
Abstract
Although visual and AI-generated disinformation have been associated with alarming political consequences, we currently lack a clear empirical understanding of the effects of different forms of visual disinformation. Against this background, we rely on a pre-registered experimental study in the United States (N = 982) in which we exposed participants to various modes of textual and visual disinformation on two different issues: The disappearance of flight MH370 and the Russian invasion of Ukraine. Findings show that, for MH370, there was no difference in credibility between textual, AI-generated, or video-based disinformation. Yet, for the Russian invasion of Ukraine, video-based disinformation was perceived as more credible than textual or image-based disinformation. Our findings indicate that the consequences of visual disinformation are context-bound: Especially in the case of polarizing issues, the out-of-context placement of videos can serve as a plausible form of deceptive evidence.
Keywords
Introduction
Disinformation—inaccurate or false information that is intended to mislead—is often visual in form (e.g. Yang et al., 2023). This visual component is, however, often neglected in research on disinformation (Weikmann and Lecheler, 2023). As case in point, many viral videos on the war in Ukraine were based on decontextualized footage, or deliberately mislabeled images to promote false interpretations (Hameleers, 2025). Using videos or still images, malicious actors may exploit the persuasive advantage of visual information over text. Specifically, as videos and images offer a seemingly unmediated and direct link to reality, they may sidestep suspicion through the “seeing is believing” heuristic (Sundar et al., 2021).
In this setting, this article explores whether and how different forms of deceptive visual evidence—either generated by AI or based on the deceptive re-contextualization of videos—yield stronger effects than textual disinformation, and whether visual disinformation is more resilient to correction due to its “true to life” qualities (e.g. Sundar et al., 2021). Concretely, we compare whether visual disinformation exerts a stronger influence on credibility, emotions, and engagement compared to textual disinformation that has been the most common focus in extant research on disinformation. Finally, we explore whether higher levels of media trust, self-perceived literacy and less pronounced conspiracy mentalities on the individual-level may contribute to weaker effects of disinformation as these factors are associated with higher levels of resilience (Humprecht et al., 2020). Considering the minimal effects of political deepfakes found in previous studies (e.g. Dobber et al., 2020), and the high salience of low-tech forms of visual disinformation and decontextualization online (e.g. Brennen et al., 2021), this study focuses on the effects of low-resource forms of visual disinformation: The deliberate decontextualization and mislabeling of videos versus the use of AI-generated still images.
We specifically rely on an experiment in the setting of the United States where trust in the news media is low, whereas citizens are extremely worried about their ability to discern between false and true information (Newman et al., 2024). Here, we focus on visual disinformation on the Russian war in Ukraine and the disappearance of flight MH370. These two issues were chosen as they both offer a discursive opportunity structure for the creation of compelling counter-factual narratives. Yet, they differ in salience and the availability of accessible materials and existing visual proof: Whereas there was a lot of “evidence” available for the causes and consequences of the war, which was more saliently covered in the news early December 2023, flight MH370 was surrounded by a lack of palpable evidence. The issue of MH370, however, offered a central case for conspiracy theories suggesting the involvement of evil political elites. Although the issue of flight MH370 was covered frequently in U.S media even years after its disappearance, it was a less dominant issue in established news coverage. As news users encounter established news on this issue less regularly, it is important to assess how the cultivation of disinformation narratives around this issue may affect credibility, emotions, and engagement. The two issues may thus be relevant to consider in the context of visual disinformation for different reasons.
We specifically compared decontextualized videos to AI-generated images as they are (a) prominent forms of visual disinformation (e.g. Yang et al., 2023) and (b) represent contrasting clusters in the visual disinformation space consisting of modal richness and technological sophistication as main dimensions: Video-based decontextualized disinformation represents high modal richness and low sophistication, while AI-generated images represent low modal richness and high sophistication (e.g. Weikmann and Lecheler, 2023).
In the remainder of the article, we will review the literature on the effects of visual versus textual disinformation, and the effectiveness of fact-checks. Based on this, hypotheses on the effects of visual versus textual disinformation are proposed. We then present the methodological framework of the experimental study. After this, the findings are discussed in light of the hypotheses, and interpretated against the backdrop of existing literature in the discussion section. The integrative contribution that this article aims to make is a comprehensive assessment of whether forms of disinformation surrounded by popular concerns—generative AI and decontextualized videos—have stronger political consequences and correspond to lower resilience than textual disinformation. By comparing effects across a more salient politicized issue versus a more dormant issue, we also explore the dependency of disinformation’s influence across contexts that offer different opportunity structures for deception.
Theoretical framework
Visual disinformation: the manipulation and decontextualization of images and videos
In this study, we test whether different forms of visual disinformation have a relatively stronger impact on credibility assessments, emotional responses, and engagement than textual disinformation. Together, we regard these outcomes as relevant for the targeted influence of disinformation campaigns, as they correspond to the perceived truth value of falsehoods, the affective responses triggered among recipients, and the potential for virality by motivating its distribution through online crowds. In this article, we define visual disinformation as an umbrella term for intentionally manipulated information that contains a decontextualized, manipulated, or fabricated visual component (also see, for example, Hameleers, 2025). The term visual disinformation can refer to the deceptive use of various modalities, such as decontextualized images paired with text, cropped video fragments, or synthetic images or videos created with Artificial Intelligence, such as deepfakes. Crucially, although AI-generated images or decontextualized videos can be generated for entertainment purposes, we regard the act of generating such messages as deliberate. In the issues central to this study, we regard the political nature of the disinformation messages as a signal of potential deception: The war in Ukraine and the suggestion of terrorist attacks in the case of flight MH370 is likely to be driven by political or identitarian motives rather than entertainment. However, our definition of disinformation is motivated by alleged potential to deceive and mislead as we cannot offer proof for the underlying motivations of disseminators.
Although many alarming statements have been voiced about deepfakes and other highly sophisticated modes of deception, deepfake videos are (currently) not very salient modes of visual disinformation (see, for example, Brennen et al., 2021). Visual disinformation that requires less manipulative sophistication while being high in modal richness (i.e. decontextualized video fragments) are more prevalent online. This may be explained as less resources and skills are needed to create decontextualized videos, whereas the rich mode of presentation and the seemingly direct reference to reality may still offer a persuasive mode of presentation (e.g. Brennen et al., 2021; Weikmann and Lecheler, 2023). For this reason, we first of all focus on decontextualized video fragments as visual disinformation with a relatively low level of sophistication but high modal richness.
Another prominent form of visual disinformation concerns the use of more sophisticated forms to manipulate still images, for example, through generative AI. Visual disinformation for which images are manipulated or fabricated and used as evidence for a deceptive claim are often used in online settings and on social media platforms, such as Facebook (e.g. Yang et al., 2023). Although images can be manipulated using less sophisticated software, for example, by cropping images, AI can also be used to generate synthetic images from scratch.
Taken together, we compare the effects of visual disinformation based on video-based decontextualization and visual disinformation based on AI-generated still images because these modes of visual disinformation are (a) highly prevalent online; (b) made available for free to online users; (c) accessible without technical skills; and (d) allowing for the plausible creation of deceptive visual proof. Yet, they differ in the richness of the modality used: Still images and videos may be processed differently based on the cognitive resources they require, and the ways in which they are processed (e.g. Sundar, 2008).
The effects of visual versus textual disinformation
The general argument of this article is that visual disinformation represents a stronger connection to reality compared to the abstract representations of reality in textual disinformation, which may also make such visual forms of deception more effective in signaling credibility, fueling emotions, or generating clicks and engagement. Compared to textual descriptions of events or issues, visuals offer a direct indication of reality, which has also been referred to as the quality of indexicality (Messaris and Abraham, 2001; Powell et al., 2018). In other words, images are, more than text, able to establish a physical connection between the image and the observer by showing an apparently unmediated depiction of reality and truth. This means that textual representations are regarded as more distant from reality than visuals, as textual descriptions of events involve more distance from things that happened, more subjective interpretation, and less vividness. Visuals, in contrast, are seemingly less mediated and more closely capture the reality they refer to: They “show” something that has happened instead of reducing this to a “written” representation of what happened.
Related to the quality of indexicality, visual disinformation may motivate heuristic processing through the realism heuristic (Sundar, 2008). This “seeing is believing” heuristic may signal the trustworthiness of visual disinformation and may motivate recipients to not engage in the critical evaluation of message arguments but rather judge the veracity based on the rich modality that signals reality directly without the interference of distant descriptions (Weikmann and Lecheler, 2023). Against this backdrop, we expect that visual disinformation, more than textual disinformation, may sidestep deception detection: The rich mode of presentation may avoid the activation of suspicion, herewith promoting processing via the realism heuristic, while avoiding the systematic processing of false interpretations of visual proof.
Yet, to date, we know little about the effects of visual disinformation beyond enhancing the credibility of manipulated information. Here, we specifically look at emotional responses as affective outcome, and engagement with the content of the message as a behavioral outcome of disinformation. Here, engagement is understood as the extent to which people intend to engage with the disinformation by sharing it online, verify the information by finding additional content, or engage in face-to-face interactions to share and discuss the message. As such, it may contribute to the virality of disinformation and the absence of filtering mechanisms that would prevent the further dissemination of falsehoods. Although visually framed information should elicit stronger emotions and stronger message-congruent behavioral intentions than text due to its attention-grabbing and vivid representation of reality (Powell et al., 2018), we lack empirical research on whether this also applies to disinformation. However, we expect that the indexicality of visual disinformation can be extrapolated to effects on emotions and intentional behaviors related to the engagement with disinformation. We raise the following hypotheses:
Although videos offer a higher level of modal richness than still images (Weikmann and Lecheler, 2023), we currently lack research comparing the effects of video-based disinformation to the deceptive use of still images generated with AI. We therefore raise the following research question: Are there differences in the effects of AI-generated still images versus decontextualized videos in credibility, emotional effects, or engagement? (RQ1). The purpose of the research question is to compare the effects of the two forms of visual disinformation distinguished, and to assess whether there are significant differences in the three dependent variables across the video and still image disinformation conditions.
The role of distrust and self-perceived media literacy
We expect that participants with lower trust in the news media are most likely to engage with and find disinformation credible. This expectation is in line with the findings of Zimmermann and Kohring (2020), who found that disinformation in the electoral context was most likely to be believed by people with lower trust in the media. In the context of this study, we expect that when people do not trust the news media, they are expected to be more inclined to reject conventional truth claims and herewith accept the alternative claims on truth forwarded in disinformation narratives.
Beyond generic levels of distrust, we expect that conspiracy mindsets or mentalities moderate the effects of political disinformation. In line with extant literature, we conceptualize conspiracy mindsets or mentalities as a general individual-level tendency to endorse conspiracy theories (Imhoff et al., 2022). Conspiracy theories, in turn, are defined as alternative explanations of evens suggesting that “evil” forces of power are plotting a scheme against the people, and deliberately hide reality to maintain or gain (political) power (Bruder et al., 2013). Given that research consistently shows that people’s endorsement of one conspiracy theory is linked to others, it is relevant to consider conspiracy mindsets as broader predispositions to generally interpret situations (i.e. the disappearance of an airplane) as a conspiracy (Imhoff et al., 2022).
We expect that the delegitimizing and anti-establishment perspective forwarded in the studied disinformation narratives is most persuasive for people with a conspiracist mentality (Daunt et al., 2023). Conspiracy mentalities are especially relevant to consider in the context of visual disinformation, as it forwards seemingly authentic and palpable “evidence” that puts pieces of the puzzle together. It herewith legitimizes an alternative reality allegedly indicated by the visuals as direct proof. Thus, for people with a more pronounced conspiracy mentality, the evidential value of false visuals may resonate with their frame of reference emphasizing that the reality is hidden from the ordinary people, but revealed through the visual evidence provided. Concretely, applied to the disinformation narratives studied, we expect that people with a stronger tendency to endorse conspiracies are less resilient to disinformation’s effects. The disinformation narratives are congruent with “alternative explanations of events” and highlight that the mainstream narratives on the two issues, and especially the disappearance of MH370, are untrue and “hide” the actual reality. This congruence between conspiracy-related predispositions and the disinformation narratives is expected to augment visual disinformation’s effects on credibility, engagement, and emotions. We therefore introduce the following hypotheses:
As there is no existing research on the role of distrust for visual disinformation exposure in particular, we raise the following research question: To what extent is the moderating role of distrust in the media and conspiracist mentalities similar or different for exposure to textual versus video-based or disinformation based on AI-generated still images? (RQ2).
Next to (dis)trust, media literacy may be an important factor to consider when it comes to the effects of disinformation. Higher levels of media literacy have been associated with a more accurate discernment between true and false statements (e.g. Jones-Jang et al., 2021). More specifically, higher levels of media literacy indicate more critical verification skills, considering that more media literate recipients may be more likely to recognize which deceptive techniques have been used to mislead them, while being aware of their own (confirmation) biases at play when exposed to (political) information. This leads us to the following hypothesis:
Arguably, the levels of sophistication and richer modalities embedded in visual disinformation (Weikmann and Lecheler, 2023) make the detection of deception a more complex task, requiring recipients to verify the authenticity and correct use of the visual information presented alongside the textual description of events. Yet, considering the lack of research on the role of media literacy related to the detection of visual deception, we raise an exploratory research question: To what extent is the moderating role of media literacy similar or different for exposure to textual versus video-based disinformation or disinformation based on AI-generated still images? (RQ3).
Fact-checking visual disinformation
Most research to date indicates that fact-checks are effective in correcting misinformation and false political beliefs (e.g. Walter et al., 2020). In addition, exposure to fact-checking information is found to lower the credibility of misinformation statements people were exposed to (Hameleers and Van der Meer, 2020). The corrective information in fact-checks may be effective as it directly responds to false claims, while presenting different sources of evidence to highlight the discrepancy between what actually happened and the disinformation narrative (Lewandowsky et al., 2012).
The visual nature of many (digital) disinformation campaigns has made the verification and falsification of visual disinformation a daily task of fact-checkers throughout the globe, who, for example, rely on OSINT (Open Source Intelligence) and geo tracking to assess whether certain videos or images came from a certain time and place. In this setting, we are in need of empirical evidence on the effectiveness of fact-checks that correct visual disinformation. Here, it is of particular interest to explore whether the types of evidence used in fact-checking are applicable to the nature of visual disinformation. Considering the strong evidence on the effectiveness of fact-checking in general, we formulate the following hypothesis:
Methods
Sample
Data collection was outsourced to Kantar, an international research agency relying on large voluntary opt-in panels of participants. From the panel, participants were randomly invited to participate in this study via e-mail (inclusion criteria included eligibility to vote and residing in the United States, exclusion criteria included being younger than 18 years old or non-compliance with the informed consent procedures). We achieved 982 completes (completion rate 89.4%). This number was lower than the number in the pre-registration, as we mistakenly considered an additional variable in the power calculations which was eventually not included in the design of the study (and also not considered for the actual pre-registration, data collection, or analyses). Soft quota on age, gender, and education were used to make sure that the sample distributions reflected the U.S. population as close as possible. We assessed that the final distributions of the sample (i.e. in age, gender, and education) deviated less than ten percent from distributions in the sampled population. The mean age of participants was 46.22 years (SD = 17.22). Regarding gender, 50.3% self-identified as female. We also obtained a good balance in level of education: 46.1% was lower educated, 30.0% had completed a moderate level of education, and 23.9% was higher educated. We also obtained a representative balance regarding partisanship: 31.7% mostly identified as Republican, 28.8% as Democrat, and 30.4% as Independent. 9.1% did not want to disclose their partisan affiliation.
Design
We relied on a between-subjects experimental design with a 3 (Disinformation: The deceptive use of decontextualized videos versus AI-generated still images versus text-based disinformation) × 2 (Correction: Present versus absent) + 3 control (authentic video versus authentic image versus authentic text matched with the topic of the disinformation stimuli) between-subjects factorial design. Data were collected between December 5 and 11, 2023. The hypotheses and design were pre-registered at: https://aspredicted.org/6MX_9VL (Hameleers and van der Meer, 2025). The topic was varied as a within-subjects factor: Participants saw disinformation on both the missing MH370 airplane and peace negotiations between Zelenskyy and Putin. The order in which the messages were presented was randomized to rule out effects of ordering. To enhance external validity, participants were exposed to disinformation presented in the format of plausible and real news without a specific well-known source cue. Although prior experiences and previous encounters with information on both topics could prime deception, such information was not present in existing news coverage at the time of data collection in December 2023.
The design, measures, and procedures of the experiment were reviewed and approved by the University of Amsterdam’s Institutional Review Board under number FMG-5377. Given the sensitivity of the issues and the potentially deceptive influence of disinformation, a very detailed and careful debriefing procedure was included that did not only clarify that participants were exposed to disinformation, but also fact-checked the specific claims being made. In addition, participants were offered a list of suggestions on how to find credible news on the two issues. We made sure that the debriefing message was visible for all participants and used a forced exposure screen with a minimum exposure time.
Independent variables and manipulation
All the stimuli scripts can be found in Online Supplemental Appendix A. For the narrative on MH370, an existing verified news article with the title “What we know, and still don’t know, about the missing MH370 plane” was used as a baseline and control condition. To create the disinformation conditions, we based ourselves on existing disinformation stories that have been circulating after the disappearance of flight MH370. Concretely, the disinformation narrative falsely stated that “New information of anonymous sources confirms that the aircraft was shot out of the sky by terrorists.” As there is no evidence of such an attack, and as the interpretation that terrorists were involved is deceptive and unsubstantiated, we consider this a disinformation narrative. In the visual disinformation condition in which a decontextualized video was shown, real footage of a missile attack on another airplane was deceptively used as evidence to support the false claim that MH370 was hit by a surface-to-air missile (SAM). Although the video is authentic, it actually shows footage of a military attack on a different (military) aircraft.
For the visual disinformation condition containing an image, we used an AI-generated image of debris paired with a missile and a hole in the cockpit confirming that the airplane was taken out of the sky. The same deceptive text as used in the video-based disinformation narrative was paired with the image that acted as proof for the false claim that MH370 was hit by an SAM. The disinformation conditions thus politicized the relatively low salient issue of the MH370 by associating it with an act of terrorism. The framing of terrorism was highly salient in the United States at the time of data collection. Contributing to disinformation’s political goal to sow discord, unrest, and confusion, this disinformation condition suggested terrorism without explicitly pointing to perpetrators or countries involved—leaving it up to recipients to interpret the suggested act of terrorism in a way that fitted their own beliefs.
We followed a similar approach for the disinformation conditions about the alleged peace negotiations between Putin and Zelenskyy. A real news article that discussed the potential of peace negotiations between Russia and Ukraine served as a template: “Ukraine war: What are the chances of a peace deal with Russia to end the conflict?” This article was based on expert knowledge and evidence, and simply stressed the uncertainty surrounding the potential of peace deals—which was based on the best available expert knowledge.
In the disinformation narrative, the false claim that the political leaders are closing in on a peace agreement was put forward. The article stated that “A peace deal with Russia to end the conflict is in the making.” As there was no support for this claim, and as the article falsely claims that the two leaders were recently seen together sitting down in one room to discuss the final terms of the peace deal, we consider it disinformation. The visual disinformation conditions were created in a similar way as the disinformation on flight MH370. In the still image condition, a AI-generated fabricated image showing Putin and Zelenskyy shaking hands was used. In the decontextualized video, actual footage of Putin and Zelenskyy being in one room for other peace negotiations was used. However, this footage came from peace negotiations before the 2022 invasion, and thus represents the deceptive use of videos as evidence.
To design the fact-checking conditions, we based ourselves on earlier experimental set-ups that have pointed to the positive effects of corrective information (e.g. Nyhan et al., 2019) as well as existing fact-checking interventions. The stimuli can be found in Supplemental Appendix A. We did not include explicit source cues to avoid a priming effect. The articles were presented as short online messages on a news website with different categories (i.e. United States, World, Politics, Business, and Opinion).
It can be noted that the visual disinformation conditions also had an important textual element. The design of the stimuli was informed by content analyses of visual disinformation (Brennen et al., 2021; Hameleers, 2025) indicating that, especially in the context of decontextualization, visual disinformation narratives consist of a more encompassing storyline beyond the visual alone. Hence, although authentic visuals are used in the case of decontextualization, they become part of a disinformation narrative when they are falsely interpreted as evidence for an event that did not take place, as is the case in our experimental stimuli.
Measures
The perceived credibility of the (dis)information was measured with two separate scales for the two issues. All individual items were similar and measured on a scale from 1 (completely disagree) to 7 (completely agree). We used seven items, which we based on extant disinformation research assessing the perceived truth value and accuracy of manipulated information (e.g. Schaewitz et al., 2020). Items included “the message tried to mislead me” (reverse-coded), “The message reflects reality,” “The message reflects the truth about MH370/the war in Ukraine,” “The message is completely made up (reverse-coded), “The message contains factual inaccuracies (reverse-coded), “The message is fabricated” (reverse-coded) and “The message is credible” (average credibility of messages on the war in Ukraine: M = 3.26, SD = 1.23, Cronbach’s alpha = .81; average credibility of messages on MH370: M = 3.61, SD = 1.20, Cronbach’s alpha = .80). The statements generally aimed to assess the extent to which participants believed that the disinformation was credible, trustworthy, not deceptive, and reflexive of truth. Credibility, as such, was operationalized as the perceived truth value and honesty of the messages.
For engagement, we relied on six statements tapping the extent to which participants would be willing to engage in information-seeking or engagement related to the information presented (all measured on a scale from 1 = not willing at all to 7 = definitely willing to do that). Basing ourselves on other studies that mapped engagement with deceptive forms of political information, we used statements such as “share the articles on social media” “talking to family, friends, or acquaintances about the articles” (average engagement intentions for messages on the war in Ukraine: M = 3.43, SD = 1.67, Cronbach’s alpha = .87; average engagement intentions for messages on the MH370: M = 3.56, SD = 1.62, Cronbach’s alpha = .86).
To measure emotional responses, we rely on a battery of discrete emotions and ask people to reflect on the extent to which they experienced these emotions when reading the different articles (anger, sadness, disappointment, hope, fear, frustration, powerlessness, and pride, also see Powell et al., 2018). On a 7-point scale (not at all, very strongly), the average level of elicited emotional responses for the messages on the war in Ukraine was 3.56 (SD = 1.54, Cronbach’s alpha = .90). The mean was 3.67 for the messages on the MH370 (SD = 1.41, Cronbach’s alpha = .88). As robustness checks, we also re-ran the analyses for the emotional responses separately, and for the sub-set of items only including the negative emotions. The results were similar for these alternative re-configurations, which is why we report on the outcomes of aggregated emotional responses in the remainder of this article.
Media distrust was measured using a battery of items tapping people’s evaluations of the news media’s performances and expectations (see, for example, Fawzi et al., 2021; Strömbäck et al., 2020). We used reverse-coded statements as we aimed to measure distrust in the media (also see Engelke et al., 2019). Items include “The news media are an unreliable source of factual information” and “The news media give a distorted picture of reality” (M = 4.59, SD = 1.55, Cronbach’s alpha = .91).
For the measurement of conspiracy mentality, we rely on a shortened battery of existing validated scales that measure the individual-level tendency to support conspiracist worldviews (see Bruder et al., 2013). We included six statements (measured on 7-point scales, where 1 = completely disagree and 7 = completely agree), such as “A few powerful groups of people determine the destiny of millions” and “Most people do not see how much our lives are determined by plots hatched in secret” (M = 4.81, SD = 1.40, Cronbach’s alpha = .84).
Finally, we used a battery of items to assess participants’ self-perceived level of media literacy (also see Vraga et al., 2015). The statements (again measured on 7-point scales, where 1 = completely disagree and 7 = completely agree) include items such as “I always look critically at how the media get their facts and sources” and “I am able to distinguish truth from fiction and lies” (M = 5.15, SD = 1.12, Cronbach’s alpha = .89).
Procedures
Supplemental Appendix C details the procedures of the experiment and outcomes of the manipulation checks. In the survey, participants were exposed to two stimuli presented as news articles in a random order in the online environment of Qualtrics. Importantly, to avoid effects of exposure to the stimuli on moderating variables, we measured conspiracy reasoning, media trust, and media literacy prior to exposure to the stimuli. Although such questions may prime the processing of stimuli, the random assignment to conditions assures that this effect is controlled for in the design—especially given that post hoc randomization checks ensured that the scores on these variables are equally distributed across conditions. We also included distracting questions between exposure to the stimuli and the measurement of moderators.
After exposure to the stimuli, all participants rated the credibility, emotionality, and intentions to engage with the content. Manipulation checks were included at the end of the survey. The findings indicate that participants successfully recalled the manipulations and the content they were exposed to in the different disinformation conditions. Participants were extensively debriefed at the end of the study.
Results
The direct effects of exposure to visual disinformation
The first aim formalized under the hypotheses was to assess whether visual disinformation (AI-generated images or video-based decontextualization) would yield higher levels of credibility, emotions, and engagement compared to textual disinformation. To test Hypotheses 1–3, we used mean score comparisons (ANOVAs and corrected pairwise t-tests). The results are depicted in Figures 1 to 3 (MH370) and Figures 4 to 6 (war in Ukraine). For the issue of the MH370, our findings offer no support for H1: There are no significant differences in the perceived credibility, emotional responses, or engagement in response to text-based versus image-based or video-based disinformation. We do, however, see that all disinformation messages were perceived as significantly less credible than the control condition, F(606) = 6.69, p < 0.001, LSD post hoc analysis showed significant difference across groups on 95% family-wise confidence level. In light of RQ1, for the issue of flight MH370, it can also be concluded that there are no differences across the different forms of visual disinformation when it comes to credibility, post-test F(606) = 6.69, p < 0.001: mean difference still image (M = 3.57) versus video (M = 3.75) = −.18 [−.56; .21], p = .64. Visual disinformation, both as still images and video-based decontextualization, does not have persuasive advantages over text-based disinformation.
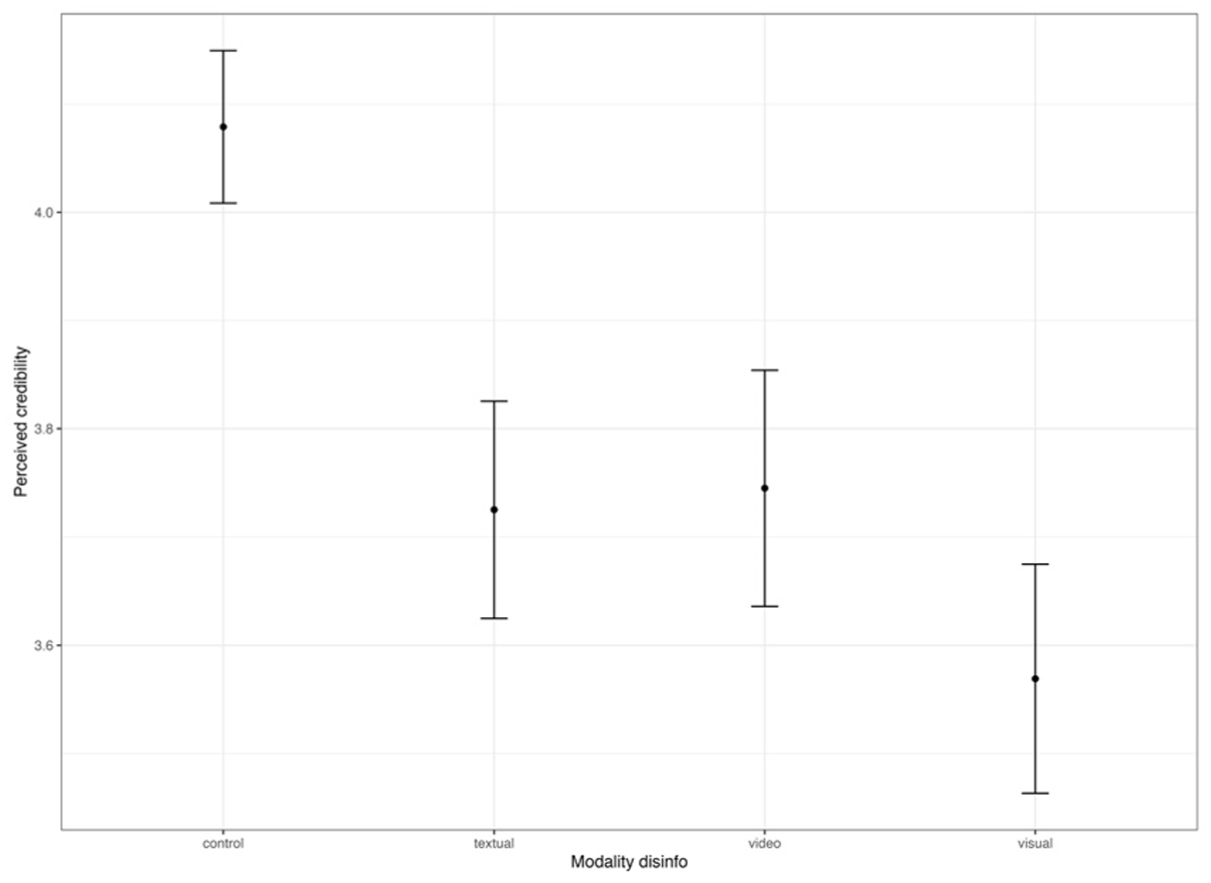
Perceived credibility of disinformation across conditions, topic MH370.
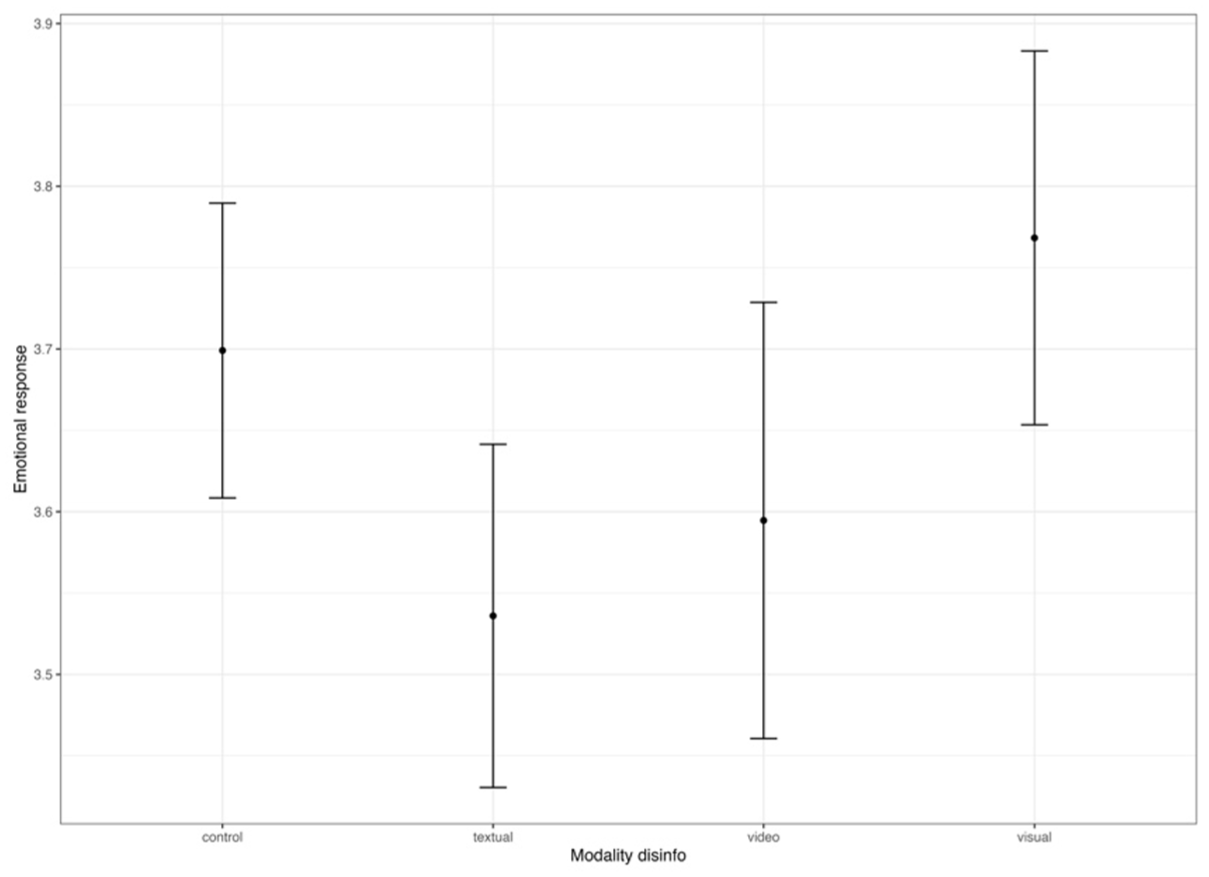
Emotional responses of disinformation across conditions, topic MH370.
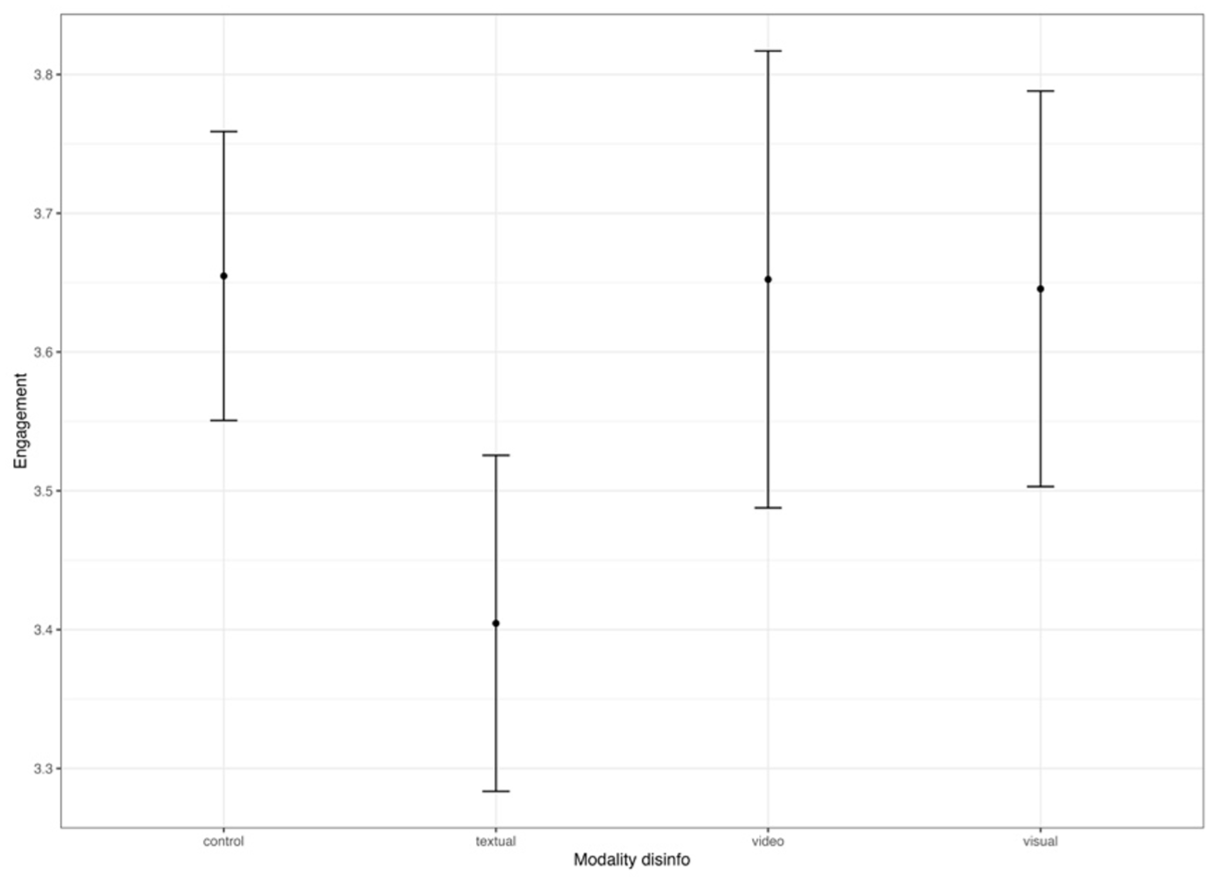
Engagement with disinformation across conditions, topic MH370.
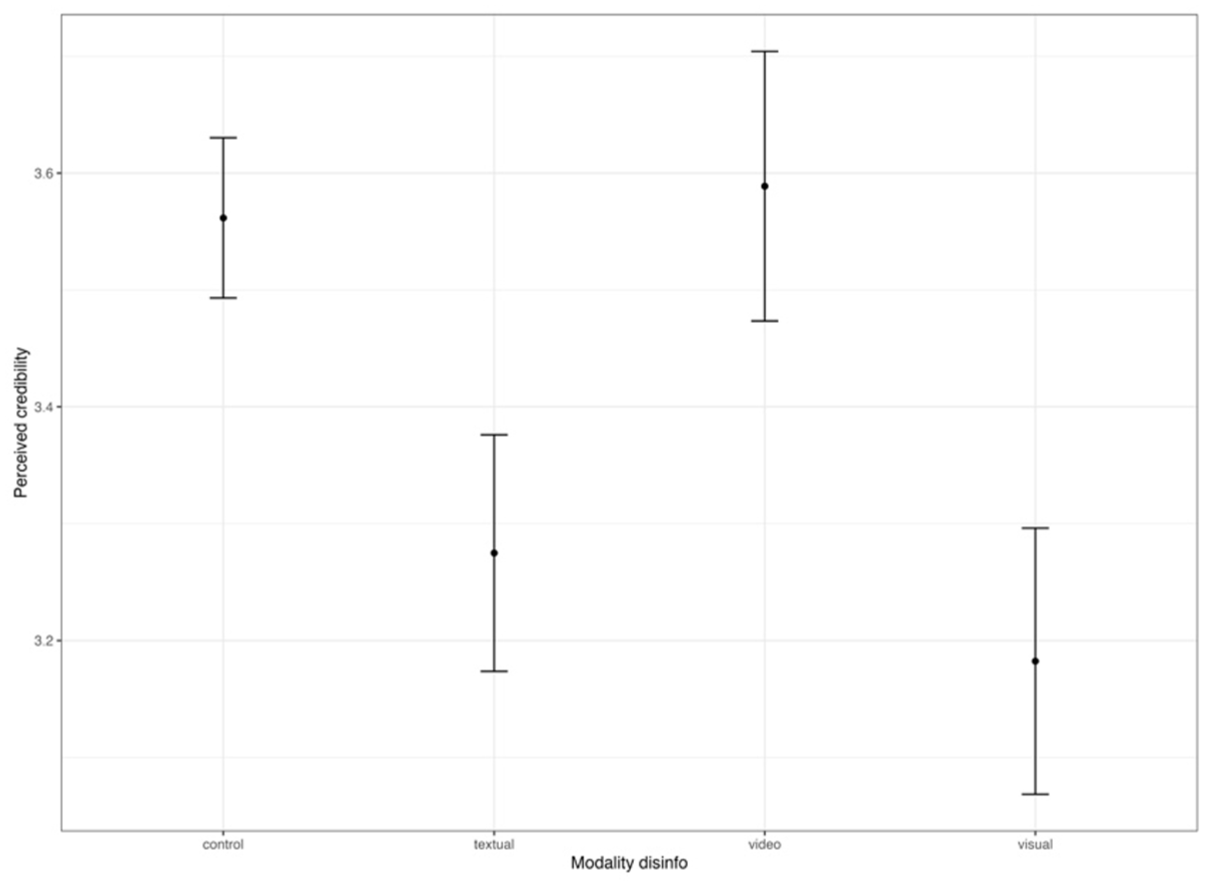
Perceived credibility of disinformation across conditions, topic war Ukraine.
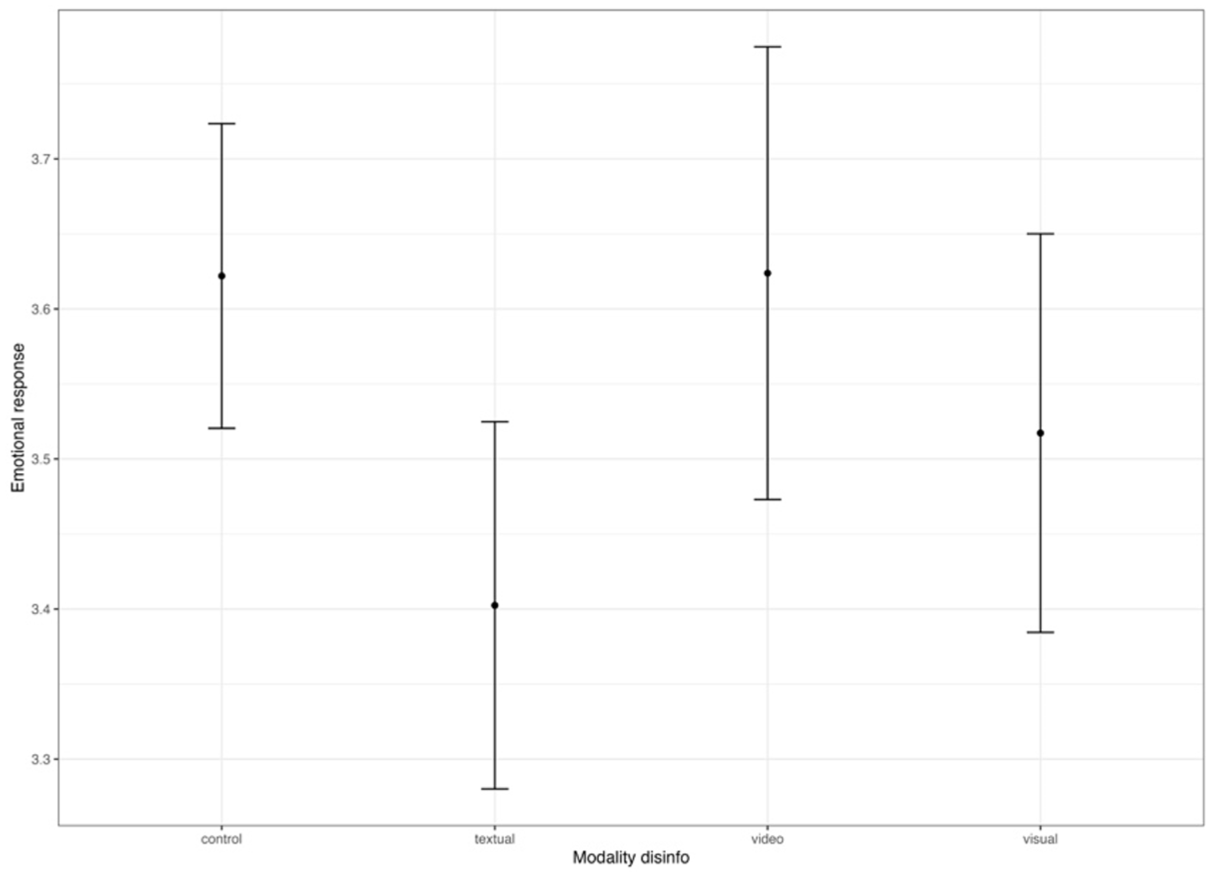
Emotional responses of disinformation across conditions, topic war Ukraine.
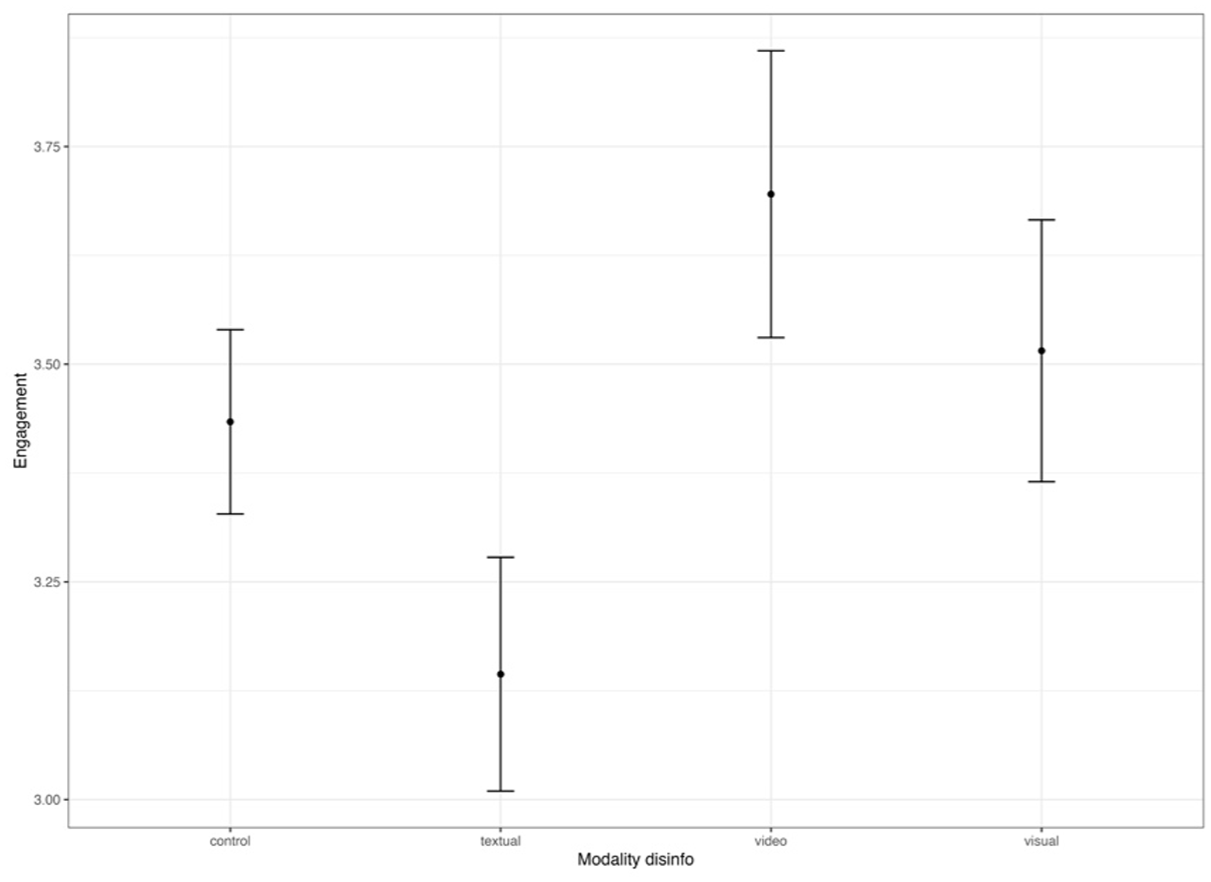
Engagement with disinformation across conditions, topic war Ukraine.
Looking at the effects of disinformation on the war in Ukraine, our findings lend more support for H1: F(606) = 4.42, p < 0.001. Post hoc analyses using LSD post hoc tests show that, compared to text-based (p < .05) and visual disinformation (p < .05), a video-based disinformation narrative yields higher levels of perceived credibility than text (RQ1): post-test, F(606) = 4.42, p < 0.001: Mean difference still image (M = 3.18) versus video (M = 3.59) = −.41 [−.08; −.01], p = .04.
As demonstrated in Figure 5, our findings lend no support for H2. In contrast to the expectations of the second hypothesis, and irrespective of the issue, image-based or video-based disinformation yields similar emotional responses as text-based disinformation. However, again only for disinformation related to the war in Ukraine, we find some support for H3: F(606) = 2.36, p < .001. For RQ1, this means that there are no differences across still images and video disinformation for both the issue of MH 370, F(606) = 1.42, p = .50, difference still image (M = 3.77) and video (M = 3.60): .17, [−.29; .61], p = .76, and the war in Ukraine, F(606) = 1.62, p = .55, difference visual (M = 3.51) and video (M = 3.62): −.11, [−.63; .41], p = .95.
In line with the third hypothesis predicting higher engagement with visual compared to textual disinformation, the subsequent pairwise main score comparison using the LSD post hoc test shows that video-based disinformation yields higher levels of engagement with disinformation than deceptive information based on text (p < .01). The difference between textual and visual disinformation is only marginally significant (p < .10). This also sheds light on RQ1: for the war in Ukraine, video-based disinformation yields no stronger effects than image-based disinformation, F(606) = 1.62, p = .55; mean difference still image (M = 3.51) and video (M = 3.69): −.17, [−.74; .38], p = .84. For the issue of MH370, no differences are observed, F(606) = 1.62, p = .55, mean difference still image (M = 3.65) and video (M = 3.65): −.00, [−.56; .53], p = 1.00.
The moderating role of distrust, conspiracy mindsets and media literacy
Beyond the main effects, we hypothesized that disinformation’s effects would be moderated by media distrust (H4) (see Supplemental Appendix B1), conspiracist mentality (H5) (see Supplemental Appendix B2), and self-perceived media literacy (H6), so that lower levels of trust and literacy, and higher conspiracy mentalities, would yield stronger effects of visual disinformation (see Supplemental Appendix B3). We tested these moderated effects with OLS-regression models. For disinformation on the MH370, we only find a significant two-way interaction effect between media distrust and exposure to textual and video disinformation on its perceived credibility (Supplemental Appendix B1, Model 2): textual and video disinformation are seen more credible for participants with higher levels of distrust in the media. For RQ2, this means that for the effect on credibility, the moderating variables media distrust (MH370: video, b = .16, p < .10, still image, b = .08, n.s., and textual modality, b = .19, p < .05) played only a bigger role in the effect of textual disinformation condition (Wald coefficient comparison test: p < .10) and not in the comparison between textual and video disinformation (Wald coefficient comparison test: n.s.). All future Wald coefficient comparison tests turned back insignificant for the other dependent variables across both issues.
Our findings further indicate that for the issue of flight MH370, the effects of disinformation on credibility were strongest for participants with more pronounced conspiracist mentalities (Supplemental Appendix B2, Model 2), which supports H5a. The patterns are similar across the different modalities. The two-way interaction effects between disinformation exposure and conspiracy mentalities were, however, not found for emotional responses (H5b) or engagement (H5c). Thus, conspiracy mentalities generally did not moderate the effects of disinformation on credibility (Supplemental Appendix B2, Model 8) or engagement (Supplemental Appendix B2, Model 12) in the context of this issue. Regarding RQ2, Wald coefficient comparison tests did not yield significant differences between the interaction with textual compared to video or still image disinformation across both issues and all three dependent variables (despite some differences in significance across effect sizes).
As can be seen in Supplemental Appendix B3, our findings generally do not lend support for H6: For disinformation on both the MH370 and the war in Ukraine, participants with higher levels of self-perceived media literacy were not affected differently by disinformation exposure. There was one exception in line with the predictions postulated under H6: The higher participants’ self-perceived media literacy, the less they engaged with textual disinformation on the MH370 (versus accurate information presented in the control condition) (Supplemental Appendix B3, Model 6). Regarding RQ3, only for the issue of flight MH370 and the dependent variable engagement, we find a stronger interaction effect between media literacy with textual disinformation (b = −.24) versus video (b = .17; Wald coefficient comparison test = p < .01) and still-image-based disinformation (b = .10; Wald coefficient comparison test = p < .06). Wald coefficient comparison tests did not show any other differences in effect sizes of the moderation with media literacy across both issues and other dependent variables. Together, we find only few differences in effects for textual disinformation in comparison with video-based decontextualized disinformation and disinformation based on AI-generated still images.
Can fact-checks adequately correct visual disinformation?
We finally postulated that exposure to a fact-check article lowers the perceived credibility of disinformation (H7). Our findings lend support for this hypothesis (see Figure 7). For both issues, ANOVA analyses, issue MH370: F(736) = 5.58, p < 0.001; issue war Ukraine: F(736) = 4.43, p < 0.001, showed that exposure to a fact-check article debunking the claims of the disinformation article significantly lowered the credibility of disinformation (MH370: F = 24.12, p < 0.001; war in Ukraine: F = 15.97, p < 0.001). The modality of the disinformation did, however, not play any role in the effects of fact-checking information (interaction terms: MH370: F = 0.01, n.s.; war Ukraine: F = 1.07, n.s.).
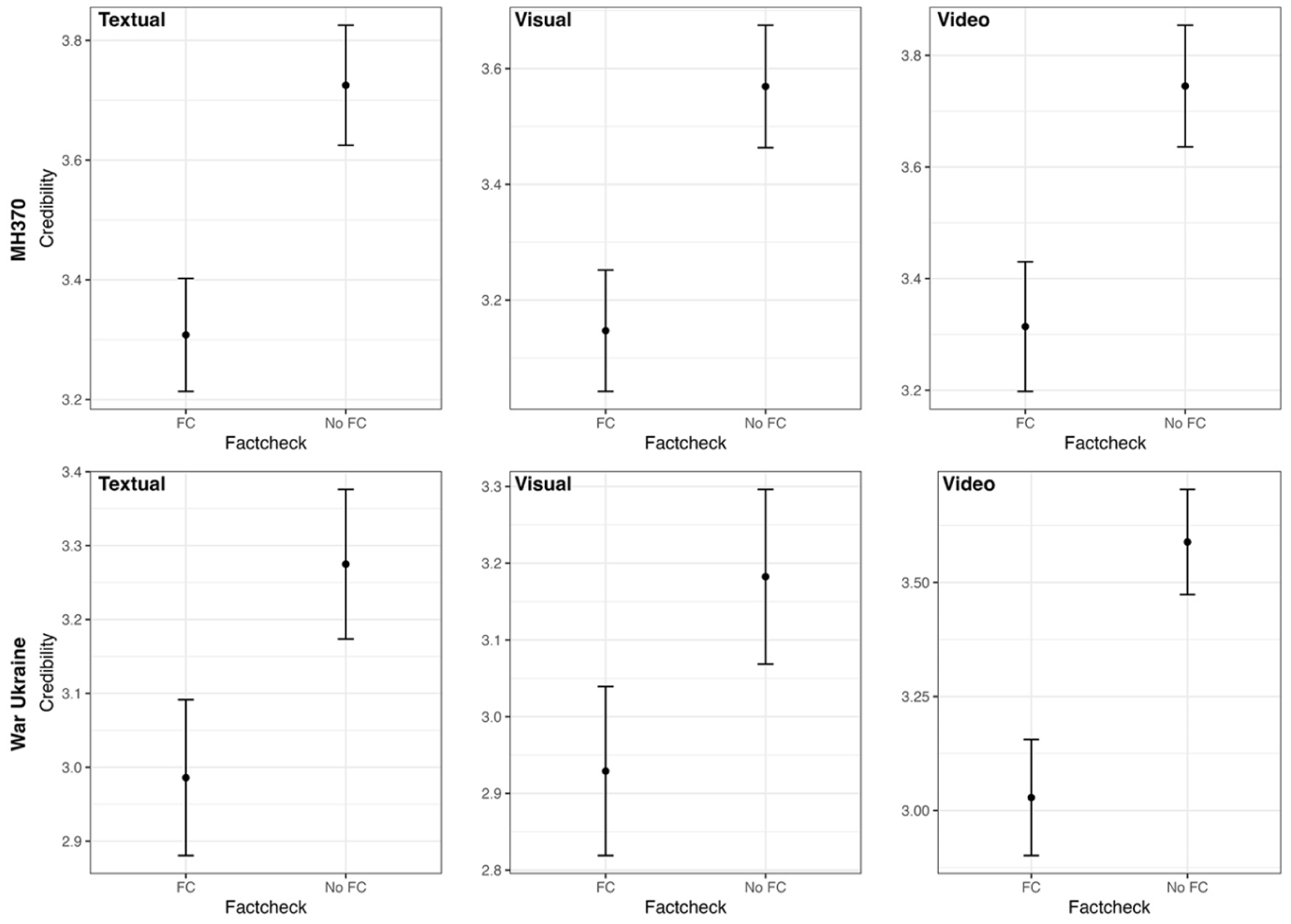
Credibility rating after exposure to fact-check message across conditions.
Exploratory analyses
Although we did not pre-register any hypotheses on the moderating role of prior political beliefs related to the two issues, it can be argued that one’s existing political beliefs influence their reception of disinformation. As additional exploratory analyses, we therefore investigated whether exposure to disinformation yielded different effects on (a) credibility, (b) emotions and (c) engagement for people with different beliefs on the issues and ideological self-placements. We rely on three moderators; ideological self-placement—10-point Likert-type scale, self-placement ranging from left to right (M = 5.89, SD = 2.75); partisan perceptions about the war in Ukraine (M = 3.78, SD = 1.46, Cronbach’s alpha = .79) and terrorist attacks as a proxy for issue attitudes congruent with the MH370 message (M = 4.05, SD = 1.68, Cronbach’s alpha = .72).
Supplemental Appendix D shows that right-leaning participants are less likely to respond emotionally to a disinformation video on MH370 (Model 4) or engage with textual disinformation for this issue (Models 6 and 12). They are also less likely to believe textual disinformation about a ceasefire for the war in Ukraine (Model 8) and less likely to engage with it (Model 12). Next, Supplemental Appendix E shows that participants with stronger issue-specific partisan beliefs are more likely to perceive disinformation as more credible (Models 2 and 8). In addition, for the MH370 case, those with stronger beliefs are less likely to engage with textual disinformation (Model 6).
Discussion
In line with previous experimental studies, our findings indicate that visual disinformation is not universally perceived as more credible or believable than textual disinformation (e.g. Barari et al., 2025; Dobber et al., 2020; Vaccari and Chadwick, 2020). Yet, the findings depend on the topic: Only video-based disinformation on the war in Ukraine was more credible and yielded more engagement than textual disinformation. This also sheds light on the comparison between two different modes of visual disinformation distinguished in the experiment: Video-based decontextualized disinformation is more credible and engaging than still images for the issue of the war in Ukraine. Arguably, the issue of the disappearance of flight MH370 was surrounded by a less polarized political debate at the time of data collection in December 2023, and there was less available information present in people’s newsfeeds. Thus, visual disinformation may exert stronger effects for highly salient issues compared to issues that are less representative of the dominant media and political agenda.
Another explanation for why video-based decontextualization outperformed text in the context of the war in Ukraine is the wide availability of directly relevant existing footage closely connected to the statements of the disinformation message. Concretely, there was a lot of real video footage available that depicted the world leaders together, which allowed for the plausible decontextualization of an old video that directly corresponded with the disinformation narrative. For the MH370 disaster, such evidence was less widely available, and the visual disinformation narratives consequentially offered a less direct representation of the counter-factual claim that the MH370 was shot down based on a terrorist attack.
Another major difference between both issues was related to the moderating role of participants’ pre-treatment conspiracy mindsets. Only for disinformation related to the disappearance of MH370, conspiracy mindsets contributed to stronger effects of disinformation on credibility perceptions. We can explain this finding in the context of the epistemic discussions surrounding the different issues. Although, around December 2023, fragmented factual evidence on flight MH370 was available, the mystery surrounding the causes of the disaster created a discursive opportunity for conspiracies to thrive. Thus, in the context of the uncertainty surrounding evidence-based explanations of the disappearance, alternative narratives abounded. In this setting, disinformation may in particular offer a credible interpretation of reality for people inclined to support conspiracies (e.g. Frischlich et al., 2021).
Our findings finally support research indicating that fact-checking can be effective in lowering the credibility of disinformation (e.g. Walter et al., 2020). Extending existing work on fact-checking, we show that corrective information is equally credible across the three modalities distinguished in this study. As such, although there are strong concerns about the effects of visual disinformation based on the realism heuristic it offers (e.g. Sundar et al., 2021), we show that factual misperceptions can be corrected to a similar degree across textual disinformation, video-based re-contextualization and the AI-driven generation of fake images.
As a practical recommendation, our findings suggest that fact-checkers and journalists do not have to rely on substantially different tools to correct disinformation across modalities. Yet, as we implemented in the design of our experiment, it is important to explicate how deceptive visuals deviate from the original footage and empirical reality. Concretely, we suggest corrections of visual disinformation to (1) reveal what techniques were used to create, doctor, re-interpret or alter original footage and images; (2) how the context of visuals can be used to deceptively re-interpret reality in line with the political aims of the senders. This may stimulate a more critical understanding of the (mis)use of visuals in disinformation beyond the facticity of the statements or visuals outside of their context.
This study has some noteworthy limitations that can be addressed in future research. First of all, although our experiment aimed to incorporate a variety of visual disinformation types as identified in extant literature (Weikmann and Lecheler, 2023), we did not focus on the effects of AI-generated videos, or decontextualized still images. We omitted AI-generated videos as they were relatively rare at the time of data collection (e.g. Yang et al., 2023), and omitted image-based decontextualization as the nature of such visual disinformation, as well as its application and uses, is very similar to video-based decontextualization (Hameleers, 2025). Hence, for both videos and still images, the main purpose of contextualization is to use authentic visual information as “evidence” for something that never happened (e.g. Brennen et al., 2021).
Second, we contrasted two issues that differ on many factors, such as the salience in public debate, and the level of polarization and partisanship reflective in the discourses surrounding the issues. To assess the robustness and transferability of our findings, we suggest future research to rely on less polarized and politicized issues (i.e. in celebrity news and health care), and also compare the effects of visual disinformation across different national settings. In addition, we suggest to strengthen generalizability by comparing disinformation narratives that are inherently political and reflexive of socio-political disputes, such as immigration, climate change, and the economic redistribution of resources.
Third, the external validity of the experimental findings is limited as we only measured short-term effects of exposure to a single stimulus. In real life, people may come across multiple (visual) disinformation messages that may affect them both immediately and on a longer-term. Although some responses that we measured, such as willingness to engage with the message, may also stem from direct exposure in reality, emotions and credibility may also be affected by delayed or repeated exposure to disinformation stimuli. As extant research suggests that the effects of deepfakes on credibility are not likely to persist over time (Hameleers et al., 2024), it can be argued that effects mainly happen on the short-term. Although it is a limitation of our design, it can be suggested that the fast-paced and fragmented nature of digital information ecologies offer a context for the short-term cultivation of direct responses to stimuli, for example, by sharing a disinformation message directly to boost its virality.
Conclusion
Our main findings demonstrate that the effectiveness of using visual disinformation in the form of deceptive re-contextualization is contingent upon the availability of credible footage that can be used as “evidence” for deceptive claims (also see, for example, Brennen et al., 2021). The central take-away point is that video-based disinformation can be more credible and engaging than textual or still-image based disinformation, but this depends on the extent to which existing footage can plausibly be recontextualized to function as direct proof for disinformed claims on reality. This finding shows that concerns on the alleged unprecedented impact of generative AI in disinformation are potentially overrated, and leave a blind spot for forms of disinformation that are more prevalent and easier to create.
Supplemental Material
sj-docx-1-nms-10.1177_14614448251409208 – Supplemental material for Beyond textual disinformation: Comparing the effects of textual disinformation to AI-generated and video-based visual disinformation across different issues
Supplemental material, sj-docx-1-nms-10.1177_14614448251409208 for Beyond textual disinformation: Comparing the effects of textual disinformation to AI-generated and video-based visual disinformation across different issues by Michael Hameleers and Toni van der Meer in New Media & Society
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.