
Abstract
In addition to serving as an introduction to the subject, this paper suggests a conceptual framework for the investigation of issues of classification and quantification related to migration and the ethnically and religiously diverse societies in Europe. Nationality, ethnicity and religion are situational, contextual and dynamic social phenomena which tend to defy rigid classification, making it especially difficult to capture and quantify these entities in order to organize and represent them in an intelligible manner in official statistics (e.g. censuses), institutional governing practices or in academic survey research. By drawing on previous work by demographers and social researchers, we suggest a typological classification of ways in which diverse populations become statistically visible or invisible. We show that the rationale for creating classifications and particular sets of categories changes, depending on the political field in which data are used in the governance of populations and migration. A science studies perspective can make these diverse taxonomies the object of studies to understand how they are embedded within, and how they sustain, power relations. By focusing on practices of classification as instruments of research and governance, this special issue contributes to a reflection on the conditions and effects of quantifying practices in culturally diverse and constantly changing societies, in which the line between government and academia, between power and knowledge, is frequently indistinct.
Keywords
Migration and the ethnic and religious pluralization it brings along have been the subject of divisive political debates in nearly all European countries. These debates routinely draw on statistical representations of migration and diversity and the challenges they may entail. Quantification techniques differ across the continent, and are repeatedly the subject of debates among statisticians, researchers and politicians. 1 In 1991 this led to the category of ethnicity being included on the British census; and in 2001 the category of religion. A debate in France on the possibility of collecting diversity statistics was ended by a constitutional ban on official data on ethnic or religious affiliations in 2007. While religious affiliation was introduced as a category on the German census, ethnic data are not collected. However, the ‘migration background’ category was introduced into the microcensus in 2005 – a synthesized variable based on (former) citizenship and place of birth. 2
While academic debates have so far shown a rather narrow focus on data with explicit reference to ethnicity, less attention has been dedicated to data collection on related concepts. This special issue therefore takes a step back and widens the focus to include investigations of the creation and development of related variables for classification such as migration, religion and citizenship as well as synthesized variables. By regarding the data collection process as a social practice itself, this special issue puts quantification back into its social and historical context.
This issue, situated between migration and diversity studies and science and technology studies, discusses how social facts related to migration, ethnicity, minorities and religion are captured, and how people, movements and culture are made countable and thus quantifiable. The texts in this collection address the taxonomic work of creating orders or classification systems in preparation for quantification that then enable the production of statistical knowledge. Examples given in this compilation of articles refer to official statistical and bureaucratic concepts, and in one case the statistical enterprise of an international organization (the International Labour Organization, ILO, see Stricker, 2019), but, we argue, the debate is equally relevant for academic survey research.
To quantify these dynamic, situational and context-dependent phenomena relating to national ethno-cultural diversity requires the establishment of a classifying order. Adapting a notion by the philosopher of science Ian Hacking, we can speak of ‘making up’ ethnicities, migrants and religious people. Hacking points out the significance of statistics for the biopolitics of population and the specific statistical subjectivation process: categorizing data (2007; Foucault, 2004). Hacking speaks of the ‘subversive, unintended effect’ of counting (1982: 280). Alain Desrosières describes this taxonomic work, the unspoken premise of counting as the ‘obscure side of both scientific and political work’ (1998: 236; Supik, 2014). Yet statistics, as we argue here, is by no means a black box. The case studies in this special issue show that the methods and practices involved in creating the numbers that so significantly shape the modern understanding of societies are identifiable: the work of developing taxonomies, deciding on categories and definitions, sorting, ordering and constructing complex indicators to describe the Social.
In her monograph ‘The Averaged American’, Sarah Igo (2007) demonstrates the creative potential of statistical representations of society. Tracing the first polls and academic surveys in the United States, the sociologist and historian unravels the history of surveys themselves. On this basis Igo understands socio-scientific representations not (only) as majority opinions of ‘normal people’ but also as an index of political and epistemological power that brought about a particular form of modern consciousness; a popular mode of knowing in the 20th century. Quantitative surveys, according to Igo, played a major role in moulding the understanding of modern nation states: who was part of them and who was located at the fringes or extremes (2007: 283).
A conceptual framework for studying the quantification of migration, ethnicity and religion
This article presents a heuristic framework from a science studies perspective for investigating issues of classification, quantification and measurement related to migration and the ethnically and religiously diverse societies of Europe. Building on earlier work on quantification in the field of religion (Johansen and Spielhaus, 2012) and ethnicity (Rallu et al., 2006; Simpson, 2002; Supik, 2014), we suggest a framework with which to understand statistical representations of ethnicity, migration and religion as social practices in social contexts. It distinguishes four phases of social quantification that represent different practices in the investigation of social realities: preparing to count, collecting data, interpreting data and governing with data (see Table 1).
Measuring ethnicity, religion and migration. Typology of quantification as a social practice in its social context.
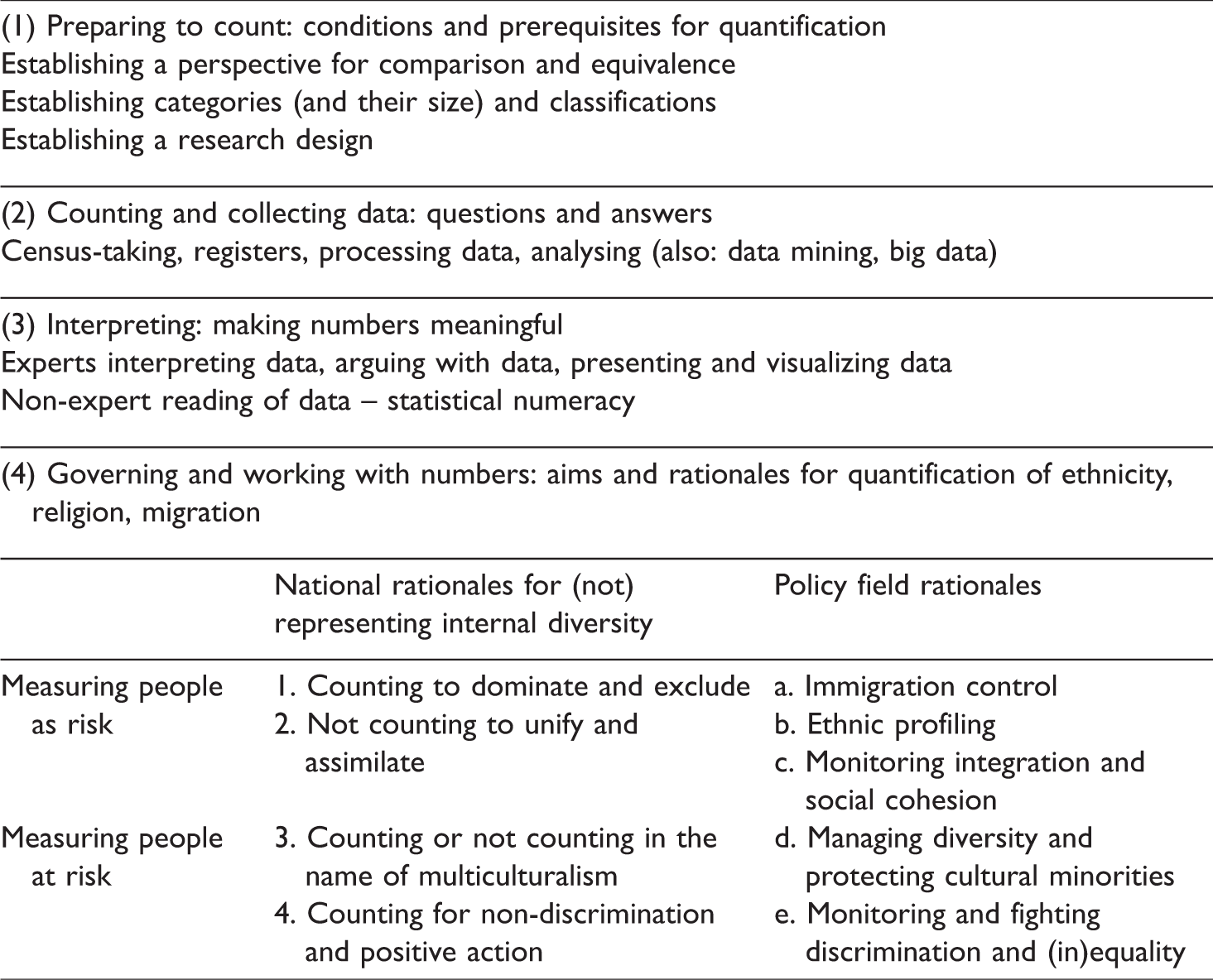
Preparing to count
A crucial part of the work happens before social phenomena become quantifiable. This first practice, preparing to count, includes establishing a perspective for comparison and equivalence (Heintz, 2010), which means creating categories and classifications. Before the counting begins, a point of view has to be established, from which phenomena become or appear so similar that their treatment as ‘counting to the same category’, or being two distinct values of the same variable, seems intelligible. Alain Desrosières (1998: 237) calls this process the ‘construction of consistent classes of equivalences’. For example, the introduction of the ‘ethnic group’ variable into the British census classification in 1991 offered a new perspective on British society, depicting its ethnic diversity for the first time. Another example, historically reconstructed by Anne-Kathrin Will (2019) in this volume, is the introduction of the category ‘persons with migration background’ into the German microcensus in 2005, establishing a population group that had been not conceivable until that point, comprising people possessing German citizenship and those without, as well as people born inside the country and others born elsewhere. On a more ground-breaking level, Yann Stricker (2019) shows in this issue how in the early 20th century, the International Labour Organization (ILO) worked hard to establish an internationally comparative perspective on migration for the first time. By doing so, the ILO made the countable figure of the migrant, and the notion of international migration, appear. Until that point, only immigrants and emigrants, people entering or leaving a territory, had been recorded.
Another step in preparing to count is to develop an order; to prepare a taxonomy that will accommodate all possible cases. Even more than other social indicators, statistical categories of nationality, ethnicity and religion fix the entities they aim to sort and represent within an intelligible and useful order. Such a taxonomy aims to be consistent, unequivocal (unambiguous, distinct), comprehensive, exclusive and intersubjectively understandable (Bowker and Star, 1999: 10f.; Supik, 2014: 89ff.). The social phenomena of ethnicity, nationality and religion, however, are highly situational, contextual and dynamic (Baumann, 2002), and often tend to defy classification. More importantly, they blend into one another. Ethnicity, nationality, country of birth and religion are in many cases used as proxies for each other, in social surveys as well as in everyday communication. In German-speaking countries, the term ‘migration background’ has become a ‘pseudo-ethnic’ category (see Horvath, 2019), and ‘is grounded in descent, even though it is framed as citizenship’ (Will, 2019).
Counting and collecting data
The second set of practices concerns the actual data collection process; that is to say, the counting. During the last decades, a number of researchers have turned their gaze towards the people and practices involved in quantification. In his book ‘Those who count’, Mihai Surdu analyses the dilemma of constructivist theories on ethnicity being supported by essentialising practices of enumeration (2016: 42f). Part of the groundwork for statistical representation is establishing the size of a population group because no random survey sample can be drawn if the absolute size of the researched (sub-) population is unknown. The questions of definition raised by this need have been shown in the case of quantifying Muslim populations in Europe, where, in the absence of data on religion, migration background tends to serve as a proxy when recruiting respondents (Spielhaus, 2011). Investigating the data collection process as a social practice includes examining the data subject’s position and agency in this endeavour, as Mihai Surdu (2019) in this volume exemplifies for Roma in surveys and censuses in South Eastern Europe. Who is selected for data collection and on the basis of which criteria? Are data taken from registers, or are the subjects actually approached and asked? Is participation voluntary or obligatory? What options do subjects have to determine their answer or refuse to answer? Can they use their own words and language; can they choose from several options or even give multiple answers? These conditions of the data collection process determine the power relations between the data subject and the survey-taker and/or researchers. Data protection and privacy laws regulate the possibilities of ‘resistance by the known to the knowers’ (Hacking, 2007: 306).
Interpreting: Making numbers meaningful
The third practice is the interpretation of numbers. Without interpretation, numbers remain meaningless. However, the interpretation is always influenced by the categories and comparisons established in previous phases. As social statistics shape social discourse in modern nation states (Igo, 2007), experts and non-experts – groups with diverging statistical numeracy – make sense of the numbers. Interpreters are statisticians and survey researchers as well as social scientists and other professionals, such as accountants and administrators, who do not always produce the data themselves. Non-experts communicate and receive numerical information every day through reports, official documents and the media. Hence, we distinguish between two ways of interpreting data.
Presenting data, arguing with data, interpreting data by experts
Experts do not just count things and release the results, they take many decisions to determine which results are worth reporting and publishing, which further calculations should be made, how results should be visualized, which headlines to use, and so on. These decisions involve explicit and implicit hypotheses. One example for such a hypothesis-driven process is to decide that immigrants from majority Muslim countries and their descendants in Europe are often all counted as Muslims. Thus the overall number of Muslims is increased, and religious minorities and non-religious people become invisible.
Everyday or non-expert reading of data – Statistical numeracy
Not only experts interpret data; social statistics are omnipresent in any professional context or in the media. Numeracy education in schools includes learning to understand percentages and calculations of probability. More intuitively accessible infographics are developed in statistical reports and media to facilitate the reader’s understanding. Increasingly, statistical offices make their data accessible online, available for the public to download, and for anyone to use for their own calculations. Unsurprisingly this also leads to different readings and perhaps even simplifications or false conclusions. Correlations are easily interpreted as causal relations; and as Elisabeth Schilling (2019) shows in this issue, averages are taken as being of paramount importance, not only for a statistical group but also for any single individual. However, not only the numerical knowledge itself, but also the categories developed for and through quantifications are spreading into everyday discourse, where they may acquire a different meaning. Kenneth Horvath’s contribution to this volume shows this in the case of the category ‘migration background’.
Governing with numbers – Putting data to work in policies
Finally, research on the practice of governing and working with numbers explores the different rationales of classification, data collection and data reporting. For what purpose are various types of data collected? Which policies do they serve? Depending on the political field in which data are put to use, the rationale for classification and the set of categories may change. The fourfold scheme offered by Rallu et al. (2006) systematizes different national approaches to ethnic classification and the ways in which nation states create statistical visibility/invisibility within their diverse populations. The authors’ concern is explicitly ethnic classification, with no other differentiations such as migration or religious affiliations, and they assume consistency in any nation state’s rationale in this regard:
Counting to dominate and exclude
Examples of this rationale for ethnic data collection provided by Rallu et al. (2006) are mostly historical, such as colonial states, South Africa under the apartheid regime, and the Soviet Union. National Socialist Germany should be added to this type. Common to all these examples is the systematic abuse of ethnicity data. Also important in this regard is William Seltzer and Margo Anderson’s article ‘The Dark Side of Numbers’ (2001), which names numerous well-documented cases of human rights abuses such as forced migration, internment, segregation and genocide; enabled or promoted by the means of ethnic data.
Not counting to unify and assimilate
Contemporary Spain, France and Germany are examples of this national rationale, as well as the Western African economic area, where (with the exception of Cote d'Ivoire) statistics do not even include citizenship as a distinctive variable. France is often referred to as a paradigmatic case, with the egalité des citoyens being such a constitutive element of the nation’s ethos that making internal diversity visible is regarded as unconstitutional (Rallu et al., 2006: 535).
Counting or not counting in the name of multiculturalism
Examples of this rationale mentioned by Rallu et al. (2006) are Latin American states, where hybridity and mixing are positively valued and any enduring ethnic differences in the population are expected to be levelled out over generations. Brazil, however, presents a case where data on ethnicity are collected and show that the ideal of hybridization is countered by processes of discrimination.
Counting for non-discrimination and positive action
Examples in this case are provided by the United Kingdom, Canada from the 1960s onwards and the United States since the Civil Rights Movement. In these national contexts equality legislation together with a positive stance towards the internally diverse composition of the nation make racial discrimination illegitimate, and politics to actively counter inequality among ethnic groups (positive action or, in the United States, affirmative action) are enacted (Rallu et al., 2006: 534ff).
Beyond these four rationales employed by governments to explain why they sort their populations by ethnicity, or why they do not, the bureaucratic practices of nation states may be internally heterogeneous and supranational regulations many, in many cases, bind national politics to norms and reporting commitments. In different policy fields, nation states may apply diverging and even contradictory strategies. Therefore, we draw on a further typology suggested by Ludi Simpson (2002). As a comparative perspective, Simpson’s typology questions the effects for the statistically represented subjects and sorts statistical monitoring contexts according to whether they regard the subjects monitored as ‘persons at risk’ or ‘persons as risk’ (see also von Unger, Odukoya and Scott, 2019).
Measuring people as risk
Controlling immigration and migration
States aim to control movements across their borders, especially entries to, but also exits from their territory. Monitoring migration itself focuses on the activity of border crossing: on the action, not the subject; on the flows, not the stocks. There is also interest in the different qualities that migrants might possess, and efforts are made to gain knowledge about these qualities: Who is dangerous? Who is valuable (i.e. highly skilled, wealthy)? Who can claim a right to asylum? Whose life is in danger, who is sick (in need of humanitarian aid and/or a potential carrier of infectious disease; von Unger, Scott and Odukoya, 2019)? In the public discourse, immigration easily becomes a highly emotionalized numbers game.
Security policies: Racial and ethnic profiling
On the one hand, there is the practice of ‘eyeballing’ people and picking persons who fit a certain profile in the eyes of security personnel, police officers or border patrol guards. On the other hand, data profiles are produced to screen whole populations, such as for terrorists. For example after 9/11, German universities opened their student registers to screen for male students of Middle Eastern nationalities studying technical sciences.
Monitoring integration and social cohesion
Data collection is essentially part of all policy fields of the welfare state, including health, housing, education and the labour market. This special issue provides case studies for British and German health policies (von Unger, Scott and Odukoya), French housing policies (Belmessous) and German education policies (Horvath). Data are put to use with the aim of integration and social cohesion, in order to integrate a population consisting of majority and minority groups. The overall aim of preventing social conflict is followed in principle by adjusting the minority groups’ educational success, health status, labour market participation and so on to that of the majority group.
Measuring people at risk
Managing diversity and protecting cultural minorities
These are policies that regard ethnic, religious, linguistic and cultural diversity as values in pluralistic democracies and protect the right of minorities to be different, to exercise rights of freedom equally but differently from majority populations. Data are always needed, for example to provide translation services in hospitals or heritage language classes in schools.
Monitoring discrimination and equality/inequality
The aim of these policies is to provide equal rights, equal treatment and equal opportunities to all members of society, regardless of their minority or majority status and regardless of their gender, sexual orientation, age, belief, ethnic group or disability. To reach equality in this sense, active policies (‘Positive Action’) to combat discrimination are implemented, accompanied by equality or diversity monitoring.
As this typology of social practices involved in the statistical measurement of ethnicity, migration and religion indicates, supported by with the case studies in this special issue, quantifications can take a wide range of forms and can be analysed not only with regards to their methodologies and aims but also with regard to the power relations they are embedded in and the power effects they produce.
Ongoing debates on ethnicity data in continental Western Europe
A discursive gap still divides national contexts where data on ethnicity (based on self-identification) is collected and others where it is not. Hence, several articles on this issue engage with the question of why, in continental Western European contexts, the diversity of populations remains statistically invisible. With the exception of France, academics in continental European immigrant countries hardly even discuss the option of collecting ethnic data (for exceptions, see Supik, 2017). One exception was a panel discussion during the international conference ‘Measuring Ethnicity and Migration’ held in October 2015 in Germany. The panel brought together experts from France, Britain, Germany and the European Network Against Racism (ENAR) to address the collection of ‘equality data’. At the heart of this debate was not so much the question of whether the collection of quantitative data on ethnicity is a good or a bad thing per se; rather, the panellists deemed the aim of the data collection to be the more crucial point. From this discussion, it transpired that there was a strong demand for data collected through self-ascribed, subjective ethnic identification, which would enable the measurement of racial discrimination. In the meantime, representatives of German civil society entered the debate (Neue Deutsche Organisationen, 2017), and the Federal Anti-Discrimination Agency (FADA) began searching for viable ways to collect more suitable data on discrimination experiences and populations at risk of discrimination in official statistics and academic surveys (Baumann et al., 2018).
Four contributions to this special issue (Surdu, von Unger et al., Will and Horvath) address the collection of data based on an explicit notion of ethnic difference. Mihai Surdu suggests a general moratorium on surveys targeted at Roma. Drawing on policies and research targeted at Roma, he concludes that even though some may have been intended to combat discrimination, they may have detrimental effects such as further stigmatization and isolation, as well as also providing legitimacy for ethno-political entrepreneurs, project managers and scholars. Von Unger, Scott and Odukoya show how, in public health monitoring, national practices exist that explicitly reference ethnic data or completely omit it, and that these function alongside one other. Will argues that the (German) concept of ‘migration background’, is in need of revision, ‘maybe even a replacement of the category with one based on self-identification’. Surdu and Horvath warn that populist and extremist right-wing governments and parties draw on population statistics as well. At the beginning of the millennium all European member states reformed their equality legislation and developed new policies to combat racist discrimination. To enable the monitoring of the status quo, anti-racism activists, as well as supra- and international organizations, have repeatedly called for appropriate data to be collected. More than one and a half decades into the millennium, the extreme right has gained influence in most EU member states. This political development necessitates a revision of data collection practices that is cognizant of possible side effects and the misuse of both categories and data: How can statistics responsibly and consciously depict the diversity and inequality of European societies in a period when racist and essentialising notions of dichotomously imagined communities of ‘us’ and ‘them’ are gaining political influence?
Studying the quantification of ethnicity, religion and migration
By investigating statistical methods as important tools for the social sciences, this special issue aims to contribute to the accountability of the production and use of statistics on culturally diverse and constantly changing societies, in which the line between government and academia, between power and knowledge, is increasingly blurred. Based on a selection of papers presented at the aforementioned ‘Measuring Ethnicity and Migration’ conference, this special issue aims to place statistical measurement and quantitative data production about contemporary – especially European – immigrant societies within a social context. These studies contribute to efforts to investigate social statistics as a set of powerful practices by delving into historical investigations, looking back at the colonial origins of enumeration and their postcolonial repercussions, by taking comparative perspectives of different nation states, especially the three largest Western European immigration societies: Britain, France and Germany. Furthermore, these papers investigate European perspectives of and on its largest transnational intersecting and internally highly diverse minority groups: ‘the Roma’ and ‘the Muslims’. Other contributions shed light on the ‘making up’ of such ‘different kinds of people’ (Hacking, 2007) as ‘pupils or students’ in Germany and ‘carriers of infectious diseases’ in the UK and Germany.
Yann Stricker shows how establishing statistical classes of equivalence (Desrosières, 1998) to describe international migration movements enables an internationally comparative viewpoint. Statistical representation becomes the bird’s-eye perspective or, in Haraway's (1991) words, the ‘god-trick to see everything from nowhere’. By historically investigating the emergence of the notion of international migration, Stricker hints at the immediate link between nation and race. The rise of the nation after the First World War is interlocked with the notion of racial unity and order. As the orientation of African Nationalism towards role models such as Hindu nationalism in India or anti-British Irish resistance shows, the colour-line (DuBois, 1994[1903]) is not (yet) the paradigmatic line of difference.
By depicting statistical techniques for enumeration and data collection on Roma in Eastern and Western Europe over several centuries, Mihai Surdu highlights some crucial and often hidden preconditions of statistical data production. Including rich historical detail, Surdu uses the case of Europe’s largest ethnic minority, the Roma, to show how differently official statistical data collection, target group surveys and censuses of the general population subjectify data subjects. Only recently were respondents given any choice in determining their answers or the categories under which they were defined. Data subjects’ freedom of choice is still very limited, and survey production processes often forcefully produce third-party ascriptions.
Anne-Kathrin Will investigates the appearance and development of the concept of ‘persons with a migration background’ at the turn of the millennium in the microcensus by the German Federal Statistical Office. She shows how, from the 1950s to the 1980s, official statistics were very much concerned with making visible different kinds of ethnic German immigrants to the Federal Republic of Germany, namely refugees and expelled persons from the German Democratic Republic and Eastern European Countries. When the concept of ‘migration background’ was implemented, these groups, which had previously been statistically visible, became invisible and were included in the category of persons without a migration background. Will proceeds to show how the introduction of the ‘migration background’ category was derived from international educational research, and she analyses the lines of difference the concept produces.
In his article, Kenneth Horvath uses the concept of ‘ethnic boundary making’ to analyse the statistical category of ‘migration background’ as a pseudo-ethnic category. He concentrates on the use of the label ‘migration background’ in the field of education, where the officially sanctioned, and thus seemingly ‘politically correct’, terminology is used in practice as a category, with a different and more ambiguous meaning than in statistics. Horvath shows that ‘migration background’ as a category in practice is informed not only by ethnic but also by class differences.
Hella von Unger, Penelope Scott and Dennis Odukoya look at national classification systems in the field of public health in Germany and the UK. They demonstrate how, within these systems, categorization practices in the field of health reporting for TB create distinct populations, immigrant/migrant groups and (in the UK) ethnic groups as part of health governance. In the context of surveys and health statistics related to the spread of TB, the construction of immigrant/migrants as ‘carriers of disease’ is tied to a larger interpretive frame positioning immigrant/migrants as a threat to the nations’ wellbeing.
In her investigation of housing policies in the Lyon area, Fatiha Belmessous depicts the contradictory policies aimed at Algerian immigrants in France. French constitutional equality doctrine did not apparently hinder the implementation of population categories in housing administration practices. Belmessous describes how France sustains a myth about the equality of its citizens while at the same time maintaining a legal status differentiation between French people and Algerians, one that was adopted from colonial Algeria into the French territory and is still in place now. In the case of housing policies, Belmessous details how there have always been – on all bureaucratic levels, national and local – categories of practice in place that draw a line between ‘French French’ and ‘Algerian French’.
Elisabeth Schillings contribution examines the everyday use and implications of knowledge produced by statistical measurement. She looks at the effects it has on individuals in civic society with average numeracy trying to respond to this implicitly and tacitly present knowledge. Can statistical knowledge actually be useful for individuals and their personal choices? This question is pivotal, as Schilling shows, for individual life planning, when looking to one’s unforeseeable future and assessing the chances and risks of specific decisions. Statistical knowledge is also central to professionals in the welfare, education and social sectors, who advise other people or take decisions affecting their lives.
These case studies investigate the quantification of ethnicity, religion and migration from different angles and with different scopes: in historical and international perspectives, in urban or national frameworks or on the micro level of single individuals. They show how quantification techniques and social practices give shape and, in part, determine spaces for agency, policy making and equally for further research in the field of ethnicity, religion and migration.
Footnotes
Acknowledgements
We want to thank Tino Plümecke for helpful comments, Seda-Nur Asçı and Bilal Yilmaz for helping with the manuscript preparation and Sophie Perl for her excellent work on the language editing of this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Thyssen Foundation and the German Sociological Association, Section Migration and Ethnic Minorities funded the conference ‘Measuring Ethnicity and Migration – Classification and Statistical Representation in Academic Research and Administration’ on 8–9 October 2015 at the Institute for Advanced Studies in the Humanities (KWI) Essen, Germany at which first drafts of the papers were presented.