
Abstract
Railway bridges are essential components of any transportation system and are typically subjected to several environmental and operational actions that can cause damage. Furthermore, they are not easily replaced, and their failure can have catastrophic consequences. Considering the expected lifespan of bridges, it is essential to guarantee their adequate serviceability and safety. In this scenario, emerges the Structural Health Monitoring (SHM), which allows the early identification of damage before it becomes critical. Damage identification is usually performed by the comparison between the damaged and undamaged responses obtained from monitoring data. Among the several features extracted from the responses, the time-series models exhibit a better performance, capability of early damage detection, and may also be applied within online damage detection strategies using unsupervised machine learning frameworks. In this paper, a review of advanced time-series methodologies for damage detection is presented. Initially, several time-series models often used in SHM are described, such as Autoregressive Models (AR), Recurrent Neural Networks (RNN), Gated Recurrent Unit (GRU), and Long Short-Term Memory (LSTM). Later, the framework where these models are usually applied is also detailed, including the latest upgrades and most relevant results. Finally, the conclusions summarize and elucidate the current perspectives and research gaps on the time-series models.
Keywords
Introduction
The railway network infrastructure plays a vital role by connecting different regions and allowing services and goods to be transported. Railway bridges are critical components on these large-scale transportation systems that require permanent attention by infrastructure managers (Azim, 2021; Chalouhi et al., 2017). During their large life cycle, these structures might change both traffic and environmental load conditions as well as materials properties. For the former, it must be pointed the increasing traffic volume, vehicle speed, and axle loads, as well as extreme temperature changes or even the occurrence of exceptional events. For the latter, it should be referred to the often-observed degradation processes associated with corrosion and fatigue (Chalouhi et al., 2017; Matsuoka et al., 2021). Hence, Structural Health Monitoring (SHM) systems for the condition assessment of railway bridges have been widely documented as a tool to ensure an adequate structural performance during the structure’s life cycle based on safety and economic criteria.
In recent SHM systems, the condition assessment involves measuring the structural responses under traffic/environmental loads and data analytics based on machine learning to identify changes in the material or geometric properties, including boundary conditions and structural connectivity, that may compromise the current or future structural performance (Datteo et al., 2018; Figueiredo et al., 2011). Typically, a SHM strategy for damage identification requires four steps, namely, the operational evaluation, data acquisition, feature extraction, and statistical discrimination. These steps aim to retain valuable and interpretable information about the bridges’ structural condition.
Considering the outcomes, the damage identification process is hierarchical. This means that at a lower level it only performs damage detection (presence or absence of damage) and at higher levels, it provides details about the location, severity, and type of damage. An efficient feature extraction is crucial for the hierarchical level of condition assessment. The features derived from the collected data of damaged and undamaged conditions must be highly sensitive to damage.
Nevertheless, the environmental and operational variations (EOVs) are often retained in this feature extraction process (Azim and Gül, 2021; Meixedo et al., 2022). For that, pattern recognition techniques have been increasingly applied, enabling to discriminate EOVs from damage. The efficiency of these novel techniques was proved by Meixedo et al. (2022) where a damage simply modeled as a 5% stiffness reduction was properly identified.
The time-series models are one of the most used vibration-based methodologies within SHM. It consists of methods to model relationships among any time-series data, that is, information that presents patterns along time. The linear time-series models are focused on parametric models, such as autoregressive (AR), exponential smoothing, or structural time-series models. More recently, machine learning offers a different perspective, solely based on data, avoiding the need for manual user modeling (Ahmed et al., 2010). Additionally, machine learning models may be classified as a time-series model only when applied to time-series data (Lim and Zohren, 2021).
Recent reviews mentioning time-series models applied to bridges’ condition assessment.
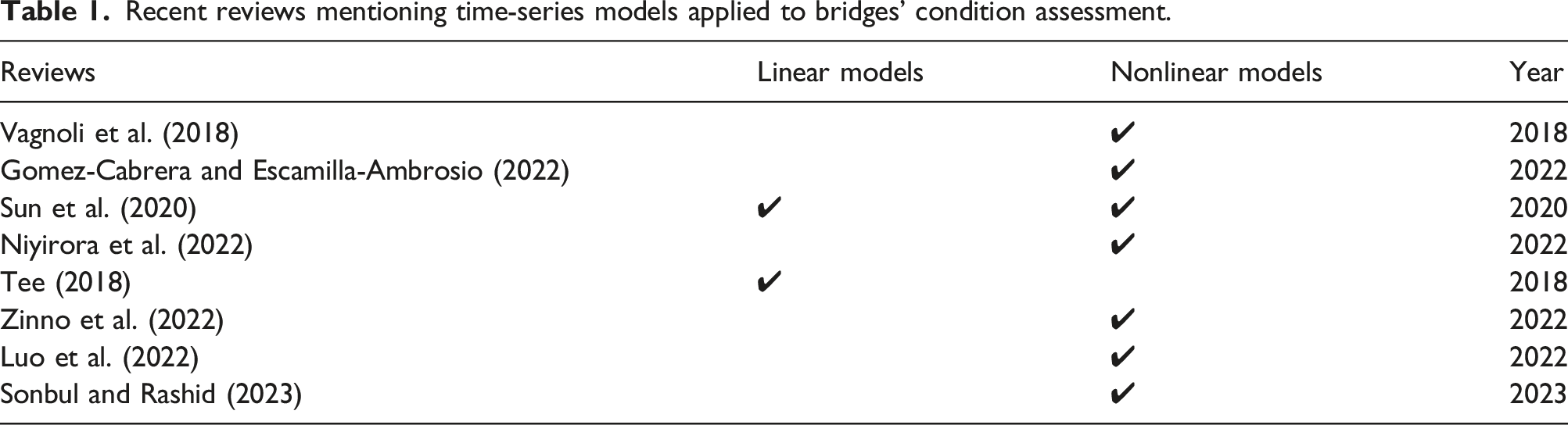
This table highlights the absence of recent comprehensive reviews focusing on the application of linear models to the field of bridge condition assessment. Among the limited number of reviews that use linear models, only one, Tee (2018), stands out for its thorough theoretical description; however, concerning the applications, the author does not analyze in deep the bridges structures. In contrast, while a considerable volume of reviews has examined nonlinear models, a significant portion of these predominantly concentrates on ANNs and CNNs. Additionally, almost none of them analyses the nonlinear together with linear models, elucidating its differences, potentialities, and limitations. Only Sun et al. (2020) briefly mention both linear and nonlinear models, and RNN and LSTM, yet offer only a brief introduction.
In turn, the specific application of these models to the domain of railway bridges is scarce in the existing literature. To address this gap, Figure 1 presents the process of a Scopus database search. This first search intends only to grant an overview about time-series model applied in damage detection on bridges. The keywords used are grouped into three specific categories: models, goals, and application. The search logic with the terms used in the query are presented with examples. Also, the filters used to select only the results related to bridges are condensed, and finally, the proportions of the outcomes that are related to railway or highway bridges. Scopus search process and results’.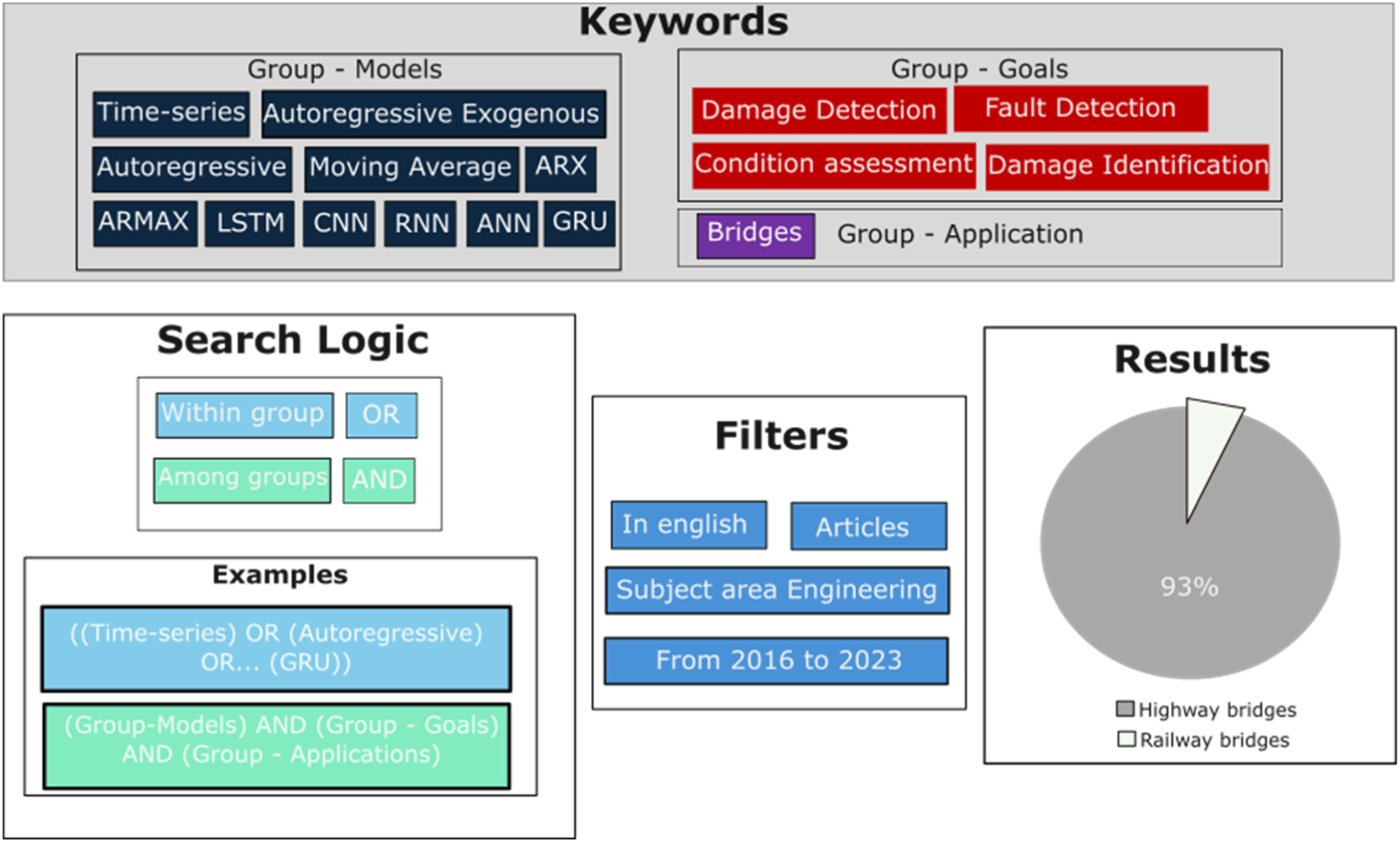
Figure 1 demonstrates a discernible disparity in research attention between railway bridges and highway bridges in the context of time-series models’ and SHM. Hence, there is a lack of comprehensive reviews covering both linear and nonlinear time-series models used in assessing bridge condition state. Therefore, this review intends to contribute addressing the following gaps: • Absence of reviews considering simultaneously both linear and nonlinear time-series models in SHM context, discussing its architecture, inherent potentialities, and limitations. • Limited quantity of reviews detailing and examining the applications of RNN, GRU, LSTM, and NARX models in the context of bridges’ condition assessment. • Lack of reviews that comprehensively analyze time-series models specifically applied to the diagnosis of damage in railway bridges.
Addressing these topics, initially, an overview is conducted using relevant publications related to the application of time-series models to bridges. This section lays out the theoretical basis, explaining the linear models AR, ARMA, ARX, ARMAX, ARIMA, the nonlinear models ANN, CNN, RNN, NARX, GRU and LSTM, and their proper use, regarding real-world SHM applications. Next, only studies that applied the models to condition assessment in railway bridges are discussed. This section describes the efficiency of linear models when combined with normalization procedures in identifying damage and even assessing its severity or localization. Moreover, it outlines the ability of nonlinear models to address EOVs and explores the potential for damage localization through the implementation of exogenous inputs and severity assessment, mainly by hypothesis testing. Finally, the paper review is summarized, outlining the challenge associated with optimizing hyperparameters of time-series models, accounting for EOVs, and training the models to applications in real-world scenarios.
Overview of time-series models for condition assessment of bridges
Time-series models serve as an efficient methodology used in signal processing and feature extraction applications. For SHM, an initial model, corresponding to a reference condition, that is, without damage, is trained by fitting models’ coefficients to time-series data (acceleration, displacement, strains, etc.) with the primary aim of forecasting responses. Later, this process is repeated for data supposedly altered by damage. The coefficients and residuals of the obtained models (difference between the model prediction and the measured values) are expected to change (Entezami and Shariatmadar, 2019; Tee, 2018). For the coefficients, these changes may be identified upon recalibration of the model using a dataset featuring structural damage. For the residuals, changes in the statistical distribution might be noted (Entezami and Shariatmadar, 2019; Farahani and Penumadu, 2016; Tee, 2018).
The time-series data, used to build the models, can be classified into four distinct categories: (i) stationary or non-stationary; (ii) linear or nonlinear; (iii) univariate or multivariate; and (iv) Gaussian or non-Gaussian (Entezami, 2021; Kitagawa, 2010). Stationarity refers to the variability of statistical moments within a dataset. As depicted in Figure 2, where stationary (a) and non-stationary data (b and (c) with respect to the mean are illustrated. Additionally, Figure 2(d) shows data that is non-stationary with regards to variance. Sample signals illustrating time-series data: (a) stationary and linear (b) non-stationary and linear (c) non-stationary and non-linear (d) non-stationary and linear.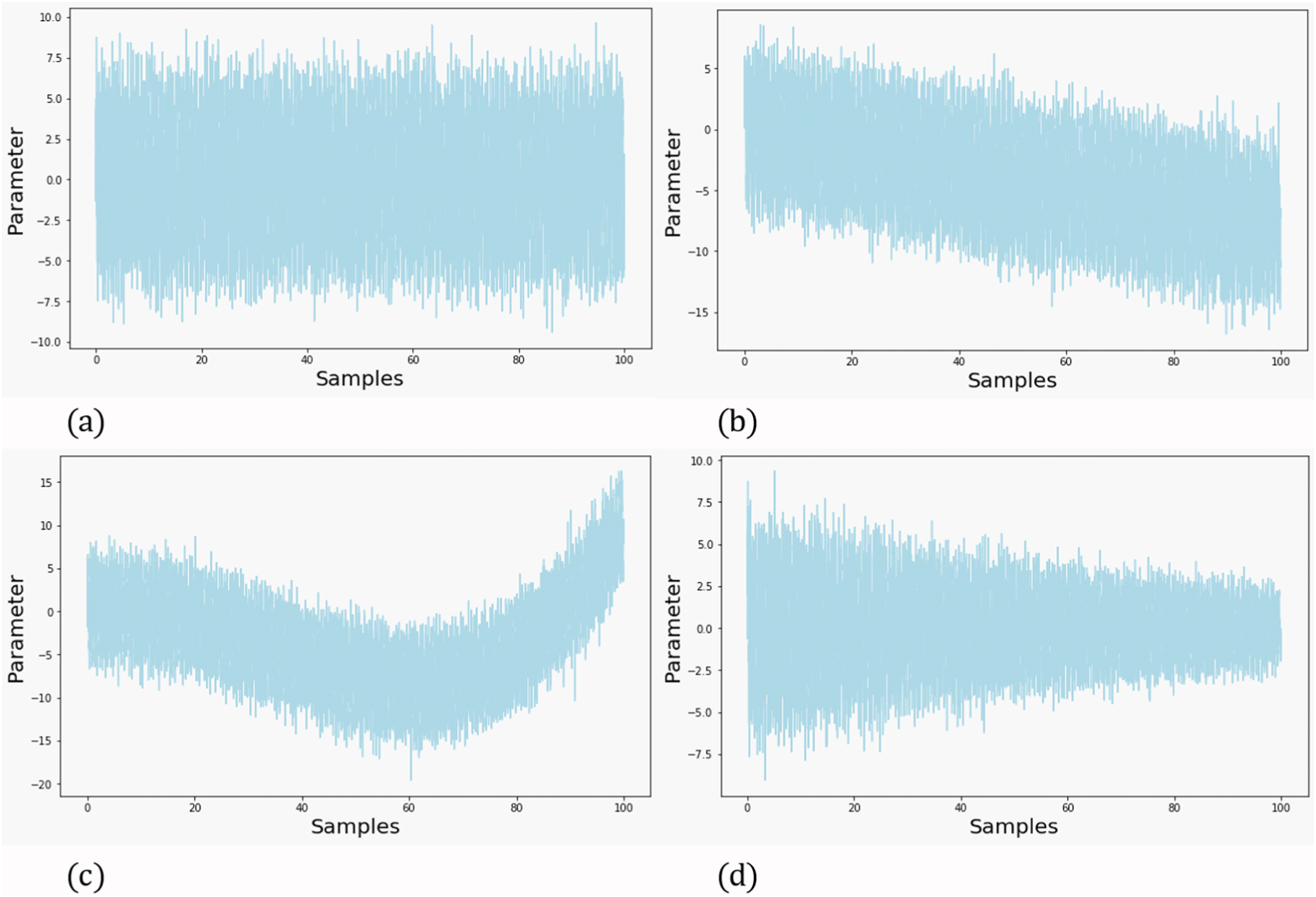
Furthermore, the categorization of linear and non-linear concerns the suitability of data to be reproduced. Figure 2(a)–(d) depict linear data, whereas Figure 2(c) illustrates nonlinear data. Moving forward, the distinction between univariate and multivariate data relate to whether it consists into single or multiple features. Since data is usually collected from multiple sensors, most time-series data are multivariate. However, the models can employ them individually or together. Lastly, classification into Gaussian or non-Gaussian depends on whether the distribution is normal or not. The categorization of a given dataset plays a crucial role in determining the most suitable time-series model, thereby improving the predictive performance.
For instance, when examining the pure acceleration response of a railway bridge, it tends to exhibit features of stationarity, linearity, and Gaussian distribution. This inherent stationarity allows time-invariant models, such as linear models, to effectively predict responses across a defined time window (Azim and Gül, 2020; Datteo et al., 2018; Matsuoka et al., 2021; Meixedo et al., 2022). However, as there are environmental and operational variations (EOVs), normalization must be done, especially to the aforementioned models, due to the presence of nonlinear responses (Azim, 2021; Meixedo et al., 2022; Wang et al., 2022). Furthermore, the Gaussian nature of the data allows for efficient anomaly detection through hypothesis testing, established with a designated confidence boundary (Meixedo et al., 2021; Santos et al., 2016). On the other hand, nonlinear models demonstrate versatility across a wide spectrum of time-series data (Chalouhi et al., 2017; Lawal et al., 2023; Wang et al., 2022). Essentially, they could capture complex nonlinear relationships as well as perform data compression and fusion operations.
In the context of the railway bridges damage diagnosis, this paper will focus on the description of both linear models and nonlinear time-series models. Figure 3 highlights the chosen models within these paradigms, which will undergo comprehensive analysis. The linear time-series models section will provide a brief overview of the widely employed linear models in the context of SHM. Subsequently, The nonlinear time-series models section will elaborate on nonlinear time-series models, including methods that consider sequential data structures such as RNN, NARX, GRU, and LSTM, as well as those that do not, necessarily, rely on it, such as ANN and CNN. Analyzed time-series models.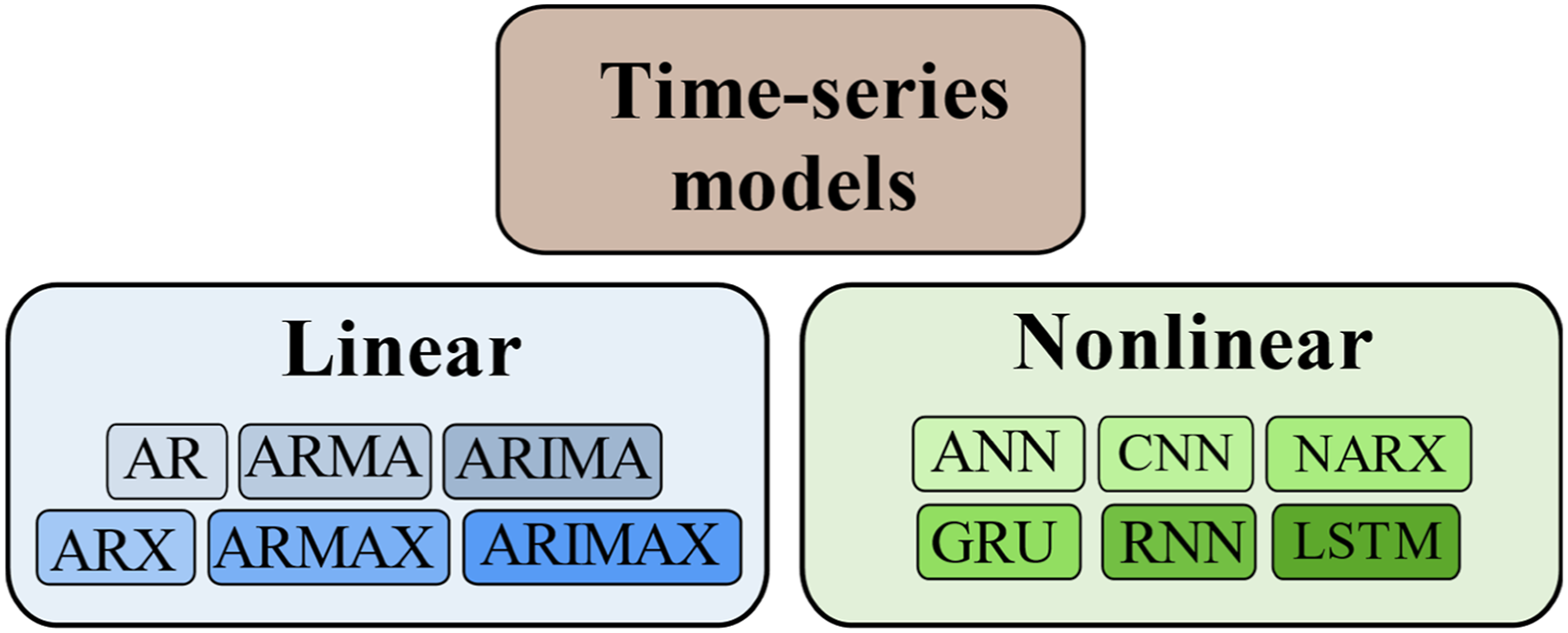
Linear time-series models
Fundamental autoregressive models assume that the outputs of a specific time-series data exhibit a linear dependence on their preceding values, along with a stochastic element. This concept is summarized in equation (1), which defines the AR model:
In scenarios where responses are observed across multiple points (a multivariate time-series), the response at each sensor can be forecasted using the output from a chosen reference channel together with inputs from other channels. This methodology is the exogenous autoregressive model (ARX), as represented in equation (2):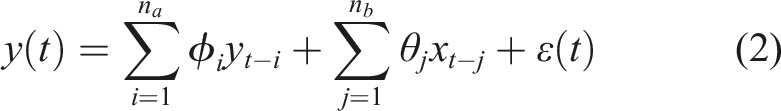
One possible way is to introduce an error equation, usually associated with Moving Average processes (MA) (Sonbul and Rashid, 2023), in AR (equation (1)) or in ARX models, obtaining, respectively, the autoregressive moving average (ARMA), described by equation (3), and the moving average exogenous autoregressive models (ARMAX), expressed in equation (4).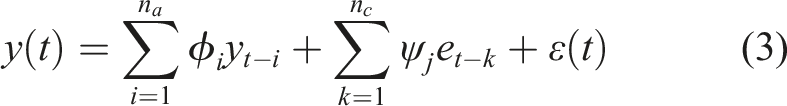
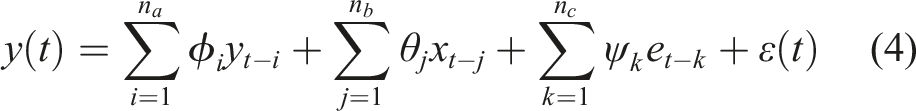
The previous models are based on the stationarity of data. When there is no stationarity on the raw data, the difference between the responses, may be considered in the time-series model. The Autoregressive Integrated Moving Average (ARIMA) and its version with exogenous input (ARIMAX) models use this approach, subtracting the current value from a previous value. To a simpler representation of the model, the backshift operator 
The difference between measures is defined by equation (6).
Dividing both sides by 
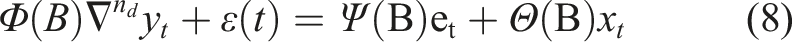


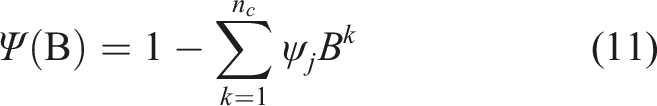
The model order Autoregressive models’ structure.
Finally, the estimation of the model order is of utmost importance for accurately capturing temporal patterns. For linear endogenous models, the use of criteria such as the Bayesian Information Criterion (BIC) or Akaike Information Criterion (AIC) is common (Datteo et al., 2018; Meixedo et al., 2022). For exogenous or non-linear models, criteria such as Mean Squared Error (MSE), Normalized Root Mean Square Error (NRMSE), Mean Absolute Error (MAE), among others, have proven to be suitable for order selection (Gong et al., 2023; Meixedo et al., 2021; Tee, 2018; Wang et al., 2022).
Nonlinear times-series models
Given that the connections between attributes that perturb an analyzed response often arise from nonlinear combinations, the development of a framework capable of accurate prediction requires the integration of nonlinear models. For SHM, a particularly suitable method is the use of ANNs, which will be briefly discussed below.
The ANN is an efficient nonlinear statistical model well-suited for both classification and regression tasks. At its core, this model comprises processing elements, or neurons, that employ nonlinear functions to map attributes to corresponding outputs (Finotti et al., 2019). The topology of an ANN is commonly represented through a network diagram, as depicted in Figure 5. ANN network diagram.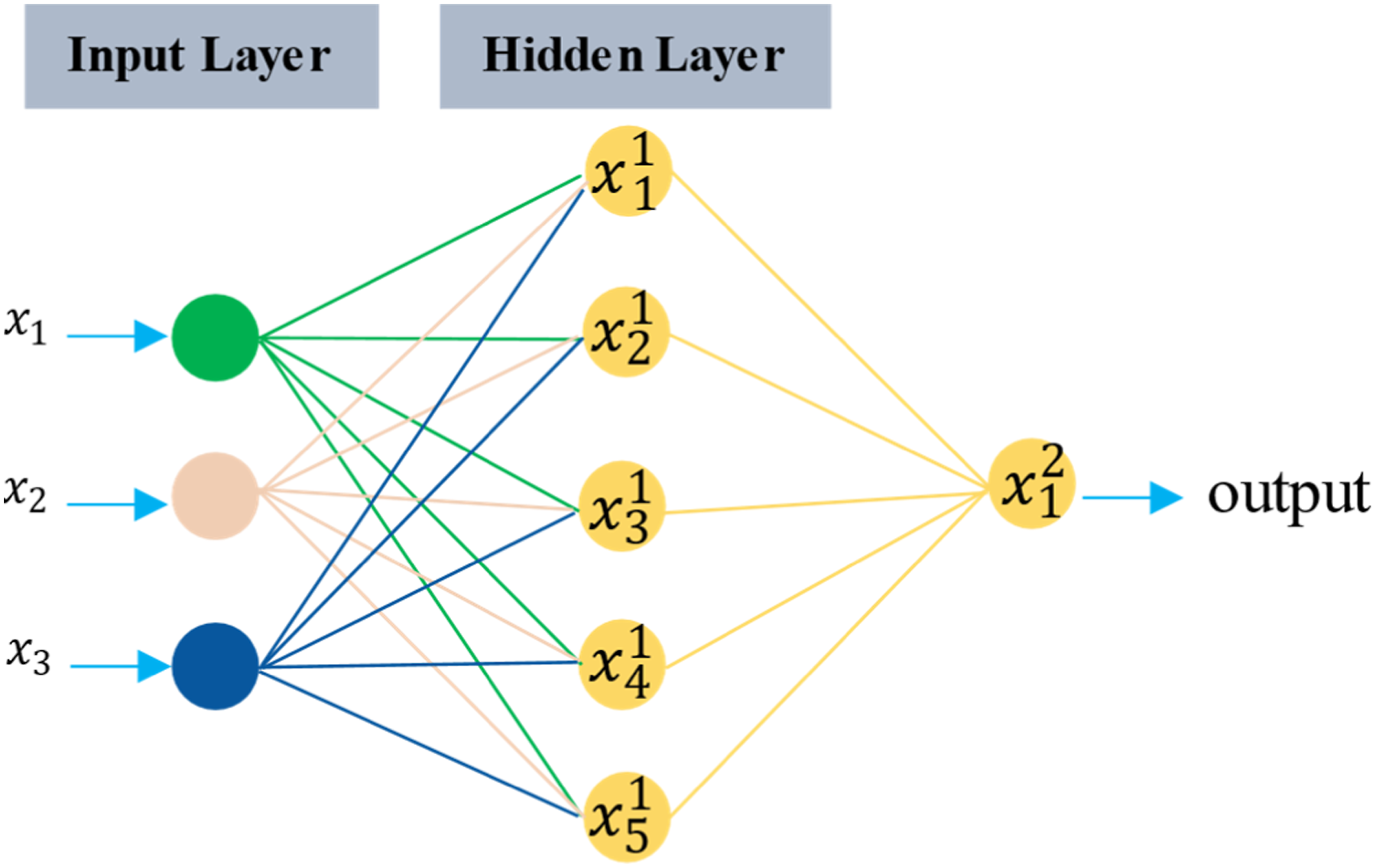
Where Basic CNN architecture.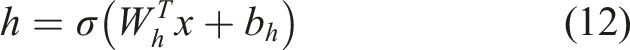
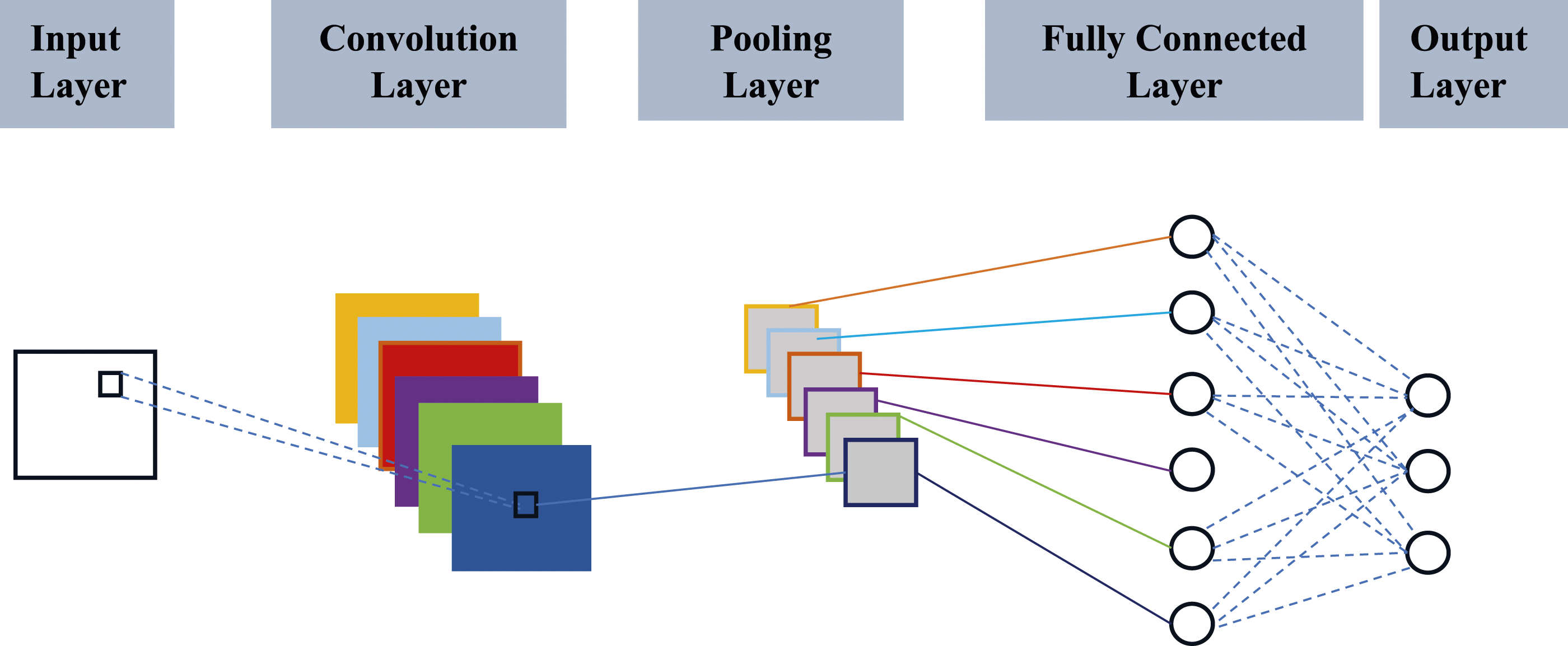
Lastly, the outcomes derived from the pooling layers are integrated as inputs into an ANN. A typical CNN architecture encompasses a sequence of operations, namely feature extraction, normalization, and data compression. Despite the prevalent association of CNNs with image processing, their use extends beyond that, including applications within SHM. Even multivariate time-series data can profit from the inherent capabilities of this model (Parisi et al., 2022).
Regarding sequential data, RNN, NARX, GRU, and LSTM stand as more efficient propositions for ANN models. RNN employs node (neuron) outputs as feedback to nodes in previous layers, like a NARX definition. The distinction lies in NARX’s integration of exogenous inputs. Figure 7 showcases a rudimentary unfolded RNN architecture. Unfolded RNN architecture.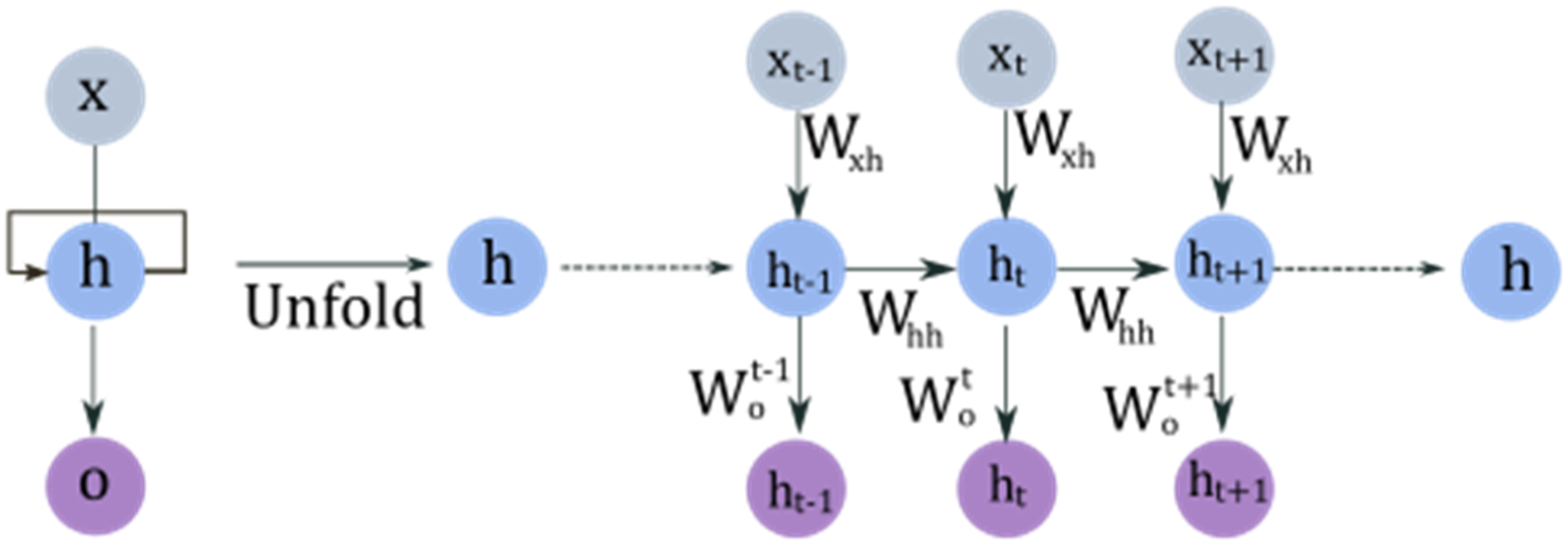
To the RNN exemplified in Figure 6 the values on the hidden layers are recursively calculated by equation (13):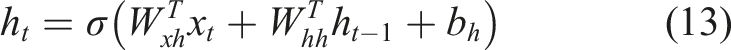
And the output is calculated by equation (14):
For the NARX model depicted in Figure 8, each response function is a product of endogenous ( NARX model with 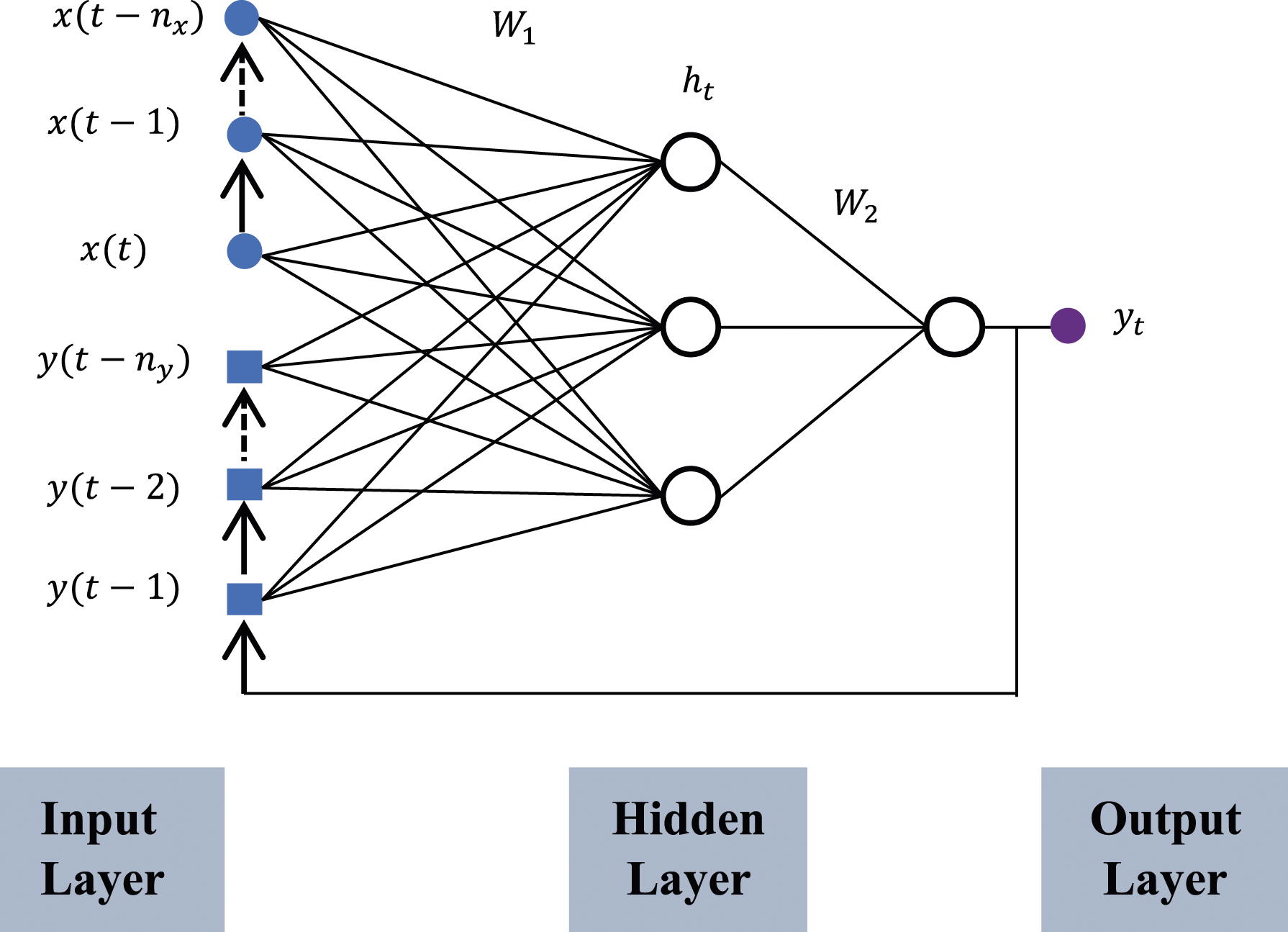
The incorporation of these supplementary inputs involves the inclusion of an additional term in equation (14). As a result, the model is given by:
The RNN may be obtained from the NARX by using solely the output values. In turn, the RNN is a nonlinear generalization of a linear regression applied to sequential data, such as time-series data. In particular, the prediction of RNNs relies on the second derivatives within each hidden layer. However, this architectural design can be susceptible to the vanishing gradient problem, that is, the situation where the gradients of the loss function with respect to the model’s parameters become extremely small as they are backpropagated through multiple layers during the optimization process. Therefore, the algorithm exhibits problems in learning from inputs distanced from the predicted response. For instance, in the work by Bui-Ngoc et al. (2022), a CNN-RNN framework was applied to acceleration measurements using the well-known Z-24 bridge benchmark. Despite employing CNN for data compression, the loss function for training and test dataset did not converge (due to overfitting) which might lead to inadequate results to real world application.
One effective strategy to tackle this issue involves incorporating neurons, or gates, that explicitly facilitate the retention or omission of inputs. This innovative model is termed GRU, and its mathematical representation is illustrated in equation (16):

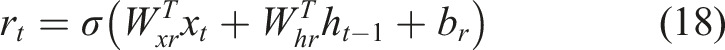
The subscripts indicate the layer of the weights and biases, and
In recent applications of GRU within the context of SHM, some employ the model in conjunction with a CNN framework. In this setup, CNN serves to model spatial relationships and short-term temporal connections among various sensors in an instrumented bridge. The output of the CNN is then input to a GRU, enabling the learning of long-term temporal dependencies. Notably, these combined models have demonstrated remarkable accuracies, achieving 94.92% for a laboratory-scaled concrete bridge and 85.11% for a three-story frame structure from the well-known IASC-ASCE Benchmark (Yang et al., 2020, 2021).
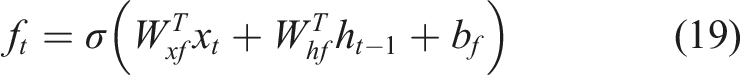

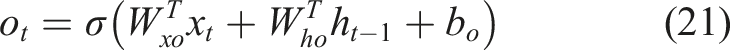


Models’ features.
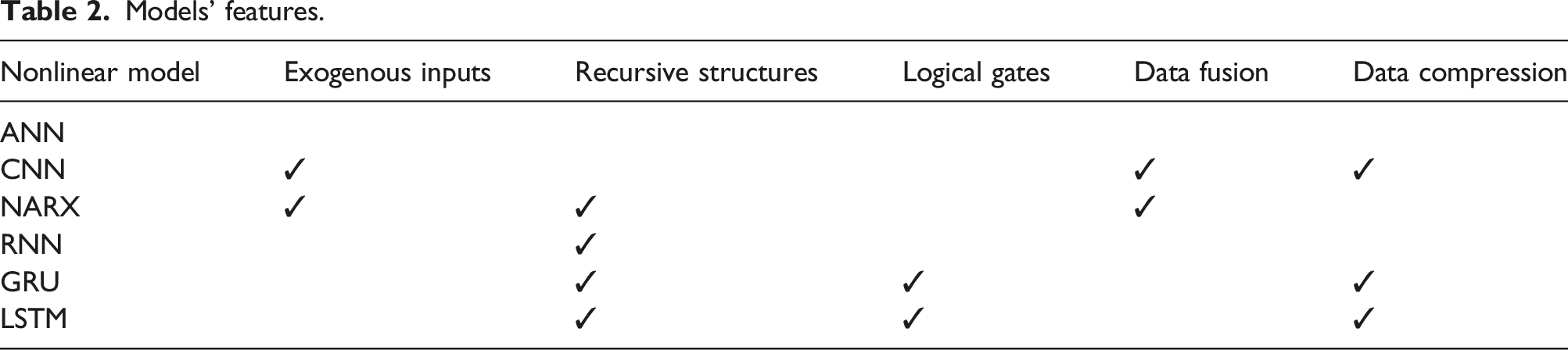
From the information presented in Table 2, it becomes evident that the ANN model, in comparison, assumes the role of a fundamental nonlinear model. Furthermore, the architectures of the GRU and LSTM models share similarities. The primary distinction resides in the quantity of logical gates, which facilitates more effective data regulation during the training process. Notably, the “Data Compression” column pertains to models featuring distinctive structures, like pooling layers in CNN or the forget gates within GRU and LSTM architectures.
Application of time-series models for condition assessment of railway bridges
Linear time-series models
The selection of each study to be analyzed in this section, was grounded in their relevance to the chosen focus, that is, works that utilized time series models for damage identification in railway bridges. This selection was based on theoretical consistency and coherence, author metrics such as the number of citations and h-index, as well as the metrics of the works themselves. Consequently, only publications that are relevant, recognized by the academic community, indexed in reliable databases, and that bring relevant aspects in the use of time-series models were selected.
Linear models offer a range of applications owing to their adaptability, efficiency, and economical computational requirements. These attributes manifest across diverse datasets (Azim, 2021; Datteo et al., 2018; Meixedo et al., 2022) and performance (Azim and Gül, 2020; Meixedo et al., 2021) on the methodologies outlined in overview of time-series models.
Azim and Gül (2019) introduced an enhanced damage strategy rooted in the ARX framework (equation (2)), building upon a similar methodology proposed by Mei and Gül (2016). In the updated version, biaxial acceleration responses and operational variables (train speed and loadings) were incorporated. A Finite Element Model (FEM) encompassing the deck, girders, and track was developed to simulate baseline and impaired responses. The model consisted into five beam elements for the girders and a plate element for the steel deck supporting one single track with no description of its modelling. The supports were considered as hinges, restraining only translation. The train was COOPER E80 with the corresponding loading schema defined according to the American Railway Engineering and Maintenance of Way Association. Four distinct damage scenarios were replicated: stiffness reduction in beams, loss of moment capacity, alterations in support restraints, and deck stiffness deterioration. The selected DSF was the fitting ratio (FR), defined as follows:
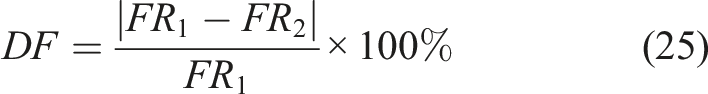
This feature allows damage severity and location assessment, even though always in reference to a fixed benchmark. In essence, this feature is a distance-based metric for anomaly detection, as the difference between a reference state and a damaged is expected to increase as abnormality becomes greater. Furthermore, the feature is expected to increase when close to a localized damage. Consequently, the strategic deployment of the sensor network assumes a crucial role in determining the effectiveness of location-related data. The endogenous and exogenous order of the model was determined solely based on physical modeling and subsequently fixed, whereas the more appropriate procedure for establishing it should rely on metrics such as the Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Normalized Root Mean Square Error (NRMSE), among others (Datteo et al., 2018). Without such metrics is not possible to understand if the chosen model order correctly captured the system dynamics.
While the threshold was established based on the outcomes of baseline simulations, the statistical methodology for achieving the specified 99.7% confidence level was solely based on the DFs obtained to the reference state. Some outcomes are presented in Figure 9. DFs to beams N1 to N10 with stiffness loss of: (a) 10% (b) 40% (Azim and Gül, 2019).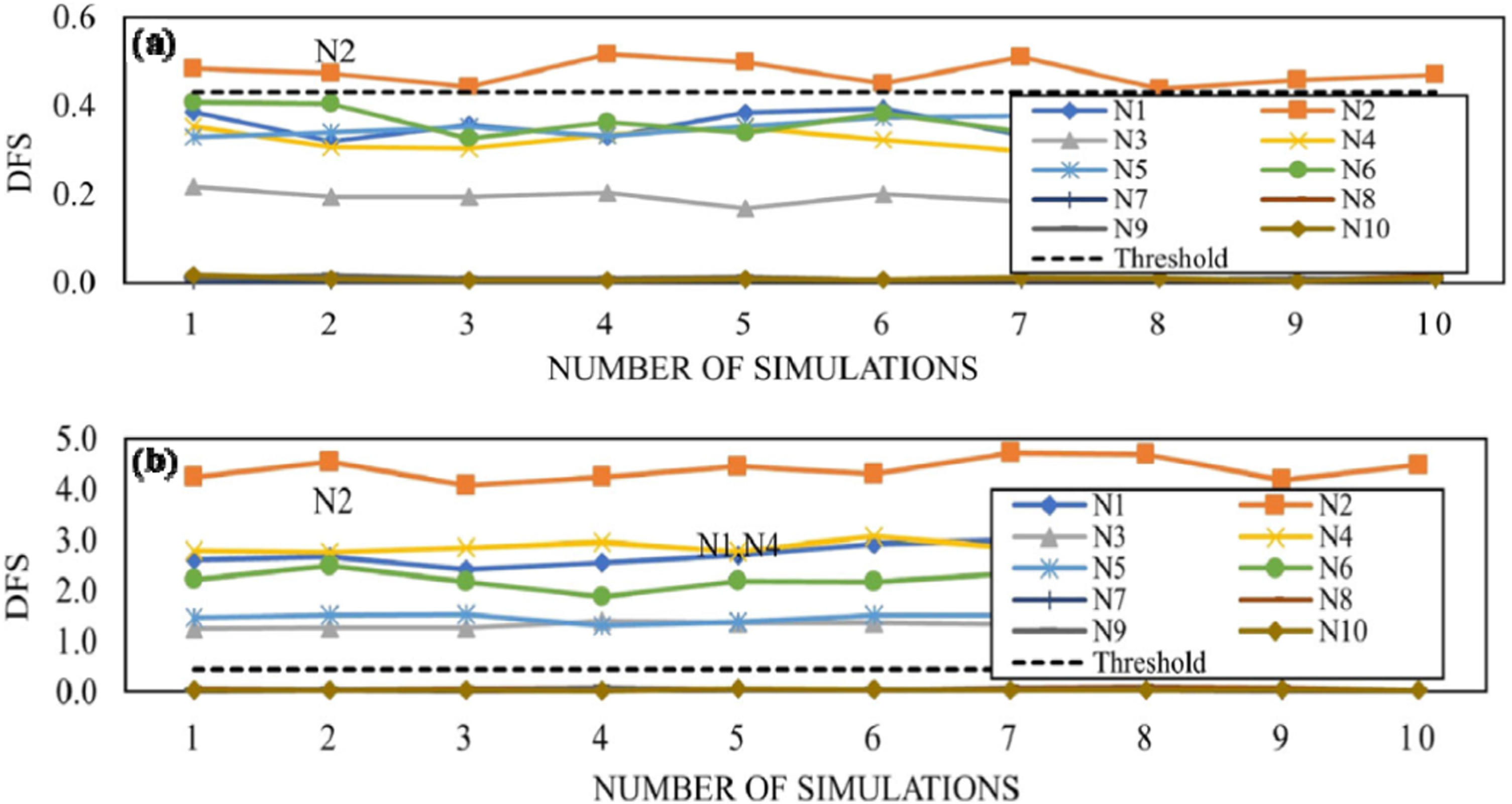
The outcomes showcased the model’s ability to gauge severity of a specific damage, as higher DFs values corresponded to more pronounced modeled damages. Furthermore, for beams with simulated damage (beam N2), higher DFS values were obtained for nodes of the damaged bars. This sensitivity to damage location is particularly pronounced for larger reductions in stiffness.
The study illustrates the damage sensitivity of the indicator for the specific scenario proposed. However, the approach could benefit from employing statistical discrimination methods, such as distances or statistical distributions, coupled with thresholds and subsequent associated metrics, to facilitate a more detailed analysis of the methodology’s performance.
A comparable study undertaken by the same research group (Azim and Gül, 2020) followed a similar trajectory with slight adjustments in the confidence level (99%). This methodology was applied to a distinct railway truss bridge model featuring alternative damage scenarios. The authors crafted a FEM to generate reference acceleration responses (unchanged or baseline) and damage configurations involving 20%–30% stiffness loss in specific bars. Clusters were made to train an ARMAX models using only the neighbor’s sensors information, without explicitly explain the criteria for that selection.
Notably, the proposed DSF could detect damage location and severity as increasing stiffnesses losses resulted in increasing DF only to the damaged bars. While the proposed damage detection framework demonstrates proficiency in offering damage localization insight, to the specific tailored example, its applicability to experimental data and strategies addressing EOV remains unexplored. This could potentially represent a limitation of the method, given that the employed autoregressive models are fundamentally linear in nature. Furthermore, this study also has the same issues of the previous concerning model order, statistical discrimination strategies and absence of metrics that could allow to better analyze the framework performance.
Conversely, Meixedo et al. (2021) used the potential of linear models in a robust damage detection methodology. Initially, the authors conducted the modeling and validation of the finite element model of the bridge over the Sado River, utilizing real data (Meixedo et al., 2022). The model was meticulously constructed, considering various components such as piers, sleepers, ballast-containing beams, rails, arches, hangers, transverse stiffeners, diaphragms, and diagonals as beam elements, as well as the concrete slab and the steel box girder as shell elements, among other elements. The support was modeled considering the bearing devices at the top of each pier. The validation of the static behavior of the model was conducted using temperature data. Meanwhile, the validation of the dynamic behavior was performed by simulating the passage of an Alfa Pendular train traveling at 216 km/h.
The authors introduced AR coefficients that underwent normalization through two distinct techniques: Multiple Linear Regression (MLR) and Principal Component Analysis (PCA). In the MLR-based normalization, temperature and train speed were used as inputs to a multivariate linear regression model, with AR coefficients serving as outputs. Next, the responses obtained using these coefficients were used to subtract the EOVs effects from the acceleration records.
The second normalization type, based on PCA, involved an orthonormal projection into a lower-dimensional vectorial subspace. By progressively discarding principal components associated with higher retained variance, the method aimed to filter out EOVs (Rastin et al., 2021). This sequential reduction in dimensionality helped to mitigate their impact on the analysis.
Subsequently, the Mahalanobis Distance (MD) was employed to fusion data from distinct sensors, condensing information about a given state into a single index that aimed to gauge the dissimilarity between responses. Generally, the distance-based methods presume that outliers will have significantly different distances from the normal behavior. In this study, the MD for the damage scenarios dataset is expected to increase from the reference scenarios.
The index obtained by calculating MD was not flagged based on supervised judgment. A Confidence Boundary (CB) was defined through the application of an inverse cumulative distribution function (ICDF), clustering MD outputs into damage or undamaged states, in a more objective and robust approach. The framework addressed AR model limitations regarding EOV, while using their potential. The model’s adequate performance was underscored by the framework’s application to data simulated via a well calibrated model of the Sado River railway bridge. Following the validation of a FEM through monitoring data, as previously mentioned, multiple damage scenarios were simulated and the noise, which was measured on site, was added to each corresponding sensor. The damage scenarios were simulated based on the most feasible occurrences due to bridge’s vulnerabilities. Those related to corrosion and friction increments in the bearing devices were assumed as most likely.
Acceleration responses from 100 simulations, accounting for varying temperature, train models, and speeds, were leveraged to establish the reference baseline state. An additional 114 simulations were conducted to simulate damage scenarios involving stiffness reduction in bridge elements and an increase in friction coefficients at bearings, with varying degrees of severity. The primary outcomes are depicted in Figure 10. DI to four damaged scenarios varying environmental and operational conditions with CB to: (a) MLR-based features (b) PCA-based features (Meixedo et al., 2021).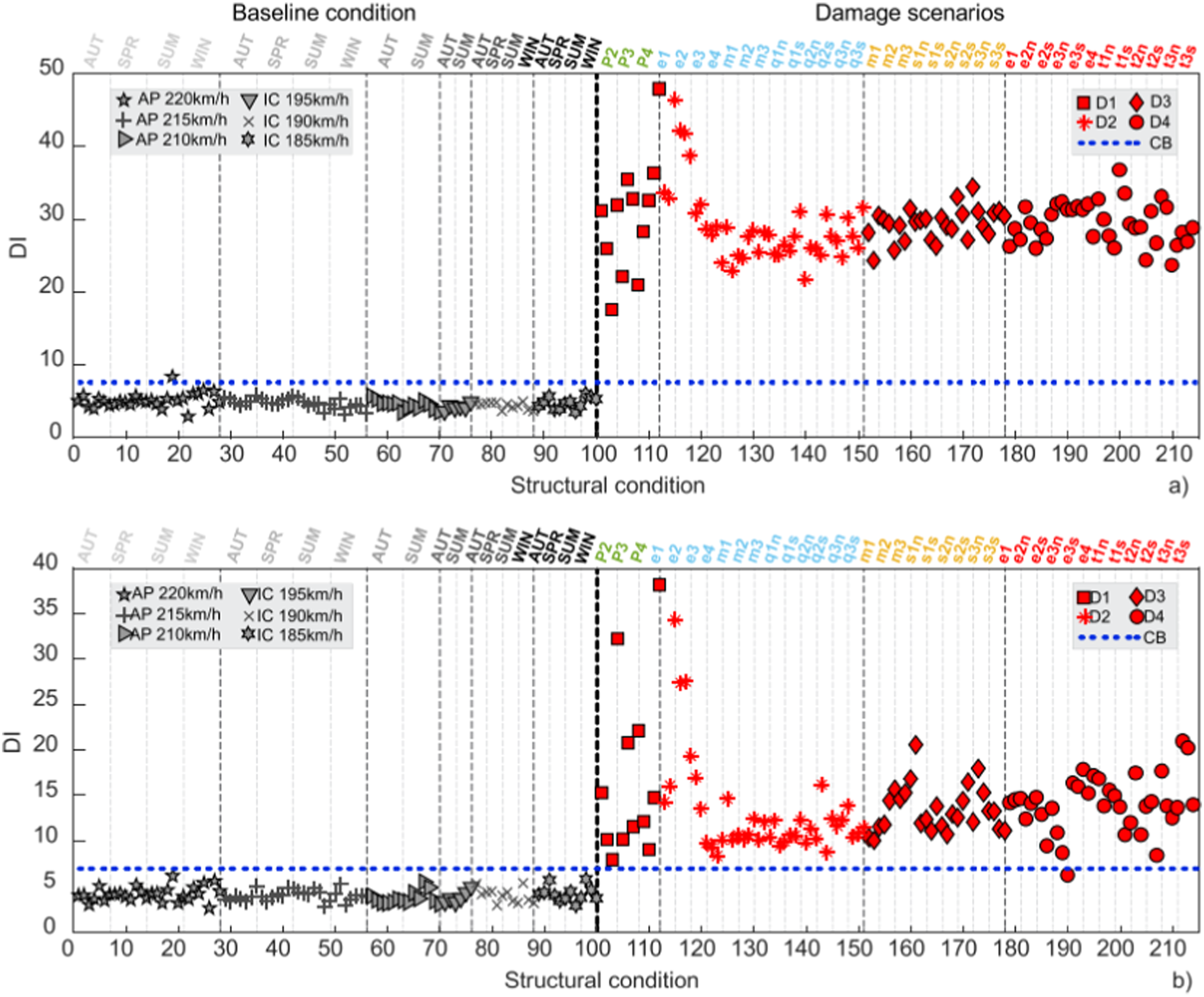
Figure 10 provides a visual representation of the sensitivity and stability of the Damage Index (DI) concerning various simulated EOV conditions. The MLR-based framework demonstrated a mere 1% Type-I error (False positive), while the PCA-based framework exhibited a 0.88% Type-II error.
The results present a consistent approach, estimating the endogenous order of the AR model using the BIC and employing distances associated with the ICDF, which reduces subjectivity in anomaly detection. However, the strategy employed does not facilitate the acquisition of metrics such as Cohen’s Kappa, F1-score, and F2-score, which are crucial for assessing the robustness of the method and its generalization capability (Grandini et al., 2020).
Given that AR coefficients constitute a univariate time-series model, they usually only identify damage. However, enhanced real-world applications may be achieved through exogenous models, like ARX or ARMAX. They leverage data from other sensors to achieve more accurate response modeling, particularly with respect to EOV and localization information, as presented in overview section.
In a recent advancement, the same authors exploited ARX as a feature extractor within an online and unsupervised damage detection framework (Meixedo et al., 2022). Apart from introducing cluster analysis for feature discrimination, the methodology closely reproduces the preceding steps—baseline and damage scenario simulations, feature extraction, normalization, and data fusion. On this approach, the ARX model order to a sensor, was chosen by minimizing NRMSE. One possible improvement would be to allow the model order of different sensors to vary within a cluster. Considering that the sensors are distributed spatially, the time-series data pattern are expected to change within a cluster. However, this implementation would increase the computational cost. Leveraging the k-means algorithm, this adaptation culminated in a fully automated, real-time damage detection framework.
The average dissimilarity between clusters (DC) is tested within a designated window of train passages, allowing the classification of bridge condition. After detailed assessment of optimal window length and the influence of the number of sensors, the outcomes surpassed those of the AR model. Remarkably, this framework effectively evaluated damage across diverse elements while maintaining a low false detection rate, as demonstrated in Figure 11. False detection rate to four different damage scenarios with varying window length (Meixedo et al., 2022).
Figure 11 depicts the efficiency of the online unsupervised methodology, identifying damages based on a moving window procedure comprising 19 train passages, keeping errors to a minimum. The proposed framework lacks the ability to localize damage, an aspect highlighted by the authors, who suggested considering extended applications of exogenous models as a potential way to achieve this goal. Nevertheless, the previous limitation regarding the metrics used for performance evaluation persists. The isolated assessment of the false detection rate does not permit generalizations, thereby not asserting that the methodology would be effective if applied in different scenarios.
Azim (2021) adopted a methodology comparable to their prior works (Azim, 2021; Azim and Gül, 2019), applied to the same bridge truss bridge (Azim, 2021) and using an equivalent DSF. The authors developed a simplified Finite Element Model (FEM) composed of bar elements. The supports at one end of the bridge were modeled as hinges, and at the other end, the pier supports were treated as rollers. Additionally, frictional resistance was not taken into account. The threshold encompassed incorporating two train types (E80 and E90) at speeds of 40 and 50 km/h and introducing artificial noise equivalent to 5% of the maximum Root Mean Square Error (RMSE). After executing 200 simulations, the threshold was set at 99%.
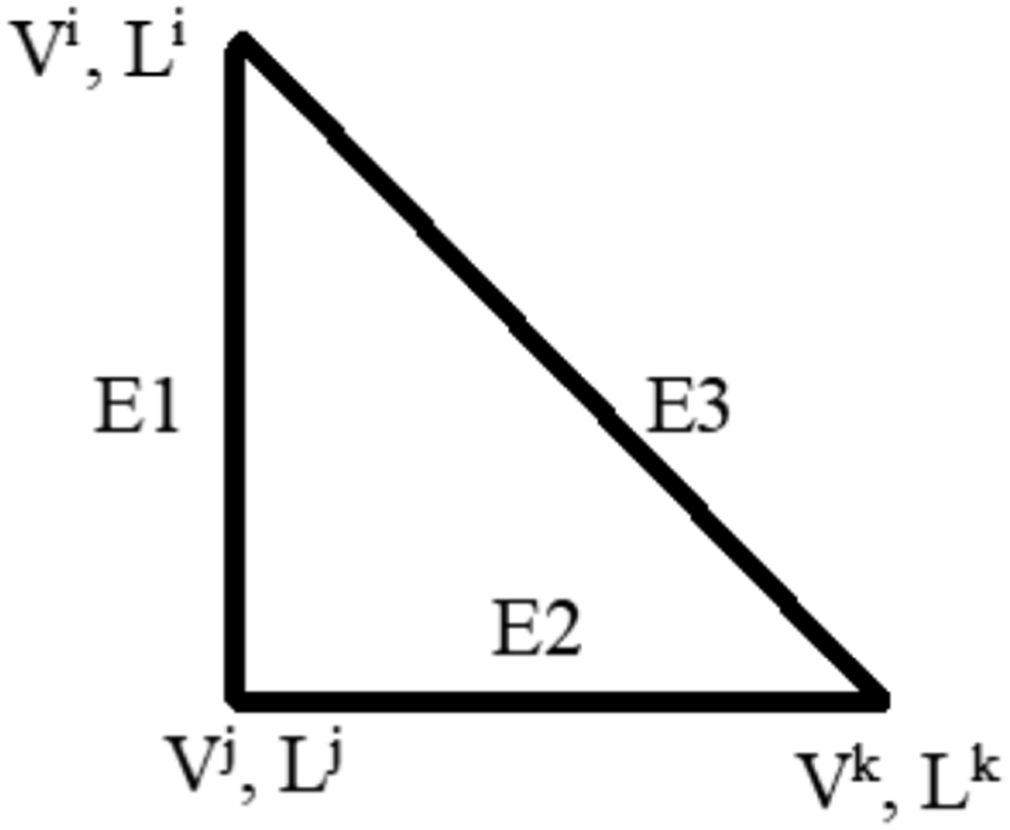
An additional modification entailed implementing PCA for strain measurements. Initially, the authors aggregated each sensor’s response into a matrix, subsequently applying PCA. The first two principal components, representing the most significant variances, were plotted onto a 2D plane using the eigenvectors of the strain matrix as axes. The distance between these components was then computed using the following equation: Truss elements and nodes (Azim and Gül, 2021).
Consider the vertical monitored components Damage scenario of 20% stiffness loss at bars 21, 31 and 44: (a) Bridge Elements (b) 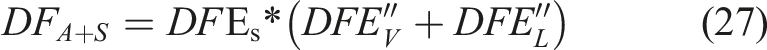
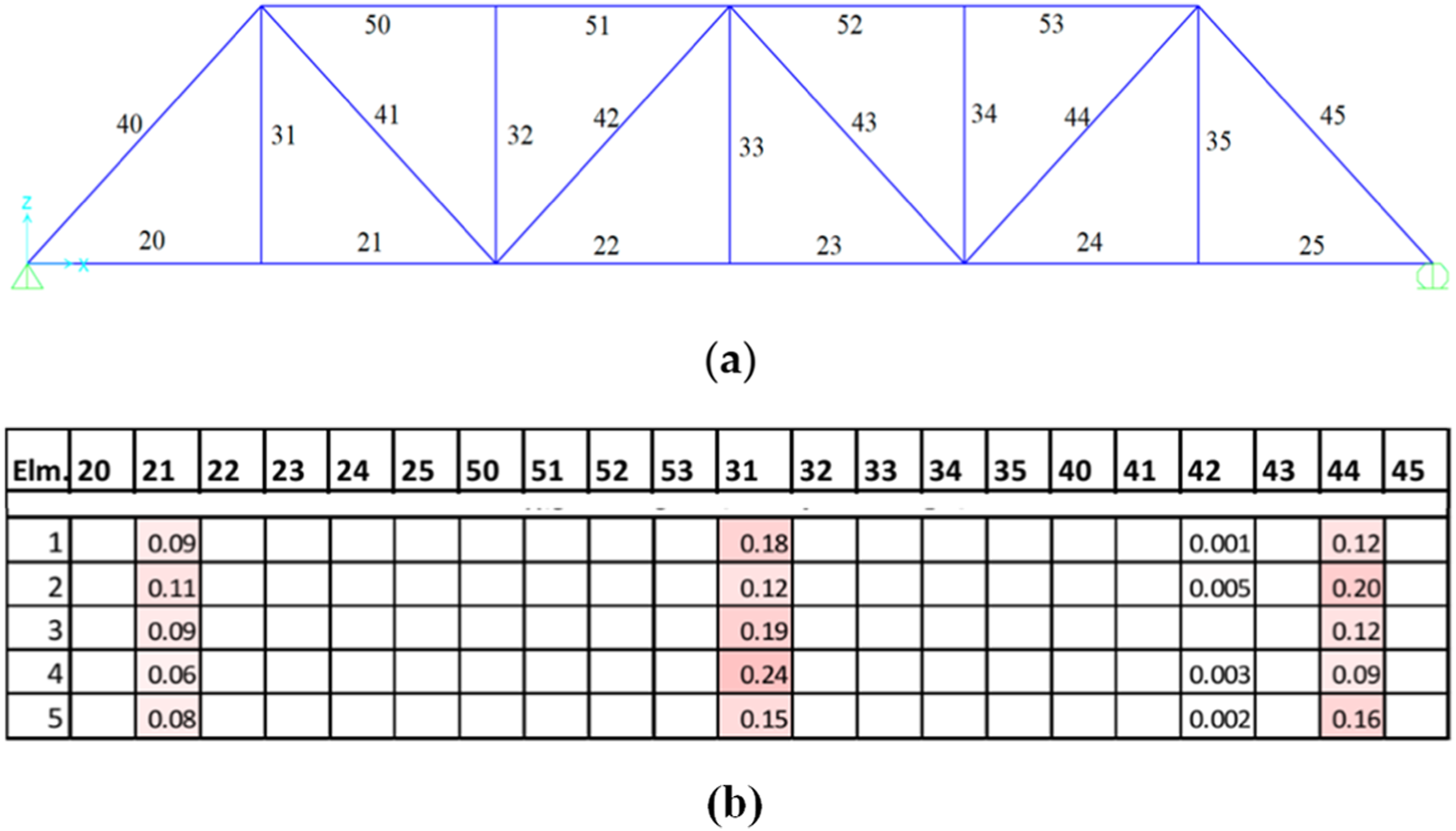
In Figure 13, the
The discussed damage detection strategies primarily rely on the application of least squares to determine AR coefficients, subsequently leading to the formulation of a damage index. However, alternative strategies exist for coefficient determination. A recent example by Gong et al. (2023) pertains to the detection of settlements in railway bridge piers, using an adapted version of AR models. Rather than employing least squares, they employed a Robust Weighted Total Least-Squares (RWTLS) technique to derive the coefficients of equation (1). This approach leverages the residual error normalized by standard deviation to construct a robust estimator via a weights function.
Subsequently, the authors introduced an Adaptive Dynamic Cubic Exponential Smoothing (ADCES) model. The fundamental premise centers on the notion that extreme values in the time-series introduce randomness that interferes with the established pattern captured and fitted by the time-series model. To enhance the objectivity of methodology, the ADCES initial values and smoothing coefficients were determined through Particle Swarm Optimization. These values were further dynamically adapted across the dataset via Optimal Nonnegative Variable Weight Combination.
An application of this framework was made to pier settlements in the Xi’an–Chengdu high-speed railway in China. The dataset comprised three sets of 20 weekly observations for the years 2014 and 2015. The first 10 observations were used as training data, while the subsequent 10 were designated for testing. The performance of predictions was evaluated using three error metrics: Mean Absolute Error (MAE), Mean Absolute Percentage (MAP), and Root Mean Squared Error (RMSE). As the authors are creating a predictive model the better model may be associated to the minimum error. The proposed model has a better performance than pure RWTLS-AR, and then ADCES when comparing models’ predictions. The obtained errors of the proposed method were compared with pure ADCES or RWTLS-AR, Discrete Gray Model-Linear Regression (DGM-LR), Gray Model-Autoregressive Integrated Moving Average (GM-ARIMA), and Metabolic Gray Model-Cubic Exponential Smoothing (MGM-CES). The authors methodology presented a reduction of 73.789% in MAE and 78.692% in RMSE. This pattern of enhanced performance carried across all analyzed datasets. However, this predictive model is heavily dependent on the variables considered, such that related to adjustments made to handle outliers and to achieve optimized estimates with limited information. Hence, this framework is not necessarily replicable in other contexts.
While AR and ANN models constitute distinct categories, authors sometimes amalgamate them to create a comprehensive framework for robust damage detection. Zhang et al. (2019) exemplify this approach by employing an Auto Associative Neural Network (AANN) to mitigate the impact of EOV on ARX coefficients, which were used as DSFs for a footbridge. In this novel framework, the AANN’s ability to model nonlinear relationships was leveraged to effectively address EOV-induced disturbances that affect ARX coefficients.
Nonlinear time-series models
Initially, the literature predominantly employed ANN for time-series data under the assumption that the residual errors of a regression ANN would conform to a normal distribution. However, only in recent years studies explicitly sought to incorporate specific architectures that could take advantage of the sequential data structure. Frameworks such as RNNs, GRUs, and LSTMs are examples of this evolving approach within the field of SHM.
A straightforward yet effective approach was developed by Finotti et al. (2019), adopting a supervised methodology. The authors extracted 10 statistical indicators from acceleration responses and used them to train both an ANN and a SVM model. These models were designed for classification, categorizing samples into undamaged or two levels of damage conditions for laboratory data, and subsequently distinguishing between undamaged and damaged states for a railway bridge.
Validation of the proposed methodology was conducted using data acquired from a bridge located on the South-East high-speed track between Sens and Soucy, in France. Data were collected before and after a strengthening procedure, covering a total of 15 tests pre- and 13 post-procedure tests. The measurements captured acceleration responses triggered by the passage of trains. Employing eight vertical and two horizontal accelerometers, the data was sampled. Figure 14 illustrates the sensitivity of statistical moments to damage. Statistical moments of accelerations responses before and after strengthening (Finotti et al., 2019).
Given that the specific values were not provided, the results presented in Figure 14 do not provide the necessary granularity to discern which statistical moments are most sensitive to damage—thus making it impossible to identify the optimal feature. However, it is important to note that these statistical indicators are employed only as inputs for subsequent classifiers within the methodology. To the classification aspect, the ensuing confusion matrices are displayed succinctly in Figure 15(a) and (b). Confusion matrices before and after strengthening for: (a) ANN (b) SVM (Finotti et al., 2019).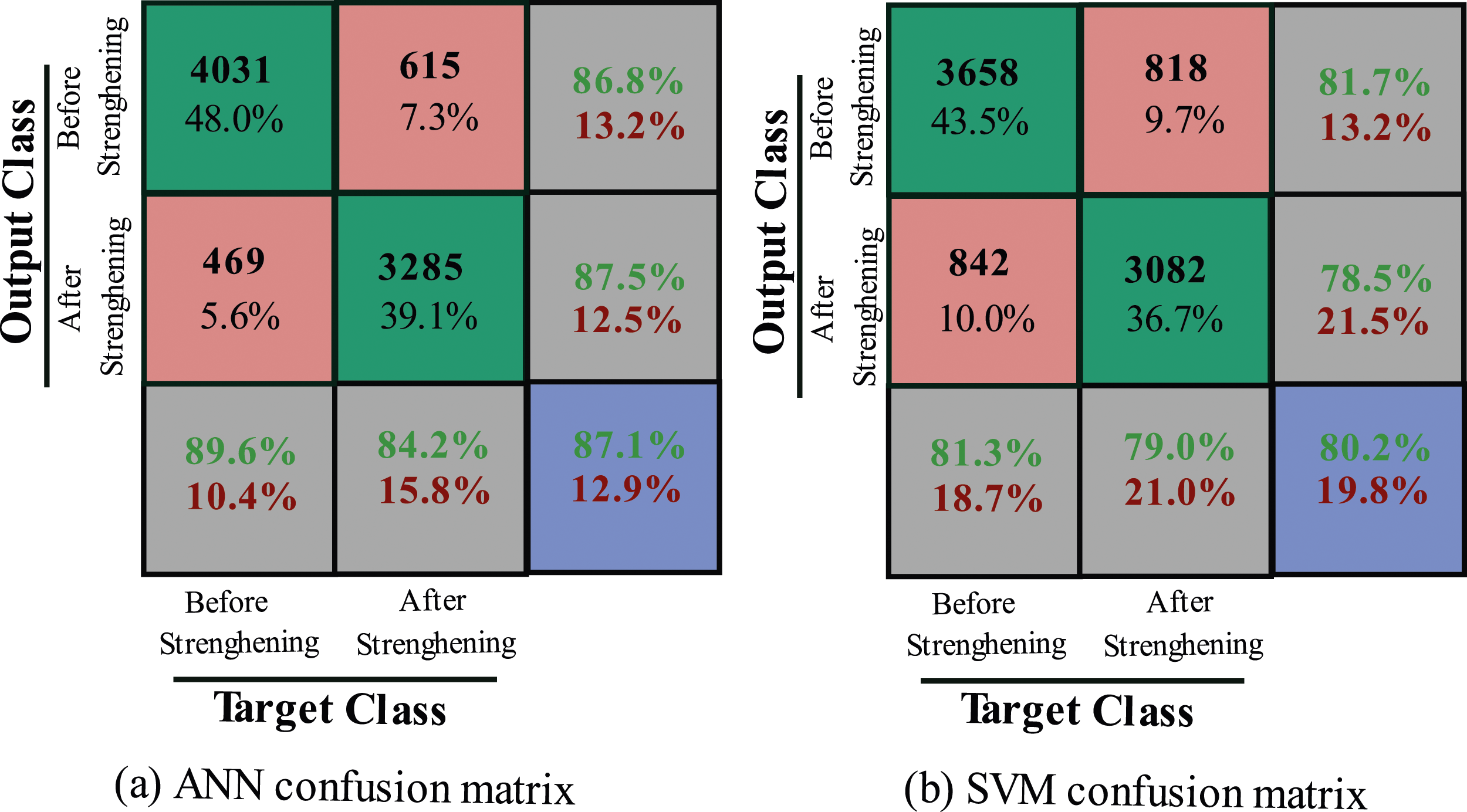
Figure 15 provides a depiction of the outcomes, encompassing the true positive and negative rates, as well as the false positive and negative rates pertinent to the classification task. The accuracy metric, situated in the blue quadrant, attains a commendable 87.1%, accompanied by an error rate of 12.9%. While accuracy gives an average evaluation of a classifier’s performance, a more detailed and comprehensive analysis can be achieved through the consideration of diverse metrics. Similarly, the error rate, while informative, lacks the granularity to distinguish between different types of errors.
Classification Metrics for ANN and SVM.

With the Type I and Type II errors closely aligned, the other metrics exhibit relatively minor fluctuations. Although recall slightly trails accuracy, precision shows a marginal increase. This divergence in precision and recall signifies that the classifier tends to erroneously assign a greater number of Type II errors—precisely the opposite of the desired outcome concerning safety considerations. However, the F1-Score, which summarizes the information from precision and recall into a single score, reflects an overall satisfactory performance. This metric is particularly valuable, as it offers a balanced assessment that is more fitting than a simple arithmetic mean (as seen in accuracy), revealing issues in either precision or recall. The corroborating results from the Area Under the Curve (AUC) confirm these findings and provide a clearer perspective, ultimately underscoring the superior performance of the ANN. Finally, given that strategies employing binary classification often have limited information for damaged states, other metrics suitable for imbalanced datasets, such as PR-AUC or Cohen Kappa, could be used.
The outlined approach employed both SVM and ANN to address a supervised classification problem. An alternative use involves defining a predictive model for responses, wherein the prediction errors may be used as DSF. A regression-based ANN methodology is exemplified by Chalouhi et al. (2017). In this study, the authors proposed a method for damage detection in a railway bridge using accelerations and temperature measurements as inputs. The collected data, covering both reference and current conditions, was preprocessed to extract pertinent attributes such as running direction, speed, and axle count, thereby facilitating grouping of the training dataset and identification of the most prevalent vehicle type. Subsequently, the ANN was trained to simulate the bridge’s acceleration responses under varying speeds for the predominant train type. The prediction error ( DI per train simulation to reference condition (in blue) and altered condition (red) (Chalouhi et al., 2017).
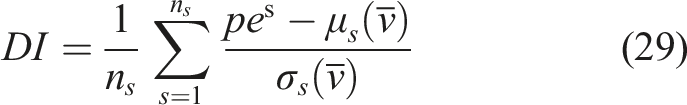
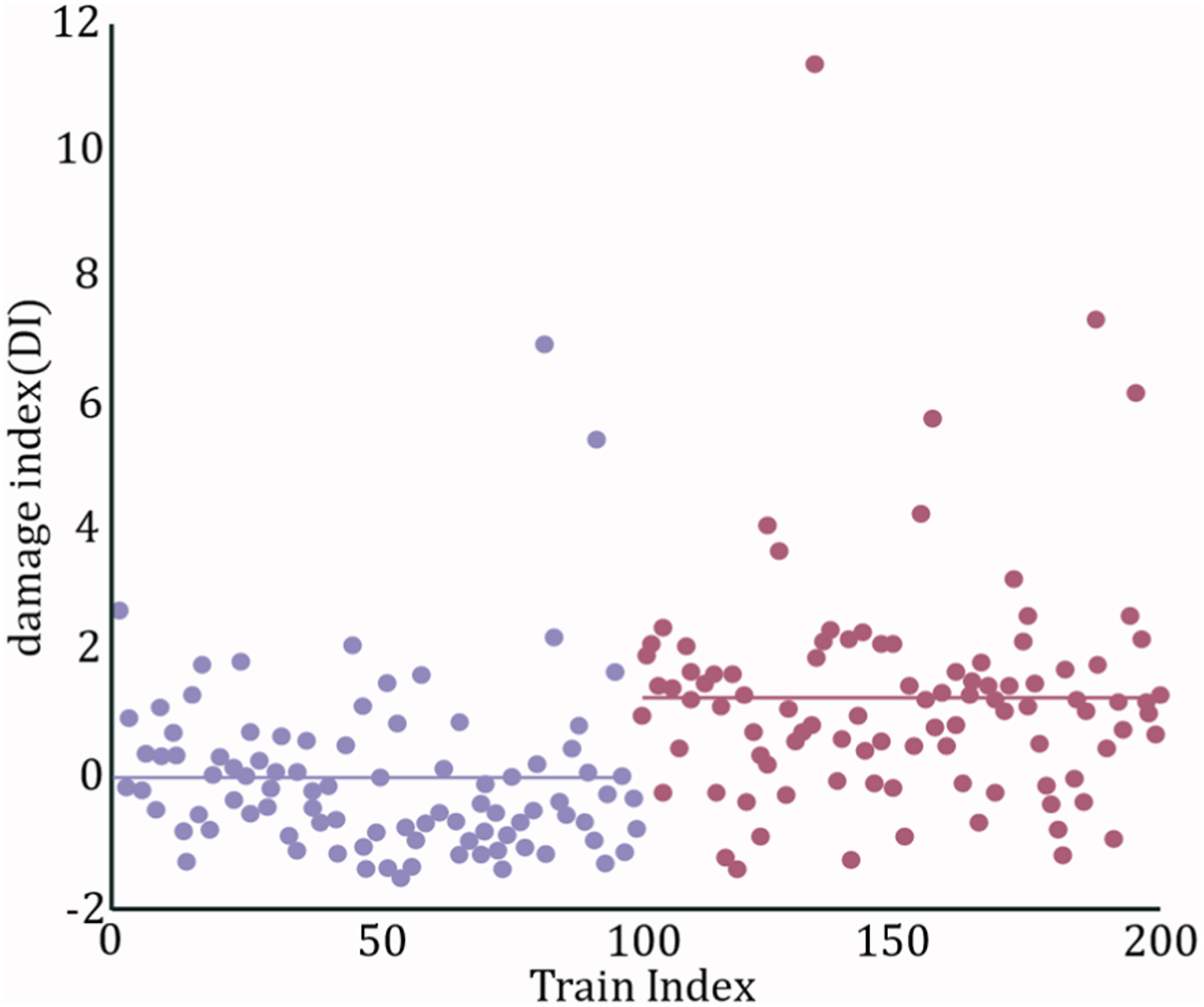
Figure 16 shows discrepancies between the reference condition (blue) and the current condition (red). Meanwhile the AUC, which serves as an indicator of a classifier’s effectiveness, yielded a satisfactory value of 0.7786. Nevertheless, information regarding the selection of the model’s hyperparameters, as well as other pertinent metrics for the binary classification problem, were not presented. This compromises the ability to analyze the model’s performance, as the adopted isolated indicators do not allow for the discernment of issues such as overfitting, or whether the classifier’s performance is equivalent to a random classifier solely based on frequency of the samples.
A distinct study was presented by Santos et al. (2016), introducing an unsupervised and online framework for damage detection. This approach leverages rotations, displacements, and temperature measurements collected from a sensor network on an hourly basis to train an ANN. For each attribute, residual errors were derived by subtracting measured data from predicted values. By virtue of the ANN’s capacity to capture nonlinear relationships, it effectively accounts for the influence of EOVs.
Subsequently, numerous damage scenarios were simulated by introducing stiffness reductions in a FEM of the railway bridge. The model was tri-dimensional with 404 beam elements. According to the authors, the model’s geometry reproduced the original design drawings, and the boundary conditions were defined according to the results obtained from geotechnical tests conducted during the construction. The model was calibrated using real measurements, until displacements and rotations responses with the added noise, were equivalent to those acquired in situ.
The authors employed the dataset from each damage scenario in its entirety, aiming for the methodology to be entirely unsupervised. However, this approach increases the risks of overfitting, thereby diminishing the applicability of the results to other structures.
Separate ANNs were trained for each of the stiffness reductions. Employing the k-means clustering method, the authors determined the optimal number of partitions based on the highest value of the global silhouette index (SIL) and calculated the dissimilarity among the various partitions (DC). The dissimilarity between a reference and damaged cluster is expected to increase. Thus, this feature allows statistical discrimination.
A CB was established under the assumption of a normal distribution for DC. Finally, an index was devised based on the relationship between DC and CB. This index effectively indicates whether a feature’s behavior is within the confidence boundary (implying no damage) or falls outside (indicating potential damage). Figure 17 illustrates the false detection rate—a ratio between incorrectly and correctly assigned statuses—while varying the number of days considered for training the ANN. False Detection rate of the strategy proposed by Santos et al. to several stiffness reductions values (Santos et al., 2016).
The methodology was efficient in detecting stiffness variations as subtle as 1% within the context of simulated damaged scenarios, to the tailored problem. However, the model could benefit from hyperparameter optimization, instead of fixing it, using other metrics for performance, and cross validation, to assure the capability of generalization, essential to a damage detection model to real world application.
Neves et al. (2018) introduced an unsupervised approach for ANN-based damage detection, employing a FEM encompassing bridge deck, two steel girders, steel cross bracings, and a single track to represent a generic railway bridge. The girders and deck were modeled as shell elements, and cross bracings as bar elements. All connections among the elements were modeled as rigid. The study considered two distinct damage scenarios: The first damage scenario simulated the removal of a section of the bottom flange of one girder beam; the second scenario consisted of the removal of one bracing. For the former, the modelling intended to reproduce a damage situation where fatigue crack exists, for the later, to reproduce a situation where there is looseness in the bolted connection. This analysis comprised 300 simulations of train crossings, with speeds ranging from 70 to 100 km/h in 0.1 km/h increments. The acceleration responses were used to train an ANN. Subsequently, the RMSE was computed using equation (30), thereby serving as metric to gauge the predictive performance of the trained model.
Ghiasi et al. (2022) used a CNN-based model to not only detect damage but also assess its severity. Initially, the authors constructed a FEM of the Callington Railway bridge constituted by beam elements to the steel beams, and shell elements for the concrete slab. The FE model undergoes excitation through a load characterized by a Gaussian white noise random matrix, as referenced in Parisi et al. (2022), aiming to simulate the bridge’s natural vibrations after the passage of the train. The time step for the transient analysis was chosen by a sensitivity analysis. The calibration of this FEM was achieved using accelerations measured on site. Subsequently, the authors simulated 255 damage scenarios with both unnoisy and noisy conditions with various signal-to-noise ratios (SNR), added for considering measurements disturbances. In essence three different corrosion levels, each inducing cross-sectional losses of 10%, 20%, and 40%, distributed across various locations along with varying noise conditions. This cumulative effort led to a total of 256 distinct damage scenarios. Each simulation had six vectors of acceleration values spanning 1300-time steps, captured at a temporal resolution of 0.0015 s.
Leveraging this dataset, a CNN was trained to distinguish between damaged and undamaged states while also measuring the severity of the damage. Figure 18 illustrates the classification outcomes for the simulated damage scenarios. Classification results to minor, moderate, and heavy damage levels (Ghiasi et al., 2022).
The accuracy results for damage detection are along the green diagonal, exhibiting an achievement of 99.51%. A high accuracy is reflected in these outcomes. Remarkably, only a single error was observed in terms of damage level classification, where a minor damage instance (10% cross-sectional loss) was wrongly labeled as moderate (20%). However, as previously mentioned, accuracy is a generalist indicator, unsuitable for identifying issues related to the methodology that would compromise its application with different data sets.
A presentation technique employed to show the classifier’s outcomes is the implementation of a t-Distributed Stochastic Neighbor Embedding (t-SNE). This algorithm facilitates the projection of feature vectors, extracted by the CNN, onto a two-dimensional plane. The result is a visually intuitive representation that enables effective data visualization. This novel visualization approach is exemplified in Figure 19, offering a useful way to visualize the distribution and separation of data points within the two-dimensional space. CNN features vector projected into a 2D space (Ghiasi et al., 2022).
The projection visually demonstrates CNN’s ability to accurately group simulated damage levels. Despite these promising findings, it is important to note that no real-world data application was conducted, potentially introducing challenges when detailed information about damage extent labeling might not be readily available.
Another efficient CNN-based approach was pioneered by Parisi et al. (2022), using strain data as a basis. The authors created a FEM model of the Quisi Bridge in Valencia, Spain. The trusses were modeled using bar elements, and the stiffening plates as shell elements. In the first span the supports were considered fixed on one end and mobile on another end. Finally, no noise addition was mentioned, and no real data was used to calibrate the model. While adhering to the fundamental steps shared by many of the frameworks—such as establishing a FEM of a railway bridge, defining damage scenarios and locations—the authors introduced a novel development by engaging in feature selection. This strategic selection aimed to retain only pertinent information through the application of a distance-based machine learning algorithm.
In this method, a Kth Nearest Neighbor Algorithm (KNN) was deployed for each damage scenario, with the accuracy metric serving as a determinant of a sensor’s utility in condition assessment. Given the utilization of time-series data, the authors introduced Dynamic Time Warping (DTW) in conjunction with KNN to ascertain the optimal number of sensors for achieving the highest accuracy. Subsequently, this acquired knowledge was employed to train a dedicated CNN for each damage scenario.
Reference responses were obtained by subjecting the FEM of the bridge to controlled conditions. Among all bridge elements, 10 were randomly selected, and three levels of damage were systematically applied to each of these elements via the FEM representation. The feature selection procedure, characterized by KNN and DTW, returned a critical value of elements for KNN ( Confusion matrix with accuracy for (a) 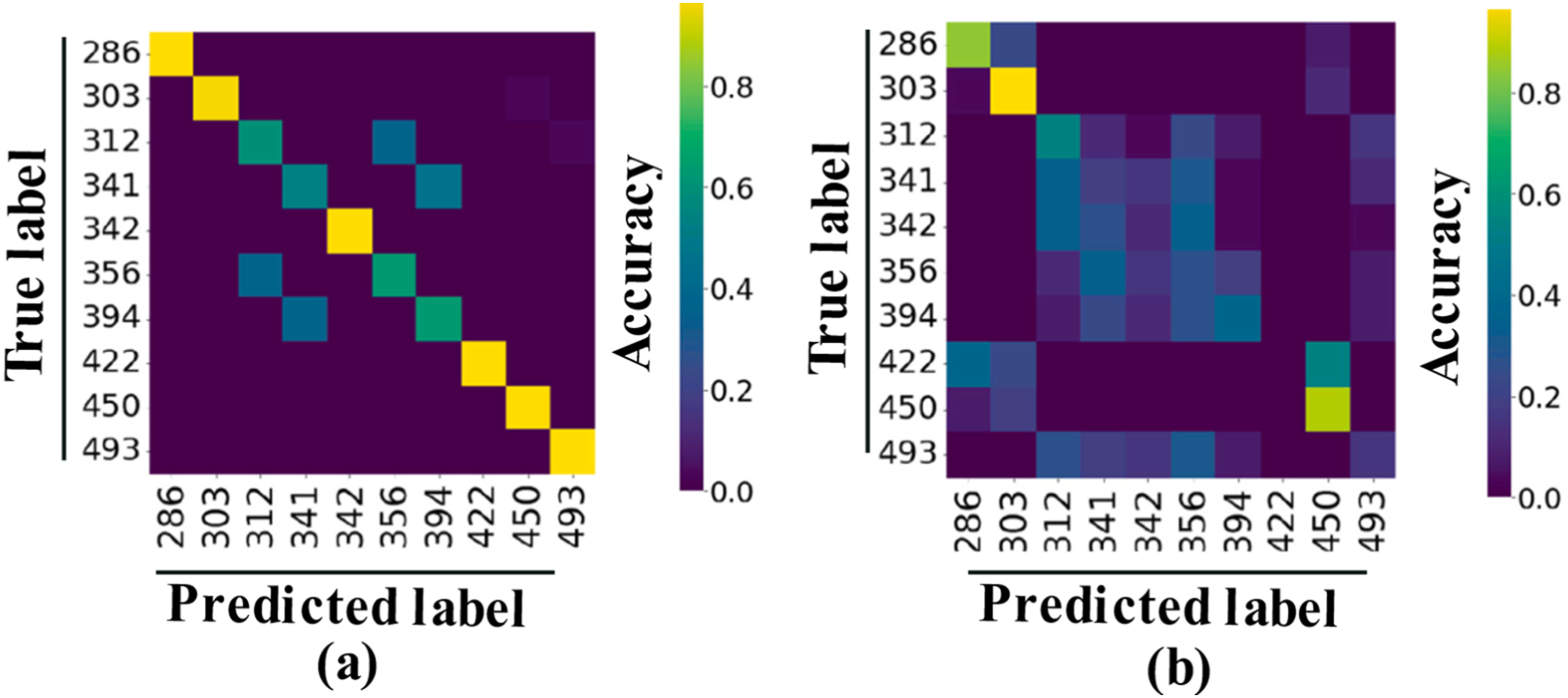
Figure 20 effectively illustrates the impact of incorporating a varying number of sensors in a classification context, specifically in terms of accurately identifying the selected elements as damaged. In Figure 20(a), there is remarkably reduced dispersion of points (with nearly all data points aligned along the diagonal) and consequently high accuracy. On the contrary, for
DL and DA Assessment (Parisi et al., 2022).

Table 5 provides a comprehensive overview of the accuracy achieved through the KNN-DTW feature selection process for each hierarchical level: Damage Location (DL) and Damage Severity (DA). The methodology demonstrated adequate ability to accurately pinpoint damage based on pre-selected data. In terms of severity assessment, although feature selection does not have exceptionally high values, the CNN still produces satisfactory accuracy metrics. The main limitation lies in the requirement for information about damage severities and locations, which is typically not readily available in real-world applications. As CNN is adept at capturing nonlinear relationships, the impact of EOV may not significantly disrupt the effectiveness of the proposed method. By its very nature, the method deals with overfitting by restraining its training set. Thus, analyze other metrics could allow to better understand the potential of the method. Additionally, the FEM was not calibrated with real data. As the approach rely on it to generate information, this compromises real world applications.
A recent application (Han et al., 2019) employed the NARX model to characterize train-bridge responses with the aim of predicting accelerations on the bridge. The architecture comprises 10 nodes within the hidden layer, with a sigmoid activation function and MSE as the loss function. To emulate track irregularities, the authors created a FEM to the bridge consisting solely of beam elements to girders and piers. No information regarding constraint were presented. To the train, a nonlinear 2-DOF system representing a quarter-vehicle model of vehicle suspension was used. Based on a German high-speed railway spectra, the authors generated 10,000 stochastic excitations. Subsequently, a bridge was simulated with track irregularities, featuring a train speed of 200 km/h. A total of one thousand simulations were carried out, and the outcomes present adequate predictions to the irregularities simulated.
Despite the absence of explicit metrics, the presentation of a relative error of the order of 
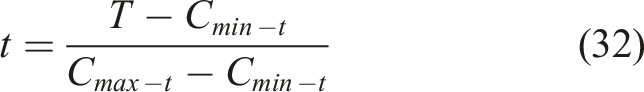
The normalized data was introduced in the LSTM, with optimized parameters. As a small learning rate increases the computational costs and a higher generates an unstable convergence process, determining the optimum value is a crucial task concerning big data. The authors employed grid search to determine the hyperparameters, which is a high computational cost yet efficient method. However, there is no description of isolated optimization process for each input variable. This would be the better scenario due to the different pattern that displacements and temperature exhibit on time. One option to reduce the inherent higher computational cost of this approach is to use gradient-based hyperparameter search. After training, the squared error index (SE) was obtained by equation (33):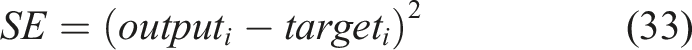
Next, since errors are expected to change in the presence of damage, hypothesis tests were conducted to determine the differences between the current condition and the reference condition. In sequence, data collected from deflections and temperature of the Chongqing Egongyan Rail Transit Bridge over 15 months was used to establish the baseline. As damage scenario measurements were not available, a FEM was used to obtain data for different cable cross-section reduction of 0.3, 0.5, 1.0, 1.5, 2.0, and 2.5%. The authors presented no details about the modelling of the bridge.” The authors presented no detailing about the modelling of the bridge. After, a right-tail
A correlation emerged between the modeled stiffness loss and the t-value, reflecting a positive relationship. This correlation has a dual advantage, enabling both qualitative and quantitative assessments of damage severity. Consequently, the framework holds the potential to establish a robust early warning system. To further elucidate the methodology’s performance in the context of the lowest detected damage level (0.5%), an in-depth analysis of accuracy metrics was conducted. The findings reveal an accuracy exceeding 75% when using data spanning more than 30 days. Moreover, an intriguing aspect was explored by exclusively employing deflection data for training the LSTM model. This approach succeeded in detecting damages with a cross-sectional reduction as little as 1%. However, crucial evaluation metrics such as Type-I and Type-II errors, as well as precision, recall, F1-score and F2-score that could be provided, as the framework is a binary classifier problem, were regrettably not provided, hindering a comprehensive analysis of this approach. Also, the application of the framework to benchmark datasets would grant further evidence regarding the robustness of the method.
A LSTM-based strategy was introduced by Yue et al. (2021), centered around deflection and temperature deflection data from a combined highway and railway cable-stayed bridge situated over the Yangtze River. After establishing the correlation between temperature and deflection to the collected data, the researchers proceeded to train an LSTM model on the initial 75% of the dataset. Subsequently, deviations spanning from 0.25% to 2% were introduced into the final 25% of the dataset to assess the model’s ability to identify anomalies.
The t-test was used to verify if the LSTM model’s predictions to damaged and undamaged scenarios presented a different distribution. On this statistical hypothesis testing, the null hypothesis (
Other applications of linear and nonlinear models
Certainly, linear, and nonlinear models have versatile applications within the field of SHM. For instance, Al-Zuriqat et al. (2023) introduced a fault detection framework known as Adaptive Fault Detecting based on Analytical Redundancy (AFDAR), which combines MA processes with ANN. In this methodology, a designated output point is chosen within a sensor network, and an ANN is trained using acceleration measurements from correlated sensors to predict responses at that point. The predicted outputs from the ANN are then compared to the actual data from the single sensor until a predefined threshold for damage detection is met. Employing MA processes, if a particular sensor is consistently flagged with faults within each time window, the ANN stop using data from that sensor to prevent compromising the framework. However, this approach relies on engineering judgment to establish the threshold, relying on professional expertise.
In a similar vein, He et al. (2016) integrated ARIMA models into an early warning system designed to predict abutment settlements on the Tiajin-Beijing railway bridge during the construction of the Cuiheng Road Underpass. By utilizing 2 years’ worth of data, the authors forecasted abutment settlements for the subsequent 3 months. By that, is possible to infer a model order of 24. However, no detail regarding the criteria used to establish it was given. A non-optimized model order may lead to overfitting. The proposal model achieved an error of only 1% in relation to the targeted period (the third month). The authors do not inform whether they use true targets, that is, if for the second and third prediction they used the predicted or the true value. Furthermore, the authors established thresholds based on errors of prediction regarding the theoretical values for two levels of warning. However, the predictions are highly dependent on the models’ hyperparameter values. Without an objective way of establishing it, there is no guarantee that the predictions would keep the same average error. Finally, the authors do not state if there was any warning active during the monitoring time.
Discussed papers models, main results and data precedence.
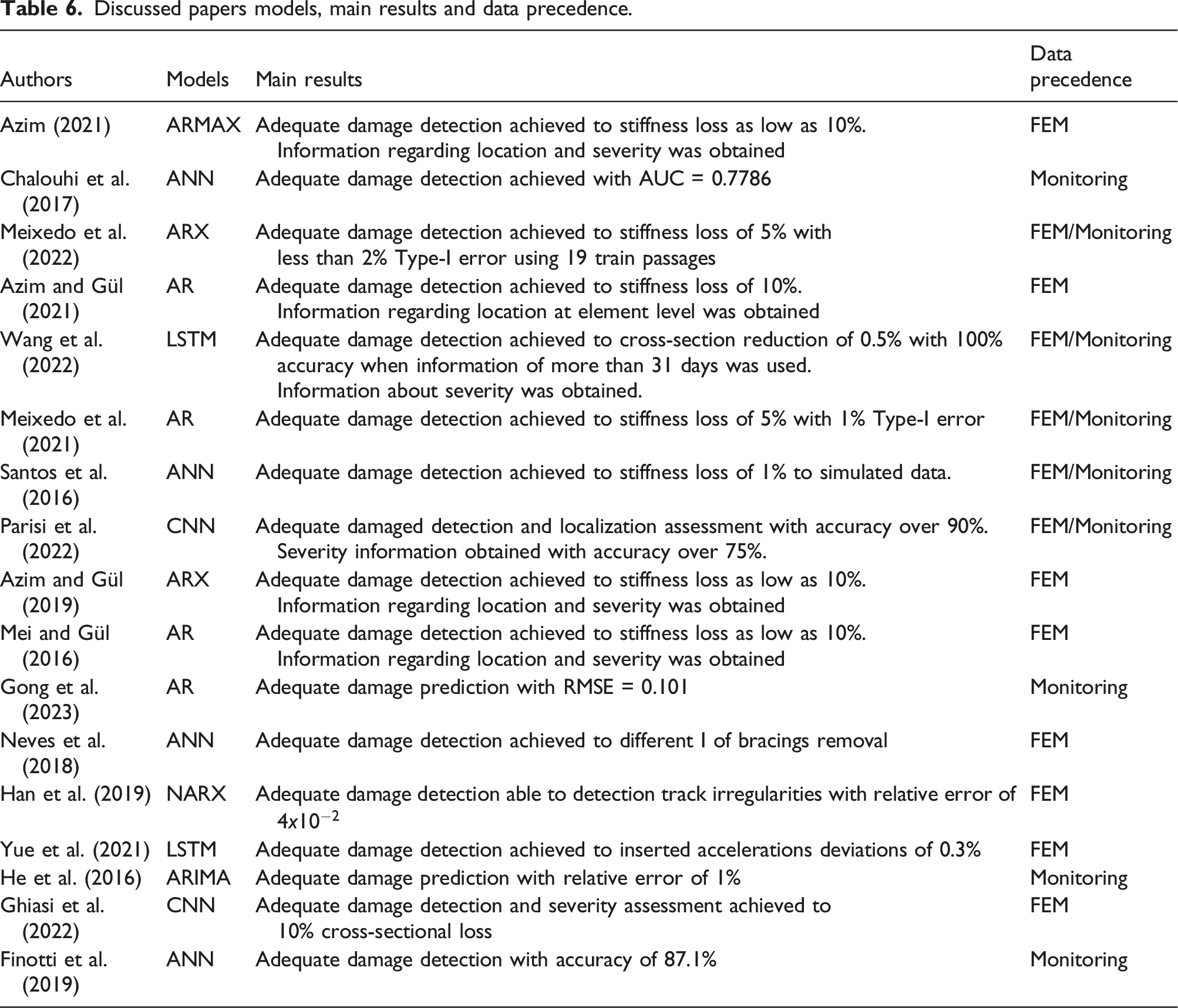
The table highlights the main results, emphasizing the damage detection hierarch level and the type of data used, which is relevant to analyze the robustness of the methodologies. The selected studies offer a comprehensive overview of the possibilities for using time series models. Among the analyses woven throughout the text, emphasis is placed on the scant consideration of the influence of EOVs, the need for both hyperparameter optimization, and the evaluation of results obtained in the models. For example, fixing model order may not allow to the model learn the patterns along time properly. For the evaluation metrics, while accuracy is widely prevalent across various works, this indicator is generalist and does not allow for a complete characterization of the model. It is necessary to understand how and where the model is right or wrong, as well as if it is generalist enough to work on new data.
Conclusions
This article presents and discusses linear and nonlinear time series models, analyzing their application in the assessment of the condition of railway bridges. The development of these models has enabled more effective utilization of collected data due to their flexibility, ease of application, and capacity to retain relevant information. Both linear and nonlinear models have demonstrated their robustness and efficacy in diagnosing damages in railway bridges, even allowing for the extraction of location and severity information from collected data. However, further studies are needed to consolidate these methodologies for practical integration into SHM systems.
As discussed, models trained to predict time responses exhibit sensitivity to both damage and variations in train loads, speed, and environmental conditions. An appropriate analysis should observe how the employed model responds to external factors, including additional normalization processes when necessary. In this context, the article emphasizes the effectiveness of linear models when used within an appropriate strategy and the intrinsic capability of nonlinear models to handle these external factors.
Despite the recent advancements presented, most studies rely on simplified numerical models that are inadequate to represent the complexity of railway bridge responses and the variability of various loading conditions. Application in real-world scenarios would require a verification of the robustness and sensitivity of the methodology, as well as to optimize model hyperparameters to balance computational cost and performance, capturing the underlying time-patterns adequately.
Numerous steps can be taken to further develop this field. Initially, greater utilization of various forms of linear models is suggested to consolidate application methodologies. In their architecture, different levels of diagnosis and susceptibility to environmental and operational variations should be extensively evaluated. Different model order choosing criteria could be explored, comparing performance and computational cost. When dealing with exogenous models the cluster techniques tend to be the same. However, as computational capabilities are growing, different techniques must be tried, for example, optimize the model order for each exogenous sensors, using KNN as information selection criteria, among others.
Similarly, a deeper understanding of nonlinear models is required. This class is capable of learning complex response patterns, modeling environmental and operational influences without additional inputs, with higher sensitivity. Subsequently, extensive studies should be conducted, assessing the trade-off between computational cost and the hierarchical level of the damage detection strategy, aiming for optimized allocation of methodologies and resources.
Finally, since these methods are data-driven, consolidation as a practical tool for SHM must involve application to real collected data from railway bridges, with metrics that allow to completely characterize the framework performance to the study and to new data.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first author was financially supported by Fundação Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) under grant number 88887.816768/2023-00 and Fundação para o Desenvolvimento Tecnológico da Engenharia (FDTE) on the project 1924. The first and the fourth authors integrates the research project “Inspeção e Monitoramento de Obras de Arte Especiais por meio de Técnicas Remotas e não Invasivas” of Cátedra Under Rail - VALE. The second and third authors were financially supported by: Base Funding - UIDB/04708/2020 with DOI 10.54499/UIDB/04708/2020 (https://doi.org/10.54499/UIDB/04708/2020) and Programmatic Funding - UIDP/04708/2020 with DOI 10.54499/UIDP/04708/2020 (https://doi.org/10.54499/UIDP/04708/2020) of the CONSTRUCT - Instituto de I&D em Estruturas e Construções - funded by national funds through the FCT/MCTES (PIDDAC).