
Abstract
Generalized Multiple Indicators, Multiple Causes Measurement Error Models (G-MIMIC ME) can be used to study the effects of an unobservable latent variable on a set of outcomes when the causes of the latent variables are unobserved. The errors associated with the unobserved causal variables can be due to either bias recall or day-to-day variability. Another potential source of error, the Berkson error, is due to individual variations that arise from the assignment of group data to individual subjects. In this article, we accomplish the following: (a) extend the classical linear MIMIC models to allow both Berkson and classical measurement errors where the distributions of the outcome variables belong in the exponential family, (b) develop likelihood based estimation methods using the MC-EM algorithm and (c) estimate the variance of the classical measurement error associated with the approximation of the amount of radiation dose received by atomic bomb survivors at the time of their exposure. The G-MIMIC ME model is applied to study the effect of genetic damage, a latent construct based on exposure to radiation, and the effect of radiation dose on physical indicators of genetic damage.
Keywords
Introduction
The biological effects of ionizing radiation on exposed body organs varies depending on the dosage received at the time of exposure and also on the organ in question. Ionizing radiation can have several effects on living cells including their damage or the damage of the DNA within the cell's nucleus (Awa, 1997). Cells have a natural repair mechanism whereby the initial damage due to the exposure can result in their self-repair while still functioning either normally or abnormally following the repair. Characteristics of cellular damage due to exposure to ionizing radiation include the deletion of segments of the DNA. In studying the effects of ionizing radiation on genetic damage among subjects exposed to high levels of radiation doses, such as a subset of the atomic bomb survivors, genetic damage can be seen as an underlying latent construct where it is not directly observable but can be measured by various indicators or assays. Some of these assays include the chromosome aberrations (CA) and the glycophorin A (GPA) assays. Chromosome aberrations are often used as biomarkers for genetic damage where some of the damages to the chromosome include changes in the number of chromosomes on each DNA strand or changes to the structure of the chromosome (Awa, 1997; Fenech, 2002; Rana et al., 2010). Some of these structural abnormalities result from the breakage of chromosomes or incorrectly joining of the resulting fragments during the repair mechanisms (Awa, 1997). Another indicator of genetic damage is the GPA assay (Grant and Bigbee, 1993). GPA is a molecule found in mature red blood cells among individuals with M/N blood types. The GPA assay has been considered a biodosimeter for exposure to ionizing radiation and has also been considered an intermediate biomarker for genetic damage (Grant and Bigbee, 1993). This assay has been recommended as an intermediate biomarker for genetic damage among individuals exposed to chronic exposure to radiation and is considered a ‘powerful cumulative biodosimeter’ (Grant and Bigbee, 1993). The assay measures the number of variant cells that have lost expression of the M allele in blood samples from subjects with heterozygous M/N alleles (Grant and Bigbee, 1993). It has also been used as a biomarker for individual DNA repair capacity and cancer risk following genetic or DNA damage (Kyoizumi et al., 2005).
In studying the effects of ionizing radiation on indicators of genetic damage, a variation of the multiple indicators, multiple causes measurement error (MIMIC ME) (Tekwe et al., 2014) models can be applied. MIMIC ME models are useful for studying the effects of an underlying latent construct on its multiple outcomes or indicators when some of its causes are measured with error in linear settings. For example, the true ionizing radiation dose received by atomic bomb survivors at the time of their exposure is unknown but is measured by the Dosimetry 2002 (DS02), a physical dosimetry system developed by the Radiation Effects Research Foundation (RERF) for estimating true radiation doses. DS02 is defined using a physical dosimetry system based on the survivor reported distance and shielding at the time of exposure. Once obtained, the self-reported location data are placed on the map of the city and all individuals reporting to be at similar distances away from the hypocenter are all assigned distances based on the grid in which their reported distance falls. All survivors whose self-reported distance are within the same grid are assigned the averaged DS02 calculated for the grid based on the distance associated with the centre of the grid. The self-reported measures of location and shielding introduce classical measurement error into the dosimetry system while the Berkson error is introduced to the system due to the fact that all individuals within each grid are assigned the same DS02 values based on the averaged distance. The Berkson error is an averaging error that occurs when individuals with similar characteristics are assigned an average value of a measurement rather than their individual measured value.
It is well known that one of the effects of exposure to ionizing radiation is genetic damage. Genetic damage due to ionizing radiation is not directly observable; however, indicators such as the GPA and CA assays are used to estimate its physical manifestation. In this manuscript, we define the generalized multiple indicators, multiple causes measurement error (G-MIMIC ME) models which allow the relationship between a latent construct and its multiple outcomes to be of the generalized linear form while one of the the causal variables for the underlying latent construct is measured with error. The defined G-MIMIC ME model allows a mixture of both Berkson and classical measurement errors.
The outline of the article is as follows: In Sections 2 and 3, we define the G-MIMIC ME model and discuss its estimation, respectively. The application of the model to our motivating example and the results are presented in Sections 4 and 5. The results from a brief simulation study are provided in Section 6 and some concluding remarks can be found in Section 7.
Generalized multiple indicators, multiple causes measurement error models
The G-MIMIC ME model extends the classical linear MIMIC model (Zellner, 1970; Goldberger, 1972; Joreskog and Goldberger, 1975; Skrondal and Rabe-Hesketh, 2004) to the generalized linear model setting with a mixture of both Berkson and classical measurement errors. The defined model is a structural equation model with multiple causes including error-free covariates and a single true covariate measured with error. It is a combination of a confirmatory factor analysis with a common underlying factor or latent construct and path models with covariates in the generalized linear setting. The use of latent constructs is prevalent in fields such as the social sciences or medicine. For example, in medical terminology, syndromes are not directly observable. However, they are defined based on their multiple indicators which occur simultaneously to be defined collectively as a syndrome. The G-MIMIC ME model with the subscript for the





The effect of T
i
on the The YY
ij
’s are conditionally independent given the latent variables T
i
, X
i
and the error-free covariates, The random variables The latent construct, T
i
, is independent of all random variables except, The random error The true covariate measured with error, X
i
, is independent of the error terms
Given
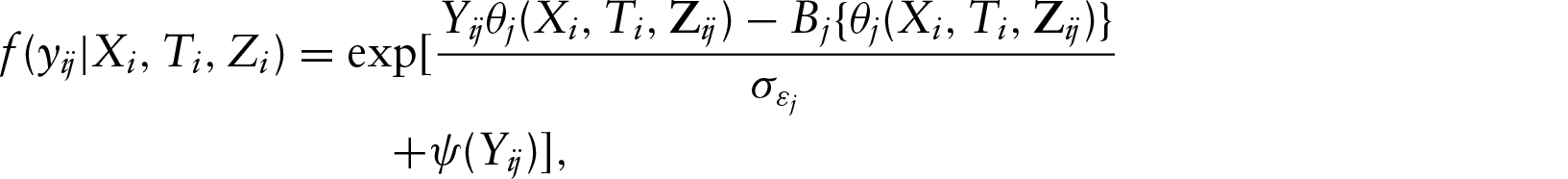
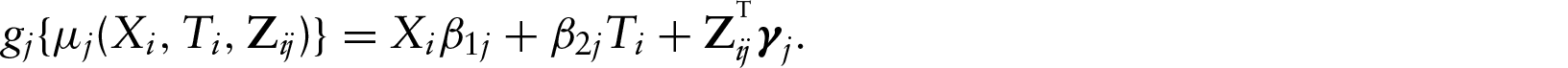
In Figure 1, we provide a path diagram for the defined model. The model is illustrated with one underlying latent construct
The model when
. Given
,
and T, the outcomes Y’s are conditionally independent.

The G-MIMIC ME model can be re-written in its reduced form by substituting the causal equation for T
i
into the structural equation models for the outcome variables. The reduced form equation is expressed as:

The identifiability of non-linear structural equation models are often done on a case by case basis. As in most measurement error problems, additional information from the data are usually used to identify the model. Our defined model can be identified under any of the following conditions: The Berkson measurement error variance, Both measurement error variances Repeated measures on
In this manuscript, we focus on the instrumental variable approach to identify the model. However, any of the two other conditions can also be used to identify the model based on the available data. We propose the estimation of the reduced form parameters by employing the MC-EM algorithm (Wei and Tanner, 1990).
Estimation
MC-EM estimation of the G-MIMIC ME
We propose an extension of the EM algorithm, namely the MC-EM (Wei and Tanner, 1990) algorithm, to obtain the maximum likelihood estimates (MLEs) of the identified model. The EM (Dempster et al., 1997) is an iterative procedure for finding the MLEs in missing data settings. The E-step of the EM algorithm requires the calculation of the expectation of the complete data log likelihood,
By applying the MC-EM algorithm, we treat the measurement error problem as a missing data problem, where the observations on the outcome variables

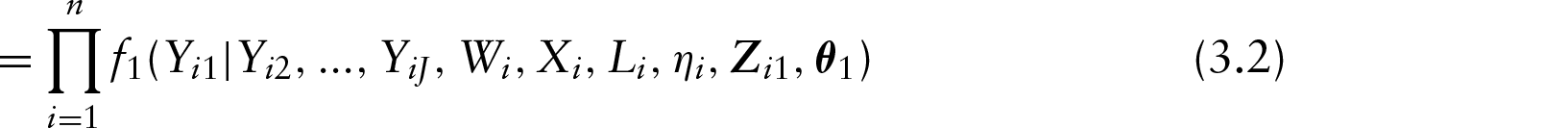


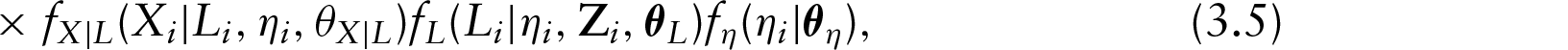
To obtain the standard errors for the estimators, the Oakes (1999) method which adjusts for the observed data likelihood can be used. Another option is to use re-sampling approaches such as the bootstrap method (Efron, 1979) to obtain the standard errors. For our current motivating example, the standard errors for the MC-EM estimates were obtained using the bootstrap approach.
Instrumental variable analysis can be used to identify the model parameters of the defined model. An instrumental variable,

Application of the G-MIMIC ME model
Background and data
In this article, we apply the G-MIMIC ME model to the atomic bomb survivors data collected by RERF. We define the variables in our application as follows: T
i
is the underlying latent construct defined as the overall genetic damage. This underlying latent construct has two physical manifestations, namely, chromosome aberrations

A subset of the Adult Health Study (AHS) in Hiroshima and Nagasaki, Japan who were exposed within 500 m to 2500 m from the hypocenter with complete data were included in the study. For the current analysis, survivors with
Model and instrument
In our data,
In our analysis, we assumed
A side goal of the analysis is to obtain an estimate of

where
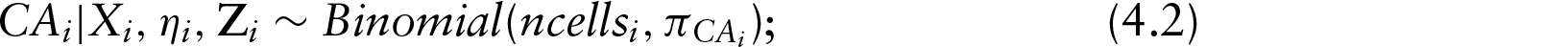




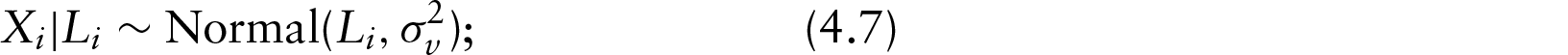
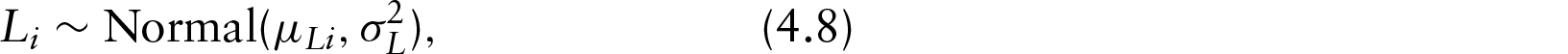
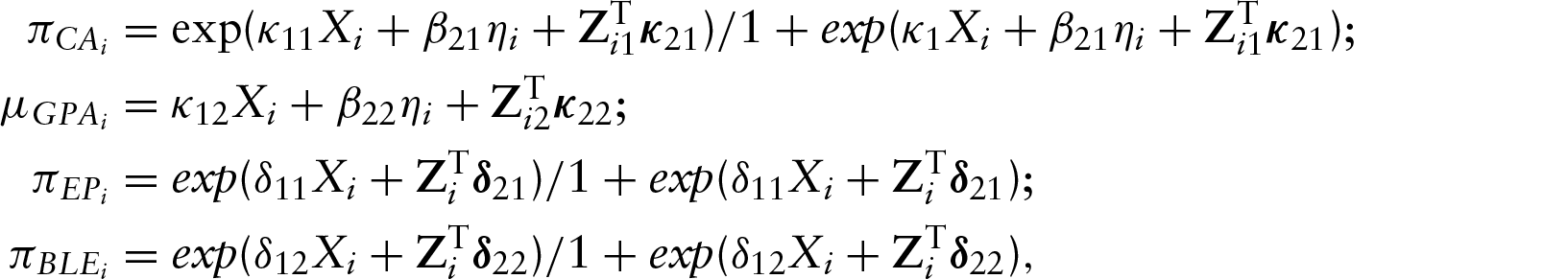
In this section, we discuss the results from our application of the G-MIMIC ME model with instrumental variables to RERF data. The Gibbs sampler was used in the MC-E step (please see the Appendix for additional details). Based on the evaluation of the convergence of the simulated latent variables, we find that the generated data for
Results from the analysis of CA, Loggpa, EP and Bleeding.
= mixed (Berkson and classical) measurement error adjusted estimates,
= classical measurement error adjusted estimates,
= unadjusted parameter estimates,
=
= percentage change in the CME adjusted estimates from the MME adjusted estimates,
=
= percentage change in the unadjusted estimates from the MME adjusted estimates

Results from the analysis of CA, Loggpa, EP and Bleeding.
= mixed (Berkson and classical) measurement error adjusted estimates,
= classical measurement error adjusted estimates,
= unadjusted parameter estimates,
=
= percentage change in the CME adjusted estimates from the MME adjusted estimates,
=
= percentage change in the unadjusted estimates from the MME adjusted estimates
Overall, we find that CA is highly predictive as an assay for genetic damage
The results from the modeling of the instrumental variables, epilation and bleeding, are also included in Table 1. A statistically significant relationship was found between true radiation dose and epilation, after adjusting for age at the time of exposure and the gender of the survivor (p-value
Epilation and internal bleeding were used as instrumental variables to identify the model due to the presence of the classical measurement error,
Impact of measurement error on the parameter estimates
Table 1 also provides measurement error adjusted and unadjusted parameter estimates. The table also includes the percentage changes from the parameter estimates based on the adjustment of the mixture of measurement errors. Overall, we find that adjusting for the measurement errors has massive impacts on the estimated parameters. The effects of failing to adjust for any measurement error in estimating the error-free covariates tend to depend on the error-free covariate. However, we find that failing to account for any measurement error leads to under-estimating the effects of true radiation dose while over-estimating the effects of the overall genetic damage on its outcomes. We also find that failing to account for the Berkson error leads to over-estimating the true effects of the radiation dose. The percentage changes in the estimated coefficient on true radiation dose when comparing the classical measurement adjusted alone to the estimates based on the adjustment of the mixture of measurement errors range from
Sensitivity analysis of the parameter estimates to assumed values of
and starting values of
In this section, we provide a discussion of the sensitivity of the parameter estimates to the assumed known values for the Berkson error and the starting values for
In general, the coefficients on the error-free covariates and the underlying latent construct, the overall genetic damage, were the least sensitive to
We also assessed the sensitivity of the estimates of
Illustration of identifiability of the G-MIMIC ME
Impact of assumed known values of
and initial values of
on the estimated model parameters for CA analysis. The subscript in
represents the assumed known value for
and initial value for
, respectively
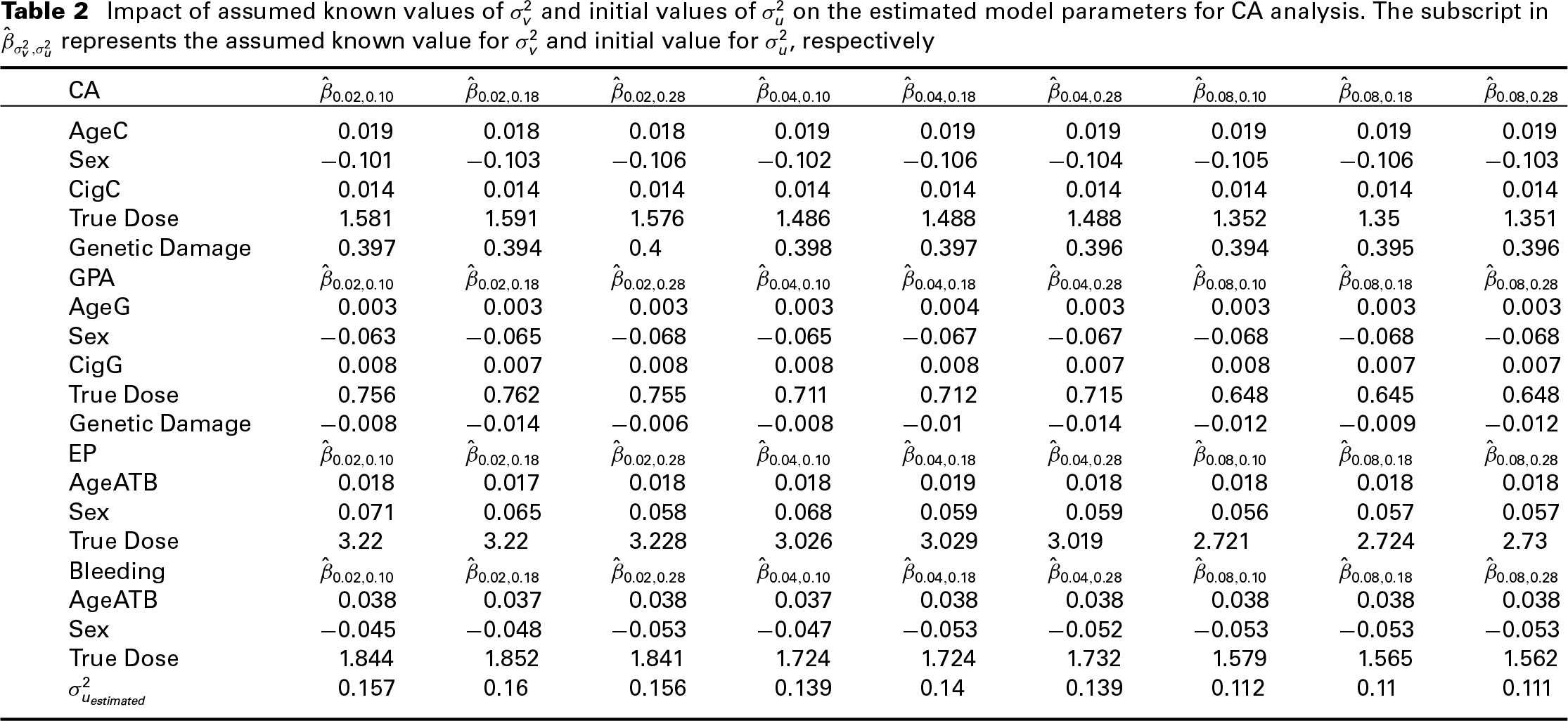
Impact of assumed known values of
and initial values of
on the estimated model parameters for CA analysis. The subscript in
represents the assumed known value for
and initial value for
, respectively
Identifiability results from the CA analysis
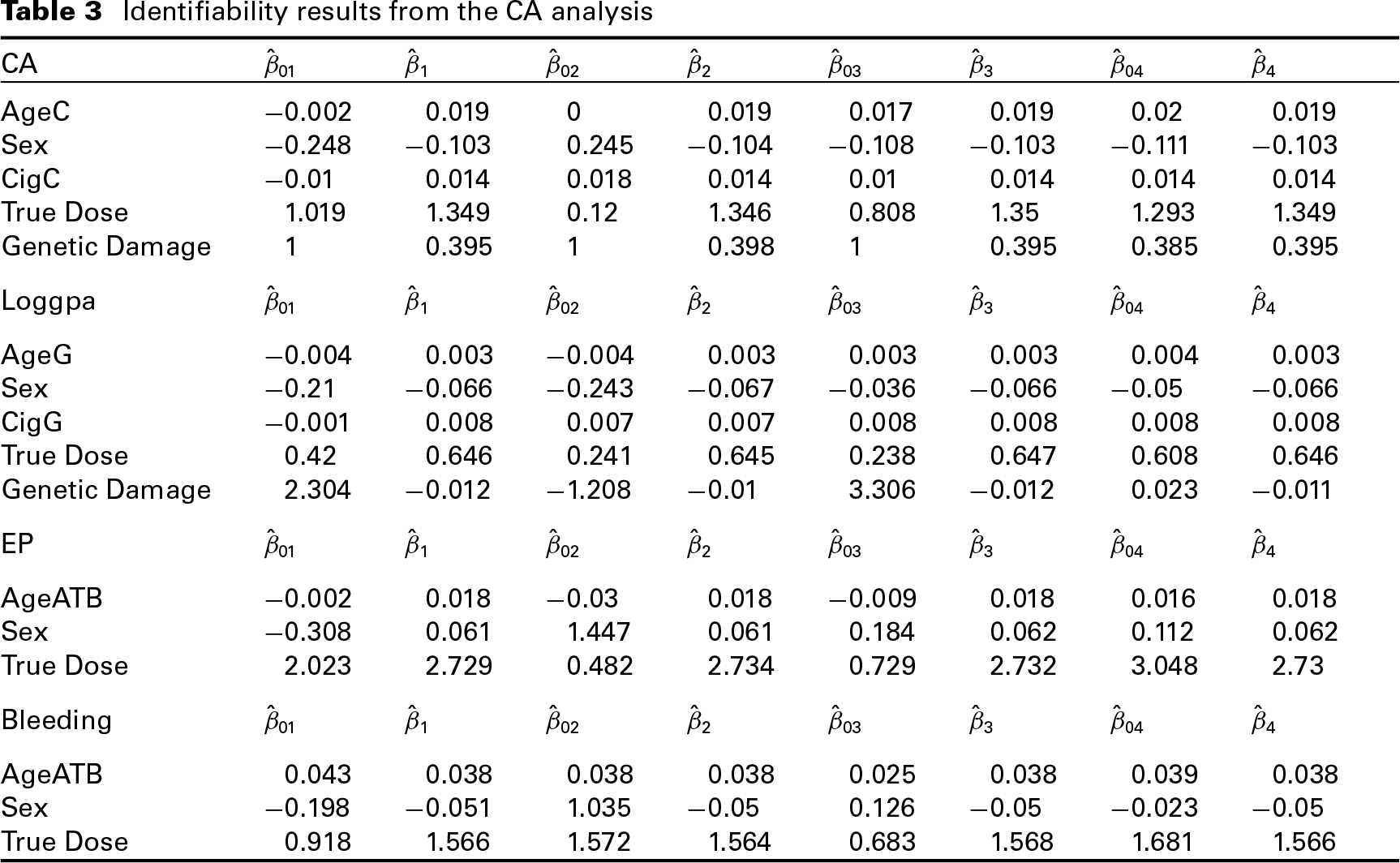
To illustrate identifiability, we analyzed the data under different starting values for the parameters (see Table 3). Four different sets of starting values were used to see if the estimated values would converge to the same maximum likelihood estimate. Based on our analysis, we find that the estimated model parameters all converge to the same values regardless of the starting values used. Thus, we conclude that the model is identified with known
A simulation study was performed to assess the impact of ignoring measurement error in estimating the effects of true radiation dose on the relevant outcomes. We generated a dataset similar to our motivating example. The data were generated under the assumption that the variances of the classical and Berkson measurement errors were
Figure 2 provides the results from the simulated dataset for all the models considered. The solid blue line in the figure indicates the true
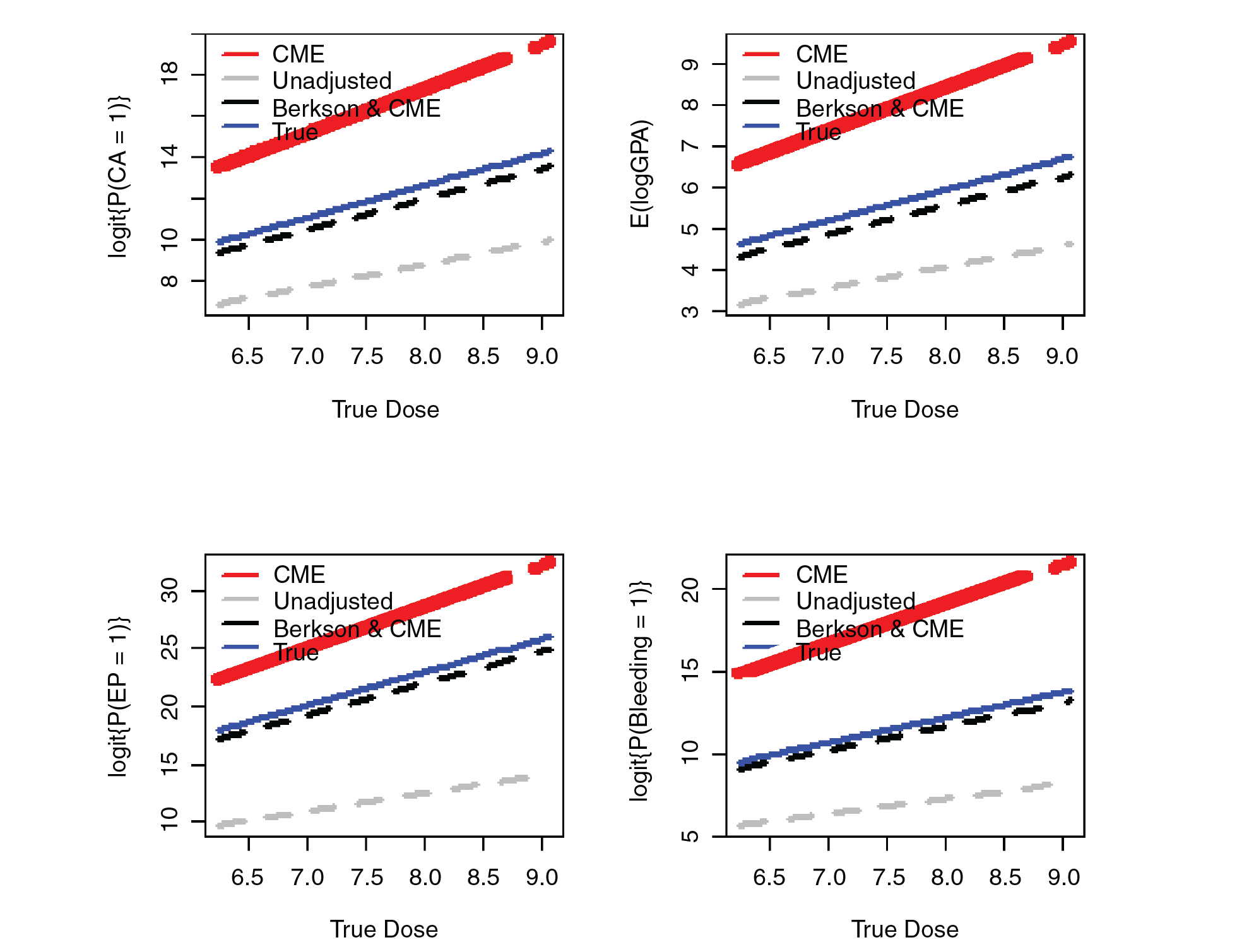
In this article, we applied the G-MIMIC ME model with an instrumental variable to assess the impact of true radiation dose and overall genetic damage on the physical indicators of overall genetic damage CA and log(GPA). The G-MIMIC ME model allows for the predictor variable in the causal equation for the underlying latent construct, T
i
, to be measured imprecisely as in the case of DS02 estimates of radiation dose among survivors of the atomic bomb. The presence of classical measurement error introduces an additional complexity involving the estimation of the regression coefficients. The complication involves lack of identification of the variance of the classical measurement error,
Our current model, the G-MIMIC ME model allows us to assess the direct effect of an underlying latent construct on its physical indicators or outcomes after adjusting for error-free covariates and a true covariate prone to both classical and Berkson measurement errors.
Appendix
One of the complications often faced by researchers implementing the EM (Dempster et al., 1997) algorithm involves the need to explicitly calculate the expected log likelihood of the complete data. The EM algorithm was extended by Wei and Tanner (Wei and Tanner, 1990) to the Monte Carlo EM (MC-EM) algorithm. The MC-EM algorithm does not require the direct computation of the expected log likelihood of the complete data. MC-EM is an approximation method that works in estimating functions due to the weak law of large numbers. Rather than directly calculating the expected log likelihood as required under the EM algorithm, the MC-EM algorithm is based on simulating the missing data, Y
mis
, from its conditional distribution, 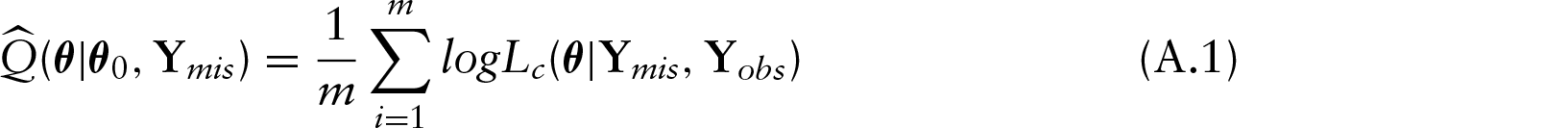
where Y
mis
represents the missing data while Y
obs
represents the observed data. The
The maximization step involves the maximization of the approximated completed data log likelihood to obtain the parameter estimates under the conditional independence assumption. Under the conditional independence assumption, the structural parameters associated with each outcome or indicator variable can be obtained independently of the parameters associated with the other outcomes.
Our MC-EM approach can be summarized as follows:
Obtain initial values, θ(0). Simulate M Markov chain Monte Carlo samples Fill in the simulated M MCMC samples as replacement data for the missing data in Create an expanded dataset for each subject (i = 1,..., n) based on the M simulated
Monte Carlo samples from (2). The original incomplete and expanded complete dataset are indicated below for the ith subject:
Approximate the Q function using the expanded data as follows:
M-step: Maximize Repeat this process at the tth iteration by generating a new set of samples Maximize the resulting Q-function,



We note that under the conditional independence assumption, the Q functions associated with each conditional distribution for each outcome variable can be obtained independently. Once the expanded or concatenated data have been created, maximization of this likelihood can be done using optimization techniques such as the Newton Ralphson algorithm. Another approach to obtaining the parameter estimates is to use readily available procedures in statistical packages such as PROC GLM in SAS or the GLM function in R to analyze the augmented dataset as if Q were a log likelihood function constructed from i.i.d. observations. This method of maximizing the likelihood works because the approximated Q function is a pseudo-loglikelihood that has the form of a likelihood of Mn independent observations as illustrated in the expression for Q above. Once we obtain the MC-EM based parameter estimates, we perform inferential procedures on the estimated parameters.
To obtain the standard errors for the estimators, the Oakes' (1991) method which adjusts for the observed data likelihood can be used. Another option is to use the bootstrap method to obtain the standard errors. For our current motivating example, the standard errors for the MC-EM estimates were obtained using the bootstrap approach.
Acknowledgments
The Radiation Effects Research Foundation (RERF), Hiroshima and Nagasaki, Japan is a private, non-profit foundation funded by the Japanese Ministry of Health, Labour and Welfare (MHLW) and the U.S. Department of Energy (DOE), the latter in part through the DOE Award DE-HS0000031 to the National Academy of Sciences. This publication was supported by RERF Research Protocol A5-11. The views of the authors do not necessarily reflect those of the two governments.