
Abstract
Given the challenges in capturing temporal dependencies within sports event data and the imbalance between global and local feature representations, this study introduces a Transformer-based model designed to address these issues. By leveraging a multi-head self-attention mechanism, the model effectively captures dynamic features across different time granularities, thereby enhancing the analysis of temporal event data and improving the accuracy of win rate prediction. Specifically, a time-segment encoding strategy is first employed to partition the event sequence data, enabling independent processing of features within each temporal segment. Subsequently, a multi-level Transformer architecture is constructed to extract both short-term and long-term dependencies at different hierarchical levels, facilitating a more comprehensive understanding of game dynamics. To further refine feature representation, a dynamic self-attention adjustment mechanism is incorporated, allowing the model to adaptively focus on salient features based on the characteristics of the input data. Experimental results demonstrate that, in comparison with baseline models—including Logistic Regression (LR), Support Vector Machine (SVM), Random Forest (RF), Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN), and Extreme Gradient Boosting (XGBoost)—the proposed model achieves superior performance. Specifically, it improves prediction accuracy by 10.7%, 8.3%, 3.9%, 6.0%, 4.3%, and 2.4%, respectively, and enhances precision by 10.6%, 9.4%, 5.0%, 6.5%, 4.5%, and 3.6%, respectively. These findings underscore the model’s effectiveness in handling complex temporal sequences and multi-layered feature structures, thereby significantly improving the accuracy and robustness of win rate predictions in sports events.
Keywords
Introduction
In the era of big data, the scale and complexity of sports event data are growing rapidly. Taking football as an example, its game statistics, player performance, tactical analysis, and other dimensions have brought unprecedented opportunities and challenges for a deep understanding of the laws of competitive sports and improving the prediction accuracy of wins and losses.1,2 Existing football event data analysis methods lack the mining of complex time correlation and dynamics in the competition process, resulting in large errors in practice.3,4 In particular, when the data on the actual field presents the characteristics of rapid changes and multi-dimensional interactions, it is difficult for existing methods to cope with such complex dynamic changes. Self-attention mechanism and Transformer model are key technologies that have achieved breakthroughs in natural language processing research in recent years, and have outstanding advantages in time series modeling and global information capture.5–7 Applying them to football event data analysis and win rate prediction, mining complex time series relationships from event data has very important practical significance for improving the event analysis accuracy and guiding athletes to conduct scientific training and competition decisions.
In the existing research on sports event data analysis and win rate prediction, scholars mainly focus on using statistical models and machine learning algorithms to improve the accuracy and reliability of predictions.8,9 To improve the prediction accuracy of game results, Sharma Manoj proposed a badminton game result prediction technology based on correlation feature weighted naive Bayes. The results of each tournament with reduced features were analyzed and compared with the full feature dataset. The results showed that compared with other proposed classifiers, the proposed method showed significant performance in predicting the matching results of the reduced feature dataset. 10 To achieve scientific adjustment of strategies during the game, Li Hang used adaptive back-propagation neural network (BPNN) to construct a game prediction model and made predictions using football game data as samples. The results showed that the prediction model established by the improved adaptive BPNN algorithm had a smaller prediction error after rolling prediction and had higher accuracy and reliability. 11 Jain Praphula Kumar proposed a sports performance prediction method based on data mining. To verify the effect of the proposed model, a case study on predicting the results of the Indian Super League was presented. The results showed that the best prediction accuracy of the constructed model was 70.58%. 12 Sarlis Vangelis used data science techniques and algorithms to examine player performance statistics over 20 seasons to reveal the key factors that affect team success at critical moments. The results showed that this method helped make more informed decisions in high-risk basketball environments and advances the field of sports analytics. 13 Buhamra N, based on a regression model, modeled the probability of the top-ranked player winning by considering potential covariates, and compared the predicted results of the 2022 tournament with the actual results through a rolling window strategy to verify the rationality of the proposed hypothesis. 14 Hsu Yu-Chia combined a CNN classifier for implicit pattern recognition with a logistic regression model for matching result judgment to predict odds from the betting market and the actual score of each game. The empirical test results showed that the method used was superior in pattern recognition and prediction accuracy of each team’s personal historical data. 15 These studies can effectively improve the understanding and prediction of event results by analyzing historical event data, team and player performance data, etc. However, most methods are still insufficient in describing the dynamics of long-term spans.
The Transformer model has strong advantages in parallel computing and can precisely capture the dynamics of long-span sequence data.16,17 Currently, many studies have analyzed the application of self-attention mechanism and Transformer model in time series data processing and feature extraction. Yang Chaocheng proposed a model with a dual attention mechanism to target the deep local features and complex dependencies in time series data. This model used a dynamic weighted window to divide sequence segments with strong discernibility and assigned larger weights to mine local features containing important information. Experimental results showed that the proposed model could effectively process time series data. 18 Su Yaqian proposed an adaptive self-attention moving average model. By applying the self-attention mechanism, the weights of data at different time points were adaptively determined to calculate the moving average, and finally they were combined for time series prediction. Finally, a large number of experiments on two real datasets proved the effectiveness of this method. 19 In sports event data analysis, to consider the time factor in football game analysis, Yeung Calvin applied a Transformer-based neural labeling spatiotemporal point process model designed specifically for football event data, and tested it using open source football event data. The results showed that the proposed model successfully predicted future events, with an overall improvement of 4% compared to the baseline model. 20 Existing research has improved the understanding of the dynamics in event time series data by applying the Transformer architecture and self-attention mechanism, but there is still room for further exploration in the balance of global and local features in the model over a long time span.
To enhance the accuracy of dynamic analysis for event-based time series data and improve the effectiveness of outcome prediction, this study proposes a novel approach by integrating the Transformer model with its self-attention mechanism, using football match data as the primary application domain. The model leverages a combination of time-segment encoding and a multi-level Transformer architecture to effectively capture both short-term and long-term temporal dependencies inherent in football events, thus enabling a more nuanced understanding of game dynamics.
In the experimental evaluation, the proposed model demonstrates significant performance gains over several baseline methods, including Logistic Regression (LR), Support Vector Machine (SVM), Random Forest (RF), Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN), and Extreme Gradient Boosting (XGBoost). Specifically, the model achieves improvements in accuracy by 10.7%, 8.3%, 3.9%, 6.0%, 4.3%, and 2.4%, respectively; in precision by 10.6%, 9.4%, 5.0%, 6.5%, 4.5%, and 3.6%; in F1 score by 16.1%, 11.8%, 7.1%, 4.7%, 11.1%, and 5.9%; and in Kappa coefficient by 21.7%, 16.7%, 8.3%, 6.0%, 15.4%, and 10.7%, respectively. Moreover, the ablation experiments confirm the critical contribution of each model component to the overall performance, validating the effectiveness of the proposed architecture.
The key innovation of this study lies in the integration of a time-segment encoding strategy with a hierarchical Transformer framework, which allows for fine-grained modeling of multi-scale temporal patterns in complex sports event data. This design effectively addresses the limitations of traditional models in handling intricate time series correlations. Additionally, a dynamic self-attention adjustment mechanism is introduced, enabling the model to adaptively modulate attention weights based on the contextual characteristics of event data, thereby further enhancing predictive accuracy.
This research contributes to the field of sports analytics by providing a robust and scalable framework for time series modeling and outcome prediction in dynamic event-driven environments. It offers theoretical insights into the modeling of temporal dependencies and practical implications for decision-making in competitive sports, such as match preparation, tactical adjustments, and real-time performance forecasting.
Event data analysis and win rate prediction model
Data processing
Datasets
Some data examples.
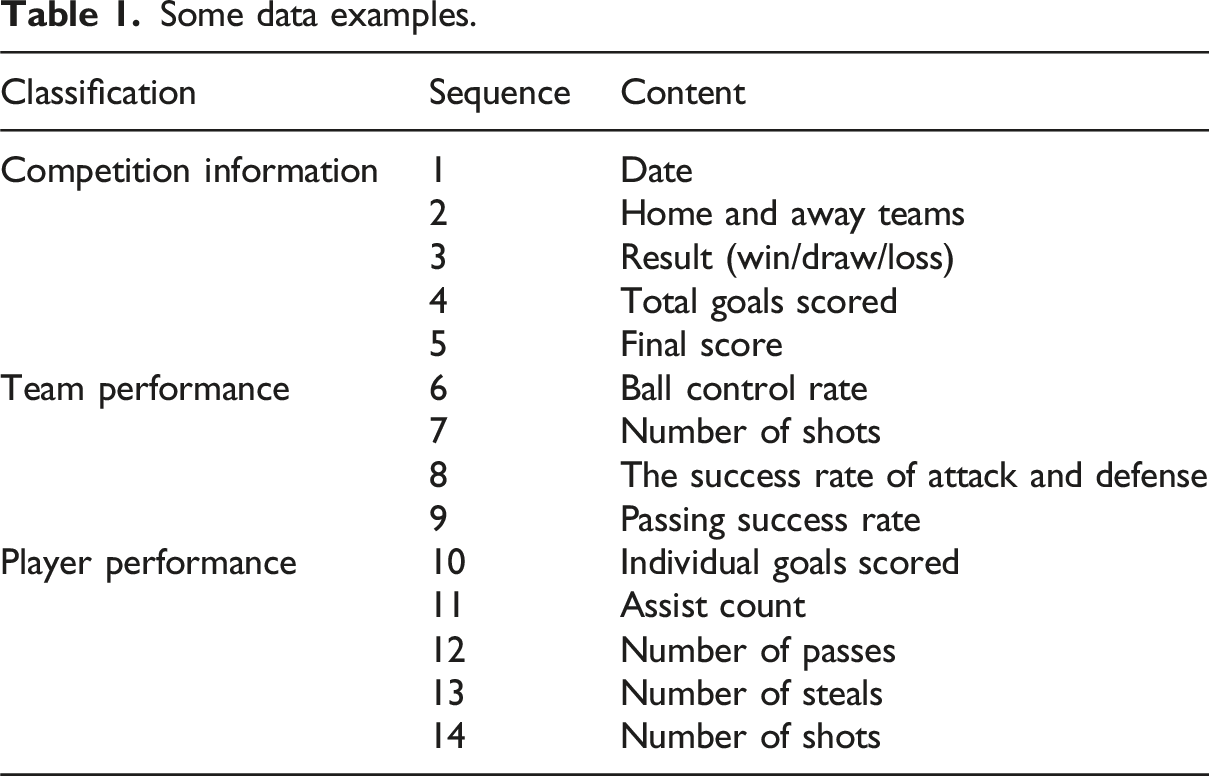
All data comes from Football-Data.co.uk. Data is automatically captured from official channels and formatted. The data for each season and each game are sorted in time series. The data processing is shown in Figure 1. Data processing.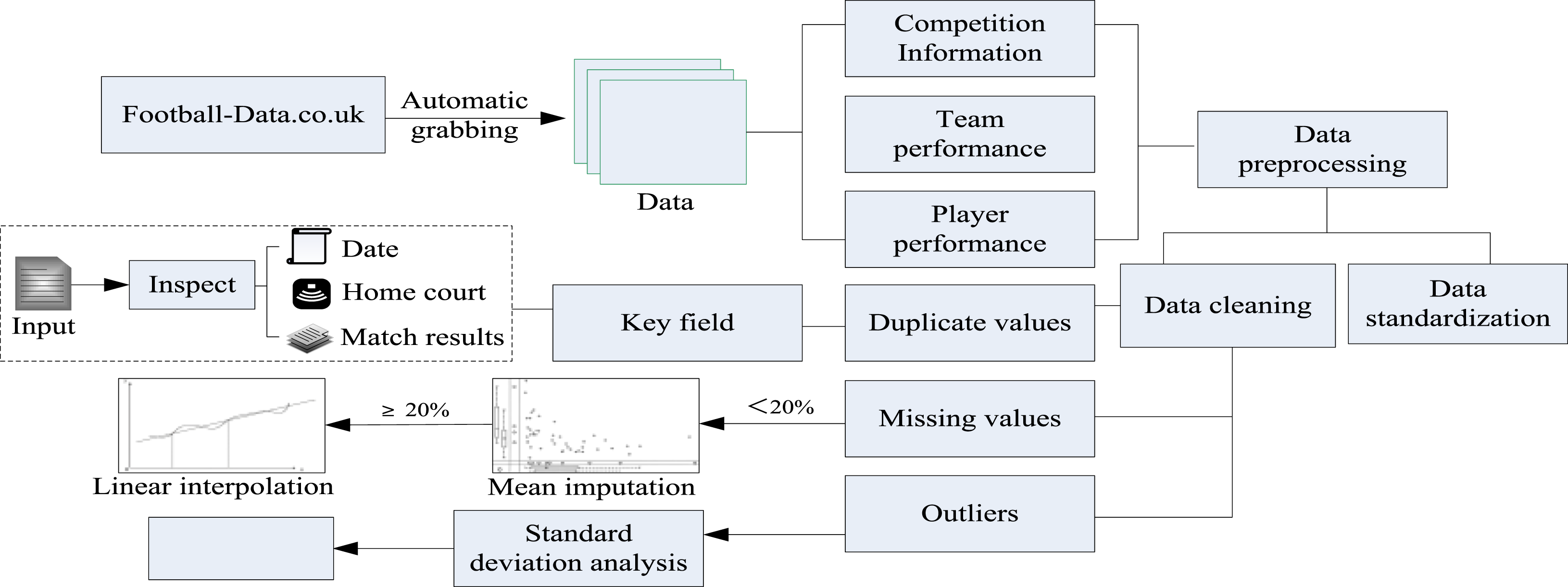
Data cleaning
The collected data is cleaned to eliminate duplicate values, missing values, and outliers. For duplicate values, all data are checked to ensure that there is only one record for each game. Duplicate data is eliminated by checking the uniqueness of the key fields of date, home field, and game results:
Here,
For missing records, if the missing ratio is small (<20%), the average filling method is used for correction:
Among them,
For features with a large missing ratio (≥20%), linear interpolation is used for filling:
Among them,
For outliers caused by data collection problems, the standard deviation analysis method is used, and outliers that exceed 3 times the standard deviation of the mean are regarded as outliers. Outliers are truncated according to upper and lower limits:
Among them,
Data standardization
The huge difference in scale between various elements makes some features account for too large a proportion in learning, thus affecting the final learning effect. To this end, each type of numerical feature is standardized so that its mean is 0 and its variance is 1. The specific formula is:
Feature engineering
Feature selection
Feature selection aims to eliminate irrelevant or redundant features, reduce the complexity of the model, and improve the generalization performance of the model. This article adopts the feature selection method based on the RF model and the recursive feature elimination (RFE) method to screen out features with better prediction performance.
RF measures the importance of features by calculating the average information gain for each feature during model training21–23:
Among them,
RFE is a method for selecting the best features by removing non-significant features one by one. In each iteration, RFE trains the model and evaluates the importance of each feature, removing the least important features and leaving only the most valuable features24,25:
Among them,
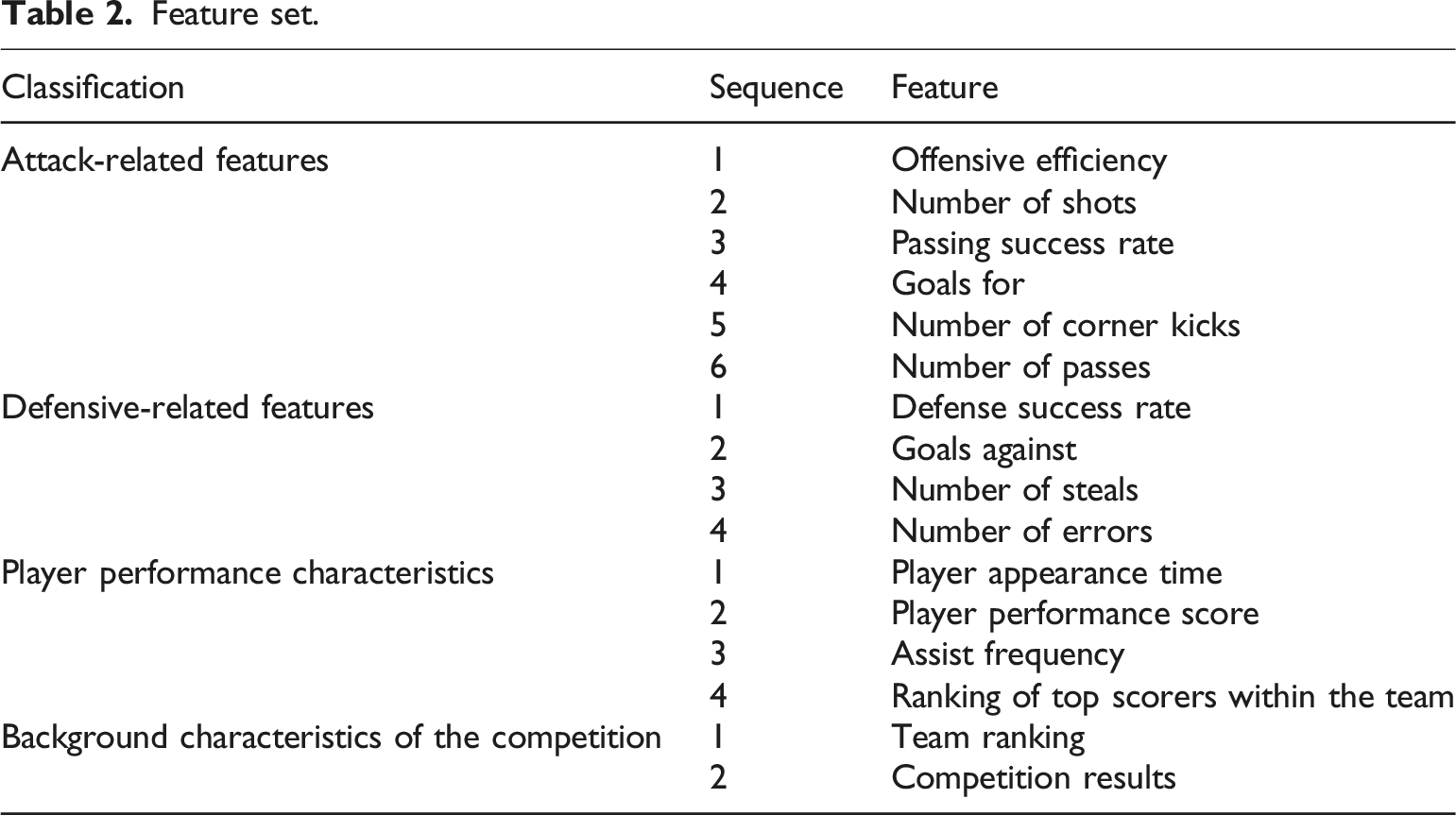
On this basis, the features are further divided into four categories: offensive-related features, defensive-related features, player performance features, and game background features.
Feature dimensionality reduction
To reduce redundant features, the features are reduced in dimensionality, and only the most valuable information is retained. This article adopts the principal component analysis (PCA) method. PCA linearly transforms the data in the original feature space into a new low-dimensional space, which preserves most of the data information and selects the feature dimension with the most information for the purpose of maximizing the variance26,27:
Among them,
Feature set.
Transformer prediction model construction
In every link of a football game, especially the transition between the first and second half, the team’s tactical adjustments, and the change in the player’s fatigue level, the final results are affected to a certain extent. The Transformer model can capture the overall correlation when processing data with a long time. Its core idea is to use the self-attention mechanism to establish a direct connection between nodes and capture the long-term dependence in the data.28,29 Unlike traditional recurrent neural networks, Transformer does not rely on time series, and can achieve efficient parallel processing of time series data, greatly improving computational efficiency. At the same time, the model can process data at different time scales, which is particularly suitable for the analysis of long-term span data such as football.
This article combines time segment encoding with a multi-level Transformer architecture to improve the model’s ability to capture short-term and long-term correlations in football event data. First, the time domain coding method is used to divide the event process into several fixed time periods. On this basis, the time-granular data is processed based on multi-level Transformer. The low-level Transformer captures the dynamic changes on a short time scale, while the high-level Transformer focuses on analyzing the overall correlation across time segments to discover important and long-term event trends. Through this hierarchical modeling method, the model can truly reflect the complex dynamic changes during the game.
Time segment encoding
First, the game process is divided into several time segments of equal length, each of which contains relevant features of a certain period.
For the characteristics of each time period, based on the time segment encoding method, time domain information is added to the data features, as shown in Figure 2. A fixed vector is added to the input data in each time period to determine the time period corresponding to the current data. At this time, the coding is based on a single fixed time length. Time segment encoding strategy.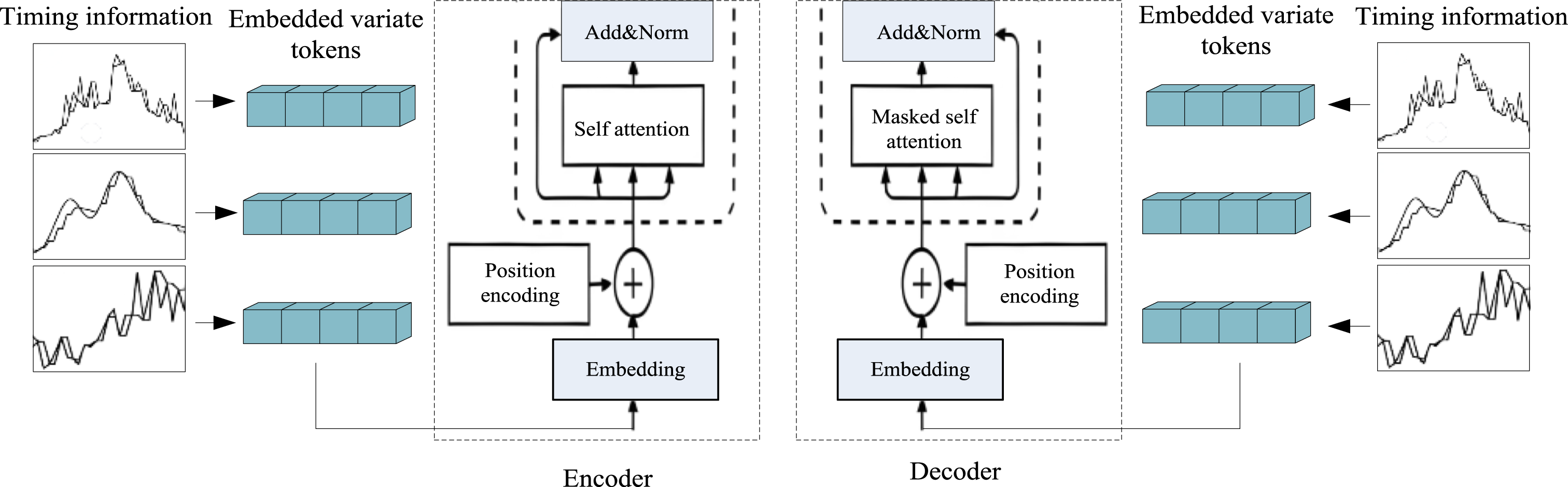
For the position of a certain time segment, the corresponding position coding is expressed as:

Here,
On this basis, the relative position representation mechanism is applied to improve the ability to understand time series data. Compared with the traditional position encoding method, the relative position representation takes into account both the absolute position of the event and the relative distance between events. Assuming that the positions of the two time segments are 
Here,
Multi-level Transformer architecture
To meet the needs of balancing global and local features in the game, a multi-scale Transformer architecture is designed. On this basis, it is divided into two levels, high and low, where the low-level task is to capture short-term correlations and the high-level task is to determine the long-term trend of the event, as shown in Figure 3. Multi-level Transformer architecture.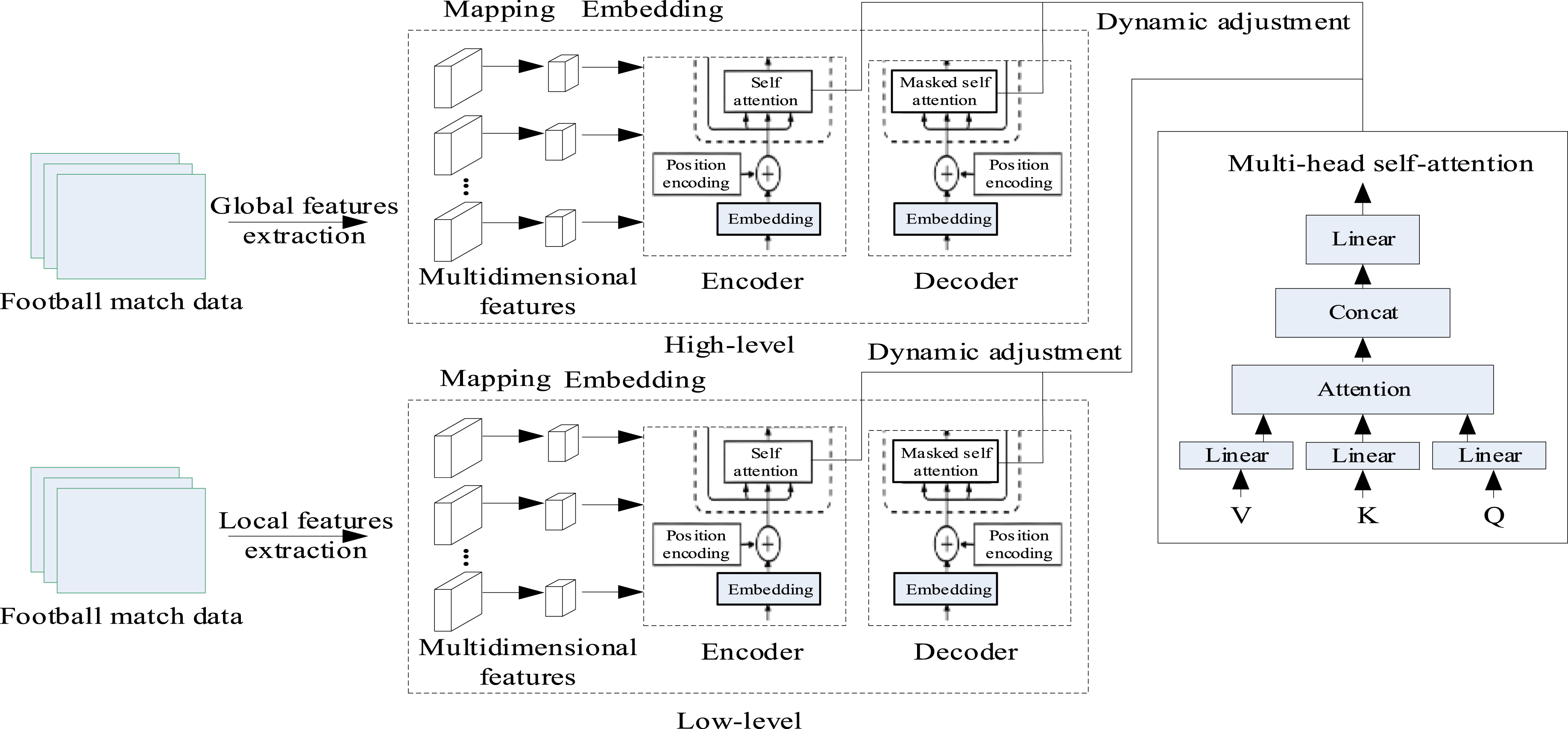
In Figure 3, the goal of the low-level Transformer is to extract local features from each time point. In a football match, each short period is accompanied by specific tactical changes, fluctuations in player status, or sudden emergencies. The low-level Transformer uses its own attention mechanism to effectively process these details and accurately capture short-term correlations. The high-level Transformer focuses on global features and uses multiple levels of self-attention mechanisms to model long-term complex temporal relationships.
Low-level Transformer
The low-level Transformer enables the model to make full use of the contextual information of other attributes and dynamically adjust the data in each period. In the self-attention mechanism, the input data is decomposed into three types of vector representations: query, key, and value. 30 Its vector representation calculates the similarity between the features in each period and determines its impact on the final result.
The input data of each period is represented by a matrix 


Here,
Using the self-attention mechanism, the similarity between the query and the key is calculated to obtain the attention weight of each feature, which is expressed as: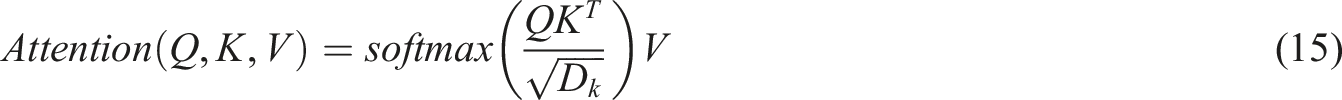
Here, 
On this basis, the multi-head self-attention mechanism is applied to improve the model performance. The query, key, and value matrices are divided into several heads, and each head performs attention calculation independently. Then, the attention of each head is spliced, and finally, the final result is obtained through linear transformation. The formula of multi-head self-attention is: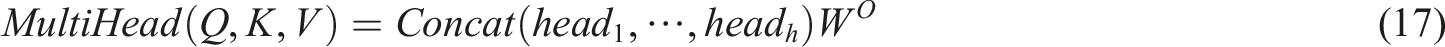
Among them,
Based on the weighted summation and the self-attention mechanism of multiple heads, the most important local features in the time series data are efficiently extracted and migrated to the next level.
High-level Transformer
The core of high-level Transformer is still the self-attention mechanism, but the difference from low-level Transformer is that it does not extract local features from a single time segment, but extracts global features from cross-time segments. The feature expression of each time segment is transformed to obtain the output representation 
It describes the feature information in different time periods.
After completing the query, key, value mapping and global dependency calculations, the multi-head self-attention mechanism is also used to realize the direct connection between different time points to obtain the overall information.
Each layer of Transformer performs self-attention calculations. This article applies a dynamic adjustment function
In each time period or data cluster of the model, the time-varying features such as the number of attacks and pass accuracy are dynamically adjusted. The dynamic adjustment of the attention weight matrix 

Among them,
Finally, through the step-by-step processing of multi-layer Transformer, the overall correlation in the cross-time event data is gradually captured, and the feature expression of long-term correlation is obtained based on this. The output of each time segment is represented by
The residual connection and layer normalization methods are used to achieve effective fusion of multi-layer information. Residual connection can effectively solve the problem of gradient loss and ensure efficient training of the network; layer normalization can standardize the results of each layer, thereby improving the stability of the model and accelerating the convergence speed. The formula for using these two combinations is: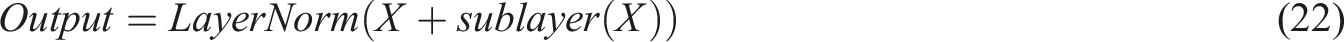
Event data analysis and win rate prediction experiment
Experimental setting
To verify the effect of the sports event data analysis and win rate prediction model using the self-attention mechanism and Transformer, an experimental analysis is conducted. The data collected from Football-Data.co.uk is used as the main experimental sample of this article. In terms of experimental setting, datasets are divided into a training set (80%) and a test set (20%).
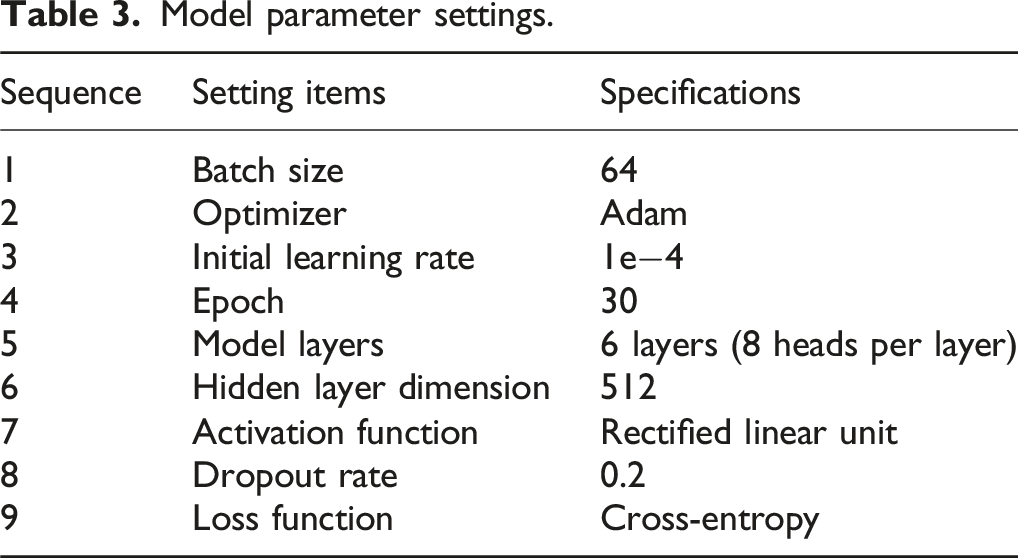
Model parameter settings.
To comprehensively evaluate the model performance, accuracy, precision, F1 score and Kappa coefficient are selected as evaluation indicators. The specific formula is:
Among them, 

Among them, the 

Among them,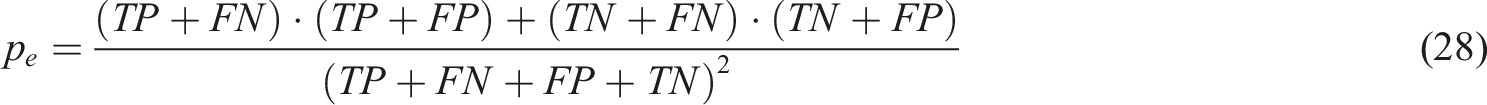

To fully verify the model effect, LR, SVM, RF, LSTM, CNN, and XGBoost models are selected for comparison. All models are trained and tested on the same dataset.
Experimental results
Accuracy and precision
In event prediction, the performance of each model in all win rate predictions and in positive class predictions is compared through accuracy and precision. The results are shown in Figure 4. Accuracy and precision results.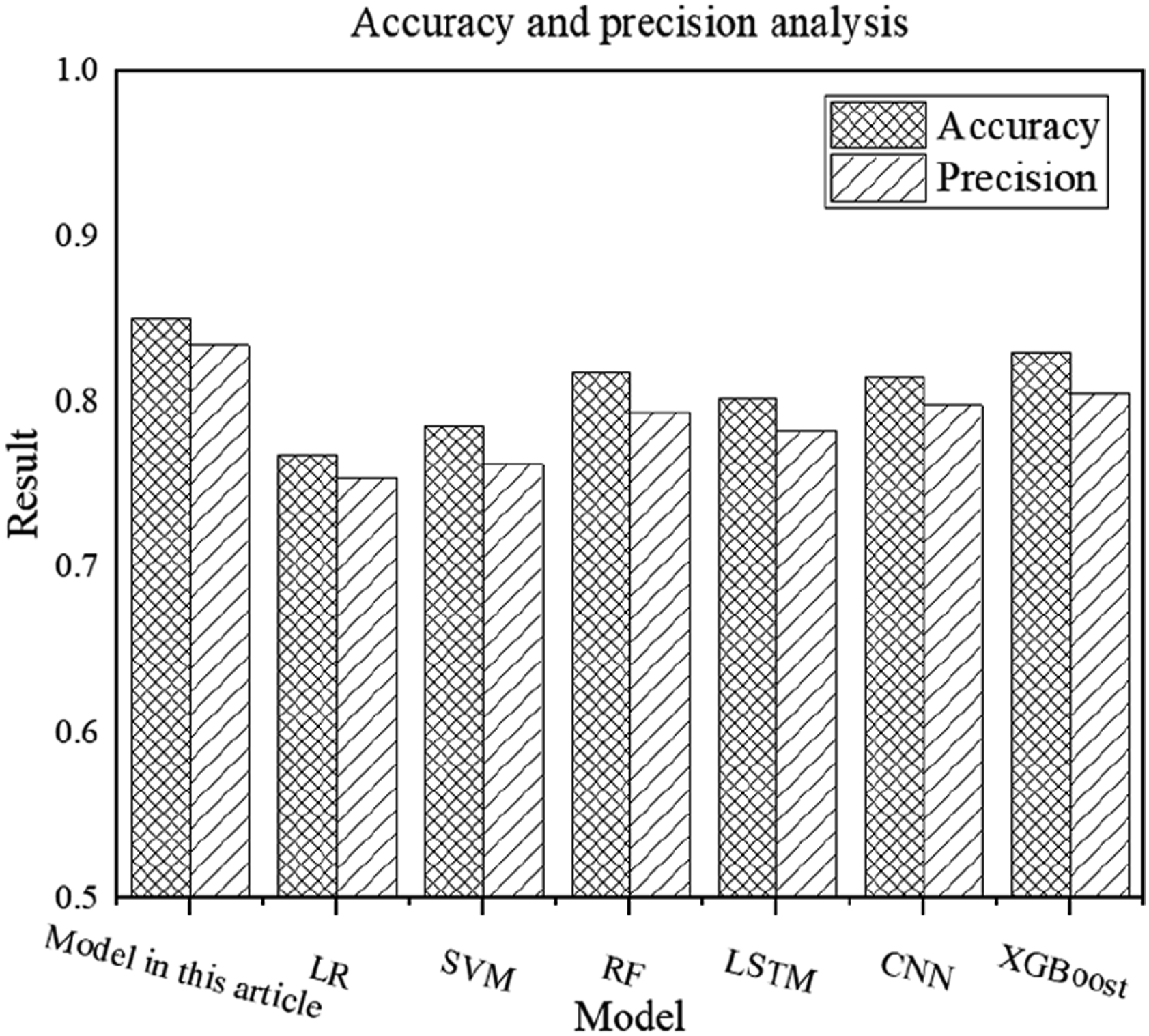
Figure 4 shows the accuracy and precision results of different models. Among them, compared with other models, the accuracy and precision results of this model are generally more ideal, with specific accuracy and precision reaching 0.850 and 0.834, respectively. The accuracy results of LR, SVM, RF, LSTM, CNN, and XGBoost models are 0.768, 0.785, 0.818, 0.802, 0.815, and 0.830, respectively; the precision results are 0.754, 0.762, 0.794, 0.783, 0.798, and 0.805, respectively. In comparison, the accuracy of this model in football event prediction has increased by 10.7%, 8.3%, 3.9%, 6.0%, 4.3%, and 2.4%; the precision has increased by 10.6%, 9.4%, 5.0%, 6.5%, 4.5%, and 3.6%.
This result shows that the proposed method has stronger and more accurate prediction ability for complex time series data of football events. Its self-attention mechanism can dynamically capture long-term and short-term dependencies, overcoming the performance bottleneck encountered by existing methods when processing sequence data, especially the dependence on complex data. At the same time, the multi-level Transformer framework improves the model’s dynamic perception of data, which effectively improves the model’s prediction accuracy and precision.
F1 score
This article further evaluates the effectiveness of the model in football event data analysis and win rate prediction by comparing the F1 scores of different models. Models with higher F1 scores usually mean more balanced predictions in various categories, and the comparison results are shown in Figure 5. F1 score results.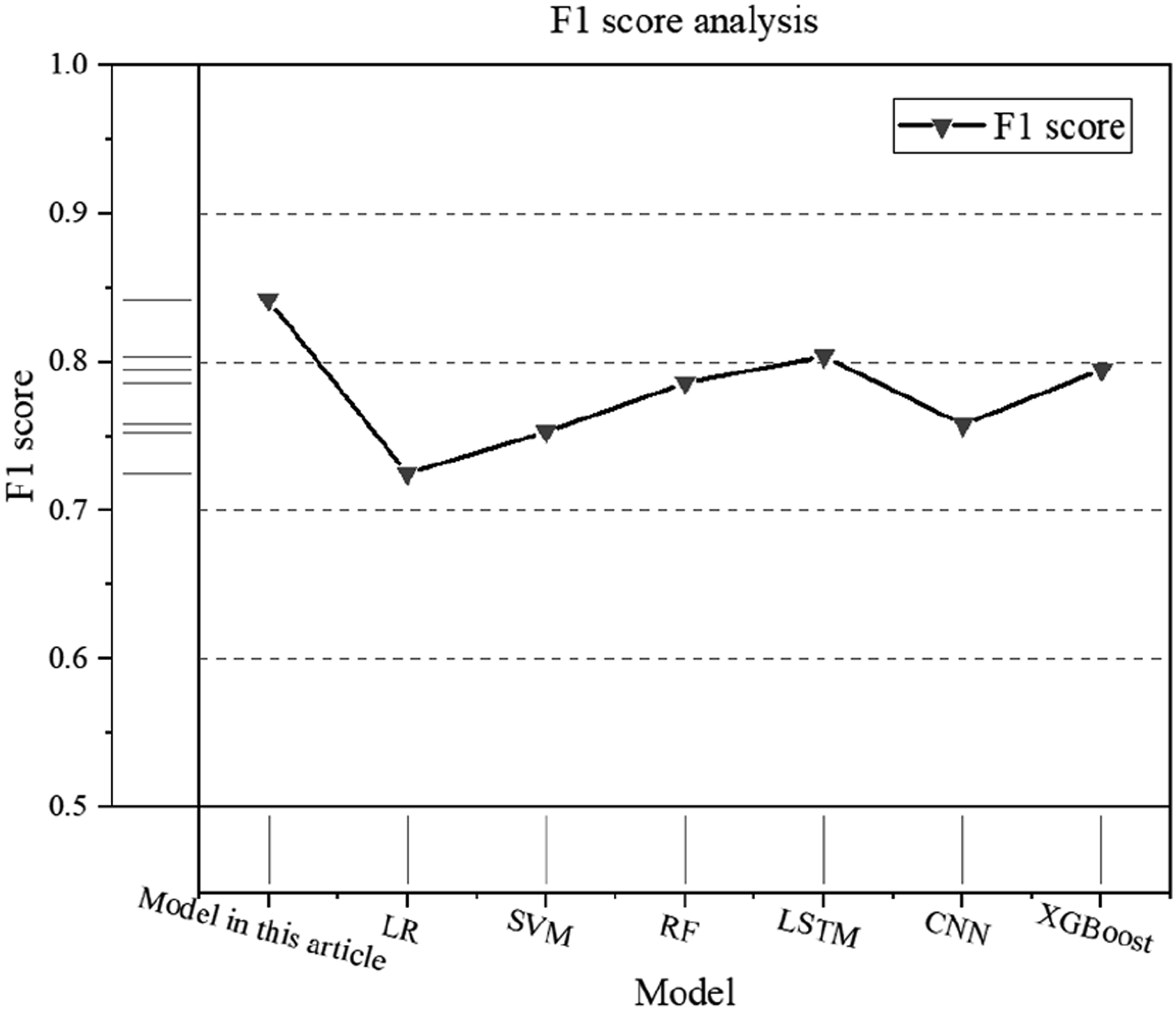
From the F1 score results in Figure 5, compared with LR, SVM, RF, LSTM, CNN, and XGBoost models, the model in this article performs more balanced in event prediction, with an F1 score of 0.842, while the F1 scores of other control models are 0.725, 0.753, 0.786, 0.804, 0.758, and 0.795, respectively. Compared with the control model, the F1 score of the model in this article in the prediction analysis increases by 16.1%, 11.8%, 7.1%, 4.7%, 11.1%, and 5.9%, respectively.
The performance of other models in football event prediction is not ideal, mainly because they cannot handle complex time series data and long-term correlation well. LR and SVM methods are difficult to reflect the nonlinear characteristics of data due to the assumption of linear relationship and high computational complexity. Although the RF method can reduce overfitting, it is difficult to mine complex dynamic changes. Although LSTM has advantages in time series data processing, it also has the problem of gradient loss. CNN can extract local features, but its ability to build models for long time series correlation is very limited. The XGBoost algorithm has good ability to deal with nonlinear problems, but its ability to extract the overall time series is very poor. Overall, the model in this article is based on multi-layer transformation to achieve effective fusion of different time granularity, local and global features, further improving the F1 score.
Kappa coefficient
The Kappa coefficient is a statistical indicator used to measure the performance of a classification model. It takes into account the consistency between the correct classification of the classification model and the random classification to correct the error applied by random consistency. The comparison results of each model are shown in Figure 6. Kappa coefficient results.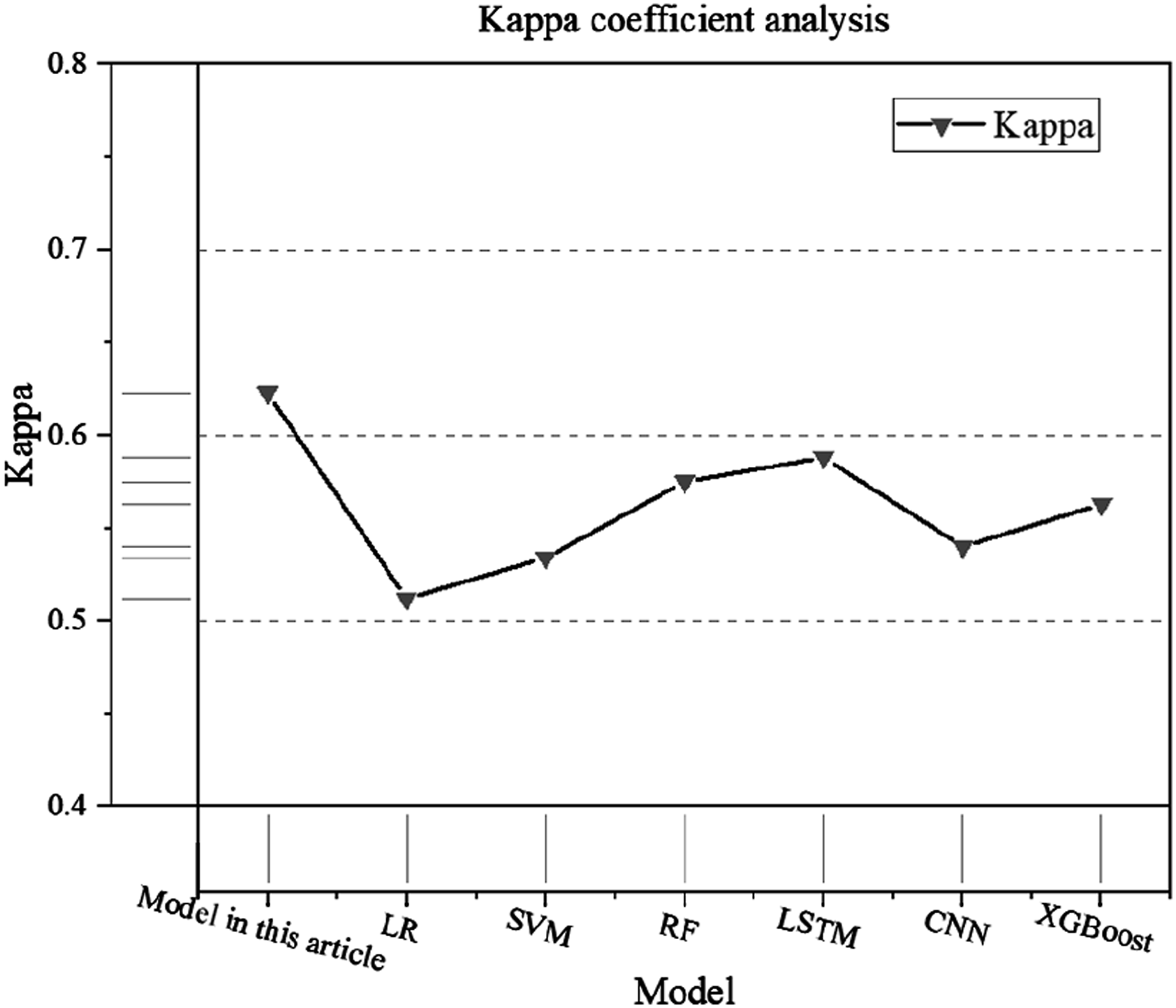
In Figure 6, the Kappa coefficient results of each model show great differences. The Kappa coefficient of the model in this article reaches 0.623, and the Kappa coefficients of LR, SVM, RF, LSTM, CNN, and XGBoost models are 0.512, 0.534, 0.575, 0.588, 0.540, and 0.563, respectively. Compared with the control model, the Kappa coefficient results of this article are improved by 21.7%, 16.7%, 8.3%, 6.0%, 15.4%, and 10.7%, respectively.
The Kappa coefficient reflects the consistency between the model event prediction and the true value. In contrast, the Kappa coefficients of LR, SVM, RF, LSTM, CNN, and XGBoost models are very small. This is because their simulation ability in time series is limited, resulting in low consistency in their predictions. Based on the multi-level Transformer framework and multi-head self-attention mechanism, the model in this article models the complex time series and long-short correlation in football match data, thereby improving the credibility of match predictions. Compared with other models, the proposed model has better stability in predicting dynamic event data.
Ablation experiment
To further verify the role of each component of the proposed model in predictive analysis, an ablation experiment is conducted on the proposed model, and its variants are divided into. (1) The proposed model: that is, the improved Transformer model of this article. (2) Removing time segment encoding: only using the standard Transformer structure without time segment encoding. (3) Removing multi-level architecture: only using a single-layer Transformer to process time series data of each granularity. (4) Removing the dynamic self-attention adjustment mechanism: only using the Transformer model with static attention weights.
Ablation experiment results.
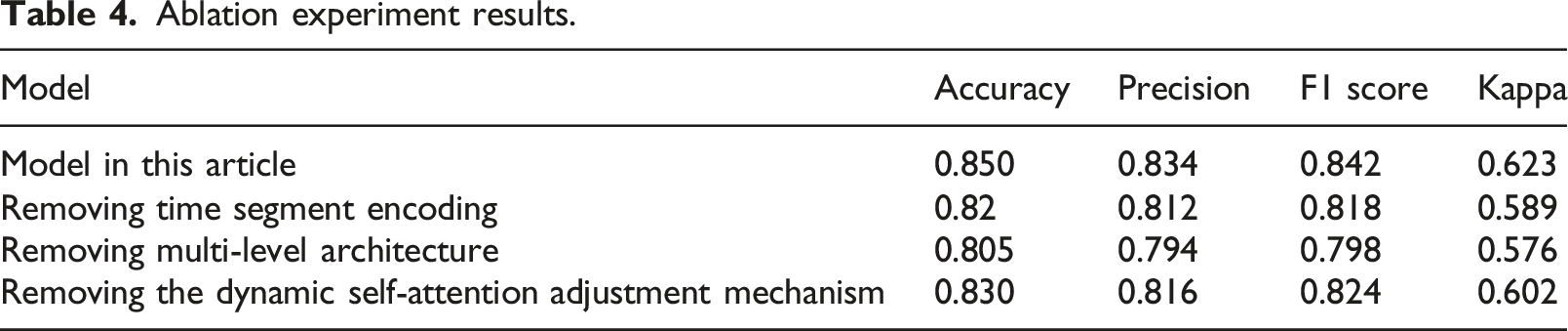
As can be seen from Table 4, the improved model in this article performs best in all evaluation indicators. After removing each component, the model performance shows a decline to varying degrees, which means that each module in this model plays a key role in the overall event prediction and analysis performance.
Discussion
In this article, the effectiveness of the football event data analysis and win rate prediction model using the self-attention mechanism and Transformer is verified in the experiment. The experimental results show that the accuracy, precision, F1 score, and Kappa coefficient of this model are significantly better than those of LR, SVM, RF, LSTM, CNN, and XGBoost models. Among them, the highest improvement in accuracy and precision is 10.7% and 10.6%, respectively; the F1 score result verifies the balanced performance of this model, and its F1 score is improved by up to 16.1%. The highest improvement in the Kappa coefficient is 21.7%. The results show that the method can better reflect the temporal characteristics and complex correlations of football match data. Based on the time segment encoding strategy and multi-level Transformer architecture, the long-term span data of football events is analyzed. Not only the local features are captured through the low layer, but also the global features are captured through the high layer, which improves the overall prediction performance of the model. On this basis, the dynamic attention adjustment mechanism is used to enhance the model’s emphasis on key features, so that it can be dynamically adjusted with the data features to improve the prediction accuracy and credibility. This article combines the self-attention mechanism with the Transformer model to overcome the bottleneck problem of the existing model in time series data analysis, and verifies each module through ablation experiments, providing a new reference perspective for sports event data analysis and game result prediction.
Conclusions
To enhance the scientific rigor of event analysis and improve the accuracy of outcome prediction, this study proposes a method that captures features across multiple time granularities by combining a time-segment encoding strategy with a multi-level Transformer architecture. Additionally, a dynamic self-attention adjustment mechanism is introduced, enabling the model to adaptively recalibrate attention weights based on the evolving characteristics of the input data, thereby significantly improving model performance.
Experimental results demonstrate that the proposed model outperforms traditional approaches—including Logistic Regression (LR), Support Vector Machine (SVM), Random Forest (RF), Long Short-Term Memory (LSTM), Convolutional Neural Network (CNN), and Extreme Gradient Boosting (XGBoost)—across all four evaluation metrics. The model shows strong capabilities in analyzing time series dependencies and predicting event win rates, underscoring its effectiveness in handling complex, temporally structured sports data.
Nevertheless, this study has certain limitations. The experimental dataset is relatively limited in both size and diversity, which may constrain the model’s generalizability. Furthermore, the computational cost of training the Transformer-based architecture is relatively high, which may pose challenges for real-time or large-scale deployment. Future research can address these issues by expanding the dataset to include a broader range of sports events, optimizing the model’s training efficiency, and incorporating complementary algorithms. Such efforts would further promote the high-quality development of event data analysis and predictive modeling in sports analytics.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Chongqing Preschool Education College Scientific Research Platform in 2024. Project name: Digital Elderly Care Service Big Data Application Research Center (Grant Number: 2024KYPT-01). This work was supported by the 2023 project of science and technology research program of Chongqing Education Commission of China (No: KJQN202302904). This work was supported by the Chongqing Preschool Education College Early Childhood Sports and Health Research Centre (No. 2023KYPT-01).
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article