
Abstract
Qualitative interviews are increasingly being utilized within the context of intervention trials. While there is emerging assistance for conducting and reporting qualitative analysis, there are limited practical resources available for researchers engaging in a group coding process and interested in ensuring adequate Intercoder Reliability (ICR); the amount of agreement between two or more coders for the codes applied to qualitative text. Assessing the reliability of the coding helps establish the credibility of qualitative findings. We discuss our experience calculating ICR in the context of a behavioural HIV prevention trial for young women in South Africa which involves multiple rounds of longitudinal qualitative data collection. We document the steps that we took to improve ICR in this study, the challenges to improving ICR, and the value of the process to qualitative data analysis. As a result, we provide guidelines for other researchers to consider as they embark on large qualitative projects.
Qualitative content analysis has become increasingly popular in public health and other health-related fields. The large number of participants in qualitative studies and demands on researchers’ time means that few individuals are able to complete coding their dataset alone, and it is common for teams of coders to work together on data sets. When coding is conducted by a team of researchers, it is vital that the allocation of text segments to different codes is consistent between texts and coders (Burla et al., 2008). To assess the consistency of coding among multiple coders, one method is to calculate the amount of agreement between coders with a measure of Intercoder Reliability (ICR). A high level of ICR demonstrates that the coding is both reliable and replicable, which therefore strengthens evidence that the results of a qualitative study are scientifically valid (Kurasaki, 2000).
Although current qualitative publication guidelines suggest including information on the number of researchers engaged in coding for analysis of qualitative data, they fail to indicate the importance of documenting ICR (Tong et al., 2007). Reporting on ICR is infrequently included in published qualitative studies when there are teams of coders; attention has been drawn in both communication studies (Lombard et al., 2002) and sociology (Campbell et al., 2013) to a lack of reporting about ICR. We suggest that the same is true of published qualitative research in the public health and health communication fields, where reporting of ICR is infrequent. As a result, there are few existing practical guidelines for multiple coders working on a single project on how to calculate and report ICR. Recent publications in other fields have explicitly called on researchers to add insights on ICR to the literature (Campbell et al., 2013).
Using ICR in qualitative studies
ICR is a measure to assess the agreement among multiple coders for how they assign codes to text segments; it also evaluates the extent to which these coders make similar coding decisions in assessing the characteristics of text (Kurasaki, 2000; Lombard et al., 2002). This is important as systematically different patterns of coding might result in substantial bias in research results. The calculation of ICR has other benefits, including increasing the comprehensibility of analysis and providing sound interpretation of data. Additionally, ICR is also useful for identifying weaknesses such as imprecise code definitions or overlapping meaning in the coding scheme, as well as adjusting and improving the training of coders (Burla et al., 2008).
A number of statistical calculations can be used for reporting on ICR as a measure of coding agreement (for additional information see Artstein and Poesio, 2008). Existing ICR guidelines suggest that using a simple percentage of agreement is not sufficient. Percentage agreement consistently over-estimates agreement because there is no allowance for agreement as a result of chance (Hruschka et al., 2004). Alternative measures that can accommodate chance include Cohen’s kappa (Cohen, 1960), and Krippendorff’s alpha (Krippendorff, 2004). Krippendorf’s alpha is better able to correct for chance and is equipped to handle multiple coders (Hayes and Krippendorff, 2007), but is computationally and conceptually difficult. The key difference between Cohen’s kappa and Krippendroff’s alpha is that alpha measures observed and expected disagreement, rather than agreement (Artstein and Poesio, 2008). Cohen’s kappa is less computationally complex and typically produces values that are nearly identical to alpha in smaller samples (Gwet, 2012). Therefore, we chose Cohen’s kappa to measure reliability among our team of coders.
Cohen’s kappa attempts to measure agreement between two coders accounting for their chance agreement. Thus, the calculation specifies how much agreement we would expect by chance, how much agreement over and above chance was achieved and computes the ratio of these values to find how much agreement was actually observed over and above what would be expected by chance. The formula for this is expressed as follows:

where Ao is the observed difference and Ae is the amount of agreement expected by chance.
Cohen’s kappa has a value from -1 to 1: a value of 0 depicts purely incidental agreement; values below 0 indicate agreement worse than chance; a value between 0 and 1 indicates some degree of agreement. The closer the score is to 1 the better the agreement which has been reached; however, a conclusive criterion for a kappa value that denotes sufficient agreement remains elusive. Burla et al. (2008) note that kappa values of 0.40–0.60 are considered satisfactory agreement and values above 0.80 suggest perfect agreement. In contrast, Lombard et al. (2002) maintain that 0.90 is acceptable, despite values over 0.70 being consistently used in exploratory research. In reality, achieving kappa of 0.90 by a single coder over multiple days might be challenging. Guidelines for reliability of coding data in HIV behavioural research propose using ⩾0.80–0.90 as a target, although acknowledge that this level of agreement is high because it presupposes the need for clinical significance in treatment decision making. This might not necessarily be required for studies other than those assigning treatment or making clinical diagnoses (Hruschka et al., 2004).
We report here on our experience of conducting ICR on the qualitative component of a large ongoing randomized controlled trial of a behavioural HIV prevention intervention. The study aims to target structural drivers of HIV risk (in this case, poverty and education) through assessing the efficacy of providing a cash transfer conditional on school attendance to young South African women and their families. Although the main study outcome is HIV incident infection, we will also assess the impact on herpes simplex virus type 2 (HSV-2), sexual behaviour, and school attendance. Understanding the social implications of providing adolescent girls with access to cash in contexts of poverty is of particular significance to the qualitative researchers on the study. The study is currently underway but details about planned activities are available elsewhere (MacPhail et al., 2013). As well as collecting quantitative survey data from 2,500 young women, the study allocated a sub-set of young women (n = 30) to participate in multiple rounds of longitudinal qualitative data collection through individual interviews and household interviews with family members (n = 30) of the young women. The aim of the current paper is to describe the process of conducting group coding, provide practical guidelines for managing the group coding process and working towards acceptable levels of ICR in qualitative studies.
A working method for calculating ICR with multiple coders
As a qualitative team, we had relatively little experience in working with multiple coders; in the past, the scope of our work had been small enough for a single coder or we had not specifically examined the issue of ICR (much like many other qualitative researchers). In this instance, the qualitative component of the study was led by one of the main study principal investigators (PI) with many years of experience in qualitative data collection and analysis (CM). The coding process was undertaken by a postgraduate qualitative data manager (NK), who was responsible for managing the qualitative fieldwork team, and a PhD student engaged with the study data (MR). At a later stage in the study, when the volume of data increased, an additional postgraduate-level coder was added to the team. The team was dispersed across three continents during the coding process. The process we outline here was one that we developed over time as we worked with the data. The emphasis here is on process. While the original impetus for calculating ICR was to generate a kappa score that could be included in final publications submitted to journals with a more biomedical (and therefore quantitative) focus, we were also driven by a desire to improve our methodological skills and increase the validity of the findings we were generating. During the early part of the study we also recognized the value of the process of working to increase ICR.
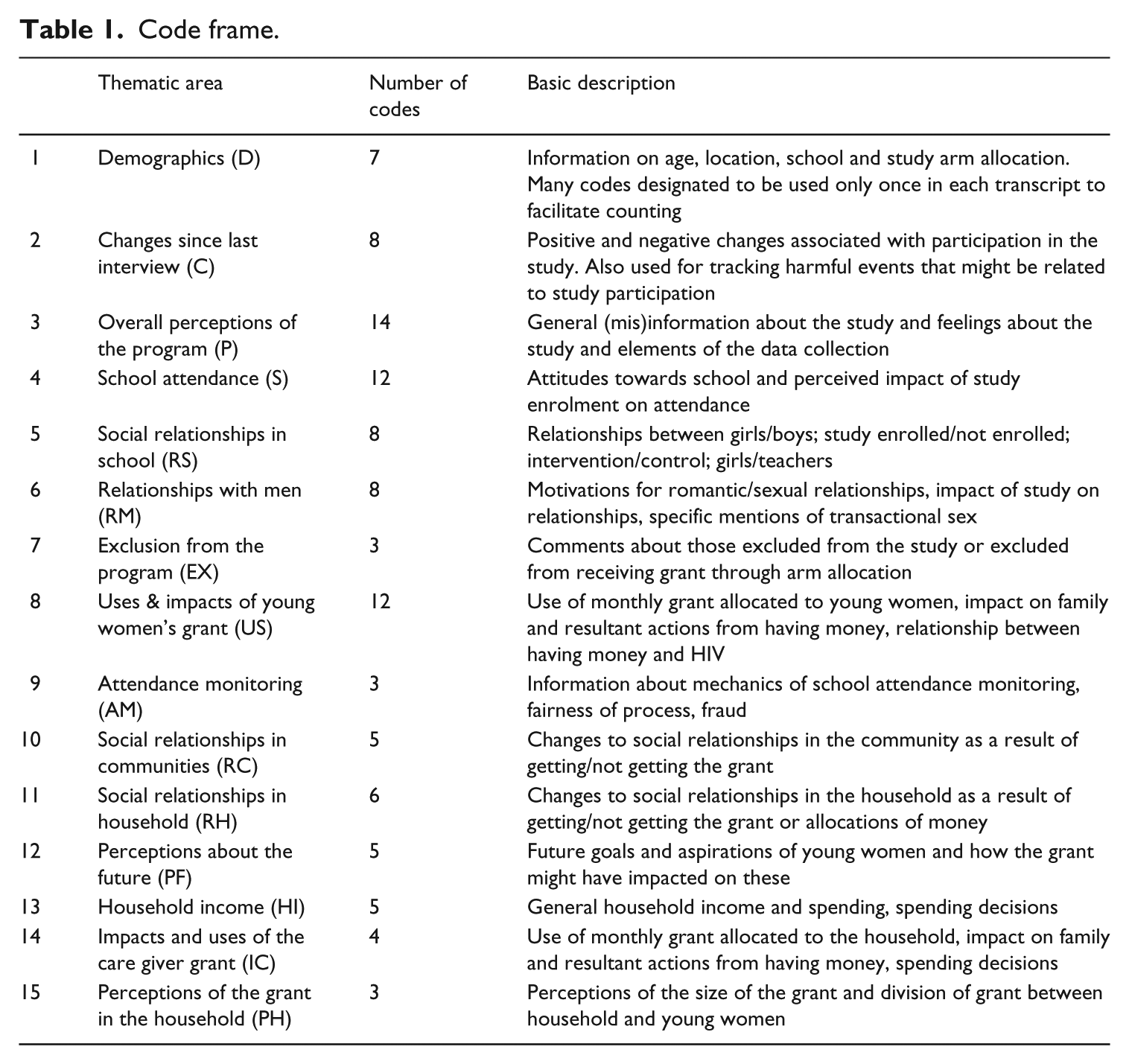
Code frame
The code frame was generated by two researchers working on the study (CM & NK). To begin, it was constructed deductively, using a framework analysis methodology (Pope et al., 2000) based on the topic guides being used to gather the data. A further inductive stage was completed in which the researchers added additional codes based on reading the initial transcripts and identifying unexpected issues and topics that had emerged during data collection. The final code frame consisted of 103 individual codes located across 15 main thematic or interest areas. For example, the main thematic area ‘Household Income’ contained nine codes which categorized information about money in the household as: different sources of income; who spends money in the household; items income spent on; who makes spending decisions; what money is given to children; household spending conditional cash transfer (CCT) money; who controls CCT money; spending CCT money vs other; and spending CCT money vs Child Support Grant money. The 103 codes is a significant number of codes, particularly when calculating ICR, given that current recommendations suggest using no more than 40 codes (Hruschka et al., 2004; MacQueen et al., 1998); however, when we developed the code frame, we were not aware of recommendations for number of codes when calculating ICR. Additionally, the complexity of the issues being investigated in the study justified the inclusion of such a large number of codes. Once finalized, the code strategy in this study allowed for no changes to the code frame by individual coders; however, provision was made for adding codes. Each of the 15 thematic areas contained a ‘catch all’ code in which coders were able to include data quotations 1 they felt were important, and fit into a specific theme, but could not be allocated to an existing code. These quotations were discussed by the team and the qualitative data manager and PI decided how to allocate the quotations to existing codes or to develop new codes. As the longitudinal data collection progresses, a further three codes have been added to the frame to date (see Table 1) and we expect that some further codes will be added.
Code frame.
Coding process
All transcripts were imported into Atlas.ti version 7.0 by a single researcher and allocated out to the coders, who are located in two different countries. Coders worked independently on the same transcript. While codes are usually mutually exclusive in content analysis, in our study we encouraged allocating text segments to multiple codes to ensure that the complexity of the data was properly accounted for. As noted by other researchers collecting semi-structured interviews, responses to a single question in this type of data tend to be open-ended and cover more than one topic, making the use of several simultaneous codes both appropriate and necessary for capturing complex and numerous ideas (Campbell et al., 2013).
The same authors discuss some of the challenges associated with determining the units of analysis to which codes are applied in qualitative analysis. Campbell et al. (2013) highlight that in terms of calculating coder agreement and reliability, the easiest solution is to work with clearly demarcated segments of the text, such as sentences or paragraphs. This strategy is, however, problematic from an analytical perspective as it removes text from its context and might alter the meaning intended by the participant. Using ‘units of meaning’ therefore makes more sense from the perspective of investigating the meaning of a participant’s data. Like Campbell et al., we focused our coding on ‘units of meaning’ despite the challenges that this would generate for calculating ICR. However, we also created rules to guide the unit of analysis by size. These stipulated that: all text had to be coded; the unit of analysis could not be smaller than a complete paragraph; and, that the interviewer question should always be included in the quotation assigned as a single unit of analysis. Coders still had the freedom to allocate multiple paragraphs to a single code and create units of analysis of any size as long as each coded segment comprised full paragraphs. While the first of these two rules appear arbitrary, they attempted to deal with concerns about unitization (identifying appropriate block of text for coding) by allowing coders to maintain text units in context, but simultaneously increasing the chances of ensuring reliability by mandating text unit size. Despite these initial parameters, unit of analysis was to be an ongoing challenge for us in achieving acceptable ICR.
There is limited agreement on the sample size to be used in calculating ICR. Suggested sample size ranges from “the selection of three passages to be coded by all coders” to as much as 25 per cent of the total transcripts (Campbell et al., 2013; Lacy and Riffe, 1996). Given the large range of potential suggested sample sizes and that our study collected longitudinal data in multiple rounds of data collection, we decided to calculate ICR on the first 10 transcripts in the first round of data collection as this represented 25 per cent of the first round. If this amount was insufficient to generate acceptable ICR, we were prepared to continue the process with a larger number of transcripts. Thereafter, a 10 per cent sample of transcripts will be coded for the remainder of the study to ensure that ICR remains acceptable as the study progresses (not reported here). We found little evidence of ongoing ICR calculations in the literature, but felt that this was a valuable process to ensure that there was not unintentional drift in the manner in which our coding team applied the codes, particularly since our team was not able to meet in person often. Note that our concerns with sample size here are distinct from the usual concerns with adequate sample size for the purposes of analysis within a study; an issue that will be addressed through consideration of data saturation in the main analysis of this data (Guest et al., 2006).
Calculating ICR
We chose to code each transcript, calculate ICR, discuss feedback, and reach agreement on the coding before moving onto the next transcript. After each coder coded the same transcript as two separate hermeneutic units (HU 2 ; the entirety of the analytic project in Atlas.ti), the two HUs were merged in Atlas.ti (this effectively created a single transcript with two sets of coding) and sent to the study principal investigator who calculated the ICR. After each iteration, the study PI provided detailed feedback, particularly focusing on instances where coded quotations varied widely (indicated by low kappa scores indicating there was neither agreement nor overlap of codes). Initially feedback about codes was likely to be a straightforward ‘wrong’ and ‘right’ (see example in Figure 1). In this instance we worked through the ICR, paying particular attention to codes where there was no overlap between the two coders. We returned to the transcript to discuss which codes were most appropriate and in this instance determined that Coder 2’s coding was wrong because there was a specific code for issues about randomization. In later iterations of the process the discussion became more nuanced as the differences required deep thought about why one code might have been preferred over another. ICR was calculated on all codes in the code frame; in hindsight, it might have been more appropriate to select the specific codes most frequently used in the coding process and to base ICR calculations on these. As the number of codes increases, the likelihood of chance agreement decreases as does the likelihood of real agreement because there are so many codes for coders to choose from and remember. However, given that some element of achieving high ICR relies on familiarity with the code frame, and knowing that once ICR was established we would be working with the full code frame, we continued to assess ICR across all codes.

Example of right and wrong coding.
Unlike other qualitative data analysis programs, Atlas.ti version 7.0 does not currently have an imbedded ICR calculation tool. Rather, users are referred to the Coding Analysis Toolkit (CAT) at http://cat.ucsur.pitt.edu/ which allows for uploading of both raw and Atlas-coded datasets for calculation of ICR (Lu and Shulman, 2008). The site is provided free by the Qualitative Data Analysis Program (QADP) of the Universities of Pittsburgh and Massachusetts Amherst. Other qualitative data analysis programs, such as NVivo, now contain their own ICR calculators. We measured ICR on each transcript using Cohen’s kappa scores; each calculation generated an overall kappa (or ‘true’ kappa score) in which exact agreement was measured and a score reflecting the kappa score when overlapping coding was taken into account. Overlapping kappa scores reflect instances where the two coders allocate the same code to a section of text that overlaps but is not exactly the same size. This decision was based on the fact that we were looking at agreement/disagreement in coding strategy, rather than at more nuanced differences.
Working to improve ICR
This process of improving our kappa scores was not a simple one and included numerous email and telephone communications between the coders and the study PI. After each transcript had been coded separately by the two coders, merged and ICR calculated, the study PI reviewed the original transcripts to examine each code where there was (i) no overlap at all in the text being allocated to specific codes, indicating that the coders were not using the same codes at all, and (ii) where perfect matches appeared to be challenging to achieve as quotation size was variable. This involved working with the merged Atlas.ti HU and the CAT-generated ICR reports to assess whether low ICR could be attributed to system issues, such as textual units of analysis, or to the use of different codes. It was reassuring that in most instances where coders had used different codes, the codes used were from the same thematic code group. This finding was used as the basis for further email and phone discussions and refinement of the code definitions to ensure that all coders were interpreting them in the same manner or merging of codes with definitions that were indistinguishable from one another in practice. Unsurprisingly, codes with limited applications (such as single use codes) and codes dedicated to content were more likely to generate high ICR than codes focused on meaning. Other researchers have chosen to remove such codes from analysis of ICR to limit their influence on calculations of reliability (Campbell et al., 2013); however, we retained all codes in calculations.
Additionally, the coders used all opportunities when they were in the same location to meet and work through transcripts that had already been coded; discussing choices they had made and talking about the code definitions. These discussions ensured that errors relating to different allocations of codes were reduced considerably. Finally, the study PI sought additional information from the CAT developers and from the Atlas.ti forum on challenges encountered during the process.
We documented the ICR scores achieved for our first 10 coded transcripts (see Table 2). Our first attempts at coding generated very poor ICR (overall kappa of 0.02 and 0.16 if overlapping was included). Some of the disagreement, as reflected by the poor kappa, stems from situations in which one coder failed to apply a code that the other coder had used. Burla et al. (2008) indicate that non-assignment of a code by an individual coder is likely to be because of insufficient understanding of the code definition and in which instances the code should be used. Despite having worked through the code frame together in detail, we found that the coders had very different ideas about when to use codes: one coder tended to use very specific codes that captured every nuance of the data, while the other often used a single code that captured a main idea of the quotation (see Figure 2). In this example, the initial segment of the transcripts was coded identically by the two coders. Thereafter, Coder 2 chose C1.1, a very general code about positive changes associated with study participation, across a text unit overlapping with her previous coding. Coder 1 did not overlap codes, but used two codes from the same theme which coded for both sexual behaviour and positive impact on romantic relationships. Coder 2 also used the Impact Risk Behaviour code, but not the Positive Boyfriend Impact code. Despite this initial challenge, once coding had progressed for some time, both coders consistently allocated quotations to the same general group of codes (or theme), if not identical codes.
Kappa scores for 10 iterations of Intercoder Reliability calculation.

The code frame was designed to accommodate both interviews with young women and with their household. This transcript was the first household interview that we coded – this used codes that the team had not previously used and explains the dip in Kappa score.
As there were only minor differences in the allocation of codes between the coders at this point, it is likely that the overall kappa exceeds the overlapping kappa due to how these values were calculated, rather than as a result of better agreement overall compared to overlapping codes.

Example of nuanced versus more general coding.
Additionally, although we had established rules about starting and ending quotations before we started coding, there was considerable variation between the two coders. It became apparent that the study PI and one of the coders were ‘splitters’ – likely to allocate numerous small quotations to a number of relatively specific codes, while the other coder tended more towards ‘chunking’ large sections of text and allocating these larger segments to a smaller number of codes. More than differences in code allocation, this appeared to be the main reason for our low ICR score. Given that it is easier to merge more detailed codes later during analysis than it is to separate out larger codes, we settled on a process of using more codes more often, rather than coding large amounts of text into a single code. We also discovered the need for absolute precision in the start and end point of coded segments. Even if coding matched in all other respects, the inclusion by only one coder of a full stop or additional space would be recorded in the calculation as an ‘overlap’ rather than an overall ‘match’ and affect the Cohen’s kappa that was generated. Once quotation size was standardized between the two coders, ICR improved radically.
Examining the kappa scores generated by this project in Table 2, it is clear that in the initial stages of the project (transcripts 1–4) agreement on quotation or text segment size was a major source of coder disagreement. It was during this stage that we noted a tendency of one coder to include an additional space after the full stop at the end of a coded segment. Resolving such a minor inconsistency in our coding rules generated large increases in our kappa scores, as evidenced by the jump in kappa between transcript 4 and transcript 5. It is also evidenced in the smaller gap between kappa and kappa (including overlap) scores in the latter transcripts. The early stages of the project were specifically about refining the system that we used, whereas increases in kappa score from transcripts 5–10 were more complicated and about the interpretation of code use, rather than the manner in which the coding was being done.
Our study had two main types of data collection: interviews with young women and then also with a family member in their household. We developed a single code frame for analysis of both types of interviews, recognizing that some codes would only be suitable for one specific type of interview but that there would be others that could be used across the two different interview types. As can be seen from the kappa score for transcript 8, the improvements in coder agreement that we had been experiencing in the study were not maintained after a change in data source, largely because coders were working with codes that they might not previously have used in the young women’s interviews and therefore had not discussed or considered as deeply as the other codes.
Although final kappa scores were on the lower end of acceptable at the end of the ICR process, overall there was agreement when we examined the transcripts coded by both coders qualitatively. The use of completely different codes for the same quotations had declined significantly and in all instances quotations were coded using codes from the same theme or group, even if there was not complete agreement in the exact code used. We chose to continue with coding the remaining interviews given that calculating ICR had taken a significant amount of time (a full year). We were also confident of continuing to engage with ICR in this study through our strategy of assessing ICR at designated times throughout the remainder of the study (as discussed previously).
Important lessons learned from the ICR process
While it might seem tempting to avoid the challenges of calculating ICR in qualitative analysis, given that so few publications require this information, the process is a vital one for ensuring that the information generated and extrapolated from the data is consistent and meaningful. The process of working through the ICR calculations for this study allowed a widely dispersed team multiple opportunities to engage with the data that was emerging from the study and the coding frame.
We found that the impetus to achieve an acceptable level of coder agreement (indicated in our kappa score) was beneficial in driving continued discussion of the codes; likely the greatest benefit of the process. Specifically, working to achieve acceptable ICR was beneficial in three specific ways: (1) saving time in the coding process at a later stage of the project; (2) facilitating the work across multiple locations; and, (3) ensuring that the codes adequately represented emergent themes in the data. We have used the methods outlined here on two further occasions: first, when we added an additional coder to the study team; and second, in a completely separate study. In these instances we generated kappa scores of 0.75 and 0.92 in the first ICR calculations respectively. So what were the key lessons that we believe important to consider when undertaking a multi-coder qualitative analysis?
The finalized code frame should be developed before starting the coding process or reaching sufficient intercoder agreement, and should have the subsequent analysis in mind. We specified some codes in this project that could only be used once in each transcript. This was to ensure that we had a reliable means of ‘counting’ some variables. A further useful discussion between coders might also specify the degree of specificity to be adopted when coding. Given the different natural coding styles of various team members, we were forced early on to specify how decisions might be made about appropriate code use. In our case, the rule that we enforced was that the most specific code should be used, rather than a more general code. It might be argued that early in the process our codes were not sufficiently differentiated: the ICR process contributed to developing more clearly defined codes.
Firm ‘coding rules’ should be established before beginning any coding, ensuring that these rules are detailed and specific. When training coders to use qualitative data analysis software which calculates ICR similarly to CAT, specific emphasis should be paid to precision in selecting quotations to ensure that true matches in coding are recognized by addressing otherwise small coding differences, such as one coder including a hard return in the quotation and the other not doing so. This should include the size of quotations to be allocated to a specific code. In this instance, we had relatively loose rules: all text had to be coded, questions from the interviewer had to be included in the coding (this assists with understanding context in the analysis phase), and quotations had to be full paragraphs, although multiple paragraphs could be coded as a single code. In a subsequent multiple coder project, mentioned above, we further specified the size of quotations, such that two paragraphs following on from one another within the same code would be each allocated the code, rather than allocating the code once across both paragraphs. We found that this method of coding was effective for achieving agreement more rapidly by reducing variation in the allocation of codes to different size quotations.
Our process of improving ICR was greatly enhanced by understanding the meaning of the kappa versus the kappa including overlap scores. A high kappa including overlap is especially useful in the initial stages of calculating ICR. This measure suggests that coders share a common understanding of the meaning of the codes and are largely coding the same text segments with the same codes, but that agreement on quotation length is imperfect. This suggests problems with the coding process rather than with code definitions or coders’ understanding of the codes. A high overall kappa score suggests that coders are in agreement about when to use specific codes, but also that the process of allocating quotations to codes is working. These different scores might then be of varying usefulness through the life of the coding project while working towards specific ICR goals. Ultimately, a high overall kappa (excluding overlap) will be the best measure of reliability between coders and a high value would be the aim of the process.
Our experience of a significant dip in kappa scores when we included a household interview in the ICR sample suggests that, in large studies where a single code frame might be used for different types of interview, familiarity with the coding frame in relation to all interviews is important for coders in the initial stages of the process. As we progress through the multiple rounds of data collection, the coders occasionally (10% of the time) will code the same transcript and we will calculate ICR on 10 per cent of transcripts, alternating between interviews with young women and with households to ensure that reliability is being measured across both data collection types.
We found some specific issues with regard to calculating ICR when coding with Atlas.ti. There is relatively little practical information available for Atlas.ti users wanting to calculate ICR (see Friese, 2012), thus much of the process requires trial and error. Calculating ICR in Atlas.ti requires concerted attention to how the HUs from more than one coder are merged together into a single file. However, little information is available on a strategy for merging coded transcripts. Atlas.ti allows for four stock merge strategies; none of which work for ICR calculations without adopting some user-defined tweaks. We selected the first stock option ‘same PDs 3 and Codes’ but then manually altered how quotations were handled, from the preselected ‘unify’ option which effectively merges all quotations to ‘add’ so that the same quotation from different coders could be viewed in a single transcript at the same time. We also recommend that when coding in groups, it is important that each coder individually login to Atlas.ti to identify the coder who applied each code; this is particularly significant for transcripts that will be used for ICR calculations given that more than one individual’s codes are present in the merged HU.
Coding in Atlas.ti and using the associated CAT to calculate ICR has some limitations in terms of the data it is able to generate. While the CAT generates both Cohen’s kappa and Krippendorff’s alpha, results might be problematic as both calculations are based on the assumption that a single code can be applied to a quotation. In our study, we allowed for multiple codes to be allocated to quotations. Eccleston et al. (2001) suggest that using Mezzich’s kappa might be a more appropriate measure for calculating ICR in data where codes are not used exclusively and in which the similar codes can be grouped thematically in the code frame such as our study. The study by Eccleston and colleagues is believed to be the first study using Mezzich’s kappa and suggests that qualitative analysis software developers might need to broaden ICR measures to better address different types of coding strategies.
We recognize that the methods we outline here differ significantly from that proposed by Hruschka and colleagues, specifically with regard to the fact that we have calculated ICR in a stepwise fashion, assessing kappa scores for each transcript alone. In contrast, Hruschka et al. (2004: 321) documented a process in which ‘coders coded text segments that they had coded and discussed in previous rounds’. They therefore question whether their process of calculating ICR might have led to coders experiencing what they term ‘iterative convergence’; agreement in coding based on their numerous discussions of specific transcripts. We believe that our method of only coding each transcript once removes this uncertainty. Of course, this process requires that once agreement has been reached about how to use specific codes, transcripts used in the ICR calculation have to be revisited to reconcile differences and a final coded transcript kept in the project database.
We further suggest that the ICR process not be viewed as a ‘once off’ exercise at the beginning of data analysis, but rather an ongoing component of coding. Varying levels of engagement with long-term projects over time may influence familiarity with and ease of use of coding frames and impact on continued ICR. To alleviate this problem, we plan for double coding, and ICR calculation, of every tenth transcript through the duration of the project as an ongoing check that levels of ICR remain acceptable. If kappa scores fall below acceptable levels, we plan to stop the individual coding process, identify particular problem codes, conduct retraining on coding and double code all transcripts again until acceptable kappa scores are achieved.
Conclusions
Appreciation for the rich information inherent in qualitative enquiry has increased the use of qualitative in-depth methods in a range of disciplines, particularly public health. Despite continued debate about whether or not qualitative research ought to be judged using criteria derived from positivist traditions, qualitative researchers have also been criticized for providing inadequate evidence for the conclusions they draw (Hruschka et al., 2004). Validity and reliability are not however only the purview of quantitative research; they should be the aim of all researchers (Morse, 1999).To ensure that qualitative data generate reliable conclusions and recommendations in a context where multiple data coders might work together on the preliminary components of analysis, examining ICR is essential. Since embarking on this process, we found very little practical assistance in determining which measures might be best for our study and for working through the process of translating double coded data into meaningful interpretations of reliability. We have documented here some useful aspects of the practicalities of engaging in an ICR calculation process.
While there is the temptation to view success in terms of the final kappa score achieved through calculating ICR, the process itself proved to be the main value of undertaking an assessment of reliability. Like Hruschka et al. (2004: 232), our view of ICR as ‘a useful assessment of the quality of the process by which data becomes conclusions’ has been confirmed. Not only did the process of calculating ICR generate a code frame and process most likely to generate useful data, we were also able to engage with the data as a research team early, and in more detail, than is usually the case in large studies where pressure on data collection often subsumes the iterative process of analysis.
Footnotes
Acknowledgements
We thank Stuart Wark, John Scott and Kathy McKay for commenting on earlier versions of the manuscript.
Declaration of interest
The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: HPTN 068, a grant (1RO1MH087118-01) from the National Institutes of Mental Health, and the Collaborative Research Network of the University of New England.
Notes
Author biographies
Nomhle Khoza, MA, is a qualitative data manager at the Wits Reproductive Health & HIV Institute, also a PhD candidate at the school of Public Health, University of the Witwatersrand, South Africa.