
Abstract
We describe two interesting and innovative strands of Murray Aitkin's research publications, dealing with mixture models and with Bayesian inference. Of his considerable publications on mixture models, we focus on a nonparametric random effects approach in generalized linear mixed modelling, which has proven useful in a wide variety of applications. As an early proponent of ways of implementing the Bayesian paradigm, Aitkin proposed an alternative Bayes factor based on a posterior mean likelihood. We discuss these innovative approaches and some research lines motivated by them and also suggest future related methodological implementations.
Keywords
Introduction
We are delighted to be invited to contribute to this issue in honour of Professor Murray Aitkin. In a journal devoted to issues of statistical modelling, relating to a statistical society in which he was instrumental in the early days by helping to make statisticians more fully aware of the capabilities of generalized linear models (e.g., through workshops and the influential text by Aitkin et al., 1989), the Editors have an excellent idea to devote an issue to his creative contributions as well as those of others whom he has influenced.
Murray Aitkin's research interests have always been quite broad, with specialties including Bayesian and likelihood theory, generalized linear models and some particular cases such as item response models, mixture models including latent class models and random effects models, statistical computing and neural network models. Anyone who has ever attended a statistics conference at which Professor Aitkin has been present can attest to the insightful comments he invariably makes following a presentation that deals with any aspect of statistical science.
In our contribution, we focus on some of Aitkin's many research publications that deal with mixture models and with Bayesian inference. Some of his contributions relate to our own interests and have motivated our own research work. A considerable number of his publications over the years, dating back to about 1980 and continuing to the present, have focused on mixture models of various types. In particular, his published output includes some of the first articles dealing with random effects in generalized linear models (e.g., Aitkin et al., 1981a; Bock and Aitkin, 1981). In Section 2 of this article, we discuss his proposal of a nonparametric random effects approach in such models, illustrating with an example. Aitkin also has been a frequent contributor to the literature on Bayesian inference, starting with an influential discussion paper for the Royal Statistical Society (Aitkin, 1991). This important early contribution dealt with Bayes factors (BFs), and he proposed an alternative formulation based on the mean of the likelihood function with respect to the posterior rather than the prior distribution. In Section 3, we discuss this contribution as well as some literature that has dealt with it. In each section, we also suggest possible future research work and methodological implementations that are motivated by this discussion.
Contributions on nonparametric mixture modelling
Many of Murray Aitkin's research publications have dealt with mixture models of a wide variety of types. Such models include latent class models and other finite mixture models and the generalized linear model that includes random effects, that is, the generalized linear mixed model (GLMM). Here we focus on an innovative idea of his for using nonparametric structure instead of assuming normality for the random effects in GLMMs.
Nonparametric random effects in generalized linear mixed models
For clustered data such as with repeated measures or in a longitudinal study, let

Since
We refer to Table 1, from the 2018 General Social Survey (GSS) in the USA, for a simple example in which such an approach may be natural. Subjects were asked whether they supported legalized abortion in each of three situations. (We ignore here seeming contradictions in people's responses, such as some subjects supporting legalization for any reason but being opposed in a particular situation.) A cluster is a set of the three observations for a particular subject, with subjects classified by gender. With such a controversial issue, the population might be polarized, with some people likely to support legalization regardless of the context, and some likely to oppose it regardless of the context. A third group of subjects may have response dependent on the context. With
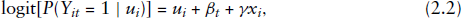
Support (1 = yes, 0 = no) for legalized abortion in three situations: (a) if the family has a very low income and cannot afford any more children, (b) when the woman is not married and does not want to marry the man, and (c) when the woman wants it for any reason

One of us (Agresti) used Aitkin's nonparametric approach with GLMMs for a variety of scenarios. For example, for a logit model for a vector of binary responses observed under multiple conditions, Agresti (1997) showed that a nonparametric treatment of the random effects vector implies marginally a multivariate loglinear model having quasi-symmetric structure for the cross-classification of responses at the various conditions. For binary responses in multi-centre data comparing two treatments, such as clinical trials, Agresti and Hartzel (2000) used the nonparametric GLMM approach with the logit and other link functions to describe the mean and variability of centre-specific effects such as log odds ratios and risk ratios. Hartzel et al. (2001b) employed this approach with ordinal responses, describing centre-specific log odds ratios that result from models that apply the logit link to cumulative response probabilities or to pairs of adjacent response probabilities. Hartzel et al. (2001a) used it in a more general context for GLMMs with multinomial (nominal and ordinal) responses and generalized Aitkin's EM algorithm. In all such cases, simulations suggested that the method performed well for estimating fixed effects even when the standard model with a normal random effect truly holds. However, the nonparametric approach did not estimate the mixture distribution or its variance well. This is not surprising, because the maximum likelihood estimate of the mixture distribution (with an unspecified number of mass points) is typically highly discrete, with relatively few mass points, even though it often facilitates a good approximation of the marginal likelihood.
Agresti et al. (2004) investigated the impact of misspecification of the random effects distribution, using models with various actual random effects structures. For instance, consider estimation of the mean log odds ratio for comparison of two groups in several 2
For years, one could fit many GLMMs with nonparametric random effects using a GLIM macro, and recently Einbeck et al. (2018) provided the R package npmlreg for fitting of such models. Table 2 shows edited output for nonparametric fitting of the simple GLMM (2.2) to Table 1, specifying three mass points to represent polarization with a middle group having opinion depending on the situation. At the estimated locations for the polarized mass points, which are quite extreme and about equally likely, for each gender the probabilities of supporting legalization are close to 0 for each situation or close to 1 for each. In this output, we regard standard errors and log-likelihood values informally, as the GSS uses sampling more complex than a simple random sample. It is informative to note, however, that when we instead assume a normal random effect, Gaussian quadrature with 100 quadrature points has
Fitting of GLMM in R to Table 1, with nonparametric and normal treatment of random effect term
Although simple, the nonparametric approach has disadvantages. These include often poor estimates of the variance component, standard asymptotic theory for model comparison not being appropriate (when we regard the number of mixture mass points as unknown), identifiability issues, and less adaptability to multivariate random effects modelling and multilevel modelling than using a multivariate normal random effect.
Aitkin (1999b) used the nonparametric random effects approach for meta-analysis of multi-centre trials. He used the logit model, focusing on variability in log odds ratios such as described above. In practice, it would often be desirable to use a log or an identity link function, in which case summary effects relate to ratios or differences of proportions, which are simpler to interpret and sometimes more relevant. Agresti and Hartzel (2000) used these links for multiple 2× 2 tables but noted the structural problem in using a continuous random effects distribution in modelling a probability or its log. Estimates exist that deal with heterogeneity in meta-analyses outside the context of a logit model. For instance, DerSimonian and Laird (1986) weighted sample estimates inversely proportional to estimated variances. However, Wald-type methods for categorical data that use estimated variances often behave poorly, especially for applications in which the probability of the outcome of interest is close to zero for each group, in which case sometimes all members of a group make the same response. How successful might a nonparametric random effects approach be for obtaining estimates for those non-standard link models?
For GLMMs, some authors have suggested replacing a normal random effects distribution by a finite mixture of normals. For instance, Agresti et al. (2004) used the
A particularly important case to consider is when the variance of the random effects depends strongly on values of covariates, as this can result in substantial bias in estimating fixed effects in ordinary GLMMs (Heagerty and Zeger, 2000). Also, for a GLMM, how can one estimate an unspecified but continuous mixture distribution with more precision than the nonparametric random effects approach does with its relatively few mass points, and does this make any difference for the resulting inference? Can the nonparametric approach be used effectively with multiple random effects and possibly multilevel structure, especially when good estimates are needed of variance components are highly heterogeneous? A referee pointed out that the nonparametric random effects approach would be useful for classification purposes, because it implicitly produces posterior probabilities of class memberships.
The research results quoted above dealt with modest numbers of parameters, such as multi-centre trials for about 30 centres. In these days of big data, it would be of interest to study the effect of misspecification of the random effects distribution for a sparse asymptotic framework in which the number of parameters grows with the sample size or even exceeds it. For instance, under what conditions does one obtain consistency of estimation of an average treatment effect and of variance components? Can regularization methods, such as the lasso, apply directly to GLMMs with nonparametric random effect? Finally, for all types of applications, further attention could be paid to the disadvantages mentioned at the end of Section 2.1.
Contributions on Bayes factors
Murray Aitkin has a long record of developing ways to implement Bayesian inference. Early work focused on an alternative to the BF introduced in a highly cited discussion paper for the Royal Statistical Society (Aitkin, 1991). A more recent work focuses on fundamental issues such as ways of assessing the credibility of confidence intervals and prediction intervals (Aitkin and Liu, 2018). His publications include a book (Aitkin, 2010) that presents a unified Bayesian treatment of inference and model comparisons using simple diffuse prior specifications and that re-visits long-term interests of his, such as finite mixture models and variance component models. Here we focus on his innovative idea of an alternative type of BF and some related research results.
Bayes factor using posterior mean likelihood
One of Professor Aitkin's most relevant contributions related to Bayesian inference is the proposal of the posterior BF, initially formulated in Aitkin (1991). Suppose that, with reference to a set of data represented by the vector 
The posterior BF proposed by Aitkin (1991) is used in the usual way, so that model
Aitkin has also discussed the idea of relying on the posterior mean of the likelihood function for selecting a statistical model in other papers, among which it is worth recalling Aitkin (1997), Aitkin et al. (2014) and Aitkin et al. (2015). The latter, in particular, is focused on two very interesting applications, namely the use of the posterior BF for selecting the number of components in a finite mixture model of normal distributions and the number of classes in a latent class model. Aitkin et al. (2014) focuses on models for using networks to investigate social group structure. In it, groups are identified via latent classes, the number of which is selected using Bayesian methodology. These applications inspired methodological extensions, and this is a characteristic of Prof. Aitkin's research attitude. He proposed to rely on a more sophisticated criterion than merely taking the posterior mean of the likelihood under each model. In particular, for each model
In Aitkin et al. (2015) a certain advantage emerges of this selection criterion in comparison to popular alternatives, such as the Deviance Information Criterion (Spiegelhalter et al., 2002). This result relates to an observation, formulated by Aitkin (2001), about Bayesian inference for finite mixture models. In particular, evidence is shown of the sensitivity of the selected number of components to the assumed prior structure. This criticism also occurs in an interesting overview of different Bayesian analyses of the popular Galaxy data (Roeder, 1990), showing that very different conclusions have been reached about the number of mixture components suitable to properly model these data.
A standard technique to perform Bayesian inference is based on the use of Monte Carlo algorithms, in particular in the Markov chain version (MCMC); see Robert and Casella (2013). As is well known, for a certain model
The possibility of obtaining the posterior mean of the likelihood function by a simple average along the path of the Markov chain is an interesting aspect that, in our opinion, has not been sufficiently stressed and exploited. In particular, once an MCMC algorithm is available, obtaining the posterior BF requires one merely to write and run a small amount of extra code; compare this with the ordinary BF based on the ratio of marginal likelihoods, in which case more sophisticated methods are required (see, for instance, Chib, 1995). Moreover, a simple parallelization is possible, when computing the posterior BF, in the setting in which the same model is estimated on the basis of parallel chains run on the entire dataset.
As outlined in Section 3.1, Aitkin has also proposed a more sophisticated criterion than that simply based on computing the posterior mean of the likelihood, which relies on stochastic ordering. More precisely, on the basis of parallel MCMC chains run separately for each model, Aitkin et al. (2015) proposed a consensus criterion to compare the models based on computing

A final point of interest concerns the computation of the posterior BF on the basis of the output of the Reversible Jump (RJ) algorithm (Green, 1995; Richardson and Green, 1997) that is used when (quoting Professor Peter Green), ‘the number of things you do not know is one of the things you do not know’. In fact, while the conventional BF is obtained from this output on the basis of the number of times each single model has been visited by the Markov chain that moves between subspaces of different dimensions, the posterior BF is obtained by elaborating the subchains referred to each single model treated as if these chains were produced from separate MCMC algorithms. In other words, the computation is performed within each subspace. Moreover, Bartolucci et al. (2006) showed that the RJ output may be elaborated in a more efficient way in order to obtain the conventional BF on the basis of the acceptance probabilities between models, a quantity that is computed at each step. An open research question is then whether, also in a RJ framework, the number of visits to each model may be somehow exploited to estimate the posterior BF and, subsequently, if the technique of Bartolucci et al. (2006) may be exploited also in this case to improve this estimate. Indeed, a similar question concerns the use of a parallel MCMC algorithm to obtain the posterior BF, where techniques such as the one proposed in Meng and Wong (1996) could be profitably used to improve the precision of the estimate of the posterior BF; see also Mira and Nicholls (2004) and Bartolucci et al. (2018).
We conclude by noting, again, how versatile Aitkin's contributions are, ranging from likelihood to Bayesian approaches to statistical inference; from methodological to application driven papers, from computational to theoretical. This is not the right venue to discuss them, but his topics of application have been highly diverse, as illustrated by article titles such as ‘Stillbirths among offspring of male radiation workers at Sellafield nuclear reprocessing plant’ (a co-authored Lancet article in 1999) and ‘Teaching styles and pupil progress’ (Aitkin et al., 1981b). In these difficult days for our planet, we would very much value a modelling expert like Professor Aitkin wrangling ‘coronavirus data’ and making reliable predictions on where we are heading.
Footnotes
Declaration of conflicting interests
Funding
The authors received no financial support for the research, authorship and/or publication of this article.