
Abstract
In this study, we investigate how quantification of Wikipedia biographies can shed light on worldwide longitudinal gender inequality trends, a macro-level dimension of human development. We present the Wikidata Human Gender Indicator (WHGI), located within a set of indicators allowing comparative study of gender inequality through space and time, the Wikipedia Gender Indicators (WIGI), based on metadata available through the Wikidata database. Our research confirms that gender inequality is a phenomenon with a long history, but whose patterns can be analyzed and quantified on a larger scale than previously thought possible. Through the use of Inglehart–Welzel cultural clusters, we show that gender inequality can be analyzed with regard to world’s cultures. We also show a steadily improving trend in the coverage of women and other genders in reference works.
Introduction
It is an unfortunate but unavoidable fact that encyclopedias always have had a gender bias. One of the dimensions of this bias is the contributors’ gender distribution (Reagle and Rhue, 2011; Thomas, 1992). Just as there were few women authors among contributors to traditional, printed encyclopedias, recent surveys indicate that women constitute only around 13–16% of Wikipedia contributors, or Wikipedians (Glott et al., 2010; Hill and Shaw, 2013).
A detailed analysis of Wikipedia editor gender dynamics has been offered by Lam et al. (2011) and Hargittai and Shaw (2014), and the gender disparity of Wikipedia editors has been the topic of mainstream press coverage, itself a subject analyzed in detail by Eckert and Steiner (2013). We have now arrived closer to understanding why those biases persist in Wikipedia, with one of the main factors being the persisting gender imbalance in computer-related fields, reaching an apex in the Free, Libre and Open Source Software community, where women make up only 1% of participants (Ghosh et al., 2002; Reagle, 2013), and with which Wikipedia’s community is closely associated (Konieczny, 2009).
The vast majority of press articles and academic studies (e.g. Collier and Bear, 2012; Glott et al., 2010; Graells-Garrido et al., 2015; Hill and Shaw, 2013; Lam et al., 2011) have focused on the variations of the research question “Why are so few of Wikipedia’s contributors women?,” relevant to the volunteers and the Wikimedia Foundation (WMF), and illuminating the gender gap on the meso- and micro-levels of our society. For example, Wagner et al. (2016) wrote that “the narrow diversity of editors may foster the glass-ceiling effect since it is well known that individuals generally favor people from their in-group over people from their out-group” and noted that Wikipedia policies, while often assumed to be gender neutral, where much less so in the beginning of the project, still may require further improvement (e.g. one of Wikipedia’s pillar policies, NPOV [neutral point of view]—discussing neutrality—still does not explicitly addresses gender bias). A similar argument has been made by Graells-Garrido et al. (2015), who described a specific gender-themed Wikipedia controversy of 2013 (which was reported in mainstream media, including in The New York Times), where women novelists started to be excluded from the Wikipedia’s category “American Novelists” to be included in the specific, gendered category “American Women Novelists.” However, little research has been done to analyze the skew of biographical coverage, a bias represented by unequal numbers of biographical articles on Wikipedia when divided by the subject’s gender. This pattern of gender inequality, which we believe is of relevance to the macro-level topic of human development, has been indicated by exploratory studies of Lam et al. (2011), Reagle and Rhue (2011), Eom et al. (2014), Klein (2013a, 2013b, 2014), and Wagner et al. (2016).
In the following study, we investigate how the quantification of biographical articles on Wikipedia can add to our understanding of the macro-level gender inequality. Specifically, we measure the ratio of women and non-binary-gendered Wikipedia biographies to total Wikipedia biographies with data from Wikidata and call this the Wikidata Human Gender Indicator (WHGI). Utilizing Wikidata’s information on biographical historical context, we inspect place and time of birth and/or death, analyzed across different cultural, linguistic, and social categories. We intend to show the usefulness of WHGI by showing its application to the following research questions:
RQ1. Is the Wikidata Human Gender Index a reliable indicator and what can it tell us about the world’s notable people?
RQ2. In the WHGI, what are the variations and trends by date of birth, date of death, culture, country, and language?
RQ3. What can we learn about specific cultures from variations in variables such as biographies unique to single languages, article quality, or the proportion of celebrities?
On a broad level, our research questions are focused around two aspects of bias. The first is concerned with what the world’s largest user-generated biography data set can tell us about “notable people” in the world throughout history (RQ1). The second bias is related to how the biography gender ratio can contribute to the monitoring and measuring the gender equality dimension, particularly in the context of the community and content development of Wikipedia (RQ2 and 3).
Our indicators presented in this article are intended to supplement existing gender inequality indices. As noted by Fanchette (1974) and Rossi and Gilmartin (1980), the concept of an “index” refers to a specific “weighted combination of two or more indicators.” Because we do not do such weighting, instead of an index, this article derives a gender “indicator”—the WHGI. We view this indicator as part of a broader set of indicators (which could perhaps be compiled into an index) found in the Wikipedia context, which can include the gender proportions of Wikipedia editors, administrators, readers, and WMF staff and board members. We call this proposed set of indicators the Wikipedia Gender Indicators (WIGI), of which the WHGI is just one component. We demonstrate their usability by showing how the ratio of women and non-binary individuals to total biographies by country can be used to measure worldwide differences in gender equality relevant to existing human development indices. We argue that the WHGI can be useful in supplementing indexes such as the Gender Development Index (GDI), which use indicators such as “women’s shares of parliamentary seats” and “women and men labor force participation rates,” to capture various dimensions of gender equality and human development.
Although in this study we often discuss the well-known Wikipedia (world’s largest and most popular reference work), we rely extensively on data provided by Wikidata. Wikidata is a project that aims to gather data from all WMF projects (including but not limited to Wikipedias of different languages) in a single location in a form that can both be read both by humans and machines. Crucially, Wikidata includes an entry for each article created on Wikipedia projects (relying solely on English Wikipedia would exclude numerous biographies from other language Wikipedias that don’t yet have an entry in English Wikipedia). Our use of Wikidata constitutes a significant difference, and we hope a step forward, from majority of prior literature on Wikipedia and gender gap, which primarily relied on data limited to English Wikipedia.
Gender gap indices and indicators
We refrain from a thorough methodological analysis of the pros and cons of gender gap indices, indicators, and related topics and refer the interested reader to the works by Klasen (2006, 2007), Mills (2010), and Hawken and Munck (2011); however, a brief overview of this topic is in order to justify the reason for our proposed approach and to locate our proposed indicator in the wider frame of reference of the macro-scale, human development–related work on gender inequality measurement.
A number of measures have been proposed in theoretical literature, and several major indices and indicators related to human development and gender disparities have been successfully implemented over a period of years, with no consensus on which is superior (Beneria and Permanyer, 2010; Hawken and Munck, 2011; Mills, 2010). Dreschler et al. (2008a, 2008b) note that this topic is likely too complex for a single index or set of indicators and recommend a multi-indicator approach for any studies that want to aim for comprehensiveness.
Although one could trace the idea of an index to measure gender-sensitive topics to decades of gender studies literature, the idea has not been successfully implemented until the past few years of the 20th century. Two pioneering measures of gender equality now seen as “traditional” are the United Nations Development Programme (UNDP)’s Gender-related Development Index (GDI) and the Gender Empowerment Measure (GEM), introduced only in 1995. More recently, three new measures were developed: the Gender Equity Index (GEI) introduced by Social Watch in 2005, the Global Gender Gap Index (GGGI) developed by the World Economic Forum in 2006, and the Social Institutions and Gender Index (SIGI) of the Organisation for Economic Co-operation and Development (OECD) Development Centre from 2007.
One of the key limitations of those indices and their indicators is their reliance on modern statistical data, which reduces their global coverage; even the broadest of those indices rank less than 75% of present-day countries. It also forces them to focus on the past few decades—the period for which such data are available; thus, the lack of reliable statistics prevents creation of any index for measuring gender inequality that has a deeper historical perspective (Klasen, 2006). Echoing the call of Dreschler et al. (2008a, 2008b) for the development of indicators able to address other dimensions of the gender inequality and McDonald’s (2000) request for a measure with a longitudinal perspective facilitating historical and anthropological studies, we therefore propose a new conceptual measure: WIGI. Like SIGI, it is not indented to replace any prior index or set of indicators, but instead we hope it will be a complementary tool. WIGI would consist of many indicators out of which we focus on one of its components: the WHGI which uses Wikipedia’s biographies and extends the scope of possible analysis throughout the entire recorded human history.
We close by presenting different indicators and their relevant contexts and units of analysis. Please note the major difference in the unit of analysis (in particular, country vs language used in the WHGI) between WIGI and the other major indices. This distinction in the units of analysis and aggregation is the reason WHGI uses extra data to determine the citizenship of the biography, to make our results comparable to the previous human development–related, macro-scale gender indices that mostly use countries as the main data aggregation/analysis unit (Table 1). We discuss the details of data transformation in the subsequent sections.
Gender index landscape.

GEI: Gender Equity Index; GDI: Gender Development Index; GGGI: Global Gender Gap Index; SIGI: Social Institutions and Gender Index; WIGI: Wikipedia Gender Indicators; WHGI: Wikidata Human Gender Indicator.
Methods
This project has been conducted in an Open Notebook Science (grounded theory) way, where we have been posting our results and receiving feedback as we work. We worked remotely and had conversations about our in progress research on a wiki page (https://meta.wikimedia.org/wiki/Research_talk:Wikipedia_Gender_Inequality_Index) where other researchers gave us feedback. Throughout our research, we published several blogs 1 about our preliminary results whereby we received yet more feedback, including corroborating findings from Manske (2015). We have constructed a website to display our results. 2 It updates weekly with Wikidata and our code and data are freely available there.
Software and data
In order to work with the most comprehensive database, we have opted to not limit our research to the (most commonly studied) English Wikipedia data set, but work with data from all 285 different language Wikipedias that existed as of October 2014. We started by obtaining data from the Wikidata database dump. To extract the data from it, we used the Wikidata Toolkit (https://github.com/Wikidata/Wikidata-Toolkit) Java Library to subset the entire data into just those items about humans and then output the results as a CSV. The resulting data set was in turn analyzed using the python-pandas statistical software. Through the quarry tool (http://quarry.wmflabs.org/), we queried publicly available Wikipedia database replicas to determine article sizes. We used the pywikibot and mwparserfromhell python libraries to get article text for specific biographies during our celebrity hypothesis testing.
Amazon’s Mechanical Turk service was utilized to aggregate our list of ethnicities and citizenship. Two independent coders sorted the list into the nine Inglehart–Welzel (2005) cultural clusters (Figure 1). Our coders agreed on 68% of cases, and we solved mismatches manually.
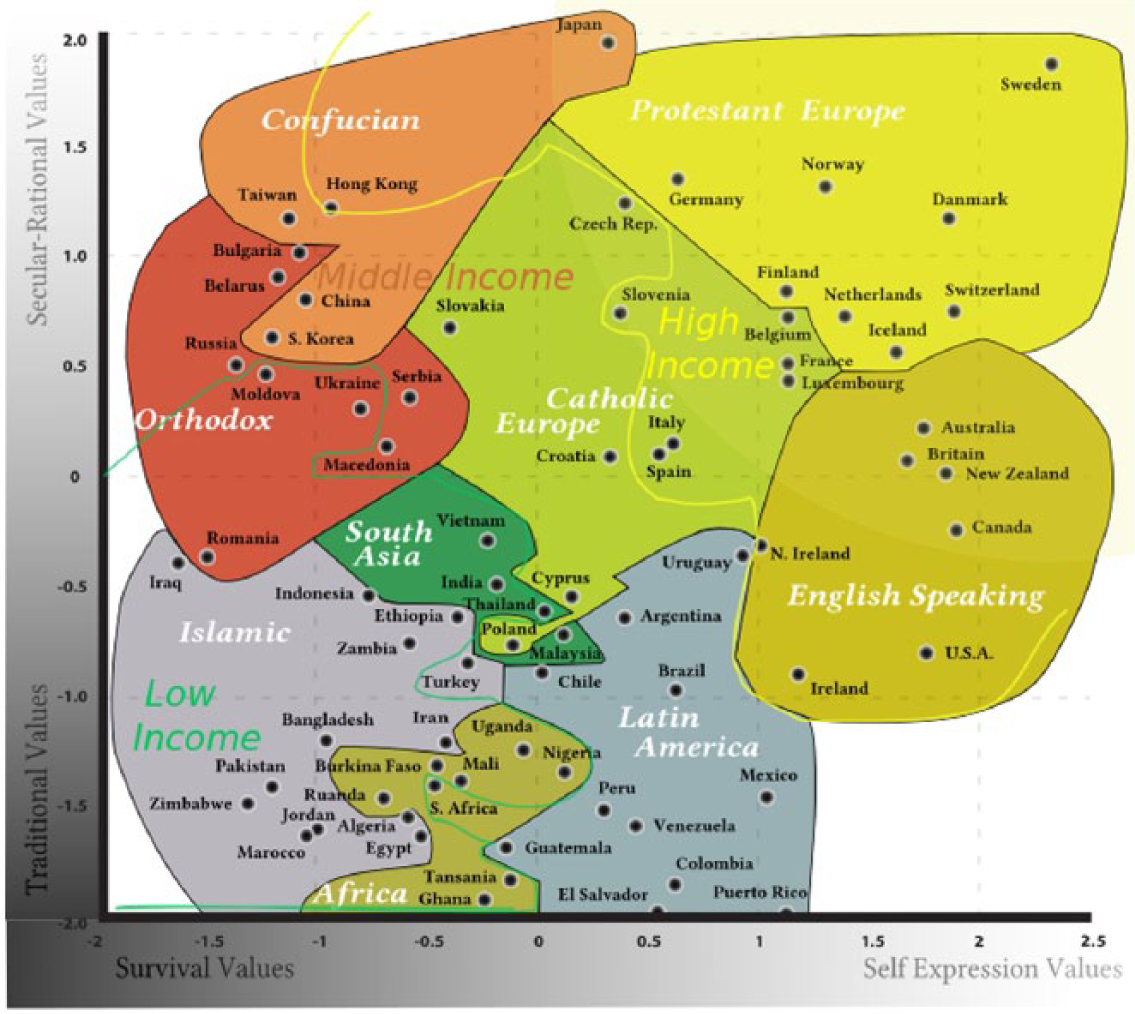
Inglehart and Welzel cultural clusters. By DancingPhilosopher (CC BY-SA 3.0).
Indicators construction
Hawken and Munck’s (2011) work was invaluable in laying out a framework for designing future gender inequality indices and sets of indicators. We want to provide the reader upfront with the answers to the following methodological questions that they raise.
What is the overarching theoretical concept being measured?
All gender gap indices and sets of indicators can be understood as “measures of the concept of human development” adjusted for the gender dimension (Hawken and Munck, 2011). Human development is usually defined as “enlarging people’s choices” (UNDP, 1997: 15), and the gender dimension introduces a comparison between different genders.
What indicators are selected and how to connect to the conceptual dimensions of the overarching concept?
We focus on simple and reliable measures of date of birth and culture. One of our indicators—what percentage of different genders have a biography in the target language—can be seen as conceptually similar to the indicator of a having a high-end political and economic position, and correspondingly, the indicator of number of individuals with a Wikipedia biography per unit of time or region is similar to the number of holders of political and economic positions. We test this assumption.
All large Wikipedia language editions have a dedicated “Notability” policy for determining which individuals should be included in the scope of the project; though, this policy is not identical on all Wikipedias. The English Wikipedia policy states that “A person is presumed to be notable if he or she has received significant coverage in reliable secondary sources that are independent of the subject.” What’s important for us is the end result: that while some individuals may be notable due to the virtue of their position (member of parliament, royalty, etc.), Wikipedia does not recognize most middle and even senior managers or technicians as notable solely on the virtue of their position. This means that our data set can be seen as comparable, methodologically wise, but not identical, to those used in other indices discussed here. A generalization that Wikipedia, like all encyclopedias, writes about “people who are seen as important” should be sufficient, though we (as well as Wikipedia itself) remain conscious of the gender bias present in determining who is important (which is, after all, what we are measuring here). Readers interested in further discussion of Wikipedia’s notability and gender bias may also consult Graells-Garrido et al. (2015).
How are the indicator scales designed?
Hawken and Munck (2011) suggest that indicator scales should be consistent with the concept being measured while offering as much nuance as possible. Our indicator scale is a ratio of gendered biographies to total biographies, disaggregated by place of birth or citizenship, born within a specific time frame.
How are values assigned to each indicator?
Hawken and Munck (2011) recommend the use of a method assigning values to indicators that are replicable and that generate reliable and valid measures. As our data were collected through data mining, we avoid the most common problems related to subjective measurement such as expert surveys of unknown reliability.
Results
Descriptive statistics
As of 14 October 2014, we inspected a total of 2,561,999 biographies, that is, any Wikidata item with the Wikidata semantic property “instance of: human” (“P31 = Q5” in Wikidata vocabulary). On each of those items we looked for the following additional properties and found them on the number of items shown in Table 2.
Descriptive statistics for WHGI data set.
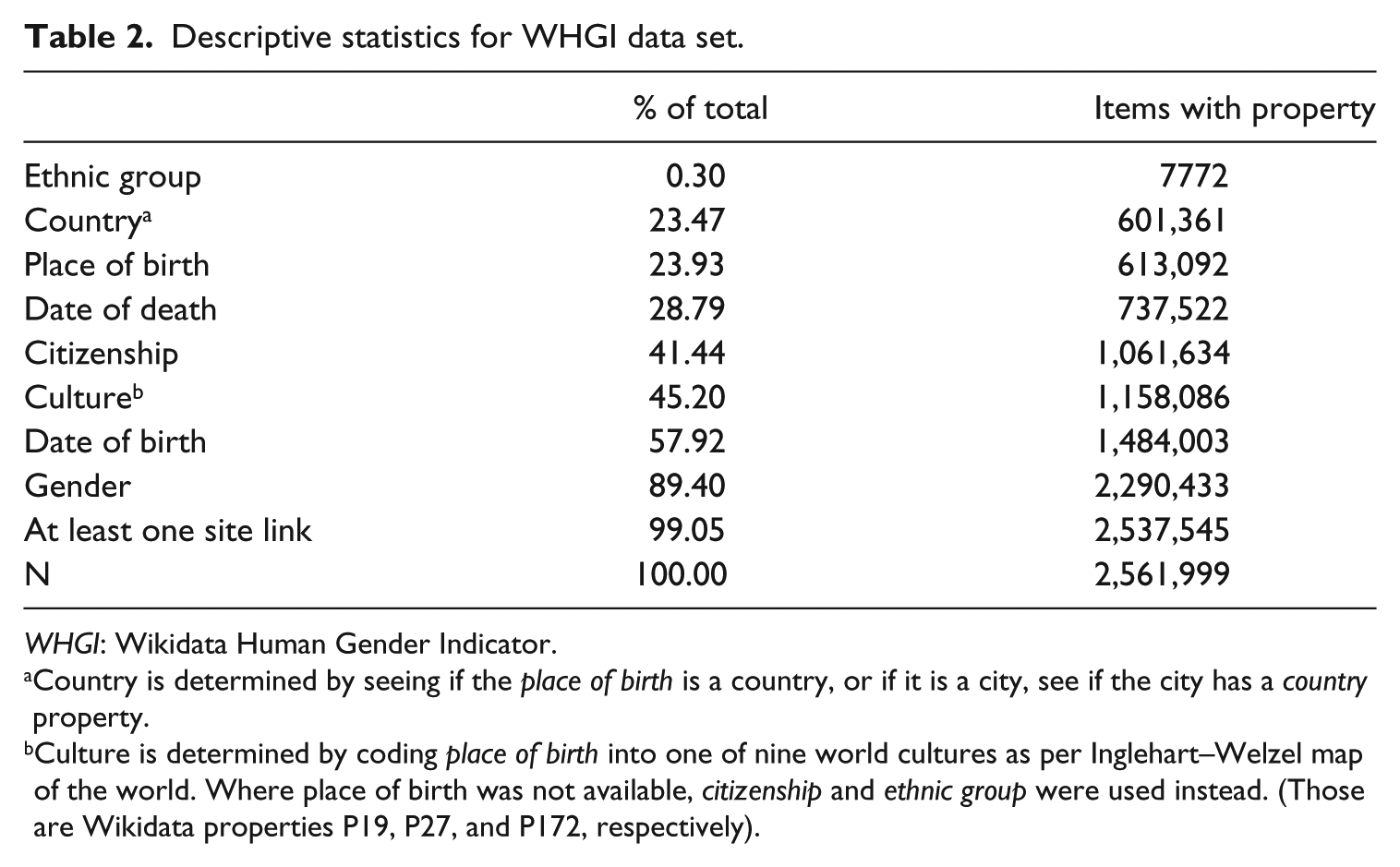
WHGI: Wikidata Human Gender Indicator.
Country is determined by seeing if the place of birth is a country, or if it is a city, see if the city has a country property.
Culture is determined by coding place of birth into one of nine world cultures as per Inglehart–Welzel map of the world. Where place of birth was not available, citizenship and ethnic group were used instead. (Those are Wikidata properties P19, P27, and P172, respectively).
The first derived statistic of interest is the total gender breakdown. As we’ve seen, above 10.3% is of unknown gender, otherwise we encounter in Wikidata 13.9% women, 75.7% men. We also find 152 cases of non-binary gender. Normalizing the percentages to only known-gender humans, we have 84.4% men, 15.6% women, and ≈0.0001% non-binary in Wikidata.
Sanity checking and indicator verification
We carry out a sanity check on whether our data seem to reflect the world at large, by correlating our data with the historical census data and the four other gender indices mentioned.
We find that Wikipedia biographies seem to be highly correlated with world’s historical (Pearson correlation coefficient = .983 with p < .01), though unsurprisingly the ratio of Wikipedia’s coverage (the percentage of people alive meeting the “notability” criteria) increases as we move closer to the modern times (see Figure 2).

Population comparison between world history and Wikidata.
Next, for each of the four alternate indices, we use the country rankings to produce the Spearman rank correlation statistic between the two rankings. Then, we perform a calibration step to find the starting decade to use in subsetting WHGI which produces the highest correlation with the alternative index. Table 3 shows four calibration results, and Figure 3 shows a visualization of WHGI-country starting with birthdates only after 1910.
Correlations of WHGI-country with alternative indices.

GEI: Gender Equity Index; GDI: Gender Development Index; GGGI: Global Gender Gap Index; SIGI: Social Institutions and Gender Index.
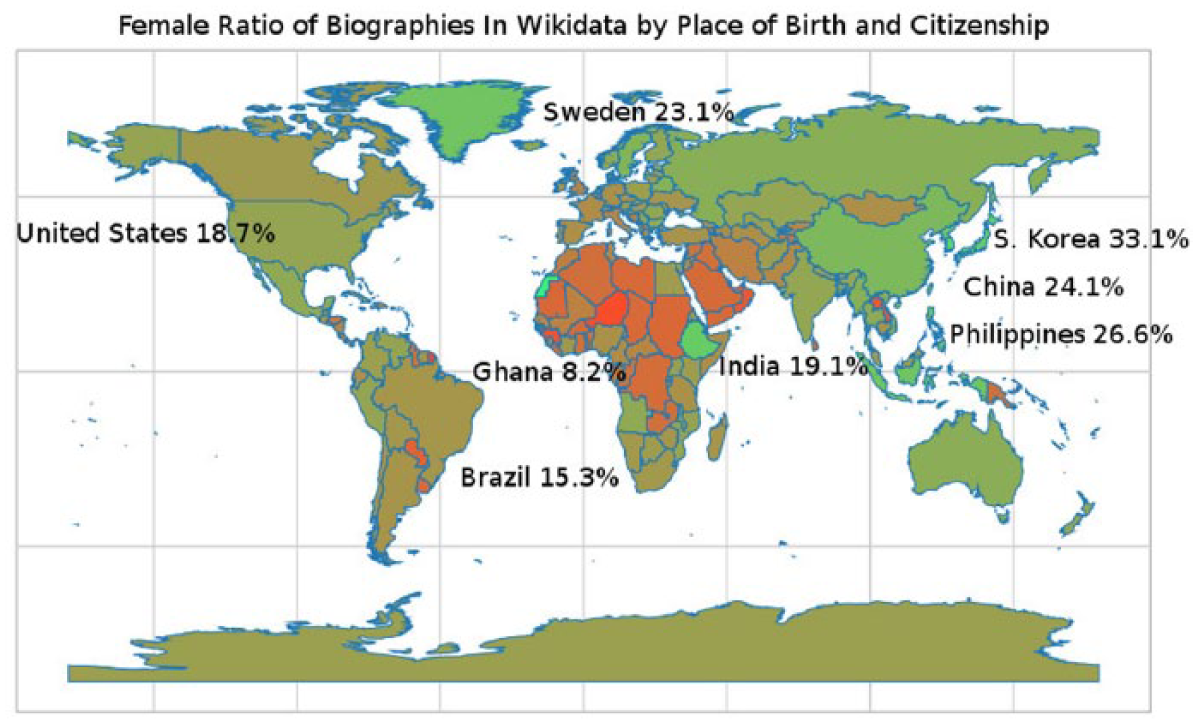
WHGI-country world map visualization. View interactive version at http://whgi.wmflabs.org/data.html.
Each alternative index shows a statistically significant correlation to our WHGI-country measure. This suggests that the proportion of women in Wikidata biographical items associated with a country can be a helpful tool in enhancing gender inequality indices. In addition, the fact that each alternative index most highly correlates when we consider only those biographies starting around 1900 is a positive sanity check for our data in the light of the fact that traditional indices talk about modern history.
Gender ratios by culture
We find a large difference in absolute number of biographies by culture. It might be that biographies of Europeans and English speakers are simply more likely to be described in Wikidata at the moment, as an artifact of the volunteer import process (since most of Wikipedia volunteers come from those regions). Still, although the European and English-speaking world dominate in total items, they do show differences in gender ratios, though perhaps the most surprising findings, discussed later in the “Celebrity hypothesis” section, relate to the Confucian and South Asian cultures.
We make a cross-tabulation of gender by our aggregated culture measure. A chi-square test shows the observed distributions of gender by culture to vary significantly (p < .01). We graph the woman percentage of biographies by culture in Figure 4.
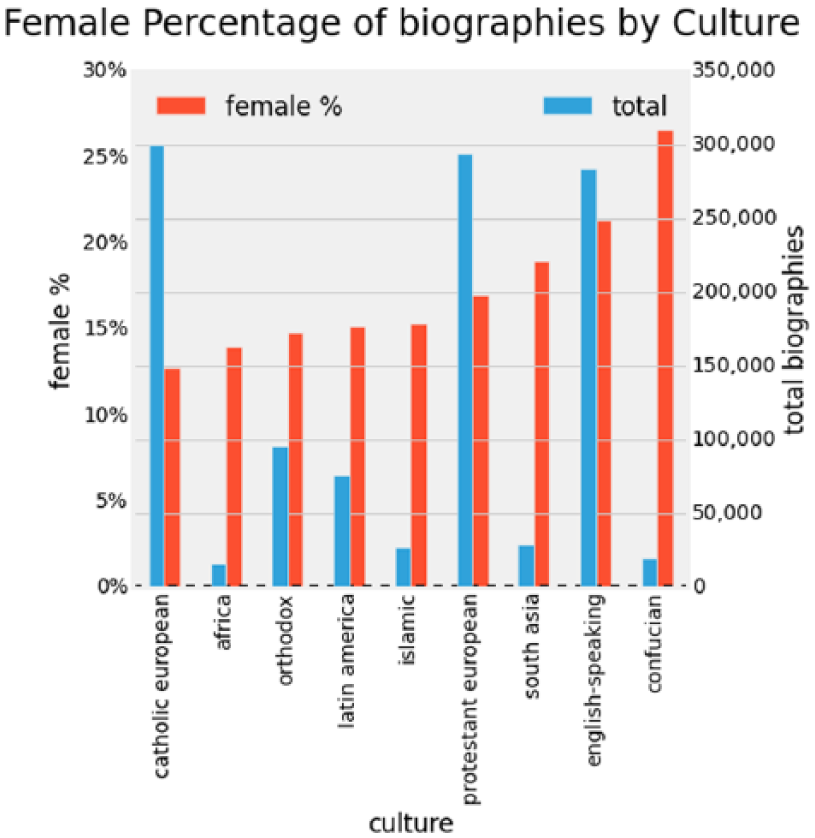
Ratio of women biographies by culture.
Next, we provide the same graph for non-binary percentages of biographies by culture in Figure 5. The cultures are ordered in the same way as the woman graph for ease of comparison. Notice that the ordering of total items is relatively similar to the woman graph—which suggests that similar factors affect recording of woman biographies and those of non-binary gender individuals.
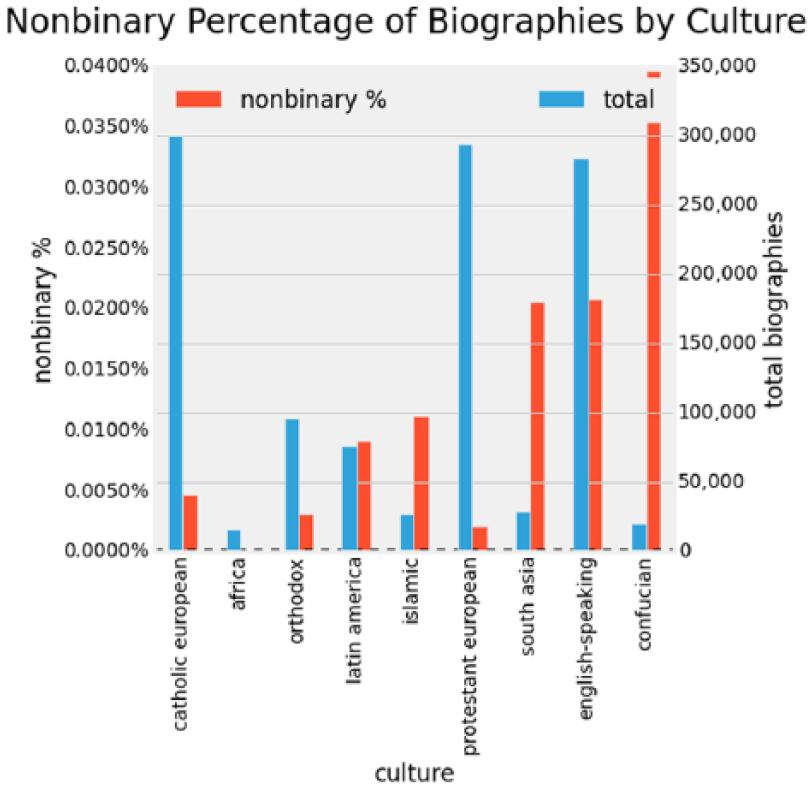
Ratio of non-binary biographies by culture.
The original Wikidata policy stated that gender assignment “must be one of ‘male,’ ‘female,’ or ‘intersex’” but has since changed with community discussion. Currently, Wikidata is allowing an increasing list of non-binary values. Looking at two particular values, we observed a 5:1 ratio of transgender women to transgender men, which is similar to the 3:1 ratio reported in the work by Landén et al. (1996). And similarly that 89 transgender women of about 2,500,000 items are equivalent to about 1:30,000 ratio, which is a number that is typically reported in mainstream media (Conway, 2001).
Gender over time
We start looking at how the ratios of women and non-binary genders develop over time in Figure 6. We adjust our viewing window here to start at 1400CE here because the data are otherwise too sparse to provide meaningful visual data. We aggregate the non-binary genders into a single class for the ease of visualization.
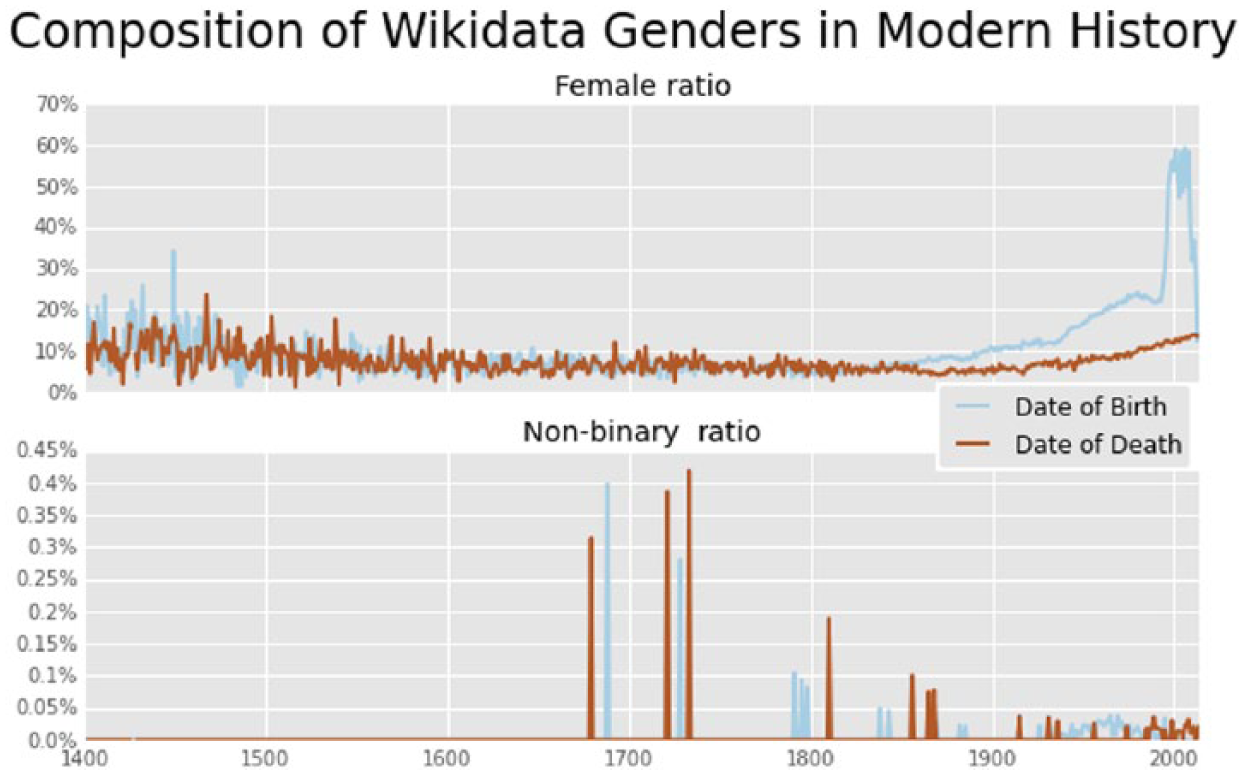
Gender ratios over time.
Since about 1800 to present, the ratio of women biographies is greater when using the date of birth measure than the date of death measure. In other words, we find that recording women date of birth has become more prominent than date of death.
Even with discounting very recent trends of the past 20 years, which describe humans who are just entering adulthood or younger, the women ratio by date of birth is rising exponentially. Although it may not necessarily indicate equity, fitting an exponential model to this rise in ratio we can calculate when the women percentage would reach approximately 50%. That model gives the equation female ratio (year) = 0.987−1.106(year) + 2309.169 + 0.038 and solving it yields that it would be February 2034 when the exponential extrapolation would reach 50% women representation. We suspect that in reality we will encounter a logistics model—not an exponential model—but presently we haven’t encountered the inflection point of slowing rate of growth yet.
Gender by culture over time
Next, we combine the three variables—gender, culture, and time. To note our sample size as we continue, only 951,101 or about 35% of total records have all of date of birth, culture, and gender data.
In Figure 7, we see that the recent past around 1800 is a low point for women recognition in all cultures and most of recorded history. Likewise, visually it is evident that historical trends in different cultures have peaked at much higher ratios than one or two centuries ago. In the modern historical graph, we can see a rise occurring for all cultures, and super-linear growth even for the Confucian and South Asian countries. The sky-rocketing ratios after 1990 are less significant as noted above, due to inherent non-notability of young individuals.
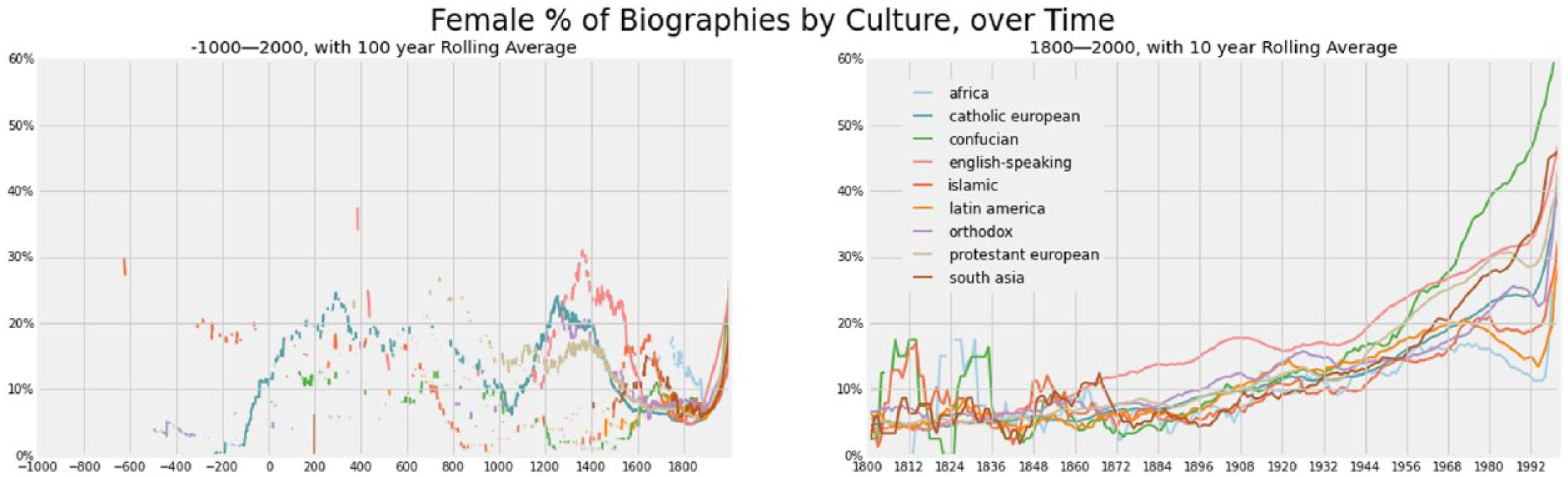
Gender ratios over time and culture.
Gender by Wikipedia language
Now let us recall that there is one more dimension we have recorded, the sitelink dimension, which indicates whether or not for an item a Wikipedia language has an entry for it. To clarify what this means in practice, say for instance that Finnish Wikipedia has an article about a Japanese human; the sitelink dimension records this as content on Finnish Wikipedia. With these data, we can analyze the women and non-binary tendencies of a Wikipedia language, rather than a nationality or culture. Figure 8 shows the relative frequencies of women articles per Wikipedia language versus the size of the language.
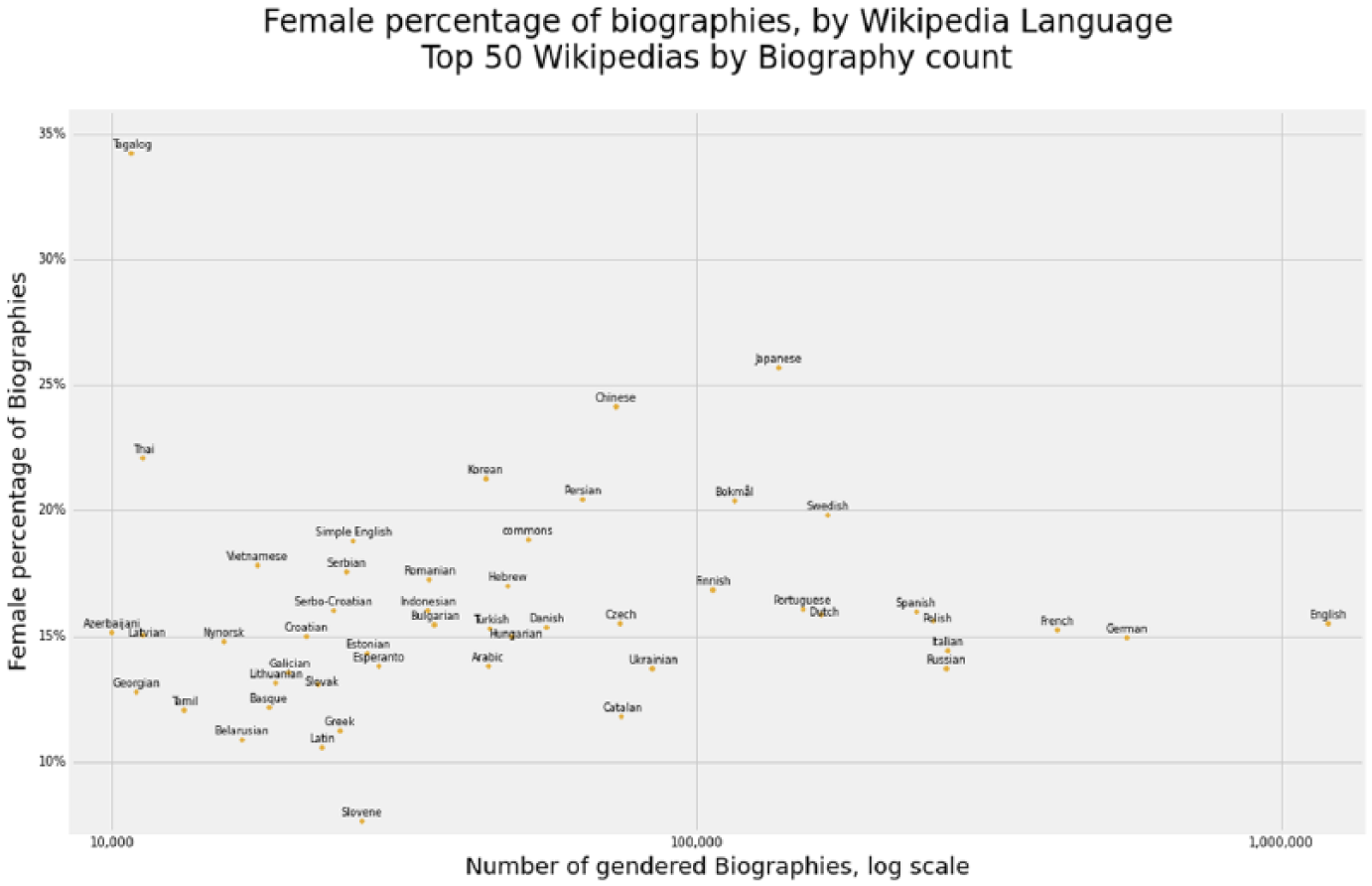
Ratio of women biographies by language of top 50 Wikipedias.
The visual technique we use is to look at for the points whose magnitude from the origin is greatest. In general, there is no simple trend linking Wikipedia size to women representation. We see relatively a flat constant rate, with a few Wikipedias standing out in terms of high women representation, like the Japanese, Chinese, and Tagalog. So again we are seeing some evidence for the languages of Confucian and South Asian cultures being less gender biased. We repeat the analysis for non-binary humans in Figure 9.

Ratio of non-binary biographies by language of top 50 Wikipedias.
With only 152 data points, the reliability of this analysis is low, but we again see the languages of Confucian and South Asian countries toward the top. Viewing by Wikipedia gives us an overview of how a Wikipedia treats gender, but only part of each language’s culture shines through as each language has articles about world biographies as well as local biographies.
Gender by aggregated language
To further test the impact of cultural influence, we aggregated the languages into the nine World Cultures discussed previously. Since there are only 285 languages, we assigned all of the languages by hand, rather than resorting to Mechanical Turk. In addition, we created a separate category for the constructed-language Wikipedias. The technique used here is that every Wikidata item counts toward a culture if a sitelink exists in at least one language associated with that culture. So if an article has language links to English, Chinese, and Japanese Wikipedia, that item counts only once toward each of the English-speaking and Confucian categories. In viewing the plot of the aggregated languages (Figure 10), we still cannot see a clear trend emerging between total biographies and women ratio.
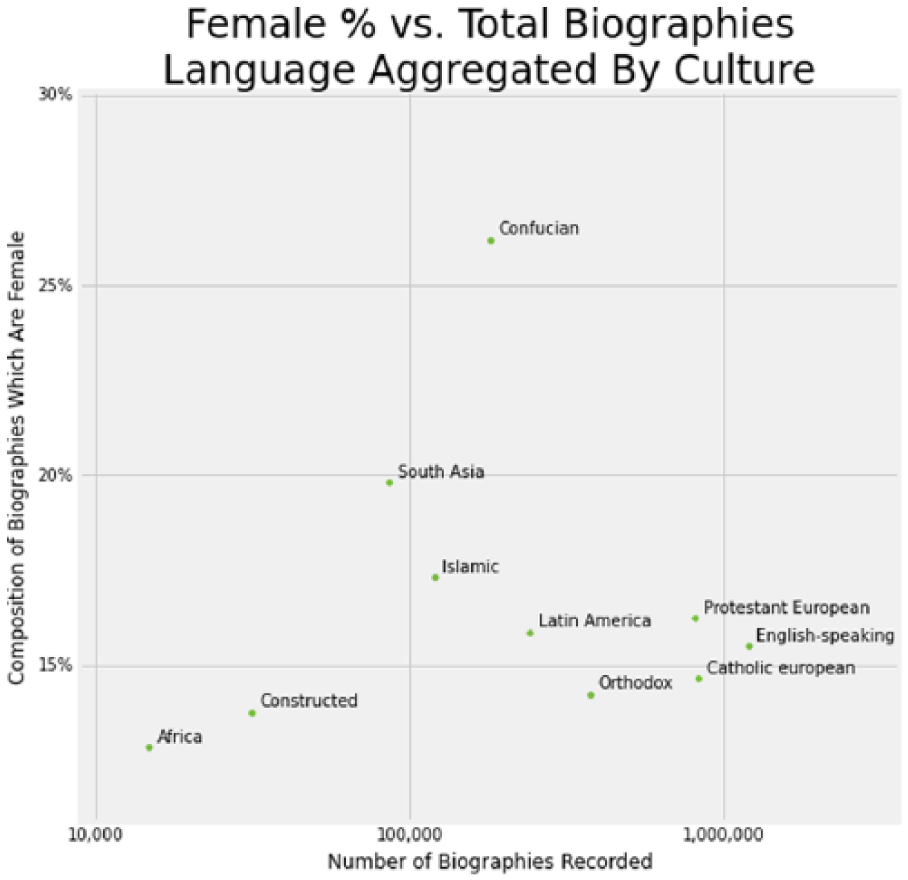
Ratio of women to total biographies by culture-aggregated language.
However, we see the Confucian and South Asian cultures confirmed as the top 2 cultures in terms of women biography ratio. We also see the European/English-speaking cultures clustering very closely to each other, showing not much difference either in total biographies or in women ratio. Islamic, Latin American, and Orthodox cultures show an inverse relation between size and women ratio, but that is not consistent with the African and Constructed-Languages trend.
Local heroes and heroines
We now turn to looking at “local heroes and heroines,” that is separating articles into those which exists in only one language—which we call “language-unique”—and those that exist in more than one language—which we call “language-many.” (Another way of thinking of such articles is that they are about figures of local interest, who are not internationally famous and are less likely to be translated to other languages with which they have little if any connection.) We then compute a measure, graphed in Figure 11, which is the difference between language-unique and language-many women ratios, which describes how especially woman focused a language is when talking about figures of local interest.
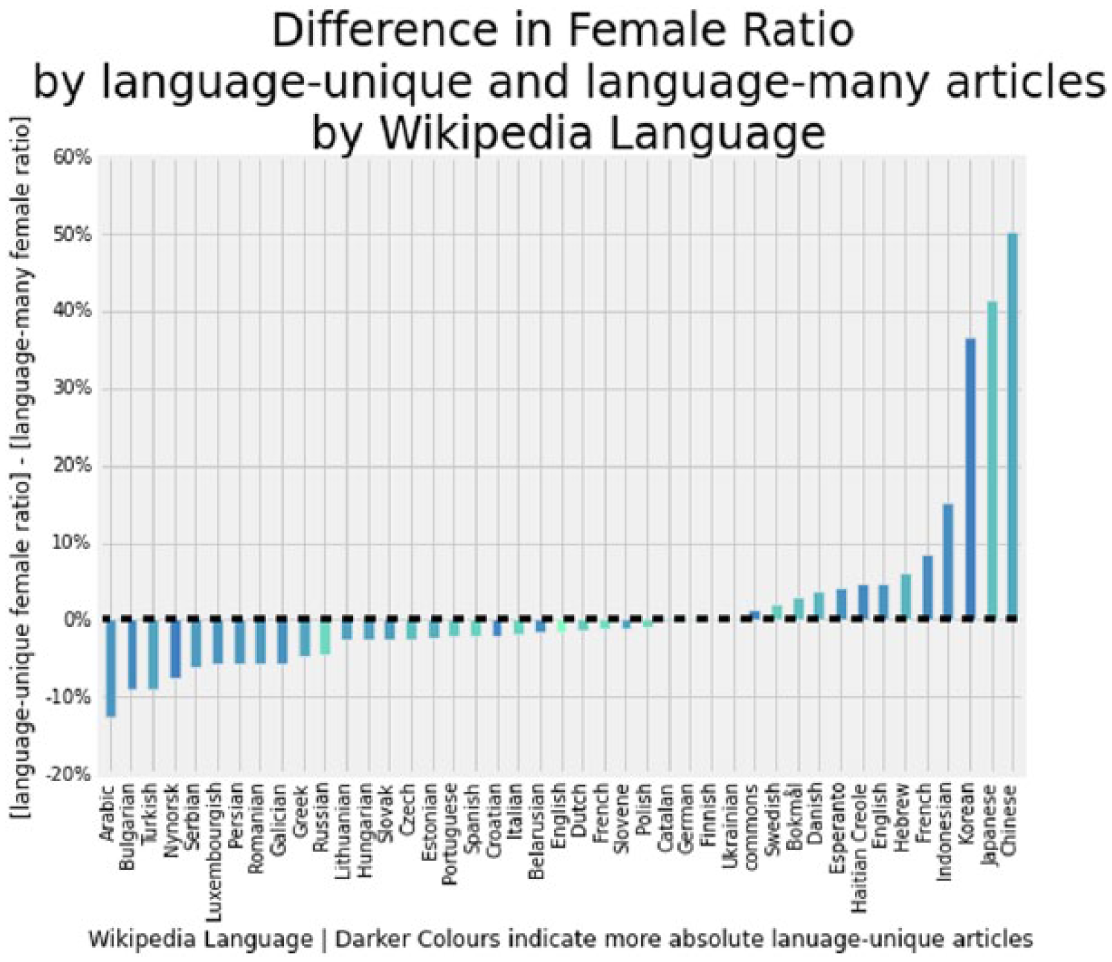
Difference in women ratio by language-unique and language-many articles by language of Wikipedia. Notice that we also provide a color guide which displays the absolute number of language-unique articles (darker is larger).
In the local heroes’ (and heroines’) view, we see ranges from about −11% in Arabic to about +50% in Chinese. This means that biographies that exist only in Arabic are 11% less likely to be about women than biographies in Arabic that also exist in other languages. Likewise, those articles that exist only in Chinese, compared to articles which are in Chinese and at least one other language, are 50% more likely to be about women. Confucian South Asian and also Nordic languages seem to also focus more on women-oriented articles for figures of local interest.
Celebrity hypothesis
In this section, we would like to outline one line of inquiry for others to engage with, serving as an example of what insights related to gender equality, human development, and culture can be drawn from Wikipedia/Wikidata, in general, and WHGI, in particular. We call it the celebrity hypothesis and it represents our attempt to explain our finding that Wikipedias in Confucian- and South Asian-cluster languages have higher (better) ratios of women to men biographies than Wikipedias from other language clusters, yet are commonly seen by other gender gap indices and literature as only moderately successful when it comes to achieving traditionally measured gender equality (e.g. in workforce, politics). Initially, we suspected that a data error resulted in biased results falsely increasing the women ration for Confucian/South Asian countries, and as one of the error-checking methods, we run additional queries and reviewed sample articles. We did not identify any error but instead observed that more female biographies from those regions appeared to be of celebrities (actresses, musicians, etc.) than those from other (e.g. English) Wikipedias. We therefore speculated that those cultures may be more celebrity-focused, resulting in editors from those countries being more likely to create articles on celebrities (instead of, e.g., politicians or historical figures) and decided to test this hypothesis, incorporating it into our ongoing research in the spirit of grounded theory.
To do so, for the Chinese, Japanese, Korean, Tagalog, Urdu (which displayed high women ratios), German, and English Wikipedias (to act as baselines, with those two Wikipedias being selected due to their size and reasonably high rankings when it comes to traditional measures of gender equality), we retrieved the page content of each Biography from 1930 until 1989. We used 1989 as a cutoff to avoid any skewing from the reasons why someone born after 1990 might be notable, that is, children of notable people. The English or foreign language words that are associated with celebrity are described in Table 4. We also note that the words we use represent only a part of what could be seen as celebrity and this should be seen as only a starting point for related research, which could include further professions (e.g. related to sport or new media) and additional languages.
Celebrity terms tested.
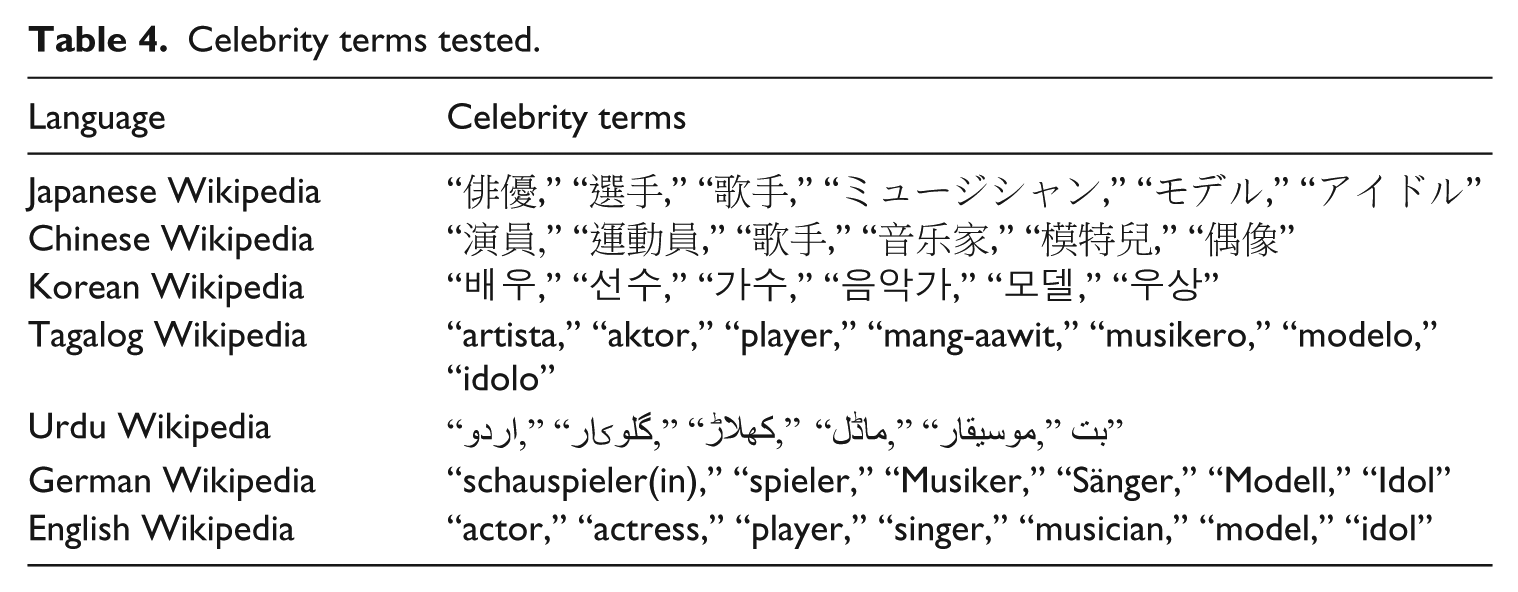
A celebrity was defined as a biography that contains one of the above words within the first 200 characters of its Wikipedia entry.
We show a heatmap comparing the language, the decade and, the gender, and celebrity percentage in Figure 12.

Heatmap of percentage of celebrity biographies by decade of birth versus Wikipedia language by gender.
We can see then the women matrix is darker in general that the other two matrices, visually indicating that women are more likely to be celebrities among these languages. Likewise, one can see that in general the transition of the heatmap to being darker at the top than bottom, which describes increase in the percentage of celebrities among biographies in most languages in recent years. Finally, we observe some vertical-striped features showing that some languages, in particular, Tagalog, include more celebrities across gender and time.
To determine the significance of the effects, we perform a logistic regression analysis in predicting the celebrity percentage variable. The coefficients are shown in Table 5.
Celebrity logistic regression.
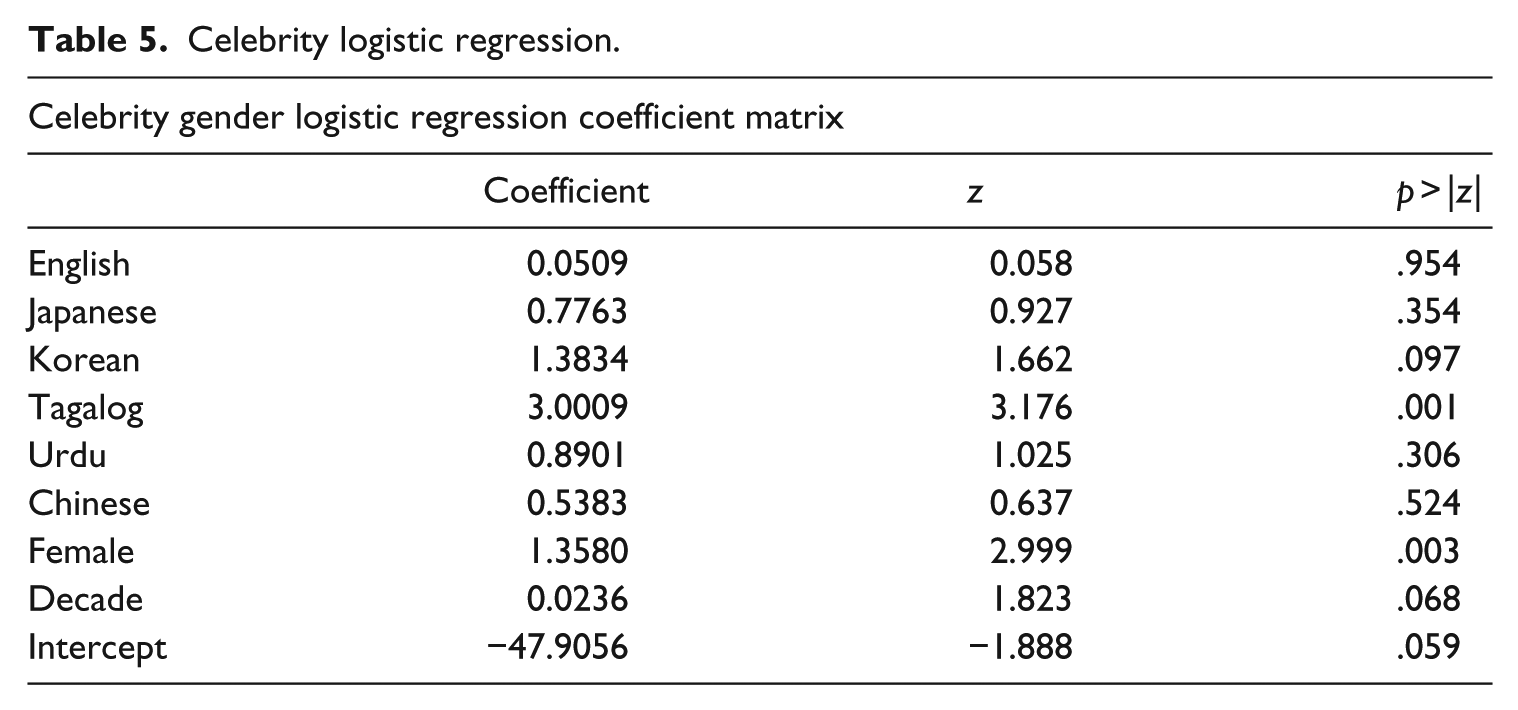
The female, and Tagalog, variables are significant predictors of celebrity with p < .05. Marginally significant are decade and Korean. This partially supports the notion that women recorded in Wikipedias, particularly in the Confucian and South Asian clusters of languages, have a higher tendency to be a celebrity, and that in general over time these Wikipedias are becoming more celebrity-focused.
Discussion
RQ1. Is the Wikidata Human Gender Index a reliable indicator and what can it tell us about the world’s notable people?
We compared the occurrence of birthdates of the set of humans in Wikidata to the historical population of the Earth and found a very high correlation, which suggests that our data set is at the very least a sane representation of the larger world. We then correlated the women ratio of humans in Wikidata by place of birth and citizenship (WHGI-country) to four major inequality indices and found significant correlations with each.
Since WHGI is generated from Wikipedias, which have notability policies, it can be seen as indicator of the “world’s notable people.” In particular, we found that the GEI is most similar to WHGI-country and the least to GDI. Investigating those indices’ methodologies, we found overlapping features of education and economic position, but divergences in empowerment (GEI) and health (GDI). This means that according to Wikipedia, being a notable person is less about to life expectancy, somewhat more about education and economic status, and even more about positions of power.
RQ2. In the WHGI, what are the variations and trends by date of birth, date of death, culture, country, and language?
In response to RQ2, we compared the number of Wikipedia biographies by gender and by date of birth and death. We found a difference in the trends of gender ratios between date of birth and date of death. Women’s representations in the encyclopedia have been higher in ancient history than in some modern history but rely on sparser data. In the modern age, especially since a globally identified low point of the 19th century, women ratios have been rising by both date of birth and death measures. Although both women ratios are rising, date of birth data are more common than the date of death data. A possible interpretation of this fact is that we are viewing an artifact of a social tendency that women are notable by birth because of their familial status (e.g. royal family or daughter of famous person), but recording date of death has more to do with earning lifetime notability in a biased world. Still, women ratios are rising, and at an exponential rate. Using the current exponential rate, we calculate that in 2034 binary gender ratios will reach numerical parity (as the speed of creation of women biographies catches up to that of the men biographies).
With our data split by our “culture” dimension, we see cultures range independently of their size from about 12% to 27% women biography representation over time. We also saw a similar relation between representation of non-binary genders and women representation.
When viewing our culture dimension longitudinally, we see very different historical trends among different cultures. For instance, we see the Catholic Europe having an early peak around AD 200, later around 1200, which is followed by the English-speaking culture peaking around 1300 to around 30%.
Approaching modern history, around 19th century, all cultures seemed to have a low, flat women ratio, but have been rising since. In that rise, we find the women ratio increasing in Confucian and South Asian cultures more quickly than others, followed by English-speaking and European cultures where the ratio is growing but at slower rate. Islamic, Latin American, and Orthodox cultures have also seen improvement in their ratios but data suggest that in most recent years the growth has been stagnant or slightly declining.
We looked at correlations between women ratio and the size of a Wikipedia by number of gendered articles and found that there is no simple trend linking number of gendered articles of a Wikipedia to women ratio. Likewise, even when we aggregated our languages into world cultures, there was no obvious way that the total number of articles was related to women ratio.
From the perspective of non-binary genders, we find evidence that our data line up with baseline mainstream statistics about non-binary genders. With our transgender ratio at 5:1 and population prevalence at 1:30,000, we find that Wikipedias are representing a similar view of the world.
RQ3. What can we learn from variations in externally augmented variables such as biographies unique to single languages, article quality, or the proportion of celebrities?
We created a local hero measure, which focused on biographies that were unique to single languages. The local hero ratings showed differences ranging from −11% to +50% in terms of likelihood that a local hero would be a woman. Since the local hero measure speaks specifically about one language without influence from another, it could be valuable data for editors of that language to determine how their Wikipedia’s policies and culture are compared to other languages.
Using article length as a rough proxy for article quality (a basic, but sufficient measure, per the work by Blumenstock (2008)), we saw a significant constant relationship between mean article sizes and gender across all languages. With a strong R2 fit of .844, this measure is useful to all editors of the encyclopedia that on average they are prone to write less about women. That is, a culture may include more women biographies articles but still the length and attention paid to those biographies are lower.
In exploring the celebrity hypothesis, we found that the language of a Wikipedia can be a significant predictor in determining article celebrity tendencies. Moreover, women in our test data were significantly more likely to be celebrities, a trend that is on the rise with regard to the more recent biographies. Therefore, content development efforts in a particular Wikipedia could use their current celebrity levels as one of the indicators of their level of gender bias.
Gender “representative” equality may be quantitatively increased by more focus on women celebrities in biographies, but such phenomena may conceal the actual social gender inequality in cross-cultural comparisons. In other words, regardless of how many women tend to be celebrities, in general, it could be that Wikipedia’s representation might be gender-unequal especially in celebrities. Another way this statistic could be interpreted is that although some Wikipedias may be more inclusive of women, if they have a higher likelihood of notability because they are celebrities, then perhaps this signals increasing inequality from a human development point of view. That is, if the notion of celebrity is more about objectification of women than power in society, the improvement of the WHGI may be simply masking a different type of gender bias (a crude statistic that illustrates this point is that biographies of female porn actresses outnumber male porn actors roughly 2:1, which is, however, hardly representative of any progress in a human development dimension).
Our current understanding of the gender dynamics affecting social construction of knowledge of Wikipedia is still insufficient to be able to point to the preferred explanation, and it is likely that both factors discussed here, as well others yet to be identified, play a role in creating the observed data patterns.
Limitations
While we think the indicators we discuss here will be a valuable addition to our understanding of worldwide longitudinal gender inequality trends as well, we want to stress that all indicators have important limitations: they only capture a limited dimension of the topic they measure.
Representational bias
Almost all of the world’s reference works are affected by gender bias in their contributors’ gender and in the biographies listed (except those designed to correct for such biases, an approach which introduces its own set of issues) (Reagle and Rhue, 2011).
Therefore, the fact that our data set shows Wikipedia biographies are primarily about men is a compound result of at least two factors:
First, women and non-binary lack of empowerment throughout history, resulting in their lack of access to positions of power or fame that would merit their notability.
Second, an outcome of the Wikipedia’s predominantly male editor base (WMF, 2011) unconscious preference to create articles about women and on topics of (at least stereotypical) interest to men, such as military history (Forte et al., 2009; Lam et al., 2011; Wagner et al., 2016). Unfortunately, no prior studies have suggested how those factors may be weighted (a topic we hope future studies will pursue further).
No studies have been carried out to determine how, exactly, the above biases translate into reduced likelihood of a women biography being created, compared to a men or non-binary biography. Lam et al. (2011) went further to suggest that the under-representation of women contributors could have a detrimental effect on content coverage; however, this effect has never been quantified.
In order to view our data in an in-between meso-level of aggregation, we have decided to present data using the nine cultural clusters proposed by Inglehart and Welzel (2005): English-speaking, Latin America, Catholic Europe, Protestant Europe, African, Islamic, South Asian, Orthodox, and Confucian. We acknowledge that Inglehart–Welzel method introduces another set of biases and that those cultural clusters are conceptually limited to modern period (year 1500 and later) in history. For instance, the notion of having a Protestant and Catholic world before Protestantism and Catholicism is problematic, to say the least, so is the fact that individual born in ancient Greece is classified as Orthodox in this method. Nonetheless due to inevitable correlation between Wikipedia’s biographies and world’s population (Pearson = .983**(** indicate level of significance)), over 98.5% (N = 1,340,754) of biographies with recorded year of birth fall into that period of history. As such, we believe that the use of those cultural clusters does significantly improve the interpretation of the data, aggregating similar patterns from culturally similar countries, but the reader should keep in mind that the names of Inglehart–Welzel cultural clusters are not historically sound given the time scope of our data (all of human history). Alternative ways of aggregating the worlds’ cultures could offer further insight, and we hope that future analysis of Wikipedia database will allow for comparison of results obtained from different cultural aggregations.
Data reliability
Furthermore, Wikipedia, while already the largest reference work created by humankind (already about 10 times the size of the second largest, i.e., Britannica, in article count) is not yet complete and may never be. In addition, Wikidata may not fully reflect all the knowledge in Wikipedia because the integration process is still unfinished. Many items are still missing data, for example, as of the time we finalized our study, only 89.5% entries had a gender property in Wikidata, and just 23.47% had country information. Unless the missing country information is uniformly distributed among cultures, this gives our ranking some sampling bias.
In lack of any specific data on this topic, this study is based on the assumption that within the scope of limitations discussed above, a comparative analysis of the gender of the world’s notable people throughout history is nonetheless possible. It is possible that future studies will introduce techniques to counteract various the biases, thus modifying our results and conclusions. We would also like to broaden the scope of our work to include other indicators that could be weighted and combined into an index, as conceptualized in Table 1. We look forward to such proposals, and we hope that the open nature of our data set will make the creation of derivative, weighted indices an easy process.
Conclusion
To what degree is this bias of coverage shown in the gender distribution of subjects of Wikipedia’s biographical articles a reflection of our gender-unequal reality and an editor issue? Because Wikipedia is embedded in so many of the daily activities and routines of the steadily growing number of Internet users (comprising, as of late 2010s, more than half of the worlds’ population), it is not just a reflection of the world—it also a tool used to produce it. In that, it is no different from other media, such as literature, television, or video games. As the data presented here show that percentage of notable women increases through time, another metric should be possible, based on Reagle and Rhue’s (2011) work: one measuring when Wikipedia will stop being biased against inclusion of women, in other words—when there is no statistically significant difference between whether a missing biography is that of a men or women. Such a metric may also help design a set of weights for a refined version of the conceptual WIGI indicator, to form an entirely new index, along with the WHGI.
We asked what we can learn from Wikipedia about the gender of the word’s notable people. Our research confirms that gender inequality is a phenomenon with a long history, but whose patterns can be analyzed and quantified on a longitudinal larger scale than what was previously thought possible (albeit with caveats). Through the use of Inglehart–Welzel cultural clusters, we show that gender inequality can be analyzed with regard to world’s cultures. Put together, coverage of women shows a steadily improving trend, though one with aspects that deserve careful follow-up analysis (such as the high ranking of the Confucian and South Asian clusters). And certainly, it also confirms that Wikipedia, like all of the worlds’ reference works, is very biased toward men, lending further weight to the WMF and gender activists efforts to introduce more women and non-binary-gendered biographies through edit-a-thons and similar projects mentioned earlier.
A major question to consider in future research is, as noted in our limitations, to answer to what degree data in Wikipedia/Wikidata are “indicative” or “reflective” of social phenomena at large and to what degree it is merely an outcome of biases and inequalities present in the Wikipedia project. We show some aspects of this skew in correlation to human development indices and a celebrity bias, but more work needs to be done. Certainly, understanding the biases of Wikipedia’s social construction would be a valuable contribution to our understanding of inequality and gender dynamics in collaborative, virtual environments; however, discussion of such biases is not the primary goal of our contribution. Instead, we want to draw attention to the potential of Wikipedia/Wikidata to be used to analyze large-scale social phenomena and the need to continue developing data reliability there; this will make our understanding of its comparative biases against other data sets more complete.
There are, of course, numerous avenues of future research that we hope our project will facilitate. A few thoughts we hope will prove useful in that regard are as follows: (1) We used article length as a proxy when discussing Wikipedia’s article quality, corroborating our finding with other proxies suggested by literature, for example, number of references, might be useful. (2) Accounting for the year, the article was created may allow analysis of how the gender bias through time changed, in Wikipedia context, over the past 20 years. (3) Further cross-referencing, for example, with a similar index based on Britannica’s or the Library of Congress’ contents could allow for more refined estimates of the gender-related biases in reference works. (4) Using models of culture other than Inglehart and Welzel’s could show new dimensions of cultural gender gap. (5) Additional refinement of what counts as a celebrity, coupled with analysis of gender biases of notability policies in different-language Wikipedias, could help to refine results related to the celebrity hypothesis.
In summary, we hope that this study shows how Wikipedia and Wikidata, though certainly affected by a number of limitations, can be used to further our understanding of social phenomena, including those related to gender inequalities. At the micro- and meso-level, we supplement existing data on women’s involvement with Wikipedia, thus enhancing our knowledge about the gender gaps affecting the editorial and content development of Wikipedia, and reflective of much of the similar organizations online (Ghosh et al., 2002, Reagle, 2013). We hope that those findings will be of use to Wikipedia volunteers, allowing them to craft better policies and tools aimed at reducing gender gap in their project. At the macro-level, we hope that the WIGI, in general, and the WHGI, in particular, presented here, will prove to be a useful supplemental measure to enhance human development–related gender inequality indices, as well as providing a quantitative measure to analyze this topic for time periods and regions not covered by more traditional data sets.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.