
Abstract
Although increasing evidence has demonstrated the benefits of mobile technology in diverse aspects of language learning, research on the use of mobiles in task-based instruction has been scarce. Particularly, there has been little research directly investigating predictors of the quality of mobile-assisted, video-making tasks. To fill the gap and contribute to the area of emerging technology-mediated, task-based language teaching, the current study examined predicting factors of the quality of digital-video-making task outcomes. Forty-eight Korean high school students completed a digital-video-making task using a mobile application called KineMaster. Students created a self-introduction storytelling video focusing on their experiences of success or failure in their life. To examine predicting factors (English writing proficiency, first language narrative ability, digital literacy, intrinsic and extrinsic motivation), multiple data sources were gathered: timed argumentative English essays and Korean writing samples on the same narrative topic, a digital literacy questionnaire, and a motivation survey. For data analyses, the quality of the digital-video-making task outcome was scored using an analytic rubric assessing the use of multi-modes, language use, and task fulfillment. Students’ English and Korean narrative essays were rated for English writing proficiency and first language narrative ability, respectively. Digital literacy and motivation questionnaires were analysed quantitatively, and the composite scores were included in statistical models. Multiple regression models were created to investigate which factors predicted the quality of the digital-video-making task outcome. The results showed that English writing proficiency and first language narrative ability significantly predicted the quality of language use and task fulfillment. The findings shed light on mobile-assisted task performance in foreign language classrooms.
Keywords
I Introduction
Derived from the fields of m-learning and computer-assisted language learning (CALL), mobile-assisted language learning (MALL) has received substantial attention for its potential educational value and impact in classrooms (Ducate & Lomicka, 2013). Nowadays, mobile phones are virtually ubiquitous, and students are intimately familiar with the way they work. Although increasing attention has been paid to the benefits of mobile technology in diverse aspects of language learning (Viberg & Grönlund, 2012), the role of mobile devices in task-based language learning has not been systematically addressed. In particular, little is known about what factors predict the quality of mobile-assisted task output. In the current study, we examined a video-making task, which has become one of the most popular digital tasks in many countries due to a surge of social media users (e.g. YouTube). Additionally, video-making tasks have received growing attention from a multimodal composing task perspective (i.e. the use of multi-modes such as texts, pictures, and music to make meaning; Kim & Belcher, 2020). To bridge the gap in the literature, the current study aims to investigate five factors (English writing proficiency, first language (L1) narrative ability, digital literacy skills, intrinsic motivation, extrinsic motivation) and their ability to predict the quality of mobile-assisted, video-making task output among English as a foreign language (EFL) students in a Korean high school context. Given the proliferation of mobile-assisted, video-making tasks in this digital age, this study would make a timely contribution to the field of MALL and technology-mediated task-based language teaching (TBLT).
II Literature review
1 Technology-mediated, task-based language teaching
To date, although integrating language tasks and new technologies for language learning has received emerging attention from the fields of TBLT and CALL, the best ways to fuse the two dimensions–tasks and technology–for language learning have not been greatly explored (González-Lloret & Ortega, 2014). In response to this lack of investigation, González-Lloret and Ortega (2014) and González-Lloret (2015) propose technology-mediated TBLT as a new conceptualization of technology-and-task integration. They distinguish technology-mediated TBLT from using technology by merely translating or extending tasks to technology-assisted environments (e.g. online environments). In technology-mediated TBLT, they argue, three requirements should be considered. First, tasks in technology-mediated TBLT should be identified based on the following definitional features of a task: a primary focus on meaning, goal orientation, learner-centeredness, holism (authenticity and real-world relationship), and reflective learning (González-Lloret & Ortega, 2014, pp. 5–6). That is, to be qualified as tasks, the primary focus should be put on meaning; there is a goal which needs to be achieved; it should be designed based on learners’ needs; it should resemble real-world language use by having authenticity and a real-world relationship; and it should involve opportunities for reflection and self-reflection. As tasks have been used in diverse contexts with different operationalizations, it is necessary for new technologies to be combined with tasks that are defined based on the aforementioned five characteristics. Second, González-Lloret and Ortega argue that we should recognize the effects that technology has on the learning process. That is, technology is no longer simply a tool of instruction or delivery, but rather creates new needs and becomes part of the curriculum (p. 7). Lastly, they claim that both tasks and technologies must be considered at a curricular level, including needs analysis, development of pedagogic units, and assessment.
In the current study, we chose from the existing array of instructional technological tools and focused on the use of mobile applications in classroom contexts. As the use of mobile phones has increased exponentially and become ubiquitous (Ducate & Lomicka, 2013; Kukulska-Hulme & Viberg, 2018), researchers have identified several pedagogical benefits that the use of mobile devices can provide to second language (L2) classrooms, including greater flexibility and accessibility (Chen, Carger, & Smith, 2017) through powerful features of mobile devices (e.g. ubiquity, multimedia support, and greater communication capabilities; Godwin-Jones, 2017), and effectiveness in developing communication skills and pronunciation (Kukulska-Hulme & Viberg, 2018; Wrigglesworth, 2019). In particular, MALL creates a learning environment in which learners can engage in tasks that are more closely related to their current surroundings (e.g. outside of the classroom), without depending on fixed computers (Kukulska-Hulme, 2009). Despite these potential advantages, MALL is still an underresearched area, as Burston (2014) argues that MALL remains ‘on the fringes’ (p. 103) of language learning. In particular, there is a lack of studies conducted in K-12 settings (Lan, Sun, & Chang, 2007; Nah, White, & Sussex, 2008), as substantial studies have only been conducted with adult participants. Finally, little is known about the effects of MALL in promoting writing skills, among others (Chen et al., 2017).
To this end, out of the many possible technologically-mediated task types employed today (e.g. collaborative writing tasks through Web 2.0 tools, text-based chats in computer-mediated environments, 3D virtual worlds tasks; see González-Lloret & Ortega, 2014 for the use of technology-mediated tasks), for the current study, we chose a mobile-assisted, digital-video-making task. A mobile-assisted, digital-video-making task is considered a real-world task because, in this day and age, creating and sharing video content (e.g. vlog entries) on an online video-sharing platform (e.g. YouTube, Vimeo) is becoming a popular, commonplace practice among young generations, particularly teenagers. Also, mobile applications may provide better learning environments for students to create narrated digital videos because students can easily access their own photos and are able to more easily control their own smartphones or tablet PCs than school computers. The following section presents a review of literature on the use of digital-video-making tasks.
2 Digital-video-making tasks in second language classrooms
Recently, digital-video-making tasks (also known as multimodal composing tasks, Belcher, 2017) have been increasingly used in language classrooms, in part due to the recognition of their pedagogical potential for fostering L2 writing development (Oskoz & Elola, 2016a). To examine the role and potential of digital-video-making tasks in L2 writing, previous studies have examined different types of digital-video-making tasks such as narratives (Balaman, 2018), a tourist attraction introduction video (Nishioka, 2016), argumentations (Kim & Belcher, 2020), a movie review (Kim & Kang, 2020), and collaborative video-making tasks (Smeda, Dakich, & Sharda, 2014).
Digital-video-making tasks are based on the multimodal design of writing (Jewitt, 2011), which views communication as a meaning-making process that involves diverse semiotic modes such as text, images, sounds, videos, and communication technologies to make meaning (Belcher, 2017). The notion of the multimodality of meaning-making has been acknowledged in the field of L2 writing and education, particularly due to the advent of new technologies (Mills, 2010), based on the question regarding ‘what it means to write in the digital age’ (Hafner & Ho, 2020). While performing a digital-video-making task, learners can utilize a variety of semiotic tools which permit a variety of modes to present and enrich meaning (e.g. narration, video clips, images, icons, written texts, music), without limiting their meaning-making process to language only.
To date, many studies have reported the affordances and benefits of digital-video-making tasks in the language classroom: empowering learners who struggle with traditional writing approaches by tapping into various learning styles, such as visuo-spatial and musical learning styles (Reid, Burn, & Parker, 2002); promoting learners’ motivation (Balaman, 2018; Jiang & Luk, 2016; Yoon, 2014); providing a real-world context for task performance, as learners can create a video for a real audience in a virtual space such as YouTube (Hafner & Miller, 2011); diversifying students’ writing experiences by allowing for a variety of topics (Christiansen & Koelzer, 2016); enhancing learner language development (Lee, 2014; Oskoz & Elola, 2014; Reyes Torres, Pich Ponce, & García Pastor, 2012); and developing communication and language skills (Chen et al., 2017; Hwang et al., 2014; Vandommele, Van den Branden, Van Gorp, & De Maeyer, 2017). Particularly, positive relationships between digital-video-making tasks and growth in L2 writing skills have been reported (Balaman, 2018; Vandommele et al., 2017). The digital-video-making task promotes not only L2 writing skills, but also other linguistic skills (i.e. speaking, listening, reading; Yoon, 2014) and grammar development (Nishioka, 2016). In addition to their facilitative effects on language development, digital-video-making tasks have other educational benefits such as promoting digital literacy and multimodal design skills (Smeda et al., 2014).
While many benefits of digital-video-making tasks in L2 learning have been documented, challenges that arise when incorporating digital-video-making tasks in language classrooms have also been discussed in the literature. For instance, potential challenges include struggles for learners who are only familiar with traditional forms of writing tasks (Oskoz & Elola, 2014), difficulties in orchestrating multi-modes (Hafner, 2014), and dealing with the cognitive demands created by the integration of English-learning and digital video creation, such as the orchestration of multiple resources to convey meaning (Jiang & Luk, 2016).
Also, recently, researchers have begun to explore how to assess digital stories, as they require not just the exclusive use of texts, but rather a combination of multiple semiotic tools (e.g. texts, video, narration, icons). Elements in the assessment of digital-video-making tasks include factors related to the process and the final product (Oskoz & Elola, 2016b). To evaluate the process, Oskoz and Elola (2020) suggest including process-related elements that concern different aspects of the creation process in formative assessment, such as the analysis of samples, producing a digital video, providing and receiving feedback, and completing the video and polishing the language. The final product of a digital-video-making task has been the main focus in evaluating digital-video-making task outcomes. Assessment of the final outcome has considered different areas such as language use, organization, content, and multimodal design. In the L2 classrooms in which language learning is the main objective, language use is considered an important assessment element, and thus it is often included as a separate trait in rubrics, which may not be in line with the principles of multimodal composing. For example, Oskoz and Elola (2020) included grammar (i.e. use of diverse L2 grammatical structures, occurrences of grammatical errors) and vocabulary (i.e. use of diverse L2 vocabulary) in the rubric. In terms of content and organization, evaluation criteria concern aspects such as inclusion of required elements (Oskoz & Elola, 2020) and effective organization of information (Hafner & Ho, 2020). Lastly, in order to acknowledge the importance of multimodal ensembles, assessment criteria have been expanded by evaluating the quality of multimodal design in terms of a range of presentational modes, such as visual, aural, textual, gestural, and oral designs (Hafner & Ho, 2020; Hung, Chiu, & Yeh, 2013; Kim & Kang, 2020; Oskoz & Elola, 2020).
In sum, digital-video-making tasks have been assessed in regard to various aspects, such as process, content, organization, multimodal design, and language use. Although assessment is an essential component in an L2 classroom where digital-video-making tasks are implemented, it is still an underresearched area (Hafner & Ho, 2020). Compared to substantial research findings regarding the predicting factors of the quality of mono-modal writing (i.e. text-oriented writing; e.g. Crossley & McNamara, 2012; Engber, 1995; He & Shi, 2012; Kormos, 2012; Ong, 2015; Sasaki & Hirose, 1996), previous research on digital-video-making tasks has rarely examined which learner-related factors, such as L2 proficiency, L1 narrative abilities, digital literacy, and motivation, might affect L2 learners’ task performance.
Based on what has been examined regarding video-making task outcomes, the current study considered the unique characteristics of video-making tasks when determining the quality of task outcomes. First of all, the defined quality of digital-video-making task outcome concerns both task completion and language abilities following Long (2015), who accentuated the two dimensions as fundamental aspects of task-based assessment. Additionally, the quality of multi-modes was considered, as completion of the video-making task requires use of various digital semiotic modes. Thus, the quality of mobile-assisted, video-making task outcomes was measured in terms of three components: use of multi-modes, quality of language use, and quality of task fulfillment. Use of multi-modes concerns whether a variety of multi-modes are used in a concerted way to achieve ‘semiotic harmony’ (Kress, 2010, p. 157) and whether all modes are used to clearly and effectively deliver the message of the video. Multi-modes are semiotic means that are used to convey meaning, such as moving and still images, animation, sounds, music, and texts (Takayoshi & Selfe, 2007). Quality of language use pertains to students’ overall language quality in task outcomes, involving accuracy, syntactic complexity, lexical sophistication, and intelligibility and speech rate when oral narration is incorporated in the video. Lastly, quality of task fulfillment focuses on the completeness of task outcome in terms of content and organization.
3 Potential factors affecting the quality of mobile-assisted, video-making task outcome
As a part of task affordances, it is important to understand the factors that are associated with the quality of digital-video-making task outcomes. To date, no research has examined potential factors that affect the quality of video-making tasks. Thus, we considered previous research that explored the quality of monomodal writing (e.g. Kubota, 1998) and other types of task outcomes (e.g. Appel & Gilabert, 2002; Tavakoli, 2009). To examine possible predictive learner-related factors, in the current study, a total of five variables were selected: English writing proficiency, L1 narrative abilities, digital literacy, intrinsic motivation, and extrinsic motivation. First, English proficiency has long been considered one of the most important learner factors in task performance research (e.g. Ekiert, Lampropoulou, Révész, & Torgersen, 2018; Ishikawa, 2006; Kawauchi, 2005). As in Godwin-Jones (2012), the current study hypothesized that students’ English proficiency, particularly writing proficiency, might be associated with the quality of digital-video-making tasks.
Secondly, L1 narrative ability – how effectively learners can describe an event by including important aspects of the event with details – was included because the genre of the task is narrative, and the learners’ narrative ability in their L1 may play a role in the quality of digital video outcomes. Also, we became interested in the relationship between L1 narrative ability and the quality of digital videos because of evidence that L1 and L2 writing have a positive relationship in terms of quality (e.g. Kamimura, 1996; Kubota, 1998) and the fact that language teachers often wonder whether the quality of L2 writing is affected by students’ low L2 proficiency or their ability to narrate stories. Thus, we examined L1 narrative ability as well.
Additionally, digital literacy was identified as a potential predicting learner variable, as not only language skills but also the use of technology is necessary for digital-video-making tasks. The choice of this variable was also motivated by an increasing call for the incorporation of digital literacy skills in technology-mediated language classrooms (Hafner, Chik, & Jones, 2015; Lai & Li, 2011; Lotherington & Jenson, 2011; Murray, 2005), in addition to the possible impact of students’ ability to learn technology through mobile-assisted English writing (Chen et al., 2017).
Lastly, learners’ motivation for learning English was selected since motivation for learning an L2 has been considered a key individual difference that influences successful L2 acquisition (Dörnyei, 1998; Dörnyei & Ushioda, 2011) as well as one of the critical components that affect writing quality (Archibald & Jeffery, 2000; Kellogg, 1994; Lo & Hyland, 2007; Mak & Coniam, 2008) and task performance (Appel & Gilabert, 2002). In the current study, as the digital-video-making task was incorporated in an English-language class as a final project to assess learners’ English learning and to provide an opportunity to use English in a communicative context, it was hypothesized that the quality of video outcomes could have been affected by how motivated learners were regarding English language learning. The learners who participated in the current study were from intact EFL high school classrooms, which consist of students with mixed English proficiency levels ranging from very low to high intermediate, and were learning English as part of their mandatory secondary education. Thus, it was expected that learners might have different levels of motivation for English learning and that students’ motivation might have an impact on their video-making task performance. That is, for example, some students might be intrinsically motivated to learn English because they are interested in American culture while others might be extrinsically motivated to learn English because getting a good grade on school exams is important for Korean high school students’ future academic path (e.g. entering a university). Therefore, it was warranted to investigate both intrinsic and extrinsic motivation. Also, as motivation is theoretically defined in terms of two dimensions, the current study included both intrinsic motivation and extrinsic motivation as potential predicting variables (Deci & Ryan, 1985).
In sum, to date, the use of mobile-assisted tasks in TBLT has been rare. Also, compared to cumulated evidence on the predictors of quality of other type of tasks (e.g. L2 writing performance), little research has been carried out to directly examine predicting factors of the quality of mobile-assisted, video-making tasks. To fill the gap, we designed a mobile-assisted, video-making task and conducted a classroom-based study.
4 Purpose of the study
The goal of the current study is to investigate what factors predict the quality of videos produced by Korean adolescent EFL learners, who are considered ‘digital natives’ (Prensky, 2001). The genre of digital video – a narrative in which students describe their experiences by including diverse resources such as their photos, voice, and texts – was chosen considering the authenticity of the task (Ellis, 2003; Long, 2015), in that a digital-video-making task resembles what students are frequently asked to do in the real world of the digital era (e.g. create a YouTube video about themselves). The current study was guided by the following research question: How are English writing proficiency, L1 narrative ability, digital literacy, and intrinsic and extrinsic motivation related to the quality of Korean EFL adolescent learners’ mobile-assisted, digital-video-making task outcomes? Because of a lack of prior research, no predetermined hypothesis was proposed prior to the study, and the study was exploratory in nature.
III Methods
1 Participants
A total of forty-eight 1st-year Korean high school students (equivalent to the 10th grade in the US educational system; age, M = 16.88, SD = .33) participated in the study (24 males and 24 females). They came from two intact regular English classes at the same high school. Their experience learning English was, on average, 8.4 years. At the time of data collection, they had four hours of regular English instruction every week which mainly focused on reading, listening, vocabulary, and grammar. Results of a background survey indicated that students had multiple reasons for learning English, such as to get a good score on a school exam, to enter a prestigious college, to get a decent job, and to communicate with foreigners. Also, similar to students surveyed in the Korean Press Foundation (2019)’s report on the teenagers’ use of media, these students frequently used online video-sharing platforms such as YouTube to gather information.
2 Materials
a Digital-video-making task
The students completed an English-language, digital-video-making task individually as a final project of their first semester high school regular English class. The students were asked to create a narrative digital story that is at least one-minute-long and were given the following scenario: You are planning to apply for a summer camp that will be hosted at a university during summer break. You are required to submit a digital video in English in which you introduce yourself based on the prompt – Talk about a time when you experienced success or failure. Describe the experience and say why it was a success or failure for you. Explain how that experience has affected your life. This digital-video-making task and its scenario were designed following the principles of TBLT defining authentic, real-world tasks for the students who participated in the current study because this type of task is often provided to Korean high school students. Students completed the task individually, including planning their story, selecting semiotic modes to be included in the video, creating the video, and reviewing the final output. Even though tasks are often performed collaboratively, tasks can be carried out in various work formats: individually, in pairs or in groups, or a combination of both (Van den Branden, 2016). As the task in the current study was to create a narrative video on each student’s experience in success or failure in their life, we believed that individual task is more authentic and intrinsically motivating for students to perform.
A brief session on the technology needed for completing the task and the meaning of multimodal design was provided before students started working on the task. Students were allowed to ask questions or get help from their teacher and peers regarding linguistic forms or meaning, the task itself, and technical issues. Also, the teacher circulated throughout the classroom while students were planning and creating their videos to provide constructive feedback and to help students with the obstacles that they encountered. This assistance took the form of teacher-learner interactions and whole-class discussions.
To create their digital video, students used a mobile video editor application called KineMaster. Students used their own smartphones or tablets, as they could access their own photos stored in their mobiles, and they were more familiar with their own devices than with school computers. When producing the digital video, students created it entirely in English and incorporated multiple elements, such as English written texts, English oral narration (recording their own voice either while reading an English script (which was not presented in the video) or reading out loud what was presented in the written text), pictures, video clips, icons, and music.
b Independent argumentative essay
To evaluate English writing proficiency, students completed a timed argumentative writing task based on a topic that is similar to TOEFL iBT prompts. For 30 minutes, students individually completed the writing task on the following prompt: If you could make one important change in a school that you are attending, what change would you make? (Shin, 2019). The task was completed using pen and paper.
c Korean narrative writing
Students performed a narrative writing task in their native language (i.e. Korean) on the same prompt as the digital-video-making task (i.e. Talk about a time when you experienced success or failure. Describe the experience and say why it was a success or failure for you. Explain how that experience has affected your life.). The purpose of this task was to assess students’ narrative ability in Korean on the given topic. That is, by assessing an essay in which students could use their native language, it was possible to measure the extent to which students could develop a narrative on the same topic as the video-making task, which might not be clearly manifested if they were asked to write in their L2 (i.e. English).
d Digital literacy questionnaire
To collect information about students’ digital literacy skills, a questionnaire, which was adapted from Son (2015), was administered. In the digital literacy questionnaire, we focused on the two dimensions of ‘Doing’ (i.e. actions in the physical world, e.g. sharing pictures with friends via email) and ‘Meaning’ (i.e. forms of representation, e.g. making meaning via multimodal web pages) included in a model of digital literacies suggested by Jones and Hafner (2012). For the purpose of the current study, we selected two categories – typing skill on a cellphone and skills of mobile functions – because typing skills and skills of mobile device functions are necessary abilities to perform ‘actions that are at the heart of everyday literacy practices’ (Jones & Hafner, 2012, p. 6; ‘Doing’) and are common means of making different kinds of meanings in the digital age (‘Meaning’). Also, they are required skills for completing a digital-video-making task. The item related to typing skills asked students to rate their typing abilities in English using a cellphone on a six-point Likert scale: (1) very poor, (2) poor, (3) somewhat poor, (4) somewhat good, (5) good, and (6) very good. Skills connected to mobile functions included editing pictures, editing music, watching YouTube videos, conducting web searches, file-sharing, using dictionary applications, and creating PowerPoint presentations or Word documents. All items were rated on a six-point Likert scale: (1) I don’t know what this function is, (2) I almost don’t know how to use this, (3) I cannot do this skillfully, (4) I know how to use this; (5) I can do this skillfully, and (6) I can do this very skillfully.
e Motivation questionnaire
In the current study, motivation was operationalized as intrinsic motivation and extrinsic motivation (Deci & Ryan, 1985) for learning English and investigated through a motivation questionnaire. Although a total of 29 items were originally included in the questionnaire, only 12 items that involved these two types of motivation were selected for analysis (see Figure 1). A six-point Likert scale was employed for all 12 items: (1) strongly disagree, (2) disagree, (3) somewhat disagree, (4) somewhat agree, (5) agree, and (6) strongly agree.
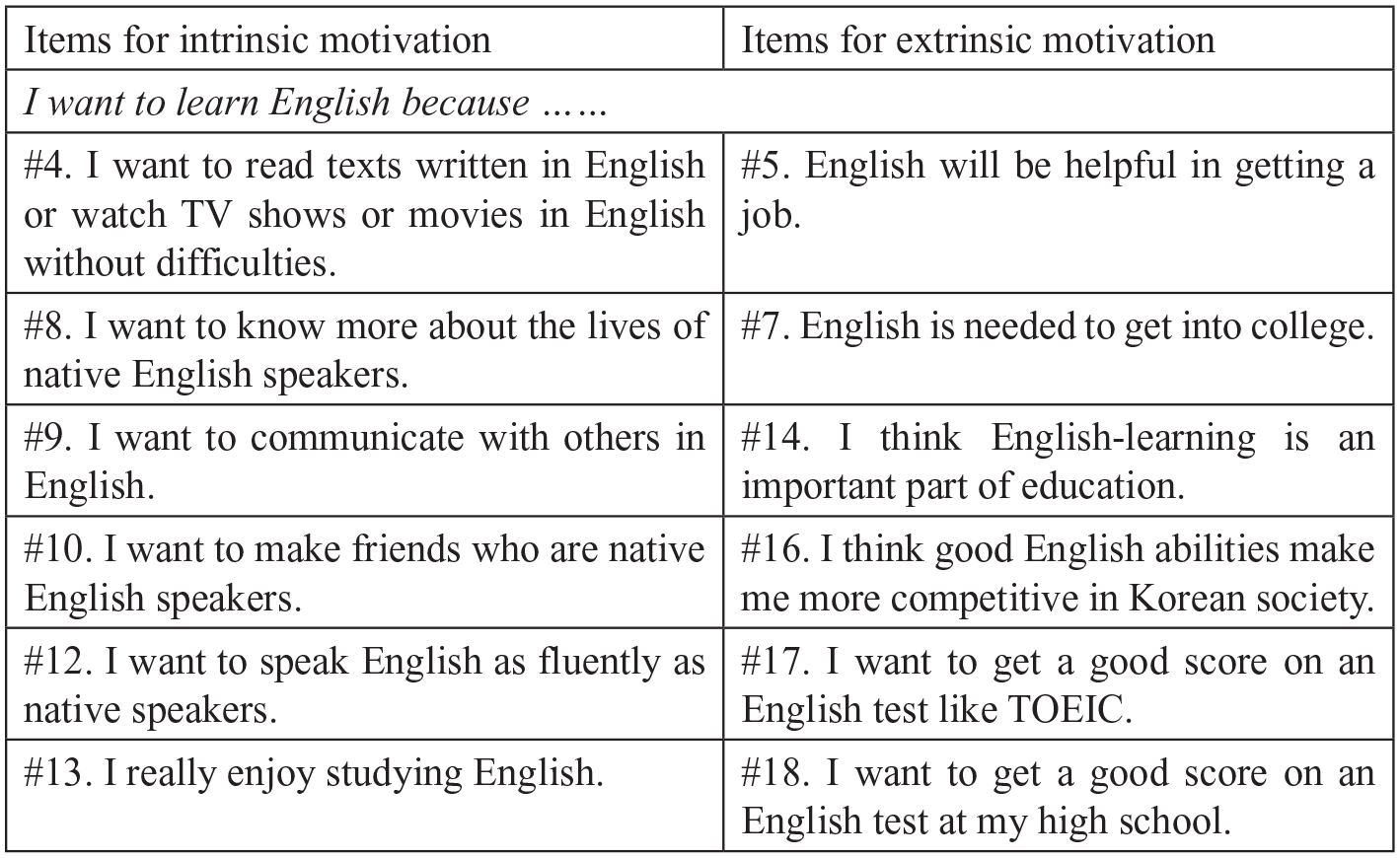
Items from the motivation questionnaire.
f Language background questionnaire
A language background questionnaire was given to each student at the beginning of the semester. The questionnaire was designed to collect information about students’ language learning practices, the length of their English-learning experience, time spent on studying English per week, and experience living and studying in an English-speaking country.
3 Procedure
Before students performed the digital-video-making task, they participated in a short workshop (20 minutes) in which they learned how to use new technologies (e.g. KineMaster) and how to perform a mobile-assisted, video-making task. Students also watched examples of narrative digital videos because students had not previously performed a task of this genre. Then, the students completed the digital-video-making task individually over two sessions (50 minutes each) during their regular English class time. As the task was carried out during their regular English class time and the task outcome was expected to be a digital multimodal composition, students were asked to pay attention to their language (i.e. English) as well as the digital semiotic means that they employed. Also, the instructions highlighted that semiotic modes should be used to effectively and clearly deliver their message and should be performed in orchestration (i.e. used together harmoniously) to make meaning. Students used their own mobile devices in their regular classroom setting by installing the mobile video-editing application KineMaster. The objective of the mobile-assisted task was to create a digital narrative video based on students’ experiences of success or failure in their life.
As shown in Figure 2, on Day 1, each student completed a timed English writing task (30 minutes) based on a TOEFL iBT independent writing test using pen and paper and received a short training on KineMaster and multimodality. The next day, students wrote an essay in their native language (i.e. Korean) about their experience of success or failure (20 minutes). Then, they individually planned for the digital-video-making task using a planning sheet that contained the scenario, prompt, and an outline template. On Days 6 and 7, the students produced their digital video. They were encouraged to incorporate multiple semiotic modes, such as texts, pictures, video clips, drawings, icons, music, and narration. On the last day of the study, a digital literacy questionnaire and a motivation questionnaire were administered (20 minutes total).

Procedure of the study.
4 Data coding and analysis
a Scoring digital-video-making task performance
The quality of students’ digital-video-making task performance was measured based on the scores of the task outcome ratings. An analytic rubric (adapted from Burnett, Frazee, Hanggi, & Madden, 2014) was used; it consists of three components: Use of multi-modes, Quality of language use, and Quality of task fulfillment (see supplemental material). The rubric considers both task completion (Quality of task fulfillment) and language abilities (Quality of language use) as essential areas for assessment since the mobile-assisted, video-making task was implemented in the context of an EFL classroom in which learners performed a task for the purpose of learning English. Based on Long (2015), who highlighted task fulfillment in terms of ‘a measurable behavioral outcome’ (p. 332), Quality of task fulfillment is defined as the extent to which the video coherently includes all required components, using appropriate linguistic tools such as cohesive devices (i.e. cohesion) and is ready for an audience to view the outcome. Accordingly, content (i.e. whether it effectively addresses the given topic by including two required parts: the description of an experience and reflection on that experience) and organization (i.e. whether the content (i.e. story) is organized coherently using appropriate linguistic tools such as cohesive devices) are assessed for this component. In terms of Quality of language use, the rubric evaluates linguistic accuracy, syntactic complexity and diversity, lexical sophistication, and intelligibility (when oral narration is included). However, minor errors that do not hinder readers’ understanding are not penalized. Also, the rubric evaluates multimodal design (Use of multi-modes) since the final outcome of task performance was in the form of a multimodal composition. Use of multi-modes measures how effectively various semiotic modes are used in a harmonious way to clearly communicate the author’s intended message. Multi-modes refer to semiotic means that are used to convey meaning such as visual resources (e.g. moving images, icons, drawings, pictures), sounds, music, written texts, and narration. For example, if a picture that is irrelevant to the content is used, the video receives a lower rating on Use of multi-modes.
When assessing digital videos, both written texts presented in the video and oral speech were taken into account. The digital video products were rated on a scale of 0 to 5, and scores between whole scores (e.g. 2.5) were allowed when only one of two or three components was met in a given category. Two trained raters graded all of the digital video products, and a final score was obtained by averaging the two raters’ scores. A Pearson correlation was calculated for interrater reliability. There was a very strong positive correlation between the two raters, indicating strong agreement, r = 0.95, n = 48, p < 0.001 for use of multi-modes, r = 0.96, n = 48, p < 0.001 for quality of language use; r = 0.96, n = 48, p < 0.001, for quality of task fulfillment. When the two raters’ scores differed by 1 point or more, the raters reviewed the videos, and final scores were drawn through discussion after resolving any disagreement.
b English writing proficiency
Students’ English essays were scored using an analytic rubric that was developed based on the TOEFL iBT independent writing rubric, which is originally a holistic rubric (see supplemental material). The analytic rubric was used to assess several components of writing skills (i.e. content, organization, and language use). Content concerns whether the essay effectively addresses the topic by providing a clear opinion statement and details. Organization evaluates the development of the essay organization and the relationships among ideas to create cohesion, particularly through effective use of conjunctions. As for Language Use, participants’ overall command of English, syntactic complexity, and lexical choice were assessed. For each construct, 0 to 5 points (with a 0.5 scale) were possible, with a maximum total score of 15. All English essays were scored by two trained raters. Then, the scores from the two raters were averaged. A Pearson correlation indicated very strong agreement between the two raters, r = 0.89, n = 48, p = 0.001. When a difference in scores between two raters was 1 or greater than 1, a third rater was invited to score the English essay. Then, the third rater’s score was averaged with the score with a smaller degree of disagreement.
c L1 narrative ability
To gauge how well students were able to develop a narrative around a given topic (i.e. an experience evidencing success or failure), their Korean narrative essays were evaluated. A holistic rubric was created based on assessment criteria used in the Korean arts national curriculum in Korea. The quality of narration was measured focusing on the following: (1) a description of the experience, including details and (2) reasons why the experience was a failure or a success/the effects of the experience on their life (see supplemental material). The points ranged from 0 (no credit) to 5 (excellent) with a 0.5 scale. All 48 Korean essays were rated by two trained raters, and the averaged scores were used as final scores. A Pearson correlation was calculated, and a very strong positive correlation between the two raters was found, indicating strong agreement between the raters, r = 0.84, n = 48, p = 0.001. When there was a difference of 1 point or more in two raters’ scores, disagreements were resolved through discussion and final scores were determined.
d Digital literacy questionnaire and motivation questionnaire
For digital literacy, a total of eight questionnaire items were included in the study, and ratings on those eight items related to digital literacy were averaged to obtain a digital literacy score for each student. Students’ motivation levels were measured based on questionnaire items for intrinsic motivation (six items) and extrinsic motivation (six items). A mean score of the six items for each type of motivation was calculated to obtain an intrinsic motivation score and an extrinsic motivation score for each student. The reliability of each questionnaire was measured using Cronbach’s alpha and the internal consistency of each instrument was acceptable: .83 (digital literacy questionnaire), .86 (intrinsic motivation), and .84 (extrinsic motivation).
e Statistical analysis
Using R (R Core Team, 2018), three multiple linear regression analyses were conducted – one for each component in the analytic rubric – to investigate what factors predicted the quality of digital-video-making task outcomes: use of multi-modes, quality of language use, and quality of task fulfillment. The dataset satisfied assumptions for multiple linear regression (i.e. normal distribution of the residuals, homogeneity of variances, linearity, and multicollinearity).
IV Results
The current study examined how English writing proficiency, L1 narration ability, digital literacy, and two types of motivation were related to the quality of EFL adolescent learners’ mobile-assisted, digital-video-making task outcomes. Before presenting the results for the research question, in order to provide descriptions of students’ digital video products, Table 1 summarizes the number of scenes included, duration of the videos, and the number of words included, based on oral narration and written texts in scenes.
Overview of digital-video-task outcomes.
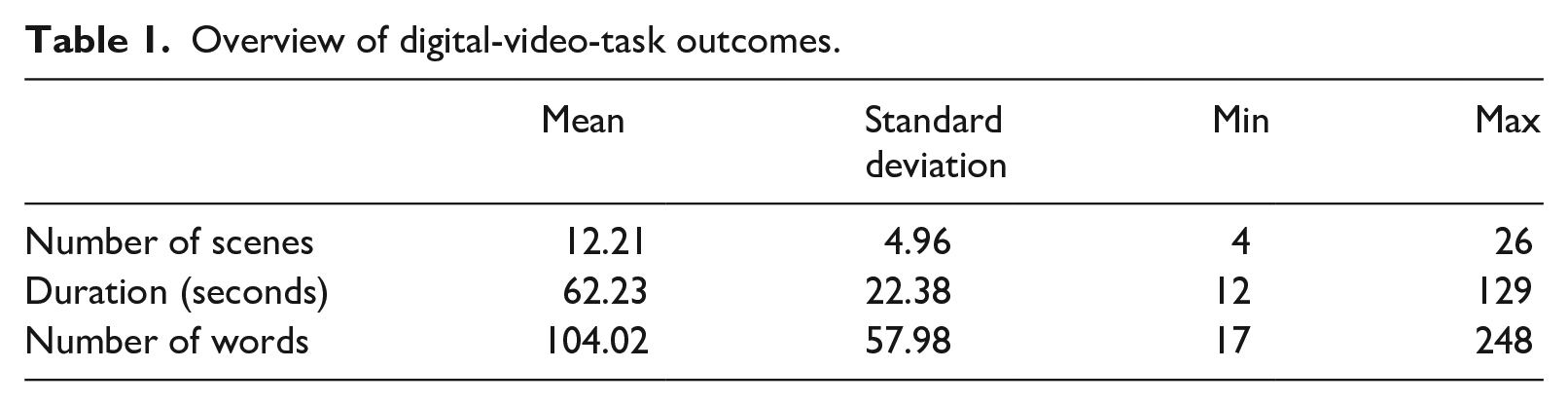
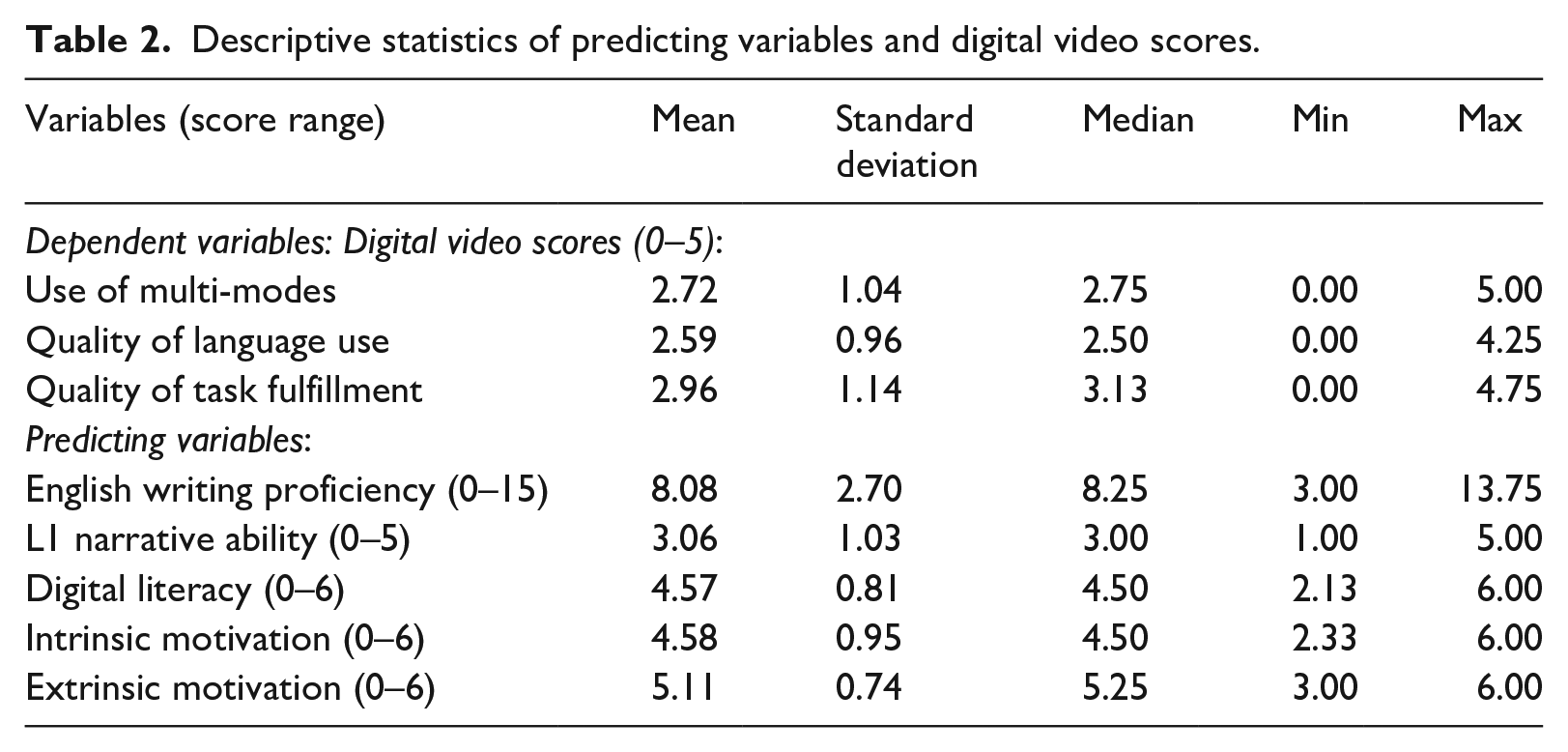
Table 2 presents descriptive statistics of the five predicting variables and three dependent variables (digital video scores: use of multi-modes, quality of language use, quality of task fulfillment (content and organization)). On average, students received 8.08 (SD = 2.70) out of 15 for English writing proficiency, and no student received the maximum possible score for English writing proficiency. The mean score for L1 narration ability was 3.06 (SD = 1.03), and it ranged from 1 to 5. Digital literacy was negatively skewed, which means that students tended to have a relatively high level of digital literacy on average (M = 4.57, SD = 0.81). Both types of motivation were also skewed towards a high level (intrinsic motivation: M = 4.58, SD = 0.95; extrinsic motivation: M = 5.11, SD = 0.74).
Descriptive statistics of predicting variables and digital video scores.
To investigate how the five key factors – English writing proficiency, L1 narrative ability, digital literacy, and two types of motivation – contributed to the quality of digital-video-making task outcomes, three multiple linear regressions were conducted (for correlations between variables, see the correlation matrix in supplemental material). Two multiple linear regression models were found to be statistically significant. First, Model 2 significantly predicted quality of language, F(5, 42) = 14.07, p < .001, R2 = .63, adj. R2 = .58, f2 = 1.70. It explained 63% of the variance in the scores for quality of language use in the digital video scores. Model 3 also significantly predicted quality of task fulfillment, F(5, 42) = 6.56, p < .001, R2 = . 44, adj. R2 = .37, f2 = .79. Model 3 was able to account for 44% of the variance in the scores for quality of task fulfillment. However, scores of use of multi-modes were not significantly predicted by the multiple linear regression model (Model 1), F(5, 42) = 0.82, p = .54, R2 = .09, adj. R2 = -.019, f2 = 0.10. As shown in Table 3, two variables, English writing proficiency and L1 narrative ability, were significant predictors of both the score of quality of language use and the score of quality of task fulfillment. However, it was noted that the standard coefficient of L1 narrative ability was more conducive to both quality of language use and quality of task fulfillment than English writing proficiency. Linear regression models with interactions reported no significant interaction effect between English writing proficiency and L1 narration ability for predicting quality of language use and/or quality of task fulfillment.
Results of multiple linear regression analyses predicting the quality of digital videos.
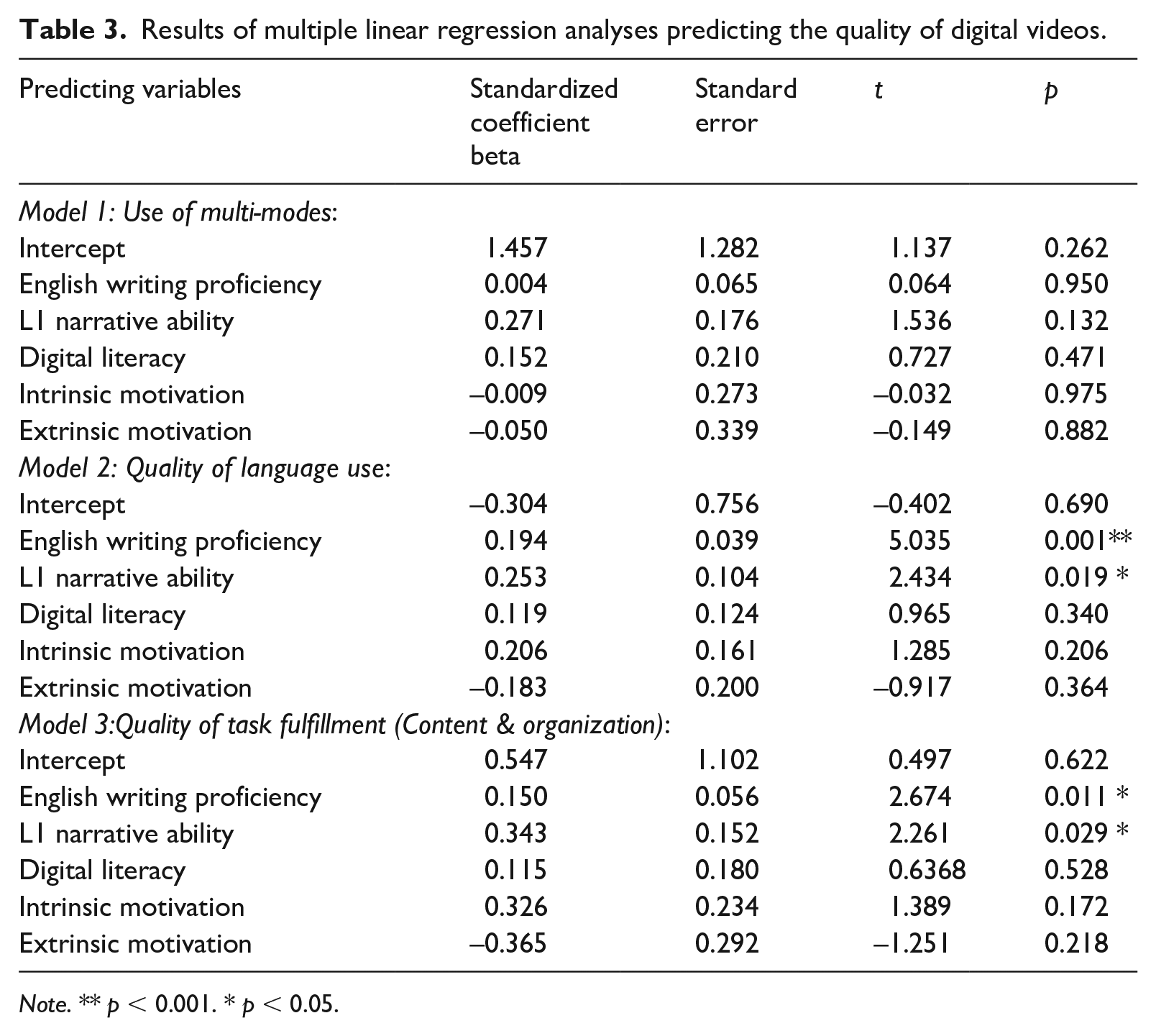
Note. ** p < 0.001. * p < 0.05.
In order to further explore the contribution of the two significant predictors (English writing proficiency and L1 narration ability) to the quality of digital-video-making task outcomes, digital video samples from two students were examined in detail: one student (Participant 11) who scored very high in English writing, L1 narration ability, and quality of language use and quality of task fulfillment (content and organization) in the digital video rating, and one student (Participant 23) who scored very low in the aforementioned areas. Table 4 summarizes the scores that the students received for English writing, L1 narrative ability, and the components comprising the quality of digital videos along with an overview of their video outcomes, including number of scenes, duration, and number of multi-modes used in the video. A wide gap exists between the two learners and their task outcomes not only in English writing proficiency, L1 narrative ability, and digital video scores, but also in the number of scenes, duration, and the number of visual, audio, and textual resources utilized.
English writing proficiency, first language (L1) narration ability, and detailed information about videos for two students (Participants 11 and 23).

As shown in Table 4, Participant 11, who received high scores on quality of language use and quality of task fulfillment (content and organization) for his digital video, scored 13 out of 15 on his independent English writing task and 4 out of 5 for Korean narrative ability. In contrast, Participant 23, whose video scored lower in terms of quality of language use and quality of task fulfillment, received 5.5 out of 15 for her English writing proficiency and 1.25 for the Korean written narration. These two samples demonstrate a pattern in the data that students with low levels of English writing proficiency and L2 narration abilities were unable to produce digital videos of good language quality and with fully elaborated, coherent content. To illustrate, Participant 23 exhibited low levels of English writing proficiency (score: 5.5 out of 15) and L1 narration ability (1.25 out of 5). Her digital video (see Figure 3 for all scenes) was not successfully completed in that it did not address the given topic by effectively tackling the two required parts of the task, and it lacked cohesion between ideas. She attempted to describe her experience of failure using different modes, such as drawings and written texts, but did not include a sufficient level of detail. Additionally, her video failed to successfully explain why she thought that her experience was a failure and how it influenced her life. In terms of organization, the digital video had limited organization due to a lack of cohesion (i.e. no use of appropriate transitions). Similar to her performance on the Korean narrative essay, she did not recall or use adequate details to describe her failure and how it impacted her life, and this might have led to ineffective communication and a low quality of content development and poor organization in her digital video. Also, as shown by insufficient scores for her English writing ability, she was incapable of producing a well-organized, fully-developed English text of a good quality of language use. This lack of skill in traditional English writing seems to have been transferred to content development and organization of the multimodal composition in digital-video-task performance. The digital video created by Participant 23 also demonstrated a weak command of English and used simple syntactic structures and a limited range of lexical items, as shown in Figure 3. This poor quality of language use in the mobile-assisted video might be tied to her low English writing proficiency, which similarly showed simplistic structures (e.g. I getting fat), uses of basic vocabulary (fat, sad), and linguistic errors (e.g. my fail, on diet).

Screenshots from Participant 23’s digital video.
Participant 11, who had a higher level of English writing proficiency and good Korean narrative abilities, presented a different profile. In terms of English writing proficiency, he demonstrated strength in content, organization, and language use. Also, he produced a Korean narrative of high quality with adequately developed content. With respect to quality of task fulfillment, his video task outcome included detailed descriptions and reflections on his experience (see Figure 4 for part of his video). What is noticeable in his video is that reflections on his failure or success were presented explicitly through narration, whereas other students did not clearly address this topic, or did not include it in their videos at all. Participant 11 organized his ideas using appropriate transitions, such as conjunctive adverbs and cohesive devices (e.g. on the contrary). With regard to the quality of language, he demonstrated good use of English vocabulary and grammar and employed complex English structures, even though there were some minor errors. Compared to low scorers on the quality of language use, his video clearly showed his ability to use syntactically varied and complex sentences and more sophisticated vocabulary (e.g. estimate, realize, ability), which might be closely linked to his high English writing proficiency.
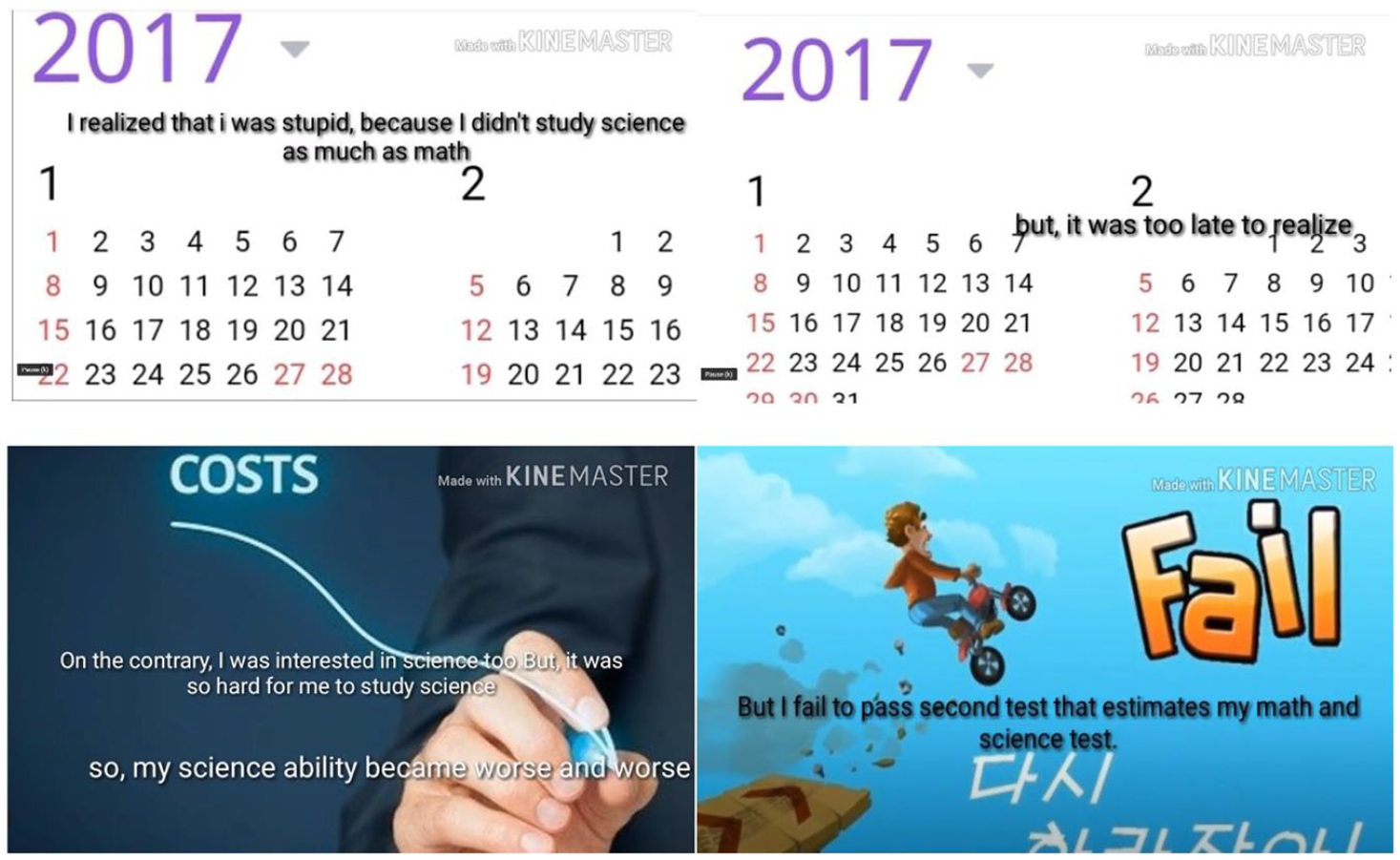
Screenshots from Participant 11’s digital video.
Overall, in the current study, English writing proficiency and L1 narrative ability were the statistically significant predictors of two components of the quality of digital video. Learners who were capable of producing high quality English texts and Korean narratives used higher quality language in their mobile-assisted video projects and produced adequately developed, well-organized videos. Conversely, learners who have low levels of English writing ability and Korean narration did not show high achievement in terms of accurate and complex language use or task fulfillment (i.e. content and organization). However, the present study did not find a statistically significant contribution of predictive variables to the use of multi-modes. To illustrate the lack of predicting capacity, a sample video from Participant 22 is presented. Out of a possible 5 points for the following categories, her digital video scored 4 (use of multi-modes), 1.5 (quality of language use), and 1.5 (quality of task fulfillment). As reflected in the scores, her digital video project demonstrated a high quality of multimodal design through her use of various semiotic means (e.g. drawing, narration, written text) in a harmonious manner to clearly convey her message (see Figure 5). Low scorers in the use of multi-modes often used mismatched multi-modes; for example, to describe an experience of success in which his eyesight improved, a learner used a picture of a group of enlisted soldiers wearing glasses and incorporated an English written text stating, ‘However, my eyesight has improve when I went out PC café.’ This mismatch in image and text failed to create a multimodal ensemble. In contrast, Participant 22 prepared her own drawings that effectively and precisely delivered the intended message, along with written text included in the scene and her verbatim narration. However, this effective use of multimodal design was not necessarily associated with her English writing proficiency (3 out of 15) or her L1 narrative ability (1.25 out of 5).

Screenshots from Participant 22’s digital video.
The cases of Participant 22 and 23 illustrated two patterns among low English ability students: those who make efforts to compensate for their limited language abilities with multi-modes (Participant 22) and those who did not make such efforts (Participant 23). A careful scrutiny of students’ task outcomes showed that there were more low ability students like Participant 23 who were not directed towards a compensation strategy by resorting on multi-modes. Further, although Participant 11 showed good quality of English use and effective multimodal design, the majority of high English ability students scored high on their language use but received lower scores on the use of multi-modes as exhibited in Participant 33’s case (use of multi-modes: 1.25, quality of language use: 3.75, quality of task fulfillment: 4.25 out of 5; see Figure 6). This may indicate that high language competency leads to over-reliance on the linguistic mode and a lack of harmonious use of diverse semiotic modes to make meaning.

Screenshots from Participant 33’s digital video.
V Discussion
The purpose of the current study was to investigate how learner-related factors such as English writing proficiency, L1 narration ability, digital literacy, intrinsic motivation, and extrinsic motivation were associated with Korean high school students’ mobile-assisted task outcomes. The results revealed that English writing proficiency and L1 narrative ability were predictive of two elements of the quality of digital-video-making task outcomes – quality of language use and quality of task fulfillment (content and organization) – indicating that students who have good English writing skills and L1 narrative skills performed better on a mobile-assisted task that required storytelling in terms of language, content, and organization. This might be attributed to the fact that in the digital-video-task performance, text-oriented English writing abilities still played a significant role in determining linguistic performance, in terms of accuracy, structural complexity, and lexical sophistication, even though the video drew on various communicative means. Results also revealed that students who were capable of generating ideas and developing adequate details in their L1 exhibited better English use by producing fewer errors, more complex syntax, more varied sentences, and more sophisticated vocabulary. This might be accounted for by Skehan’s Trade-Off Hypothesis (1998), in that when learners are already familiar with the content of a task, they might be able to pay more attention to the quality of language that they use to complete the task.
In addition, the results indicated that participants’ Korean narrative ability on the same topic made a significant contribution to the quality of task fulfillment in the video-making task outcome, which is operationalized in terms of content and organization. In order to assess the quality of students’ storytelling abilities without English proficiency as a confounding variable, we asked students to respond to the prompt in Korean in the current study. This seemed to be a reasonable way to measure students’ L1 narrative ability on the same topic. Students who achieved a higher level of content development on the topic in Korean produced more successful task outcomes by creating a digital introduction video that presented their experience and reflections with sufficient details and by organizing their ideas cohesively and systematically through the use of different semiotic tools. This finding seems to be in line with previous studies such as Tedick (1990) and He and Shi (2012), which revealed that topic knowledge has significant effects on writing development. Additionally, this result confirms the positive interrelationship between L1 writing ability and L2 writing found in Kamimura (1996), which revealed that students who produced more idea units and received higher ratings in Japanese compositions tended to do so in their L2 English compositions as well. Additionally, the quality of task fulfillment was significantly predicted by students’ English writing ability, which indicates that although the digital-video-making task required more than monomodal English use, since English texts were the major semiotic tool, learner’s writing ability significantly predicted the quality of content and organization (i.e. task fulfillment).
In the current study, although the two variables (i.e. English writing proficiency and L1 narrative ability) predicted the scores of quality of language use and quality of task fulfillment, they did not predict the multimodal quality of the digital video. A possible explanation could be that even though multimodal design includes the use of English texts among semiotic modes, language itself is not a defining component in terms of the quality of multimodality in a digital-video-task outcome. Also, being able to develop content adequately, which was manifested through students’ L1 narrative ability, might not be closely linked to utilizing diverse communicative means harmoniously. A lack of significant contribution of any predicting factors to the use of multi-modes suggests that it is possible that other factors may have impacted students’ use of digital multi-modes, such as creativity. For example, a few studies have explored the potential role of creativity in L2 production, and evidence of a positive relationship between components of creativity and some aspects of L2 performance has been documented (e.g. Albert & Kormos, 2004; McDonough, Crawford, & Mackey, 2015). Even though these studies focused on linguistic features of L2 performance, considering what constitutes creativity as defined by Torrance (1969) – ‘the capacity to detect gaps, propose various solutions to solve problems, produce novel ideas, re-combine them, and intuit a novel relationship between ideas’ (cited in Almeida et al., 2008, p. 54) – creativity might play a role in the use of multi-modes and the multimodal design of a digital video because the mobile-assisted, video-making task requires learners to tackle a problem (i.e. creating a competitive self-introduction video in order to be accepted to a college summer camp) by coming up with different ideas (i.e. their experience of success or failure and how it affected their life) and systematically organizing their ideas. Furthermore, L1 studies on digital storytelling, which requires multimodal design, show that not only can digital storytelling promote creativity (Gresham, 2014; Smyrnaiou, Georgakopoulou, & Sotiriou, 2020), but creativity is also needed when creating digital storytelling (Hernández-Ramos & De La Paz, 2009; Kajder & Swenson, 2004; Liu, Tai, & Liu, 2018). To date, creativity has not been explored in the digital-video-making task literature, and researchers may want to examine the relationship between creativity and task outcomes in the future.
In the current study, neither digital literacy nor motivation made a statistically significant contribution to any component of the quality of the mobile-assisted, video-making task. The degree of variation in digital literacy among students under investigation might have not differed enough to impact the quality of their digital videos. Nowadays, Korean high school students are very comfortable with different uses of mobile phones, and thus virtually all students tended to have a similarly high level of digital literacy (i.e. ceiling effect). Thus, there was no significant effect for digital literacy on the quality of task outcomes among these highly digitalized students. By examining all the required skills for making videos using KineMaster and as demonstrated in the reliability measure (Cronbach’s alpha = .83), our survey, which was adapted from Son (2015) and Son, Park and Park (2017), is considered a valid measure. However, it should be noted that we used self-reported data. Thus, different operationalizations of digital literacy (e.g. ability of using KineMaster, ability of editing videos) might have resulted in different findings regarding the role of digital literacy.
With regard to the two motivational factors, the mean scores of both types of motivation were quite high (intrinsic motivation: M = 4.58 (out of 6), SD = 0.95; extrinsic motivation: M = 5.11 (out of 6), SD = 0.74), indicating that all students showed a high level of motivation for learning English both intrinsically and extrinsically, which resulted in a lack of difference among them in terms of motivation level. This might have accounted for a lack of significant contribution of motivation to the three elements in the quality of the video-making task. Also, the correlation matrix (supplemental material) demonstrated that intrinsic motivation was moderately correlated with quality of language use and quality of task fulfillment (r = 0.33 for quality of language use, r = 0.29 for quality of task fulfillment). However, this significant medium correlation might not have been strong enough to make an independent contribution, and the contribution of intrinsic motivation might have been subsumed by other predictive factors (e.g. English writing proficiency). This could be another possible explanation for the lack of an observed contribution of motivation to the quality of the digital-video-making task.
The findings from the current study have some pedagogical implications for language classrooms that employ mobile-assisted, video-making tasks. First of all, the study suggests affordances of implementing mobile-assisted, video-making-tasks in a Korean high school context. It was our first attempt at designing such a task for high school students using a mobile app, and although the quality of the task outcomes varied as reported in this study, students overall were able to complete the task within the limited time by utilizing various modes. Although the quality of some task outcomes appears low compared to the range, the majority of the students seemed to be able to successfully deliver meaning using not only English texts but also other semiotic tools. The results indicated that learners’ English writing proficiency had a distinct significant contribution to language use and task fulfillment in video-making task outcomes. More specifically, although students were asked to employ a variety of multimodal tools available through the mobile application (e.g. pictures, music, movies) to complete the task, English writing ability was found to be a significant factor for predicting not only the quality of language features, but also the content and organization of digital videos (i.e. task fulfillment). This might be an informative finding for those who are reluctant to implement such multimodal video tasks in English writing classes. Although the multimodal nature of video-making tasks may appear to value writing practices to a lesser degree, English writing skills still seem to play a significant role in video-making tasks. If a language teacher implements mobile-assisted, video-making tasks, students’ English writing proficiency should be considered as an important factor when designing tasks using similar video-creating applications (e.g. KineMaster). However, the lack of a significant relationship between English writing proficiency and the quality of the multimodal nature of the task outcome suggests that English proficiency was not a significant factor affecting learners’ use of semiotic tools harmoniously to make meaning as a part of task performance. Thus, when designing and implementing multimodal video-making tasks in classroom contexts, teachers may consider different factors that might affect task performance (e.g. creativity) besides language ability as well as learner needs in order to present tasks that are not entirely focusing on language ability.
Some of the students in the current study exhibited interesting trends in the use of multi-modes, which illustrates the insignificant relation between English writing proficiency and the use of multi-modes. The majority of the students with higher English language abilities tended to overuse language compared to other semiotic modes, which resulted in the lack of semiotic harmony or an ineffective multimodal design in their videos. Among students with lower English language abilities, while some students tried to use other semiotic tools in order to compensate for their lack of linguistic knowledge (Oxford, 1990), other students did not use this compensation strategy (i.e. employing different semiotic means) despite their limited language resources. Therefore, acknowledging these two patterns (i.e. underuse of multi-modes and overuse of language by high ability students and underuse of multi-modes by low ability students), teachers may need to offer explicit strategy training sessions to high and low proficiency students to leverage diverse multi-modes and the importance of semiotic harmony.
Korean narrative ability was also found to be an important factor as it was shown to have a distinct significant contribution to language use and content development and organization (i.e. task fulfillment) in video-making task outcomes. Particularly, the results suggested that Korean narrative ability seemed to contribute more to the two components of quality of digital-video-making task outcomes than English writing proficiency. This highlights the importance of topic knowledge and understanding of genre prior to task performance. Students might benefit from planning activities designed to enhance their understanding of a given topic and genre knowledge as described in the triadic componential framework of task design (particularly, prior knowledge and planning time; Robinson, 2001, 2005, 2007) and shown in pretask planning studies in the TBLT literature demonstrating the positive effects of planning time (Ellis & Yuan, 2004; Kim, 2013; Ong & Zhang, 2010; Rahimi & Zhang, 2018). Also, teachers might want to consider incorporating an open-topic task, in which students can select a topic based on their own interests and familiarity, about which they would already have sufficient topic knowledge.
In the current study, most students seem to have had sufficient digital literacy associated with the use of mobile phones. Also, students received one short training session (i.e. 20 minutes) on the new mobile application (i.e. KineMaster) and on how to create a mobile-assisted video, which seemed to be sufficient for them to carry out the task using the new mobile application. However, for other learner populations with less knowledge of technological tools or experience with multimedia, a short training workshop might not be sufficient. Thus, when teachers introduce a new mobile application for task performance, it is important to offer training sessions so that students feel prepared to carry out the task using the new technology. That is, providing appropriate support prior to video-making tasks would be an important component of a mobile-assisted language classroom in order to scaffold students’ successful learning.
Some limitations of the current study should be considered in future research. First, the current study examined mobile-assisted task performance by using one type of task (i.e. a narrative digital-video-making task) and a specific task prompt. Thus, the findings might not be generalizable to other types of mobile-assisted task performance. Future studies should consider including different types of mobile-assisted L2 tasks (e.g. creating social media posts, producing a vlog of an outdoor activity, ordering a gift for a friend using a shopping application) using various applications and various task prompts to develop a fuller picture of the quality of mobile-assisted task performance and to test for the affordances of mobile devices in a systematic manner. Additionally, the current study focused on task outcomes and did not consider task-as-a-process data. In order to understand students’ use of different technological tools on mobile devices and how language is used during task performance, their performance during the video creation process should be recorded and analysed. Lastly, considering that there were five predictive factors, the inclusion of a larger number of participants would have been ideal in order to ensure greater precision of the estimates. Mobile-assisted task performance research is still in its infancy, and future research is warranted to explore the diverse opportunities that mobile-assisted language teaching can offer to students who belong to digital generations.
VI Conclusions
Even though digital-video-making tasks have drawn increasing attention from educators and researchers, little evidence has been documented on the factors that predict the quality of digitally-made videos, particularly how learner-related factors such as English writing proficiency, L1 narrative ability, the level of digital literacy skills, and learners’ motivation for learning English would contribute to task outcomes. The findings from the current study indicated that students with high(er) English writing proficiency and those who have good L1 narrative ability may produce mobile-assisted digital videos of higher linguistic quality and with more well-developed content.
To conclude, one of the main contributions of this study was the exploration of a mobile application to complete a video-making-task. As the use of mobile phones is ubiquitous, and students are very comfortable with using mobile phones on a daily basis, mobile-assisted language teaching methods in classroom contexts warrant future research. We hope that the findings of the current study can provide practitioners with some factors to consider when designing and implementing mobile-assisted, video-making tasks.
Supplemental Material
sj-docx-1-ltr-10.1177_13621688211047984 – Supplemental material for Examining the quality of mobile-assisted, video-making task outcomes: The role of proficiency, narrative ability, digital literacy, and motivation
Supplemental material, sj-docx-1-ltr-10.1177_13621688211047984 for Examining the quality of mobile-assisted, video-making task outcomes: The role of proficiency, narrative ability, digital literacy, and motivation by Sanghee Kang and YouJin Kim in Language Teaching Research
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.