
Abstract
Aims and objectives:
This study aims to redress the paucity of research on the semantics of loanwords, by extending and empirically testing Backus’s ((2001). The role of semantic specificity in insertional codeswitching: Evidence from Dutch-Turkish. Jacobson, Rodolfo (Hg): Codeswitching Worldwide. Bd, 2, 125–154) Specificity Hypothesis – ‘Embedded language elements in code-switching have a high degree of semantic specificity’ (p. 128).
Approach:
Adopting a concept-based approach to examine loanwords in a large, reliable corpus, the study pursues the following question: Do loanwords have a high degree of semantic specificity relative to their receiving-language equivalents? Specificity is operationalized as an entropy measure of the target word’s environment, the assumption being that more specific words have less variety in their surrounding context.
Data and analysis:
To test this hypothesis, Anglicisms in a 24-million-word newspaper corpus of Argentine Spanish were processed in three stages: detecting loanwords, selecting semantic equivalents, and measuring specificity.
Findings/conclusions:
A Wilcoxon Signed-Rank Test revealed that loanwords receive significantly lower entropy scores, that is, they are more specific than their Spanish equivalents. The results suggest a possible motive for adopting loanwords when terms already exist in the source language, namely, to utilize words that provide more nuanced meaning.
Originality:
Methodologically, this study offers innovative applications of computational methods to loanword research, employing a distributional model to measure entropy. Theoretically, it addresses an underrepresented aspect of loanword adoption, semantics, by extending Backus’s hypothesis to loanwords and increasing its scope to data often viewed as ‘monolingual’.
Significance/implications:
The conclusions offer novel perspectives on loanwords with existing semantic equivalents, often viewed as ‘unnecessary’ when compared to loanwords that introduce new concepts into the recipient language (e.g. blog). With the notion of specificity, we may understand these loanwords as disruptors to the semantic system of the recipient language, dividing up the semantic space formerly occupied solely by the native equivalent, thus increasing the level of nuance expressed in the original concept.
Introduction
As a prolific result of language contact, loanwords have long been of interest in historical and contact linguistics (see Poplack & Dion, 2012). How loanwords, manifested in both direct and indirect contact contexts, are incorporated into a recipient language has been well explored from numerous perspectives, including their morphological gender assignment (Poplack, Pousada, & Sankoff, 1982; Smead, 2000), their orthographic adaptation (Kang, 2011; Vendelin & Peperkamp, 2006), and the micro- and macro-social factors that facilitate their adoption (Poplack, Sankoff, & Miller, 1988; Thomason & Kaufman, 1988). Now more than ever, loanwords from English in particular have garnered much attention for their growing ubiquity in languages around the world, such as in German (Onysko & Winter-Froemel, 2011), Japanese (Irwin, 2011), Jordanian Arabic (Al Btoush, 2014), and Argentine Spanish (Bordelois, 2011). Empirical research on Anglicisms is further bolstered by the availability of ‘big’ data sourced from internet text (e.g. Twitter, blogs, online newspapers), which is rendered usable through computational linguistic methods that allow for its efficient processing.
In spite of the growing body of research on this contact feature, the semantic properties of individual loanwords remain largely understudied. Attention to the semantics of loanwords may be hindered by the challenges associated with the empirical testing of aspects of word meaning, such as how to define the denotational specificity of a word. However, the study of loanword semantics is important in contact linguistics in that loanwords can affect changes in recipient-language semantic systems and an understanding of loanwords’ semantic properties can possibly shed light on motivations for their adoption. The semantics of another contact feature, bilingual code-switching, has been analyzed by Backus (2001), who proposes that ‘embedded language elements in code-switching have a high degree of semantic specificity’ (p. 128). While Backus’s Specificity Hypothesis was put forward to account for bilingual alternations, the present work seeks to extend its scope to English nouns that appear in ‘monolingual’ contexts.
In pursuing this aim, the present study sets forth three innovative applications of corpus data and computational tools in testing whether Anglicisms extracted from a large, reliable data set of Argentine Spanish have a high degree of semantic specificity. This research implements a concept-based method (Zenner, Speelman, & Geeraerts, 2012), referencing the recipient language’s semantic equivalent for each loanword to create a consistent and appropriate unit of comparison. For example, the specificity of the Anglicism manager is compared to the specificity of the native Spanish equivalent gerente. In addition, the work presents a definition and operationalization of specificity, informed by distributional semantics. Lastly, the study offers a novel approach to computing specificity, utilizing an entropy measure of the target word’s environment, the assumption being that more specific nouns have less variety in their surrounding context. This approach in its current state is limited to single lexical insertions and requires a large data set; however, further research within this area will hopefully expand its reach to also address issues central to code-switching. Extending Backus’s Specificity Hypothesis to borrowing, we predict that loanwords are more specific than their native equivalents.
The article proceeds as follows. Firstly, the extant research on the semantics of loanwords will be reviewed, followed by a brief discussion of distributional semantics and its relevance for the present investigation of loanword specificity. At the center of the paper are the corpus description and the methods; the 24-million-word corpus of Argentine Spanish is described in detail along with the three stages of corpus processing: loanword identification, selection of semantic equivalents, and measurement of their specificity. Next, the loanwords identified in the newspaper corpus are subject to both quantitative and qualitative analyses. Finally, the results are discussed to draw conclusions on the role of semantic specificity in loanword adoption and success.
Literature review
Semantic analysis of loanwords
Of the numerous studies on loanwords, few undertake semantic analyses. Although small in number, those studies that do attend to loanword semantics pursue a variety of approaches to the topic. One approach is to classify loanwords based on the semantic relationship between loanwords and the existing lexicon of the recipient language. This relationship, mentioned as early as Weinreich (1953), can be used to create two categories of loanwords: (i) loanwords with no existing semantic equivalent in the recipient language, for example the English loanword blog in Spanish; and (ii) loanwords that do have an existing semantic equivalent in the recipient language, for example the English loanword performance in Spanish, which is synonymous with actuación. These contrasting categories have been referred to by various terms: necessary and luxury (cf. Onysko & Winter-Froemel, 2011), unique and synonymic (Bookless, 1982), core and cultural (Myers-Scotton, 2002), catachrestic and non-catachrestic (Onysko & Winter-Froemel, 2011), but the basic premise remains the same. In one of the first studies to focus solely on this distinction, Bookless concludes that unique loanwords possess high referential value and cause minimum semantic rearranging in the receptor language because they do not displace other words. In contrast, loanwords with existing equivalents contain more stylistic than referential value and often demand a reshuffling of the recipient-language semantic system; this disruption, he argues, results in greater confusion on the part of speakers, as connotations and shifting meanings must be considered in choosing between the loan and the native word.
One limitation of Bookless’ work is its reliance on isolated examples of English loanwords in Spanish selected by the author, that is, the work presents a conceptual analysis of the unique versus synonymic taxonomy, rather than an empirical study. More recently, Onysko and Winter-Froemel (2011) adopt an empirical approach in their study of the distinction between loanwords with semantic equivalents and those without, drawing on a 5-million-word corpus of the German newsmagazine Der Spiegel. These authors posit that this distinction can be used to explain the pragmatic feature of markedness: loanwords with an existing semantic equivalent are more marked than those without one. Their analysis revealed that about a third of the loanword tokens analyzed enter the German language as semantic innovations, while the remaining two thirds compete with existing German equivalents. Although Onysko and Winter-Froemel conclude that this classification is viable, they caution that the distinction is not always clear-cut, due to complications such as polysemy of the loanword or its change in meaning over time. Thus, this categorization may only be possible from a synchronic perspective and is not strictly an either/or decision.
Another corpus-based study of loanwords, published by Zenner et al. (2012), also makes use of this semantic distinction as a factor in their model to predict the success of English loanwords appearing in two Dutch newspaper corpora, together totaling over 1.6 billion words. For their purposes, the authors distinguished the two categories by the status of the loanwords at their time of adoption. Necessary loanwords – as they refer to them – are introduced to fill a lexical gap, and thus do not initially compete with an existing equivalent, although they note that later equivalents may be invented to fulfill this role, (e.g. voetbalvandaal for hooligan). In contrast, luxury loanwords already have an existing equivalent when they are introduced into a recipient language. A comparison of the two categories indicated that necessary loanwords had slightly higher chances of success than loanwords with native equivalents.
Other studies make use of this same categorization to explore functions of loanwords vis-à-vis their semantic equivalents. Peterson and Vaattovaara (2014) have analyzed the use of the Finnish native politeness marker kiitos in comparison with the English loanword pliis, finding that the two share little overlap as they are used differently ‘grammatically, pragmatically and in terms of social distinctiveness’ (p. 247). Andersen (2014) explores the phenomenon of pragmatic borrowing in the use of English in Norwegian, proposing a taxonomy that is relevant for any language pair. Finally, Hornikx, Meurs, and Boer (2010) explore the use of loanwords relative to their equivalents to understand if Dutch participants’ comprehension of loanwords affects their attitudes towards them, specifically their use in Dutch advertising.
Another approach to the semantics of loanwords is to make use of semantic domains, also referred to as lexical fields, to classify loanwords into categories, as it is often believed that loanwords arise more frequently with reference to topics relevant to the source language (Aaron, 2014; Winter-Froemel & Onysko 2012; Zenner et al., 2012). The analysis of semantic domains is seldom the sole focus of study, but rather a supplementary component to a larger question of loanword adaptation processes. In analyzing English loanwords in Dutch, Zenner et al. (2012) found sports and information and technology to be the two categories in which loanword incorporation was most successful, in comparison to the other three semantic categories they coded for: business, social, and deviance. In a similar study, Winter-Froemel & Onysko (2012) found the most common semantic categories for loanwords to be information and computer technology, business, music and television, clothing, and sports. Different findings are offered by Aaron (2014), whose work on Spanish in New Mexico showed that of the 17 categories coded for, kinship terms made up the most frequently borrowed items. The divergence of Aaron’s findings may be explained by differences in genres (colloquial speech text versus newspaper text) and/or by differences in the metrics to assess the success of a semantic domain. For each semantic domain, Aaron totaled all uses of nouns pertaining to that domain and determined what percentage of those nouns were loanwords. For instance, of the 238 kinship terms used in the corpus (e.g. abuela, papá, sister, grandpa), 136 were English-origin insertions, around 57%. In contrast, the other studies determined which semantic category of loanwords held the highest number of types (unique lemmas) relative to the other categories. The differences in findings may also suggest that the semantic categories that are most frequently borrowed reflect the type of contact (intense versus weak, see Zenner, Speelman, & Geeraerts (2014) for a discussion of the differences between intense and weak contact situations) as well as the cultural value of the source language within the given community (see Bullock, Serigos, & Toribio, 2015).
Yet another approach to the study of the semantics of loanwords is to divide them into those with one word sense and those with multiple senses. For example, the English loanword, chip, as used in German has multiple meanings, referring to either a potato-based snack, a technological component, or the currency used in casinos. This category has been studied in relation to its potential impact on the success of a loanword. Chesley and Baayen (2010, p. 1353) posit that in possessing an ‘increased range of denotata’ a polysemous loanword could be used with more frequency and therefore has an increased likelihood of successful entrenchment. They found this prediction to hold true for loanwords in culturally restricted contexts, that is, contexts that refer to the culture associated with the source language of the loanword. However, the same pattern did not hold true for loanwords in culturally unrestricted contexts, that is, those that do not necessarily refer back to the source language culture. Hlavac (2006) found that the distinction between uni- and polyfunctional words impacted their frequency of use when comparing English borrowings to their Croatian counterparts; polyfunctional words, whether borrowed or native, increased in frequency compared to their alternative.
One of the most thorough discussions of the semantics of loanwords is provided by Winter-Froemel (2013). Following a usage-based approach, she tackles the issue of variance in the form of loanwords (ex. people and pipole in French) and semantic change of loanwords from the receiving language (ex. sombrero ‘hat’ → ‘type of hat with a wide brim’). Approached from the level of speaker–hearer, her analysis highlights the role of the hearer in introducing new interpretations of loanwords, specifically resulting in two types of semantic shifts: specialization and metonymy.
For the most part, previous approaches to the semantics of loanwords share two features: they employ manual and non-numerical means to categorize loanwords into discrete categories, and most compare the differing semantic properties between loanwords, rather than compare the semantic properties of loanwords to those of receptor-language equivalents. The present study offers a new approach, classifying loanwords using a numeric measurement that contrasts them with native words, while additionally addressing an understudied aspect of loanword semantics: specificity.
The notion of specificity within the literature of contemporary contact linguistics was examined by Backus (2001) with reference to Turkish-Dutch bilingual speech. He observed that first-generation bilinguals inserted Dutch words into Turkish clauses and that these lexical switches typically came from specific semantic domains. Drawing on Myers-Scotton’s (1993) Matrix Language Frame model, Backus formalized this observation in the Specificity Hypothesis: ‘Embedded language elements in code-switching have a high degree of semantic specificity’ (2001, p. 128). The hypothesis encapsulates the idea that insertion is facilitated for words that have highly specific meaning, and whose cross-linguistic equivalents, where they exist, conjure up different connotations (see also Myers-Scotton & Jake, 1995). Support is offered in Anderson and Toribio’s (2007) study of Spanish-English mixing, where insertion of lexical items denoting concepts specialized within the Little Red Riding Hood fairytale (e.g. hunter) were judged to be less marked/more felicitous than insertion of core nouns (e.g. bed) in the same story.
Left unspecified in these studies is the unit of comparison when testing the specificity of embedded items – a loanword is more highly semantically specific than what? The present study adopts a concept-based approach, using the semantic equivalents of loanwords against which to compare them (Zenner et al., 2012). Also left unresolved in previous studies is an empirically testable definition of specificity. Backus offers the replacement test, that is, highly specific words are hard to replace with a synonym, while more general words are easy to replace with something more specific. For example, the general term tree is easily replaced by a more specific term such as oak or dogwood, while those two terms are not readily replaceable with a singular specific term. However, this definition of specificity presents issues that must be surmounted. For instance, it does not produce reliable or replicable results, due to its subjectivity. In addition, it only divides words into two categories – specific, that is, cannot be replaced, or non-specific, that is, can be replaced – leaving many word pairings uncomparable. Thus, while this definition may address one aspect of specificity, it leaves information uncaptured. In order to find a more robust definition of specificity and a means by which to quantify it, this study turns to the field of distributional semantics, elaborated on in the following section.
Distributional semantics
Distributional semantics has roots in both cognitive science and computational linguistics (Lenci, 2008). The cognitive perspective establishes a framework for understanding word meaning, which this study will extend to define word specificity. The computational perspective provides the methods by which to capture and quantify word meaning on a large scale, which this study will adapt to measure word specificity.
Before defining word specificity, it is necessary to understand how distributional semantics approaches word meaning in general. Researchers within this field study word meaning with respect to its surrounding context or distribution. This relationship between word meaning and its context is often summed up by the quote from Firth (1957, p. 11), ‘You shall know a word by the company it keeps’, that is, a word’s meaning can be derived from its surrounding context. To exemplify this point, consider sentence (1) below, presented by Erk (2016).
On our last evening, the boatman killed an
The context surrounding the word alligator provides readers unfamiliar with this word with several clues to its meaning; learning that an alligator crawls and can be killed, readers may deduce it is an animal, and learning that an alligator goes hunting, readers may deduce it is carnivorous. Thus, from the context alone, a definition begins to form. That definition may be further refined, as readers come across additional contexts in which the word alligator occurs.
In addition to meaning, word contexts can be used to provide information as to how specific and/or general a word is. The assumption is that the more specific a word is, the less variety it will have in its surrounding context, that is, it will co-occur with a more narrow set of words. For example, consider two words from the same semantic domain yet with different levels of specificity: food and cashew. Tokens from the British National Corpus (BNC), seen in Table 1, show that although the two words share some contexts (carbohydrate, garden, and price), cashew co-occurs with fewer words compared to food, such as pledge, thought, weapon. Thus, the variability of a word’s surrounding context can provide insight as to how specific the word is.
Examples of food and cashew in the British National Corpus.
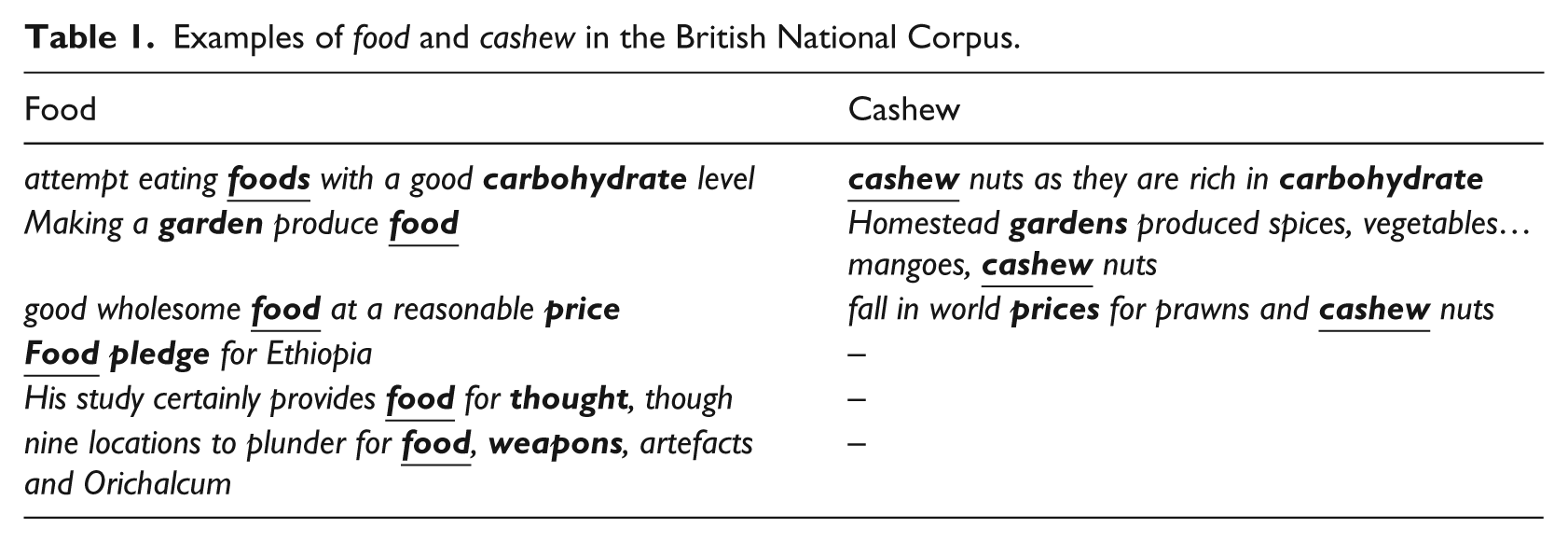
Taking this distributional perspective, this study defines word specificity relatively: words used within a narrow set of contexts are more specific than words used across varied contexts.
This distributional understanding of word meaning and word specificity may be quantified, utilizing methods from computational linguistics. These methods for capturing and quantifying word meaning are based on their distribution in large bodies of text (Erk, 2012; Turney & Pantel, 2010). They rely on big data to construct profiles of words, which reflect their meanings and relationships to other words. In practical terms, distributional models utilize large corpora to create high-dimensional context vectors. The context vector for a given word contains the words that it co-occurs with along with their number of co-occurrences. For example, the context vector for food, collected from the BNC, includes the following words and counts (among many others): eating: 139, thought: 136, price: 51, pledge: 14, carbohydrate: 6. Context vectors have been utilized for information retrieval (Manning, Raghavan, & Schütze, 2008), word sense disambiguation (Erk, McCarthy, & Gaylord, 2012), and word specificity (Caraballo & Charniak, 1999), to name only a few of the current applications.
It is the application of vectors to word specificity that will be relevant in this study. By identifying and quantifying the surrounding contexts of a target word appearing within a corpus, Caraballo and Charniak were able to create a numerical score for how specific a word is, which allowed them to rank words into a hierarchy of specificity. The challenge of translating this phenomenon into a numerical score will be explained below.
The present study: questions and methods
The present study pursues a semantic analysis of loanwords, examining their specificity relative to that of their native-language equivalents. More specifically, the work extends Backus’s Specificity Hypothesis, developed for lexical insertions in oral bilingual code-switching, to the analysis of donor-language loans in ‘monolingual’ recipient-language contexts. Thus, the study aims to address theoretical questions and methodological concerns: Are loanwords more semantically specific than their receptor-language alternatives? What does it mean for a word to be semantically specific? How can specificity be empirically measured?
In responding to these questions, the study utilizes a concept-based approach from cognitive linguistics, a context-based understanding of word meaning from distributional semantics, and distributional models from computational linguistics. This section describes the corpus used for the analysis, defines the scope of loanwords and the processes applied in extracting them from the corpus, and presents the definition of specificity used in this study along with the model and parameters used to measure it.
Corpus
Argentine Spanish is particularly useful for loanword research because it demonstrates a large influx of Anglicisms that often do not undergo orthographic alteration, making them easier to identify in written texts. In order to gather a large enough data set, two national newspapers were selected to create a corpus: La Nación and Clarín. Both newspapers appear online and are the two most widely read newspapers in Argentina (Boczkowski & de Santos, 2007). To ensure that a broad range of topics was included, articles from all sections – including Politics, Economy, International, Opinion, Sports, Technology – were downloaded using Python scripts written by the researcher from the daily archives for the one-year period from June 2013 to May 2014. Issues with downloading and text encoding caused a few days to be eliminated, thus not all days from this time period are represented. The resultant corpus reached over 24 million words. It was subsequently parsed for part-of-speech (POS) and lemma using the open-source probabilistic tagger, TreeTagger (Schmid, 1994).
Loanwords
Definition
Before identifying the English loanwords in the corpus, it was necessary to set the parameters as to what constitutes a loanword, as there are numerous definitions for the term. This study adheres to the conservative definition provided by Haugen (1950): loanwords are words whose phonemic shape and meaning have been imported into a recipient language with no morphemic substitution. This definition includes only loanwords that are identifiable as English, thus loanwords that have been orthographically modified will be excluded. For example, the adapted loanword fútbol, from the English football, will be excluded due to its phonemic modification, but the unadapted loanword shopping will be included. This narrow definition of loanwords was chosen for two reasons. Firstly, a manual examination of segments of the corpus and the researcher’s prior knowledge of the Argentine dialect revealed that the vast majority of loanwords remain unadapted upon initial adoption to the Argentine dialect. Those that are adapted are most often long-standing loanwords, which are commonly viewed by native speakers as part of the Spanish language rather than foreignisms. As this study is interested in the semantic properties of loanwords versus their native equivalents, newer and more identifiably foreign loanwords are of greater interest than long-standing, integrated borrowings that may no longer compete with an equivalent and/or are viewed as native words by speakers, for example, fútbol ‘football’ or estrés ‘stress’. Secondly, the automatic detection of loanwords, described in the following section, is currently only capable of finding unadapted loanwords.
This concept-based study will be limited to nouns, which are universally the most widely borrowed part of speech (Haspelmath, 2008) and for which semantic equivalents may be more readily available. However, this specificity measure and other distributional models may be applied to other open-class parts of speech, including verbs, adjectives, and adverbs (see Baroni & Lenci, 2011).
Identification
To find all tokens of English origin in the Argentine corpus, an automated English identifier was developed. Although not in large number, other English identifiers may be found in the literature, most of which use one or a combination of the following methods: lookup, character n-gram, and pattern matching (see Alex, 2008; Andersen, 2005; Koo, 2015; Pfister & Romsdorfer, 2003). The system designed for this study makes use of a lookup method, similar to Alex (2008). The two stages that comprise this system – (1) collecting all tokens that are not recognized as Spanish and (2) checking the non-Spanish tokens (which include borrowings from various languages, proper names, onomatopoeia, etc.) to see if they are English – are further explained below.
To identify words that are not Spanish, the algorithm makes use of two special tags generated by TreeTagger. The first tag palabra extranjera (PE) ‘foreign word’ is a POS tag that TreeTagger outputs when it recognizes the token as foreign, along with the corresponding lemma tag. However, most foreign items, including many Anglicisms, are not recognized by TreeTagger. When TreeTagger fails to recognize a word, it outputs the lemma tag <unknown>. Table 2 illustrates a sample TreeTagger output for the sentence pidió input de sus managers ‘he/she asked for input from his/her managers’. The Spanish token pidieron ‘they asked for’ receives the POS tag verbo lexical finito (VLfin) ‘finite lexical verb’ and the lemma pedir ‘to ask for’, while the two foreign items input and managers received the POS tag PE and the lemma tag <unknown>, respectively.
Sample TreeTagger output.

POS: part-of-speech.
With this first stage of the algorithm, all tokens with the POS tag PE or the lemma tag <unknown> were collected. The one exception is that tokens beginning with a capital letter were not included, in order to avoid proper nouns, such as General Motors. Although this process also excludes sentence-initial nouns, the exclusion is not considered to be consequential because Spanish typically does not permit sentences beginning with bare nouns. In addition, in order to preserve the integrity of collocations such as the loan phrase think tank, multi-word tokens were collected and evaluated in chunks using the IOB tagging technique, in which each token is tagged as inside (I), outside (O), or beginning (B) of a multi-token chunk (Jurafsky & Martin, 2008). These loan phrases were included in the analysis and treated just as any other single-word token; thus, since the phrase think tank appeared 69 times, the phrase think tank was recorded as one unit with a count of 69, rather than having two separate single-word entries: think with a count of 69 and tank with a count of 69.
The tokens returned by this automated process include the target items, that is, Anglicisms (e.g. input, managers), but also borrowings from other languages (e.g. spaghetti from Italian), misspellings (e.g. pidio instead of pidió ‘he/she asked for’), and Spanish words that are not recognized by TreeTagger due to sparse training data (e.g. canonización ‘canonization’, ancestral ‘ancestral’). Thus, in the second stage, to remove non-English tokens from this list, these tokens were lemmatized using an English lemmatizer from the Natural Language Toolkit (Bird, Klein, & Loper, 2009) and checked automatically for membership in a modified English dictionary. This dictionary came from the UNIX operating system and was stripped of all homographs appearing in the Spanish dictionary, Diccionario de la Real Academia Española (DRAE), so that homographs between the two languages that were not recognized by TreeTagger, such as ancestral, were not considered English.
The final stage involved manually inspecting all remaining tokens for any words erroneously identified as Anglicisms, such as loanwords from other languages that were included in the English dictionary (e.g. cadenza, leitmotiv, burka) and homographs between the two languages that were not present in the Spanish dictionary (e.g. postdoctoral). The major challenge for the automatic identification is the fact that UNIX’s English dictionary is extremely robust in comparison to the Spanish lexicon used by TreeTagger and DRAE; it encompasses numerous foreignisms and homographs with Spanish that are absent from Spanish sources, hence the need for the subsequent manual inspection.
Selection of semantic equivalents
After identifying the Anglicisms in the corpus, loanwords that complied with three criteria were selected for further analysis: firstly, loanwords had to function as nouns; secondly, they had to appear 50 or more times throughout the corpus, because the ensuing computational analysis uses word vectors that require higher counts for improved accuracy; and, thirdly, they had to have viable semantic equivalents that also appeared 50 or more times. The working definition for semantic equivalents was drawn from the discussion of near-synonyms versus true synonyms, as presented by Zenner et al (2012), in which the researchers sought to distinguish ‘those near-synonyms which are maximally equivalent with a given English …noun’ (p. 760), from true synonyms. True synonyms – ‘two words [that] can replace each other in any given context without changing the propositional content of the sentence they are used in’ (see Edmonds & Hirst, 2002, p. 107) – are actually quite rare and not a feasible concept for natural languages.
This current study is interested in the relationship that is formed between loanwords and the existing semantic system, specifically loanwords relative to their closest native alternative, be they true synonyms or near-synonyms. The aim is to capture the closest alternative available to a speaker, even if that alternative functions more as a hypernym, such as apariencia for to look, rather than a true synonym, such as celebridad and celebrity. The same reasoning applies to those loanwords whose semantic equivalents are polysemous (ex. equipo - ‘team’ or ‘equipment’). Limiting the equivalents to true synonyms would exclude the majority of tokens from this study and thus unnecessarily narrow the scope of this study. However, one loanword stock was excluded from the analysis due to that fact that it itself is polysemous – referring to either the supply of a store or a financial security – thus it has two separate semantic equivalents in Spanish. The current design of the study does not handle two semantic equivalents for one loanword, although future work hopes to remedy this as the polysemy of the loanwords themselves is an important semantic issue to be explored.
With this goal of selecting near-synonyms, a list of potential equivalents was gathered using the online translator wordreference.com and the DRAE. Together the researcher and a native Argentine Spanish speaker then selected the most viable semantic equivalent (see the Appendix for a complete list). Only one semantic equivalent was chosen for each loanword, as the goal of the study was to identify the one closest equivalent rather than obtaining a list of potentially related words. This choice had the benefit of maintaining a binary setup for the data, which allowed for a straightforward comparison with the paired statistical test.
The criteria by which loanwords were selected for analysis – function as noun, have an equivalent, and appear 50 or more times – led to the exclusion of potential loanwords for two main issues. One, some loanwords had a semantic equivalent that did not appear in the corpus or appeared with low counts; such was the case with freezer and its equivalent congelador. Two, some loanwords had no semantic equivalent, such as blog. Thus while the three criteria are necessary to ensure appropriate and sufficient data for the algorithm to process, they greatly limit the number of tokens applicable for analysis. There were 72 Anglicisms that met both the frequency and POS criteria, but only 30 of those had a viable semantic equivalent. Thus, a supplemental qualitative analysis was also used to explore the semantic profile of those 42 loanwords that were not analyzed quantitatively.
Computational model: measuring specificity
The final step in processing the corpus was to measure the semantic specificity of the loanwords and their native equivalents suitable for quantitative analysis. These 60 words (30 loanwords + 30 equivalents) will be referred to as target words. Recall that for this study, specificity is defined distributionally; words used within a narrow set of contexts are more specific than words used across varied contexts, as exemplified with BNC corpus results for food and cashew above. While the terms ‘narrow’ and ‘varied’ may appear subjective, they become quantifiable, replicable and, thus, objective by calculating the entropy of a word’s distribution. Entropy measures the complexity or disorder within a system. Applied to word specificity, as a word’s distribution becomes more complex, that is, varied, its entropy increases.
The entropy measure proposed in this study is a modified version of the one presented by Caraballo and Charniak (1999). Caraballo and Charniak sought to determine the most accurate computational method for ranking words according to specificity. Drawing on a corpus of 15 million words, they evaluated nine measures on their ability to correctly rank three hierarchies of noun hypernyms constructed from WordNet (see Figure 1).

Sample hierarchy of noun hypernyms.
Each of the nine measurements was evaluated on its ability to reproduce the hypernym hierarchies from an unordered set of words, utilizing the corpus alone as a data set. The most accurate of the measures tested were as follows: (i) entropy of the rightmost modifier; (ii) frequency; and (iii) entropy of words appearing within a 50-word window of the target, all of which performed with over 80% accuracy in reconstructing the hypernym hierarchy.
As they achieved equally high accuracy, the three measures were each considered to be used for the specificity measure in this study. The entropy of the rightmost modifier was discarded because it requires syntactic parsing. The frequency measurement was discarded because by ignoring the surrounding context, it does not measure specificity in accordance with the distributional definition proposed in this study. >From a linguist’s perspective, although there may exist a correlation between a word’s frequency and the specificity of its meaning, the two concepts are clearly distinct and this paper aims to quantify and analyze the latter. The entropy of the 50-word window does not require additional parsing and utilizes the surrounding context, reflecting the distributional hypothesis that a word’s meaning is informed by its context. Thus, the entropy of the 50-word window was selected as the method to calculate specificity. The entropy measure for a given target word is calculated as
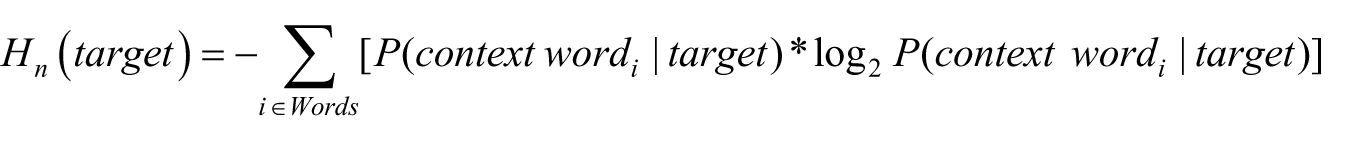
where Hn (target) is the entropy score, P (context word|target) is the probability that context word will appear within an n-word window of the target, given the word target, and Words is the set of context words that appear in target’s context window (2). Probabilities are calculated for each target word from its context vector (as described in Distributional semantics). The reasoning is that nouns with greater specificity have less variety in their surrounding context, resulting in a lower the entropy score.
This entropy calculation comprises several parameters, such as context window size, context type, and dimensionality reduction (Lapesa & Evert, 2014). The parameter settings in this model were as follows: only nouns, verbs, adjectives, and adverbs with counts of 30 or more, appearing within a 50-word window of the target were included as in the context vectors, since function words and infrequent words offer little valuable information as to the semantic context. For this same reason, stop words, such as ser ‘to be’, haber ‘to have’, and estar ‘to be’, were also excluded.
One problem with the entropy measure as presented by Caraballo and Charniak (1999) is its sensitivity to frequency. For example, if we wish to compare word A, which occurs 100 times, to word B, which occurs 50 times, this entropy measure gives A double the opportunity to show variety in its surrounding context, thus frequency to some degree affects the resulting score. This fact did not pose a problem for their task-oriented study. However, since the current study has the conceptual goals of measuring the linguistic concept of specificity as separate from frequency, the overlap proves to be a problem.
To remove the effect of frequency from the entropy measure, a technique to artificially keep the frequency the same for all target words was added: bootstrapping. Bootstrapping is a statistical technique in which a parameter of a population is estimated by drawing random samples with replacement from the data set available (see Gries, 2006, for another application of bootstrapping in a corpus study). For each target word, a sample of 50 occurrences along with their surrounding context was drawn with replacement from the corpus to calculate an entropy score, thus holding the frequency constant at 50 for all target words. This process was repeated 1000 times for each target word, resulting in a set of entropy scores, which were averaged to produce the final entropy score. The two parameters – sample size: 50 and number of samples: 1000 per target word – were chosen because 50 was the minimum requirement for target words and 1000 samples ensured convergence across the estimate scores.
To check the accuracy of this resulting entropy model with bootstrapping on the present 24-million-word corpus (small by computational linguistic standards, where 1-billion-word corpora are common), a trial set of 10 word pairs, similar to that used by Caraballo and Charniak, was selected. The test set, shown in Table 3, is comprised of word pairs: one general term and one hyponym, following the definition: a Y is a hyponym of X if a native speaker accepts the sentence ‘Y is a kind of X’. A paired T-test was applied to the entropy scores of the general terms compared to their hyponyms. The results show that the general terms receive significantly higher entropy scores than their hyponym counterpart (T9 = 4.25, p < 0.01). Thus, the entropy model was considered sufficiently accurate to measure specificity.
Test set of word pairs for entropy model.
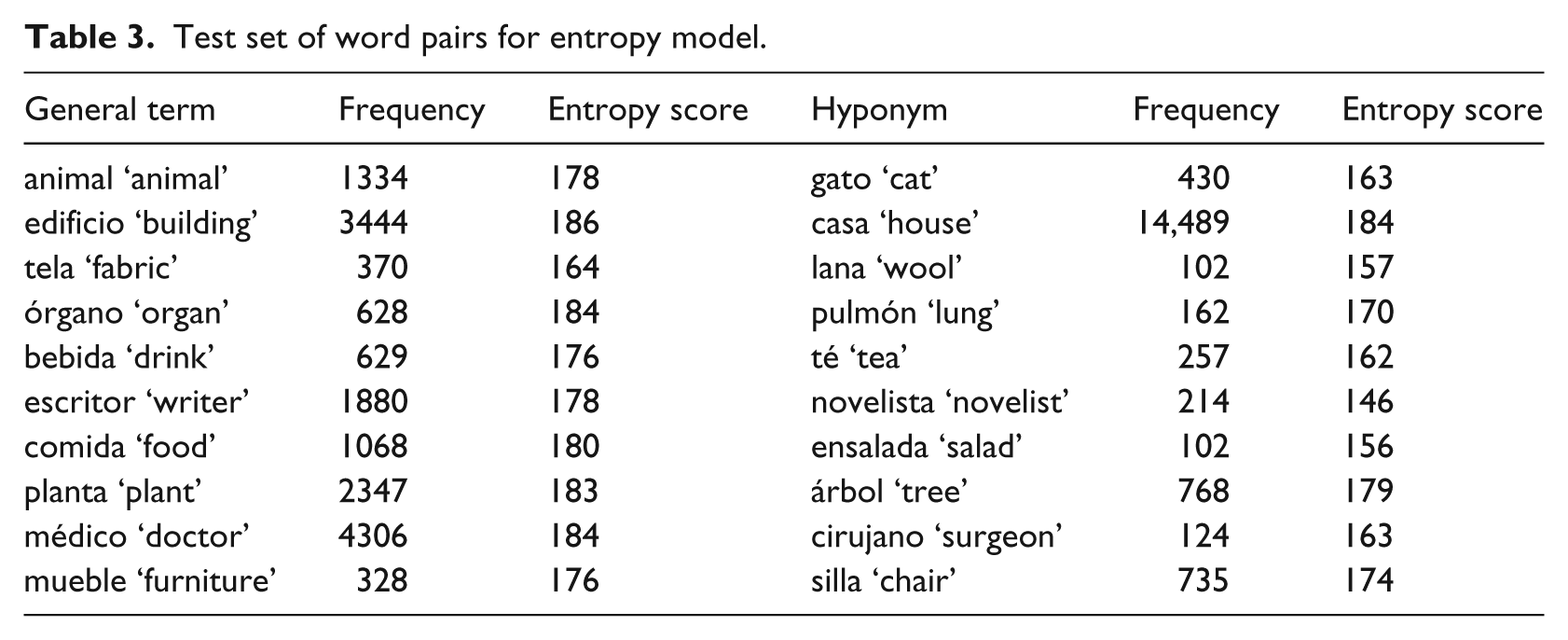
This entropy model, trained on this 24-million-word corpus of Argentine newspapers, was used to measure the 30 loanword and equivalent pairs to empirically test the Specificity Hypothesis.
Results and discussion
This section will present the quantitative analysis of the 30 Anglicisms and their equivalents, using entropy to measure their specificity, as well as a qualitative analysis of all 72 high-frequency loanwords (30 plus the 42 Anglicisms that were not applicable for the specificity measure).
Quantitative
The 30 loanwords and their semantic equivalents were analyzed using an entropy measure. The entropy measure for each word was calculated by considering the probabilities of the surrounding context appearing with each of the target words. Thus, a word that appeared in a greater variety of contexts would receive a higher entropy score, indicating low specificity. A table of the loanwords and equivalents with their entropy scores can be found in the Appendix. The distribution of entropy scores for each loanword and its native equivalent appears in Figure 2; the dotted lines represent the loanword-equivalent pairs in which the loanword’s entropy score was lower than its equivalent’s, that is, pairs that support the proposed Specificity Hypothesis. The dashed lines represent those pairings that showed the opposite trend, that is, pairs in which the loanword had a higher entropy score than its equivalent. The solid bold line represents the general trend, calculated as the mean score of loanwords and equivalents.
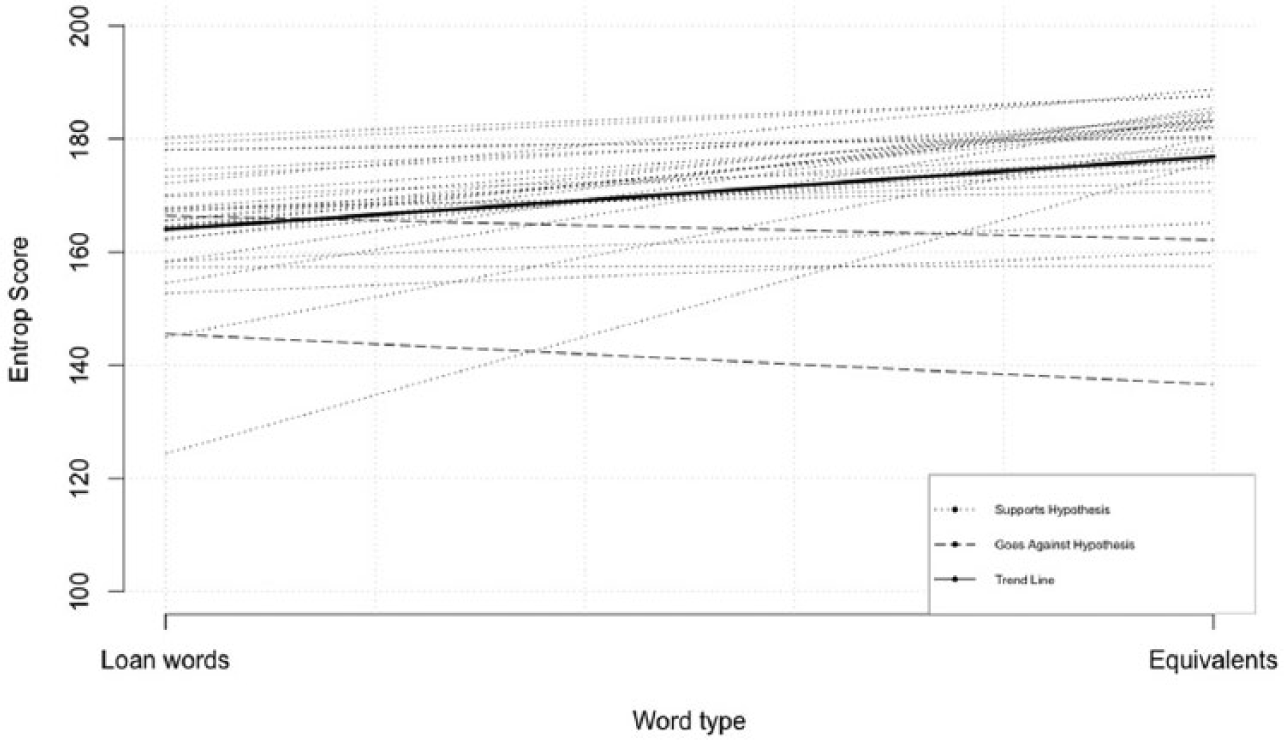
The entropy scores of loanwords as compared to their equivalents.
Visually, it is clear that the dotted lines far outnumber the dashed lines and the bolded trend line shows an increase in entropy score when moving from loanwords to native equivalents. To check the statistical significance of this observed pattern, a nonparametric alternative to the paired t-test, the Wilcoxon Signed-Rank Test, was used. A nonparametric test was deemed necessary after both visually inspecting multiple iterations of the data graphed in a scatter plot and running the Shapiro–Wilk test (p = 0.13) confirmed the data was not normally distributed (p = 0.1326). The Wilcoxon Signed-Rank Test revealed that loanwords had significantly lower entropy scores than their native counterparts (V = 447, p < 0.01). Thus, loanwords were found in more narrow contexts relative to their equivalents.
The principal research question – Are loanwords semantically specific? – is answered in the affirmative, according to the general trend provided by the quantitative analysis and following the distributional definition of specificity. These Anglicisms in the Argentine Spanish corpus were used within a significantly narrower set of contexts, meaning that they were more specific than their counterparts, supporting the extension of the Specificity Hypothesis.
Qualitative
Of the 72 high-frequency English-origin nouns found in the newspaper corpus, 42 (58%) were disqualified from the computational analysis for two reasons. In some cases, the semantic equivalent had low counts or did not appear in the corpus, for example, congelador ‘freezer’ did not appear in the corpus, although the loanword freezer was prevalent. In addition, some loanwords had no single word or collocation that served as semantic equivalent. For example, un thriller could be replaced in Spanish by the compound adjective de suspenso, which could be added to the noun libro ‘book’ or película ‘movie’, but there was no single word or phrase that could reliably serve as an equivalent.
These loanwords, along with the 30 from the quantitative analysis discussed above, will be analyzed qualitatively by examining the contexts in which they appear and considering their location along the loanword trajectories described in Weinreich’s seminal book Languages in Contact. Weinreich (1953) proposes that loanwords initially cause confusion for a speech community and then follow one of two trajectories: replacement, in which the loanword overtakes and occupies the complete space of the original native word, or specialization, in which the native and borrowed terms refine their meanings so that both become more specialized, resulting in their sharing the semantic space that was once occupied by just the native term. Another trajectory that is present in this data set is one in which the loanword introduces a new concept into the existing recipient lexicon, thus the loanword lacks a semantic equivalent.
Replacement
The semantic equivalents whose frequency proved too low for the computational analysis reflect the process of being replaced by the loanword. There are 17 such loanwords in the corpus, including default, country, shorts, jeans, broker, ferry, and freezer, which offer shorter or one-word alternatives to their native counterparts: incumplimiento, barrio privado, pantalones cortos, vaqueros, corredor de bolsa, transbordador, and congelador. These loanwords and equivalents fall into semantic domains commonly cited in other Anglicism studies: technology, fashion, and lifestyle. Rather than occupying a more specific semantic domain than their equivalents, these loanwords appear to have completely or nearly completely occupied the entire semantic domain of the equivalent, thus explaining their shrinking to non-existent presence in the corpus.
From the quantitative analysis, three pairs had a pattern that also seemed to suggest that a process of replacement was underway. This pattern, in which the loanword had a higher or an almost equal entropy score (i.e. lower and equal specificity) relative to its equivalent, for example tablet:tableta, stud:potrillo, and jockey:jinete, showed that the loanwords occupied similar, if not greater, semantic space than their native equivalents. Thus, these pairs may represent an earlier stage of replacement, whereby the equivalent is still prevalent, yet distributionally they are comparable, both competing for the same semantic space. For example, stud ‘a male horse’ is clearly gaining ground over the native padrillo in both distribution – with an entropy score of 146 compared to 137– and in frequency – 146 tokens versus 54. 1
The pair tablet:tableta highlights a more complex case, where the semantic equivalent tableta shows much greatly frequency (677 cases compared to 222), although a slightly more narrow distribution (162 compared to 166). 2 Upon exploring the contexts, it appears that tableta appears predominantly in reference to specific products (ex. La tableta T810 posee una pantalla HD ‘the tablet T810 has an HD screen’), while tablet appears in specific product contexts as well (ex. a nueva tablet, llamada iPad Air ‘a new tablet called iPad Air’) but also in more general discussion of technology (ex. podemos asistir compu en mano, o tablet ‘we can attend computer in hand or tablet’). Thus although still very prevalent, the semantic equivalent tableta may not have the same scope as tablet, possibly suggesting its replacement at some point, although further in the future. These loanword and equivalent pairings do not seem to directly support the Specificity Hypothesis, but reflect another trajectory that loanwords may take in their integration to the recipient language.
Specificity
The process of specificity is well documented in the discussion of the quantitative analysis above, as 27 of the 30 numerically reflected this process. Two of the loanword-equivalent pairs with the largest entropy difference, doodle:dibujo and bullying:abuso, serve as clear examples. The loanword doodle is used exclusively to reference the Google doodles (ex. El doodle de Google celebra los 50 años de Doctor Who. ‘Google’s doodle celebrates 50 years of Doctor Who’) and never refers to a generic sketch or drawing as it can in English. In those cases, the more generic term dibujo ‘drawing’ was utilized. The Anglicism doodle, then, has entered the lexicon in a very specialized manner to refer to one specific type of drawing and in this corpus shows no signs of expanding to broader contexts that the English usage would suggest possible (ex. Her notebook is filled with doodles). Bullying, too, has carved out a semantic space within the broader category of abuso, although its use more closely matches its English scope. Both words appear in contexts about children and families (ex. El bullying es un problema de chicos que lo resuelven los adultos. ‘Bullying is a problem for children that is resolved by adults.’ Las jóvenes y las familias que habrían sido afectadas y condenamos absolutamente cualquier acto de maltrato, abuso y agresión… ‘The girls and families that have been affected and we condemn absolutely any act of mistreat, abuse or aggression…’). However, abuso has a much greater scope, commonly appearing in collocations such as abuso de poder ‘abuse of power’, abuso de autoridad ‘abuse of authority’, in which bullying does not fit. Thus, although abuso has the ability to cover the same semantic domain and more as bullying, the loanword references a more specific type of abuse that did not have its own name before.
While these loanwords create a new division with a semantic space, other loanwords offer an unambiguous alternative to polysemous native words. This is the case for the loanword and equivalent pairs team:equipo ‘team’ or ‘equipment’, stand:puesto ‘stand’ or ‘position’, crack:estrella ‘star/celestial body’ or ‘star/famous person’. Loanwords with polysemous equivalents clearly lend support to the Specificity Hypothesis in that the native equivalent may be used in broader contexts due to their multiple meanings. These loanwords are more specific than their semantic equivalents by the simple measure of number of word senses. The polysemy of the semantic equivalent may contribute to the success of the loanword, as the loanword offers an unambiguous alternative. The polysemy of borrowings themselves has been shown to contribute to their success in a study on Anglicisms in French conducted by Chesley (2010); she found that polysemous borrowings were more likely to become well entrenched into the recipient language than those with one word sense.
New concept
The last trajectory of loanwords is those that introduce a new concept such as hockey or blog, which essentially create a new semantic space within the existing recipient-language lexicon. They are easily identifiable in that they lack a clear semantic equivalent. In this data set, these loanwords included numerous sports terms (scrum, hockey, welter, court, wing, chukker, handicap, rally), several technology terms (blog, chat, drone, streaming, hacker, notebook), a few business terms (lobby, holdout), and several that could loosely be grouped as entertainment terms (thriller, rock, punk, pub, best seller). These loanwords have no viable alternative or require a description to convey the same idea; some are challenging to classify, such as lobby, which expresses a similar idea as the phrases presión política ‘political pressure’ or influencia política ‘political influence’, but these are not perfect substitutes and may carry negative connotations not shared by the loanword. As these loanwords have no equivalents, it is impossible to quantify their specificity via the concept-based approach applied in this study. Interestingly, they may be categorized as highly specific via the replacement test offered by Backus (2001) – highly specific words are hard to replace with a synonym – hence, still supporting the Specificity Hypothesis, even while lacking an equivalent.
When approached from a diachronic perspective, one complication to this seemingly clearly definable category arises; native equivalents may be subsequently introduced as equivalents to these terms, often multi-word collocations (e.g. the phrase pirata informático was introduced as an alternative to the loanword hacker, according to Spanish data on Google Ngram Viewer). This phenomenon of creating native equivalents after the adoption of a loanword has been documented in other loanword studies (Onysko & Winter-Froemel, 2011) and often results from notions of language purism or the need to avoid loanwords in formal documents. While native synonyms may emerge as alternatives, they often struggle to gain ground after a lagging start. Pirata informático shows relatively low use as compared to its loanword counterpart in the present Argentine corpus and in Google Ngram Viewer. 3 However, once both forms exist, they must follow one of the two trajectories proposed by Weinreich: specialization or replacement. Future work may explore this diachronic perspective to understand the role of time depth in loanword semantics, although this current study limits itself to a synchronic perspective.
Conclusion
The research presented here has provided a semantic analysis of loanwords, pulling from various fields to create a unique perspective on this understudied aspect of lexical borrowings: from distributional semantics, specificity was defined distributionally; from cognitive linguistics, loanwords were analyzed using the concept-based approach; and from computational linguistics, distributional models were adapted to quantifiably measure specificity. Utilizing these methods, 72 high-frequency noun borrowings were extracted and analyzed from a 24-million-word corpus of Argentine newspaper Spanish.
The quantitative measure for specificity presented here allows for processing large data sets in a replicable, unbiased manner. However, it constrains the number of tokens that may be analyzed – over half of the tokens of interest were excluded from the computational analysis due to their lack of an equivalent or low counts of the equivalent. This model, as it currently stands, is restricted to large data sets and is most suitable for singletons or frequent multiple word expressions; thus, it is not practical for more extensively bilingual texts involving longer code-switched spans. Advances in computational linguistics, both with regards to distributional models and bilingual language processing, may remedy some of these limitations. Automated language annotation algorithms have already been developed, which could aid in expanding the model proposed here to code-switched texts (see Neupane et al., 2015; Toribio, Bullock, Serigos, Neupane, & Ball, 2015). It is worth noting, too, that this model is applicable for monolingual inquiries as well; for example, neologisms could be subject to this same computational, semantic analysis.
The limitations of the quantitative method were addressed through a qualitative analysis, which has allowed for the computational results to be interpreted within a larger discussion of loanword trajectories, as presented by Weinreich, revealing two separate patterns that may define the semantic development of lexical borrowings. Thus, although specificity is not the only semantic option, it is a strong trend among new borrowings and demonstrates the effect of loanwords on the recipient language’s semantic system. As both qualitative and quantitative approaches examine loanwords that appear over 50 times, the effect of specificity is probably still underestimated, given that low-frequency loanwords are likely to be specific due to their limited contextual appearances.
The Anglicisms in the corpus that were suitable for quantitative analysis demonstrated a clear pattern of higher specificity than their native equivalents. As specificity was operationalized as a measurement of variability of the surrounding context, these results reflect the fact that loanwords are utilized in more narrow contexts, implying a specific or nuanced meaning as compared to their counterparts. In a similar vein, the majority of loanwords that were not suitable for computational analysis also followed a pattern of demonstrating high specificity. Thus, both the qualitative and quantitative findings support Backus’s Specificity Hypothesis.
This pattern may suggest that loanwords’ specificity is itself a motive for borrowing them, although it is not possible to empirically prove cause and effect with this type of data set. Speakers of the recipient language may find a borrowed word’s precision motive enough to temporarily (or permanently) abandon the semantic equivalent that previously acted as the default and unmarked choice. Another motive for borrowing cited in the literature is their ability to serve as prestige markers (Bullock et al., 2015; Ngom, 2000). In contexts where the source language is highly regarded, the prestige of a borrowed word may, in fact, contribute to its specificity. Since meaning is not just denotation, a more prestigious connotation would likely lead to a more specific contextual usage. However, methodologically separating the concepts of prestige and specificity is not yet possible given the currently proposed analysis.
This study offers novel perspectives on loanwords with existing semantic equivalents, often viewed as ‘unnecessary’ when compared to loanwords that introduce new concepts into the recipient language. With the notion of specificity, we may understand these loanwords as disruptors to the semantic system of the recipient language, dividing up the semantic space formerly occupied solely by the native equivalent, thus increasing the level of nuance expressed in the original concept. This offers a different perspective from Bookless’ observation that loanwords with existing equivalents contain more stylistic than referential value: The specificity value of loanwords may, in fact, imply a referential value as well.
In addition to the support found for the Specificity Hypothesis, two other patterns of loanword semantics emerged: replacement and introduction of a new concept. Three pairs from the quantitative analysis and loanwords with low equivalent counts from the qualitative analysis reflect a process of replacement rather than specificity in which the loanword eventually takes over the whole semantic space previously occupied by the native equivalent. Other loanwords that had no equivalent introduce a new concept. These loanwords create a new semantic space within the existing lexicon, although they too may be viewed as specific, according to the replacement test presented by Backus (2001). A diachronic perspective may shed light on the trajectory of these three semantic patterns as change over time or the introduction of native equivalents may alter the final semantic role of lexical borrowings in the recipient lexicon.
In utilizing a corpus of Argentine Spanish, this study extended the empirical scope of Backus’s Specificity Hypothesis to new domains, that is, to data often viewed as ‘monolingual’ or representing a situation of weak language contact. What remains to be tested is if this hypothesis holds true for loanwords appearing in situations of more direct bilingualism, such as the Spanish spoken across the USA. As language attitudes towards contact features vary greatly across communities, they may also impact the semantic reshuffling that occurs during loanword adoption.
Footnotes
Appendix
Entropy measures and frequency for loanwords and their semantic equivalents.
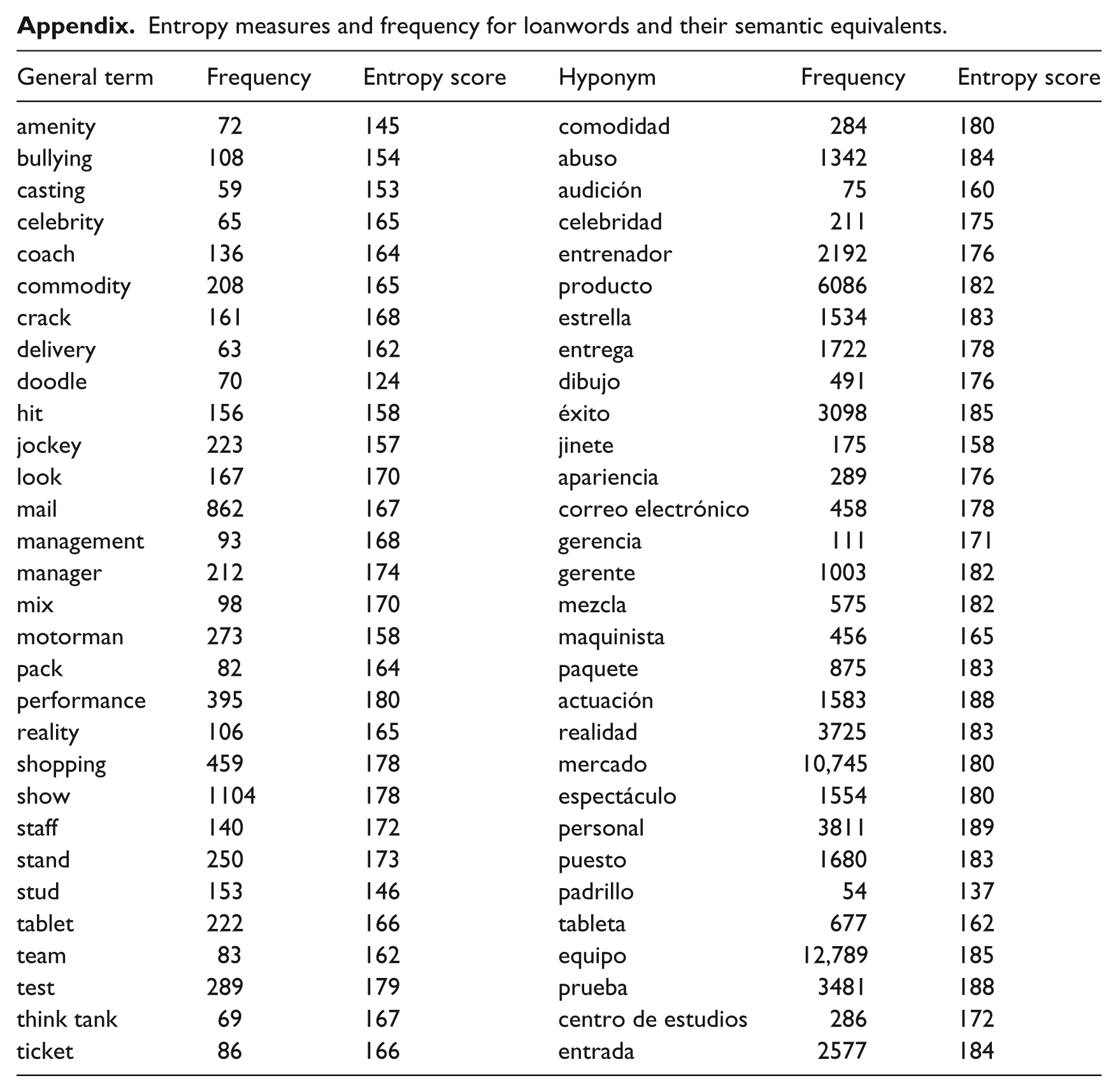
| General term | Frequency | Entropy score | Hyponym | Frequency | Entropy score |
|---|---|---|---|---|---|
| amenity | 72 | 145 | comodidad | 284 | 180 |
| bullying | 108 | 154 | abuso | 1342 | 184 |
| casting | 59 | 153 | audición | 75 | 160 |
| celebrity | 65 | 165 | celebridad | 211 | 175 |
| coach | 136 | 164 | entrenador | 2192 | 176 |
| commodity | 208 | 165 | producto | 6086 | 182 |
| crack | 161 | 168 | estrella | 1534 | 183 |
| delivery | 63 | 162 | entrega | 1722 | 178 |
| doodle | 70 | 124 | dibujo | 491 | 176 |
| hit | 156 | 158 | éxito | 3098 | 185 |
| jockey | 223 | 157 | jinete | 175 | 158 |
| look | 167 | 170 | apariencia | 289 | 176 |
| 862 | 167 | correo electrónico | 458 | 178 | |
| management | 93 | 168 | gerencia | 111 | 171 |
| manager | 212 | 174 | gerente | 1003 | 182 |
| mix | 98 | 170 | mezcla | 575 | 182 |
| motorman | 273 | 158 | maquinista | 456 | 165 |
| pack | 82 | 164 | paquete | 875 | 183 |
| performance | 395 | 180 | actuación | 1583 | 188 |
| reality | 106 | 165 | realidad | 3725 | 183 |
| shopping | 459 | 178 | mercado | 10,745 | 180 |
| show | 1104 | 178 | espectáculo | 1554 | 180 |
| staff | 140 | 172 | personal | 3811 | 189 |
| stand | 250 | 173 | puesto | 1680 | 183 |
| stud | 153 | 146 | padrillo | 54 | 137 |
| tablet | 222 | 166 | tableta | 677 | 162 |
| team | 83 | 162 | equipo | 12,789 | 185 |
| test | 289 | 179 | prueba | 3481 | 188 |
| think tank | 69 | 167 | centro de estudios | 286 | 172 |
| ticket | 86 | 166 | entrada | 2577 | 184 |
Acknowledgements
I would like to thank Almeida Jacqueline Toribio, Barbara Bullock, and Katrin Erk for their invaluable feedback and assistance with various aspects of this work. I also would like to thank the anonymous reviewers for their insightful comments on earlier versions of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.