
Abstract
Traditional talent matching methods generally rely on manual rules and static feature analysis, which makes it difficult for the model to adapt to the rapidly changing employment market and the personalized needs of job seekers, resulting in insufficient matching precision and poor adaptability. This paper constructs an innovative talent matching model based on the optimized support vector machine (SVM) algorithm to address this problem. Firstly, dynamic employment market data and multi-dimensional job seeker features are used to build a more intelligent and personalized matching framework. This study proposes an innovative intelligent talent matching model that enhances the understanding of the relationship between jobs and job seekers through data cleaning, standardization, and feature extraction using TF-IDF technology. By optimizing the SVM kernel function and fine-tuning hyperparameters, the model’s classification performance in complex matching tasks is improved. Additionally, the integration of real-time dynamic data updates and incremental learning methods enables the model to automatically adapt to market changes, improving the timeliness and accuracy of matching results. In the design of the multi-dimensional matching model, this paper further integrates job seeker potential analysis and job development potential to optimize the recommendation strategy. Compared to traditional keyword matching and logistic regression models, the proposed model significantly outperforms others in talent matching, achieving a maximum matching accuracy of 0.91, a maximum F1-score of 0.93, an average response time of 2.02 minutes, and an average update frequency of 14.03 times per hour. The results demonstrate that this innovative talent matching model provides a more efficient, personalized, and intelligent solution for the dynamic employment market, advancing the development of talent matching technology.
Keywords
Introduction
As the global job market is changing rapidly and the labor market is becoming increasingly diverse, traditional talent matching methods can no longer meet current market demands. Traditional keyword matching and fixed rule-based screening simply match job seekers’ resumes with job descriptions, ignoring the personalized career development needs of job seekers and the dynamic requirements of jobs.1,2 These matching methods have the problem of insufficient precision when facing complex job requirements and multi-dimensional features of job seekers.3,4 With the changes in job requirements and the diversification of job seekers’ career paths, traditional methods cannot effectively adapt to the dynamic changes in the market.5,6 In addition, as corporate recruitment needs gradually diversify and job descriptions become increasingly complex, traditional methods cannot fully consider deep-level factors such as job seekers’ backgrounds, potential, and career goals, resulting in oversimplified recommendation results and a lack of personalization.7,8 These methods have the problem of static matching, and when faced with real-time changing market demands, they have shortcomings such as poor adaptability and slow response speed.9,10 Therefore, improving the precision, adaptability, and personalized recommendation of talent matching models is an issue that needs urgent attention in current talent matching research.
Talent matching has long been a critical area of research, with scholars proposing various algorithmic solutions to improve its effectiveness. Early approaches relied heavily on rule-based engines or simple statistical models, which performed static analyses of job seekers’ resumes and job descriptions.11,12 While these methods laid the groundwork for talent matching, their inability to adapt to dynamic and complex scenarios limited their practical utility. With the advent of machine learning, supervised learning algorithms like support vector machines (SVM) were introduced to address more intricate classification challenges in high-dimensional feature spaces, achieving notable improvements in accuracy and stability.13–16 Despite these advancements, recent studies have highlighted the need to incorporate dynamic labor market data and personalized job seeker characteristics to further refine matching outcomes.17,18 However, challenges related to precision, flexibility, and adaptability in real-world applications persist.
To overcome these limitations, this paper proposes an innovative model that integrates dynamic employment market data with multi-dimensional job seeker features to construct a precise and intelligent matching framework. Through systematic steps such as data preprocessing, feature extraction, and feature selection, the model combines SVM optimization, dynamic data integration, and multi-dimensional feature fusion to address the shortcomings of traditional methods. The primary objective of this research is to enhance matching precision and deliver highly personalized job recommendations by leveraging advanced computational techniques. By doing so, the proposed model not only improves the accuracy and efficiency of talent matching but also provides a robust solution tailored to the complexities of modern labor markets, offering significant value for both job seekers and employers.
Related work
In talent matching, traditional methods usually match based on keywords, experience, and academic qualifications. However, as market demands change and job seekers’ needs diversify, these rule-based approaches are difficult to adapt to the rapidly changing employment environment. Therefore, more and more studies have begun to use machine learning algorithms to improve matching precision and adaptability.19,20
The earliest machine learning methods used classification algorithms based on traditional features to perform talent matching.21,22 However, many traditional machine learning models rely on static data and cannot respond to market changes and job seekers’ personalized needs. Ni Q combined deep neural network technology with digital human resource management knowledge to systematically study the problem of person-job matching, achieved precise matching analysis between job seekers and jobs, and improved the efficiency and accuracy of human resource management. 23 Shet used machine learning to achieve a multi-dimensional evaluation of “quality recruitment,” providing a new method and perspective for improving the quality of organizational recruitment. 24 However, these methods lack effective responses to fluctuations in job demand and changes in industry development. Some studies have applied dynamic market data and incremental learning techniques to talent matching models to improve their adaptability and real-time performance so as to overcome the limitations.25,26 Although this method improves the matching quality, it still faces problems with matching precision and model adaptability when the market changes.
In recent years, research on talent matching has increasingly emphasized multi-dimensional frameworks to enhance matching outcomes. For instance, approaches leveraging multi-task learning and deep learning27,28 have been proposed to account for job seekers’ long-term career goals, interest preferences, and the growth potential of job positions. These methods aim to incorporate more personalized factors, enabling the model to better align with the unique needs of job seekers. However, such approaches often depend heavily on large volumes of historical data and significant computational resources, and they still struggle to address the challenge of rapid adaptability in dynamic market environments.29,30
To tackle these limitations, this paper introduces an optimized SVM-based talent matching model that integrates dynamic market data updates and incremental learning mechanisms. By refining the SVM training process, the proposed method achieves higher matching precision while adapting to real-time data streams and market fluctuations, thereby improving both adaptability and response speed. Furthermore, this study incorporates an analysis of job seekers’ potential and an assessment of job development potential into the framework. A multi-dimensional matching approach is developed, aiming to overcome the issues of limited flexibility and poor real-time performance that plague existing methods. This innovation not only enhances the precision of talent matching but also ensures the model remains responsive and relevant in fast-changing labor markets.
Talent matching model construction and optimization
Data collection and preprocessing
The data set comes from a public and free platform, covering job seekers’ resumes, job recruitment requirements, and industry trend information. The job seeker data is from the Students (Job Seekers) Data dataset on Kaggle, which includes job seekers’ education, work experience, skills, cities, and other information. The job recruitment requirements data is from the Real/Fake Job Listings Dataset on Kaggle, which contains job titles, company information, job requirements, salary ranges, and so on. Industry trend data is from the Global Economic Monitor data set on Kaggle, which provides statistics such as global industry employment trends and salary changes. The system can comprehensively obtain job seekers’ background information, job requirements, and industry trends through these data sets, thereby providing richer and more accurate basic data for model training. 70% of the collected data is used for model training, 15% for validation and hyperparameter tuning, and 15% for final model evaluation. Figure 1 presents the data preprocessing. Data collection and preprocessing process.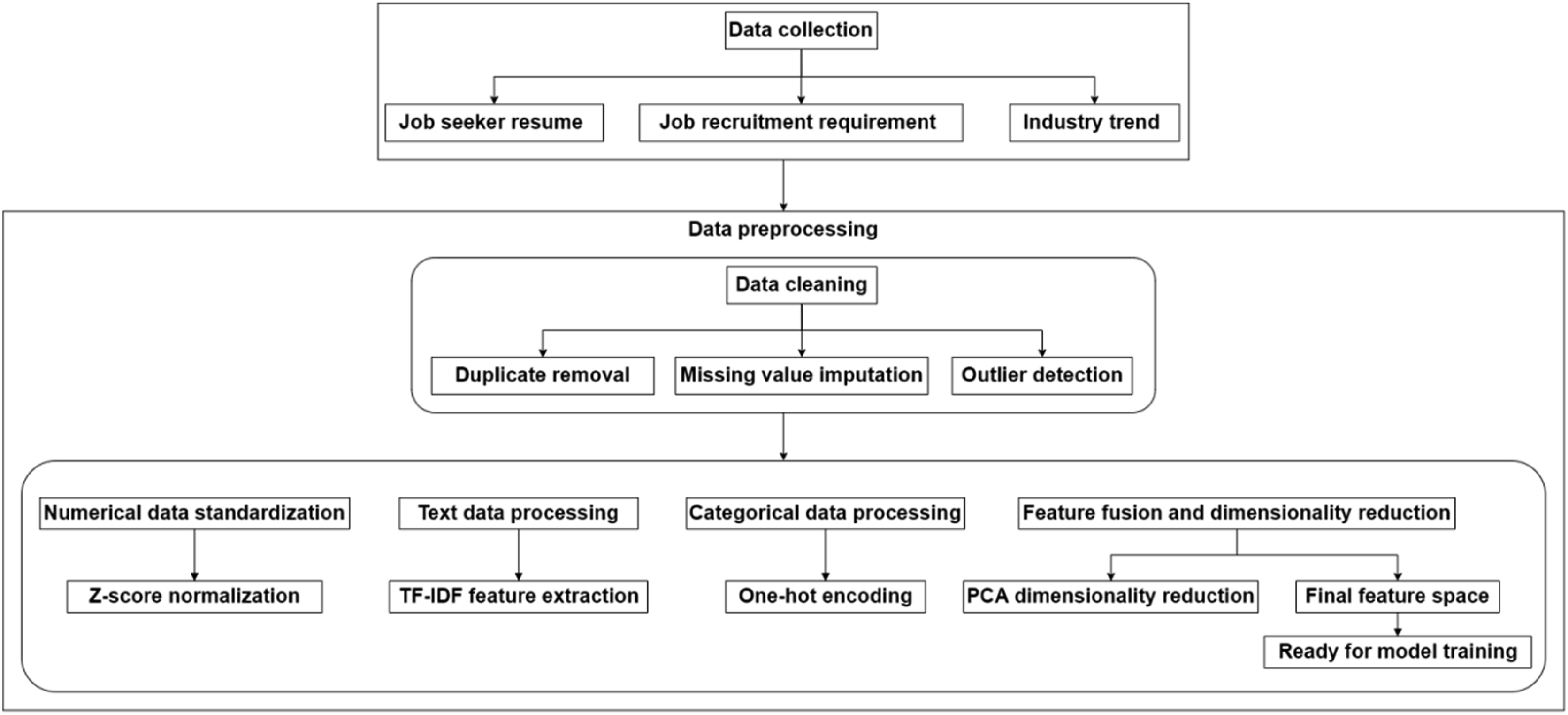
During the data cleaning phase, the raw data is first deduplicated to remove duplicate records to avoid redundant effects of the same data on model training. For missing value processing, numerical data such as salary and years of service are filled with the mean to retain the central tendency of the data. Categorical data such as job category and education level are filled with the mode to ensure that the distribution of categorical variables remains consistent.
Outliers are detected and corrected after dealing with duplicate data and missing values. A standard deviation-based method is used in this process to identify outliers. The mean and standard deviation of each data feature are used to determine whether there are values exceeding the standard deviation of 3. Unreasonable outliers are corrected according to the upper and lower quartiles of the data, further enhancing the reliability and quality of the data.
Regarding numerical data standardization, the Z-score standardization method is used to normalize all numerical features. After standardization, all features are converted to a standard normal distribution with zero mean and unit variance. The formula is:

Meanwhile, the term frequency-inverse document frequency (TF-IDF) technology is used to extract features from text data, such as job descriptions, skills, and work experience. TF-IDF assigns each term a weight that considers both the local frequency of the term and its rarity across all documents. Keywords in job descriptions and job seekers’ resumes are converted into vector form after TF-IDF processing to facilitate subsequent matching and calculation.
In the text data preprocessing, word segmentation of job descriptions and job seekers’ resumes is performed using tools supporting multiple languages. In Chinese data processing, the Jieba word segmentation tool is used, combined with a custom stop word list to remove high-frequency words without practical meaning. Regarding English data, word_tokenize is used for word segmentation, and the standard English stop word list is also used for removal. All text data is processed using Porter Stemmer and Snowball Stemmer during the stemming process to unify the basic form of the vocabulary. The TF-IDF weights are then calculated for the processed text data to generate a sparse matrix representation of each text.
For categorical data such as industry type and job category, the one-hot encoding method is used to convert categorical variables into numerical data. Each category is mapped to a vector, and each dimension in the vector represents a feature of the category. In addition, a hierarchical coding method is used for categorical data with a hierarchical structure. Different numerical labels are assigned to each category according to the hierarchical relationship of the categories, ensuring that the hierarchical characteristics of the categorical data are fully expressed.
After data preprocessing, all processed features are subjected to feature fusion and dimensionality reduction operations to form a high-dimensional feature space, including job descriptions, job seekers’ resumes, and industry trends. Principal components analysis (PCA) is used for dimensionality reduction to reduce the dimension of the feature space. It can effectively remove redundant features and reduce noise by maximizing variance. Its advantage is that it can simplify the data structure, reduce the risk of overfitting, and improve the model’s generalization ability. The goal of PCA is to find a new set of orthogonal bases by eigendecomposing the covariance matrix to maximize the variance of the projected data. The calculation formulas are:


Data preprocessing ensures the integrity and consistency of the data and eliminates the potential impact of redundant and abnormal data on model performance. Numerical data are unified to the same scale to avoid the adverse effects of dimensional differences on model training. At the same time, the TF-IDF method enables the key information in job descriptions and job seekers’ resumes to be effectively represented, enhancing the model’s understanding of text features. Data preprocessing ensures that the model can maintain efficient learning and adaptation capabilities in incremental learning scenarios by reducing noise and overfitting risks during training.
Feature engineering and feature selection
In feature engineering, features of practical significance for the matching task are first extracted from job seekers’ resumes and job descriptions. The features extracted from the job seekers’ resumes include education, work experience, skills, and city. Education and work experience are binarized. The hierarchical data are mapped into ordered values. Skills are extracted by keywords and converted into Boolean values. The features in the job description include job title, required skills, and job responsibilities, which are converted into vector representation after TF-IDF processing. Figure 2 presents the feature engineering and selection process. Feature engineering and feature selection process.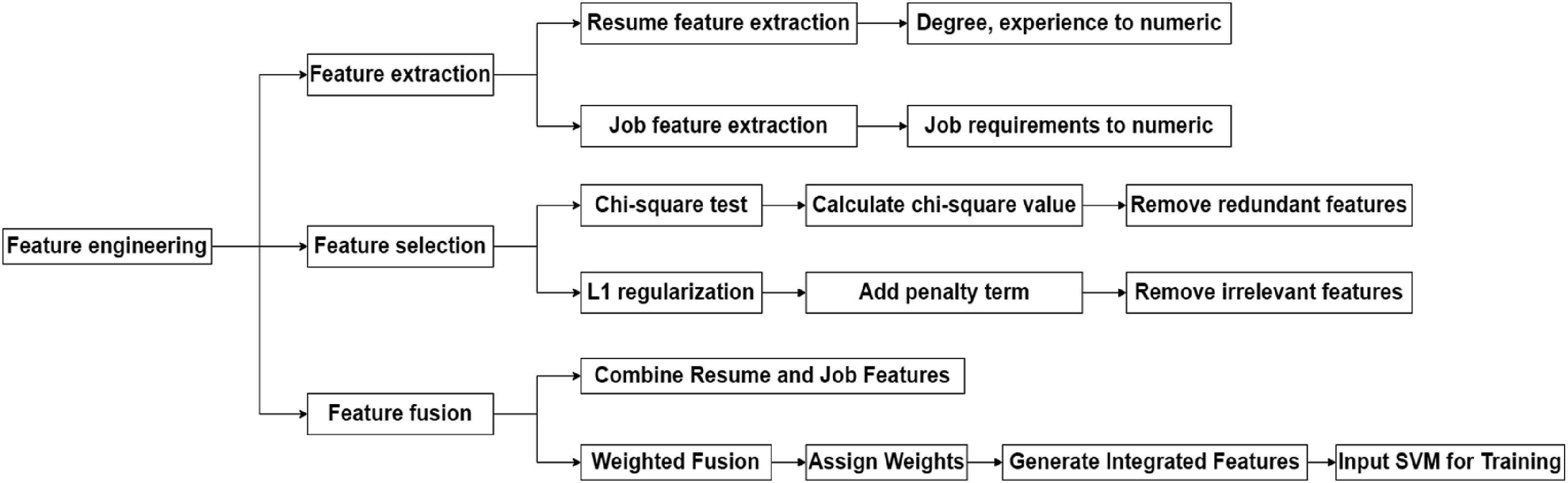
During the feature selection process, the chi-square test is used to assess the correlation between each feature and the job matching. This method is suitable for categorical data and measures independence by comparing the observed frequencies with the expected frequencies. Its limitation is that it cannot process continuous variables and is unsuitable for features with low-frequency categories or many missing values. The chi-square statistic is used to measure the independence between categorical variables, and the formula is:

In addition to the chi-square test, L1 regularization is used for feature selection. L1 regularization makes some feature coefficients approach zero through the penalty term. Combining the two can complement each other in feature selection and improve the model’s training efficiency and prediction precision. The L1 regularization penalty term is the sum of the absolute values of all feature coefficients, and the formula is:

L1 regularization compresses the coefficients of unimportant features to zero, reducing the dimension of the feature space. In the matching model between job seeker resumes and job descriptions, through automatic feature selection with L1 regularization, the model only retains features with a strong relationship with the job matching.
In the feature fusion stage, features of multiple dimensions, such as job seekers’ personal features, job-seeking intentions and job requirements, and industry trends, are combined. Next, these multi-dimensional information are weighted and fused, and different feature dimensions are weighted to generate a comprehensive feature representation. In the weighted fusion process, a weight coefficient is assigned to each feature according to its importance and contribution to the matching task. The Pearson correlation coefficient between each feature and the target variable is calculated to determine the weight. Features with higher correlation coefficients are given higher weights.
Support vector machine algorithm optimization
The core objective of SVM algorithm optimization is to adjust the kernel function and hyperparameters to improve model performance. The kernel function uses a radial basis function (RBF) kernel, which can map data points from the original space to a high-dimensional feature space, effectively capturing complex nonlinear patterns in the data. A combination of grid search and K-fold cross-validation is used to optimize the kernel function parameter

In the grid search phase, the search range of kernel function parameters is defined, and all parameter combinations are traversed. Each set of parameters is evaluated through K-fold cross-validation, and the parameter combination with the best verification result is selected.
Hyperparameter tuning is another key step in optimizing SVM, mainly involving the penalty parameter C and the width parameter of the RBF kernel. In SVM, C controls the tolerance for classification errors. Larger C values penalize errors more severely, while smaller C values allow more classification errors. A grid search method is used to traverse multiple C values, and the classification performance of each C value is evaluated by cross-validation to determine the most appropriate C value. The range of C values is set to [0.1, 1, 10, 100], and the range of the width parameter (γ) of the RBF kernel is [0.001, 0.01, 0.1, 1, 10]. Regarding the selection of the C value, a larger C value increases the model’s penalty for classification errors, prompting the model to fit the training data as accurately as possible, but it may lead to overfitting when the data is noisy. A smaller C value tolerates more classification errors, which may reduce the risk of overfitting, but it may also lead to underfitting and affect the model’s generalization ability.
The standard SVM training method is used in model training. The classification performance is improved during the training process by optimizing the decision boundary. The model uses the support vector to determine the optimal hyperplane. Unlike traditional machine learning models, SVM is trained by focusing on support vectors without being affected by the rest of the data points, thus avoiding the risk of overfitting caused by redundant information. During the training process, the SVM optimizer iteratively adjusts the model parameters, gradually approaching the optimal classification boundary and ultimately enables the model to effectively classify and accurately match job seekers and job data in the training set.
The optimized SVM model can use high-dimensional mapping to solve nonlinear features and complex relationships in the data when processing job seekers’ resumes and job requirements. Various features in the data, such as education, skills, and work experience, are mapped to a high-dimensional feature space through the RBF kernel, enabling the model to achieve more precise classification in the new space. In this way, SVM can avoid the limitations of linear kernel methods in processing high-dimensional data and effectively reduce redundant features’ interference in model training.
Leveraging the degree of matching between job seekers and jobs in the optimized model, the system classifies and predicts unknown data by utilizing the decision boundary derived from the training process, ultimately producing a job matching score. Through careful optimization of the kernel function and fine-tuning of hyperparameters, the SVM model significantly improves matching accuracy and enhances its adaptability in pairing job seekers with appropriate positions. This approach ensures better precision in job matching, offering a more reliable solution for dynamic employment scenarios.
The SVM model can more flexibly cope with complex matching tasks between job seekers and jobs by optimizing the kernel function and hyperparameters. This study adopts a class weight adjustment method by giving higher weights to samples from fewer classes during training to deal with the data imbalance problem. The performance of the optimized SVM model is evaluated using indicators such as classification precision and F1-score to ensure the accuracy and effectiveness of the model in matching job seekers with jobs.
Dynamic data integration and incremental learning
In the stage of dynamic data integration and incremental learning, the implementation of real-time data updates and incremental learning ensures the real-time performance and accuracy of data by building an efficient data flow architecture. The data stream system adopts Kafka and Flink as the stream processing framework and connects with multiple recruitment platforms and industry data sources through application programming interfaces (API) to obtain real-time data on job seekers’ resumes, job information, and industry trends. Kafka is responsible for efficient data transmission, and Flink is used for real-time streaming data processing. Whenever new job information or job seeker data is updated, the data stream system immediately obtains and processes the data to ensure that the system can reflect the latest job requirements and job seeker status in the market.
The key to real-time data updates lies in efficient transmission and processing. To achieve this, an asynchronous data transmission mechanism is implemented, which significantly enhances real-time data transfer performance. Compared to traditional synchronous transmission, the asynchronous mechanism reduces transmission delays and improves throughput. In high-concurrency scenarios, this mechanism effectively mitigates the computational bottleneck caused by waiting for data transfer to complete, thus boosting the system’s overall processing efficiency. Additionally, an efficient data preprocessing pipeline enables rapid data cleaning, deduplication, missing value imputation, and other essential operations upon data arrival.
To further optimize performance, the data stream system employs a priority queue mechanism to prioritize frequently updated data, ensuring that the model can quickly incorporate the latest recruitment information and job seeker dynamics amid large-scale data flows.
Incremental learning is facilitated through the online training mechanism of the SVM. As new data arrives, the algorithm updates the support vectors and decision boundary through local adjustments. A cache mechanism is used to improve efficiency by storing only critical support vectors and representative samples, which are selected for updates via sample selection strategies. Initially, the model is built on a small training set, and as new data is added, the model is fine-tuned by updating only the support vectors and decision boundaries. This approach enables continuous model improvement without unnecessary recalculations, ensuring efficient adaptation to evolving data.
During the incremental learning process, the system dynamically adjusts the hyperparameters of the SVM for each batch of data through a combination of grid search and cross-validation to process different batches of incremental data so that the model can maintain optimal performance when processing new data. The optimization process of grid search is expressed as:

A sliding window mechanism is used to control the time range of training data to avoid unnecessary historical data interference on current predictions. Smaller windows can make the model more sensitive to near-term market fluctuations but can lead to neglect of long-term trends. Larger windows help capture long-term trends but reduce the ability to adapt to sudden market changes. In this regard, the window size is set to the data within the past 30 days. After each incremental update, the model is tested on the validation set to prevent overfitting during incremental learning.
Multi-dimensional matching model design
In the design of the multi-dimensional matching model, features of multiple dimensions, such as job seekers’ personal abilities and job-seeking intentions, are comprehensively considered. The job seeker’s personal abilities are converted into a set of numerical vectors. The job-seeking intention is quantified into scores of multiple dimensions by analyzing the job seeker’s behavior data and then constructed as part of the job seeker’s feature vector through weighted fusion. The weighted average and splicing methods are used to integrate features from different sources. Resume-related features and behavior data features are unified through weighted averages. Job descriptions and industry trends are combined with other features through splicing. Figure 3 shows the matching model framework. Multi-dimensional matching model framework.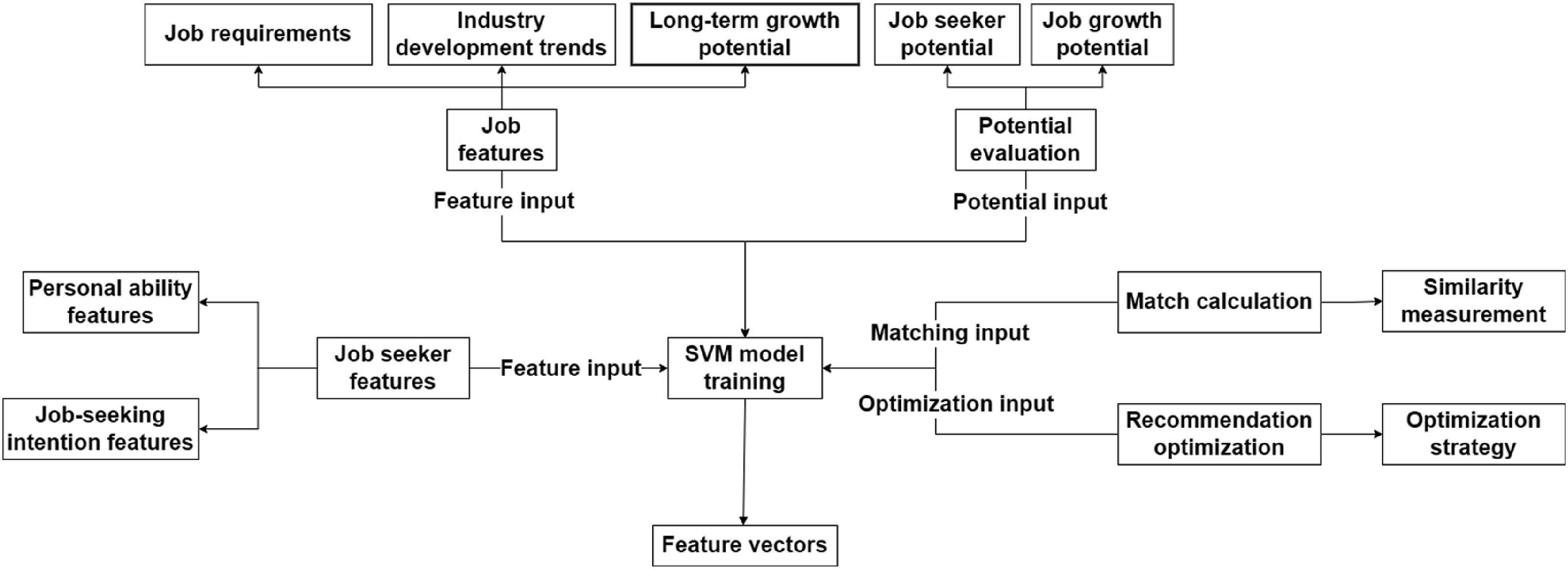
The features of a job include job requirements, industry development trends, and the long-term growth potential of the job. Job requirements are extracted from job description texts, and factors such as industry trends are quantified through external industry reports and historical recruitment data, thus forming a multi-dimensional description of the job. These features work together to build a matching assessment system between job seekers and jobs.
The matching degree is calculated based on the similarity between the job seeker and the job feature vector. When calculating the matching degree, the model considers various distance measurement methods and flexibly selects the appropriate one according to different feature types. Salary range and work experience are calculated using Euclidean distance. The Jaccard similarity is used for industries and job types. TF-IDF combined with cosine similarity is used for text descriptions to measure the similarity between texts.
When faced with missing or incomplete data, the system uses mean filling to process numerical features, and categorical features are filled through the K nearest neighbor algorithm. In addition, in the case of incomplete features, the system reduces the impact of missing data on matching results by assigning appropriate weights to missing data, ensuring that matching accuracy is maintained when data is incomplete.
Regarding job seeker potential assessment, the model analyzes multi-dimensional data such as their historical job-seeking behavior, career preferences, and job change records, combines time series analysis and regression analysis, and uses regression analysis algorithms to predict job seekers’ future career development directions. The regression model is of the form:
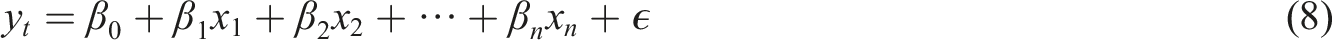
The job seeker potential is analyzed through regression analysis of historical job changes, promotion speed, salary growth, and other indicators to obtain a potential score. The job growth potential assessment is based on industry data and company recruitment records to quantify the future development prospects of the job. The job seeker potential and job growth potential are weighted according to the weights when matching, and the recommendation strategy is optimized to ensure that the recommendation is in line with the job seeker’s current capabilities and provides long-term development opportunities. The growth potential of a job is quantified into a score that reflects the prospects for the job to develop in the next few years.
In matching optimization, the system considers the current matching degree and adds time weight to optimize the recommendation strategy by weighting the potential of job seekers and the potential for job growth. Through multi-dimensional feature fusion and potential evaluation models, an intelligent matching mechanism that comprehensively considers multiple factors is formed.
All feature vectors are standardized and input into the SVM model for training. During incremental learning, the hyperparameters of the SVM model are dynamically adjusted through grid search and cross-validation. In addition, online learning methods are used to gradually adjust hyperparameters, enabling the model to continuously optimize in dynamic environments. The incremental learning mechanism ensures that as new data is added, the model can dynamically adjust to adapt to market changes and changes in job seeker needs.
Matching result optimization and personalized recommendation
In the matching result optimization and personalized recommendation part, the job matching results output by SVM are first sorted by similarity, and the Jacard similarity measurement method is used to calculate the similarity between job seekers and job features. Specifically, Jacard similarity measures the ratio of the intersection and union of the job seeker’s feature set and the job feature set, which is used to quantify the degree of matching and optimize the recommendation results accordingly to ensure more precise job recommendations. The matching score is the output of the SVM model, which is used to judge the matching degree between the job and the job seeker, thereby optimizing the recommendation results.
A weighted recommendation mechanism is used in personalized recommendation adjustment. A personalized feature model is constructed by extracting job seekers’ historical job-seeking behavior, job application records, interaction data, skill information in resumes, and career preferences. The model analyzes job seekers’ career goals, industry preferences, and salary expectations and groups’ job seekers through clustering algorithms to identify typical features of different groups. These features are used to adjust the recommendation strategy and improve the personalization of recommendations. During the recommendation process, priority is given to the job seeker’s long-term career development goals. The system recommends jobs with good promotion potential if the job seeker attaches importance to career advancement opportunities. The promotion potential of jobs is comprehensively evaluated through factors such as industry development trends, salary growth forecasts, and changes in job vacancies to ensure that the recommended jobs meet current needs and meet the job seekers’ long-term career plans.
The order of job recommendations is optimized using a weighted fusion algorithm. The algorithm combines the matching degree, job seekers’ individual needs and the job growth potential to calculate the final score for the job recommendation. The weights of each dimension are automatically learned and adjusted through algorithms, ensuring that the recommendation system is highly adaptable to different groups of job seekers. In addition, the model can dynamically adjust and monitor changes in industry demand and the job market in real time and adjust the recommendation strategy accordingly.
Model application and evaluation
Experimental design
Comparative experiments are carried out with the traditional keyword matching method and logistic regression model to verify the optimized SVM model’s accuracy, recommendation quality, and dynamic adaptability in talent matching. In the experiment, a test set is used to evaluate the model’s generalization ability. 10 epochs of tests are conducted, and market change scenarios are simulated in each epoch of tests. The evaluation indicators used in the experiment include matching accuracy, recommendation quality, personalized recommendation degree, and dynamic adaptability. Among them, dynamic adaptability specifically examines key performance indicators such as the model’s response time, data stream processing time, prediction update frequency, and adaptation period when dealing with market fluctuations. Through the comprehensive evaluation of these indicators, the experiment aims to comprehensively analyze the performance of the optimized SVM model in a dynamic environment and verify its effectiveness and advantages in the rapidly changing employment market.
Application evaluation
Matching accuracy
Matching accuracy is measured by calculating the proportion of recommended jobs that are correctly matched to job seekers, which considers accuracy, recall, precision, and F1-score. The higher the matching accuracy, the more the jobs recommended by the model meet the needs of job seekers. Figure 4 shows the matching accuracy results of the three methods. Comparison of matching accuracy of three models. (a) Accuracy, (b) recall, (c) precision, and (d) F1-score.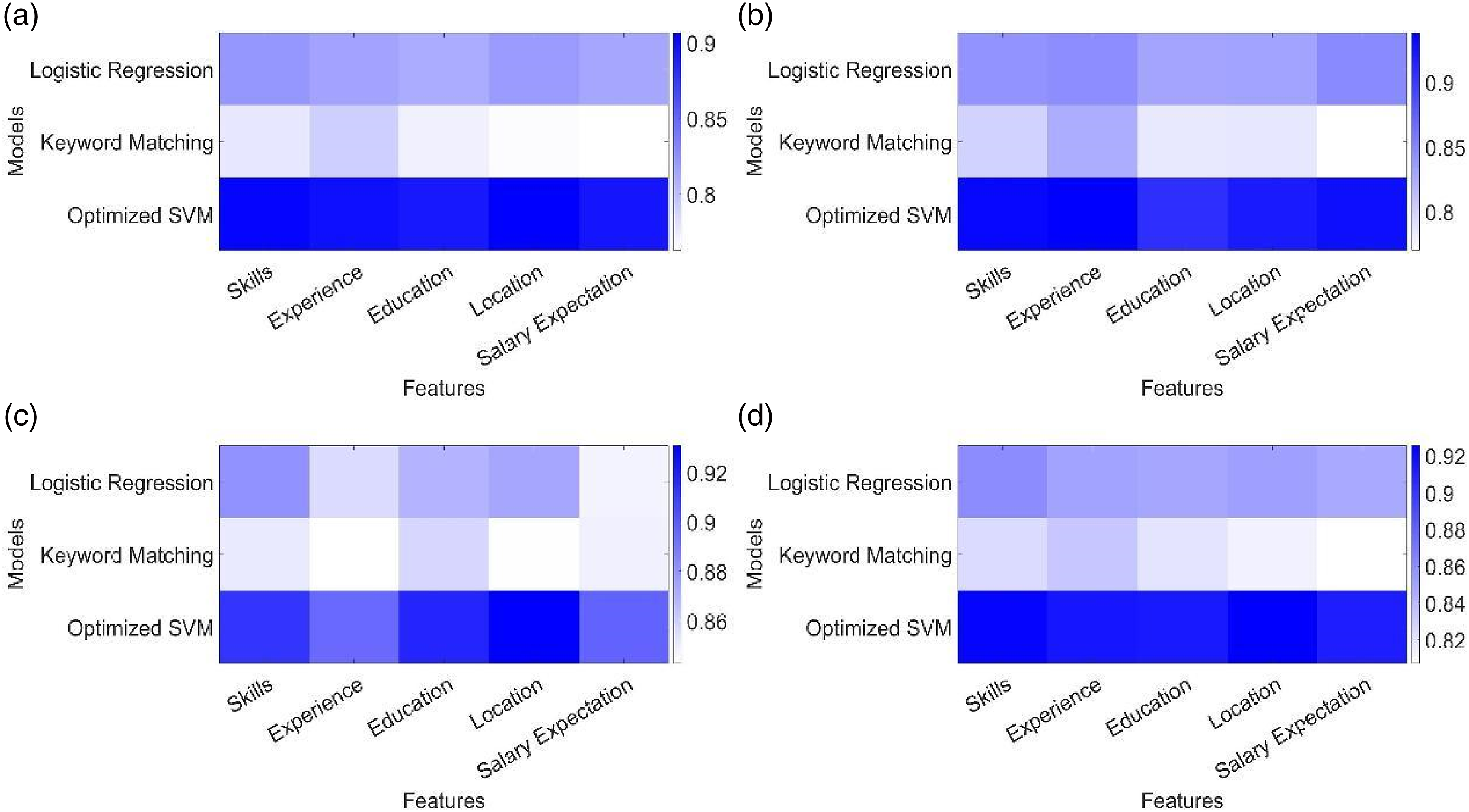
The results in Figure 4 show that the model in this paper is superior to the other two methods in all indicators. The accuracy of the model in this paper is between 0.89 and 0.91, and the highest F1-score is 0.93, which is higher than that of the other two methods. Regarding precision and recall, the model in this paper also demonstrates significant advantages, with a precision ranging from 0.89 to 0.93 and an average recall of about 0.93, both much higher than those of the other two methods. These results indicate that the model in this paper can better adapt to dynamic market changes and the personalized needs of job seekers.
Recommendation quality
The quality of recommendations reflects the precision and relevance of the recommended jobs to job seekers’ needs by calculating the matching degree between the jobs and job seekers in various feature dimensions. Figure 5 shows the matching effects of the three talent matching models on five key feature dimensions, skills, experience, education, location, and salary expectation. Comparison of recommendation quality of three models.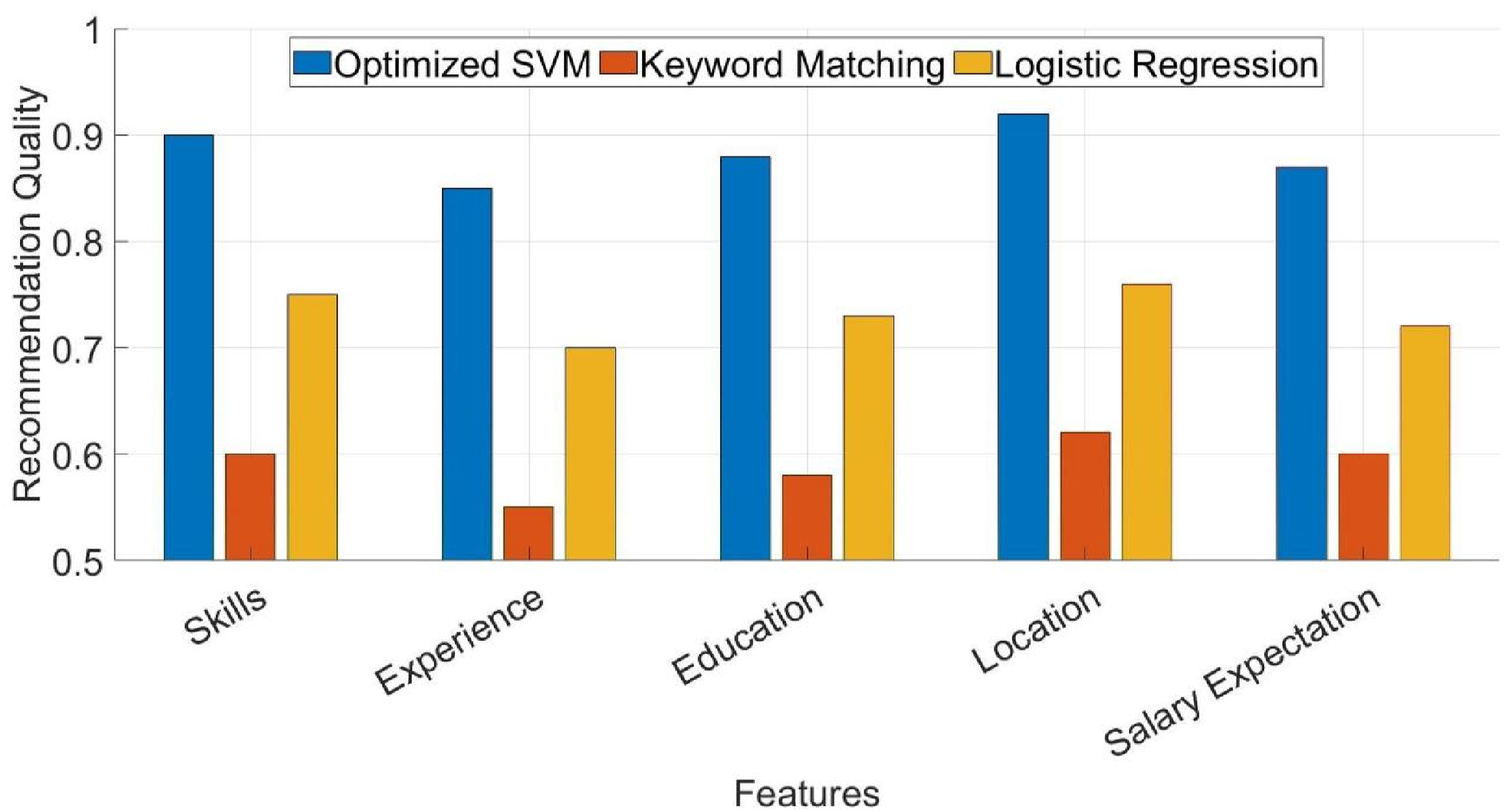
In Figure 5, the model in this paper performs well in all dimensions. Regarding skill matching, the recommendation quality score of the model in this paper reaches 0.9. It also performs well in terms of experience, education, location, and salary expectation, which are 0.85, 0.88, 0.92, and 0.87, respectively, far exceeding the scores of the other two. The scores of the logistic regression model are generally between that of the optimized SVM and that of the keyword matching, the performance of which is relatively balanced. In summary, the model in this paper shows stronger matching ability in all dimensions. It can provide more precise job recommendations, especially when considering the personalized needs and complex features of job seekers.
Personalized recommendation degree
Comparison of personalized recommendation degree of three models.
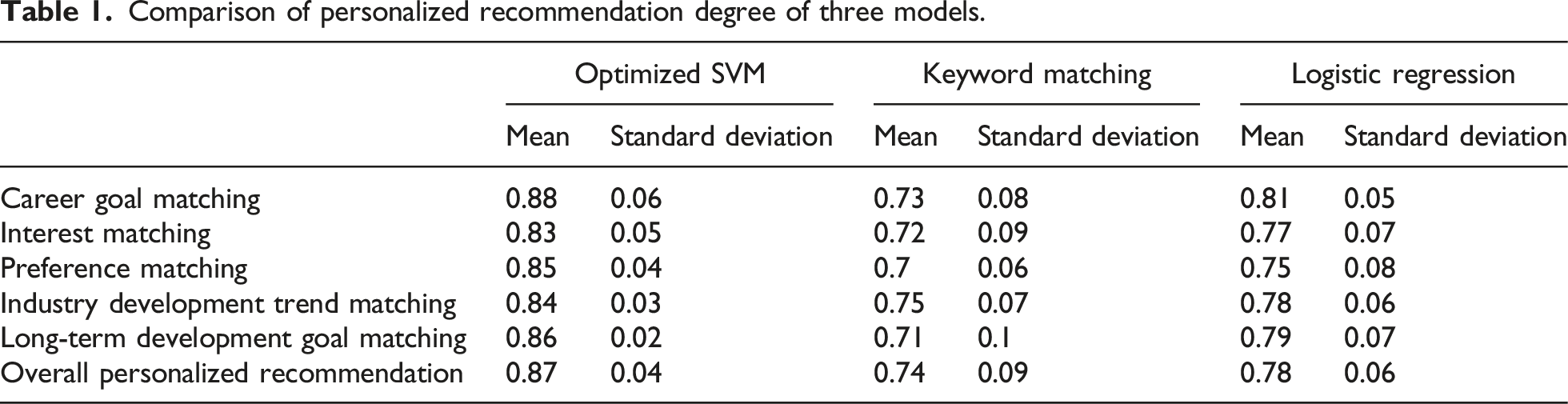
Table 1 shows that the model in this paper performs well in all indicators, with recommendation levels of 0.88 and 0.86 in career goal matching and long-term development goal matching, respectively. Keyword matching has lower scores in all dimensions, while logistic regression scores are in the middle. The lower standard deviation indicates that the recommendation effect of the model in this paper is more stable. Overall, the model in this paper is superior to keyword matching and logistic regression in terms of the accuracy and stability of personalized recommendations.
Dynamic adaptability
Dynamic adaptability evaluates the model’s responsiveness and processing efficiency in dealing with market fluctuations. In this indicator, the response time measures the time it takes for the model to adjust and generate recommendations after receiving market changes. The data stream processing time reflects the model’s efficiency in making predictions under real-time data streams. The prediction update frequency indicates how many times the model updates its recommendations per hour. The adaptation period is the time required for the model to fully adapt to market changes and provide stable recommendations. These indicators comprehensively evaluate the model’s adaptability and real-time adjustment capabilities in a dynamic environment, as shown in Figure 6. Comparison of dynamic adaptability of three models. (a) Dynamic adaptability evaluates the model’s, (b) Dynamic adaptability evaluates the model’s, and (c) Dynamic adaptability evaluates the model’s.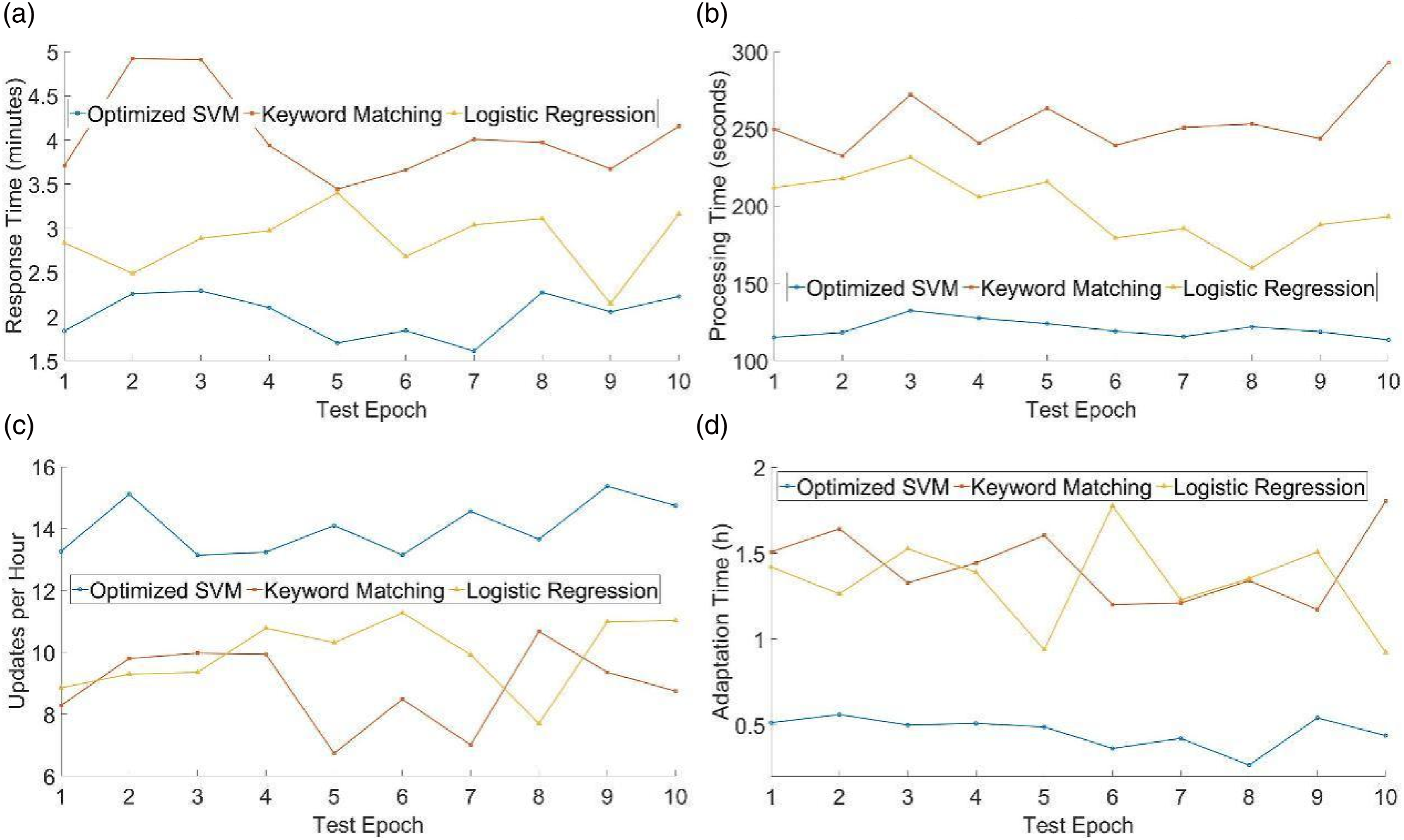
The results in Figure 6 show that the average response time of the model in this paper is 2.02 minutes, lower than the 4.04 minutes of keyword matching and the 2.87 minutes of logistic regression. In terms of data processing time, the average processing time of the model in this paper is 120.7 seconds. In comparison, that of keyword matching and logistic regression is 253.8 seconds and 198.91 seconds, respectively. Regarding update frequency, the average update frequency of the model in this paper is 14.03 times/hour, better than 8.9 times/hour of keyword matching and 9.95 times/hour of logistic regression. In terms of adaptation time, the average adaptation time of the model in this paper is 0.46 hours, which is much lower than that of the other two. In summary, the optimized SVM model performs superiorly regarding response speed, processing efficiency, and adaptability.
Conclusion
This paper constructs an innovative talent matching model by optimizing the SVM algorithm to address the limitations of traditional matching methods in the dynamic employment market. The model comprehensively utilizes dynamic employment market data and multi-dimensional job seeker features. After sophisticated data preprocessing and feature extraction and selection, it significantly improves matching accuracy, recommendation quality, and personalized recommendation degree. Experimental results show that the model achieves a matching accuracy of 0.91 and an F1-score of 0.93, demonstrating excellent matching performance and stability. In terms of dynamic adaptability, the model shows the ability to respond quickly to market changes, with an average response time of 2.02 minutes and an update frequency of 14.03 times per hour, effectively improving the timeliness of matching results.
However, the computational efficiency of the model when handling large-scale datasets still requires further optimization. Future research could investigate parallel processing strategies for the algorithm, which would significantly improve its computational speed in large-scale data environments. Additionally, integrating deep learning techniques could enable the model to better explore and understand complex feature relationships, leading to more accurate talent matching. Another crucial area for future development is enhancing the interpretability of the model. Improving interpretability would provide job seekers and employers with a more transparent and trustworthy basis for matching, ultimately boosting the practicality and user satisfaction of the talent matching system.