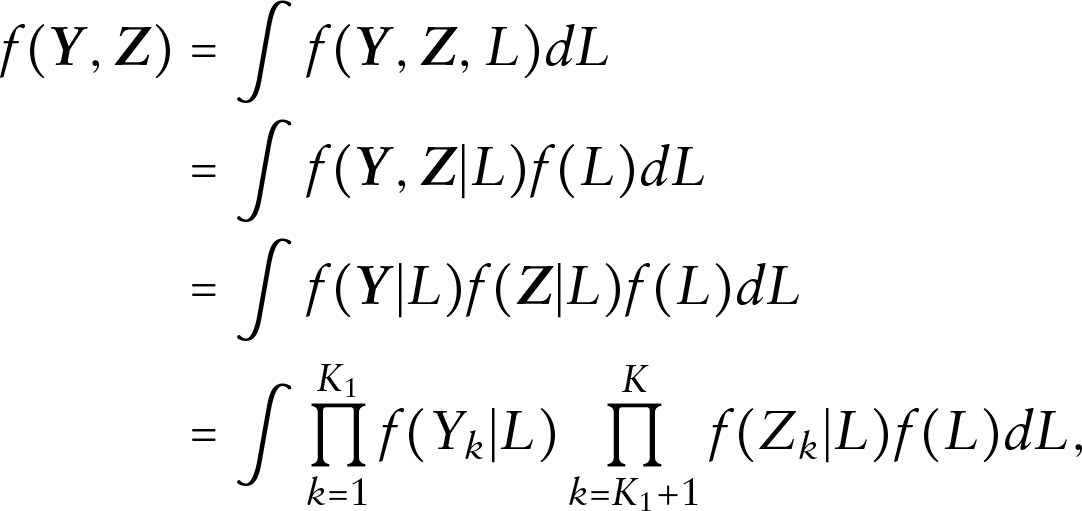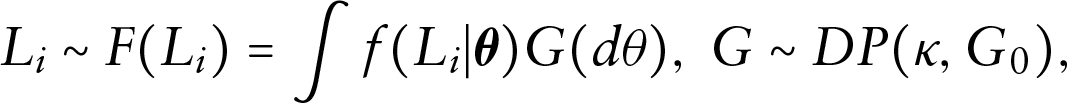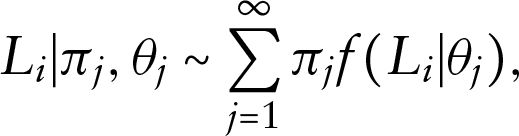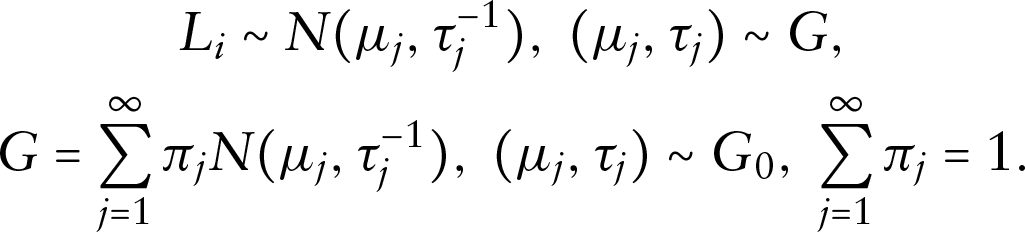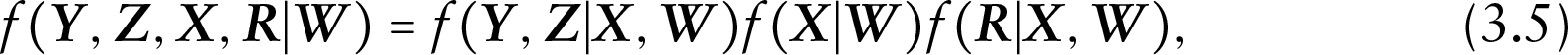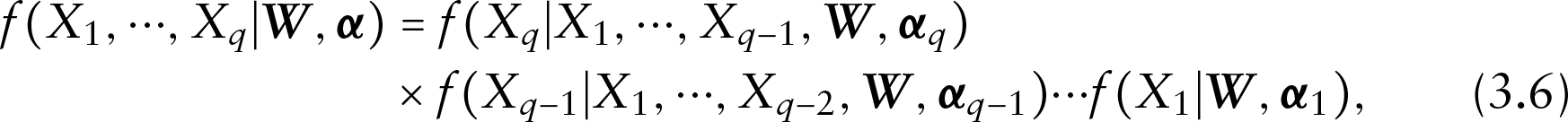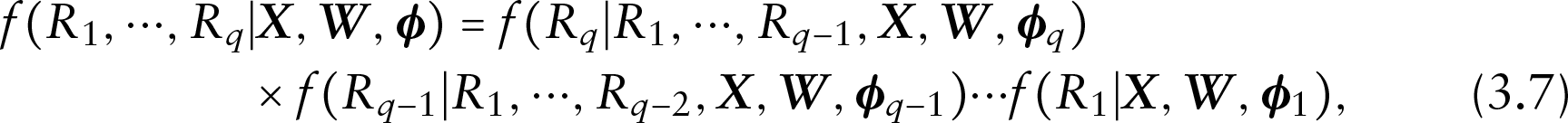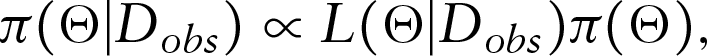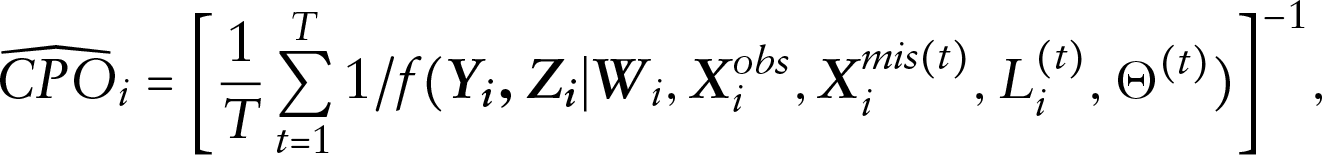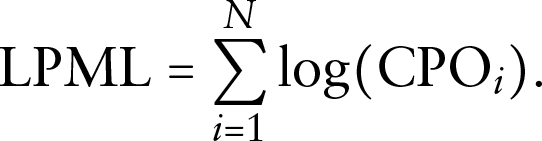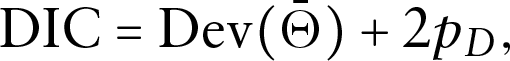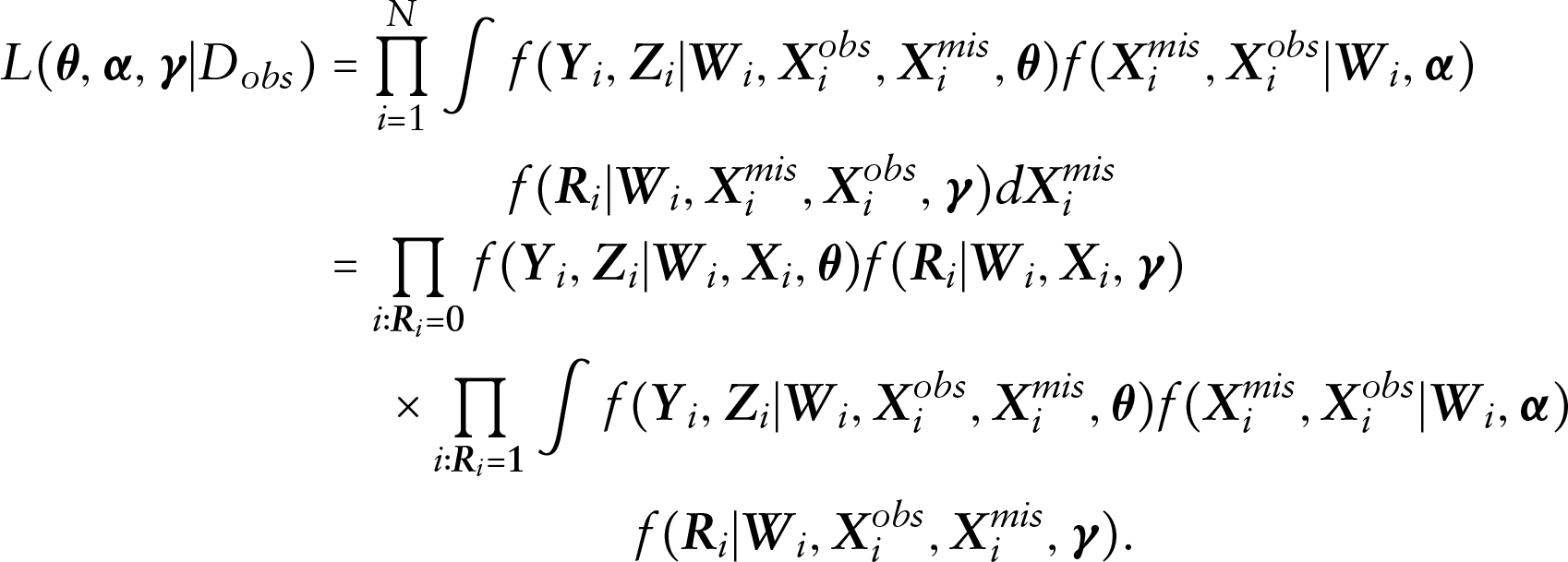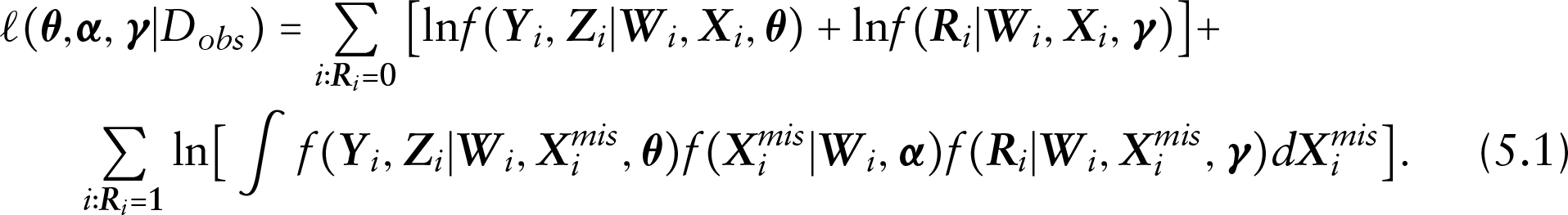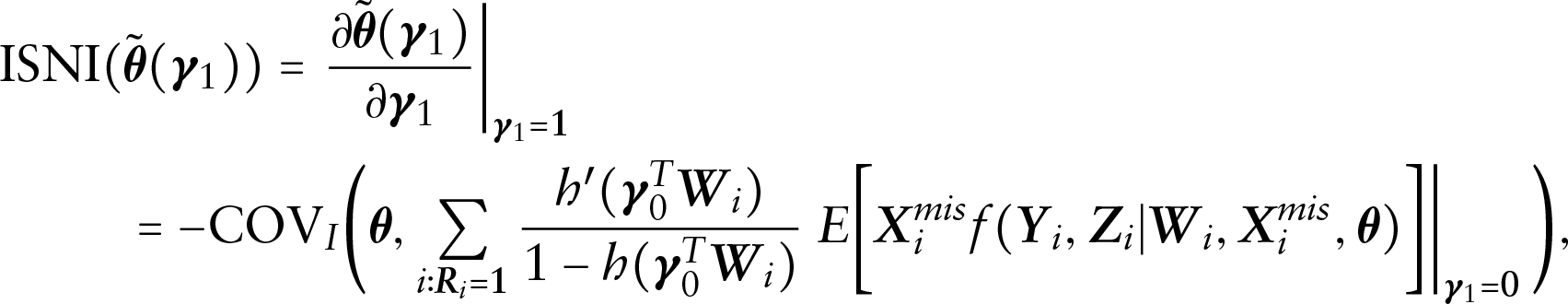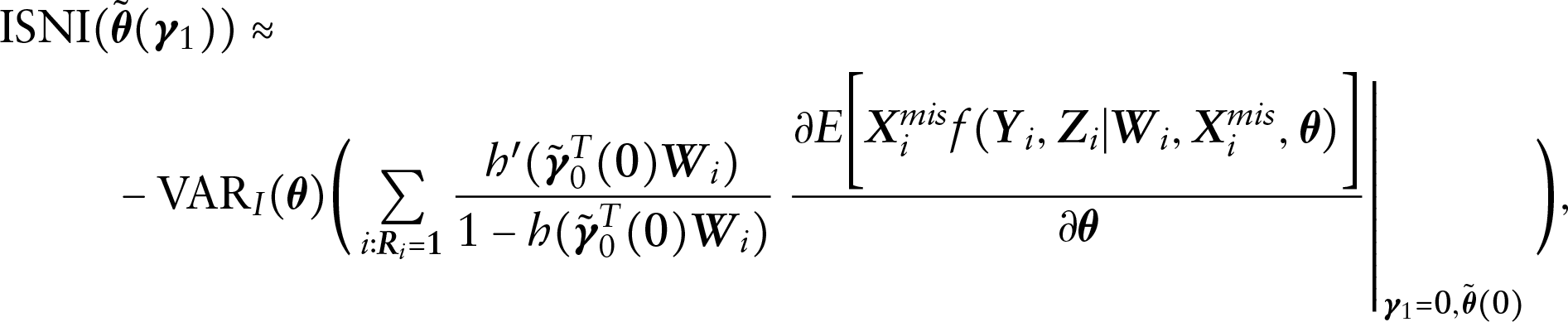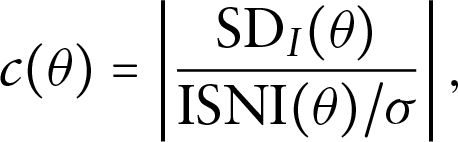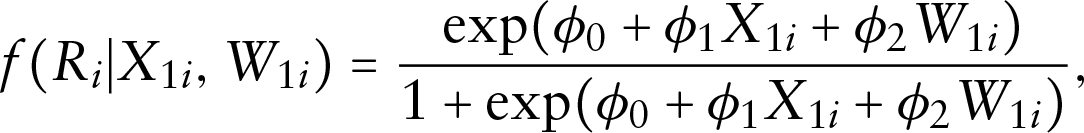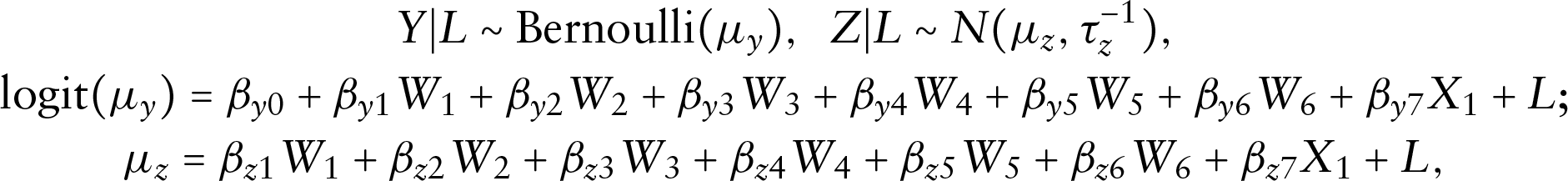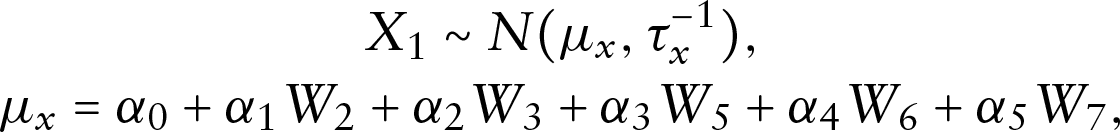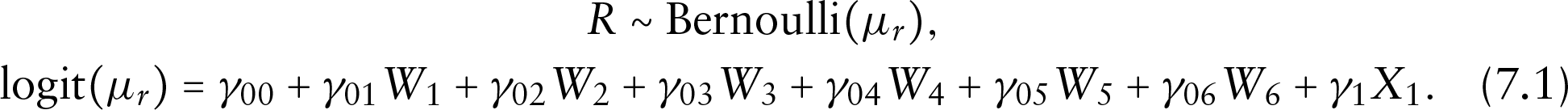Motivated by the China Health and Nutrition Survey (CHNS) data, a semiparametric latent variable model with a Dirichlet process (DP) mixtures prior on the latent variable is proposed to jointly analyse mixed binary and continuous responses. Non-ignorable missing covariates are considered through a selection model framework where a missing covariate model and a missing data mechanism model are included. The logarithm of the pseudo-marginal likelihood (LPML) is applied for selecting the priors, and the deviance information criterion measure focusing on the missing data mechanism model only is used for selecting different missing data mechanisms. A Bayesian index of local sensitivity to non-ignorability (ISNI) is extended to explore the local sensitivity of the parameters in our model. A simulation study is carried out to examine the empirical performance of the proposed methodology. Finally, the proposed model and the ISNI index are applied to analyse the CHNS data in the motivating example.
Multiple responses of mixed data types are common in a variety of data analysis problems, such as multiple aspects of a subject in survey sampling or multiple measurements of a drug in medicine study. In such cases, joint models can assess the effects of covariates on multiple correlated responses while considering the dependence among these responses, through which joint modelling has significant efficiency gains than separate analysis (McCulloch, 2008). In joint analysis, it is vital to build a joint distribution for the mixed responses. One approach is to build the joint model through copulas, which is relatively difficult to implement (Song and Song, 2007). Another approach is factorizing the joint distribution as a product of a marginal distribution of one set of responses and a conditional distribution of another set of responses (Tate, 1954). However, the main drawback of this approach is that different directions of factorization may lead to different results (Wu, 2013). Sammel et al. (1997) proposed a latent variable model (LVM) for joint modelling, which was also referred as generalized latent trait model in Moustaki and Knott (2000). In LVM, the dependence among the responses is captured through a shared latent variable, and it is assumed that these responses are conditionally independent given this latent variable, which is straightforward and easy to implement.
For mathematical convenience, the latent variable is traditionally assumed to be normally distributed, which is not necessarily appropriate in practice. In order to overcome the limitation of the normality assumption, other distributions have been considered in the literature, such as multivariate -distribution for non-normal data with symmetrical heavy tails (Lee and Xia, 2006), and skew-normal distribution for skewed and non-symmetric continuous responses (Azzalini and Capitanio, 1999; Jara et al., 2008; Lin et al., 2009; Baghfalaki and Ganjali, 2011). In order to dealing with the uncertainty about the parametric form of these priors, nonparametric priors in Bayesian framework provide an alternative to address this problem (Müller et al., 2015). The Dirichlet process (DP) prior is one of the most common nonparametric prior due to its computational ease and interpretability (Görür and Rasmussen, 2010; Müller et al., 2015; Murray and Reiter, 2016; Ma and Chen, 2019). For practical and computational convenience, Ishwaran and Zarepour (2000) and Ishwaran and James (2001) introduced a truncated version and the stick-breaking representation of the DP prior. However, the discreteness of DP makes the prior not that appealing for all applications. When the unknown distribution is known to be continuous, applying DP prior would be awkward for its discrete nature (Rodriguez and Müller, 2013). In order to mitigate this limitation of DP, a DP mixtures of continuous distributions can be used as an alternative prior for the latent variable. A DP mixtures model can be seen as a mixture model with infinitely many components and can be defined without the need to determining the number of components (Lo, 1984). In this article, the latent variable in LVM is assigned with a DP mixture of normals prior to take advantages of the flexibility and properties of this nonparameteric prior.
Missing data arises frequently in various studies, such as the missing covariates in our motivating example. In the literature, one approach is excluding the missing records and carrying out a complete case (CC) analysis. Another approach is to assume that the missing data mechanism is ignorable. However, this ignorability assumption does not always hold in reality. In this article, non-ignorable missing data mechanism is assumed according to the feature of the missing covariates, and a selection model framework is employed to integrate the response model, the missing covariate model and the missing data mechanism model. Since the actual missing data mechanism is unknown, sensitivity analysis is necessary to determine the departure from ignorable missingness. Daniels and Hogan (2008) applied a pattern mixture model with a large number of sensitivity parameters. Verbeke et al. (2001) proposed the local influence approach based on individual-specific infinitesimal perturbations around the MAR model. Ganjali and REZAEI (2005) developed the global sensitivity analysis using a generalized Heckman model. Troxel et al. (2004) proposed an index of local sensitivity based on a Taylor series approximation to the non-ignorable likelihood, which is named index of local sensitivity to non-ignorability (ISNI). The ISNI index has been applied to the potential outcome model and the censored data (Xie and Heitjan, 2004; Zhang and Heitjan, 2005, 2006), and was extended to longitudinal data by Ma et al. (2005) and Xie (2008). In Bayesian framework, Zhang and Heitjan (2007) adapted the ISNI method to Bayesian inference in coarsened data model, based on which Xie (2009) extended this method in longitudinal settings. In this article, we extend the ISNI method for LVM in Bayesian framework with non-ignorable missing covariates. One of the advantages of ISNI method is that the calculation of the index only requires the posterior draws or summary statistics of the ignorable model (Xie, 2009).
The remaining of the article is organized as follows. Section 2 introduces the China Health and Nutrition Survey (CHNS) dataset as the motivating example. In Section 3 the proposed LVM with non-ignorable missing covariates is built. Section 4 introduces Bayesian inference and model comparison criteria. The ISNI method for quantifying the sensitivity to MNAR is introduced in Section 5. In Section 6, a simulation study is conducted to verify the performance of the proposed methodology, and application to the CHNS dataset is introduced in Section 7. Finally, a brief conclusion is given in Section 8.
Motivating example
In recent years, the primary health policy in healthcare reform around the world is expanding health insurance coverage, giving rise to a question about the relationship between health insurance and individual health. In China, the coverage rate of the New Rural Cooperative Medical Insurance (NRCMI) increases rapidly, while the key issue is that whether it would result in an improvement in the health of its participants. For investigation, data from the CHNS is used. CHNS, an international collaborative project between University of North Carolina at Chapel Hill and the Chinese Center for Disease Control and Prevention, was designed to examine how the social and economic transformation of Chinese society has affected the health and nutritional status of the Chinese population.
In this article, we try to explore the effects of NRCMI insurance on health style of the respondents. Two variables, drinking or smoking habit and daily calorie intake, are selected as the two outcomes for reflecting the health style of a person. Drinking or smoking habit is a dummy variable representing whether the individual has a habit of drinking or smoking, while daily calorie intake is a continuous variable reflecting the amount of calorie intake per day. The key explanatory variable in our analysis is a dummy variable indicating whether a respondent has enroled in the NRCMI insurance in the survey year. Other social-demographic characteristics include age, gender, marital status, education level and wage. Age is recorded in years; gender is categorized as male and female; marital status is divided into married and single (including never married, divorced, widowed and separated); education level is classified into three levels including primary or illiterate, junior school and high school and above and wage is a continuous variable indicating the economic condition of an individual, which suffers from missing values. The missing percentage is up to 42.51%, leading to 3 075 missing responds among a total number of 7 234 individuals. In order to model this missing covariate, another variable working hour is considered. A summary of these variables are given in Table 1.
Summary of the variables in the motivating example
Data type
Characteristics
Mean (Standard deviation)
Continuous
Log(Daily calorie intake)
7.5660 (0.3656)
Age
49.78 (14.48)
Log(Wage)
3.3507 (3.7271)
Log(Working hours)
2.1256 (1.7696)
Data type
Characteristics
Proportion (%)
Binary
Drinking/smoking habit
43.38
NRCMI enrolment
71.58
Gender-Male
49.13
Marital status-Married
87.35
Categorical
Education level:
Primary or illiterate
43.07
Junior school
35.02
High school and above
21.91
In this motivating example, the two responses, drinking or smoking habit and daily calorie intake, are in the form of mixed data types. By applying a Kruskal–Wallis test for these two responses, it is shown that these two responses are related to each other with a test statistics value of 269.90 at a significance level of 0.05. As a result, we cannot simply ignore the dependence between these two outcomes and apply a separate analysis. Instead, a joint analysis is preferred in order to consider the relationship between them. In addition, there are missing values in one of the covariates in this dataset, which would lead to lower power if simply applying a CC analysis. Moreover, when the missing data mechanism is not missing completely at random (MCAR), the CC approach would lead to biased estimates. Therefore, models should be built for the missing covariate and even for the missing data mechanism.
The proposed model
Complete data model
Consider a dataset with subjects and outcome variables, such that the first outcome variables are binary while the remaining outcome variables are continuous. For , the binary and continuous measurements of the th subject for variable are denoted by and , respectively. The vector of mixed binary and continuous outcome variables can be denoted by , where and . Considering the dependence among these mixed responses, the LVM is employed for joint analysis.
Suppose denotes the shared latent variable in the LVM. Based on the assumption that all the mixed outcomes are conditionally independent given this latent variable, the joint distribution in the LVM can be given as
where and are the conditional distributions of and given , respectively. For the conditional distribution of the binary outcome, a Bernoulli distribution can be assigned as, for ,
where is the intercept, and is the coefficient vector corresponding to the -dimensional covariate vector .
Similarly, we assume a normal conditional distribution for the continuous outcome, which is given by, for :
where represents the precision parameter for variable . The intercept here is restricted to be 0 for identification, and represents the coefficient vector.
For the latent variable , a DP mixtures prior is assigned. Suppose the unknown distribution for the random samples of the latent variable is denoted by . A DP mixtures prior on is denoted by
where is the kernel of the DP mixtures prior, which is indexed by a finite dimensional parameter . Similar to the DP prior, the DP mixtures prior can also be represented through the stick-breaking construction (Sethuraman, 1994). Therefore, we have
where and .
DP mixtures are countable mixtures with an infinite number of components and specific priors on the weights and the component-specific parameters . The DP mixtures prior can support on a large class of distributions depending on appropriate choices of the kernel (Barrientos et al., 2012; Rodriguez and Müller, 2013). For a DP mixture of normals, we have
which is equivalent to
The DP mixture of normals prior allows a flexible continuous distribution for the latent variable.
According to models (3.1)–(3.3), when observing complete data , the likelihood of the unknown parameters can be obtained as
where and are given in (3.1) and (3.2), respectively.
Incomplete data model
In some situations such as our motivating example, missing values may occur in some of the covariates. In such cases, a selection model within the Bayesian framework can be applied to accommodate missing data situations. For the -dimensional covariates , suppose that the first covariates have missing values while the remaining covariates are completely observed, which are denoted by and , respectively. Then we have , where is the covariates subjected to missingness, and refers to the fully observed covariates. The corresponding -dimensional missing indicators can be denoted by , where for , with if is missing and if is observed. Furthermore, let refer to the components of that are observed and refer to the components of that are missing. Suppose that denotes the observed data. The incomplete data likelihood can be obtained by integrating out the missing components , which is given by
where denotes the joint distribution of the observed data, missing covariates and missingness probabilities, which, in selection model framework, is given as
where and represent the distributions of the missing covariates and missing indicators, respectively.
Model for the missing covariates
In the joint distribution (3.5), it is crucial to specify a model for the missing covariates. Following Lipsitz and Ibrahim (1996) and Ibrahim et al. (1999), the missing covariates distribution can be specified through a series of one-dimensional conditional distributions given by
where is the indexing parameter vector for the th conditional distribution, and . Here, we assume that are distinct.
There are many choices for defining (3.6), and Chen and Ibrahim (2001) gave some guidelines for specifying this distribution. For missing categorical covariates, logistic, probit or complementary log-log links are suitable for the conditional missing covariate distribution. Ordinal regression models can be applied for the missing ordinal covariates, while Poisson regression can be used for count variables. Both normal, log-normal and exponential distributions can be built for the continuous covariates.
In our motivating example, there is only one continuous missing covariate Wage, thus the missing covariate distribution can be simplified as , and a normal distribution can be built as , where is the mean function and is the precision parameter.
Model for the missing data mechanism
Similar to the missing covariates distribution, the model for the missing data mechanism can also be written as the form of a product of one-dimensional conditional distributions as (3.6), which is given by
where parameterizes the missing data mechanism model with as a vector of indexing parameters for the th conditional distribution. For these one-dimensional conditional distributions for the binary missing indicators, a logistic or probit regression model can be built.
According to Rubin (1976), there are three types of missing data mechanisms, including MCAR, missing at random (MAR), and missing not at random (MNAR). Under some conditions, MCAR and MAR are categorized as ignorable missingness since the missingness does not depend on the missing variables, while MNAR is regarded as non-ignorable.
In our motivating example, the model for the missing data mechanism can be simplified as since there is only one covariate that suffers from missing. A logit regression model can be assumed for . For the missing covariate Wage, it is more likely to be missing if it is of high or low levels (Mason et al., 2010). Therefore, we assume that the missing data mechanism of this covariate is non-ignorable, meaning that the missingness depends on the missing covariate itself.
Bayesian inference and model comparison
Bayesian inference
Within the Bayesian framework, posterior estimates of the parameters can be obtained from their corresponding posterior distributions through Markov chain Monte Carlo (MCMC) algorithms. Suppose , is the vector of parameters, where , and are the parameters corresponding to the DP mixture of normals prior on the latent variable. The joint posterior distribution is given by
where is the incomplete data likelihood given in (3.1) and is the joint prior distribution of the parameters. Generally, we assume that the priors of the parameters are independent a prior. In this article, the following priors are assigned: , , , , , , , , , and . Note that , , , and are pre-specified hyperparameters. In this article, we use and .
Usually, the posterior distributions of the parameters cannot be obtained easily due to high-dimensional integrals. MCMC algorithms provide an alternative to sample from the posterior distributions. It requires sampling the following parameters in turn from their respective full conditional distributions. Several existing packages and software facilitate the implementation of the MCMC algorithms, such as WinBUGS (Spiegelhalter et al., 2003), JAGS (Hornik et al., 2003), Stan (Stan Development Team, 2019) and nimble (de Valpine et al., 2017). nimble is a relatively new and powerful R package for programming with BUGS models using syntax similar to WinBUGS and JAGS, but with more flexibility in defining the models and algorithms. Users can interface with R, and nimble will generate C++ code for faster computation (Ma and Chen, 2019). In this article, we use nimble for implementing the MCMC sampling algorithms for posterior inference.
Model comparison
Model comparison is an important topic in statistical modelling since the actual model, and the missing data mechanism are unknown. For our model, we mainly focus on selecting (a) different priors for the latent variable and (b) different models for the missing data mechanism. For (a), we employ the logarithm of the pseudo-marginal likelihood (LPML) for model comparison. LPML can be calculated via the conditional predictive ordinates (CPOs Geisser, 1993). Let denote the observed dataset with the th observation deleted. The CPO statistic in our model with non-ignorable missing covariates can be defined as
where is the posterior density of given . In practice, a Monte Carlo estimate of the CPO can be obtained from MCMC samples of the posterior distributions. Suppose are the observations simulated from the conditional distribution via MCMC algorithms at the th iteration, then the Monte Carlo estimate of CPO is given by
and LPML can be given as
A larger value of LPML means a better fit of the model.
For (b), since the main objective is to assess the fit of the model for the missing data mechanism model, here we use the conditional version of deviance information criterion (DIC; Spiegelhalter et al., 2002), , to select the missing data mechanism model. The DIC is defined as
where is the deviance function, is the effective number of model parameters, is the posterior mean of the parameters and is the posterior mean of . For , the deviance function is defined using the missing data mechanism model only, which is . A smaller value represents that the missing data mechanism model is more preferred.
ISNI in latent variable model with missing covariates
In this section, we extend the Bayesian ISNI to the proposed LVM with missing covariates. The response model is specified via the LVM, the missing covariate model is and the model for the missing data mechanism can be rewritten as . With this model, the missing data mechanism is ignorable if and the parameter of interest is distinct from . Given these distributions, the incomplete data likelihood can be written as
The corresponding log-likelihood is denoted by
According to Xie (2009), the ISNI can be defined as
where is a mean function and denotes the posterior covariance under the ignorable model.
Alternatively, the ISNI can be approximated as
where is the posterior variance-covariance matrix of under the ignorable model, and and represent the posterior means of and under the ignorable model, respectively. With MCMC sampling iterations, ISNI of each parameter of interest can be obtained.
When the response is continuous, the value of ISNI depends on the scale of the continuous response. In order to compare the sensitivity of on different parameters, a transformation can be made as
where is the posterior standard deviation of the parameter under the ignorable model, is the standard deviation of the continuous response. A small value means large local sensitivity (Xie, 2009).
Simulation study
In this section, a simulation study is conducted to verify the performance of the model comparison criteria and the proposed methodology. datasets were simulated with observations in each dataset. In each replication, the latent variable was generated from a mixture of two normal distributions , leading to be a bimodal variable. Covariates were generated with and following standard normal distributions. was generated from with , , and . We assumed that and , meaning that two mixed responses were generated, one of which was a binary response , and the other was a continuous response . We assumed that , and . Missing data for were generated with a non-ignorable missing data mechanism. Specifically, let if was missing and if was observed. A logistic regression model was built for the missing indicator as
where , and . The average percentage of missing in simulations in this study is about 28%.
For the binary and continuous responses, model (3.1) and (3.2) are fitted, respectively. For the missing covariate , a normal distribution is assumed with mean and precision . For the missing data mechanism model, we firstly assume a non-ignorable model, which is given by
For the performance of LPML, we compare models with different priors on the latent variable and calculate the percentage that the criteria choosing the correct model. Let denote the true model where follows a mixture normal distribution , denote the model with a DP mixture of normals prior for denote the model with a normal prior for , and denote the model with a -distributed prior for . The average values of LPML under these three models are shown in Table 2.
The average of the LPML values of the competitive models with different priors on
Model
LPML
251.93
258.07
262.45
286.17
From Table 2, we can see that model has the largest LPML value among the competitive models, indicating that LPML can choose the true model in this simulation. with a DP mixtures prior on the latent variable is more preferred than the other two models due to a larger LPML value. The percentage that the criteria selecting over is 71%, and the percentage for selecting over is 100%. Therefore, under the setting that actually follows a normal mixture model, besides the true model, the DP mixture of normals prior performs better than normal priors and heavy-tailed priors.
Here, we apply the measure for selecting the model for missing data mechanism. In model , we assume an non-ignorable missingness model that the missingness depends on the missing variable itself. We build another model similar to except for the model for missing data mechanism, denoting by . The missingness model in only depends on the observed variables, leading to an ignorable missing data mechanism assumption, that is, . The values for models and are 65.64 and 100.95, respectively. Since have a smaller value of , the non-ignorable missingness model is selected over the ignorable one in model , which conforms to our simulation setting.
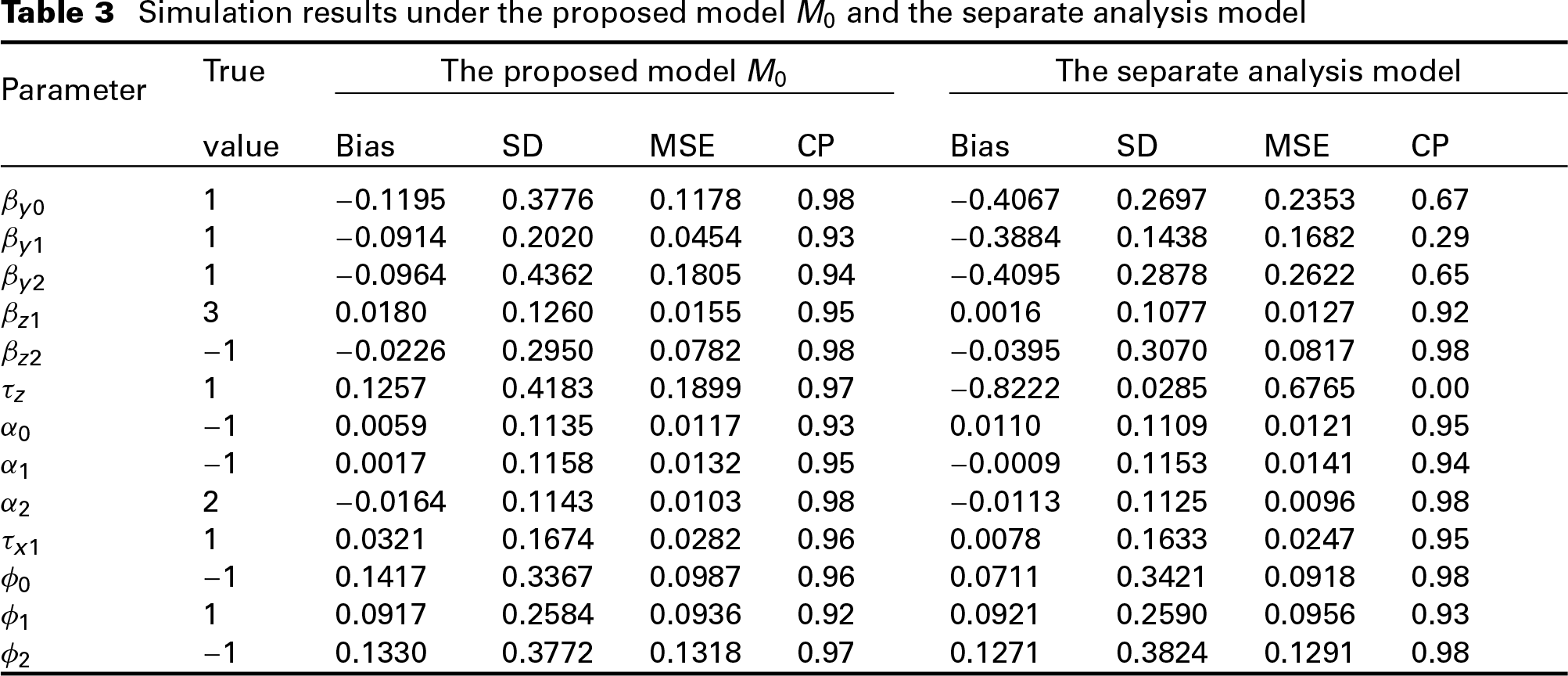
For assessing the precision of the posterior estimates, we employ the following assessment measures. Take parameter as an example: , , and , where denotes the posterior estimation of in the th iteration, denotes the true value of parameter , denotes the posterior standard deviation of the estimate and denotes the estimated 95% HPD interval of in the th iteration. The simulation results under the proposed model and the alternative models are shown in Table 3.
Simulation results under the proposed model and the separate analysis model
*Parameter
True
The proposed model
The separate analysis model
value
Bias
SD
MSE
CP
Bias
SD
MSE
CP
1
0.1195
0.3776
0.1178
0.98
0.4067
0.2697
0.2353
0.67
1
0.0914
0.2020
0.0454
0.93
0.3884
0.1438
0.1682
0.29
1
0.0964
0.4362
0.1805
0.94
0.4095
0.2878
0.2622
0.65
3
0.0180
0.1260
0.0155
0.95
0.0016
0.1077
0.0127
0.92
1
0.0226
0.2950
0.0782
0.98
0.0395
0.3070
0.0817
0.98
1
0.1257
0.4183
0.1899
0.97
0.8222
0.0285
0.6765
0.00
1
0.0059
0.1135
0.0117
0.93
0.0110
0.1109
0.0121
0.95
1
0.0017
0.1158
0.0132
0.95
0.0009
0.1153
0.0141
0.94
2
0.0164
0.1143
0.0103
0.98
0.0113
0.1125
0.0096
0.98
1
0.0321
0.1674
0.0282
0.96
0.0078
0.1633
0.0247
0.95
1
0.1417
0.3367
0.0987
0.96
0.0711
0.3421
0.0918
0.98
1
0.0917
0.2584
0.0936
0.92
0.0921
0.2590
0.0956
0.93
1
0.1330
0.3772
0.1318
0.97
0.1271
0.3824
0.1291
0.98
From Table 3, we can see that the posterior estimates have relatively small bias and MSE, and the CPs of the estimates are both larger than 0.92, indicating that the posterior estimation procedure has good performance under our simulation setting.
We also carry out the separate analysis to explore the difference between joint analysis and separate analysis. For separate analysis, we build the model without the latent variable in (3.1) and (3.2). By excluding , the dependence between these two responses is no longer considered and independence is assumed instead. The LPML value for the separate analysis model is 302.33, and by comparing it with the LPML value of model in Table 2, we can say that the model comparison criteria chooses the joint analysis model as the better model. The posterior estimates under the separate analysis model are shown in Table 3 as well. From Table 3, we can see that generally, under the separate analysis model, the bias and MSE of the posterior estimates of parameters in the response model, especially in the binary response model, are greatly larger than those under the joint analysis model. Besides, the corresponding CPs are smaller than 0.70, indicating that separate analysis is not good enough under our simulation setting.
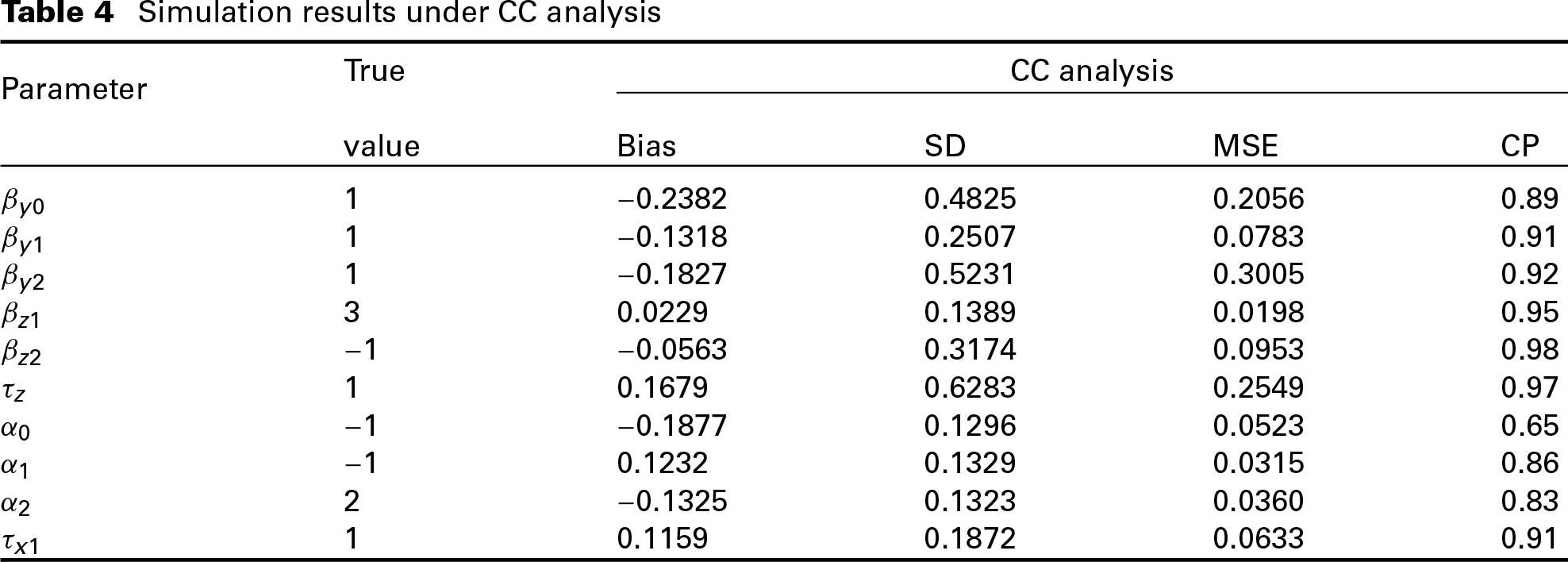
We also carry out a CC analysis to explore the impact of ignoring the missingness on the posterior estimates. In each replication, the missing records are excluded and model (3.1) and (3.2) are fitted. The simulation results of the CC analysis are given in Table 4. By comparing the results in Table 4 with those under model , we can see that the bias and MSE of the posterior estimates under CC analysis are larger than those under the proposed model, indicating that simply excluding the missing records may lead to more biased estimates when the missing data mechanism is not MCAR.
Simulation results under CC analysis
*Parameter
True
CC analysis
value
Bias
SD
MSE
CP
1
0.2382
0.4825
0.2056
0.89
1
0.1318
0.2507
0.0783
0.91
1
0.1827
0.5231
0.3005
0.92
3
0.0229
0.1389
0.0198
0.95
1
0.0563
0.3174
0.0953
0.98
1
0.1679
0.6283
0.2549
0.97
1
0.1877
0.1296
0.0523
0.65
1
0.1232
0.1329
0.0315
0.86
2
0.1325
0.1323
0.0360
0.83
1
0.1159
0.1872
0.0633
0.91
Application in CHNS data
In this section, the proposed methodology is applied to analyse the data introduced in Section 2. The binary response variable is drinking or smoking habit (), and the continuous response variable is daily calorie intake (). The covariates used for predicting these two responses include NRCMI enrolment (), Age (), Gender (), Marital status (), Education level (Junior schools (), High school and above ()) and Wage (), where Wage suffers from missingness. Model (3.1)–(3.2) are built as
where the latent variable follows a DP mixture of normals prior described in (3.3). For the missing covariate , a normal linear model is assigned as
where refers to the Working hour. The missing data mechanism model for the missing indicator is given as
For Bayesian implementation, priors on the unknown parameters are given as described before. R and nimble are used for programming, and a single Markov chain is used with 4 500 samples for posterior estimation after a burn-in of 500 samples. The thinning interval is set to be 10. We assume different priors for and apply LPML for model selection. The proposed model with a DP mixture of normals prior on is denoted by , the model with a normal prior is denoted by and the model with a -distributed prior is denoted by . The LPML results for these competitive models are shown in Table 5.
The average of the LPML values of the competitive models with different priors on for CHNS data
Model
LPML
5 268.04
5 746.75
6 196.36
From Table 5, we can see that the model with a DP mixture of normals prior on is more preferred than the other two models since the LPML value of model is the largest. The measure is used for selecting from the non-ignorable and ignorable missing data mechanism models. The model (7.1) used in model represents an non-ignorable missingness model since the missingness depends on the missing covariate . The corresponding value is 7 190.66. Let denote the LVM model with ignorable missingness model, which is (7.1) without the last term , and the value is 8 110.50. By comparing these two values, we can see that the non-ignorable missingness model is preferred over the ignorable one for the CHNS data.
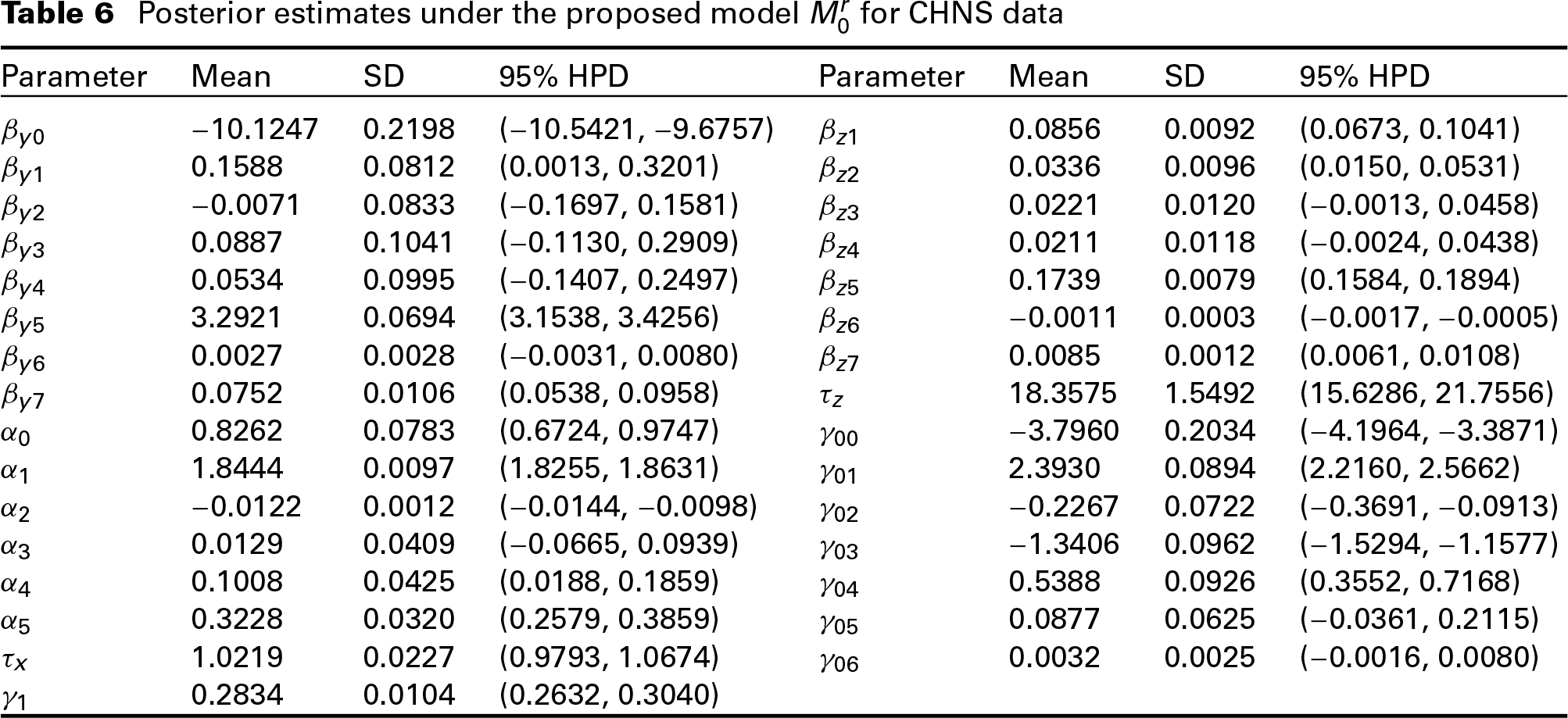
The posterior means, posterior standard deviations and posterior 95% HPD interval of the parameters under model are given in Table 6. From Table 6, we can see that for the binary response model, coefficients , and are significantly larger than 0, meaning that NRCMI enrolment, Junior schools education level and the missing variable Wage have significant positive impact on the drinking or smoking habit. For the continuous response, coefficients , , , and are significantly different from 0, meaning that NRCMI enrolment, Age, Junior schools education level and Wage have positive impact on daily calorie intake, while High school and above education level has negative impact on daily calorie intake. We can see that NRCMI insurance enrolment has impact on health style of the respondents. The probability of having drinking or smoking habit and the amount of daily calorie intake are larger for the respondents who enrol in the NRCMI insurance than those who do not enrol in the NRCMI insurance.
Posterior estimates under the proposed model for CHNS data
Parameter
Mean
SD
95% HPD
Parameter
Mean
SD
95% HPD
10.1247
0.2198
(10.5421, 9.6757)
0.0856
0.0092
(0.0673, 0.1041)
0.1588
0.0812
(0.0013, 0.3201)
0.0336
0.0096
(0.0150, 0.0531)
0.0071
0.0833
(0.1697, 0.1581)
0.0221
0.0120
(0.0013, 0.0458)
0.0887
0.1041
(0.1130, 0.2909)
0.0211
0.0118
(0.0024, 0.0438)
0.0534
0.0995
(0.1407, 0.2497)
0.1739
0.0079
(0.1584, 0.1894)
3.2921
0.0694
(3.1538, 3.4256)
0.0011
0.0003
(0.0017, 0.0005)
0.0027
0.0028
(0.0031, 0.0080)
0.0085
0.0012
(0.0061, 0.0108)
0.0752
0.0106
(0.0538, 0.0958)
18.3575
1.5492
(15.6286, 21.7556)
0.8262
0.0783
(0.6724, 0.9747)
3.7960
0.2034
(4.1964, 3.3871)
1.8444
0.0097
(1.8255, 1.8631)
2.3930
0.0894
(2.2160, 2.5662)
0.0122
0.0012
(0.0144, 0.0098)
0.2267
0.0722
(0.3691, 0.0913)
0.0129
0.0409
(0.0665, 0.0939)
1.3406
0.0962
(1.5294, 1.1577)
0.1008
0.0425
(0.0188, 0.1859)
0.5388
0.0926
(0.3552, 0.7168)
0.3228
0.0320
(0.2579, 0.3859)
0.0877
0.0625
(0.0361, 0.2115)
1.0219
0.0227
(0.9793, 1.0674)
0.0032
0.0025
(0.0016, 0.0080)
0.2834
0.0104
(0.2632, 0.3040)
For the missing covariate model, coefficients , and are significant, meaning that Age, High school and above education level, and Working hour can help predict the missing values of Wage. For the missing data mechanism model, coefficients , , and are significant. Therefore, NRCMI enrolment, Age, Gender and Marital status can help explain the missingness. People who enrol in the insurance, younger person, females and the married ones tend to reject to report their wage information.
Since the true missing data mechanism is unknown in our study, we carry out a sensitivity analysis using the ISNI index introduced in Section 5 to explore the sensitivity of the parameters on the missingness model. Posterior estimation results in the model with ignorable missing data mechanism, , is used for calculating ISNI values of the parameters. Table 7 shows the ISNI values of the parameters in the response model.
ISNI values of the parameters in the response model for CHNS data
Parameter
ISNI
0.0058
0.0156
0.0004
0.0059
0.0037
0.0061
0.0004
0.0017
c
0.0058
0.0156
0.0004
0.0040
0.0069
0.0026
0.0001
0.0002
For the parameters in the binary response model, we can see that has the largest local sensitivity than and since it has the smallest value among these three parameters in Table 7. The local sensitivity of is larger than that of . Similarly, in the continuous response model, the local sensitivity of and are larger than those of and . Through ISNI, we can explore the local sensitivity of the parameters using posterior sampling information under the model with ignorable missing data mechanism. This provides computational convenience than carrying out sensitivity analysis through comparing posterior estimates for a range of the sensitivity parameters.
Conclusion
In this article, a semiparametric LVM is built for jointly analysing mixed binary and continuous responses with non-ignorable missing covariate. A DP mixture of normals prior is assigned for the latent variable in the LVM. The LPML measure is used for comparing different priors, and the measure is applied for selecting the missing data mechanism model. An index for measuring the local sensitivity of the parameters, ISNI, is developed to accommodate LVM with non-ignorable missing covariates. The empirical performance of the proposed methodology is examined through a simulation study. And the proposed methodology is applied for the CHNS data to jointly analyse the mixed responses.
Some extensions can be considered for this study. Our proposed methodology is developed for cross-sectional data, which can be extended to longitudinal data structure or other complex data structures. Some other mixed data types, such as ordinal and count variables, can also be considered. In our study, we only take account of missing values in one covariate. More complex situations—including multiple missing covariates, and missing response and covariates—can also be a direction for further research.
Supplementary materials
Supplementary materials for this article, including the code of the model, are available from http://www.statmod.org/smij/archive.html.
Footnotes
Declaration of conflicting interests
Funding
This work was supported by Initial Scientific Research Fund of Young Teachers in Shenzhen University (Grant number 000002110164).
References
1.
AzzaliniACapitanioA (1999) Statistical applications of the multivariate skew normal distribution. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 61, 579–602.
2.
BaghfalakiTGanjaliM (2011) An EM estimation approach for analyzing bivariate skew normal data with non-monotone missing values. Communications in Sta- tistics: Theory and Methods, 40, 1671–86.
3.
BarrientosAFJaraAQuintanaFA (2012) On the support of MacEachern's dependent Dirichlet processes and extensions. Bayesian Analysis, 7277–310.
4.
ChenM-HIbrahimJG (2001) Maximum likelihood methods for cure rate models with missing covariates. Biometrics, 57, 43–52.
5.
DanielsMJHoganJW (2008) Missing Data in Longitudinal Studies: Strategies for Bayesian Modeling and Sensitivity Analysis. Boca Raton: Chapman and Hall/CRC.
6.
De ValpinePTurekDPaciorekCJAnderson-BergmanCLangDTBodikR (2017) Programming with models: Writing statistical algorithms for general model structures with nimble. Journal of Computational and Graphical Statistics, 26, 403–13.
7.
GanjaliMRezaeiM (2005) An influence approach for sensitivity analysis of non- random dropout based on the covariance structure. Iranian Journal of Science and Technology (Sciences), 29, 287–94.
8.
GeisserS (1993) Predictive Inference: An Introduction. London: Chapman and Hall/CRC.
9.
GörürDRasmussenCE (2010) Dirichlet process Gaussian mixture models: Choice of the base distribution. Journal of Computer Science and Technology, 25, 653–64.
10.
HornikK.LeischF.ZeileisA. (2003). Jags: A program for analysis of Bayesian graphical models using Gibbs sampling. In Proceedings of DSC, volume 2, pages 1–1.
11.
IbrahimJGLipsitzSRChenM-H (1999) Missing covariates in generalized linear models when the missing data mechanism is non-ignorable. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 61, 173–90.
12.
IbrahimJGChenM-HSinhaD (2001) Bayesian Survival Analysis. New York, NY: Springer-Verlag.
13.
IshwaranHJamesLF (2001) Gibbs sampling methods for stick-breaking priors. Journal of the American Statistical Association, 96, 161–73.
14.
IshwaranHZarepourM (2000) Markov chain Monte Carlo in approximate Dirichlet and Beta two-parameter process hierarchical models. Biometrika, 87, 371–90.
15.
JaraAQuintanaFMartínES (2008) Linear mixed models with skew-elliptical distributions: A Bayesian approach. Computational Statistics & Data Analysis, 52, 5033–5045.
16.
LeeS-YXiaY-M (2006) Maximum likelihood methods in treating outliers and symmetrically heavy-tailed distributions for nonlinear structural equation models with missing data. Psychometrika, 71, 565–85.
17.
LinTIHoHJChenCL (2009) Analysis of multivariate skew normal models with incomplete data. Journal of Multivariate Analysis, 100, 2337–51.
18.
LipsitzSRIbrahimJG (1996) A conditional model for incomplete covariates in para- metric regression models. Biometrika, 83, 916–22.
19.
LoAY (1984) On a class of Bayesian nonpara- metric estimates: I. Annals of the Institute of Statistical Mathematics, 12, 351–57.
20.
MaGTroxelABHeitjanDF (2005) An index of local sensitivity to nonignorable drop-out in longitudinal modelling. Statistics in Medicine, 24, 2129–50.
21.
MaZChenG (2019) Bayesian semiparametric latent variable model with DP prior for joint analysis: Implementation with nimble. Statistical Modelling. doi: 10.1177/1471082X18810118
22.
MasonABestNRichardsonSPlewisI (2010) Strategy for modelling non-random missing data mechanisms in observational studies using Bayesian methods. URL http://www.bias-project.org.uk/papers/StrategySubmitted.pdf (last accessed 22 January 2020).
23.
McCullochC (2008). Joint modelling of mixed outcome types using latent variables. Statistical Methods in Medical Research, 17, 53–73.
MüllerPQuintanaFAJaraAHansonT (2015) Bayesian Nonparametric Data Analysis. New York, NY: Springer.
26.
MurrayJSReiterJP (2016) Multiple imputation of missing categorical and continuous values via Bayesian mixture models with local dependence. Journal of the American Statistical Association, 111, 1466–79.
27.
RodriguezAMüllerP (2013) Nonparametric Bayesian inference. NSF-CBMS Regional Conference Series in Probability and Statistics, 9, 1–110. URL https://www-jstor-org.web.bisu.edu.cn/stable/nsfcbmsregconf.9.01 (last accessed 22 January 2020).
28.
RubinDB (1976) Inference and missing data. Biometrika, 63, 581–92.
29.
SammelMDRyanLMLeglerJM (1997) Latent variable models for mixed discrete and continuous outcomes. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 59, 667–78.
30.
SethuramanJ (1994) A constructive definition of Dirichlet priors. Statistica sinica, 4, 639–50.
31.
SongPX-K (2007) Correlated Data Analysis: Modeling, Analytics, and Applications. New York, NY: Springer-Verlag.
32.
SpiegelhalterDJBestNGCarlinBPVan Der LindeA (2002) Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 64, 583–639.
33.
SpiegelhalterDJThomasABestNGLunD (2003) WinBUGS Version 1.4.1 User Manual. Cambridge: MRC Biostatistics Unit, University of Cambridge. URL https://www.mrc-bsu.cam.ac.uk/software/bugs/the-bugs-project-winbugs/(last accessed 22 January 2020).
34.
Stan Development Team (2019) Stan Modeling Language Users Guide and Reference Manual, Version 2.21. URL https://mc-stan.org/docs/2_21/stan-users-guide-2_21.pdf(last accessed 4 February 2020).
35.
TateRF (1954) Correlation between a discrete and a continuous variable: Point-biserial correlation. The Annals of Mathematical Statistics, 25, 603–07.
36.
TroxelABMaGHeitjanDF (2004) An index of local sensitivity to nonignorability. Statistica Sinica, 14, 1221–37.
37.
VerbekeGMolenberghsGThijsHLesaffreEKenwardMG (2001) Sensitivity analysis for nonrandom dropout: A local influence approach. Biometrics, 57, 7–14.
38.
WuB (2013) Contributions to copula modeling of mixed discrete-continuous outcomes. PhD thesis, University of Calgary, Calgary.
39.
XieH (2008) A local sensitivity analysis approach to longitudinal non-Gaussian data with non-ignorable dropout. Statistics in Medicine, 27, 3155–77.
40.
XieH (2009) Bayesian inference from incomplete longitudinal data: A simple method to qua- ntify sensitivity to nonignorable dropout. Statistics in Medicine, 28, 2725–47.
41.
XieHHeitjanDF (2004) Sensitivity analysis of causal inference in a clinical trial subject to crossover. Clinical Trials, 1, 21–30.
ZhangJHeitjanDF (2006) A simple local sensitivity analysis tool for nonignorable coarsening: Application to dependent censoring. Biometrics, 62, 1260–68.
44.
ZhangJHeitjanDF (2007). Impact of nonignorable coarsening on Bayesian inference. Biostatistics, 8, 722–43.