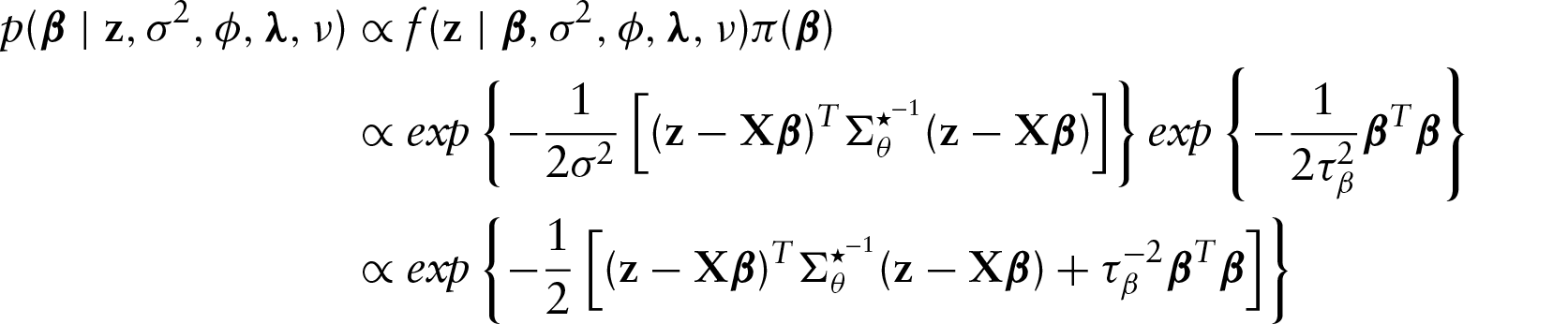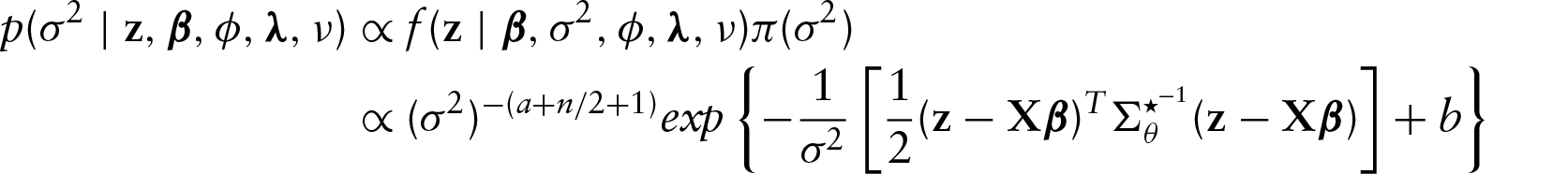Abstract
This work considers residual analysis and predictive techniques for the identification of individual and multiple outliers in geostatistical data. The standardized Bayesian spatial residual is proposed and computed for three competing models: the Gaussian, Student-t and Gaussian-log-Gaussian spatial processes. In this context, the spatial models are investigated regarding their plausibility for datasets contaminated with outliers. The posterior probability of an outlying observation is computed based on the standardized residuals and different thresholds for outlier discrimination are tested. From a predictive point of view, methods such as the conditional predictive ordinate, the predictive concordance and the Savage–Dickey density ratio for hypothesis testing are investigated for identification of outliers in the spatial setting. For illustration, contaminated datasets are considered to assess the performance of the three spatial models for identification of outliers in spatial data. Furthermore, an application to wind speed modelling is presented to illustrate the usefulness of the proposed tools to detect regions with large wind speeds.
Keywords
Introduction
From a theoretical viewpoint, statistical inference goes beyond parameter estimation and prediction (refer Robert, 2007, p. 343). Often, tests are performed regarding model parameters which are based on models that are not adequate for the data under study. That is, checking model adequacy should not rely on model parameter testing. Some verification of model goodness of fit is then called for. From a Bayesian perspective, the issue is the same: statements are made regarding the posterior distribution, which is also based on the chosen sampling distribution of the data. The usual model criticism is based on model comparison and prediction for only a few out-of-sample observations.
A stylized fact of statistical applications in general is that if the data contain aberrant observations, the estimated model will generally not be a good representation of the phenomenon under study, leading to poor predictions of out-of-sample observations. An important tool for model verification and identification of atypical observations is residual analysis. In the classical linear regression model, the residuals are usually defined as the difference between observed and fitted values, and observations with large residuals are classified as outliers (refer Montgomery et al., 2006, p. 123). In the Bayesian context, Chaloner and Brant (1988) defined an outlier as an observation with large random error generated by the sampling distribution of the data. In this case, the discrepant observation might be detected through the posterior distribution of these random errors. Alternatively, Freeman (1980) considered an outlier to be any observation which was not generated by the mechanism generating the majority of the data. In the independent datasetting, several papers have discussed the detection of outliers, such as West (1984), who considered heavy-tailed distributions defined through a Gaussian mixture model to accommodate and detect outliers in a regression set-up.
In several applied settings, the identification of outliers is crucial to improve model fit and predictive power. In particular, for some applications the focus of outlier identification is not the deletion of these observations, since they can provide interesting interpretations and economic advantages. As an illustration, in the context of wind power generation, there are two important aspects related to outlier identification. First, extreme wind speeds can be costly, since turbines can only withstand a certain range of wind speeds without suffering damage. Thus, outlier detection is essential to keep the system behaving properly. See Sarkar et al. (2011) for a discussion about failure in power generation systems due to large wind speeds. Another aspect is the installation of new turbines, which requires the identification of locations with potentially large wind speeds. In this case, identification of outlying wind speeds can indicate economically viable new sites. Escalante (2007) considers an extreme value distribution to accommodate extreme winds in the model.
In the context of spatial statistics, the issue of outlier detection or modelling is even more important than in the independent case. Prediction at new locations is usually based on kriging ideas, and kriging predictors are well known to be affected by outliers since they are obtained as linear combinations of observations. In geostatistics, an outlier may have a strong effect on the prediction of its neighbours when the observed value of the process at this location is much higher or lower than expected for that region. According to Chilès and Delfiner (1999), in applied settings, even small changes in some regions in space might cause large differences between the predicted and observed process. Observations in these regions should not be discarded, since this might cause bias in the estimation of parameters and predictions (Chilès and Delfiner 1999 p. 221).
Several papers have proposed robust alternatives or modifications of the usual kriging predictor. Fournier and Furrer (2005) proposed a model to robustify the kriging predictor by defining the model for geostatistical data as a mixture of a spatial process and a contamination process. In this proposal, each site has a corresponding contamination variable that indicates whether the site is contaminated or not. The optimal predictor in this case depends on weights which will be affected by the contamination variables. However, the predictor is unfeasible in practice and an approximation is considered. Fournier and Furrer (2005) proposed the Gaussian-log-Gaussian process which is able to capture heterogeneity in space through a mixing process used to increase the Gaussian process variability. This proposal is an alternative to the usual Gaussian process which is very sensitive to outliers. The mixture approach is able to both accommodate and detect outliers. The detection step is done through hypothesis testing. In particular, Palacios and Steel (2006) considered Bayes factors for that purpose. The hypothesis testing based on Bayes factors will depend on the loss function considered to reach a conclusion regarding the outlying observation. Thus, it might be useful to consider other identification techniques together with the hypothesis testing.
A potentially robust alternative model for spatial processes is the Student-t process, discussed in Roislien and Omre (2006). However, this process inflates the variance of the whole process in the presence of outliers in the data and does not allow for individual or regional outlier detection, since it does not allow for different tail behaviour across space. Welsh 1997 discussed robustness misinterpretation in the context of multivariate t-distributions.
In the literature, few proposals deal with model checking or validation for correlated data. In particular, few papers discuss model checking for random functions. Hasllet (1999) described a deletion scheme for models based on correlated observations. Fraccaro et al. (2000) and Houseman et al. (2004) proposed graphical diagnostics for time-series models. Houseman et al. (2004) proposed a rotated residual for independent and time-series data which has good asymptotic properties. Bastos and O’Hagan (2008) proposed Bayesian diagnostics for computer models through Cholesky decomposition of the covariance matrix. That proposal results in numerical and graphical tools for model checking in the context of Gaussian processes. Juna et al. (2014) proposed Bayesian diagnostics for computer models through Cholesky decomposition of the covariance matrix. That proposal results in numerical and graphical tools for model checking in the context of Gaussian processes. Juna et al. (2014) proposed model criticism for spatial Gaussian processes based on computing pivotal quantities for the realizations of the stochastic process. The practical use of this proposal depends on the definition of subdomains in the spatial region of interest.
This work is motivated by the idea that model determination or checking should be based on residual analysis, predictive performance and outlier detection. In particular, this article extends the Bayesian residual approach of Chaloner and Brant (1988) to accommodate spatially correlated observations. The data are assumed to vary continuously in a spatial domain of interest D and residual analysis and predictive techniques are investigated aiming to identify potential outliers or regions of larger variability in the data.
In this context, the posterior probability of a large residual, the predictive concordance measure and the Bayes factor hypothesis test for outlier detection are compared for their ability to detect outliers in geostatistical data. In particular, we compute the probability of a set of two or more observations being outliers. In spatial data modelling, due to correlation and smoothness assumptions regarding the process, it is natural for neighbouring observations to be jointly affected by a mechanism generating outliers. Thus, a detection tool must be able to capture this kind of behaviour in the data. Furthermore, we propose a measure based on cross-validation ideas which is similar to the predictive concordance however, it removes the observation being tested from the data used for estimation. In this context, the effect of an outlier will be perceived more clearly using the proposed measure. This is of particular interest in small data applications.
The chosen model is crucial for the definition of residuals, so we consider the usual Gaussian process and an alternative flexible mixture process for geostatistical data. A simulated study is performed to indicate practical guidelines for residual analysis in geostatistical modelling with emphasis in outlier detection. An application in wind speed modelling illustrates that deletion of aberrant observations is not always the ultimate goal of outlier investigation.
The article is organized as follows. Section 2 describes three competing models for geostatistical data analysis: the Gaussian process, the Student-t process and the Gaussian-log-Gaussian process previously proposed in the literature. Section 3 presents the proposed spatial residual for outlier identification, discusses the predictive approach and defines a new measure for outlier detection which is based on cross-validation ideas. In addition, the hypothesis test based on Savage–Dickey ratios as presented in Palacios and Steel (2006) is considered for outlier identification and compared with the other proposed techniques. Section 4 illustrates the methods for outlier detection with contaminated datasets and an application to Brazilian wind speed data. A simulated study with replications is performed to verify the potential usefulness of the outlier identification techniques considered in this work. Section 5 concludes and discusses future developments.
Mixture modelling for outlier detection
This section presents a benchmark model and a robust model for spatial data analysis. These models will be compared in the context of the outlier detection tools presented in this work. Inference for model parameters and predictive distributions are also described.
Spatial mixture model
Here we present the mixture model proposed in Palacios and Steel (2006) which mimics a mechanism for outlier generation in a geostatistical context and accommodates spatial heterogeneity. Consider the spatial process defined in

where
(1)

with correlation function
(2)

Similar to the Gaussian process, the Student-t process has the advantage of depending only on the mean and covariance functions for its definition. Details about the Student-t process in a non-Bayesian context may be seen in Roislien and Omre (2006).
(3)

with
Although the Student-t model allows for variance inflation, it increases the kurtosis of the process in every location and does not allow for individual changes in variability. For the GLG model, if
In this article, we investigate these three models for the detection of outliers in spatial data. For that purpose, we compare the performance of methods for outlier detection in the context of correlated data. Furthermore, we propose a new measure based on cross-validation ideas and extend the Bayesian residual proposed by Chaloner and Brant (1988) to the spatial context.
We follow the Bayesian approach for model estimation and prediction which is based on the posterior distribution for model parameters. The posterior distribution is obtained by the Bayes rule, which is given by

that is,
Markov chain Monte Carlo (MCMC) methods are applied to estimate the posterior distribution
For the Student-t spatial process, the likelihood function is given by

with
For the Gaussian-log-Gaussian spatial process, we assume a mixing variable
In the context of prediction, let


where we have partitioned

For the STM, the conditional distributions remain Student-t with degrees of freedom

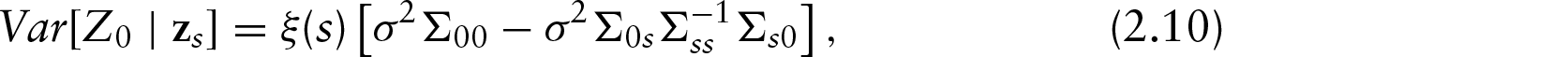
where

where
For the GLG case and conditional on the mixing variables
In this section, we describe three approaches to outlier detection in spatial modelling: the posterior probability computation of a large residual, predictive techniques such as the predictive concordance and hypothesis testing for the latent mixing variables. In this context, techniques used for univariate data are extended to spatial data analysis.
Bayesian residual analysis

If the errors have Gaussian distribution, then approximately
In the geostatistical setting, we set the value of
Furthermore, we investigate the joint posterior probability of two or more observations being outliers. This is a phenomenon which is expected in spatial applications. In particular, due to spatial correlation of observations and smoothness of the spatial process, two observations, for example, which are close together are expected to have large errors if there is a mechanism causing outliers in the spatial region where these two observations are located. Thus, the joint posterior probability that the pair

In particular, the variance process
An alternative definition of an outlier was given by Gelfand (1996). An observation is said to be aberrant or discrepant if it is in the tails of the predictive posterior distribution. The author defined the predictive concordance for observed value

with
Note that the

where

The proposed measure is similar to the predictive concordance, but it leaves
A different approach to outlier detection considers inference directly in the mixing process

with the ratio
Simulated dataset
In this subsection, the Gaussian, Student-t and Gaussian-log-Gaussian models presented in Section 2.1 are considered for the identification of outliers in contaminated datasets. For that purpose, we perform spatial residual analysis and compute the predictive concordance measure and the Bayes factor hypothesis test for outlier detection. Then we compare the methods regarding their ability to detect aberrant observations in geostatistical data. The data considered for simulation are realizations from a Gaussian processes, which after contamination presents outliers. West (1984) commented that contaminated datasets, simulated originally from the Gaussian distribution and then contaminated to characterize aberrant observations, are a useful tool to evaluate the performance of robust models.
Assume that
Three scenarios were evaluated for each of the 50 replicates: no contamination
Spatial locations considered for data simulation in the contaminated data scenarios. Locations in blue circles represent the contaminated locations in each scenario. Plot (a) represents scenario 2 and (b) represents scenario 3
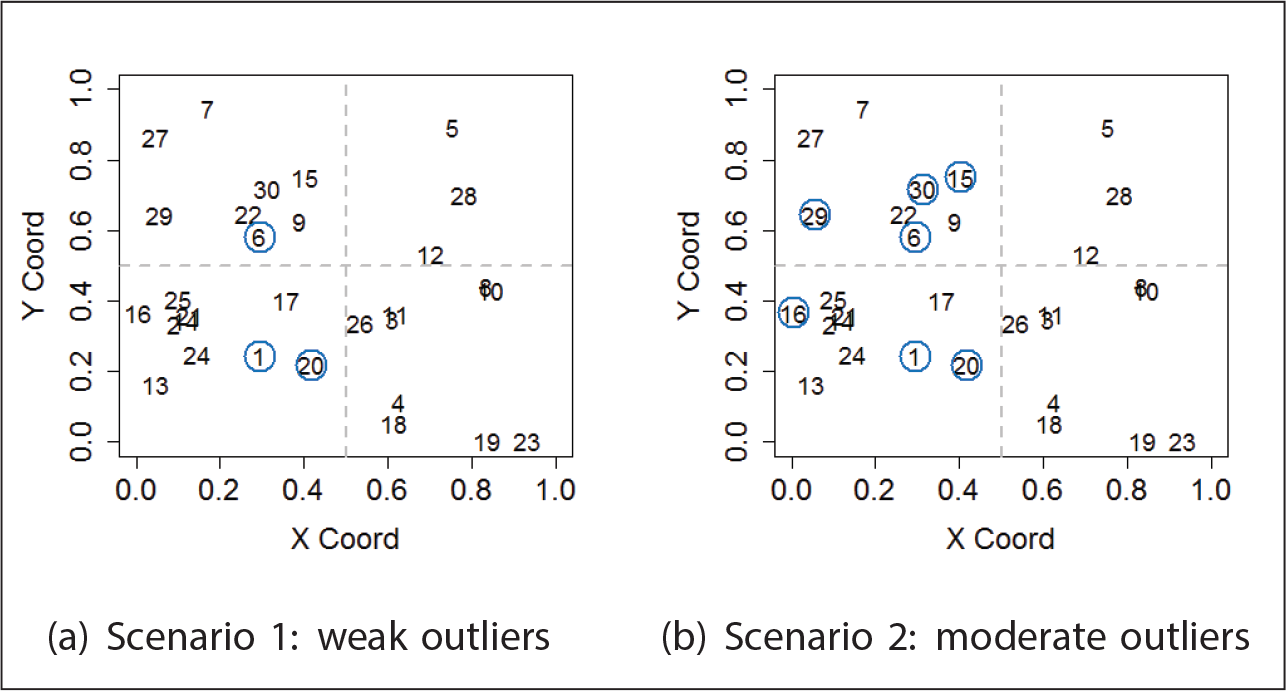
Spatial locations considered for data simulation in the contaminated data scenarios. Locations in blue circles represent the contaminated locations in each scenario. Plot (a) represents scenario 2 and (b) represents scenario 3
Parameter estimation and prediction follow the Bayesian paradigm as presented in subsection 2.2. The chains for the simulated parameters have burn-in of 50 000 and lag of 30 with resulting posterior sample size of 5 001. Convergence was checked using the
Percentage of right classification based on posterior residual probabilities of outliers
for replicated datasets. Non and cont mean non-contaminated and contaminated observations, respectively

We now present a summary of the results for the 50 replicated datasets to illustrate the usefulness of the proposed tools for spatial outlier detection. The results of the simulated study are used to define benchmarks for hypothesis tests along the applications. Figure 2 presents the spatial residuals for one selected illustrative dataset. For scenario 1, the residuals behaved as expected and no aberrant observation is identified. For scenario 2, all models are able to detect observations 1 and 20 as potential outliers, but only the GLGM identifies observation 6 as a potential outlier. For scenario 3, all models are able to detect observations 1, 15 and 20 as potential outliers, but only the GLGM identifies observations 6, 16, 29 and 30 as outliers.

In the context of spatial analysis, the identification of neighbouring observations which are outliers is of great interest. Table 2 confirms that only GLGM is able to correctly identify multiple outliers. Indeed, threshold
Results in percentage for posterior residual probabilities of multiple outliers for replicated datasets

Furthermore, the predictive measures were computed for the contaminated scenarios. The measure
Percentage of right classification based on predictive measures
,
and
for replicated datasets

We computed the Savage–Dickey density ratio to test the hypothesis of
Percentage of correct outlier indications by the Savage–Dickey density ratio
for hypothesis testing in favour of
for the 50 replicated datasets. Values of
for outlier identification are

Overall, the analysis of residuals highlights the main potential outliers in the data. The plot of residuals correctly indicates no outlier in the Gaussian data scenario for all models. However, the plot fails to indicate outliers for non-robust models. This might be due to inflation of variance of the Gaussian and Student-t models, which are unable to accommodate different tail behaviours across space. The posterior probability of large random errors gives a very precise indication of outliers in the Gaussian-log-Gaussian case. The threshold
In recent years, the use of wind energy has increased rapidly in Brazil, with the main wind farms being located in the South and Northeast regions. Nowadays, wind power corresponds to approximately
Turbines in Espinhaço and Rio Verde regions of the state of Minas Gerais

Turbines in Espinhaço and Rio Verde regions of the state of Minas Gerais
The spatial mean was adjusted considering the latitude, longitude and altitude as covariates. The mixture models considered were the Gaussian and Gaussian-log-Gaussian models, as presented in subsection 2.1. Posterior inference for model parameters was performed as discussed in subsection 2.2. The prior distributions considered were
Table 5 presents the probability of outliers for thresholds
Standard Bayesian spatial residual posterior distribution
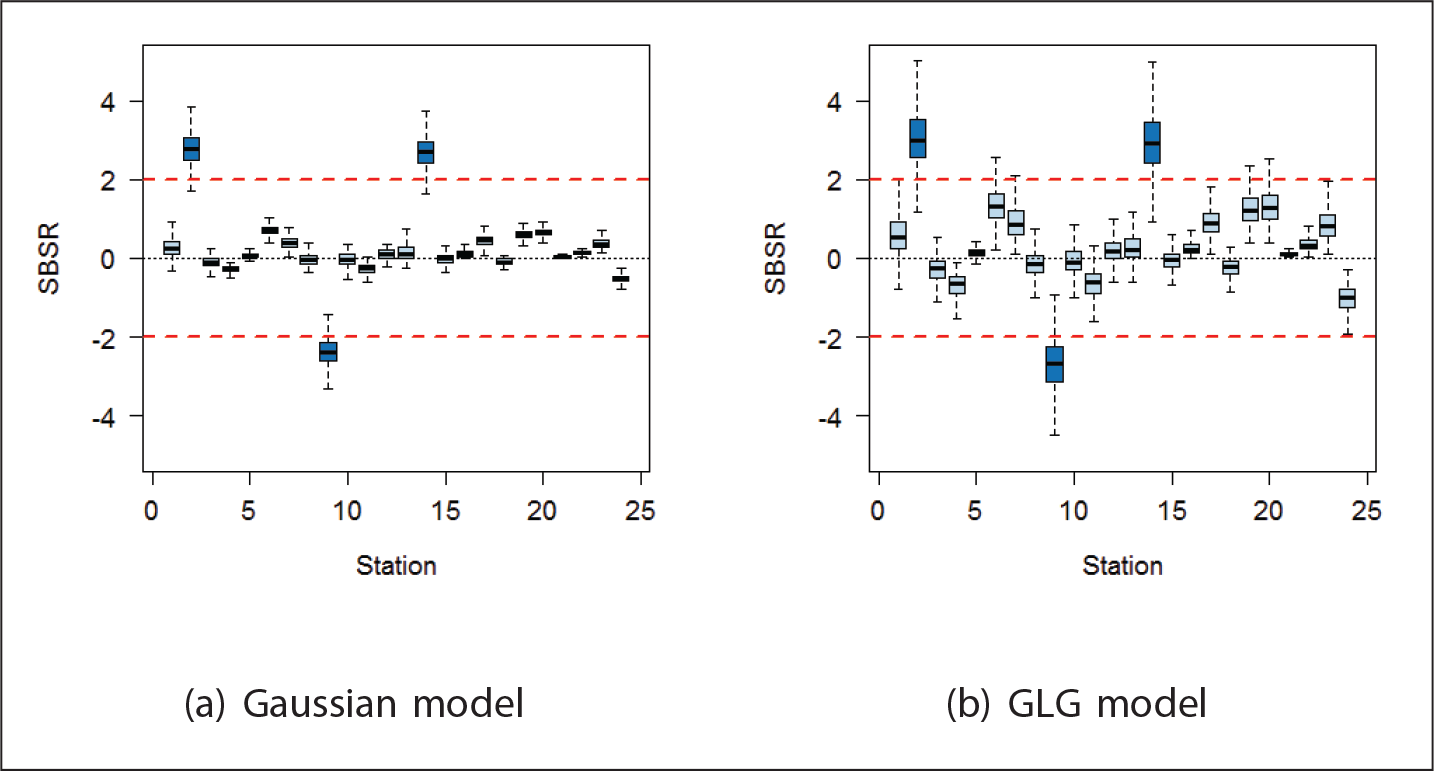
Standardized residuals and posterior probabilities of outliers,
. Large values of
indicate outliers. Boldface observations represent the observations classified as outliers
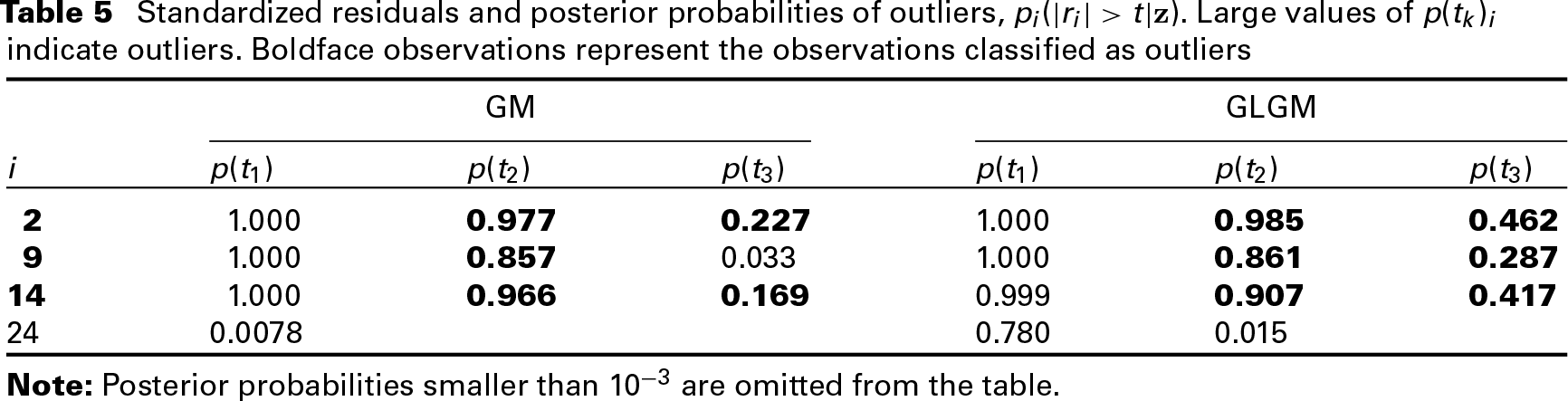
Table 6 presents the predictive approaches
Predictive measures
,
,
for some observations in the sample. Boldfaced observations represent the observations classified as outliers
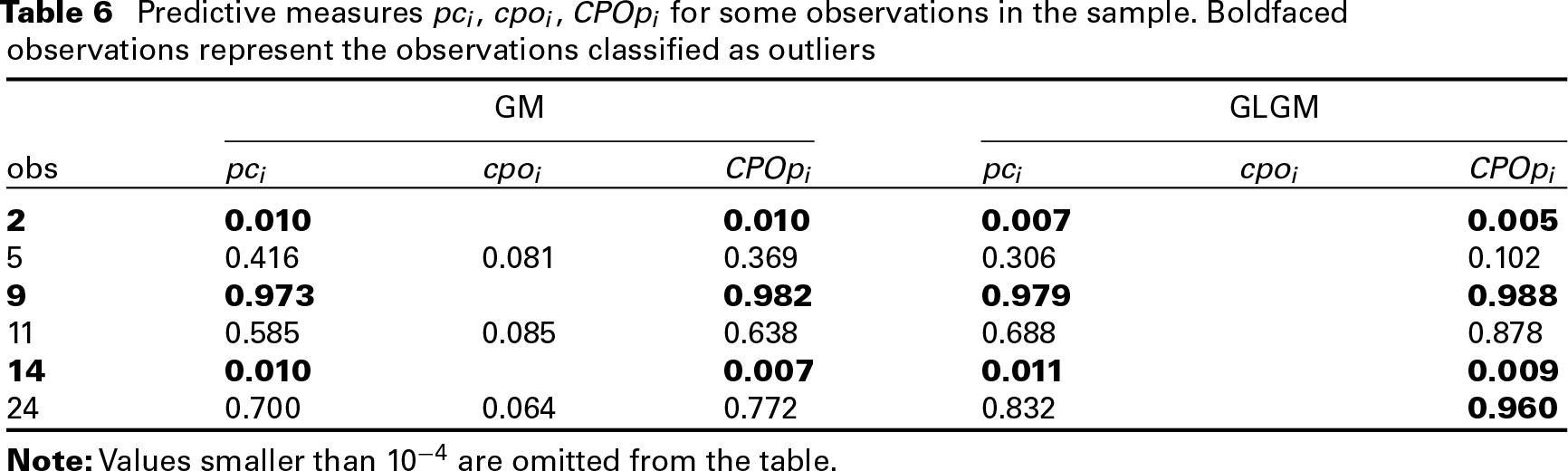
Table 7 presents the Bayes factor based on the Savage–Dickey approximation. Observations 2, 9 and 14 are indicated as potential outliers by the Bayes factor test with
Savage–Dickey density ratio
for hypothesis testing in favour of
. Boldface observations represent evidence of outliers (
)

The three observations classified as outliers in this application are within the boundaries of the spatial region considered. Further investigation should be performed to explain the larger residuals obtained for these locations. Figure 5 presents the posterior variance for each location defined by
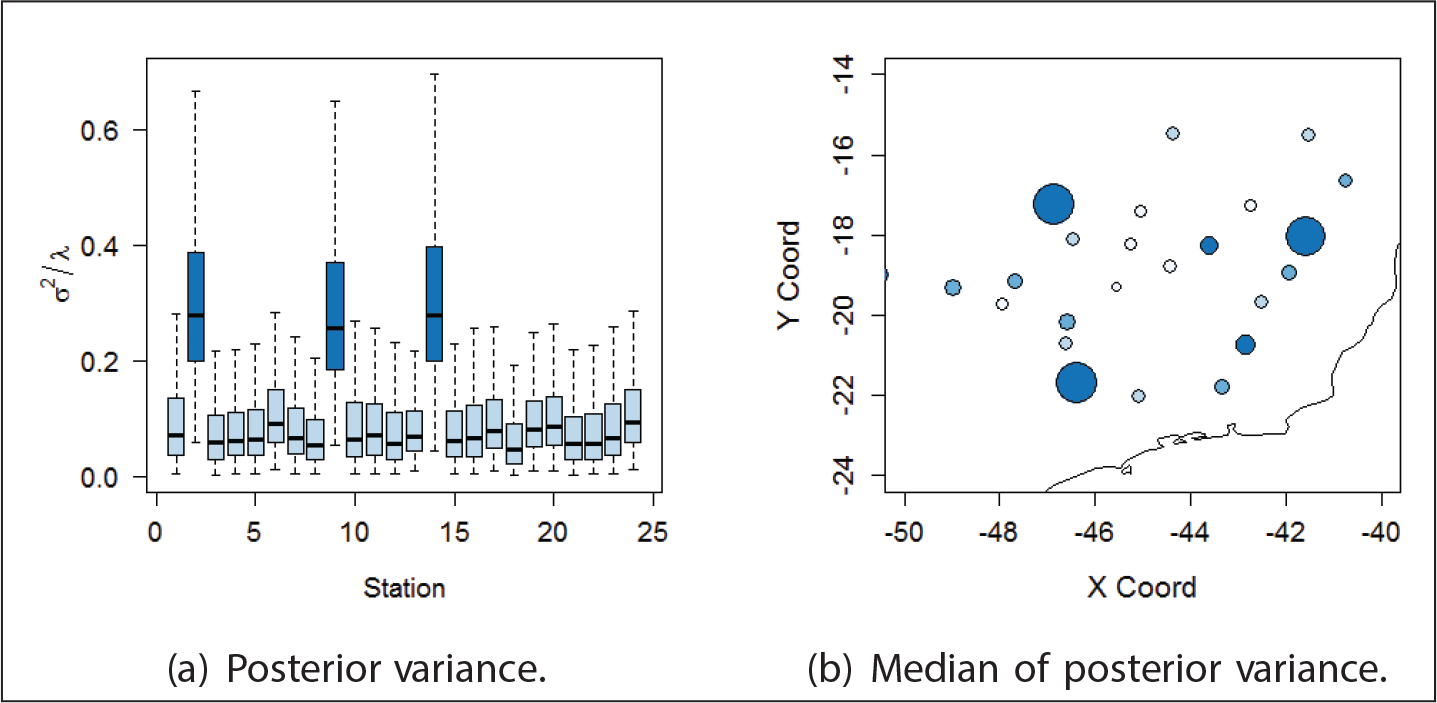
The idea that the Student-t process would result in robust to outliers is misleading since the degree of freedom is the same in all spatial locations, leading to inflation in the global variance. Thus, this model does not allow for actual detection of regions with aberrant observation in spatial data. These ideas were discussed in Breusch et al. (1997) and Palacios and Steel (2006). This work contributes by presenting simulation for spatial contaminated datasets and obtaining no detection of most of outliers in the data using the Student-t model. The Student-t process for spatial data was not able to detect outliers either by marginal probabilities or multiple detection procedures. The GLG mixture process, on the other hand, indicated the outliers in all simulated scenarios for all detection tools presented in this work. The residual analysis presented here is purely spatial in the sense that the mixture process is considered in space only. Fonseca and Steel (2011) considered a mixture model in space–time, which is not exploited in this work.
The spatial Bayesian residuals, the proposed cross-validation p-value and the Savage–Dickey density were investigated in this study. Specifically, the probability of a large random error is a useful tool for outlier detection, although it depends on the threshold specification. Our simulated study with replicated datasets indicated that threshold
Often in statistical data analysis, tests and inferences are performed regarding model parameters based on models which may not be adequate for the data. In order to add flexibility to the analysis, general models such as the mixture spatial models accommodate more general data behaviours. In this context, there is a growing literature which aims to loosen the usual model assumptions. For instance, Klein et al. (2015) proposed using of distributional regression, which allows for more flexibility in complex response distributions. Besides that, other techniques can be considered and extended to accommodate spatially correlated data such as quantile regression (Reich et al., 2011).
In the direction of model criticism and outlier detection, the cross-validation method is a powerful tool to assess the goodness of fit of spatial models and is an interesting approach for future investigation. From the Bayesian point of view, various authors have suggested the use of cross-validation. (See Stern and Cressie, 2000; Alqallaf and Gustafson, 2001; Vehtari and Lampinen, 2002; Marshall and Spiegelhalter, 2003; Vehtari et al., 2017). This direction will be pursued in future research.
Supplementary materials
Supplementary materials for this article are available from http://www.statmod..
Acknowledgements
We thank the referees and the editor for helpful comments. This work was part of the Master’s dissertation of Viviana GR Lobo under the supervision of TCO Fonseca.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
Lobo benefited from a scholarship from Conselho de Aperfeiçoamento de Pessoal de Nível Superior (CAPES), Brazil. TCO Fonseca was partially supported by Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq).
Appendix
Markov Chain Monte Carlo sampler
The prior distributions considered for the parameters, the complete conditional distributions and proposal densities used in the MCMC algorithm are detailed as follows.
Gaussian Bayesian model
Consider the likelihood given in Equation (2.5) with exponential correlation function and covariance matrix The conditional distribution of The conditional distribution of
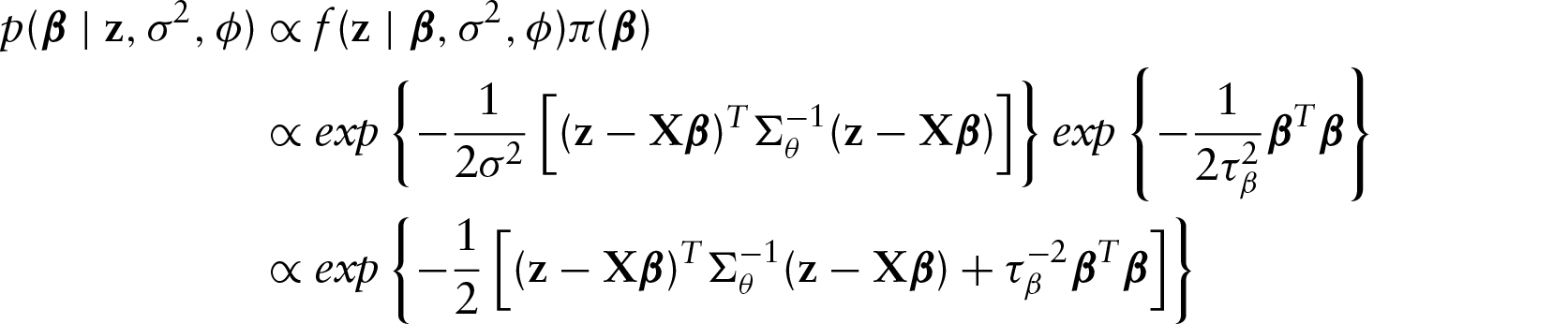


Student-t Bayesian model
Consider the likelihood given in Equation (2.6) with exponential correlation function and covariance matrix Jeffreys independent prior distribution (Fonseca et al., 2008): with The proposed density in the MCMC sampler is



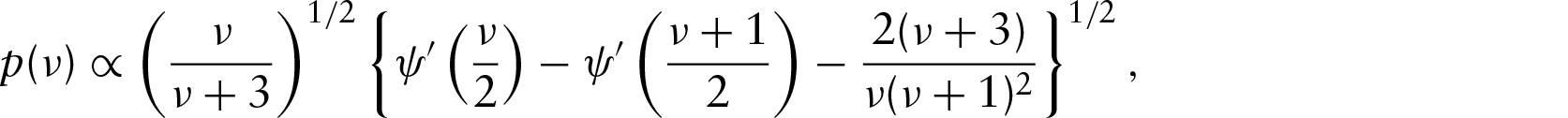
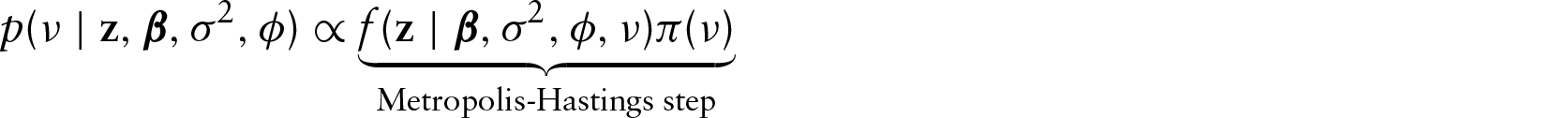
GLG Bayesian model
We follow Palacios and Steel (2006) in the simulation from the posterior distribution for parameters in the GLG model. We consider the likelihood of GLGM with exponential correlation function and covariance matrix given by The conditional distribution of The conditional distribution of Thus,