
Abstract
Abstract:
Function-on-scalar regression models feature a function over some domain as the
response while the regressors are scalars. Collections of time series as well as
2D or 3D images can be considered as functional responses. We provide a hands-on
introduction for a flexible semiparametric approach for function-on-scalar
regression, using spatially referenced time series of ground velocity
measurements from large-scale simulated earthquake data as a running example. We
discuss important practical considerations and challenges in the modelling
process and outline best practices. The outline of our approach is complemented
by comprehensive
Keywords
Introduction
Regression models for functional responses try to model structures like time-dependent processes or 2D or 3D images (Ramsay and Silverman, 2005). Functional data are thereby defined as data that vary over a specific domain 𝒯, for example, time. Observations typically consist of measurements at individual points over that domain.
One valid alternative to functional response regression for data structured like this is longitudinal data analysis, modelling the separate measurements along each function using scalar regression while explicitly specifying their temporal correlation structure, for example, by including (random) time effects or by assuming autocorrelated residuals over time. However, eliciting an appropriate correlation structure is usually non-trivial. Using functional regression, correlation structures over the functional domain can be modelled flexibly and implicitly.
A functional approach should be the method of choice if the shape of a response over its functional domain is of main interest. Functional regression models enable researchers to quantify how various parameters influence the expected level and shape of the functional responses.
If the response is of a functional nature and all predictor variables are constant over the functional responses’ domain, the corresponding model is a function-on-scalar regression model. This work gives an introduction to this model class aimed at researchers looking for a pragmatic overview on how to apply this method without having to dive deeper into the technical part of it. As such, our focus is on explaining general concepts rather than providing detailed mathematical explanations of the method. Furthermore, we list important practical considerations and give advice on which methods are needed in which situation. Throughout the text, we show how to apply the methods using real-world data.
Various approaches to model function-on-scalar data exist. Our main focus lies on the
flexible framework of Greven and
Scheipl (2017a) which covers models of the form

Well-written introductions to the basic concepts and philosophy of functional data analysis are given in Ramsay and Silverman (2005) and Ramsay et al. (2009). Reviews of current research can be found in Morris (2015) and Wang et al.(2015). Readers interested in an in-depth review of available implementations for function-on-function and scalar-on-function regression models are pointed to Greven and Scheipl (2017a). An alternative approach that is closely related to the approach used here was developed by Reiss et al. (2010).
We perform our analyses in
The article is structured as follows: Section 2 introduces the running example for this work. Important statistical aspects of semiparametric regression are sketched in Section 3. Section 4 discusses concepts and challenges of function-on-scalar regression. We finish with a discussion and outlook in Section 5.
If the main interest lies in predicting or analysing specific characteristics of the functional response, alternative approaches are often more adequate. In particular, the function-on-scalar regression approach presented here is not well suited for predicting peak ground velocities as the penalized estimation of smooth structures tends to systematically underestimate the maxima.
Bauer (2016) used function-on-scalar regression to quantify how frictional failure across an earthquake fault affects ground velocities at different distances from the earthquake's hypocentre over time. Figure 1’s left panel shows three typical observations of the functional response ground velocity over the functional domain time. All covariates in the study were constant over time.
Left: Typical observations of absolute ground velocity over time. Peak
ground velocity is delayed and decreases as the hypocentral distance
increases. Middle: Overall functional mean of the ground velocities based on
model (3.1) which only contains the intercept. Right: Estimated mean ground
velocities by categorized hypocentral distance, based on model (3.2)
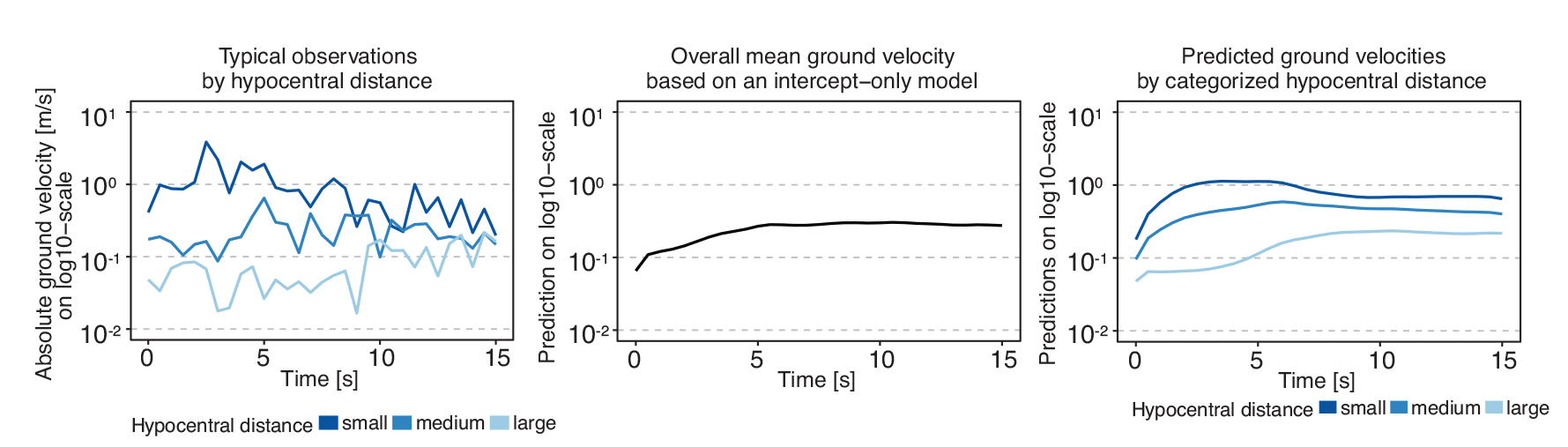
Left: Typical observations of absolute ground velocity over time. Peak ground velocity is delayed and decreases as the hypocentral distance increases. Middle: Overall functional mean of the ground velocities based on model (3.1) which only contains the intercept. Right: Estimated mean ground velocities by categorized hypocentral distance, based on model (3.2)
The aim of statistical modelling is to gain a better understanding of the
associations between initial seismic conditions like fault stress and fault strength
prior to earthquakes as well as local topography and geology with the temporal and
spatial distribution of ground movement caused by an earthquake. The data is derived
from large-scale in silico earthquake scenario simulations with the
open source software SeisSol (Breuer et al., 2014; Pelties et al., 2014
Shaking velocity and ground movement was recorded in high temporal resolution at a
dense network of virtual seismometers distributed across Southern California. In the
notation of (1.1), each response function
The analysis is focused on the effects of five physical parameters on ground velocity: three frictional resistance variables, the direction of the regional tectonic background stress and the soil material of the simulated area: either rock or sediment. These parameters were pre-set in each seismic simulation. As seen in Figure 1, distance from the fault has an important effect on both the shape and the level as well.
The regression framework introduced by Greven and Scheipl (2017a) is based on additive or semiparametric regression models. Such models are one approach for estimating nonlinear effects of variables. In the following, we will introduce the basic modelling concepts of semiparametric functional regression by practically motivating differently complex models, each followed by a brief summary of the most important methodological basics.
Semiparametric models with one-dimensional smooth effects
In the simplest setting, we estimate the overall functional mean of ground
velocities using a model only containing a functional intercept and no
covariates:

As a next step, we want to assess a possible association of ground velocities
with hypocentral distance, that is, we also want to quantify just how
different curves at different hypocentral distances are on average.
This can be done by extending Equation (3.1) with a dummy-coded
categorical covariate
Estimation of the functional intercept and the time-varying distance category effects is performed using a spline-based approach, where the effect is represented as the sum of scaled spline basis functions. Readers not familiar with this and other basic concepts regarding penalized estimation for generalized additive models are pointed to Fahrmeir et al. (2013) or Wood (2006). In a nutshell, penalization is a useful tool in estimating smooth effects as it allows estimation of nonlinear effects simply by defining the maximally possible wiggliness of each effect's shape, which is limited by the number of spline basis functions being used for that effect. Overfitting is then prevented by using an estimation criterion that punishes complexity of the effect estimates (i.e., wigglier shapes) while simultaneously rewarding goodness of fit. Parameters that control the relative weights in this trade-off between a good fit of the training data on one hand and a parsimonious model with simple effect shapes that is more likely to generalize well for previously unseen test data on the other hand are estimated from the data automatically.
Many different spline bases are available for one-dimensional smooth effects, cf.
the documentation for
Some more specialized spline bases are very useful in particular situations and easily available in the software we use here, for example, cyclic splines for periodic effects where boundary values must be equal or soap film smooths for fits with constraints along complex domain boundaries like seashores. Morris (2017) compares a Bayesian wavelet-based approach well suited for spiky data on regular grids to the method described here.
Using the spline-based approach, both the estimation of time-varying effects and of effects that vary nonlinearly over the variable domain itself is possible. An example for the latter is given in Figure 2’s left panel, which shows the estimated effect of the variable slip weakening, that is, the distance over which initial friction diminishes to its minimum. Higher values in this parameter correspond to bigger overall friction and thus to ground velocity curves that have a lower level overall. Note that this type of time-constant effect does not affect the shape of the functional responses, only their overall level.
Putting all currently described effect shapes together, we are now capable of
specifying models of the form
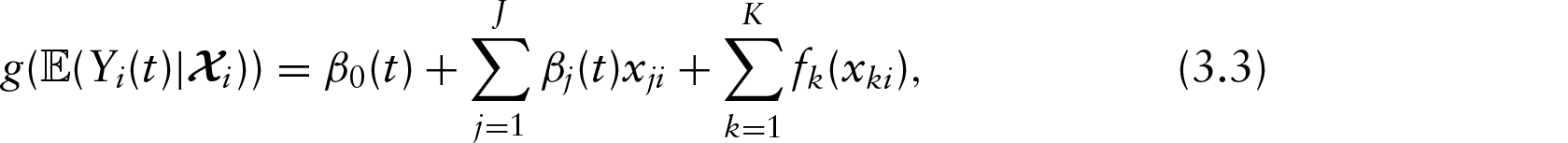
As a final step, we now include multidimensional smooth effects into the model. Such effects can vary nonlinearly both over the domain of the functional response and the domain of the covariate (or multiple covariate domains in the case of interaction effects). As an example, the three rightmost panels of Figure 2 visualize the estimated nonlinear time-varying effect of the hypocentral distance. To facilitate interpretation of the effect, it is shown using both a heatmap (panel 3) as well as a 3D surface (panel 4). In addition, a comparison of the predictions for specific values is a valuable tool as well (panel 2). One can see (a) that smaller hypocentral distances correspond to higher ground velocities (note the large negative slope of the estimated surface along the distance axis), (b) that the initial peak of ground velocity sets in later the farther away from the earthquake centre the virtual seismometers are located (note that the peak for a given distance is located higher up the time axis as distance increases), (c) that the peak becomes somewhat less pronounced for larger distances and (d) that the effect is almost linear over hypocentral distance.
Panel 1: Estimated time-constant effect of slip
weakening
fslip(xslip),
which implies a (nonlinear) shift in the average level of
as
xslip changes. 2:
Predictions for specific values of hypocentral distance with remaining
covariates set to realistic values. 3, 4: Effect of
hypocentral distance visualized using a heatmap and a 3D surface. Note
that values in panels 1, 3 and 4 are on the scale of the additive
predictor (i.e., log
e
([m/s])), while panel 2
is on log10-scale
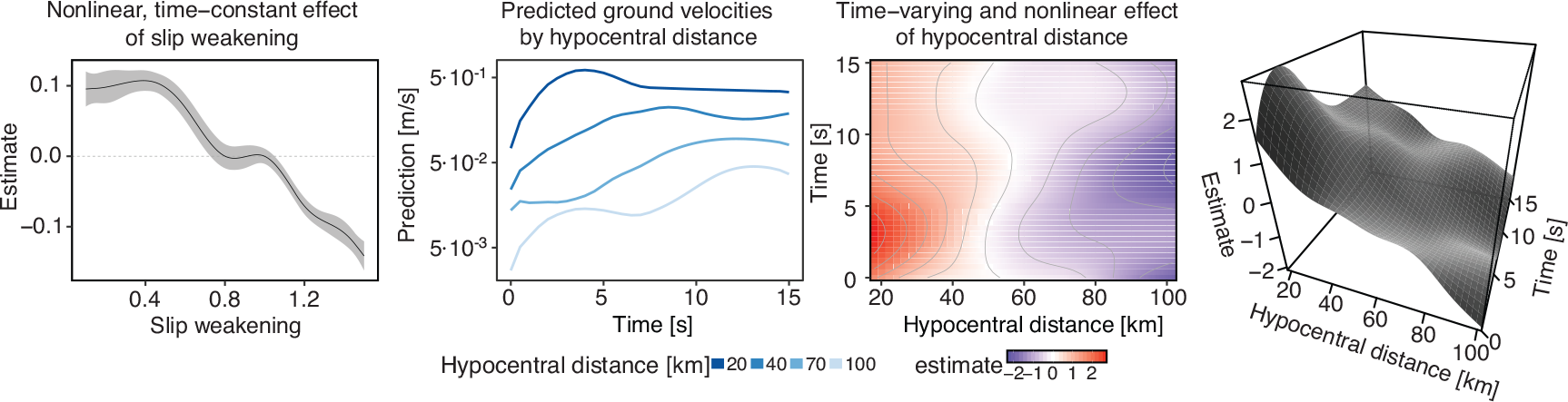
Panel 1: Estimated time-constant effect of slip
weakening
fslip(xslip),
which implies a (nonlinear) shift in the average level of
as
xslip changes. 2:
Predictions for specific values of hypocentral distance with remaining
covariates set to realistic values. 3, 4: Effect of
hypocentral distance visualized using a heatmap and a 3D surface. Note
that values in panels 1, 3 and 4 are on the scale of the additive
predictor (i.e., log
e
([m/s])), while panel 2
is on log10-scale
Incorporation of multidimensional smooths into Equation (3.3) is
easily done by generalizing it to

We briefly sketch two possibilities for setting up a multidimensional spline
basis for representing effects
Since the number of basis functions limits the maximal complexity of the shape of
any effect
In some situations, the placement of the basis functions over the effect's domain can be of great importance. If no further information is available an equidistant placement is a valid approach. In contrast, a user-specified placement can make sense if the data are spread very unequally across the domain and the researcher supposes that the effect will vary more strongly in regions where more data points lie or when a few data points lie far beyond the main data cloud. In such cases, it can be more efficient to place more knots in regions with more data, especially in situations with small to moderate sample size.
Inference and model checking
This section focuses on setting up and evaluating a function-on-scalar model. As
motivated in the last section, the general model of Greven and Scheipl (2017a) can be written
as
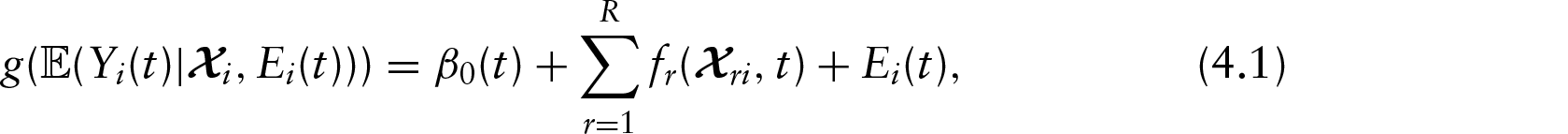
In many practical applications, the assumption of independence along
Generally speaking, all response distributions from scalar regression are also available for use in models with a functional response. Whether effects are constant or varying over the functional domain should be investigated for all variables (metric and categorical). How appropriate effect types can be determined as part of the modelling process is outlined in Section 4.4.
CIs for smooth effects can either be constructed globally (or simultaneously), pointwise or intervalwise, the interpretation being that the CI overlaps the true effect globally, at a specific point or in a specific interval with a given probability, respectively. This is an area of active research; see, for example, Krivobokova et al. (2010) or Marra and Wood (2012). As a generally applicable method, bootstrapping can be used to construct all different types of CIs. However, it can be computationally expensive—often prohibitively so for high-dimensional data or complex models.
Several bootstrap strategies exist that can be used in this context. The most
established approach in the context of regression modelling is the conditional
or parametric bootstrap (Efron and Tibshirani, 1994), which consists of the following steps
for constructing a pointwise CI for the linear coefficient Create Calculate the model on each of the Define the CI using empirical quantiles, for example, the 2.5%
and 97.5% quantiles to obtain a 95% CI.

Note that parametric bootstrapping heavily relies on the underlying model being specified correctly. In case of violation of the model assumptions, this approach can lead to overly optimistic intervals and instead nonparametric bootstrapping should be used, where resampling is based on the raw data (Efron, 1979). Because of the exemplaric character of our running example we use nonparametric bootstrapping to estimate CIs.
As an alternative to bootstrapping, the empirical Bayesian CIs
developed by Marra and Wood
(2012), which are an extension of Nychka's (1988) CIs, are
computationally efficient and implemented in
Left: Comparison of the Marra and Wood (2012) CIs and pointwise,
nonparametric bootstrap-based CIs (95%) using 1000 Bootstrap samples for
the smooth effect of sediment velocity. Right: Pointwise, nonparametric
bootstrap-based CIs (95%) and point estimate for the time-varying smooth
effect of hypocentral distance using 1000 Bootstrap samples
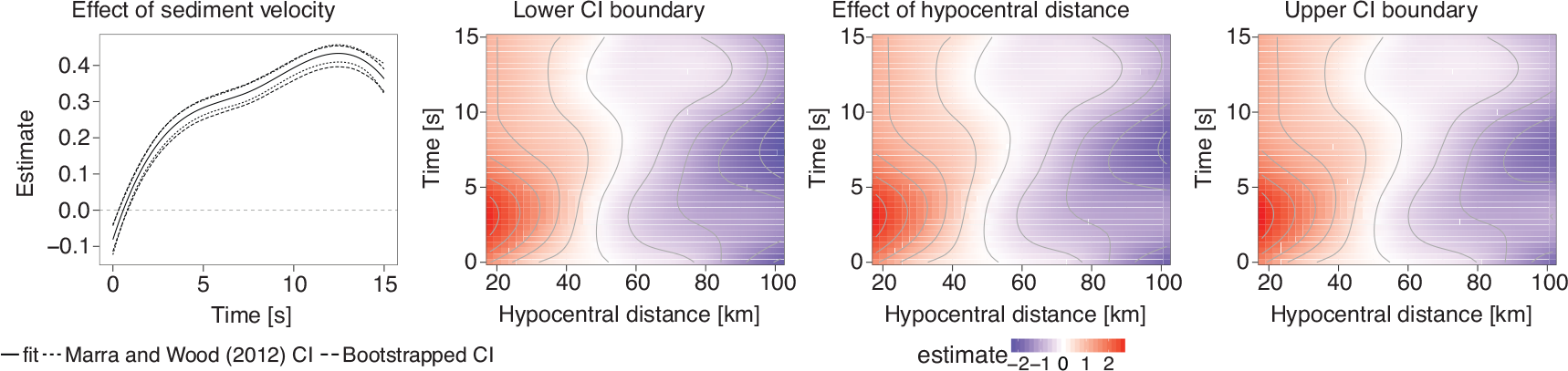
Left: Comparison of the Marra and Wood (2012) CIs and pointwise, nonparametric bootstrap-based CIs (95%) using 1000 Bootstrap samples for the smooth effect of sediment velocity. Right: Pointwise, nonparametric bootstrap-based CIs (95%) and point estimate for the time-varying smooth effect of hypocentral distance using 1000 Bootstrap samples
In contrast to one-dimensional effects, visualization of uncertainty for multidimensional smooth effects is more complex as a 3D surface plot cannot be used to show both the point estimate and CIs. Instead, the best approach is to use separate heatmaps for the point estimate, the lower CI boundary and the upper CI boundary using identical colour legends, as shown in Figure 3. Looking at the estimates, it can be seen that the uncertainty about the effect of hypocentral distance is rather small.
Regarding predictions, both pointwise CIs for the predicted mean values and pointwise prediction intervals can be obtained based on Wood (2006, Ch. 1.3.6). For intervalwise or global versions of both interval types again bootstrap-based methods have to be used, but our practical experience suggests that the differences to pointwise CIs are usually negligible for practical purposes.
Most of the relevant hypotheses in function-on-scalar regression can be tested
using the five test approaches listed in Table 1. All tests apart from the
bootstrap are Wald-like tests which are based on the approximate normal
distribution of the estimated regression coefficients. For details, see Wood (2013) and Marra and Wood (2012).
The appropriate test distribution mostly depends on the question whether the
scale or dispersion parameter
Overview on relevant tests, based on whether the scale or dispersion
parameter
ϕ
has to be estimated or not.
(1) test based on Wood (2006, 4.8.5); (2) test
based on Wood (2013)

Overview on relevant tests, based on whether the scale or dispersion
parameter
ϕ
has to be estimated or not.
(1) test based on Wood (2006, 4.8.5); (2) test
based on Wood (2013)
Hypotheses for scalar coefficients of the form
Note that all the tests given earlier are conditional on the estimated penalty
parameters that control the effective degrees of freedom of each term. However,
neglecting smoothing parameter uncertainty does not seem to have a large
negative impact on the validity of p-values and the performance
of CIs unless penalty parameters are poorly identified (Marra and Wood, 2012). An approach to
account for smoothing parameter uncertainty in p-value
calculation is outlined in Wood et al., (2016b) and implemented in
An overview on the most important hypotheses in function-on-scalar regression is
given in Table 2,
which lists possible research questions together with the appropriate tests. As
a special note, testing whether two scalar effects (or two smooth effects) of
Overview on possible hypotheses with corresponding tests. (0) tests are only reported for the case of unknown scale parameter ϕ. If ϕ is known we refer to Table 1; (1) F-test based on Wood (2006, 4.8.5); (2) F-test based on Wood (2013)

Apart from the penalized likelihood-based (or empirical
Bayesian) framework introduced here, fully Bayesian inference like, for example,
the framework of Morris
(2017), see Section 4.6, often allows for easier handling of complex
or non-standard inferential problems. When relying on the software
implementation of the Greven
and Scheipl (2017a) framework in the
Working with generally high-dimensional functional data, researchers should be
aware that, all else being equal, large sample sizes lead to smaller
p-values in the case of
We now list some further challenges that are specific to dealing with functional data. A first comparison of different modelling approaches regarding those problems is given and is complemented by the main discussion in Section 4.6.
If the functional responses have hierarchical, longitudinal or spatio-temporal structure, there may be non-negligible inter-curve correlation that the model has to account for. In the case of grouped data, that is, longitudinal or hierarchical data, functional random intercepts and slopes varying over the functional domain of the response can be incorporated into the model (Greven and Scheipl, 2017a). Spatio-temporal correlation with a pre-specified structure between functional responses can be included explicitly by including smooth effects over space or time. Scheipl et al. (2015, Online Appendix C) contains a worked example and code for spatially correlated curves.
Another common problem when dealing with time-varying functional
data is misalignment or phase variation of functional
observations. This means that certain salient features of the functional
responses like peaks or plateaus do not occur at the exact same time points. Few
functional data analysis frameworks are currently able to incorporate both phase
and amplitude variation (cf.
Functional data are frequently high-dimensional and estimation of complex models
can be very expensive, both in terms of computation time and memory
requirements. Pragmatically speaking, analysts facing such a problem should
consider downsizing the data, for example, by reducing the resolution of
functional measurements over the functional domain or by using only a subset of
the data for estimation and the remainder for model validation. Highly efficient
estimation algorithms are available for some approaches. For the class of
spline-based models we focus on here, one can use the algorithm of Wood et al. (2016a),
which is implemented in the function
Finally, users should be aware that some methods for functional data are only applicable if the functional observations contain no missing measurements and were observed on a regular grid, that is, all functional observations are evaluated at the same points of the functional domain. A comparison of the applicability of various function-on-scalar regression frameworks is given in Section 4.6.
Model selection
Generally speaking, model selection in functional regression models underlies the same principles as in scalar regression (see, e.g., Marra and Wood, 2011; Fahrmeir et al., 2013, Ch. 3.4.3). Using model selection in function-on-scalar regression can be useful for various issues, for example, for deciding which response distribution and link function is optimally suited to the data or whether an effect should be incorporated linearly or as a smooth curve. Additionally, very high-dimensional data often reduces the effectiveness of penalization methods as the information in the observed data overwhelms the penalization prior (Gelman et al., 2014). In such situations it can be necessary to use model selection to optimize the number of basis functions for each smooth effect.
Leeb and Pötscher (2005) propose a test set based approach to prevent overfitting and preserve valid p-values when performing model selection. For smaller datasets, k-fold cross validation is a valid alternative (Hastie et al., 2009). Using one of those two approaches, the best model can, for example, be found by using the prediction error as the optimization measure. When model selection is based on training set performance, other criteria like AIC or LR tests should be used (Fahrmeir et al., 2013). Note that if using the semiparametric approach smoothing parameter uncertainty should be accounted for in AIC computation (see Wood et al., 2016b).
For our data, we use a test set based model selection approach with mean square prediction error (MSE) as the criterion for two purposes. First, penalization did not work very well in this setting, probably due to the massive amount of data available. Therefore, we use a pragmatic model selection procedure to select the number of basis functions for each smooth effect and to decide whether individual effects should be incorporated as a smooth effect or linearly. Second, we use model selection to choose between different response distributions and link functions.
Model evaluation
Model assumptions for functional response regression are mostly the same as in respective scalar models, that is, observations are independent conditional on the additive predictor. Model evaluation is mainly done by visualizing the residual structure.
From left to right: Residuals versus fitted values, residuals versus
space, residuals versus the functional domain, autocovariance of
residuals over the functional domain. The black dot in the second plot
marks the epicentre
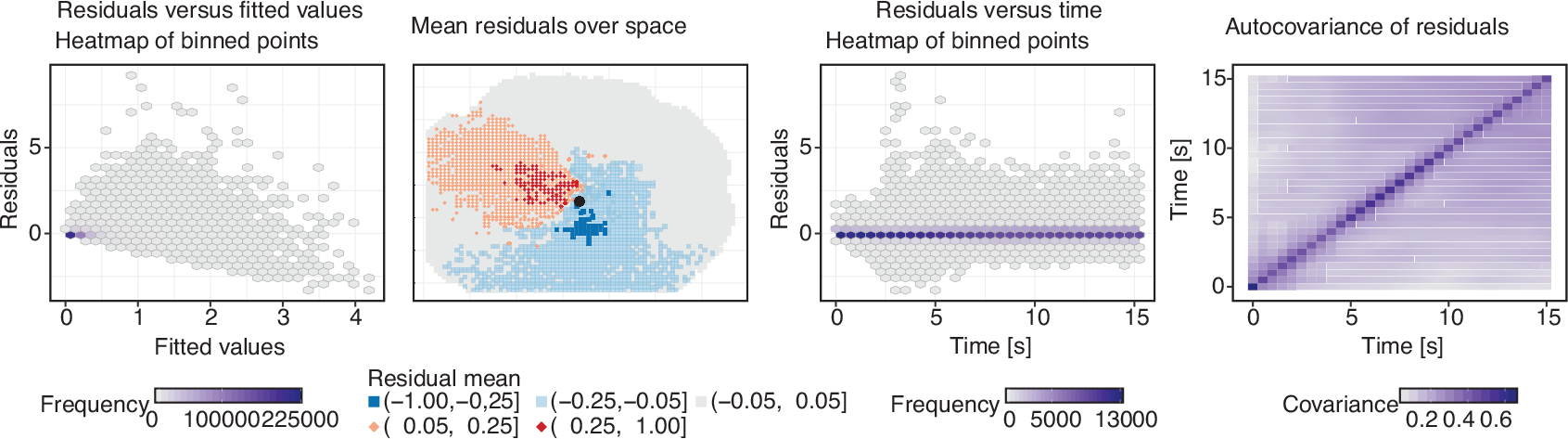
From left to right: Residuals versus fitted values, residuals versus space, residuals versus the functional domain, autocovariance of residuals over the functional domain. The black dot in the second plot marks the epicentre
A selection of useful residual plots is shown in Figure 4. The structure of the residuals
plotted against the fitted values (panel 1) is acceptable. Most measurements are
predicted approximately correct. The odd structure of negative residuals is
based on the ground velocities being non-negative, which results in highly
negative residuals not being possible. Plotting the mean residuals over space
(panel 2) shows that a substantial spatial struture is remaining in the
residuals. Nearly all regions where ground velocities were substantially
underestimated are west of the earthquake centre, while seismometer readings in
regions to the east and to the south of the epicentre were overestimated. Across
time, however, we again observe an acceptable amount of residual structure—the
hexbin plot (panel 3) does not show any systematic deviations from a constant
trend at zero, with some extreme peak ground velocities observed at around five
seconds. As functional data often are very high-dimensional standard
scatterplots of the residuals, having the problem of overplotting should
generally be avoided in favour of alternative plots like density plots or
hexagonal binning (Carr
et al., 2016), as was done in the left and middle plots of Figure 4. The empirical
autocovariance of the residuals (panel 4) corresponds well enough to the model
assumptions: it is fairly constant along the diagonal (i.e., the variance of the
residuals is fairly homogeneous over functional domain
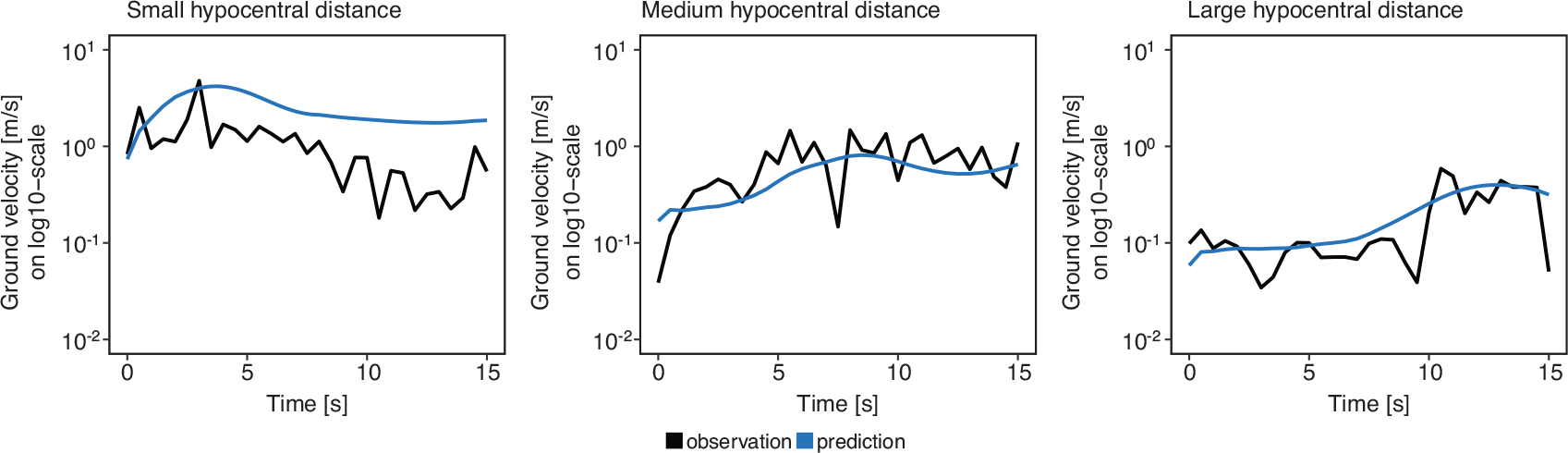
For an evaluation of the prediction power of the model, measures like MSE of the predictions can be calculated. We also recommend graphical evaluation of predictions for single functional observations as was done in Figure 5 to get an overview on model performance.
Comparison of model predictions and raw observations for typical observations with different hypocentral distances
As alternative approaches to semiparametric regression we only cover the most versatile frameworks for performing function-on-scalar regression. The capabilities of the respective software implementations are also outlined, a comprehensive comparison of available software implementations is given in Table 3 of Greven and Scheipl (2017b). Many specialized function-on-scalar regression methods have been proposed in the literature, oftentimes with corresponding small software implementations, which we do not cover here. See Morris (2015) for an in-depth review of this field.
The semiparametric approach of Greven and Scheipl (2017a) was already
outlined extensively. The methodology is ready-to-use in the
One class of alternative approaches includes a pre-smoothing step prior to model
estimation, meaning that each functional observation is smoothed and the
resulting smooth curve is then treated as the functional observation (see, e.g.,
Ramsay and Silverman,
2005). The disadvantage is that the measurement error removed by the
smoothing step is not taken into account in subsequent inference. On the plus
side, this can allow for more efficient estimation as the smooth curve can then
be represented compactly by the vector of spline coefficients yielding the
smoothed curve. The
An overview of nonparametric methods and their applications is provided in Ferraty and Vieu
(2006). Their regression approaches are usually based on kernel methods
and are able to model highly nonlinear associations. However, the methods mostly
cover only univariate models with a single covariate. Febrero-Bande et al. (2012) introduce
the
The componentwise gradient boosting framework of Brockhaus et al. (2016b) is spline based
and extremely versatile. With boosting being a popular, very efficient yet very
powerful estimation technique, it represents a neat alternative to the standard
regression approach. The advantages are most noticeable when working with very
high-dimensional data requiring an efficient estimation technique or when
dealing with data situations with more parameters than observations, as such
settings remain computationally feasible using a boosting approach. Also, the
boosting approach automatically performs variable selection. However,
uncertainty quantification for boosting is currently only possible using
computationally expensive resampling techniques like bootstrapping (Hastie et al., 2009).
The method is implemented in the
As another alternative, fully Bayesian functional regression can be used. The
most comprehensive framework we are aware of is the one of Morris (2017) and collaborators, who
also provide a comprehensive comparison to the approach of Greven and Scheipl (2017a). Generally
speaking, fully Bayesian approaches have the advantage that diverse between- and
within-function correlation structures can be incorporated into the model in a
very flexible way. Also, handling inference is much easier as approximate
posterior distributions of all parameters are available in the form of MCMC
samples. Readers interested in a general introduction to Bayesian distributional
regression are pointed to the tutorial paper by Umlauf and Kneib (2018). Unfortunately,
the Morris (2017)
framework lacks a comprehensive and well-documented publicly available software
implementation at the time of writing. A C++ and Matlab implementation called
Discussion and outlook
This work provides an introduction into the general concepts of function-on-scalar
regression. Important practical considerations and best practices are outlined for
the most important modelling tasks. We hope that researchers can use this work as a
starting point for applying functional regression models to their own data.
Comprehensive
We concentrated on the semiparametric approach of Greven and Scheipl (2017a) as this
framework is rather flexible in terms of incorporating different types of covariate
effects, is applicable for both regular and irregular data with possible missing
values, and is accompanied by a flexible implementation of function-on-scalar
regression in the
As this work is mainly aimed at introducing the approach to those not familiar with functional response regression and to offer advice on the correct application of such methods, it should be clear that not all methodological aspects of functional regression are covered. One crucial point we have not discussed is the use of functional principal components (fPCs) as a popular alternative to using spline basis functions. fPCs often lead to a very compact basis and nicely interpretable results. An overview on fPC-based approaches is given in Wang et al. (2016). Note that functional residuals and other functional random effects can be represented using fPCs as well in the approach described here (cf. Greven and Scheipl, 2017a).
Finally, we look forward to the ongoing development of ready-to-use and robust methodology for functional regression. Being both an important method for working with complex data structures and a field where research is still needed for some important aspects, functional regression stays one of the currently most exciting fields of modern statistics.
Footnotes
Acknowledgements
Financial support by the German Research Foundation for the development of