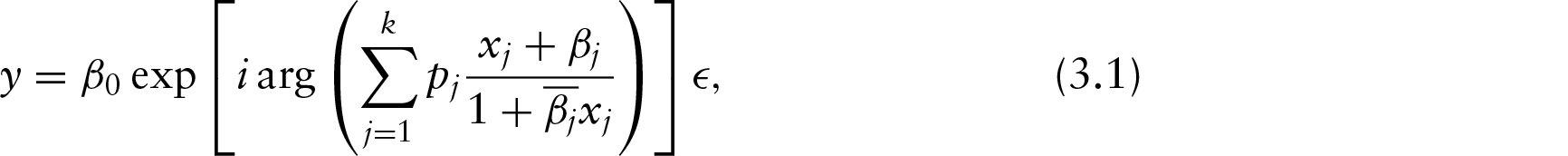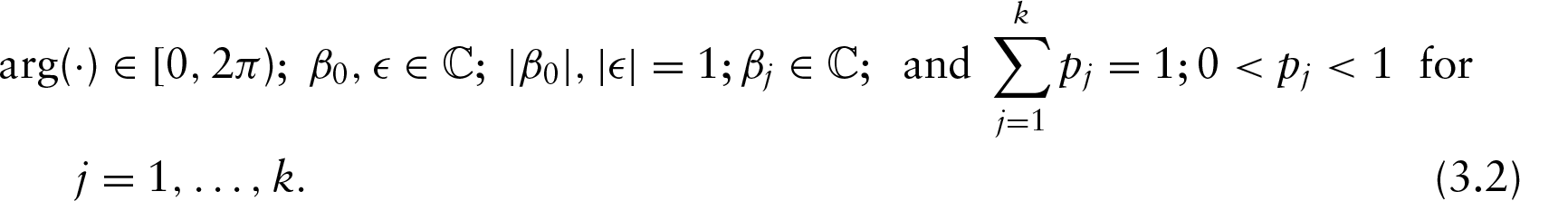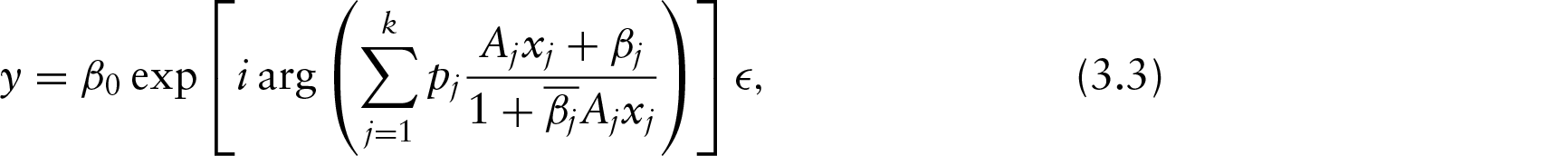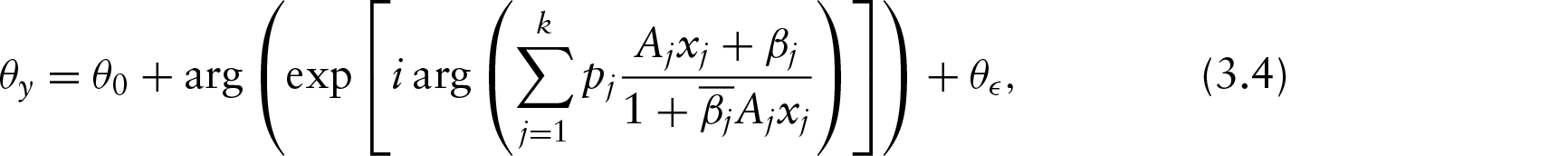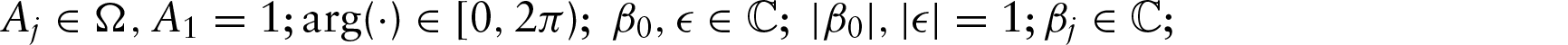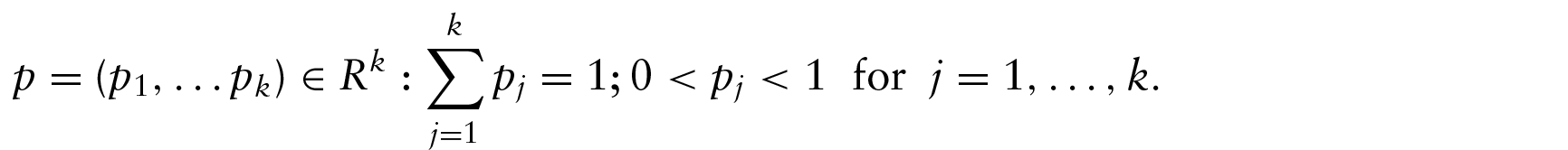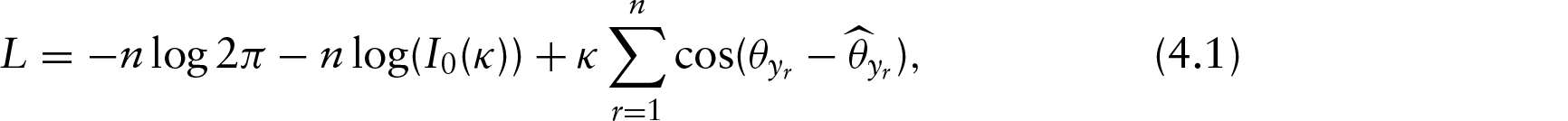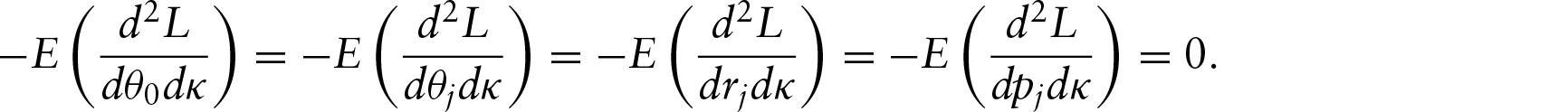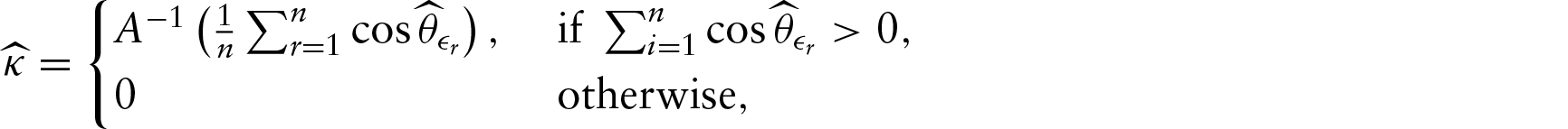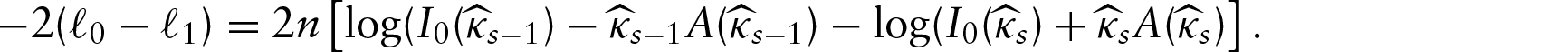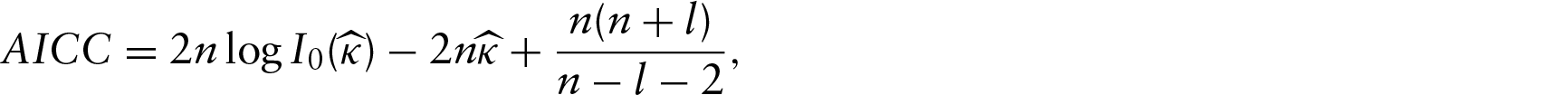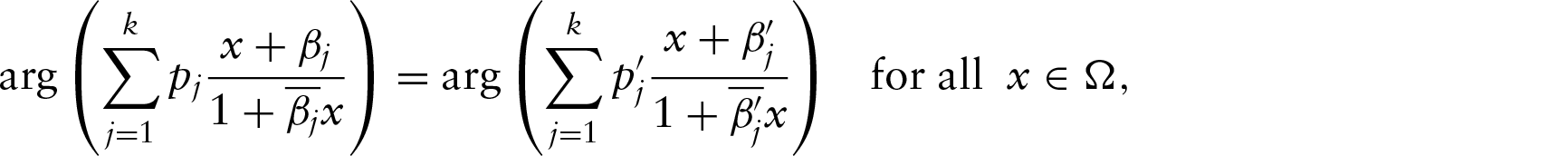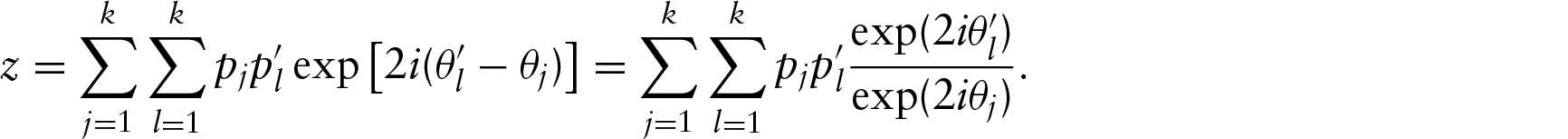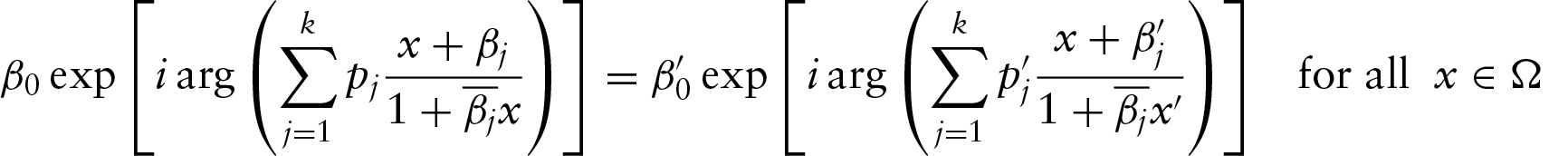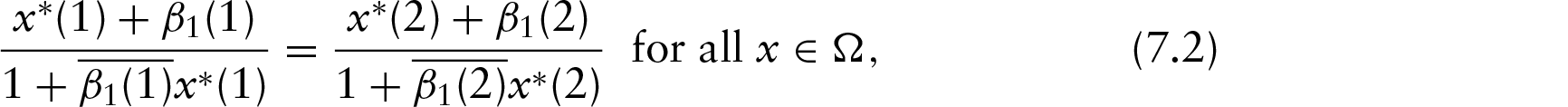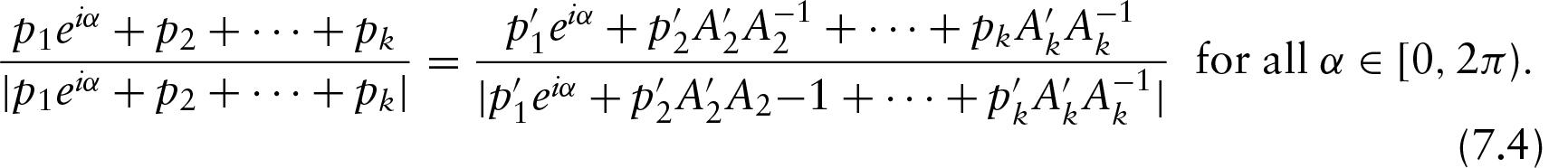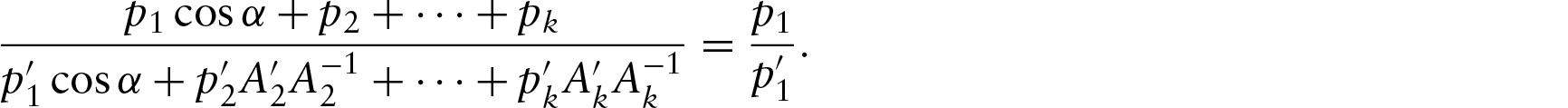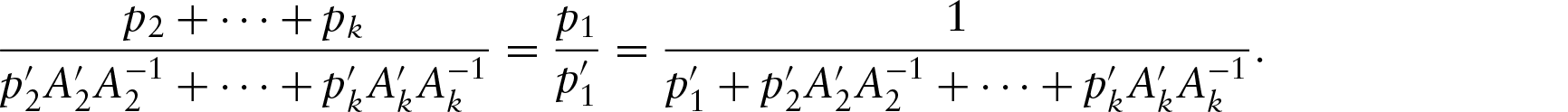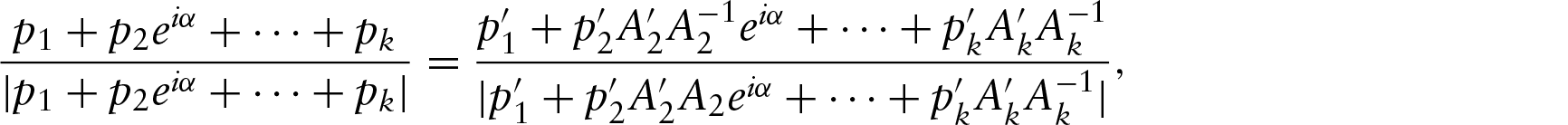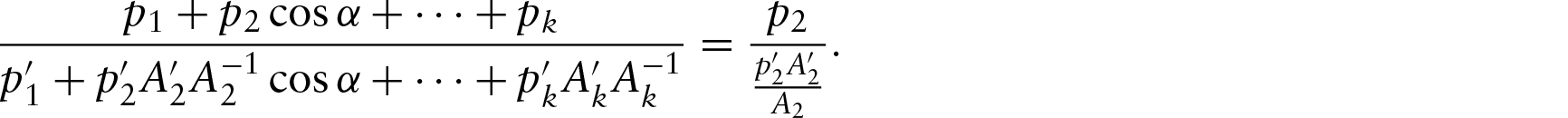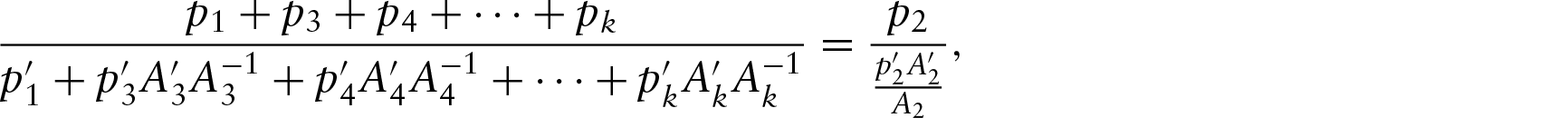In this article, we consider the circular–circular regression model using Möbius transformation. We first consider the model provided by Kato et al. (2008) for only one circular regressor and prove the identifiability of the model. After that, a methodology is discussed to reduce the prediction error of this model. We then introduce the two multiple circular–circular regression models with multiple circular regressors. We prove the identifiability of the models and discuss their geometry. We then discuss the parameter estimation procedure followed by simulation study. The methodologies are illustrated by some real datasets.
There are numerous real-life applications of circular or directional data such as wind direction, direction of migration of birds, angular data in ophthalmological studies, etc., and also periodic data. However, only limited statistical methodologies are available in the statistical literature for modelling and analysing such datasets.
Regression problem for circular data becomes much more complicated than the usual linear regression. There are some existing works on circular–circular regression, where a circular variable is regressed on a circular variable, and linear–circular regression, where a linear variable is regressed on a circular variable. The circular–circular regression mentioned in Rivest (1997) regresses the circular dependent variable on an independent variable by decentring the dependent variable. Downs and Mardia (2002) used tangent link function for regression. Minh and Farnum (2003) used bilinear transformation from the unit circle to the real line and it is related to Möbius transformation. Hussin et al. (2004) discussed the simple linear regression approach for predicting a dependent circular random variable on the basis of an independent circular random variable. This approach is very simple and easy to implement, but it has difficulty due to the dependence on the direction considered as the angle 0. Kato et al. (2008) suggested circular–circular regression by using the Möbius transformation method. Both Downs and Mardia (2002) and Kato et al. (2008) used Möbius transformation for the regression. But, all these works are done with only one circular regressor. Sengupta et al. (2013) discussed inverse circular regression where more than one observation corresponding to the dependent variables are considered, then they suggested to take the circular mean of the observations.
Multiple circular–circular regression deals with establishing the dependence of circular random variables on more than one independent circular random variables. Examples of such dependence can be seen by regressing the direction of migration of birds on wind direction and time of the day. As date of the year and time of the day can also be considered as circular random variables, the multiple circular–circular regression models can also help in establishing relationships of one periodic random variables on others. One such example is predicting the wind direction based on the date of the year and the time of the day. So far our knowledge goes, there are not many published works on circular–circular regression with multiple circular regressors. Multiple circular–circular regression is mentioned in the Theorem 2.3.1 of Hughes (2007), where a multivariate von Mises distribution is used to show the dependence of a circular response based on multiple circular covariates. The aim of this present article is to give an alternative approach for multiple circular–circular regression by extending the geometrical approach of Kato et al. (2008); their method gives good analytical results.
The rest of the article is organized as follows. In Section 2, we first discuss the concept introduced by Kato et al. (2008). We prove the identifiability of their model, which they ignored. In Section 3, our model for multiple circular regression (MCR) is introduced and the proof of identifiability of the model is provided. The geometrical interpretation of the model and the applications of the model in the case of single circular covariate and multiple circular covariates are also discussed in the same section. Based on the regression model of Kato et al. (2008), an alternative model is also discussed for multiple circular–circular regression. In Section 4, we provide estimation of the model parameters and simulation studies are carried out. We introduce a new type of plot (called the donut-plot) for pictorial representation of our analysis. The methodology is illustrated by some real datasets in Section 5. Section 6 concludes.
Circular–circular regression
Hussin et al. (2004) used the usual linear regression model for circular–circular regression. The drawback of this method is that it does not give the same prediction for x and x+2π if the regression coefficient is not an integer. Also, this model is very much dependent on the choice of the angle 0, that means it gives different non-equivalent regression functions for different orientations of 0 degrees of the independent circular random variable. Thus, it is necessary to consider the problem of circular–circular regression differently. Various authors have considered different models for the circular–circular case. In this article, we have extended the idea of Kato et al. (2008) model which is described in the present section.
Model
Möbius transformation is a closed group transformation in the complex plane . For the set , the Möbius transformation function is defined by
where , , is the conjugate of a. Taking the regression function in a similar form, Kato et al. (2008) defined the circular–circular regression as follows.
Let θy and θx be circular random variables. Taking and , the regression of y on x is
where ; and follows the wrapped Cauchy distribution , where . The parameter of the wrapped Cauchy distribution is a complex number lying inside the unit circle. The condition ensures that the mean angle for the error is 0. Here, the wrapped Cauchy distribution is used due to the ease in finding the joint distribution of (y,x) and some elegant properties of the wrapped Cauchy distributions. But, other distributions for angular error, such as the von Mises distribution and asymmetric generalized von Mises distribution, which is mentioned in Sengupta et al. (2013), can also be used.
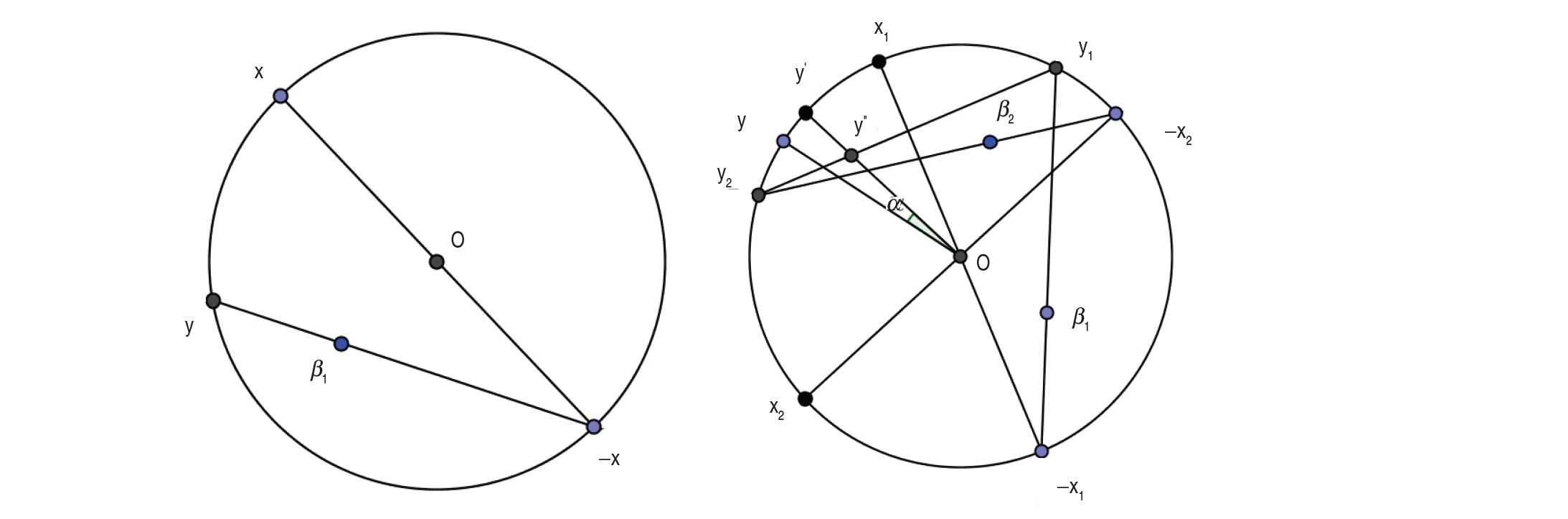
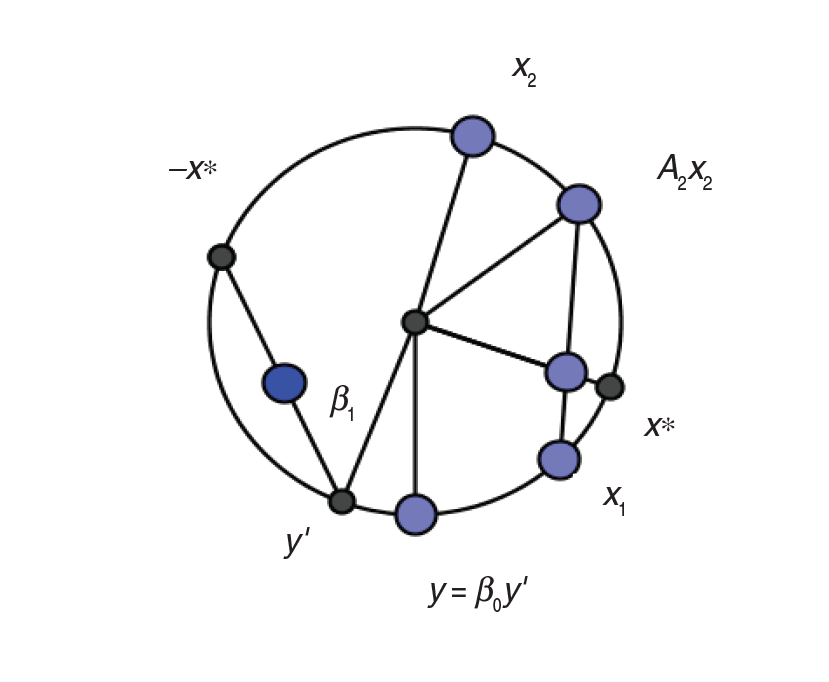
The regression function, which is a form of Möbius transformation, is a mapping of unit circle onto itself. Here, β0 is a rotation parameter while β1 is a fixed point in the complex plane. The predicted point y given x is the intersection of the unit circle with the line joining −x and β1. This is shown in Figure 1. The case of is also discussed by Kato et al. (2008). In this case, first the fixed point is taken to be . Then this point is joined to . The intersection of this line with the unit circle is the predicted point y.
In this model, it can be seen that if is closer to 1, the function results in the y-values concentrating around . When , we have ; which is just a rotation. Thus, the regression function defined above can be used for regression when there is only rotation and also in the case when there is reflection about any axis.
Left: Regression model demonstrated for one regressor taking β0=1; Right: Regression model demonstrated for two regressors
Identifiability issue in circular–circular regression
Identifiability of a model means that no two sets of parameters give the same distribution. This is important because otherwise there will be various choices of the parameter set which describe the same thing.
Kato et al. (2008) did not consider the identifiability issue of this model. However, the regression curve given by the Möbius transformation is identifiable. This is because for all , there exists only a single point β1 inside the disc through which the projection line (the line joining −x and β1) is taken. The case for , as discussed in Kato et al. (2008), seems different from the case of . However, the geometry in this case can also be explained similarly. This can be shown by comparing the individual coordinates of the predicted point from both the geometries. Without loss of generality, we can take β1 to be lying on the real axis. This is because any orientation of the circle is equivalent to any other orientation by a rotation. After changing the complex plane to , this is directly implied. The intersection of the line joining and , where , with the unit circle is . Changing this in the complex form yields . Thus, both the geometries are similar. In both the cases, as the final projection point is unique, the model remains identifiable.
Mathematically, for a given point x and given β1, taking β0=1, the predicted point y is the point at the circle which lies on the line joining −x to β1. Thus, other possible values of which give the same y for this given x can only be the points lying on this line. This is true for all . Hence, for all , the points x, β1 and should be collinear. But, if we take (), then the three points () will again be collinear if and only if . Thus, β1 is unique and hence the model is identifiable. Here, β0 is just a rotation parameter which can be dealt with by rotation directly as done in Theorem 7.2 (see the Appendix).
Multiple circular regression models
Model I (MCR1)
Let , , be circular random variables. Our aim is to regress θy on 's. Let and for all j. Then, y can be modelled as
where
The model is not defined for when . If , then, this problem can be overcome if we define . If , then while checking the maximum of log-likelihood during data analysis, for a particular parameter set, such sample points should be ignored and the maximum likelihood should be divided by the number of sample points considered for any parameter set. The proposed model also becomes unidentifiable when for all j. This can be rectified by modifying the parameter space such that at least one .
Note that Equation (3.1) is a multiple circular extension of circular–circular regression proposed by Kato et al. (2008).
The case of two regressors is shown in the right panel of Figure 1. Here O is the centre, and
where .
The examples of such model can be the direction of bird migration regressed on wind direction and time of year when all the three variables are circular in nature.
The proof of identifiability for this model is given in Appendix A.
Geometry of multiple circular regression
Theorem 7.1 can also be used to improve the fit of the circular–circular regression when there is only one circular covariate. The geometry is shown in the left panel of Figure 1, which is as follows:
Step 1: .
Step 2: passing through β1.
Step 3: Rotate by to obtain y. (In the figure, , and hence .)
In the case of bivariate circular regression as explained in this article, the right panel of Figure 1 shows the regression. The geometry can be described as follows:
Step 1: .
Step 2: passing through β1.
Step 3: passing through β2.
Step 4: Join y1 and y2 and take .
Step 5: The regressed point is the projection of line joining centre O and on the circle.
Step 6: Rotate by to get y.
For the general case, we can obtain as given in Steps 3 and 4. Then we can take . Now, the regressed point will be the projection of line joining centre O and on the circle, which is . Then, as in Step 6, y can be obtained by rotation of by anticlockwise.
Note: The bivariate case and the general case are explained only for . The case of for any j can be dealt similarly only by incorporating the geometry as described in that case earlier for one regressor for getting the projection point corresponding to that regressor.
Multiple circular regression
The model described above is helpful in the case of multiple circular regressors. After specifying the direction of 0 angle for each covariate, the parameters pjs can be used to gauge the magnitude of effect of each covariate on the response. The higher the value of a particular pj, the higher is the effect of that particular regressor xj on the response y. This can be said because pjs are nothing but weight parameters. Thus, the model can also be used to check the relative effect of the regressors on the response variable.
In MCR also, new parameters corresponding to the covariates can be added as specified in single regressor case to get a better fit than before. The removal of the dependency of the parameter pj's on the orientation of the covariates can be done by adding another parameter Aj for each covariate and hence, the new model can be written as the following:
The regression function can also be written in the form of tangent link function. In such case, the regression function can be written as
where
The proof of identifiability of this model proceeds similarly as is done in Theorem 7.1 and Theorem 7.2.
Invariance and rotational equivariance of parameters
Circular regression models must be origin independent. Hence, for every rotation of the covariates and responses, a desirable feature is to get the same predicted mean direction by changing the model parameters. Also, p must be invariant of the rotations. We shall denote the parameters of the previous model by (β0, Aj's, βj's, p) and the new model parameters by (β0(n), Aj(n)'s, βj(n)'s, p(n)).
The predicted mean direction of an MCR1 model can also be written as
where A1=1. A change in the 0 angle is the same as multiplying by a unit complex number W. It can be seen directly from Equation (3.5) that if the response y is rotated and the new response is Wy, where , there exists a model which gives the same prediction if all the parameters are the same except forβ0. Thus, (Wβ0, Aj's, βj's, p) gives the same prediction in the new model as was given by (β0, Aj's, βj's, p) in the previous model.
When x1 is rotated to Wx1, then the new model parameters which give the same predicted mean direction are .
When , , is rotated by W, then the new equivalent model parameters are . The meaning of p is completely preserved as it is invariant with respect to any rotation.
Fixing means fixing this value with respect to one of the covariates. The model does not depend on which covariate is chosen as because if in another case is chosen as the covariate such that is fixed, then the parameters with respect to the new model which give the same predicted mean direction are ().
Multiple circular regression II (MCR2)
The problem with the model MCR1 is that adding a new covariate results in adding four new parameters to the model: , where . Thus, we propose an alternative multiple circular–circular regression model having an increase in two parameters per covariate. We write
where
The representation in terms of tangent link function is
The parameters 's, , 's are defined as earlier. The interpretation of the parameters are the same and the rotational equivariance ofβ0, 's, 's is exactly similar to what was discussed in the previous section. By fixing , we have locked the location of x1, hence it can easily be seen that β1 is rotationally equivariant with x1. The tangent link function in Downs and Mardia (2002) and the Möbius transformation in Kato et al. (2008) are mathematically equivalent for one covariate. It can be seen that the equivalence of the MCR2 model with Downs and Mardia (2002) is maintained if we consider as defined in MCR2 as the covariate in Downs and Mardia (2002). The Figure for the regression function in case of two covariates is shown in Figure 2. The identifiability of this model is proved in Appendix B.
Regression model demonstrated for two covariates
Invariance and rotational equivariance of parameters
As explained in Section 3.2.2, there must exist an equivalent model with respect to the rotation of the circular variables in MCR2 also. From Equation (3.5), it can be directly seen that if y is rotated by W, then the new model parameters giving the same predicted mean direction as the previous one will be (Wβ0, Aj's, β1, pj's).
Thus, the equivalent new model parameters when x1 is rotated to Wx1 are . When, is rotated to , then the equivalent new model parameters are .
The choice of does not change the prediction because the equivalent new parameters will then be .
Estimation of parameters
Maximum likelihood estimators
When s are all known for , and the angular error follows the wrapped Cauchy distribution , the estimation of andβ0 can be done by the method proposed by Kent and Tyler (1988). This estimation can also be done by the method of moments as described in Kato et al. (2008). When the angular error follows asymmetric generalized von Mises distribution, then the MCR1 model is of the form
and the MCR2 model can be written as
In both these cases, follows AGvM(0,0,1,1) distribution. In this case, when 's, 's and 's are known, can be estimated and then by subtracting the bias in error, the maximum likelihood estimates (MLE) of can be obtained, as mentioned in Section 3.3 of Sengupta et al. (2013).
If the angular error follows , then the MLEs ofβ0 and reduce to
where , or 0 according as or not. If MCR1 is used, then
If MCR2 is used, then
The maximization of log-likelihood for von Mises case is equivalent to the minimization of circular distances , between and , as
where is the estimated value corresponding to the jth regressor. Therefore, for any value of κ, the likelihood is maximized when the circular distance is minimized. Thus, instead of maximizing the more complicated log-likelihood function, the circular distance function can be minimized and then estimate of can be found through the estimates of 's and 's.
Now, for the first model, is maximized when is the circular mean of s, and hence this is equivalent to maximizing
where
In case of the second model, is maximized when is the circular mean of s, and hence this is equivalent to maximizing
where
Finding the maximum likelihood numerically is not easy in these models because of the presence of many local maxima. The presence of local maxima in case of a specific example can be seen from Figure 3. In the Figure, we have taken the case of the MCR2 model and shown the behaviour of likelihood function with the change of parameters by fixing all but one parameter and changing the non-fixed parameter. The parameters considered are , and . From the figure, it can be seen that the likelihood has local maxima both for b1 and b2. Both the local maxima can be seen as small spikes on the left of the global maximum. The figure at the right hand side in the second row shows the local maximum at b2 where the likelihood function is plotted near the local maxima. A similar figure can be obtained on plotting the likelihood near the local maximum for the graph b1 versus L. Thus, gradient-descent method for finding the global maximum of the likelihood function may not converge to appropriate point. Thus, while using the gradient-descent methods, different initial values should be taken for the parameters.
Plots for Likelihood Function. [Top row:] Graphs of likelihood (L) against (Left:) and (Right:) b1. [Middle row:] Graphs of likelihood (L) against (Left:) b2 and (Right:) b2 near the local maximum. [Bottom row:] Graph of likelihood (L) against
Another very useful alternative for finding the global maximum is to use the bootstrap restarting method discussed in Wood (2001). The steps required for approximating the MLE by bootstrap restarting for our set-up are the following:
Step 1: Take an initial parameter set q0.
Step 2: Starting from q0, find a local maximum qi and calculate , the log-likelihood function.
Step 3: Take a bootstrap sample from the dataset.
Step 4: Find taking as the starting parameter.
Step 5: Check if . If it is so, then take , else take and repeat the steps from 1 to 5 until convergence.
As already mentioned, for the parameter set, taking the parameters related to are enough because we can get the MLE of β0 and directly from these parameters.
Fisher information matrix
If angular error follows , then , , and
Hence, asymptotically, the MLE of and the MLEs of for all j will be independent. Other terms of the Fisher information matrix can be found numerically as the equations are very complex.
Similarly, if the angular error follows , then
Thus, the MLE of ψ will be asymptotically independent of the MLEs of for all k. Other terms of the matrix can be similarly obtained, although some of the functions are very complex and they can be computed numerically.
Improving the fit in case of single regressor
In case of circular–circular regression of Kato et al. (2008), one circular variable is regressed on only one circular regressor. The fit of the regression can be improved by using the model proposed in the article by adding one new parameter and correspondingly at each step and calculating the accuracy in terms of the sum of cosines of the angles between the fitted and observed value. A new pair of parameters can be added till the improvement in fitting is more than a predefined value. This is similar to adding the powers of x in the linear regression case so that the fitting is improved. This case can also be equated to the case when in multiple linear regression, orthogonal polynomials of the regressor x are added and penalty is calculated until the improvement in fitting is less than a predefined value. Here, also a method similar to adjusted may be used to calculate the optimum number of s.
Here we intend to define the circular version of statistic, and denote it by . For illustration, we assume that follows distribution, the von Mises distribution with location 0 and concentration parameter , with probability density function (pdf) given by
where , and , and
the modified Bessel function of the first kind of order . Denote . As is the concentration parameter, higher value of indicates a better fit. Here , the MLE of , comes out to be
where and is the estimated value of from the data. Now, note that is a monotonically increasing function of . Thus, can be used to check the goodness of fit of the model, which is similar to in the linear case, where
Here . It can be easily seen that the value of lies in , and is larger for a better fit. In fact, for a perfect fit (where for all ), and for a disastrous fit (where , the maximum possible departure, for all ). There is one big difference between and because unlike in the linear case, does not incorporate the percentage of variation due to the difference in decomposition of cosine and squared functions.
However, a more objective method to check the significance of change can be through the log-likelihood. Given the model and assuming angular error following distribution, the likelihood based testing for the addition of parameters can be done in the following way. Under the model given in equations (3.1) and (3.2), the log-likelihood ratio test statistic for against can be used to check for any significant difference by adding new parameter .
Let denote the maximum of log-likelihood of y given x under , and denote the same under . For using Likelihood Ratio Test (LRT), we need to find the distribution of . However, if , then the parameter becomes unidentifiable. This is because can take any value when . Moreover, even if and is equal to any one of , then the parameters 's become non-identifiable. Hence, the regularity condition of model identifiability for the standard asymptotic chi-squared distribution of the LRT statistic is not satisfied by the model under null hypothesis. Thus, we need an alternative approach.
McLachlan (1987) discussed a problem where the LRT statistic was bootstrapped to estimate the number of components in a normal mixture. Here, we consider a similar methodology in our article. First, based on the sample, MLEs of the model parameters were found using number of 's, and for the same sample, MLEs were found by using number of 's. Based on the estimates from the first model, bootstrap samples of the same sample size as of the original sample were generated. Our case is a bit different from McLachlan (1987) as the bootstrap sample is bivariate . Let the distribution of be known. Then, an independent bootstrap sample for is generated from the distribution of . This generation of from its distribution is considered because then the fitted model will not only be good for the sample data but it will be good over the whole sample space of . Based on each of these , is generated using the estimates based on the model under null hypothesis. This bootstrap sample hence obtained is used to estimate the parameters under both the models. The same process is repeated independently times, and is calculated each time. The value of the jth order statistic of the replications can be taken as an estimator of the quantile of order , and the -value can be assessed with respect to the ordered bootstrap replications of .
Under the assumption of von Mises distribution for angular error,
Now, is an increasing function of . As is a strictly increasing function of for , we have . Hence,
indicates that is a decreasing function of . Thus, the higher the difference between successive 's, the higher the significance of new parameter. The value of also explains if there is any significant reduction in when new parameter is added.
Other circular distributions for will work as well. One such example can be the wrapped Cauchy distribution as described earlier by Kato et al. (2008). When angular error follows the wrapped Cauchy distribution with 0 mean, then arg(, where . In this case, the model is a good fit if is closer to 1.
Standard model selection criteria like the bias-corrected Akaike information criterion (AICC) can also be used to select the appropriate candidate for the model; see Lund (1999) in this context. For von Mises error distribution,
where is the number of parameters estimated for the mean direction.
Donut-plot
A new type of plot is also introduced in this present article. This plot is called donut-plot. The problem with normal x versus y graph in circular cases is that it depends on the choice of ‘0’. The spokeplot, introduced by Zubairi et al. (2008) and as shown in Kato et al. (2008), is a very good pictorial representation of observed versus estimated values. But, when the sample size is large, usually a lot of lines criss-cross each other and in that case the plot is not very clear. See the spokeplot at the left in the bottom row of Figure 5.
The donut-plot is used to plot the estimated value and the corresponding observed value. Let the estimated angle be and the observed angle be . Then, this plot shows the point . Thus, if the fit is good, then more points will be near the circumference of the circle with centre at 0 and radius =2, while a bad fit results in more points inside the unit radius disc. Here, as in spokeplot, we do not need to delete the outliers. The donut-plot can be further improved by using different coloured dots for clockwise and anticlockwise deviations. This is because it also shows the direction in which the estimated points are deviating from the observed values. In the donut-plots given in Section 5, we have used solid circles for clockwise deviations and empty circles for anticlockwise deviations. Thus, the donut-plot provides an alternative to the x versus y graph and the spokeplot.
Simulation
Simulation studies are done for the MCR case when the angular variable is regressed on two independent angular covariates and . The simulation is performed both for the MCR1 and MCR2 models. The method employed for finding the global maximum in this article is by giving different initial values to the optim function in R. The simulation results, for the MCR1 model, are shown in Table 1 and the simulation results for the MCR2 model are shown in Tables 2 and 3. Table 1 shows the estimates when the data is generated from the MCR1 model and estimates are the MLE based on the MCR1 model. Table 2 shows the estimates when the data is generated from the MCR2 model and estimates are the MLE based on the MCR2 model. In the tables, the sample standard errors (se's) for the estimates of linear variables and sample circular variances for the estimates of circular variables are given in parentheses. The definition of sample circular variance is the one used in equation (2.3.3) of Mardia and Jupp (2000). The sample circular variance is , where is the mean resultant length of the unit complex numbers corresponding to the MLEs of the circular parameters. The mean of the estimates are the mean of MLE found from 1 000 runs and the standard deviations (SDs) are the SD of the MLEs found from the 1 000 runs. Consequently the se's are calculated. We carried out extensive computations, but reported the results for only three parameter combinations and for sample sizes 20 (small sample case, similar to Example 1 in Section 5.1), 80 (moderate sample size, close to the situation of Example 2 of Section 5.2), and 200 (large sample case). The estimates are quite close, even for a small sample case, and the estimates improve as the sample size increases. However, the estimate of is not quite good when the sample size is small (like 20), the estimate improves with the increase in sample size. For the MCR2 model, we have also changed p and it can be seen from Table 2 and Table 3 that for low p, the se's of the MLEs are high.
In Table 1, β1 and are represented by and , respectively, represent the argument of , gives the argument ofβ0 and p represents the weight of the first covariate. In Table 2, represents β1, is the argument ofβ0, p is the weight of the first covariate and is the argument of .
Estimates (and se in parentheses) of the parameters for MCR1
Estimates
True value
n=200
n=80
n=20
κ=3
3.095 (0.009)
3.318 (0.015)
5.621 (0.080)
b11=0.7
0.707 (0.002)
0.704 (0.005)
0.572 (0.012)
b12=0
0.000 (0.002)
0.002 (0.005)
−0.003 (0.012)
b21=0.5
0.459 (0.005)
0.389 (0.005)
0.225 (0.011)
b22=0
0.005 (0.006)
0.003 (0.009)
0.001 (0.013)
p=0.4
0.411 (0.001)
0.427 (0.001)
0.449 (0.002)
Aθ0=0
0.008 (0.036)
0.003 (0.104)
0.009 (0.302)
θ0=0
−0.005 (0.018)
0.001 (0.049)
−0.002 (0.182)
κ=3
3.101 (0.008)
3.337 (0.015)
5.634 (0.090)
b11=0.7
0.707 (0.002)
0.710 (0.005)
0.585 (0.012)
b12=0
0.006 (0.002)
0.004 (0.005)
0.003 (0.012)
b21=0.5
0.461 (0.002)
0.386 (0.005)
0.217 (0.011)
b22=0
−0.015 (0.005)
0.015 (0.009)
0.016 (0.014)
p=0.4
0.411 (0.001)
0.430 (0.001)
0.449 (0.002)
Aθ0=π/3
1.024 (0.034)
1.067 (0.109)
1.085 (0.336)
θ0=0
0.015 (0.017)
−0.020 (0.053)
−0.025 (0.206)
κ=1.5
1.564 (0.005)
1.729 (0.008)
2.837 (0.038)
b11=0.7
0.706 (0.005)
0.670 (0.008)
0.517 (0.015)
b12=0
0.002 (0.005)
−0.006 (0.008)
0.013 (0.014)
b21=0.5
0.388 (0.005)
0.282 (0.008)
0.187 (0.014)
b22=0
0.001 (0.009)
0.010 (0.012)
−0.009 (0.015)
p=0.4
0.432 (0.001)
0.451 (0.001)
0.470 (0.001)
Aθ0=0
0.004 (0.102)
0.032 (0.222)
0.010 (0.338)
θ0=0
−0.008 (0.050)
−0.022 (0.116)
−0.006 (0.239)
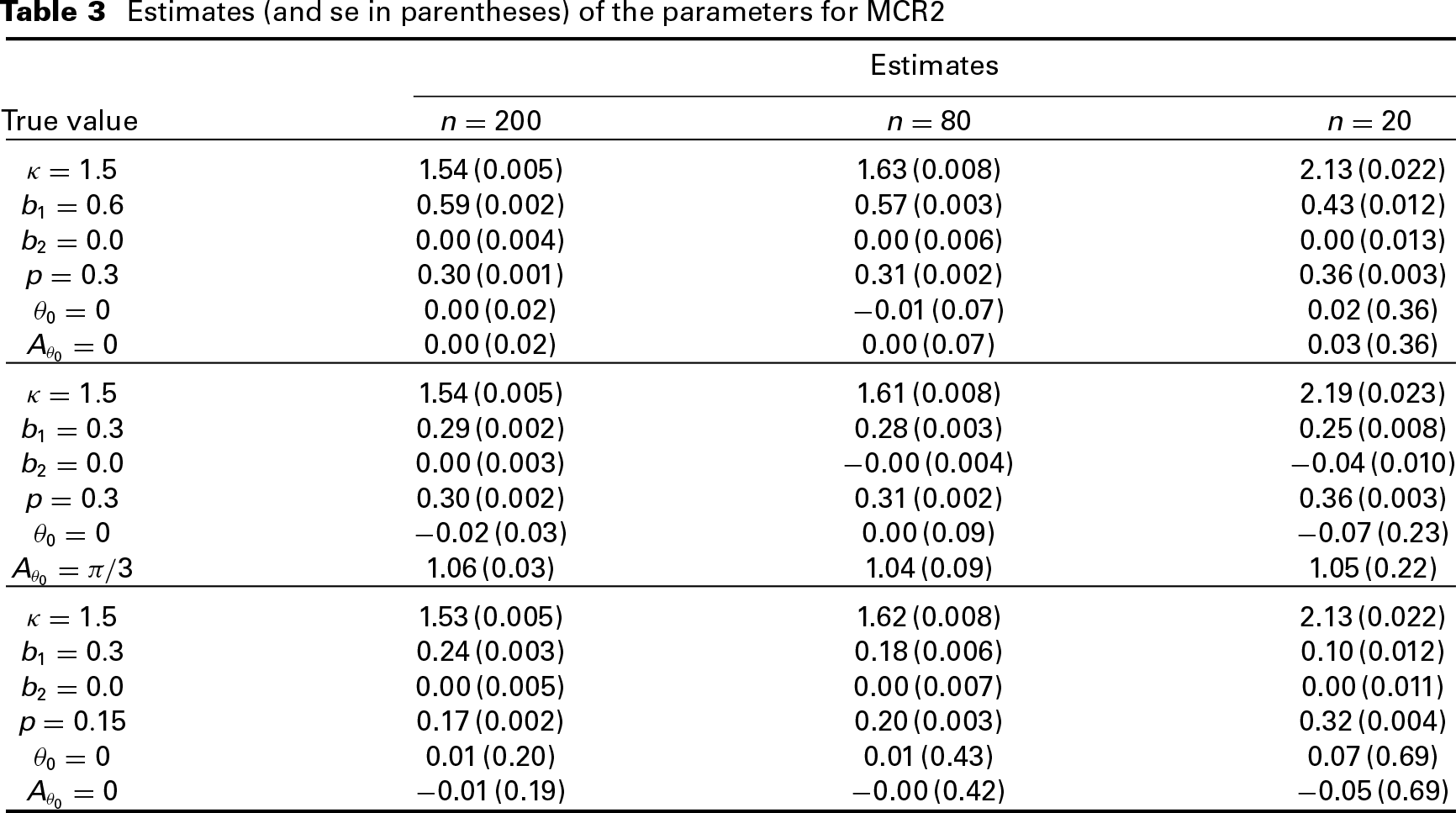
Estimates (and se in parentheses) of the parameters for MCR2
Estimates
True value
n=200
n=80
n=20
κ=3
3.08 (0.009)
3.21 (0.015)
4.32 (0.051)
b1=0.3
0.28 (0.001)
0.25 (0.003)
0.14 (0.007)
b2=0.0
0.00 (0.003)
−0.01 (0.005)
−0.01 (0.008)
p=0.15
0.16 (0.001)
0.14 (0.002)
0.24 (0.003)
θ0=0
−0.01 (0.07)
0.03 (0.2)
0.02 (0.55)
Aθ0=0
0.01 (0.07)
−0.02 (0.2)
−0.03 (0.55)
κ=3
3.06 (0.008)
3.22 (0.015)
4.32 (0.053)
b1=0.6
0.60 (0.001)
0.59 (0.002)
0.52 (0.004)
b2=0.0
0.00 (0.002)
0.00 (0.003)
−0.03 (0.006)
p=0.25
0.25 (0.001)
0.25 (0.002)
0.28 (0.003)
θ0=0
0.00 (0.01)
−0.00 (0.04)
−0.04 (0.15)
Aθ0=0
0.00 (0.01)
−0.00 (0.04)
0.02 (0.19)
κ=3
3.08 (0.008)
3.22 (0.015)
4.23 (0.051)
b1=0.3
0.30 (0.001)
0.30 (0.002)
0.28 (0.009)
b2=0.0
0.00 (0.002)
0.00 (0.003)
0.02 (0.005)
p=0.3
0.30 (0.001)
0.30 (0.001)
0.32 (0.003)
θ0=0
0.01 (0.01)
−0.02 (0.02)
0.02 (0.13)
Aθ0=π/3
1.04 (0.01)
1.06 (0.02)
1.04 (0.13)
Estimates (and se in parentheses) of the parameters for MCR2
Estimates
True value
n=200
n=80
n=20
κ=1.5
1.54 (0.005)
1.63 (0.008)
2.13 (0.022)
b1=0.6
0.59 (0.002)
0.57 (0.003)
0.43 (0.012)
b2=0.0
0.00 (0.004)
0.00 (0.006)
0.00 (0.013)
p=0.3
0.30 (0.001)
0.31 (0.002)
0.36 (0.003)
θ0=0
0.00 (0.02)
−0.01 (0.07)
0.02 (0.36)
Aθ0=0
0.00 (0.02)
0.00 (0.07)
0.03 (0.36)
κ=1.5
1.54 (0.005)
1.61 (0.008)
2.19 (0.023)
b1=0.3
0.29 (0.002)
0.28 (0.003)
0.25 (0.008)
b2=0.0
0.00 (0.003)
−0.00 (0.004)
−0.04 (0.010)
p=0.3
0.30 (0.002)
0.31 (0.002)
0.36 (0.003)
θ0=0
−0.02 (0.03)
0.00 (0.09)
−0.07 (0.23)
Aθ0=π/3
1.06 (0.03)
1.04 (0.09)
1.05 (0.22)
κ=1.5
1.53 (0.005)
1.62 (0.008)
2.13 (0.022)
b1=0.3
0.24 (0.003)
0.18 (0.006)
0.10 (0.012)
b2=0.0
0.00 (0.005)
0.00 (0.007)
0.00 (0.011)
p=0.15
0.17 (0.002)
0.20 (0.003)
0.32 (0.004)
θ0=0
0.01 (0.20)
0.01 (0.43)
0.07 (0.69)
Aθ0=0
−0.01 (0.19)
−0.00 (0.42)
−0.05 (0.69)
Simulation for robustness
In this article, we have considered von Mises distribution for angular error. Kato et al. (2008) used the wrapped Cauchy distribution for angular error. Cauchy distribution is a heavy-tailed distribution. Thus, we have compared the case when the angular error follows von Mises distribution with zero mean to the case when the angular error follows the wrapped Cauchy distribution with real parameter. We have simulated the data from the MCR2 model for this comparison. We have used an accuracy measure mentioned below for checking which among the wrapped Cauchy and von Mises distribution is more robust distribution for the error. For this, first we have taken the true distribution of angular error to be von Mises and then found the accuracy at different sample sizes by assuming both the wrapped Cauchy and von Mises distribution for the angular error. Then, we have taken the wrapped Cauchy distribution as the true distribution for the angular error and then again found the accuracy assuming both the wrapped Cauchy distribution as well as von Mises distribution for angular error.
Accuracy values when angular error follows von Mises distribution
,
n=20
n=80
n=200
κ
VM
WC
VM
WC
VM
WC
1.5
121.17
119.87
49.77
48.71
14.56
12.62
3
163.15
162.19
66.05
64.97
17.44
16.34
4.5
176.71
176.26
79.97
70.47
18.22
17.65
6
182.71
182.49
73.35
73.06
18.67
18.21
For all the simulations, true parameter values are fixed at , , and . In Table 4, the error follows von Mises distribution with zero mean direction and different values of the concentration parameter . For each of these cases, 1 000 simulations are done at three sample sizes . The robustness is measured with respect to the total accuracy in prediction. The total accuracy is defined as the sum of cosines of the angles between the predicted mean direction and the observed mean direction, that is,
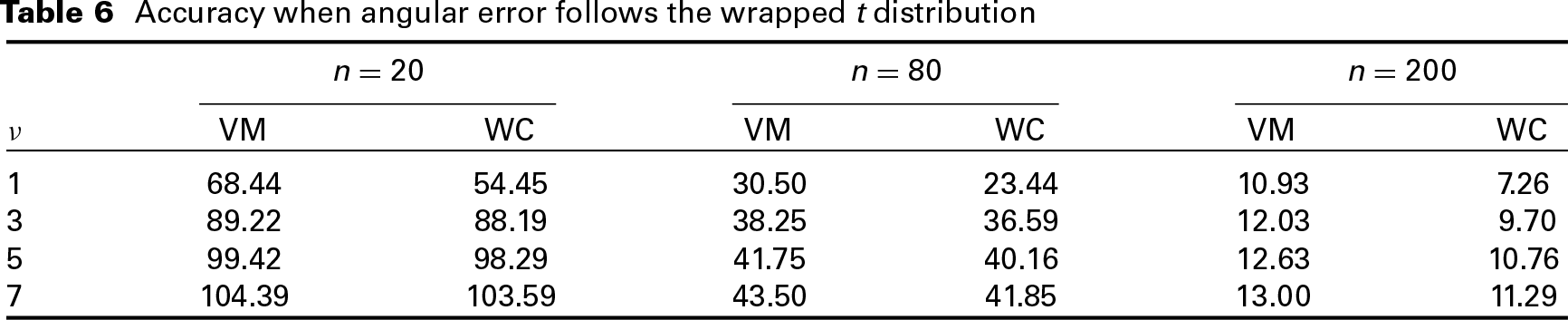
The mean value of the Accuracy over 1 000 simulations is used to check the robustness. This accuracy measure is defined using circular distance, see Sengupta et al. (2013) for details. In Table 5, the distribution for angular error is considered to be the wrapped Cauchy with different values of parameter at the above mentioned sample sizes. For each of the cases, 1 000 simulations are done and the total accuracy is found by assuming that the angular error follows the wrapped Cauchy and then by assuming that the angular error follows the von Mises distribution. Then, we have taken the case when angular error follows the wrapped distribution with the scale parameter 1 and mean as 0 at different degrees of freedom ( at different sample sizes. Then, we have obtained the mean total accuracy based on 1 000 simulations by assuming first that the angular error follows wrapped Cauchy distribution and again assuming that the angular error follows von Mises distribution. The results are given in Table 6. Note that for the wrapped reduces to wrapped Cauchy with , and the performance of the wrapped for in Table 6 is expected to be in between those corresponding to and in Table 5, closer to the case corresponding to . Our results are obtained accordingly.
From the results in Tables 4, 5 and 6, it can be seen that the von Mises distribution not only gives better results than the wrapped Cauchy distribution when the true density of the angular error is von Mises but also when the true density is the wrapped Cauchy or the wrapped . This might be for our specific choice of Accuracy, which is a term in the expression of the log-likelihood for von Mises distribution we maximize to find the MLE of von Mises parameters; see Equation (4.3).
Accuracy when angular error follows the wrapped Cauchy distribution
,
n=20
n=80
n=200
ρ
VM
WC
VM
WC
VM
WC
0.2
46.91
45.70
23.76
20.96
10.09
7.12
0.4
82.53
81.33
34.98
34.28
11.51
9.65
0.6
121.29
121.23
49.49
48.52
14.02
12.73
0.8
160.41
159.73
64.52
64.24
16.72
16.08
Accuracy when angular error follows the wrapped t distribution
,
n=20
n=80
n=200
ν
VM
WC
VM
WC
VM
WC
1
68.44
54.45
30.50
23.44
10.93
7.26
3
89.22
88.19
38.25
36.59
12.03
9.70
5
99.42
98.29
41.75
40.16
12.63
10.76
7
104.39
103.59
43.50
41.85
13.00
11.29
Data analysis
Example: Single regressor
The data analysis for the case of one circular regressor and one circular response variable is used here to show the advantage of the model in improving the fit in the case of a single regressor. The data were also used in Kato et al. (2008). The wind direction was measured each day at a weather station in Milwaukee for 21 consecutive days at 6 a.m. and 12 noon (Johnson and Wherly (1977), Table 2). The response variable is the wind direction at 12 noon and the covariate is the wind direction at 6 a.m. Watson's test (1983) indicates no significant departure of the angular error from distributions in both one parameter and two parameter cases at 1% significance level (p-values are 0.248 and 0.523, respectively).
The MLEs for the parameters when only one is used, come out to be: , , and . Here, the estimate of β1 is obtained using the estimates of and .
When both β1 and are considered in the model, the MLE for the parameters come out to be 0.637 +0.597i, , , , and . Here, β1 and are estimated by taking and and then estimating the values of . The estimates of all the parameters are given in Table 7.
The estimates of SD of the parameters reported in the tables are found by taking the inverse of the hessian matrix at the MLEs.
Estimates of parameters (SD in parentheses) for the Milwaukee wind data when (a) only β1 is used; (b) β1 and β2 are used
only β1 is used
β1 and β2 are used
r→ 0.265 (0.192)
r1→ 0.658 (0.004)
θ1→ 1.362 (0.539)
θ1→ 0.171 (0.026)
θ0→ 0.719 (0.297)
r2→ 0.874 (0.003)
κ→ 1.113 (0.380)
θ2→ 2.389 (0.026)
p→ 0.499 (0.002)
θ0→ 0.501 (0.249)
κ→ 1.710 (0.478)
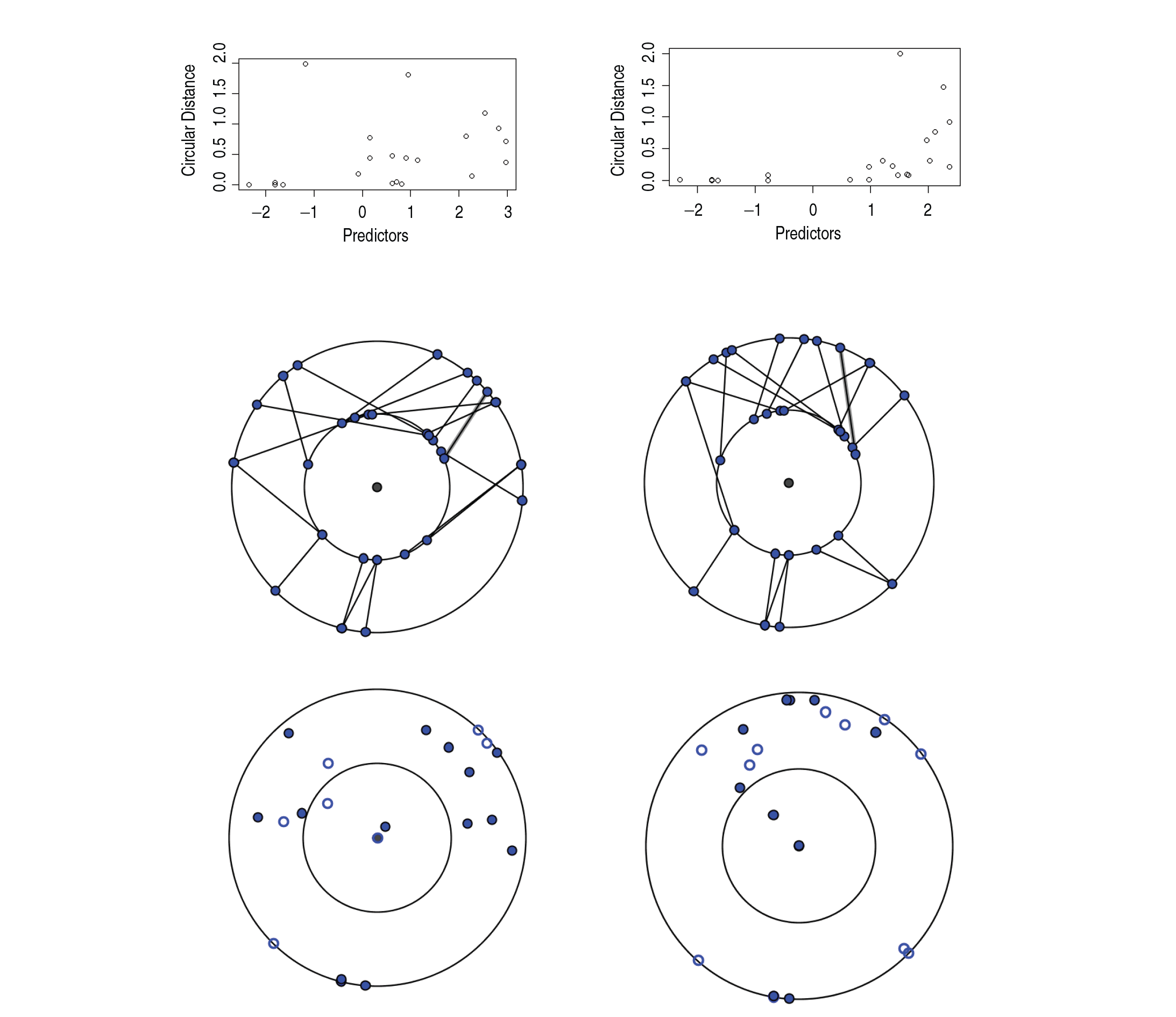
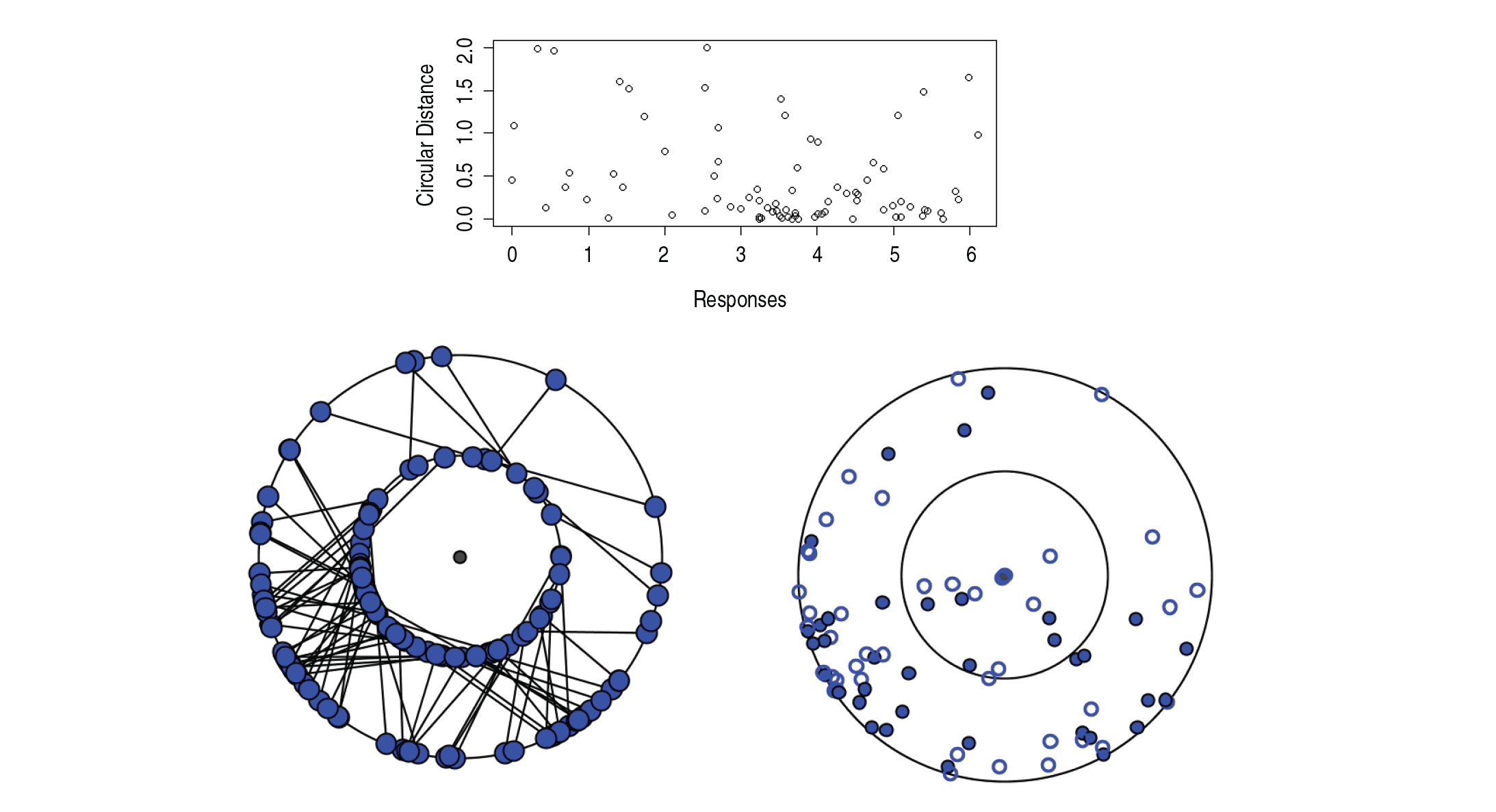
By looking at and , it can be said that the second model fits the data better than the first one. The graph between circular distance ()), and predictors for both the cases are shown in the top row of Figure 4. Comparing the two plots, it can be said that the fit is better in the second case. Then, the bootstrapping procedure for was used to approximate the true distribution of under the null hypothesis as described in Section 4.3 with . First, Watson's test was performed on the data and it could not reject uniformity for . Then, 's were generated based on 's generated from uniform distribution over . The estimate of 0.95-sample quantile based on 25 such bootstrapping comes to be 12.629 and the 0.9-sample quantile estimate comes to be 9.137. The observed value of Λ from the sample is 9.265. Hence, the choice of the first model is not rejected at 5% significance level while the null hypothesis is rejected and the second model is chosen at the 10% significance level. The AICC statistic as defined in Lund (1999) is −3.126 and −1.775 for the first and the second cases, respectively, showing the preference for the first model, but the difference is not large.
The spokeplots are shown in the middle row of Figure 4, while the proposed donut-plots are shown in the bottom row of Figure 4. The left figure in each row corresponds to the model with only one β, and the right hand figure is for two βs. The R codes of this data analysis can be obtained from the authors upon request.
Plots for Milwaukee data. [Top row:] Graph of circular distance versus predictors when (Left:) only β1 is used and when (Right:) are used.
[Middle row:] Spokeplot when (Left:) only β1 is used and when (Right:) β1 and are used. [Bottom row:] Donut-plot when (Left:) only β1 is used and when (Right:) β1 and are used
Example: Multiple regressors
We consider a similar weather data with one circular response and two circular covariates to illustrate the MCR application of the model. The data used is the wind direction data in Ambikapur district of Chhattisgarh from September 2011 to June 2012. The data is taken from the website of Agricultural Meteorology Division, India Meteorological Department, Ministry of Earth Sciences (http://www.imdagrimet.gov.in/winddirection). The dataset consists of 81 points, each corresponding to a different date and a particular hourly time corresponding to the date. The circular covariates considered here are the the date of the year and the time of the day. For the time of the day, 00:00 hrs is considered to be the zero angle; for the time of the year, 8th June (the date corresponding to the first data point) is considered to be the zero angle. Data analysis is done for both the MCR1 and MCR2 models.
Plots for Chhattisgarh data. [Top row:] Graph of circular distance versus predictors. [Bottom row:] (Left:) Spokeplot; (Right:) Donut-plot
Plots for Chhattisgarh data.(MCR2) [Top row:] Graph of circular distance versus predictors. [Bottom row:] (Left:) Spokeplot; (Right:) Donut-plot
In case of MCR1 model, the goodness of fit test using Watson's test (1983) indicated no significant departure from the von Mises distribution for the angular error at 1% significance level (p-value ). Consequently, the MLEs of the parameters () are obtained. Here, β1 is the parameter corresponding to time of the day, and is the parameter corresponding to the date of the year. The MLEs of the parameters are: , , , , . The graph between circular distances and response values is shown in the top row of Figure 5. The spokeplot excluding the outliers is shown in the left of the bottom row, while the donut-plot is shown in the bottom right of Figure 5. Here, β1 and are estimated by first taking and and then estimating the values of . The estimates of all the parameters are given in the left panel of Table 8.
Estimates of parameters (SD in parentheses) of the Chhattisgarh data when there are two covariates
MCR1
MCR2
b1→ 1.921 (0.257)
b1→ 0.076 (0.237)
b12→ −1.773 (0.192)
b2→ −1.222 (0.096)
b21→ −0.100 (0.202)
p→ 0.247 (0.073)
b22→ 1.136 (0.032)
θ0→ 5.627 (0.160)
p→ 0.469 (0.004)
Aθ0=→ 4.878 (0.138)
Aθ0=→ 1.791 (0.173)
κ→ 1.05 (0.191)
θ0→ 2.867 (0.134)
κ→ 1.293 (0.208)
When data analysis is done by using teh MCR2 model, Watson's test (1983) indicates that there is no significant departure from the assumption of the angular error following von Mises distribution 1% level (p-value =). Then the MLEs of the parameters are obtained. The MLEs for this case are tabulated in the right panel of Table 8. The graph between circular distances and response values is shown in the top row of Figure 6. The spokeplot excluding the outliers is shown in the left of bottom row, while the donut-plot is shown in the bottom right of Figure 5. The R codes of this data analysis can be obtained from the authors upon request.
Concluding remarks
Fisher and Lee (1992), Downs and Mardia (2002) and Kato et al. (2008) have proposed circular–circular regression and circular–linear regression for one circular regressor and one circular response or one circular response and one linear regressor. Our case is more general as we consider multiple circular predictors. For comparison with single predictor, we have added a penalty term to reduce the error and improve the results.
The amount of existing literature on multiple circular–circular regression is scanty. The proposed models provide some working solutions in modelling multiple circular–circular regression. However, as expected, the complexity of interpretation and estimation of the parameters increase considerably with the increase in number of covariates.
The assumption of angular error following von Mises distribution is similar to Downs and Mardia (2002). But, Kato et al. (2008) considered the wrapped Cauchy distribution. The assumption of angular error following von Mises distribution has been considered by Sengupta et al. (2013) but they have considered inverse circular–circular regression case which is different from our case.
Multiple circular–circular regression case with the help of multivariate von Mises distribution is considered in Hughes (2007). We have shown a different method based on a geometrical approach to multiple circular–circular regression which is different from the Hughes (2007) method. This is the new contribution of the present article, as far as our knowledge goes.
The model proposed can also be used when there are both linear and circular covariates with appropriate link functions as recommended by Downs and Mardia (2002) or Sengupta et al. (2013). In such a case, the regressed point will have to be first converted to a unit complex number and then, using weight parameter p, the regression can be done.
The joint distribution of the response variable and the regressors can also be obtained as in Kato et al. (2008).
Appendix
Appendix A
The identifiability of the MCR1 can be shown through the following theorems.
and . Thus, Equation (7.2) is a polynomial in x of degree . Thus, the maximum number of solutions of Equation (7.2) can be , which is finite. Hence, the model is unique.
Hence, the given statement is true only when
Theorem 7.2. Let , and . Then,
implies .
Proof: Let, . Then, rotating the axes to an angle anticlockwise, it can be seen from the previous theorem that the result will hold uniquely. This is because then the new 's will be nothing but .
Note: Theorem 7.1 is enough to say that the model is identifiable in case of MCR with more than one regressors because if there are no two models corresponding to then, there cannot be two different models for all .
Appendix B
The identifiability of the MCR2 model when can be proved through the following theorem.
Theorem 7.3. Let, . Then
implies where for and . Then, if we take for each j, we have and . Denoting , Equation (7.3) implies
By the identifiability of Kato et al. (2008) regression model, this immediately gives
Hence, by Equation (7.3) and Equation (7.4), for all x,
The above theorem proves the identifiability when . When , the identifiability can be proved as mentioned in Theorem 7.2.
Footnotes
Acknowledgments
The authors wish to thank the Editor Jeffrey S. Simonoff, an Associate Editor and two anonymous referees for their constructive suggestions which led to this improved version over some earlier versions of the manuscript.
FisherNILeeAJ (1992) Regression models for an angular response. Biometrika, 48, 665–77.
3.
HughesG (2007) Multivariate and time series models for circular data with applications to protein conformational angles. Unpublished PhD thesis, The University of Leeds.
4.
HussinAGFiellerNRJStillmanEC (2004) Linear regression for circular variables with application to directional data. Journal of Applied Science and Technology, 9, 1–6
5.
JohnsonRAWehrlyTE (1977) Measures and models for angular correlation and angular–linear correlation. Journal of the Royal Statistical Society B, 39, 222–29.
6.
KatoSShimizuKShiehGS (2008) A circular–circular regression model. Statistica Sinica, 18, 633–45.
7.
KentJTTylerDE (1988) Maximum likelihood estimation for the wrapped Cauchy distribution. Journal of Applied Statistics, 15, 247–54.
8.
LundU (1999) Least circular distance regression for directional data. Journal of Applied Statistics, 26, 723–33.
McLachlanGJ (1987) On bootstrapping the likelihood ratio test statistic for the number of components in a normal mixture. A class of statistics with asymptotically normal distribution. Journal of the Royal Statistical Society, Series C (Applied Statistics), 36, 318–24.
11.
MinhDLPFarnumNR (2003) Using bilinear transformations to induce probability distributions. Communications in Statististics–Theory Methods, 32, 1–9.
12.
RvestLP (1997) A decentred predictor for circular–circular regression. Biometrika, 84, 318–24.
WatsonGS (1983) Statistics on Spheres. New York: John Wiley.
15.
WodSN (2001) Minimizing model fitting objectives that contain spurious local minima by bootstrap restarting. Biometrics, 57, 240–44.
16.
ZubairiYZHussainFHussainAG (2008) An alternative analysis of two Circular variables via graphical representation: An application to the Malaysian wind data. Computer and Information Science, 1, 3–8.