
Abstract
Aims:
Cross-language interference studies of language control mainly focus on the lexical level, whereas language control may occur at the smallest unit phonemic level of language. In the present study, we examined the role of language control during cross-language phoneme processing.
Design:
Participants used one language to name pinyin or alphabet in the single-language blocks, and they used two languages for naming in the mixed-language blocks.
Data and analysis:
Using a linear mixed-effects model, we built models for mixing costs and switching costs based on reaction times (RTs) and accuracy.
Findings:
Switching between Chinese (L1) and English (L2) phonetic symbols revealed both mixing and switching costs.
Originality:
The findings suggest that switching of cross-language phonemes requires not only global control of the non-target phonemes, but also local control of the non-target phonemes.
Significance:
Just as cross-language interference control occurs at the lexical level, this study demonstrates that control also occurs at the phonemic level.
Introduction
Bilinguals are able to communicate in one or both of their languages according to various contexts and situational needs. For instance, bilinguals may use their first language (L1) with family members and a second (L2) with colleagues, or they may find themselves switching back and forth between both languages among other bilinguals who speak the same two languages. The situation in which one language is used for communication is defined as a single language context and the situation in which both languages are used is referred to as mixed language context. Experimental designs can simulate single and mixed language contexts by asking participants to respond to series of trials that are repeated in the same language or both languages, respectively. The reduced performance of repeated trials in mixed language contexts can be observed through mixing costs which arise as bilinguals globally inhibit the nontarget language interference, reflecting the sustained inhibition (Branzi et al., 2016; Declerck, 2020; Guo et al., 2011; Kleinman & Gollan, 2018; Rossi et al., 2018; Wu & Thierry, 2017). Compared with repeated trials in a mixed language context, switch trials generally elicit switching costs such that they have slower naming latencies and higher error rates (Liu et al., 2021; Liu, Kong, et al., 2020; Liu, Zhang, et al., 2020; Philipp et al., 2008; Weissberger et al., 2015). According to the adaptive control hypothesis (ACH, Green & Abutalebi, 2013), switching costs are the consequence of local inhibition of cross-language interference, implying transient inhibition (Branzi et al., 2016; Declerck, 2020; Declerck & Philipp, 2015a; Green, 1998; Guo et al., 2011; Kleinman & Gollan, 2018; Meuter & Allport, 1999; Rossi et al., 2018; Wu & Thierry, 2017). Both language mixing and switching costs allow us to analyze the specific mechanism of language control.
Although an accumulating number of studies have explored the role of language control in suppressing interference at the lexical level during language switching (Abutalebi & Green, 2008; Bialystok et al., 2012; Blanco-Elorrieta & Pylkkänen, 2016, 2017; Blanco-Elorrieta et al., 2018; Branzi et al., 2016; Declerck & Philipp, 2015a; Declerck et al., 2012; Kleinman & Gollan, 2018; Linck et al., 2012, 2020; Prior & Gollan, 2011; Schwieter & Sunderman, 2008), less attention has been given to the level of sound. That said, there are important differences between word and phonemic representations that should be considered when examining language control. Phonemic representations are less susceptible to interference from semantics and graphemes and in the case of languages that have vastly distinct orthographic systems such as English and Chinese (Baranov & Kraevskaya, 2017), these issues become even more complicated. For instance, Chinese and English may not be studied at the same level, such as “car” and “汽车,” which are very different in form. In the present study, the interference from semantics and orthography was eliminated.
A phoneme is the smallest phonetic unit according to the natural features of utterance and is the basic component of a word (Daube et al., 2019; Fricke et al., 2016; Grainger et al., 2003; Mesgarani et al., 2014; Morais, 2021; Stevenson et al., 2017). The theory of phonological encoding (Coltheart et al., 1979; Dell, 1986, 1988; Levelt et al., 1999; Qu et al., 2012, 2020) considers the importance of phonemes as units during word production in which information about pronunciation is retrieved from the mental lexicon in phonemic units (Qu et al.). Macizo (2016) found that naming latencies were slower when color names and picture names were phonologically related in L1 compared with when they were unrelated. These results suggest that the two languages’ phonological systems have been activated parallelly and that L1 phonology influences L2 production. Declerck et al. (2013) also demonstrated that phonologies influence language activation in a study which showed that language-specific phonology (phonemes that do not appear in the other language) elicited faster RTs in the L1 compared with L2 and that language-unspecific phonology (without any language-specific phoneme) elicited faster RTs in L2 than L1. The authors argued that articulation was a locus of language control. In a follow-up study, Declerck and Philipp (2015b) used the picture–word interference paradigm to measure the influence of phonological overlap on language control. The findings showed that the switching cost in L1 phonological overlap was greater than that of L2. The above studies indicate that cross-language phonemes will affect language switching and that phonemes constitute important units in language control and production.
A few electrophysiological studies have asked Mandarin native speakers to name pictures with phonetic overlap in color adjective-noun phrase. Their findings showed that event related potential (ERP) amplitude were influenced by phonemic overlap from 200 to 300 ms, supporting the assumption that phonemes may be processed as units and play a role in language production (Qu et al., 2012, 2020). Christoffels et al. (2007) also provided evidence that phonological processing affects early stages of German (L1)–Dutch (L2) production. Besides, Roelofs and Verhoef (2006) hold that phonological representations between languages (especially, Dutch–English) are shared. However, previous research has left unexamined the role of semantics and letters in language control. In addition, these studies illustrate that language control mechanisms suppress interference at the phonemic level, but do not distinguish between the types of language control in different contexts. If inhibition of the nontarget language is assumed to take place at the lemma level, this implies that phonological activation will be restricted to the selected, relevant lexical node. Accordingly, the present study will address the following questions: What are the specific stages of phonology’s involvement in bilingual production? Does phonology suppression occur independently from letters and semantics, or is it part of word suppression interference?
Present study
The current study includes single and mixed language contexts to assess the mechanism of global and local control on cross-language phonemes. Participants were required to name phonemes in their L1 or L2 according to color cues. Phonological encoding theory (Qu et al., 2020) considers phonemes as a unit of word production, and thus, phonemes may exhibit similar mechanisms as bilingual word switching. There may also be local and global inhibition of phonemic processing as shown by switching and mixing costs in different language contexts. The phonemes of the two languages are not only different in pronunciation, but also distinct in meaning and can affect bilingual language control. Conversely, if phonemes are not a separate unit, switching between two languages with the same form but with different pronunciation is consisted of a task switch, and thus should not affect language switching and mixing costs.
Method
Participants
Thirty-six right-handed Chinese (L1)–English (L2) bilinguals from Liaoning Normal University were recruited in the study. All participants (24 female, 12 male) were on average 23 years old (SD = 2.46), had normal or corrected-to-normal vision, and had no history of neurological or psychological impairments. The study was approved by the Research Center of Brain and Cognitive Neuroscience at the university and all participants provided their written informed consent to take part.
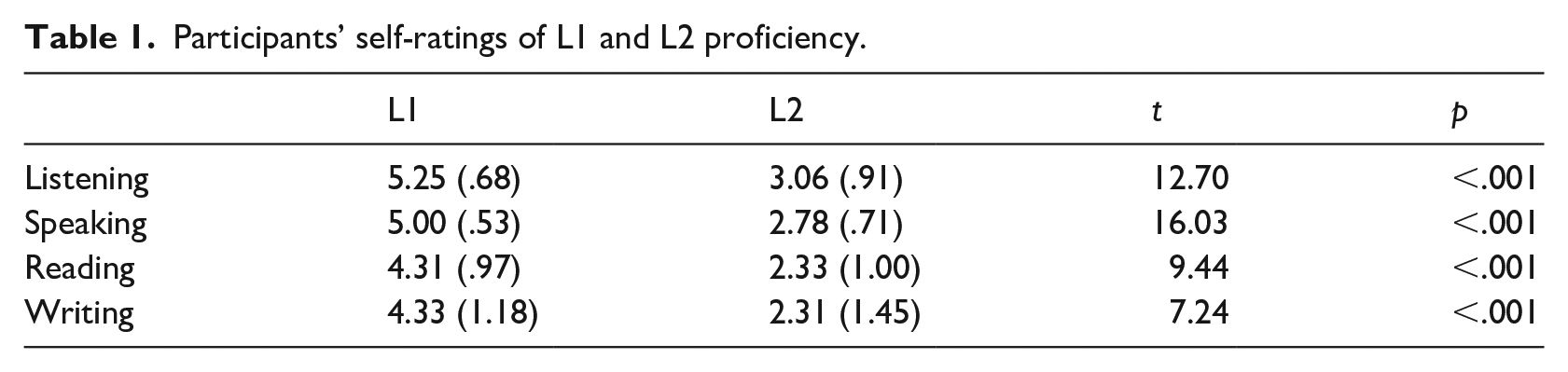
At the time of the study, the participants had studied English for an average of 14 years. We used the Oxford Placement Test (OPT, maximum score 50 points; Allan, 2004) to gather information about their L2 proficiency. The mean OPT score was 31.81 (SD = 5.3), implying an intermediate level of L2 as in previous studies testing this population (e.g., Liang & Chen, 2014; Liu et al., 2016). We also asked the participants to rate their language abilities in both the L1 and L2. These self-ratings were given on a six-point scale in which “6” indicated “perfect proficiency” and “1” indicated “no proficiency.” Paired-sample t-tests found significantly higher L1 proficiency in listening, speaking, reading, and writing (see Table 1).
Participants’ self-ratings of L1 and L2 proficiency.
Materials
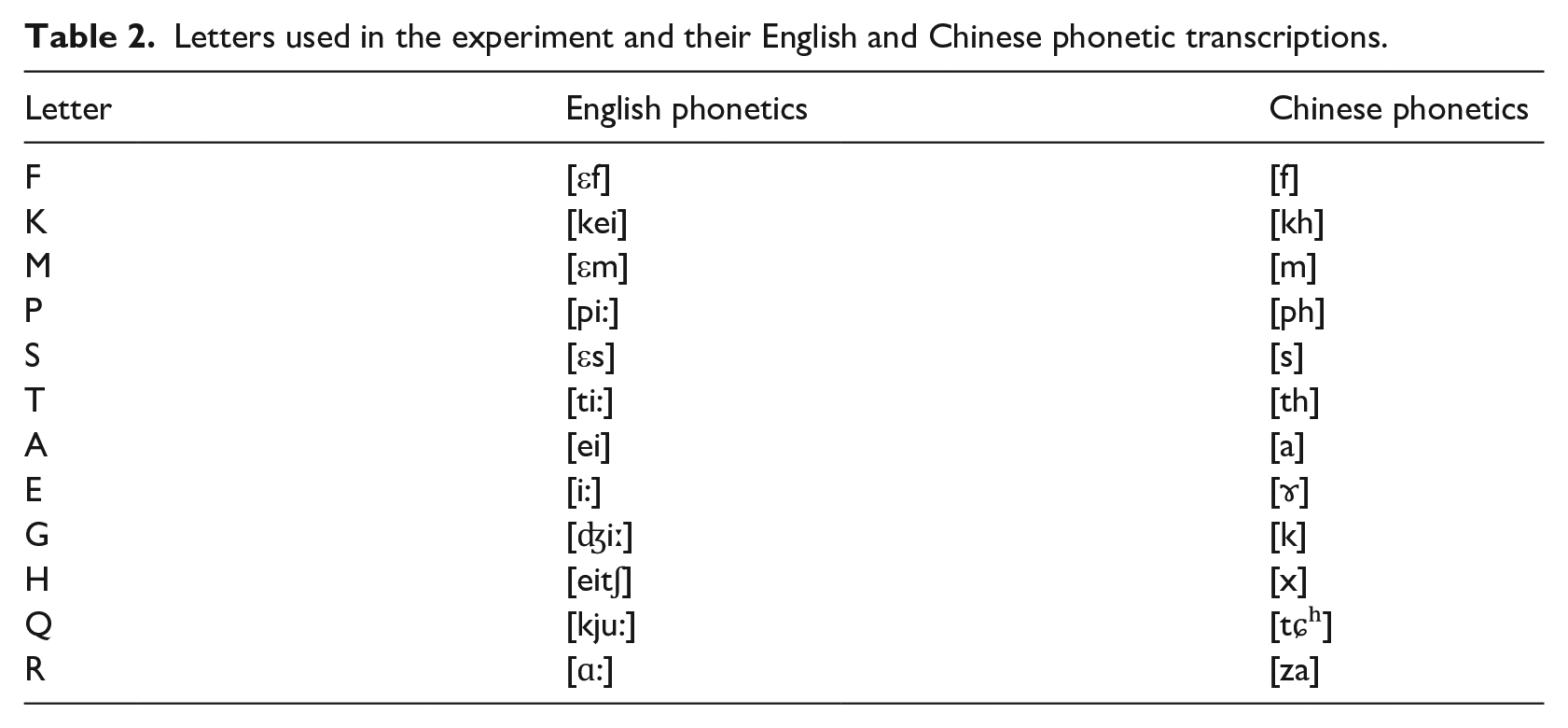
We randomly selected 12 letters, their English (L2) phonetic symbols, and Chinese (L1) phonetic symbols to include in the experiment (see Table 2). We adopted the international phonetic alphabet (IPA) as the unified standard for alphabet selection. The phonetic transcription of English alphabet is derived from IPA (https://tophonetics.com/), and the phonetic alphabet of Chinese pinyin is based on the Chinese Dictionary (https://www.zdic.net/ts/fulu).
Letters used in the experiment and their English and Chinese phonetic transcriptions.
Procedure
To reduce misidentification and misnaming of the letters, participants were asked to familiarize themselves with L1 pinyin and L2 alphabet pronunciations before the formal experiment. The experiment was programmed with E-PRIME 2.0 and displayed on a 17-in. CRT screen with a resolution of 1280 × 1028. The stimulus letters were presented in white font in the center of a black screen. The experiment included a single L1 block, a single L2 block, and two mixed language blocks (see Figure 1). At the beginning of each block, the participants did a practice set of trials that were the same as the formal experiment. The practice block consisted of eight trials of letters to be named that were not in the formal experiment. In the formal experiment, there were 36 trials and 2 warm-up trials in the single language blocks, and 72 trials and 2 warm-up trials in the mixed language blocks. Each letter appeared six times in each block. In the single language blocks, participants always named letters in the same language; these trials were called stay trials. In the mixed language blocks, if the language of two consecutive trials was the same (L1–L1 or L2–L2), the second trial was considered a repeat trial. If the language of the current trial was different from the previous trial (L1–L2 or L2–L1), the current trial was called a switch trial. The trials were ordered pseudo-randomly and the number of repeat and switch trials was equal in the experiment.

(a, b) Experimental blocks and (c) procedure.
As shown in Figure 1(c), the procedure of each trial started with a cue (red or blue) appearing on the screen for 250 ms, indicating in which language the subsequent letter was to be named. The color-language association was counterbalanced across participants (i.e., half of the participants associated red with L1 and blue with L2 and the other half associated blue with L1 and red with L2). After a blank screen of 500 ms, a target letter appeared. Naming latencies were recorded by a serial response box. The letter was displayed until a response or after 3,000 ms if no response was recorded.
Data analyses
Reaction times (RTs) and accuracy for letter naming were analyzed using the lme4 package (lme4 version 1.1-23, Bates et al., 2014) and lmerTest package (Kuznetsova et al., 2017). Before conducting the data analyses, we moved RTs less than 200 ms and greater than 2500 ms and those that were ±2.5 SD from a participant’s overall mean (de Bruin et al., 2018; Li et al., 2015; Martín et al., 2010; Philipp et al., 2007). This resulted in a total of 5.08% data removed. Using a linear mixed-effects model, we built two models: A model for global control, in which Language (L1, L2) and Sequenceglobal (stay, repeat) were treated as fixed effects; and a model for local control where Language (L1, L2) and Sequencelocal (repeat, switch) were set as fixed effects. These two models included participants and items as random effects (random intercepts and slopes). When models did not converge, we removed the slope that explained the least amount of variance until the model converged. Parameters were estimated with restricted maximum likelihood (REML). Below we report the results from the best-fitting model as justified by the data.
Results
Accuracy results
Responses were considered incorrect when participants named the letter in the wrong language, self-corrected an error, paused, stammered, or signed, or did not respond. Table 3 and Figure 2(a) show the accuracy results of global control in which the main effect of Sequenceglobal revealed mixing costs, which was indicated by lower accuracy in repeat trials (M = .96 ± .19) than in stay trials (M = .98 ± .13).
Best-fitting linear mixed model of global control accuracy.
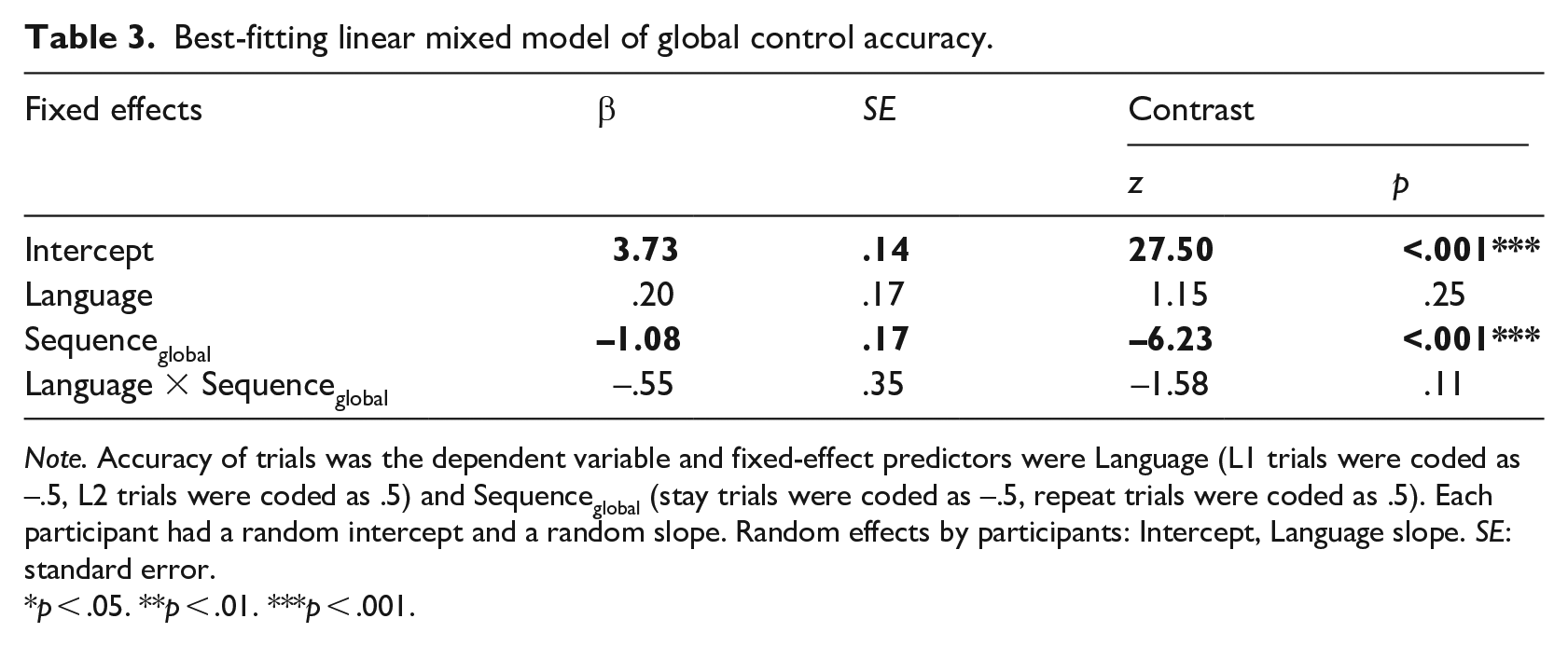
Note. Accuracy of trials was the dependent variable and fixed-effect predictors were Language (L1 trials were coded as –.5, L2 trials were coded as .5) and Sequenceglobal (stay trials were coded as –.5, repeat trials were coded as .5). Each participant had a random intercept and a random slope. Random effects by participants: Intercept, Language slope. SE: standard error.
p < .05. **p < .01. ***p < .001.
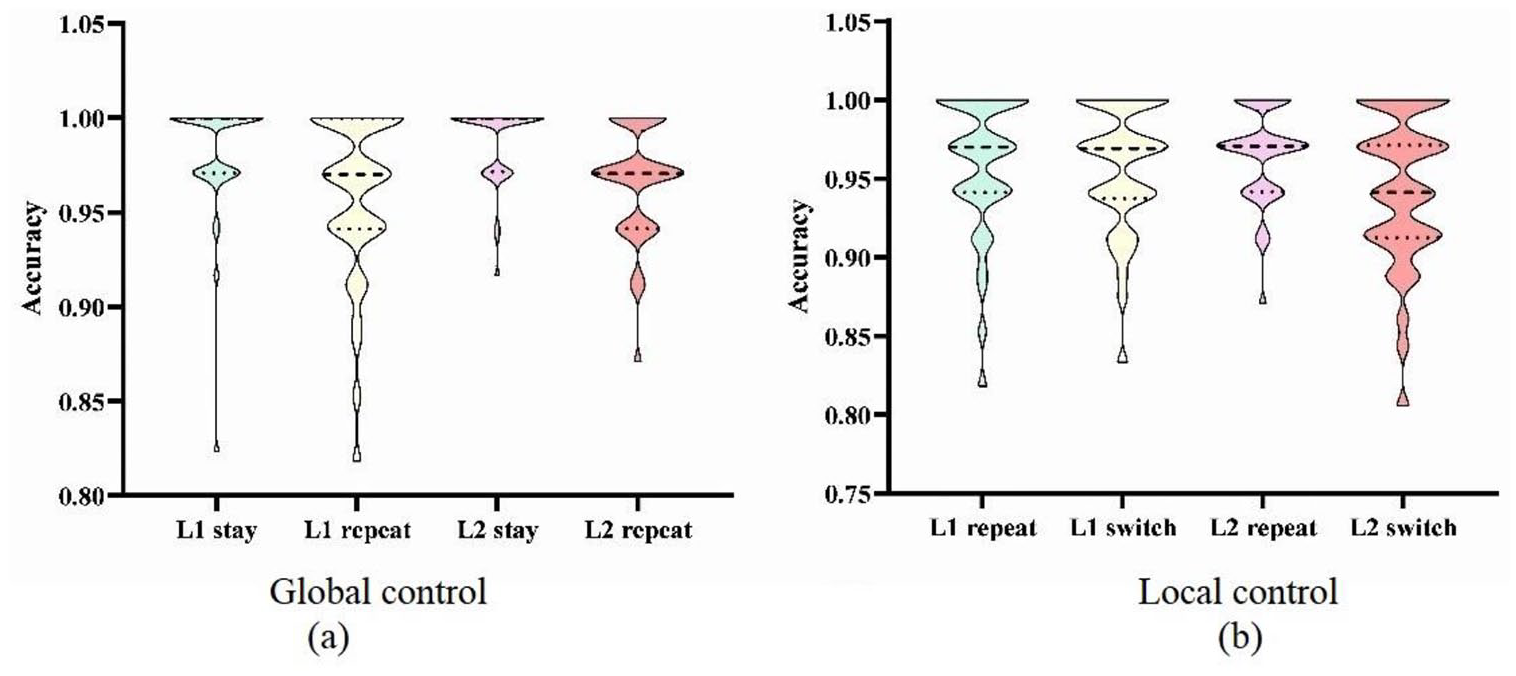
Results of accuracy analyses for global control (a) and local control (b).
Table 4 and Figure 2(b) display the accuracy results for local control where a main effect of Sequencelocal revealed that there was lower accuracy in switch trials (M = .94 ± .22) compared with repeat trials (M = .96 ± .19).
Best-fitting linear mixed model of local control accuracy.
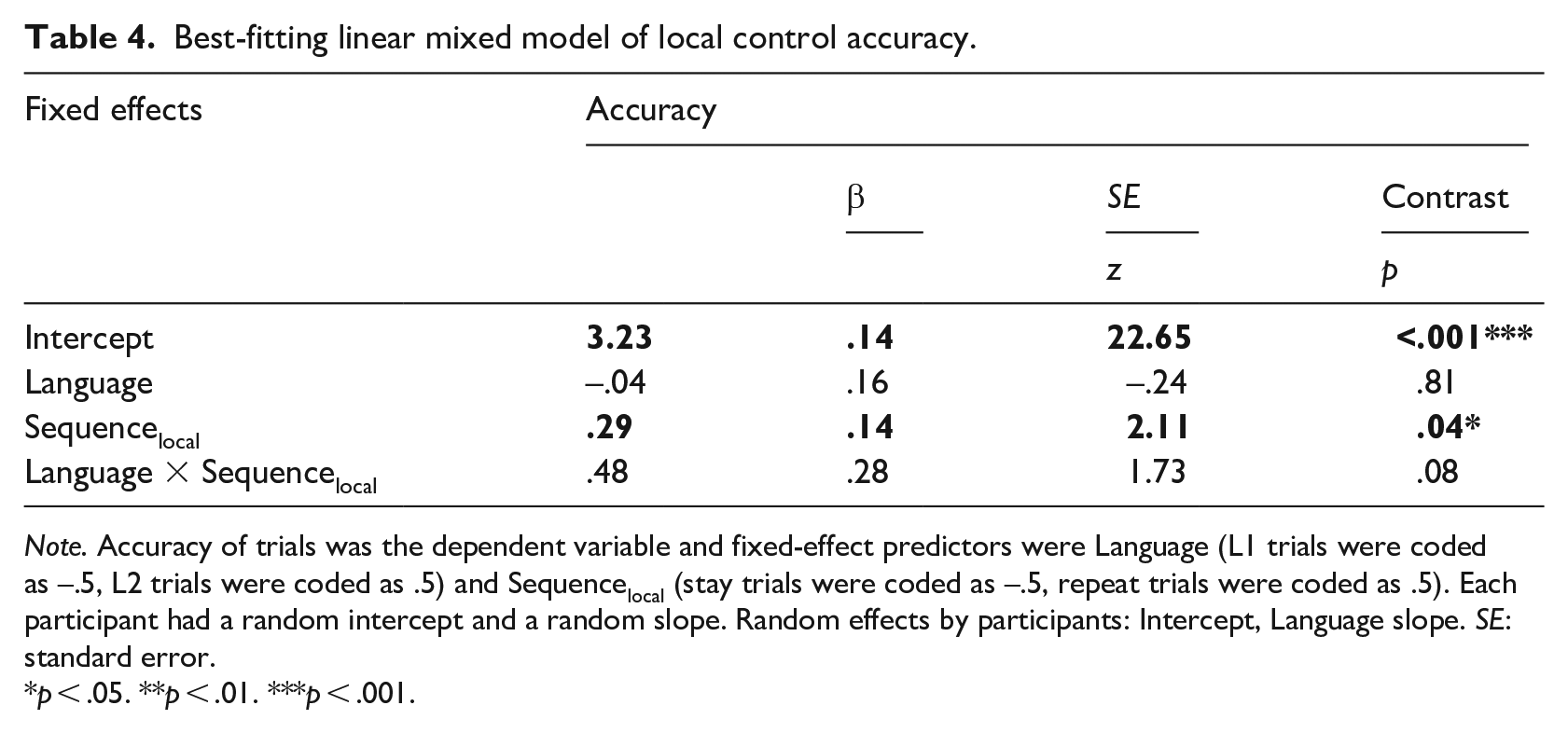
Note. Accuracy of trials was the dependent variable and fixed-effect predictors were Language (L1 trials were coded as –.5, L2 trials were coded as .5) and Sequencelocal (stay trials were coded as –.5, repeat trials were coded as .5). Each participant had a random intercept and a random slope. Random effects by participants: Intercept, Language slope. SE: standard error.
p < .05. **p < .01. ***p < .001.
RTs results
As shown in Table 5 and Figure 3(a), for global control, we found a main effect of Language, indicating that naming letters in the L1 (747 ± 229 ms) was slower than in the L2 (715 ± 240 ms). The main effect of Sequenceglobal revealed mixing costs, such that responses in repeat trials (939 ± 316 ms) were slower than in stay trials (731 ± 236 ms).
Best-fitting linear mixed model for global control RTs.
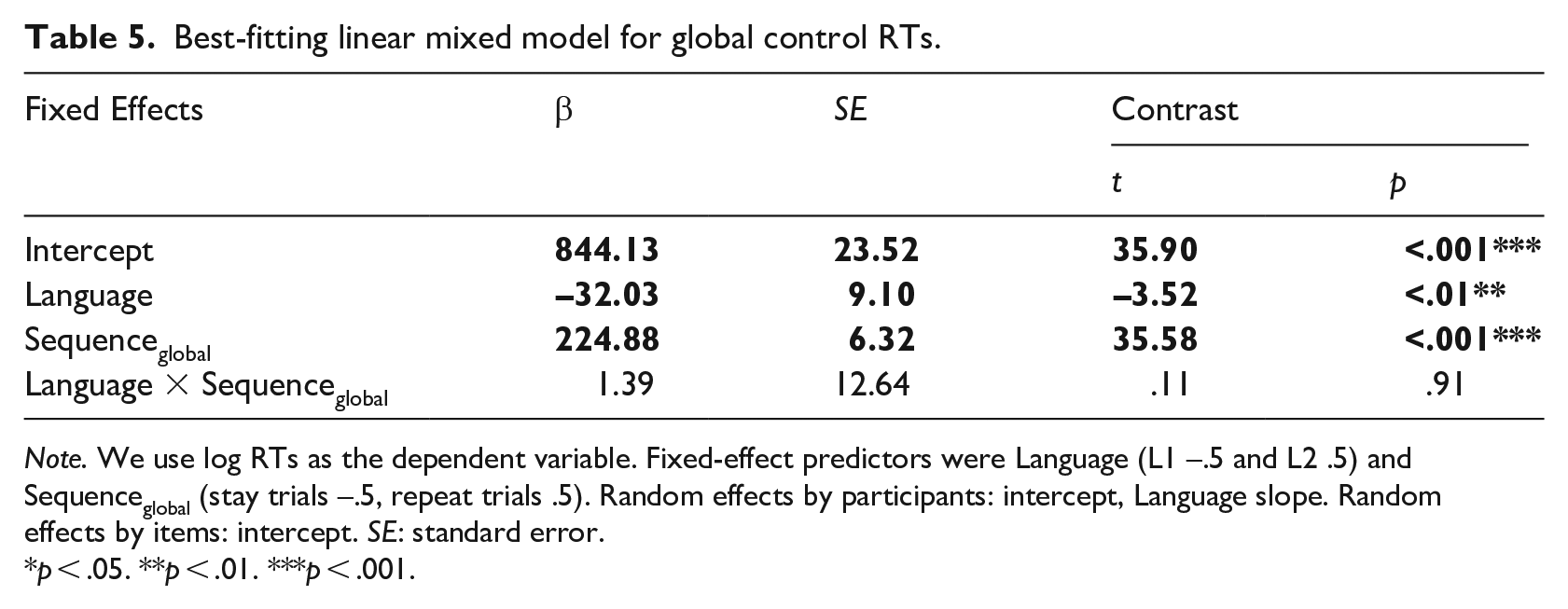
Note. We use log RTs as the dependent variable. Fixed-effect predictors were Language (L1 –.5 and L2 .5) and Sequenceglobal (stay trials –.5, repeat trials .5). Random effects by participants: intercept, Language slope. Random effects by items: intercept. SE: standard error.
p < .05. **p < .01. ***p < .001.
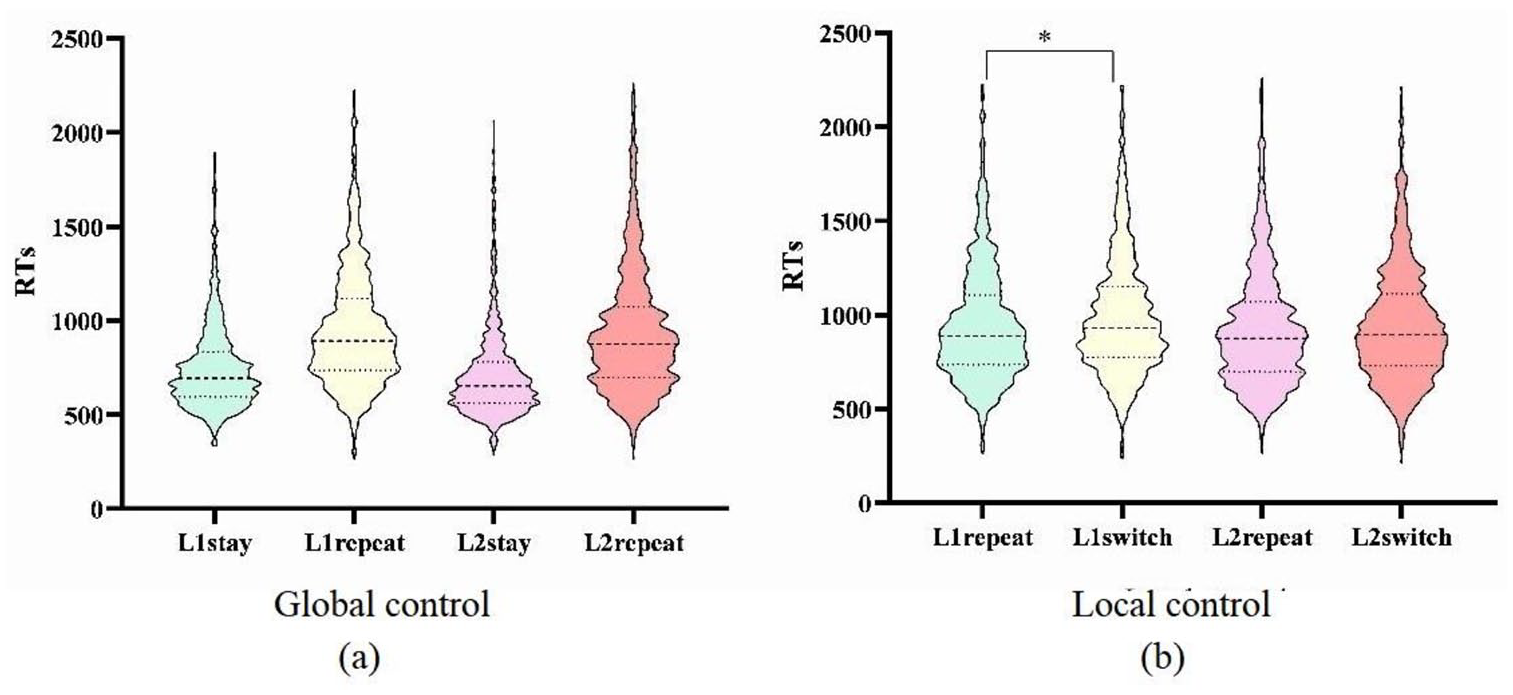
Results of RT analyses for global control (a) and local control (b).
As shown in Table 6 and Figure 3(b), for local control, the main effect of Language was significant, such that L2 naming (939 ± 315 ms) was faster than L1 (971 ± 316 ms). The main effect of Sequencelocal, revealed switching costs: naming was slower in switch trials (970 ± 316 ms) relative to repeat trials (939 ± 316 ms). There was also a two-way interaction between Language × Sequencelocal, suggesting that for the L1 particularly, there were larger asymmetry (48 ms) between switch and repeat trials (switch trials: M = 995 ± 322 ms and repeat trials: M = 947 ± 309 ms; β = .05, SE = .01, t = 4.75, p < .001) compared with L2 (15 ms) (switch trials: M = 946 ± 308 ms and repeat trials: M = 931 ± 322 ms; β = .02, SE = .01, t = 1.91, p = .06).
Best-fitting linear mixed model of local control RTs.

Note. We use log RTs as the dependent variable. Fixed-effect predictors were Language (L1 –.5 and L2 .5) and Sequencelocal (Repeat trials –.5 and Switch trials .5). Random effects by participants: intercept, Language slope. Random effects by items: intercept. SE: standard error.
p < .05. **p < .01. ***p < .001.
Discussion
The current study investigated global and local control during cross-language phoneme processing using a cued language switching paradigm. The results demonstrated that letters were named slower and less accurate in repeat trials compared with stay trials, indicating that bilinguals globally control language-interference in single language contexts. The findings also showed that letters were named slower and less accurate in switch trials relative to repeat trials, suggesting that bilinguals use local control to suppress cross-language interference in a mixed language context. Taken together, these findings point to the existence of global and local control in cross-language phoneme switching which we interpret through the ACH (Green & Abutalebi, 2013).
The findings offer additional support for the ACH. In accordance with the hypothesis, we found mixing and switching costs at the phonemic level, an observation that is consistent with studies showing similar effects at the lexical level (Branzi et al., 2016; de Bruin et al., 2018; Gambi & Hartsuiker, 2016; Gollan et al., 2014; Guo et al., 2011; Khodos et al., 2021; Kleinman & Gollan, 2018; Prior & Gollan, 2011). In other words, cross-language phoneme interference also appears to be involved in global and local control. According to the ACH, bilinguals face cross-language interference, but it is less cognitively demanding to globally inhibit interference from a nontarget language consistently throughout a single language context than to locally suppress cross-language interference in a mixed language context. Consequently, in the present study, naming letters in repeat trials was slower and less accurate in the mixed language context than naming letters in stay trials in the single language contexts. These patterns indicate that in cross-language phoneme processing, bilinguals must first suppress interference of cross-language schema. Moreover, although letter switching seems relatively straightforward, bilinguals make errors and incur switching and mixing costs as a consequent of the recruitment of different language control in distinct contexts.
In addition to suppressing the cross-language interference of language schema, interference also needs to be suppressed at the phonemic level. Several word production models assume that lemmas compete for selection (de Bruin et al., 2014, 2018; Gambi & Hartsuiker, 2016; Guo et al., 2011; Kleinman & Gollan, 2018; Prior & Gollan, 2011). Our results showed that switch trials were named slower and less accurate than repeat trials, indicating that local control occurred on the cross-language phonemic level. The bilingual participants who took part in the present study were L1 speakers of Chinese with an intermediate proficiency level in L2 English. The relative differences in dominance between the two languages is significantly large and as a result, there are observable differences in the amount of inhibition required for the dominant L1 compared with the non-dominant L2 (Green, 1998). We argue that the greater switching costs in the L1 relative to the L2 indicates transient inhibition of cross-language phonemes. This finding is in line with Declerck et al.’s (2015b) results suggesting that cross-language interference occurs at the phonological level and requires inhibition.
On a practical note, bilinguals often use more global control to suppress the activation of other languages, such as when talking to family members or foreign colleagues. However, even in mixed language contexts in social (non-experimental) settings, admittedly bilinguals likely switch between their languages less often and less naturally compared to an experimental setting that has been specifically designed to elicit language switching. As such, the ecological validity of a laboratory-based switching environment could be strengthened in future work that examines bilingual language switching in naturalistic, conversational settings. Nonetheless, our experimental approach is very common in research on bilingual language control and offers meaningful implications about the existence of local and global control at the phonemic level. Finally, we would like to mention that this study was based on the letter naming/switching performance among less-proficient bilinguals. Balanced bilinguals, who command an equal or nearly-equal dominance in both languages, may have more efficient language control in suppressing cross-language interference (Costa & Santesteban, 2004; Schwieter & Sunderman, 2008), which may reduce, to some extent, mixing and switching costs. The effects arising from balanced versus unbalanced bilingualism with respect to global and local control is an issue that merits further exploration.
Conclusion
In the current study, we assessed language control at the phonemic level. The findings revealed that cross-language interference occurred not only at the language schema level, but also at the phonemic level as reflected by mixing and switching costs. These patterns imply that cross-language interference must be controlled at the sound level, just as it does at the lexical level.
Footnotes
Availability of data and materials
The datasets generated and analyzed in this study are available in the OSF repository. The role of language control in cross-language phoneme. Retrieved from osf.io/7a9vj
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Grants from Liaoning Social Science Planning Fund of China (L20AYY001), Dalian Science and Technology Star Fund of China (2020RQ055) and Youth Foundation of Social Science and Humanity, China Ministry of Education (21YJC190009).