
Abstract
Lexical inference through reading is considered an important method for vocabulary building; however, empirical research has not consistently offered strong evidence of the application of lexical inference in second language vocabulary learning. A recently burgeoning line of research focuses on second language (L2) lexical inference of compounds in Chinese, a language that is both orthographically and typologically distant from English. In this study, we asked intermediate level Chinese L2 learners to think aloud while performing inferencing activities. We discuss the benefit of supportive context to inferencing and learning, and learners’ coordinate and interactive use of context and word-internal cues. Further, we proposed a model that captures such interactivity and highlights the composite of Chinese L2 learners’ intraword awareness. This suggests that interactive use of various cue sources and a simultaneous focus on form and on meaning can lead to encouraging outcomes for lexical inferencing and retention.
I Introduction
Vocabulary learning from context has always drawn considerable interest from reading and language acquisition researchers. Since children build vocabulary rapidly through reading, which also constitutes an essential source of exposure to new words in the second language (L2) context, it has been hypothesized that lexical inferencing, the process of identifying the meanings of unfamiliar words using cues from the word itself and its surrounding context, may be a first step in incremental vocabulary learning for foreign language students. However, in reality, learners often do not attempt to infer the meanings of unfamiliar words when encountering them in reading (Wesche & Paribakht, 2009, p. 10). Therefore, some scholars have introduced various additional treatments such as enhanced text presentation, gloss on digital platforms, and repeated practices to help learners focus on the form and meaning of particular words in order to improve learning outcomes (e.g. Grace, 1998; Laufer & Rozovski-Roitblat, 2015; Webb, 2008; Wesche & Paribakht, 2000). Regardless, the literature generally reported low retention of lexical information through lexical inferencing in reading (e.g. Hu & Nassaji, 2012; Waring & Takaki, 2003). Compared to the number of studies performed on lexical inference in second language (L2) learning of alphabetic languages such as English, much less is known regarding the mechanisms and nature of lexical inferencing in L2 Chinese. While some recent studies have suggested that certain knowledge sources such as vocabulary and morphological awareness contribute to L2 Chinese compound inferencing (e.g. Ke & Koda, 2017, 2019), it is imperative, both pedagogically and theoretically, to investigate how learners use different knowledge sources coordinatively when engaged in the process, and how learning and retention can be enhanced. The purpose of the current study is to address these issues.
II Literature review
1 Vocabulary learning through lexical inference
Despite on-going interest in the effectiveness of learning vocabulary through lexical inference in context, scholars have acknowledged that natural context (i.e. authentic reading texts without modifications for pedagogical purposes) can be confusing, ambiguous, or may even provide cues contrary to the unfamiliar words’ actual meaning (Frantzen, 2003; Hamada, 2014). Even when the context is considered to play a ‘supportive’ role, it generally provides only ‘cues’ to the meaning and does not reveal an exact definition of the target word. Effective use of contextual information for vocabulary acquisition may also be more challenging for L2 learners than for first-language (L1) children because L2 learners are limited by their linguistic proficiency, knowledge of vocabulary, and unfamiliarity with the spoken form of words (Bensoussan & Laufer, 1984). One should also be aware of the differences between inferencing and learning. While successful lexical inference can constitute the initial step of gaining lexical knowledge (Wesche & Paribakht, 2009), some argue that this step lacks robust representation and often cannot be retained (Elgort & Warren, 2014).
An analysis of the results of existing L2 studies indicates that the success rate of lexical inference has indeed generally been low. For instance, Frantzen (2003) reported a 28% accuracy rate from with-context inferencing before classroom treatment. Nassaji (2006) found that out of a total of 199 target words in reading passages specifically designed for lexical inference, participants were only able to completely infer the meaning of 51 and partially infer the meaning of 37 words. Researchers of lexical inference, specifically of kanji in Japanese using Chinese characters, also reported a relatively low success rate, including Chen (2018) (averages of 0.54 and 0.59 out of a total score of 2.0 respectively for without-context and with-context scenarios), Kondo-Brown (2006) (16.7% accuracy rate), and Mori (2002) (0.71, 0.75, and 1.39 out of four, respectively, for kanji-only, context-only, and kanji-context-both conditions). Moreover, many earlier studies suffered from the limitation that retention over time was not measured by a later test. For scholars who did include this vital piece, retention was low. For instance, Hu and Nassaji (2012) reported that among the 59 words successfully inferred from reading passages, 4 and 12 were retained, respectively, for easy-to-infer and difficult-to-infer items after one week.
These outcomes suggest that lexical inference even within a supported context can be a challenge for learners, and if educators choose to use context-based lexical inference as a pedagogical tool for vocabulary learning, they must also incorporate theoretically sound instructional designs. From a theoretical perspective, Hulstijn and Laufer (2001) proposed the construct of ‘involvement load’, which suggests that lexical learning and retention can be enhanced if learners put significant mental effort into completing a cognitive activity. The concept consists of three components: a motivational component of ‘need’ (such as the need to not only comprehend but also to produce a word), and two cognitive components of ‘search’ (i.e. meaning identification) and ‘evaluation’ (e.g. making associations with other words and checking whether a guess fits into the context of the sentence). While the theory has been found to effectively explain L2 inferencing and general vocabulary learning in alphabetic languages (e.g. Nassaji & Hu, 2012; Wesche & Paribakht, 2009; Zou, 2017), it is necessary to explore how the cognitive components in these areas are manifested in a language that is typologically distinct from English.
2 L2 lexical inference in alphabetic languages
Contextual and word-internal information constitute two major cue sources in lexical inference (Mori, 2002; Paribakht & Wesche, 2006). The former can pose syntactic and semantic constraints that may help learners hypothesize the word’s lexical features, and word-internal strategies reflect learners’ intraword awareness, i.e. sensitivity regarding word structures and morphological and phonological knowledge (Koda, 2005). Most studies in alphabetic languages assess lexical inference within context. A productive line of research since Haastrup (1991) that utilizes introspective data has revealed that when inferencing, learners use word-internal strategies including phonological and orthographic structures of the word, morphology knowledge, and word associations by relying on shared clusters of letters, and context-based inferencing strategies including applying grammatical knowledge, semantic information, and extralinguistic knowledge (de Bot, Paribakht, & Wesche, 1997; Paribakht & Wesche, 1999).
Many scholars have analysed the relationship between context and inference, although they have yet to determine if learners primarily rely on contextual or word-internal sources to infer meaning, and if the process is inductive (i.e. one looks for contextual clues first) or deductive (one seeks word-internal clues first) (Huckin & Bloch, 1993; Wesche & Paribakht, 2009). To tease apart the relative strengths of information cues for inferencing, Hamada (2014) used a multiple-choice design with options giving meanings consistent with morphology and options giving meanings matching the context. She found that beginner-level ESL learners, compared to more advanced learners, relied more on morphological information. In general, evidence suggests that it is beneficial to combine these cue sources in lexical inference (Nassaji, 2006).
3 The Chinese writing system, word structure, and lexical inference
Studies of L2 lexical inference in Chinese have started to draw researchers’ attention only recently. Due to the language’s logographic writing system and distinctively prevalent compounding structure, lexical inference studies in Chinese may reveal cross-linguistic commonalities and language-specific patterns of how learners use context and intraword information. The following features of Chinese are relevant to our discussion. First, compounding is the major word formation strategy in Chinese, as over 75% of Chinese words are morphologically complex (Chen et al., 2009). Second, whereas an English word is visually presented as a linear cluster of letters, Chinese characters are more visually complex. A character is the basic orthographic unit that generally corresponds to a morpheme, which is typically monosyllabic in modern Chinese, although multi-syllabic (i.e. multi-character) morphemes also exist (DeFrancis, 1989). A character can be visualized as a two-dimensional square, which in most cases can be broken down into chunks (i.e. the smallest integral visual forms within a character that serve no semantic or phonetic function) or radicals (which are sub-character orthographic units with semantic or phonetic functions). For instance, 抱 (bao ‘hug; hold’) is the combination of a semantic radical 扌 meaning ‘hand’, and the phonetic radical 包 (bao), which is further composed of 勹 and 巳, chunks that do not contribute to the character’s meaning or sound. It should be noted that although the vast majority of Chinese characters (over 82%) are made up of a semantic and a phonetic radical (e.g. DeFrancis, 1989; Taylor & Taylor, 1995), semantic radicals contribute to the character’s meaning only indirectly, and phonetic radicals (due to sound changes over the years) do not usually provide reliable cues for form-sound mapping. Due to the unique characteristics of the Chinese writing system, intraword awareness, or requisite capabilities of morphological and phonological decoding of a word in lexical inference and recognition (Koda, 2005), may be very different in Chinese and English. In English, morphological awareness involves the ability to correctly segment linearly arranged letters for sound and morphological information. In Chinese, while structural awareness of how multi-syllabic words are linearly segmented is important, using information from sub-morphemic components such as phonetic and semantic radicals is also an inherent part of reading (Shu, Anderson, & Zhang, 1995; Taft & Zhu, 1997).
Due to the prevalence of compound structures in Chinese, earlier studies on lexical inference focused on the role of structures in decontextualized situations. Researchers often found that words with a parallel compound structure or a modifier-head structure are inherently easier to infer than others (Gan, 2009, 2010). 1 Recently, some scholars have uncovered preliminary evidence that greater morphological and orthographic awareness contributes to a higher level of lexical inference success. A recent series of studies, using word segmentation, morphological analysis, and multiple choice lexical inference tasks, suggested that morphological awareness contributed to L2 Chinese lexical inference directly (Wu, 2017; Zhang & Koda, 2018) or indirectly (Ke & Koda, 2017, 2019). Using correlation analysis similar to the above studies, Chen (2018) further contended that morphological awareness may be a significant contributing factor to inferencing success for more skilled learners. Moreover, Chinese as a foreign language (CFL) reading studies at the character level suggest that orthographic knowledge including the recognition of radicals and knowledge about their positional specificity (i.e. the feature of a certain graphemic symbol that it serves as a semantic radical only when it occurs in a certain position) plays a role in identifying the meaning of characters (Jackson, Everson, Ke, 2003; Xu, Chang, & Perfetti, 2014). Given these findings, it can be hypothesized that both morphological awareness and orthographic knowledge are inherent aspects of one’s ability to infer the meaning of Chinese compound words.
The above-mentioned studies were mostly carried out in decontextualized situations. To learn more about how learners combine word-internal and contextual cues, Fang and Jiang (2012) exposed learners to three conditions: compound words only, context only (where the target word was blacked out), and target words shown in context. They reported individual variations in how students were able to use cues, suggesting that context poses more syntactic constraints whereas word-internal structure yields more clues for semantic constraints. Huang (2014) and Huang (2018) were among the only studies to date that used a Think-Aloud Protocol (TAP) to investigate Chinese L2 lexical inference in reading. In her 2014 study, her intermediate proficiency level participants found sentence context clues and world knowledge to be the most useful strategies in contextualized lexical inference. In her 2018 study, she found that Chinese L2 learners often used strategies in clusters or pairs to facilitate the reading of passages. Specifically, out of 40 cases of successful word/phrase inference in a reading scenario, 23 involved simultaneous use of context and character meaning.
In sum, lexical inference studies of English revealed an array of word-internal and context-level strategies, and suggested that learners, depending on individual skill levels, may either over-rely on one of the sources or use them both. In addition, recent studies have focused on Chinese lexical inference in decontextualized scenarios; however, little is known about learners’ thought processes when they encounter unknown words in context. Across languages, evidence is scarce as to the extent of retention with regard to context-based inference. The present study on intermediate level Chinese L2 learners’ compound word inferencing attempts to bridge these gaps by employing the TAP technique. In addition, we investigate how cognitive processes involved in lexical inference may support the learning of Chinese compounds.
In order to isolate the variable that may be associated with structural compositions, we examined one specific compound structure in Chinese, namely the Resultative Verb Compounds (RVCs). This structure exemplifies how Chinese and English encode telic events differently. Thus, we may test the level of learners’ structural sensitivity in the second language through lexical inferencing. RVCs consist of two root verbs: V1 and V2, in which the former is an action verb indicating the cause, and the latter is a state or action verb indicating a change of state or an action caused by V1. The complement constituent in RVCs exemplifies the productive nature of Chinese morphemes (Xiao & McEnery, 2004) and is often polysemous, a feature consistent with the lack of one-to-one grapheme-morpheme mapping in Chinese. For instance, V2 complement -dao means ‘arrive’ in zou-dao ‘walk-arrive’ and means ‘attain’ in zuo-dao ‘do-attain; accomplish’. The complement can be in the form of multi-syllabic morphemes (zou-xiaqu ‘walk-downwards’), which requires structural sensitivity for segmentation. Due to the fact that RVCs are also frequently used, they pose quite a challenge for L2 learners (Wu, 2011; Zhang, 2011). 2 We ask the following research questions in this study.
To what extent does supportive context help with Chinese L2 learners’ lexical inference, as compared to decontextualized compound word inference? Can vocabulary learning, measured by retention, be observed in the context-based inferencing condition?
What word-internal and context-related strategies are used by L2 learners of Chinese when they encounter new compounds? In comparison to the taxonomy suggested in lexical inference studies in alphabetic languages, are there new patterns or strategies in L2 Chinese compound word inference?
What difficulties do learners encounter regarding compound word inferencing? What do these difficulties reveal about intermediate level learners’ ability to use context and their intraword awareness?
III Methodology
1 Participants and materials
Twenty-two students of Chinese as a foreign language (CFL) who were enrolled in a fourth semester Chinese language course at a university in Northeastern USA were recruited to participate in this study. At the time that the experiment was conducted, participants had received approximately 340 hours of classroom instruction in Chinese and had learned approximately 1,000 words. According to their scores on the required rigid placement test, all had similar proficiency levels.
The materials for the experiment consisted of 12 RVCs, which included six polysemous complements: -dao (‘arrive; attain’), -si (‘die’; exaggeration as in ‘starving to death’), -hao (‘well; complete’), -xiaqu (‘downward; continuously’), -qilai (‘up; start to’), -chulai (‘outward; out’). Those polysemous morphemes were chosen based on Thompson (1973) and Xiao and McEnery (2004), and in reference with L2 participants’ textbooks. Both the V1 and V2 morphemes, including their graphic forms and meanings, had occurred in other compounds or as free words in L2 learners’ learned materials in classes prior to the experiment. 3 This morpheme selection criterion was implemented so that learners would not be entirely unfamiliar with the graphic forms of the visually complex characters. For instance, prior to the experiment, participants had learned RVCs zou-dao (‘walk-arrive; walk to’) and ting-dao (‘listen-attain; hear’) from their textbooks. Therefore, they had prior exposure to examples of -到 with both the meanings of ‘arrival’ and ‘attainment’ in their RVC forms. Consequently, we designed two experimental items fei-dao (‘fly-arrive; arrive by plane’) and ban-dao (‘deal-attain; achieve’), where -dao indicates ‘arrival’ and ‘attainment’, respectively. In addition, we designed 12 sentences containing these compounds. The sentence context was directive and informative (Hamada, 2014), providing moderately strong cues to the target compounds. With the exception of the target compounds, all vocabulary words in the sentences were introduced in participants’ language curriculum prior to the experiment. We consulted the participants’ language instructors for advice regarding the finalization of the materials.
2 Procedure
Participants filled out a language background survey before the experiment. All were born in the USA. Ten of the 21 had taken one to five years of high school Chinese classes before enrolling in college-level courses. Three participants had family members who spoke Mandarin Chinese or other dialects. One had resided in China before the age of five, and three had experienced short-term stays in China ranging from two weeks to two months. As data from the main experiment did not indicate differences between these students and others, all participant data were included in further analysis.
The main tasks were conducted on paper-and-pencil, with a TAP technique. In the experiment, participants completed the tasks in language labs, and were instructed to speak out aloud into a recorder-connected microphone what was going through their minds when they were actively engaged in the task. In the 10-minute training session to familiarize them with the TAP technique, they were given practice items such as determining whether the composition of two characters constitutes a word and inferring the meanings of unfamiliar compounds with other morphological structures (e.g. nominal compounds with modifier-head structure). They were told to think aloud in either Chinese or English and were reminded to constantly verbalize their thoughts while inferencing.
Participants completed two tasks for the main experiment, which respectively constituted no-context and with-context inferencing conditions. In Task 1, participants were given written questionnaires containing a list of compound words. They were instructed to write down (in English) the meanings of the target compound words. After questionnaires for Task 1 were collected, participants went on to Task 2, in which target compounds appeared in sentences. TAP was used in both tasks. All participants completed Task 1 in 10 minutes and Task 2 in 20 minutes. 4 Target words and sentence contexts for the two tasks are shown in Appendix 1.
A delayed posttest to assess retention was conducted three weeks after the main experiment. The written section contained a list of 22 compounds with the 12 RVC items from the main experiments and 10 fillers. The fillers were all two-character novel compounds in other structures with familiar morphemes. The target and filler items were randomized in the order of presentation. Participants were asked to write down the meanings of those compounds and the procedure took approximately 5 minutes.
3 Coding
After data were collected, participants’ TAP recordings were transcribed. Scores on each response were based on both their written responses and transcriptions. Responses were scored based on the following criteria. One score was assigned to each of the two morphemes and one additional score was assigned to the internal structure of the result verb.
0: The participant provided no meaningful response or gave a meaning unrelated to the target item (e.g. participant responded with ‘put on’ for ti-chulai ‘kick out’).
1: The participant interpreted one morpheme correctly, whereas interpretation of the other morpheme was incorrect or absent. The response was somewhat relevant to the correct answer (e.g. a response of ‘to end/die’ for yang-si ‘raise (a pet) badly that it died’).
2: The participant provided a meaning that was mostly correct. For instance, the participant accurately interpreted one of the two constituents as well as segmented and analysed the compound’s structures; however, he or she inaccurately interpreted the other constituent (e.g. a response of ‘continue kicking’ for ti-chulai ‘kick out’, or a response of ‘start to snow’ for xia-qi-yu-lai ‘start to rain’).
3: The participant provided an answer that was correct. (Minor script errors were disregarded.)
For this part of the coding (i.e. scoring), the two researchers first went through a small subset of participants’ responses (10 items) and discussed scoring for items of uncertainty. After resolving ambiguities of scoring, the two authors independently scored all responses. The Pearson’s r for the inter-rater reliability was 0.987. Any discrepancies were resolved through discussion.
For coding the introspective data (i.e. participants’ inferencing process) and developing categories for participants’ inferencing strategies, we adopted an open code approach (Creswell & Creswell, 2018). After reading over the transcripts to get an overall sense of the information and jotting down notes, the first researcher (i.e. first author) independently developed codes for various strategies using previously identified inferencing categories discussed in the literature. She added new codes and deleted irrelevant ones based on observed patterns in the current data and grouped the codes when appropriate. She also checked the data and coding several times before determining that the chosen categorization strategy best reflected the data. The second researcher then reviewed the coding system based on examples and referred back to the entire introspective dataset to determine if more codes needed to be developed or eliminated.
IV Results and discussion
1 Facilitation of context
Our first research question concerned the potential facilitation of context in the outcome of lexical inferencing with regard to vocabulary learning. We will discuss comparisons of means between the no-context and the within-context conditions as well as the levels of retention observed in the delayed posttest. Participants achieved mean scores of 1.52 for Task 1 and 2.14 for Task 2. The pairwise t-test showed significant differences between participants’ inferencing success regarding the two conditions (t = 10.28, p < .0001, Cohen’s d = 2.19). In other words, providing participants with within-sentence context led to greater inferencing success than did the no-context condition. We found that context facilitated lexical inferencing significantly.
To explore the learning outcome of inferencing within context, participants’ completion of Task 2 was considered to be a treatment, and Task 1 scores were viewed as a ‘pretest’ result. That is, after three weeks, participants had a mean score of 1.84, a significant improvement over their pre-treatment scores of 1.52 for Task 1 (t = 4.74, p = .0001, Cohen’s d = 1.01). This suggests that participants gained lexical knowledge by engaging in context-based lexical inferencing. Moreover, they retained that knowledge during the three-week period. Descriptive results of participants’ mean scores and standard deviations in Tasks 1 and 2 as well as the delayed posttest are shown in Table 1.
Means and standard deviations of participants’ scores in tasks and posttest.

Note. Scoring based on a 4-point scale where the maximum is 3.
2 Taxonomy of lexical inferencing strategies
Our second research question pertained to learners’ lexical inferencing strategies based on context and word-internal cues. We identified prototypical examples of various strategies by analysing the introspective data, which in this case were the transcripts from the TAP technique. Determining the exact number of each type of strategy employed was not relevant to this research, because as previous literature has suggested, the exact percentages of strategies used depend on the nature of the texts, word structure, and individual differences (e.g. Fang & Jiang, 2012; Hu & Nassaji, 2012, 2014; Mori, 2002). We then identified an assortment of strategies that respectively reflected learners’ use of intraword awareness and context cues. For word-internal strategies, learners (1) explicitly used the word formation rules; (2) made analogies to familiar V-complement compounds; (3) made associations to a familiar compound sharing the same character with the target word, and (4) used a character’s orthographic units to extract semantic or phonetic information, which included using semantic radicals to interpret meanings or employing the pronunciation of a similar graphemic symbol to infer phonological information. Table 2, shown below, gives a summary and examples of the strategies.
Word-internal strategies and examples.
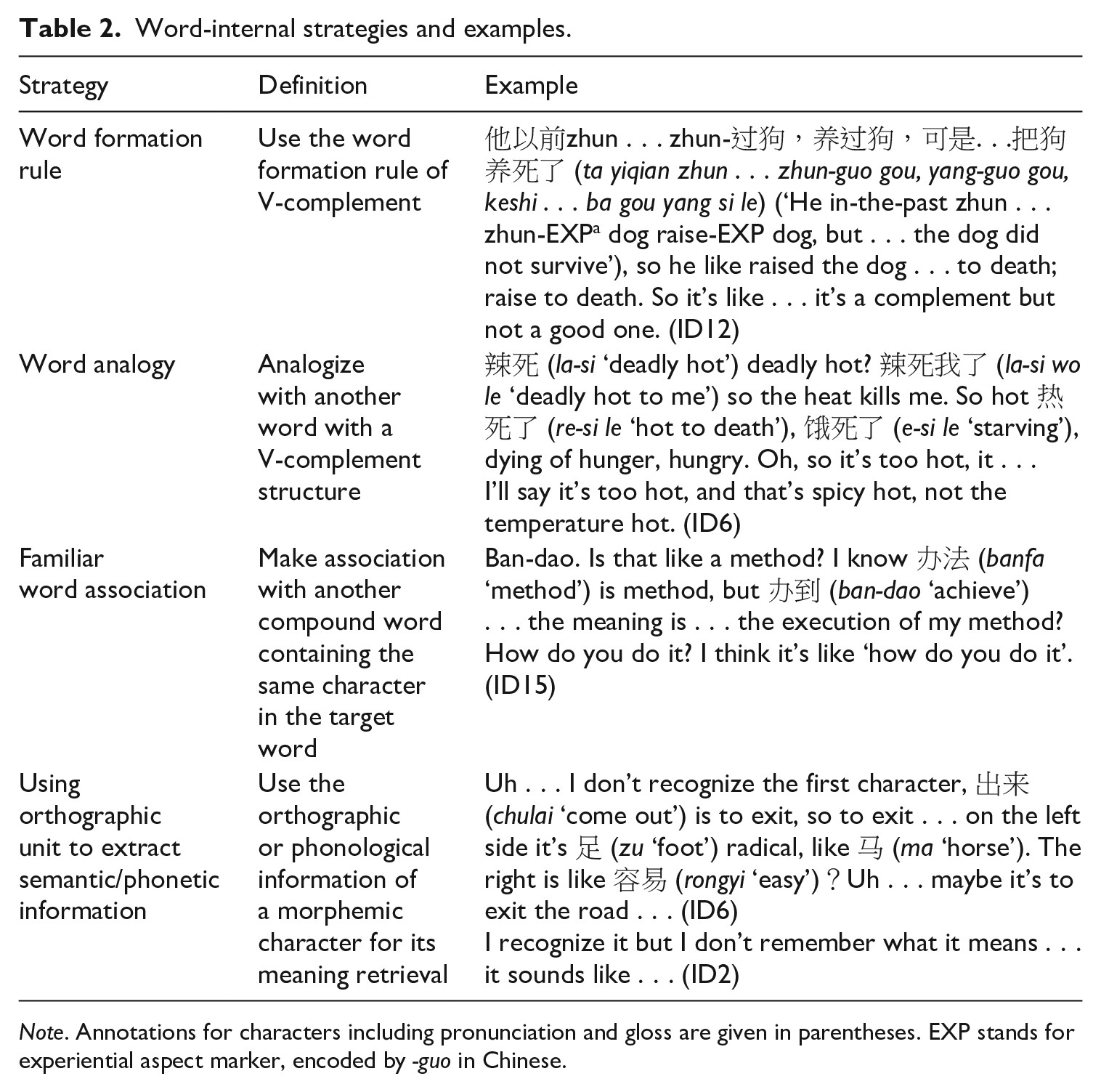
Note. Annotations for characters including pronunciation and gloss are given in parentheses. EXP stands for experiential aspect marker, encoded by -guo in Chinese.
Learners utilized context cues by (1) using real world knowledge (e.g. plausibility based on real-life situations); (2) conducting syntactic analysis; (3) using semantic contextual information to identify meaning or to evaluate a guess, and (4) relying on context to facilitate character recognition. These strategies and examples are presented in Table 3.
Context-based strategies and examples.
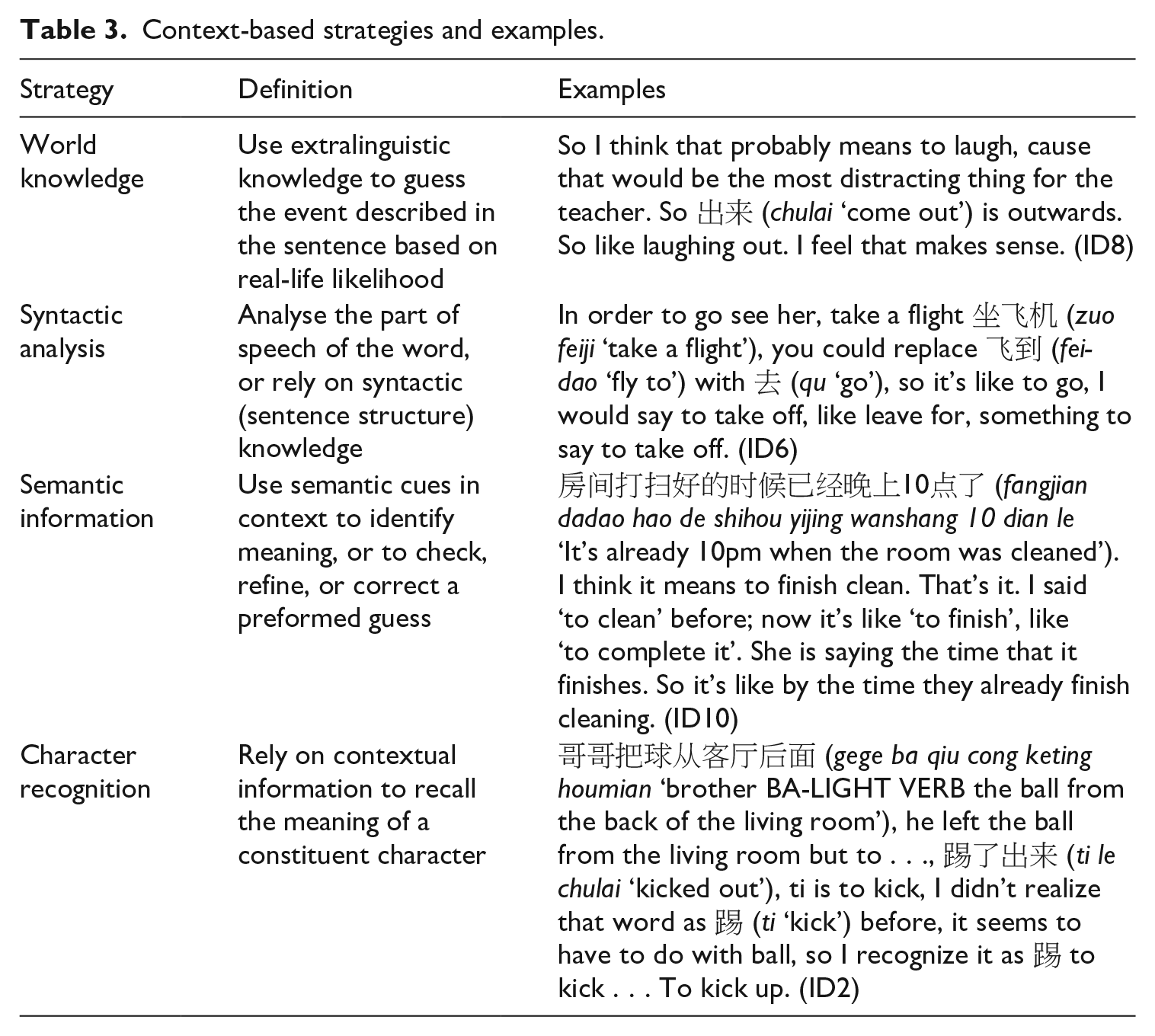
We will now discuss several interpretations of the results. First, learners’ performance in the no-context condition (Task 1) (1.52/3) indicated that they had a relatively high level of familiarity with the morphemes and the metalinguistic knowledge to interpret the verb-result structure. The TAP data also indicated that participants were able to clearly explain the structural relationships between morphemes, including identifying the second constituent as a ‘complement’ and specifying its general semantic functions. For instance, ID6 thought out aloud for item chi-hao-fan (‘finish having food’) with the following: Well eat food? Hao-chi is tasty, so chi-hao could be . . . oh . . . it’s complement? It’s complement, so finish eating, and be ready to move on to the next thing, to be done.
Participants were also able to apply high levels of metalinguistic awareness even when they did not fully recognize the graphemic forms of the constituent character. For instance, although they were unable to recognize the V1 component, the participant quoted below deduced that the compound lasi-le (‘extremely spicy’) was an exaggeration of a certain attribute by comparing it to a familiar compound with the same structure.
The third one, I recognize 死 (si ‘death’), but I don’t think I recognize the first word before 死, so I . . . am going to say, it’s not 累 (lei ‘tired’), it’s definitely some kind of . . . some kind of word . . . so I just guess it is just an exaggeration like 累死了 (lei-si le ‘tired to death’). (ID3)
This corroborates earlier studies that reported intermediate level learners’ structural sensitivity towards Chinese compounds in general (Gan, 2008; Shu et al., 1995). For instance, Ke & Koda (2017) found that L2 learners can infer the meaning of words with affixoids and familiar bases more readily than non-affixoid words or morphologically simple multi-character words, indicating the significance of structural awareness in L2 Chinese lexical inference. In the present study, learners’ verbalization of the word formation rule and word analogy strategies both reflected their metalinguistic knowledge of the target word’s structure.
Second, significant differences among the mean scores on the two tasks and the delayed posttest and Task 1 confirmed that a supportive context greatly increases retention. As mentioned, previous studies generally reported much more limited benefits of context, especially with regard to retention. Van Den Broek et al. (2018) concluded that while informative context increases the chance of meaning identification, it reduces the possibility of retention because easily achieved inferencing does not involve the effortful processing needed for a successful long-term outcome. We suggest that significant retention in this study may be due to several factors: (1) the enhancing effect of structural repetition, (2) a combination of tasks focusing on form and meaning, and (3) the highly interactive and integrative nature of the process.
In this study, participants were exposed to one consistent compound structure (i.e. verb-complement). Repeated encounters are predicated to consolidate representations of the inferred word (Wesche & Paribakht, 2009). In existing studies of vocabulary learning through reading, repetitions were generally operationalized as the number of encounters that learners experience with a specific target word, with divergent result (for a review, see Laufer & Rozovski-Roitblat, 2015). In this study, while each target word occurred in context only once, the repeated presentations of the verb-complement structure made it easier for participants to notice the words’ internal structures, facilitating analysis and synthesis of this vital information. This can benefit both inferencing and learning.
Furthermore, context-based inferencing of target words with the same compound structure combines the benefit of form-focused and meaning-focused learning. Researchers of English L2 lexical inferencing have found fascinating interactions of form and meaning, information extraction and retention. For example, Webb (2008) reported that informative text led to better meaning recall and recognition, whereas repeated exposures helped improve form recall and recognition. Hu and Nassaji (2012), who measured inferencing success and retention, categorized learners’ strategies as ‘meaning-focused’ (using textual cues, discourse knowledge, paraphrasing, etc.) and ‘form-focused’ (analysing form, analogy, etc.). They reported a positive and significant correlation between learners’ meaning-focused strategies and inferencing success, as well as a positive correlation between form-focused strategies and retention. The authors suggested that if learners relied primarily on the ‘meaning’ approach, inferencing might be achieved without one’s sufficient attention to word’s formal properties, and as a consequence, the form-meaning connection could be weak. The authors thus suggested the benefit of combining meaning-focused and form-focused cue strategies for retention. In the current study, meaning-focused cues were provided by the informative context, and form-focused cues were made salient by consistent presentations of the target words’ internal structures. In other words, context-based lexical inference of a list of compound words with the same internal structure can direct learners’ attention to meaning and form at the same time.
Finally, we argue, as seen in Section V, that context-based inferencing, particularly when it comes to compound words or morphologically complex words, is a highly interactive process and is not simply inductive or deductive. More complex interactions mean a higher level of mental involvement, which in turn enhances retention.
3 Interactions of contextual and word-internal cue use
In our second research question, we asked if new patterns of lexical inferencing strategies can be found in Chinese. The introspective data revealed that learners frequently combine strategies. First, Table 4 gives examples of how learners coordinate strategy use to complete both tasks. Note that context-based strategies were not just used for Task 2. In Task 1, in which target words were presented without context, participants sometimes created a sentence to evaluate their guesses. While no earlier studies had made the same observation, this could be an effective strategy, as syntactic constraints are often present both within the word and in context. By creating a test sentence, learners had the opportunity to check if the hypothesized grammatical categories or collocations fit into any familiar patterns.
Examples of coordinated use of strategies.

Second, one of the context-based strategies highlighted in this study was character or morpheme recognition. In other words, context helps learners use word-internal cues more effectively. Whereas earlier studies reported combination strategies of using context and character decoding at the same time (Huang, 2018), we found evidence that facilitation from context supports character decoding or morpheme recognition. For instance, one participant could not correctly recognize the central verb in several RVCs including ban-dao, yang-si, ti-chulai, but the sentence context helped her recall those characters or morphemes that would otherwise be only unrecognizable graphemic forms. Table 5 shows a comparison of her introspective inferencing process as she engaged in the two tasks.
Comparisons of a participant (ID1)’s inferencing in task 1 and task 2.

Note. 办 (‘handle’),养 (‘raise),踢 (‘kick’) are orthographically similar to 为 (‘for’, pronounced wei, a homophone with 味 wei ‘flavor’), 流/淹 (liu/yan ‘stream’/‘drown’),汤 (tang ‘soup’).
This participant was unsuccessful at inferencing these items in Task 1, because she was unable to recognize the key characters. By relying solely on the orthographic form, she incorrectly mapped 办 (ban ‘handle’) to the sound and meaning of 为 (wei ‘due to’), an orthographically similar character with an entirely different meaning. The same goes with her misrecognition of 养 (yang ‘raise’) as 淹 (yan ‘drown’) and 踢 (ti ‘kick’) as 汤 (tang ‘soup’). However, the semantic context provided in Task 2 prompted her to correctly identify the sounds and meanings of the characters because the sentences with embedded target words contained semantic information related to one’s achievement, pet, and ball. Due to the large number of orthographically similar characters and homophones, character form recognition and complex form-sound/form meaning mapping is challenging in L2 reading (Everson, 2011). Similar to the example above, several participants’ thought processes as they performed the two tasks revealed both their difficulties with character meaning/sound retrieval during reading and the facilitation of context for character recognition.
Such morpheme recognition facilitated by contextual cues can then contribute to word meaning identification. In other words, when inferencing with context, participants integrated information across sentence, word, and morpheme levels, allowing the cue sources to build upon one another. Contextual and word-internal information work together, instead of being simply competitive or additive. As learners engage in this process, their lexical inferencing becomes elaborative and involves not only the ‘search’ for meaning but also the utilization of various steps of ‘evaluation’ and integration.
4 Learner difficulties with compound word inferencing
Our third research question concerned learners’ difficulties when inferring new compounds in context. Two main sources were learners’ (1) unsuccessful use of context, and (2) difficulties with character (i.e. morpheme) recognition.
5 Unsuccessful use of context
Unsuccessful use of context may be due to inadequate use of contextual cues or to the nature of the context itself. While the former can occur if learners do not have the appropriate proficiency (Frantzen, 2003; Pulido, 2007), we found instances in which participants’ text comprehension should have provided cues to lead them to a correct answer; however, this type of analysis did not take place. Examples are provided in Table 6.
Learners’ difficulties in inferencing and examples.

Note. The target words in characters, with pronunciation and gloss, are given in parentheses.
The target word, xia-qi-yu-lai ‘start to rain’, was provided in the context of a sentence indicating that the weather was good in the morning, but the situation changed in the afternoon. However, even though he was able to comprehend the sentence, the participant did not rectify his initial wrong ‘guess’ formed in Task 1. Similar observations can be made with regard to several participants’ incorrect inferences, including chi-hao (fan) (‘finish eating food’, inferred as ‘to eat good food’), zhu-xiaqu (‘continue to live’, inferred as ‘start to live’), even though the sentence context in Task 2 did not support these interpretations.
Those errors replicate a finding in Frantzen (2003), which she termed ‘oblivious certainty’ (p.176). Huckin and Bloch (1993) claimed that ‘context clues seem to have little effect when learners have word level commitments in mind’ (pp. 168–169). The observation suggests that sufficient use of contextual cues requires more than simple comprehension. Learners need to pay attention to details and consistently use details for verification, and be willing to, upon finding negative evidence, give up an initial guess and reanalyse.
Such unsuccessful use of contextual cues can also be due to the type of context provided. Despite the informative nature of the context in our study, which was specifically chosen to support inferencing, constraints provided by context were not sufficient for one to determine the specific meaning of words. In fact, they allowed for quite a wide range of possible fillers. This can be illustrated by ID8’s response, shown in Table 6. This participant realized that the action in the sentence involved a ball, but incorrectly inferred ti-chulai (‘kick out’) as ‘throw out’. In another example (not shown in Table 6), several participants inferred 抱起来 (bao-qilai ‘pick someone up’) to mean 跑起来 (pao-qilai ‘start to jog/run’) in a sentence that describes a mother trying to comfort a baby. The errors occurred because 跑 ‘run’ is orthographically and phonetically similar to 抱 ‘hug’, and the incorrect inference seemed to make sense in the context.
These examples further demonstrate the importance of combining cue sources at the word and context levels. For instance, in the above examples of 踢出来 (ti-chulai ‘kick out’) and 跑起来 (pao-qilai ‘start to jog/run’), a skillful learner may be able to use the semantic radical 足 ‘foot’ in the first character in combination with the semantic context clues to determine a correct answer. As many radicals provide clues about the meaning of characters by suggesting their semantic categories, and context delineates the range of possible fillers, combining these cue- crossing word boundaries is more likely to lead to successful inferencing than relying on one cue source alone.
6 Character or morpheme recognition in inferencing
In many cases, participants also had difficulties recognizing characters or morphemes. For example, they confided that the orthographic form of the characters appeared familiar but they could not recall their meanings. When difficulties arose, they relied on (1) orthographic forms to help with meaning/sound recall, or (2) familiar compound associations or analogies. Inaccurate inferencing could arise in both cases, as seen in examples shown in Table 6.
While the strategy of defining a character by its form can be beneficial, it is not very reliable. Learners not only need the visual-orthographic skill to analyse characters but also must be able to differentiate radicals from chunks and realize the limitations of radicals’ meaning/sound-indicating functions. Orthographically similar forms can be another source of confusion. In the example in Table 6, participant ID18 attempted to determine the meaning of 养 (yang ‘raise) based on several of the character’s orthographic units, but the effort was not fruitful. In addition, the large number of homophones means that a correct form-sound link does not necessarily lead to correct identification of meaning. For instance, several participants erroneously identified 办到 (ban-dao ‘achieve’) as 搬到 (ban-dao ‘move to’). Thus, the quality of form-meaning representation is crucial for morpheme recognition.
In addition, participants’ word association or analogy did not always lead to successful result, as both Chinese characters in general and the verbal complements under examination can be interpreted in many ways in different compounds, and segmenting a constituting morpheme’s meaning from a compound requires in-depth vocabulary knowledge and morphological awareness. In the example in Table 6, participant ID2 attempted to extract the meaning of ban in ban-dao (‘achieve’) from the known compound word bangong-shi (‘handle-business-room’, or ‘office’). However, when he failed to segment the known compound into the correct component structure, extracting the constituting character’s meaning was not possible. In another example, participant ID10 tried to induce the meaning of the complement -qilai (‘up’) in bao-qilai (‘pick up’) through analogizing it with xiang-qilai (‘recall’), kan-qilai (‘look like’), etc., but due to the polysemous nature of this complement, his attempt was not successful.
These types of learner difficulties with character recognition corroborated results of Huang’s study (2014). With the morphosyllabic nature of Chinese writing system, accessing the character’s meaning and sound equals morpheme identification and contributes directly to compound word interpretation (Shu et al., 1995). Gan (2008) suggested that among the factors examined, including syntactic information, semantic context, and the internal structures of words, L2 learners’ ability to determine morpheme meaning had the greatest impact on successful compound inferencing. The current examination of participants’ strategies and difficulties suggests that morpheme recognition is affected by learners’ linguistic and metalinguistic competencies in several areas including effectively using orthographic units for form and sound interpretation and learners’ ability to extract the meaning of the morpheme from other compounds. In addition, analysis of the target compound’s structure and contextual cues can inform morpheme recognition.
The above findings indicate that form-meaning mapping at the character level is crucial for successful Chinese compound word inferencing. In addition, inferencing may be more likely achieved when learners use multiple cue sources interactively.
V Further discussion
While confirming that Chinese L2 learners used a variety of inferencing strategies similar to those reported in studies of alphabetic languages, evidence in this study particularly suggests the importance of morpheme recognition to inferencing success. Previously, scholars have emphasized learners’ ‘morphological awareness’ to explain use of word-internal strategies. This includes the linear segmentation of a word’s orthographic units for semantic and phonetic decoding in alphabetic languages and a similarly linear segmentation and analysis of compound words based on internal structures (Ke & Koda, 2017). In contrast, we suggest here that the nature and components of intraword awareness among Chinese readers involves essential aspects beyond the traditional morphological and phonological awareness. Specifically, Chinese readers’ orthographic knowledge including understanding of submorphemic components such as radicals plays a major role in lexical inference. In addition, segmentation as the first step of conducting intraword analysis in Chinese involves the visual-orthographic skill of understanding graphemes not linearly but in a two-dimensional space. Effective use of word-internal cues relies on one’s competencies to understand the structure of multi-syllable words while simultaneously focusing on character and subcharacter components in order to integrate pronunciation and meaning.
In other words, while lexical inference universally involves intraword awareness and utilizing contextual information, we suggest language-specific natures of ‘intraword awarenesss’ for reading in Chinese. Morpheme recognition, compound structure awareness, and context are the three major knowledge sources for Chinese compound inferencing. Figure 1 illustrates the relationship between them, and all the identified strategies mentioned earlier pertain to those sources. Specifically, in order to identify the meanings of characters (morpheme recognition), learners rely on orthographic shapes for sound and meaning cues (‘form link/sound link’), and they also extract the character’s meaning from other compound (‘word association’). Learners’ application of compound structure knowledge is reflected in their verbalization of the ‘word formation rules’ and use of ‘analogy’. Meanwhile, meaning identification can also be derived through semantic and syntactic constraints embedded in context.

Interactive process of inferencing.
This suggests that the thought processes involved in compound word inference are interactive and the three source components are interconnected. For instance, context not only offers cues about the target word’s meaning but also provides information about the sub-word level to facilitate morpheme recognition. There is also a connection between context and compound structure knowledge, as sentence context provides clues about the word’s grammatical category. For example, depending on if the word is judged to be a verb, noun, or adjective, this can lead to different morphological analysis.
Interaction between these components means that if a learner relies solely on one source alone, he or she may not be able to successfully infer meaning. Our findings and results of earlier studies (e.g. Frantzen, 2003) show that a learner’s willingness to re-evaluate an initial guess by considering the cues from other sources directly affects his or her inferencing success. Integration of information from various sources also means that the process of ‘evaluation’ (i.e. checking the accuracy of an initial guess) (Hulstijn & Laufer, 2001; Nassaji, 2006, p. 392) is as important as ‘meaning search’. Unlike some researchers who have proposed a potential sequence of lexical inference from context to word or from word to context (e.g. Huckin & Bloch, 1993; Kondo-Brown, 2006), we propose that meaning search can begin at any level (morpheme, word, or sentence context), and checking can also come from various sources. Rather than following a top-down or bottom-up path, the process of meaning searching and checking is interactive. As such, learners should always be encouraged to check if an initial guess fits all relevant knowledge sources, including knowledge of the world, context, word structure, and constituting morphemes.
Lexical inferencing in this study may be particularly interactive, because participants’ experience in the no-context condition may have encouraged them to actively evaluate their guesses once words occur in context. The study was also designed to draw participants’ attention to both form and meaning by providing them with repeated encounters of the same verb-complement structure. When target words are compounds, learners need to integrate cues from multiple levels including those at the morpheme, word, and context levels, as shown in Figure 1. These factors can facilitate the formation of an elaborate network of lexical information. In other words, significant retention in this study can be explained by learners’ higher level of mental involvement during context-based inferencing (Hulstijn & Laufer, 2001).
VI Conclusions and implications
In this study, we confirmed the supportive role of context in Chinese compound word inferencing and learning. In addition, learners are more likely to succeed when they employ strategies such as morpheme identification from context when they use both context and word-internal information in interactive ways for lexical inference. We suggest that language specific features of CFL learners’ ‘intraword awareness’ involves their visual-orthographic skill of segmenting graphemic units in two dimensions and their orthographic knowledge, along with their compound word structural awareness. We also argue that lexical inference computation procedures are interactive instead of strictly sequential, and higher levels of integration and interaction lead to better inferencing outcome and more robust mental representations. While the model we proposed in Figure 1 was based on Chinese compound inferencing, the interactive nature of the knowledge sources in lexical inference are relevant to other languages. Our results support for the ‘Involvement Load Hypothesis’ by offering evidence from Chinese vocabulary learning through lexical inference.
In our attempt to bridge the gap between more theoretically-oriented earlier studies and practical teaching, we have taken a step toward systematic exploration by using lexical inference as an instructional technique to help students learn vocabulary in CFL. Several pedagogical implications can be drawn. First, students of Chinese must be reminded that both orthographic structure analysis and radical knowledge may be highly useful for identifying unfamiliar words during reading. Secondly, when encountering new words, learners should be encouraged to formulate a guess by combining various cue sources, and they should keep verifying their guesses till the identified meaning fits information at all levels. This process will aid in inferencing, memory retention and vocabulary building. Third, when using lexical inference as a vocabulary learning activity, instructors can use techniques that direct students’ attention to form (e.g. word structure), while providing them with an informative context that supports semantic inferencing. For languages with productive compounding morphology or derivational morphology, grouping words with the same structure together is one technique to make the structure salient, encouraging participants to notice the word-formation rule.
The study has several limitations. First, the quantitative results were based on a small sample size. Therefore, the effect of inferencing success and retention is subject to further verification. A possible future study can compare the effect of vocabulary learning through rote memorization and context-based lexical inferencing. Second, to improve the practicality of this research for vocabulary teaching, future scholars may wish to assess learners’ vocabulary knowledge gains in both interpretative and productive tasks, and measure learners’ depth of vocabulary knowledge achieved through inferencing. Finally, we tested the lexical inference of one specific compound type in this study. While the interactive model proposed can account for several observations made in this study, the preliminary proposal is subject to further verification and modification from studies of other compound types and other languages. We hope this research can lead to fruitful discussions regarding the interactive natures of lexical inference.
Footnotes
Appendix 1
Declaration of Conflicting Interests
While the same cohort of participants were asked to participate in a different study on their inferencing of Chinese resultative compounds with metaphorical complements, the authors declared that they have not published and are not in the process of publishing any study that may overlap with the current one in terms of research questions or experimental materials.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.