
Abstract
The aim of this paper is to examine the role of language dominance in loanword phonology. It is investigated how onset clusters in loanwords are integrated into Turkish by two groups: English-Turkish bilinguals in Turkey and Swedish-Turkish bilinguals in Sweden. It is hypothesised that the bilinguals in Sweden will display significantly higher rates of cluster adoption because Turkish is not the dominant language there.
The data were collected through an oral loanword elicitation task, a text recitation task in the second languages and a questionnaire on language proficiency and use.
The study had 53 participants (24 in Turkey and 29 in Sweden). The material consisted of 29 loanwords from English and French, and of 50 structurally comparable words in the bilinguals’ second languages. The data were analysed auditively by the author and subjected to an interrater reliability test.
The results confirmed the hypothesis as the bilinguals in Sweden displayed significantly higher cluster adoption rates. The difference between the groups’ medians was 36.5 percentage points. Furthermore, it was shown that in individual speakers the combination of accurate second-language pronunciation, and clearly higher proficiency in the second language (corresponding to the donor language) compared to the L1 (i.e. the recipient language) guaranteed very high cluster adoption rates.
This paper provides the first rigorous quantitative proof for the theoretical assumption that accurate pronunciation is not sufficient for structural adoption in loanword phonology but needs to be complemented with sociolinguistic variables. Furthermore, it demonstrates in greater detail than before how societal and individual dominance are connected and through which channels they impact loanword integration.
Self-reported relative proficiency in the donor language was shown to be a powerful predictor of the sociolinguistic incentive to adopt and could therefore be used as a quick and reliable alternative to elaborate and time-consuming attitude investigations in loanword phonology.
Keywords
Introduction
An important insight from loanword phonology studies that discuss the choice between adaptation and adoption (i.e. the preservation of original pronunciation), is that the ability to accurately pronounce a foreign structure is not sufficient in explaining the choice between these two integration strategies (e.g. Aktürk-Drake, 2011, 2014; Friesner, 2009a; Paradis & LaCharité, 1997, 2008; Poplack et al., 1988). Even when borrowers have the necessary linguistic competence in the donor language (which is often a second or foreign language), they are sometimes known to alter their pronunciation when they produce the same word as a loanword in their first language (L1) (Aktürk-Drake, 2014; Friesner, 2009b). To paraphrase Friesner (2009a), loanword phonology cannot be reduced to a foreign accent.
Several authors have, therefore, argued that we also need to take further factors into consideration (Aktürk-Drake, 2011, 2014; Friesner, 2009a, 2009b; Paradis & LaCharité, 1997, 2008; Thomason, 2001). The most commonly mentioned factors on the societal level are the degree of community bilingualism (Croft, 2000, pp. 201–207; Johanson, 2002, pp. 5–6; Paradis & LaCharité, 2008; Sakel, 2007, pp. 19, 25; Thomason, 2001, pp. 70–71) and the socio-political status of the donor language as a minority or majority language (Poplack et al., 1988; Thomason, 2001). Paradis and LaCharité (2008) claim that a high degree of community bilingualism increases the likelihood of adoption. Poplack et al. (1988) also found that adoption is more common when the recipient language is a minority language in a context where the donor language is the majority language. A few other studies have found that different measures of donor-language proficiency on the individual level play an important role for the outcome of loanword integration (Aktürk-Drake, 2011, 2014; Friesner, 2009a; Poplack et al., 1988). However, no study has hitherto attempted to capture the relationship between the societal and individual levels in order to provide a more comprehensive account of the loanword integration process in an individual speaker who is embedded in a specific societal context.
Objectives
The aforementioned societal factors, community bilingualism and socio-political status, as well as the individual factor proficiency can be viewed as different expressions of the dominance relationship between the donor and recipient languages in borrowing societies and individuals. Following this reasoning, the present paper will investigate the prevalence of adoption in loanwords in two bilingual groups of Turkish speakers with different language dominance statuses. The first group are English-Turkish bilinguals in Turkey, where the recipient language Turkish is societally dominant as the majority language. The second group consists of Swedish-Turkish bilinguals in Sweden, where Turkish is not societally dominant as a minority language. The group in Turkey will be referred to as elite bilinguals because they constitute a small urban minority of Turkish native speakers with typically high socioeconomic (hence elite) status who have become bilingual in the international lingua franca English through secondary and/or tertiary education (de Mejía, 2002, p. 5; Skutnabb-Kangas, 1984, p. 97). The group in Sweden will instead be referred to as heritage bilinguals since it is made up of speakers of Turkish as a heritage language in Sweden, who have also acquired the societally dominant language Swedish as a second language (L2).
The structural focus is word-initial onset clusters that are present in the original forms of loanwords, which are established words in contemporary Turkish. As native Turkish words lack onset clusters altogether, the main question regarding the phonological integration of such clusters is if Turkish speakers will adapt the clusters in loanwords by breaking them up through epenthesis or if they will adopt them as innovations by preserving them as clusters. As will be discussed in greater detail under the Methodology section, all loanwords included in this study (such as the word step) either come from English or have phonetically similar counterparts in the bilingual participants’ strongest L2. Furthermore, these loanwords’ standard orthography in Turkish includes the original cluster (as in the Turkish spelling <step>). Thus, the original form of these loanwords with an initial onset cluster can be safely assumed to be apparent for the participants of the present study.
The main hypothesis of the paper is that the heritage bilinguals in Sweden will display significantly higher rates of cluster adoption than the elite bilinguals in Turkey due to the difference in the societal dominance of the recipient language Turkish. This hypothesis will be tested on the societal level though the comparison the two groups’ cluster adoption rates in loanwords. On the individual level, dominance will be measured through the bilingual speakers’ self-reported relative proficiency in their L2 and their language use.
Background
Loanwords with original word-initial onset clusters in Turkish
Turkish is one of many languages in the world that do not contain any onset clusters in their native inventory (Maddieson, 2011). However, historical contact with languages that contain onset clusters (henceforth cluster languages) has resulted in the borrowing of a great number of words with original onset clusters into Turkish. In Nişanyan’s (2007) etymological dictionary of Turkish with just under 16,000 entries, the number of loanwords with original word-initial consonant clusters amount to 514 (i.e. 3.3% of the entire dictionary). Of these, 75% are indicated by Nişanyan (2007) to have been borrowed between the years 1800 and 1960, predominantly from French and English.
Regarding the contemporary Turkish pronunciation of loanwords with original word-initial onset clusters, one attested option is to adapt the clusters through the insertion of an epenthetic vowel between the cluster consonants as in Output 1 in Example 1. Another attested option is to adopt the cluster as in Output 2 in Example 1.
(1) Donor Original input Turkish Output 1 Output 2 language orthography adaptation adoption a. English <step> [step] <step> [s b. French <scandale> [skɑ̃dal] <skandal> [s c. English <tramway> [tɹæmweɪ] <tramvay> [t d. French <plan> [plɑ̃] <plan> [p
The epenthetic vowel is always one of the four high vowels of Turkish: [i], [y], [ɯ] and [u]. Usually, the precise choice of vowel is dictated by harmony processes. The palatal rules of Turkish vowel harmony require that the epenthetic vowel have the same palatal value as the subsequent vowel in the stem, as can be seen in 1a–c. However, not only vowels but also some consonants are palatally classified in Turkish, such as [l], which behaves as [−back]. When such a palatally classified consonant is part of the onset cluster, as can be seen in 1d, this onset consonant’s palatal classification overrules the palatal classification of the subsequent vowel in determining the palatal value of the epenthetic vowel.
To date no empirical studies have been carried out on how Turkish speakers actually pronounce words with original onset clusters. Turkologists and Turkish linguists who discuss whether onset clusters can be considered licit syllable structure in contemporary Turkish (based on introspection and limited observations) are not in agreement. Some claim that onset clusters are licit in Turkish (Demircan, 2009; Ergenç, 2002; Özsoy, 2004) while others claim that they are still illicit (Benzer, 2010; Göksel & Kerslake, 2005; Lewis, 2000). Clements and Sezer (1982) and İskender (2008) are the only authors who allow for the possibility of variation. İskender (2008) suggests that knowledge of cluster languages may be responsible for (interpersonal) variation. Clements and Sezer (1982, p. 246) conjecture that (intrapersonal) variation depends on style or register, where epenthesis occurs in “normal or colloquial pronunciation” while cluster adoption occurs in “careful or learned pronunciation”.
We do not know for certain how such cluster loanwords were pronounced historically by the first borrowers. What we know is that the orthography of many cluster loanwords initially included a prothetic or epenthetic vowel in the Turkish Latin alphabet that was introduced in 1928, either as the only orthographic variant or as one of two variants (the other containing a preserved cluster). However, since the orthography reform of 1965, the non-epenthesised variant has been established as a strong orthographic norm in most loanwords of this type.
Two theoretical channels through which language dominance impacts loanword integration
One established way of measuring individual dominance is by comparing a bilingual’s proficiency in his/her two languages (Grosjean, 2010, pp.34−35; Romaine, 1995, pp.12−19). It is also well-known that bilinguals tend to be more proficient in the majority language, that is, the societally dominant language. What is meant by a speaker’s linguistic competence to adopt clusters (cluster competence) in this paper is that s/he has acquired the ability to accurately produce consonant clusters in the word-initial onset position. As Thomason (2001, p. 69) puts it, “since you cannot borrow what you do not know, control of the source language’s structure is certainly needed before structural features can be borrowed.” Concepts similar to linguistic competence are commonly used as explanatory variables in research concerning contact-induced change (Johanson, 2002; Matras, 2007; McMahon, 1994; Thomason, 2001). Thus, societal dominance exerts an important influence on individual dominance through the channel of competence. Key facts from second-language acquisition (SLA) research help shed light on how this channel operates.
It is assumed here that cluster competence is obtained through the acquisition of a cluster language as a L2. If a bilingual speaker has a nativelike accent in a cluster language, we can safely assume that this will also include accurate pronunciation of onset clusters. The literature overview carried out by Piske, Mackay, and Flege (2001) found that the factors age of onset for L2 acquisition and motivation had a significant impact on the nativelikeness of accent in a L2. Several studies also point to the beneficial effect of higher degrees of exposure for progressing towards a more nativelike pronunciation through the interactive use of the L2 (Derwing, 2008, p. 350; Flege, 2012). When the target language enjoys majority-language status in the learner’s acquisition context, the effect of this societal dominance on individual learners’ motivation to learn the target language and their exposure to it through extensive use is considered to be greater than in a context where it is not the majority language (Oxford, 2002, p. 247). Regarding the age of onset, a well-established view in the literature is that the probability of nativelike pronunciation decreases linearly with increasing biological age (Flege, 1995; Hyltenstam & Abrahamsson, 2003). Majority languages tend to be acquired earlier, typically already before school age, by members of linguistic minorities compared to other languages learnt by majority speakers in school. Thus, societal dominance exerts an important influence on individual speakers’ competence in the donor language through motivational boost, very early acquisition and high exposure. Hence, we would expect the heritage bilinguals in Sweden to display higher cluster competence than the elite bilinguals in Turkey.
Aktürk-Drake (2015, pp. 101−104) proposes that for adoption to prevail over adaptation, speakers with the necessary linguistic competence also need to have sufficient sociolinguistic incentive to transfer the accurate pronunciation from their L2 to their L1. Both a speaker’s individual dominance in the donor language and his/her personal attitude towards it contribute to his/her total incentive to adopt. Here, individual dominance is largely taken to be a reflection of societal dominance conditions, whereas attitudes capture the individual’s more idiosyncratic tendencies. Positive attitudes can be reinforced by L2 dominance, while negative attitudes can potentially be counteracted/balanced by L2 dominance. When a donor language is societally dominant, there are many recipient-language speakers who are bilingual and use the donor language on a regular basis. This is assumed to create a social context where the adoption of donor-language structures is not conspicuous or even desirable, ergo a high sociolinguistic incentive to adopt. This mechanism constitutes the second channel of impact for language dominance. Regarding the two groups in this study, it is expected that the contribution of language dominance to a speaker’s total sociolinguistic incentive to adopt will be greater among the heritage bilinguals than among the elite bilinguals.
Methodology
The participants
The data in this study come partly from a larger study on heritage speakers of Turkish in Sweden. Moreover, bilingual speakers were recruited in Turkey for this study.
This provided us with a total sample of 53 bilingual participants, consisting of 24 elite bilinguals in Turkey and 29 heritage bilinguals in Sweden. The main characteristics of these two groups are summarised in Table 1. The two groups were matched with regard to their size (row 1), biological age (row 3) and their education level (row 2).
Overview of the biographical characteristics of the two bilingual groups.

M: mean; SD: standard deviation; L2: second language.
The criterion for bilingualism in this paper is to have spent a total of one year minimum in an environment (abroad, in a bilingual institution of education, at work or in a relationship) where the speaker used a cluster language on a daily basis as a means of oral communication. When we look at the groups’ cluster-language acquisition backgrounds (rows 4 and 5 in Table 1), we observe considerable differences between them. Firstly, in terms of age of onset, the bilinguals in Turkey can be viewed as successive bilinguals, whereas the bilinguals in Sweden tend to be simultaneous bilinguals because the great majority of them started acquiring both languages prior to age 3 (row 4). Secondly, all bilinguals in Sweden have acquired their cluster language Swedish in a L2 environment from the onset, whereas 58% of the bilinguals in Turkey started their cluster-language acquisition in a foreign-language environment first and were exposed to a L2 environment later in life (row 5).
For all members of the bilingual group in Sweden, Swedish was the first acquired and strongest cluster language. All members of the bilingual group in Turkey reported English as their strongest cluster language, and for most of them English was also the first acquired cluster language. However, four of them had acquired German as their first cluster language from age 10 onwards, and English as their second cluster language from age 12 onwards, in bilingual German-Turkish schools in Turkey.
The material
The first part of the material consisted of a questionnaire concerning the participant’s biographical information as well as questions on language proficiency and use. Using an ascending scale from 0 to 10, the bilinguals were asked to report their proficiency in all of their languages concerning five different language skills that are used by the Common European Framework of Reference for Languages: speaking, listening, conversation, reading and writing. The participants were encouraged to base their scores on comparisons between different skills and across their languages. Their overall proficiency scores were later calculated by taking the mean of the scores for these five skills (henceforth L1 proficiency and L2 proficiency).
In the bilingualism literature, two of the most common ways of measuring bilingual speakers’ language dominance are comparing their proficiency levels in both languages (i.e. calculating the difference between the levels) and determining the portion of each language in the speakers’ overall language use (Grosjean, 2010, pp. 34–35; Romaine, 1995, pp. 12–19). A few earlier studies have used similar measures on the individual level and have found that they play an important role for the outcome of loanword integration (Friesner, 2009a; Poplack et al., 1988).
Using self-reports as a measure of proficiency is in many cases problematic due to reliability issues related to the speaker’s ability and willingness to objectively assess their absolute proficiency. Therefore, a relative L2 proficiency score was calculated by subtracting the speakers’ overall proficiency score in the L1 Turkish from their proficiency score in the strongest cluster language, henceforth referred to as the L2 (i.e. English in Turkey and Swedish in Sweden). Thus, this score provides us with a self-report on relative proficiency. In contrast to methodological problems associated with using self-reports as measures of absolute proficiency, speakers are generally known in bilingualism research to provide more reliable assessments of their language dominance based on relative proficiency (Nortier, 2008, p. 39). Hamers and Blanc (2010, p. 40) comment that “[t]he differential scores between the self-evaluations of proficiency in the two languages are good predictors of the degree of bilingual competence” [my emphasis].
Regarding language use, L1 use data were preferred to L2 use data here because more detailed L1 use data were available within the framework of the aforementioned project on Turkish as a heritage language in Sweden. The bilingual participants were first asked to indicate their 10 most frequent interlocutors. Then they reported for each interlocutor if they used only Turkish, mostly Turkish but also another language/other languages, Turkish as much as another language/other languages, mostly another language/other languages but also Turkish, or no Turkish with that person. In coding, these five options were assigned descending numeric values from 4 to 0 (4 for only Turkish and 0 for no Turkish). In order to calculate the percentage of L1 use within the participant’s total language use with all 10 interlocutors, the numeric values for all interlocutors were added (maximum value: 40) and multiplied with 2.5.
The data on onset clusters regarding loanwords in Turkish were collected through elicitation. Elicited data were preferred to natural speech data mainly in order to ensure that a balanced sample of onset clusters of different types were present in the recordings. To this end, both the sonority distance (SD) between the onset consonants and the size of the clusters were controlled. For reasons of space, the differences in the pronunciation of these different types of onset clusters will, however, not be reported in this paper. The object of the elicitation was made as little transparent as possible for the participants by using an oral fill-in-the-blanks task. In this task, the participants were given 150 linguistically demanding sentences in Turkish in written form. The sentences had one blank slot each and an adjacent word in parenthesis that needed to be suffixed orally for the successful completion of the sentence. The task contained 29 different loanwords, of which only 10 occurred in the blank slot while those remaining were dispersed across the rest of the sentences in order to disguise the object of the investigation.
The selection of the loanwords was based on the factors cluster type and phonetic similarity across the investigated languages, as can be seen in the Appendix. The included loanwords were mostly generic nouns borrowed from English or French (and a few international words of non-English origin, which are likely to have been borrowed via English or French). There were also seven non-generic nouns, which were either place or brand names. All loanwords were well-established as they had been in use for at least a couple of decades, and in most cases for more than half a century.
As can be seen in the Appendix, the loanwords included in this study either come from English, the strongest L2 of the bilinguals in Turkey, or have phonetically similar, ergo transparent, counterparts in the bilinguals’ L2s English and Swedish, respectively. This is because they are either cognates with the corresponding word in the L2s or loanwords from the same language. Furthermore, their standard orthography in Turkish with a cluster reflects their original pronunciation and signals that they are loanwords. To give an example, the English word step has been borrowed into both Turkish and Swedish with its original orthography. In Swedish, it is structurally indistinguishable from a native word. Therefore, what really matters for the purpose of the present study is not explicit etymological knowledge, that is, that it was borrowed from English (which most speakers do not know about), but the implicit structural knowledge that the word’s original pronunciation (regardless of the actual donor language) has an initial onset cluster. This implicit knowledge is, in turn, based on the word’s unusual orthography in Turkish and on the bilingual’s knowledge of a L2 that is a cluster language containing a structurally and semantically similar word. In this sense, cluster adoption in this study means pronouncing clusters in loanword forms in the L1 Turkish just as the speakers would in the corresponding words in their L2s.
The numeric value for the dependent variable cluster adoption rate for each participant expresses in what percentage of the 29 loanwords with original word-initial onset clusters the participant actually produced a cluster in his/her L1 speech. In words with several tokens, the mean value of all tokens was taken as the overall cluster value for that word. The participants’ pronunciation of the same types of onset clusters as found in the L1 data was also tested in their L2. They were given a one-page text in the respective L2 that included 50 words with word-initial onset clusters. They were asked to read this text aloud. The L2 clusters were of the exact same types as in the L1 data but the distribution of the words among these types was not the same. Therefore, in the analysis, weighting with coefficients was used in order to calculate L2 cluster rates that would be directly comparable with the L1 cluster rates.
As can be seen in the Appendix, the loanword sample contained initial onset clusters of two consonants with a SD of +3 (words 1–11, 38%), with a SD of +2 (words 12–15, 14%), with a SD of −1 (words 16–24, 31%) as well as initial onset clusters of three consonants (words 25–29, 17%). Accordingly, the clusters occurring in the text recitation task in the L2 were also categorised into the same four types as in the L1 clusters. For every speaker, a mean L2 cluster rate (in per cent) was calculated for each cluster type and these means were later weighted by multiplication with the percentages indicated above for the L1 cluster types (e.g. with 0.38 for clusters with a SD of +3). Then these four weighted means were added to produce the weighted L2 cluster rate mean for every speaker, thus making this mean qualitatively comparable with the L1 cluster rate means with the same cluster-type weight.
The recording of both L1 and L2 data was done with the help of a portable computer, a table-top microphone and the computer program Wavesurfer. The recordings were then analysed auditively by the author. In order to provide a reliability check for the author’s analysis, approximately 10% of the L1 data (five out of 53 speakers) were also analysed by a Turkish linguist and approximately 8% of the L2 data in English (two out of 24 speakers) and Swedish (two out of 29 speakers) were analysed by a Swedish linguist with advanced proficiency in English. The dichotomous coding in all analyses entailed documenting if the speakers produced a cluster or not. The interrater reliability was found to be Kappa = 0.83 (p < .001), 95% CI (0.728, 0.932) concerning L1 data and Kappa = 0.67 (p < .001), 95% CI (0.537, 0.803) concerning L2 data. Based on these high Kappa values above 0.6, which indicates substantial agreement between raters, it was concluded that the author’s initial analysis was sufficiently reliable to serve as the basis for this study.
Results
In Figure 1 we can see with which frequency different cluster adoption rate means were used by the 53 individual speakers in the study. This value expresses in what percentage of all cases a speaker produced an onset cluster in loanwords in the L1 Turkish. The higher frequencies for cluster adoption rates on the right-hand side of the figure show that the speakers displayed rather high adoption rates in general. The frequency distribution in the figure illustrates that the distribution of the dependent variable (i.e. cluster adoption rate) was not normal but rather one that is partly flat and partly skewed towards the higher end of the adoption scale. Due to this distribution pattern and the small size of the two groups, non-parametric tests were used in the following analysis.
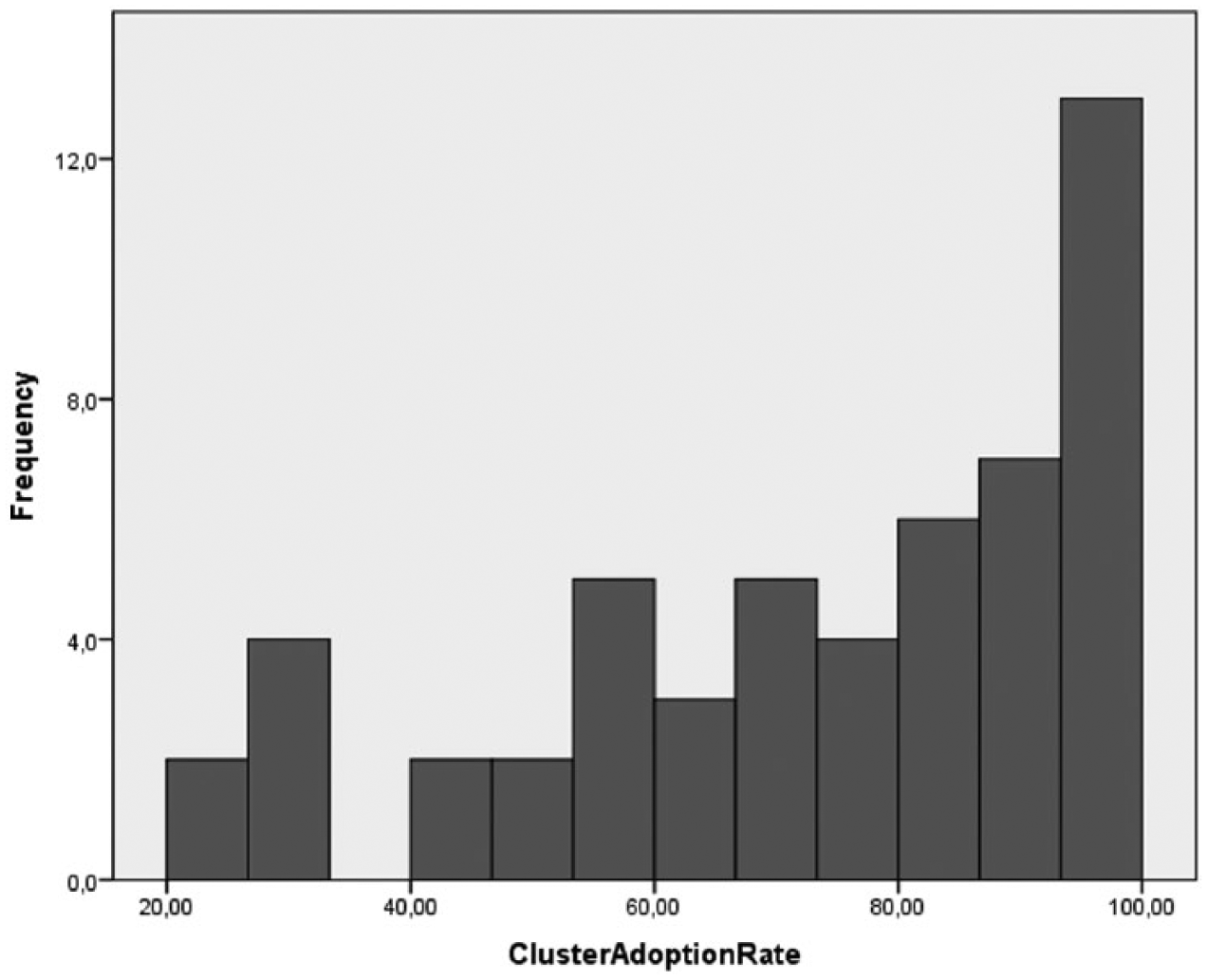
The distribution of cluster adoption rates in loanwords in per cent according to speakers who used the same mean rate (frequency).
Table 2 summarises the results regarding the dependent variable cluster adoption rate (row 1) and the different independent variables measuring linguistic competence (row 2) and language dominance (rows 3 and 4) for the two groups of bilingual speakers.
The key statistics per group and group comparisons across all investigated variables.

L1: first language; L2: second language.
As the p-values for the Mann–Whitney U-tests in the rightmost column of Table 2 illustrate, the two bilingual groups were significantly different from one another in all four variables and the effect size was large in all cases, as illustrated by r-values above 0.5. The group medians in the first row show that the heritage bilinguals in Sweden employed cluster adoption in loanwords at a much higher rate compared to the elite bilinguals in Turkey. The heritage bilinguals also displayed more accurate cluster pronunciation in their L2 (row 2), although both groups turned out to have very high group medians for this variable. Furthermore, the heritage bilinguals had greater relative L2 proficiency (row 3), that is, tended to be more proficient in their L2 Swedish, compared to the elite bilinguals who, in contrast, tended to be more proficient in their L1 Turkish. The elite bilinguals in Turkey reported using their L1 Turkish nearly twice as frequently as the heritage bilinguals in Sweden (row 4).
The correlations between the dependent variable cluster adoption rate and the three independent variables are presented in Table 3. We can see that the p-values for all variables were below the 5% level. We can also observe relatively high correlation values with all three independent variables in the first row.
Correlation values between the different variables among all bilinguals (one-tailed Spearman).

L2: second language.
In order to discern the impact of competence from that of non-competence-based factors, the bilingual speakers were divided into in two competence groups in Table 4 depending on whether they had a L2 cluster rate of 100% or lower.
Cluster adoption rates for two groups of bilingual speakers with varying cluster competence.
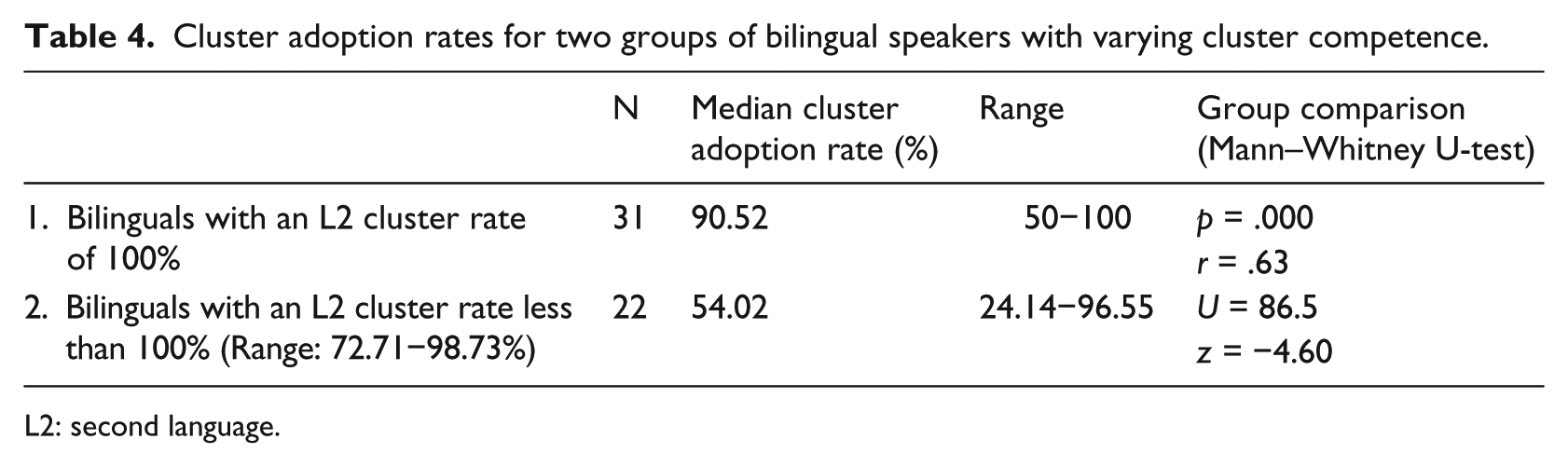
L2: second language.
As the Mann–Whitney U-test result in the last column of Table 4 shows, the bilingual group with a L2 cluster rate of 100% displayed significantly higher cluster adoption rates than the bilingual group with L2 cluster rates below 100%. In order to focus on the effect of cluster incentive alone, the 31 speakers with a L2 cluster rate of 100% were investigated further. In this group the attested variation in cluster adoption rates can be attributed entirely to differences in cluster incentive. The correlation between the dependent variable cluster adoption rate and the independent variables L1 use and relative proficiency in L2, which measure cluster incentive through L2 dominance, are presented in Table 5. The results show that there was a moderate negative correlation with L1 use and a strong positive correlation with relative L2 proficiency.
Correlation values between the different variables among bilinguals with a second-language (L2) cluster rate of 100% (one-tailed Spearman).

L1: first language; L2: second language.
The precise distributions of the correlations in Table 5 are presented in Figures 2 and 3, where the bilinguals in Turkey and Sweden are marked by different shapes and colours. The different strengths of the correlations are reflected in the scatter patterns in these figures. Dashed horizontal lines indicate the minimum level of L1 use and relative L2 proficiency, respectively, that were attested among the four full adopters, that is, speakers with a cluster adoption rate of 100%.
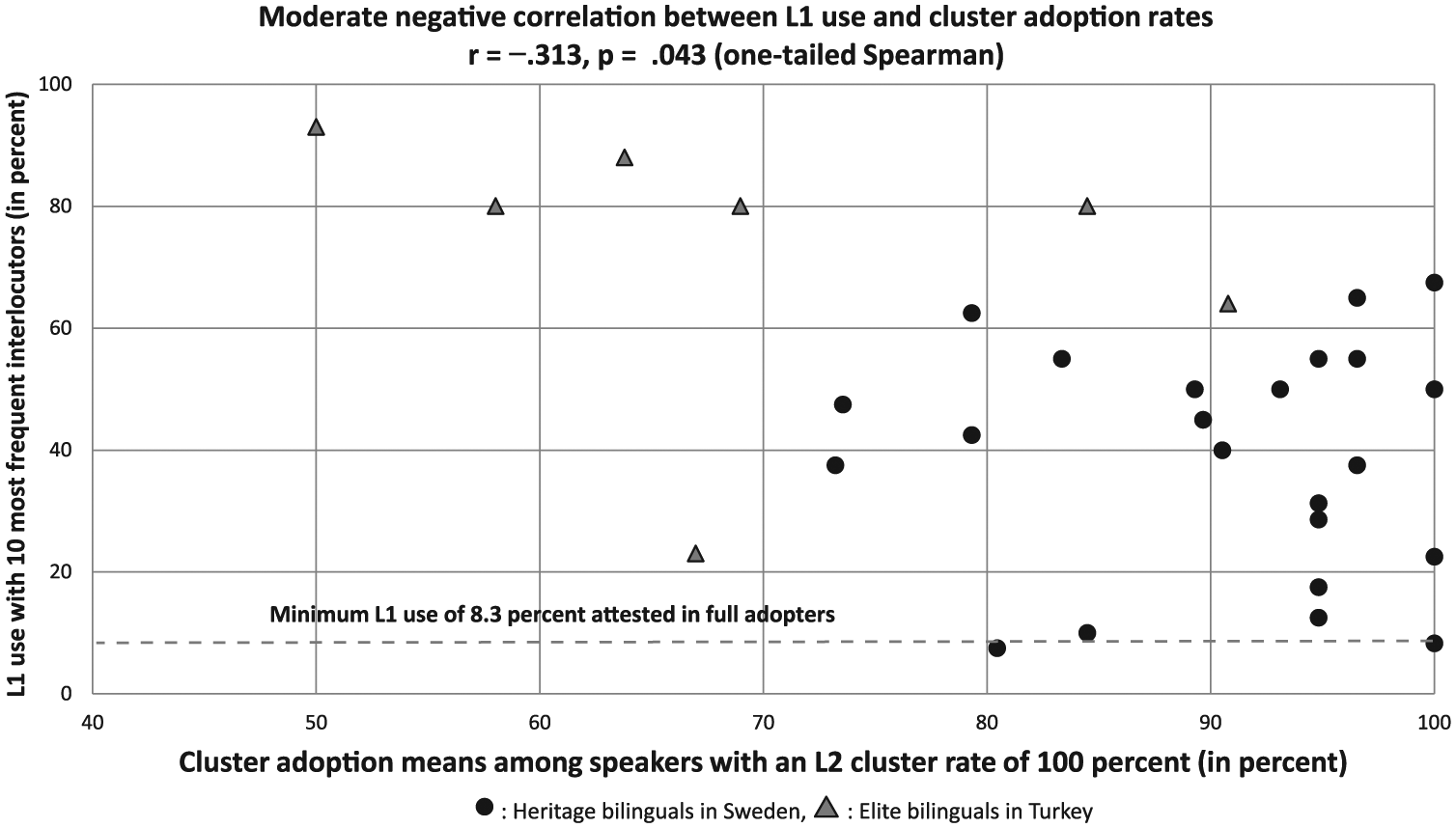
The correlation between first-language (L1) use and cluster adoption rate among bilinguals with a second-language (L2) cluster rate of 100%.
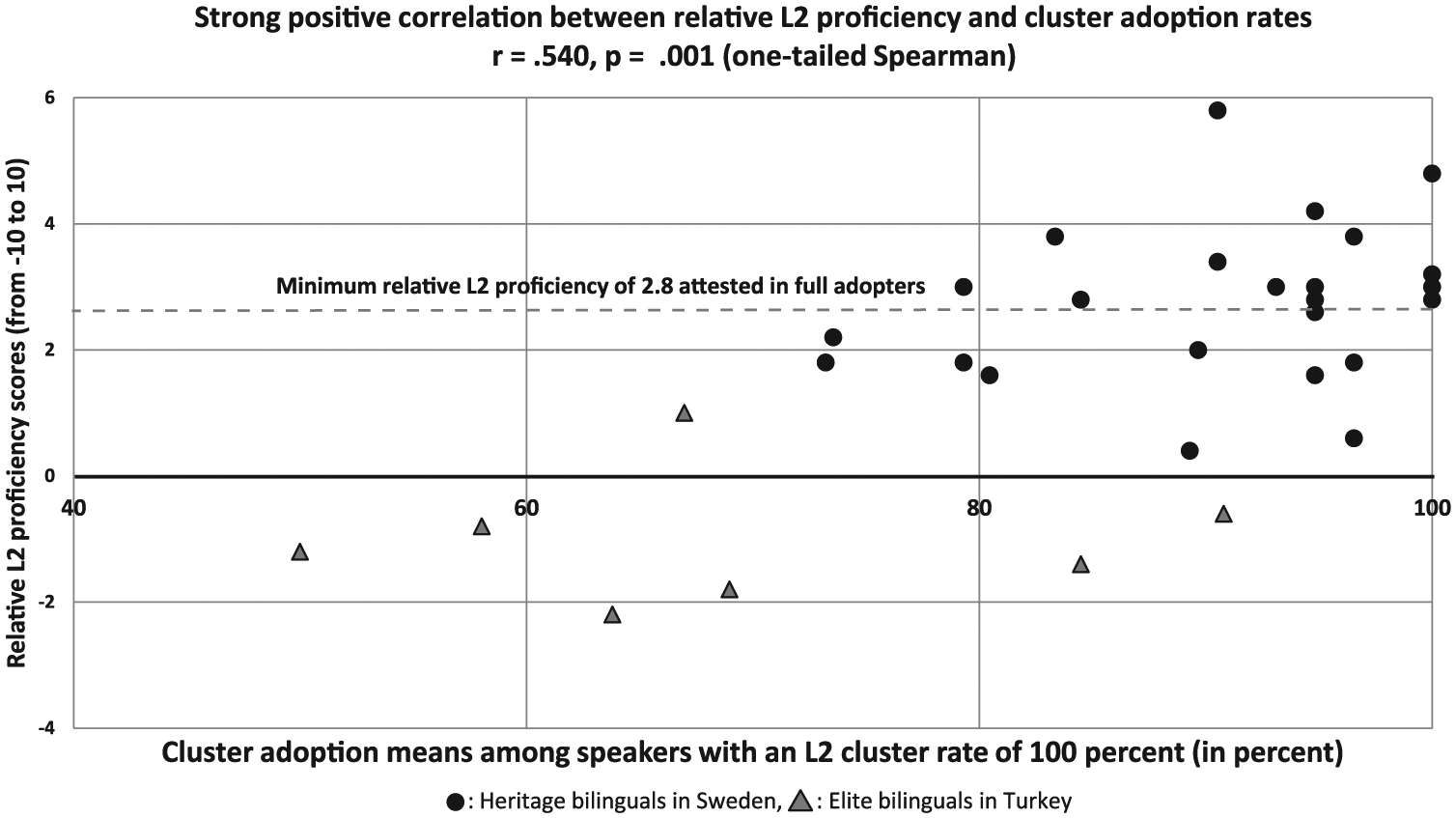
The correlation between relative second-language (L2) proficiency and cluster adoption rate among bilinguals with a L2 cluster rate of 100%.
Discussion
Cluster adoption rates in the two bilingual groups
As the first row of Table 2 illustrated, the heritage bilinguals in Sweden displayed significantly higher cluster adoption rates than the elite bilinguals in Turkey. The former group’s adoption median turned out to be 36.5 percentage points higher than the latter’s. This result confirms the main hypothesis of the paper and proves that the societal dominance status of the recipient language as a minority or majority language had a central impact on loanword borrowers’/users’ phonological integration patterns. This finding is completely in line with previous findings in the literature that were mentioned in the introduction. Furthermore, the ranges for the two groups revealed that the heritage bilinguals more uniformly preferred adoption while we found greater heterogeneity among the elite bilinguals in Turkey. This pattern suggests that the more societally dominant the cluster language was, the more monolithic its impact was on the individual bilingual speakers’ integration choice.
Explaining the differences between the groups
Where this paper goes further than previous studies is the explanatory mechanism containing competence- and incentive-related channels through which societal dominance exerts a crucial influence on the individual level and impacts the speakers’ adoption rates. This mechanism provided us with the background assumptions that the heritage bilingual group should display both greater linguistic competence (as measured through L2 cluster rates) and greater L2 dominance (as measured by relative L2 proficiency and L1 use). The fact that these assumptions were confirmed by the results in rows 2–4 of Table 2 proves that the current approach delivers greater explanatory depth and more solid quantitative proof compared to previous studies. Thus, we can not only confirm the main hypothesis but we can also explain why we can confirm it.
Although the group means for L2 cluster rates were very high in both groups, the heritage bilinguals still had significantly higher L2 cluster rates as the distribution in the former group was more homogeneous. The exact distributions in Figures 2 and 3 showed that those 31 speakers (out of 53) who displayed a L2 cluster rate of 100% were not exclusively but mainly in the bilingual group in Sweden. Twenty-five of the 29 bilinguals in Sweden had a L2 cluster rate of 100% as opposed to only six of the 24 bilinguals in Turkey. The statistical analyses in Table 4 confirmed that this difference in cluster competence was significant and that the median cluster adoption rate of the bilinguals with a L2 cluster rate of 100% was 36.5 percentage points higher. These results corroborate previous findings in the literature and provide the first detailed quantitative proof for the fact that linguistic competence plays an important role in loanword phonology. Moreover, the second row of Table 3 showed that there was a significant correlation between L2 cluster rates (i.e. cluster competence) and the two measures of individual dominance. By taking the SLA factors age of onset, degree of exposure and motivation into account, the present analysis emphasises the important competence-based link regarding language dominance between the societal and individual levels.
As hypothesised, the results point to a further link regarding the two measures of language dominance in individuals. The significantly different group medians in rows 3–4 of Table 2 regarding relative L2 proficiency and L1 use revealed an important divide between the elite bilinguals and the heritage bilinguals. As expected, the respective societally dominant language (i.e. majority language) in both countries turned out to be the language that both bilingual groups tended to report being more proficient in and to use more often. The bilinguals’ L1 Turkish was used nearly twice as often by the elite bilingual group in Turkey compared to the heritage bilingual group in Sweden. Further proof for this relationship was delivered by the strong correlations in Table 3 between these two variables and cluster adoption rates (negative for L1 use, positive for relative L2 proficiency) among all bilinguals. Table 5 and Figures 2 and 3 also illustrated that bilingual speakers did not necessarily need to be dominant in their L2 in absolute terms in order for language dominance to exert an impact on their cluster adoption rates. Even those speakers who were relatively less dominant in their L1 displayed greater adoption rates then the speakers who were more dominant in their L1.
Focusing on the results in Table 5 for the 31 bilinguals with a L2 cluster rate of 100%, and thereby cancelling out competence-based effects, enables us to discern that not only L1 use but also relative L2 proficiency went a long way in explaining the variation in cluster adoption rates. The moderate-to-strong correlations in Table 5 showed that the attested variation could be successfully accounted for by individual language dominance as measured by both variables. These results confirm the previously hypothesised incentive-related link between the societal and individual levels regarding language dominance.
Explaining adoption distribution patterns across all bilinguals
All three explanatory variables in Table 3 correlated strongly with cluster adoption rates among all 53 bilinguals, which showed that both competence and dominance variables had an important impact on cluster adoption rates. We found the strongest correlation with the variable relative L2 proficiency (r = .760). The distributions among the 31 bilinguals with a L2 cluster rate of 100% in Figures 2 and 3 illustrated where the four full adopters (i.e. those speakers with a cluster adoption rate of 100%) were situated in reference to other bilinguals, as indicated by the dashed horizontal lines. All four full adopters had a L2 cluster rate of 100%, suggesting that competence at the ceiling level is a necessary condition for full adoption. Since the full adopters in Figure 2 had a rather wide dispersion in their L1 use, with one individual having a very low degree of L1 use around 10%, this variable did not prove useful for discussing necessary and sufficient conditions for cluster adoption. In contrast, Figure 3 displayed a more concentrated distribution in relative L2 proficiency among the full adopters and therefore provided a much clearer picture. The four full adopters displayed a minimum relative L2 proficiency score of 2.8 out of 10, where the highest reported score was just under 6. This suggests that a L2 cluster rate of 100% and clearly higher proficiency in L2 than in L1 are necessary for full adoption. However, 11 speakers in Figure 3 fulfilled both necessary conditions without displaying full adoption. This means that these conditions were not sufficient for full adoption. Nonetheless, these conditions led to a minimum adoption rate of 79.31%, which can be viewed as guaranteeing high adoption rates.
Conclusion
By investigating the integration of word-initial onset clusters in established loanwords in Turkish by two different bilingual groups in Turkey and Sweden, this paper has demonstrated that language dominance is an important factor in loanword phonology. The main hypothesis that adoption is more likely when the recipient language is a minority language (as in Sweden) as opposed to when it is the societally dominant majority language (as in Turkey) was confirmed. The heritage bilinguals in Sweden, who had the cluster language Swedish as their L2, displayed a median cluster adoption rate that was 36.5 percentage points higher compared to that of the elite bilinguals in Turkey. This robust difference was statistically proven to be due to the heritage bilinguals’ higher linguistic competence and greater sociolinguistic incentive (as operationalised through two measures of individual dominance) to adopt clusters in loanwords. It was argued that the societal dominance of a cluster language impacted individual bilinguals’ cluster competence through the factors of motivation, exposure and age of onset in the acquisition of a cluster language. There was a strong positive correlation between relative L2 proficiency and cluster competence. Hence, societal dominance underpinned individual dominance (as measured by relative L2 proficiency), which in turn influenced the speakers’ competence to adopt clusters. By focusing on speakers with a L2 cluster rate of 100%, the paper has also shown that the impact of the two measures of individual dominance (i.e. relative L2 proficiency and L1 use) went beyond competence, as strong correlations between these two variables and cluster adoption rates could be observed among these bilinguals too. This suggests that individual dominance in a cluster language contributed greatly to the speakers’ sociolinguistic incentive to adopt. Thus, the societal dominance of the cluster language crucially influenced individual dominance, which, in turn, had a significant impact on both the competence and the incentive to adopt clusters in loanwords.
Footnotes
Appendix
Overview of the included loanwords with original word-initial onset clusters in Turkish.
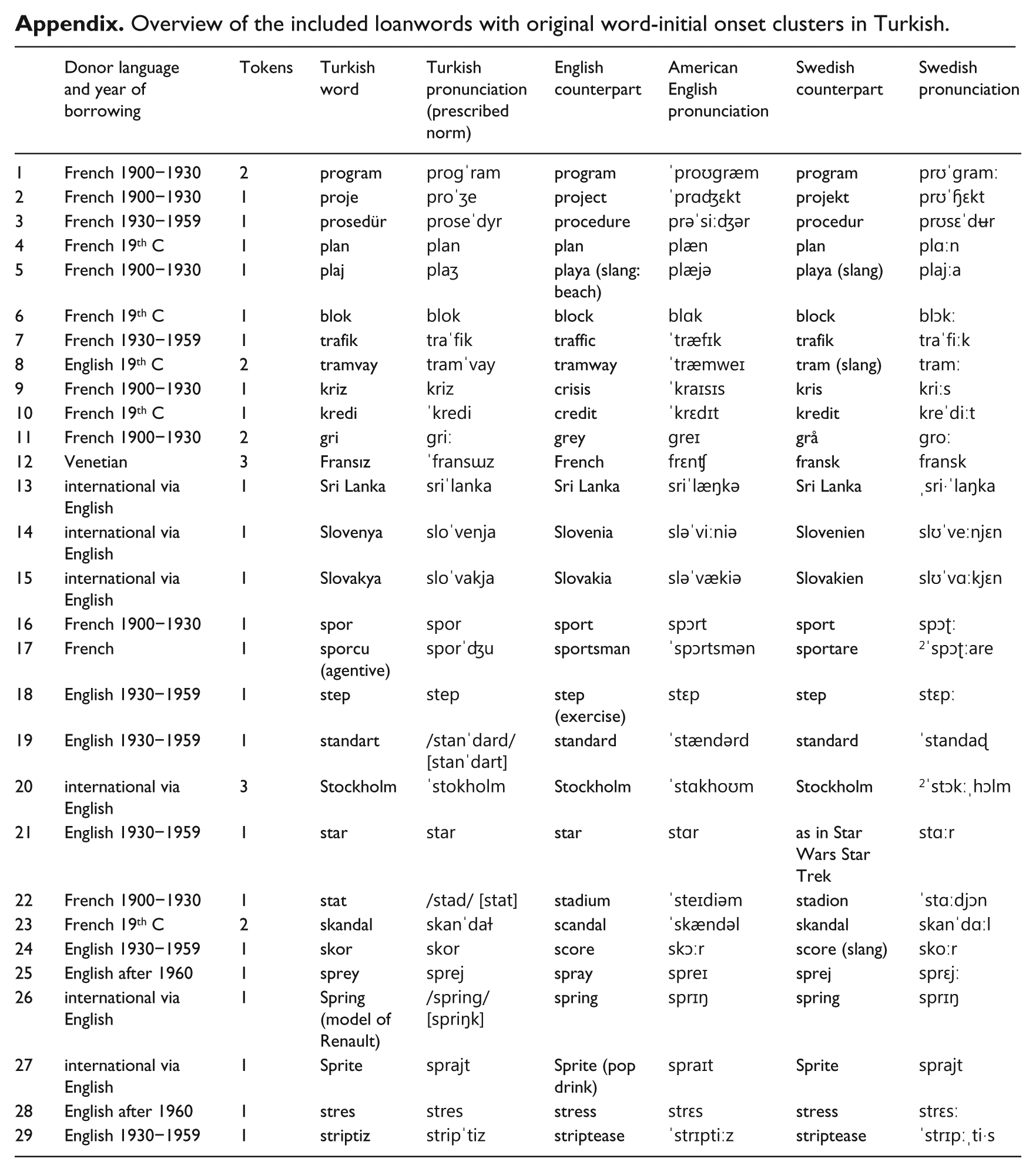
| Donor language and year of borrowing | Tokens | Turkish word | Turkish pronunciation (prescribed norm) | English counterpart | American English pronunciation | Swedish counterpart | Swedish pronunciation | |
|---|---|---|---|---|---|---|---|---|
| 1 | French 1900−1930 | 2 | program | proɡˈram | program | ˈproʊɡræm | program | prʊˈɡramː |
| 2 | French 1900−1930 | 1 | proje | proˈʒe | project | ˈprɑʤɛkt | projekt | prʊˈɧɛkt |
| 3 | French 1930−1959 | 1 | prosedür | proseˈdyr | procedure | prəˈsiːʤər | procedur | prʊsɛˈdʉr |
| 4 | French 19th C | 1 | plan | plan | plan | plæn | plan | plɑːn |
| 5 | French 1900−1930 | 1 | plaj | plaʒ | playa (slang: beach) | plæjə | playa (slang) | plajːa |
| 6 | French 19th C | 1 | blok | blok | block | blɑk | block | blɔkː |
| 7 | French 1930−1959 | 1 | trafik | traˈfik | traffic | ˈtræfɪk | trafik | traˈfiːk |
| 8 | English 19th C | 2 | tramvay | tramˈvay | tramway | ˈtræmweɪ | tram (slang) | tramː |
| 9 | French 1900−1930 | 1 | kriz | kriz | crisis | ˈkraɪsɪs | kris | kriːs |
| 10 | French 19th C | 1 | kredi | ˈkredi | credit | ˈkrɛdɪt | kredit | kreˈdiːt |
| 11 | French 1900−1930 | 2 | gri | ɡriː | grey | ɡreɪ | grå | ɡroː |
| 12 | Venetian | 3 | Fransız | ˈfransɯz | French | frɛnʧ | fransk | fransk |
| 13 | international via English | 1 | Sri Lanka | sriˈlanka | Sri Lanka | sriˈlæŋkə | Sri Lanka | ˌsriˑˈlaŋka |
| 14 | international via English | 1 | Slovenya | sloˈvenja | Slovenia | sləˈviːniə | Slovenien | slʊˈveːnjɛn |
| 15 | international via English | 1 | Slovakya | sloˈvakja | Slovakia | sləˈvækiə | Slovakien | slʊˈvɑːkjɛn |
| 16 | French 1900−1930 | 1 | spor | spor | sport | spɔrt | sport | spɔʈː |
| 17 | French | 1 | sporcu (agentive) | sporˈʤu | sportsman | ˈspɔrtsmən | sportare | 2ˈspɔʈːare |
| 18 | English 1930−1959 | 1 | step | step | step (exercise) | stɛp | step | stɛpː |
| 19 | English 1930−1959 | 1 | standart | /stanˈdard/ [stanˈdart] | standard | ˈstændərd | standard | ˈstandaɖ |
| 20 | international via English | 3 | Stockholm | ˈstokholm | Stockholm | ˈstɑkhoʊm | Stockholm | 2ˈstɔkːˌhɔlm |
| 21 | English 1930−1959 | 1 | star | star | star | stɑr | as in Star Wars Star Trek | stɑːr |
| 22 | French 1900−1930 | 1 | stat | /stad/ [stat] | stadium | ˈsteɪdiəm | stadion | ˈstɑːdjɔn |
| 23 | French 19th C | 2 | skandal | skanˈdaɫ | scandal | ˈskændəl | skandal | skanˈdɑːl |
| 24 | English 1930−1959 | 1 | skor | skor | score | skɔːr | score (slang) | skoːr |
| 25 | English after 1960 | 1 | sprey | sprej | spray | spreɪ | sprej | sprɛjː |
| 26 | international via English | 1 | Spring (model of Renault) | /spring/ [spriŋk] | spring | sprɪŋ | spring | sprɪŋ |
| 27 | international via English | 1 | Sprite | sprajt | Sprite (pop drink) | spraɪt | Sprite | sprajt |
| 28 | English after 1960 | 1 | stres | stres | stress | strɛs | stress | strɛsː |
| 29 | English 1930−1959 | 1 | striptiz | stripˈtiz | striptease | ˈstrɪptiːz | striptease | ˈstrɪpːˌtiˑs |
Acknowledgements
I am indebted to Maria Wingstedt and Hatice Zora for helping me with the linguistic analyses and to Guillermo Montero Melis for enlightening discussions on statistical issues. I would also like to thank Niclas Abrahamsson and Kari Fraurud for providing me with useful comments on earlier drafts and Ezra Alexander for help with my English.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was partly funded by a scholarship from the Swedish Research Institute in Istanbul.