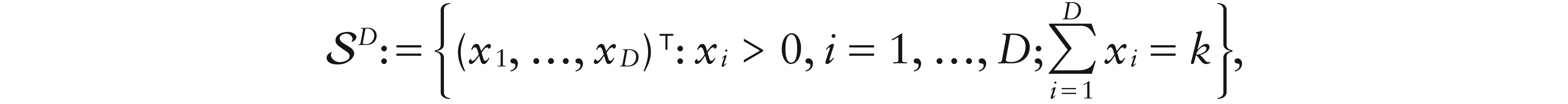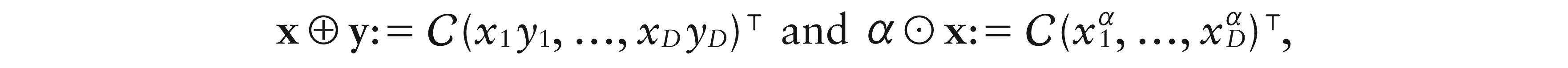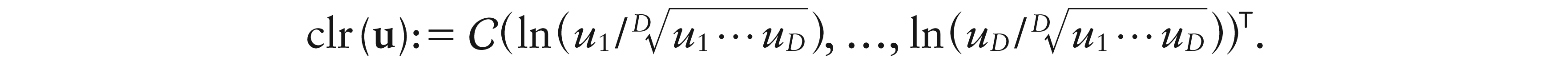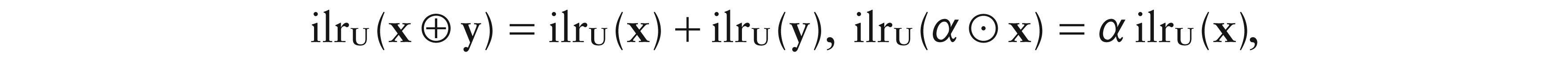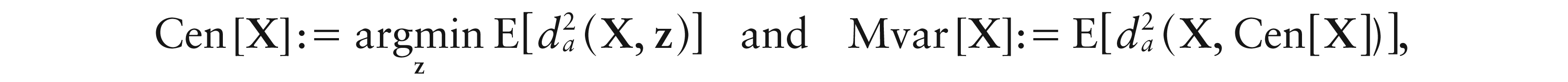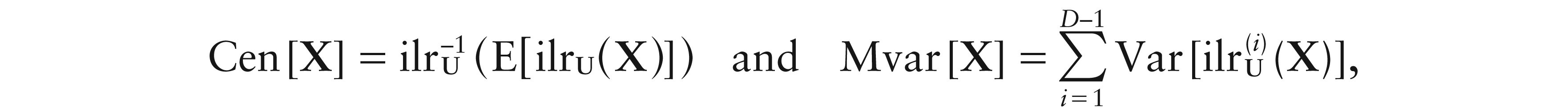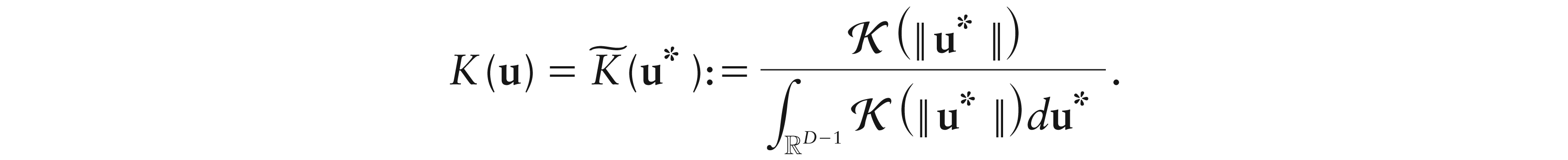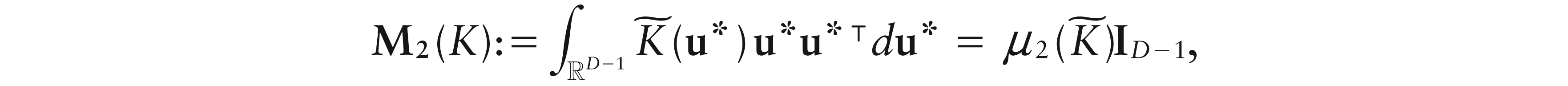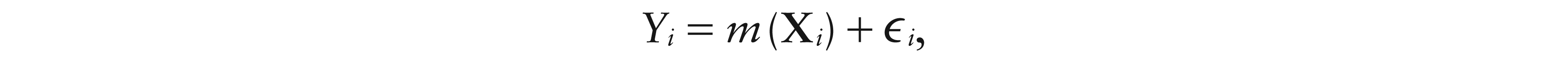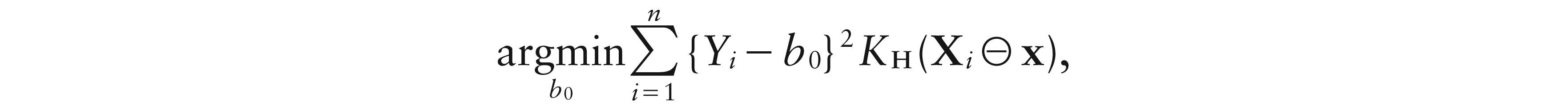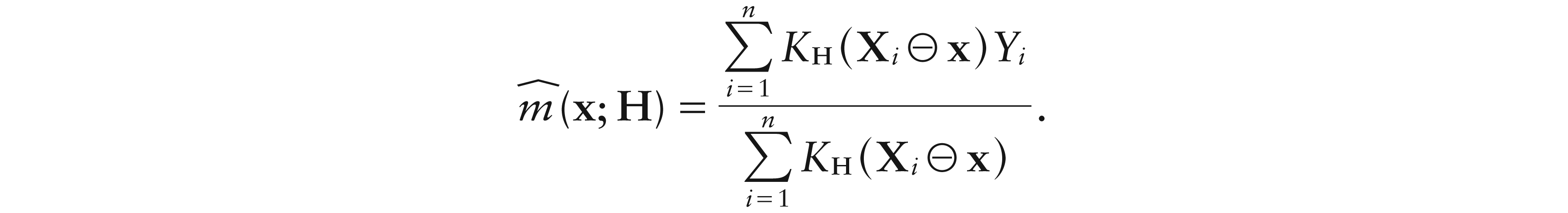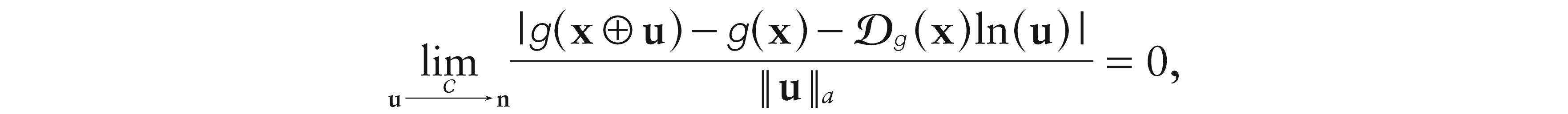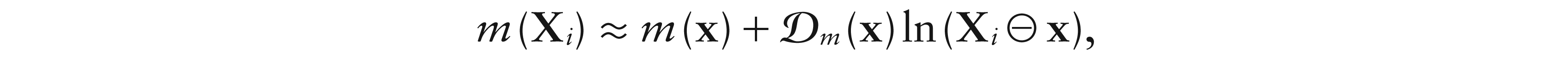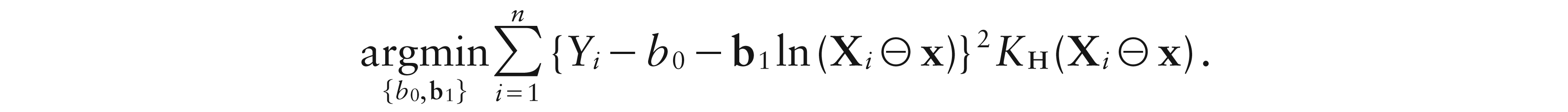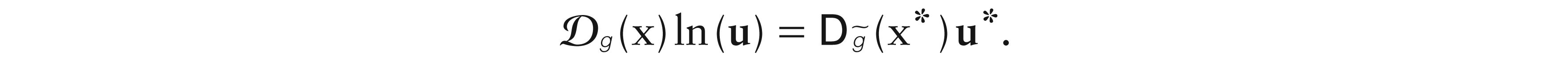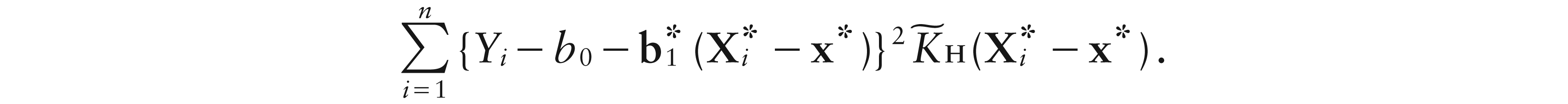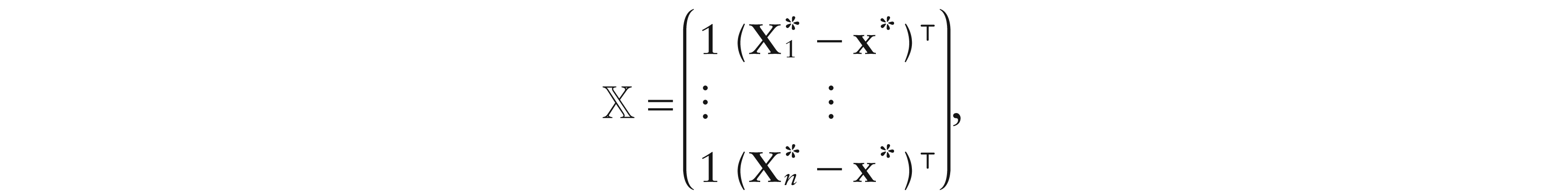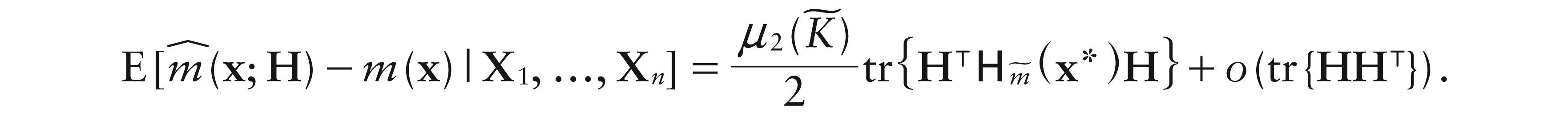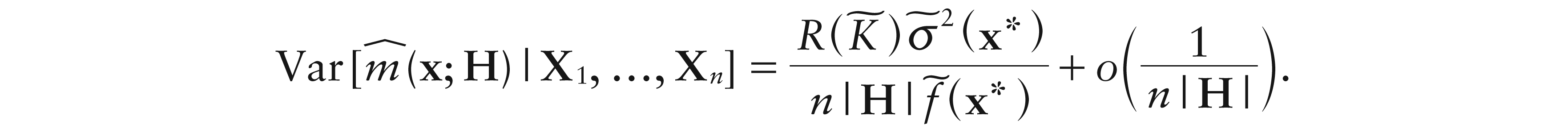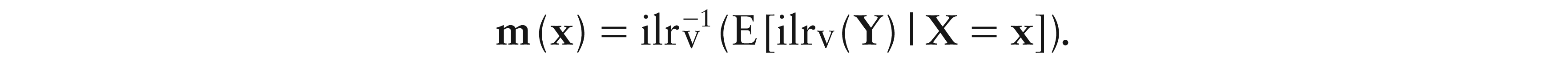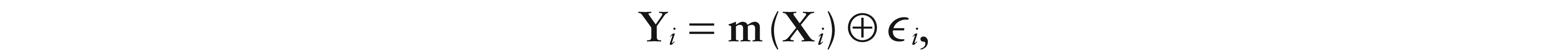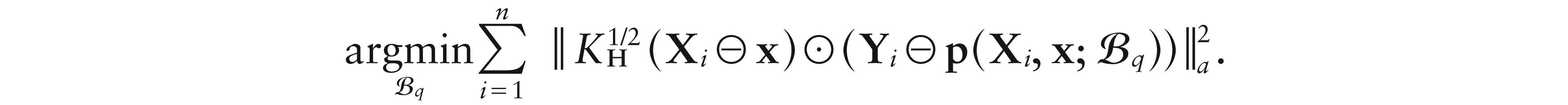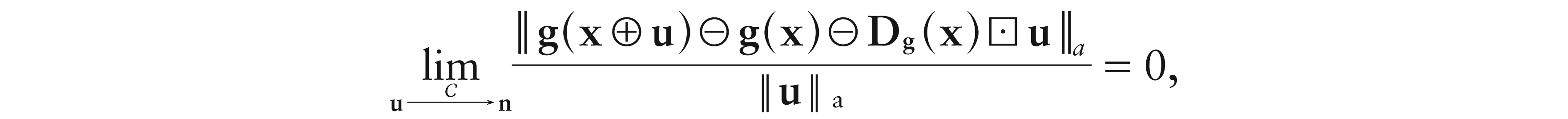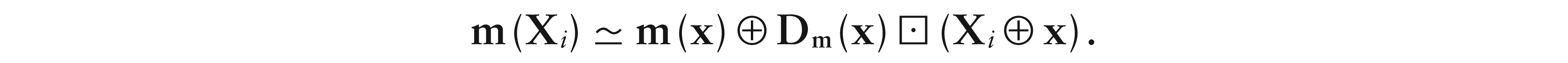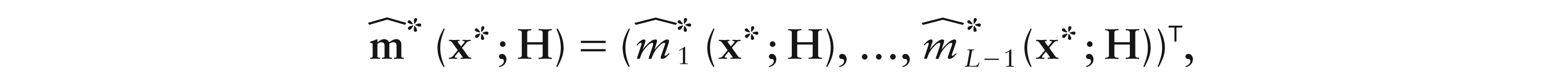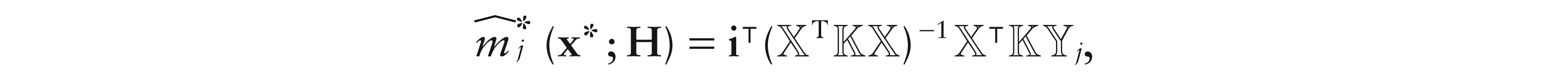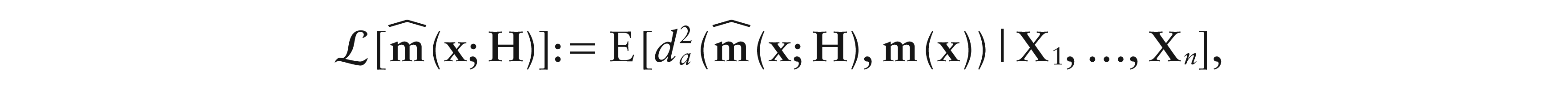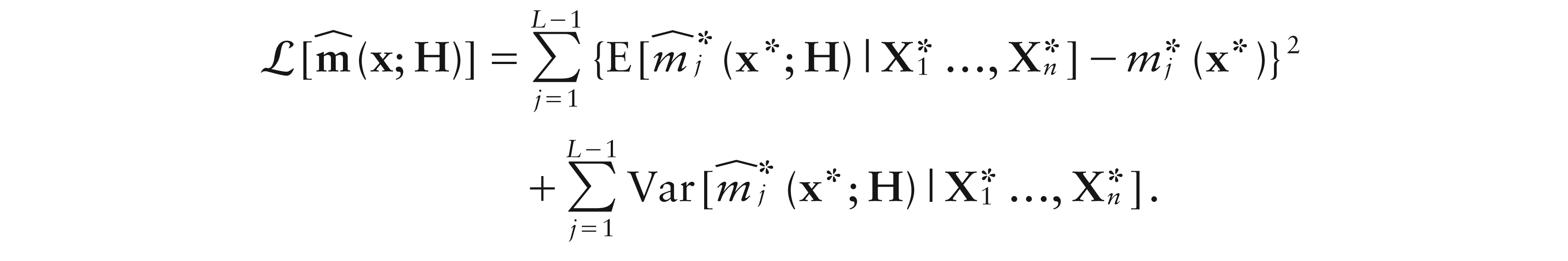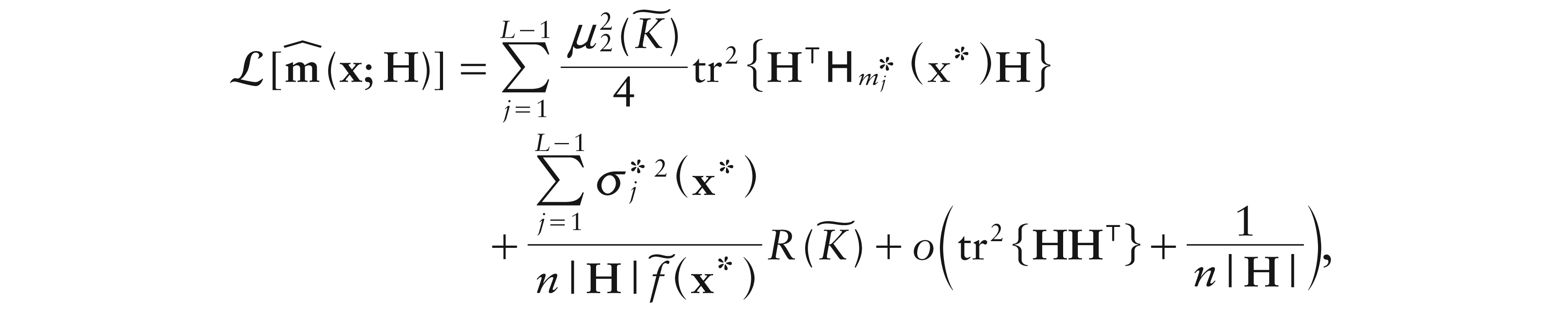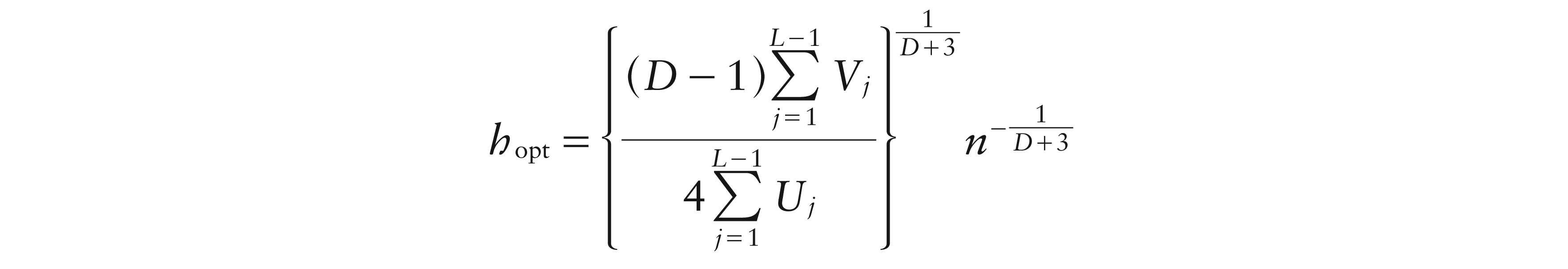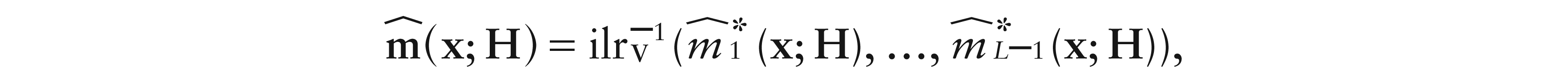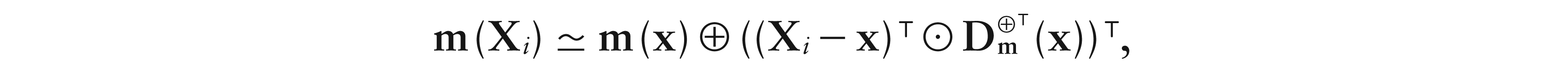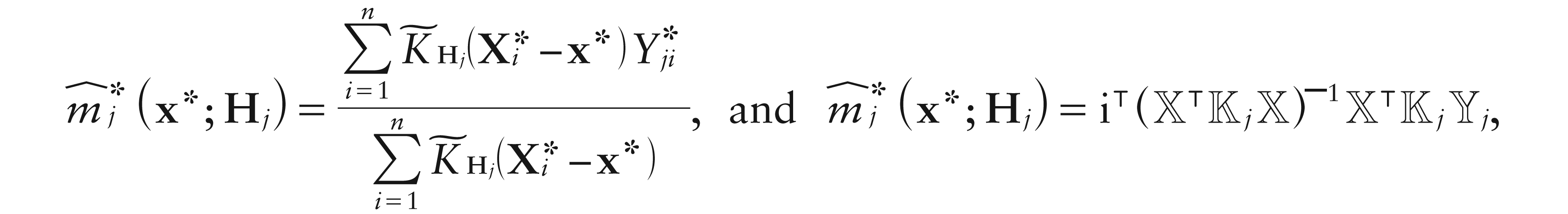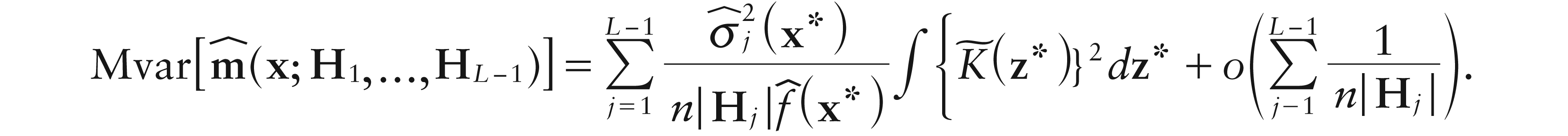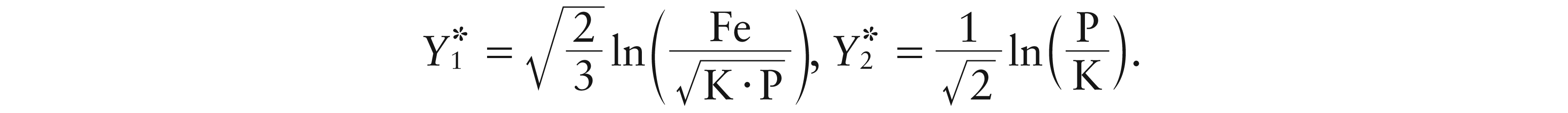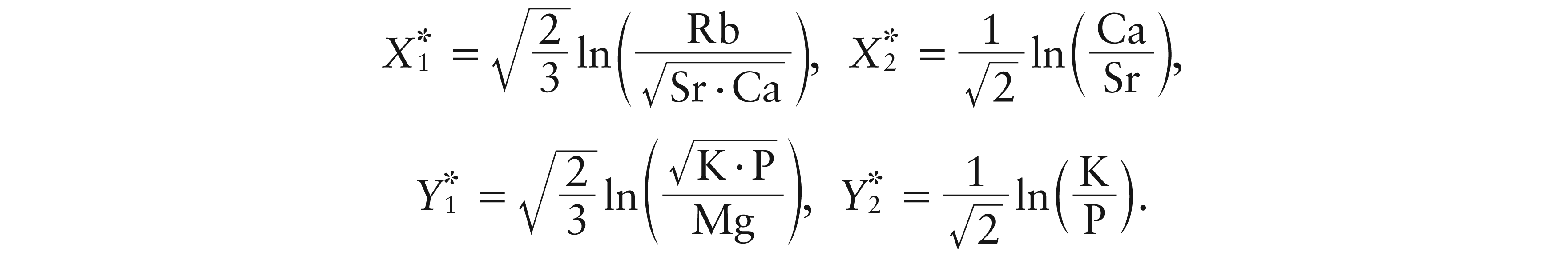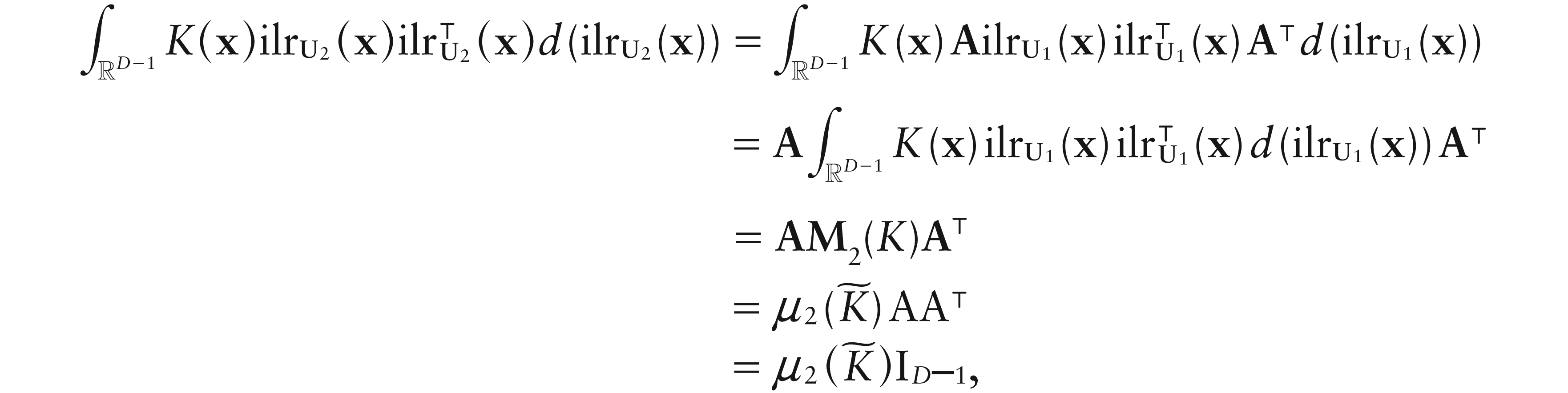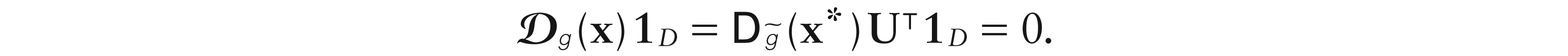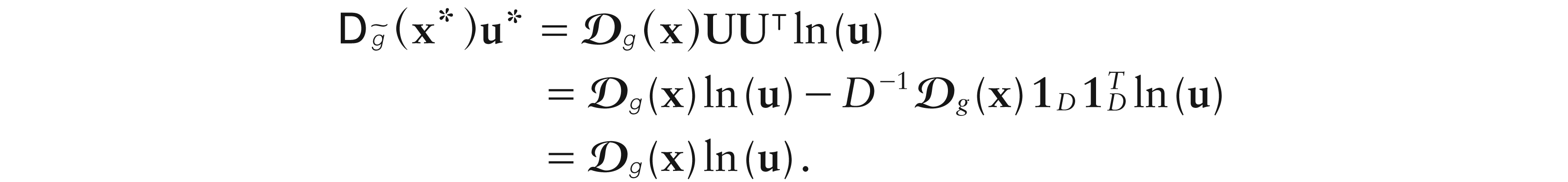Regression for compositional data has been considered only from a parametric point of view. We introduce local constant and local linear smoothing for this problem, and treat the cases when the response, the predictor or both of them are compositions. To this end, we introduce suitable series expansions of the regression function at a point, along with a class of simplicial kernels. Our methods are formulated according to the Aitchison geometry of the simplex and then, using some relevant properties of the isometric log-ratio transformation, are developed following the principle of ‘working on coordinates’. Asymptotic properties and real-data case studies show the effectiveness of the methods.
Compositional data, or compositions, are sets of portions of a whole. A D-part composition, D +, lies on the simplex
where k is a positive real constant.
Typical examples of compositional data include mineral compositions of rocks, proportions of pollutants in air or in rivers, compositions of electorates, distributions of financial funds or percentages of expenditures in a country. For a recent comprehensive account on compositional data see Pawlowsky-Glahn and Buccianti (2011) and the references therein.
A simple approach to statistical analysis of compositional data uses transformations into the Euclidean space. Egozcue et al. (2003) introduced the isometric log-ratio (ilr) transformation of D-parts compositions. Such transformation gives coordinates in D–1 (ilr coordinates), and exhibits some advantages with respect to the previously proposed transformations.
The case of a real-valued response predicted by a composition has been traditionally modelled using various polynomial forms of the parts of the predictor by Scheffè (1958) and Scheffè (1963). Additionally, Aitchison and Bacon-Shone (1984) proposed to work with log transformations of the predictors, which, clearly, removes the constraint of a constant sum. Recently, Hron et al. (2012) discussed a linear model based on ilr coordinates representation, overcoming some interpretability drawbacks arising from the previous models, and allowing standard inference on the parameters.
Aitchison (1982) and Hijazi and Jernigan (2009) modelled regression of a compositional response on a real predictor assuming, as distribution for residuals, the Dirichlet or the logistic-normal distributions. For the same problem, Tolosana-Delgado and Van Den Boogart (2011) and Egozcue et al. (2012) proposed a linear model using ilr coordinates of the response, allowing ordinary least-squares theory on the space of coordinates. The above-mentioned approaches have a parametric nature.
Latterly, some work adapted non-parametric regression to non-Euclidean manifolds. For example, Di Marzio et al. (2013) pursue the circular case, and Di Marzio et al. (2014) the spherical one. The idea is to develop an intrinsic approach to get readily applicable methods without transforming data via link functions. Analogously, in the present paper, we introduce non-parametric estimators for the regression function when: i) the predictor is compositional and the response is real (simplicial-real regression); ii) the predictor and the response are both compositions (simplicial-simplicial regression); iii) the predictor is real and the response is compositional (real-simplicial regression). All of our smoothers have a local polynomial nature, where a derivative of the regression function is estimated as the coefficient of a term in the series expansion of the regression function at a point. Such a coefficient is found by solving a locally weighted least-squares problem. For each kind of regression, we discuss two estimators, the constant fit, which is based on a single-term expansion of the regression function, and the linear fit which, instead, uses two of such terms.
In Section 2, we collect some preliminaries on the Aitchison geometry of the simplex, along with some properties of the ilr transformation. Then, in Section 3, a class of simplicial kernels is introduced, and in Section 4 we consider non-parametric estimation of a simplicial-real regression function. Non-parametric estimation of the regression function with compositional response is the subject of Sections 5 and 6 for the cases where the predictor is compositional and real, respectively. In Section 7, we discuss directional smoothing for the simplicial response case. Finally, Section 8 provides some real-data applications, along with some comparisons with existing methods.
Preliminaries
Perturbation and powering are the basic operations in the Aitchison geometry (Aitchison, 1982, 1986). For D-part compositions x and y, and α ∈ , they are, respectively, defined as
where is the closure of . Furthermore, the difference perturbation is defined as .
Perturbation and powering induce a (D – 1)-dimensional real-vector space structure on D.
Let the set {e1, …, eD–1} be an orthonormal basis of D, and denote as U the associated basis-contrast matrix, i.e., the D (D – 1) matrix with ith column given by centred log-ratio (clr) clr(ei), i ∈ {1, …, D – 1}, where for u ∈ D,
The ilr transformation related to U, say ilrU, is the one-to-one linear transformation relating the vector x* ∈ D–1 to x ∈ D, as follows:
The ilr transformation defines an isomorphism between D and D–1, i.e., for each x, y ∈ D and a ∈ ,
and exhibits the property of being isometric, i.e., , where
is the Aitchison distance, while stands for the Euclidean norm. Clearly, for x ∈ D, the Aitchison norm, which is defined as , with n(1, …, 1) being the neutral element of perturbation, satisfies . Note that zeros are not allowed in the definition of these metric elements. Those zero values need to be treated previously with specific techniques that can be found, e.g., in Martín-Fernandez et al. (2012) and references therein.
Using Aitchison geometry, Pawlowsky-Glahn and Egozcue (2001) defined the centre and the metric variance of a D-part random composition X, respectively, as
which, using the ilr coordinates of X, can be respectively expressed as
with denoting the ith entry of ilrU(X), i ∈ {1, ..., D – 1}.
From now on, we denote U and V as the basis-contrast matrices associated with selected orthonormal bases for D and L, respectively. Moreover, for a function g : D , let be the composite function . Furthermore, for a function g : DL, we denote as g* : D–1L–1 the function .
Kernels on the simplex
Kernels on the simplex have been introduced, for the task of density estimation, by Aitchison and Lauder (1985) and Chacón et al. (2011). First, the authors proposed the multivariate Dirichlet distribution, ‘recommended only when there is suspicion of sparseness in the data’, and the additive logistic normal kernel. The latter is based on a logarithmic transformation, and requires particular structures of the bandwidth matrix to guarantee the invariance of the estimate under permutation of the components. More recently, Chacón et al. (2011) introduced the isometric log-ratio normal kernel, which is based on the ilr transformation of data. Such kernel overcomes the drawbacks of the previous ones, having, in particular, the property of being invariant under changing of the orthonormal basis.
A class of simplicial kernels, which includes the isometric log-ratio normal kernel, can be constructed starting from univariate Euclidean ones as follows.
Definition 1.Letbe a continuous function with maximum at 0 such that (–u)(u) ≥ 0, u ∈ , and . A D-variate simplicial kernel can be defined, for eachu ∈ D, as
wherestands for the Aitchison measure onD.
Notice that i) for a set , , with being the Lebesgue measure on D–1, and ii) , for u*ilrU(u). Therefore, a kernel in Definition 1 corresponds to a radially symmetric one in the space of coordinates, i.e.,
Notice that a simplicial kernel K in Definition 1 is a density on D with respect to the Aitchison measure, whereas is a density on D–1 with respect to the Lebesgue measure.
Remark 1.It is easily seen that kernels in (3.1) are invariant under changing of orthonormal basis inD. In fact, lettinganddenote isometric log-ratio transformations corresponding to two different orthonormal bases, there exists an orthogonal matrixAsuch that, for eachu ∈ D. Then, by orthogonality ofA, it follows that, and .
Using the same arguments as in Chacón et al. (2011), it can be easily seen that all kernels in this class match the property of being invariant under changing of basis for D. From (3.1), the order of a simplicial kernel can be defined as the order of the corresponding kernel in the space of coordinates. Specifically, letting be a second-order Euclidean kernel, the second moment of K is
with , and Is denoting the identity matrix of order . Moreover, the following holds.
Result 1.Let K be a second-order simplicial kernel. Then, M2(K) is unaffected by the choice of the basis forD.
Proof. See Appendix.
Let H be a symmetric positive definite matrix of order D – 1; then a simplicial kernel at x ∈ D, centered at y ∈ D and rescaled by H, is .
Remark 2.It is easily seen thatis invariant under changing of orthonormal basis forD. In fact, lettingandbe the coordinates corresponding to two different orthonormal bases, and moreover, lettingH(1)andH(2)be the bandwidth matrices obtained using the respective ilr vectors, then there exists an orthogonal matrixAsuch thatand. By orthogonality ofA, it follows that, and.
Simplicial-real regression
Given an D -valued random sample {(Xi, Yi), i1, …, n}, assume the model
where , and the ɛis, conditioned on the Xis, are independent and identically distributed real-valued random variables with E and Var. Then, a local constant estimator for m(x) can be defined as the solution of
with being a simplicial kernel in Definition 1, rescaled by the smoothing matrix H. This leads to
To obtain the local linear version of the above estimator, we recall the following.
Definition 2.A functionis called-differentiable atx ∈ D if there exists a unique 1 D vector Dg(x), satisfying Dg(x)1D0, such that
whereindicates that, and ln(u)(ln(u1), ..., ln(uD)).
Remark 3.The vectorg(x) is called-derivative of g at x (Barceló-Vidal et al., 2011), and defines a linear form on the simplex. Also,-differentiability of g implies differentiability of, whose gradient at, say, satisfies.
Now, assuming -differentiability of m at x, we see that m(Xi) can be expanded according to the following first-order Taylor series,
and a local linear estimator for m(x) is the solution for b0 of
Now, to derive an explicit form for local linear estimator, we need the following.
Result 2.Letbe-differentiable atx ∈ D, then it holds that, for anyu ∈ D,
Proof. See Appendix.
Now, in virtue of (3.1) and Result 2, the loss in (4.2) can be rewritten as
Hence, letting , , and
the solution for b0 of the minimization of (4.3) over is
where i stands for a D 1 vector having 1 as its first entry and 0 elsewhere. Thus, standard asymptotic results (e.g., Ruppert and Wand, 1994) hold. In particular, denoting the design density as f, and as , we have
Result 3.Given an-valued random sample {(Xi, Yi), i1, ..., n} consider estimators (4.1) and (4.4) atx ∈ D. If
,each entries of the Hessian matrix of, andare all continuous atx*;
where for a real-valued function g defined onD,stands for the Hessian matrix ofatx*, whereas for estimator (4.4),
Moreover, for both estimators,
Concerning the optimal smoothing, starting from Result 3, when HID–1h, h > 0, the value of h minimizing the asymptotic mean squared error (given by the sum of the leading terms of conditional squared bias and variance) of local constant (local linear respectively) smoother with domain in D leads to the same optimal rate achieved for a local constant (local linear, respectively) smoother with domain in D–1.
Simplicial-simplicial regression
Given the random compositions and , the dependence of Y on X can be well described by the function minimizing the risk E . This function defines the centre of the random composition Y conditioned on X, which, at , can be expressed as
Given an -valued random sample , we assume the model
where Cen and Mvar .
Now, local polynomial estimators of m(x) can be obtained by approximating m(Xi) in a neighborhood of x by a qth degree simplicial polynomial , with denoting a set of coefficients, and considering the solution for the first entry of , say , of the following least-squares problem
In particular, when q0, we have , and , so the solution for b0 of (5.2) defines a local constant estimator for m(x).
To deal with q1, letting 0s (1s, respectively) denote an s 1 vector of zeros (ones, respectively), we preliminarily need the following.
Definition 3.The function is said to be differentiable atxif there is a unique LD matrix, sayDg(x), satisfying , and such that, for ,
where for a matrixAwith (i, j)th entry,.
Now, assuming differentiability up to the first order of m at x, we get the following Taylor series expansion
Hence, letting , and , a local linear estimator for m(x) can be obtained as the solution for b0 of (5.2) with q1.
To get our smoothers in an explicit form, we first observe that, by the properties of isometric log-ratio transformation, loss (5.2), with q1, satisfies
where , , , whereas B*VTBU. The solution for b0 of (5.2) over is the ilr inverse transformation of the solution for of the minimization of (5.3) over .
Now, letting be the jth entry of , j ∈ {1, ..., L – 1}, the minimization of (5.3) over gives
where
with , and being the jth coordinate of . Hence, a local linear estimator is defined by applying ilr to (5.4). Concerning the local constant estimator, the same arguments hold with due modifications, yielding
where
An accuracy measure for our estimators can be defined as
which can be considered as the simplicial counterpart of the mean squared error. Now, using the fact that, for compositions X and z, , loss (5.5) can be decomposed as
Hence, denoting the design density as f, and assuming conditions 1–3 of Result 3, with (, respectively), in place of (, respectively), the above loss, for both local constant and local linear estimators, can be derived starting from Result 3, yielding
for local constant case, and
for local linear estimator.
Hence, assuming that HhID–1, the value h minimizing the asymptotic version of (5.5), is given by
where Vj (Uj, respectively) is the part of the leading term of the variance (squared bias respectively) of depending neither on h nor on n.
Real-simplicial regression
Given an ℝDL-valued random sample {(Xi, Yi), i1, …, n}, assume the model (5.1), where now the Xis are ℝD-valued random variables. Hence, a local constant estimator for m at x can be defined as the solution for of
with , L being a standard multivariate kernel defined on ℝD, and H a positive definite smoothing matrix of order D. Now, the properties fulfilled by the ilr transformation imply that the solution of the above least-squares problem can be obtained as the ilr inverse of the solution of
and similar arguments as in the previous section lead to
where stands for a classical local constant estimator of a real-valued regression function defined on D.
The construction of the local linear estimator of m(x) needs the following.
Definition 4.A functionis differentiable atiff it exists a unique LD matrixsatisfying, such that, for,
where for an LD matrixA, .
Now, assuming that m is smooth enough, this Taylor expansion holds
and a local linear estimator for m(x) can be defined as the solution for b0 of the minimization, over {b0, B}, of the loss (6.1) with b0 replaced by .
Thus, invoking again the properties of the ilr transformation, along with , we have that, for ,
Hence, reasoning as in the local constant case, a linear smoother is defined as (6.2), with jth entry being a classical local linear estimator for a real-valued regression function defined on ℝD.
Hence, letting L be a second-order Euclidean kernel, and HhID, h > 0, the value of h minimizing the asymptotic version of the resulting loss (5.5) is
where Wj (Zj respectively) is the part in the asymptotic variance (squared bias respectively) of depending neither on h nor on n.
Multiple smoothing matrices
Directional smoothing (i.e., a distinct bandwidth for each ilr coordinate) would appear a sensible choice whenever isotropy hypotheses are not feasible. We propose such a generalization to recover those applications in which the ilr coordinates (of the simplicial response) can be interpreted in themselves without going back to the simplex (see, e.g., Section 8.1). Specifically, here we tackle this problem for the simplicial-simplicial regression case discussed in Section 5.
where K:VK* V, with V being the basis-contrast matrix, and , with the Hjs being smoothing matrices of order D – 1.
Remark 4.The matrixKis invariant under changing of basis for L. Specifically, denoting asWa basis-contrast matrix (different fromV)associated with an orthonormal basis forL, then there exists an orthogonal matrix, sayC, satisfyingWVC. Consequently, expressingK* in the new basis leads toK** :CK* C, and it can be easily seen that
WK**WVCCK*CCVK.
Now, the solution for b0 of the minimization of (7.1) over yields
where for q0 and q1, we respectively have
with .
Hence, under the assumptions of Result, it is straightforward to see that asymptotic biases of the above estimators are the same as those obtained in Section 5 for local constant and local linear ones, respectively, with Hj in place of H, while for both estimators
Finally, assuming HjhjID–1, the value of hj minimizing the asymptotic version of is
Remark 5.A Referee warned out that above described directional smoothing strategy could give place to difficulties of interpretation from the perspective of application because different smoothing in different ratios can result in predictions leaving the convex hull of the observations.
Real-data applications
We consider two real-data case studies on concentration of chemical elements using the Kola dataset. The Kola Ecogeochemistry Project (1992–1998) is an environmental investigation in Arctic Europe aimed both to study the impact of major industrial activities in the western Kola Peninsula and to obtain a regional mapping of heavy metals and pollution ecosystems. Samples of soil were taken in four different layers: moss, O-horizon, B-horizon and C-horizon. See Reimann et al. (1998) for details. The whole dataset is available in the package StatDA of the (see Filzmoser and Steiger, 2009).
Regression from IR to 3
We compare our non-parametric method with the linear parametric one introduced by Egozcue et al. (2012). In Egozcue et al. (2012), three chemical elements are considered: Fe (Iron), K (Potassium) and P (Phosphorus), all taken from the O-horizon layer of soil. They studied the concentration of these three elements as dependent on latitude, longitude and elevation of the examined soil, founding that elevation is the only highly significant predictor. On the basis of their results, we focus on simple regression, where the above minerals are explained only by elevation, say X. We use the same balances, or coordinates, as Egozcue et al. (2012):
Denoting the ith observed response as (), we perform two separate regression estimates on () and (), respectively. We use the simplicial Epanechnikov kernel, defined according to (3.1), and set two cross-validated smoothing parameters as follows:
where the estimate is performed after leaving the observation (Xi, Yji) out of the sample. For the local constant fit, we obtained (h1140, h273.5), whereas for the local linear one, we got (h1260, h2105.7).
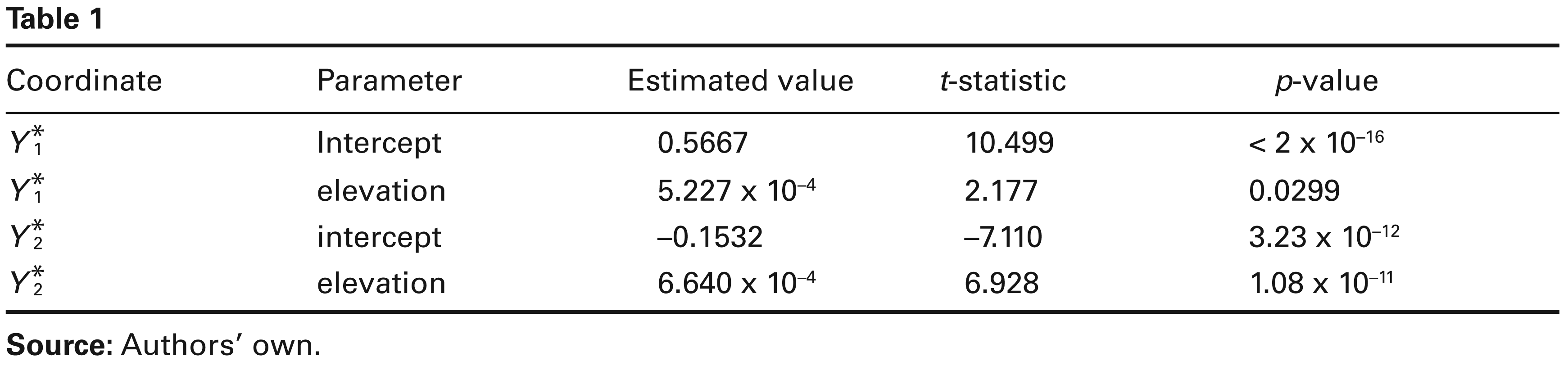
The simple, linear parametric estimate is summarized in Table 1:
Authors’ own.
Coordinate
Parameter
Estimated value
t-statistic
p-value
Intercept
0.5667
10.499
< 2 x 10–16
elevation
5.227 x 10–4
2.177
0.0299
intercept
–0.1532
–7.110
3.23 x 10–12
elevation
6.640 x 10–4
6.928
1.08 x 10–11
We can note that elevation is highly significant only for the coordinate . Since Fe is notoriously independent from elevation, only P and K are responsible for such a significance. In particular, the ratio P over K increases with the elevation.
Source: Authors’ own.
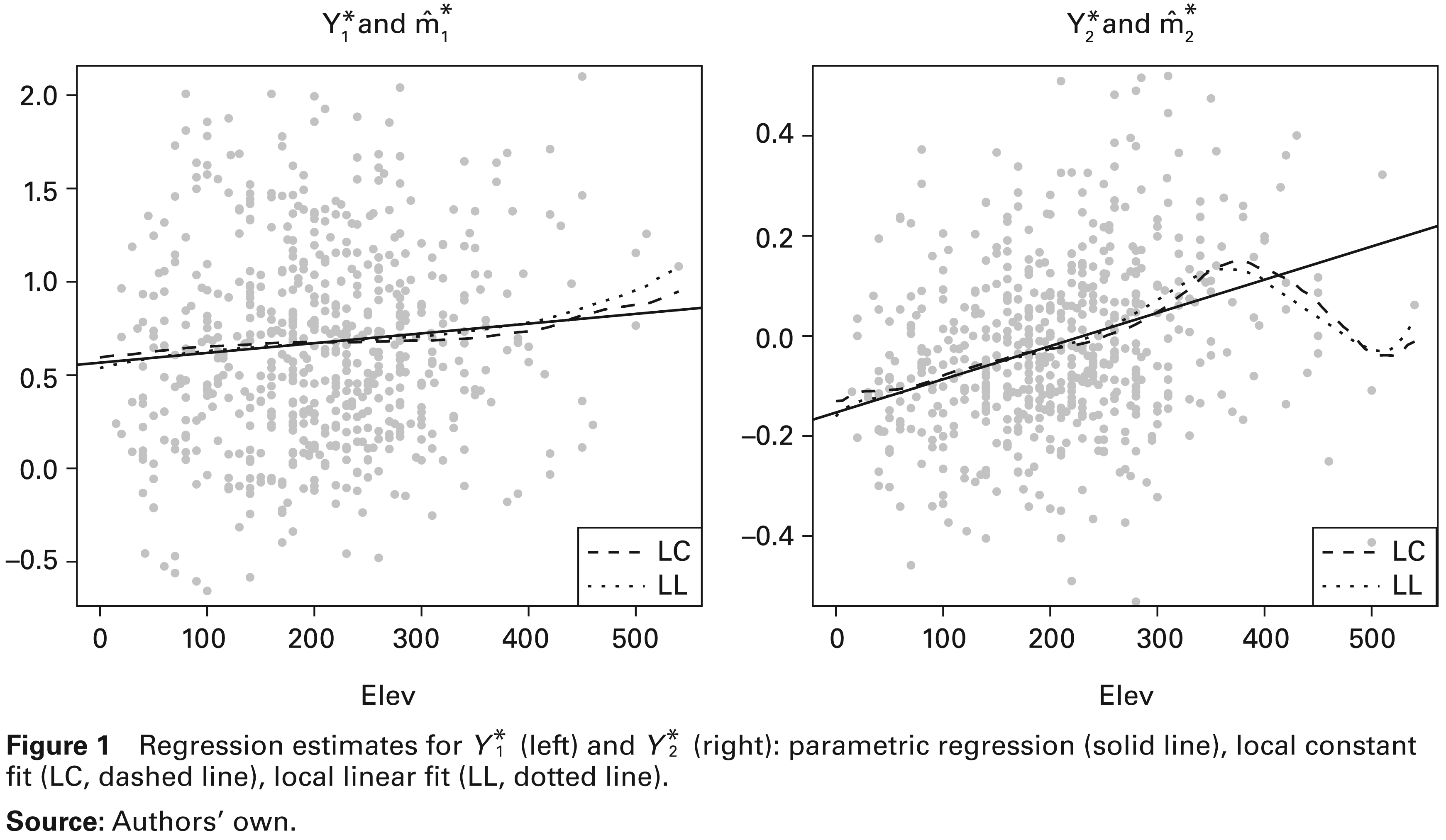
In Figure 1 (left), the parametric, local constant and local linear fits are represented for the case. Our non-parametric estimators largely confirm the parametric one.
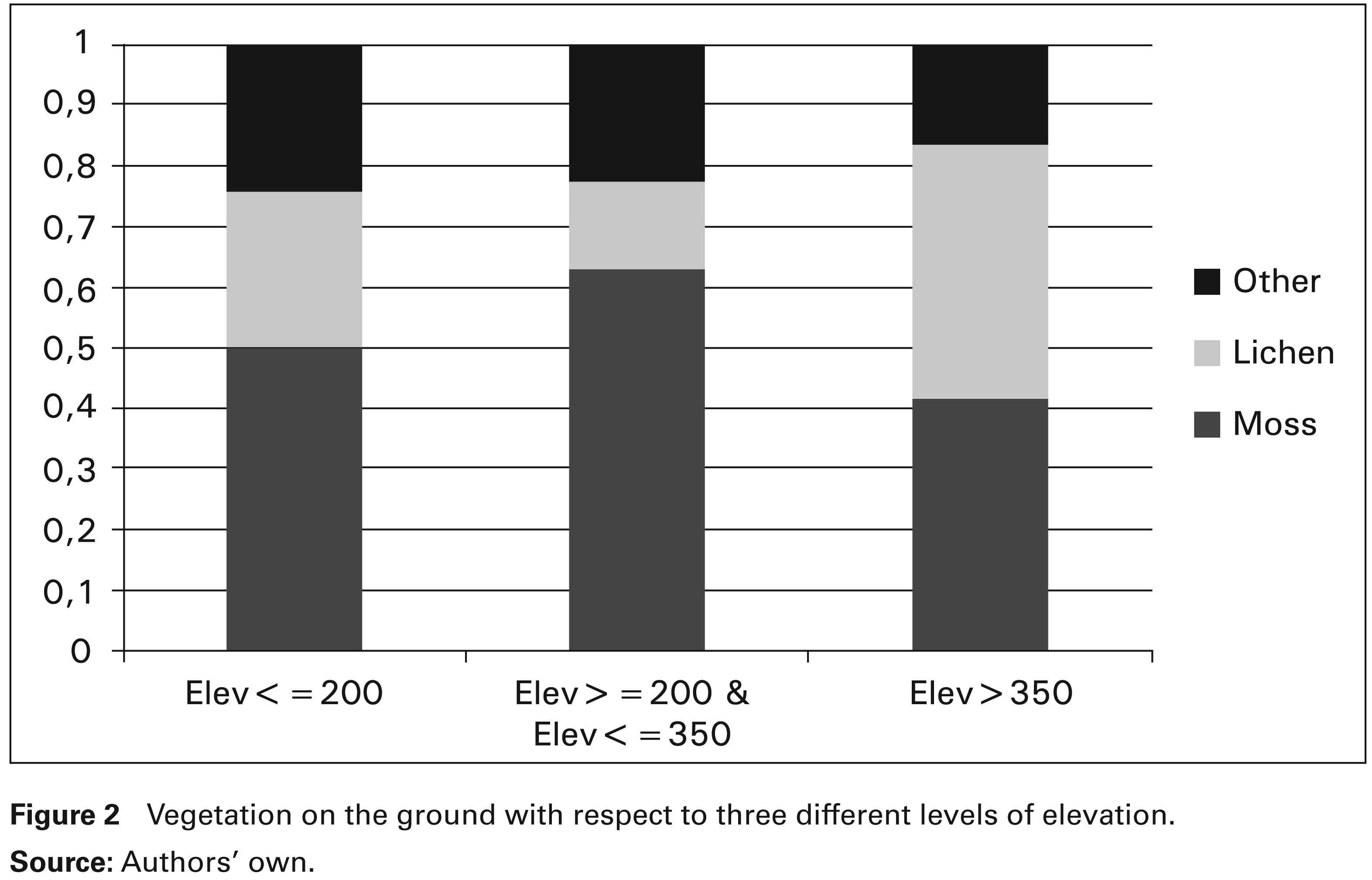
Coming at the second regression fit, where the log-ratio of P over K is the response, we do not observe the same agreement as before; see Figure 1 (right). Specifically, for elevations higher than 350 m, local fits show a decreasing trend, differently from the parametric method. Surely, the parametric linear regression is locally inadequate if we consider that only one out of the 10 observations with the highest elevation is above the straight line. Overall, we can affirm that the local method correctly detects a trend change. To understand the physical phenomenon underpinning such a trend change, we firstly investigated a possible relation between elevation and the lithology of the soil. Indeed, it doesn’t seem to be any relation between them in our data, while vegetation on the ground seem strictly related, as follows. The ground, in our case, is mainly composed of moss and lichens, see Figure 2. Now, the moss, which represents the majority of vegetation, first increases as elevation increases, but after 350 m, it exhibits a trend inversion. By contrast, the behaviour of lichens is opposite, first decreasing and then, after 350 m, reaching the same proportion as the moss. Now consider that moss is a green plant and lichens are a symbiosis of fungus and algae. Consequently, moss requires more phosphorus-over-potassium than lichens. In particular, phosphorus is a nutrient element for green plants, whereas potassium is present, in our case, as a mineral. Our conclusion here is that the presence of moss and lichens, when related to elevation, seems to confirm the trend of .
Source: Authors’ own.
Regression from 3 to 3
As the second real-data case study, we present a regression where a three-part composition of the O-horizon layer (Sr (Strontium), Rb (Rubidium) and Ca (Calcium)) predicts a three-part composition of the moss layer (Mg (Magnesium), K (Potassium) and P (Phosphorus)). As a benchmark, we adopt a simple parametric approach made of two linear regressions based on ilr transformations.
We use the following balances:
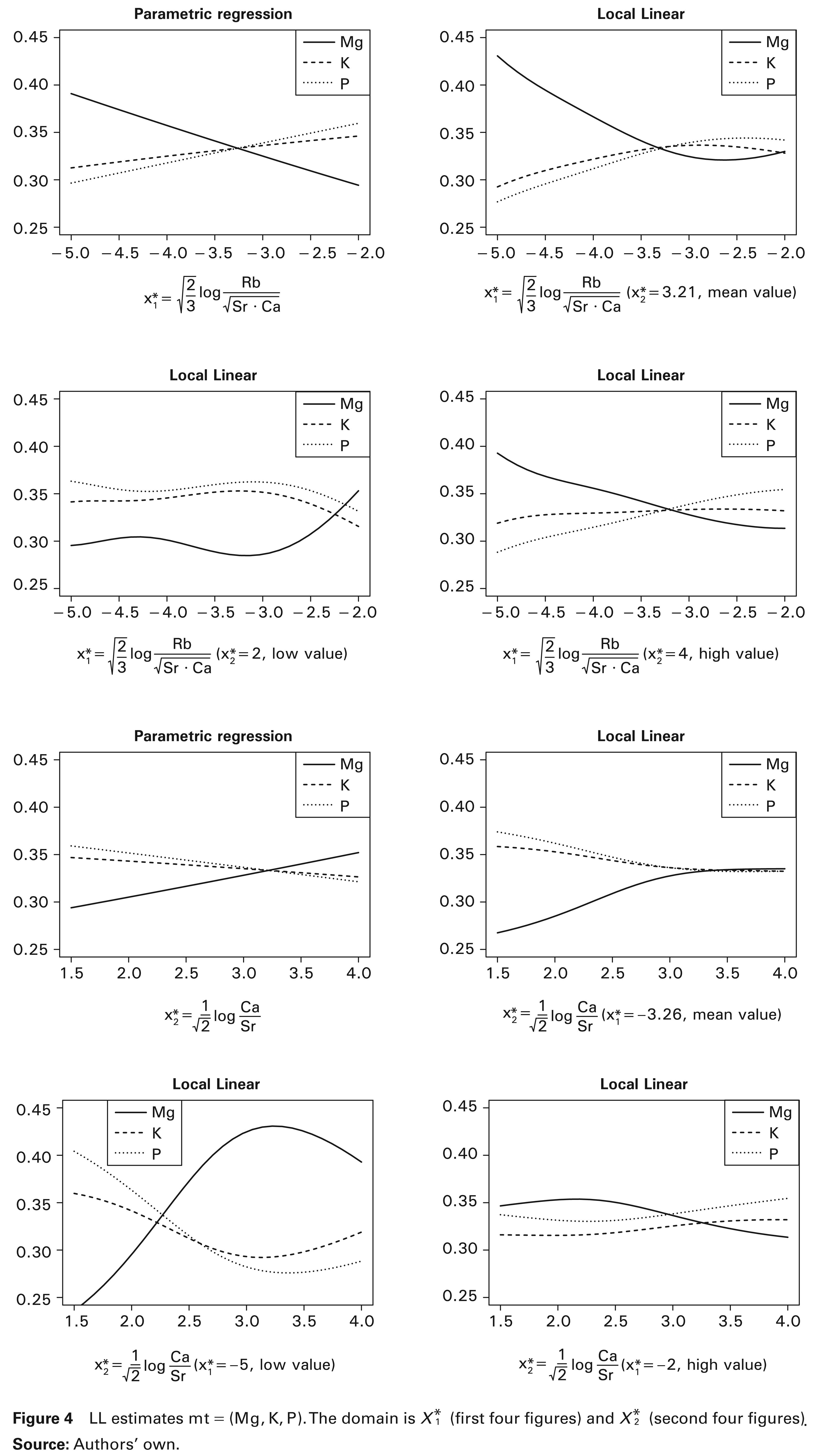
Applying the cross-validation criterion, the values obtained for the smoothing parameters of local linear estimators (with simplicial normal kernel) of the coordinates are h10.64 and h21.20, respectively. The plots in Figure 3 have (, ) as domain and (top) and (bottom) as ordinate. Figure 4 considers (or ) as domain and the three components of Y(Mg, K, P) for particular values of ( respectively) as ordinate.
From Figure 3, we can see that, as general trend, increases with , while remains unchanged. The behaviour of as dependent on can be explained by Figure 4, where we see that K and P grow while Mg decreases. Also, decreases as increases, this happens because K and P decrease while Mg becomes higher. Similarly as before, remains nearly constant with respect to .
From a geochemical point of view, the above trends can be motivated by observing that Rb and K have the same trend since the source of Rb is K-feldspar, and also that Ca and Mg are proportional as well since they are both bivalent, and in Ca-carbonate it is possible to have also Mg at 50%.
Some departures from the general trend are exhibited by the non-parametric fits as follows. First, has a seemingly parabolic trend rather than linear, and it depends essentially on the behaviour of Mg. Moreover, when Rb is high—relative to its mean values—Mg does not increase with (essentially with Ca), but it is almost constant or tends to decrease. To find an explanation for this phenomenon, we have to look at the lithology of the ground.
In our samples, soils that are relatively rich in Rb are granitic, alkaline rocks, granulites or other igneous rocks. But these are poor in carbonates; therefore, an opposite trend between Ca and Mg seems to be natural. In fact, we have either minerals rich in Ca, or rich in Mg. This different behaviour of Ca and Mg in Rb-rich soils could not be grasped by linear parametric regression, while seems to be highlighted by our local fits.
Source: Authors’ own.
Source: Authors’ own.
Appendix
PROOF OF RESULT 1. Let and denote the ilr transformations corresponding to two different orthonormal bases for D, and let M2(K) be the matrix in Equation (3.2) defined using . Moreover, let A be the orthogonal matrix of order D – 1, such that . Recalling that, by orthogonality of A, d, it results.
where the second identity holds because M2(K) is a diagonal matrix, while the last one follows by orthogonality of A.
PROOF OF RESULT 2. Since , and , it results
Now, because of , and , we have
Footnotes
Acknowledgements
The authors are grateful to J.J. Egozcue, V. Pawlowsky-Glahn and R. Tolosana-Delgado for various useful discussions and suggestions. The authors also thank two Referees for their constructive comments which led to an improved presentation.
References
1.
AitchisonJ (1982) The statistical analysis of compositional data (with discussion). Journal of the Royal Statistical Society, Series B, 44, 139–77.
2.
AitchisonJ (1986) The statistical analysis of compositional data. Monographs on statistics and applied probability. (Reprinted 2003 with additional material by The Blackburn Press). London: Chapman & Hall Ltd., 416.
3.
AitchisonJBacon-ShoneJ (1984) Log contrast models for experiments with mixtures. Biometrika, 71, 323–30.
4.
AitchisonJLauderIJ (1985) Kernel density estimation for compositional data. Applied Statistics, 34, 129–37.
5.
Barceló-VidalCMartín-FernandezJAMateu-FiguerasG (2011) Compositional differential calculus on the simplex. In Pawlowsky-GlahnVBucciantiA, (eds). Compositional Data Analysis: Theory and Applications, Chichester UK: Wiley, 176–90.
6.
ChacónJEMateu-FiguerasGMartín-FernándezJA (2011) Gaussian kernels for density estimation with compositional data. Computers & Geosciences, 37, 702–11.
7.
Di MarzioMPanzeraATaylorCC (2013) Non-parametric regression for circular responses. Scandinavian Journal of Statistics, 40, 238–55.
8.
Di MarzioMPanzeraATaylorCC (2014) Nonparametric regression for spherical data. Journal of the American Statistical Association, 109, 748–63.
9.
EgozcueJJDaunis-i-EstadellaJPawlowsky-GlahnVHronK (2012) Simplicial regression. The normal model. Journal of Applied Probability and Statistics, 6, 87–108.
10.
EgozcueJJPawlowsky-GlahnVMateu-FiguerasGBarceló-VidalC (2003) Isometric logratio transformations for compositional data analysis. Mathematical Geology, 35, 279–300.
11.
FilzmoserPSteigerB (2009) StatDA: Statistical Analysis for Environmental Data. R package version 1.1.
12.
HijaziRHJerniganRW (2009) Modelling compositional data using Dirichlet regression models. Journal of Applied Probability and Statistics, 4, 77–91.
13.
HronKFilzmoserPThompsonK (2012) Linear regression with compositional explanatory variables. Journal of Applied Statistics, 39, 1115–28.
14.
Martín-FernandezJAHronKFilzmoserPPalarea-AlbaladejoJ (2012) Modelbased replacement of rounded zeros in compositional data: Classical and robust approach. Computational Statistics & Data Analysis, 56, 2688–704.
15.
Pawlowsky-GlahnVBucciantiA (eds) (2011) Compositional Data Analysis. Theory and Applications. John Wiley & Sons Ltd.
16.
Pawlowsky-GlahnVEgozcueJJ (2001) Geometric approach to statistical analysis on the simplex. Stochastic Environmental Research and Risk Assessment (SERRA), 15, 384–98.
17.
ReimannCÄyräsMChekushinVBogatyrevI, (1988) Environmental geochemical atlas of the Central Barents Region. Geological Survey of Norway (NGU), Geological Survey of Finland (GTK) and Centrl Kola Expedition (CKE). Special publication, Trondheim, Espoo, Monchegorsk.
18.
RuppertDWandMP (1994) Multivariate locally weighted least squares regression. The Annals of Statistics, 22, 1346–70.
19.
ScheffèH (1958) Experiments with mixtures. Journal of the Royal Statistical Society, Series B, 22, 344–60.
20.
ScheffèH (1963) The simplex-centroid design for experiments with mixtures. Journal of the Royal Statistical Society, Series B, 22, 235–63.
21.
Tolosana-DelgadoRVan Den BoogartKG (2011) Linear models with compositions in R. In Pawlowsky-GlahnVBucciantiA, eds, Compositional Data Analysis: Theory and Applications, Chichester, UK: Wiley, 356–71.