
Abstract
In traditional paired comparison models heterogeneity in the population is simply ignored and it is assumed that all persons or subjects have the same preference structure. In the models considered here the preference of an object over another object is explicitly modelled as depending on subject-specific covariates, therefore allowing for heterogeneity in the population. Since by construction the models contain a large number of parameters we propose to use penalized estimation procedures to obtain estimates of the parameters. The used regularized estimation approach penalizes the differences between the parameters corresponding to single covariates. It enforces variable selection and allows to find clusters of objects with respect to covariates. We consider simple binary but also ordinal paired comparisons models. The method is applied to data from a pre-election study from Germany.
Introduction
Paired comparison is a well established method to measure the relative preference or dominance of objects or items. The aim is to find the underlying preference scale by presenting the objects in pairs. The method has been used in various areas, for example, in psychology, to measure the intensity or attractiveness of stimuli, in marketing, to evaluate the attractiveness of brands, in social sciences, to investigate value orientation (e.g., Francis et al., 2002). In all these applications the objects or stimuli are presented in an experiment. But paired comparisons are also found in sports whenever two players or teams compete in a tournament. Then the non-observable scale to be found refers to the strengths of the competitors. Paired comparisons can also be obtained from ranked data (Francis et al., 2002) or from rating scale data (Dittrich et al., 2007). In this kind of data, respondents rank a predefined number of objects or assign values from a Likert scale to the objects, always referring to a certain attitude of the respondents towards the objects. Building differences between the ranks or rating scales yields (binary or ordered) paired comparison data. We consider an application that shows how to analyse rating scales for the preference of parties by paired comparisons. In a German pre-election study the respondents were asked to scale the most well-known German parties. The focus of the analysis is on the inclusion of subject-specific covariates to account for the heterogeneity in the population and to investigate which variables determine the preference. More precisely, we investigate which clusters of parties are distinguished by specific covariates allowing that some covariates have no effect on the preference at all.
The most widely used model for paired comparison data is the Bradley-Terry-Luce (BTL) model. It has been proposed by Bradley and Terry (1952) and is strongly linked to Luce's choice axiom (Luce, 1959). The basic model has been extended in various ways allowing for dependencies among responses, time dependence or simultaneous ranking with respect to more than one attribute. Overviews are found in the review of Bradley (1976), the monograph of David (1988) and more recently in the review of Cattelan (2012). The method proposed in this work can be applied both to binary and ordered response. Former approaches for ordered responses in paired comparisons include Tutz (1986) and Agresti (1992). Dittrich et al. (2004) combine ordered responses and the inclusion of covariates within a log-linear model framework that uses the Poisson-multinomial equivalence.
In traditional paired comparison models it is assumed that the strengths of the objects are fixed and equal for all subjects. Early versions of the explicit modelling of heterogeneity by including subject-specific covariates were given by Tutz (1989) and Dittrich et al. (1998). Various models with subject-specific covariates have been considered since then, see Dittrich et al. (2000), Francis et al. (2002), Hatzinger et al. (2009), Dittrich et al. (2007), Francis et al. (2010), Turner and Firth (2012) and Francis et al. (2014). Software has been provided by Hatzinger and Dittrich (2012). When introducing subject-specific variables, the main problem is the large number of parameters that has to be estimated. Therefore, it is important to keep the dimensionality of the model as low as possible. One way to obtain a smaller model is to use only those covariates that are needed. Variable selection methods, which are based on information criteria such as Akaike information criterion (AIC) and Bayesian information criterion (BIC) have been used by Dittrich et al. (2000), Francis et al. (2002), Francis et al. (2010). More recently, Casalicchio et al. (2015) presented a boosting approach that is able to select explanatory variables. A quite different approach has been proposed by Strobl et al. (2011). It is based on recursive partitioning techniques (also known as trees) and automatically selects the relevant variables among a potentially large set of variables. The method proposed here is an alternative to handle the inherently high dimensional estimation problem that comes with the inclusion of explanatory variables. Maximum likelihood (ML) estimation is replaced by penalized estimation methods. By using a specific lasso-type penalty, the method is able to form clusters of objects that share the same effect of the explanatory variables which generate heterogeneity.
In Section 2 the basic BTL model for binary and ordered response is introduced. Then the model is extended to include subject-specific covariates. Section 3 contains the integration of the proposed model into the framework of generalized linear models (GLMs) and the penalty term is introduced. Section 3 also describes the implementation of the algorithm, the search for the optimal tuning parameter and the calculation of bootstrap confidence intervals. In Section 4, the method is applied to data from the German Longitudinal Election Study (GLES).
Bradley-Terry models with covariates
The basic model
Let

With the random variable

Bradley-Terry models with ordered response
In some applications, paired comparison data can or should not be reduced to binary decisions. For example, in sport events like football matches where draws are also possible, simple binary paired comparisons are not appropriate. A model that allows for ordinal responses is the cumulative BTL model (Tutz, 1986; Agresti, 1992). It is an extension of the Rao-Kupper model for ties (Rao and Kupper, 1967), which has been widely used, see, for example, Dittrich et al. (2004) and Bockenholt (2001). The general model for

The strength parameters
Formally, model (2.1) is a cumulative logit model, also called a proportional odds model. For a response variable consisting of
The models considered so far assume that all
Let
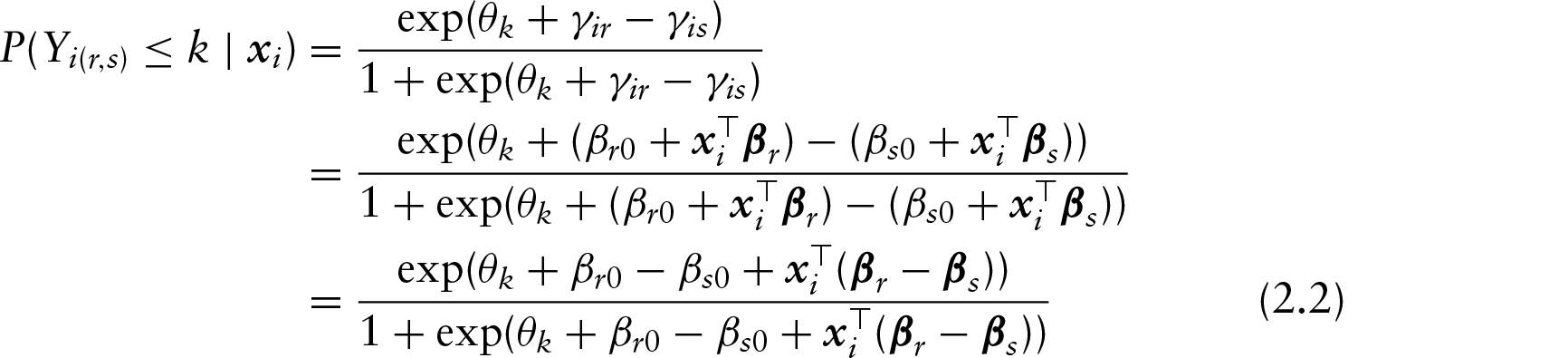
As in model (2.1), the sum-to-zero constraints
The model allows for different preference structures in sub-populations. For illustration, let us consider the simple case where the subject-specific variable codes a subgroup like gender, which has two possible values. Let

In case of continuous variables like age in years, the interpretation is quite similar. Here,
The model accounts for the heterogeneity in the population by explicitly linking the attractiveness of objects to explanatory variables. The object-specific parameters
The main problem with the general model (2.2) is the number of parameters that are involved. One has (with the given restrictions)
Embedding into generalized linear models
First, the ordinal Bradley-Terry model is embedded into the framework of GLMs. In the ordinal Bradley-Terry model without covariates the linear predictor
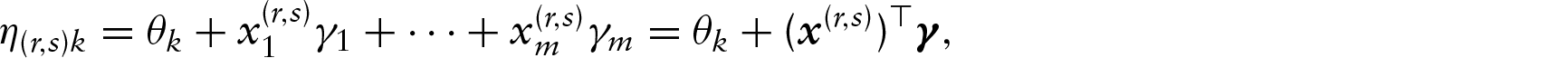
In the general model with covariates, and therefore explicit modelling of heterogeneity, the linear predictor has the form
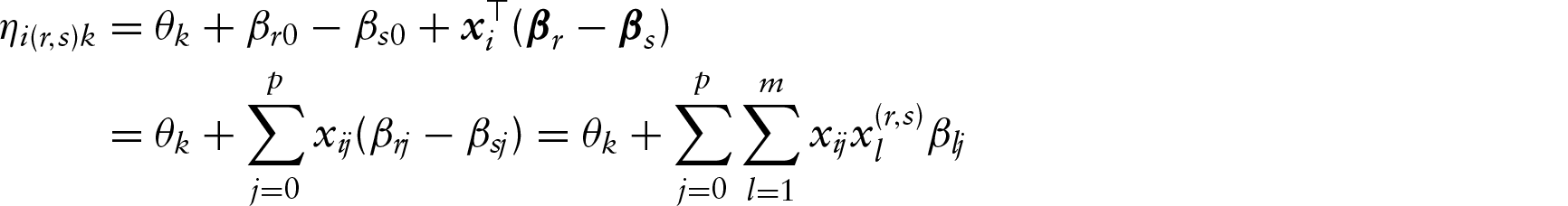
The link between the linear predictor and the probability
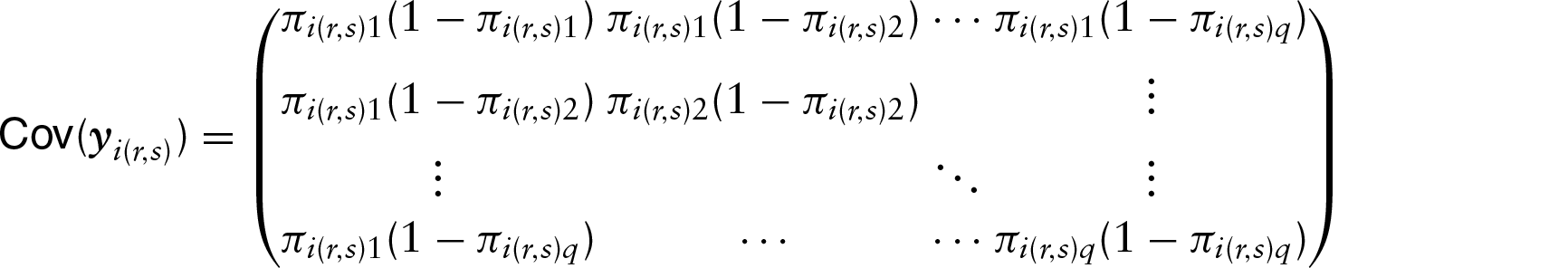
Because of the restrictions

Selection by penalization
In regression models with

However, the simple lasso cannot be used directly since penalty terms for paired comparison models have to account for the specific structure of the model. In particular, in model (2.2) one has the parameters of the regular (ordinal) BTL model, namely the threshold parameters and, for each object

The penalty has the effect that the parameters referring to the same covariate are shrunk towards each other. For large values of
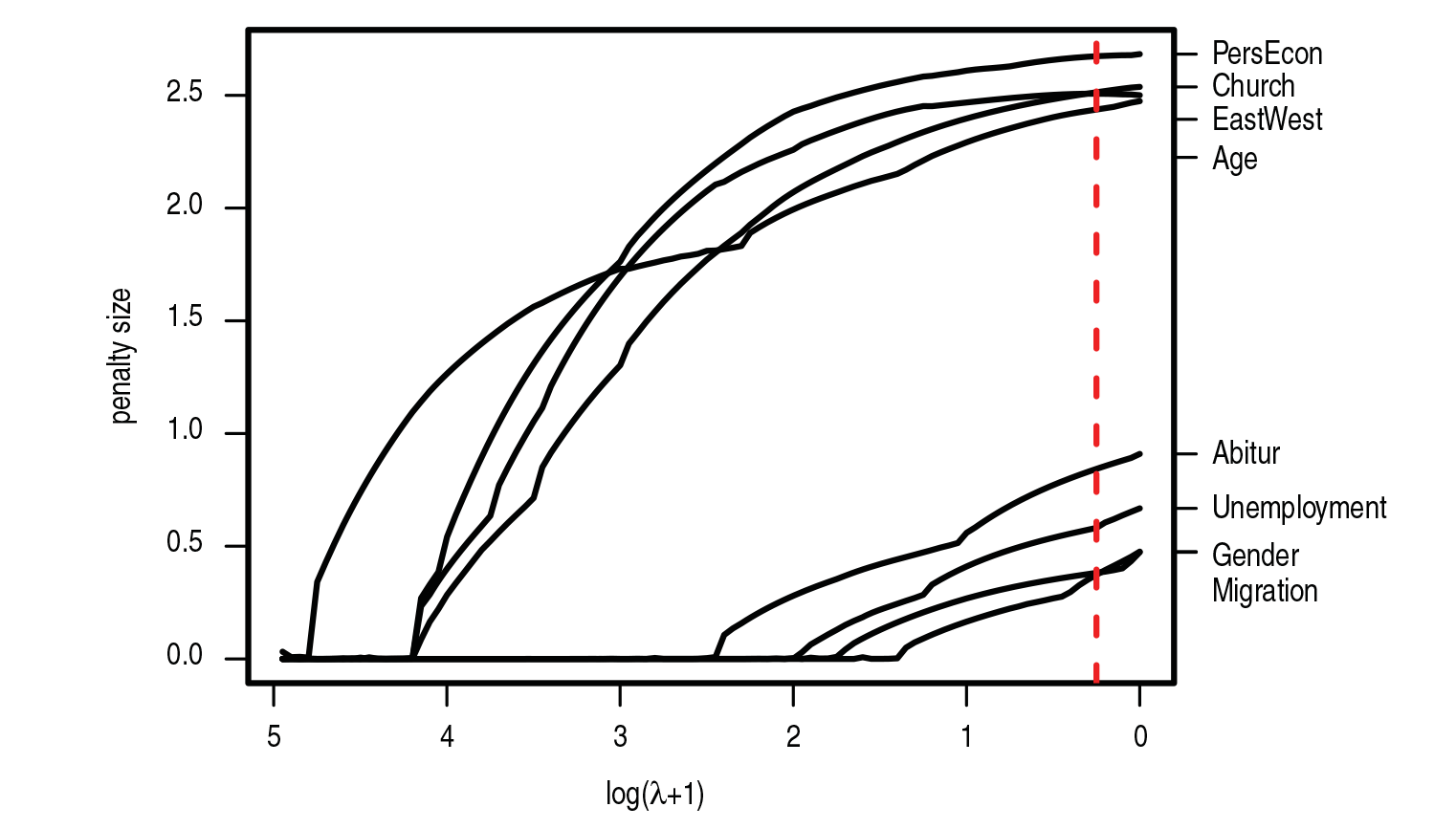
For illustration, Figure 1 shows the coefficient paths corresponding to a covariate
Exemplary coefficient paths for a covariate
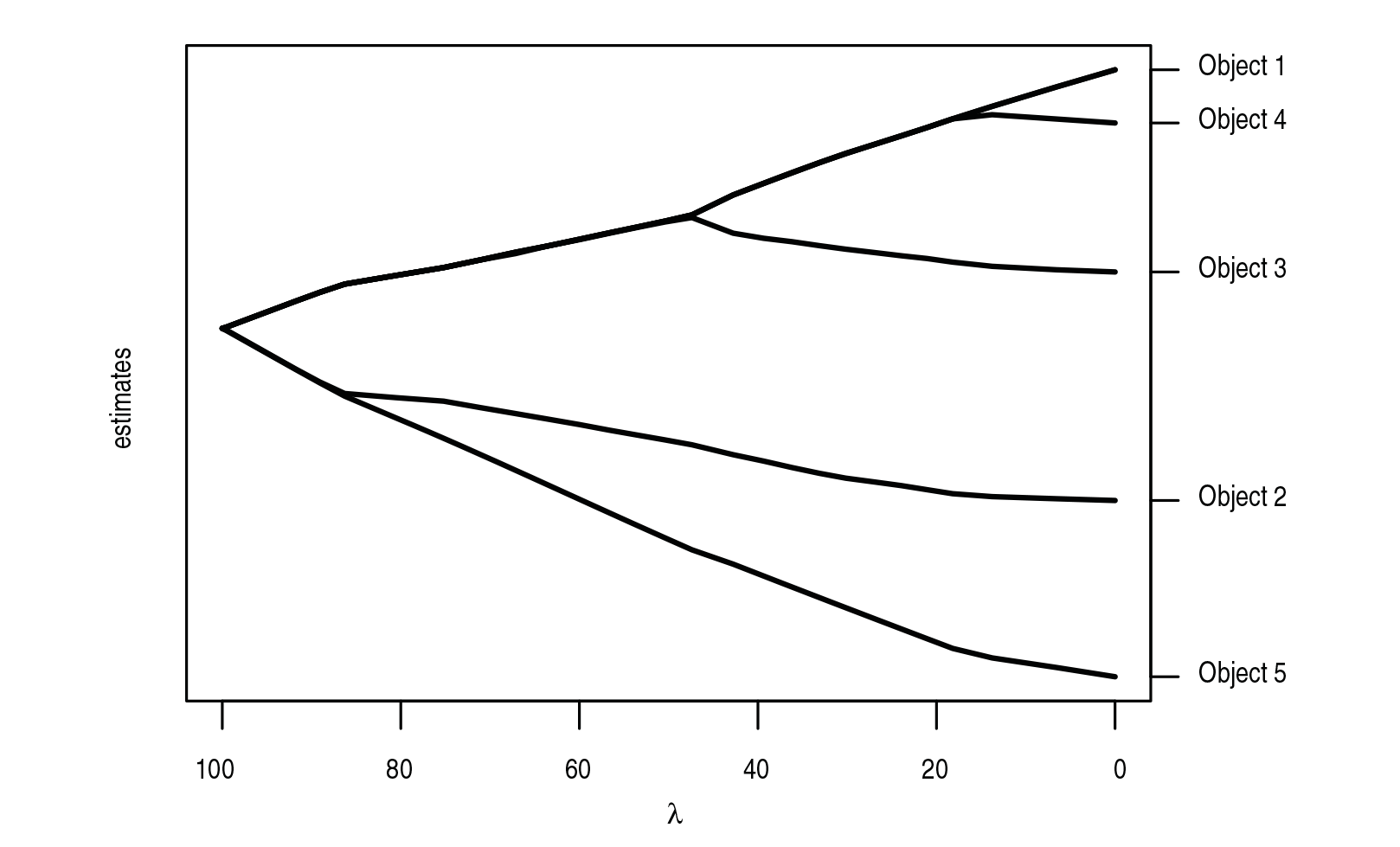
Zou (2006) proposed the so-called adaptive lasso as an extension of the regular lasso. In contrast to regular lasso, it provides consistency in terms of variable selection. In the adaptive lasso, the single penalty terms are weighted with the inverses of the unpenalized ML estimates. In a similar way the weight parameters
Lasso penalized cumulative logit models have, for example, been used in Archer and Williams (2012) and are implemented for (R R Core Team, 2016) in Archer (2014a) and Archer (2014b). However, these implementations are limited to lasso penalties for coefficients. They cannot be used to penalize differences between parameters as required in the paired comparison case. Moreover, in order to obtain consistent estimates we want to include the weights
Choice of penalty parameter
The performance of penalized estimation methods is essentially determined by the choice of the tuning parameter λ. It determines which covariates modify the attractiveness and form the clusters within the chosen covariates. Mostly, two different approaches are used to determine tunings parameters, namely model selection criteria and cross-validation. Model selection criteria like the AIC Akaike, 1973) or the BIC (Schwarz, 1978) try to find a compromise between the complexity of the model and the model fit. The complexity of a model is determined by its degrees of freedom. While for ML estimation, the degrees of freedom simply correspond to the number of parameters, the degrees of freedom for penalized likelihood approaches, in particular with a penalty applied on differences, are not straightforward. Therefore, we use cross-validation. In cross-validation, the data set is divided into a predefined number of subsets. Each subset is once used as a test data set while the remaining subsets serve as training data. The model is fitted (for a predefined grid of values for the tuning parameter

Confidence intervals
In contrast to ML estimators, for estimators from penalized likelihood approaches one cannot use the information matrix to obtain standard errors or confidence intervals. Therefore, alternative techniques have to be used. We propose to use the bootstrap method for that purpose. The main idea of bootstrap is to replace an unkown distribution by the respective empirical distribution function. Then, for a predefined number of bootstrap iterations B, a subsample from the empirical distribution function is drawn. The proposed procedure is applied to the sampled data set, including the model selection using cross-validation. Therefore, the additional variance originating from the process of model selection is incorportated in the resulting confidence intervals. Finally, for every parameter bootstrap confidence intervals can be calculated using the empirical
Application to pre-election data from Germany
The proposed method is applied to data from the GLES, (see Rattinger et al., 2014). The GLES is a long-term study of the German electoral process. It collects pre- and post-election data for several federal elections.
Data
The data we are using here originate from the pre-election survey for the German federal election in 2013. In this specific part of the study, 2003 persons were asked to rate the most important parties. Altogether, the survey covered seven different parties. In the following, we only consider the five (at that time point) most important parties, the smaller parties AfD (Alternative für Deutschland/Alternative for Germany) and the Pirate Party (Piratenpartei) were eliminated. Therefore, only the parties that actually entered the German parliament Bundestag, are taken into consideration. These are the CDU/CSU (Christlich Demokratische Union/Christian Democratic Union and Christlich-Soziale Union/Christian Social Union), the SPD (Sozialdemokratische Partei Deutschlands/Social Democratic Party of Germany), the Greens (Die Grünen), the Left Party (Linkspartei) and the FDP (Freie Demokratische Partei/Free Democratic Party). For the upcoming federal election, the participants rated the single parties on a discrete scale from

The transformation of rating scales to ordered paired comparison data was proposed by Dittrich et al. (2007). They also describe in detail the advantages of the transformation for the analysis of rating scales. In particular, the use of categories of the Likert scale may vary over individuals. By considering the differences between parties, interpersonal incomparabilities do not matter anymore. Moreover, the alternative strategy, namely direct modelling of the Likert scales, calls for multivariate models. Since each person responds to all the items one should model all the responses simultaneously. Common multivariate regression methods, which assume a normally distributed response, cannot be recommended for ordinal responses. Alternative models are marginal models with an ordinal response structure by using generalized equations estimation methodology (see, for example, Miller et al., 1993; Fahrmeir and Pritscher, 1996; Heagerty and Zeger, 1996). However, for ordinal data they are hard to handle and no procedure to reduce the number of parameters seems available. More seriously, marginal models focus on the responses not the differences between them.
For the GLES study, only residents in the Federal Republic of Germany with German citizenship, a minimum age of 16 years and living in private households were eligible (Rattinger et al., 2014). In our analysis, only persons with a minimum age of 18 years (which is necessary to be entitled to vote in federal elections) are included. After eliminating all persons who rated less than two parties (because two parties are required to have at least one paired comparison for a person), the remaining data set contains Age: age of participant in years Gender (1: female; 0: male) EastWest (1: East Germany/former GDR; 0: West Germany/former FRG) PersEcon Personal economic situation (1: good or very good; 0: neither/nor, bad or very bad) Abitur School leaving certificate (1: Abitur/A levels; 0: else) Unemployment (1: currently unemployed; 0: else) Church (1: Attendance in Church/Mosque/Synagogue/...: at least once a month; 0: else) Migration: Are you a migrant/not German since birth? (1: yes; 0: no)
The age of the participants ranges from 18 years to 99 years. The variable EastWest refers to the current place of residence where all Berlin residents are assigned to East Germany. As mentioned before, it is necessary that all covariates are on comparable scales. Therefore, all variables have been standardized and centered before the analysis.
Results
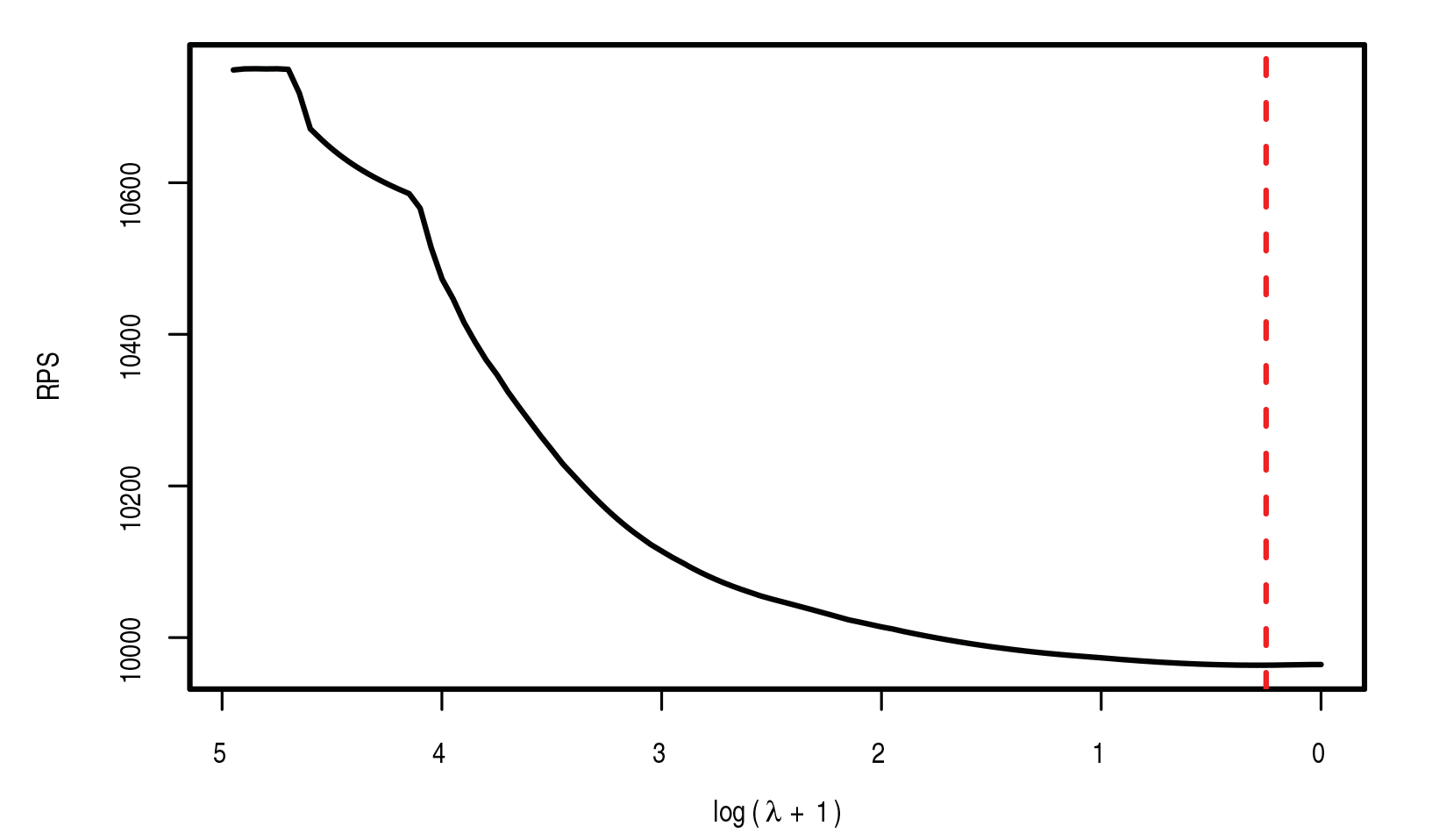
In the following, the results for the proposed method are presented for a model where all covariates described above are considered as possibly influential variables. The optimal model is determined by 10-fold cross-validation. Figure 2 shows the RPSs obtained by cross-validation plotted against
RPS path for 10-fold cross-validation, dashed vertical line represents model with lowest deviance
Coefficient paths for all unpenalized parameters (threshold parameters
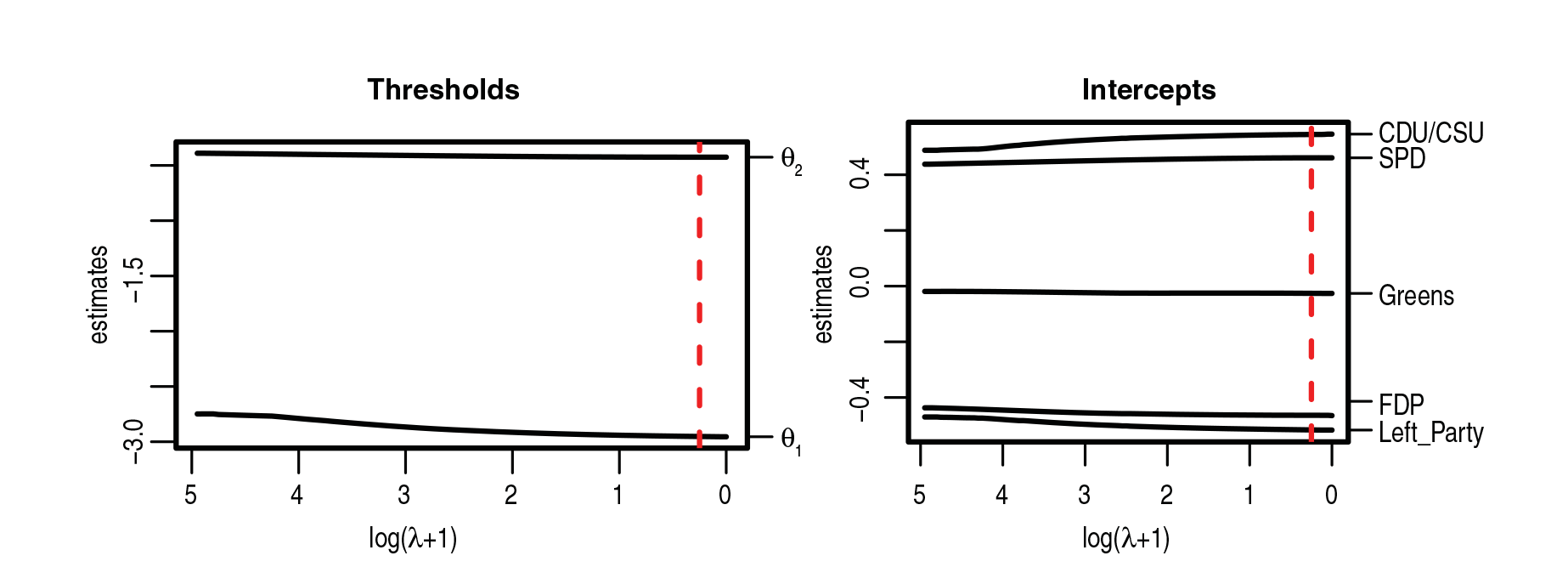
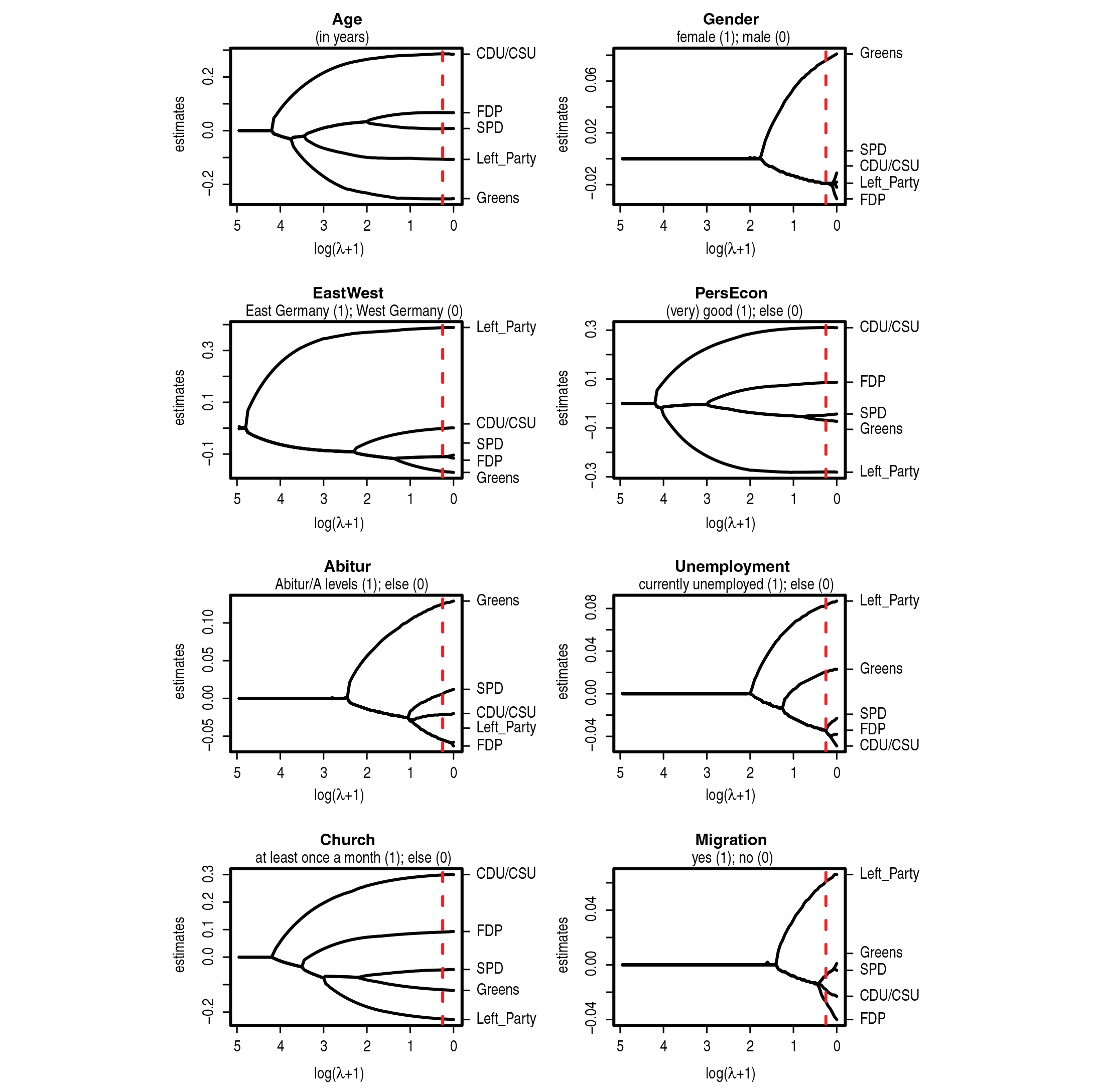
Figure 4 shows the corresponding coefficient paths for the eight covariates. The coefficient paths are drawn separately for each covariate. It is seen how the penalty term enforces clustering of the different parties. The dashed vertical lines represent the optimal model according to the 10-fold cross-validation.
The coefficient paths allow for interesting insights into how the preference of the voters for certain parties depends on characteristics of the voters themselves. Let us first consider the covariate unemployment. With respect to unemployment, the parties can be divided into three clusters. The Left Party and the Greens form single clusters while CDU, SPD and FDP form another cluster. As a global tendency one sees that unemployed persons tend to prefer the younger parties (Greens and Left Party) while the tendency to the more established parties (SPD, CDU, FDP) is reduced. For gender, only two different clusters are identified in the final model. The Greens are much more attractive to female than to male voters and form a cluster of their own. All remaining parties belong to a second cluster and are more attractive to male voters than to female voters. Also the variable Abitur has a very different effect for the Greens compared to all other parties confirming the reputation of the Greens to be a party attractive to those more highly educated. Overall, no variable is eliminated completely from the model, each variable has at least two clusters of parties. The variables age and church attendance have a specific impact on the preference of parties and every party forms a cluster of its own.
Coefficient paths separately for all eight (scaled) covariates. Dashed vertical lines represent optimal model according to 10-fold cross-validation
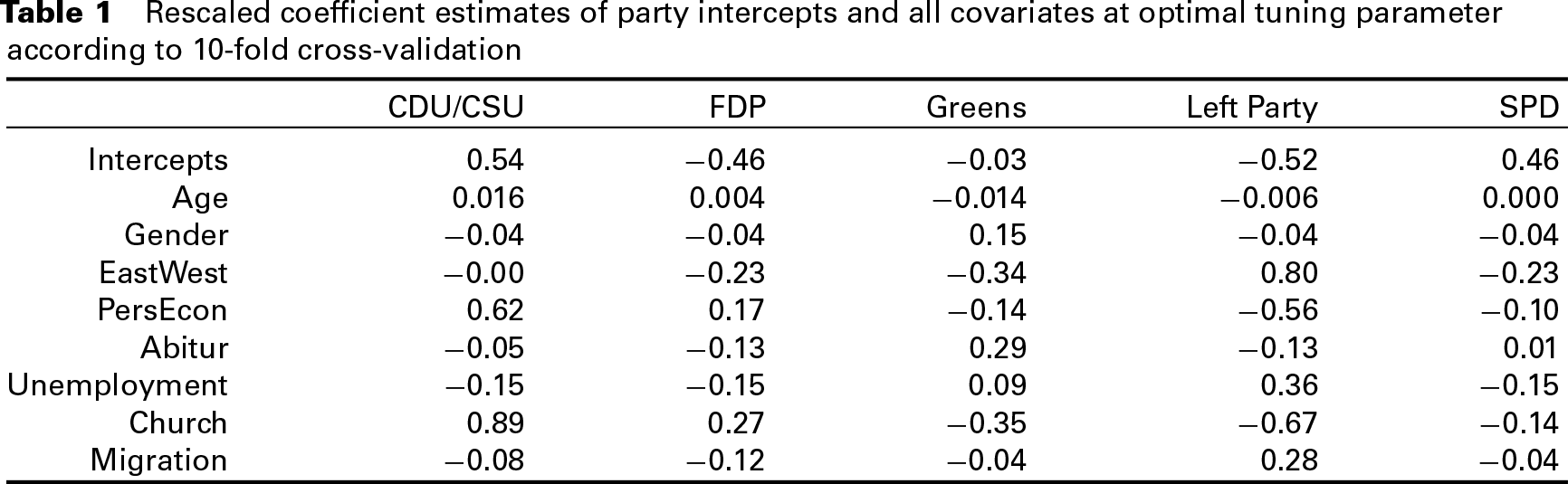
The resulting parameters (as estimated at the optimal tuning parameter according to the 10-fold cross-validation) are summarized in Table 1. In contrast to Figure 4, the coefficients have been rescaled so that they are interpretable with regard to the original scale of the variables. For example, when age is increased by 10 years, the attractiveness of the CDU/CSU increases by 0.16.
Rescaled coefficient estimates of party intercepts and all covariates at optimal tuning parameter according to 10-fold cross-validation
Paths representing the sums of absolute differences for the scaled parameters of all eight covariates. Dashed vertical line represents optimal model according to 10-fold cross-validation
Rescaled coefficient estimates and 95% bootstrap confidence intervals separately for all eight covariates

Finally,
For illustration, in the following different computational times of the application are reported. The proposed method is implemented in the
For the analysis, a computer with an Intel Xeon 2.60 GHz processor was used. As mentioned before, the data set contains
Concluding remarks
A method that reduces the dimensionality in ordered paired comparison model with subject-specific covariates is proposed. The developed feature selection approach utilizes penalization techniques with a specific lasso-type penalty. The penalty has two main features: First, the penalty clusters objects with regard to certain covariates. Therefore, one can identify clusters of objects whose preferences are equally affected by a covariate. Second, the penalty can eliminate whole covariates from the model indicating that the respective covariates do not affect the preference for one or another object (although in our application all variables had an effect on the preference). Bootstrap intervals can be calculated, which can be used to compare parameter estimates with respect to their variation.
In particular the ability to select and cluster distinguishes the method from the alternative approaches to model subject-specific effects. The methods that select variables by using information criteria, as considered, for example, by Dittrich et al. (2000), Francis et al. (2002) or Francis et al. (2010), exclude whole variables but do not identify clusters. The same holds for the boosting approach proposed by Casalicchio et al. (2015) because boosting methods are not designed to allow fusion of parameters. An additional advantage of penalty methods over boosting approaches is that the structure of the regularization is more clearly defined. In contrast to Strobl et al. (2011), where the underlying structure is searched for by recursive partitioning techniques, we consider a parametric model that allows for easy interpretation of parameters and clustering.
The proposed method could be extended in various ways. First, the restriction of the covariate effects to linear terms could be weakened by allowing for smooth covariate effects. A big challenge with such an approach would be to find an appropriate penalty term to have a similar cluster effect as for the linear terms. Second, the model could be extended by object-specific covariates similar to Tutz and Schauberger (2015). For the application to the data from the GLES in this work, this would correspond to the inclusion of party-specific covariates, for example the popularity of the respective leading candidates.