
Abstract
Aims and objectives/purpose/research questions:
Bilingual lexical processing is non-selective, which allows for activation of the non-target language, even when reading in a different script. However, while the influence of cross-script L1 lexical knowledge has been demonstrated in isolated word reading, it is unknown whether it survives in more natural reading tasks. We investigated whether crosslinguistic facilitation due to phonological similarity, semantic similarity, and L1 cognate frequency, is observed when different-script bilinguals read cognate words in their L2 in sentence context and in isolation.
Design/methodology/approach:
Two tasks were conducted with the same Japanese-English bilinguals and target items: A self-paced English reading task with non-highlighted target items embedded in sentence context; and an English lexical decision task. A monolingual control group also completed both tasks.
Data and analysis:
108 cognate items were embedded in sentence context and read by 23 Japanese-English bilinguals and 23 English monolinguals for meaning comprehension. The same items were then responded to by the same participants in lexical decision. Linear mixed-effects models were used to investigate the impact of continuous measures of L1–L2 phonological and semantic similarity, L1 cognate frequency, and L2 proficiency, while controlling for L2 lexical characteristics.
Findings/conclusions:
Cross-linguistic phonological and semantic similarity, as well as cognate frequency, partially determined reading times of words in both tasks but only in bilingual, not monolingual, reading. These effects were modulated by task, revealing reduced cross-linguistic facilitation in sentence reading relative to lexical decision.
Originality:
This is the first study to investigate different-script cognate processing in sentence context and compare it with isolated word reading.
Significance/implications:
Although bilinguals do not switch off their L1 during L2 reading, the type of task partially determines how cross-linguistic effects impact reading times. The degree of overlap of Japanese-English cognates is less influential in natural reading tasks compared with isolated word reading tasks.
Keywords
Introduction
Cross-linguistic influence from the first language (L1) while reading in a second language (L2) is a well-attested phenomenon. At the lexical level, words that share form and meaning across languages, such as cognates and loanwords, provide a benefit in processing referred to in psycholinguistics as the cognate facilitation effect. Bilinguals process such words more quickly and accurately relative to noncognate controls in a wide range of tasks (e.g. Costa et al., 2000; Dijkstra et al., 2010) and with a wide range of known languages, including those that share script, such as Dutch-English (e.g. Dijkstra et al., 2010), and those that do not, such as Hebrew-English (Gollan et al., 1997), Korean-English (Kim & Davis, 2003), Greek-English (Voga & Grainger, 2007), Arabic-Hebrew (Degani et al., 2018) and Chinese-English (Zhang et al., 2019).
Most relevant to the present study is the cross-script advantage observed for cognates during Japanese-English bilinguals’ lexical processing. Studies have found this advantage in picture naming (Allen & Conklin, 2013; Hoshino & Kroll, 2008) and lexical decision (Allen & Conklin, 2013; Miwa et al., 2014). Studies utilizing the masked priming paradigm have also demonstrated cross-script priming effects with Japanese-English cognates (Allen et al., 2015) and have shown a cognate masked priming advantage (Lupker et al., 2015; Nakayama et al., 2012, 2013). For instance, Nakayama et al. (2012) found that responses to L2 English targets (e.g. GUIDE) were faster when preceded by L1 cognate primes (e.g. ガイド/gaido/“guide”) than when preceded by unrelated primes. In addition, they showed that responses to the same target were faster when the prime was phonologically similar but unrelated in meaning (e.g. サイド/saido/“side”) than when the prime was unrelated (also see Ando et al., 2015). Taken together, Nakayama and colleagues’ results revealed that cross-linguistic phonological activation occurs in different-script languages (see also Peleg et al., 2019, for Arabic-Hebrew bilinguals), but cross-linguistic activation is greater when both phonology and semantics are shared, as in the case of cognates.
The cross-script advantage of cognates is due to the twin attributes of phonological and semantic overlap, both of which have been shown to contribute fine-grained faciliatory effects in L2 reading. For instance, when Japanese-English cognates (e.g. guide-ガイド/gaido/) have a higher degree of phonological overlap, they generate a greater priming effect (Nakayama et al., 2014). Similar findings have also been found using bilinguals’ ratings of phonological similarity outside of the masked priming paradigm, which indicate a quantifiable difference in cross-linguistic activation according to the degree of shared phonology (Allen & Conklin, 2013; Miwa et al., 2014). In addition, greater semantic overlap, again measured by bilinguals’ ratings, has also been shown to facilitate recognition of cognates (Miwa et al., 2014) though this may be affected by stimulus composition (see Allen & Conklin, 2013).
Overall, these studies demonstrate that when reading words in a different-script L2, the other language is not “switched off” automatically but continues to influence the word recognition process. An important and unresearched issue is whether these cross-linguistic effects are observed in more “natural” tasks, such as when reading sentences for general comprehension.
For same-script bilinguals, cognate words are typically processed more quickly than noncognates during L2 reading in sentence contexts (e.g. Bultena et al., 2014, 2015; Dijkstra et al., 2015; Van Assche et al., 2013; see van Assche et al., 2012, for a review; and Lauro & Schwartz, 2017, for a meta-analysis) and in longer texts (Balling, 2013; Cop et al., 2017). This cross-linguistic facilitation tends to be greater when the sentence provides only minimal semantic context (i.e. low-constraint sentences) than when the sentence provides richer context (i.e. high-constraint sentences) (e.g. Duyck et al., 2007; Libben & Titone, 2009; Schwartz & Kroll, 2006; Van Hell & De Groot, 2008). Moreover, at the fine-grained level, same-script studies have shown that cognates with higher orthographic overlap are typically responded to more quickly in sentence reading (Bultena et al., 2014; Duyck et al., 2007; Van Assche et al., 2009, 2011). For instance, Bultena et al. (2014) used two different paradigms, self-paced sentence reading and sentence reading while eye-movements were recorded, and found orthographic similarity to be a significant predictor of reading times in both tasks.
For different-script bilinguals, no study has yet investigated whether cross-linguistic lexical facilitation occurs when reading sentences. This issue is important because it concerns whether phonological and semantic similarity alone (i.e. without shared orthography) are sufficient for a cognate effect to emerge when words are presented in context. According to the BIA+ model (Dijkstra & van Heuven, 2002) both of a bilingual’s languages are activated regardless of whether they have same or different scripts. The BIA+ predicts an additive role of phonology and some support for this comes from same-script cognate studies (e.g. Dijkstra et al., 2010; Schwartz et al., 2007). However, researchers have struggled to disentangle continuous measures of form overlap (orthography and phonology) because they are typically highly correlated (e.g. r = .94, Dijkstra et al., 2010; Van Assche et al., 2011) and thus may be confounded. Utilizing different-script languages presents a way around this issue, allowing us to investigate the theoretically important and open question of whether phonological facilitation persists in a sentence context.
The present study
The aim of the present study is to assess whether cross-linguistic features in different-script languages influence L2 word reading when target words are presented within a sentence context. To this end, we conducted a self-paced reading study with Japanese-English bilinguals who read English sentences containing a target word that shared some degree of form and meaning across languages. To determine the magnitude of any cross-linguistic effects in the self-paced reading task, the same participants completed an L2 lexical decision task with the same target words and their response times were directly compared across the two tasks. Furthermore, to investigate the impact of cross-linguistic similarity at a fine-grained level, we focused exclusively on Japanese-English cognates and adopted a multi-trait, gradient definition including three indices: phonological similarity, semantic similarity, and cognate frequency. This approach is based on previous studies (e.g. Dijkstra et al., 2010; Miwa et al., 2014) and allows for investigation of the contributions of each aspect of cross-linguistic lexical facilitation. That is, rather than adopting a dichotomous factor of cognate/noncognate, we assume that cross-linguistic facilitation is not an all-or-nothing effect but one of degree. Crucially, this degree of facilitation is expected to vary according to lexical properties even when all target items share some degree of form and meaning. Finally, to determine whether the effects observed are unique to bilingual participants, we conducted a control experiment in which English-speaking monolinguals completed the same self-paced reading and lexical decision tasks.
Our predictions for the experiments are as follows: Firstly, measures of cross-linguistic lexical characteristics were expected to be significant only in the bilingual experiment. Secondly, based on previous studies and the predictions of the BIA+, we expected to see faciliatory effects of all cross-linguistic predictors in lexical decision. We also expected these effects in self-paced reading if the nature of the task allows sufficient time for cross-linguistic processing to impact reading times. However, it is also possible that null cross-linguistic effects are observed due to relatively slow activation of the overlapping phonological codes required for cross-linguistic facilitation in different-script languages. More precisely, this would occur because the context provides cues that speed lexical access and because sentence reading typically does not require responses to target words, which allows the reader to move quickly to the next word. In addition, we expect that the degree of semantic similarity may be of less relevance because the provision of context will allow the bilingual reader to access the L2 meaning quickly and more accurately than in isolated word tasks, such as lexical decision. Finally, Japanese cognate frequency is expected to facilitate reading times if bilinguals activate L1 representations during contextualized reading. Taken together, the results will be informative for understanding whether cross-linguistic effects that are typically observed in isolated word reading persist in tasks that are more akin to real-life reading, that is, when participants read words in context for comprehension without their attention being drawn specifically to the target words under investigation. In the following sections we present the bilingual experiment which consisted of the self-paced reading and lexical decision tasks, followed by identical tasks conducted in the monolingual control experiment.
Method
Participants
Twenty-four native speakers of Japanese taking English courses at a Japanese university (all females, age M = 22.0, SD = 4.7) were paid for participating in the bilingual experiment. They had intermediate proficiency according to their self-ratings (M = 6.1, SD = 1.0, 1 = non-user, to 10 = native-like ability). In addition, prior to the experiment English proficiency was assessed using the Vocabulary Size Test (VST; Nation & Beglar, 2007), which is a widely-used measure of receptive lexical knowledge, and indicated participants were at a high intermediate level of lexical proficiency (M = 65.4 (out of 140), SD = 14.2) with an estimated English vocabulary size of 6540 words.
Twenty-four undergraduates (16 female, age M = 18.9, SD = 0.7) at a U.K. university who were native speakers of English and had no knowledge of Japanese participated in the monolingual control experiment for course credit.
No participants suffered from visual or reading difficulties. The materials, procedure, and analysis described hereafter were the same in the bilingual and monolingual experiments.
Experimental stimuli
We initially selected 284 English nouns between four and six letters long used in Dijkstra et al. (2010). Each target word was then embedded in a low-constraint sentence preceded by the and followed by and. This was done to avoid predictability created by the preceding word (e.g. a or an) and to restrict the syntactical variety of the sentences thus allowing participants to focus on lexical content. Sentences were in the present or past tense and were of one of two basic structures, each of which had the conjunction and followed by either a noun or a verb (e.g. I added the tomato and celery to the pot, or the dog ran to the alley and barked loudly). Target words did not appear in any other sentences and the number of words before and after the target was between three and seven.
To confirm that the sentence stem prior to the target word did not allow prediction of the target word, 13 native English speakers at a UK university completed an online sentence-completion task for course credit. Participants completed 284 sentence stems by adding a plausible word. Of all the sentences, 24 (8%) were completed using the target word by one participant or more (M = 2.0; SD = 1.1). Due to the small number, these items were retained and a predictor, target word predictability (number of target responses per item / total responses per item), was included in the self-paced reading analysis to statistically account for target word predictability.
The sentence completion study also revealed variation in the number of similar responses given following the sentences’ stems. For example, for the stem we listened to the, where the target was story, responses included radio and music four times each, and five other words, giving a total of seven different responses (i.e. word types). To account for this variation, the ratio of word types in the responses was calculated for each sentence (number of word types / the total number of responses), and this measure, stem predictability, was included in the self-paced reading task analysis.
From the initial 284 items, 108 were selected for analysis considering the semantic and phonological similarity of the English word and its Japanese loanword equivalent, and the frequency and familiarity of the loanword in Japanese (Appendix 1). Each selected item had the same contextual meaning in both languages and was not homonymous in Japanese (e.g. ダート/daato/ can refer to both dirt and dart in English and so was not included). To confirm the degree of semantic and formal overlap between English and Japanese cognate translations, 29 Japanese-English bilinguals (all female, aged between 19 and 21, VST M = 54, SD = 9.7) rated all Japanese-English cognate word pairs (e.g. テーブル-table) for semantic similarity and phonological similarity on a 7-point scale (1 = completely different, 7 = identical).
To be certain all items would be known in Japanese and thus potentially benefit from cross-linguistic facilitation, the loanword equivalent of each item had a minimum frequency of one occurrence per million words in Japanese according to the Balanced Corpus of Contemporary Written Japanese (BCCWJ; Maekawa et al., 2014; National Institute for Japanese Language and Linguistics, 2013) because previous research has suggested this to be a useful benchmark of whether the loanword will be known (Allen, 2019c). Moreover, we consulted a database of familiarity ratings for Japanese words (Amano & Kondo, 2003) and selected only items that were rated as reasonably familiar (i.e. mean rating >4.5 on a scale of 1–7). Finally, 29 participants from a similar population to those in the bilingual experiment confirmed their knowledge of the items: each item was reported known to an average of 99.5% (SD = 2.0) and to at least 26 out of 29 of the respondents. Table 1 shows descriptive statistics of the items.
Descriptive statistics for items used in the analyses.
Procedure for self-paced reading
Participants were tested on a Macintosh Desktop computer with a button box (Cedrus RB-740) using PsychoPy (v1.84.2; Peirce, 2007). Stimuli were presented in courier 18 pt lowercase black letters in the center of a white screen, aligned to the left so that each sentence could be presented on a single line.
The self-paced sentence-reading task resembled that of Bultena et al. (2014). Participants read a sentence presented from left to right beginning with an asterisk. Participants pushed a button to see each word (Figure 1) and reading times were measured as the duration between two button presses. After a quarter of the trials, participants answered a yes/no comprehension question to ensure that they read the sentences for meaning. The experiment was conducted in four blocks with a break after each and four practice trials began each block. Instructions were provided in English and participants used their dominant hand during the task. The task took around 30 minutes to complete.

Example of consecutive presentation of words within sentence frame.
The same participants completed a lexical decision task with the same items used in the self-paced reading task. In addition, 284 nonwords were selected from the English Lexicon database (Balota et al., 2007), matched to the target items on length and orthographic neighborhood size (ps > .3). The equipment used was the same as that in the sentence reading task. Stimuli were presented in courier 18 pts lowercase black letters in the center of a white screen. Instructions were provided in English at the beginning asking participants to decide as quickly and accurately as possible whether what appeared on the screen was an English word or not. Participants used their dominant hand for “Yes” responses.
Each trial began with a fixation for 800 ms, followed by a blank screen of 300 ms prior to the stimulus, which was presented for 1500 ms or until a response was made. A 10-trial practice session preceded the task, in which participants were shown the accuracy and response time following each trial. The experiment was performed in four blocks with a break after each block. Three dummy items were presented at the beginning of each block. Items were presented pseudo-randomly with no more than five of either item type presented consecutively. The task took around 15 minutes to complete. Following the lexical decision task participants completed a brief language history questionnaire.
Predictors and analyses
Cross-linguistic predictors included semantic similarity and phonological similarity, which were derived from the mean scores of the ratings described above, and Japanese cognate frequency, which was the BCCWJ frequency of the Japanese cognate translation transformed to log(frequency + 1). In addition, bilingual participants’ accuracy (%) on the Vocabulary Size Test was used as a measure of their L2 proficiency.
English language control predictors were included in the analyses to account for variance in the items that was not related to cross-linguistic factors: (Log-transformed) English word frequency (SUBTLEXUS; Brysbaert & New, 2009), word length, orthographic Levenshtein distance (Yarkoni et al., 2008), and concreteness (Brysbaert et al., 2014). In addition, Trial number was included to measure any practice or fatigue effects.
Some of the above predictors were naturally correlated and so were residualized. This involved fitting a linear model for a predictor and its correlated predictor, and extracting the residuals of this model for use in the analysis (see Miwa et al., 2014). All predictors were scaled for the analyses.
Finally, to investigate the impact of cross-linguistic effects in contextualized and isolated word reading, data from both tasks were combined and task was added as a factor to the model. Interactions between this factor and other predictors would indicate significant differences in processing effects in the two task types.
Analyses were conducted in R version 3.0.2 (R Core Development Team, 2013) using the function lmer in the package lme4 (version 1.1-7; Bates et al., 2015). Reading times were transformed for the analysis (−1000/RT). All predictors and the two-way interactions between them were added to a model with random intercepts for subjects and items. The model was backward-simplified automatically using the step function in lmerTest (version 2.0-20, Kuznetsova et al., 2017), which applies log-likelihood testing by first removing non-significant interactions then main effects. Following this, by-subject random slopes for all main effects (and a by-item random slope for L2 proficiency in the bilingual analysis) were added successively and maintained if they significantly improved the model. To increase the reliability and replicability of the findings, alpha was set at .01 during the modelling process.
Results
Bilingual experiment
Participants responded accurately to comprehension questions during the self-paced reading task (accuracy M = 84.0%, SD = 7.0%), though one participant had below 75% accuracy overall and was thus removed, leaving 23 participants in the analysis. This high accuracy threshold was used because we wanted to be sure that participants were sufficiently comprehending the sentences. Following visual inspection, outlier cut-off points were determined. Responses of <150 ms and >2000 ms were removed (2.4% of data) leaving 2419 trials in the bilingual self-paced reading analysis. The lexical decision analysis consisted of the same 23 participants, whose mean item response accuracy was 94.2% (SD = 3.2%). Two items had overall accuracy rates of below 70% and were removed, leaving 106 items in the analysis. Responses below 150 ms or above 1500 ms (1.1% of data) and inaccurate responses (3.2% of data) were removed, leaving 2378 trials in the bilingual lexical decision analysis. The total number of trials in bilingual combined analysis was 4797.
Table 2 shows the final model for the bilingual data. Task was highly significant and revealed that response times were much faster in the self-paced reading task than in lexical decision. (i.e. M = 557 ms, SD = 306 ms; and M = 625 ms, SD = 166 ms, respectively). Moreover, task interacted with trial showing how participants’ reading sped up dramatically over the course of the self-paced reading experiment (Figure 2). In addition, the significant effect of L2 proficiency shows that participants with higher proficiency responded more quickly to items in both tasks than those with lower proficiency.
Results of the mixed-effects model for bilingual self-paced reading and lexical decision.

β is the standardized model coefficient created by scaling the response variable and numerical predictors; Pseudo R2 (fixed effects) = 0.20; Pseudo R2 (total) = 0.45; AIC = 8434.
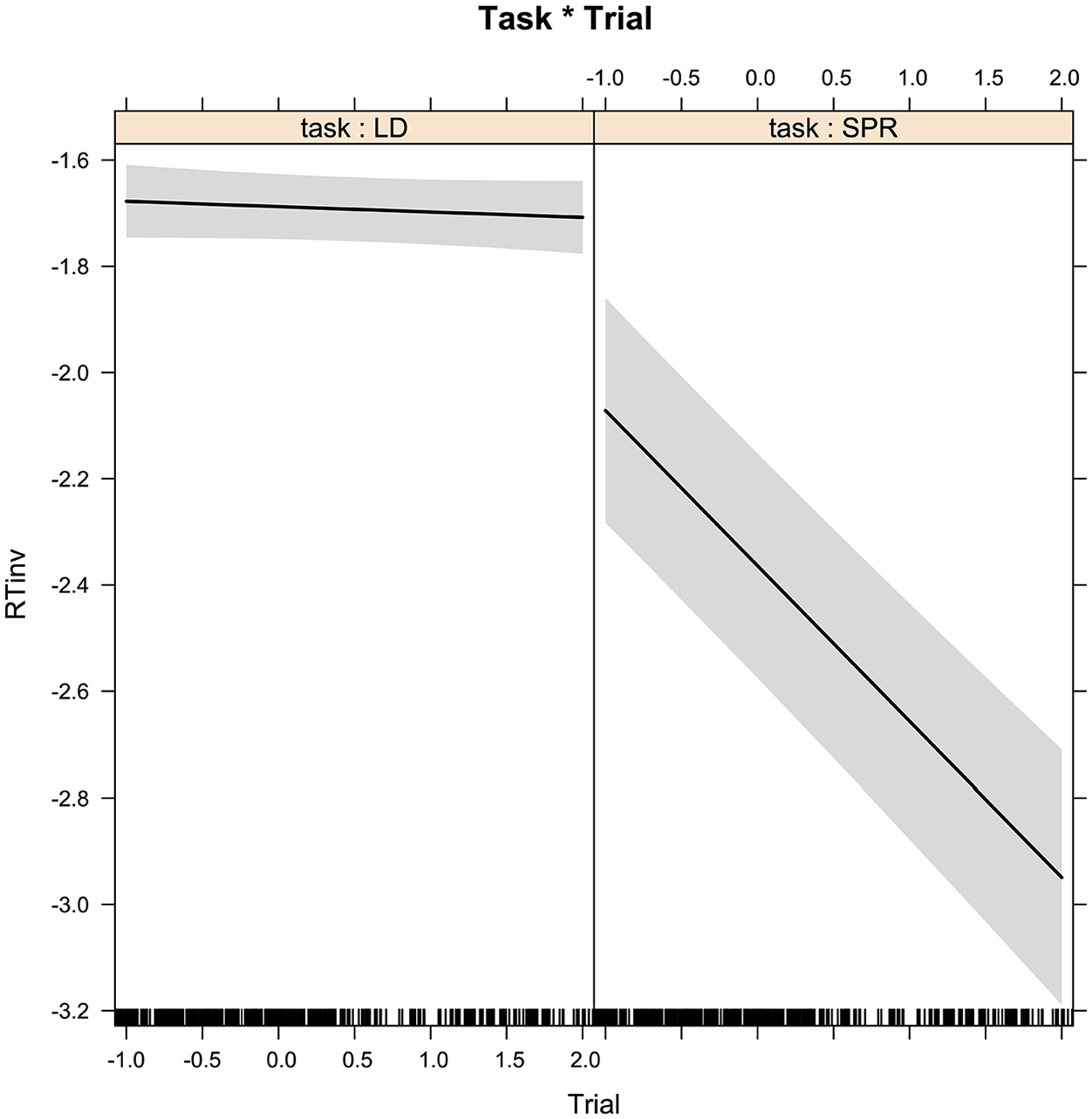
Trial effect by task in the bilingual experiment.
All of the cross-linguistic predictors (phonological similarity, semantic similarity, and Japanese cognate frequency) were significant and faciliatory in the combined model. In addition, an interaction between semantic similarity and task reveals that the effect of semantic similarity occurred only in lexical decision (Figure 3). In contrast, the absence of interactions between task and the other cross-linguistic predictors suggests they had similar faciliatory effects in both tasks. However, inspection of individual models (Appendix 2) reveals a more complex picture: phonological similarity was significant as a main effect but only in lexical decision, whereas Japanese cognate frequency was not significant as a main effect in either model; however, both predictors featured in the interactions discussed below.
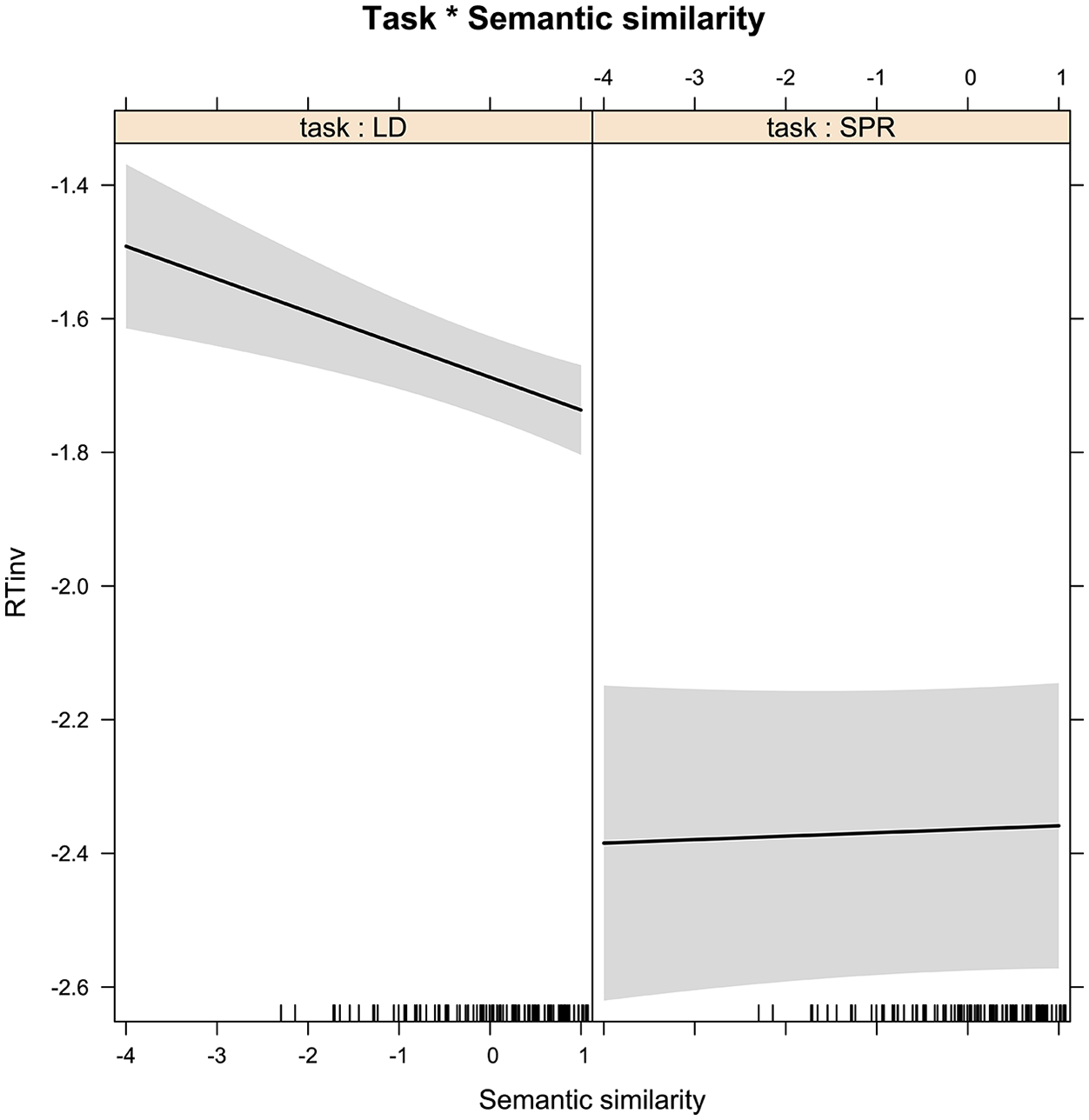
Semantic similarity effect by task in the bilingual experiment.
Table 2 and Figure 4 show that Japanese cognate frequency mediated the effects of phonological similarity and L2 proficiency. That is, when the English words had lower frequency cognates in Japanese, the faciliatory effects of phonological similarity and L2 proficiency were greatest. In contrast, English words with higher frequency cognates in Japanese were not facilitated by these variables, especially in the case of phonological similarity. Inspection of separate models revealed that these interactions were significant only in self-paced reading.

Interactions of phonological similarity and L2 proficiency with Japanese cognate frequency in the bilingual experiment.
Regarding English-language control predictors, there was a strong and faciliatory effect of English word frequency. Inhibitory effects of length and orthographic Levenshtein distance were observed and these effects both reduced over the course of the experiment as indicated by the interactions with trial. Finally, concreteness was significant, showing items that were more abstract tended to be read and responded to more quickly. Inspection of individual models shows that this effect arose primarily in the self-paced reading task.
Monolingual experiment
One participant had less than 75% accuracy on the responses to the comprehension questions in the monolingual self-paced reading task and so was removed, leaving 23 participants. The remaining participants’ responses were highly accurate, showing they were reading for comprehension (accuracy M = 95.4%, SD = 4.3%). Outlier responses of <150 ms and >2000 ms were removed (1.6% of data) leaving 2440 trials. The same 23 participants were included in the monolingual lexical decision analysis, for which they had a mean accuracy of 96.9% (SD = 0.03%). No items had accuracy rates of below 70%. Responses below 150 ms or above 1500 ms (0.4% of data) and inaccurate responses (2.3% of data) were removed, leaving 2419 trials in the following analyses. The total number of trials in monolingual combined analysis was 4859.
Table 3 shows the final model for the monolingual data. There was a significant difference between the speed of responses between the two tasks, with response speed for self-paced reading being markedly faster. The average response time was 320 ms (SD = 125 ms) in self-paced reading and 555 ms (SD = 209) in lexical decision. Moreover, as in bilingual self-paced reading, an interaction between task and trial shows that response times significantly decreased over time. There was an expected English word frequency effect, as observed in bilingual reading. Finally, concreteness interacted with task revealing that it had a greater effect in self-paced reading and, as in the bilingual experiment, more abstract words were read more quickly.
Results of the mixed-effects model for monolingual self-paced reading and lexical decision.

β is the standardized model coefficient created by scaling the response variable and the numerical predictors; Pseudo R2 (fixed effects) = 0.51; Pseudo R2 (total) = 0.78; AIC = 9030.
Inspection of separate models for each task reveals that trial was significant in both tasks but the size of the effect was many magnitudes greater in self-paced reading. In fact, due to the speed of monolingual self-paced reading, other than trial no predictors remained in the final model. In contrast, the final model for lexical decision included English word frequency as well as interactions between trial and length, and trial and orthographic neighborhood distance, both of which showed inhibitory effects that were greater at the beginning of the experiment but attenuated over time.
Discussion
The present study examined whether cross-linguistic lexical effects emerge in sentence reading and in isolated word reading for different-script cognates, and additionally whether such effects were present in the same tasks with monolinguals. The findings demonstrate that significant effects of phonological and semantic similarity, and cognate frequency, were present in the bilingual experiment but absent from an identical monolingual experiment. This provides evidence that these measures reflect aspects of bilingual lexical processing, rather than capturing aspects of generic lexical processing or the properties of the words in English. Moreover, the findings support the non-selective view of lexical access, that is, when bilinguals read in the L2, lexical access is implicitly influenced by L1 lexical knowledge even when no overt L1 cues are present in the task.
Our study is the first to examine cross-linguistic effects in sentence reading with bilinguals whose languages differ in script. We specifically investigated the role of individual cross-linguistic predictors that make up the “cognate facilitation effect” rather than comparing reading times for cognates and noncognates. By analyzing reading times for cognates in bilingual sentence reading and lexical decision, we show how the type of task used partially determined the extent to which these cross-linguistic features impact bilingual lexical processing.
Phonological similarity between English words and their Japanese loanword counterparts significantly predicted reading times in both bilingual experiments. Thus, phonological overlap is sufficient to manifest an advantage in processing in the absence of shared orthography, which supports the findings with different-script bilinguals in general (e.g. Gollan et al., 1997; Kim & Davis, 2003; Voga & Grainger, 2007) and with Japanese-English bilinguals specifically (Allen & Conklin, 2013; Miwa et al., 2014).
Phonological similarity was faciliatory as a main effect in lexical decision, while in self-paced reading it was faciliatory only for words that had low-frequency L1-cognates and which therefore were processed more slowly (i.e. in comparison with words with high-frequency L1-cognates; Japanese cognate frequency is discussed in more detail below). These findings suggest that, when orthographic cues are absent, facilitation based on cross-linguistic formal similarity is evident but reduced when word reading is fast (i.e. in contextualized word reading).
Overall, the finding that sentence context did not completely eliminate cross-linguistic activation of phonology supports the predictions of the BIA+, which assumes non-selective activation of lexical candidates during both isolated and contextualized word recognition. The BIA+ holds that language membership (i.e. the language of the sentence) does not create language-selective processing, as assumed in the earlier BIA model (Van Heuven et al., 1998) and in alternative theories of bilingual lexical processing (e.g. Grosjean, 1997). However, as assumed in the BIA+, task demands appear to be crucial in determining whether bilingual effects are observed in reading times. That is, the difference in impact of cross-linguistic features appears to depend on the speed at which participants read words and the type of response that they are required to produce.
The reduced impact of phonological similarity may be due to the time required to access phonological information in the L1 during L2 reading: in same-script language reading, orthographic cues are processed initially, leading to immediate L2–L1 cross-linguistic activation at the sub-lexical and lexical orthographic levels. This activation accounts for the significant orthographic similarity effects observed in same-script sentence-reading studies (e.g. Bultena et al., 2014; Cop et al., 2017; Van Assche et al., 2009, 2011; but see Experiment 3 in Duyck et al., 2007). In different-script bilingual reading, L2–L1 cross-linguistic activation is initially via cross-linguistic activation of phonology, which occurs after orthographic processing in the L2. This delay in activation may explain why we observed much reduced effects of cross-linguistic phonological overlap in sentence reading.
Another important finding was observed in the role of semantic similarity in the two tasks. In the combined bilingual model, and in lexical decision specifically, semantic similarity between English and Japanese words was shown to significantly facilitate response times. That is, words which overlap more across languages in terms of their conceptual representations were recognized more quickly by bilinguals reading in a second language. This is consistent with previous research with Japanese-English bilinguals (Miwa et al., 2014) and with the predictions of the BIA+ (Dijkstra & van Heuven, 2002), which assumes that the degree of facilitation is proportional to the degree of overlap in semantic features of the cognate. However, the absence of this effect in sentence reading points to the role of context: When participants read words embedded in context, even a non-constraining context as provided in the present study, sufficient cues to word meaning are provided in the L2 rendering the similarity to L1 concepts ineffectual in speeding reading times.
In addition to the availability of context, word reading times in bilingual self-paced reading were fast, which is likely to play a role in the null effect of cross-linguistic semantic similarity. Although the L1 semantic features are expected to become activated via shared connections across languages, and via feedback mechanisms between lexical and sub-lexical representations as postulated in the BIA+, lexical access during L2 sentence reading proceeds so quickly that L1–L2 semantic similarity may have no observable impact on word reading times.
Importantly, all of the English words and their loanword equivalents were contextually appropriate. In a different situation where the L1 cognate meaning conflicts with the contextual meaning in the L2 sentence, a measurable delay in processing may be observed (for instance, see the findings for false-cognate processing in a semantic-relatedness task with Arabic-Hebrew bilinguals in Degani et al., 2018). However, given that there were no overt (i.e. orthographic) cues to the L1 in the task, it is also plausible that L2 context supports L2 reading sufficiently to override any such interference. Future research using L2 words with contextually inappropriate L1-meanings (i.e. false-cognates) is necessary to investigate this issue.
The third cross-linguistic measure, Japanese cognate frequency, was notably less prominent in both bilingual tasks compared with previous studies. This measure is assumed to reflect the resting level of activation of the lexical representation in the L1 and thus reflects how well the cognates are likely to be known in the L1. In studies with Japanese-English bilinguals, it has been shown to predict response times in lexical decision (Miwa et al., 2014) and accuracy on tests of lexical knowledge (Allen, 2019a, 2019b). In the present study, however, cognate frequency played a more specific role in that it modulated effects of phonological similarity and L2 proficiency during sentence reading, while it did not influence processing in lexical decision. In contextualized reading, when cognates were higher frequency, they were less likely to receive additional facilitation in the form of phonological similarity. This suggests that processing for these words in self-paced reading was already at ceiling. Moreover, responses by participants with lower L2 proficiency were facilitated by higher Japanese cognate frequency, most likely because their responses were slower overall, which allowed for L1 cognate knowledge to play a more significant role. Although we initially expected cognate frequency to play a more important role in modulating bilingual lexical processing in lexical decision, its reduced role overall may be explained by the fact that all English words had relatively high-frequency cognates in Japanese, whereas in previous studies English words with cognates of a greater range of frequency were included (as well as noncognates which had a frequency of zero). Studies using items with a greater range of cognate frequency would be expected to demonstrate a faciliatory role of cognate frequency.
Limitations
This is the first study to investigate cross-linguistic effects in different-script languages when reading words in context. However, more research is needed to explore these effects in a wider range of conditions and circumstances. Importantly, we observed minimal cross-linguistic effects with semantically low-constraint sentences (i.e. ones in which the target word was not predictable). Cross-linguistic effects are expected to be further diminished in high-constraint sentences, which provide strong contextual cues to the specific target word in the L2 and thus further speed up lexical access (see Lauro & Schwartz, 2017). Also, it is unclear whether cross-linguistic effects would emerge with other different-script bilinguals (e.g. Hebrew-English) or with bilinguals of lower/higher L2 proficiency, in tasks where reading may be even faster (i.e. with eye-tracking), or when using target words other than nouns (see e.g. Bultena et al., 2014). With the aim of moving towards a more comprehensive model of bilingual lexical processing, future studies will need to clarify the impact of these conditions upon cross-linguistic effects in different-script languages.
Conclusion
It was demonstrated that a difference in script does not eliminate cross-linguistic effects when bilinguals read words in sentences and in isolation. This is the first study to show the impact of cross-linguistic lexical similarity with etymologically unrelated and orthographically distinct languages when bilinguals read sentences for meaning. Notably, our findings indicate that these cross-linguistic effects are reduced in more “natural” reading tasks, such as sentence reading. Although this conclusion applies most directly to Japanese-English bilinguals reading in their L2 (English), it may also extend to readers in other bilingual populations. The implication is that while bilinguals do not switch off their L1 during L2 reading, the type of task considerably affects whether cross-linguistic effects are observed and whether these impact reading times. Finally, while previous research has typically focused on “cognates” and “noncognates,” this study emphasizes the importance of focusing on the distinct elements of the “cognate effect,” that is, the distinct roles of formal and semantic similarity.
Footnotes
Appendix 2
Appendix 1.
Items and sentence contexts used in experiments.

| English target item | Japanese cognate translation* | Japanese Romanized form** | Sentence context | |
|---|---|---|---|---|
| 1 | Chaos | カオス | kaosu | They tried to escape the chaos and brutality of war. |
| 2 | Moment | モーメント | moomento | I will never forget the moment and often recall it. |
| 3 | Roof | ルーフ | ruufu | The cat climbed to the roof and would not come down. |
| 4 | Detail | ディテール | diteeru | They were amazed at the detail and quality of the work. |
| 5 | Fire | ファイア | faia | We could see the fire and called for help. |
| 6 | Plant | プラント | puranto | She lifted the plant and put it in the sunlight. |
| 7 | Seed | シード | shiido | The sunlight warmed the seed and it sprouted. |
| 8 | Trace | トレース | toreesu | We could see the trace and copied it. |
| 9 | Wind | ウインド | uindo | I really dislike the wind and hail on this island. |
| 10 | Pill | ピル | piru | She took the pill and felt better. |
| 11 | Wing | ウイング | uingu | The flames began on the wing and spread from there. |
| 12 | Metal | メタル | metaru | The buyers looked up at the metal and concrete structure. |
| 13 | Saddle | サドル | sadoru | I got into the saddle and turned the throttle. |
| 14 | Angle | アングル | anguru | It was the angle and pressure that made him miss. |
| 15 | Head | ヘッド | heddo | Remove the head and the scales of the fish. |
| 16 | Hope | ホープ | hoopu | It was for the hope and glory of victory. |
| 17 | Candy | キャンデー | kyandee | The children devoured the candy and pleaded for more. |
| 18 | Chair | チェア | chea | The teacher walked to the chair and sat down. |
| 19 | Plate | プレート | pureeto | The child threw the plate and it smashed. |
| 20 | Echo | エコー | ekoo | The audience could hear the echo and feedback from the speakers. |
| 21 | Noise | ノイズ | noizu | The passengers were surprised by the noise and commotion. |
| 22 | Virgin | バージン | baajin | The children looked at the virgin and child picture in amazement. |
| 23 | Tenant | テナント | tenanto | She called the tenant and insisted that he pay up. |
| 24 | Paint | ペイント | peinto | They bought the paint and the brushes. |
| 25 | メール | meeru | I went out to collect the mail and buy some tea. | |
| 26 | Watch | ウォッチ | uocchi | I looked at the watch and dreamed I could buy it. |
| 27 | Target | ターゲット | taagetto | They saw the target and fired. |
| 28 | Gate | ゲート | geeto | We rushed to the gate and barely caught the flight. |
| 29 | Girl | ガール | gaaru | The parcel was delivered to the girl and her family. |
| 30 | Prince | プリンス | purinsu | It was the ceremony of the prince and princess’ engagement. |
| 31 | Loss | ロス | rosu | He ignored the loss and invested again. |
| 32 | Angel | エンジェル | enjeru | The filmakers wanted the angel and demon film to be a hit. |
| 33 | Total | トータル | tootaru | I looked at the total and almost fainted. |
| 34 | King | キング | kingu | The soldiers met the king and received a medal. |
| 35 | Chain | チェーン | cheen | The old lady put on the chain and looked out through the door. |
| 36 | Monkey | モンキー | monkii | It was about the monkey and the coconut. |
| 37 | Rail | レール | reeru | Take the rail and walk carefully. |
| 38 | Woman | ウーマン | uuman | The police arrested the woman and charged her. |
| 39 | Cherry | チェリー | cherii | The squirrels picked at the cherry and fought over it. |
| 40 | Summer | サマー | samaa | The teachers awaited the summer and other vacations. |
| 41 | Desk | デスク | desuku | The clerk stood at the desk and sighed. |
| 42 | Anchor | アンカー | ankaa | The men raised the anchor and set sail. |
| 43 | Sugar | シュガー | shugaa | I asked for the sugar and a spoon. |
| 44 | Napkin | ナプキン | napukin | The elderly man dropped the napkin and struggled to retrieve it . |
| 45 | Bottle | ボトル | botoru | The sailors caught the bottle and read the letter inside. |
| 46 | Ring | リング | ringu | He decided to buy the ring and propose to her. |
| 47 | Sock | ソックス | sokkusu | Mother picked up the sock and asked whose it was. |
| 48 | Mirror | ミラー | miraa | She peered into the mirror and didn’t recognize herself. |
| 49 | Circle | サークル | saakuru | They formed the circle and sang together. |
| 50 | Rhythm | リズム | rizumu | Just keep the rhythm and dance. |
| 51 | Plan | プラン | puran | The engineers took the plan and built the bridge. |
| 52 | Garden | ガーデン | gaaden | The dog ran to the garden and barked loudly. |
| 53 | Error | エラー | eraa | I regretted the error and tried not to do it again. |
| 54 | Gold | ゴールド | goorudo | The banker took the gold and silver from the safe. |
| 55 | Bucket | バケツ | baketsu | The children left the bucket and spade at the shore. |
| 56 | Love | ラブ | rabu | There is nothing better than the love and affection of a cat. |
| 57 | Price | プライス | puraisu | I was not happy with the price and the service provided. |
| 58 | Shoe | シューズ | shuuzu | The stewardess held the shoe and wondered. |
| 59 | Coin | コイン | koin | The teenager found the coin and picked it up. |
| 60 | Silk | シルク | shiruku | The feel of the silk and its hue made him buy it. |
| 61 | Oven | オーブン | oobun | The gloves were on the oven and melted a little. |
| 62 | School | スクール | sukuuru | He arrived at the school and went in. |
| 63 | body | ボディー | bodii | It is good for the body and soul. |
| 64 | case | ケース | keesu | The steward looked at the case and refused |
| 65 | model | モデル | moderu | The audience regarded the model and applauded her. |
| 66 | joke | ジョーク | jooku | We did not understand the joke and felt embarrassed. |
| 67 | doctor | ドクター | dokutaa | I went to see the doctor and got some medicine. |
| 68 | money | マネー | manee | The man took the money and ran off. |
| 69 | beach | ビーチ | biichi | The gulls landed on the beach and searched for crabs. |
| 70 | screen | スクリーン | sukuriin | The assistant wiped the screen and started the computer. |
| 71 | milk | ミルク | miruku | We left some of the milk and bread out for the cats. |
| 72 | type | タイプ | taipu | The lady selected the type and quantity of flowers. |
| 73 | water | ウォーター | uootaa | We looked out at the water and dreamed of sailing away. |
| 74 | spoon | スプーン | supuun | The baby grabbed the spoon and threw it. |
| 75 | fruit | フルーツ | furuutsu | The hawk flew to the fruit and pecked at it. |
| 76 | knife | ナイフ | naifu | I picked up the knife and fork and began to eat. |
| 77 | guide | ガイド | gaido | I followed the guide and saw the sights. |
| 78 | skirt | スカート | sukaato | The customer returned the skirt and asked for a refund. |
| 79 | tire | タイヤ | taiya | We fixed the tire and continued our journey. |
| 80 | office | オフィス | ofisu | They cleaned up the office and took their leave. |
| 81 | pants | パンツ | pantsu | The traveller unpacked the pants and pyjamas from his luggage. |
| 82 | idea | アイディア | aidia | She had the idea and developed it thoroughly. |
| 83 | ポケット | poketto | It was in the pocket and I didn’t realize. | |
| 84 | guitar | ギター | gitaa | The youngster picked up the guitar and played a tune. |
| 85 | mask | マスク | masuku | The boy wore the mask and pretended to be Dracula. |
| 86 | soup | スープ | suupu | They had the soup and bread for lunch. |
| 87 | card | カード | kaado | I forgot the card and went home to get it. |
| 88 | melon | メロン | meron | The children carried the melon and then broke it up. |
| 89 | circus | サーカス | saakasu | Everyone was excited about the circus and ran into town. |
| 90 | tennis | テニス | tenisu | He was excited by the tennis and bought a racket. |
| 91 | story | ストーリー | sutoorii | We listened to the story and thought about its meaning. |
| 92 | advice | アドバイス | adobaisu | The son rejected the advice and suggestions of his parents. |
| 93 | power | パワー | pawaa | He always desired the power and status of a politician. |
| 94 | menu | メニュー | menyuu | He passed the menu and we ordered together. |
| 95 | member | メンバー | menbaa | The secretary asked the member and then renewed his subscription. |
| 96 | sport | スポーツ | supootsu | They saw the sport and drank beer. |
| 97 | kiss | キス | kisu | I did not expect the kiss and was very embarrassed. |
| 98 | point | ポイント | pointo | I did not see the point and gave up. |
| 99 | banana | バナナ | banana | The assistant saw the banana and returned it to the shelf. |
| 100 | design | デザイン | desain | I really like the design and feel of this sofa. |
| 101 | lion | ライオン | raion | They were scared by the lion and stayed close together. |
| 102 | cheese | チーズ | chiizu | We requested more of the cheese and biscuits. |
| 103 | drama | ドラマ | dorama | I did not like the drama and so I turned it off. |
| 104 | engine | エンジン | enjin | The mechanic said the engine and gearbox needed work. |
| 105 | hotel | ホテル | hoteru | They decided to visit the hotel and check-in first. |
| 106 | tomato | トマト | tomato | I added the tomato and celery to the pot. |
| 107 | chance | チャンス | chansu | The employee got the chance and she took it. |
| 108 | coffee | コーヒー | koohii | The gentleman brought the coffee and cake for us. |
Japanese cognate translations were acquired from the Balanced Corpus of Contemporary Written Japanese (Maekawa et al., 2014; National Institute for Japanese Language and Linguistics, 2013).
Japanese Romanized form is written using the Hepburn system though for simplicity we do not use macrons for the extended vowels and instead double the preceding vowel to show lengthening (e.g. peace, ピース, piisu).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.