
Abstract
In this article, we consider a novel regression model with observed factors. To allow for the prediction of future observations, we model the observed factors using a flexible multivariate stochastic volatility (MSV) structure with separate dynamics for the volatilities and the correlation matrix. The correlation matrix of the factors is time varying, and its evolution is described by an inverse Wishart process. We develop an estimation procedure based on Bayesian Markov chain Monte Carlo methods, which has two major advantages compared to existing methods for similar models in the literature. First, the procedure is computationally more efficient. Second, it can be applied to calculate the predictive distributions for future observations. We compare the proposed model with other multivariate volatility models using Fama-French factors and portfolio weighted return data. The result shows that our model has better predictive performance.
Keywords
1 Introduction
Over the last two decades, multivariate stochastic volatility (MSV) models have become an important class in financial econometrics, largely due to the successful utilization of Bayesian Markov chain Monte Carlo (MCMC) methods in model estimation. Recent developments in the MSV literature focus on dimension reduction via factor analysis, given that the complexity of computation and the difficulty in model interpretation drastically increase as the dimension of data increases. Harvey et al. (1994) first discussed the MSV factor structure. Bayesian methodology was introduced to the factor MSV (FMSV) models by Jacquier et al. (1995), where the stochastic volatility (SV) process is imposed on the factor structure. Pitt and Shephard (1999), Chib et al. (2006) and Lopes and Carvalho (2007) consider different specifications that allow more complicated factor dynamics.
A common feature of these FMSV models is the diagonality restriction imposed on the factor correlation/covariance matrix, implying that the factors are uncorrelated. This assumption could be unrealistic in real problems, especially when the factors are observable. To relax the diagonality assumption in a time-varying framework, Philipov and Glickman (2006b) introduced a dynamic FMSV model in which the inverse factor covariance matrices are driven by Wishart processes. The model is a straightforward application of factor analysis to the work of Philipov and Glickman (2006a). The inverse Wishart specification introduced by Philipov and Glickman (2006a, 2006b) is appealing because it can be estimated via MCMC methods. Asai and McAleer (2009) (hereafter AM) propose a dynamic correlation MSV model (DCMSV) based on MCMC techniques, where the return series are directly modelled with SV processes and the covariance evolution is characterized by the inverse Wishart distribution. Since Philipov and Glickman (2006a, 2006b) and AM’s models have similarity on the covariance specification, following AM, in this article we term this class of models the ‘Wishart Inverse Covariance’ (WIC). Philipov and Glickman (2006a, 2006b) and AM demonstrate the usefulness of the WIC models in portfolio analysis and risk management. Moreover, AM show with real data that their WIC model works well in capturing the evolution of the correlation matrix, while the dynamic conditional correlation (DCC) GARCH (Engle, 2002) models fail.
There are several major issues in existent WIC MSV/FMSV models. First, the time effect among different series is controlled by only one scalar persistence parameter, which is likely to be too restrictive in practice. To resolve this issue, we propose an observed dynamic-correlation FMSV model (DCFMSV). The basic model form of DCFMSV is similar to that of AM, but the structure is applied to a factor model. Compared with the FMSV of Philipov and Glickman (2006b) (hereafter PG), DCFMSV provides more flexibility because it allows for different time effects on the factors by introducing separate SV processes. Due to the factor structure, applications of DCFMSV to large datasets can be more advantageous than AM’s DC-MSV model. Another issue with the WIC models lies in the MCMC implementation. Philipov and Glickman (2006a) and AM propose different MCMC methods to conduct the posterior simulation. However, these methods may be either time consuming or potentially inaccurate. We propose a computationally more efficient algorithm that is free from the potential inaccuracy. Moreover, because the algorithm treats the estimation of the parameters and the latent variables simultaneously, it improves the disadvantage of AM’s two-stage method that cannot be easily utilized for future prediction.
This article makes a two-fold contribution. First, we introduce a novel flexible factor model to the WIC MSV literature, where the factors are observable. The model is an extension of AM’s DC-MSV to the factor model framework. Second, we develop a computationally more efficient MCMC algorithm that applies to the whole class of WIC models. The algorithm not only improves computational efficiency but also makes forecasting feasible and thus significantly increases the usefulness of the WIC models.
The remainder of the article is organized as follows. Section 2 presents the model and discusses the Bayesian estimation. Section 3 introduces the MCMC algorithm and conducts a Monte Carlo study using real data to compare the computational efficiency between the proposed scheme and AM’s method. Section 4 provides an empirical example using Fama-French’s factors and portfolio weighted return data. Based on the quality of one-step-ahead predictions, the DCFMSV is compared with AM’s DC-MSV, PG’s FMSV and the well-known DCC-GARCH model. Section 5 presents concluding remarks and some further discussions.
2 The model
2.1 Model specification
Suppose that at time t we have a p-dimensional vector of asset returns,
where


where N(x|μ, 2) is a univariate normal density in x with mean μ and variance 2, and ο is the element-wise multiplication operator. The stochastic sequences {ε
t
, t ≥ 1} and {
The covariance matrix
The dynamics of
where Wq(
In the WIC context, there are two different ways to define the scale matrix. AM use Equation (2.5), while PG adopt a BEKK-type representation
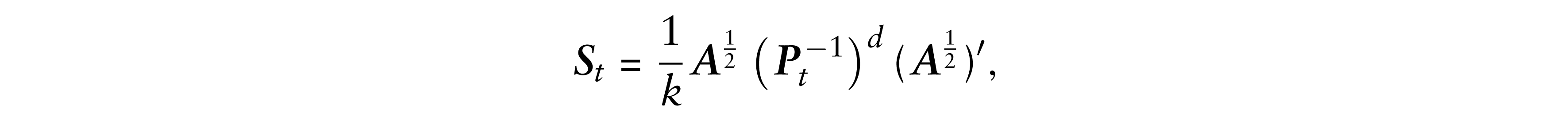
where
Although the DCFMSV specification is similar to AM’s DC-MSV, the two models are fundamentally different in several aspects. First, AM adopt the settings (2.2a)–(2.5) to model the return series, while DCFMSV applies the settings to the observed factors. This difference is the main advantage of DCFMSV over DC-MSV, as the utilization of a factor structure largely reduces the computational cost and makes the results more interpretable. In the example given later, we have a dataset of 10 industry portfolios, which means for the modelling with DC-MSV, there are 55 elements to be estimated in the correlation matrix. However, if we apply DCFMSV with three common factors, the number of the correlation parameters is reduced to only six. As a consequence of the less complex dependence structure, the estimation result is much easier to interpret and the running time is drastically reduced. Another difference between DCFMSV and DC-MSV is in the sampling scheme. As will be discussed later, the algorithm we develop for DCFMSV can carry out broader analyses, such as forecasting.
2.2 Priors
There are two parameters in Equation (2.1), the measurement equation. For the idiosyncratic variances

where etr(
We adopt the priors suggested by Kim et al. (1998) for the SV parameters. For μi and
Following PG and AM, the priors for the correlation-level parameters are chosen as follows: for
2.3 Bayesian estimation
2.3.1 Joint distribution
We estimate the model using an MCMC simulation method described in the following. Let the observed returns
The joint density of (
where
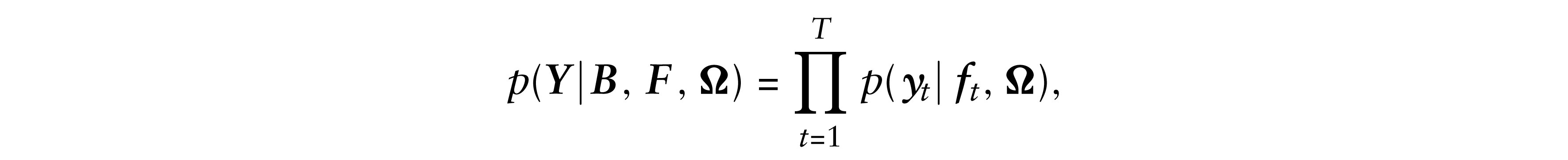
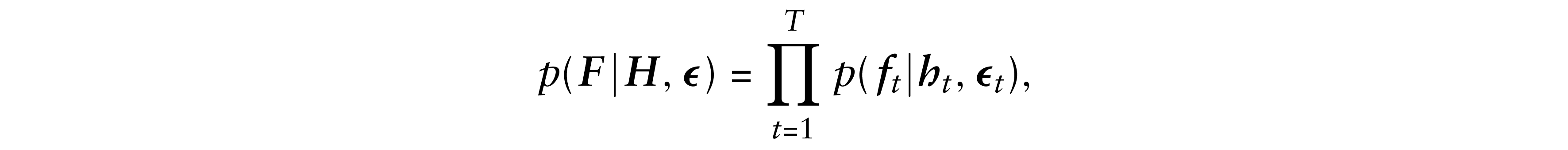
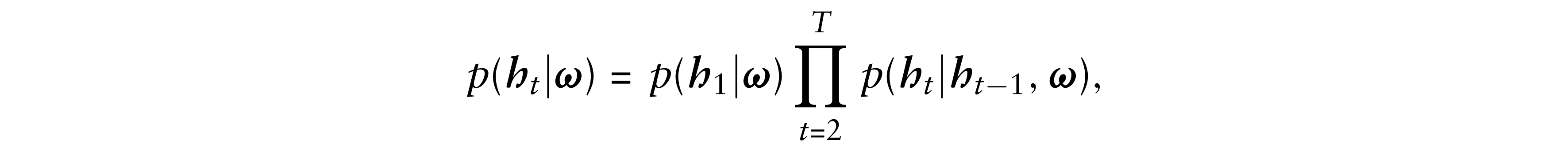
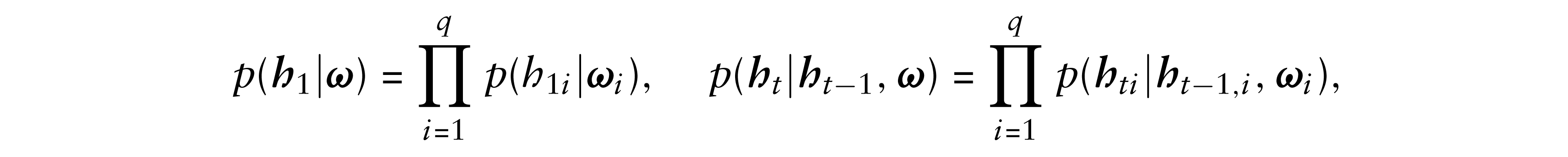
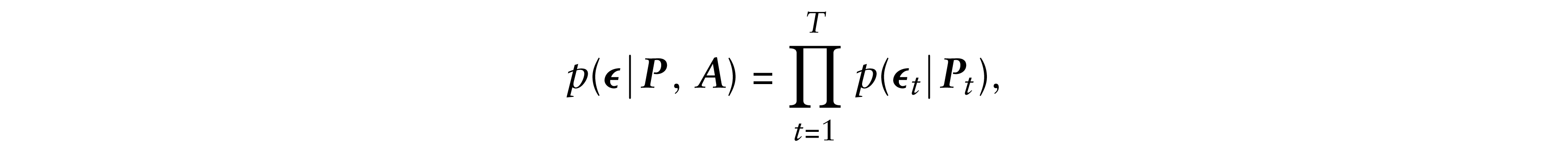
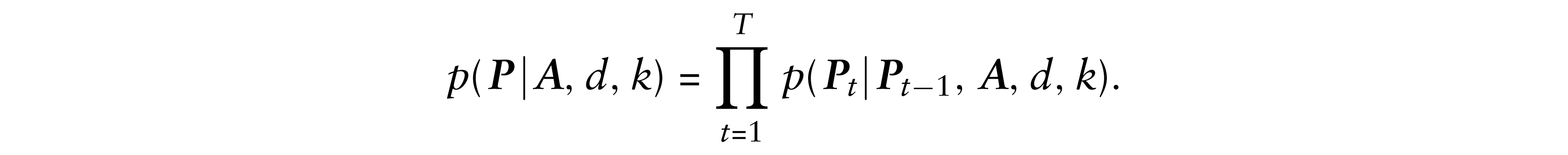
The densities p(
2.3.2 Conditional posterior distributions
We sample from the following conditional posterior distributions. For
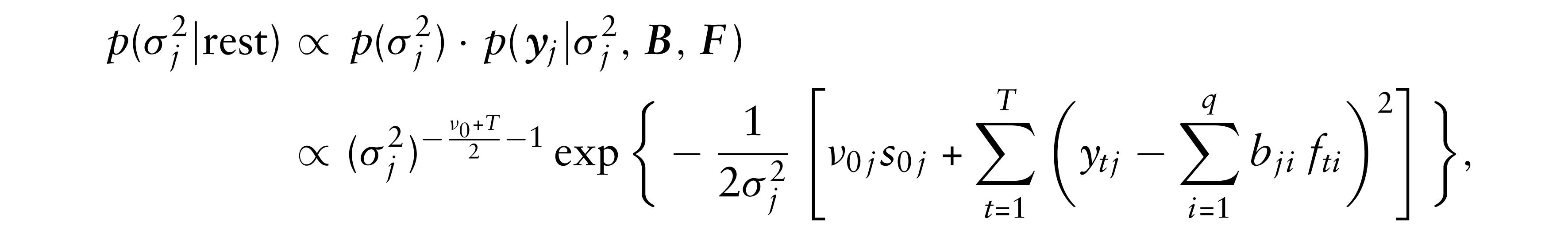
where ytj is the jth element of
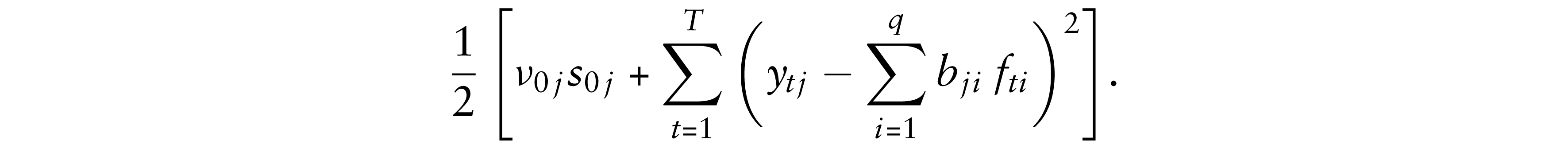
The posterior density of
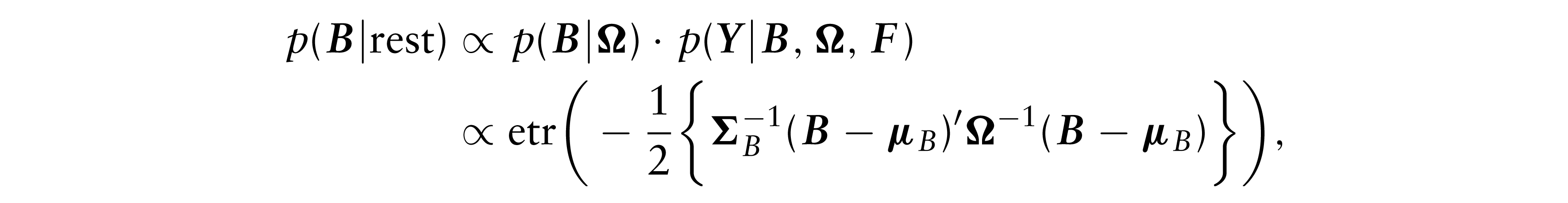
where
We will discuss how to sample the SV parameters
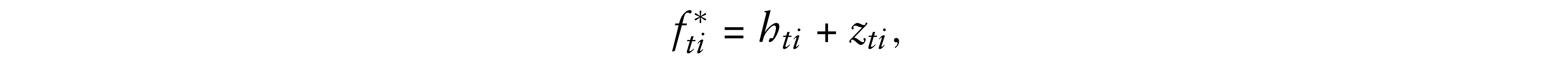
where
Given that
2.4 MCMC algorithm
The complete MCMC algorithm is given as follows:
Step 0: Initialize Step 1: Sample Step 2: Sample Step 3: Sample Obtain the standardized factors Step 4: Sample Step 5: Sample Step 6: Sample d|rest. Step 7: Sample k|rest. Step 8: Go to Step 1.
Looping Steps 1 to 8 is a complete sweep of the MCMC sampler. To sample the parameters in Steps 4 to 7, we develop a method that is computationally more efficient compared with AM’s scheme. The detail is given in next section.
Note that Steps 2 to 4 connect the SV processes and the correlation matrices. To deal with the part, AM suggest a two-stage procedure. In the first stage, they estimate the SV parameters
3 Computationally efficient sampling for correlation parameters
The posterior distribution function of k has a complicated form in the WIC models. PG use a common straightforward stratified sampling (see, e.g., Liu, 2001) to make draws from this univariate density. However, it may be difficult to choose a suitable number of strata (grids). Utilization of too many grids will increase computational cost, and insufficient grids will render the sampling inaccurate due to the heterogeneity within subregions. AM do not consider the stratified sampling. Instead, they suggest using the adaptive rejection Metropolis sampling (ARMS) of Gilks et al. (1995).
It is known that if the posterior density is assured to be log-concave, the adaptive rejection sampling (ARS) of Gilks (1992) can be more efficient than ARMS. Efficiency increases for two reasons. First, as the log-concavity is known, we no longer need to perform the additional point-evaluation of the log-density required by the call to the ARMS function. Second, we can construct the squeezing functions so that the function evaluation may be saved in each rejection step. Figure 1 shows the log posterior distribution function of k using the data simulated from the settings of AM’s Example 3.3. Clearly, the log density presents a concave shape, motivating the application of ARS in lieu of ARMS to improve computational efficiency. Here we emphasize that, in practice, switching from ARMS to ARS is cost-free, as most ARS and ARMS packages offer both options, for example, OX, R, WinBUGS and the C program by Gilks et al. (1995).
Plot of the log posterior of k, simulated using AM’s Example 3.3.
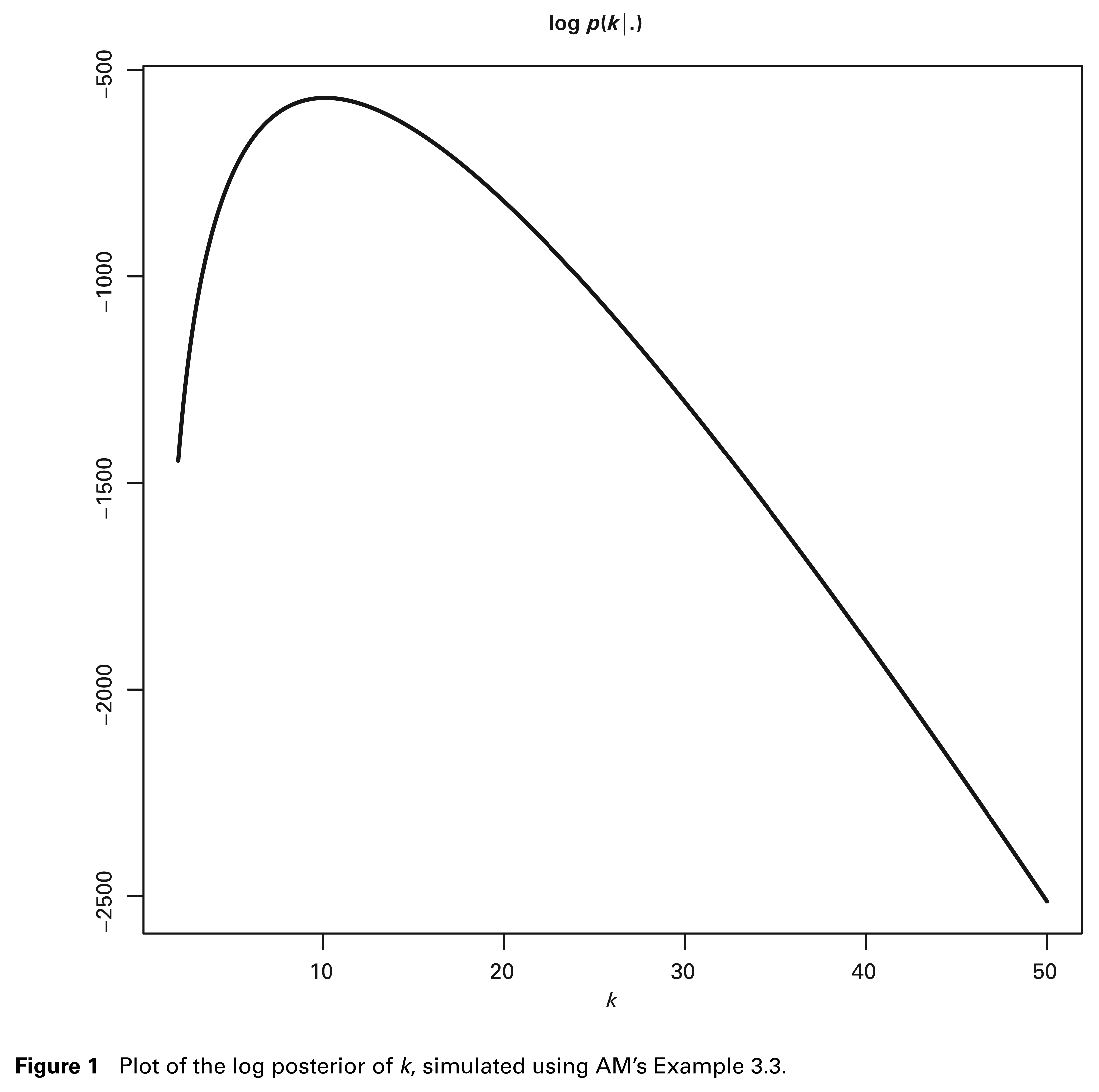
The following section discusses the log-concavity of the conditional posterior of k. We also apply Sherman-Morrison-Woodbury formula (SMW, see, e.g., Monahan, 2001) to reduce the computational burden during the update of the augmented latent covariance matrices. The utilization of ARS for k and SMW formula for the latent variables, taken together, form the basis of our sampling scheme that provides better computational efficiency.
3.1 The conditional posterior distribution of k
For the prior of k, PG consider the following gamma prior
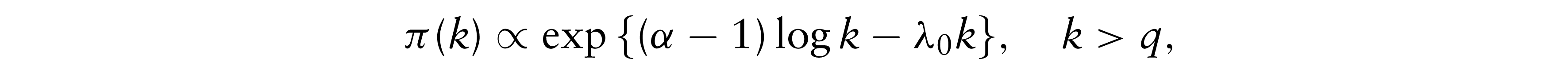
where q is the dimension of the
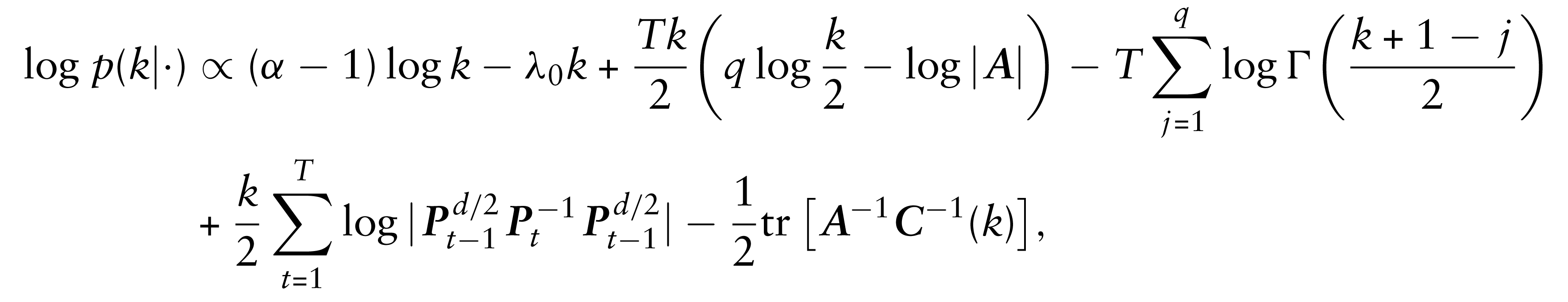
where
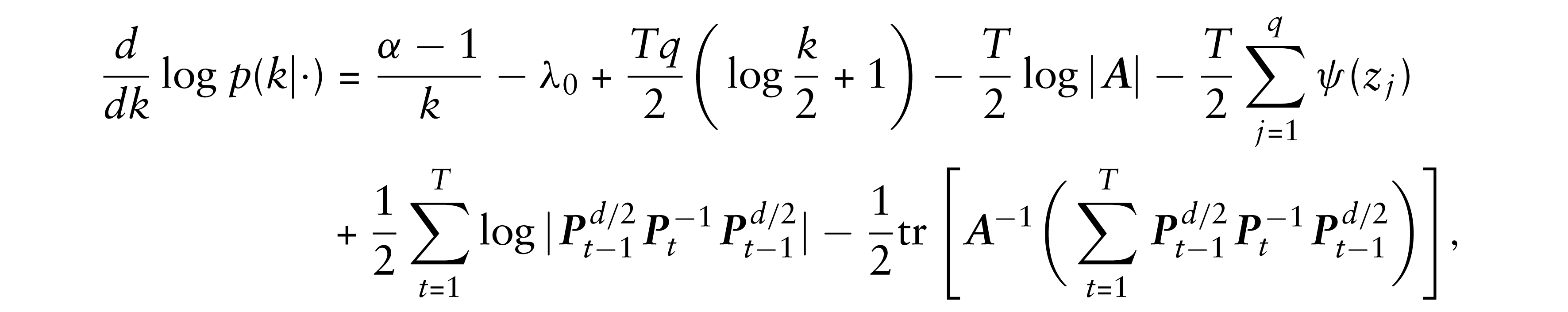
where ψ(•) is a digamma function and
We then obtain the second-order derivative as:
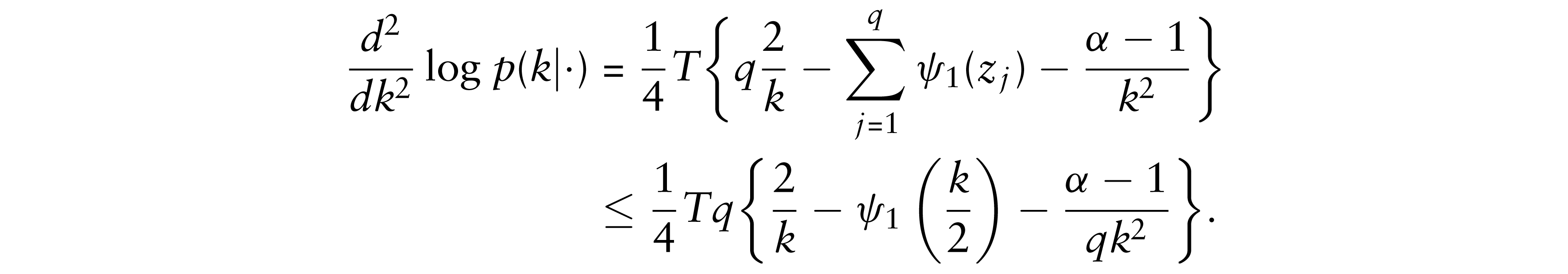
The inequality comes from the fact that the trigamma function ψ1(x) is strictly decreasing in x. Accordingly, since
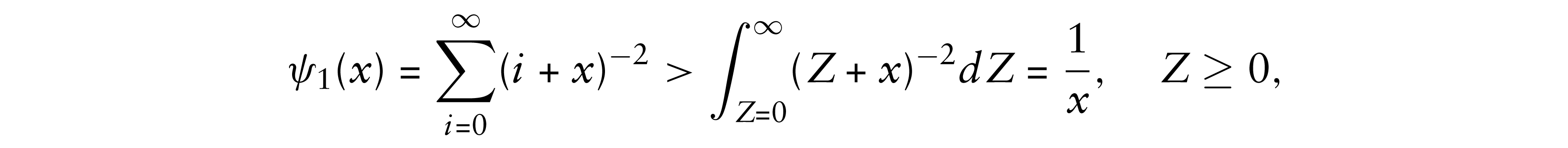
the result immediately follows.
3.2 Use of Sherman-Morrison-Woodbury formula
In the MCMC estimation, we need to update the inverse covariance matrix whose conditional posterior is proportional to a Wishart distribution with the scale matrix

where
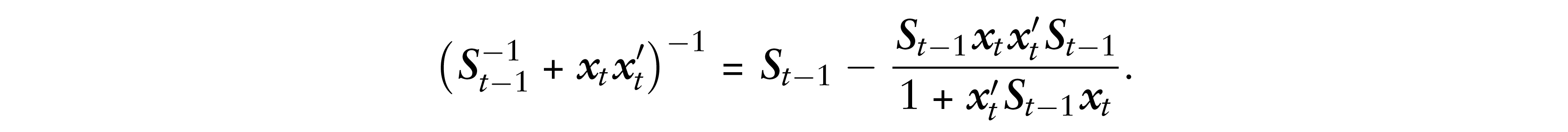
Since in each sweep,
3.3 Comparison in computational efficiency
This section conducts a study using real data to show that our proposed scheme, denoted by ‘ARS+SMW’, is computationally more efficient than AM’s procedure, denoted as ‘ARMS+NoSMW’. Here the readers should be reminded that, in ‘ARS+SMW’, only k is sampled using ARS; for the other univariate parameter, d, following AM, we use ARMS to make draws. The raw data are collected from Yahoo Finance and consist of four series of weekly stock market indices, namely, the Dow Jones Industrial Average, the Hang Seng Index, the Korea Composite Stock Price Index and the Taiwan Weighted Stock Index. The sample period from 7 July 1997 to 9 November 2009 contains T = 452 observations. The returns are calculated by 100 × (log Pit – log Pi,t–1), where Pit is the closing price on week t for stock market i. We fit the data with AM’s DC-MSV. Following AM, we first estimate the SV parameters and obtain the standardized series. After the pre-processing step, we estimate the correlation-level parameters for 20 times using ARS+SMW and ARMS+NoSMW, respectively. In each replication we run N = 30 000 MCMC iterations, with the first 10 000 draws discarded, and the remaining M = 20 000 are kept. The programs are written in OX (Doornik, 2007) Console 6.21 on a Windows7 platform, on a laptop equipped with an Intel i7 M620 2.67 GHz central processing unit and 4 GB random access memory. Note that we do not output the result for the SV part since the SV estimation stage is of no interest in the study.
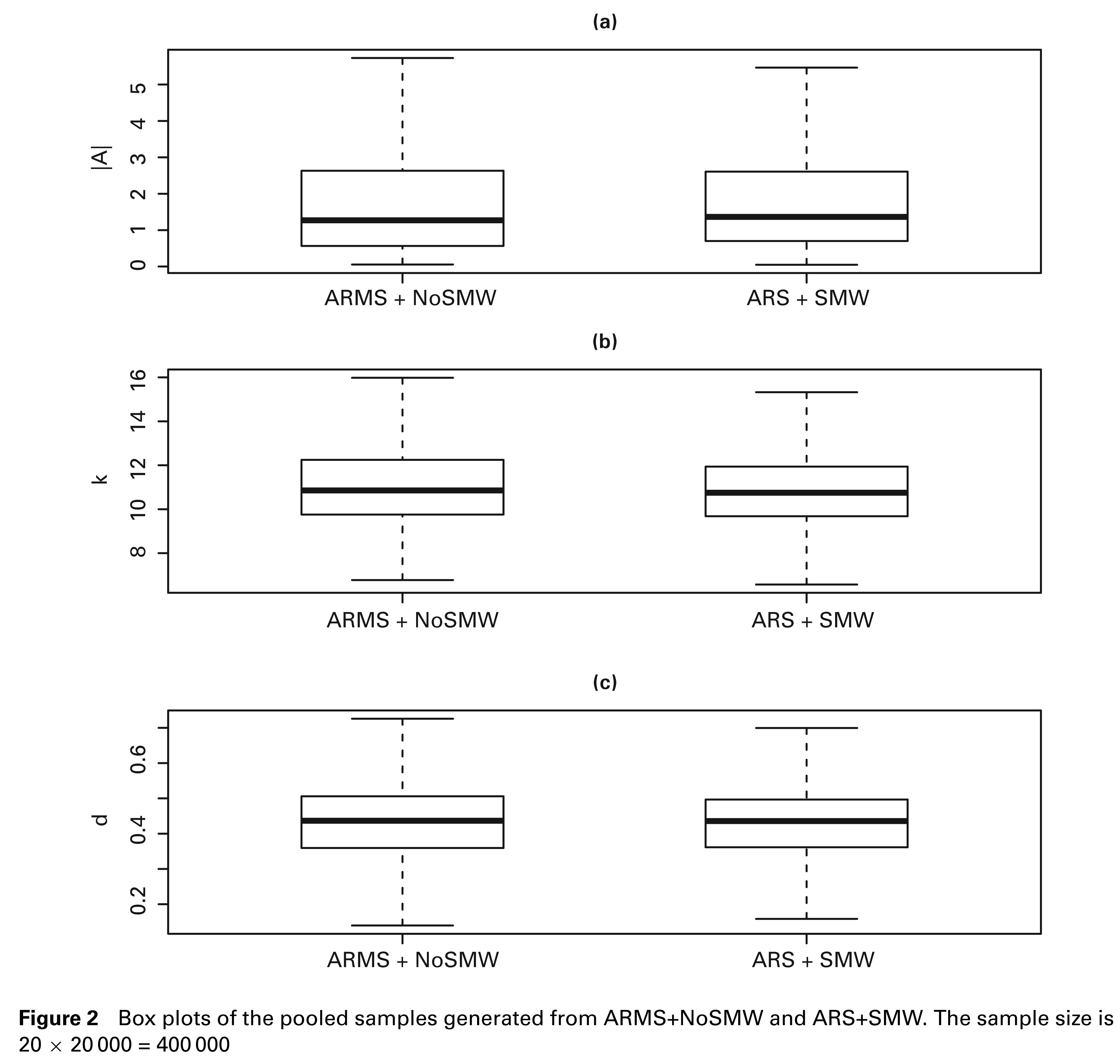
It is important to ensure that the samples generated from ARMS+NoSMW and ARS+SMW are comparable. To compare the posterior draws, for each method we pool all the MCMC draws together, generating a sample size of 20 × 20 000 = 400 000. Figures 2 (a), (b) and (c) show the box plots of |
Box plots of the pooled samples generated from ARMS+NoSMW and ARS+SMW. The sample size is 20 × 20 000 = 400 000
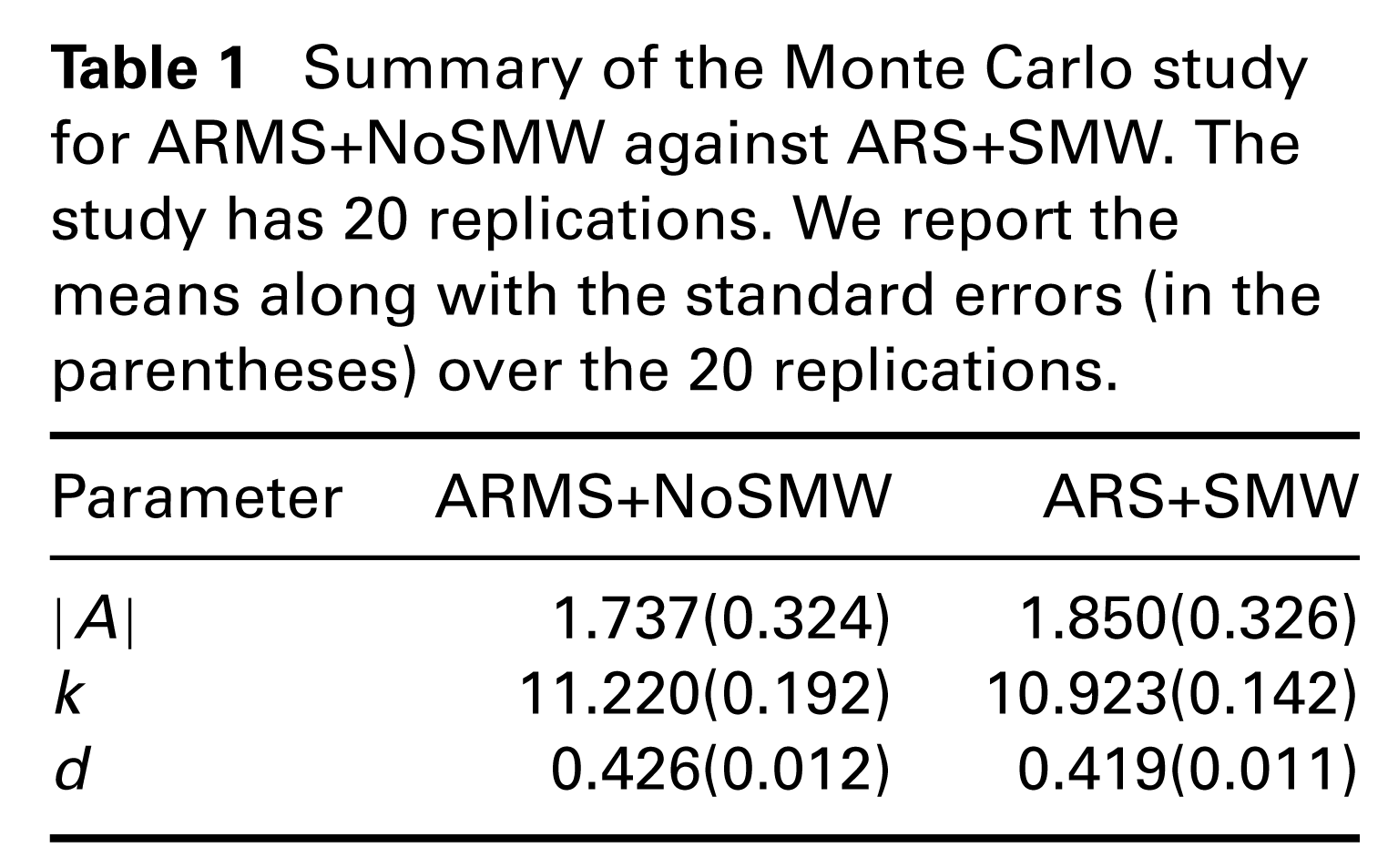
Summary of the Monte Carlo study for ARMS+NoSMW against ARS+SMW. The study has 20 replications. We report the means along with the standard errors (in the parentheses) over the 20 replications.
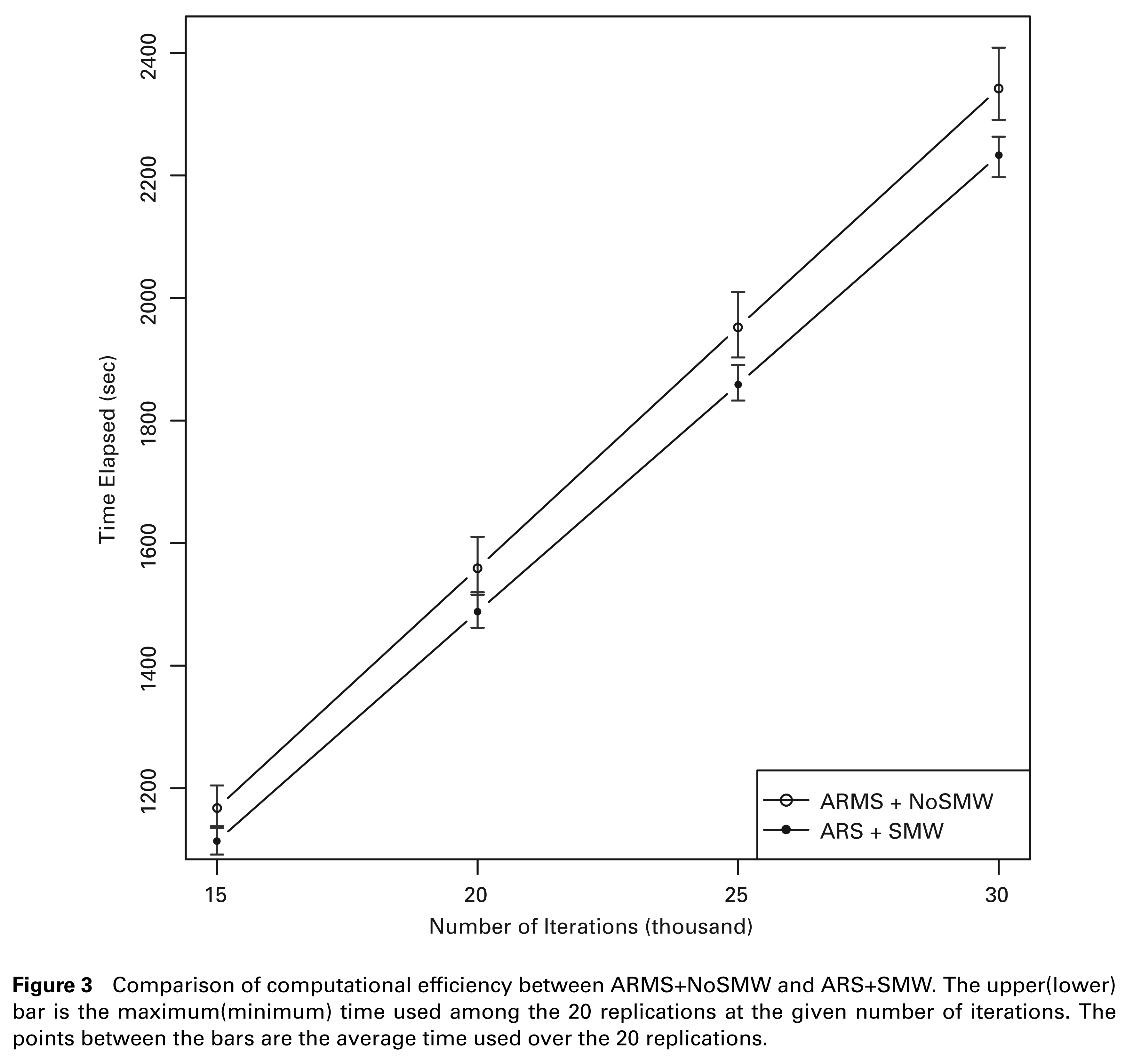
To compare computational efficiency, in each replication we record the time elapsed at n = 15 000, 20 000, 25 000, and 30 000 iterations, and for each n, we find the minimum, average and maximum values among the 20 replications. Figure 3 shows the results. It is interesting to first note that the increase of the running time against the number of iterations is larger for ARMS+NoSMW than for ARS+SMW. Hence, although the minimum–maximum time intervals overlap for n ≤ 20 000, in the end they become disjoint. The result not only presents strong evidence that ARS+SMW is more efficient, but it also indicates that ARS+SMW can be even more advantageous if more MCMC iterations are required. At n = 30 000, where one single MCMC is completed, the average time taken by ARMS+NoSMW(ARS+SMW) is 2 341.9(2 225.4) seconds, showing that ARS+SMW improves the computational efficiency by 5.2%. This can be a considerable saving of time in some practical use, especially when we need to conduct the estimation procedure for multiple times. It is also of our interest to evaluate the contribution from SMW formula alone. We conduct the same experiment for the combination ‘ARMS+SMW’ and compare it with ARMS+NoSMW. The average time to complete a replication with ARMS+SMW is 2 287.4 seconds, indicating that the use of SMW formula saves about 2.4% in running time.
4 Empirical study
In this section we provide an example of how DCFMSV works and compare it with three existing volatility models, namely, AM’s DC-MSV, PG’s diagonal idiosyncratic covariance matrix FMSV model (see equation (9) in PG) and the well-known DCC-GARCH, which belongs to the family of GARCH-type volatility models. It should be emphasized that our purpose is to compare the predictive performance rather than to illustrate more applications. PG have used real data to demonstrate how the WIC FMSV model can be applied to out-of-sample portfolio optimization.
Comparison of computational efficiency between ARMS+NoSMW and ARS+SMW. The upper(lower) bar is the maximum(minimum) time used among the 20 replications at the given number of iterations. The points between the bars are the average time used over the 20 replications.
4.1 The data
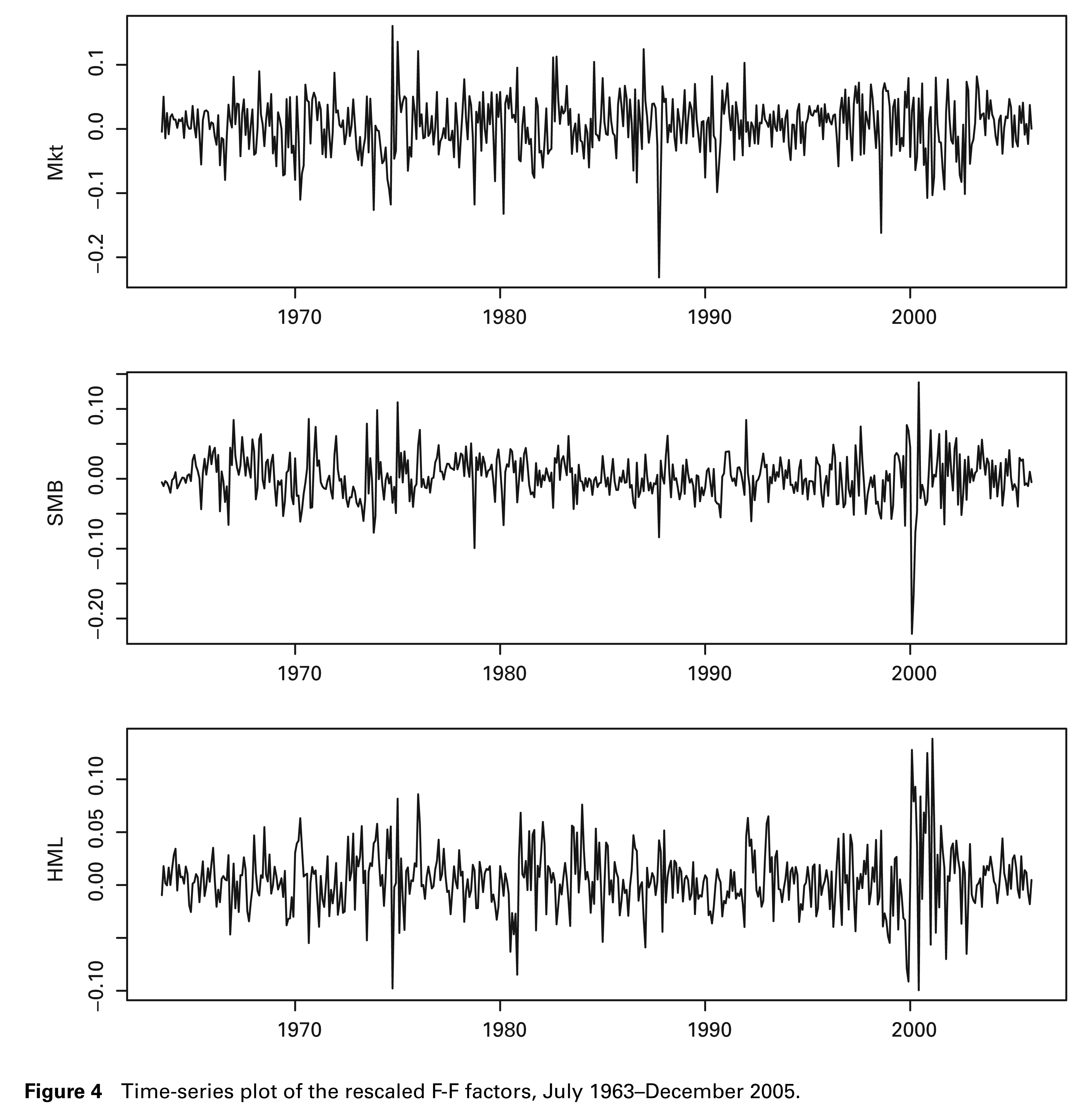
The example is illustrated with monthly data. We choose three Fama-French (F-F) factors: the market excess return (MKT), the Small-Minus-Big (SMB) and the High-Minus-Low (HML) factors. The return series are the average value weighted returns for 10 industry portfolios. The 10 portfolios are NoDur, Durbl, Manuf, Enrgy, HiTec, Telcm, Shops, Hlth, Utils and Other. We obtain the factors and returns from Dr. Kenneth French’s data library. The observation period is from July 1963 to December 2005 with a total sample size of 510. A detailed description for these data can be found in the data library. All data are converted to a (−1,1) scale by multiplying by 0.01. Figure 4 shows the time-series plots of the three rescaled F-F factors. As can be seen clearly, the factor volatilities have quite different patterns. The heterogeneity in factor volatilities suggests that permitting the factors to have separate SV processes is helpful in describing the dynamics.
4.2 Model comparison
The specification of AM’s DC-MSV is identical to settings (2.2a)–(2.5). For PG’s FMSV model, we have the following specification:
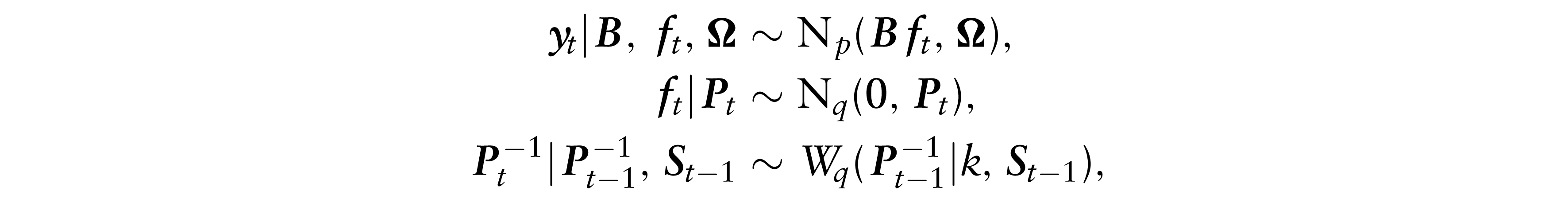
where the matrix 
where M is the specific model, Ft is the information collected up to time t and θM is the set of parameters for M. The cumulative log predictive Bayes factor of Model 1 against Model 0 is calculated by

Kass and Raftery (1995) suggest the log scoring rule for the evaluation of model predictive quality: if log(B1,0) < 0, the evidence is in favour of Model 0; if log(B1,0) ∈ [0, 1), the evidence is not worth more than a bare mention; if log(B1,0) ∈ [1, 3), the evidence is positively in favour of Model 1; if log(B1,0) ∈ [3, 5), the evidence is strongly in favour of Model 1; if log(B1,0) > 5, we have very strong evidence in favour of Model 1. The out-of-sample prediction period is three-year long, from January 2006 to December 2008, with a total length N = 36. This time frame covers two market conditions: a relatively calm market before 2007, and the post-2007 period with a relatively volatile market due to the subprime crisis, in which we can compare model performance across different market conditions. The one-step-ahead prediction is conducted on a rolling basis, that is, if we use observations
Time-series plot of the rescaled F-F factors, July 1963–December 2005.
Results for the comparison of DCFMSV (DCF) against AM’s DC-MSV (AM), PG’s FMSV (PG) and DCC-GARCH (DCC) based on the cumulative log predictive Bayes factor
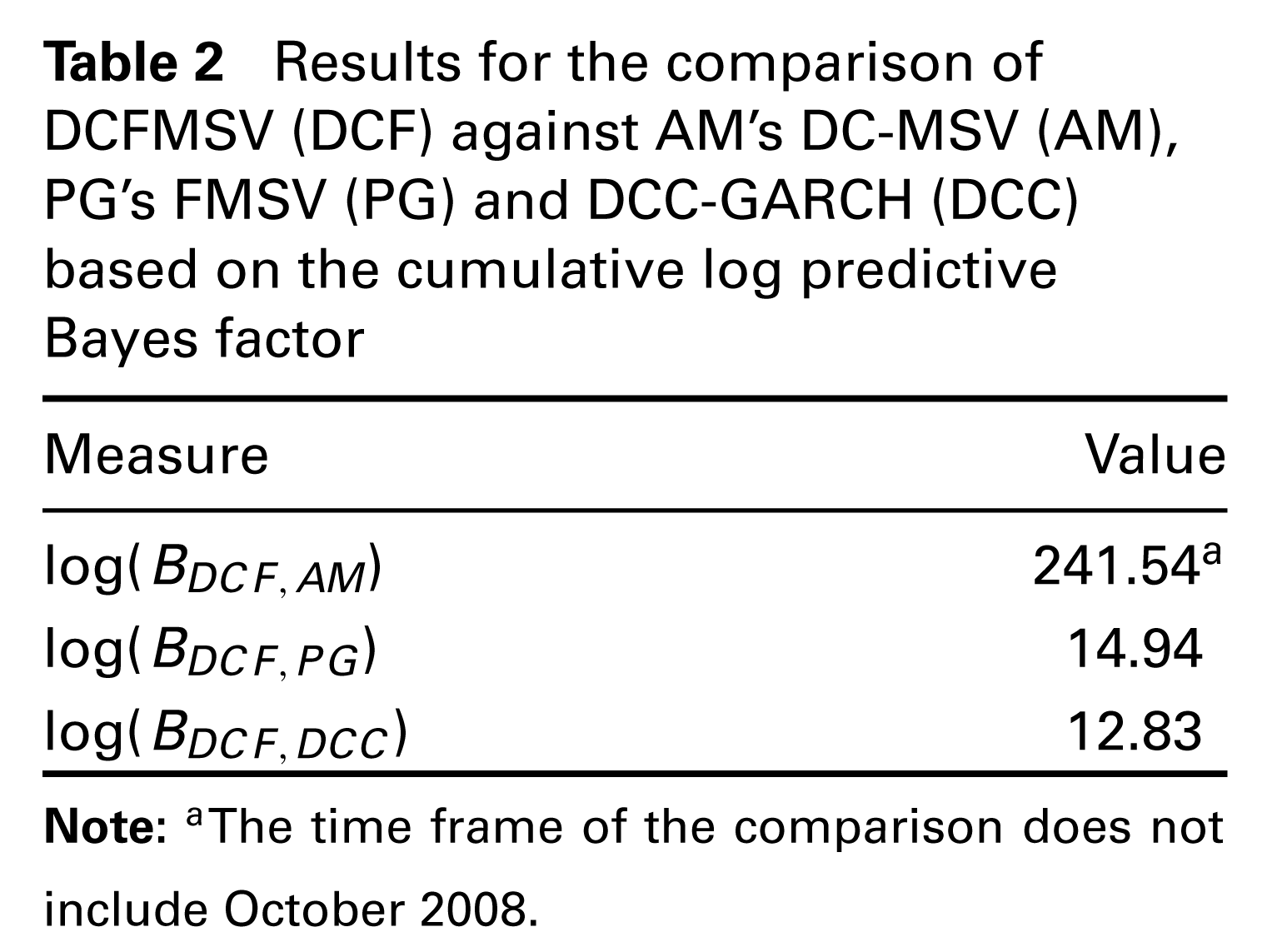
Table 2 summarizes the results. The values log(BDCF,AM), log(BDCF,PG) and log(BDCF,DCC) are the cumulative log predictive Bayes factor of DCFMSV against AM’s DC-MSV, PG’s FMSV and DCC-GARCH, respectively. Contrary to our expectation, the first result suggested by log(BDCF,AM) indicates that DC-MSV performs much worse than its ‘factored’ version, DCFMSV. This result may not be surprising. As we point out in the introduction, since the whole large dependence structure is governed by simply one scalar parameter d, all the 55 elements have to compromise with each other to some extent. Moreover, DC-MSV performs particularly poorly in turbulent periods. For October 2008, the month right after the bailout of Fannie Mae and Freddie Mac, the predictive likelihood under DC-MSV is not even available because the value is smaller than the minimum value representable by the software package. In addition to the poor predictive quality, the rapid increase in computational cost makes DC-MSV unfavourable to work with. The running time of DC-MSV on the 10-dimensional data is more than seven times as much as that of DCFMSV with three factors. From both perspectives we argue that DCFMSV is more suitable than DC-MSV when the dimension of data is large. The other results in Table 2 show the superiority of DCFMSV over PG’s FMSV and the DCC-GARCH model.
The empirical study offers another chance to compare the computational efficiency. We utilize both ARMS+NoSMW and ARS+SMW to estimate DCFMSV. The running time taken by ARMS+NoSMW (ARS+SMW) is 85 960 (82 438) seconds, showing that ARS+SMW saves almost 1 hour, which we believe is quite favourable for practitioners. Notice that, compared to the result of the Monte Carlo study in Section 3.3, here the improvement by ARS+SMW is reduced to 4.2%. This is because the augmented factor covariance matrix is only of dimension 3, and consequently, SMW formula makes limited contribution. Figure 5 is the plot of the running time for each forecasting period. It is readily seen that the time curve of ARS+SMW is uniformly below that of ARMS+NoSMW. Moreover, the running time increases as the time frame expands, and the difference between the two time curves is enlarged. The pattern implies that, for the applications that require repeated estimation, the use of ARS+SMW is even more favourable.
We close this section with the discussion on the choice of the number of factors, which is an important issue that is not explored in PG. To deal with the model selection problem, we suggest a straightforward solution utilizing the cumulative log predictive Bayes factor. For example, suppose we want to select between the three-factor (full) model and the two-factor (reduced) model which contains the pair of factors (MKT, SMB). We calculate and obtain log(BReduced, Full) = 5.82 > 5, by which we would select the two-factor model since it provides a better fit to the data.
Comparison of computational efficiency between ARMS+NoSMW and ARS+SMW using real data.

5 Conclusion and discussion
This article proposes a flexible dynamic-correlation FMSVmodel in which the factors are observable. The novelty of the model is its ability to simultaneously allow the factors to have separate SV processes and the factor covariance matrices to follow an inverse Wishart process. To estimate the model, we develop a computationally efficient method based on Bayesian MCMC algorithms. The method makes two contributions to the WIC literature. First, it substantially improves the computational efficiency of MCMC sampling. Second, forecasting can be carried out with the algorithm, which in turn provides a solution to the choice of the number of factors. These improvements to a great extent broaden the scope of the WIC model applications. The result of the model comparison based on predictive quality shows that DCFMSV outperforms all other competing models, including AM’s DC-MSV, PG’s FMSV and DCC-GARCH.
In DCFMSV we can as well apply a latent factor structure, where the factors need to be estimated. However, because of the well-known nonidentifiability problem, some constraints such as the lower triangular condition on the loading matrix must be imposed (see, for example, Geweke and Zhou, 1996; Lopes and West, 2004). Concern arises when applying this type of constraints, in view of the fact that the zero structure on the upper triangle blocks the channels through which the factors come into the system. As a result, the first series
Footnotes
Acknowledgements
The author is grateful to Professor Robert Kohn at the University of New South Wales, Sydney, Australia, for his valuable comments on the article.