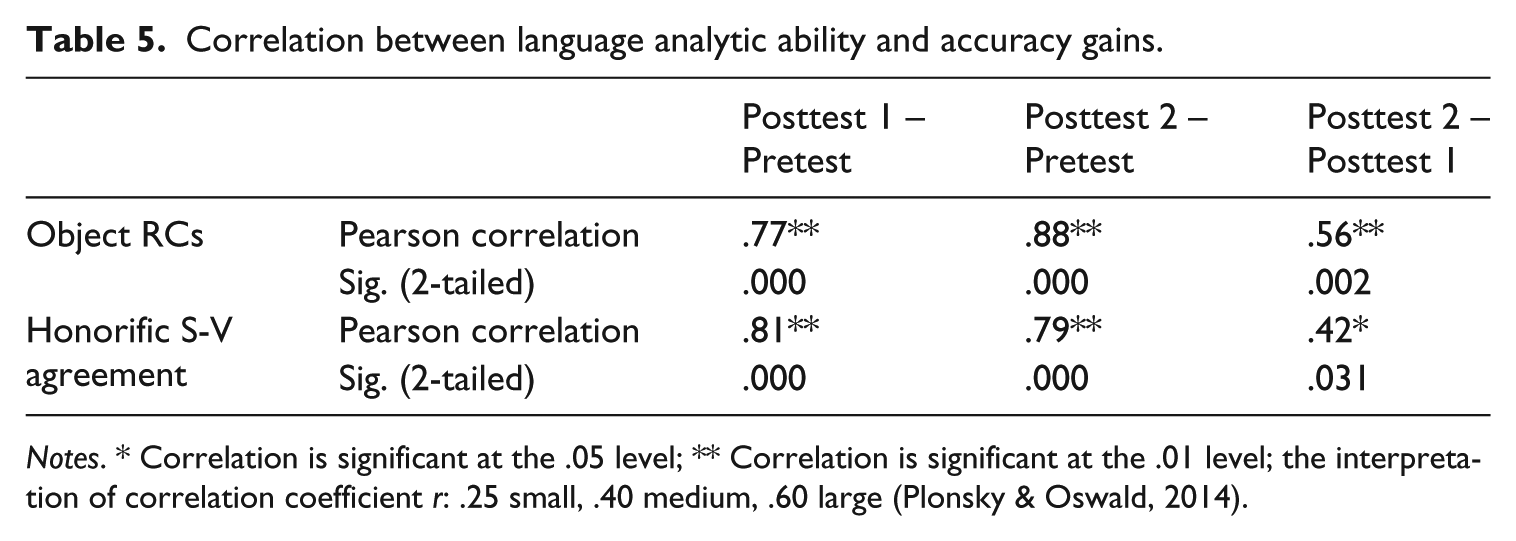
Notes. * Correlation is significant at the .05 level; ** Correlation is significant at the .01 level; the interpretation of correlation coefficient r: .25 small, .40 medium, .60 large (Plonsky & Oswald, 2014).
V Discussion
The results of the current study indicated that recasts were effective in the accuracy development of the object RCs and the honorific S-V agreement. However, recasts were more effective for the object RCs. This result was congruent with Jeon (2007). Differential effects can be first accounted for based on the different levels of salience and communicative values of the two forms. As explained earlier, the honorific S-V agreement is less salient and has lower communicative value than the object RCs. The variations of the suffix -si might hinder learners from noticing recasts targeting the error of the form. In addition, the inaccurate use of -kkeyse and the honorific suffix -si were less likely to hinder the interlocutors from correctly understanding each other’s meaning. In contrast, the accurate use of the relative and nominative markers might be important since the errors on these markers easily result in a communication breakdown.
At this point, however, one question arises. As mentioned previously, Lee (2002) reported an opposite outcome: learners more often produced accurate incorporation of recasts targeting the error of the honorific -si than of the object RCs. The different outcomes might reside in that, while Lee measured the incorporation of recasts (i.e. modified output), Jeon (2007) and the current study assessed learners’ accurate use in the posttests after recast treatments. However, considering that learners’ incorporation of CF has been valued as an indication of their noticing of the corrected forms (Egi, 2010), one can say that in Lee learners noticed the correction targeting the honorific -si more often than the object RCs. In other words, the honorific -si was noticeable; thus, the different measurement used in Lee may not entirely account for the different results obtained in both Jeon and the current study.
Another possible explanation can be offered based on Lee’s (2002) narrow focus on the use of the suffix -si without considering -kkeyse. In Korean, some variations in honorific rules are possible in the use of -si and -kkeyse depending on the relationship among speaker, referent, and addressee. For instance, let us consider the case where a speaker is talking to her grandfather about her father. According to the traditional honorific rule, honorific expressions should not be used as in (6), since the addressee (grandfather) is older than the referent (father) (The National Institute of the Korean Language, 2011).
(6) Halapeci, apeci-ka thoykun-hayss-sup-ni-ta. Grandfather, father came back from work.
However, nowadays, the following sentence is also acceptable. In (7), the verb suffix -si is used although the addressee is older than the referent (The National Institute of the Korean Language, 2011).
(7) Halapeci, apeci-ka thoykun-ha- Grandfather, father came back from work.
Still, (8) is not acceptable although a certain degree of honorification is acceptable as in (7).
(8) Halapeci, apeci- Grandfather, father came back from work.
It might be complicated for L2 Korean learners to identify when they should or should not use -kkeyse and -si and learn the proper use of various honorific expressions. Especially, when their L1 does not have honorifics, as in the current study, learning Korean honorifics can be very challenging since learning honorifics is more than just learning a language form. Brown (2011) notes that using the honorifics requires more than just knowing ‘how’ and ‘when’ to use the forms. Using honorifics ‘require[s], at least on some level, that the speaker adopts or negotiates a “Korean” identity and the social positions and roles that this entails’ (p. 85). The use of honorifics necessitates the understanding of social convention and norms. This point of view leads us to consider Kecskes’ (2006) argument: what becomes salient to L2 learners depends on conventions and familiarity with both linguistic and sociocultural experiences. Thus, one can say that the honorific S-V agreement is not salient not only from a linguistic perspective but also from a sociocultural perspective for the participants of the current study who have a short period of exposure to Korean language and society and whose L1 does not have honorifics. Furthermore, the use of the honorific particle -kkeyse is sometimes replaced by other subject markers such as -i and -ka in informal situations. It is easy to hear Korean speakers articulate a sentence like the one in (9): (9) Sensayng-nim- The teacher speaks a word.
In this sentence, the verb suffix -si is used, but -i replaces the honorific particle -kkeyse. Grammatically and pragmatically it is not appropriate. Nevertheless, in an informal spoken context, -i or -ka is very often used as a subject particle. Exposure to this kind of language input might lead learners to hypothesize that both -i (-ka) and -kkeyse are acceptable. Along with the low salience and communicative value of the honorific S-V agreement, its complex, alternative, and informal usages might hinder learners from recognizing recasts as corrections to their incorrect use of the honorific S-V agreement. They might think of recasts as an alternative way of expressing the same meaning.
The current study also corroborated the positive role that LAA has in L2 accuracy development (Li, 2013; Skehan, 2016; Trofimovich et al., 2007): learners with higher LAA showed more accuracy development in both object RCs and honorifics compared to learners with lower LAA. Recasts can boost learner noticing of certain linguistic forms in input by offering both positive and negative evidence (Leeman, 2003), but they do not explicitly indicate that learners have made errors and do not provide any explanations for the rule. In order to benefit from recasts, learners should notice and find the rule on their own, and in this regard, LAA seems to play an important role: ‘learners with stronger analytical skills may be more likely to engage in a “deeper” processing of a recast and therefore undertake a more efficient analysis of its formal properties than learners with weaker analytic skills’ (Trofimovich et al., 2007, p. 193). Benson and DeKeyser (2018) also emphasized the power of LAA in inferring the rule. The study showed that participants with lower LAA benefited more from metalinguistic feedback than direct correction. Direct correction provides models but not the rule like recasts do, while metalinguistic feedback offers the rule. Finding the rule ‘puts more of a burden on the learner’ and in this case ‘aptitude becomes more important’ (p. 19).
Learners’ LAA was related to accuracy improvement in both target forms regardless of their different levels of salience, and this finding differs from Li’s (2015b) claim that there is no relationship between LAA and recasts in the development of non-salient language features. One of Li’s arguments for the ineffectiveness of recasts for learning non-salient features was that recasts might not be explicit enough to be considered as correction for even learners with high LAA. In Sheen (2007), Li (2015b), and the current study, recasts were not offered in an identical way. However, recasts were offered in a similar way in that they were used in a relatively explicit form, targeting the predetermined language forms (i.e. intensive recasts). In addition, they were also provided in a declarative form with some emphases on the corrected part (e.g. prosodic stress on the corrected part or reformulation of the only incorrect segment). Therefore, the degree of explicitness generated by the manner of recast provision might not be the reason for the divergent findings. The question remains, then, what would be? It might be that the explicitness of recasts learners perceive is also determined by the context where recasts are used (Lyster & Mori, 2006). Sheen (2007) conducted the study in intact classes, and recasts were offered to the errors learners made while retelling a given story to the whole class. Learners would be less attentive to recasts provided in a classroom than recasts offered in a one-on-one dyadic interaction. In Li (2015b), as in the current study, recasts were offered in a dyadic interactional context. Although both Li and the current study used the communicative activities designed to elicit the target forms, the activities employed in this study might have been more form-oriented in that learners were asked to make descriptions within a given condition (e.g. using the provided sentence subject). This condition might have led learners to attend to form, and learners with high LAA might have noticed and interpreted recasts as correction targeting even the less salient form, the honorification. Yilmaz’s (2013) assertion supports this explanation: ‘when learners notice the corrective intent in implicit feedback, a stronger relationship between learners’ performance and cognitive abilities (i.e. LAA and WMC) could be expected’ (p. 362).
VI Conclusions
Due to their implicit nature, recasts may result in varying L2 learning outcomes depending on the salience of the targeted forms and learners’ LAA. In this regard, recasts may be explicit enough to draw attention to forms, provided that the forms under consideration have high salience and communicative value and that learners have high LAA. However, if the targeted forms are not salient and have low communicative value, the teacher needs to consider ways of enhancing the noticeability of the corrected forms when providing recasts. This can be done by stressing the corrected forms and targeting a single error. For those forms, explicit CF could be a more appropriate strategy. Furthermore, it seems crucial to clearly explain to learners the rules for forms that diverge from their L1 in linguistic and/or sociocultural usage and/or which have alternative usages depending on the situation (e.g. the honorific S-V agreement). This would help them to conceptualize the unfamiliar forms and social norms, and this could also prevent them from arriving at incorrect hypotheses based on the varying input they receive outside the classroom. In addition, while learners are expected to figure out the rule of the corrected form when the teacher uses recasts as a CF strategy, those with weaker LAA might be less capable of identifying and generating rules than learners with stronger LAA. Thus, in order for learners with weaker LAA to develop accuracy, it would be more effective to provide a preceding rule explanation session before the teacher uses recasts as interactional CF rather than using recasts alone (Erlam, 2005).
As a means of concluding this article and suggesting future research directions, five major limitations are pointed out. First, in this study, recasts were provided to language forms about which the participants already had some prior knowledge. Providing recasts that target language forms about which learners have little knowledge may yield different outcomes. Since recasts provide not only negative evidence as correction but also positive evidence, it has been argued that they are useful to address language errors about which learners have little knowledge (Long, 2007). Thus, it would be worth examining the roles of recasts and LAA in learning L2 structures about which learners have little knowledge (Li, Zhu, & Ellis, 2016). Second, the current study focused on two forms which have different levels of communicative value and salience. There are other elements which decide the level of difficulty in learning L2 forms, such as frequency and complexity (Ellis, 2007). Future research that investigates how these elements influence the effects of recasts on L2 development is certainly needed. Third, in the current study, the pretest was used as an attempt to minimize individual variations from prior knowledge of the target forms, but this could not rule out the possibility that the participants’ overall proficiency would affect the extent to which they benefited from recasts. Controlling the level of learner proficiency in a more carefully regulated way needs to be guaranteed in future research. Fourth, the three versions of the tests (Pretest – Posttest 1 – Posttest 2) were not counterbalanced in administering the tests. Although the study ensured that each test was equally difficult by using the pictures depicting similar situations across the tests, the possibility that the different versions of the tests influenced the results should be acknowledged. Finally, in the current study, recasts were offered during a one-on-one interaction in a laboratory setting, and the results cannot represent how recasts work in a classroom. In order to increase ecological validity, classroom-based research is needed to offer useful information and guidelines for L2 classroom instruction.
Supplemental Material
APPENDIX_Table_Pictures – Supplemental material for The relative effect of recasts on L2 Korean learners’ accuracy development of two different forms and its relationship with language analytic ability
Supplemental material, APPENDIX_Table_Pictures for The relative effect of recasts on L2 Korean learners’ accuracy development of two different forms and its relationship with language analytic ability by Ji Hyun Kim in Language Teaching Research
Footnotes
Appendix
Learner profiles.
| Student | Gender | Nationality | Age | First language |
Language(s) spoken other than one’s L1 and Korean | Length of time studying Korean in home county (months) | Length of time studying Korean in Korea |
Length of residence in Korea |
|---|---|---|---|---|---|---|---|---|
| 01 | Female | USA | 21 | English | Spanish | 6 | 5 | 7 |
| 02 | Male | USA | 24 | English | French | 4 | 4 | |
| 03 | Female | USA | 18 | English | Spanish, Italian | 5.5 | 4 | 6 |
| 04 | Female | USA | 22 | English | Spanish | 5 | 5.5 | |
| 05 | Female | USA | 19 | English | Spanish, French | 6 | 4 | 8 |
| 06 | Male | USA | 22 | English | Spanish | 5.5 | 6.5 | |
| 07 | Male | USA | 25 | English | Spanish | 5 | 5.5 | |
| 08 | Female | USA | 22 | English | French | 5 | 5 | 7 |
| 09 | Female | USA | 24 | English | Spanish | 5 | 5 | |
| 10 | Female | USA | 21 | English | Spanish, French | 7 | 5 | 7 |
| 11 | Male | USA | 21 | English | Spanish | 6 | 5 | 7 |
| 12 | Female | Canada | 20 | English | French | 6 | 5 | 8 |
| 13 | Female | Canada | 22 | English | French | 5 | 6 | |
| 14 | Female | Canada | 22 | English | 3 | 4 | ||
| 15 | Female | Canada | 21 | English | French | 6 | 4 | 8 |
| 16 | Male | Canada | 20 | English | 3 | 4.5 | ||
| 17 | Male | Canada | 19 | English | French | 5 | 7 | |
| 18 | Male | Canada | 19 | English | 5 | 8 | ||
| 19 | Female | Canada | 20 | English | French, Italian | 4 | 5 | |
| 20 | Male | Germany | 22 | German | English, French | 5 | 5.5 | |
| 21 | Male | Germany | 24 | German | English | 5 | 6 | |
| 22 | Female | Germany | 20 | German | English, French, Italian | 6 | 5 | 7 |
| 23 | Female | Germany | 22 | German | English | 4.5 | 5 | |
| 24 | Female | Germany | 20 | German | English, Italian | 5 | 3.5 | 6 |
| 25 | Male | Germany | 22 | German | English | 5 | 5 | |
| 26 | Male | Germany | 22 | German | English, French | 6 | 5 | 7 |
| 27 | Female | Germany | 23 | German | English | 5 | 6 | |
| 28 | Female | Australia | 19 | English | Italian | 5 | 4 | 6.5 |
| 29 | Male | Australia | 20 | English | Italian | 5 | 5.5 | |
| 30 | Male | Australia | 19 | English | 5 | 6 | ||
| 31 | Female | Australia | 20 | English | 5 | 5 | ||
| 32 | Female | Australia | 22 | English | French | 4 | 5 | |
| 33 | Male | Australia | 23 | English | 5 | 6.5 | ||
| 34 | Female | Italy | 20 | Italian | English, French, German | 6 | 4 | 7 |
| 35 | Male | Italy | 24 | Italian | English, French | 6 | 7 | |
| 36 | Female | Italy | 20 | Italian | English, French | 6 | 7 | |
| 37 | Female | Italy | 19 | Italian | English | 5 | 4 | 6 |
| 38 | Male | Italy | 21 | Italian | English, German | 5 | 5 | |
| 39 | Female | Italy | 22 | Italian | English, French | 3.5 | 4 | |
| 40 | Male | Spain | 24 | Spanish | English | 5 | 6 | |
| 41 | Male | Spain | 20 | Spanish | English | 5 | 4 | 6 |
| 42 | Female | Spain | 21 | Spanish | English, French | 5 | 6.5 | |
| 43 | Female | Spain | 19 | Spanish | English | 6 | 6 | |
| 44 | Female | Spain | 22 | Spanish | English | 5 | 5 | |
| 45 | Male | Spain | 25 | Spanish | English | 4 | 5 |
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.