
Abstract
Purpose:
To contribute to the establishment of a novel approach to language documentation that includes bilingual and multilingual speech data. This approach would open this domain of study to work by specialists of bilingualism and multilingualism.
Approach:
Within language documentation, the approach adopted in this paper exemplifies the “contemporary communicative ecology” mode of documentation. This radically differs from the “ancestral-code” mode of documentation that characterizes most language documentation corpora. Within the context of multilingualism studies, this paper advocates for the inclusion of a strong ethnographic component to research on multilingualism.
Data and Analysis:
The data presented comes from a context characterized by small-scale multilingualism, and the analyses provided are by and large focused on uncovering aspects of local metapragmatics.
Conclusions:
Conducting language documentation in contexts of small-scale multilingualism requires that the adequacy of a corpus is assessed with regard to sociolinguistic, rather than only structural linguistic, requirements. The notion of sociolinguistic adequacy is discussed in detail in analytical terms and illustrated through an example taken from ongoing research led by the authors.
Originality:
To date, there are no existing publications reviewing in the detail provided here how the documentation of multilingual speech in contexts of small-scale multilingualism should be structured. The contribution is highly original, in particular, for its theoretical grounding of the proposed approach.
Significance/Implications:
This article can serve as a reference for those interested in methodological and theoretical concerns relating to the practice of language documentation in contexts of small-scale multilingualism across the world. It may also help clarify ways for sociolinguists to engage more closely with work on language documentation, a domain that has thus far remained primarily informed by structural linguistic approaches.
Keywords
Small-scale multilingualism and language documentation
Arising out of concerns about language endangerment (Hale et al., 1992), and still mostly conducted in endangerment contexts, language documentation (henceforth LD) has provided a wealth of new data that has mostly supported the agenda of structural linguists (e.g., typologists, syntacticians, phonologists, etc.). Work within LD has been carried out mainly by adopting a mode of documentation focusing on “ancestral codes,” an expression coined by Woodbury (2005, 2011) to refer to the process of creating a documentary corpus theorized (i.e., ideated) in terms of adherence to one specific language (or code) that is in danger of fading out of use in a given speech community. 1 As a result, the overwhelming majority of the LD corpora produced to date are focused on monolingual data only (see also Epps, 2021, on the need to go beyond the “ancestral code” in LD).
It is clear that this monolingual bias reflects more (Western) scholarly agendas rather than the lived reality of speech communities. For one thing, contexts of endangerment are, by definition, contexts of language shift, and this obviously implies that communities impacted by endangerment are in fact bilingual or multilingual. 2 However interesting from a scientific point of view, it is understandable that documenting multilingual speech in contexts of language shift may be seen as a paradoxical (if not masochistic) choice for a linguist working on the documentation of an endangered language with an eye on language maintenance or revitalization like many documenters are. Funding bodies also may promote a monolingual bias, even if this is unintentional.
The lived multilingual realities of an endangered language speech community may fall much more clearly within the scope of a “sensitive” documenter if we consider them from a different perspective. Recent literature has made abundantly clear that multilingualism in contexts of language endangerment is in many cases not to be ascribed only to the process of language shift, but is also engendered by indigenous societal dynamics (see, e.g., Cobbinah et al., 2017; Di Carlo, 2018; Epps, 2018; Rumsey, 2018; Singer, 2018).
In post-colonial contexts, which account for a large part of language endangerment contexts, if multilingualism is widespread within a certain speech community, then this is likely due to the interplay of two distinct dynamics. On the one hand, the colonial past has produced specific social and cultural dynamics relating to key areas of social life such as, for example, social hierarchy, power, and conceptions of identity, which constitute the major features of the sociolinguistic life of those societies today, especially in growing cities. This dynamic is tightly connected with the spread of ex-colonial languages and, to some degree, also of certain lingua francas—such as Cameroon Pidgin English (CPE) in Anglophone Cameroon (see, e.g., Menang, 2004).
On the other hand, the indigenous societal contexts continue pre-colonial dynamics that, to varying degrees, still provide ground for the reproduction of certain “endogenous” sociolinguistic processes often characterized by small-scale, relatively egalitarian social dynamics (see, e.g., Di Carlo et al., 2019; Lüpke, 2016). These dynamics are tightly connected to situations in which individuals’ multilingual repertoires include mainly “small”, highly localized languages, thus leading to the use of the term “small-scale multilingualism.” 3
Crucially for the LD agenda, the “discovery” of small-scale multilingualism has also demonstrated that not all forms of multilingualism are equally implicated in assessing the degree of endangerment of a language. Colonially mediated dynamics may lead to subtractive multilingualism or other processes of language hierarchization that eventually lead to loss of ancestral languages. By contrast, the indigenous dynamics of pre-colonial origin represent historical continuities, reproducing language ecologies (Haugen, 1972) that, in most cases, have in fact favored the maintenance of languages, even of those spoken by relatively small communities (see, e.g., Cobbinah, 2020; Epps, 2018).
There is another central fact, which Childs et al. (2014) note: Sociolinguistic contexts are more fragile than lexico-grammatical codes and, therefore, intrinsically more endangered. It is these contexts that will disappear first as smaller communities become transformed by contact with larger ones. Significant lexical data can be collected from even a single “rememberer”. . .but documenting a language’s sociolinguistic context requires an active speech community. (Childs et al., 2014, p. 172)
In other words, small-scale multilingual practices and metapragmatic knowledges must be considered key features that are lost relatively early under endangerment. For this reason, while all forms of multilingualism, even those threatening the survival of endangered languages, are worth being documented, the documentation of small-scale multilingual practices and metapragmatic knowledges seems to us to be all the more urgent.
Conducting documentation of small-scale multilingualism practices can be done only when the documenter targets the lived realities of the speech community, rather than operating from a predetermined notion that their focus should be on the collection of data from a single language (see also Dobrin & Berson, 2011). In contrast to the “ancestral-code mode” that is characteristic of most documentary projects, this is what Woodbury (2011) refers to as the documentation of the “contemporary communicative ecology” (p. 179). This embodies the idealized “unselective” approach to LD, where whatever emerges in daily interactions can potentially be recorded and annotated, irrespective of the languages speakers happen to use (see also Himmelmann, 1998, p. 168).
While advocated by some scholars (e.g., Childs et al., 2014), this documentary approach is in fact quite uncommon in LD, as evidenced by an examination of the kinds of projects that are funded by organizations like the Endangered Languages Documentation Programme (www.eldp.net). We believe that it is likely that a major factor in this tendency is uncertainty around how to collect an adequate documentary corpus.
The main goal of this article is to start filling this gap by proposing a foundation for an alternative, viable, and principled view of LD that builds multilingual practices into its core. We do this in the hope that more pieces of a shared methodology will follow in the near future—with contributions also from sociolinguists, who have remained somewhat outside of the LD “movement” (see, e.g., Meyerhoff, 2019)—and that this will eventually result in more projects focused on such contexts and in a generalized higher concern among scholars and funding agencies for the documentation of small-scale multilingualism phenomena. While our proposals most directly concern the practices of linguistics working on LD, we believe that, if adopted, they would have significant positive impacts in other areas of investigation, such as the study of bilingualism and multilingualism. Moreover, by promoting approaches within LD that put multilingualism at the center of documentation (see also many of the essays in Di Carlo & Good, 2020), we also hope that this will help promote expanded dialog between scholars focusing on multilingualism and those working on endangered languages. Finally, within sociolinguistics itself, the present work represents an attempt at providing a principled methodological contribution that we believe is relevant to current developments towards “globalizing sociolinguistics” (see, e.g., the papers in Smakman & Heinrich, 2015, especially Meyerhoff & Stanford, 2015).
In order to achieve our main goal, we first provide an example taken from a recent detailed study of small-scale multilingualism in an African context (second section), which will serve as a concrete example of a research situation one may face when documenting small-scale multilingualism. Then, in the third section, we discuss issues of adequacy of documentary corpora, focusing on what appear to have been key obstacles for the development of multilingual LD. In that section, we introduce two keys to this article: the concepts of sociolinguistic adequacy and of indexical space. The fourth section is devoted to outlining the consequences that such a re-appraisal has on the treatment of speech data and, in the fifth section, we summarize the methodology we have applied in our work. The Supplementary Materials provide an attempt to exemplify the methodology through the main lessons learned in a documentary project focused on small-scale multilingualism in rural Cameroon.
An example of documented multilingual data
In order to lay out context for the conceptual discussion below, in this section we provide a partly analyzed fragment of a multilingual dialog from the research of Ojong Diba (2019, 2020) in Table 1. Further discussion of the research process through which this data was collected is presented in the Supplementary Materials. The setting for this conversation is the small village of Buu, in the Lower Fungom region of Cameroon (see Good et al., 2011, and Di Carlo, 2011, for a linguistic and ethnographic overview of this region respectively). All the villages mentioned below are located within one hour’s walking distance of each other.
Interaction between M, V, and T (drawn from Ojong Diba, 2019, pp. 199–205).

CPE: Cameroon Pidgin English.
The participants are M, T, and V. M (female, ca. 40) is from the village of Buu, T (male, ca. 40) is from the nearby village of Fang and is a hunter, and V (female, ca. 40) is a friend of M’s and, like her, comes from Buu. The villages of Buu and Fang are associated with different languages—having ISO 639-3 and Glottolog codes [boe; mund1328] 4 and [fak; fang1248], respectively—and are each referred to using the same name as the village. All three participants can communicate in Buu, Fang, and CPE—which is the lingua franca of the part of Cameroon where Lower Fungom is located—and these are the three languages found in the dialog below. This means that the choice of which language to speak at any given point can be considered socially meaningful.
In the dialog, M and V are chatting in front of M’s house in Buu. T stops while passing along with a dead game animal in his hands because M indicates that she would like to buy it. The languages used are: Fang (italics),
Examples like the one in Table 1 are clearly of documentary interest since they demonstrate the way in which speakers of a set of endangered languages—which is the case for all of the local languages of Lower Fungom (see Supplementary Materials)—deploy multiple languages over the course of their daily lives, which is a critical part of how they are used. A documentary project collecting monolingual data from Lower Fungom would paint a false record of the speech practices of its communities. Moreover, data like this is important for understanding how self-reported information from individuals about their linguistic knowledge and about the way they use multiple languages align with their actual linguistic knowledge and patterns of language use (see, e.g., Mba and Nsen Tem, 2020).
This example also demonstrates an important methodological point in terms of the kinds of analyses that are and are not present. There is no interlinear glossing or transcription of tone (even though all the languages make extensive use of tone). Moreover, the segmental transcription is quite rough, and not properly phonemicized. 5 In this regard, the quality of the data falls short of best practice for a “classical” (i.e., monolingual) documentation project.
Nevertheless, important generalizations regarding local linguistic practices can still be derived from Table 1 when it is considered within the entirety of Ojong Diba’s corpus. For instance, this corpus includes detailed accounts of the speakers’ multilingual repertoires, of their “sociolinguistic life” (including topics such as mobility, special language rights, etc.), and of the space in which the interaction takes place, both from an external and a culture-internal perspective. Therefore, less information in some areas is balanced by more information in other areas.
To be slightly more specific, Table 1 illustrates that Ojong Diba’s corpus can allow for the analysis of participants’ language choices. While T and V keep using their own “home languages,” M carefully selects the language according to whom she is speaking, that is, Fang with T and Buu with V (CPE sometime “perhaps” is best considered a borrowing rather than an instance of code-switching).
This type of interaction exemplifies fundamental traits of Lower Fungom metapragmatic knowledge (see the Widening the scope of LD corpora: Symbols and indices section for further discussion of metapragmatics). Throughout the corpus one finds that, regardless of the extent of the multilingual competence of any two speakers, one-to-one interactions are by and large monolingual (cf. Cobbinah et al., 2017, for a very different situation found in a context of small-scale multilingualism in southern Senegal). The choice of the language, when it is anything other than CPE (i.e., when speakers can communicate using a local language), depends on a number of contextual and individual-based factors and cannot be predicted in any general way other than, perhaps, that priority is given to more senior individuals in making the choice. What can be predicted, based on the corpus in Ojong Diba (2019) (see also Ojong Diba, 2020, pp. 23–25), is that switching between local codes when any two speakers address each other is an atypical choice. It can occur when there is an abrupt change in the immediate context (e.g., as a result of the sudden arrival of a new listener) or to signal specific kinds of social meaning. In particular, it can serve as an attempt to distance one’s social connection to the addressee by using a language that signals the lack of a close relationship (see other examples in Di Carlo et al., 2019, 2020; Ojong Diba, 2019). The only case in which the semiotic significance of code-switching is somewhat neutralized is when the switch occurs between a local language and CPE. This phenomenon is probably due to the fact that, in the local context, the use of CPE transcends the dense network of possible affiliations with one or the other village-based communities, which are also key for the representation of kinship relations—switching to CPE in other parts of Cameroon, like in francophone areas, might instead convey a radically different, and more significant, social meaning.
This example helps clarify the question that lies behind the discussion below: What would LD look like if it began from the assumption that the documentation of multilingualism was at the center of a project rather than at the periphery? In proposing an answer to this question, we should be clear that we do not mean to suggest that projects based on the ancestral-code approach and that focus on structural linguistic analysis should not move forward, since these are also clearly valuable. Rather, we believe that the approach we outline here and the more traditional approach can complement each other and allow us to document languages in a richer way than would be possible by adopting either approach alone.
In the next section, we will try to structure this proposal by discussing and reframing fundamental issues of adequacy with regard to the audience, the scope, and the semiotic order of the contents of LD corpora.
Corpus adequacy
Adequacy and audiences
Summarizing Himmelmann (1998, p. 166), LD aims to create “a comprehensive record of the linguistic practices characteristic of a given speech community,” that is amenable to further analysis. While language descriptions are generally useful only to grammatically oriented and comparative linguists, suitably annotated documentary corpora have the potential of being of use to a larger group of scholars including, for instance, anthropologists, sociolinguists, discourse analysts, or historians, in addition to linguists.
The issue of corpus adequacy is pertinent for LD as a whole (see, e.g., Michael, 2011; Woodbury, 2011), but it clearly becomes more crucial when the documentary focus includes multilingual speech. The “further analyses” that can be made on such a corpus can potentially derive from one of the many traditions of research on multilingualism in domains as varied as psycholinguistics, language acquisition, the sociology of language, and sociolinguistics. Each have their own levels of analysis, which in its turn are made possible by focusing on certain types of data over others.
The usual intended audience of LD corpora is structurally oriented linguists rather than sociolinguists, social psychologists of language, psycholinguists, or even speaker communities (cf. Dobrin, 2008; Grinevald, 2001). It is on the background of their needs, then, that adequacy of an LD corpus has generally been assessed. From the structural linguists’ perspective—that is, where languages are primarily understood as lexico-grammatical codes—a corpus is adequate when it provides data qua words, sentences, and texts transcribed phonologically (not phonetically nor in a simplified alphabet) and also analyzed grammatically to varying degrees of detail.
The emphasis on adequacy at a lexico-grammatical level can be seen as one major factor accounting for the overall rarity of LD corpora containing multilingual speech data. If an LD project were to target spontaneous linguistic practices, the resulting corpus would include sizable multilingual materials in multiple little-known languages. In order to properly annotate the recordings, linguistic adequacy would require that detailed linguistic knowledge of all the languages recorded be accumulated so that phonological transcriptions and morphosyntactic annotations can be produced. However, if gaining enough linguistic knowledge is a demanding task for one undocumented language, it becomes utterly unrealistic when the same is expected for a number of such languages and the time available is bound to the duration of a research project (often coinciding with an individual’s doctoral research, see, e.g., Crippen & Robinson, 2013).
Facing these kinds of expectations, it is easy to imagine that hardly any linguist would embark on such an enterprise. What structural linguists often fail to appreciate is that there are other options available. Multilingualism can be studied even in the absence of detailed structural understanding of all the languages involved. Scientifically legitimate conclusions for linguistics can be reached, and these are also likely to provide important information and insights on the language–culture nexus (see Michael, 2011) that may eventually be beneficial to the structural linguistic level of analysis itself.
Given this background, before deciding which audience to address in the construction of a corpus and, therefore, what it must possess in order to be adequate, we believe it is first necessary to base these considerations on firm epistemological grounds that are as discipline independent as possible.
Widening the scope of LD corpora: Symbols and indices
There are two main kinds of meaning that signs can convey: indexical and referential (or semantico-referential). Indexical meanings are those that depend on context (e.g., who “I” is, when “now” is, what “that” is, or the meaning of code-switching for a particular language in a particular interaction). Semantico-referential meaning (or function) is referred to with this label because it references “things” and states in the world (making it referential) and because it works based on semantics (i.e., intrinsic, code-dependent meaning) rather than on pragmatics (i.e., context-dependent meaning).
In speech, hardly any sign falls within only one of the above types and produces only one or the other kind of meaning. More commonly, when used in context, linguistic signs are associated with multiple functionalities (see, e.g., Silverstein, 1976, p. 45). For instance, there are always multiple ways of conveying the same message, and the choice of how to encode it will inevitably convey some kind of meaning beyond semantico-referential meaning (e.g., whether a request is made via an imperative or an indirect question). In LD corpora, linguists have dealt mostly with semantico-referential meanings—contained in dictionaries, grammars, and texts—and have therefore specialized in the documentation and analysis of language signs qua symbols. 6 By contrast, indexical meanings, and the way they are obtained via language signs qua indices, do not normally fall within the scope of LD corpora except for those encoded by grammatical items, such as demonstratives and other so-called “indexicals” (including pronouns, many circumstantial morphemes, and so on; see Braun, 2017, for an overview of indexicals).
This is not an approach that one can adopt when multilingual behaviors are part of an LD corpus, for one simple reason: The use of multiple languages by one and the same speaker, or within a given speech community, is often not required for the production of semantico-referential meaning and is instead connected with the expression of indexical meanings primarily related to representations of participants’ selves (see, e.g., Irvine & Gal, 2000; Le Page & Tabouret-Keller, 1985) and of context (see, e.g., the contextualization cues of Gumperz, 1982) through the language that they choose to speak. Successful communication at this level is obtained by producing signs from multiple languages whose associated indexical layer of meaning will be decoded by the other interactants in appropriate ways because all of them share, to varying degrees, a common sense of how to use (signs from) lexico-grammatical codes in culturally appropriate ways. That is, they have a shared metapragmatic knowledge—not just a shared grammar—and at least some portions of “indexical space” in common (see the Contents of LD corpora: A re-appraisal and the notion of “indexical space” section below)—not just a common lexicon. In many small communities, a key feature of metapragmatic knowledge is when the use of a given language is called for.
We begin then with an assumption that a key goal in collecting an LD corpus reflecting the multilingual behaviors of a community is to collect the data that is required to understand the indexical value of language choice in interaction. If this is the case, what, then, should an LD corpus of multilingual data contain? We explore this question in the next section.
Contents of LD corpora: A re-appraisal and the notion of “indexical space”
A documentary corpus typically includes speech recordings (in the form of both video and audio files), annotations on the recordings (such as transcriptions, translations, etc.), metadata at the level of the recording session (e.g., date and place of recording, participants recorded, etc.), and a collection of analytical statements that, taken together, help users make sense of what is referenced in the annotations (typical examples are dictionaries and sketch grammars). Theoretically, there are no limits as to the domains of knowledge that are covered in annotations and analytical statements, which can include observations about ethnographic, geographic, sociolinguistic, musicological, or even ethological aspects of interest found in the recordings. To date, however, LD corpora contain mostly speech data with linguistic annotations only.
Due to the fact that multilingual behaviors foreground the indexical dimension of meaning-making of linguistic signs (as discussed just above in the Widening the scope of LD corpora: Symbols and indices section), corpora containing recordings of multilingual speech will have to also provide annotations and analytical statements that allow a user to make sense of how indexical meanings are produced. Dictionaries and grammars enrich the corpus user by illuminating the relationships existing between, on the one hand, linguistic signs and the “universe of the nameable” (i.e., lexicon) and, on the other, between linguistic signs themselves (i.e., grammar). Likewise, when the linguistic signs recorded instantiate indexical relationships with elements found in the context of the speech event, then an adequate corpus is one that includes not only speech data but also sufficient reliable information about the contexts and items that are indexed. It is important to note here that we speak of “contexts” in the plural. Inspired by Goodwin and Duranti (1992), we identify two main types of context that documentary efforts should be directed to: situational and extra-situational. In rough terms, the former refers to the locale in which a recorded interaction takes place. The latter includes both metalinguistic and metapragmatic knowledges—and therefore a sizable amount of ethnographic knowledge about the speech community—as these are highly influential in determining how people shape their multilingual behaviors. For this reason, data at both levels should be collected and included in the documentary corpus. The universe of what can be indexed linguistically using a certain kind of metapragmatic knowledge is what we call here its “indexical space”. 7
Issues concerning the adequacy of corpora with regard to how much of the indexical space they must capture and the tools to be used will not be considered in detail here (although see the An overview of the approach proposed section for an overview). What is more important in the present context is the observation that, for an LD corpus of multilingual data to be adequate, annotations and analytical statements cannot be limited only to the linguistic level but should also cover a broad range of contextual factors (e.g., ethnographic, sociolinguistic, etc., following the seminal proposals of Hymes (1972[1986]) for an ethnography of speaking, including its SPEAKING mnemonic, which lies at the foundations of the approach presented here). Depending on the levels of annotation and analyses that are needed, the ways in which multilingual speech data are to be collected and approached will need to be adjusted. We develop this point further in the fourth and fifth sections (see also Supplementary Materials).
Multilingual speech data
Multilingual speech in natural conversation is manifested in phenomena such as borrowing, calquing, and code-switching. Drawing on some of the methods commonly used to analyze these phenomena, we can identify linguistic, sociolinguistic, and pragmatic levels of analysis. Linguistic analyses can be focused on lexical choices, or on the syntax, morphology, and phonology of multilingual speech. Sociolinguistic and pragmatic levels of analysis can be focused on language attitudes, social indexicality, language vitality, style, turn-taking, phenomena connected to accommodation, and metapragmatic knowledge.
However different from each other they are as to the type of linguistic knowledge that they build upon, at closer inspection one realizes that knowledge of the indexical space is necessary at all of these levels due to the fact that multilingual speech is inherently indexical in nature, as discussed in the third section. Different degrees of need for detailed linguistic knowledge across levels of analysis are connected mainly to matters of the scale of the analytical units. When the observable vector of an index is “a language as a whole”—as it is, for example, in many instances of code-switching phenomena—then an initial analysis does not need to be based on the observation of micro-phenomena—such as phonological variants—but can be performed on entire chunks of speech flow, from sentences to speech turns to even entire speech events, as was done in the example presented in Table 1.
Of course, providing a phonological transcription would be of great value for supporting more in-depth analyses. However, we want to emphasize that the enormous efforts required to obtain it would radically jeopardize the documentation project whose success, in fact, does not depend on such linguistic detail but, rather, on details about the indexical meanings produced during the interaction, and this can be achieved even without a phonological transcription. A key claim we are making here, therefore, is that, in LD corpora of contemporary communicative practices in contexts of small-scale multilingualism, a general understanding of the conceptual space that is being used by speakers to produce indexical meanings can be reached before embarking on the task of obtaining detailed grammatical knowledge. Within this domain, priority must be given to matters such as the identification of the codes used, the repertoires available to interactants, and the social significance of the codes present in the indexical space before substantial efforts are made to increase the grammatical knowledge of the codes involved (if any such efforts can be made).
Such requirements, taken together, comprise what we refer to, for the sake of convenience, as “sociolinguistic adequacy.” The documentary model that we develop here is intended to ensure that LD corpora of multilingual speech can meet such a threshold. 8 Structural linguistic adequacy in such cases is, we believe, less urgent because, without knowledge of the indexical space, multilingual behaviors will hardly be interpretable and, due to the lack of reliable annotations about the indexical meanings produced in speech data, the corpus will be less amenable to further analyses. In addition to being less urgent, achieving structural linguistic adequacy in contexts of small-scale multilingualism is often an unrealistic goal.
These things being said, we do not intend to suggest that sociolinguistic and structural linguistic adequacy should be taken as two opposite, mutually exclusive approaches. Rather, we view them as two cycles of a larger process. This recalls the words of Grinevald (2001, p. 288) about the interplay between descriptive and documentary approaches in LD. She concludes that “the process would start with an initial description, this description becoming essential for a wider type of documentation, which itself will allow for a more sophisticated and comprehensive description, and so on.” While she focuses on the relationship between documentation and description, we are, instead, emphasizing two different approaches to documentation itself. For multilingual documentation, the key phase is the one in which sociolinguistic adequacy, instead of structural linguistic adequacy, is at the forefront: This will then provide essential background for a more detailed description of multilingual speech data, followed by more in-depth sociolinguistic analyses, which will feed improved linguistic analyses, and so on.
Achieving sociolinguistic adequacy
The challenge of “relinquished control”
One key underpinning of sociolinguistic adequacy, especially when projects are conducted in contexts of small-scale multilingualism, is that it entails a greater reliance on speaker consultants for the production of primary data (i.e., minimally processed data such as free translations or identification of the codes used in the recordings) rather than of raw data only (i.e., speech). 9 Standard approaches to structural linguistic analysis may rely on the analyses of raw data produced by consultants, for instance in the form of careful re-pronunciations of naturalistic speech to assist in transcription or free translations produced by them. However, these are generally “filtered” to create primary linguistic data through long-standing analytic techniques such as those that support phonemic and morphological analysis.
By contrast, such filtering would be inappropriate for a corpus aiming for sociolinguistic adequacy where the analyses that speakers produce are not merely a tool for the linguist to arrive at the “right” structural analysis but, rather, are, in and of themselves, a key kind of data for understanding locally salient indexical meanings. In practice, this “unfiltering” is most readily observed in instances where consultants are asked to comment on recordings of their (multilingual) linguistic practices. In addition to identifying other participants in the recording and the named varieties used in the interaction, the consultant can also be asked about the motivations that led them to use or switch to a certain language. Of course, not all information collected in this way should be taken at face value, since folk rationalizations may or may not be revealing of metapragmatic knowledge, which is the ultimate target of sociolinguistic adequacy. Nonetheless, language choice in interaction is often subject to conscious metapragmatic manipulation and, for this reason, speakers may not only be aware of their motivations, but also able to articulate them, thereby producing primary data that the researcher will not filter through an existing “grammar” but, rather, integrate into the corpus in various ways—for example, via session-based or topic-based notes, annotations to the recording, etc. 10
In contexts of small-scale multilingualism, common low-control research activities are those in which the researcher not only needs to rely on the help of native speakers to make recordings (raw data) and produce annotations (primary data), but also cannot directly check their accuracy (i.e., no filtering is possible). This could occur, for instance, when a researcher must rely on a consultant’s judgment that a given stretch of discourse involves the use of a number of different “languages” that the researcher has not had much exposure to, as was the case, for instance, in the analysis of the data presented in Table 1. The evident shortcoming of such a situation of “relinquished control,” well described by Grinevald (2001, p. 301) as “one of the most difficult constraints for academics to accept” is the risk of not being able to guarantee data validity (see, e.g., Tillery, 2000). However, this potential weakness can be countered in two ways: (a) by having multiple consultants do the same kind of work for the same data and then comparing the results for misalignments between them, which can then be addressed in various ways, such as focus group sessions, and (b) by sampling local metapragmatic knowledge indirectly through tools such as the Matched-Guise Test technique (see Chenemo & Neba, 2020, for an interesting adaptation of this tool to a rural African context).
The need for an ethnographic approach
A fundamental consideration to make at this point concerns what kinds of research methods can still be considered “high-control activities” in such a research scenario. For one thing, these are key for the scholarly world to accept the model proposed here. The kind of documentation we are proposing does not mean recording whatever people say and collecting whatever accounts they offer of their behaviors indiscriminately. For sociolinguistic adequacy to be met, it is essential that the approach is ethnographic in kind, which means researchers should be trained in how to identify and understand as much as possible about the speakers’ own perspectives.
This becomes evident, for instance, in the identification of the codes used by speakers, an activity that should be rooted in the concept of local saliency prior to any possible categorization facilitated by the use of linguistic comparative tools—whose aim is to assess the distance between codes and, therefore, “establish” whether these are, for example, “separate languages” or “just dialects of a single language.” If a code is named and is systematically identified in recordings by consultants, then it must be documented as an element of the community’s linguistic repertoire, regardless of its degree of similarity with any other code present in the repertoire (see also Esene Agwara, 2020, p. 189, and Khanina, 2021, for a similar ethnographic exercise carried out in Siberia). 11
Another example of what an effective ethnographic approach may entail in practice concerns the speakers themselves. These, too, must be “documented” as their available roles and identities are likely to shape the way they speak with other community members. The basic (auto-)ethnographic recognition here is that salient features of personal and social identity are culture specific and, therefore, initially inaccessible to outside researchers. For this reason, speakers should not be categorized solely according to widely used sociological parameters such as age, gender, socio-economic status, and occupation. Rather, additional efforts are required in order to collect information that will initially be particularly wide ranging and encompass topics that do not immediately lead to systematization—such as people’s life histories and kinship and other relations within and outside of the community—and that can be narrowed down to a set of more salient features—such as the provenance of people’s personal names (see, e.g., Di Carlo, 2021; Di Carlo & Good, 2014, pp. 249–250; Esene Agwara, 2020, pp. 189–190)—only when more data becomes available.
What we have said in this section so far brings about one first (i.e., not the only) requirement for those embarking in the creation of a multilingual LD corpus: Anyone “preparing for fieldwork should read the contemporary ethnographic literature on the broader region in which they plan to work” (Dobrin, 2008, p. 317). Not doing so would risk failing to see many important areas of data collection that have already been identified by previous work. 12
An overview of the approach proposed
Based on the discussion above, we provide an overview of the data collection approach that we advocate in Table 2, including possible associated research outputs and activities. The abbreviations H, L, and HL refer to the degree of control researchers have on the corresponding activity: H = high control, L = low control, HL = high control on tools, low control on output (i.e., strategies are needed to maximize data validity, see the The challenge of “relinquished control” section above). 13
Research strategies for achieving sociolinguistic adequacy across domains, targets, outputs, activities, and degree of researcher control.
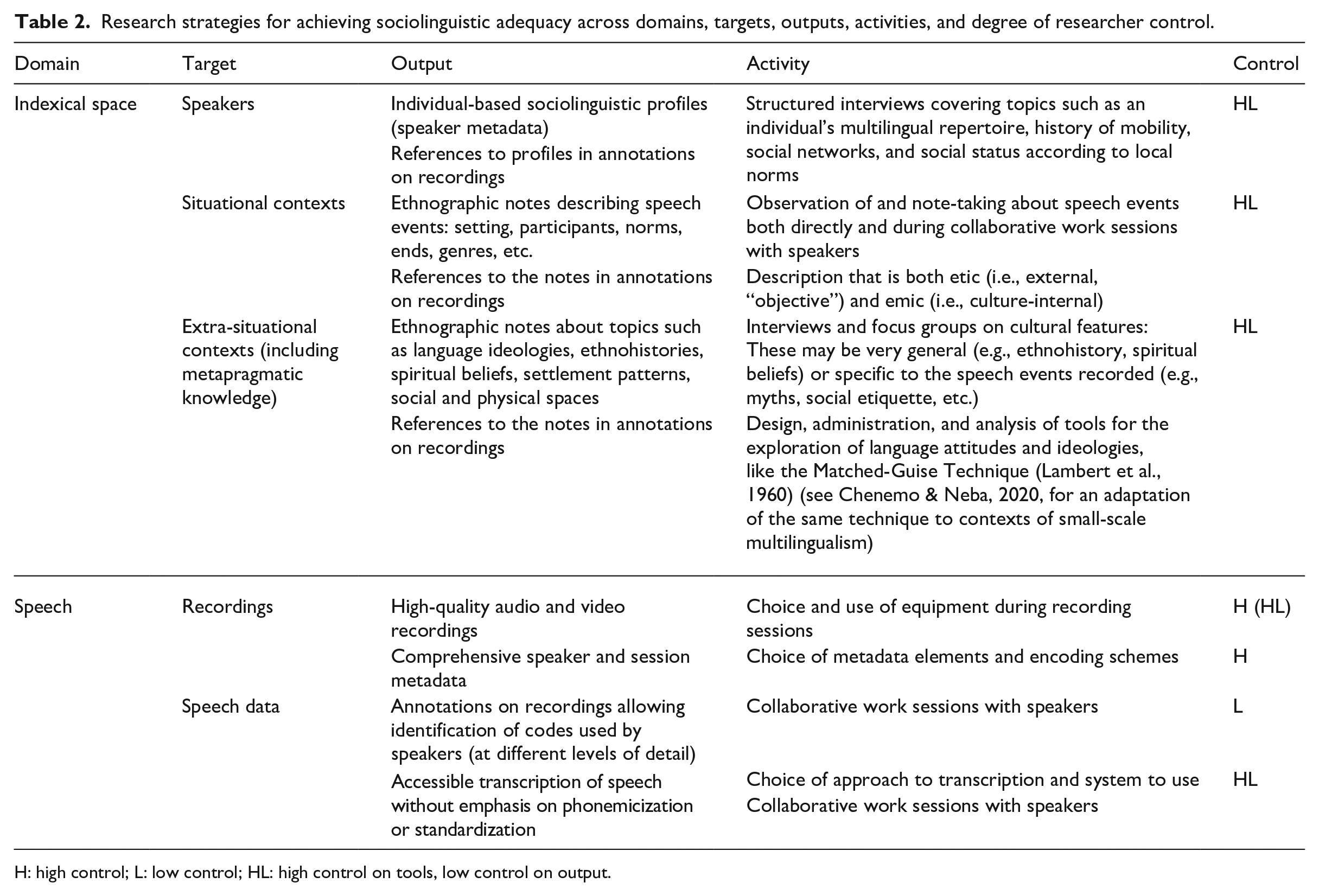
H: high control; L: low control; HL: high control on tools, low control on output.
Conclusion
In this article, we have tried to re-imagine LD from the perspective of those who plan to target contexts of small-scale multilingualism. The key step in this process has been an appraisal of the larger-than-usual weight that must be given to the indexical function of linguistic signs in a corpus containing multilingual speech data, as compared to more typical monolingual LD corpora. This has led us to propose that such a corpus will have to include both speech data (i.e., recordings of speech events) as well as information about what we called here the “indexical space”—that is, speakers’ metadata plus situational and extra-situational context, which together amount to the ideal universe of whatever can be indexed using language through the metapragmatic knowledge that is shared by members of a given speech community. Our claim has been that “sociolinguistic adequacy” must be prioritized in the creation of multilingual LD corpora over structural linguistic adequacy, and we have summarized its main theoretical (fifth section) and practical aspects (see Supplementary Materials).
We want to emphasize here that a sociolinguistically adequate documentary corpus, such as this one, makes it possible to gain access to information that can feed many other types of analysis, not only sociolinguistic, but also linguistic, anthropological, and historical. This can be seen, for example, in the insights on strategies of identity construction through language choice that are discussed by Di Carlo et al. (2020) or the historical and ethnographic interpretation of small-scale multilingualism in the Casamance region of Senegal found in Lüpke (2018). Crucially, it could also inform efforts at revitalization as the local language ecology that is being documented is clearly connected with the maintenance of small languages.
A final remark should be made with respect to the intended audience of this article. As with most methodological proposals, those whose work would be most directly impacted is a relatively small set of specialists, in this case scholars whose research focuses on the documentation of endangered languages. At the same time, the research situations discussed above—that is, contexts of small-scale multilingualism—will be of interest to a much wider range of scholars, such as sociolinguists who, by and large, are not normally involved in the creation of LD corpora. We hope others, especially scholars whose research focuses on multilingualism, even if it has been primarily oriented towards “large-scale” societies, will continue a conversation we have only started here, fill gaps we have left open, and point out ways in which the approach outlined above needs to be refined. We also hope that our proposal will have the consequence of reaffirming the need for a multidisciplinary and team-based approach to LD (pace Austin & Grenoble 2007, p. 22), especially when the documentary task is as complex as the one we have focused on in this article.
Supplemental Material
sj-pdf-1-ijb-10.1177_13670069211023144 – Supplemental material for Towards a coherent methodology for the documentation of small-scale multilingualism: Dealing with speech data
Supplemental material, sj-pdf-1-ijb-10.1177_13670069211023144 for Towards a coherent methodology for the documentation of small-scale multilingualism: Dealing with speech data by Pierpaolo Di Carlo, Rachel A. Ojong Diba and Jeff Good in International Journal of Bilingualism
Footnotes
Acknowledgements
We would like to acknowledge audience members at the Typology of Small-Scale Multilingualism conference held at the Collegium de Lyon, 15–17 April 2019 for their input on the research underlying this paper as well as the editors of the special issue and three anonymous reviewers of the manuscript itself. One reviewer, in particular, provided a series of insightful comments that we were not in a position to address in this paper, but that we hope to consider in future work. The order of the authors reflects the fact that the first two authors contributed more or less equally to the paper, while the last author’s contribution was more limited. The first author’s contributions focused, in particular, on the overall theoretical framing of the paper, the second author provided key data, analyses, and consideration of practical concerns related to research of the sort described here, and the third author provided general contributions to the overall structure and framing of the paper and also contributed to the text itself.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by US National Science Foundation Awards BCS-1360763 and BCS-1761639.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
![]() ).
).
![]() ), which he directs. In addition, he has done work on theoretical and methodological issues in the area of language documentation and the synchrony, diachrony, and typology of linear relations within morphology and syntax.
), which he directs. In addition, he has done work on theoretical and methodological issues in the area of language documentation and the synchrony, diachrony, and typology of linear relations within morphology and syntax.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.