
Abstract
Purpose:
This article proposes a new definition of cross-linguistic influence on anaphora resolution in situations of language contact appealing to the Position of Antecedent Strategy.
Design:
To this effect it examines existing evidence for and definitions of cross-linguistic influence across Spanish, Italian, Greek, and English, four languages research has concentrated on most intensively.
Data and analysis:
Methodological and theoretical issues are brought to the fore and the evidence of cross-linguistic influence re-evaluated in light of recent investigations of L1 processing of Spanish, Italian, and Greek anaphora.
Findings/conclusions:
The re-evaluation points to the conclusion that null pronouns are interpreted and processed in similar ways by native speakers, L2 speakers, and L1 attriters, even if speakers have contact with or are very proficient in languages such as English or Swedish where null anaphora is unavailable. Overt pronouns in Italian are more similar to Greek than Spanish and cross-linguistic influence affects only overt anaphora.
Originality:
If cross-linguistic influence is conceived in terms of the Position of Antecedent Strategy, then apparently contradictory cases such as the over-production of overt forms by Spanish speakers of Italian and the balanced co-reference of Spanish overt forms to topic and non-topic antecedents can be accounted for.
Significance/implications:
Cross-linguistic influence takes place from the language with less towards the language with more categorical biases. Recommendations for future research with the populations studied, data analysis and collection, and linguistic structures examined are made.
Background
Robust evidence exists that the null subject L1 of late bilinguals undergoing attrition to a non-null subject L2 and the null subject L1 of early bilinguals whose L2 is a non-null subject language are prone to ‘optionality’, especially in relation to anaphora resolution (for L1 attrition see Cardinaletti, 2005; Helland, 2004; Montrul, 2004; Tsimpli, Sorace, Heycock, & Filiaci, 2004; for various studies of bilingualism see Hacohen & Schaeffer, 2007; Müller, Cantone, Kupisch, & Schmitz, 2002; Müller, Kupisch, Schmitz, & Cantone, 2006; Paradis & Navarro, 2003; Pinto, 2004; Serratrice, Sorace, & Paoli, 2004). The term optionality in this context refers to the empirical observation that compared with native speakers, L1 attriters, early and late bilingual speakers have less categorical preferences for choice of antecedents to certain pronoun types (Sorace & Filiaci, 2006).
Considerable research on anaphoric dependencies in contexts of language contact 1 has devoted its attention to optionality. Most of this research widely exploits a fundamental distinction originally formulated for Italian by Carminati’s Position of Antecedent Strategy (PAS) (Carminati, 2002). The distinction regards the interpretive differences between null and overt pronouns in null subject languages, exemplified in (1):

‘The mother kisses her daughter, while she is wearing her coat.’

‘While she is wearing her coat, the mother kisses her daughter.’ (from Sorace & Filiaci, 2006, p. 352)
Carminati (2002) showed native Italians display the following processing biases. In forward (1a) and backward (1b) anaphora constructions, the null pronominal subject pro in the embedded clause has a strong structural bias for an antecedent in Spec IP, usually the matrix lexical subject and topic of the sentence, expressed by coindexation via the subscript i. In contrast, overt pronominal subjects such as lei ‘she’ have a weaker bias because in addition to co-reference with Spec IP antecedents, they refer to constituents in less prominent syntactic positions such as the object figlia ‘daughter’ or an extra-linguistic referent, coindexed via the subscript k and j respectively. The overt pronoun’s bias is weaker in that forcing co-reference of a null subject with non-subject antecedents incurs a greater processing cost than forcing co-reference of an overt subject to any of its possible antecedents.
Sorace and Filiaci (2006) found that while native and near-native Italian preferences for interpretation of null subjects are strikingly similar in both forward and backward anaphora, the two groups diverge when resolving overt forms. More specifically, even though both groups co-reference the embedded overt form to the matrix complement and the extra-linguistic referent, the near-natives also favour the matrix lexical subject (51%) and do so twice as much as the natives (23%). This divergence between natives and near-natives, which is remarkably attested in L1 attrition and early bilingualism (Sorace & Filiaci, 2006), has led to a flourishing of replication studies in both L2 comprehension and production (Belletti, Bennati, & Sorace, 2007; Ellert, 2013; Jegerski, VanPatten, & Keating, 2011; Lubbers-Quesada & Blackwell, 2009; Margaza & Bel, 2006; Mendes & Iribarren, 2007; Montrul, Dias, & Thomé-Williams, 2008; Roberts, Gullberg, & Indefrey, 2008; Rothman, 2009; Wilson, 2009, inter alia). Whilst various accounts have been debated to explain divergence, in one way or another, they all hinge upon the concept of cross-linguistic influence (CLI). Sorace and Filiaci (2006), for instance, maintain that near-natives are affected by a form of CLI denoted by differences between English and Italian pronominal inventories (p. 362). The role of CLI, however, remains poorly understood because the research from which it stems is problematic (see peer commentaries in the special issue in Linguistic Approaches to Bilingualism, 2012). Firstly, four definitions of CLI not fully compatible with each other have been proposed (Belletti et al., 2007; Kaltsa, Tsimpli, & Rothman, 2015; Sorace & Filiaci, 2006; Tsimpli et al., 2004). Secondly, none of these definitions can account for the full range of results on anaphora resolution available. Lastly, the research method from which the definitions stem does not effectively demonstrate the involvement of CLI.
The aim of this paper is to provide a more plausible account of CLI on anaphora resolution in situations of language contact that is compatible with the full range of relevant studies. It also argues that a plausible account need exploit the PAS as framework of choice to account for data across language combinations. I lend support to this new vision by considering various methodological and theoretical issues with studies from which CLI accounts stem. Subsequently, the findings of these studies are re-evaluated in the light of more recent L1 investigations. From the discussion, it will also emerge that overt pronouns in Italian are more similar to Greek than Spanish. The main contribution of this paper is, thus, both theoretical and methodological in nature.
The studies considered mostly involve contact between English, a non-null subject language, and three null subject languages, Italian, Spanish, and Greek, and were selected based on the following criteria: (1) studies of intra-sentential anaphora; (2) employ tasks compatible with the most widespread design of Sorace and Filiaci (2006); and (3) studies of late bilingualism. 2 Other variables such as age effects (Papadoupoulou, Peristeri, Plemmenou, Marinis, & Tsimpli, 2015), age of first exposure to L2 as in heritage speakers or child bilingualism (Hacohen & Schaeffer, 2007; Kaltsa et al., 2015; Keating, Van Patten, & Jegerski, 2011; Serratrice et al., 2004), quality of input (Sorace, Serratrice, Filiaci, & Baldo, 2009, among others) are set aside for reasons of space.
Cross-linguistic influence in studies of anaphora resolution
L2 Italian
Compatible results to Sorace and Filiaci (2006) were found in Belletti et al. (2007) who studied forward and backward anaphora preferences by native and near-native speakers of Italian. The expected divergence between the native and near-native speakers was found for both types of anaphora but was more pronounced in the backward condition. Belletti et al., unlike Sorace and Filiaci, did not consider the PAS when accounting for their results, concluding instead that optionality was due to overt forms not being co-referenced to a complement or external referent in the L1. This L1-laden explanation, however, must not be mistaken as coterminous to CLI. Kaltsa et al. (2015), for instance, have recently defined CLI as an effect from one language to the other that is specific to certain grammatical phenomena, restricted to only some domains of language, and one direction (i.e. from English to Italian but not the opposite) (see also Argyri & Sorace, 2007; Cuza, Pérez-Leroux, & Sánchez, 2013; Dopke, 1998; Müller & Hulk, 2001; Serratrice, Sorace, Filiaci, & Baldo, 2011; Tsimpli et al., 2004; Yip & Matthews, 2000). Belletti et al.’s (2007) L1-focused account differs from Kaltsa et al.’s (2015) CLI definition in that it emphasises difficulties in the co-existence of L1 and L2 interface constraints: when the L1 lacks an L2 constraint, the L2 is affected.
Belletti et al. (2007) beg the question: what exactly are the L1 constraints and how do near-native speakers of English process anaphora resolution in their native language? Furthermore, their account predicts language pairings such as Spanish to Italian or Greek to Italian should result in minimal optionality insofar as co-existence of L1 and L2 interface constraints is uncomplicated in these scenarios.
Such prediction is disconfirmed by a study where the L1 and L2 constraints were not believed to differ as much. In Bini (1993) the participants’ L1 was Spanish, a null subject language whose syntax-discourse constraints were believed to overlap considerably with Italian. 3 In spoken production, the L2 speakers of Bini (1993) were found to overextend overt pronouns to contexts of topic continuity where use of a null subject is more felicitous and preferred by native Italians. Thus, the L2 production of pronominal subjects by Spanish-Italian speakers mirrors the findings of the English-Italian comprehension data, despite the L1 and L2 being (apparently) very similar for the syntactic-pragmatic constraints involved. 4 In my analysis, I reveal how the contradictory results in Bini can be uniformly accounted for by CLI if framed in a slightly different manner.
L2 Spanish
Two studies conducted on another null subject L2, Spanish, have also looked at CLI as a putative account of divergence between native–non-natives, adopting a method comparable with the L2 Italian studies, Jegerski et al. (2011) and Keating et al. (2011). Keating et al. (2011) set out to establish whether native and advanced English-Spanish speakers both show the division of labour in antecedent assignment between Spanish null and overt pronouns predicted by Carminati’s PAS. The two groups were compared for choice of a matrix subject or complement as possible antecedents to null and overt pronouns in forward anaphora (2a, b). Their method differed from the L2 Italian studies in three ways. First, a forced-choice interpretation task was used instead of picture verification, which required participants choose between words rather than pictures. Second, choice was binary rather than ternary in that the extra-linguistic referent was not a possible choice (2a, b):

b. Quién corría en el parque? ‘who ran in the park?’ A. Alicia B. Elena
A final difference lies with only testing forward anaphora.
It was found that only the natives show a statistically significant preference for null over overt pronouns when co-referencing to the Spec IP antecedent. Moreover, compared with native Italians in the L2 Italian studies, the native Spanish fall short of displaying a clear division of labour between the two pronouns: overt forms are co-referenced to the matrix subject 54% of the time by the Spanish compared with only 20% by the Italians in Sorace and Filiaci (2006) and Belletti et al. (2007), who largely preferred the complement or external referent. Thus, while Italian null and overt pronouns have distinct biases for antecedents, in Spanish this is not the case. At first blush, then, the native Spanish speakers’ results suggest that the operation of the PAS may vary across the spectrum of null subject languages despite their typological closeness. I return to this important finding later when discussing work directly comparing the processing of anaphora in L1 Italian, Spanish, and Greek studies in Table 3. As for the advanced L2 speakers, they also fail to show the type of bias predicted by the PAS inasmuch as more than half the time both null and overt pronouns co-referred with a matrix subject. This absence of a clear bias in favour of a Spec IP antecedent for null and overt pronouns is even stronger than the one found for the natives. According to Keating et al. (2011) “null and overt subject pronouns are in a state of free variation when it comes to establishing (topic) continuity” (p. 215). Another possibility here, though, is that CLI on Spanish overt pronouns from English is at stake. If pragmatic constraints on anaphora resolution in English are balanced across the range of discourse functions (e.g. topic continuity, topic shift, emphasis), then all possible antecedents may have equal chances of being selected by Spanish overt pronouns.
The second L2 Spanish study, Jegerski et al. (2011), had precisely this goal: to ascertain whether CLI from L1 English was implicated in L2 Spanish interpretations. In a series of experiments, Jegerski et al. compared data on anaphora resolution in L1 English with the L1 and L2 Spanish data in Keating et al. (2011) by translating the Spanish stimuli into English and administering them to the L2 English-Spanish speakers in Keating et al. In order to detect CLI, Jegerski et al. first qualified the effects of principles of discourse structure on English anaphora resolution by resorting to Segmented Discourse Representation Theory (Asher, 1993; Asher & Vieu, 2005). This theory stipulates that the syntactic relationship of anaphora resolution in English depends foremost on the way pronouns and referents are linked in discourse. These can be parallel events (i.e. coordinate function) introduced by adverbials like while or events in a hierarchical relationship (i.e. subordination function) introduced by adverbials like before/after. Because discourse function has an effect on anaphora resolution, co-reference of the antecedent in Spec IP with the pronoun in the subordinate clause (only overt pronouns are licensed in English finite clauses) will be higher for stimuli where the function is coordinate than subordinate, due to topic continuity being more easily established (Jegerski et al., 2011, p. 489). Furthermore, if CLI from English affects Spanish anaphora resolution, it was predicted that:
the L1 English data would reflect the discourse function asymmetry presented above following Segmented Discourse Representation Theory; 5
the L1 English asymmetry need also reflect on the L2 Spanish data because the L2 strategy is L1 bound;
the L1 English asymmetry should not hold for the L1 Spanish group as Spanish is subject to the PAS.
The L1 English data elicited only from the intermediate L2 Spanish group yielded some evidence consistent with the first prediction: in English, selection of a Spec IP antecedent to the overt pronoun is higher when the two clauses are discourse-coordinated rather than subordinated (p. 490). Thus, prediction (1) was partially met. In turn, when resolving L2 Spanish anaphora, the same intermediate L2 group reflected the asymmetry displayed in their L1 English, consistent with prediction (2). Moreover, the L1 Spanish patterns for overt pronouns did not overlap with the asymmetry found for L1 English. Results for null Spanish anaphora in the L1 Spanish data were consistent with the PAS for Italian as Spec IP antecedents were significantly preferred to non-Spec IP and were unaffected by discourse function. Thus, the L1 Spanish results fulfilled prediction (3).
In contrast to the intermediate group, the advanced L2 Spanish group’s patterns in completing the L2 Spanish task were neither L1 English nor L2 Spanish-like. Overall, Keating et al. conclude their results show CLI from English to Spanish in both L2 groups and that activation of the PAS may differ between native Spanish and Italian. In the discussion, I return to a few important differences between this study and the other studies treated so far. Results from the L2 Italian and Spanish studies are summarised in Table 1.
Key findings related to CLI of L1 on L2 anaphora resolution.

Note. Top: topic; Comp: complement; AStatistically significant preference for a topic referent compared with natives; BNo statistically significant preference for a topic referent compared with natives; CSpec IP antecedents preferred if pronoun in coordinated while clause but only significant in by-item analysis.
L1 attrition of null subject languages
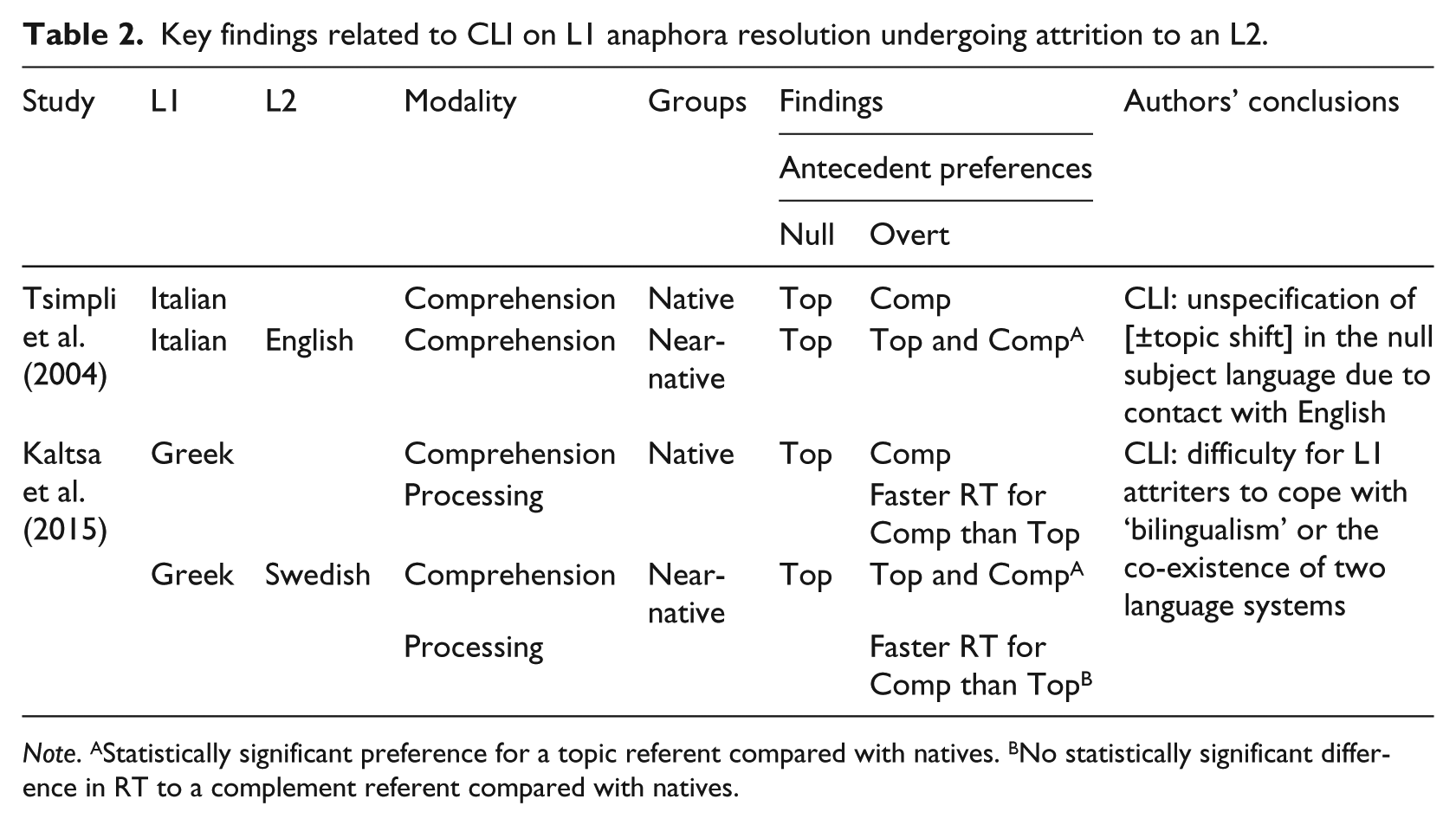
CLI is also a contested source of divergence in contexts of language attrition between L1 Italian, Greek, and Spanish and L2 English. Tsimpli et al. (2004) tested native and attrited Italian near-native speakers of English who came into contact with L2 later on in life on the production and interpretation of null and overt subjects in the L1. Their experiment was identical in all aspects to the L2 Italian studies, with the exception of a few items. Tsimpli et al.’s results show the attrited group preferred a subject antecedent to overt pronouns significantly more than the native speakers, consistent with the findings for the English near-native speakers of Italian in the L2 studies. Tsimpli et al. explain their attrited group’s preference as a form of CLI on a syntactic-discourse feature labelled [topic-shift]. While null and overt pronouns are specified as – and + [topic-shift] respectively in Italian, the authors claim in attrited grammars the feature has become unspecified due to contact with English where only the overt pronoun is allowed and the ± specification is irrelevant to pronouns. Without any L1 English data or L2 data from another L1 group, though, the CLI proposal by Tsimpli et al. is debatable. Furthermore, their position is at odds with Keating et al.’s processing-based proposal underpinned by Segmented Discourse Representation Theory and the PAS.
Another study of L1 attrition linked to CLI is Kaltsa et al. (2015). One goal of this study was to explore whether CLI from L2 Swedish affects overt pronoun anaphora resolution in L1 Greek by comparing attrited Greek speakers of Swedish and age-matched native speakers of Greek on an online self-paced listening experiment. The L1 attriters were born and raised in Greece and immigrated to Sweden during adulthood, when they began to learn Swedish either in naturalistic or instructed settings. The stimuli completed by participants were a Greek equivalent to the forward anaphora items used in Tsimpli et al. (2004). Methodologically, the traditional picture verification task of Sorace and Filiaci was conducted as an online task by asking participants to move through the stimuli by pressing a button whilst listening to each segment of the sentence. A sample stimulus is given in (4):
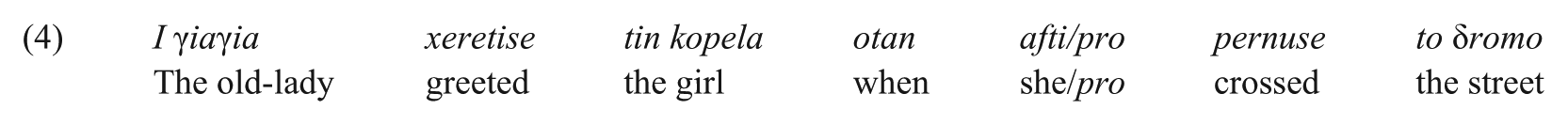
‘The old-lady greeted the girl when she crossed the street.’
At the beginning of each trial, participants were shown a picture representing either the subject γiaγia, complement tin kopela, or other referent to the pronoun afti. As soon as the picture was shown, participants started listening to each segment of the sentence in (4). At the press of a button each segment would be played so that when the end of the sentence was reached, participants had to decide whether or not a picture matched the sentence. Following the decision, they were presented, in consecutive manner, two other pictures depicting the remaining potential referents and asked again to make a decision. Thus, unlike Belletti et al. (2007), Sorace and Filiaci (2006), and Tsimpli et al. (2004), in this study the picture depicting each of the three referents was shown to participants one at a time. 6 Another difference to previous studies is the score assigned to the matching of a picture: if a participant decided the picture and referent matched they scored 100, otherwise a mismatch scored 0.
Given Swedish is a non-null subject language where overt forms can refer to antecedents expressing either topic continuity or topic shift, it was predicted that the L1 attriters would differ from the control group by virtue of displaying a less categorical preference for any of the possible antecedents in the interpretation of overt pronouns. Furthermore, the effect of CLI from Swedish to Greek was surmised to be noticeable in listening response times: Greek controls were expected to be faster than the Greek-Swedish attrited group in matching both overt forms to non-subject antecedents and null pronouns to subject antecedents.
Results show three distinct patterns. First, both groups unequivocally prefer co-reference of null rather than overt pronouns with matrix subjects. The groups also show a pattern of co-reference to the overt form that is very different from the null, in that overt forms are matched to a complement antecedent at a significantly higher rate than the subject and other referent. Next, a group effect was found inasmuch as the attrited group preferred associating overt pronouns to the matrix subject far more than controls. Lastly, response times show a processing advantage for the controls insofar as they respond faster than the experimental group to co-reference of an overt pronoun with non-subject antecedents and null pronouns with subject antecedents, consistent with Kaltsa et al.’s prediction of CLI. In light of this, the authors redefine CLI as a difficulty on the part of the L1 attriters to cope with ‘bilingualism’ or the co-existence of two language systems (p. 283). This definition, however, is not particularly informative with respect to other language pairings or defining the difficulty experienced by attriters, nor did the study test the constraints on anaphora resolution in Swedish supposed to influence Greek. Results from L1 attrition studies are summarised in Table 2.
Key findings related to CLI on L1 anaphora resolution undergoing attrition to an L2.
Note. AStatistically significant preference for a topic referent compared with natives. BNo statistically significant difference in RT to a complement referent compared with natives.
Overall, if framed in terms of the PAS, Kaltsa et al.’s results suggest the null subject property of Greek is preserved even under attrition, reflecting an uncompromised bias for Spec IP antecedents like Italian and Spanish. Conversely, overt anaphora resolution is more similar to Italian than Spanish; while Keating et al. (2014) found a weak bias for either subject or object antecedents to overt Spanish pronouns, native Italians and Greeks showed a similar stronger bias for co-reference to object antecedents. Crucially, this study thus suggests that not all null subject languages are alike in relation to the PAS and the interaction of syntax and discourse constraints.
L1 Greek, Spanish, and Italian
L1 studies of null subject languages have also yielded identifiable differences in anaphora resolution across Spanish, Italian, and Greek. These studies have important implications for the issue of CLI. Papadopoulou et al. (2015) examined anaphora resolution in a group of adult speakers of mainland Greek using the same method of Kaltsa et al. (2015) composed of offline and online components. The scoring method for match and mismatch responses in the offline component stipulated a 5 for a match and 1 for a mismatch. In the offline component, it was predicted that all participants would show fairly categorical co-reference of null pronouns to subject antecedents. For the online component, the matching decision times at the end of the sentence were predicted to be shorter for subject rather than non-subject antecedents. As for the overt pronouns, the authors expected a greater preference for matching to object rather than subject antecedents in the offline component, and shorter response times at the end of sentences when matching to object rather than subject antecedents in the online component.
Results of the offline component for null pronouns are strikingly similar to those from native groups of other Greek (Kaltsa et al., 2015; Mitsakaki, 2001), Italian (Belletti et al., 2007; Carminati, 2002; Filiaci, 2010; Sorace & Filiaci, 2006) and Spanish studies (Alonso-Ovalle, Clifton, Frazier, & Férnandez-Solera, 2002; Filiaci, 2010; Jegerski et al., 2011; Keating et al., 2011): null pronouns are preferably matched to the subject rather than complement and extra-linguistic referents to a significant degree. As for the online measure, statistically significant shorter response times were found when participants matched the null pronoun to subjects rather than objects. Together these results confirm the authors’ predictions for null anaphors. As for the overt pronouns, a significant preference for matching overt pronouns to complements over the other referents was found in the offline component, while in the online component, response times were significantly faster for matching to complements rather than the other referents, confirming the second set of predictions for overt anaphors.
The null anaphora results are fully consistent with those obtained for native Italian (Belletti et al., 2007; Sorace & Filiaci, 2006) and Spanish speakers (Keating et al., 2011; Jegerski et al., 2011). In contrast, findings for the overt pronouns are consistent with research on Greek (Dimitriadis, 1996; Kaltsa et al., 2015; Mitsakaki, 2001) and Italian (Belletti et al., 2007; Carminati, 2002; Filiaci, 2010; Sorace & Filiaci, 2006; Tsimpli et al., 2004) but not Spanish (Filiaci, 2010; Keating et al., 2011; Jegerski et al., 2011) where preferences for a subject versus non-subject antecedent are not statistically significant. Papadopoulou et al. (2015) explain these differences appealing to an account in Filiaci, Sorace, & Carreiras (2013, p. 5) based originally on Cardinaletti and Starke (1999). Two kinds of pronominals, weak and strong, are distinguished. Spanish overt pronouns like èl and ella are more like weak English overt pronouns he and she than strong Italian pronouns lui and lei. While weak pronouns co-refer to topics, the strong link to objects. The closest of kin to weak Spanish èl is Italian egli which can only be interpreted as co-referent to a prominent discourse antecedent. Papadopoulou et al. argue that the differences found between Greek and Spanish overt pronouns are due to the former resembling Italian strong pronouns. However, it may also be that task differences between the Greek and the Spanish studies in terms of the binary versus ternary choice can account for the discrepancy. Another possibility, non-mutually exclusive with the one based on Filiaci et al. (2013), is that Greek and Italian overt pronoun biases are stronger than Spanish, following the PAS as a framework for interpretation.
In general, results from all the studies so far suggest strong similarities for the interpretation and processing of null pronouns but subtle differences for the overt. If framed in terms of the PAS, the bias of null pronouns for topic antecedents is nearly identical, whereas the bias of overt forms for object antecedents is weaker in Spanish.
Filiaci et al. (2013) set out specifically to test differences in Spanish and Italian interpretation of anaphora resolution. To this effect, they investigated whether the PAS applied equally to these two languages. Italian sentences such as those in (5a) and (6a) were translated into Spanish (5b) and (6b):


Anaphora resolution in sentences (5) and (6) was disambiguated by verb-related semantics: in (5) only Giovanni/Bernardo can apologise, while in (6) only Franco/Carlos can be offended. Sentence (5) was predicted to yield higher error rates and a processing penalty for both Italian and Spanish speakers when presented in the Ø rather than the lui/èl condition since null pronouns are expected to co-refer to topics (subscript i) rather than non-topics (subscript j). The interpretation of (6) was not predicted to result in any processing penalties in the Ø condition for either group given null pronouns naturally refer to the referent already favoured by the semantics of the sentence. In turn, reading times with lui/èl were predicted to induce a penalty only for the Italian group, resulting in slower response times than in the Ø condition, given overt pronouns in Spanish can also refer to a topic (Cardinaletti & Starke, 1999). It should be noted that, compared with the studies discussed so far, the clauses in which anaphors are placed are reversed in Filiaci et al. (2013): anaphors were subject of the subordinate clause while potential antecedents were subject and object of the main clause.
Adult Spanish and Italian natives were tested via a self-paced reading task exploiting sentences like (5) and (6). The task mechanics were similar to those of Kaltsa et al. (2015) and Papadopoulou et al. (2015), except participants moved along the sentence by reading rather than listening. The results discussed here pertain to only one of two experiments conducted, in which sentences unfolded clause by clause rather than phrase by phrase. Participants made a matching decision at the end of sentences when they were presented with a comprehension question probing reference to either the subject or the object of the subordinate clause in (5) and (6). The questions, however, were asked only for half of the total number of test stimuli. For the purpose of comparison with Kaltsa et al. (2015) and Papadopoulou et al. (2015), I focus only on error rate and response times to the comprehension questions which were asked at the end of the sentence.
Results were congruent with the predictions. Errors for null subjects forced to co-refer to non-topics (example 5) are higher than topics (example 6) for both groups. In contrast, Italian speakers commit significantly more errors than the Spanish when the overt pronoun is forced to co-refer to a topic. In the online component, response times were slowest for both groups when the forced interpretations clash with the way null anaphors co-refer to antecedents following the PAS. However, while the Italian speakers also show slower responses when forced to co-refer an overt pronoun to a topic antecedent as expected by the PAS, the Spanish do not. 7 Moreover, the difference between Spanish response times for co-reference of overt pronouns with topic and non-topic antecedents is not statistically significant, suggesting lack of sensitivity to syntactic prominence. This ‘insensitivity’ of Spanish overt pronouns mirrors the results for the Spanish natives in the L2 Spanish studies where no significant differences in preference for a subject antecedent to an overt than null pronoun were found. On the whole, this is the most important result: while the Spanish speakers have higher error rates and slower response times when overt forms are co-referred to a non-topic, Italian speakers have higher errors and slower response times when they co-refer to a topic. Overall, these results suggest Spanish and Italian share the strong bias for null pronouns but differ for bias strength of overt pronouns. Results from the L1 studies are summarised in Table 3.
Key findings related to CLI in L1 anaphora resolution studies.

Note. Top: topic; Comp: complement; A Only significant in by-participant analysis. B Only significant in by-item analysis; SDRT: Segmented Discourse Representation Theory (Asher, 1993).
Discussion
The purpose of this article was to provide a more plausible account of CLI in the context of anaphora resolution in situations of language contact. To this effect, I set out to analyse a family of studies bound by the study of anaphora resolution, following the research methods of Sorace and Filiaci (2006), and focusing on CLI. The eight studies, which in fairly different ways attempt to capture CLI on anaphora resolution in L2 acquisition and L1 attrition, dealt with four languages, English, Spanish, Italian, and Greek. Four definitions of CLI (Belletti et al., 2007; Kaltsa et al., 2015; Sorace & Filiaci, 2006; Tsimpli et al., 2004) and several methodological and theoretical issues surfaced from the studies. Generally speaking, the evidence considered points to a conspicuous similarity between native speakers, advanced L2 speakers, and L1 attrited speakers in the domain of null pronoun interpretation across the null subject languages. Greek, for which native speakers were shown to have a processing advantage over attriters (Kaltsa et al., 2015), is the only language in which null anaphora resolution has been found to differ between the three populations. Whether native speakers have a similar advantage over attriters in processing Italian and Spanish null anaphors is open to future scrutiny.
As for overt pronoun anaphora, the analysis pointed out nuanced differences across the null subject languages using both processing and interpretation measures. In Italian, native speakers show a more categorical bias for co-reference of overt pronouns with either a complement or external referent, reflected in both online (Filiaci et al., 2013) and offline tasks (Belletti et al., 2007; Sorace & Filiaci, 2006). Processing tasks, in particular, elicit a strong processing penalty when overt pronouns are forced to maintain topic continuity (Filiaci et al., 2013). By contrast, overt pronouns in Spanish are wired to both topic and non-topic antecedents, as reflected by interpretation (Jegerski et al., 2011; Keating et al., 2011) and processing tasks (Filiaci et al., 2013) in which participants are forced to pick either a topic or non-topic antecedent. Although it would be tempting to assume Spanish anaphora resolution bears a resemblance to English, the two are not truly compatible because in English the coordinate versus subordinate discourse function introduced by adverbials such as while and after/before, respectively, was shown to influence the selection of a matrix subject (Jegerski et al., 2011). This implies subtle differences exist even between weak English and Spanish overt pronouns and predicts divergence between English near-native speakers of Spanish, L1 Spanish, and L1 English speakers under a hypothesis of CLI. This prediction, however, needs to be examined by requiring native and non-native participants to choose between all three possible referents because the studies considered in this paper alternated between binary and ternary choices. Finally, there is the case of Greek. Overt anaphora resolution is more similar to Italian than Spanish, as reflected by statistically significant referent effects in offline matching and online processing (Papadopoulou et al., 2015). The referent effect in Greek deviates strongly from the one found in Spanish (Jegerski et al., 2011). Future studies comparing native Greek and Italian anaphora resolution are likely to shed light on the striking similarities evinced for both null and overt anaphora resolution in these languages.
Cross-linguistic influence and the PAS
I propose the best way to define CLI is as an effect that takes place from the language with more relaxed biases for antecedents towards the language with more categorical ones, where biases are best intended as those regulated by the PAS in null subject languages or Segmented Discourse Representation Theory in non-null subject languages.
It is well known that overt pronouns are co-referenced to subject antecedents more so by English near-native speakers of Italian and L1 Italian speakers undergoing attrition to L2 English than native Italians. The design employed in the studies considered, however, does not allow one to reliably conclude that native/non-native divergence is linked to CLI from English to Italian. Unless the L2 Italian learners and an additional group of native English speakers are tested on L1 English anaphora resolution, a direct comparison of L1 and L2 anaphora resolution and an unambiguous identification of CLI are not possible. This was one problematic aspect of the four studies from which CLI accounts stemmed (Belletti et al., 2007; Kaltsa et al., 2015; Sorace & Filiaci, 2006; Tsimpli et al., 2004). For example, at the heart of Belletti et al.’s account of divergence is the L1 and its inability to accommodate the new syntax-discourse constraint of L2 overt pronouns. Such an account, which places the L1 at the core, is not coterminous with CLI in the traditional sense of L1 transfer, which focused on defining the L2 when transfer takes place. In turn, Jegerski et al. (2011) aptly showed English to have a bias for matrix subjects when the discourse relationship between the subject antecedent and the overt pronoun is of coordination as in Alicia herself met with Elena while she ran in the park this morning. Thus, the design by Jegerski et al. was equipped with better measures of CLI. Coincidentally, the stimuli used by Belletti et al. with their English near-native speakers of Italian also included the adverbial mentre ‘while’. If these stimuli were re-analysed, despite the unavailability of L1 English data in the study, it may be that the correct interpretation of the divergence for overt pronouns between groups in Belletti et al. (2007) and Sorace and Filiaci (2006) is also in harmony with the view of CLI that I advocate here in relation to the PAS.
Keating et al. have shown anaphora resolution in English and Spanish differ (2011, p. 214). By distinguishing the two frameworks active on the English and Spanish, they showed differences exist in the interpretation of anaphora, particularly with respect to overt pronouns. A study comparing English and Spanish near-native of speakers of Italian with native speakers predicts differences reflecting both groups to diverge from the natives and differ from each other. The L1 English are expected to yield a higher rate of co-reference between overt pronouns and matrix subjects than the L1 Spanish and Italian controls. In a parallel fashion, a study of attrition from L2 English is likely to yield higher rates of subject antecedents to overt pronouns in L1 Spanish than L1 Italian. Thus, the findings by Keating et al. are particularly useful to future research. In addition to including L1 English data, future studies of L2 acquisition and L1 attrition need consider that while coordination clauses are but one type of structure that can be used to distinguish influence from English.
I have also argued that defining CLI in terms of the PAS can account for another heavily contentious finding, namely that divergence also occurs in situations of language contact between two null subject languages. In spoken production, adult Spanish-Italian speakers (Bini, 1993) and simultaneous Spanish-Italian bilingual children (Filiaci et al., 2013) overextend use of Italian overt pronouns to topic continuity contexts at the demise of null forms. These findings were originally interpreted as evidence against CLI in that the pragmatic constraints on the processing of null and overt pronouns in Spanish and Italian were believed to be roughly identical (Margaza & Bel, 2006, p.90, and references cited in Filiaci 2010, p.171). In this sense, influence from Spanish to Italian was not expected to lead to divergence. Sorace et al. (2009) initially explained these cases as a default processing strategy, but this was later revisited in the light of Filiaci et al. (2013) where, instead, it was proposed that default processing and CLI conspire together to explain divergence (p. 17). My analysis of data obtained offline for L1 Italian, Spanish, and Greek, in turn, has underscored that the differences between Spanish and Italian overt anaphora resolution are more conspicuous than Italian and Greek. Online tasks, likewise, have suggested the Italian and Greek overt pronouns are processed slower than the Spanish when co-referential to the constituent in Spec IP rather than the complement. In this respect, my analysis has capitalised on the importance of the PAS as a framework for research on anaphora resolution and as a tool resonating CLI.
In relation to future L2 acquisition and L1 attrition experiments, the definition of CLI I have provided in terms of the PAS makes falsifiable predictions. For L2 acquisition, it predicts greater divergence for overt anaphora resolution between native Italians and Spanish-Italian speakers than Greek-Italian speakers. For L1 attrition, it predicts greater divergence between native Italians and Italian-Spanish than Italian-Greek attriters. These predictions are expected under the assumption that CLI takes place from the language with less categorical biases, Spanish, to ones with more, namely Italian and Greek, and not vice versa. These predictions are limited to the null subject languages and English which were considered in this article. Studies of the interpretation and processing of other null subject languages are called for to extend the plausibility of the CLI account proposed (see Bel & García-Alcaraz, 2015).
Methodological issues
From the analysis, methodological issues related to three broad areas emerged: sampling, data collection and analysis, and the linguistic structures investigated. Starting with population, I suggest that future research of anaphora resolution in L2 acquisition and L1 attrition considers testing a minimum of two L1 groups, namely one ‘experimental’ L1 in which biases on anaphora differ from the L2 and one ‘control’ L1 in which biases are more similar. Alternatively, studies could employ a control group tested in the L1 for L2 acquisition, and a group tested in the L2 for L1 attrition. To clarify, in Kaltsa et al.’s (2015) study of L2 Swedish to L1 Greek attrition, the authors predicted weaker biases in the interpretation of Greek overt pronouns on the understanding that CLI from Swedish would occur. Without knowledge of the processing preferences in Swedish, though, reliable conclusions for CLI cannot be drawn. Another confound is the effect of other L2s intervening on L3 acquisition or L1 attrition. This problem, common to L2 and L1 attrition studies involving lesser-studied languages, regards the possibility knowledge of English, or other languages participants had knowledge of, may have confounded results. In Kaltsa et al. (2015), for instance, the authors did not mention whether the Greek-Swedish participants had any significant knowledge of English.
Turning to data collection and analysis, the studies considered utilised offline tasks such as picture verification or forced-choice elicitation and online tests such as self-paced listening or reading. Although the former have been used more widely, online tasks have complemented offline tasks well by eliciting physiological responses aimed at measuring processing at various critical regions of the anaphora construction. Related to the online measures, the analyses presented in this paper are limited to the types of response times considered. Future investigations may opt to focus on the interpretation of response time data at the other critical areas of the anaphora construction, which may lead to conclusions different to those observed here. As for the offline measures, it is unclear what effects, if any, the presentation of potential referents via pictures (e.g. Tsimpli et al., 2004) or words (Keating et al., 2011) has. Likewise, the effects of presentation of two (Filiaci et al., 2013) versus three referents (e.g. Sorace & Filiaci, 2006) and simultaneous (Belletti et al., 2007) versus consecutive pictures (Papadopoulou et al., 2015) are yet to be addressed. From a language-testing perspective, dichotomous items are highly undesirable for testing comprehension as they function much like true or false questions where participants have a 50% possibility of guessing based on chance (Alderson, Clapham, & Wall 2005, p. 51; Carr, 2014, p. 30). In other words, the rate of selection for one or the other referent with dichotomous items is likely to be unduly inflated. Furthermore, there is the issue of tallying error rates (Filiaci et al., 2013) versus matching preferences (Belletti et al., 2007; Sorace & Filiaci, 2006, inter alia). Even where two studies code the same response type, there is still potential for a scoring problem. In Kaltsa et al. (2015), for instance, ‘match’ responses scored 100 while ‘mismatch’ scored 0, whereas in Papadopoulou et al. (2015) matches were coded with a 5 while mismatches were 0s, despite both studies looking at the same response type. Assignment of scores is arbitrary in some cases and clarification in this area is needed because different scoring methods will likely lead to different data distribution.
Another area of data analysis worthy of mention is the way responses to comprehension questions are handled statistically. Nearly all of the studies modelled the distribution of their responses to linear regression, using ANOVA and MANOVA tests, transforming responses from a categorical variable into a scale percent variable. An exception is Filiaci et al. (2013) who modelled their responses to logistic regression, analysing their outcome as a categorical correct or incorrect variable. Tallying responses in this way, in addition to being more appropriate to the nature of the stimuli (Baayen, 2008; Jaeger, 2008, p. 434), offers considerable statistical advantages over percentage and count data which tend to violate several assumptions of normality and parametric tests, especially in experiments of the social sciences (Jaeger, 2008; Osborne, 2002). Mixed-effect modelling of data fit to logistic regression is nowadays considered the approach par excellence in linguistic research (Baayen, Davidson, & Bates, 2008; Quene & van de Bergh, 2008).
One final area with implications for research methodology is the type of linguistic structures examined. In spite of the studies by Sorace and Filiaci (2006), Belletti et al. (2007), and Tsimpli et al. (2004) reporting that native/near-native divergence for overt anaphora resolution is more statistically conspicuous in backward anaphora, subsequent studies switched to testing forward anaphora. Although my analysis has considered both directions of anaphora, future speculation on the interpretation on anaphoric dependencies should pay greater attention to this issue. In addition to anaphora direction, there is a difference in the clause type the overt or null pronoun have figured in. Filiaci et al. (2013) considered constructions in which the linear order of the anaphor and its antecedents was reversed compared with the other studies: the anaphor in the main clause preceded the antecedents located in the subordinate while or before/after clause. Discussions of the effects of anaphors interacting with clause type have not been sufficiently handled in the literature and thus remain welcome in the future.
Conclusion
The aim of this article was to inform research on two specific aspects of L2 acquisition and L1 attrition studies of anaphora resolution in English, Spanish, Italian, and Greek that have not hitherto received adequate attention: CLI and the role of the PAS. In particular, on the basis of recent L1 studies conducted on Italian, Spanish, and Greek, I argued that a re-analysis of the findings in contexts of language contact help us better define CLI now than before. The definition of CLI proposed has the potential of accounting for optionality and divergence phenomena in future studies as long as it is framed by the PAS. Furthermore, a correct characterisation of CLI in anaphora resolution requires that future studies profile anaphora resolution in the L1 − in the case of L2 acquisition − or the L2, in the case of L1 attrition. I have shown that framing what evidence of CLI is available in light of more recent investigations of L1 anaphora resolution and the PAS also reveals that the syntactic dependencies of overt Greek pronouns are more similar to Italian than Spanish while processing of null anaphora is strikingly similar across the three null subject languages.
Footnotes
Acknowledgements
I would like to thank the editor of The International Journal of Bilingualism, Prof. Li Wei, and one reviewer for their indefaticable work on and dedication to the manuscript. There are a number of scholars that I would also like to acknowledge for suggestions received along the way, including but not limited to Roger Hawkins, Antonella Sorace, Tihana Kras, and Teresa Parodi. Helpful comments were also received from members of the audience at the Eleventh Cambridge-Essex Workshop on Language Acquisition (LALA XI). My profound gratitude also goes out to Alessandro Romano and Charles Napier for the time and effort they put in to polishing up the article. Any errors are mine.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by funding from the Ministero Affari Esteri for research on Italian Language and Culture.