
Abstract
In recent years, advancements in artificial intelligence (AI) and natural language processing (NLP) have significantly changed the landscape of education. Among the most promising developments is the emergence of chatbot-based language tutors, which leverage AI to offer personalized and interactive language learning experiences. These tutors can assist learners in mastering vocabulary, grammar, pronunciation, and conversation skills across various languages. This research examines the role of chatbot-based language tutors utilizing deep learning (DL) to facilitate English language acquisition in mobile applications. Intent categorization is a fundamental component of these systems, allowing chatbots to understand user questions and respond appropriately. To address related issues, the research created a proofreading chatbot designed to help academic authors with grammatical corrections. Data was collected from a publicly available chatbot-based English learning dataset. The data was preprocessed using stop word removal and tokenization. Term Frequency Inverse Document Frequency (TF-IDF) is utilized to extract features from the preprocessed data. Efficient pigeon inspired fused bidirectional long short-term memory (EPI-BiLSTM) is applied to classify the intent based on the text to determine the user’s intent. After the classification, to address data scarcity in grammatical error correction for the English language, back translation is employed as a data augmentation tool. Back translation involves translating error-prone sentences into a different language and then translating them back to the original language, generating parallel corpora with their corrected counterparts, derived from texts. The experimental results demonstrated that EPI-BiLSTM outperforms traditional algorithms based on domain (80.5%), intent (90.3%), entity (75.2%), and average accuracy (81.3%). These findings illustrate the potential of combining chatbot-based systems and DL techniques to address both proofreading and grammatical error correction challenges in mobile applications.
Keywords
Introduction
The rapid advancements in mobile technologies have transformed language learning. Mobile technology allows learners to access resources, tools, and a platform that offers more convenience for acquiring a target language. 1 Among the revolutionary advances in this regard is a language learning module based on integrated artificial intelligence (AI) with deep learning (DL) approaches for creating intelligent, interactive language tutors. Language learning chatbots using DL algorithms serve as excellent trainers, providing a tailor-made, adaptive learning experience addressing the specific requirements and preferences of each learner in the English language acquisition process. 2 These learning chatbots provide an interactive experience for learners integrated into mobile apps, allowing students to practice live communication, grammar, pronunciation, and vocabulary exercises. 3 Advances in machine learning (ML) and natural language processing (NLP) enable chatbots to comprehend, interpret, and respond to user input in a conversational manner, which has brought them to prominence in language learning. 4 DL is a subset of ML that enhances the accuracy and performance of chatbots in language learning applications. DL uses large amounts of data and complex algorithms to recognize complex linguistic patterns, adapt to individual learning styles, and provide individualized feedback. 5
Another crucial benefit of language tutors in chatbots is the ability to make the system accessible to learners 24/7. Chatbots do not rely on a physical classroom, as students only access the human instructor within certain hours; whereas in mobile applications, chatbots are always available and ready to use whenever needed for practice. The immediate feedback given by these AI-driven tutors helps learners identify their mistakes and improve quickly, fostering a more effective and continuous learning process. 6 Besides convenience, chatbot-based language tutors can offer learners the opportunity to practice conversational English in a low-pressure environment. Constructive practice is necessary for learning. Due to time and location constraints, students cannot attend traditional classes or get enough help from teachers after class. For non-native English speakers, this is much more difficult, and there is a domain barrier. Chatbots mimic real-life conversations, allowing learners to feel more confident in their language skills. 7
Speech recognition technology adds to these interactions. DL algorithms learn and improve with experience. Data from learner languages, errors, preferences, and progress are analyzed to refine the chatbot’s responses and teaching strategy. 8 The chatbot becomes more accurate at predicting what the learner needs and provides specific exercises to meet their learning challenges. This data-driven learning method allows a chatbot to present customized material, such as exercises for vocabulary and grammar, and interactive dialogues. This means learners receive materials that fit their skill and goal level in learning. 9 This advancement of using DL in language-based tutors using chatbots marks the beginning of important developments in language acquisition. These AI-driven tutors offer innovative solutions for English language learners through personalized, interactive, and adaptable learning experiences. The flexibility to practice in a judgment-free environment, combined with the scalability and continuous improvement of DL models, makes chatbot-based language tutors a powerful tool in the ongoing evolution of language education in mobile applications. 10
The primary objective is to investigate the role of chatbot-based language tutors utilizing DL techniques to facilitate English language acquisition in mobile applications. The research focuses on developing a chatbot system that aids in grammatical error correction, enhances vocabulary, and improves conversational skills through personalized interactions. The research also explores the integration of advanced AI models to address the challenges of intent categorization and data scarcity in language learning environments. The key contributions of the research are listed as follows. (1) To introduce the EPI-BiLSTM model that improves intent classification accuracy in chatbot-based English language tutors. (2) To collect data from a publicly available Chatbot-based English learning dataset and utilize tokenization and stop word removal for preprocessing. (3) To employ back translation as a data augmentation technique, addressing data scarcity and enhancing chatbot-based proofreading capabilities in mobile applications. (4) To use the Term Frequency Inverse Document Frequency (TF-IDF) for feature extraction.
Related works
Recent advancements in chatbot technology have demonstrated significant potential in enhancing language acquisition. Assayed et al. 11 developed HSchatbot, a system designed to classify intents from questions posed by high school students. Their approach employed Random Forest (RF) and Multinomial Naïve-Bayes classifiers, with RF achieving over 90% accuracy, outperforming the Multinomial Naïve-Bayes model. Notably, the study revealed that Multinomial Naïve-Bayes performed better with TF-IDF vectorization than with CountVectorizers. Dongbo et al. 12 proposed an AI-driven method for improving chatbot comprehension of customer inquiries. Their framework combined a Bidirectional Recurrent Neural Network (BRNN) with a Fuzzy Naïve-Bayes (FNB) classifier (BRNN-FNB) to generate real-time responses. The integration of sentiment analysis enhanced interaction precision, particularly for voice-based chatbots. The model achieved 92% accuracy without sequence-to-sequence (Seq2Seq) architecture and 93% with it, demonstrating applicability in digital marketing, education, and online forums. Addressing pandemic-induced communication challenges, Yang et al. 13 developed DR-COVID, a multilingual NLP-based chatbot for COVID-19 information dissemination. Tested across multiple languages, DR-COVID exhibited high accuracy and rapid response times (1.12–2.15 seconds across devices), outperforming existing chatbots in both speed and precision. For Turkish misspelled word detection, Aytan and Şakar 14 integrated a false-positive reduction model into a two-step deep learning framework. Their approach evaluated syllable-based, character-based, and byte-pair encoding tokenizers using LSTM and Bi-LSTM architectures. The multi-class dataset revealed that tokenization strategies significantly influenced error correction efficacy.
Despite advancements, Sayenju et al. 15 highlighted persistent biases in NLP models such as BERT (Bidirectional Encoder Representations from Transformers). These biases arise from discrepancies between training corpora and domain-specific chatbot inputs, potentially compromising model generalizability in language learning contexts. Hew et al. 16 investigated chatbots in online education through two studies. In Study 1, a SMART goal-setting chatbot guided learners in structured exercises, while Study 2 employed a “learning buddy” chatbot for EFL listening practice. Both trials reported positive learner experiences, emphasizing chatbots’ usability and pedagogical value in fostering engagement. Leveraging mobile sensor networks, Jingning 17 enhanced speech recognition in an intelligent English learning system. By preprocessing voice signals and optimizing feature extraction, the system achieved robust performance against background noise and speaker variability, surpassing traditional methods in recognition accuracy. Imran et al. 18 utilized a convolutional neural network (CNN) to classify English words into nine grammatical categories (e.g., nouns, verbs, adjectives). The model achieved 97.22% overall accuracy, with perfect classification for pronouns, determiners, verbs, adverbs, and prepositions. Chi-square tests validated its utility for non-native speakers, establishing benchmarks for automated grammatical analysis. Wang 19 analyzed Duolingo, an AI-driven language tutoring system, in a study involving 125 students. The platform’s adaptive exercises and spaced repetition mechanisms improved vocabulary retention and grammar mastery, underscoring conversational AI’s role in scalable language education. Yang et al. 20 evaluated Ellie, a task-based speech chatbot for Korean EFL learners. Participants (n = 31, ages 10–15) completed three speaking tasks, achieving an 88.3% success rate. The chatbot facilitated dialogue-driven practice, addressing a critical gap in conventional EFL instruction. Chien et al. 21 implemented LINE ChatBot to improve English speaking/listening skills among 73 students. While learning gains were modest, extrinsic motivation increased significantly during anonymous interactions. Incorporating competitive elements further boosted intrinsic motivation, highlighting chatbots’ potential for engagement. Albornoz-De Luise et al. 22 developed a Rasa-based conversational agent for hypergraph problem-solving. The system achieved F1-scores of 0.965 (intent recognition) and 0.989 (entity extraction), demonstrating robust performance in natural language interaction for tutoring systems. Hsu et al. 23 designed TPBOT, a TOEIC-focused chatbot to reduce EFL learners’ speaking anxiety. Chinese students with TOEIC® oral scores <100 reported improved confidence and satisfaction, with teachers endorsing its efficacy in enhancing oral proficiency. Rizou et al. 24 created a multilingual customer service chatbot using BiLSTM and Conditional Random Fields. Evaluated on the UniWay dataset, the model effectively processed user queries in Greek and English, showcasing cross-linguistic adaptability.
While AI-powered chatbots show promise in language acquisition, critical limitations persist in mobile learning applications. First, reliance on large labeled datasets11,14,18 exacerbates data scarcity and impedes generalization across diverse learner contexts. Although models like CNNs 18 and BiLSTMs 24 excel in intent classification and error detection, they struggle with real-time grammatical correction for non-native speakers.14,20 Traditional approaches, including Seq2Seq architectures, 12 inadequately address the dynamism of conversational inputs, limiting pedagogical effectiveness. Furthermore, biases in domain-specific training data 15 risk undermining model accuracy. To address these gaps, our study proposes an EPI-BiLSTM model for intent classification, augmented by back-translation techniques. This hybrid framework enhances grammatical feedback and enables context-aware language support, optimizing mobile English acquisition.
Methodology
This section discusses all the methodologies necessary to enhance a chatbot with language learning proficiency, including dataset preparation, data augmentation, feature extraction, and other model optimization. These processes collaborate to improve a chatbot system’s ability toward intent categorization and grammatical error correction to enhance its basic English learning tool. Figure 1 shows how the methodology unfolds. Methodology flow.
Data set
Data set structure of chatbot-based English learning.

Preprocessing
Techniques like tokenization and stop word removal are major to make the input text even simpler so that the model can focus on real issues. All these preparation techniques enhance the capability of a chatbot in terms of understanding and processing the capacity of user input with reduced noise and content, making it more sorted. The process of tokenization and removing stop words are illustrated in Figure 2. Preprocessing techniques process.
Tokenization
This is another necessary preprocessing step that divides text into smaller pieces, usually words or sub words. Tokenization enables the structured analysis of text, and with tokenization, the chatbot can easily identify grammatical patterns, intent, and mistakes in user-generated utterances. This method breaks up the text into tokens, which improves user interaction and learning results. Besides, tokenization supports additional operations such as word embeddings and syntactic parsing that are crucial for DL-based language models.
Removing stop words
Effective textual preprocessing is fundamental to the improvement of the effectiveness of the language tutors based on chatbots in supporting the learning of English as a second language. One of the basic preprocessing steps involves eliminating the frequently used words in a language, which could include the usual “the,” “is,” and “in,” with no useful information content for the analysis. These words would ensure the model can focus on more important phrases that support the intent-categorizing and grammar correction processes. This stage minimizes the number of irrelevant characteristics the DL model needs to process; this is not only reducing noise in the dataset but also maximizing computational resources.
Data augmentation using back translation
To address data scarcity in grammatical error correction, we employ back translation as a data augmentation technique. This process involves selecting specific segments within the original erroneous sentence—primarily those with three or more tokens that are likely to contain grammatical errors. These segments are first translated into an intermediate language (e.g., Chinese, French, or Spanish) using a high-quality neural machine translation (NMT) model. Subsequently, the translated segment is re-translated back into English using the same or another NMT model. This two-step translation process produces paraphrased versions of the original segment, often with improved grammatical correctness and varied phrasing. The resulting paraphrased sentences serve as augmented data, providing the model with more diverse examples of correct and erroneous sentence structures. By focusing on context surrounding potential errors, back translation helps generate parallel corpora with both incorrect and corrected sentences, enabling the chatbot to learn more robust grammatical correction strategies.
By adding grammatically correct sentence variations to the data, it helps the chatbot-based system learn how to fix grammatical errors better. Back translation does better in mobile applications designed to assist in learning English by increasing the training set, which increases the strength of the model’s ability to generalize.
Extracting feature using Term Frequency Inverse Document Frequency (TF-IDF)
Chatbot-based language instructors have to extract important features from textual material to classify user intent and assist in grammatical correction. A method of feature extraction named TF-IDF measures the importance of words in a given corpus. To ensure that regularly used terms in a particular context are correctly weighted, the term frequency (TF) calculates how frequently a word emerges in a document about the total number of words. Because this is frequently occurring words that show up in several documents may not be that helpful, thereby using inverse document frequency (IDF). Advanced weight to terms that arise uniquely within a specific text while giving lower weights to those terms that appear very often in a dataset were given.
The combination of TF (equation (1)) and IDF (equation (2)) helps the chatbot to focus more on words that are more relevant to intent classification and grammatical error detection. For instance, in learning the English language, TF-IDF (equation (3)) can help the chatbot distinguish between erroneous sentences and the correct ones according to grammar, thus providing better correction and recommendations. The capacity of a chatbot to evaluate phrase structures, identify mistakes, and give contextually relevant information can be improved by utilizing TF-IDF, which eventually improves the experience of learning by users.


Efficient pigeon inspired fused bidirectional long short-term memory (EPI-BiLSTM) to classify the intend based on the text
The proposed method is the integration of Bi-LSTM and EPI. The bidirectional method manages to pick important contexts both in the future and past of text sequences, provided that it uses forward and backward processes. This EPI system has navigation algorithms through swarm intelligence to enhance the correction error of the model. If used together, it enhances the capability of grammar correction in chatbots by taking context and data of previous sequences into account in making more precise language learning.
Bidirectional long short-term memory (BiLSTM)
Grammatical error correction using chatbot-based language tutors, the traditional LSTM cell’s limitation is its inability to process both preceding and subsequent content. To address this limitation, two different LSTM hidden layers with related output in opposite directions were proposed as bidirectional recurrent neural networks. This method uses information from the past and future in the output layer. The bidirectional approach enables the model to utilize both historical and future context, which is particularly beneficial in tasks like grammatical error correction, where both contexts before and after a word or phrase may be crucial for accurate correction.
The input sequence BiLSTM structure.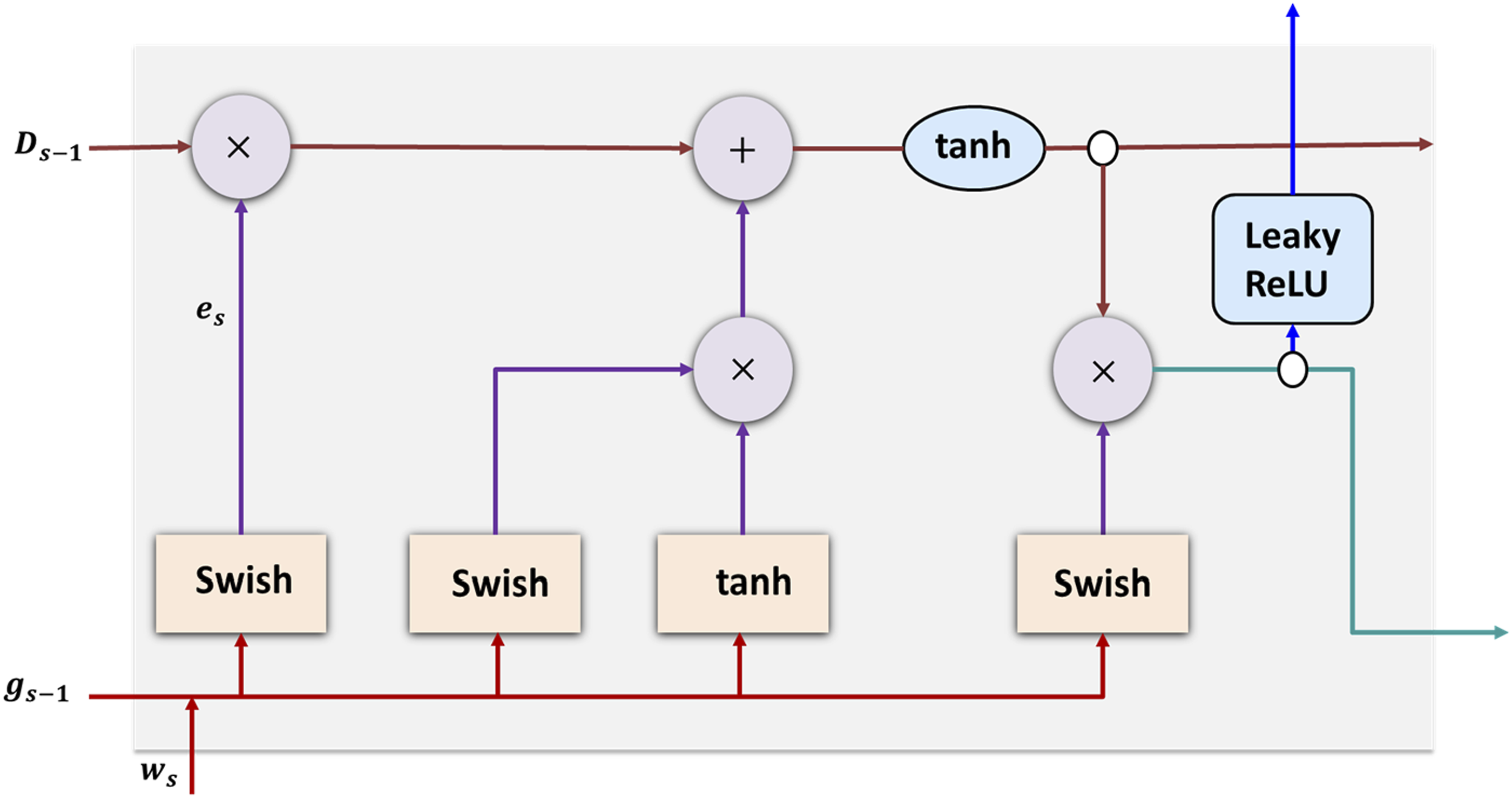
In deep networks, the choice of activation function (AF) significantly affects training dynamics and performance. For the classification model, Swish, an AF suggested and expressed as 





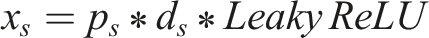
The sophisticated AF and gating mechanisms, along with the BiLSTM’s bidirectional nature, enable efficient processing of text sequences for the detection and correction of grammatical errors. The model is better able to recognize and fix grammatical errors in a sentence by taking into account both past and future contexts. This enhances the chatbot-based language tutor’s overall performance in language acquisition and grammatical correction tasks.
Efficient pigeon inspired (EPI) optimization
A swarm intelligence focused method called Pigeon Inspired Optimization (PIO) mimics the collective behavior of homing pigeons searching for their homes using landmarks, the sun, and magnetic fields as navigational aids. This optimization approach can be effectively applied to the grammatical error correction within chatbot-based language tutors. Pigeons first rely mostly on instruments that resemble compass devices to find their direction, althoughmay eventually be used to and continuously correct their course. PIO consists of two operators: the map and compass operator, which uses magnetoreception to sense the field of earth and shape the map in their brains, and the landmark operator, which simulates pigeons searching the path based on landmarks.
The models for the two operators of EPI.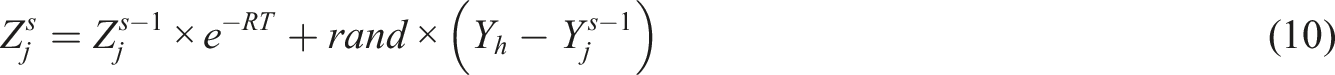

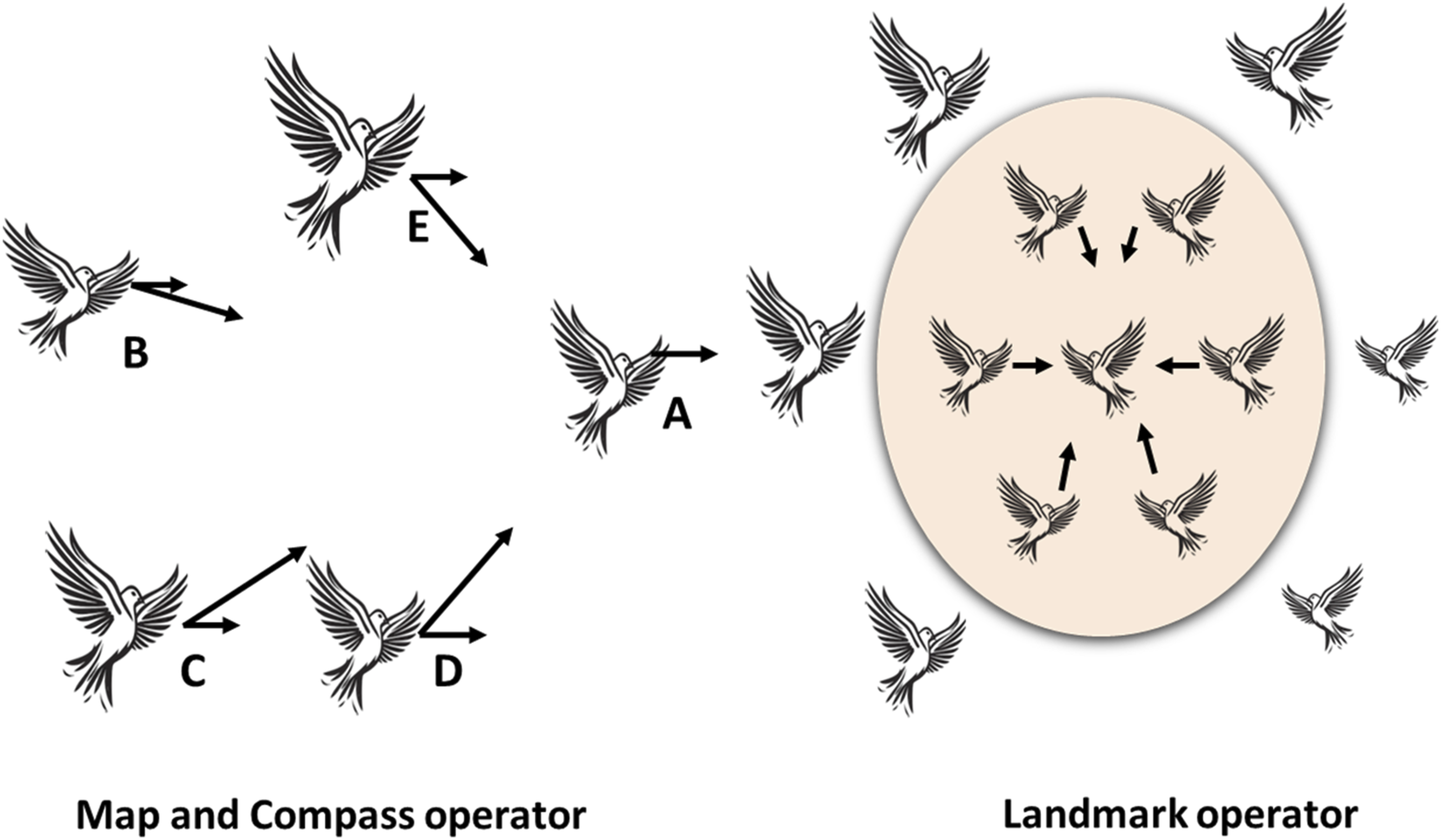
This operator mimics how pigeons use landmarks and magnetic fields to navigate, just as the language model uses linguistic structures and contextual awareness to fix grammar mistakes.



Pigeon
This operator mimics how pigeons look for landmarks to help them navigate, which is similar to how the chatbot system improves its grammar correction by considering a sentence’s context.
Object-based initialization method
Random initialization is frequently used to initialize the beginning population for meta-heuristic algorithms in the context of improving grammatical error correction for chatbot-based language learning systems. However, given the wide variety of potential grammatical structures, it could be challenging to find an ideal solution space when used for text-based tasks like grammatical error correction. A Pigeon’s position model.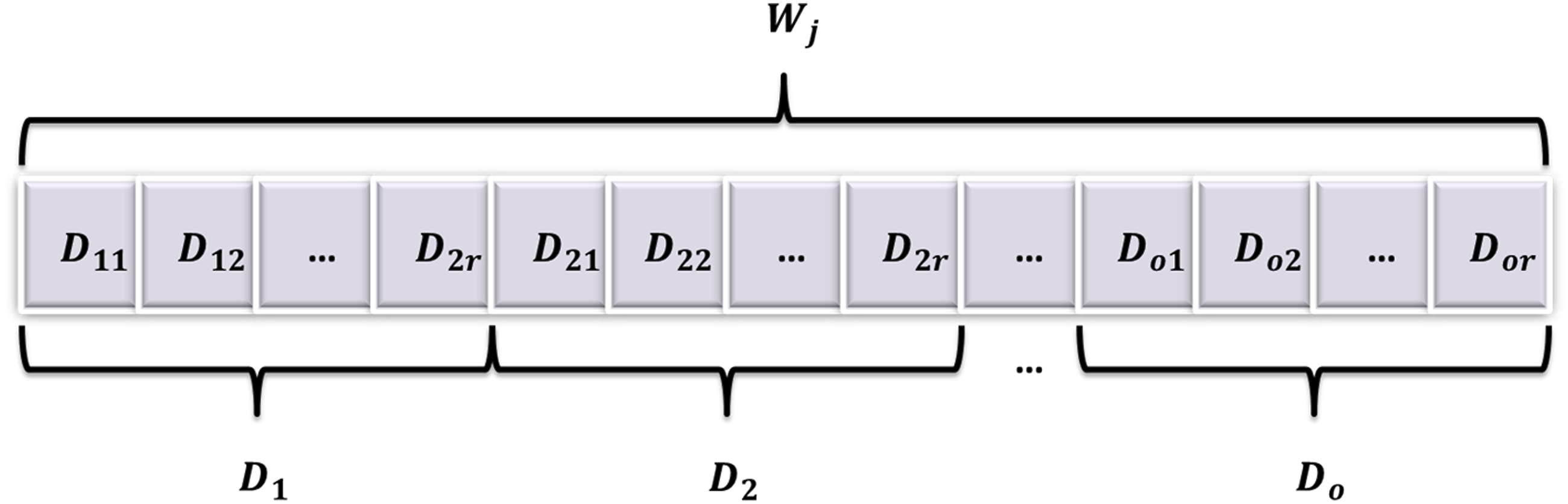
Using these context-aware clusters to start the population increases the likelihood that the chatbot will find correct grammatical corrections in real-world language learning scenarios by starting its optimization process on a more appropriate collection of error patterns.
Parameter control strategy
EPI may encounter difficulties when used for language tasks in the field of grammatical error repair. In some applications, the current parameter
The discrepancy between a pigeon’s present position and the existing global ideal position can be used to assess the quality of its initial velocity. Since the pigeon should maintain more inertia to go in the direction of the initial velocity with high quality, the smaller the difference, the better the quality. The parameter 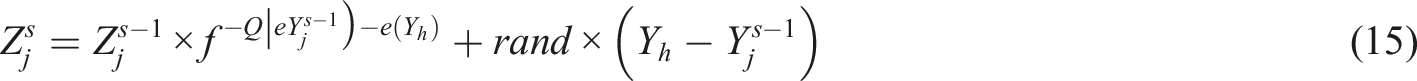
EPI implementation procedure for grammatical error correction
A chatbot is guided through a series of adjustments by the map and compass operator and landmark operator as part of the EPI optimization process for grammatical error repair. By updating its corrections according to the most recent global best correction and error pattern, the map and compass operator assists the chatbot in navigating through potential corrections. By concentrating on certain corrections, the landmark operator enables the chatbot to modify grammar according to context. Over several cycles, the chatbot’s error correction is progressively improved by combining these operators. Based on the chatbot’s current location in the correction space, the number of function evaluations for the operators is modified. This procedure is repeated until the chatbot achieves a nearly ideal grammatical correction method, utilizing linguistic patterns for dynamic enhancements.
The strengths of EPI and BiLSTM are used in the model EPI-BiLSTM. Using improved activation functions and gating techniques, the BiLSTM enhances chatbot-based language tutors’ grammatical error correction by using both past and future contexts. Imitating the pigeon navigation behavior, EPI improves the correction by fine-tuning corrections with landmark operators and updating global location by map and compass operators. The use of these techniques ensures comprehensive learning and adaptation skills by providing iterative optimization and context-aware changes, improving the grammar correction capabilities of the chatbot. Algorithm 1 provides the process of proposedEPI-BiLSTM method.

Experimental result
This section discusses system configuration, hyperparameters, and detailed experimental results, including accuracy measurements for various features and comparison with traditional models. The effective outcomes proved the superior functions of the EPI-BiLSTM model in various language learning tasks.
System configuration
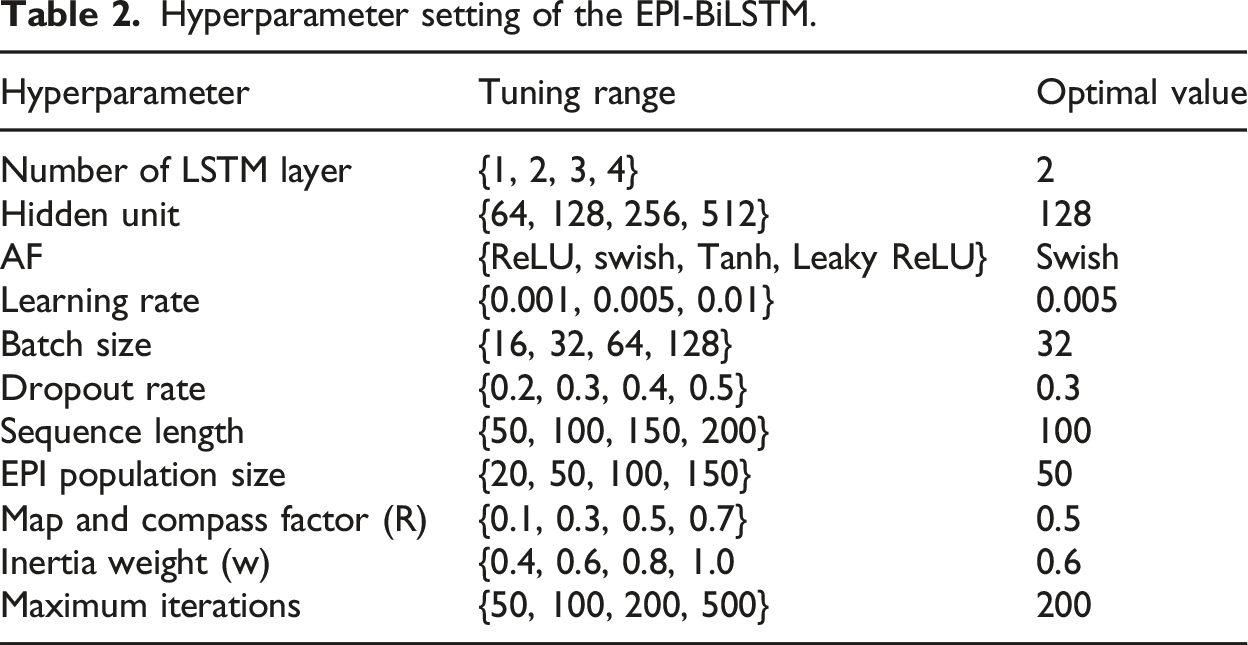
Hyperparameter setting of the EPI-BiLSTM.
Output phase
Feature-wise accuracy of the EPI-BiLSTM.


Performance accuracy across features.
Comparison phase
A proposed EPI-BiLSTM is compared to the traditional single semi-supervised multi-domain joint model (SEMI-MDJM),
26
especially on three tasks. • Model: Domain classification is essential to be able to guide the chatbot to the correct area of knowledge (e.g., determining if the user is asking about grammar or vocabulary). High accuracy in this domain guarantees that the chatbot will classify inquiries effectively and provide relevant material accordingly. • Intention: This capability of intent recognition helps the system understand what exactly the user intended to say using the message. The right response can be furnished more rapidly and accurately by the system if it can more profoundly identify the intention of the user. Significant intention accuracy is also required to give meaningful, and customized interaction. • Entity: The chatbot can understand the content of the query and respond more appropriately by identifying entities. For example, if it identifies a name or location in a question, the chatbot can modify its response accordingly. • Avg. accuracy: The average accuracy (Avg. accuracy) provides a general notion of how effective the model is at performing a large number of tasks overall. Better average accuracy indicates that the model will have consistent performance over different components and thus, result in quality user interactions with language learning applications.
Comparative evaluation of SEMI-MDJM and EPI-BiLSTM in language learning task.


Task-wise performance comparison of models.
Discussion
The performance of the chatbot system in language learning applications was enhanced by proposing a more efficient model, EPI-BiLSTM, that overcomes the limitations of the existing model. Despite its efficacy in domain classification, intent identification, and entity extraction, the current SEMI-MDJM model has several drawbacks. For one, much-labeled data is used, which takes a lot of time and resources to gather. SEMI-MDJM performance and scalability are also weakened in practical applications where the data labeling cannot be done with this dependency. Also, SEMI-MDJM fails to find appropriate entities where the queries are complicated or ambiguous, which also results in inferior responses. In addition, because the model cannot adapt to multiple languages or domains in its handling of multi-tasking, the overall model’s accuracy is further restricted in delivering customized solutions. The suggested EPI-BiLSTM model addresses these flaws by integrating a BiLSTM network, which efficiently handles context and enhances the comprehension of questions from specific domains. In addition, through the use of unlabeled conversational data, the EPI-BiLSTM model greatly reduces the need for manually annotated datasets. This enables better scalability and performance, especially in language learning applications where domain classification and intent recognition have improved significantly.
While our proposed EPI-BiLSTM framework demonstrates promising performance in intent classification and grammatical error correction within the English language context, several limitations warrant consideration. First, the reliance on high-quality translation models for back translation may pose challenges when extending to low-resource languages, potentially affecting the quality and diversity of augmented data. Second, the current approach’s scalability to larger datasets or real-time applications requires further validation, as the computational complexity of the EPI optimization and deep learning components may impact deployment efficiency. Third, the model’s adaptability to different learning contexts—such as varying proficiency levels or domain-specific language—may necessitate additional fine-tuning or domain adaptation techniques. Future research should explore multilingual extensions, optimize computational efficiency, and evaluate the approach in diverse educational settings to enhance its applicability and robustness.
Conclusion
The above experiment demonstrates the applicability of combining DL models with chatbot-based language tutors to enhance English acquisition through mobile applications. The research illustrates the need to interpret user inputs accurately, which can be fulfilled by the EPI-BiLSTM model for the classification of intent. A chatbot-based English learning dataset was used, and these data were preprocessed using techniques like stop word removal and tokenization. TF-IDF-based feature extraction enhances the working efficiency of the chatbot even with complex language patterns. A novel application of back translation for data augmentation that helps it enhance its grammatical error correction strategy in creating parallel corpora is also useful for offering accurate language corrections. The experimental results indicate that the EPI-BiLSTM surpasses traditional algorithms with higher accuracy in terms of tasks like domain (80.5%), intent (90.3%), entity (75.2%), and average accuracy (81.3%). This further indicates that combining chatbot-based systems with advanced DL techniques can improve grammatical error correction and language learning experiences to a great extent. It also opens new avenues for the development of intelligent AI-driven language acquisition tools and promises implications for personalized learning and real-time language assistance in mobile applications. Future research will explore expanding its capabilities to add support for further languages and grammar rules.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The authors declare that the data supporting the findings of this study are available within the article. The raw/derived data supporting the findings of this study are available from the corresponding author at request.