
Abstract
For slender FRP columns, predicting the global buckling critical loads is crucial in structural design. However, there is a lack of a consensus prediction method based on specialized domain knowledge. To address this issue, this study created a comprehensive database by collecting 365 experimental data related to global buckling of axially loaded pultruded FRP columns to predict buckling critical loads using such machine learning methods as extreme gradient boosting, artificial neural network, and support vector regression. The prediction accuracy and stability of the machine learning prediction methods were evaluated, and the interpretability of the features was analyzed in depth. The results show that the prediction accuracy of the traditional theoretical methods is low, while that of the machine learning methods is high. The contribution of geometric parameters to the buckling critical load is more than 80%. The contribution of material parameters to the buckling critical load is small, less than 20%. The cross-sectional moment of inertia has the most significant effect on the buckling critical load, while the shear modulus and compressive strength have a smaller effect.
Keywords
Introduction
Compared to traditional steel and reinforced concrete pressure-bearing columns, fiber-reinforced polymer (FRP) composites have high strength and low modulus, which increases their vulnerability to global flexural buckling failure (Zhan et al., 2018; Zhan and Wu, 2018a). Moreover, when FRP members undergo global flexural buckling, they exhibit poor ductility due to their linear elastic mechanical properties without a yield stage or plastic deformation (Boscato et al., 2014). The mechanical properties and mechanical response of pultruded FRP members are complex, which contributes to the uncertainty of bending buckling (Higgoda et al., 2023a). Additionally, the susceptibility of FRP columns to flexural buckling is affected by the non-uniform distribution of fiber resin across their cross-section (Feng et al., 2022). The difference in mechanical properties between FRP composites and traditional materials leads to a significant difference in predicting the critical load of global flexural buckling of pultruded FRP struts from isotropic materials (Jerath, 2021). Therefore, predicting critical loads for global flexural buckling of FRP columns becomes a significant and complex problem (Sá et al., 2021; Pacheco et al., 2021).
For PFRP struts of sufficient slenderness that fail by global buckling, (Barbero and Tomblin, 1993; Barbero and Raftoyiannis, 1993; Seangatith and Sriboonlue, 1999; Hashem and Yuan, 2001; Hewson, 1978) have demonstrated through experimental, numerical, and analytical work that the critical global buckling load can be predicted with reasonable accuracy using the classical Euler formula given by equation (1).

Pultruded FRP members have a notable characteristic of higher longitudinal elastic modulus to in-plane shear modulus ratio. Shear deformation can have a negative impact on the global flexural buckling of these members. Therefore, when predicting the critical load for buckling, it is crucial to consider the effect of shear deformation. Two well-known theories of shear deformation, Haringx and Engesser theories, have been developed to predict critical load, but their applicability and accuracy are subject to great controversy. According to certain scholars, Haringx’s shear modification formula (equation (2)) is a more precise method for predicting the buckling critical load of pultruded FRP members (Kardomateas and Dancila, 1997; Cardoso et al., 2014). However, other scholars argue that Engesser’s shear correction formula (equation (3)) is a more reliable approach for making such predictions (Lee and Hewson, 1979; Roberts, 2002; Bank LC, 2006; Vanevenhoven et al., 2010; Boscato et al., 2015).

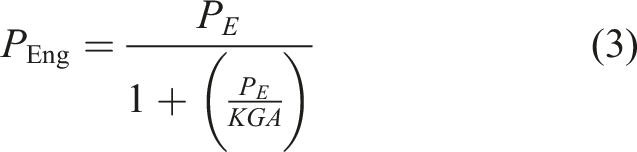
In addition to the above-mentioned critical load prediction method based on the buckling criterion, there is also an empirical formula represented by the Ayrton-Perry formula (equation. (4)), which is based on the regression of experimental data and is used to predict the global buckling critical load of imperfect columns.

However, this method requires fitting the relative initial bending rate. The polynomial equations used for fitting have always been uncertain and freely chosen by different scholars. For example, (Wang et al., 2016; Liu, 2020) chose the form of a simple linear polynomial
In summary, the global buckling of FRP columns is a very important area of research. Although several methods have been proposed for calculating the critical load for the global buckling of FRP columns, specific criteria have yet to be recognized. Thus, it is challenging to accurately predict the critical load for the global buckling of FRP columns due to their low modulus, anisotropy, and inhomogeneous resin distribution. In this case, the derivations of empirical or closed-form solutions using experiments or physics-based models are time-consuming and complex. Therefore, using machine learning-based models is an alternative approach to overcome the limitations of physics-based models (Thai, 2022).
In 1996, (Mukherjee et al., 1996) made the first attempt to model the nonlinear behavior of columns (mild steel bars) to predict a buckling load using an artificial neural network (ANN). (Sheidaii and Bahraminejad, 2012) also examined the global buckling of columns, but they focused on the post-buckling behavior and equilibrium paths. They used an ANN to predict the load-displacement curves of columns and developed the relationship between the critical load and member slenderness. At the same time, (Nguyen et al., 2021) developed an effective ANN for predicting the critical buckling load of the WTIS columns. (Kumar and Yadav, 2013) used an ANN approach to calculate the global buckling load of a beam-column with different end conditions. (Xu et al., 2021) used machine-learning algorithms to establish a unified method for the capacity prediction of stainless-steel columns that accounts for different failure modes, materials, and mechanical properties.
The above research results show that machine learning methods provide the excellent accuracy in predicting global buckling critical load. Machine learning technology has significant advantages in dealing with prediction under complex parameters and can be used as a potential solution. Compared with rule-based predictive analysis, machine learning algorithms are more efficient and powerful in automatically extracting useful patterns from large-scale high-dimensional data without relying on data engineering and domain knowledge.
In the above studies, ANN has become the mainstream machine learning algorithm for buckling strength prediction due to its ease of use and high interpretability. In contrast, other machine learning algorithms, such as Support Vector Regression (SVR) and eXtreme Gradient Boosting (XGBoost) (Xu et al., 2021), are rarely used. In addition, previous studies have focused on predicting the overall buckling performance of isotropic material columns. The prediction of the overall buckling critical load of anisotropic material columns has yet to be reported. However, the machine learning research method for isotropic columns provides a reliable theoretical and technical basis for predicting the buckling critical load of pultruded FRP columns.
The previous discussion shows that there is still a need to develop tools to predict the global buckling critical load of pultruded struts. In this study, three machine learning methods were used to predict the buckling critical load of pultruded FRP columns. Therefore, experimental data of pultruded FRP columns were collected to establish an experimental database. Secondly, three typical machine learning models commonly used for regression prediction were established to predict the flexural buckling critical load of pultruded FRP columns, including SVR, ANN, and XGBoost. The prediction accuracy and stability of the three machine learning models are also evaluated. Finally, based on the SHAP value method, the importance of input features is analyzed to explore the influence of input features on the critical load of flexural buckling of pultruded FRP columns. The term “column” used in this paper only refers to axially stressed members.
Establishment and analysis of the experimental database
Establishment of the experimental database
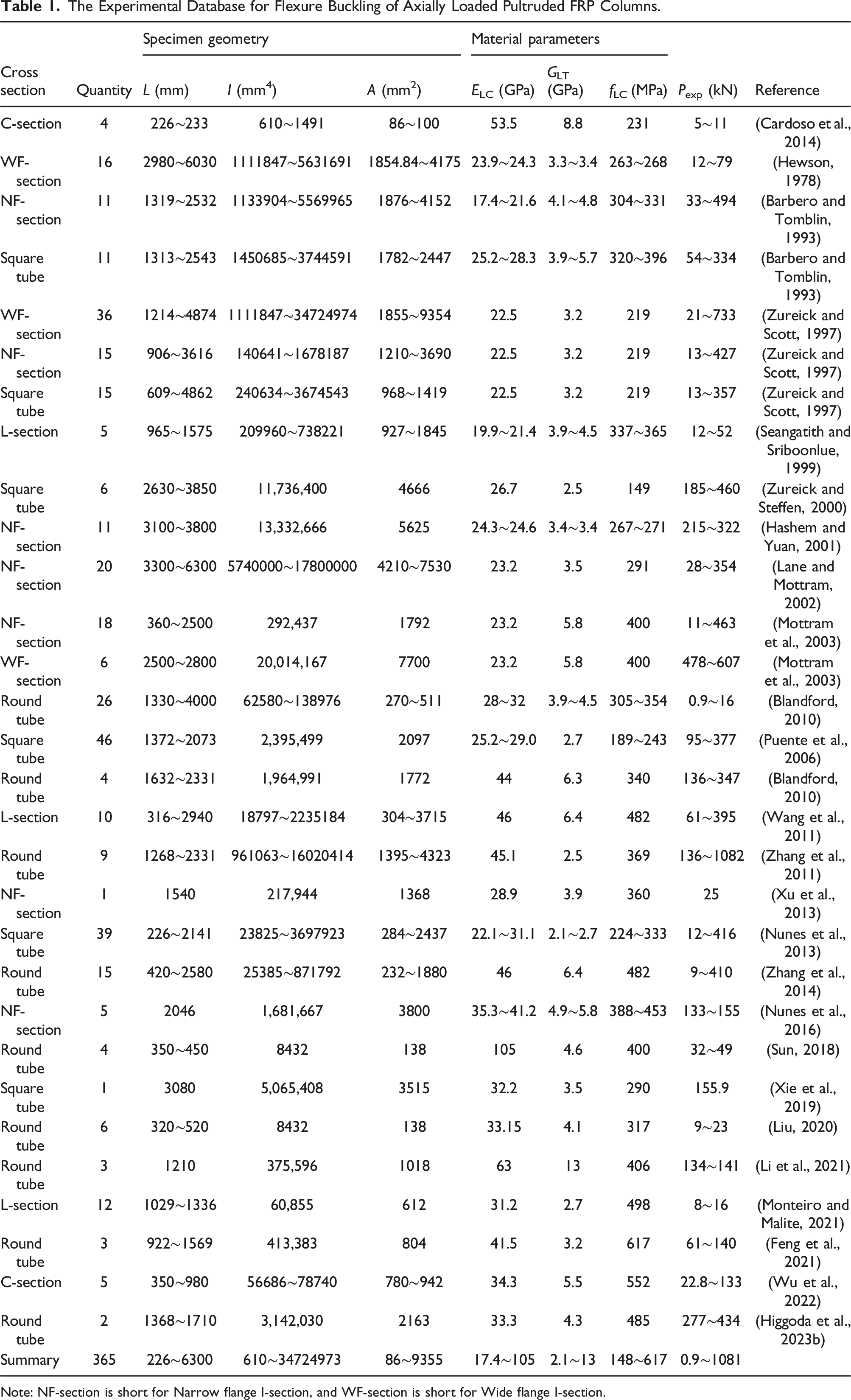
The Experimental Database for Flexure Buckling of Axially Loaded Pultruded FRP Columns.
Note: NF-section is short for Narrow flange I-section, and WF-section is short for Wide flange I-section.
Analysis of the experimental database
Previous studies of axial behavior of pultruded FRP have identified the following general conclusions as summarized by (Zureick and Scott, 1997): (a) short columns, Specimen regularized slenderness ratio distribution statistics.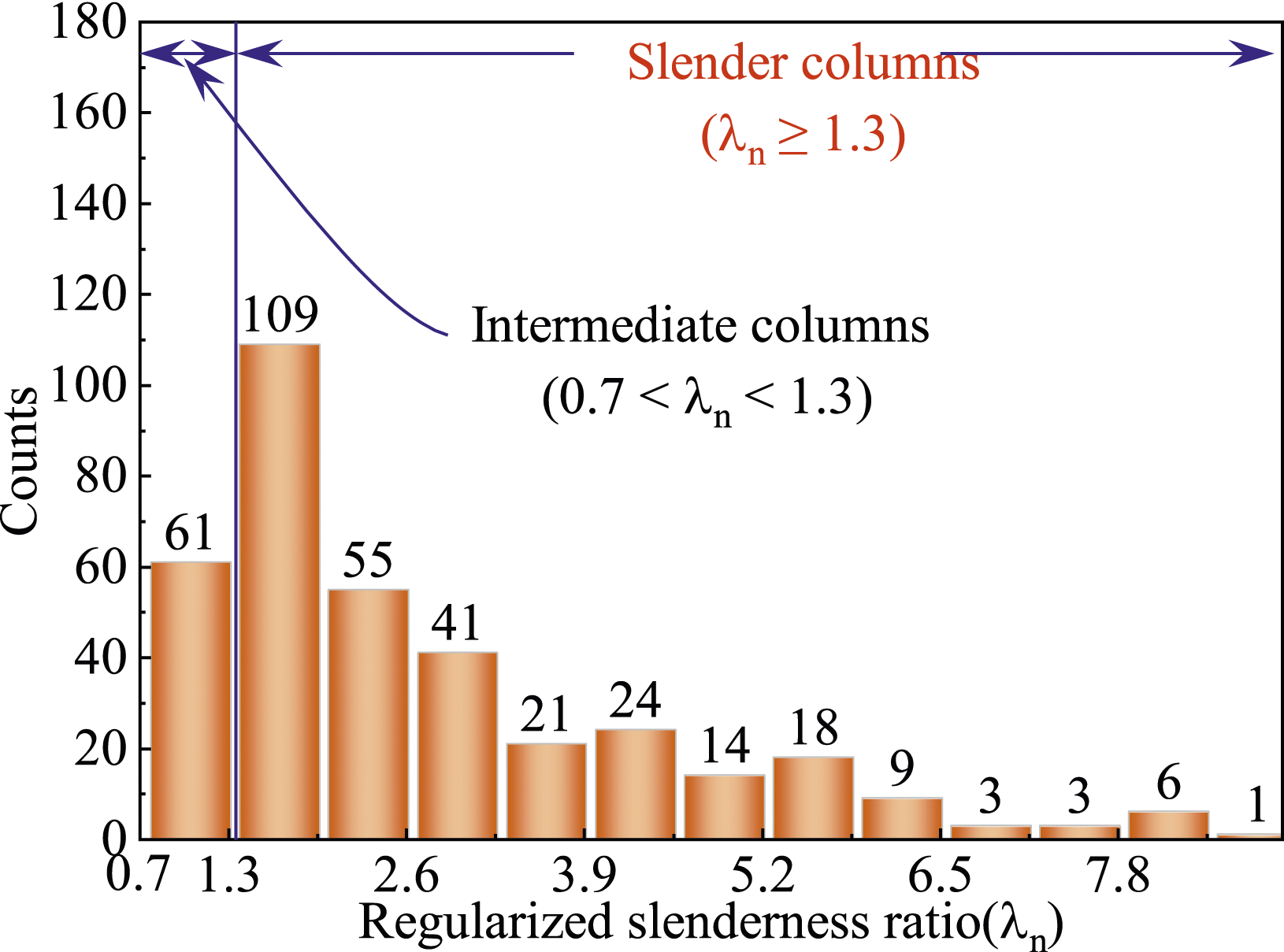
The distribution of the section types of the 365 groups of experimental specimens is shown in Figure 2. Figure 2 shows that the number of square tubes is the largest, followed by round tubes and the least number of slotted cross-sections. The number of specimens with square and round tubes together accounted for 52% of the total number of specimens. The number of specimens with other cross-sections accounted for 48% of the total number of specimens, that is, there were a comparable number of FRP columns in the form of closed cross-sections as those in the form of open cross-sections. Distribution of cross-section types.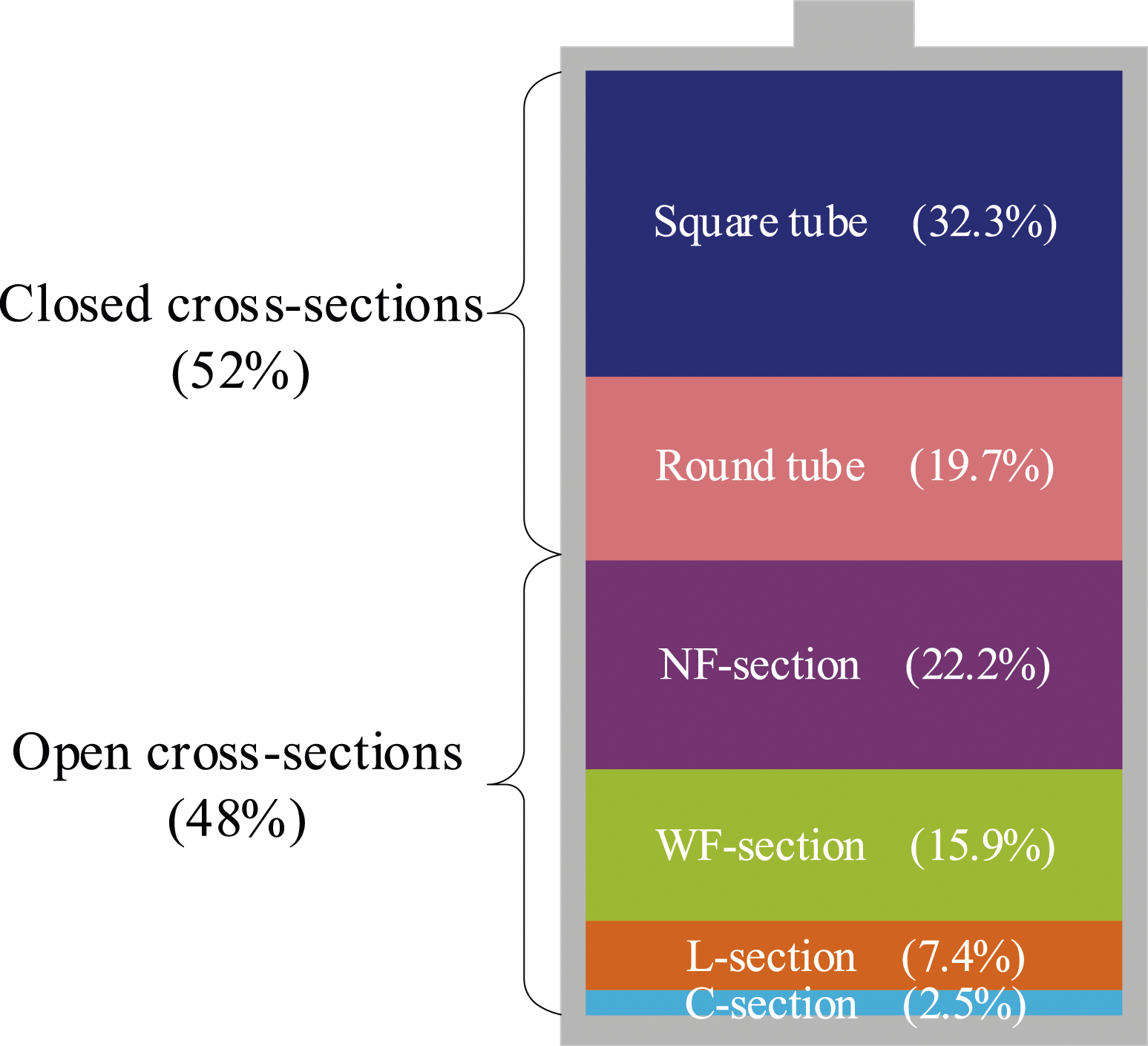
Therefore, the machine learning model trained with this database is applicable not only to FRP columns with closed cross-sections but also to FRP columns with open cross-sections.
Machine learning model
This section will follow the general workflow of machine learning in regression prediction (see Figure 3) for modeling. In addition to the collection and organization of raw data already done in the previous section, the following tasks are included: data preprocessing, machine learning algorithms, hyperparameter optimization, and performance evaluation metrics. The algorithms involved in building machine learning models in this paper are XGBoost, SVR, and ANN. The preparatory knowledge and basic principles of these machine learning algorithms can be found elsewhere, so they will be avoided. Typical workflow of Machine Learning.
Data pre-processing
The accuracy of machine learning model predictions depends greatly on the merit of the initial dataset. Therefore, before building the machine learning model, analyze the features to remove redundant data. The initial dataset is normalized or standardized to improve the learning efficiency and the generalization ability of the machine learning model.
The effective length, cross-sectional area, moment of inertia, compressive modulus, shear modulus, and compressive strength are input variables, while the buckling critical load is used as the target variable. The Pearson correlation analysis of the features was carried out, and the results are shown in Figure 4. Positive values indicate a positive correlation, while negative values represent a negative correlation. Except for the moment of inertia, almost all input features have low correlation coefficients with the output feature, remaining between −0.068 and −0.13. There is no strong linear correlation between the input features, indicating that all input features are necessary. Pearson correlation of features.
Figure 5 shows the distribution histogram of the six input parameters and one output parameter in this study. Statistical distributions of both input and output parameters.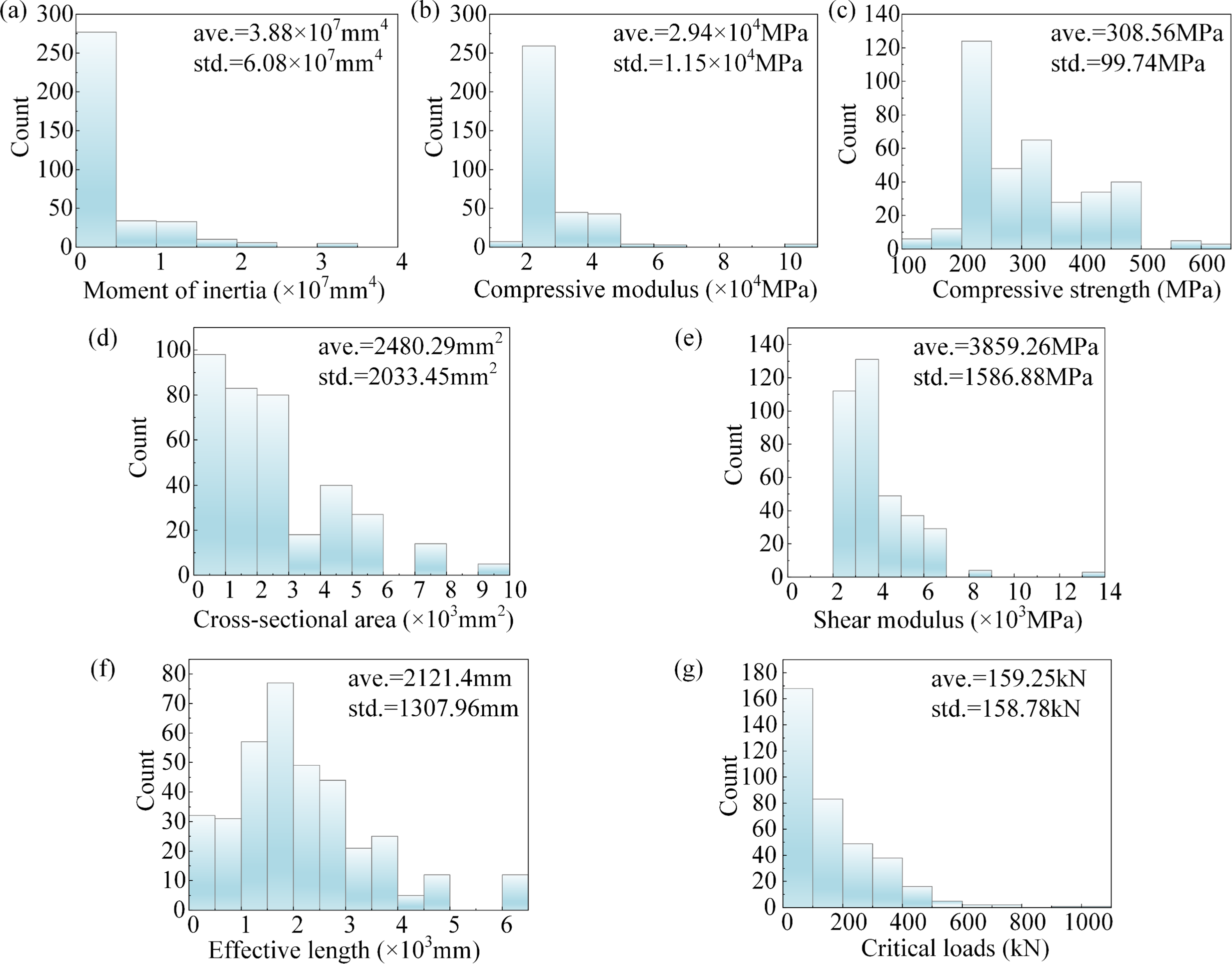
It can be seen that: (1) most of the test specimens have smaller cross-sectional moments of inertia and compression moduli. Therefore, the critical loads of most of the test specimens are also small. (2) The compressive strength of the material parameters of the test data were significantly different. (3) The number of test specimens decreased as the critical load of the members increased, and the critical load of the members for a few test data exceeds 6000.
Simultaneously, considering that the difference between the mean values of the input features (Table 1) is significant, to avoid poor model calculation results, it is essential to standardize the data. Figure 6 shows the heat map of the distribution of feature data before and after standardization. Before standardization, the feature cross-sectional moment of inertia is more significant by order of magnitude, resulting in other features that are no longer dominant and close to 0. Through standardization, each feature data gets dominant, and the overall distribution of features is between −1.6 and 6.6, within an order of magnitude. Effect of feature normalization on feature parameters. Note: 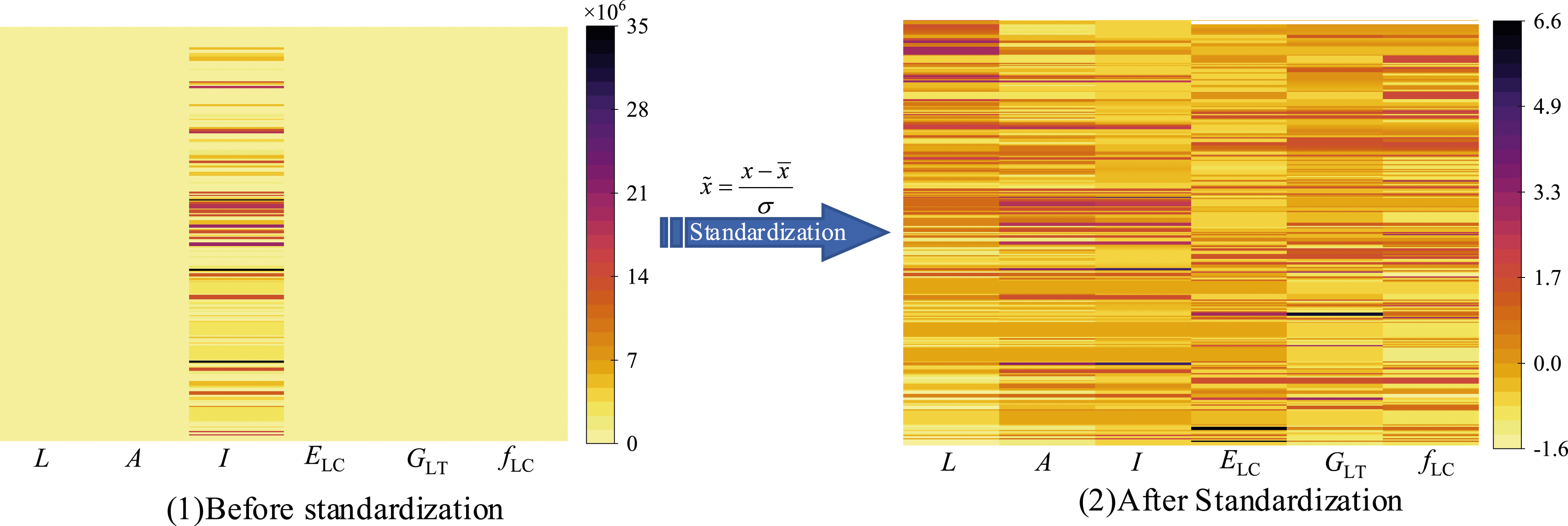
Evaluation of indicators and optimization of hyperparameters
Evaluation metrics of models
To evaluate the performance of the learning machines proposed to predict the buckling critical loads, widely used indicators have been used, including standard deviation (STD), mean squared error (MSE), root-mean-squared error (RMSE), and correlation coefficient (R2). Their related equations (4)–(6) are, respectively, as follows: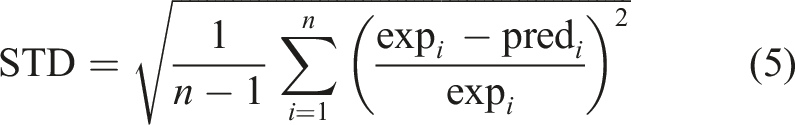
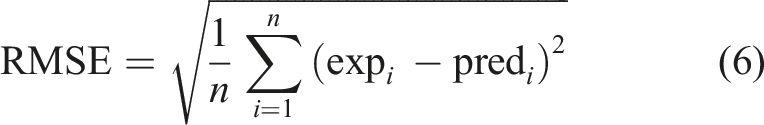
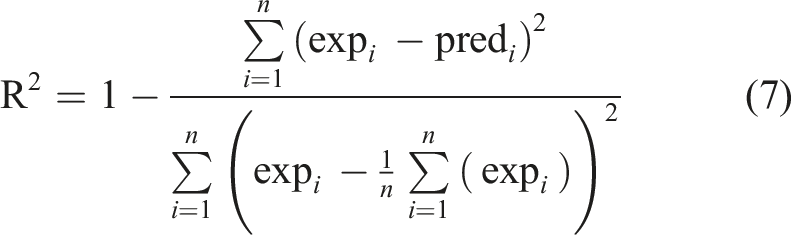
Hyperparameters optimization
In this paper, we use the experimental database in Table 1 to train machine learning models for hyperparameter optimization. The dataset is randomly sampled in the ratio of 2:8 into a training dataset (292 sets) and a testing dataset (73 sets). The random sampling division largely eliminates the effect of correlation between data on the training results. For the reconstruction ability of machine learning models, the random seed is set to ensure the consistency of the reconstructed model each time. Due to the randomness of the training set division, the training error at one time usually does not represent the generalization error of the model. To eliminate this randomness, reduce the sensitivity of the model to different training sets, and obtain a model with better generalization performance, a 10-fold cross-validation model, which is a k-fold cross-validation, is adopted. Selecting model parameters through cross-validation is more stable and comprehensive than dividing the training and testing datasets at once.
In order to enhance the models’ accuracy, this paper adopts a variety of optimization algorithms in determining the hyperparameters, with optimized curves, optimized surfaces, grid search, and random search. The specific optimization process is as follows:
(1) Hyperparameters of support vector regression model
The hyperparameters of the support vector regression algorithm are mainly calculated by optimizing the curve. Firstly, the kernel function is optimized, and the radial basis kernel function has the highest goodness of fit, see Figure 7(a); after determining the kernel function, the gamma parameter is optimized, as shown in Figure 7(b), and the goodness of fit is the highest when gamma = 0.16; in the case of the radial basis kernel function and gamma = 0.16, the penalty coefficients are optimized, as shown in Figure 7(b), and the goodness of fit is the highest when the penalty coefficient = 36.34, the best fit is obtained. Finally, the best-fitting hyperparametric model can be obtained, and the optimal values of hyperparameters are shown in Table 2. SVR hyperparameter optimization curve, (a) Preference of kernel function, (b) Optimization of gamma parameters and the penalty coefficient. Hyperparameters in SVR Model.

(2)Hyperparameters of extreme gradient boosting model
In the XGBoost algorithm model, the first hyperparameters to be determined are the number of decision trees and the maximum depth of decision trees. The number and depth of the decision tree interact with each other; the fitting effect can be improved by increasing the number of the decision tree, and the fitting effect can also be improved by increasing the depth of the decision tree, and at the same time, these two practices are also prone to overfitting, so it is necessary to set these two parameters jointly and coordinately to prevent the occurrence of overfitting. The cloud plot of the goodness-of-fit after two-parameter optimization is shown in Figure 8(a). Hyperparameters optimization of XGBoost model, (a) Optimization of the number of decision trees and decision tree depth (b) Optimization of the learning rate.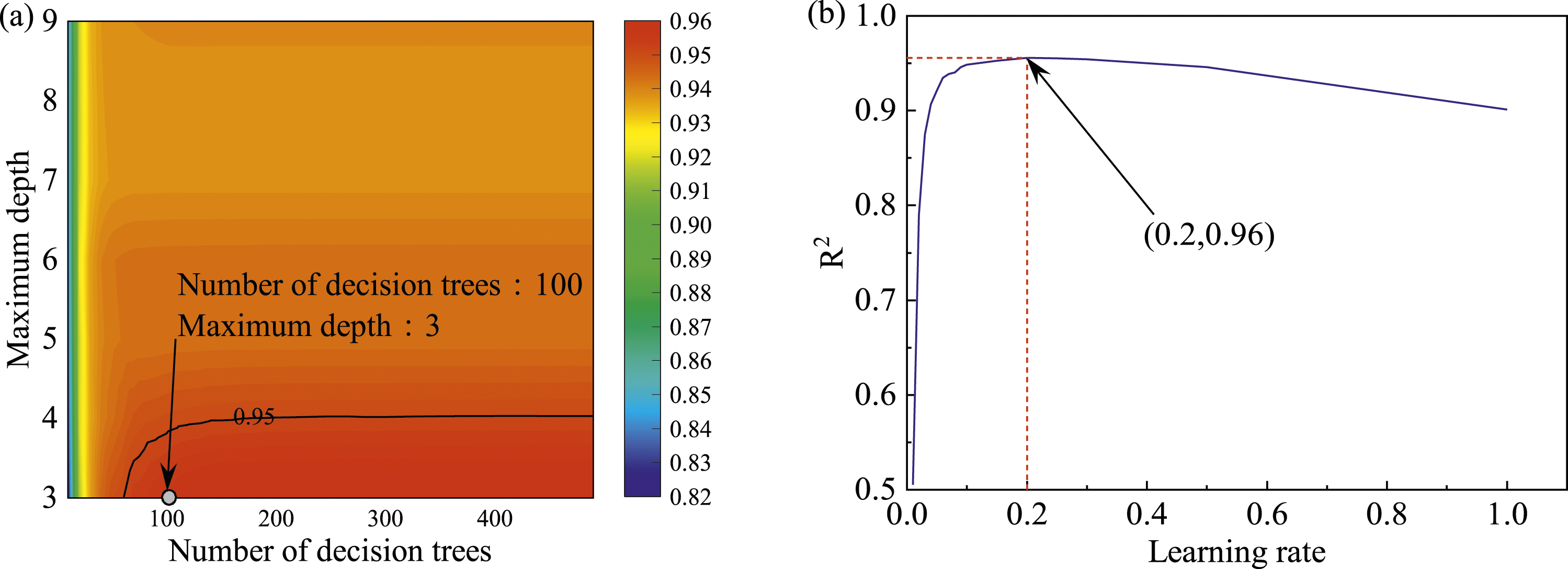
Hyperparameters in XGBoost Model.

(3)Hyperparameters of artificial neural network model
The activation function of an artificial neuron is the core parameter of the neural network structure. Therefore, the activation function is the first hyperparameter to be determined. For the regression prediction problem, the activation function of the output layer is usually chosen as a constant function, that is, the Identity function, and thus, the activation function of the hidden layer is the hyperparameter to be determined. For the neural network structure in this paper, the number of neurons in the input layer is the number of features in the training sample six. The number of neurons in the output layer is the number of prediction targets 1, but the number of hidden layers and neurons in each layer still needs to be determined. In addition to this, for the artificial neural network machine learning model, the hyperparameters that need to be determined are the weight optimizer, the initial learning rate to control the update weight compensation, and the regularization parameter to prevent overfitting. Among them, the default adaptive optimizer, Adam, is chosen for the weight optimizer, which automatically adjusts the learning rate during the training process, and the initial learning rate can be optionally set. Due to the large number of neural network hyperparameters and their interaction, the optimal hyperparameter values cannot be obtained for the optimization curve or surface.
Optimized Values of hyperparameters for Neural Networks.

The structure of the optimal artificial neural network model trained to be used for prediction is shown in Figure 9. Artificial neural network structure.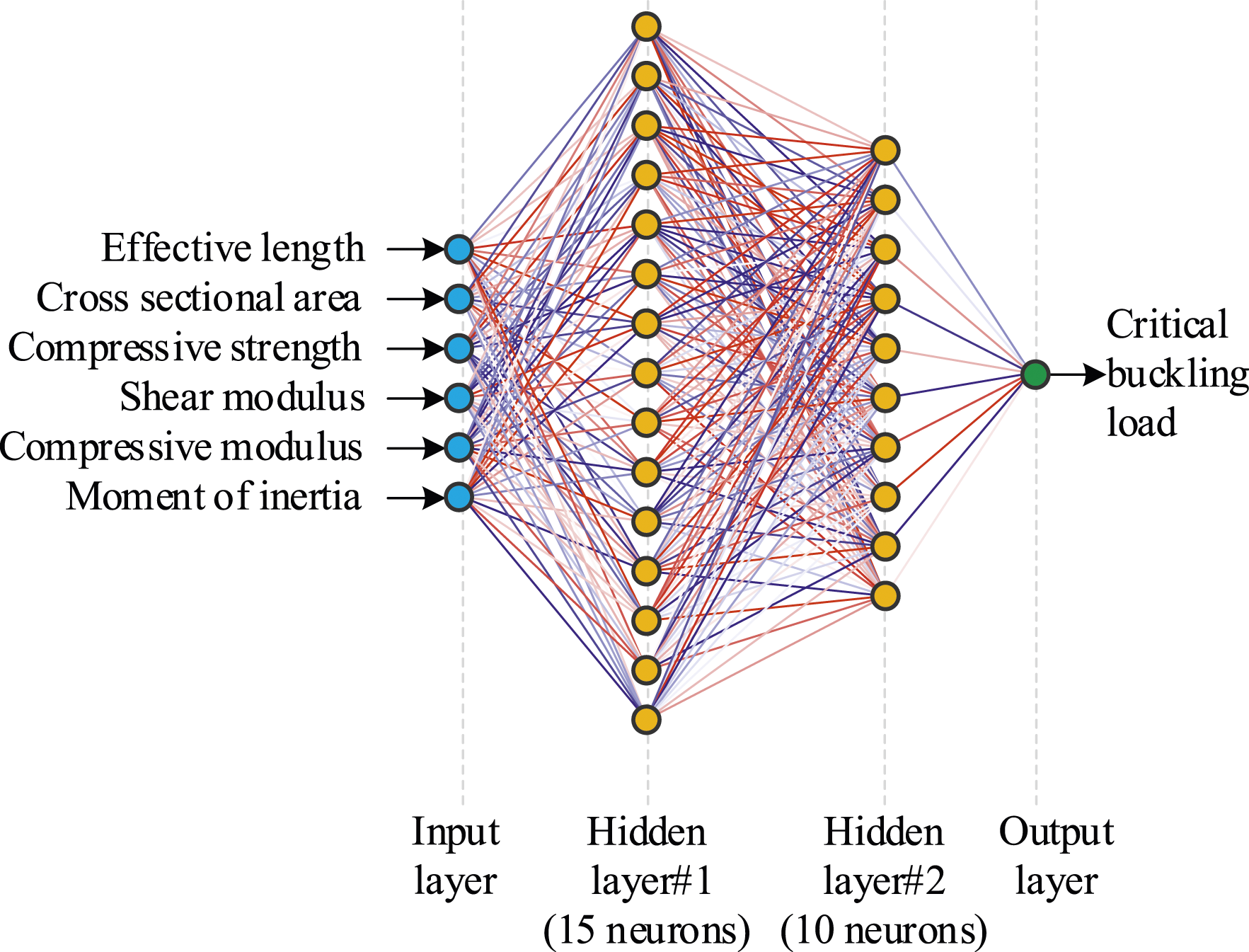
Results and discussion
Performance evaluation of machine learning models
Evaluation of prediction accuracy
In Figures 10–12, the machine learning model prediction results are compared with the experimental results. As shown in the figures, all three machine learning models, XGBoost, SVR, and ANN, obtained high XGBoost predictions versus experimental results, (a) The training dataset, (b) The testing dataset, (c) The entire dataset. SVR model predicted results versus experimental results, (a) The training dataset, (b) The testing dataset, (c) The entire dataset. ANN model predicted results versus experimental results, (a) The training dataset, (b) The testing dataset, (c) The entire dataset.
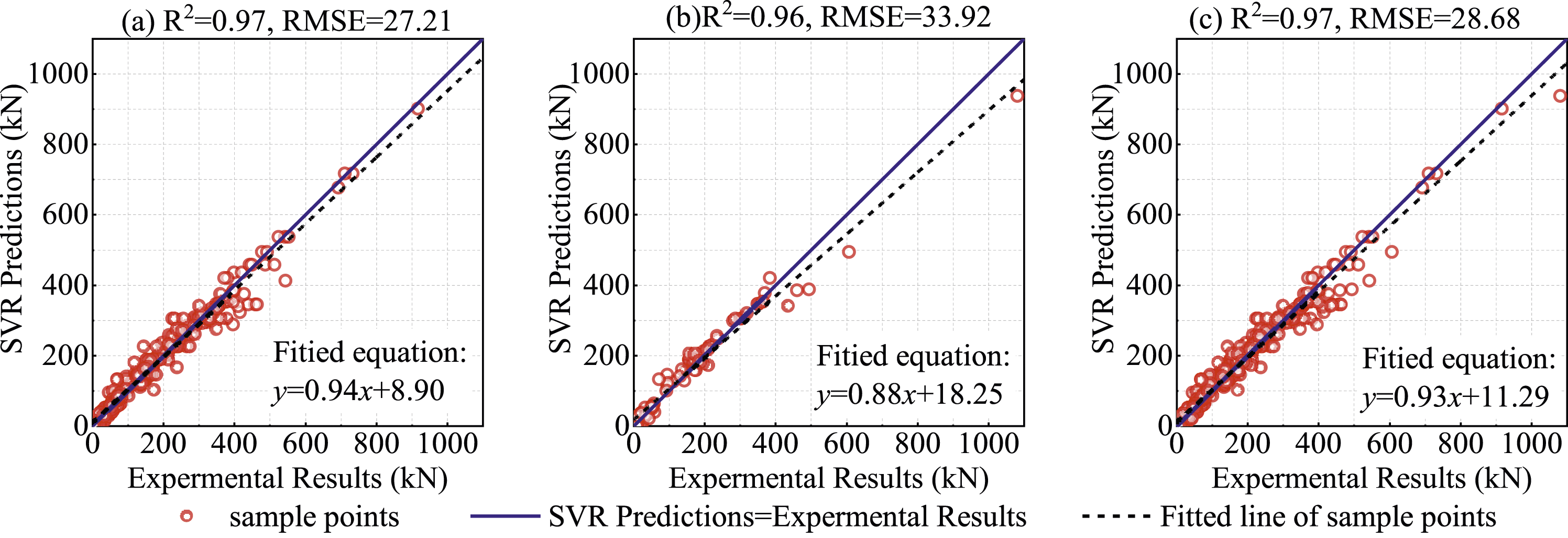
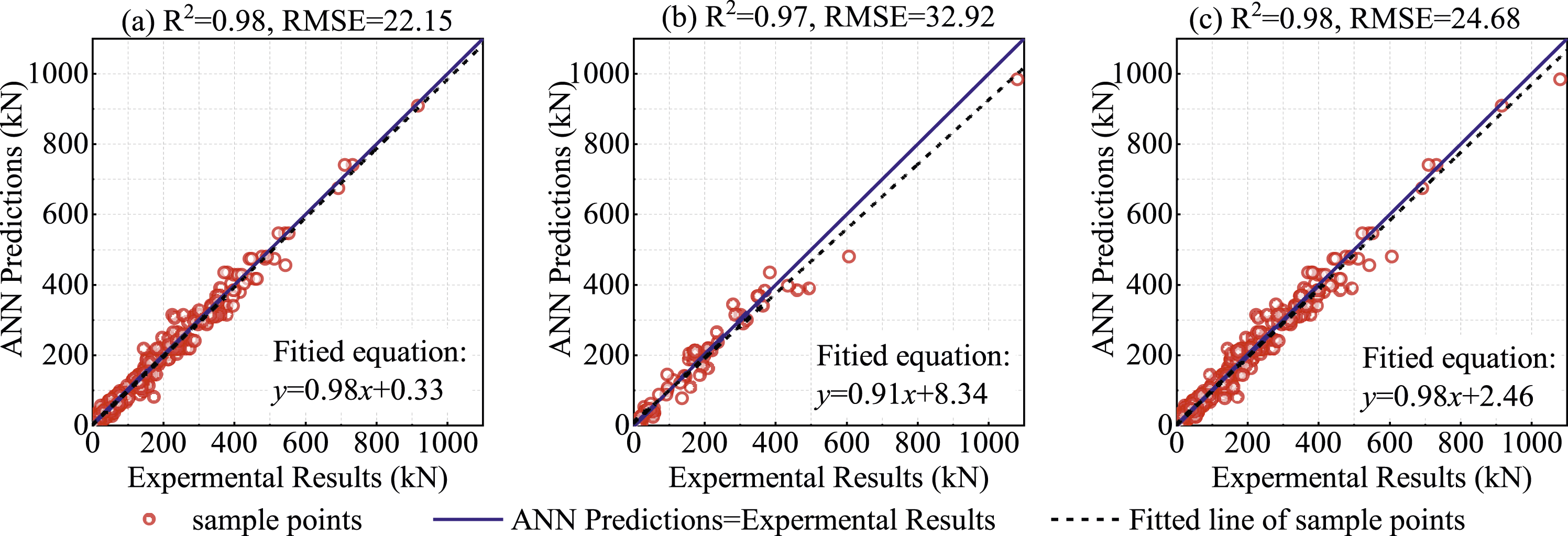
For the entire datasets, all models demonstrated a high capability of predicting the flexural buckling critical load of pultruded FRP struts. The XGBoost and ANN models achieved slightly better performance compared to the SVR.
Evaluation of prediction stability
The prediction error counts of the XGBoost, SVR, and ANN models are counted separately, which further reflects the accuracy and stability of the prediction results, as shown in Figure 13. The yellow area in the figure indicates the count of prediction errors on the training set, and the blue area indicates the count of prediction errors on the test set. The two are superimposed together to represent the prediction error counts on the entire dataset. The closer the prediction error is to the zero error, the higher the prediction accuracy is. As can be seen in the figure, the three machine learning models have the largest number of samples with prediction errors concentrated near zero error, indicating that the predicted values of the models are consistent with the actual values and the prediction accuracy is high. Error frequency count of models: (a) XGBoost model, (b) SVR model, (c) ANN model. Note. Prediction error = prediction value-experimental value.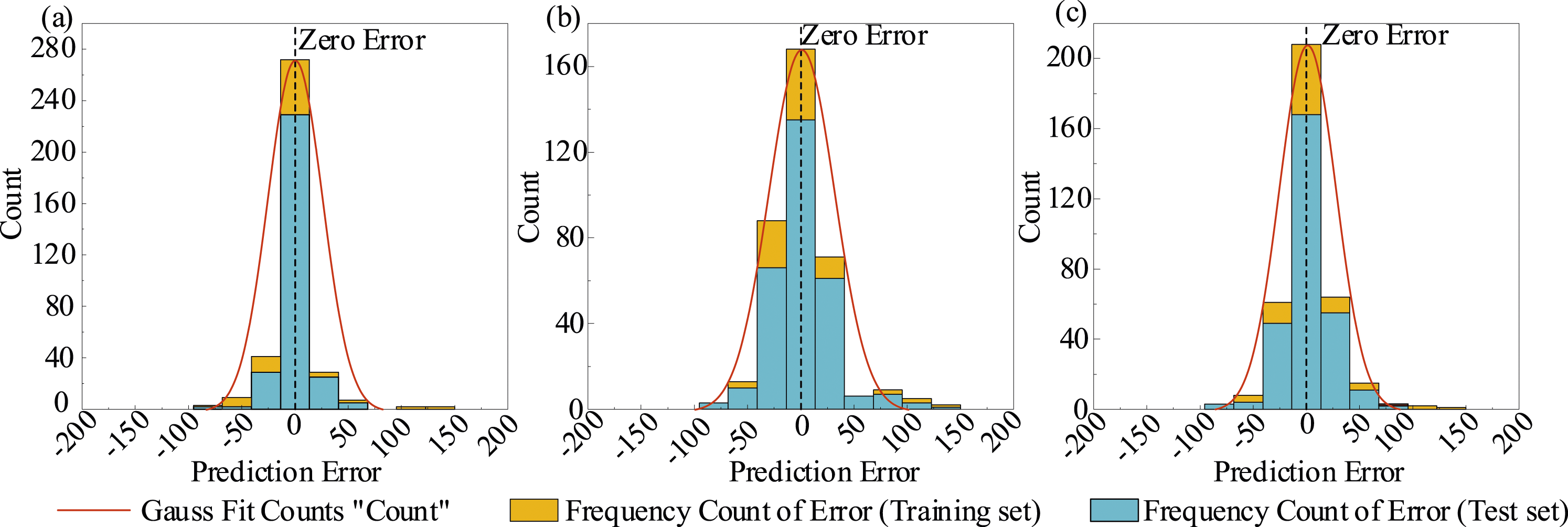
Figure 13 displays the error frequency counts of the model on the training and test sets fitted with a Gaussian curve. The graph shows that the distribution of prediction error counts conforms to the normal distribution with zero mean, the sample distribution of the zero error add-on distribution is the largest, and the sample distribution decreases with the error increase. The fact that the prediction results conform to the normal distribution indicates that the model is relatively stable. The predicted values of the model are consistent with the actual values, and the regression prediction target is well accomplished.
Comparison of prediction results with traditional algorithms
Euler’s critical load prediction method (equation (1)), Engesser’s theory-based shear-modified critical load prediction method (equation (3)), and Ayrton-Perry’s formula based on the edge yielding criterion (equation (4)) are the commonly used classical and conventional critical load prediction algorithms for buckling.
As mentioned in the introduction, no fixed form of the polynomial equation fits in the regression fitting of Perry’s formula. Therefore, the fitting relationship between the equivalent initial bending curvature and the regularized slenderness ratio needs to be optimized when using the Perry formula for prediction, and the optimization method is referred to in the literature (Zhang and Li, 2024). By optimization, the equivalent initial bending curvature of pultruded FRP members is fitted by a quadratic trinomial
Predicted results of traditional algorithms
In the entire dataset, as shown in Figure 14, the The predicted results by traditional algorithm versus experimental results, (a) Euler formula predicted results, (b) Engesser’s shear correction formula predicted results, (c)Ayrton-Perry formula predicted results.
Predicted results of machine learning algorithms versus traditional algorithms
Comparing Figure 14 with Figures 10–12, respectively, it can be seen that the prediction accuracy of traditional theoretical methods is lower than that of machine learning algorithms. In addition, the distribution of sample points in Figure 14 is skewed towards the upper line of equal value and is discrete, indicating that the prediction results of traditional theoretical algorithms are always large and discrete. In contrast, the distribution of sample points in Figures 10–12 is balanced between left and right, suggesting that the machine learning algorithm is more stable. The fitted lines for the sample points in Figure 14 are significantly above the line of equal value, indicating that the traditional theoretical model predictions are generally greater than the experimental results, which is unsafe for the design. In contrast, the fitted lines of the sample points in Figures 10–12 are all below the line of equal value, indicating that the machine learning model predictions are generally smaller than the experimental results, which is safe for the design.
To compare the machine learning models with the traditional algorithms more comprehensively, a Taylor diagram is plotted, as shown in Figure 15. The Taylor diagram graphically summarizes how close a pattern (or set of patterns) is to the base values. The similarities between these patterns are expressed by comparing and quantifying their correlation values, their centered root-mean-square error, and their standard deviation by this graph (Mousavi et al., 2023). Taylor diagram for comparison performance of the machine learning methods and existing models in terms of predicting buckling critical load of pultruded FRP columns.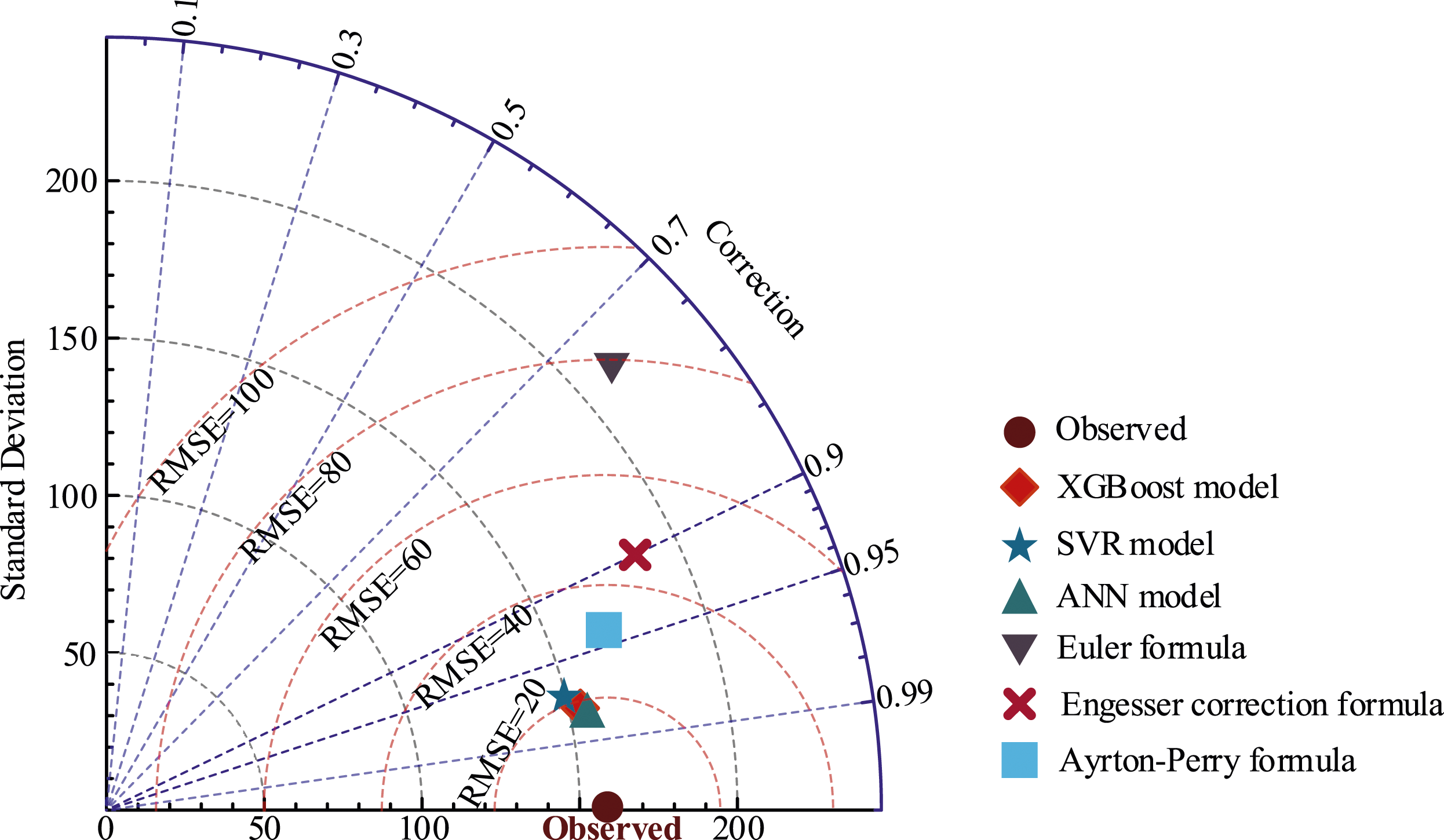
As shown in Figure 15, in general, machine learning methods, in addition to the highest R2 coefficient, have had the lowest standard deviation and the closest value of RMSE compared to the models in predicting the buckling critical loads. In the machine learning methods proposed in this regard, ANN, SVR, and XGBoost performed the best, respectively. However, there was a slight difference between the three machine learning methods in R2 coefficient and RMSE error values; the Taylor diagram shows that the standard deviation of all three machine learning methods is closer to the experimental values. These results suggest that traditional theoretical methods have significant errors and do not perform satisfactorily when facing large datasets. However, machine learning methods have been able, through their artificial intelligence and creating inter-data links, to provide extremely accurate predictions of the buckling critical loads of FRP struts, even with large datasets.
Feature interpretation and analysis
When it comes to machine learning models, they are often considered “black box models” that are difficult to explain. However, the Shapley Additive Explanations (SHAP) algorithm has been developed to help with this issue. SHAP is an ex-post algorithm that can explain machine learning models by calculating the impact of each feature on the model’s output (Zhang et al., 2022). This algorithm can be used globally and locally, and all features are considered “contributors”. For each prediction sample, the model generates a prediction value, and the SHAP value is assigned to each feature in that sample. Furthermore, this algorithm can cover almost all machine learning models.
Summarize the effects of all the features
For the three machine learning models, the SHAP values of each input feature on the output results are embodied in Figure 16. In those figures, each line in the figure represents a feature, and the horizontal coordinates are the SHAP values. The features are ordered by the average absolute value of SHAP. A broad area indicates a large number of samples aggregated. Each point is a sample, and the color from blue to red represents the increasing eigenvalues. Feature importance analysis using SHAP value, (a) XGBoost model, (b) SVR model, (3) ANN model.
The order of input variable effect on prediction accuracy of all machine learning models can be sorted by descending: moment of inertia > effective length > cross-sectional area > compressive modulus > shear modulus > compressive strength. Although the importance of various features in the machine learning models is slightly different due to different algorithms, the features with the greatest and the least impact and the order of arrangement are the same.
Importance analysis
The importance of features is usually measured by calculating the average absolute value of SHAP values for each feature. However, it may be challenging to directly compare the feature importance values of different models. Therefore, the relative importance of each feature of a model can be characterized by the percentage of each feature relative to the overall feature importance of the model. This approach calculates the percentage of a feature importance value of a model relative to the sum of all feature importance values of that model. For example, in Figure 17, the contribution of the moment of inertia to the prediction of the buckling critical load in the XGBoost model accounts for 52% of the overall feature contribution. In this way, we can compare the relative importance of features in different models without directly comparing their importance values. This can help us to understand better which features in each model have a more significant impact on the final results. Relative importance of features.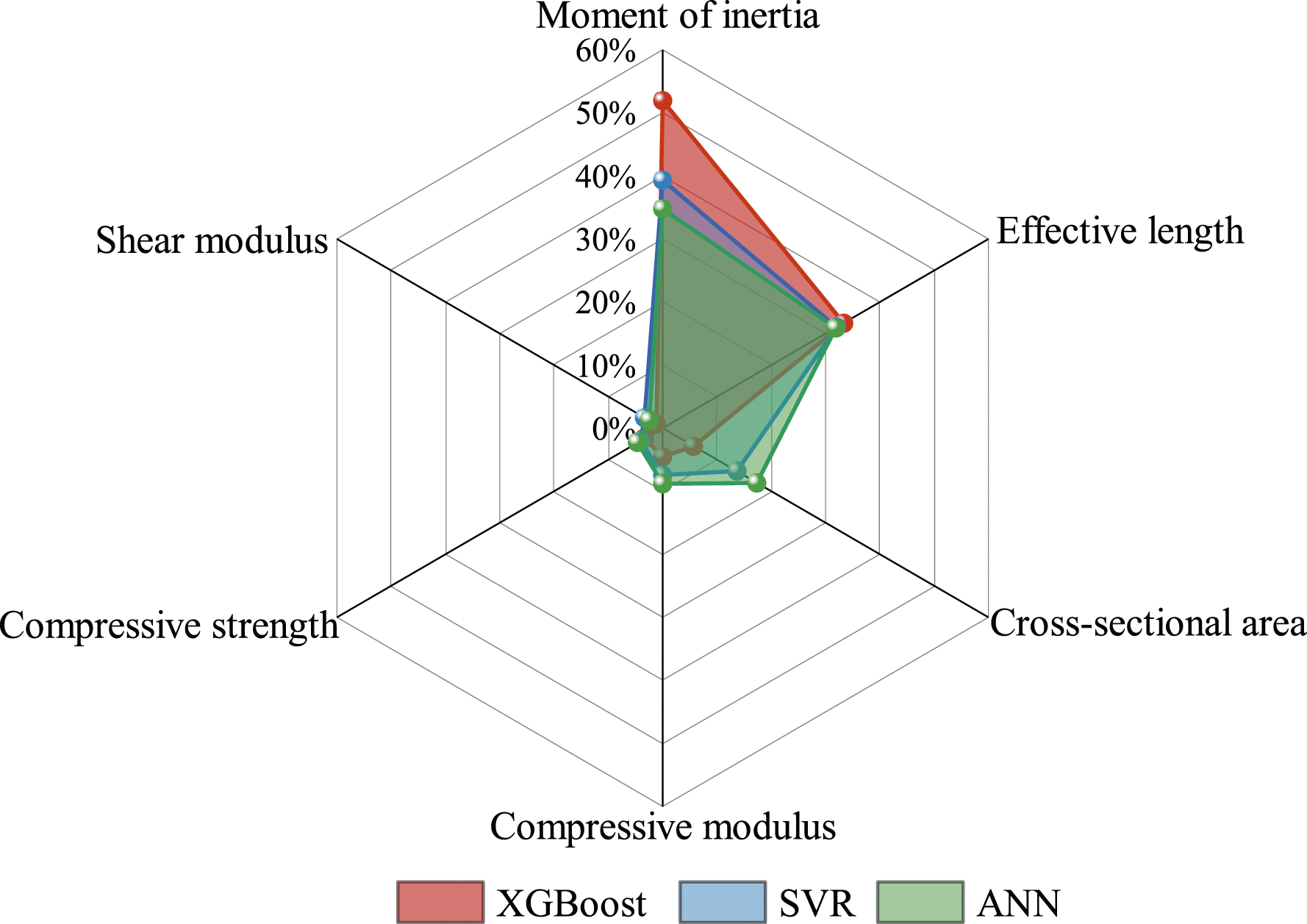
It can be seen from Figure 17 that the geometric parameters (effective length, cross-section area, moment of inertia) contribute significantly to the contribution of the critical load, more than 80%. The contribution of the material parameters (compressive modulus, shear modulus, compressive strength) to the critical load is small, at most 20%. This also verifies that the bending buckling problem is a geometric abrupt change problem, not a strength problem of material control.
Correlation analysis
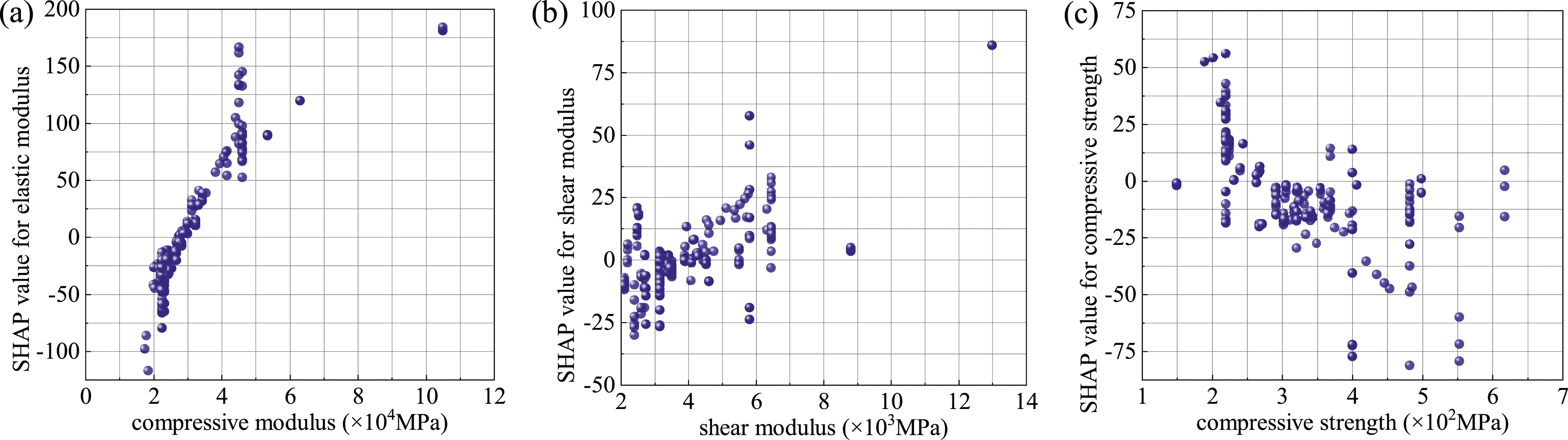
The SHAP partial dependence plot shows the marginal effect of individual features on the predicted outcome of a machine learning model, and it can show whether the relationship between the target and the features is linear, monotonic, or more complex. Taking the ANN model as an example, the effect of geometric and material parameters on the critical load is analyzed separately using SHAP local dependence plots, as shown in Figures 18 and 19. Effect of geometric parameters on prediction results, (a) effective length, (b) cross-section area, (c) moment of inertia. Effect of material parameters on prediction results, (a) compressive modulus, (b) shear modulus, (c) compressive strength.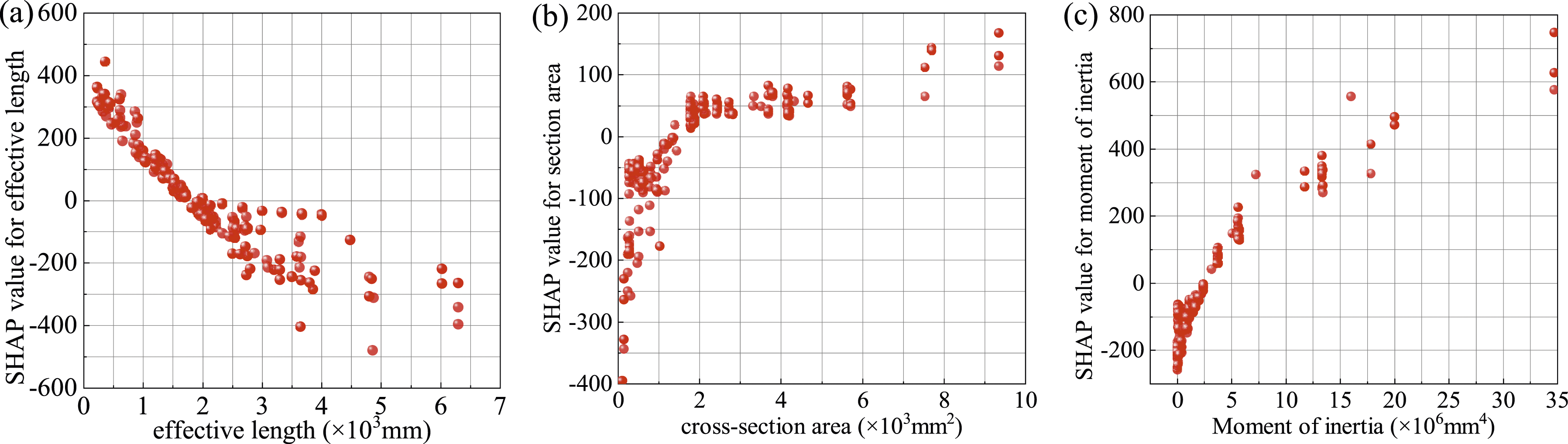
As shown in Figure 18, the SHAP value shows that cross-section area and moment of inertia have a non-linear positive correlation with the flexural critical load of the pultruded FRP members. At the same time, the effective length is a relatively obvious non-linear negative correlation.
As shown in Figure 19, the SHAP value shows that compressive modulus has a relatively obvious positive correlation with the flexural critical load of the pultruded FRP member. In contrast, the shear modulus and compressive strength have no obvious correlation.
Conclusion
In this paper, a method for predicting the buckling critical load of Pultruded FRP columns is established by a machine learning model. By analyzing the prediction accuracy of the model, the stability of the prediction, and the importance of the features, the following conclusions are as follows: (1) Machine learning methods have excellent prediction performance. Among them, the ANN model (R2 = 0.97, RMSE = 32.92) has the best prediction performance. While the prediction performance of XGBoost (R2 = 0.96, RMSE = 37.08) is worse, it is also much higher than the prediction performance of the most commonly used Euler’s formula (R2 = 0.75, RMSE = 78.66), and slightly higher than Perry’s formula (R2 = 0.94, RMSE = 39.82), which has the best prediction performance among the traditional theoretical methods. Although both the machine learning method and Perry’s formula are based on experimental data for regression prediction, the machine learning method solves the problem of uncertainty in fitting experimental data in the use of Perry’s formula. (2) The impact of six input characteristics (moment of inertia, effective length, cross-sectional area, compressive modulus, shear modulus, compressive strength) on the buckling critical load of pultruded FRP columns is well analyzed through the SHAP value. Although the importance of various features in the machine learning models is slightly different due to different algorithms, the features with the greatest and the least impact and the order of arrangement are the same. The order of input variable effect on prediction accuracy of all machine learning models can be sorted by descending: moment of inertia > effective length > cross-sectional area > compressive modulus > shear modulus > compressive strength. The effect of the moment of inertia is the most obvious, while the effects of shear modulus and compressive strength are small. (3) The contribution of geometric and material parameters to the buckling critical load is quantified by the feature analysis. The contribution of geometric parameters (effective length, cross-section area, moment of inertia) is more than 80%. Meanwhile, the contribution of material parameters (compressive modulus, shear modulus, compressive strength) is small, less than 20%. (4) Thorough analysis of the SHAP Partial dependence plot shows that the buckling critical load of pultruded FRP members has a nonlinear positive correlation with the cross-sectional area, the moment of inertia, and compression modulus, and a significant nonlinear negative correlation with effective length, while no significant correlation with shear modulus and compressive strength.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by. National Natural Science Foundation of China No (52278288).