
Abstract
As the aging of concrete structures becomes increasingly severe, crack detection has become a crucial aspect of maintaining their sustainable use. This paper investigates an automatic detection and analysis method for concrete cracks based on deep convolutional neural network architecture. The study utilized drones equipped with high-definition cameras to capture images of concrete structures such as bridges and roads, collecting over 10,000 original images containing cracks. Using Labelme software for point-by-point image annotation and applying data augmentation techniques like rotation and scaling, the dataset was expanded to 30,000 images to meet the requirements of deep learning model training. An improved AlexNet model was developed, replacing the fully connected layer with global average pooling to enhance robustness and reduce overfitting. The model achieved an average accuracy of 95.42% on the test set, outperforming traditional methods by 15%. The model also proved effective in noisy environments. Additionally, a semantic segmentation model based on Fully Convolutional Network (FCN) was introduced, incorporating atrous convolution and spatial pyramid pooling, achieving a pixel-level accuracy of 97.6%, surpassing benchmark models such as FCN and U-Net. The model accurately estimated crack width, with an error rate within ±2% compared to field measurements. This method improves detection efficiency and accuracy while reducing manual intervention, providing strong support for the maintenance of concrete structures.
Introduction
In recent years, China’s transportation field has achieved leap-forward development, and key infrastructure such as bridges, tunnels and roads has become increasingly perfect, which has firmly laid the foundation for sustained economic and social prosperity. According to the authoritative release of the “Statistical Bulletin on the Development of the Transportation Industry in 2020”, as of the end of 2020, the total mileage of China’s highway network has historically exceeded the 5.1981 million kilometers mark, and the annual new mileage has reached 185,600 km, showing an unprecedented expansion speed (Rao et al., 2021; Saeed, 2021). At the same time, the highway density has also increased significantly to 54.15 km/100 square kilometers. This data not only marks a comprehensive leap in China’s transportation infrastructure construction, but also demonstrates the country’s firm determination and brilliant achievements in improving regional interconnection and promoting all-round economic and social development (B. Kim et al., 2021; Ali et al., 2022). What is particularly outstanding is that the number and length of highway bridges across the country have increased substantially, reaching 832,500 and 52,256,200 m respectively, further consolidating the solid foundation of the transportation network.
In this process, concrete has become an indispensable material for infrastructure construction because of its high strength, high performance and environmental protection characteristics, and is widely used in various engineering projects (Dong et al., 2020). However, with the aging of facilities, the diseases faced by concrete structures have become increasingly prominent, especially cracks are the main manifestations of initial damage, and their appearance and expansion seriously threaten the safety and life of infrastructure. Affected by the long-term erosion of the natural environment and the characteristics of the material itself, the concrete surface is prone to cracks. If it is not intervened in time, the structural strength will be seriously weakened, public safety will be endangered and economic losses will be caused (Qi et al., 2022; Ren et al., 2020). Therefore, strengthening the health monitoring and maintenance of buildings, especially the efficient detection technology for concrete cracks, has become the focus and urgent need of current research, aiming at ensuring the long-term safe operation of infrastructure and the sustainable development of social economy.
At present, concrete crack detection generally relies on manual auxiliary means, such as inspection vehicle, telescope, feeler gauge and crack width measuring instrument, etc. Although these methods are simple, time-consuming, labor-intensive and inefficient, and the results are easily influenced by subjective factors (Abualigah et al., 2024; Fan et al., 2020). For high-altitude and difficult-to-reach structures, such as the detection of cracks on the top of towering buildings or the bottom of super-large bridges, it is even more necessary for personnel to take risks to work, and the potential safety hazards are significant (Masrour et al., 2020; Ye et al., 2022).
With the rapid development of intelligent technology, the traditional manual detection methods are unable to meet the efficiency and security requirements of modern infrastructure maintenance (Luo, Yussof, et al., 2024). In view of this, it is urgent to develop and implement fully automatic and highly intelligent crack detection technology, which is not only the inevitable trend of innovation and development in the field of engineering technology, but also the key path to ensure the long-term safe and stable operation of infrastructure and significantly improve the efficiency and safety of maintenance operations (Yang et al., 2020; Yu et al., 2022). Through this transformation, we can identify and deal with potential problems more accurately and efficiently, bringing revolutionary changes in infrastructure maintenance management.
With the leap of artificial intelligence, image processing and computer vision technology continue to make breakthroughs, opening up a new path for intelligent concrete crack detection (Luo et al., 2024). Detection technology based on digital image processing, with its advantages of high efficiency and low cost, especially combined with the innovative application of neural network, is gradually moving from theory to practice (Golding et al., 2022; Miao and Srimahachota, 2021). However, in the face of complex and ever-changing infrastructure environments, such as oil pollution, spots, leaves and other interferences, a single algorithm is difficult to perform multi-scene detection (Yu et al., 2024). There is an urgent need to develop a more robust, accurate, and generalized crack detection algorithm to promote efficient automated detection and repair to reduce maintenance costs.
At present, scholars at home and abroad are actively integrating image processing technology into crack detection, covering the entire process from image acquisition, analysis, preprocessing to detection (Hacıefendioğlu and Başağa, 2022; Zadeh et al., 2024). The main strategies are divided into two categories: traditional image processing methods, which directly detect cracks through gray adjustment, filtering, morphological operation and other means, without model training; Machine learning, especially deep learning technology, learns crack characteristics by building models to achieve end-to-end detection, demonstrating strong adaptability and predictive capabilities, and bringing revolutionary changes to the field of crack detection.
Traditional image processing technology has been applied to crack detection since 1960s. Crack images taken in outdoor environment are often disturbed, so pre-processing such as denoising and gray correction is needed to improve the clarity. After pretreatment, edge detection, segmentation and other technologies are used to highlight the crack characteristics (Arbaoui et al., 2021; Chaiyasarn et al., 2021). Crack detection combined with traditional methods includes threshold detection, genetic algorithm, filtering, tree structure, tensor voting and edge detection operator, etc., aiming at accurately analyzing crack characteristics.
Artificial neural network (ANN) shows its advantages in crack detection, especially BP neural network is used to identify crack probability, and impulsive coupled neural network (PCNN) has also attracted attention, but the parameter adjustment is cumbersome and the results are flawed (Flah et al., 2020). With the rise of deep learning, crack detection models based on neural networks such as DeepCrack, CrackNet, and FPHBN have been proposed one after another to improve detection accuracy and robustness through technologies such as deep convolution and feature fusion (Lv et al., 2023; Song et al., 2022). In addition, fully convolutional networks such as CrackFCN perform well in complex scenarios with high accuracy. At the same time, there are also studies focusing on crack size calculation. For example, Dug et al. used VGG16 encoder to measure crack density, which promoted the comprehensive development of crack detection technology. The method based on machine learning trains the crack detection model on a limited data set without preset conditions, and the network with diverse structures can improve the detection accuracy. However, problems such as inconsistent data sets, insufficient network robustness, large training sample requirements, high hardware requirements and computational costs need to be solved urgently, and model simplification is also a future research direction.
This study presents an enhanced deep learning framework for automatic concrete crack detection, addressing the limitations of traditional and existing deep learning methods. Key innovations include a large-scale annotated dataset, an improved AlexNet model with global average pooling, an FCN-based segmentation approach with atrous convolution and spatial pyramid pooling, and a precise crack width estimation method. The proposed system demonstrates superior accuracy, generalization, and robustness in complex real-world environments, offering an effective solution for infrastructure monitoring.
Concrete surface crack image pretreatment
Basic theory of image enhancement
Image clarity is crucial to the accuracy of crack detection. Aiming at the problem that crack images are susceptible to environmental interference, this section uses image restoration based on physical model for clarity improvement preprocessing (Palevičius et al., 2022; Wang et al., 2022). Image enhancement is divided into two methods: spatial domain and frequency domain. The former focuses on pixel processing to improve visual effects, while the latter focuses on frequency domain information, such as Fourier transform, to meet the needs of different visual tasks.
In order to improve the clarity of crack images under environmental interference, this paper applies a spatial domain based enhancement method, including linear and nonlinear transformations such as contrast stretching and gamma correction, combined with spatial filtering. These methods enhance the visibility of cracks and support subsequent detection.
Spatial domain enhancement
Spatial domain image enhancement mainly focuses on processing image pixels, and a higher-definition image is obtained by performing a series of operations on the image itself. The process of spatial domain image enhancement is showing in equation (1).

Spatial domain image enhancement methods are mainly divided into three categories: linear transformation, nonlinear transformation and spatial domain filtering. Linear transformation makes the image clearer by adjusting the dynamic range and contrast, including global linear transformation, contrast broadening, etc (Pham et al., 2023). Nonlinear transformation is more suitable for human vision. By adjusting the contrast curve to expand the dynamic range, such as logarithmic transformation and gamma correction, these methods are flexible and effective. Typical methods of nonlinear transformation include logarithmic transformation and gamma correction, etc. The log-transformation and gamma-correction expressions are shown in equations (2) and (3).


Spatial domain filtering is another important means of image enhancement, which aims to eliminate noise and blur. Methods such as median and mean filtering can remove redundant details and noise in images. In addition, the sharpening operation further improves image clarity by enhancing high-frequency components.
Frequency domain enhancement
Frequency domain enhancement reduces high-frequency components and smooths the image through low-pass filters. Commonly used filters are ideal, Butterworth, exponential and trapezoidal low-pass filters. For blurred images, high-pass filters improve low-frequency components and sharpen image features. Commonly used filters include corresponding high-pass versions. Homomorphic filtering, which combines gray transformation and frequency filtering, enhances contrast and compresses brightness based on illumination reflection model, is another effective method of frequency domain enhancement. For an input image f(x), its illumination reflection is show in equation (4).

Besides spatial domain and frequency domain enhancement, histogram processing and Retinex theory are also important image enhancement techniques. The histogram adjusts the gray distribution to improve the image, including equalization and specification, which can improve the clarity but may introduce color shift and noise. Retinex theory is based on human eye perception, emphasizing that the surface color of an object is determined by reflection characteristics and is not affected by illumination, providing a new perspective for image enhancement. The Retinex theoretical model expression is shown in (5).

Image restoration algorithm based on quadratic constraints and fog distribution
The acquisition process of fracture images is often disturbed by the complex and changeable atmospheric environment, which leads to the degradation of image quality and the significant decrease of image clarity, and then restricts the detection efficiency and accuracy. In response to this challenge, based on an in-depth understanding of the principle of atmospheric scattering, this section innovatively proposes an algorithm that combines quadratic constraints and fog distribution restoration. The algorithm cleverly combines the color prior depth of field information with Canny edge detection operator to accurately capture the edge features of cracks, and based on this, an accurate fog distribution model is constructed.
In image restoration, ‘secondary constraint’ refers to the physical conditions obtained from the atmospheric scattering model, and the estimated transmittance t (x) and atmospheric light A must meet these conditions. These constraints are integrated into the optimization framework to improve recovery accuracy. Specifically, the transmittance t(x) is limited between 0 and 1, reflecting the fact that light intensity cannot increase due to scattering, while atmospheric light A is limited within a reasonable range based on environmental conditions. The goal of optimization is to minimize the error between degraded and restored images while adhering to these constraints.
Figure 1 shows flow chart of concrete crack image preprocessing and dataset construction. BS information refers to the base station information used for image preprocessing and dataset construction. By introducing an adaptive quadratic attenuation model, the transmittance estimation is optimized, which effectively improves its adaptability under different fog concentrations. At the same time, the algorithm also integrates multi-scale morphological closed operation to finely adjust the atmospheric light, and finally realizes efficient and clear restoration of crack images, laying a solid foundation for subsequent crack detection and analysis (G. Li et al., 2020; Padsumbiya et al., 2022). The expression of the atmospheric scattering model (G. Li et al., 2020) describing the image formation process in foggy weather is shown in (6). Flow chart of concrete crack image preprocessing and dataset construction.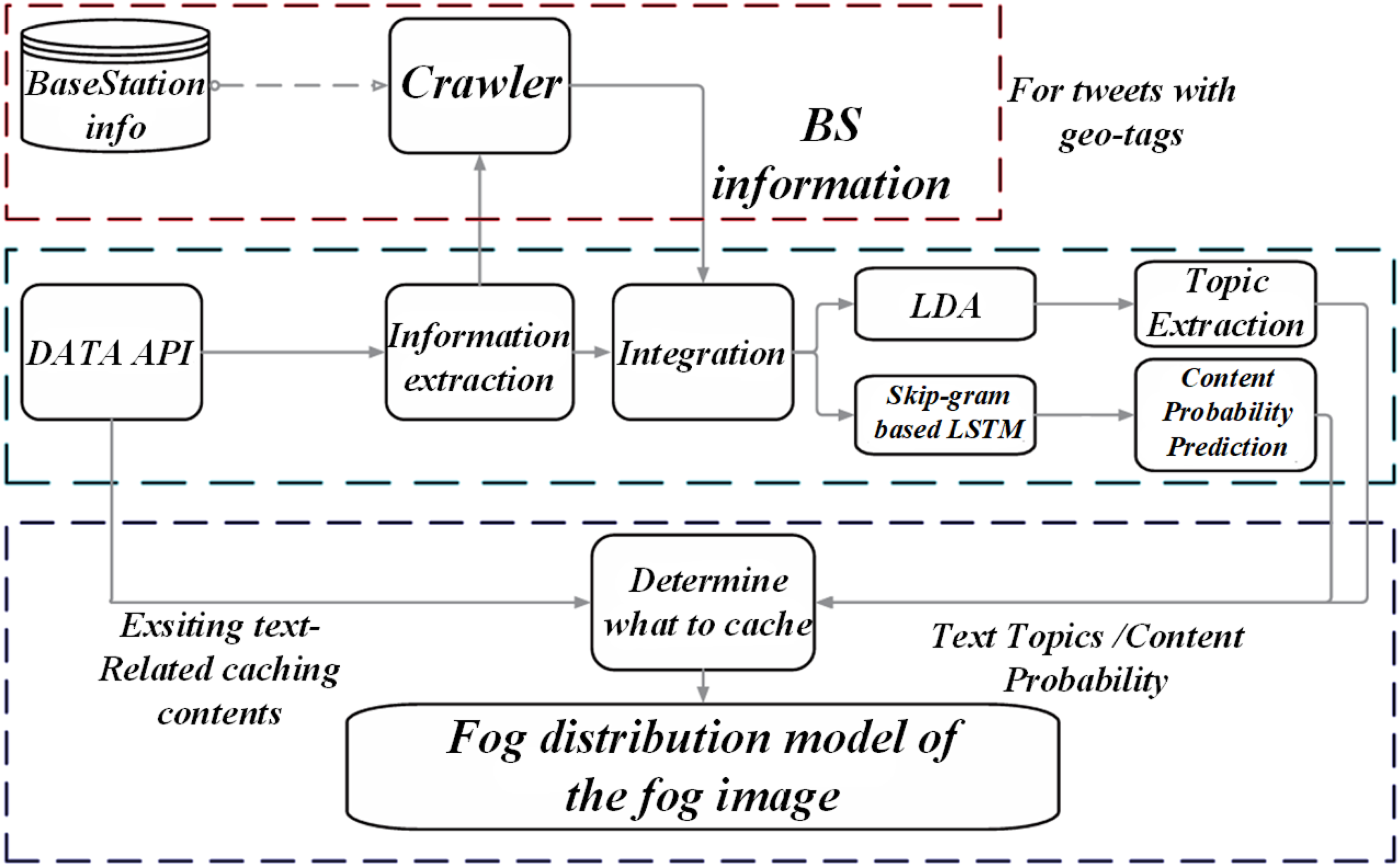
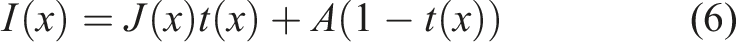
Among them, I(x) represents the number of images, J(x) represents the atmospheric light scattering coefficient, and t(x) represents the absorption coefficient. In the process of restoring clear images, under the framework of atmospheric scattering model, the core lies in accurately estimating the transmittance t(x) and the value of atmospheric light A. If we assume that the atmospheric light A is a known condition in advance, then the problem is simplified to a fine estimation of the transmittance t(x). Therefore, an effective method is to use the atmospheric scattering model, and implement the minimum channel operation at both ends of the model, that is, select the minimum value of each pixel in the image in all color channels, to further assist in the solution of transmittance (S. Li and Zhao, 2020; Padsumbiya et al., 2022). This step aims to take advantage of the physical characteristics of atmospheric scattering, reduce computational complexity and improve the accuracy of image restoration. Then the transmittance expression is shown in (7).
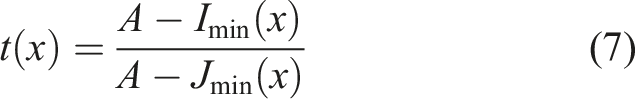
Among them, J
min
(x) represents visibility, t(x) represents absorption coefficient, and A represents haze density. Crack image sharpness degradation is similar to severe weather image degradation, and restoration processing is equivalent to defogging. Based on the atmospheric scattering model, this section proposes a fracture image restoration algorithm. Fog concentration is positively correlated with depth of field, with high transmittance in low fog area and low transmittance in high fog area. Based on this, a fog distribution model is constructed to estimate the transmittance and realize the image clarity. The positive correlation formula between fog concentration and depth of field is shown in (8).

This section is obtained using color attenuation. The fog distribution makes the texture and other information of the foggy image invisible, so this section defines an adaptive fog distribution model in combination with the depth of field distribution, and the expression is shown in (9).

In view of the efficiency and complexity of the algorithm, this section uses Canny edge detection operator to extract the rough texture distribution in foggy images. Canny detection strategy firstly applies Gaussian filter to smooth the image and effectively filter out noise interference; Subsequently, the gradient amplitude is refined by non-maximum suppression technique, and the most significant edge information is retained; Finally, through edge tracking and double threshold processing strategy, the edge position is accurately connected and determined, and the detection result that clearly reflects the texture structure of the image is obtained. Its expression is shown in (10).

In areas with far depth of field, the image quality suffers from more serious degradation due to the significant increase in fog concentration; On the contrary, in the close range, due to the relatively low concentration of fog, the image degradation phenomenon is relatively mild (Chen et al., 2023). Based on this observation, sharp images will experience faster brightness decay in the depth-of-field region, while exhibiting a slower decay trend in the close-up region. To effectively address this challenge, an adaptive quadratic constraint model is innovatively proposed in this section. The model aims to realize intelligent compensation and correction of image degradation by accurately estimating the minimum channel of clear images and making full use of the internal relationship between depth of field and fog concentration. Its expression is shown in (11).
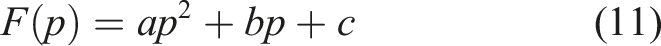
In order to improve the adaptability of the model, this section uses adaptive coefficients instead of fixed values, and based on the relationship between fog distribution and image degradation degree, and the correlation between fog and brightness, a coefficient solution algorithm is proposed: firstly, the fog map H(x) is obtained through the fog distribution model, and the quadratic term coefficient A of its pixels is calculated; Then the image is transferred to the HSV space, and the gray average value of the luminance component v(x) is extracted as the primary term coefficient b, so as to construct a more flexible quadratic constraint model, as shown in (12).
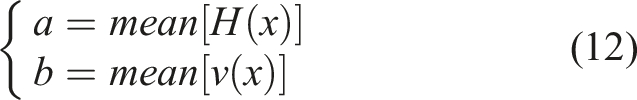
According to the quadratic attenuation model, the mapping process from the minimum channel map of the degraded image to the minimum channel map of the clear image can be expressed by (13).
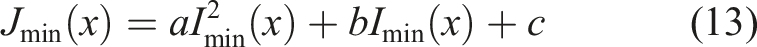
In order to ensure that the pixel values do not overflow before and after mapping, the value of constant c is 0. The transmittance expression in this section is shown in (14).
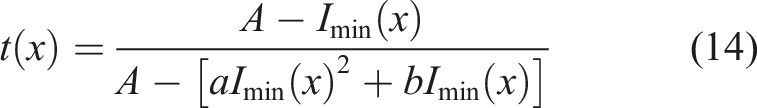
Basic theory of convolutional neural network
Convolutional neural network is a feedforward neural network known for its multi-layer convolution calculation and is a model algorithm for deep learning. It significantly affects the processing effect and learning ability through different combinations of convolution operations, and is widely used in computer vision, natural language processing, image classification, object detection and other fields (Rajadurai and Kang, 2021). CNN is mainly composed of key parts such as input layer and convolution layer.
Figure 2 shows flow chart of automatic concrete crack detection based on DCNN. In image processing, CNN inputs are mostly color or grayscale images, which are often normalized to optimize gradient descent learning. Depending on the task, the convolution structure is different, and the combination effect is significant. Commonly used convolution kernels, such as 33–99, determine the range of receptive field. Although large kernels are conducive to enriching features, they increase the computational burden, so they are often mixed and used for balance. The pooling layer reduces the dimension of feature space by averaging or maximizing pooling without reducing the depth, and realizes downsampling (Ai et al., 2022; Tabernik et al., 2023). The nonlinear layer uses activation functions (such as Sigmoid, Tanh, ReLU, etc.) to promote the transformation from linear to nonlinear and enhance the expression ability of the model. Attention mechanism originates from human vision, and its core lies in the effective allocation of resources, that is, important information gets more attention, while secondary information gets less attention or is ignored. In deep learning, the attention mechanism is embodied in adaptively generated weights, which are automatically learned by the convolutional layer to reinforce the influence of key information. Flow chart of automatic concrete crack detection based on DCNN.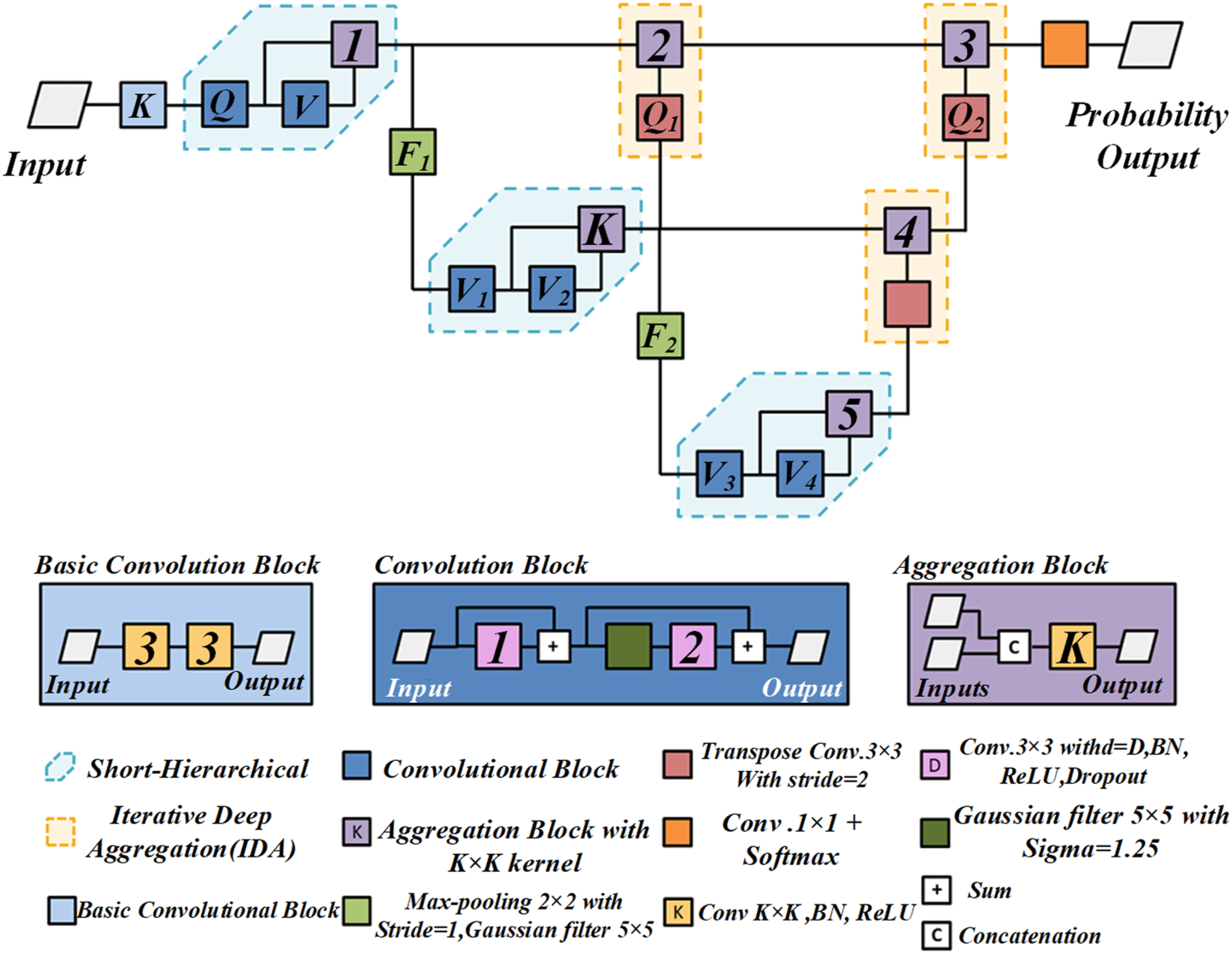
The “Improved AlexNet” proposed in this article for crack detection has several key modules aimed at achieving multi-scale feature extraction, attention fusion, and accurate crack recognition. This architecture includes an input layer that normalizes and resizes the image, followed by a convolutional layer that uses 3 × 3 kernels and ReLU activation to extract low-level features. The multi-scale feature extraction component uses various kernel sizes to capture fine and broad patterns. The attention fusion module uses multi head attention to focus on important areas, combining high-level and low-level features. The crack detection module includes a fully connected layer and a global average pooling layer to reduce overfitting. Finally, the output layer uses softmax for binary classification. The architecture of this network aims to improve crack detection, especially in complex and noisy environments.
Crack detection algorithm based on convolutional neural network
Crack detection dataset
There are various shapes of concrete surface cracks, mainly including transverse, longitudinal and network cracks, and the formation mechanism of each type of crack is different. Transverse cracks are often caused by uneven subgrade subsidence, insufficient material of pavement slab or delay of construction seam cutting, as well as the dry shrinkage and thermal expansion and contraction characteristics of cement materials, and the accumulated release of internal stress (Wang et al., 2021). Longitudinal cracks are mostly caused by shrinkage and load effects caused by unstable settlement of foundation, overload or temperature difference. However, network cracks are mainly the result of multiple factors such as overload, improper proportion of concrete, insufficient curing and rapid evaporation of water.
Figure 3 shows flow chart of analysis and visualization of crack detection results. In the field of crack detection, convolutional neural networks (CNNs) are increasingly widely used, and their performance is highly dependent on the richness and quality of training data. To this end, multiple professional data sets have emerged as the times require, such as CRACK500, which is selected from the pavement of Temple University. Through fine cutting and labeling, a huge crack image library has been built to help accurately identify the model; The CFD data set focuses on small cracks in concrete pavement, which still provides valuable materials for model training despite water damage, shadow and other interferences; GAPS384 is derived from the vehicle-mounted shooting of German asphalt pavement, covering a variety of pavement diseases. Its high-definition images and accurate labels contribute to the generalization ability of the model; As for the original crack dataset 1024, although its rich unlabeled crack images lack direct guidance, they provide a broad space for semi-supervised learning and pre-training models. These data sets together constitute an important cornerstone in the field of crack detection and promote the continuous progress and innovation of related technologies. Flow chart of analysis and visualization of crack detection results.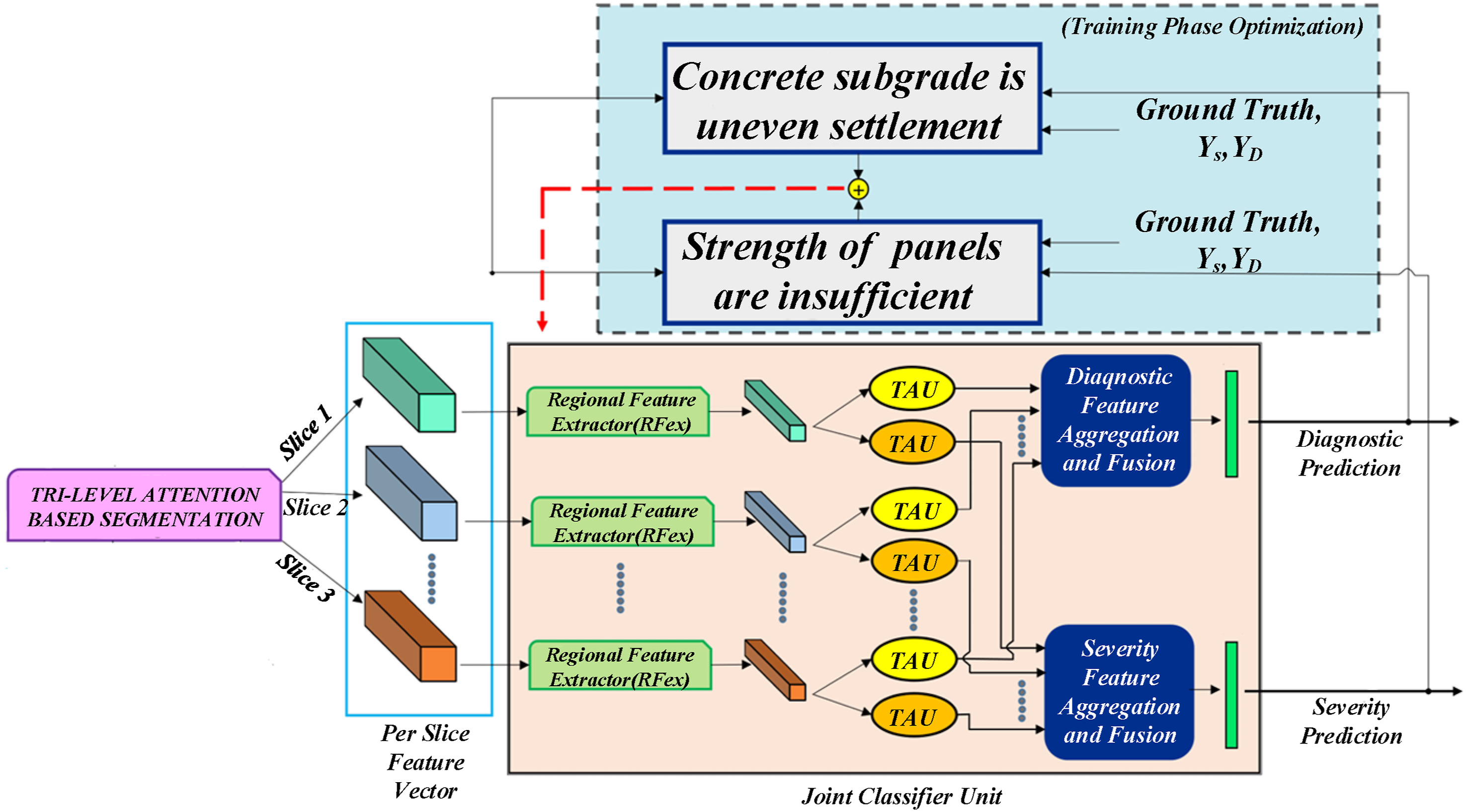
Crack detection algorithm based on parallel extraction and attention fusion network
Crack detection faces two major challenges: complex atypical crack structure and decreased image clarity. Traditional methods are difficult to balance, and their accuracy is limited. The data-driven model integrates denoising, clarity recovery and crack identification through fully supervised learning, simplifying the problem to a single crack detection task and pursuing high-precision output (Han et al., 2021; Wei et al., 2021). This section uses popular data-driven methods combined with fully supervised learning to train the model. In order to improve accuracy and reduce complexity, an attention fusion convolutional neural network is designed, including multi-scale feature extraction, attention fusion and crack detection modules. The network extracts feature through modules with different depths, uses attention mechanism to fuse high and low-level features, and finally outputs crack detection results with nonlinear mapping, effectively eliminating the influence of redundant features and improving detection accuracy.
Figure 4 shows single-structure crack scene detection. Convolutional neural networks excel in image processing and computer vision. Crack scenes often have the characteristics of single color, obvious noise and changeable structure. Supervised learning can effectively meet these challenges, while traditional methods have single feature extraction and are difficult to meet complex detection needs. Therefore, we design a multi-scale parallel feature extraction network, which is processed in parallel at different depths to obtain effective features suitable for crack detection. The mathematical expressions of the above indexes are shown in (15) and (16). Single-structure crack scene detection.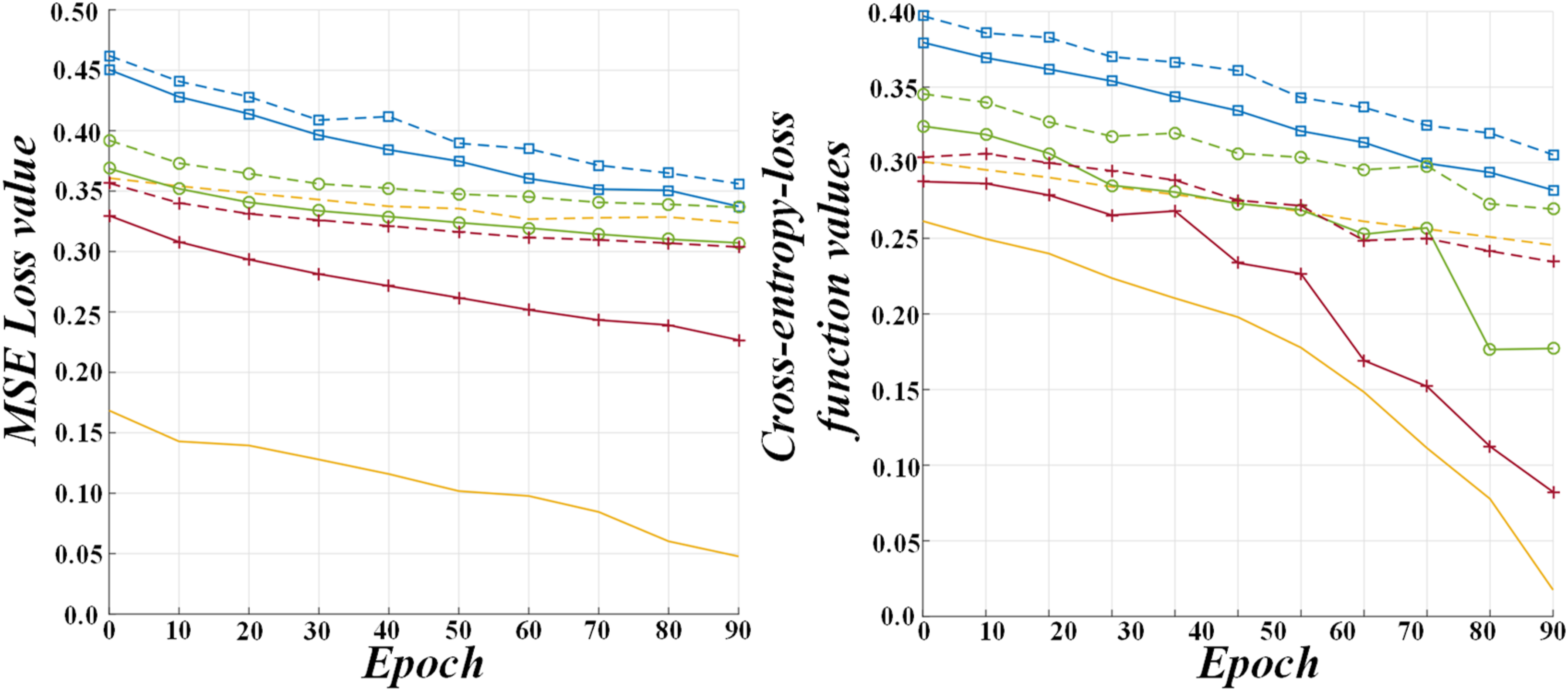
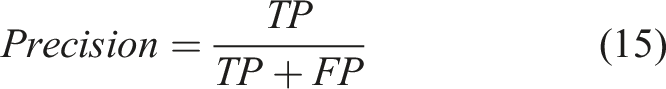

The feature extraction module is divided into two parts: low-level and high-level. The shallow network captures low-level features such as contour and edge of the image, and depicts the general shape of cracks; Deep networks extract complex high-level features through information iteration to reflect global details. In order to prevent information loss, this model adopts residual compensation strategy to ensure the comprehensiveness and accuracy of feature extraction.
In crack detection, the deep network is responsible for high-level global feature extraction, while the shallow network focuses on low-level contour features. In this model, the high-level module contains 12 layers of convolution +1 residual blocks, and the low-level module contains seven layers of convolution +1 residual blocks. Both of them adopt 3*3 convolution kernels, and the step size and filling are one to keep the size consistent and reduce the parameters and calculation amount. ReLU is used as the activation function to enhance the nonlinear processing ability of the network.
This algorithm innovatively fuses parallel convolution and attention pixel fusion technology to build a crack detection network, and directly and efficiently output the detection results. The detection module takes attention fusion output as input and is activated by 3*3 convolution and ReLU to achieve accurate detection. Tests show that the model is not afraid of challenges such as uneven illumination and complex structure. Fully supervised training focuses on feature extraction and loss minimization, and the output is close to real cracks, demonstrating excellent detection performance.
Figure 5 shows example of the original concrete surface image. This section deploys the model on hardware equipped with an Intel i5-9400 CPU (2.90 GHz) using the Python programming language and the Pytorch framework in a Windows 10 environment. Through fully supervised learning, CRACK500I39 data set is used to train the model. After 100 training cycles, the loss value converges successfully. In training, we set the learning rate to 0.001, and innovatively applied the improved stochastic gradient descent algorithm to optimize the model parameters. At the same time, in order to improve the accuracy of crack detection, we combine mean square error and perceived loss as loss functions to jointly guide the training process. The mean square error loss and perceived loss expressions are shown in (17) and (18). Example of the original concrete surface image.
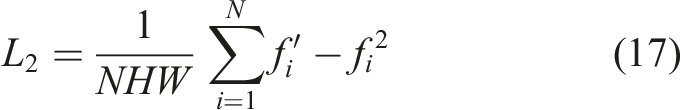
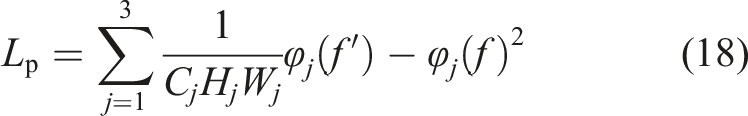
In this section model, f represents the fracture detection output, which corresponds to the dataset label f. Let N be the number of detected samples and H and W be the image sizes. φ(f') and φ(f) respectively represent the detection result and the semantic feature map of the label in the perceptual calculation, and their feature parameters include the number of channels C
j
, the height H
j
and the width W
j
. The perceptual loss is evaluated by comparing the differences between the two semantic feature maps. This model uses the feature map output by VGG-16 network to calculate this loss to improve the detection accuracy. Then the loss function of the whole training process can be expressed as shown in (19).

Experimental results and analysis
In order to fully verify the validity of the model, this section conducts experimental analysis from the two dimensions of subjective vision and quantitative indicators (Luo, M Yussof et al., 2024). Subjective evaluation visually shows the advantages and disadvantages of the algorithm, while quantitative indicators objectively evaluate the performance of each method. Since the model is based on convolutional neural network design, three similar algorithms, HEDI, SegNet and U-Net, and the classical PCNNB algorithm are specially selected for comparison (J. J. Kim et al., 2020; Pal et al., 2021). In addition, in order to highlight the advantages of the proposed method, the detection effects of single, complex structures and noisy crack scenes are specially compared.
Figure 6 shows distribution map of the dataset samples. The detection by PCNN method is incomplete and the noise is significant; Although HED reduces noise, it still has shortcomings; Seg-Net detection is comprehensive, but local cracks have fracture marks; U-Net is similar to Seg-Net, and the fracture marks are more obvious. The method in this section realizes thorough and comprehensive detection of single structural cracks, and effectively eliminates noise. The crack detection and classification loss function formula are shown in (20) and (21). Distribution map of the dataset samples.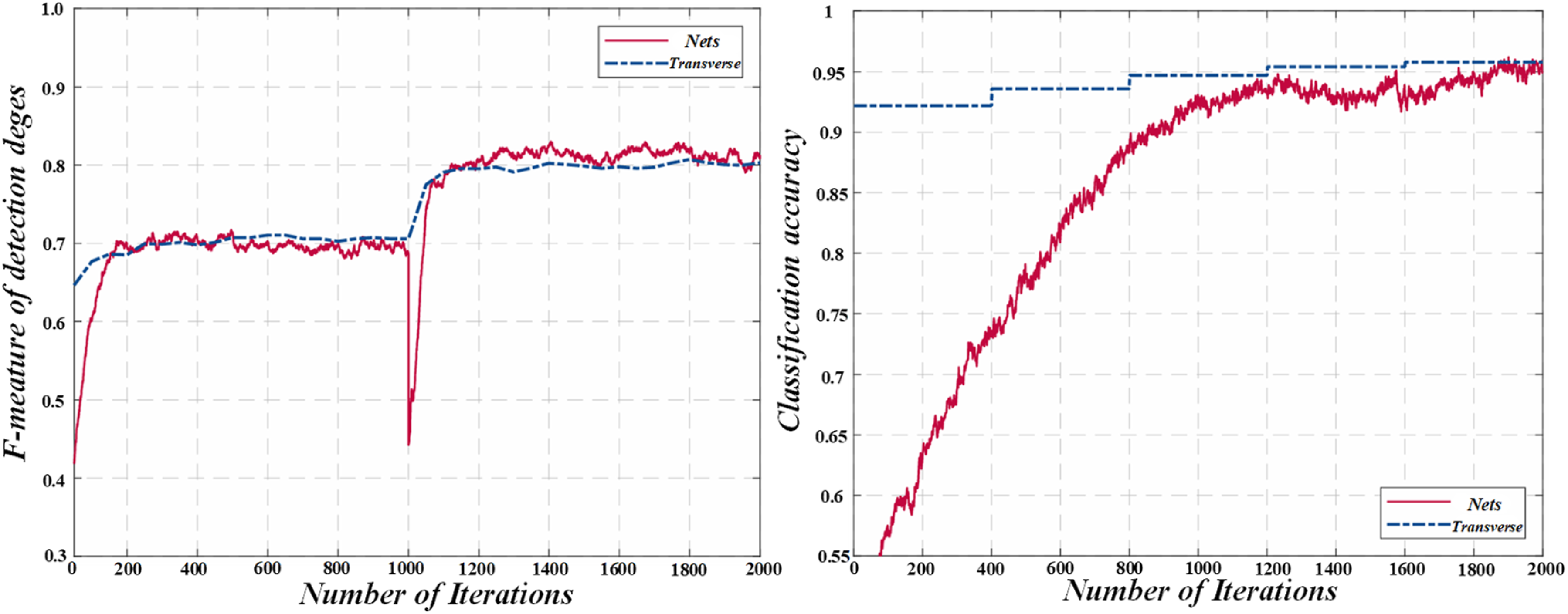

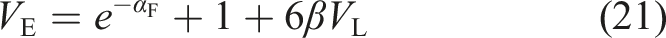
PCNN loses cracks and has significant noise, which is easy to cause false detection; Although HED reduces noise, there is still noise and cracks are seriously lost; Seg-Net and U-Net have good noise immunity, but the cracks are partially lost, resulting in fracture. The method in this section not only denoises but also retains rich crack information, and performs well.
The geometric characteristics of cracks and the resolution of input images have a direct impact on the prediction accuracy of deep learning models. In this study, high-resolution images were used to ensure fine-grained feature extraction. The width and continuity of cracks can affect edge detection and semantic segmentation results, especially in extremely thin or fractured cracks. Our preprocessing and model design aim to alleviate these challenges through enhanced filtering, attention based feature fusion, and resolution preserving convolution operations.
To further validate the fog removal algorithm, this paper conducted a detailed comparison of its performance with dark channel prior (DCP) and improved histogram equalization (IHE). The results indicate that the algorithm proposed in this paper provides significantly better image clarity, thereby improving the accuracy of crack detection. The proposed method outperforms baseline algorithms in both qualitative visual assessment and quantitative metrics such as PSNR and SSIM, demonstrating its robustness in complex and foggy environments.
Figure 7 shows training process loss and accuracy curve. The model is of the loss model type. The PCNN output has obvious glitches and a lot of crack information is lost; Although HED has no noise, the detection is rough; Although U-Net and Seg-Net have successfully denoised noise, the local fracture marks remain, especially U-Net does not perform well in complex structures. Training process loss and accuracy curve.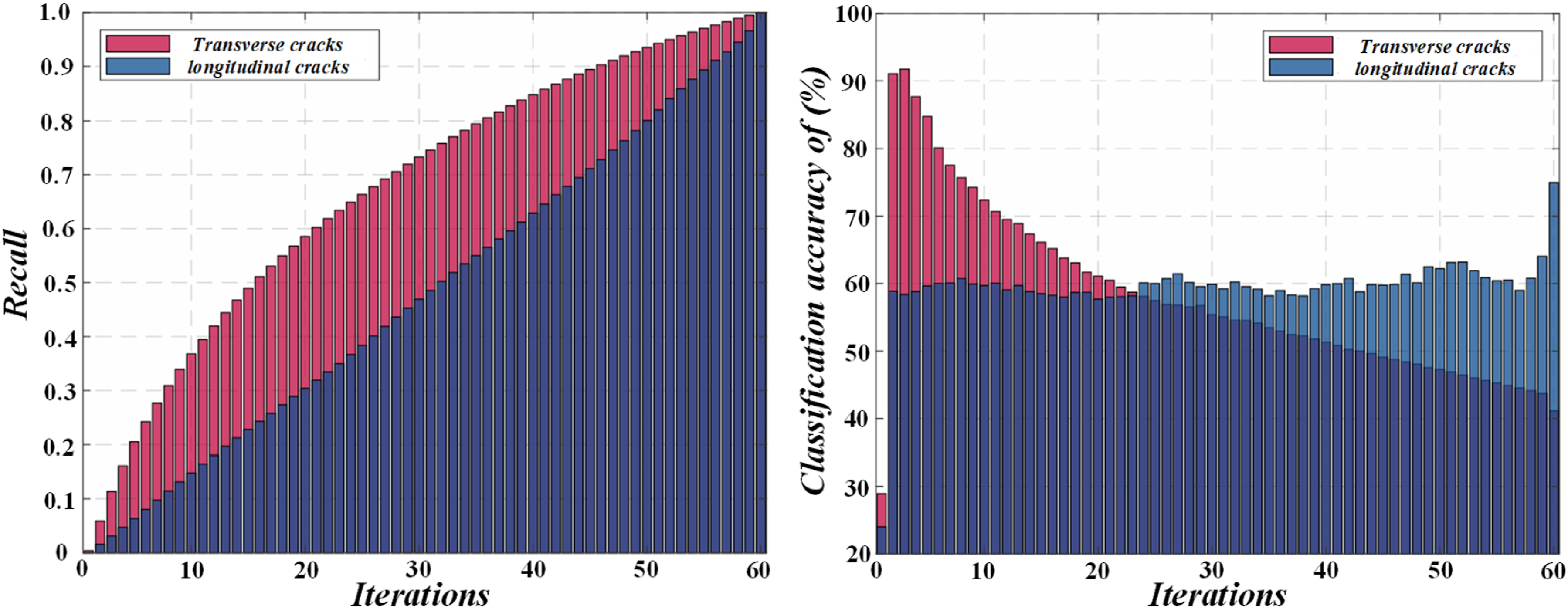
To sum up, each algorithm has its own merits in crack detection. PCNN is unable to handle complex scenes, while HED, Seg-Net, and U-Net perform better due to the advantages of convolution models, but the limitations of model design led to noise and fracture problems. The method in this section effectively eliminates noise by capturing high and low-level features, combining attention and adaptive fusion, and achieves more thorough and accurate crack detection.
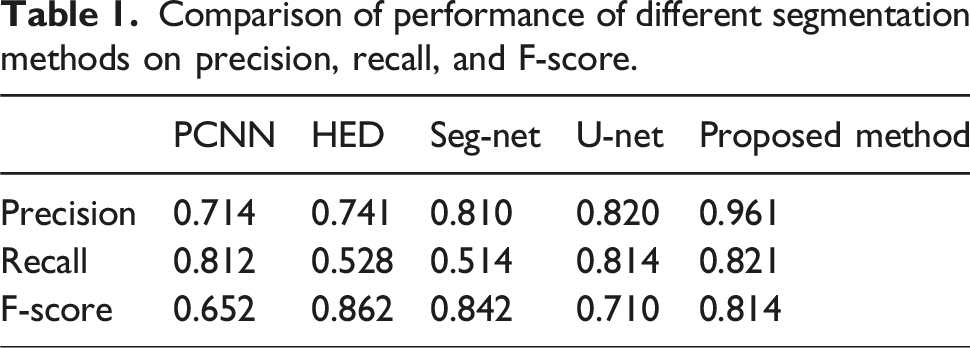
Figure 8 is a comparison of a group of single structure crack scene detection. PCNN has low accuracy, recall and F score in various crack scenes. HED outperformed PCNN, while Seg-Net led the recall rate and F-score in dark noise scenarios. As a mature network, U-Net also performs well in crack detection, and its index is higher than that of PCNN and HED. For complex structures, the objective indexes of the method in this section are optimal. Combined with subjective and objective evaluation, the method in this section is comprehensive and accurate in concrete crack detection, and all indexes are significantly better than the comparison algorithm. Table 1 Comparison of performance of different segmentation methods on precision, recall, and F-Score. Comparison of single-structure crack scene detection. Comparison of performance of different segmentation methods on precision, recall, and F-score.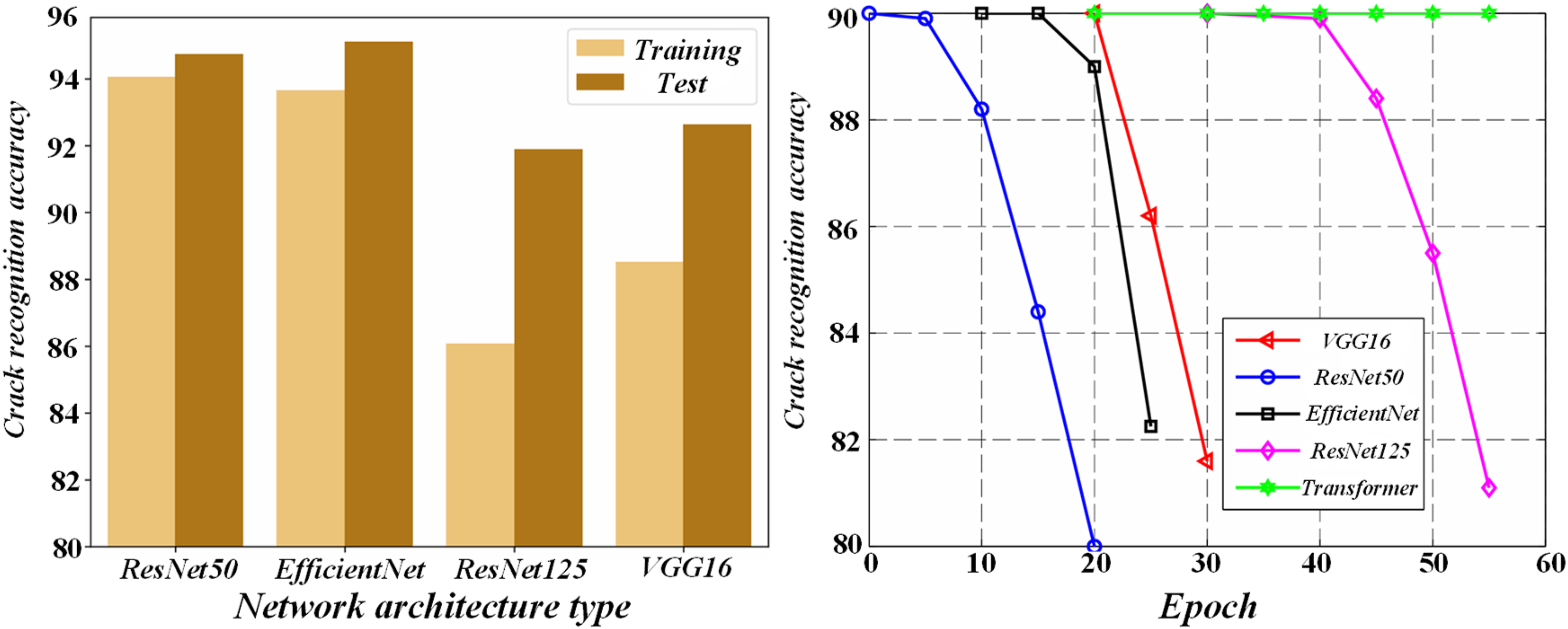
In order to verify the importance of specific modules and attention fusion in the network structure, a detailed ablation analysis is carried out. The analysis covers: (1) low-level feature detection (LFD); (2) Advanced Feature Detection (HFD); (3) No attention fusion method (NAF) is used. By comparing the results of these three configurations with the benchmark model that integrates high and low-level features and attention (H-LFD-AF), the contribution of each component is deeply discussed.
Figure 9 is a comparison of a set of crack scene detection with noisy and dark structures. When advanced features are used alone to detect cracks, there are problems of crack loss and fracture marks; However, relying only on low-level features has worse effect, with a large amount of crack information loss and poor visual effect. Comparison of crack scene detection with noise and dark structure.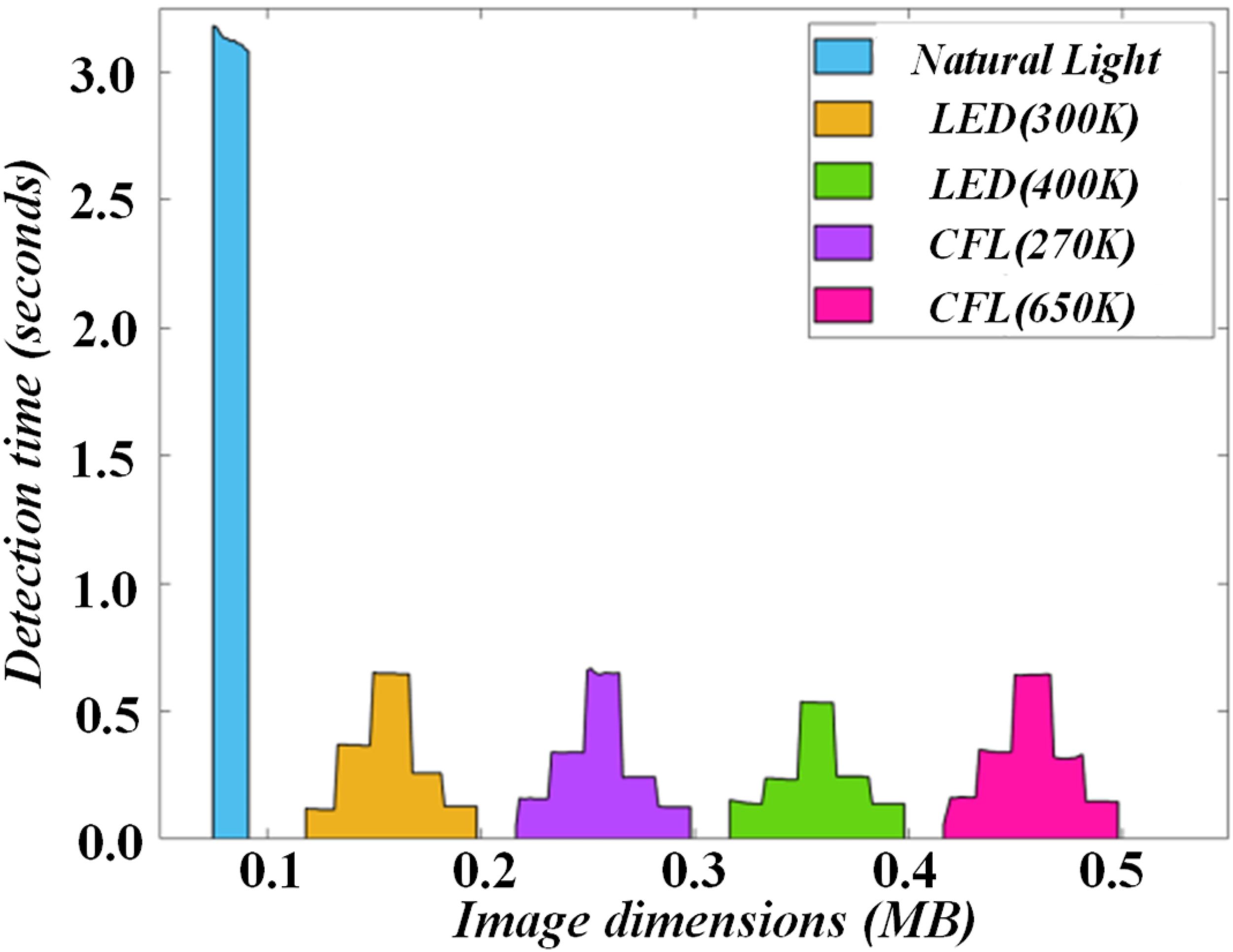
Figure 10 shows changes in the MSE loss values during the training session. Although fusing high and low-level features can effectively detect cracks, it is accompanied by increased noise because redundant features are introduced in the fusion process. Based on the subjective and objective evaluation of comprehensive ablation experiment, this model fuses high and low-level features and attention mechanism. Changes in the MSE loss values during the training session.
Figure 11 shows crack severity assessment. Effectively improves the accuracy of crack detection and verifies the effectiveness of this method. Both mean squared error loss and perceived loss are indicated as indicated in (22) and (23). Crack severity assessment.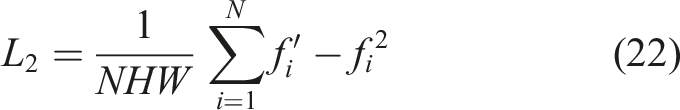
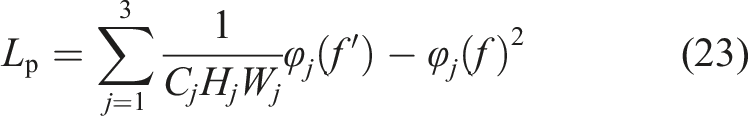

Conclusion and summary
This study collected over 10,000 raw concrete crack images using drone based data collection, and expanded the dataset to 30,000 images using data augmentation techniques such as rotation and scaling. This high-quality and diverse dataset lays a solid foundation for model training and performance.
This article proposes an improved convolutional neural network model based on AlexNet, which uses a global average pool to enhance detection robustness and prevent overfitting. In addition, a semantic segmentation model has been developed that integrates fully convolutional networks (FCN), atrous convolution, and spatial pyramid pooling for precise crack localization.
The proposed model achieved a classification accuracy of 95.42%, which is significantly better than traditional methods. The segmentation model achieved a pixel level accuracy of 97.6%, with an F1 score of 0.975 and an IoU of 89.4%. For the estimation of crack width, the error rate of the fitting method based on the least squares method is within ±2%, which verifies its reliability.
Figure 8 presents a comparison of single-structure crack scene detection, showing the performance results of the proposed method, which achieves an average accuracy of 95.42%. The figure highlights the model’s accuracy, pixel-level accuracy, and IoU values, supporting the comparative analysis. Table 1 provides a detailed comparison of different segmentation methods based on precision, recall, and F-score metrics, with the proposed method outperforming others across all metrics, reinforcing the accuracy claims made in the conclusion.
The developed system provides an effective solution for automatic detection and measurement of concrete cracks. Its high precision and robustness under various conditions make it a valuable tool for infrastructure inspection and maintenance, reducing manual workload and ensuring safety.
Footnotes
Author contributions
Conceptualization: [Jianfeng Li]; Methodology: [Pengyuan An]; Formal analysis and investigation: [Yong Luo]; Writing - original draft preparation: [Yong Luo]; Writing - review and editing: [Yong Luo]; Funding acquisition: [Yong Luo]; Resources: none; Supervision: [Yong Luo].
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated analysed during the current study are available from the first author on reasonable request.