
Abstract
Aim and objective:
The aim of this study is to show how different English single content morphemes, in particular nouns and adjectives, occur in the Persian structure by applying the Matrix Language Frame and 4M models.
Methodology:
The data collection in the present study includes tape-recordings of spontaneous conversations involving 12 Persian–English bilingual speakers at a public university in Malaysia. The IELTS participants’ scores were 6.0 or higher and they were between 20 and 40 years old.
Data and analysis:
Qualitatively, 8 hours of tape-recorded conversations were transcribed and coded carefully according to the Canonical Trilinear Representation. Quantitatively, the English content morphemes, especially nouns and adjectives, were analysed syntactically and morphosyntactically to show how they grammatically occur in the bilingual complementiser phrases.
Findings and conclusions:
The findings of this study reveal that code-switching was permissible even when it led to structural dissimilarity. Wherever it was required by a Persian principle, the inserted English elements, particularly nouns and adjectives, received different Persian markers. They may also appear without any Persian marker where required by the Persian grammar. Moreover, the data supported the Matrix Language Frame and 4M models’ principles, Morpheme order principle and System morpheme principle, and no counterexample appeared against the mentioned models.
Originality/significance/implication:
There are few studies on code-switching between Persian and English that focus on typological differences between the languages involved and the use of the Matrix Language Frame model and 4M model. Thus, the present study contributes knowledge in the field of code-switching between Persian and English and discusses how English single content morphemes, particularly nouns and adjectives, occur in the Persian structure by applying both the Matrix Language Frame model and 4M model as references.
Introduction
The present study contributes knowledge to the field of code-switching (hereafter CS) among two typologically dissimilar languages, Persian and English. The term CS includes elements of two language varieties in the same complementiser phrase (hereafter CP), in which one of the languages serves as the morphosyntactic frame of the CP (Myers-Scotton, 2002).
The main aim of this study is to identify how different English single content morphemes, in particular noun and adjective, occur in Persian–English bilingual speech. Although some researchers have carried out studies on the CS between typological dissimilar languages (e.g. Choi, 1991; Nishimura, 1986; Romaine, 1995) there is still very little investigation of CS between Persian and English as two typologically dissimilar languages. The Matrix Language Frame (hereafter MLF) and 4M models are considered as one of the most influential models in the field of CS and they have been successfully used to study different language pairs. However, there are not many studies reporting on the findings that look into Persian–English bilingual speech. Thus, the present study applies the MLF model (Myers-Scotton, 1993) and 4M model (Myers-Scotton & Jake, 2000) as references for analysing the CS between Persian and English.
Code-switching
One of the earliest definitions of CS lies in Weinreich’s description of bilingualism as “the practice of alternately using two languages” (Weinreich, 1986, p. 1). Most CS studies maintain that CS is a concept that goes beyond Weinreich’s (1986) proposal so that the CS can occur even within a sentence (Pfaff, 1979). In the same vein, Gumperz (1982, p. 59) defines CS “as the juxtaposition within the same speech exchange of passages of speech belonging to two different grammatical systems or subsystems”. Myers-Scotton (2002) asserts that CS includes the elements of two language varieties in the same CP, in which one of the languages serves as the morphosyntactic frame of the CP. The following example shows this type of CS.
(1) PAPER neveštan xeili moškel-e writing very difficult-Copula 3Sg
1
‘Writing a paper is a difficult job’
Myers-Scotton (2006) divides CS into inter-sentential switching and intra-sentential switching. Inter-sentential switching means that full sentences are code-switched while intra-sentential switching is referred as intra-clause switching. She finds that the phenomenon of the CS can be between two CPs (clauses) in the same sentence. Myers-Scotton makes a list of several advantages of CP over sentences. (i) Unlike a sentence, a CP’s status is clear. She takes note that “it can be defined unambiguously in terms of phrase structure as a complementiser or an element in specifier position followed by an IP (sentence)” (2002, p. 55). (ii) It has been used by many syntacticians so there is not this fear that its use is tied to any specific theory. (iii) Using the CP as the unit of analysis will avoid problems in terms of the status of constituents with null elements.
Muysken (2011), however, believes that there is a third category for switching such as extra-sentential/emblematic/tag-switching, which is the insertion of a tag phrase such as I mean and you know from one language into the sentence of another language. Myers-Scotton (2002) argues that extra-sentential switchings are monolingual CPs that contain a number of null elements and they, as such, cannot be considered as a type of CS.
This study focuses on the intra-sentential switchings, in particular nouns and adjectives, appearing within a CP in a single form. The following are some examples of CS including bilingual CPs from the English–Persian CS data.
(2) Badeš INTERNSHIP dǎr-am then have-1Sg ‘Then (I) have internship’ (3) Bacce-hǎ ro bǎ WORD ǎšenǎ mi-kard-im student-PL rǎ with familiar IMPF-did-1Pl ‘We made the students familiar with the words’ (4) Šomǎ SKINNY hast-i you is - 2Sg ‘You are skinny’
Differentiating Matrix language from Embedded language
Numerous studies have attempted to explain the CS phenomenon by making a distinction between the matrix language (ML) and embedded language (EL) (e.g. Sridhar & Sridhar, 1980). Thus, identifying the language that is acting as the ML is crucial. There are different approaches for clarifying the ML from EL: the first approach is used by Myers-Scotton (1993). She distinguishes ML from EL in terms of two major principles: the Morpheme Order Principle and the System Morpheme Principle. She states that in ML+EL constituents both the surface morpheme order and outside late system morphemes belong to the ML. The second approach is ‘left to right parsing’. In this approach, the first word or set of words in the sentence differentiates the ML from the EL.
A third method of distinguishing the ML from the EL is morpheme-counting. Myers-Scotton (1993) states that the ML has more morphemes in the CS within a CP. However, in 2002 she claims that morpheme-counting is not a determining factor in distinguishing the ML from the EL. A fourth possibility is mentioned by Muysken (2000). He states that often main verbs can be taken to determine the ML. Later, he finds out that in some languages, such as Hindi, a strategy of incorporating alien verbs by means of an auxiliary verb like ‘do’ has been used. Thus, he concluded that he needed to revise his idea of taking borrowed verbs as determining that the ML is clearly incorrect. Following the MLF model by Myers-Scotton (1993), this study identifies the ML based on the Morpheme order principle and the System morpheme principle.
The Matrix Language Frame and 4M models
MLF principles
Myers-Scotton (1993) has labelled the language with the dominant role in the CS process as the matrix language (ML) or frame language, while the language that is less active and does not have a dominant role in the CS is the embedded language (EL) or guest language. She then developed a new model of CS known as the MLF model.
Matrix language principle
As noted by Myers-Scotton (1993), in the process of analysing CS, one of the most important principles is the division of the roles between the ML and EL. The ML not only dictates the morphosyntactic structure of the CS sentence, but also all the productive system morphemes that originate from the ML. The other crucial distinction is the differentiation between content morphemes and system morphemes. Content morphemes are those that have a thematic role in the sentence such as nouns, verbs, adjectives, and adverbs. In contrast with the content morphemes, system morphemes do not have any thematic role. As noted by Myers-Scotton (1993), degree adverbs (e.g. very, too, so), copula, do verbs, articles, quantifiers, determiners, possessive adjectives, and inflectional morphology are all system morphemes and they lack a thematic role in the sentence. She predicts two major factors for the MLF model which are as follows: the Morpheme order principle (MOP) and the System morpheme principle (SMP).
Morpheme order principle
According to the MOP, the ML always determines the surface morpheme order in the ML+EL constituents (Myers-Scotton, 1993).
System morpheme principle
According to the SMP, all system morphemes “which have grammatical relations external to their head constituents” should come from the ML in ML+EL examples (Myers-Scotton, 2006, p. 244).It should be noted that in the 4M model, the one type of system morpheme which goes under the SMP is named as outsider late system morphemes. The model is further discussed in the following section.
4M model
Subsequently, Myers-Scotton and Jake (2000) developed a new model to explain the CS as the 4M model and define the content and system morpheme opposition more precisely. According to Myers-Scotton (2002), this new model adds precision to the MLF model and it accounts for combinations of data well beyond the scope of the MLF model. In this model, content morphemes such as nouns, adjectives, adverbs, and verbs are considered as they are included in the MLF model and can occur in both the ML and EL. However, in the 4M model Myers-Scotton and Jake (2000) categorised the system morphemes into two types: early system morphemes and late system morphemes.
Early system morphemes
Myers-Scotton and Jake (2000) found that early system morphemes usually occur with content morpheme heads. Unlike content morphemes, early system morphemes such as determiners, articles, and plural markers do not play any thematic role.
Late system morphemes
Myers-Scotton (2002) defined late system morphemes as morphemes that are structurally assigned and which receive their information from both inside and outside their maximal projection. Myers-Scotton and Jake (2000) divided the late system morphemes into two groups. The first group of the late system morphemes are bridge system morphemes, which act as bridges and integrate morphemes into larger constituents that can occur between phrases, such as the possessive element that occurs between a possessor noun and the element that is possessed (Myers-Scotton & Jake, 2009). The second group of the late system morphemes is the Outsiders that are only found in the ML. The best example of an outsider morpheme in English is the factor that shows the subject–verb agreement on the verb (Myers-Scotton, 2002).
Methodology
Research design
Singh (2006) believes that research design acts as a mapping strategy. The research design chosen for the present study is a mixed-method one. As noted by Lodico, Spaulding and Voegtle (2006), a mixed-method design is divided into the explanatory design, exploratory design and triangulation design. This study uses an exploratory design for analysing the data. The data in the present study have been collected and analysed first qualitatively by transcribing the data and then quantitatively by counting the frequency.
Participants
In this study, a non-probability purposive sampling (judgement sampling) method was chosen. According to Neuman (2014), purposive sampling is suitable for those kinds of studies that have to select members of specialised population.The CS data for the purpose of this study were recorded from spontaneous conversations among 12 Persian–English bilingual speakers at a public university in Malaysia. The participants’ IELTS scores were 6.0 or higher and they were aged between 20 and 40 years old. The participants were divided into five groups, with participants who were already familiar with one another forming each group.
Data collection method
Within the literature, two different techniques are used in order to study CS: (i) naturalistic techniques and (ii) controlled experimental techniques (Gullberg, Indefrey & Muysken, 2009). Tape-recording is one of the naturalistic techniques for studying CS phenomenon which is used in the present study. Poplack (1980) was one of the earliest researchers who started recording her data in different settings, such as the public domain, informal gatherings, and group conversations.
Data collection procedure
The conversation of the first group was recorded in a cafeteria near the School of Language, Literacies and Translation at Universiti Sains Malaysia. This group was composed of two female participants. The second group consisted of three male participants and their conversation was recorded in the home of one of the participants. The conversation between the third group was recorded between two female participants at the library of Universiti Sains Malaysia. The fourth conversation was recorded between three male participants in the School of Arts. Finally, the conversation of the fifth and the last group of participants, between two sisters, was recorded in the researcher’s house during an informal gathering.
All the 12 participants recorded were bilingual speakers and had no difficulty in speaking in either language. After a short greeting, in all cases, the participants were informed that their conversations were going to be recorded. A mobile phone with good audio feature was used as the tape-recorder for every session. During the data collection stage, the conversations were spontaneous and neither the presence of the researcher nor the tape-recorder had affected the naturalness or increased the formality of the conversations.
Data transcription
Approximately 8 hours of tape-recorded conversations were transcribed in the current study. After identifying the bilingual CPs, all English single elements in each bilingual CP were identified and categorised.
Data coding
For the grammatical analysis and exemplification in this study, the Canonical Trilinear Representation (Lehmann, 2004) is used. In this analysis, the L1 text line is matched by two L2 lines, the IMG (Interlinear Morphemic Gloss), and a free translation. Example (5) shows how bilingual CPs were grammatically coded in the study.
(5) Kelǎs-hǎ MORNING ni-st. class -PL NEG-is ‘The classes are not in the morning’
Data analysis
According to Myers-Scotton (2006), those switched elements that are used by both monolingual and bilingual speakers cannot be counted as switching elements but should be considered as borrowed elements instead. Therefore, some of the technical items, cultural names, proper nouns, and street names used by both monolingual and bilingual speakers were excluded from data.
Qualitative analysis
In the present study the data were analysed first qualitatively. The following examples show how bilingual CPs were identified in this study. Example (6) shows a bilingual sentence that consists of two monolingual CPs, one in Persian and the other one in English. This example is not a CS which happened within a CP. According to Myers-Scotton (2002), this type of bilingual sentence does not show the opposition between the ML and EL.
(6) (HE KNOWS) (ke cce-qad barname-aš sangin-e.) that how much programme- Clitic Pro3Sg heavy-Copula 3Sg ‘He knows that how heavy the programme is’
On the other hand, Example (7) is qualified as bilingual CPs. This example contains several mixed constituents and are linked to each other by a complementiser (that=ke).
(7) (adam tajob mi-kon-e az in hame EFFORT-i) person surprise IMPF-do-3Sg of this all -Des (ke PEOPLE mi-zǎr-an) that IMPF-put-3Pl ‘I’m surprised that people put in this much effort’
In Persian, however, it is possible to have null complementiser, null relative pronoun, or null conjunction. The following example includes three CPs with null elements, one monolingual CP with two bilingual CPs.
(8) (Dirooz be Ali goft-am ) (mi -toon-i in dars ro Yesterday to Ali said-1Sg IMPF-can-2Sg this subject rǎ DROP kon-i.) (bejǎš SCIENCE TAKE kon-i.) do-2Sg instead do-2Sg ‘Yesterday (I) told Ali (that) (you) can drop this subject (and) instead take Science’
Example (9) illustrates two English elements, process and complicated in a Persian–English bilingual CP.
(9) PROCESS-eš xeili COMPLICATED-e -Clitic pro 3Sg very -Copula 3Sg ‘The process is very complicated’
All the bilingual CPs in this study were classified in the same ways as the aforementioned examples.
Quantitative analysis
According to Neuman (2014), the data used for quantitative analysis are in the form of numbers and the meanings are shown in the table. In this study, after analysing the data qualitatively, the findings were counted manually and displayed in different tables in the form of numbers.
Findings
In the present study, the analysis of data shows that the CS happened 924 times (see Table 1).
Distribution of the English single insertions.
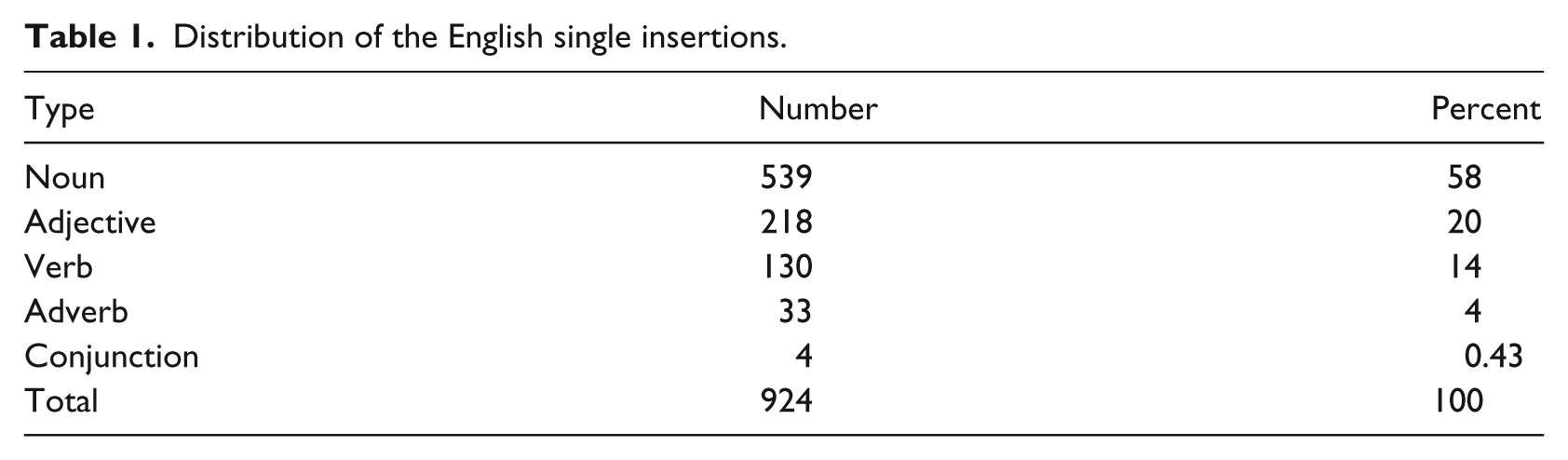
As shown in Table 1, the English single insertion involving nouns is the category that records the most number of switched elements in the present study. According to Myers-Scotton (2002), nouns are the most frequent element inserted from the EL into the ML frame. In fact, this finding confirms the findings of many other studies that mention nouns as the most frequent type of code-switched element (see Haugen, 1969; Health, 1981; Myers-Scotton, 1993; Naseh, 2002). The second most frequently switched element in the present study is adjective. After adjectives, the most frequent switched elements from English are verbs, forming 14% of single insertions found in the data. Adverbs and conjunctions form 4% and 0.43% of the insertions, respectively. Overall, the analysis of the code-switched elements shows that nouns and adjectives are the most frequent types of English elements found in this study.
English nouns in Persian frame
As the most frequent content morphemes, English single nouns are found to occur either with or without the Persian free and bound system morphemes (see Table 2.)
English nouns with or without the Persian marker.

Out of a total of 539 English nouns found in the entire corpus, 282 nouns received Persian markers and the remaining 256 did not. There was only one case in which an English noun is double marked. Myers-Scotton (2002) stated that the bare forms, as the EL content morphemes should not be excluded from the ML frame as long as the SMP is not violated.
(10) KITCHENETTE dǎr-e have-3Sg ‘It has kitchenette’
In Example (10), the English bare noun kitchenette is inserted into the sentence without any Persian marker as the Persian principle required, but the Persian structure is not violated. In Example (10) the English noun appears without any Persian marker because in the Persian equivalence no marker will be attached to the Persian noun. The example below in the parenthesis is the equivalence of Example (10).
(Ašpazkhoone dǎr-e Kitchenette have-3Sg ‘It has kitchenette’)
2
There was only one case that the English noun was double marked by both the Persian marker and English marker. For example, in the Persian–English example keywords-hǎ (keywords), Persian hǎ and English s both encode plural. See example below.
(11) Yeki az KEY WORDS-hǎ bood One of -PL was ‘It was one of the keywords’
Myers-Scotton (2002) mentioned that plural markers can be doubled in the process of CS without any violation to the ML. She pointed out that this double morphology can appear with other early system morphemes but it mostly appears with the plural markers.
The goal in illustrating how English single words integrate syntactically or morphosyntactically along with their Persian equivalence in this study is to characterise the grammatical dimensions of the insertions. The following table shows how English nouns integrate in the Persian frame morphosyntactically.
According to this table, English single nouns with the Persian word ezafe account for 78 of the total 282 English nouns with Persian markers. As outlined in Table 3, the next most frequent Persian markers are pronominal clitics, Persian plural marker hâ, Persian copula bound morphemes, Persian object marker râ, and Persian suffix –i, respectively.
The distribution of English single nouns with Persian markers in Persian frame.

The following sections will focus on the morphological and syntactic dimensions of the English single content morphemes.
English single nouns in subject position
English nouns can occur as a lexical subject in the Persian frame. In Examples (12) and (13), the English elements mushroom and dishonesty are inserted into the Persian structure without any Persian marker as the Persian structure requires. They are also placed in the subject position of the respective sentence.
(12) MUSHROOM farǎvoon bood a lot was ‘There was a lot of mushrooms’ (Qǎrcc farǎvoon bood mushroom a lot was ‘There was a lot of mushrooms’) (13) DISHONESTY dar xǎnoom-hǎ ye cciz-e tabie-e in woman-PL one thing-Ez natural-Copula 3Sg ‘Dishonesty is something natural among women’ (Khiǎnat dar xǎnoom-hǎ ye cciz-e tabie-e dishonesty in woman-PL one thing-Ez natural-Copula 3Sg ‘Dishonesty is something natural among women’)
The findings of the study also show that English nouns in the subject position can occur with the Persian markers. In Example (14), the English noun age in the subject position is suffixed first by the Persian plural marker –hǎ and then the pronominal clitic –šun that serves as a possessive pronoun. Similarly, the Persian equivalence is suffixed by the Persian plural marker –hǎ and the pronominal clitic –šun.
(14) AGE-hǎ-šun be man ne-mi-xor-e -PL-Clitic pro 3Pl to I NEG-IMPF-match-3Sg ‘They are not in the same age as me’ (sen-hǎ-šun be man ne-mi-xor-e age-PL-Clitic pro 3Pl to I NEG-IMPF-match-3Sg ‘They are not in the same age as me’)
Example (15) illustrates that the Persian pronominal clitic –ešun is attached to the English lexical subject syntax whereas, in Example (16), the English lexical subject bilingual is plural marked with the Persian plural marker –hǎ.
(15) SYNTAX-ešun bǎ-ham farq dǎr-e -Clitic pro 3Pl with-each other difference have-3Sg ‘Their syntax are different from each other’ (Nahv-ešun bǎ-ham farq dǎr-e -Clitic pro 3Pl with-each other difference have-3Sg ‘Their syntax are different from each other’) (16) BILINGUAL-hǎ grammar-ešun bad-e -PL grammar -Clitic pro 3PI bad-Copula 3Sg ‘Bilinguals are bad at grammar’ (Dozabǎne-hǎ grammar-ešun bad-e bilingual -PL grammar -Clitic pro 3PI bad-Copula 3Sg ‘Bilinguals are bad at grammar’)
In the present study, there are many cases in which English single nouns function as the direct object for the Persian verbs and are suffixed with Persian’s definite direct object rǎ. It should be noted that the direct object rǎ is used in both spoken and written forms of Persian. It sometimes appears as /ro/ or /o/ and is attached to a noun. Note that in Persian the place of object is before the verb while in English it is the other way around. Examples (17) and (18) show that the English single nouns art and questionnaire are placed in the object position preceding the object marker ro, and the verbs xunde and porkonam.
(17) Tez-hǎ-ye ART ro xund-e thesis-PL-Ez rǎ read-PSPT ‘(She/He) has read art theses’ (Tez-hǎ-ye honar ro xund-e thesis-PL-Ez art rǎ read-PSPT ‘(She/He) has read art theses’) (18) Bǎyad QUESTIONNAIRE ro por kon-an should rǎ fill do-3Pl ‘(They) should fill out the questionnaire’ (Bǎyad pǎsokhnǎme ro por kon-an should questionnaire rǎ fill do-3Pl ‘(They) should fill out the questionnaire’)
In Example (19), the English single noun speaking is suffixed first with the Persian possessive pronoun suffix –eš and then the object marker ro.
(19) SPEAKING-eš ro biš-tar qabool dǎšt-am -Clitic pro 3Sg rǎ more-COMPR accept had-1Sg ‘(His/Her) speaking skill was more acceptable to me’ (sohbat kardan-eš ro biš-tar qabool dǎšt-am speaking -Clitic pro 3Sg rǎ more-COMPR accept had-1Sg ‘(His/Her) speaking skill was more acceptable to me’)
In Example (20), the English single element index is embedded in the Persian frame by receiving the Persian clitic possessive pronoun suffix –eš and the object marker o.
(20) INDEX-eš o negǎh kon -Clitic pro 3Sg rǎ look do ‘Look at the index’ (fehrest-eš o negǎh kon index-Clitic pro 3Sg rǎ look do ‘Look at the index’) (21) Baziǎ PROBLEM-hǎ- ro faqat DESCRIBE mi-kon-an some people -PL -rǎ only IMPF-do-3Pl ‘Some people only describe the problems’ (Baziǎ moškel-hǎ- ro faqat DESCRIBE mi-kon-an some people problem -PL -rǎ only IMPF-do-3Pl ‘Some people only describe the problems’)
Example (21) shows that the single English noun problem is suffixed first by the Persian plural marker hǎ and then the object marker ro.
Example (22) illustrates that the English single noun assignment is suffixed first with the indefinite Persian marker –i and the direct object marker ro.
(22) ASSIGNMENT-i ro ke bǎyad SUBMIT kon-am -Indf rǎ that should do-1Sg ‘The assignment that I should submit’ (Taklif-i ro ke bǎyad SUBMIT kon-am assignment -Indf rǎ that should do-1Sg ‘The assignment that I should submit’)
English single nouns in quantifier and determiner phrases
As with English, all demonstrative, numerals, classifiers and measures in the Persian language precede the noun. Therefore, it appears that when two languages are similar in word order, the CS would tend to occur more easily. As shown in Examples (23) and (24), the English single nouns product and chapter are preceded first by a numeral and then by the Persian classifier tǎ.
(23) 3 tǎ PRODUCT be-het mi-frooš-e 3 CL to-you IMPF-sell-3Sg ‘(She/He) will sell you three products’ (3 tǎ mahsool be-het mi-frooš-e 3 CL product to-you IMPF-sell-3Sg ‘(She/He) will sell you three products’) (24) Lotfan 3 tǎ CHAPTER-e aval-e ye please 3 CL - Ez first -Ez a tez ro be-nevis-id thesis rǎ Subj-write-2Pl ‘Please write the first three chapters of a thesis’ (Lotfan 3 tǎ fasl-e aval-e ye please 3 CL chapter- Ez first -Ez a tez ro be-nevis-id thesis rǎ Subj-write-2Pl ‘Please write the first three chapters of a thesis’)
In English, whenever they are qualified by a numeral, nouns will be marked as plural. However, in Persian the noun phrase is not marked as plural after a numeral (Mahootian, 1997). It is important to note that in Examples (23) and (24), the English nouns follow Persian principles and are not marked for plural.
(25) 2 tǎ NOVELS gereft-am two CL got-1Sg ‘(I) got two novels’ (2 tǎ ketab dastan gereft-am two CL novel got-1Sg ‘(I) got two novels’) (26) 4 tǎ ASSIGNMENTS dǎšt-am four CL had-1Sg ‘(I) had four assignments’ (4 tǎ taklif dǎšt-am four CL assignment had-1Sg ‘(I) had four assignments’)
As shown in Examples (25) and (26), both of the English single nouns novels and assignments in the quantifier phrases are suffixed by the English plural marker –s. According to the 4M model, plural markers are early system morphemes and can be inserted from both the ML and EL. Therefore, Examples (25) and (26) do not violate the SMP.
In Example (27), the English noun item follows the Persian quantifier seri and is plural marked with the Persian plural marker –hǎ. In this case, the English noun item again follows the Persian rule.
(27) Ye seri ITEM-hǎ-ro andǎzegiri kard-e a series -PL- rǎ measure did-PSPT ‘(She/He) measures a series of items’ (Ye seri nokte-hǎ-ro andǎzegiri kard-e a series item -PL-rǎ measure did-PSPT ‘(She/He) measures a series of items’)
According to Examples (27) and its equivalence, it can be concluded that both the English noun item and the Persian noun nokte will be plural marked after the Persian quantifier series.
English single nouns in prepositional phrase
Myers-Scotton (2006) argued that EL prepositions are divided into two groups. The first group of prepositions is certainly content morphemes as they receive thematic roles (e.g. outside, inside, down, up). In contrast, the second group is either those which appear in phrasal verbs such as look up or those that clearly have little or no content such as in or of in ‘I live in beach street’, ‘book of mine’.In the present data, the Persian preposition with little content such as az (from) had appeared in the form of Persian alongside different English single nouns. Myers-Scotton and Jake (2000) pointed out that prepositions can appear both in the ML or EL form as they are not outsider late system morphemes. As shown in Examples (28) and (29), the Persian preposition az (from) occurs within the English–Persian mixed prepositional phrase.
(28) Az SCHOOL, CHAIRPERSON-emun zang zad-e bood from -Clitic pro 1Pl call hit-PSPT was ‘Our chairperson had called from school’ (Az madrese, modir-emun zang zad-e bood from school chairperson -Clitic pro 1Pl call hit-PSPT was ‘Our chairperson had called from school’) (29) PROBLEM ccekide-i az LITERATURE-e summary-Indef from -Copula 3Sg ‘The problem statement is the summary of the literature review’ (moškel ccekide-i az tarikh-e problem summary-Indef from -Copula 3Sg ‘The problem statement is the summary of the literature review’)
In Example (28), the English–Persian prepositional phrase az school occurs with the Persian preposition az (from). Similarly, in Example (29), the English–Persian prepositional phrase appears with the Persian preposition az (from).
English adjectives in Persian frame
The next most frequently found English single words in the present study are adjectives. Adjectives account for 218 of the total number of 924 single word insertions in the study (see Table 4).
English adjective with or without the Persian marker.

In fact, although in English adjectives precede nouns, in Persian the adjectives follow nouns. However, this study has found that the usage of English adjectives follows the Persian grammar, since they come after Persian nouns. Overall, English adjectives in the data appeared either with or without the Persian system morphemes as the Persian principle requires, and has shown no violation of the ML principles. They are also found to be grammatical in the present study (see Table 4). In particular, out of a total of 218 adjectives found in the data, 158 are bare forms while the rest have Persian markers. The following are examples of English adjectives appearing as bare forms.
(30) Irǎn ketǎb-hǎ-š UP-TO-DATE ni -st Iran book-PL-Clitic pro 3Sg NEG -is ‘Books in Iran are not up-to-date’
(Irǎn ketǎb-hǎ-š berooz ni -st
Iran book-PL-Clitic Pro 3Sg up-to-date NEG -is ‘Books in Iran are not up-to-date’) (31) Ketǎb-hǎ-ye ORIGINAL barǎye boo kardan xub-e book -PL-Ez for smell do good-Copula 3Sg ‘Original books are good to smell’ (Ketǎb-hǎ-ye asl barǎye boo kardan xub-e book -PL-Ez original for smell do good-Copula 3Sg ‘Original books are good to smell’)
According to Myers-Scotton (1993), during CS the morpheme order should be compatible with the ML. In Examples (30) and (31), the morpheme orders are fully in accordance with the Persian language since the English adjectives up-to-date and original follow the Persian nouns ketǎbhǎš and ketǎbhǎye.
There are also two cases in the data in which the English nouns gap and their attributive adjectives theoretical and methodological follow the Persian rules and are linked to each other with ezafe –e particle, as can be seen from Examples (32) and (33).
(32) GAP-e THEORETICAL goft-e bood -Ez said-PSPT was ‘(He/She) had mentioned a theoretical gap’ (khala-e nazari goft-e bood -Ez theoretical said-PSPT was ‘(He/She) had mentioned a theoretical gap’) (33) GAP-e METHODOLOGICAL goft-e bood -Ez said –PSPT was ‘(She/He) had mentioned a methodological gap’ (khala-e raveši goft-e bood -Ez said –PSPT was ‘(She/He) had mentioned a methodological gap’)
The data also identified some other cases where the English adjectives remain uninflected but occur with the Persian copula budan (to be). Examples (34) and (35) show how the English adjectives confused and broad are used with the Persian copula budan. It is important to note that the infinitive form of Persian copula budan is inflected by the ending suffix –am and –e and so occurs as boodam and boode.
(34) Avalǎ hanooz CONFUSED bood-am at first still was-1Sg ‘At first I was confused’
(Avalǎ hanooz gij bood-am
at first still confused was-1Sg ‘At first I was confused’) (35) Kǎr-eš xeili BROAD bood-e work-Clitic pro 3Sg very was-PSPT ‘(His/Her) work was so broad’ (Kǎr-eš xeili vasi bood-e work-Clitic pro 3Sg very broad was-PSPT ‘(His/Her) work was so broad’)
Overall, 57 instances out of 60 English adjectives are attached to the Persian bound copula morphemes (see Table 5). Example (36) below presents the English adjective easy going that is suffixed with the Persian bound copula –e.
(36) Man xeili raftǎr-am EASY GOING-e I very behaviour-Clitic pro 1Sg -Copula 3Sg ‘I am so easy going’
(Man xeili raftǎr-am rǎhat-e
I very behaviour-Clitic pro 1Sg easy going -Copula 3Sg ‘I am so easy going’)
The distribution of English single adjectives with Persian markers in Persian frame.

In only one case, an English adjective receives the Persian comparative marker –tar with the Persian copula budan (to be). Example (37) shows the English adjective funny with the comparative marker –tar and the copula bood.
(37) FUNNY-tar bood -COMPR was ‘(It) was funnier’ (Bǎnamak-tar bood funny -COMPR was ‘(It) was funnier’)
Example (38) presents the only data in the study where an English adjective is suffixed with the Persian comparative marker tar and the Persian bound copula –e.
(38) LINGUISTIC BORING-tar-e linguistic -COMPR-Copula 3Sg ‘Linguistic is more boring’ (zabǎnšenǎsi khastekonande-tar-e linguistic boring -COMPR-Copula 3Sg ‘Linguistic is more boring’)
In this study, there are some examples in which the English adjectives are embedded in Persian with their modifying nouns in English order. It should be noted that the English ADJ-N order is not compatible with the Persian N-ADJ order.
Examples (39) and (40) indicate two English adjective phrases in the Persian frame.
(39) Az in OPEN-ENDED QUESTION –hǎ bood from this -PL was ‘They were open-ended questions’ (Az in soǎl-hǎ ye baz bood from this question-PL -Ez open was ‘They were open-ended questions’) (40) Bǎyad UNSOLVED ISSUE ro nevešt should rǎ wrote ‘The unsolved issues should be written’ (Bǎyad moškel-hǎ ye hal našode ro nevešt should issue -PL -Ez unsolved rǎ wrote ‘The unsolved issues should be written’)
In Examples (39) and (40) above, the English adjectives open-ended and unsolved occur before their modifying nouns question and issue. However, these two examples show no violation to the Persian frame. It is important to note that the English phrases open-ended question and unsolved issue are suffixed with Persian markers hǎ and ro.
Discussion
Persian and English are typologically distant languages, although they are historically related. The canonical word order of Persian language is basically SOV (Karimi, 1994). However, sometimes Persian has a mixed structure. For example, spoken Persian is basically SOV but generally it is free from the basic word order. Therefore, Persian should be considered as a flexible language in contrast to strictly inflexible languages like Japanese (Karimi, 1994). Persian is a pro-drop language and, similar to other pro-drop languages, the null subject can appear as an agreement inflection on the verbs. In addition, object (direct and indirect) can be illustrated as pronominal clitics on the verbs, in which case the inflection precedes the clitics. See the example below.
(41) Khord -am -eš ate -1Sg -Clitic pro 3Sg ‘(I) ate it’
The above example shows that the subject can be dropped and the object can appear as a clitic and follow the inflection. Unlike Persian, English is a non pro-drop language and the canonical word order in English is SVO. The differences of the two languages in terms of the word order are illustrated in the chart below.

The basic structure of the noun phrase in Persian appears with different markers such as the indefinite marker-i, the object marker –rǎ and the plural marker –hǎ. In contrast with English, when numerals in Persian precede the nouns, the nouns are not plural marked (Mahootian, 1997). Example (42) shows that the noun ketǎb follows the numeral 2 and the classifier tǎ without any plural marker.
(42) 2 -tǎ ketǎb dǎr-am 2 CL book have-1Sg ‘(I) have two books’
Unlike English, the demonstratives in (this) and ǎn (that) are invariably singular, even if they modify a plural noun. Example (43) shows how the Persian demonstrative in and its modified nouns appear in Persian.
(43) in ketǎb-hǎ mǎl-e man ast this book-PL mine-Ez I is ‘These books are mine’
Example (43) illustrates that the Persian singular demonstrative in precedes the plural noun ketǎb-hǎ while in English equivalence the plural noun books follows the plural demonstrative these. In addition, the forms of verb in both sentences are different. In the Persian example, the verb is singular whereas it is plural for the English example.
Persian verbs agree with their subjects in number and person. In contrast, English verbs do not agree with their subject in person and number (excluding the third person singular). However, one of the most important exceptions to subject–verb agreement in Persian is that inanimate plural subjects can take a singular verb (Mahootian, 1997). See the example below.
(44) ketǎb-hǎ roo-ye miz-e book-PL on-Ez table-3Sg ‘The books are on the table’
The data that are introduced in the previous sections show that several English content morphemes have been inserted in Persian–English bilingual speech, although they vary in frequencies. Such divergent bilingual switches reveal that CS between Persian and English, particularly at a single level, is mostly free. Myers-Scotton (1993) predicted two major factors for the MLF model as the MOP and the SMP. In MOP, she mentioned that the ML always determines the surface morpheme order in the ML+EL constituents. As already noted, Persian and English have different typological dissimilarities in the surface structure. The first dissimilarity relates to the word order between these two languages. The data in this study reveal that this incompatibility has left no effect on switching. The following bilingual examples illustrate how the MOP works in this study.
(45) Bǎyad safh-aš ro UPDATE kon-i should page-Clitic pro 3Sg rǎ do-2Sg ‘(You) should update its page’ (46) Tamǎm-e theory-hǎ ro EVALUATE kard-e all -Ez theory-PL rǎ do- PSPT ‘(She/He has evaluated all theories’
In the above bilingual examples, the only materials from English are the verbs update and evaluate that follow the Persian word order (SOV), not the English order (SVO). As already mentioned, the object marker in Persian is rǎ that sometimes appears as /ro/ or /o/ and is attached to a noun. Examples (45) and (46) show that the objects theory-hǎ and safhaš are both placed before the object marker ro and the verbs evaluate and update. These examples support the MOP because the clause follows the Persian order, indicating that only one language can supply the morpheme order.
However, as was stated earlier, the Persian language has a mixed structure and the spoken form of language is free from a basic word order. In Example (47), the Persian verb raftam is moved to the initial position for emphasis.
(47) Raft-am SCHOOL-ešun went-1Sg 3Pl ‘(I) went to their school’
As already noted, the other dissimilarity in the surface structure between Persian and English is the place of adjectives and nouns. The position of the noun and its modifier in Persian is noun-adjective (N-ADJ) while in English it is adjective-noun (ADJ-N). The data in the current study reveal that the English nouns occur before the Persian adjectives and connect to each other by the Persian ezafe. In other words, the English adjectives appear post-nominally to modify their nouns. Example (48) illustrates that the English adjective boring appears after the Persian noun klǎs and they are connected to each other by the Persian ezafe.
(48) aslan kelǎs-hǎ-ye BORING ro doost na-dar-am at all class-PL-Ez rǎ like NEG-have-1Sg ‘I do not like boring classes at all’
Even in two cases both English nouns and their adjectives follow the Persian word order and are attached to each other by Persian ezafe (e). For the sake of clarity, the examples below are repeated.
(49) GAP-e THEORETICAL goft-e bood -Ez said-PSPT was ‘(He/She) had mentioned a theoretical gap’ (50) GAP-e METHODOLOGICAL goft-e bood -Ez said –PSPT was ‘(She/He) had mentioned a methodological gap’
Overall, Examples (48), (49) and (50) above are compatible with the Persian principle and they support the MOP. These examples also identify Persian as the ML.
Myers-Scotton (2002, p. 75) pointed out that the bridge late system morphemes “connect content morphemes with each other without reference to their properties of a head”. In the current study, the ezafe particle acts as a bridge and connects two content morphemes to each other. There is great number of English content morphemes which are connected to the Persian content morphemes by the Persian ezafe particle –e. In the entire corpus, there are only six cases where the bridges appear in the form of English. See the example below.
(51) COST OF LIVING injǎ bǎlǎ-st here high-is ‘The cost of living is high here’
In addition, there are some cases in which both the English noun and its adjective follow the English order. Myers-Scotton (2006) qualifies these types of switching as ‘Embedded Language Island’ because these phrases keep the EL word order. Although these English ADJ-N phrases are not compatible with the Persian word order, they are allowed to be inserted to the Persian frame as they are totally satisfied with Persian rules and act as a single insertion. The phrasal insertions (N-ADJ insertions) are similar to single insertions and they are integrated into the Persian frame morphosyntactically without any violation to the Persian grammar. It shows that in bilingual Persian–English CPs, these phrasal insertions act exactly the same as the single word insertions (see Examples 39 and 40).
As was mentioned earlier, in English, whenever the nouns are qualified by a numeral, they will be marked as plural. However, in Persian the noun phrase is not marked as plural after a numeral (Mahootian, 1997). There are different cases in the present study that show English nouns following the ML principle and the fact that they are not plural marked after a numeral. The example is as follows.
(52) LITERALLY, 3 tǎ SLICE-e kooccooloo bood CL -Ez small was ‘Literally, there were 3 small slices’
The singular form of the English noun slice after a numeral is evidence that Persian is the controlling word order, not English, and this is in line with the MOP.
Moreover, the data reveal that in some cases the Persian single demonstrative modifies the English plural noun.
(53) In SPEECH-hǎ FUNCTION-sun cci -e? this -PL -Clitic Pro 3Pl what-Copula 3Sg ‘What are the functions of these speeches? (54) In COMPONENT-hǎ ro dǎr-e this -PL rǎ have-3Sg ‘(It) has these components’
Examples (53) and (54) above illustrate that the Persian single demonstrative precedes the English plural nouns and they both follow the Persian principle. Overall, almost all evidence in the current study has proven that the data is compatible with the MOP without any violation to the Persian frame.
The other major factor for studying CS is the SMP (Myers-Scotton, 1993). According to Myers-Scotton (1993) only one type of system morpheme can come from the ML. Myers-Scotton and Jake (2000) clarified the SMP and gave a name to that type of system morpheme as the outsider late system morphemes.
According to Myers-Scotton (2002), clitics/affixes in many languages are excellent examples of these outsider late system morphemes. Importantly, she mentioned that if these types of morphemes come from the EL, they will violate the SMP and such occurrences could be advanced as counter-examples for the MLF and 4M models. Pronominal clitics are those system morphemes that depend on the information outside the element with which they occur. It is important to note that in Persian, when pronominal clitics act as possessive pronouns they should be attached to the nouns, but when they act as direct objects they should be attached to the verbs. The following examples are introduced for the sake of clarity.
(55) Mi-xǎ-i DESCRIBE-eš kon-i? IMPF-want-2Sg -Clitic pro 3Sg do-2Sg ‘Do (you) want to describe it?’ (56) In-hǎ RESEARCH-ešun xub bood this -PL -Clitic pro 3Pl good was ‘Their research was good’
As shown in Example (55), the pronominal clitic eš is attached to the English verb describe and acts as a direct object and in Example (56), the pronominal clitic ešun is embedded to the English noun research and acts as a possessive pronoun. Thus, the examples above support the SMP as the SMP requires such morphemes (clitics) to come from only one of the participating languages. This marks Persian as the ML in these CPs, too.
Subject–verb agreement is another type of outsider late system morphemes. As already noted, one of the typological characteristics of the Persian language is that the verbs must agree with their subjects in person and number. Below are two examples to show how English verbs occur in the Persian–English bilingual CPs.
(57) Man xeili APPLY kard-am barǎye tadris I very did-1Sg for teaching ‘I applied for teaching way too much’ (58) To faqat DESCRIBE mi-kon-i you only IMPF-do-2Sg ‘You are only describing’
In both examples above, the personal ending suffixes as the outsider late system morphemes appear in the form of the Persian language. In Example (57), the suffix am is attached to the Persian auxiliary verb kard instead of the English verb apply and is in agreement with the subject man (I). Similarly, Example (58) illustrates that the suffix –i agrees with the subject to (you) and is attached to the Persian auxiliary verb –koni. In the whole corpus of the present study there is not a single case that shows that the subject–verb agreement suffixes in the form of EL and data totally support the SMP.
Conclusion
This study offers a detailed analysis of the grammatical aspects of the CS observed in the Persian–English bilingual speech produced by 12 Persian–English bilingual speakers. Code-switching can be seen as a bilingual speech act where two or more linguistic codes are used in the course of a single conversation. The present study aims to answer the question: how do single English content morphemes, particularly nouns and adjectives, occur in Persian–English bilingual speech?
Taking all this evidence together, we conclude that CS is permissible even when it leads to structural dissimilarities. Wherever it is required by the Persian principle, the inserted English nouns and adjectives receive different Persian markers. They may also appear without any Persian marker when the Persian grammar requires so. Moreover, the present data show no counterexample to both the MLF and 4M as the data totally support both the MOP and SMP.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.