
Abstract
Human motion synthesis plays a central role in film and animation, where motion quality influences both narrative coherence and perceptual realism. While data-driven deep learning models have shown promise in automating motion generation, they often lack biomechanical fidelity, leading to physically implausible results such as limb distortion and foot sliding. To address these challenges, we propose BCMG-Net, a Biomechanically Constrained Motion Generation Network that embeds anatomical and kinetic priors into a Transformer-based architecture. Our model integrates bone length preservation, dynamic smoothness, and energy efficiency constraints directly into the training objective, ensuring structural consistency and motion naturalness. Moreover, semantic control vectors enable context-aware generation for diverse cinematic actions. Experiments conducted on Human3.6 M, CMU MoCap, and a curated film motion dataset demonstrate that BCMG-Net outperforms state-of-the-art baselines across multiple biomechanical and perceptual metrics. Joint range heatmaps, center of mass trajectories, and motion embedding analyses further validate the physical coherence of the generated motion. These results establish BCMG-Net as a practical and principled framework for physically grounded motion synthesis in high-fidelity digital storytelling.
Keywords
Introduction
Human motion plays a foundational role in visual storytelling, interactive environments, and digital character animation. In film, animation, and immersive media, the expressive power of bodily movement transcends mere kinematics—it encapsulates emotion, intention, personality, and narrative causality. The nuances of posture, timing, symmetry, and rhythm are essential for communicating physical context and character identity.1,2 Even subtle variations in joint alignment or movement tempo can dramatically affect an audience’s emotional interpretation, making motion quality a critical determinant of visual realism, believability, and narrative engagement in virtual productions. Historically, animators have relied on manual keyframing, a labor-intensive process in which artists define joint poses at specific intervals and interpolate between them to generate motion.3–5 While this technique affords significant creative control, it is limited in scalability and struggles to reproduce the fine-grained, coordinated dynamics characteristic of natural human movement. Alternatively, motion capture (MoCap) systems have become a standard in high-end production pipelines due to their ability to record precise 3D pose data from human performers. 6 However, MoCap introduces several drawbacks: it is logistically complex, incurs high financial costs, requires specialized equipment and controlled environments, and often fails to generalize across characters, motion styles, or narrative contexts. Moreover, MoCap data remains constrained by the physical limitations of the recorded performances, limiting its applicability in stylized or exaggerated animation.
In response to these constraints, the research community has turned to data-driven human motion generation, aiming to synthesize motion sequences automatically from visual, textual, or symbolic inputs. Powered by advances in deep learning, these approaches have demonstrated promising results in generating realistic, temporally coherent motion. 7 In particular, Transformer-based architectures 8 have emerged as a leading paradigm, owing to their ability to model long-range temporal dependencies and capture global spatio-temporal structure. Models such as MotionBERT, 9 ActFormer, 10 and MotionDiffuse 11 have achieved state-of-the-art results in motion prediction and style-conditioned synthesis, pushing the boundaries of motion realism.
However, despite these advances, a persistent limitation remains: most neural models prioritize positional plausibility over physical validity. That is, while the generated motion may appear visually acceptable at first glance, it often suffers from underlying biomechanical inconsistencies. Common issues include unnatural joint rotations, bone length deformations, foot sliding, and abrupt acceleration spikes—artifacts that may go unnoticed in casual viewing but become immediately apparent in professional or biomechanical contexts.12,13 These inconsistencies are particularly problematic in high-fidelity animation, clinical simulation, and digital human embodiment, where motion must adhere to both esthetic and anatomical principles. A critical analysis of these limitations reveals that they stem primarily from the absence of explicit physical constraints in the model training process. While certain efforts have integrated heuristics such as foot contact detection, phase-guided timing, or inverse kinematics post-processing, these are typically applied as external corrections rather than embedded within the learning objective. As such, they fail to shape the internal motion representation in a physically meaningful way. Few approaches to date have incorporated differentiable biomechanical priors—such as constraints on bone length constancy, inertial continuity, or energy minimization—into end-to-end learning frameworks. Even fewer evaluate their models using physically grounded criteria such as joint torque plausibility, ground reaction symmetry, or metabolic efficiency proxies. As a result, a persistent gap remains between perceptual realism and biomechanical validity, which continues to limit the deployment of neural motion models in physically critical applications.
To address this, we propose the Biomechanically Constrained Motion Generation Network (BCMG-Net), a novel framework that embeds core biomechanical priors into a deep motion generation architecture. Our method integrates spatio-temporal feature encoding, Transformer-based motion synthesis, and a suite of differentiable constraints that enforce: (i) skeletal structural consistency via bone length preservation, (ii) kinetic smoothness via temporal acceleration regularization, and (iii) energy efficiency via displacement-aware penalties. In addition to physical plausibility, BCMG-Net supports semantic conditioning, enabling controllable motion generation aligned with action labels or scene contexts. This makes our model particularly suitable for film-level animation, interactive character systems, and digital avatar creation, where motion must be both meaningful and biomechanically sound. In summary, our contributions are threefold: (1) We introduce a novel motion generation framework that integrates biomechanical constraints into a Transformer-based architecture, ensuring physical plausibility without sacrificing flexibility or expressiveness. (2) We design and incorporate differentiable loss functions for bone length, dynamics, and energy usage, enabling end-to-end learning of structurally valid and kinetically coherent motion. (3) We conduct extensive quantitative and qualitative evaluation, including perceptual studies and biomechanical visualizations, confirming the practical value and scientific validity of our approach.
Related work
Human motion modeling
Early approaches to human motion modeling were predominantly based on rule-based systems, including inverse kinematics, spline interpolation, and parametric models.14,15 While these methods allowed precise control over local pose transitions, they lacked the capacity to model global temporal dynamics and complex joint coordination, rendering them insufficient for generating naturalistic or long-term motions With the rise of deep learning, researchers began leveraging sequence models—such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, 16 and Temporal Convolutional Networks (TCNs)—for motion prediction and synthesis. 17 These approaches significantly improved the modeling of temporal dependencies and variability, enabling the generation of smoother and more temporally consistent motion sequences. However, recurrent models often suffer from long-term drift and short-range oversmoothing, especially in complex or expressive motion scenarios.
More recently, Transformer-based architectures have become dominant in the field due to their superior capacity for modeling long-range dependencies and global context. MotionBERT 9 introduced masked motion modeling and pretraining strategies for generalizable motion representations. ActFormer 10 and MotionDiffuse 11 explored conditional synthesis through attention-based modules and diffusion mechanisms, respectively. Despite their advances in positional accuracy and temporal structure, these models often prioritize perceptual coherence while neglecting physical plausibility, leading to artifacts such as unnatural joint velocities, implausible contact dynamics, or bone length distortion. The absence of explicit biomechanical modeling remains a key shortcoming across many of these architectures.
Biomechanical constraints in motion synthesis
Integrating biomechanical knowledge into data-driven motion generation remains an underexplored yet crucial direction. Some early efforts introduced soft constraints or heuristics to improve realism—for example, Wang et al. 18 employed phase-functioned neural networks to stabilize foot-ground interaction, while Zhang et al. 19 introduced contact-aware filtering and trajectory warping. More recent works have begun embedding physical considerations into the learning process itself. For example, Srifi et al., 20 proposed combining differentiable physics simulators with diffusion-based motion models to enforce physical realism in generated sequences. Feng et al. 21 introduced energy regularization and symmetric limb dynamics to stabilize gait cycles. However, these approaches are often task-specific (e.g., limited to locomotion) and not easily generalizable to diverse or stylized motion. Furthermore, many rely on modular post-processing or external physical engines rather than fully differentiable constraints embedded within the learning pipeline. Another recent example is the PoseCrafter, 22 which introduces kinematic consistency terms for pose estimation, but does not generalize to generative models. Similarly, Penichet 23 integrates biomechanical losses but focuses primarily on rehabilitation and lacks perceptual flexibility required in animation domains.
In contrast, our work proposes a unified framework that integrates differentiable, end-to-end biomechanical constraints—including bone length preservation, acceleration smoothness, and energy efficiency—directly into the loss function. This allows the model to implicitly learn physically coherent priors without reliance on post-hoc correction or domain-specific handcrafting.
Semantic control and stylization
Controllability is a critical requirement for practical deployment of motion synthesis systems, especially in interactive media and film animation. 24 Numerous studies have focused on action-conditioned motion generation, where symbolic labels (e.g., “walk,” “run,” and “jump”) or continuous latent codes are used to guide output generation. Action and Style Motion25,26 allow for control over motion style or action category via learned embeddings. Such models increase diversity and coherence of motion generation, yet they often sacrifice physical grounding in favor of expressive flexibility. Recent trends in language-driven motion generation further amplify the expressive range. PromptGen 27 ) and MotionGPT 28 introduce large language models to parse human instructions into motion sequences, achieving impressive semantic alignment. However, these models lack mechanisms to enforce anatomical plausibility or biomechanical fidelity, and may generate stylistically compelling yet physically implausible outputs.
Our framework bridges this gap by combining semantic control with biomechanical constraints. Specifically, we condition Transformer-based generation on discrete action labels while enforcing structure-aware losses throughout the training process. This enables context-aware generation that is both controllable and biomechanically grounded—an essential quality for applications in virtual production, film animation, and physical simulation.
Methods
Overall framework
We propose a novel model called Biomechanically Constrained Motion Generation Network (BCMG-Net). This model aims to synthesize naturalistic and biomechanically valid motion sequences by combining spatial-temporal feature modeling with explicit biomechanical constraints, thereby bridging data-driven learning with physical plausibility. The overall architecture of BCMG-Net is illustrated in Figure 1, which demonstrates the sequential data flow from raw video frames to motion generation under biomechanical constraints. The overall framework of the proposed BCMG-Net.
The model consists of five integrated modules: (1) data preprocessing and pseudo-3D skeleton reconstruction, (2) spatio-temporal feature encoding using ResNet and Bi-LSTM, (3) biomechanical constraint embedding, (4) semantic-controlled motion generation via Transformer, and (5) visualization and physical evaluation. This design ensures the generated motion is not only realistic but biomechanically plausible.
Data input and pose modeling
The expression of character movements in film and television works is characterized by complexity and diversity. To achieve accurate modeling and generation of these movements, the input data fed into the model must fully and precisely capture the spatial structure and temporal features of human motion. Given that existing audiovisual datasets often lack standardized 3D annotation information, this study designs a preprocessing workflow to extract and reconstruct skeletal motion data from multisource inputs. A series of normalization techniques are applied to establish a unified representation of human posture.
This research utilizes two types of data as the foundation for model training and evaluation. The first type consists of structured motion capture datasets (such as Human3.6 M and the CMU MoCap dataset), which provide precise 3D skeletal coordinates of the human body and serve as a solid basis for physical modeling and supervised learning. The second type includes unstructured real-world video data from film and television, which are transformed into a model-recognizable format via keypoint extraction and pose estimation techniques, thereby enhancing the model’s ability to adapt to complex motion scenarios in real environments.
During the keypoint extraction stage, this study incorporates pose estimation models based on deep neural networks—OpenPose and AlphaPose29,30—to extract 2D skeletal coordinates frame-by-frame from input video sequences.
As shown in Figure 2, the model transforms the 2D keypoint sequence Transformation pipeline from 2D keypoints to pseudo-3D skeleton.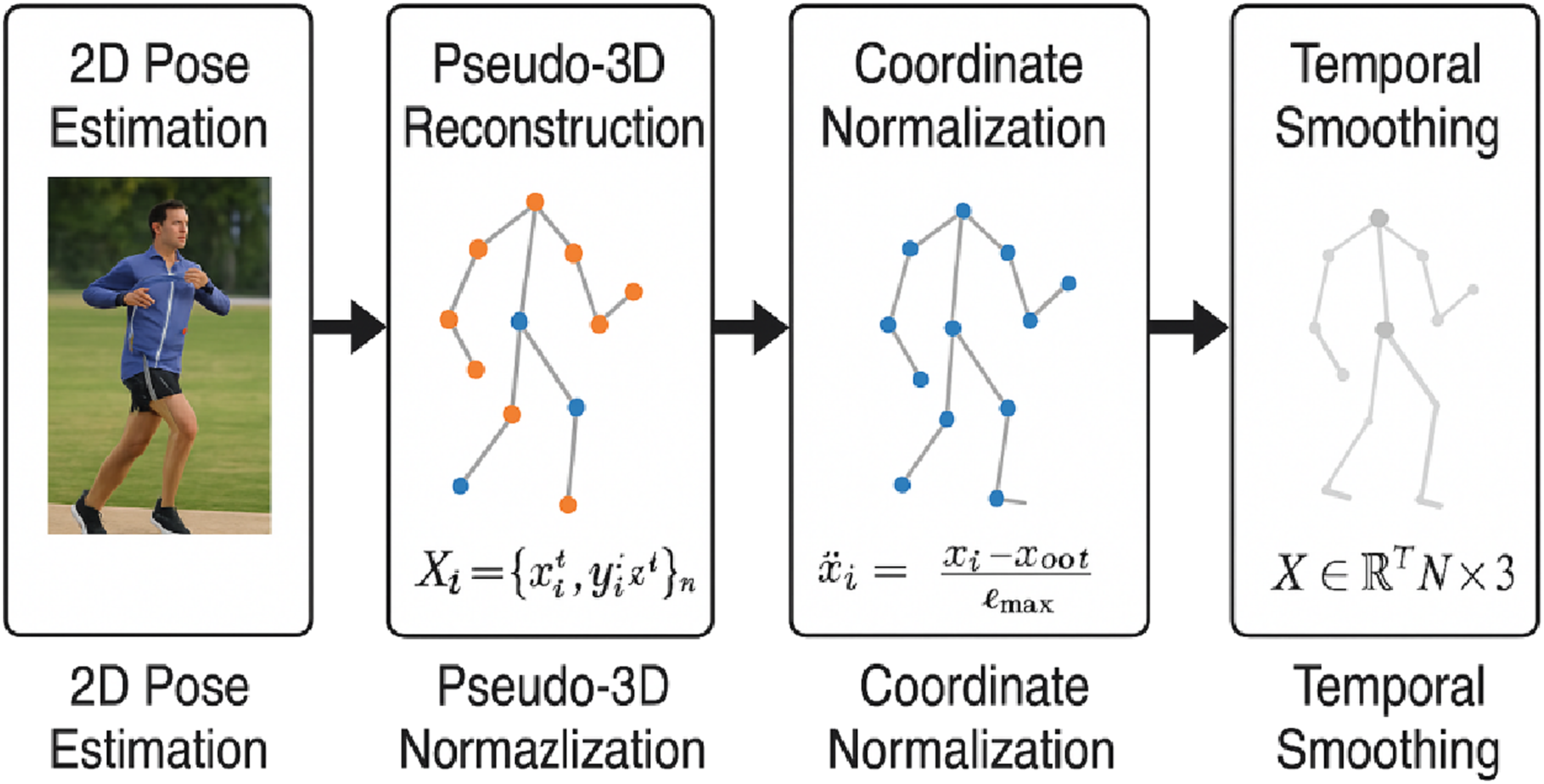
The pseudo-3D reconstruction estimates depth via monocular lifting, leveraging temporal priors and anatomical constraints, following methods similar to.29,30 Each frame image is transformed into a set of 2D human keypoints:

Here,
To address this limitation, this study further proposes a pseudo-3D reconstruction mechanism. In the absence of high-precision 3D annotations, this mechanism estimates the relative spatial position of each keypoint by leveraging the temporal continuity of keypoints across video frames and incorporating anatomical prior relationships. The resulting 3D skeletal sequence is represented as:

After completing the 3D pose modeling, the skeletal sequences undergo a normalization process to enhance data consistency and modeling stability. First, the skeleton center of each frame—typically the hip joint—is translated to the origin of the coordinate system, eliminating displacement noise and the effects of camera translation. Second, all keypoint coordinates are uniformly scaled so that the overall skeleton length is normalized to a unit interval:

Here,
To further mitigate frame-to-frame jitter and estimation errors, this study applies the Savitzky–Golay filtering algorithm to perform temporal smoothing on the keypoint sequences. This algorithm reconstructs the trajectory of each keypoint by fitting a polynomial curve within a local temporal window, thereby preserving the motion rhythm and overall trends while effectively suppressing high-frequency noise and short-term fluctuations.
After the above preprocessing steps, all pose data are uniformly encoded in the form of a 3D tensor:

Here,
Motion representation and constraint design
Human motion arises from both spatial posture and temporal evolution. Therefore, effective modeling must capture intra-frame skeletal structure and inter-frame dynamics. In BCMG-Net, we introduce a joint spatio-temporal encoding module that combines a convolutional encoder with a sequence modeling network.
For spatial encoding, we employ ResNet-50,
31
a residual convolutional network, to process each input frame’s pose image or heatmap, extracting local structural features of joint arrangements:


Here,
Biomechanical constraint modeling
In motion generation tasks driven by deep learning, merely relying on network approximation often results in motion sequences that appear “visually acceptable” but deviate from the biomechanical laws that govern actual human movement. This can lead to unrealistic joint distortions, temporal discontinuities, or physically implausible motion transitions. To address these issues, BCMG-Net introduces a series of explicit biomechanical constraints during training to enforce physical plausibility.
These constraints are designed from three perspectives: (1) skeletal structural consistency, (2) dynamic continuity, and (3) energy-efficient motion planning. Together, they form a comprehensive biomechanical framework to ensure the naturalness, stability, and efficiency of generated motions.
Skeletal consistency constraint
In human physiology, the distances between adjacent joints (bone lengths) remain constant during motion. To maintain anatomical correctness, we introduce a skeletal consistency loss that penalizes deviations in bone lengths from their reference values:

Dynamic smoothness constraint
Human motion must comply with inertia and acceleration continuity. To enforce temporal consistency, we introduce a dynamic smoothness loss based on the second-order difference across time frames, which serves as an approximation of acceleration:

This loss penalizes abrupt velocity changes, effectively promoting smooth transitions and preventing jerky or unnatural motion, especially in high-frequency body parts such as arms and ankles.
Energy efficiency constraint
From the perspective of biomechanics and neuromotor control, the human body aims to minimize unnecessary energy expenditure during movement. To reflect this principle, we propose an energy-based constraint that encourages motion sequences with minimal displacement redundancy:

This term penalizes excessive or redundant joint movement and promotes coherent and efficient motion trajectories.
Total loss function
The final training objective combines the basic reconstruction loss with the above biomechanical constraints, yielding the total loss function:
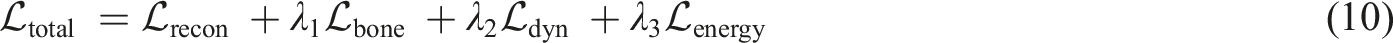
Here,
Conditional motion generation and semantic control
In real-world animation production, characters are often required to perform actions with clearly defined semantics, such as “wave goodbye,” “run forward,” or “stand up from sitting.” While these actions may vary in appearance, they are semantically consistent. Thus, enabling the model to generate motion under semantic control improves both usability and practical flexibility.
To this end, BCMG-Net integrates a conditional motion generation module based on semantic control vectors. This module takes a label embedding vector

Here,
During training, the generator is optimized using the following reconstruction loss:

This conditional generation architecture allows users to control motion generation based on simple symbolic labels, making the system compatible with text-guided animation tools or interactive authoring platforms. Furthermore, this mechanism supports domain adaptation and style transfer by conditioning on different motion “styles” such as “normal walking,” “exaggerated walking,” or “robotic movement.” In this context, “exaggerated” refers to stylistic motion derived from cartoon physics, high-speed stunt sequences, or genre-specific exaggeration such as superhero landings or animated squash-and-stretch effects. “Structural fidelity” relates to preserving joint range limits and balanced center of mass trajectories.
Motion visualization and biomechanical evaluation system
Generated motion sequences must be rigorously validated before being used in professional animation pipelines. Beyond numerical reconstruction accuracy, it is necessary to analyze their biomechanical plausibility, visual continuity, and structural fidelity. To this end, BCMG-Net incorporates a comprehensive motion visualization and evaluation system that combines 3D reconstruction, physical metric computation, and perceptual assessment.
3D motion reconstruction in unity
To support intuitive assessment of generated motion, we developed a real-time 3D visualization environment using Unity3D. The predicted motion sequence
Biomechanical metric evaluation
To complement visual inspection, we define several objective metrics to evaluate physical realism:
Skeletal Consistency Error: Variance in bone lengths across frames; Mean Acceleration:

Joint range of motion: Spatial displacement range per joint; total motion energy:

These metrics are computed across test sequences and compared with ground truth MoCap data to quantitatively assess the biomechanical plausibility and stability of the generated motion.
To supplement quantitative results, we conducted a human evaluation involving professional animators and biomechanics researchers. Participants rated each generated sequence on a 5-point Likert scale along three dimensions: motion naturalness, rhythmic coordination, and structural plausibility. Scores are aggregated to compute mean subjective ratings.
Experiments and results
Experimental setup
All experiments were conducted on a machine equipped with an NVIDIA RTX 3090 GPU, 128 GB RAM, and an AMD Ryzen 9 5950X processor. The model was implemented using PyTorch 1.13 and trained using the Adam optimizer with an initial learning rate of 0.0001 and a batch size of 32. Training was carried out for 100 epochs with early stopping based on validation loss.
Datasets
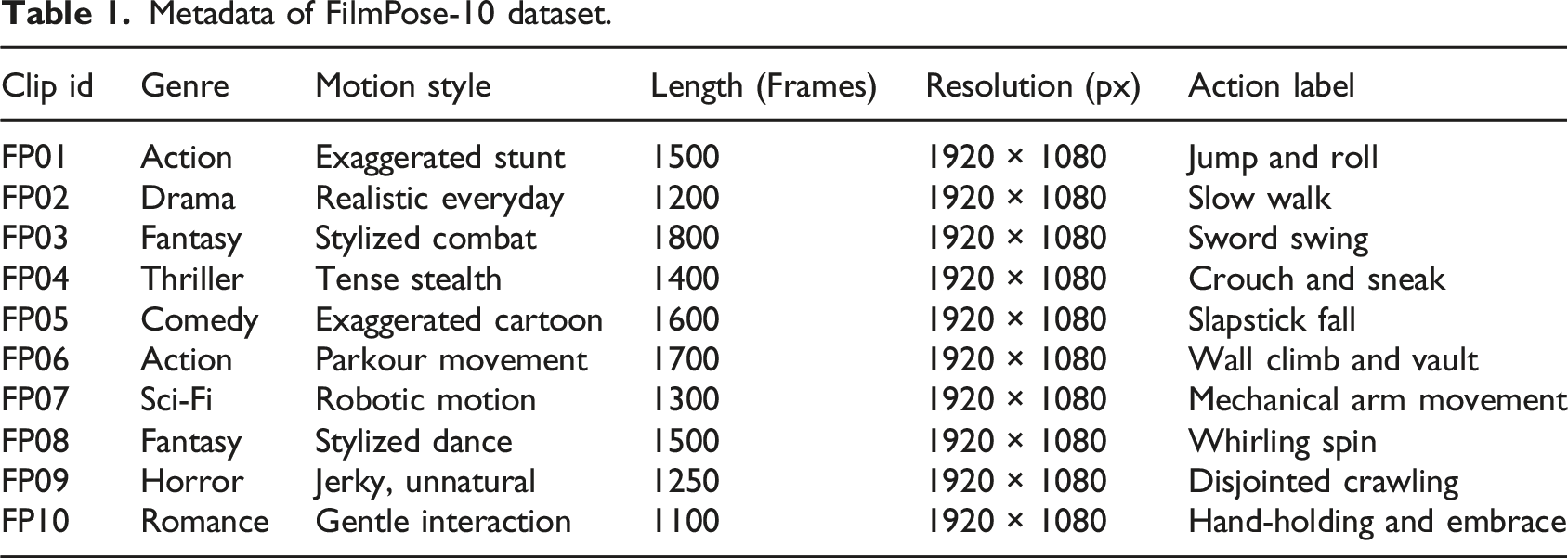
We use two publicly available motion datasets and one in-house annotated film dataset for training and evaluation: • • •
Metadata of FilmPose-10 dataset.
Evaluation metrics
To comprehensively assess model performance, we employ a combination of structural, kinematic, and perceptual evaluation metrics. These include: (1) Reconstruction Error (RE), which measures the mean Euclidean distance between predicted and ground truth joint positions; (2) Bone Length Deviation (BLD), which quantifies skeletal stability by computing standard deviation in bone lengths across frames; (3) Mean Acceleration (MA), calculated as the second-order derivative of joint positions to assess motion smoothness; (4) Motion Energy (ME), indicating the total joint displacement within a sequence; and (5) Frechet Pose Distance (FPD), which evaluates distributional similarity between synthesized and real pose sequences in a learned feature space. FPD is computed using the pretrained MotionBERT encoder as the feature extractor. We use the penultimate layer embeddings of dimension 1024 for all frames in the sequence. This follows the benchmark protocol described in 9 . Together, these metrics provide a rigorous evaluation of physical plausibility, stability, and visual quality.
Model comparison
We compared BCMG-Net against four leading models: HP-GAN 34 : A GAN-based model for motion synthesis; ST-GCN 35 : A spatio-temporal graph convolutional network that models skeleton motion as graph signals; MotionBERT 9 : A Transformer-based encoder pretrained for motion representation learning; ActFormer 10 : A Transformer model with conditioning capabilities for action-aware motion generation.
Comparison of BCMG-Net with baseline models.

BCMG-Net achieves the lowest RE of 5.21 mm, indicating superior spatial accuracy in joint position prediction. The BLD of 1.18 demonstrates its strong ability to maintain anatomical structure over time, outperforming ST-GCN (1.84) and even Transformer-based ActFormer (1.51). In terms of motion smoothness, BCMG-Net yields the lowest MA (1.26), significantly reducing erratic joint fluctuations observed in other models. Furthermore, its minimized ME (5.74) reflects a more efficient and restrained use of joint trajectories, avoiding excessive movement common in GAN-based methods. Most notably, the FPD score of 0.204 shows that BCMG-Net generates motion distributions closest to real human motion, measured in a learned perceptual embedding space. All reported metrics are averaged over five independent runs, with standard deviations reported in parentheses. Statistical significance between BCMG-Net and baselines was validated using paired t-tests (p < 0.05), confirming the robustness of the improvements. These results confirm that the integration of biomechanical constraints does not merely provide regularization—it directly enhances both physical plausibility and perceptual quality, establishing BCMG-Net as a robust framework for realistic motion generation in complex, high-fidelity scenarios.
Performance of BCMG-Net under ablations of biomechanical constraints.
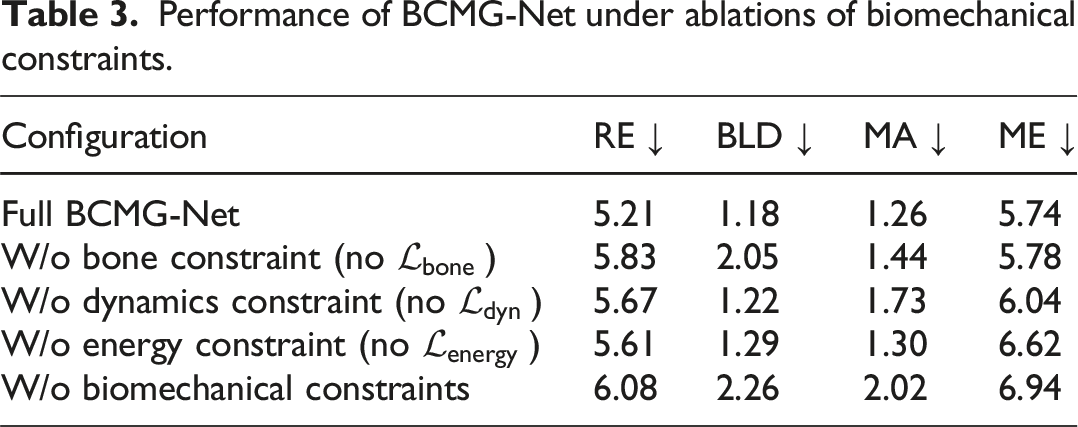
Removing the bone length constraint (
Biomechanical consistency and motion structure visualization
To further visualize the differences in motion behavior, we present four complementary evaluations in Figure 3. Multi-view visualization of motion quality across models. (a) Joint trajectory over frames; (b) histogram of velocity distributions (Velocity (units: m/s), histogram bin size: 0.05 m/s); (c) t-SNE projection of pose embeddings; (d) foot contact heatmap.
Subfigure (a) compares joint trajectories over time, where BCMG-Net closely aligns with the ground truth and avoids jitter observed in baseline outputs. Subfigure (b) reveals velocity distributions, in which BCMG-Net produces tighter, unimodal curves, while baselines exhibit broader, noisier dynamics, indicating instability. In subfigure (c), we project the pose feature embeddings into a low-dimensional space using a t-SNE-like method; BCMG-Net’s cluster overlaps significantly with the real motion cluster, while baseline points are scattered further afield, demonstrating distributional deviation. Finally, subfigure (d) visualizes a foot contact heatmap on the X-Z plane, where BCMG-Net yields consistent contact regions, confirming stable and grounded locomotion. Collectively, these visualizations reinforce the quantitative results and highlight the advantages of biomechanical regularization in producing coherent, physically valid motion.
To further assess the biomechanical plausibility of motion generated by BCMG-Net, we visualize two key indicators in Figure 4: the joint range of motion (ROM) and the trajectory of the center of mass (CoM). Biomechanical evaluation of generated motion sequences. (a) Joint range of motion (ROM) heatmap across eight joints and three models (joints labeled as H (hip), K (knee), A (ankle); ROM units: degrees); (b) center of mass (CoM) trajectory on X-Z plane during walking sequence.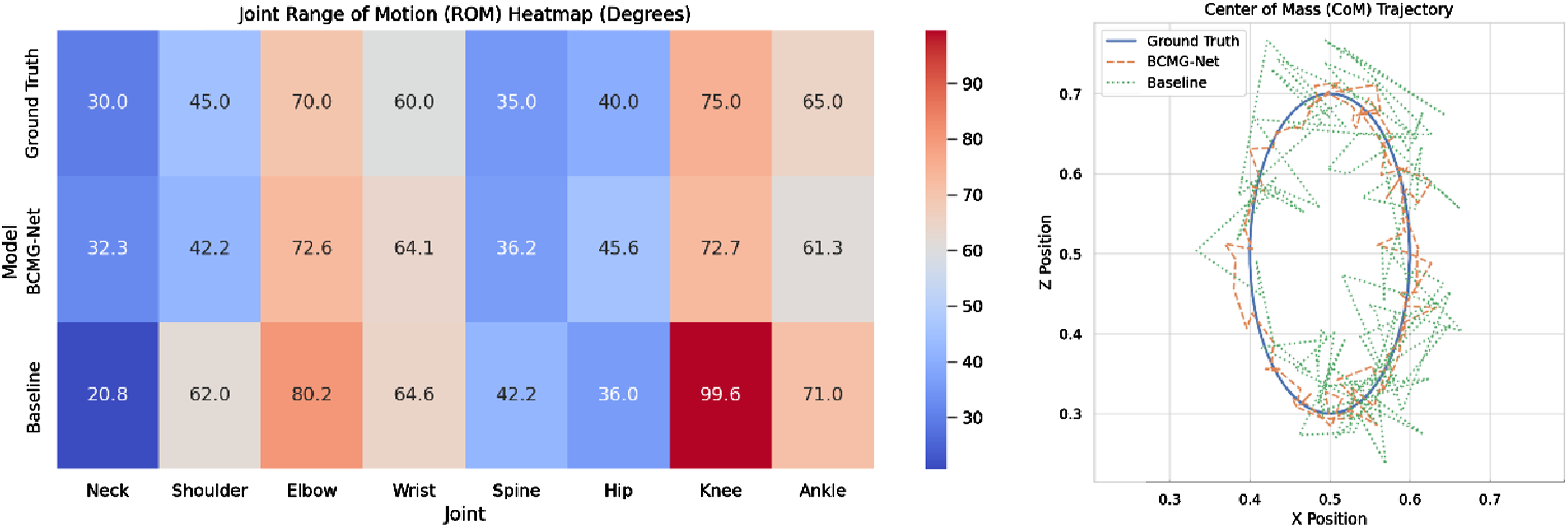
Figure 4(a) presents a ROM heatmap comparing Ground Truth, BCMG-Net, and baseline models across eight major joints. It shows that BCMG-Net closely replicates the physiological ROM observed in real human motion, with only minor deviations within acceptable biomechanical thresholds. In contrast, the baseline model often exceeds typical ROM values, especially at the knee and elbow joints, suggesting limb overextension and potential instability during motion synthesis. This indicates that the structural constraint loss
Conclusion
This study introduces BCMG-Net, a novel motion generation framework that combines data-driven learning with embedded biomechanical constraints to synthesize physically plausible and semantically controllable motion for film and animation applications. By integrating anatomical regularization (bone length preservation), dynamic continuity (acceleration smoothness), and energetic efficiency into a Transformer-based architecture, BCMG-Net bridges the gap between perceptual realism and biomechanical validity—a limitation in many existing neural motion models.
Our experiments across both structured motion capture datasets and stylized cinematic sequences show that BCMG-Net consistently achieves lower reconstruction error, higher anatomical fidelity, and more stable movement patterns compared to leading baselines. In addition to quantitative benchmarks, we employ a suite of biomechanical visualizations—ROM heatmaps and CoM trajectories—to provide interpretable and multidimensional evidence of the model’s physical coherence. Looking forward, our approach opens several directions for future research. First, integrating real-time physical simulation or differentiable physics engines may further improve dynamic realism, especially in interactive environments. Second, expanding semantic conditioning to support language-driven or multimodal control could enhance creative flexibility. Finally, adapting the framework for non-human characters or exaggerated stylized motion remains an exciting challenge for cinematic and game animation.
Despite its strengths, BCMG-Net currently depends heavily on the Human3.6 M dataset, limiting domain generalization to occluded or multi-person scenarios. Future work will explore robust adaptation to real-world noisy data and multi-character interactions.
Footnotes
Acknowledgments
I thank the anonymous reviewers whose comments and suggestions helped to improve the manuscript.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.