
Abstract
In oncology, overall survival (OS) is the optimal endpoint for measuring the clinical benefit. However, and contrary to progression-free survival (PFS) which represents a potential surrogate endpoint of OS in clinical trials, OS often requires a long follow-up where the effect of the studied treatment may be diluted by subsequent therapies. In the literature, the relationship between PFS and OS was investigated more analytically than theoretically. We propose a new statistical modelling for OS based on the two survival times: PFS and post-progression survival (PPS) which we assumed to be linked using a conditional exponential distribution. This model allows us to test the existence of an association between PFS and PPS to better understand the process of improvement or decrement of OS. We found a closed form of the correlation coefficient between PFS and both PPS and OS. We expressed them as simple formulas in function of model parameters. One of the model parameters proved to be a correlation indicator between these survival times. We also defined the likelihood of the model in order to use the maximum likelihood estimator to estimate the model parameters from Phase III randomized clinical trial data, involving patients with locally advanced non-small cell lung cancer. The results showed a significant link between PFS and PPS and a strong association between improvements in PFS and OS.
Keywords
1 Introduction
In oncology studies, clinical trials are carried out to assess the effect and confirm the effectiveness of an intervention, an experimental drug or treatment using clinical endpoints measured, generally based on the time of occurrence of an event and more specifically on the survival time. The US Food and Drug Administration (FDA) considers overall survival (OS) as the most reliable cancer endpoint to measure the clinical benefit. According to US FDA (2007) guidelines, OS is defined as the time from randomization until death from any cause. Indeed, OS considers all forces of mortality related or not to the disease of interest. For example, cancer patients face death from their cancer and also from other life-threatening situations, such as, the toxicity of the cancer therapy itself, other diseases and accidents. OS is based on the accurate statistic of date of death and is therefore easy to measure and clinically significant. However, as OS often requires lengthy and expensive clinical trials, it is not easy to conclude that an experimental treatment improves survival or not. Indeed, to approve drug efficiency or to detect treatment differences, it is necessary to monitor a considerable number of patients over a long period. That is why it is interesting to substitute OS by a valid clinical surrogate endpoint to mesure the effect of treatment after a relatively short period of time.
There are several clinical criteria that have been used to approve the effectiveness of treatment. These criteria are based on tumour assessments such as response rate that is not a time-to-event endpoint, time-to-progression (TTP) and progression-free survival (PFS). Note that a precise and detailed definition of tumour progression based on the RECIST, (Therasse et al., 2000; Eisenhauer et al., 2009) amendments is essential in the protocol. The FDA has defined PFS as the time elapsed between randomization and tumour progression or death from any cause. On the other hand, TTP is defined as the time from randomization to tumour progression where deaths occurred before progressions were censored which is not the same functional aspect as in PFS. Porzsolt et al. (2009) showed that TTP overestimates treatment effects and so it is more appropriate to use PFS as a surrogate of OS. By considering PFS as a primary endpoint, the FDA has recently approved several new cancer drugs. While there is no formal validation of PFS as a surrogate endpoint in advanced breast cancer (Burzykowski et al., 2008; Saad et al., 2010), PFS formally became a valid primary endpoint for colorectal cancer (Buyse et al., 2007; Tang et al., 2007). S. Singh and C. Law (2010) reported that the use of PFS as an endpoint in neuroendocrine tumour clinical trials may facilitate the evaluation, approval and development of new treatments.
At first sight, PFS seems to be the most suitable substitute for OS because it requires follow-up only until tumour progression. As rightly pointed out by Dr Daniel J. Sargent, a biostatistician within the North Central Cancer Treatment Group, in an article (Mayfield, 2008) ‘Most patients stop taking the study drug when their disease begins to progress, so the PFS clock stops at that point.’ Because PFS reduces the duration of clinical trials, the experimental treatment effect cannot be confounded by subsequent therapies. Furthermore, PFS includes death and thus the relationship between PFS and OS can be an even better correlation. If in fact there is a positive correlation between PFS and OS, it suggests that improvement in PFS leads to improvement in OS and so PFS may be an appropriate potential surrogate. In order to provide a surrogate endpoint for OS, several authors have empirically investigated the correlation between OS and other clinical criteria especially PFS (see Louvet et al., 2001; Ballman et al., 2007; Sherrill et al., 2007; Burzykowski et al., 2008; Lamborn et al., 2008; Foster et al., 2011; Heng et al., 2011; Hurvitz, 2011).
Despite the use of correlation approach as a statistical method in the majority of studies and the importance of PFS as a potential surrogate endpoint in the development of new anti-cancer treatments, there are few studies on parametric approaches that characterize OS and its association with PFS. Assuming an appropriate distribution for survival times, it is possible to introduce explanatory variables in the functions of risk. By taking into account more information, the estimators obtained are more efficient than the nonparametric estimators as the Kaplan and Meier (1958) estimator, and this is one of the main advantages of the parametric approaches. Begg and Larson (1982) used a parametric model where the time to tumour progression or to death was assumed to be exponential. Building on this work, Ellis et al. (2008) used other time-to-event distributions than the simple exponential such as Weibull and log Normal. Fleischer et al. (2009) developed a statistical model of OS based on exponential distributions assuming a dependency between TTP and OS. Moreover, continuous-time multi-state models are a useful way of describing medical processes allowing patients to move from one state to another, for example, from disease-free state to death state. The progressive three-state model and the illness–death model are the most commonly used three-state model. In the Markov model, the transition intensity which represents the instantaneous risk of moving from one state to another depends only on the current state. There are different models regarding the dependance of the transition intensity. First, the time-homogeneous Markov model allows transition probabilities to be found in closed form using Kolmogorov’s forward equations (Cox and Miller, 1965) where the transition intensities are assumed to be constant as functions of time. In addition, a time non-homogeneous Markov model is needed in cases where the transition intensities vary through current time. Non-homogeneous Markov processes may be modelled parametrically by assuming piecewise constant transition intensities (Perez-Ocon et al., 2001) or nonparametrically using the Aalen–Johansen estimator for the estimation of the state occupation probabilities (Aalen and Johansen, 1978). However, the Markov property may be inappropriate and may lead to biased estimates. It should be noted that Datta and Satten (2001) showed the consistency of the Aalen–Johansen estimator even when the multi-state model was not Markov. Another approach is to use the semi-Markov model in which the transition intensities not only depend on current time, but also on the duration in current state (Andersen and Keiding, 2002). Finally, avoiding the Markov property, Pepe (1991), Strauss and Shavelle (1998) and Meira-Machado et al. (2006) proposed nonparametric estimators for the probability of state occupation based on the proportion of censored and uncensored patients in each state.
In this article we propose an alternative parametric modelling for OS that is easy to understand and to implement. The proposed model generalizes the structure of dependency between PFS and OS. The rest of this article is organized as follows. The approach is described in Section 2 by generalizing the main functions which are useful for modelling. In Section 3, the general form of model likelihood is given. Section 4 presents the proposed model, the obtained correlation coefficients and also the use of covariates. Section 5 presents an application to data from a randomized Phase III clinical trial involving patients with locally advanced non-small cell lung cancer. In conclusion, there is a discussion in Section 6.
2 General model
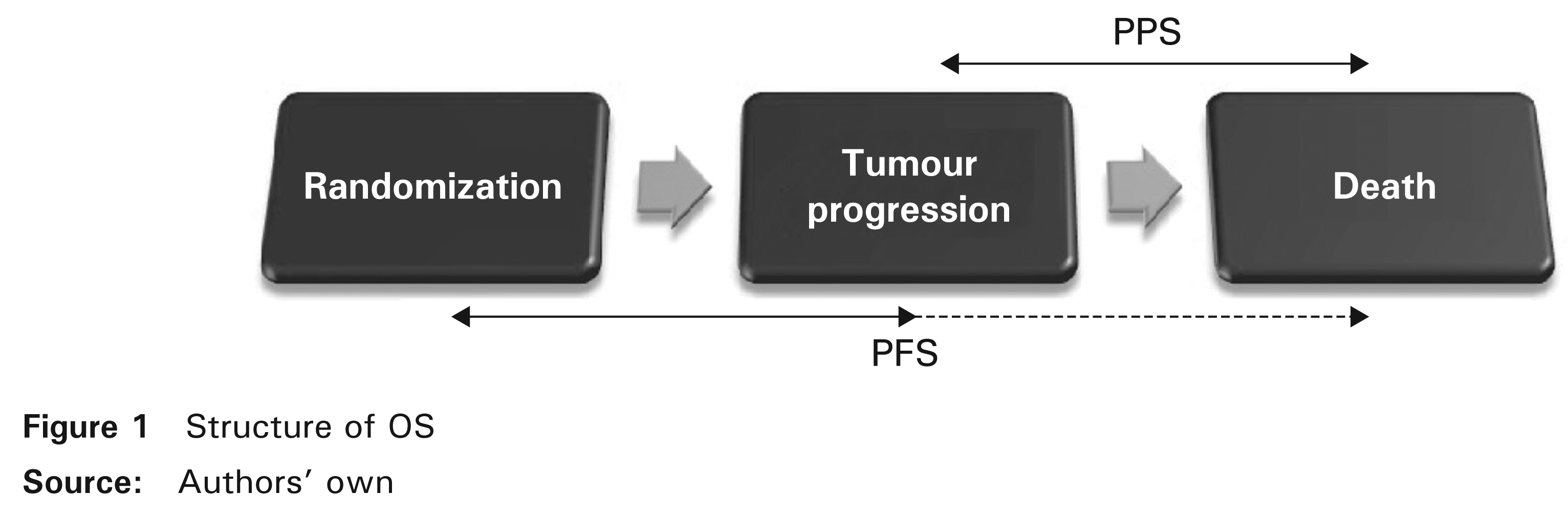
As indicated in Figure 1, if tumour progression and death have been observed then OS includes two consecutive survival times before and after progression, PFS and post-progression survival (PPS). PPS is defined as the time elapsed between tumour progression (relapse) and death. If death is the only event observed, by definition, it is regarded as a progression and therefore PFS ≤ OS. The purpose of this section is to generalize the distribution of OS that we consider to be the sum of two assumed dependent survival times, PFS and PPS.
We start with a random experiment that has a sample space R and a probability measure P on R. Suppose that T, X and Y are survival times for the experiment, where T represents OS, X is PFS and Y is PPS. These survival times take as values t, x and y respectively. We assume that X and Y could be statistically dependent. Since T = X + Y, FT, the distribution function of T, is defined as follows:
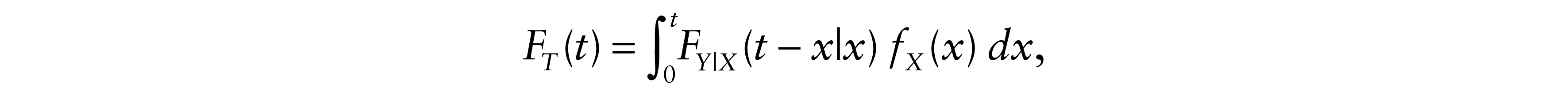
where fX is the density of X and FY|X is the conditional distribution function of Y at y given X = x.
By deriving FT(t) with respect to t, we found fT, the density of T
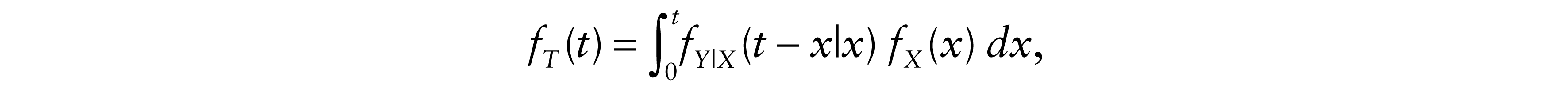
where fY|X is the conditional density of Y at y given X = x.
Given that ST(t) = 1 – FT(t), we deduced ST, the survival function of T
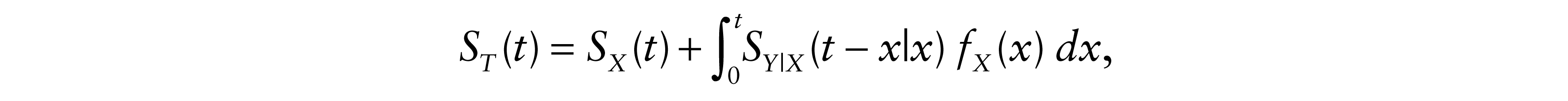
where SX is the survival function of X and SY|X is the conditional survival function of Y at y given X = x.
Moreover, S
Y
, the survival function of Y is
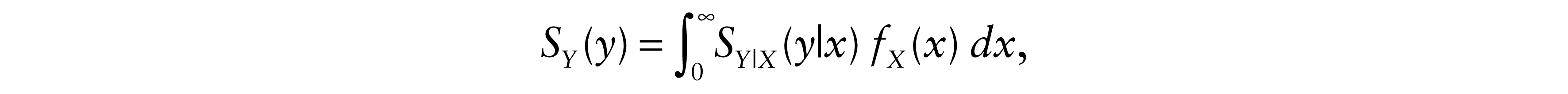
and the expectation of T is obtained as follows:
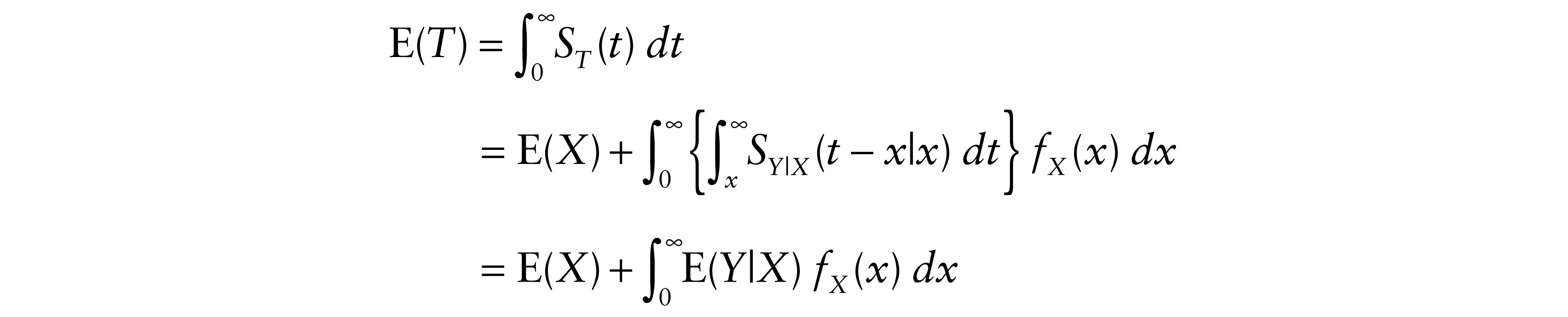
where
3 Model likelihood
In order to estimate the model parameters, we used the maximum likelihood estimator (MLE). Based on the general form of the likelihood described by Yuan et al. (2011), we constructed the likelihood of our model by a factorization of five categories representing the eventual contributions of the likelihood for each patient.
Let N be the sample size and nj(j = 1,...,5) be the number of patients in each category,
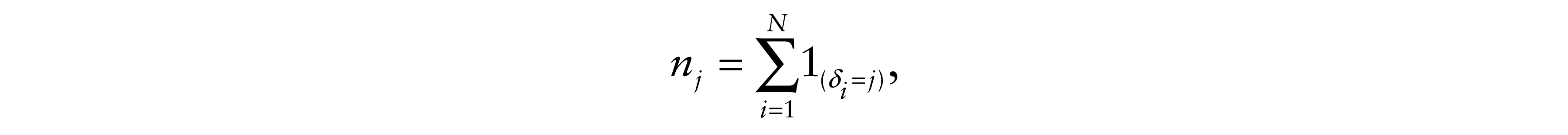
where, for the ith patient, we define δi(i = 1,...,N) as the categorical indicator, stated as follows:
For δi = 1, tumour progression and death were both observed and so the total likelihood contribution in this category is
where yi = ti – xi. For δi = 2, only tumour progression was observed and therefore death is censored. Let C be the administrative right censoring time which is assumed to be independent of survival times. Conditionally to xi, yi and If death occurred while tumour progression had not been yet observed, we have two possible likelihood contributions according to cause of death information: For δi = 3, if the observed death was related to cancer, either directly or indirectly, then the total likelihood contribution in this case becomes
because it is much more reasonable to assume that an undiagnosed relapse occurred either before or at the time of the observed cancer death (X ≤ t). Otherwise, for δi = 4, the observed death was due to causes other than cancer. In that case, relapse is censored and the total likelihood contribution is
Finally, for δi = 5, neither tumour progression nor death were observed. Patients alive at the end of follow-up and lost to follow-up are censored. Then, the total likelihood contribution is
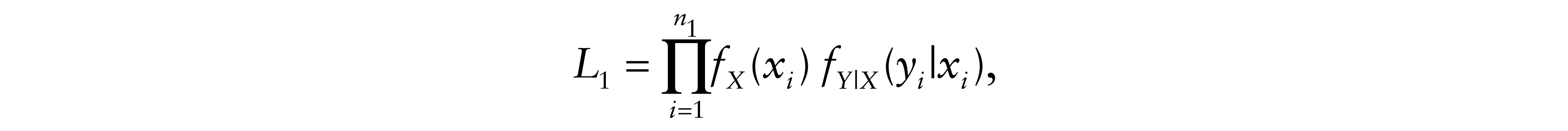
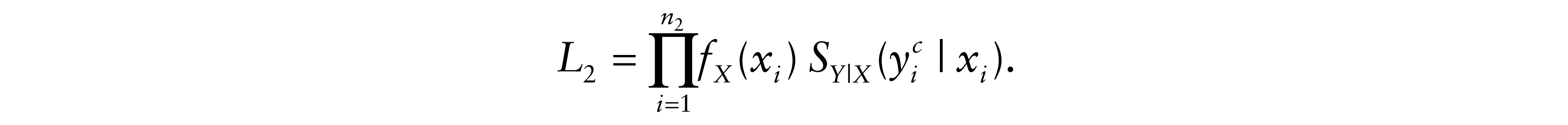
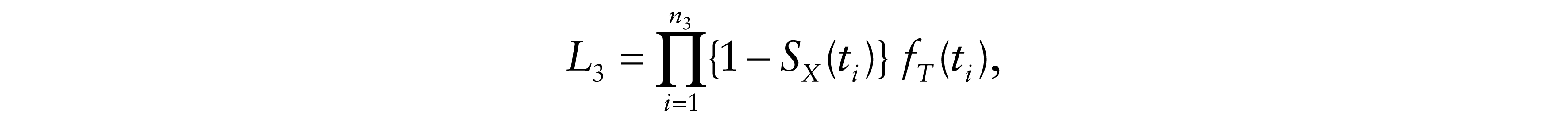
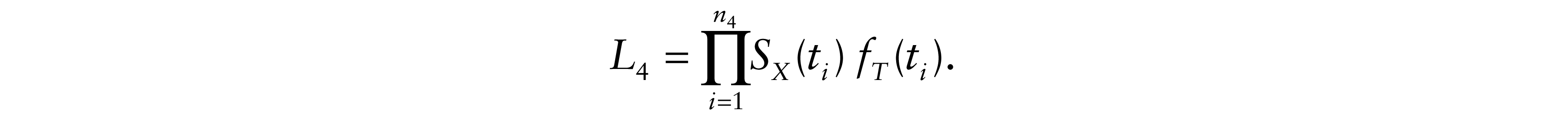
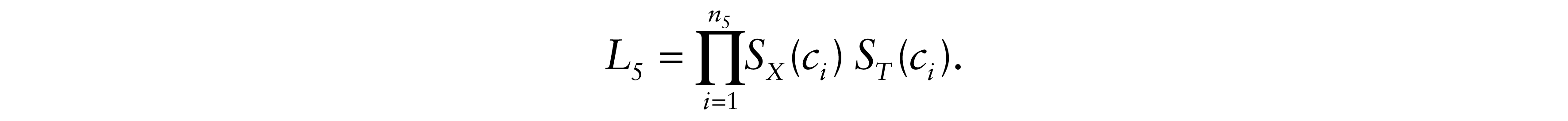
Therefore, the likelihood of the model is
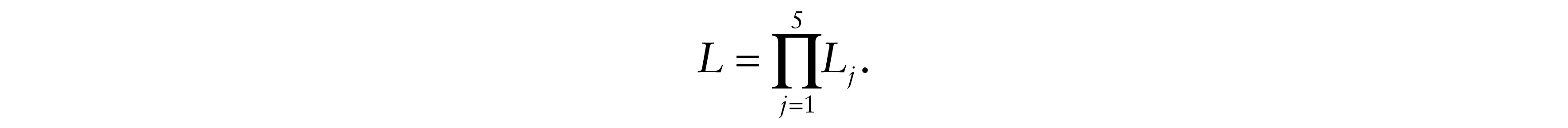
4 Proposed model
Based on the reasoning of Section 2 and the fact that the dependence structure between X and Y is represented by the conditional distribution of Y given X, we considered X and Y | X to be exponentially distributed with parameters λ and θ(x) respectively. Regarding the choice of θ(x), we preferred the flexible exponential form because it allows for analytical computation of the correlation coefficients, ease of parameter interpretation and potential goodness of fit.
For β and ν in R, we define
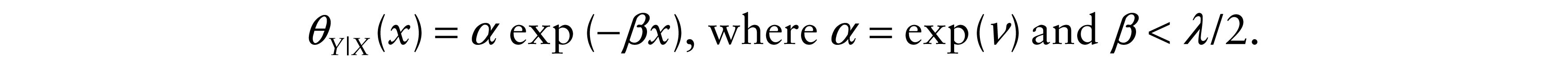
Hence, the hazard function of Y is
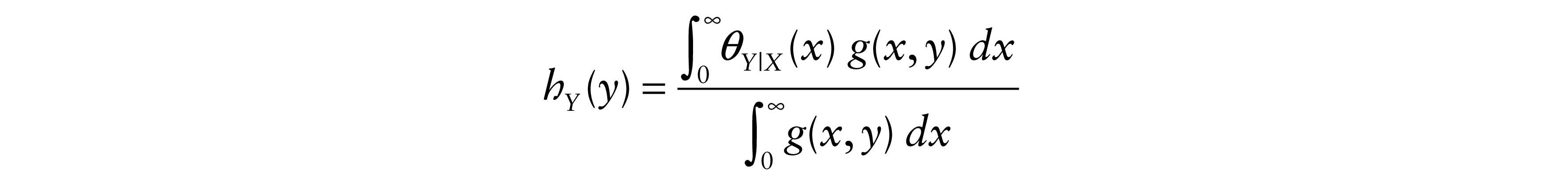
and the mortality fonction of T is
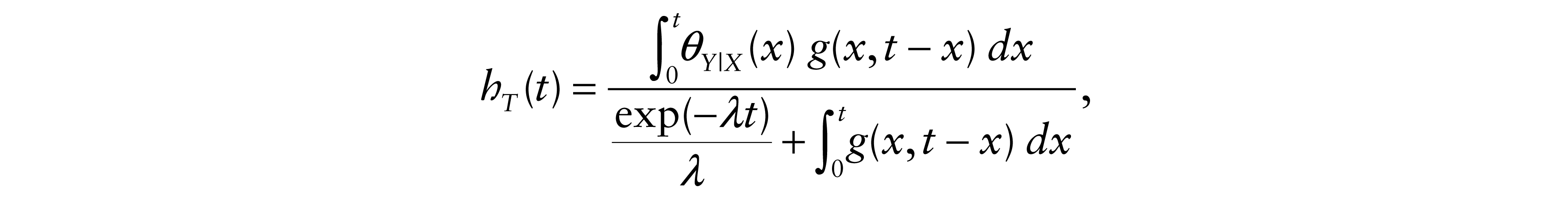
where g(x, y) = exp{–[θY|X(x)y + λx]}.
4.1 Measure of the association strength
In clinical studies, the validity of surrogate endpoints is an extremely important concept which remains fairly complex and poorly understood. Prentice (1989) established criteria to validate surrogate endpoints. These criteria essentially require that the surrogate and the true endpoints correlate. In cases where a death is related to tumour progression, there is a causal connection which most probably involves a correlation between X and T. We therefore determined correlation coefficients in order to measure the magnitude of this possible association.
First, we found the expectations of Y and T
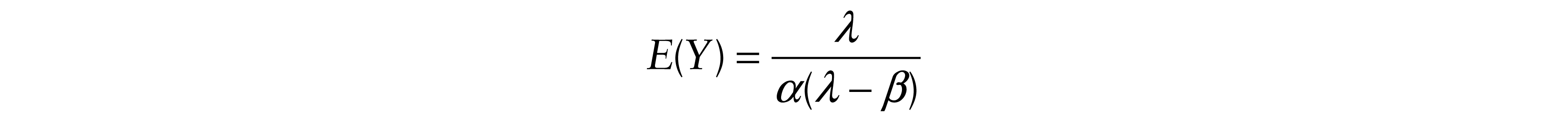
and
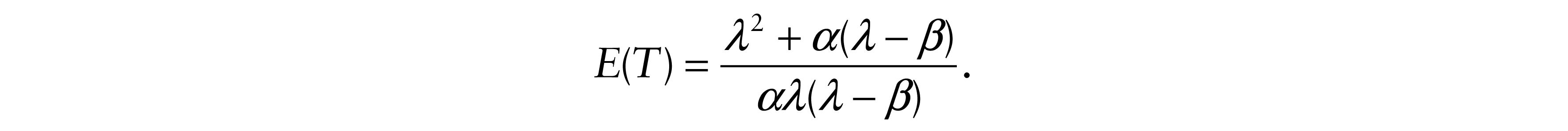
Therefore, the covariances between X and Y and also between X and T are
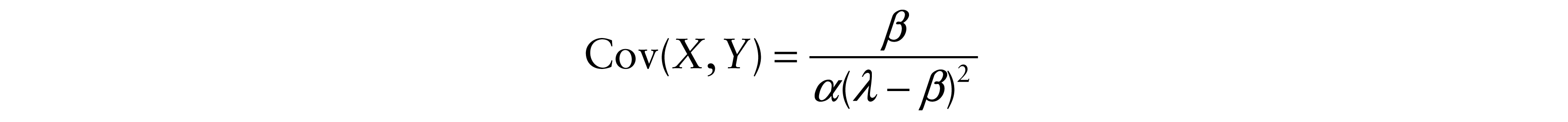
and
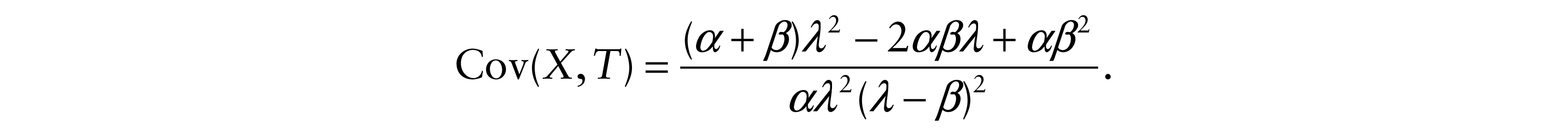
Correlation coefficient is based upon the covariance between the survival times that is a measure of how these variables change in relation to each other. So, technically the parameter β represents a correlation indicator that reveals the direction of the relationship between X and Y as well as between X and T. We noted that:
If β = 0, then Cov(X, Y) = 0 and Cov(X, T) = 1/λ2. In this case, survival times X and Y are uncorrelated, where Y follows an exponential distribution with a rate parameter α. If β > 0, then Cov(X, Y) and Cov(X, T) are positive. Thus, X and T (or Y) evolve in the same direction. In other words, for each increase in X compared to its average, we have an increase in T (or Y) compared to its average, and for every decrease in X, we have a decrease in T (or Y). f –α ≤ β < 0, then Cov(X, Y) is negative and Cov(X, T) is positive. This means (unlike X and Y) that X and T are positively correlated. It is not uncommon to observe a significant increase in X that offsets the decrease in Y and thus obtaining an increase in T. If β < –α, then Cov(X, Y) is negative and Cov(X, T) is null for
Further, we calculated variances of Y and T
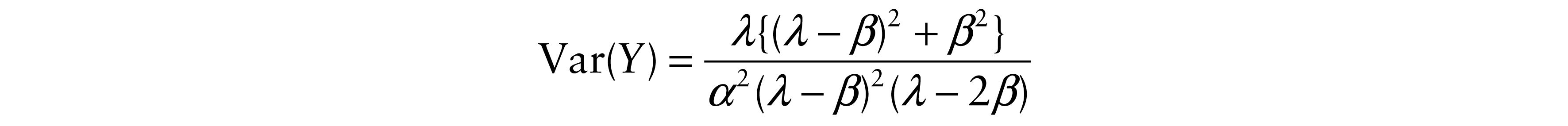
and
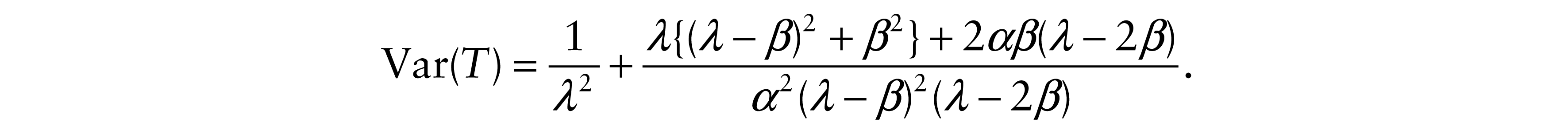
Finally, correlation coefficients were determined as
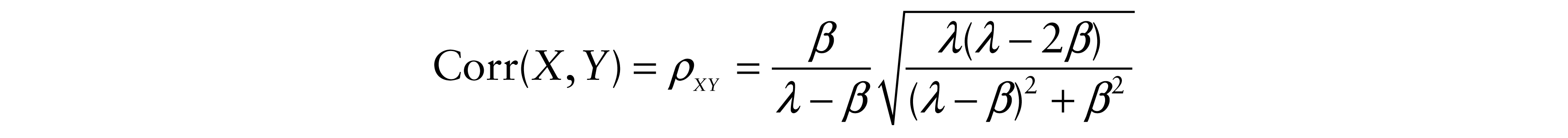
and
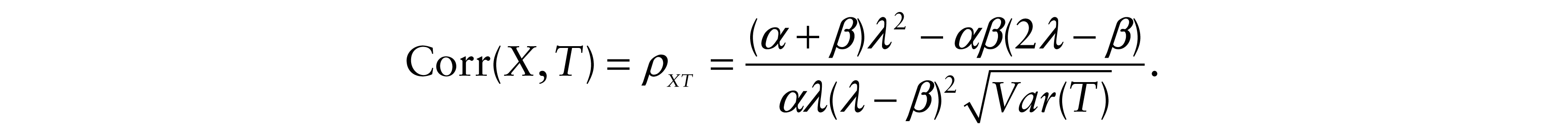
Moreover, since these values are nonlinear functions of parameters λ, ν and β, we estimated the variances of the estimated correlation coefficients
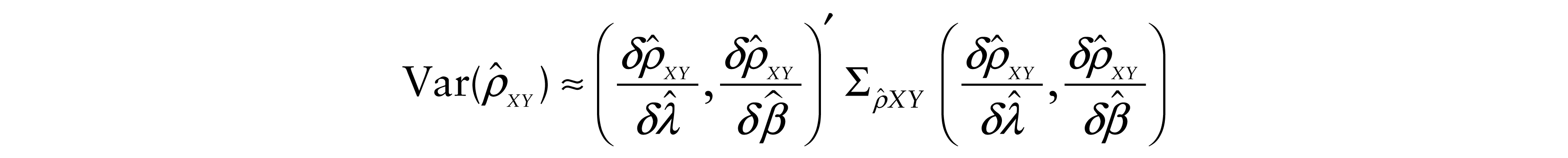
and
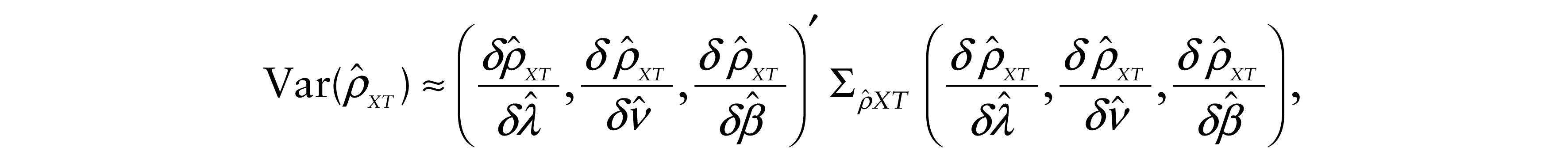
with the asymptotic variance–covariance matrices
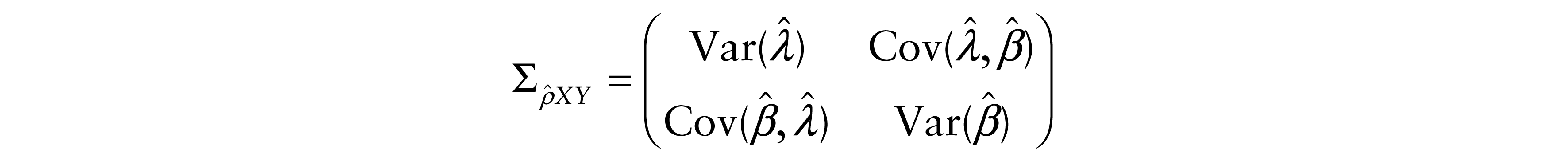
and
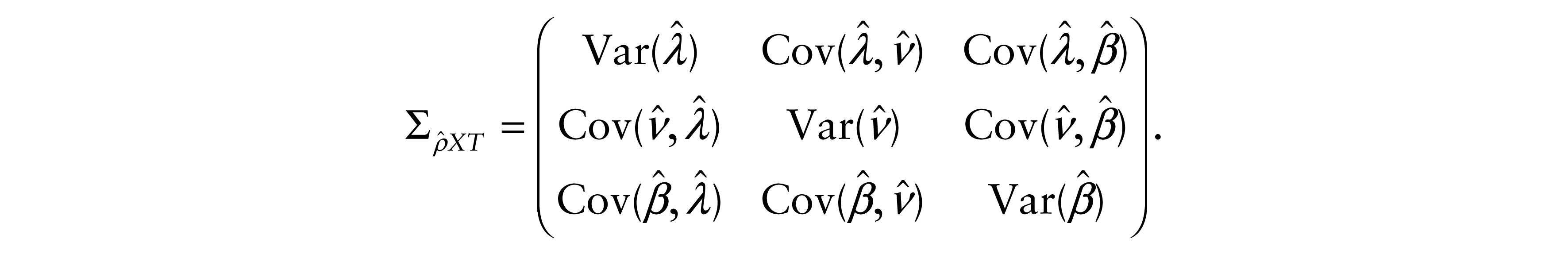
All proofs are outlined in the Appendix.
4.2 The use of covariates
The explanatory variables usually represent either individual characteristics, such as, age, sex, tumour stage and histology, or a set of one or more indicator variables representing different primary (first-line) and subsequent (second-line) treatment groups. The proposed model allows the introduction of explanatory variables. Consider z1 and z2 to be two vectors of covariates that may have had an effect on X and Y respectively. Also let γ′, γ″ be the vectors of coefficients respectively associated to z1 and z2. Thus, based on the Cox (1972) form of the proportional hazards regression model, the hazard functions of X and Y | X are
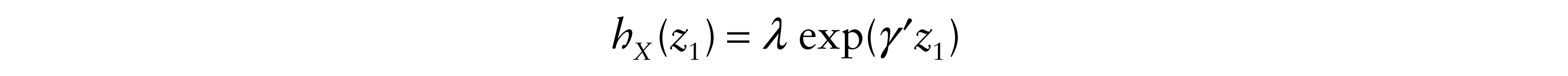
and
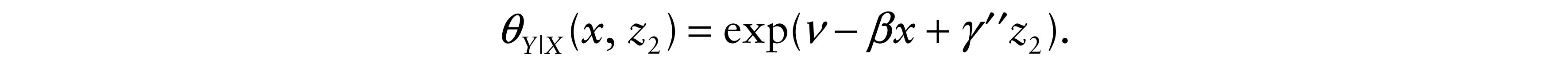
5 Application and numerical results
5.1 Database
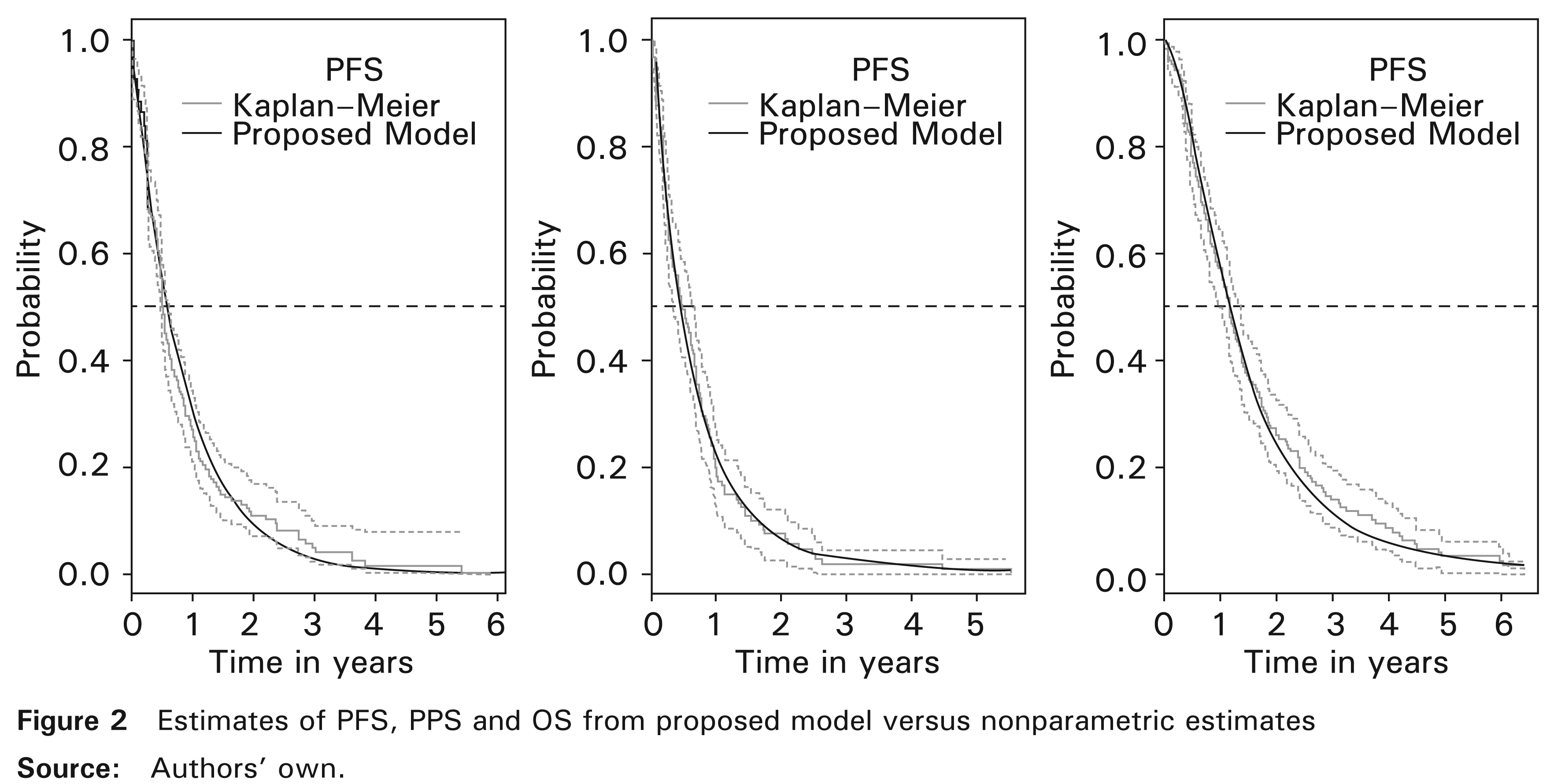
In this section, the theory presented earlier is illustrated by its application to data from a randomized Phase III clinical trial involving patients with locally advanced non-small-cell lung cancer (NSCLC) carried out by Fournel et al. (2005). The main objective of this study was to compare the results in terms of survival between chemotherapy–radiotherapy concomitant and sequential reference treatment. In the reference arm, the chemotherapy prescribed was the association of Cisplatin Vinorelbine, according to a procedure similar to that described by Le Chevalier et al. (1994). The radiotherapy was traditionally performed to deliver a dose of 66 Gy over six and a half weeks. In the concomitant arm, the same radiotherapy was used except that it was carried out at the beginning of the treatment along with chemotherapy combining Cisplatin-Etopside in accordance with the procedure described by Lee et al. (1996). This treatment is similar to that reported by Komaki et al. (1994). Following this treatment, two cycles of Cisplatin-Vinorelbine were administered so that in the two arms, patients received the same total dose of Cisplatin. Tumour progression was defined as a progression in measurable lesions or by the development of new lesions. At the end of follow-up, time-to-progression with the mode of relapse (if occurred) and survival time with cause of death (if observed) were obtained. Note that in this database, there is no information available on subsequent therapies and also the observed deaths are largely attributed to cancer. As results showed no significant difference between treatment arms neither in OS nor in PFS, we combined the two datasets as a mono-arm. In total, 182 patients were studied and were distributed as follows: n1 = 121 patients had a relapse before dying, two patients (n2 = 2) had only a relapse, n3 = 46 died from cancer without relapsing and n5 = 13 neither relapsed nor died. In years, the median follow-up yielded 1.10 (range 0.02 to 6.37). Using the nonparametric Kaplan–Meier estimator, median OS reached 1.15 (CI95%. 0.95 – 1.34), median PFS was reported as 0.50 (CI95%. 0.47 = 0.61) and median PPS was 0.46 (CI95%. 0.31-0.63).
5.2 Estimate without covariates
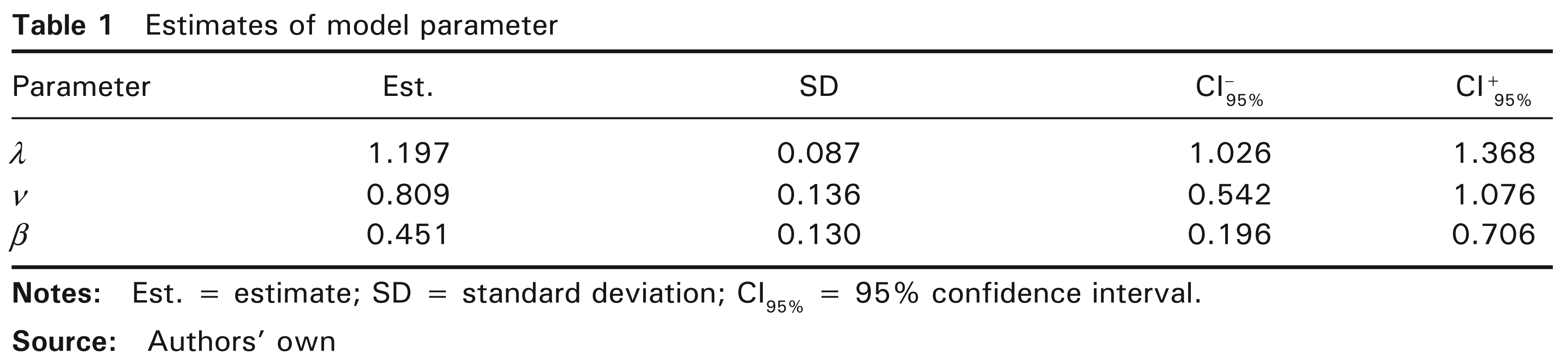
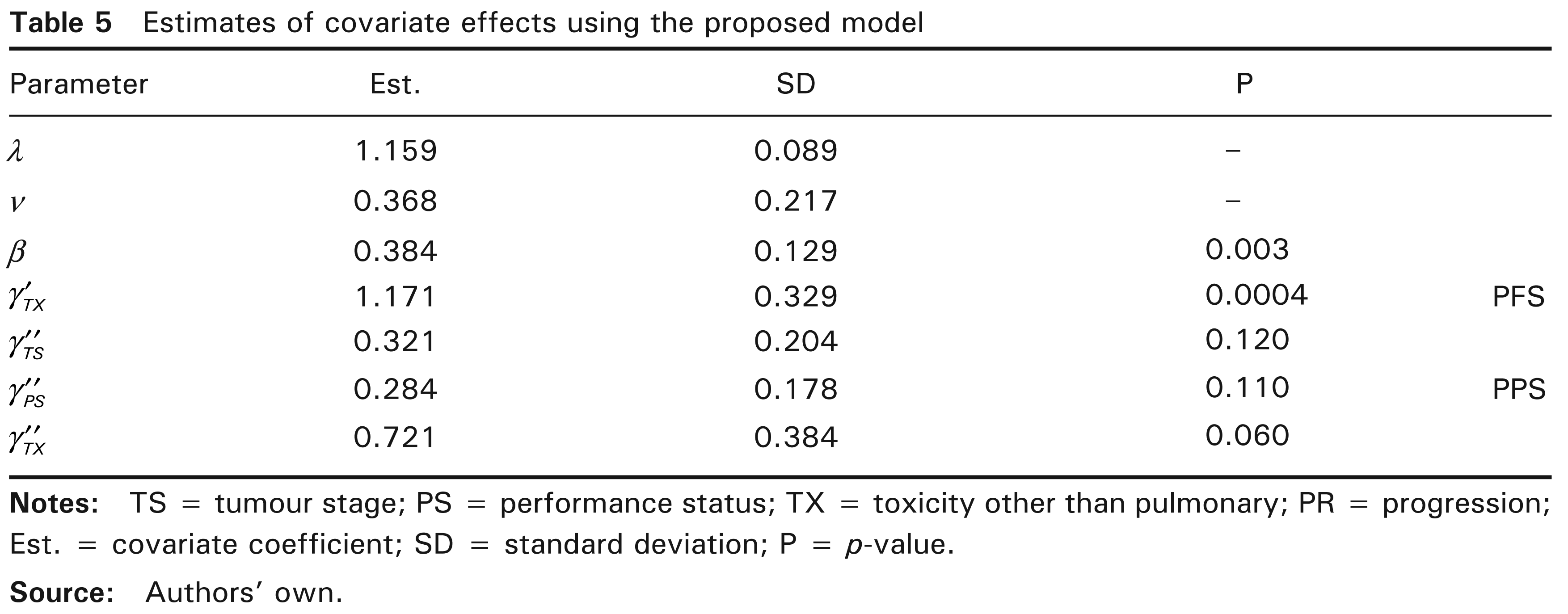
To solve the optimization problem and thereby find the MLE (see Section 3), we used the following two R software packages consecutively: DEoptim (Ardia et al., 2011) to find starting values, and alabama (Varadhan, 2011) to implement constrained optimization. The optimization algorithm was applied to a sample made up of full range of initial values to ensure that the global maximum is obtained. Through the differential evolution algorithm, DEoptim performs global optimization (for more details, see Mullen et al., 2011). In the alabama package, the constrOptim.nl and auglag functions use the augmented Lagrangian and adaptive barrier minimization algorithm in which constraints are allowed. Note that an approximate Hessian matrix can be provided both by the auglag function and by the fdHess function in the nlme R package using finite differences (Pinheiro et al., 2010). By considering the model without covariates, estimates of the three parameters and associated standard deviations and confidence intervals are obtained as set out in Table 1. Note that the model was globally significant because estimates were relatively accurate (with narrow CI). In addition, the estimator
5.3 Covariates
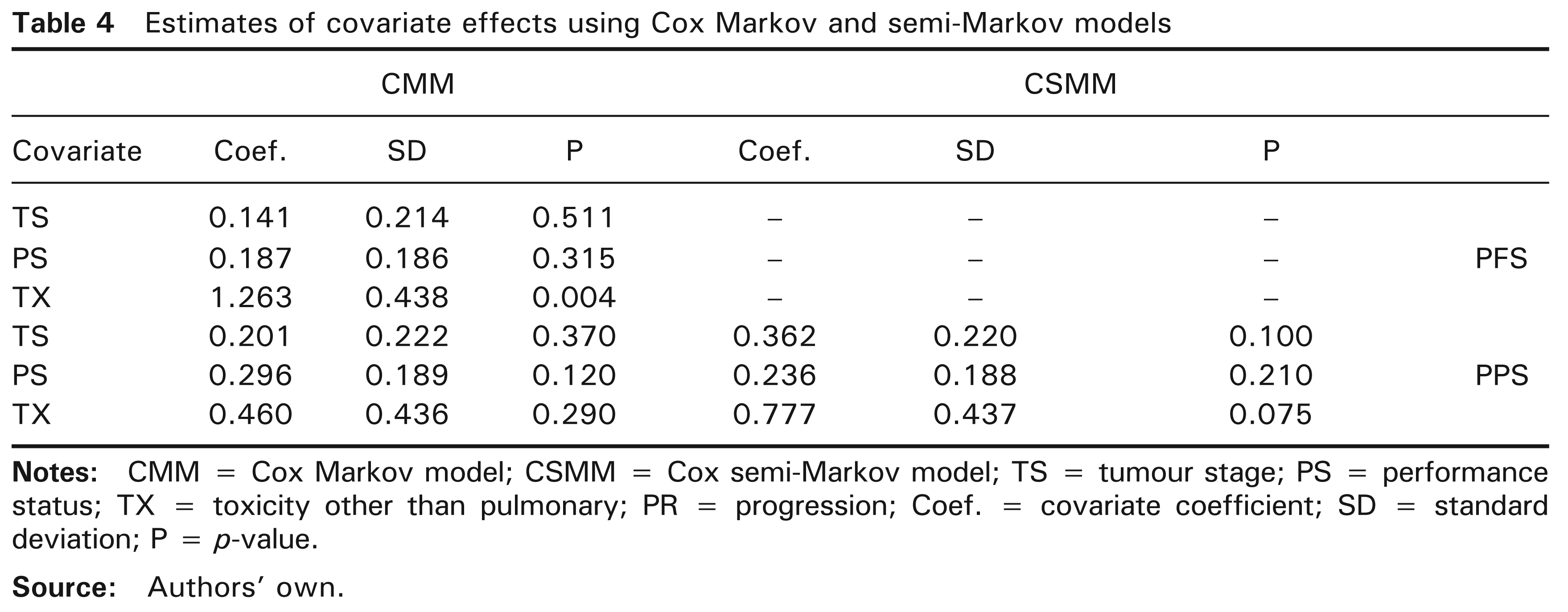
Moreover, for each patient, the database contains other available information than survival times. We used the nonparametric log-rank and generalized Wilcoxon tests with a threshold of 15% (not shown) in order to retain only the relevant covariates. The included covariates were: tumour stage (TS) coded as [0 = 3A stage; 1 = 3B stage], performance status (PS) coded as [0 = capable of normal activity; 1 = otherwise] and toxicity other than pulmonary (TX) coded as [0 = grade 0-1-2; 1 = grade 3–4]. While TX has a potential effect on PFS, PPS and OS, TS and PS have a potential effect on PPS and OS. The proportionality assumption is verified and there are globally 11 missing values in this set of covariates. However, since the purpose is to illustrate the introduction of covariates to the proposed model, the missing values were removed. Also, let progression (PR) be the time-dependent covariate coded as [0 = no tumour progression; 1 = tumour progression]. We first constructed a time-dependent Cox model (TDCM) including PR, among the three other covariates and Table 3 shows the estimates with their standard deviations and Wald P-values. Progressor patients had higher mortality than non-progressor patients. A significant effect of PR on mortality was fully expected. By taking 10% as threshold instead of the 5% default value, TX also affected mortality. The covariates TS and PS turned out to be insignificantly different from zero. In addition, the multi-state models represent an alternative to TDCM and offer further information. With a three-state model, it is even more interesting to study the covariate effects on PFS and PPS or in other terms the risk of progression and the risk of mortality after tumour progression. For such models, the Markov property is only relevant for the transition from tumour progression state to death state. However, the significance of
Estimates of model parameter
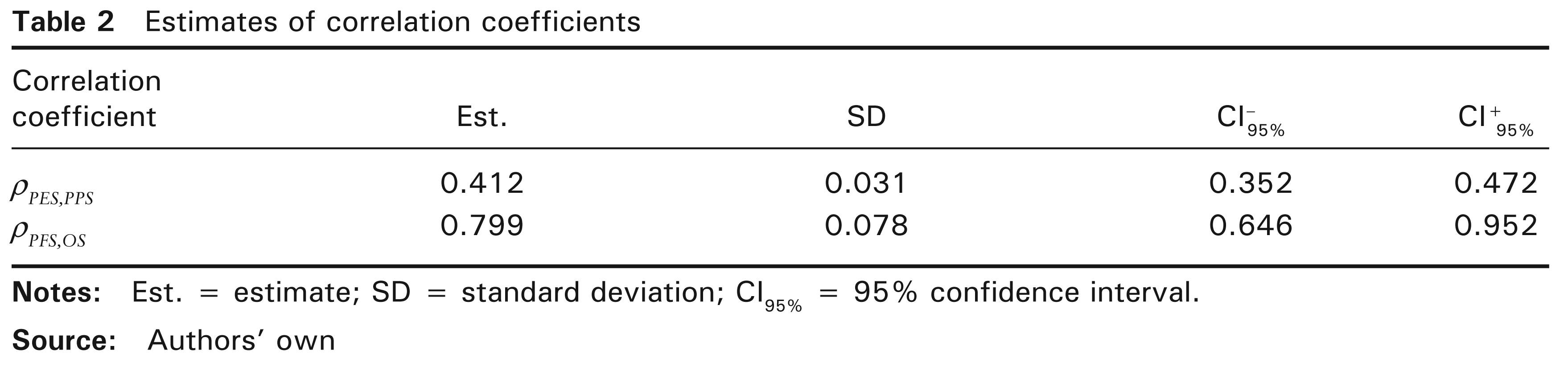
of correlation coefficients
Estimates of covariate effects using a time-dependent Cox model

Estimates of covariate effects using Cox Markov and semi-Markov models
Estimates of covariate effects using the proposed model
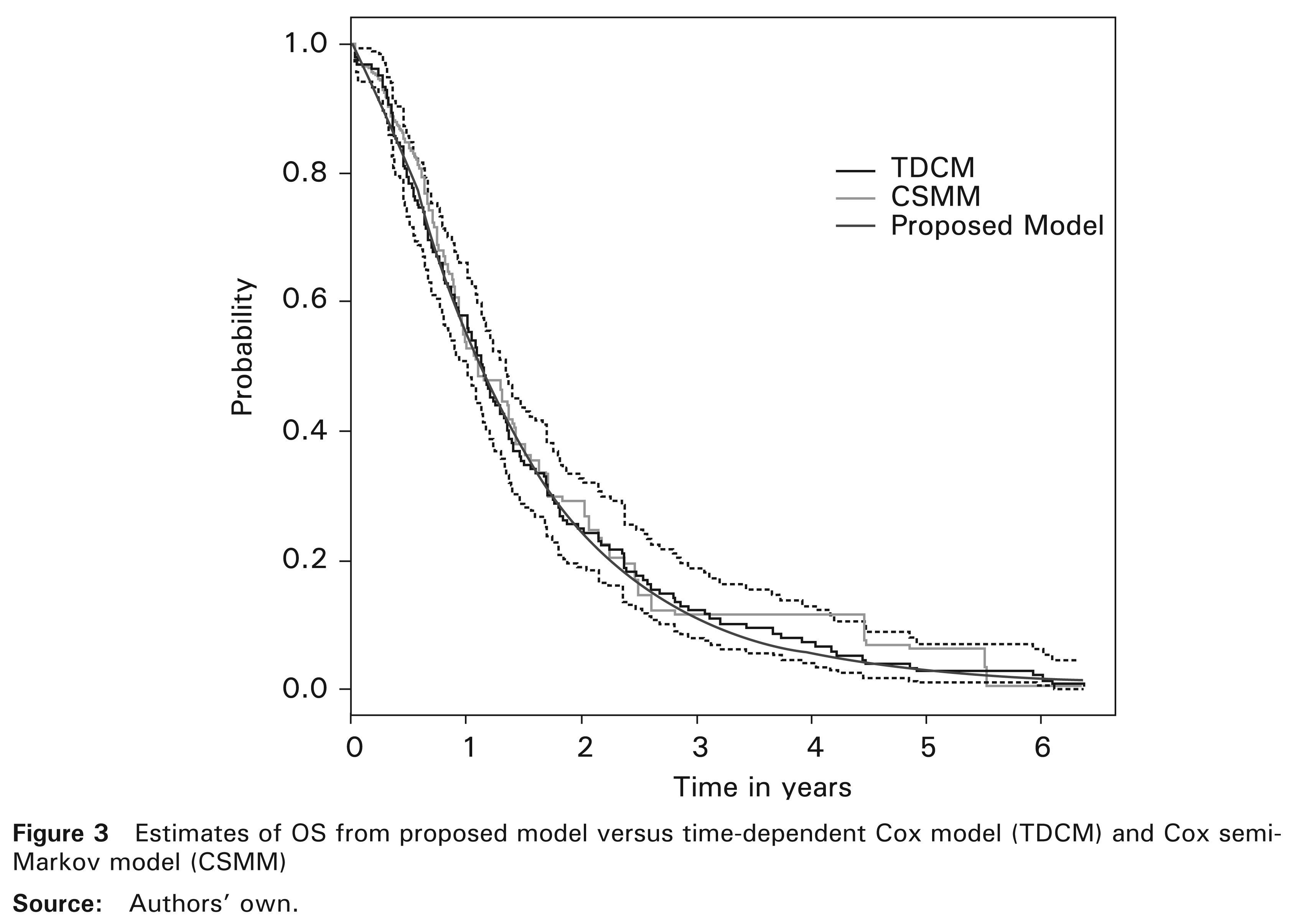
6 Discussion
In oncology drugs clinical trials, OS is considered as the gold standard primary endpoint of clinical efficacy. Moreover and for obvious reasons (see Section 1), PFS may potentially replace and predict OS. According to US FDA (2007), OS is defined as the time from randomization until death from any cause and PFS as the time elapsed between randomization and tumour progression or death from any cause, too. It must be emphasized that cause of death information (patient status) may be missing for patients lost to follow-up or unknown for patients whose cause of death is dificult to determine as long as there is no evidence of disease neither in the last medical visit nor in autopsy (Andersen et al., 1996). In this instance, the use of multiple imputation methods (see Lu and Tsiatis, 2001; Nicolaie et al., 2011) is the best way to overcome this problem.
A parametric modelling of OS has been developed in this article. In order to understand the relationship between PFS and OS, we have considered OS as two consecutive survival times which are assumed to be dependent, PFS and PPS. This assumption is represented by conditional distribution, a link between PFS and PPS. In the proposed model, we considered a particular combination of exponential distributions both for PFS and for PPS|PFS. The primary advantage of exponential distribution is that the analysis is much simpler mathematically. With that combination, it should be noted that the generalization of the exponential distribution for PFS via Weibull distribution is numerically feasible. However, the calculation of correlations and estimates of moments are not analytically possible.
Prentice (1989) criteria are designed to validate surrogate endpoints in Phase III clinical trials. These criteria foremost require that the surrogate must be a correlate of the true clinical endpoint. Correlation is a necessary condition to confirm the possibility that the surrogate may predict the true endpoint, but it is not sufficient to conclude that the surrogate can replace the clinical endpoint. A correlation indicator (β) and formulas for the correlations between PFS and both PPS and OS were demonstrated. Generally, if PFS and OS are positively correlated, improvement in PFS is likely to lead to improvement in OS. However, in this case, deducing that PFS is positively correlated with PPS is not always true because it is possible that the lengthening of PFS will offset the decrement in PPS and thus the correlation between PFS and PPS will be negative. By finding significant positive correlations between PFS and OS, several studies have proposed PFS as the most appropriate surrogate endpoint for OS, most notably Buyse et al. (2007) who used individual patient data from several historical trials in advanced colorectal cancer, also Louvet et al. (2001) who handled 29 Phase III studies involving 13,498 patients and Tang et al. (2007) who analyzed 39 randomized trials including 87 treatment arms in metastatic colorectal cancer. In extensive stage small-cell lung cancer (SCLC), Foster et al. (2011) exploited individual patient data regrouping 596 patients from 3 randomized trials and 870 untreated patients to investigate the association of PFS with OS. By showing a strong correlation, they also considered PFS as a promising substitute for OS in extensive stage SCLC, but for validation, it would be necessary to use more data from randomized Phase III trials.
The model introduced here allows for the prediction of dependencies between PFS and PPS as well as between PFS and OS. We have applied it to randomized Phase III data with patients suffering from locally advanced NSCLC (Fournel et al., 2005). Note that in this database, Weibull distribution for PFS was reduced significantly to an exponential distribution which consolidated the choice of the latter. The numerical results were consistent with those reported by the cited authors and in agreement with those obtained by Fleischer et al. (2009) concerning the same disease. However, their model was built differently and it did not take into account the dependence between PFS and PPS. With no information about subsequent therapies in this database, we found a significantly positive correlation indicator (β > 0) proving the existence of a positive association between PFS and PPS and also between PFS and OS. This means most probably that improvement in PFS has led to the lengthening of PPS and consequently to improvement in OS. Second-line treatment is usually an optimal medical therapy since it is selected based on tumour type and clinical guidelines. For instance, the clinical practice guideline proposed by Noble et al. (2006) for recurrent or progressive NSCLC. Otherwise, the proposed model can take into account the effect of subsequent therapies on mortality. Indeed, the form of the proposed model allows for multiple covariates including first-line treatment, baseline covariates and subsequent therapies. In addition, the proposed model and CSMM (Andersen et al., 2000; Meira-Machado et al., 2009) seemed to have the same ability to detect significant effects of covariates. Also, the survival probability estimates based on the proposed model seemed to closely match the nonparametric Kaplan–Meier estimator and TDCM.
In fact, with the strong positive correlation found between PFS and OS, PFS seems to be a good potential surrogate for OS in locally advanced NSCLC trials. However, parameter estimates require the use of data from large carefully selected samples. The question raised is whether PFS will be valid as a surrogate for OS with all the treatments used for the disease concerned. One can possibly answer this question by conducting a meta-analysis which includes these treatments with individual patient data using our modelling. This procedure was previously exploited by Buyse et al. (2007) for colorectal cancer treatments. In conclusion, the proposed model generalizes the structure of dependency between PFS and OS and allows for better understanding of the process of OS improvement or decrement by means of PFS and PPS. It also provides a flexible tool for survival probability estimation and the study of covariate effects.
Footnotes
Acknowledgements
Mohamed C. Belkacemi is the recipient of a fellowship from the Algerian Ministry of Higher Education and Scientific Research.
Appendix
We found the following results, given that
X ∼ Exp(λ), then E(X) = 1/λand Var(X) = 1/λ2. Y|X ∼ Exp(θY|X(x)) and θY|X(x) = αexp(–β(x) where α = exp(ν) and β < λ/2, then E(Y | X) = 1/θY|X(x) and Var(Y | X) = 1/θY|X(x)2.
We calculated the first moment of Y and thus that of T
and
In addition, the covariance between X and Y was obtained by
where
and therefore,
Using this result, we found the covariance between T and X
We also calculated the second moment of Y
Therefore,
and
Furthermore, given that the correlation coefficient between X and Y is equal to
we finally found the correlation coefficients
and also
Moreover, by combining regularity conditions with the Lindeberg-Feller central limit theorem, the MLE vector
asymptotically satisfies
where
where