
Abstract
Aims and Objectives:
This study investigates the effects of code-switching on vowel quality, pitch and duration among English–French bilinguals. Code-switching has been claimed to influence the morphology, syntax and lexicon, but not the phonology of the switched language. However, studies on voice-onset time have found subtle phonetic effects of code-switching, even though there are no categorical phonological effects. We investigate this further through the following three questions: (1) Are F1 and F2 influenced in the process of code-switching? (2) Are code-switched words hyper-articulated? (3) Does code-switching have an effect on vowel duration before voiced and voiceless consonants?
Methodology:
To address our research questions we relied on an insertional switching method where words from one language were inserted into carrier phrases of the other to simulate English–French code-switching environments. Bilingual speakers were recorded while they read code-switched sentences as well as sentences that did not involve code-switching, that is, monolingual sentences.
Data and Analysis:
The vowels of target words in the recorded utterances were compared – code-switched contexts against monolingual contexts – for vocalic duration, F0, F1 and F2.
Findings/Conclusions:
Like previous voice-onset time studies, our results indicate that code-switching does not shift the phonology to that of the embedded language. We did, however, find subtle lower level phonetic effects, especially in the French target words; we also found evidence of hyper-articulation in code-switched words. At the prosodic level, target switch-words approached the prosodic contours of the carrier phrases they are embedded in.
Originality:
The approach taken in this study is novel for its investigation of vowel properties instead of voice-onset time.
Significance:
This new approach to investigating code-switching adds to our understanding of how code-switching affects pronunciation.
Introduction
Bilingual speakers frequently and effortlessly switch between languages. These switches can take place within a sentence (1–3) and even within a word (4):
I want more korv.
‘I want more sausage.’ (English-Swedish)
Local authority donc ni nkaaa…
‘Local authority, well it’s like…’ (English–French-Kinyarwanda, Gafarnaga, 2000)
Ni nei-pian article hai mei finish a?
‘You haven’t finished that article yet?’ (Mandarin–English, Wei, 2009)
naan pooyi paaDuven Hindi song ei
I go.inf sing.1sg.fut Hindi song acc
‘I will go and sing a Hindi song’ (Tamil–English, Sankoff, Poplack, Swathi, 1990)
This use of two or more languages in the same discourse is called code-switching. 1 The present paper investigates the effects of code-switching on the production of vowels in French–English bilingual speakers.
While languages may influence each other’s morphology and syntax in code-switching contexts, results on phonological and phonetic influence have been more contradictory. Most previous studies have focused on the perception of voice-onset time (VOT) by bilingual speakers of languages that differ in how VOT is used in phonological categorization. Some early studies found that bilingual speakers have merged perceptual boundaries across languages (Caramazza, Yeni-Komshian, Zurif, Carboner, 1973), and subsequent studies have demonstrated at least some cross-language influence on perceptual boundaries (see, e.g., Elman, Diehl, Buchwald, 1977; Grosjean, 2013; Hazan & Boulakia, 1993, and the work cited in Bullock & Toribio, 2009a). A related set of issues is found in loan phonology. Boersma and Hamman (2009) argue that loan adaptation takes place through first language (L1) perception, but there is some evidence of cross-language influence in perception for proficient second language (L2) speakers. In a recent study, Kang and Schertz (2016) demonstrate that perceptual boundaries in a L2 are influenced by L2 boundaries for speakers who are proficient but not fully bilingual.
In summary, while the evidence of cross-language influence in phonetics is there, it is less clear than in morphosyntax, leading Bullock (2009, p. 171) to suggest that ‘it is unlikely that the base language functions as the phonetic equivalent of the morpho-syntactic matrix language.’
In production, the evidence, to the extent it is available, shows that cross-language influence generally does not take place (Bullock, 2009; Bullock & Toribio, 2009b; Caramazza et al., 1973; Grosjean & Miller, 1994, p. 171). A general difficulty with research on production, however, is that it is hard to distinguish between code-switching and ‘nonce borrowing’: any result that shows an apparent strong cross-language influence may be classified as a case of borrowing rather than code-switching (see discussion in e.g. Poplack, 2012; Stammers & Deuchar, 2012).
Despite the uncertain nature of some of the results, what appears to be a robust generalization is that while cross-language influence may take place at the phonetic level, for example, shifting the precise location of the phonological boundary on the VOT dimension, the phonological categories themselves remain intact under code-switching (Balukas & Koops, 2015; Bullock, 2009; Bullock & Toribio, 2009b; Olson, 2013; Piccini & Arvaniti, 2015). 2 Phonology is not borrowed across languages in the same way as morphosyntax (with the same caveat that cases of true phonological borrowing or adaptation are classifiable as lexical borrowing rather than code-switching). The literature seems to converge on the observation that for bilinguals, switching between phonological systems, especially in production, appears to be in some way ‘easier’ than switching between morphological and syntactic grammars. This point is important for the linguistic and psycholinguistic understanding of bilingualism and of language more generally. For example, this phonological immunity to code-switching lends support for a modular view of language, according to which different parts of the grammar, such as phonology and syntax, are at least partly independent from each other.
We present the results of a new experimental study of the phonetics and phonology of code-switching. The experiment follows the insertional switching design, where a word from one language is contained within a sentence that otherwise is made up of another language (see, e.g., Grosjean & Miller, 1994; Olson, 2012). We will refer to the language of the inserted word as the embedded language and the context language as the matrix language (Myers-Scotton, 1993).
This study moves away from VOT and broadens the empirical domain to vowel quality, pitch and duration. Since vowels in general display great variability across speakers, dialects and time (McAuliffe & Babel, 2011; Yallop, 2007), it seems likely that they might vary under code-switching. We specifically investigate the following questions:
Do the F1 and F2 values stay the same when words are embedded in another language?
Do vowels of code-switched words show signs of hyper-articulation, such as increased pitch and duration?
Does the difference in vowel duration before voiced and voiceless consonants remain the same in code-switching?
The first research question is the closest to questions that have previously been asked with regards to VOT, except that we focus on vowels. As mentioned above, researchers have found that consonants in code-switched words generally remain intact; they do not change categorically into similar consonants of the matrix language. However, vowels might differ from consonants in this respect. We set out to test whether the phonology of the matrix language influences the vowels of the embedded language. For example, when an English word like bit is uttered in a French context, does the vowel change into the French vowel of a word like vite? If no such categorical shift occurs, does the vowel nevertheless undergo a smaller, phonetic shift? Based on the previous VOT findings, such phonetic shifts might occur, and they may be either toward or away from the matrix language (Bullock, 2009). A shift toward the matrix language could be analyzed as direct linguistic influence. Bullock, Toribio, Davis, and Botero (2006) found that bilingual Spanish-dominant speakers of Spanish and English shifted toward Spanish VOT in their English code-switches, but the Spanish VOT did not shift toward English. This subtle, non-categorical effect was asymmetrical in the sense that it affected English only, and not Spanish. Shifts away from the matrix language have been viewed as a consequence of efforts to keep the languages distinct; see the discussion in Bullock and Toribio (2009b).
The second research question concerns hyper-articulation. Olson (2012) finds in a study of English-Spanish bilinguals that code-switched words have increased pitch and duration, which is interpreted as hyper-articulation. We will examine if the code-switched words in our French–English study also show signs of hyper-articulation.
The third research question concerns the effect of consonants on preceding vowels. Vowels are shorter before voiceless than voiced consonants (House & Fairbanks, 1953; Peterson & Lehiste, 1960, among others). This generalization holds cross-linguistically, but to different extents in different languages. For example, the effect has been reported to be generally stronger in English than in French, even though vowels in French are also shorter before voiceless consonants (Chen, 1970; Mack, 1982). We are interested in whether the difference in duration is the same in switched words as in non-switched words.
Methods
We recorded 12 speakers (seven female) bilingual in French and English (Canadian French and Canadian English). 3 The study only included speakers who were self-reported bilinguals, had native (or at least native-like) fluency in both languages and were exposed to both languages from early childhood (exposure to both languages before the age of 7). We nevertheless classified the speakers as French-dominant, English-dominant or completely balanced bilinguals based on a simple language-background questionnaire. 4 Three speakers were classified as completely balanced bilinguals, five speakers had English as a dominant language and four speakers had French as a dominant language. They were all university-age students, and they participated in the study without compensation. The participants were guaranteed anonymity.
Each experimental session took about 20 minutes, including an introduction and review of the procedure, recording and debriefing. Each session started with the participant filling out the brief language-background questionnaire and signing a consent form.
Our study was designed to create a ‘French context’ and an ‘English context’. The recordings consisted of six parts as follows: (1) The speaker read a short passage in French from a computer screen. (2) The speaker read 20 randomized French words in French carrier phrases that were presented one at a time. (3) The speaker read 20 French and 20 English words mixed in random order, all in French carrier phrases. Parts 4–6 were identical to 1–3 except English was used as the matrix language. The carrier phrases were He said X to me and Say X to me! in English, and Il dit X à moi and Dis X à lui! in French. Thus, there were four possible combinations of language and context: English in English (ENinEN, a monolingual context), English in French (ENinFR, a switched context), French in French (FRinFR, a monolingual context) and French in English (FRinEN, a switched context). Half of the speakers performed the French-dominant part first, while the other half performed the English-dominant part first. The passages that the participants read at the beginning of each part are included in Appendix 2. Note that vowels from the reading passages (Appendix 2) were not examined; only the words produced in carrier phrases were examined. The reading passages were included to create a stronger sense of French and English contexts, respectively.
The stimuli consisted of minimal pairs of monosyllabic words where the difference was the voicing of the final consonant. The stimuli were 10 lexical items in French and 10 lexical items in English. The vowels that the lexical items represent only cover part of the vowel inventories of the respective languages, as we wished to limit the scope of our study. The vowel selection was partly dictated by the availability of clear minimal pairs, and also by the fact that we wanted to include both vowels that are similar in English and French (e.g.
The recordings were made with a Tascam solid-state recorder and the target words were segmented by hand in PRAAT (Boersma & Weenink, 2016). The duration of each vowel was extracted along with the F0, F1 and F2 of the midpoint of the vowel, using a PRAAT script made publicly available by Mietta Lennes.
The statistical analyses were performed using SPSS software. To prepare the data for analysis, we aggregated the data as follows. For each participant, we (1) collapsed across multiple repetitions of each target word in the same context by obtaining the average value for each dependent variable for that word; (2) collapsed across multiple repetitions of each vowel by obtaining the average value for each dependent variable for that vowel; (3) used the data from Step 2 to further collapse across the various vowels on a per participant basis. These steps were done in order to prepare the data for within-subject analysis, by following the assumptions required by that analysis (e.g. a single data point per dependent variable and participant, see the discussion in Winter, 2011).
Results
To analyze the impact of code-switching on the dependent variables of interest (F1, F2, duration, F0), our primary analysis involved a repeated-measures analysis of variance (ANOVA) with two within-subject factors: language (English, French) and context (monolingual, switched); a separate ANOVA was conducted for each dependent variable. Below, unless otherwise indicated, only significant results are reported.
F1 and F2
The pattern of results for F1 and F2 are displayed in Figure 1. The main effect of language was significant for both dependent variables (F1: F(1,11) = 162.0 p < .001; F2: F(1,11) = 53.3, p < .001), with the English language exhibiting higher F1 and F2 values than French, respectively. This result is expected, as the French and English data involved inherently different vowels. For F1 only, the main effect of context was also significant, F(1,11) = 8.82, p = .013. To further explore the impact of context within each language, we then conducted a simple effects analysis, where we checked for an effect of context within each language separately. Both for F1 and F2, none of the simple effects were significant, although for F1, we found a trend for French (p = .06).
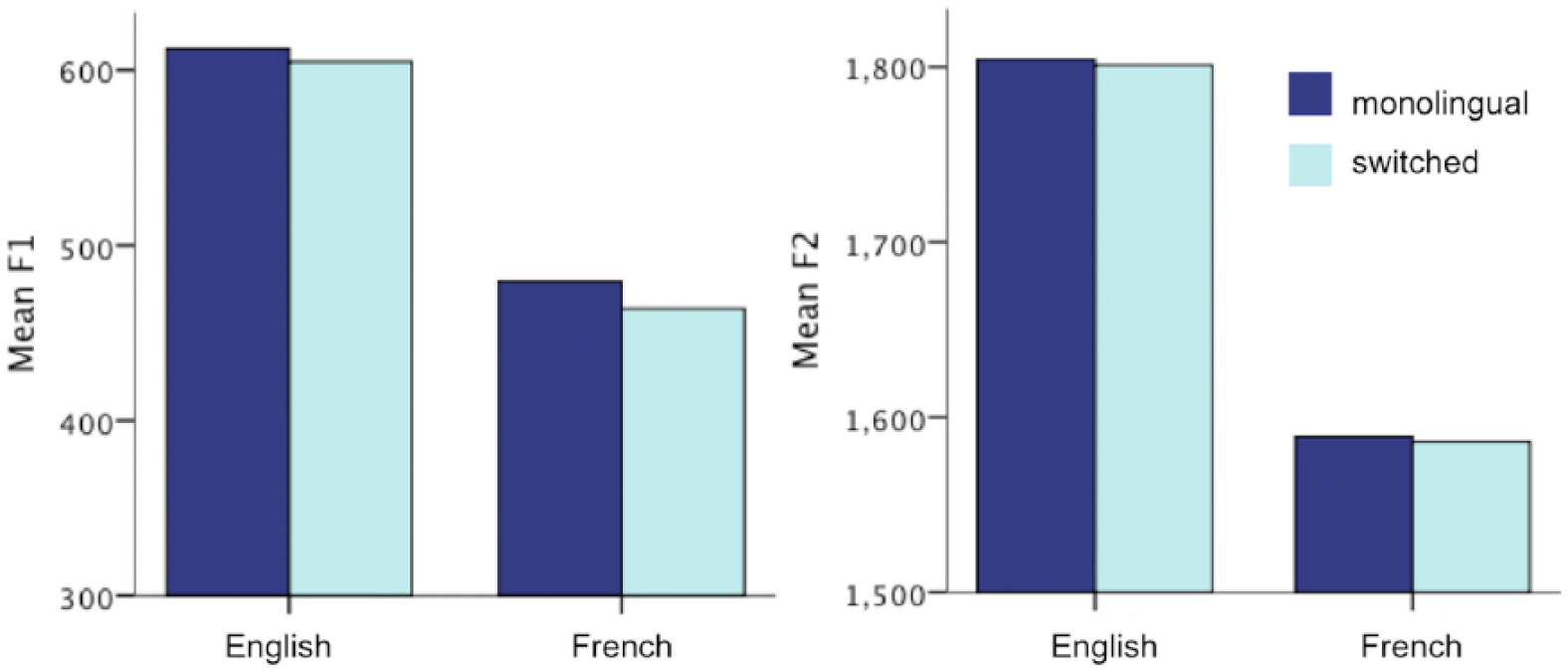
Mean vowel F1 and F2 in monolingual and switched contexts for English and French.
The above analysis focused on the overall effects on F1 and F2 collapsing across vowels, but vowels may have inherently different characteristics. Thus, collapsing across vowels has the potential to obscure results, for instance if some vowels displayed a lower F1 in a code-switched context than a monolingual context, but other vowels showed the opposite pattern (a higher F1 in a code-switched context than in a monolingual context). Such interactions could also occur for F2. We therefore tested for interactions between vowel (e.g.
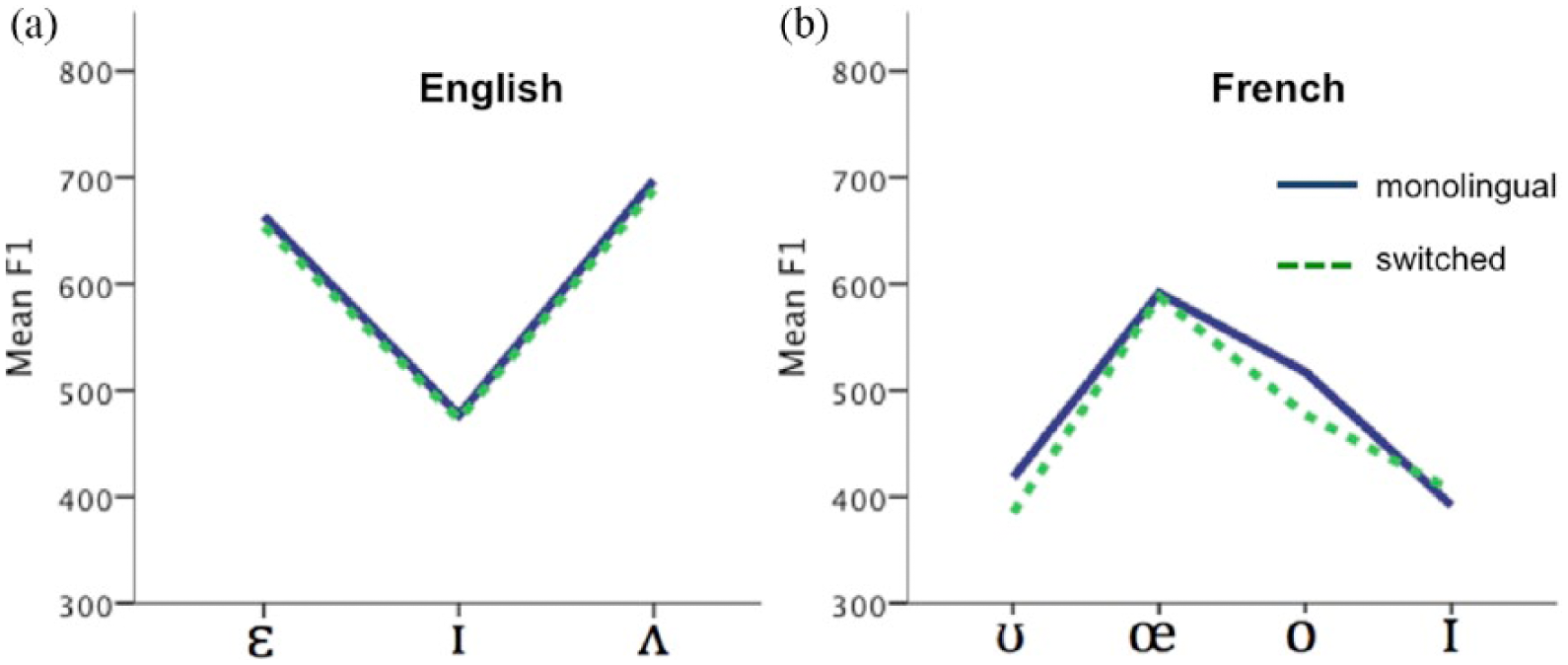
Mean vowel F1 for English (a) and French (b) in monolingual and switched contexts for each vowel.
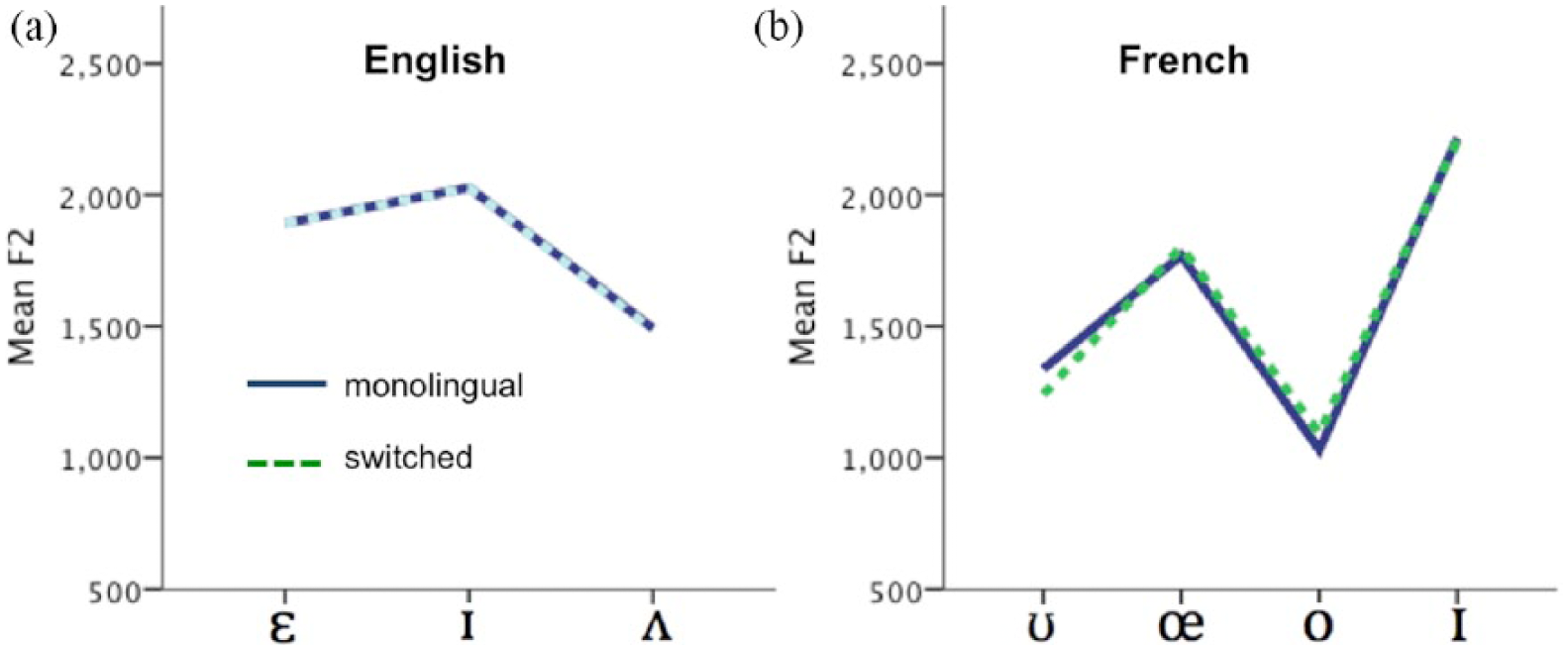
Mean vowel F2 for English (a) and French (b) in monolingual and switched contexts for each vowel.
Pitch and duration
Our analysis indicates that the code-switched vowels did show a change in duration and pitch (Figure 4). The duration of vowels in code-switched words was longer than vowels produced in a monolingual context (F(1,11) = 18.3, p = .001). This could be interpreted as a sign of hyper-articulation.

Mean vowel duration (a) and vowel F0 (b) in the monolingual and switched contexts for English and French.
The impact of code-switching on pitch (as measured by fundamental frequency, F0) was more complex, as the ANOVA indicated a significant interaction between language and context F(1,11) = 14.6, p = .003. Thus, the code-switched context did not have the same effect on pitch in French and English. Specifically, the difference in pitch between a monolingual and switched context was greater in French than in English. As evident from Figure 4, English vowels had higher pitch in a code-switched context than in a monolingual context, whereas the opposite was true for French (i.e. vowels had lower pitch in a code-switched context). The main effect of language was also significant (F(1,11) = 5.3, p = .042), with higher average F0 values in the French vowels.
Vowels before voiced and voiceless consonants
To investigate the effect of coda consonant voicing on vowel duration, we added a third within-subject factor to the ANOVA model, namely voicing (voiced, voiceless). We will refer to the duration of vowels before voiced consonants as voiced dur and to the duration of vowels before voiceless consonants as voiceless dur . Since interactions are of primary interest, we begin with results pertaining to them.
The interaction between voicing and context (monolingual or switched) was significant (F(1,11) = 6.1, p = .031). As shown in Figure 5, the difference between voiced dur and voiceless dur in a mixed context was larger than in a monolingual context. While the absolute difference in duration differs between monolingual and switched contexts, the difference taken as a ratio, while in the same direction, does not reach significance. Specifically, the ratio of voiceless dur over voiced dur was 69.6% in a monolingual context versus 66.3% in a code-switched context (the data points were aggregated by speaker); t(11) = 1.4, p = .19 (n.s.). In other words, it may be the case that the greater increase in absolute duration before voiced consonants in the switched versus monolingual context is an artifact of a general increase in duration in the switched context, but the proportional differences between durations in voiced and voiceless contexts remain stable across conditions. This agrees with the results of, for example, Smiljanic and Bradlow (2008), who find stable proportional differences across a range of conditions.

Mean vowel duration before voiced and voiceless consonants in each context.
There was no significant interaction between voicing and language. In other words, we did not find evidence in our data indicating that the difference between voiced and voiceless duration was significantly greater in one language (e.g. English) than the other. The ratios for French were 73% in monolingual contexts and 70% in switched contexts, and the ratios for English were 72% in monolingual contexts and 69% in switched contexts.
For the sake of completeness, we now report the significant main effects. As reported in the previous section, the main effect of context continued to be significant, with longer vowels occurring in a mixed context as compared to a monolingual context (F (1,11) = 17.2, p = .002). The main effect of voicing was also significant (F(1,11) = 208.0, p < .001), indicating that collapsed across context and language, voiced dur was greater than voiceless dur . In other words, vowels before voiced consonants were longer than vowels before voiceless consonants (see Figure 6, which shows details of voiced dur and voiceless dur for each language and context).

Mean vowel duration before voiced (a) and voiceless (b) consonants in each context and language.
Discussion
Vowel quality
The main question that motivated this study was whether code-switching affects vowel quality. Previous studies indicate that code-switching does not drastically affect VOT: the stop consonants of an embedded language do not take on the characteristics of consonants in the matrix language. The results of our study indicate that vowels are similar to consonants in this respect: the F1 and F2 of the vowels we examined did not shift significantly under code-switching.
The fact that speakers did not categorically shift their vowels in code-switching is thus consistent with previous studies showing that code-switching does not correlate with categorical shifts in VOT. However, Bullock and Toribio (2009b) argue that code-switching can induce smaller phonetic reflexes in bilingual production, although the effects are not phonological nor uniform across speakers. A look at the data from individual participants in our study does reveal variation along the lines suggested by Bullock and Toribio, and we agree with their conclusion that further study of this diversity is likely to yield interesting results. Like Bullock and Toribio, we noted that some individual speakers seemed to modify their pronunciation in code-switched contexts, but the speakers who did so did not follow any discernible uniform pattern. Our sample size was too small for it to be meaningful to analyze the speakers according to their language background (French-dominant or English-dominant), especially since all speakers were self-reported bilinguals. However, it is worth noting that there was no obvious difference between the subgroups as classified according to the language-background questionnaire.
There is one noticeable trend in our F1/F2 results: the French vowels seem to be more affected by code-switching than the English vowels. Recall that there was an overall effect of code-switching for F1, but when the languages were analyzed separately, the effect was not significant in English, and only marginally noticeable in French (p = .06). The difference between English and French can be seen in Figures 7 and 8, which plot the overall average F1 and F2 values for each vowel included in the study in monolingual and switched contexts. There is no discernible difference between code-switched and monolingual English vowels, but the French vowels seem to shift slightly.
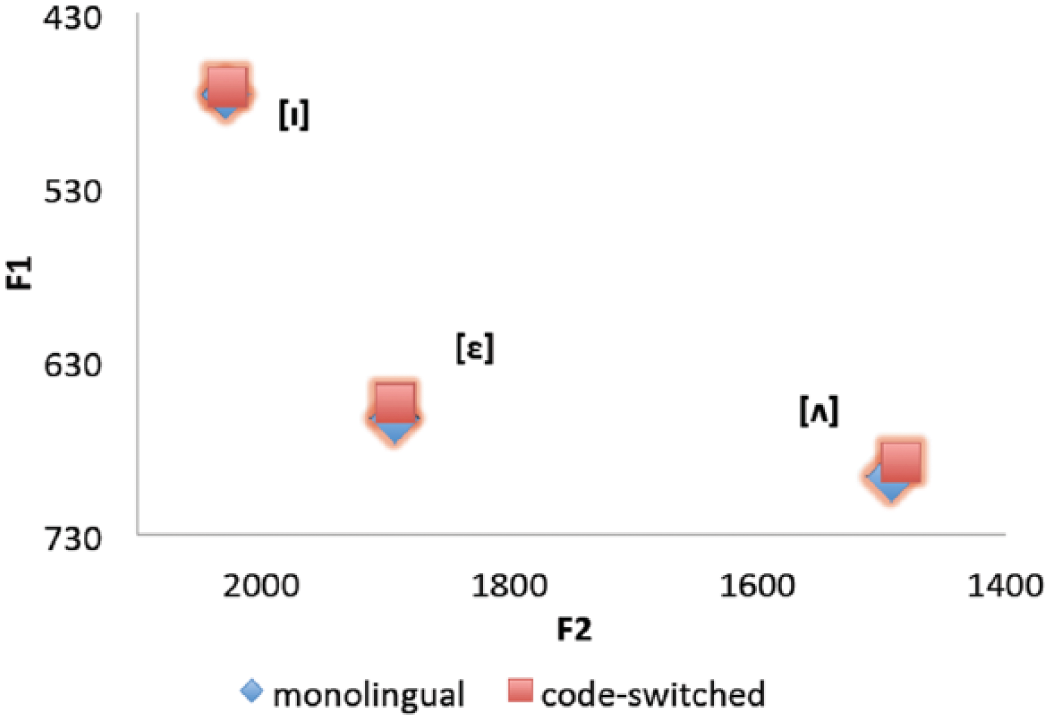
The average F1 and F2 values of the English vowels included in this study.

The average F1 and F2 values of the French vowels included in this study.
Figures 7 and 8 suggest that the French vowel quality is less stable under code-switching than the English vowel quality for our speakers, even though there is no significant shift in either language. Let us consider specifically the

The
Duration and pitch
In the study presented by Olson (2012), English-Spanish bilinguals pronounce code-switched words with increased pitch and duration. Olson (2012) interprets this as hyper-articulation of code-switched words. We similarly examined whether our data displayed evidence for hyper-articulation of code-switched words.
In both English and French, stress is typically (although not always) signalled by increases in duration, intensity and pitch (Davenport & Hannahs, 2010; Ladefoged, 2006; Walker, 1984). Given the nature of the carrier phrases, all target words were stressed, so the question is whether the shifts in pitch and duration signal extra emphasis (assumed to be a signal of hyper-articulation) in code-switching. The French and English words in our data had increased duration in code-switching contexts, and this lengthening of vowels suggests hyper-articulation (following Olson, 2012).
Code-switching also affected pitch. However, the generalizations concerning pitch were somewhat different from Olson’s Spanish–English findings. Olson (2012) found that code-switched words in both languages had higher pitch. In our study, code-switching affected English and French differently (cf. Figure 4). The interaction was significant, and the pitch of code-switched vowels approached the pitch of the other language: English words in a French context have higher pitch than they would in an English context, approaching the pitch a French word has in a French context. Similarly, French words in an English context approached the pitch of English words in an English context. In other words, the embedded words seem to take on the intonational pattern of the matrix language (the language of the carrier phrase). This is not surprising; it seems intuitively plausible that the matrix language should to some extent dictate the intonation contour of the entire sentence, and this includes the pitch of the embedded word. Recall, however, that we only measure the midpoint of the vowel of the embedded word. In future studies, we plan to examine the intonational contour of the entire phrase.
Vowel duration before voiced and voiceless consonants
As expected, the vowels in our study were longer before voiced consonants than before voiceless consonants. This was true both in monolingual and in code-switched contexts. We also found that this duration difference was greater in code-switched contexts than in monolingual contexts. We hypothesize that this may be another effect of hyper-articulation: the distinction between voiced and voiceless codas is exaggerated when the embedded language differs from the embedded language.
We did not find a large difference between French and English in the voiceless
dur
:voiced
dur
ratios, contrary to findings from some previous studies. For example, Chen (1970) reports an overall voiceless
dur
:voiced
dur
ratio of 61% for English and 87% for French. Recall from the Vowels before voiced and voiceless consonants section that the ratios in our data were 72% (monolingual) and 69% (code-switched) for English and 73% (monolingual) and 70% (code-switched) for French. There are several possible reasons for the difference between our results and Chen’s results. It could be a matter of dialectal variation: our participants were all speakers of Canadian French. Another potentially important factor is that all our speakers were bilingual. In a study of vowel duration before voiced and voiceless consonants in English and French, Mack (1982) found that the bilingual French–English speakers in her study had overall different voiceless
dur
:voiced
dur
ratios compared with the monolingual speakers. Finally, Laeufer (1992) argues that French and English are in fact not radically different with respect to the effects of voicing on vowels duration. She presents data showing that the languages show similar variation determined by linguistic and extralinguistic factors. For example, specific speech sounds display and influence duration differently. This is evident in our data as well. Recall that the words included in our study were bit, bid, bet, bed, hiss, whizz, fuss, fuzz, vite, vide, coute, coude, neuf, neuve, sauf, sauve, so the final consonants include both stops and fricatives. To illustrate the variation in the data, we give the voiceless
dur
:voiced
dur
ratios per vowels here. For English, the ratios were 76%, 68% and 66% for the
Smiljanic and Bradlow (2008) have found that under conditions of ‘clear speech’, a mode of speech that typically displays hyper-articulation, the proportional distance between the long and short vowel category remains stable compared to the non-hyper-articulated condition. Our findings are similar: there was an overall absolute durational increase in the switched context, with stable ratios across conditions. These findings support the notion that the code-switching context induces conditions similar to ‘clear speech’, including hyper-articulation.
Conclusion
The goal of this study was to add to what we know about the phonetics of code-switching. We specifically aimed to expand the empirical domain of this research area to the quality, duration and pitch of vowels. The results of our study are consistent with previous findings that code-switching does not influence phonology. Specifically, the matrix language does not influence the vowel height and backness (as measured by F1 and F2) of the vowels of the embedded words. In other words, the vowel quality seems to remain intact under code-switching: the vowels do not move into the vowel space of the vowels of the matrix language. This is comparable to the results of previous VOT studies that have shown that VOT does not shift categorically under code-switching. However, the descriptive data and trending in the statistical analyses indicate that the French vowels were somewhat affected by code-switching, but this is a low-level phonetic effect, and not a phonological effect. The vowels move slightly, but there is no evidence that they fully take on the characteristics of the vowels of the matrix language. All the participants in our study were early bilinguals and fully competent speakers in both languages, but they are also all students at an English-speaking university and the recordings were done in an English-language setting. We hypothesize that this ‘English-dominant’ setting might be responsible for the asymmetry between French and English evident in the results. These observations can be compared to the results reported by Bullock et al. (2006). Their study concerned VOT, and they also found subtle phonetic effects in one language (Spanish, the dominant language) but not the other (English). Balukas and Koops (2015); Bullock (2009), Bullock and Toribio (2009b) and Piccini and Arvaniti (2015) provide further discussion of the phonetic effects of code-switching on VOT. The data in those studies come from both spontaneous code-switching and experimental studies.
We found some evidence of hyper-articulation of code-switched vowels: vowels were overall longer in code-switched contexts, and the difference in duration between voiced dur and voiceless dur was slightly exaggerated in code-switched contexts. We suggest that this hyper-articulation can be interpreted in two different ways. The language shift might add complexity to the production of the utterance and the speech is therefore slightly slowed down. Alternatively, the speakers are perhaps accommodating (unconsciously) for their listener, recognizing that language mixing in an utterance adds to the processing load.
Finally, we found that the pitch (as measured by F0) of a code-switched word approached the pitch of a non-switched word of the other language. For example, the pitch of an English word in a French carrier sentence falls between the pitch of a French word in a French carrier sentence and the pitch of an English word in an English carrier sentence. In our interpretation, this is because the matrix language to a large extent dictates the pitch contour.
We end this paper with a couple of remarks on the limitations of this study. Firstly, our speakers were self-reported bilinguals, but ‘bilingual’ can mean a variety of things, and it would take in-depth testing to classify the speakers as balanced bilingual, or bilingual with one dominant language. Our brief language-background questionnaire is not enough to settle this question, and the study only included speakers who appear to have native-like fluency in both languages. Secondly, while a controlled experimental study like this one is convenient in that data from it can be straightforwardly analyzed quantitatively, it is unclear how well it represents spontaneous code-switching in naturalistic settings.
Footnotes
Appendix 1: Language-background questionnaire
Appendix 2: Goldilocks in English and French
Il était une fois trois ours: un papa ours, une maman ours et un bébé ours. Ils habitaient tous ensemble dans une maison jaune au milieu d’une grande forêt. Un jour, Maman Ours prépara une grande marmite de porridge délicieux et fumant pour le petit déjeuner. Il était trop chaud pour pouvoir être mangé, alors les ours décidèrent d’aller se promener en attendant que le porridge refroidisse. Près de la forêt vivait une petite fille appelée Boucles d’or. Boucles d’or n’était pas une petite fille très sage. Ce matin-là, elle jouait dans la forêt et jetait des pierres aux écureuils lorsqu’elle sentit le délicieux porridge que Maman Ours avait préparé. Elle frappa à la porte de la maison. Elle jeta un coup d’oeil par la fenêtre. Elle vit trois bols de porridge sur la table de la cuisine, mais il ne semblait y avoir personne dans la maison. Alors Boucles d’or entra dans la maison.
Once upon a time there were three bears: A father bear, a mother bear and a little bear. They lived all together in a yellow house in the middle of a big forest. One day, Mother Bear prepared a big pot of delicious hot porridge for breakfast. It was too hot to eat, so the bears decided to go for a walk while waiting for the porridge to cool. Near the forest lived a little girl named Goldilocks. Goldilocks was not a well-behaved little girl. That morning she was playing in the forest, throwing stones at squirrels, when she smelled the smell of the delicious porridge that Mother Bear had made. ‘Oh, I’m so hungry!’ thought Goldilocks. ‘I wonder if they will share their porridge with me?’ She knocked on the door of the house. She peeked in the window. She saw three bowls of porridge on the kitchen table – but it seemed that nobody was home. So Goldilocks entered the house.
Acknowledgements
We thank Marilou Guillemette and Eric Iacono for early contributions to this project. We are also thankful for valuable feedback from Raj Singh and other members of the LLI Lab at Carleton, as well as audiences at the CUNY Phonology Forum and the Institute of Cognitive Science Annual Spring Conference at Carleton University.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.